python网络爬虫——requests包
参考资料:python网络爬虫从入门到实践【第2版】
在网页设计中,纯粹HTML格式的网页通常称为静态网页,早期的网站一般都是由静态网页制作的。在网络爬虫中,静态网页的数据比较容易获取,因为所有数据都呈现在网页的HTML代码中。
在静态网页抓取中,有一个强大的requests库能够让我们轻松的发送HTTP请求,这个库功能完善,且操作非常简单。
1、安装requests库
requests库能通过pip安装。打开Windows的cmd或Mac的终端, 键入:
pip install requests
即可进行安装。
2、获取响应内容
在requests中,常用的功能是获取某个网页的内容。
# 导入requests包
import requests
# 请求网页
r=requests.get('http://www.santostang.com/')
print("文本编码:",r.encoding)
print("响应状态码:",r.status_code)
print("字符串方式的响应体:",r.text)
(1) r.text是服务器响应的内容,会自动根据响应头部的字符编码进行解码。
(2)r.encoding是服务器内容使用的文本编码。
(3)r.status_code用于检测响应的状态码,如果返回200,就表示请求成功了;如果返回的是4XX,表示客户端错误;如果返回5XX是服务器错误响应。我们可以用r.status_code来检验请求是否正确响应。
(4)r.content是字节方式的响应体,会自动解码gzip和deflate编码的响应数据。
(5)r.json()是requests中内置的JSON解码器。
3、定制requests
有些网页需要对requests的参数进行设置才能获取需要的数据,这包括传递URL参数、制定请求头、发送POST请求、设置超时等。
(1)传递URL参数
为了请求特定的数据,我们需要在URL的查询字符串中加入某些数据。如果是我们自己构建URL,那么数据一般会跟在一个问号后面,并且以键值对的形式放在URL中。例如:
http://httpbin.org/get?key1=value1
在requests中,我们可以直接把这些参数保存在字典中,用params(参数)构建至URL中。例如传递key1=value1和key2=value2到http://httpbin.org/get,可以如下编写:
import requests
url="http://httpbin.org/get"
key_dict={'key1':"value1",'key2':'value2'}
r=requests.get(url,params=key_dict)
print("URL已正确编码:",r.url)
print("字符串方式的响应体:\n",r.text)
(2)定制请求头
请求头headers提供了关于请求、响应或其他发送实体的信息。对于爬虫而言,请求头十分重要。如果没有指定请求头或请求的请求头和实际网页不一致,就可能无法返回正确的结果。
requests并不会给予定制的请求头headers的具体情况改变自己的行为,只是在最后的请求中,所有的请求头信息都会被传递进去。
