电商用户行为数据分析系统的设计与实现
本文设计并实现了一个基于Hadoop的电商用户行为数据分析系统。系统采用Flume收集用户行为日志数据,通过Kafka缓冲后存储到HDFS,利用Hive进行分层处理和数据仓库搭建,最终通过Superset实现可视化展示。研究解决了传统单机系统处理海量电商数据时的性能瓶颈问题,实现了从数据采集、处理到分析的全流程功能。系统测试验证了其可行性和可靠性,能够有效支持企业商业决策。未来可扩展元数据管理、实
电商用户行为数据分析系统的设计与实现
摘 要
由于网络技术的蓬勃发展,“线上线下结合”的行业也如雨后春笋般在全行各业中茁壮成长起来。各种各样的线下行业也纷纷的走上了线上的道路。在如今竞争越来越剧烈的背景下,现代企业在新的趋势中,要抓住机会,寻求更好的发展和突破。特别是在互联网时代,信息呈现爆炸式的增长,无时无刻都在产生大量新的数据。现在,一种全新的社会资源就是数据,它的重要性丝毫不逊色于能源与金钱。文章从大数据的角度对大数据下的企业用户行为进行了探讨,并对其进行了系统化的研究,提出了在快速发展的电子商务中,要设计一个数据分析系统来对电商的用户行为进行分析的想法。
关键词:大数据;电商;用户行为;数据分析
Design and implementation of e-commerce user behavior data analysis system
Abstract
Due to the booming development of Internet technology, The combination of online and offline industries have mushroomed in all walks of life, and a variety of offline industries have also embarked on the path of online in the context of more and more fierce competition now, modern enterprises in the new trend, to seize the opportunity to seek better development and breakthrough Especially in the Age of the Internet, information presents an explosive growth, and new data are generated in large quantities all the time. Now, a new social resource is data, whose importance is no less important than energy and money This paper discusses the enterprise user behavior under big data from the perspective of big data, and makes a systematic study of it, and puts forward the idea of designing a data analysis system to analyze the user behavior of e-commerce in the rapid development of e-commerce.
Keywords: big data;e-commerce;user behavior; data analysi
目 录
成果声明.......................................................................................... I
摘 要............................................................................................ II
第1章 引 言............................................................................... 1
1.1 研究背景............................................................................ 1
1.2 研究意义............................................................................ 1
1.3 研究现状............................................................................ 2
1.4 研究内容............................................................................ 4
