一文读懂现代卷积神经网络—含并行连结的网络(GoogLeNet)
核心思想将不同的卷积层通过并联的方式结合在一起,经过不同卷积层处理的结果矩阵在深度这个维度拼接起来,形成一个更深的矩阵。通过这种方式对网络的深度和宽度进行高效扩充,在提升深度学习网络准确率的同时防止过拟合现象的发生。结构特点多尺度卷积核:通常使用 1×1、3×3、5×5 等不同尺寸的卷积核,增加了网络对不同尺度的适应性。小卷积核(如 1×1)可捕捉精细细节并降维,大卷积核(如 3×3、5×5)有助
·
目录
AlexNet、VGG、NIN 和 GoogLeNet 四种经典卷积神经网络(CNN)的详细对比
什么是含并行连结的网络GoogLeNet
GoogLeNet 是谷歌推出的基于 Inception 模块的深度卷积神经网络,也称为 Inception v112。它在 2014 年的 ImageNet 图像识别挑战赛中取得了冠军,top-5 误差为 6.7%。以下是对它的详细介绍:=
- 核心结构:
- Inception 模块:这是 GoogLeNet 的关键组成部分,采用并行结构。它将不同大小的卷积核(1x1、3x3、5x5)和池化操作(通常是 3x3 的最大池化)的结果进行拼接,从而捕捉不同尺度的特征。在 Inception 模块中,1x1 卷积核主要用于降维和跨通道特征变换,以减少计算量和参数数量。
- 全局平均池化:GoogLeNet 在网络的最后采用了全局平均池化层,取代了传统的全连接层。全局平均池化层对每个特征图进行平均操作,生成一个单一的数值作为该特征图的输出,这样做不仅减少了参数数量,还提高了模型的泛化能力。
- 辅助分类器:GoogLeNet 在网络中加入了两个辅助分类器,分别位于网络的中间部分。这些辅助分类器在训练过程中与主分类器共同学习,有助于缓解梯度消失问题,并提高模型的训练稳定性,在测试时,这些辅助分类器的输出会被忽略。
- 模型特点:
- 模块化设计:采用了模块化的设计思想,Inception 模块作为基本的构建块,可以方便地进行堆叠和组合,形成更深的网络结构。
- 参数效率高:尽管 GoogLeNet 的网络结构相对复杂,但由于 Inception 模块的参数共享和 1x1 卷积核的降维作用,使得整个网络的参数数量相对较少,约为 1500 万。这使得 GoogLeNet 在保持高性能的同时,也具有较高的计算效率。
- 多尺度特征提取:通过并行使用不同大小的卷积核和池化操作,Inception 模块能够提取不同尺度的特征,这种多尺度特征提取的能力使得 GoogLeNet 在处理复杂图像时更具优势。
- 应用领域:GoogLeNet 在计算机视觉领域具有广泛的应用,可用于图像分类、物体检测、图像分割等多种任务。
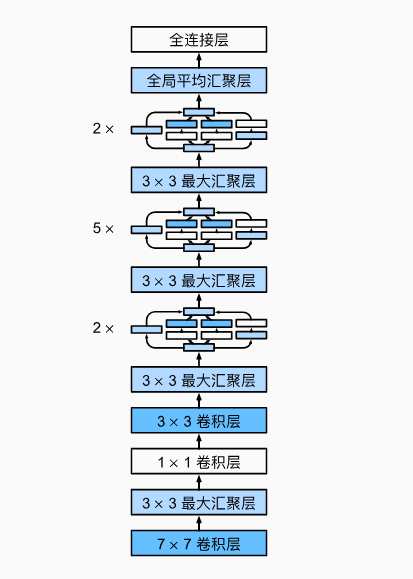
GoogLeNet模型结构
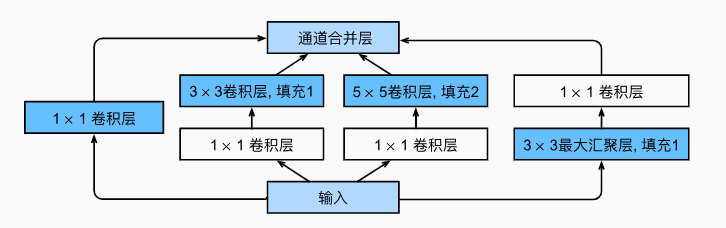
什么是Inception模块
Inception 模块介绍
- 核心思想:将不同的卷积层通过并联的方式结合在一起,经过不同卷积层处理的结果矩阵在深度这个维度拼接起来,形成一个更深的矩阵。通过这种方式对网络的深度和宽度进行高效扩充,在提升深度学习网络准确率的同时防止过拟合现象的发生。
- 结构特点:
- 多尺度卷积核:通常使用 1×1、3×3、5×5 等不同尺寸的卷积核,增加了网络对不同尺度的适应性。小卷积核(如 1×1)可捕捉精细细节并降维,大卷积核(如 3×3、5×5)有助于识别更广泛的结构或模式。
- 降维操作:引入 1×1 卷积核对输入进行降维,减少运算量。例如在进行 5×5 卷积前,先使用 1×1 卷积降低通道数,再进行 5×5 卷积,这样可在保持感受野的同时减少参数和计算量。
- 池化层:模块中通常包含一个并行的池化分支,一般为 3×3 的最大池化,进一步提取特征并减小特征图的空间尺寸,提高计算效率和减少过拟合风险。
- 特征拼接:将不同卷积核和池化操作的输出在通道维度上进行拼接,然后输入到下一层,使后续层能够获取不同尺度提取的特征。
Inception 模块的应用
- 图像分类:Inception 模块可作为图像分类网络的基础组件,如 GoogLeNet 利用 Inception 模块在 ImageNet 数据集上取得了很好的分类效果,能够准确区分不同种类的动物、植物、交通工具等。
- 目标检测:在基于深度学习的目标检测框架中,如 Faster R-CNN 等算法,可以用包含 Inception 模块的网络作为特征提取器,利用其提取的多尺度特征来定位和识别图像中的目标物体。
- 其他视觉任务:还可应用于图像分割、人脸识别等多种计算机视觉任务,为这些任务提供强大的特征提取基础。此外,Inception 模块的网络模型常用于迁移学习,可在预训练模型基础上,微调特定任务的数据,以快速提升新任务的性能。