我们如何找到正确的headers呢?我们可以使用chrome浏览器打开要请求的网页,右击网页的任意位置,在弹出的快捷菜单中单击“检查”命令。在随后打开的页面中单击network(网络)选项。在左侧的资源中找到需要请求的网页,单击需要请求的网页,在heades(标头)中可以看到requests headers(请求标头)的详细信息。
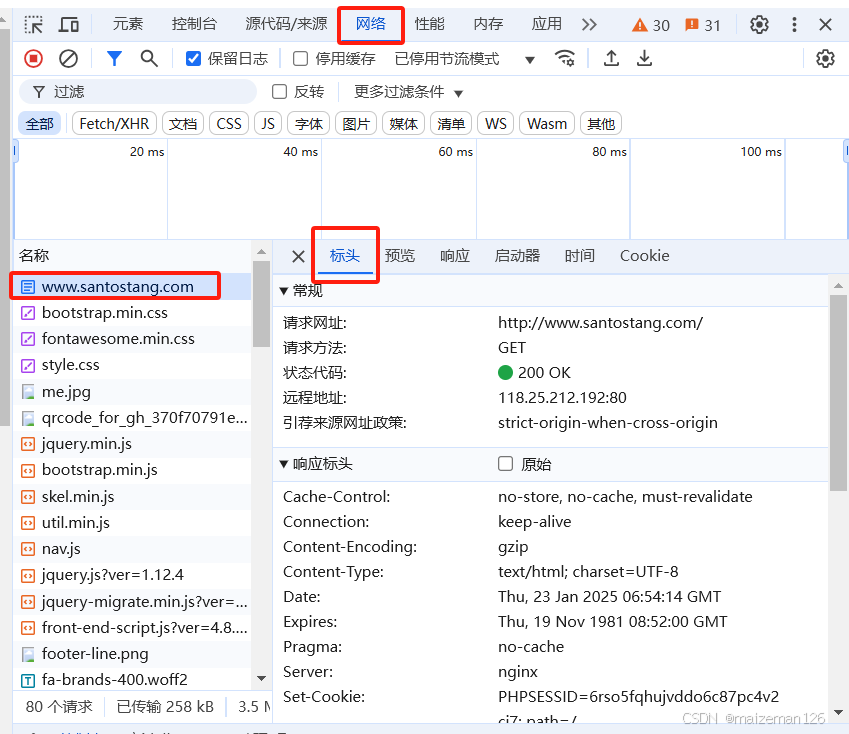
请求头的信息如下:
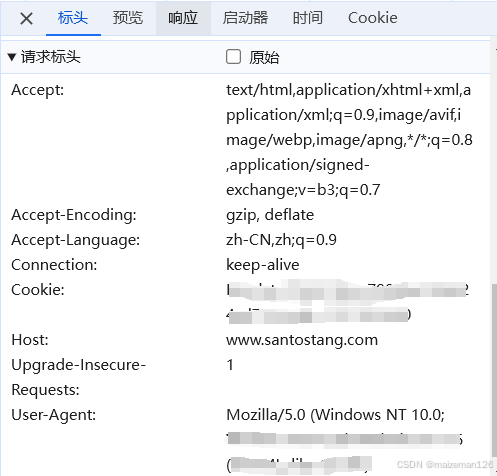
使用书中的User-Agent和Host编写请求头如下:
import requests
url="http://www.santostang.com"
headers={"User-Agent":"Mozilla/5.0(Windows NT 6.1;WOW64)AppleWebKit/537.36(KHTML,like Gecko)Chrome/57.0.2987.98 Safari/537.36",
"Host":"www.santostang.com"}
r=requests.get(url,headers=headers)
print("响应状态码:",r.status_code)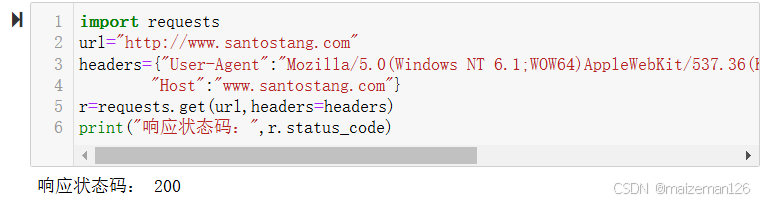
(3)发送POST请求
除了GET请求外,有时还需要发送一些编码为表单的形式的数据,如在登录的时候请求就位post,因为如果用get请求,密码就行显示在URL中,这个非常不安全。如果要实现post请求,只需要简单地传递一个字典给requests中的data参数,这个数据字典就会在发出请求的时候自动编码为表单形式。
import requests
url="http://httpbin.org/post"
key_dict={"key1":"value1","key2":"value2"}
r=requests.post(url,data=key_dict)
print(r.text)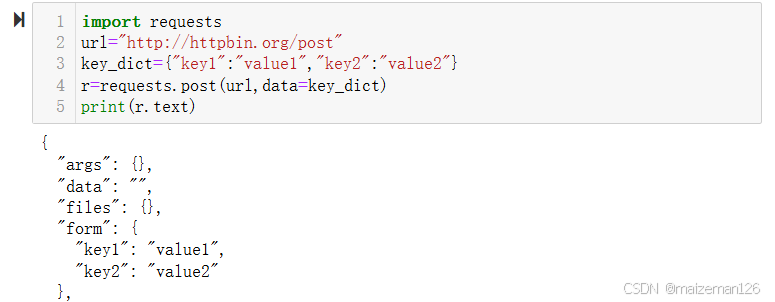
根据反馈结果,可以看到,form变量的值为key_dict输入的值。这样一个post请求就发送成功了。
4、超时
有时爬虫会遇到服务器长时间不返回,这是爬虫程序就会一直等待,造成爬虫程序没有顺利地执行。因此,可以使用requests在timeout参数设定的秒数结束后停止等待响应。意思就是如果服务器在timeout秒内没有应答,就返回异常。
现在我们把这个秒数设置为0.001秒,看看会抛出什么异常。0.001秒是为了体验timeout异常的效果而设置的,通常我们会把这个值设置为20秒。
import requests
link="http://www.santostang.com"
r=requests.get(link,timeout=0.001)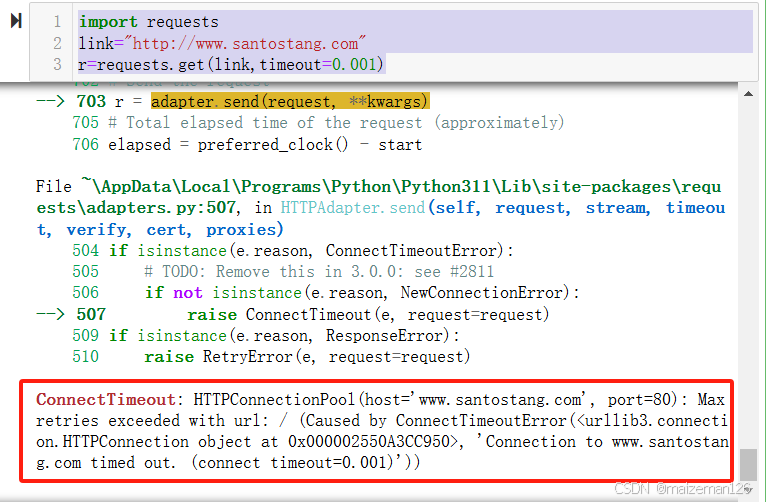
上述异常值的意思是,时间限制在0.001秒内,连接到地址为www.santostang.com的时间已到。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 41
41 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)