1.5 论文结构............................................................................ 4
第2章 系统需求分析.................................................................... 5
2.1 系统需求概述.................................................................... 5
2.2 功能需求分析.................................................................... 5
2.3 非功能需求........................................................................ 6
第3章 系统设计与技术选型........................................................ 8
3.1 系统功能设计.................................................................... 8
3.2 采集模块业务设计............................................................ 8
3.3 数仓业务设计.................................................................... 9
3.4 技术选型.......................................................................... 10
第4章 系统实现......................................................................... 12
4.1 采集模块实现.................................................................. 12
4.1.1 Hadoop安装部署.................................................... 12
4.1.2 Zookeeper安装部署............................................... 13
4.1.3 Kafka安装部署...................................................... 14
4.2 数据分析调度模块实现.................................................. 14
4.2.1 MySQL安装部署................................................... 14
4.2.2 Hive安装部署........................................................ 15
4.2.3 Azkaban安装部署.................................................. 15
4.3 数仓模块实现.................................................................. 16
4.3.1 数仓搭建-ODS层.................................................. 16
4.3.2 数仓搭建-DWD层................................................. 16
4.3.3 数仓搭建-DWS层................................................. 17
4.3.4 数仓搭建-DWT层................................................. 18
第5章 系统测试......................................................................... 19
5.1 集群启动.......................................................................... 19
5.2 Azkaban全程调度............................................................ 20
5.3 SuperSet报表可视化........................................................ 22
第6章 总结与展望...................................................................... 25