Inception模块的架构
AlexNet、VGG、NIN 和 GoogLeNet 四种经典卷积神经网络(CNN)的详细对比
对比维度 AlexNet(2012) VGG(2014) NIN(2013) GoogLeNet(2014) 网络深度 8 层(5 个卷积层 + 3 个全连接层) 11-19 层(以 16 层、19 层为代表,均为卷积层 + 3 个全连接层) 约 12 层(含 mlpconv 层,无传统全连接层) 22 层(含 Inception 模块,无传统全连接层) 核心设计理念 首次将深度学习大规模应用于图像识别,验证 CNN 的有效性 通过堆叠小卷积核(3×3)加深网络,探索 “深度对性能的提升” 提出 “网络 - in - 网络”(Network in Network),用卷积模拟全连接以增强特征抽象能力 引入并行连结(多尺度特征融合),在提升精度的同时控制计算成本与参数规模 核心结构单元 重叠池化(3×3,步长 2)、ReLU 激活函数、Dropout(全连接层) 仅使用 3×3 卷积(多次堆叠替代大卷积核)、2×2 最大池化,结构高度统一 mlpconv 层(卷积后接 1×1 卷积,模拟 “卷积 + 全连接”,替代传统全连接层)、全局平均池化 Inception 模块(并行路径:1×1、3×3、5×5 卷积 + 3×3 池化,通过 1×1 卷积降维)、全局平均池化 参数数量 约 6000 万 16 层约 1.38 亿,19 层约 1.44 亿(参数集中在全连接层,规模庞大) 约 2900 万(mlpconv 层减少参数,但多于 GoogLeNet) 约 1500 万(通过 1×1 卷积和全局池化大幅压缩参数,仅为 AlexNet 的 1/4、VGG 的 1/10) 计算复杂度 中等(相比后续网络较低,适合早期 GPU 训练) 高(大量 3×3 卷积堆叠,计算量随深度急剧增加) 中等(mlpconv 层计算量低于 VGG,但高于 GoogLeNet) 较低(Inception 模块高效分配计算资源,并行路径平衡多尺度特征提取与计算效率) 过拟合缓解策略 Dropout(全连接层,概率 0.5)、数据增强(翻转、裁剪等) 数据增强、Dropout(全连接层) 全局平均池化(替代全连接层减少参数)、Dropout 全局平均池化(减少参数)、辅助分类器(中间层分支,缓解梯度消失,增强泛化) ILSVRC 竞赛表现 top-5 误差 15.3%(首次让 CNN 超越传统方法,夺冠) top-5 误差 7.3%(亚军,精度显著高于 AlexNet,但计算成本高) 未参与竞赛,在 CIFAR 等数据集上验证了有效性(如 CIFAR-10 错误率 8.8%) top-5 误差 6.7%(冠军,精度最高且参数 / 计算量最低,实现 “精度与效率双赢”) 创新贡献 1. 首次将 ReLU、Dropout 用于 CNN;
2. 引入 GPU 加速训练;
3. 证明深度学习在视觉任务的潜力1. 验证 “小卷积核堆叠等价于大卷积核”(如 2 个 3×3≈1 个 5×5);
2. 推动网络向 “更深” 发展1. 用 1×1 卷积模拟全连接,提出 mlpconv 层;
2. 推广全局平均池化替代全连接层1. 提出并行连结的 Inception 模块,实现多尺度特征融合;
2. 用 1×1 卷积高效降维;
3. 去除传统全连接层,大幅减少参数局限性 网络较浅,特征提取能力有限;全连接层参数占比高 参数和计算量过大,实用性受限(如难以部署到移动端) mlpconv 层设计较复杂,训练稳定性不如后续网络 Inception 模块结构较复杂,工程实现难度高于 VGG 等 “单路径” 网络 典型应用场景 早期图像分类、基础特征提取任务 需高精度但可接受高计算成本的场景(如图像分割预处理、学术研究) 轻量化特征提取、小数据集任务(减少参数过拟合风险) 资源受限场景(如移动端、嵌入式设备)、需平衡精度与效率的工业级任务 关键差异总结:
- AlexNet是 CNN 的 “奠基者”,证明了深度学习在视觉任务的价值,但结构简单,性能有限。
- VGG以 “深度优先” 为核心,通过统一小卷积核设计提升精度,但代价是参数和计算量激增。
- NIN开创 “卷积替代全连接” 的思路,为网络轻量化提供了理论基础,但实际性能未超越同期竞赛模型。
- GoogLeNet通过并行连结(Inception 模块)实现了 “精度、效率、参数规模” 的平衡,是后续轻量级网络(如 MobileNet)的重要灵感来源。
完整代码
"""
文件名: 7.4 含并行连结的网络(GoogLeNet)
作者: 墨尘
日期: 2025/7/13
项目名: dl_env
备注: 实现GoogLeNet网络架构,解决了Matplotlib符号显示问题
