【强化学习】基于策略的强化学习算法——策略梯度法
相比基于价值的强化学习算法,基于策略的强化学习算法的思想是:直接找到一个最优策略 π(a|s)。这个策略能告诉智能体,在状态 s 下,应该选择动作 a 的概率,使智能体在与环境交互过程中获得的累积奖励最大。
本文介绍基于策略的强化学习算法中的策略梯度法:
Policy Gradient(策略梯度法)
策略梯度(PG)方法是一类直接优化策略 πθ(a∣s)π_θ(a∣s)πθ(a∣s)的方法,其核心思想是通过调整策略参数 θθθ 来最大化期望累积奖励,策略本身是参数化的函数(如神经网络),通过梯度上升法不断调整策略参数,以最大化累积累积奖励的期望
策略梯度定理:
在此之前,首先介绍策略梯度定理,策略梯度定理是基于策略方法的理论基础,它提供了一种直接优化策略参数 θθθ 的方法,以最大化期望累积奖励,累积奖励通常用目标函数J(θ)J(θ)J(θ)表示:

G(τ)=∑t=0TγtrtG(\tau)=\sum_{t=0}^T \gamma^t r_tG(τ)=∑t=0Tγtrt , rtr_trt 表示在时刻 t 的奖励,γ\gammaγ 表示折扣率,J(θ)J(\theta)J(θ)是所有轨迹的回报的期望值,也是优化的目标,策略梯度法是希望找到使得J(θ)J(\theta)J(θ)最大的策略参数 θθθ 。
直接计算期望的梯度比较困难,我们通常使用蒙特卡洛采样方法(通过采样来估计期望值来)近似计算梯度。具体在PG里,蒙特卡洛采样方法在策略 πθ\pi_{\theta}πθ 下采样多条轨迹,然后使用这些轨迹回报的均值来近似计算梯度。
策略梯度定理表明,目标函数J(θ)J(\theta)J(θ)对策略参数 θθθ 的梯度∇θJ(θ)\nabla_{\theta}J(\theta)∇θJ(θ)可以表示为:
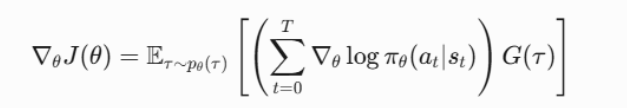
其中:
-
πθ(at∣st)\pi_{\theta}(a_t|s_t)πθ(at∣st) 表示策略 πθ\pi_{\theta}πθ 在状态 sts_tst下选择动作 ata_tat 的概率
-
∇θlogπθ(at∣st)\nabla_{\theta} log \pi_{\theta}(a_t|s_t)∇θlogπθ(at∣st) 表示策略 πθ\pi_{\theta}πθ 在状态 sts_tst下选择动作 ata_tat 的对数概率关于参数 θθθ 的梯度
解释为什么目标函数$ J(θ) $对策略参数的梯度可以这么表示?



以上,策略梯度定理介绍完了,策略梯度方法中,策略参数根据梯度上升法优化:θt+1=θt+α∇θJ(θ)\theta_{t+1} = \theta_{t} + \alpha \nabla_{\theta} J(\theta)θt+1=θt+α∇θJ(θ) ,使得策略朝着期望回报最大的方法更新
通过公式可以看出:如果某个轨迹 τ\tauτ 的累积奖励 G(τ)G(\tau)G(τ) 为正,我们就希望这个轨迹中的动作被选择的概率 πθ(at∣st)\pi_{\theta} (a_t | s_t)πθ(at∣st) 更高;如果为负,我们就希望这个轨迹中的动作被选择的概率更低。
结论:策略梯度法提供了一种直接优化策略的方法,避免了基于值函数的间接优化,核心是通过调整策略参数 ,使得高回报的动作被选择的概率增加,低回报的动作被选择的概率减少。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 23
23 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)