致 谢........................................................................................... 26
参考文献....................................................................................... 27
第1章 引 言
1.1 研究背景
近年来,随着对网络产业的不断深入和快速的发展,网络技术也越来越受欢迎,尤其是淘宝。像京东这种网络购物平台的出现,使网络逐渐融入到了人们的日常生活中,它的产品种类繁多,以及快速的送货速度。方便人民的日常活动,改善人民的生存质量,使得人民对其日益依赖。
由于网络带来的便利,使我国的网络用户的数量也在快速的增长,逐渐的达到了顶峰。从我国的互联网网络信息中心(CNNIC)所发布的第42次《中国互联网网络发展状况统计报告》来看,到2018年的6月,我国的互联网用户数量已经达到了惊人的8.02亿,普及率为57.7%。2018年第一季度,互联网用户数增加了2968万,比2017年底增加了3.8%。我国网民绝大部分是通过手机接入互联网,比例高达98.3%,约为7.88亿人。不言而喻,中国已经成为世界上最大的互联网市场。
1.2 研究意义
目前,网购已成为一种潮流,琳琅满目的网上商品正吸引着更多的人参与到在线购物中。随着用户体验感的不断提升,网络上的数据量也在不断地增加,对于电商平台而言,数据的爆发式增长是一个巨大的挑战,如何将这些数据中的杂质剔除,让它们变得更加有用就显得极为重要。尽管这是一项艰巨的任务,但它带来了大量的技术革新和商机。海量的数据中有着小数据所没有的价值和知识,准确的数据分析,可以让站点对自己有一个全新的了解,哪些地方是热门的,哪些地方需要改善,这些都是可以用数据分析的结果来展示出来。因此,数据分析技术在其中扮演着举足轻重的角色。
由于数据呈爆发式增长,使得数据结构更加的复杂,因此必须构建一个分析数据的平台。那么,该如何进行数据分析呢?数据分析是通过对大量的数据进行深度的分析,得到一组指数,希望通过这些指数可以让工作人员网站的各个部分进行全面的了解,从而对网站的缺陷做出准确的判断,并对其进行修正,为网站带来更多的利润。
1.3 研究现状
从电商平台目前的发展来看,数据分析是一种很有前途的技术,它已经被广泛地应用于各行各业,有着很大的发展空间。然而对于数据分析这个概念,至今为止,还没有一个明确的结论。但是这并不会影响我们来使用它,对于我们来说,如何分析和利用这些数据才是至关重要的。
由于互联网技术的飞速发展,各种以用户为基础的应用软件和应用程序也层出不穷。现在随着数据量的增长,要处理的数据不计其数,因此现有的数据处理方式也必须不断的更新和改善,推陈出新。而如何从海量的信息中剔除噪声和杂质,只保留最有用的信息,才是我们需要解决的问题。因此,数据挖掘分析这一项技术正逐步成为大数据技术的中心。
数据分析是指利用恰当的数据挖掘手段对所收集到的大量资讯加以分析,为了获得可用资料并形成客观结果,而对资料进行仔细调研并归纳汇总的过程。在实际中,数据挖掘分析也可帮助人们做出判断,以便采取恰当行动。数据挖掘分析的主要目的就是将隐没于一大批看起来散乱无章的资料中的内容汇总、萃取并收集起来,以便于找到所调研对象的存在规律。在实际中,数据挖掘分析也可帮助人们做出判断,以便采取恰当行动。在企业产品开发的整个完整生命周期,以及企业从市场调研到售后服务和产品处置等的所有流程中都必须合理利用数据分析的结果,以提高研究效果。在公司内部,大数据分析能够帮助人们了解公司的经营情况,产品的出售状况,以及产品的特性、产品的市场粘性、价格等等。
所以,数据分析技术在当今社会发展中有着十分广阔的发展前景,是推动社会进步的所需要的手段。
数据的存储与分析是数据分析平台中最大的核心技术之一,而Hadoop框架技术对此功能就有着决定性的作用。
Hadoop框架的主要技术是:HDFS和MapReduce。Hadoop Distributed File System (HDFS) 是Hadoop集群中最根本的文件系统,有非常高的可扩展性和容错率,还有机架感知数据存储等能力,能够很容易地在计算机上部署。MapReduce是一个适合用于在集群上实现分布式管理海量数据的技术框架,它的最大的工作单元为job,而每一个job又可以分为map任务和reduce任务。最典型的MapReduce job就是在文档中统计单词出现的次数,过程如下图所示:

图1-1 MapReduce过程
除此之外,Hadoop框架还包括像ZooKeeper、Hive、Spark、Hbase等众多项目。
由于Hadoop的高可靠性、高扩展性、高效性和高容错性,这就使得它在很国内外都得到了广泛的应用。
在国内,百度、阿里巴巴、华为、腾讯等大公司都在应用Hadoop技术。百度拥有近十个Hadoop集群,拥有2800多个单集群的机器节点,数以万计的 Hadoop机器总数,拥有超100 PB的存储能力,目前正在使用的已经超过74 PB,每日提交的作业数数以千计,每天的数据量已经达到7500 TB以上,而输出的容量已经达到1700 TB以上。百度Hadoop集群为企业数据,搜索,社区产品,广告和 LBS群体提供了一个统一的数据和储存业务[1]。华为在Hadoop方面也有很大的成就,超过了谷歌和思科。华为已经在Hadoop HA和HBase方面进行了大量的研究,并且在Hadoop上发布了自己的Hadoop技术。同时,许多科研机构中也投入了Hadoop的应用和研究,包括清华大学、中科院、华中科技大学、浙江大学等[2]。