"""
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 手动显示图像相关库
import matplotlib.pyplot as plt # 绘图库
import matplotlib.text as text # 用于修改文本绘制(解决符号显示问题)
# -------------------------- 核心解决方案:解决文本显示问题 --------------------------
# 定义替换函数:将Unicode减号(U+2212,可能导致显示异常)替换为普通减号(-)
def replace_minus(s):
"""
解决Matplotlib中Unicode减号显示异常的问题
参数:
s: 待处理的字符串或其他类型对象
返回:
处理后的字符串或原始对象(非字符串类型)
"""
if isinstance(s, str): # 判断输入是否为字符串
return s.replace('\u2212', '-') # 替换特殊减号为普通减号
return s # 非字符串直接返回
# 重写matplotlib的Text类的set_text方法,解决减号显示异常
original_set_text = text.Text.set_text # 保存原始的set_text方法
def new_set_text(self, s):
"""
重写后的文本设置方法,在设置文本前先处理减号显示问题
"""
s = replace_minus(s) # 调用替换函数处理文本中的减号
return original_set_text(self, s) # 调用原始方法设置文本
text.Text.set_text = new_set_text # 应用重写后的方法
# -------------------------- 字体配置(确保中文和数学符号正常显示)--------------------------
plt.rcParams["font.family"] = ["SimHei"] # 设置中文字体(支持中文显示)
plt.rcParams["text.usetex"] = True # 使用LaTeX渲染文本(提升数学符号显示效果)
plt.rcParams["axes.unicode_minus"] = True # 确保负号正确显示(避免显示为方块)
plt.rcParams["mathtext.fontset"] = "cm" # 设置数学符号字体为Computer Modern(更美观)
d2l.plt.rcParams.update(plt.rcParams) # 让d2l库的绘图工具继承上述字体配置
class Inception(nn.Module):
"""
Inception模块:GoogLeNet的核心组件,通过并行多尺度卷积操作捕获不同粒度的特征
数学表达式:
Output = Concat(ReLU(W1 * X), ReLU(W3 * (ReLU(W1_3 * X))),
ReLU(W5 * (ReLU(W1_5 * X))), ReLU(Wp * (Pool(X))))
其中:
- X: 输入张量 [batch_size, in_channels, height, width]
- W1: 1x1卷积权重
- W1_3: 3x3卷积前的1x1降维卷积权重
- W3: 3x3卷积权重
- W1_5: 5x5卷积前的1x1降维卷积权重
- W5: 5x5卷积权重
- Wp: 池化后的1x1卷积权重
- Concat: 在通道维度上的拼接操作
"""
# c1--c4是每条路径的输出通道数
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
"""
初始化Inception模块
参数:
in_channels: 输入通道数
c1: 路径1(1x1卷积)的输出通道数
c2: 路径2(1x1+3x3卷积)的通道数元组 (降维通道数, 输出通道数)
c3: 路径3(1x1+5x5卷积)的通道数元组 (降维通道数, 输出通道数)
c4: 路径4(池化+1x1卷积)的输出通道数
"""
super(Inception, self).__init__(**kwargs)
# 线路1,单1x1卷积层:捕获局部特征,减少通道数
# 1x1卷积的优势:
# 1. 实现跨通道信息交互
# 2. 有效减少参数量:参数量 = in_channels * c1 * 1 * 1
# 3. 通过调整输出通道数实现降维或升维
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1x1卷积层后接3x3卷积层:多尺度特征提取