在国外,2012年3月,美国政府宣布了“大数据研究和发展计划”,这个计划里,六个联邦政府的部门和机构宣布新的2亿美元的投资,提高从大量数字数据中访问、组织、收集发现信息的工具和技术水平,并且认为这事关国家安全和未来的国际竞争力[3]。Yahoo,Facebook与IBM等大企业也一直在采用Hadoop技术,其中Yahoo可以说是是Hadoop最大的支持者,Yahoo的Hadoop机器共有42000个节点,而最大的一个主节点集群则拥有4,500个节点。该节点包括双通道四核心CPUboxesw,4x1TB硬盘,16 GB内存的总群集存储总量大于350 PB,超过一千万的月作业提交数[4]。他们也会针对自己的实际状况,对Hadoop进行优化,并建立自己的大数据平台,取得了很好的结果。
Hadoop技术是当今社会上较为成熟的大数据分析技术,但是Hadoop技术也在随着用户的需求而不断进行完善和调整。
1.4 研究内容
本文主要研究了电商数据,并设计与实现了数据分析系统。由于传统的数据分析方法在单机系统上的应用受到限制,因此,在处理大量的数据时,会对系统的性能产生很大的影响。通过对Hadoop大数据平台的相关技术的分析,提出了一种基于Hadoop的数据分析系统,该系统可以通过有效数据分析方法对数据进行分析,做出更好的商务决策。该方案利用Flume收集了客户在网络购买中所形成的大量的行为数据,然后再将数据保存在HDFS的中,采用MapReduce的计算架构进行了数据处理,通过Hive从多个维度进行数据的统计和分析。首先对Hadoop平台的关键技术展开了深入的研究,并在此基础上对整个体系做出了总体架构与模块规划,并对之展开了详尽的数据收集、数据处理、统计分析、用户推荐等功能,并对其进行了实验验证。
1.5 论文结构
本文的结构安排如下:
第1章主要阐述了本文的研究背景和意义,并对国内外的研究现状进行了梳理,最后总结了本文的主要内容。
第2章主要对电商分析系统的需求进行了分析,主要包括系统的功能和非功能需求,然后根据业务流程对整个系统进行了总体设计,主要包括架构设计、功能模块划分及处理流程等。
第3章主要根据电商分析系统的需求设计进行了实现,主要包括系统开发环境和各个模块的设计。
第4章主要对整体电商数据分析系统进行分模块搭建,按照前述内容中对系统涉及的描述来实现系统。
第5章主要对电商分析系统进行测试。
第6章进行了总结与展望,并指出其中的不足及需要改善的地方。
第2章 系统需求分析
2.1 系统需求概述
网络时代的到来,使得网络交易日益受到人们的重视,网络购物也逐渐成为人们最主要的消费方式。电子商业的发展必须要符合使用者的要求,让使用者可以在购物时更加便捷、更容易地发现自己所需的物品,更准确的将产品推向顾客的需求。这是一个电子商业系统的真实价值和利益的唯一途径。
在电子商务系统中,既要保证大部分使用者的存取、采购需要,又要生成大部分的使用者行为数据与管理系统的商业资料。用户的行为信息是指用户浏览、查看、加入购物车、收藏商品等所产生的记录信息。该记录数据也包含了大量的信息,如:点击时间,手机型号,渠道来源等。商业信息是由用户订单、付款状态、订单明细、用户明细等操作过程中所记录的商业信息。这种数据可能会出现在前端或后台的数据库中。你若能利用它,将会有很大的潜在能力。
要使信息的潜力得到最大程度的发挥,就必须建立起一个数据库。从信息收集过程开始,来自不同资源的信息被系统地收集并存储在数据仓库中。在大量数据仓储系统中,能够大部分数据进行高效的数据分析与储存运算。该数据仓库将为企业决策者、运营商、数据分析师等提供数据分析服务。为客户提供多种数据业务,满足客户对信息数据的需要。
这一章着重阐述了对电子商业的数据项目的要求,包括产品描述,功能结构设计,流程图设计,各模块功能和商业功能的描述和软件的开发。
对项目的要求说明也非常关键,它不但能使程序设计者更好地理解产品的需求,也能使软件工程师更好地理解其总体的商业过程。所以,需要在说明书中对其进行更详尽的系统的功能介绍。
2.2 功能需求分析
根据2-1图显示,数据仓储体系包括数据采集平台、数据计算平台、数据可视化等三大部分。
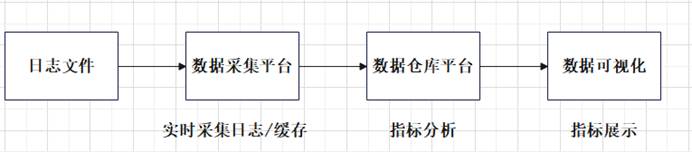
图2-1 数据仓库架构图
(1)用户功能数据采集:在大数据存储系统Hadoop中,将电子商务系统前台被埋点用户的行为数据收集,再次收集日志的时候,需要时间和缓存重新收集日志。
(2)数据仓库分析功能:Hive中的数据需要按层次来处理。分别保存,清除,合并,分解和统计。
最后条款如下所示:
- 对现阶段设备日、周和月的活动进行统计分析
- 每天新增的设备数量
- 沉默的顾客数量
- 每周返回的顾客数量
- 本周返回的顾客数量
- 保持比率
- 持续3个星期的活跃使用者人数
- 过去7个工作日中连续3个月活跃的人数
(3)可视化功能:在资料显示层面,首先要做的就是把最终的需求结果资料导入到MySQL中,或者在网页上显示这些数据资料。
2.3 非功能需求
实现数据仓储系统必须达到一下目的:
- 完整的技术方案、适当的架构和合理的服务分配
- 包括数据产生、数据收集和数据仓储模型在内的全面信息流程
- 能够处理大量的资料并进行查询
电子商业数据是对系统存储内部各部门的数据进行分析,并对其日常的业务进行统计和分析,从而在实施全过程中满足对产品的品质和性能的需求与限制。系统的性能要求直接关系到产品的品质,也直接关系到对功能要求的界定。对系统的要,以可靠性,可扩展性,易于使用为重点。
- 可靠性:由于数据收集可能存在有误,因此该系统的可靠性一定要高。在某些环节发生了故障,能够在故障发生的时候,立即发出故障信息,从而确保了之后的业务逻辑处理工作的正常运行。同时,系统的记录应该被存储,从而输出到文档中以便于使用者查阅。
- 可扩展性:Hadoop集群是分布式集群,随着技术的发展,Hadoopd的版本也在不断更新,因此常常会有更换新旧服务器的操作在应用过程中,运营商将会对其不断的改进,并添加新的服务,所以此系统一定要具有可扩展性。
- 易用性:相关的人员应当可以迅速地在设计系统中应用。
- 其他非功能性约束:编写代码的时候要对其整合,并增加一些必要的注解。
第3章 系统设计与技术选型
3.1 系统功能设计
在图中3-1显示,数据仓储系统包括数据采集平台、数据计算平台、数据可视化等三大部分。
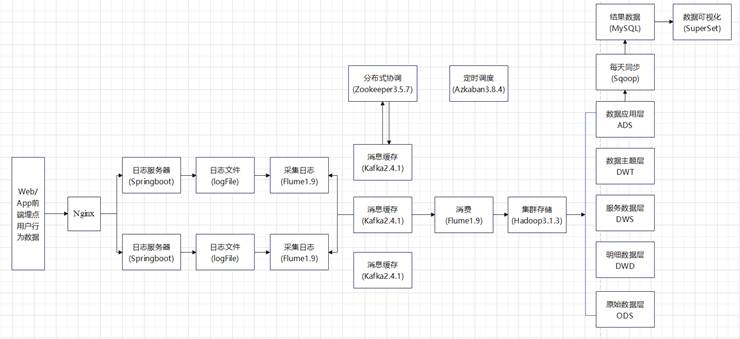
图3-1 数据仓库架构图
3.2 采集模块业务设计
在数据的获取与传送方面,该新项目的重点实现了三条:通过对网络服务器的实时记录,进行实时的数据采集,从而防止了数据丢失和数据阻塞。将数据从业务过程数据库中收集到数据库房,并将需求值导出到相关数据库以便于显示。所以,人们都选用Flume, Kafka, Sqoop。
Flume是一款高可用性、可靠、分布式和大数据收集的系统软件,它从不同的源数据系统软件中收集数据,并将其集中存储。Flume提供了许多不同的部件给使用者使用,不同的部件可以自由组合。该结构组合方式非常的灵活,能够满足用户对不同的数据收集和传送的需求。
Kafka是一种支持存储和高实时性能分布式系统的线性集群化服务平台。人们可以利用其在应用程序和解决方案之间实现高实时性和销售电价的流式数据存储,也可以提供流式应用软件的实时传送和反馈流式数据。
Sqoop是一种工具,它可以大量地从结构化数据到Hadoop,比如MySQL,Oracle。Sqoop的底层利用MapReduce程序实现抽取、转换、加载,MapReduce的固有特点确保了并行性和高的错误率,并且相对于Kettle这样的传统ETL工具来说,它在Hadoop集群上运行,降低了ETL服务器的资源利用率。在具体的情况下,提取过程的性能得到了极大的提高。
数据采集模块使用Flume来搜集储存在网络服务器资料库中的记录日志数据信息。此系统可以监视多个记录几个日志形成文件夹名字,如果中断了还可以继续传送。日志可以根据所收集的记录信息进行分类和整理,并将其传送给不同的 Kafka topic。作为一种消息中介,Kafka具备了日志缓冲功能,可以防止由于大量的并行读取和写入而导致HDFS的性能下降。同时也可以对Kafka的日志记录进行实时监测。客户Flume可以避免在HDFS下载过程中产生的小型数据库文件,从而降低运行速度,并采取适当的压缩策略来节省存储空间,减少互联网IO。
3.3 数仓业务设计
库存业务过程管理模块是通过分析从数据采集到的HDFS系统的数据,从而了解其内部组织的国际规范和运行规律,从而为相关人员提供决策参考。这一整个流程的实施,是基于对数据库进行高效分层的实现。分析工具选择Hive并配备Spark组件。
该数据库房的设计方法分为五个层次:
ODS层:初始数据层,最初的资料,最初的日志,数据即时加载,数据保持不变,不处理;
DWD层:详细数据层,结构和粒度分布与ODS级相同,能处理ODS数据(不含空值、脏数据和超限额数据);
DWS层:基于DWD的服务项目数据层,一般会对客户日、机器设备日、商店日、产品日等资料进行汇总。在这一层,一般都是以特定的维度为线索,形成宽表,例如:一位使用者当天的签到数、收藏、评论、抽奖、点击等等组成的多列表。
DWT层:基于数据层,将DWS层面的资料按照专题进行汇总,并建立完整的专题表格。
ADS层:数据应用层,还有一些人称之为 APP, DAL, DM,等等,各种各样的名称。针对数据的真实需要,各类数据报告包括 DWD、DWS和DWT三个层次,最后将统计数据与MySQL等相关数据库进行数据的实时处理。
根据ADS层的数据,选取MySQL创建相应的数据表,通过Sqoop向MySQL输出数据,最后,通过Superset对此数据进行可视化。
3.4 技术选型
系统结构的选取需要满足我们建立仓库服务平台的主要需求。作用上没有任何限制,每个国家的资源和社区尽可能丰富一点,包括各项目的成熟度和普及度要高。选取的发布内容是这样的:
Apache:运行管理过于麻烦,组件之间的兼容必须自己研究(第二选择);
CDH:并非开放源码的系统,不必顾及到组件之间的兼容问题,所以在中国使用的比较少见。
HDP:开源系统,但没有CDH稳定,国内使用的也很少。