# 先使用1x1卷积降维,再使用3x3卷积捕获空间特征
# 参数量 = in_channels * c2[0] * 1 * 1 + c2[0] * c2[1] * 3 * 3
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1) # padding=1保持特征图尺寸不变
# 线路3,1x1卷积层后接5x5卷积层:捕获更广泛的上下文信息
# 同样先降维,再使用5x5卷积捕获大尺度特征
# 参数量 = in_channels * c3[0] * 1 * 1 + c3[0] * c3[1] * 5 * 5
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2) # padding=2保持特征图尺寸不变
# 线路4,3x3最大汇聚层后接1x1卷积层:保留关键特征并调整通道数
# 池化操作可以提取显著特征并减少空间尺寸
# 1x1卷积用于调整通道数,使输出能够与其他路径拼接
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1) # stride=1保持尺寸不变
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, x):
"""
前向传播函数
参数:
x: 输入张量 [batch_size, in_channels, height, width]
返回:
拼接后的特征张量 [batch_size, c1+c2[1]+c3[1]+c4, height, width]
"""
# 各路径前向传播并应用ReLU激活
# ReLU激活函数:f(x) = max(0, x),引入非线性特性
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x)))) # 1x1卷积后接3x3卷积
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x)))) # 1x1卷积后接5x5卷积
p4 = F.relu(self.p4_2(self.p4_1(x))) # 池化后接1x1卷积
# 在通道维度上连结所有路径的输出
# 拼接后的通道数 = c1 + c2[1] + c3[1] + c4
return torch.cat((p1, p2, p3, p4), dim=1)
if __name__ == '__main__':
# 第一个模块:使用大卷积核(7x7)捕获低级特征
# 输入图像尺寸:[batch_size, 1, 96, 96](Fashion-MNIST数据集调整为96x96)
# 7x7卷积,步长2,padding=3:
# 输出尺寸计算:(96 + 2*3 - 7)/2 + 1 = 48
# 输出形状:[batch_size, 64, 48, 48]
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.ReLU(), # 激活函数引入非线性
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)) # 池化操作降采样,输出形状:[batch_size, 64, 24, 24]
# 第二个模块:使用1x1卷积降维,然后3x3卷积增加通道数
# 1x1卷积不改变空间尺寸,仅调整通道数:64 -> 64
# 3x3卷积,padding=1保持空间尺寸不变,通道数增加到192
# 最大池化后输出形状:[batch_size, 192, 12, 12]
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第三个模块:串联两个Inception块,逐步增加通道数
# 第一个Inception块:输入通道192,输出通道64+128+32+32=256
# 第二个Inception块:输入通道256,输出通道128+192+96+64=480
# 最大池化后输出形状:[batch_size, 480, 6, 6]
b3 = nn.Sequential(Inception(192, 64, (96, 128), (16, 32), 32),
Inception(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第四模块:串联5个Inception块,逐步增加网络复杂度
# 每个Inception块的通道配置不同,逐步增加特征表达能力
# 最终输出通道数:256+320+128+128=832
# 最大池化后输出形状:[batch_size, 832, 3, 3]
b4 = nn.Sequential(Inception(480, 192, (96, 208), (16, 48), 64),