经过深思熟虑之后,我们最终决定采用Apache的大数据架构。我们可以根据自己的需求对其进行个性化设计;而CDH和HDP的两个不同的是,它们的系统结构比较广泛,服务器的配置也比较高。这个新的项目使用的组件很少,所以原始的版本Apache可以达到基本要求。
版本选型如图3-1所示:
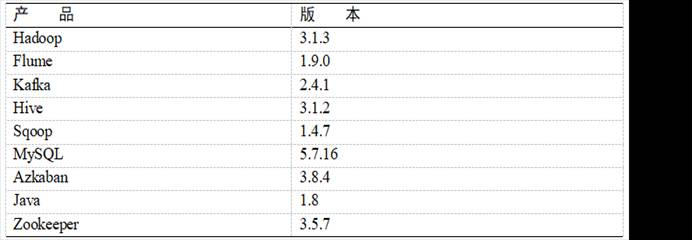
图3-2 版本选型
此外在哪个服务器上安装软件,必须遵守三个原则:
- 尽可能分开内存消耗软件
- 将更多的数据集中在一个服务器上,如Kafka,Flume,Zookeeper
- 为了便于外界的访问,客户端尽可能放置在一两个服务器上
如图3-3所示,每台服务器所需要的服务:
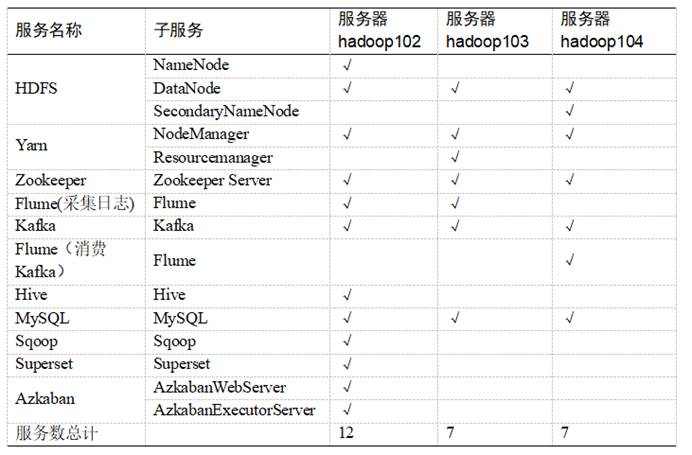
图3- 3 服务器节点
第4章 系统实现
4.1 采集模块实现
利用前端埋点技术,将网页的浏览数据汇总到后台的记录服务中。收集模块的任务是迅速地搜集用户阅读记录传送到Hadoop。
此系统用Flume来读取记录,然后把它传送到Kafka。
Kafka在这个项目中的作用就为了防止诸如双11和618这样重大的节假日期间发生的流量高峰,从而对整个系统造成一定的干扰。
利用 Flume来读取kafka的信息,然后将其上载至Hadoop。使用Flume的原因是因为其简单、易实施的结构。
Hadoop在本项目中可大量存储数据。
如图4-1所示,本系统的采集模块设计思路为:
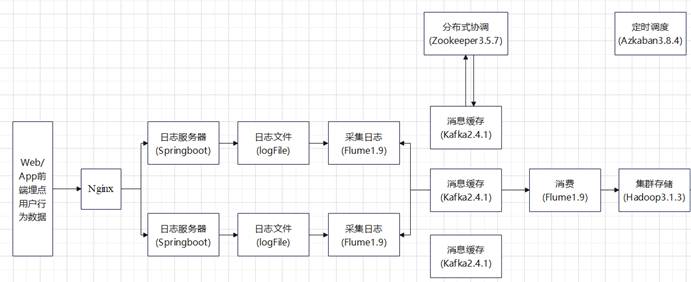
图4-1 采集模块设计
4.1.1 Hadoop安装部署
Hadoop在该项目中可大量储存资料数据,也是该收集组件的重要组成部分。接下来对Hadoop集群进行配置讲解。
Hadoop集群建立时,Hadoop在每个节点上的组态都是一样的,只要在Hadoop102上执行就可以了,然后再把本配置同传至其他两个节点。
- 将Hadoop安装程序hadoop-3.1.3.tar.gz通过XFTP上载到/opt/module文件夹,这个目录被用来保存系统搭建时的压缩文件。
- 解压并安装hadoop在根目录下的opt/module文件夹内。
- 使用Hadoop相关命令可直接在环境变量中增加hadoop,不再需要指明详细路径。取得其文件目录:修改根目录下的etc/profile文件,保存以后再执行source命令,修改完成的profile文件会立即生效。
- 五个内核文件的配置方法:
- 核心文档core-site.xml包含了NameNode地址、分布式系统入口地址和其数据存储至服务器上。
- hdfsite. xml文件主要用于对HDFS系统文本属性进行配置。
- yarn-site.xml文件主要用于对YARN的主要参数进行配置。
- Mapred-site.xml文件主要说明了MapReduce的执行结构。
- 修改workers文件的内容,选用三个联接位置作为附属联结位。
- 将已配置的Hadoop文件分配到集群上的其他机器上。
- 确保配置完成后,启动Hadoop集群,并进行相关测试。
如果是首次使用群集,需将Namecode格式化处理。在带有namenode的结点中,执行start-dfs.sh指令可开始全部datanode和SecondaryNode节点的工作和启动HDFS。通过使用start-yarn.sh来开始 yarn,命令ResourceManager和所有Nodemanager节点的运行。注意:如果NameNode和ResourceManager不在同一台计算机上,那么yarn就不能在NameNode上运行。
4.1.2 Zookeeper安装部署
Zookeeper的作用是记录Kafka行为日志。因为Kafka被用作为数据缓冲带,所以必须装上Zookeeper以确保 Kafka的工作。
装配步骤如下:
- 解压Zookeeper到根目录下的opt/module/目录下。
- 新建ZkData文件夹,储存其数据资料。
- 将根目录下opt/module/zookeeper-3.4.10目录下的zoo_sample.cfg文件重命名为zoo.cfg,并进行配置。把datadir更改为zkData文件地址。
- 新建myid在zkData文件中,当集群运行时,Zookeeper会自动读取该文档。
- 修改myid文件,把服务器相应序号写入其中,并按照所设置的服务器id和ip作对应的添入,如hadoop102+2
- 将已设定好的zookeeper拷贝到另一台计算机上,在三个结点上分别运行zookeeper。
4.1.3 Kafka安装部署
Kafka为一个分布式信息队列,基于的是发布/订阅形式。该系统启用数据资料缓冲方法,提高了Hadoop的上传速率,保证了搜集功能的安全性。
安装方法步骤如下所示:
- 解压安装程序到相应的文件夹下:/opt/module/,为方便后续操作,将其重命名为kafka。
- 在/opt/module/kafka目录下新建logs文件。
- 在/opt/module/kafka/conf/server.properties中加入重要参数。
- 将已经配置完成的kafka的安装程序分发到其他的Node节点上,并在三个服务器上运行kafka
4.2 数据分析调度模块实现
4.2.1 MySQL安装部署
行为分析系统是对使用者的需求进行分析之后,得到最终数据,并将其可视化地展示出来。显然,将海量的结果数据呈现在大数据的系统文档中是非常不便的。应将所有的数据导入进数据库中,本系统选择MySQL作为数据库,用来存储这些数据。
(1)安装包准备:使用rpm指令检测电脑安装MySql的情况,-q为query,-a为all,本方法可查找到所有的安装程序。如有,则可先将其卸载。将数据库文件压缩包mysql-libs. zip通过XFTP传到/opt/module/下,并将其解压到当前位置。
(2)安装MySQL服务器:使用rpm指令来装配MySQL,当服务器被安装之后,会产生一个预设的随机口令,这个口令储存在/root/.mysql_secret中。Root使用者可通过cat指令或sudo cat查看,数据库登录后应立即修改口令。用root或sudo检查MySQL服务的运行状态,可以看到MySQL有没有运行。
4.2.2 Hive安装部署
Hive装配步骤如下:
- 将文件Hive解压至指定文件夹中,以此来对系统的参数内容进行调整,并运行调试。
- 解压/opt/module/mysql-libs目录下的Mysql驱动文件,并将该目录下的jar包拷贝到/opt/module/Hive/lib下,运行Hive并使用它连接MySql。
- 在/opt/module/hive/conf目录下新建一个hive-site.xml文件,根据开发文档配置相应参数,将资料信息拷贝到hive-site. xml文件中。
- 打开MySQL,新建了一个Hive元数据库,并复位这个库。
- 在确保参数配置正确后,运行Hive,并进行调试。
4.2.3 Azkaban安装部署
Azkaban的装配步骤如下:
- 将Azkaban的网页服务器、运行服务器、sql运行脚本和MySQL安装文件拷贝至VM中hadoop102的/opt/module/文件夹下。
- 将Azkaban的网页服务器、运行服务器和sql运行脚本解压至同一个文件夹下,以及修改其文件夹名称。
- 打开MySQL,创建 Azkaban数据库,把解压过后的代码通过相关操作输入到Azkaban库中。
- keystore会被自动产生,会产生 keystore密钥和相应的 keystore资料,然后把keystore拷贝到Azkaban Web服务器的原始路径下。
- 使用cd指令到Azkaban Web服务器文件中的conf文件夹,然后打开azkaban.properties,并修改这个文件。
- WEB服务器使用者设定:将目录conf目录安装到Azkaban Web服务器,并将azkaban-users. xml文件进行更改,并新增管理使用者。
- 使用vi指令打开azkaban.properties,并对这个文件进行相关的参数配置。
- 将参数配置完成并保存以后,运行executor服务器,在Executor服务器文件夹中点击应用程序使它运行。
4.3 数仓模块实现
4.3.1 数仓搭建-ODS层
ODS层是基础存储数据信息的数仓模块。为了方便备份,应保存原有的资料,不要作任何改动。为了减小硬盘的存贮容量,本文采用LZO的压缩方式。建立分区表格,可以避免以后查找表格时对整张表格进行检查。建立一个用于保存电商仓储工程的全部数据的数据库,然后再引入ODS层的数据。

图4-2 创建ODS层
4.3.2 数仓搭建-DWD层
DWD数仓的工作是对ODS层进行数据过滤,减少产品类表的层级,采用 parquet和LZO的形式进行存储、压缩,降低使用容量。
为方便以后的数据处理、剖析工作,我们应该把记录分成五张表:启动、页面、动作、曝光和错误。

图4-3 创建DWD层
按照图4-3的建表方式,分别创建页面日志、动作日志、曝光日志和错误日志四张表,并数据导入进去。
4.3.3 数仓搭建-DWS层
DWS数仓,也就是数据资料汇集层,它以一个广度表格的形式生成了一个统计分析级的公用指标。从不同角度收集、整理资料,获取每日各个话题的相关数据资料。
用户的个人记录分析是基于每天活跃的用户、每周活跃的用户、每日新增的用户为指标。根据使用者行为的DWD数仓操作记录表,通过设备ID进行统计,得到DWS数仓的设备个体行为操作表单。
在数据汇总期间,使用concat_ws函数将聚集字段进行联结,以避免丢失详细资料。如果这些特定的资料在未来的发展过程中需要用到,那么可以使用爆炸函数来重新得到。
使用mid_id标识符对设备使用的个体操作记录进行分类和统计学分析。

图4-4 创建DWS层
4.3.4 数仓搭建-DWT层
在DWS数仓的搭建过程中,运营人员每天都会收集不同的主题,每天都会得到关于每个主题的准确的数据和资料。在DWT层面,开发者将会对每个不同的话题进行总结,并对每个话题进行详尽的数据解析,并制作出分析表给到运营人员。
DWT数仓层主题类型表单将记录哪关键信息?
与各个层次紧密联系的不同表单指标,包含首条、末条和截止当前所累积的指标,以及在一定时间段内的累计指标。