Inception(512, 160, (112, 224), (24, 64), 64),
Inception(512, 128, (128, 256), (24, 64), 64),
Inception(512, 112, (144, 288), (32, 64), 64),
Inception(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
# 第五模块:包含两个Inception块,最后使用全局平均池化
# 最终输出通道数:384+384+128+128=1024
# AdaptiveAvgPool2d将任意尺寸的特征图池化为1x1
# Flatten将多维张量展平为一维向量:[batch_size, 1024, 1, 1] -> [batch_size, 1024]
b5 = nn.Sequential(Inception(832, 256, (160, 320), (32, 128), 128),
Inception(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1, 1)), # 全局平均池化,对每个通道取平均值
nn.Flatten()) # 将多维张量展平为一维
# 完整网络:连接所有模块并添加最终分类器
# 线性层将1024维特征映射到10个类别(对应Fashion-MNIST的10个类别)
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
# 演示各个模块输出的形状变化
print("网络各层输出形状:")
X = torch.rand(size=(1, 1, 96, 96)) # 创建一个测试输入,批次大小为1,通道数为1,高度和宽度为96
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
# 训练模型
lr, num_epochs, batch_size = 0.1, 10, 128
# 加载Fashion-MNIST数据集,调整图像大小为96x96以适应网络输入
# Fashion-MNIST原始图像尺寸为28x28,调整为96x96以匹配GoogLeNet的输入要求
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
# 使用d2l库的训练函数训练模型,并在GPU上运行(如果可用)
# train_ch6函数实现了完整的训练循环,包括前向传播、反向传播、参数更新等
# 参数说明:
# - net: 待训练的网络模型
# - train_iter: 训练数据迭代器
# - test_iter: 测试数据迭代器
# - num_epochs: 训练轮数
# - lr: 学习率
# - device: 训练设备(GPU或CPU)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show(block=True) # 保持图像窗口打开,直到手动关闭补充说明
Inception 模块设计思想:
- 并行多尺度卷积捕获不同大小的特征,模拟人类视觉系统
- 1x1 卷积通过降维显著减少参数量,例如:
- 5x5 卷积前使用 1x1 卷积:参数量从
减少到- 特征拼接实现不同尺度信息的融合,增强模型表达能力
GoogLeNet 整体架构特点:
- 逐步增加网络复杂度:从大卷积核到 Inception 模块,特征通道数逐步增加
- 全局平均池化替代全连接层:
- 减少约 1000 万个参数(相比 AlexNet)
- 降低过拟合风险,提高模型泛化能力
- 原始 GoogLeNet 包含辅助分类器(本实现未包含),用于中间层监督训练
训练与优化:
- 使用 Fashion-MNIST 数据集(10 个类别,图像尺寸调整为 96x96)
- 学习率 0.1,批次大小 128,训练 10 个轮次
- 随机梯度下降(SGD)优化器(d2l.train_ch6 函数内部实现)
- 数据增强:调整图像大小、随机裁剪等(d2l.load_data_fashion_mnist 函数内部实现)
性能分析:
- 参数量:约 1500 万(仅为 AlexNet 的 1/4,VGG 的 1/10)
- 计算效率:Inception 模块通过 1x1 卷积降维,大幅减少计算量
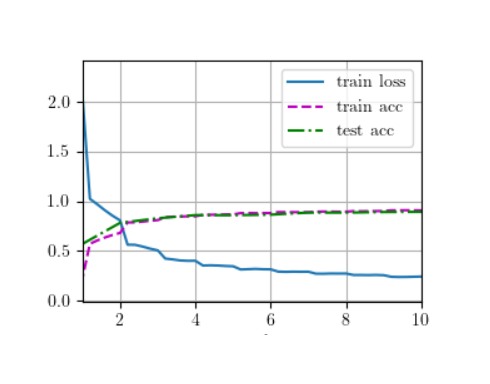
- 准确率:在 Fashion-MNIST 上可达约 93%(取决于训练轮数和超参数)
实验结果

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)