DWT数仓的设备主题表单将在每日设备个体操作记录表单里再次得到汇总和分析以此得到与每台设备更对应的详细数据。新加入的设备资料每天都会添加到主题列表中,还包括首次活动日期、以前活动日期、每日主题活动次数、总次数等数据,汇总这些数据,有利于后续相关设备规范的制定。

图4-5 创建DWT层
第5章 系统测试
库房的数据统计分析通道测试可以根据数据统计分析脚本制作得到结果数据信息。此章关键测试相应客户个人行为数据分析平台。依据数据流分析次序,最先测试收集通道,测试数据信息是不是能正常的从服务器的下载文件夹中收集并下载到HDFS系统文件。最终测试Azkaban调度通道,测试全部系统服务是不是可以根据Azkaban开展调度。
5.1 集群启动
- 使用终端模拟系统Xshell来连接虚拟机:

图5-1 账户相关参数
- 相关的脚本如图5-2所示,每个脚本都包含启动和关闭:

图5-2 相关脚本
- 使用脚本mycluser.sh群起大数据集群,启动后使用jps指令查看服务,每台服务器所需服务大致如图5-3所示:
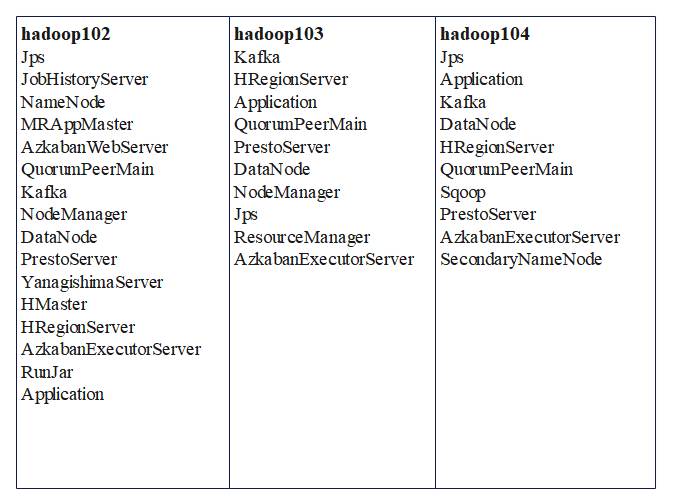
图5-3 服务器相关服务
5.2 Azkaban全程调度
- 输入URL:http://hadoop102:8081/,并且使用已设定的用户名称和密码进行登录操作Azkaban:
- 账号:atguigu
- 密码:atguigu
图5-4 Azkaban登录界面
- 打开数仓流程Project:gmall
图5-5 Azkaban项目
- 总共有6个需要进行处理的作业任务(5个主题+1个全部)
图5-6 项目作业任务
- 点击Execute Flow查看详细任务流展示
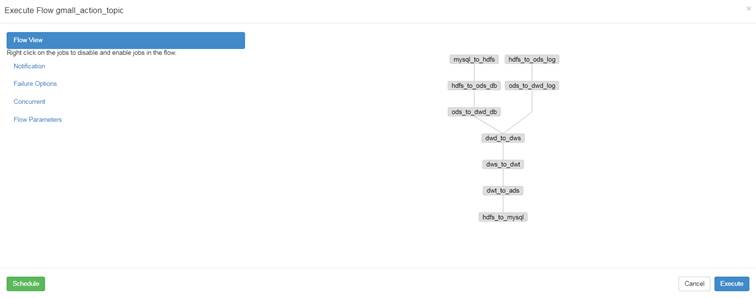
图5-7 详细任务流
- 点击Flow Parameters执行任意项目时,需要加入dt参数,并点击Excute开始执行任务
图5-8 添加相应参数
- 执行成功
图5-9 执行结果
5.3 SuperSet报表可视化
- 输入URL:http://hadoop102:8787/,并使用已设定的用户名称和密码以登录SuperSet
- 账号:atguigu
- 密码:atguigu
图5-10 SuperSet登录界面
- SuperSet分为五个主题
图5-11 SuperSet看板
- 单击主题模块,获取可视化数据表单
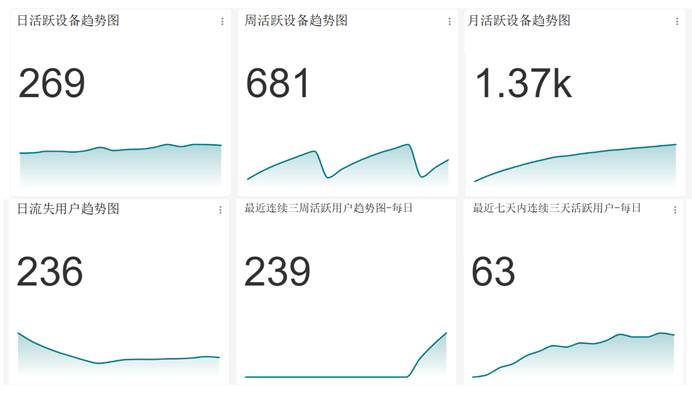
图5-12 用户行为数据图
如图5-12所示,使用SuperSet得到了日活跃趋势图、周活跃趋势图、月活跃趋势图等七个分析图。由日流失用户趋势图可知,每天流失的用户数正在逐渐的减少,网站的损失的趋势得到了缓解。
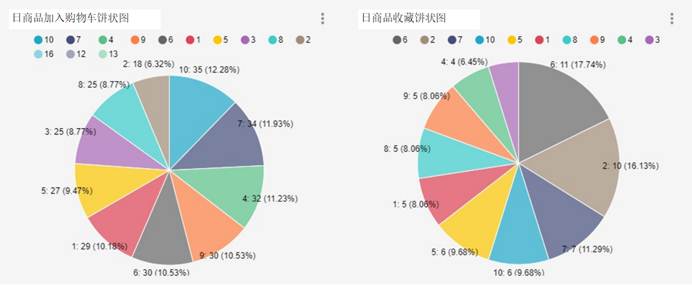
图5-13 日商品情况
如图5-13所示,按照商品代号来分析商品日加入购物车数、日收藏数,并以饼状图的形式展示出来,可以更直观的让管理者看到各种商品的占比,以此分析出那种商品更受大众的喜爱。

图5-14 日商品销售情况
如图5-14所示,我们以2020年6月14日商品的订单数与销售额为例,以中国地图的形式来进行可视化分析。可以很清晰地看出各地的销售额和订单数的差别,让管理者可以对各省份的商品投放数和投资有一定的区分。
第6章 总结与展望
在当今的商业信息化时代,“数据说话”的理念日益深入人心,通过对数据的分析,帮助公司开展业务运营和销售的决定。传统的资料处理方式存在弊端,难以进行科学、高效的研究与处理。数据信息有许多种方式,数据的复杂程度会造成数据的数据融合难度增大,数据的存储容量和数据的检索效率都很低,而且以单台计算机为基础的数据分析方法存在着诸多缺陷,仅能处理小规模、标准化数据,运算速度较慢,难以深入挖掘。公司应当应用合理的数据分析方法来做出商业决策。
本课题对所需的技术进行了深入的理论探讨。主要内容软件有:HDFS MapReduce计算框架、 YARN资源管理、Flume、Kafka、Hive等。
在此基础上,对数据分析系统中电商数据的处理功能要求及体系结构进行了设计,并给出了总体结构和流程,并将其划分为数据采集、数据分析、数据显示三大模块。这些资料表明Superset用于可视化不同的指标:柱形图、饼状图、折线图以及中国地图。
还建立了整个系统收集安全通道,数据仓库和可视化系统。实验结果表明,该系统是可行的,可靠的,正确的。电商数据分析系统能够很好地解决传统数据分析方法的不足,能够对大量的数据进行存储,从而改善用户的查询效率。该系统能够对海量的数据进行有效的挖掘,能够对企业的经营状况进行有效的分析,具备综合分析公司业务情况的能力,从而对其进行商业决策和市场战略做出正确的判断。
上述内容本论文的工作重点。因为精力和时间的限制,仍有许多方面有待改进和深化:
- 因时间限制,仅对使用者的行为进行了分析,而对商业资料的处理则有待后续的补充。
- 本计划将会引进元数据的管理及品质监测。提高项目的完善。
- 考虑添加即时询问和快速询问的能力。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 27
27 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)