关于深度学习的计算机考研复试项目(二)
但是各个因素影响程度不同,比如长得好看的往往谈的比较多,但性格好的不太一定谈的多,所以外貌权重w1相对更高。先是自己定义的模型计算出y^,再根据定义的损失函数loss进行梯度回传,逐步对参数求偏导,找到更好的参数使得loss更小。往往实际问题不仅仅只有一对输入输出,可能一个输出受到多种输入的影响,而不同的输入对输出的影响程度有所不同,及对应权重w不同。我们知道例子不是一个线性函数,这里能明显看出这
上节初步认识了深度学习是干什么的,这一讲聊聊多层神经网络
多层神经网络:
往往实际问题不仅仅只有一对输入输出,可能一个输出受到多种输入的影响,而不同的输入对输出的影响程度有所不同,及对应权重w不同
举一个简单的例子
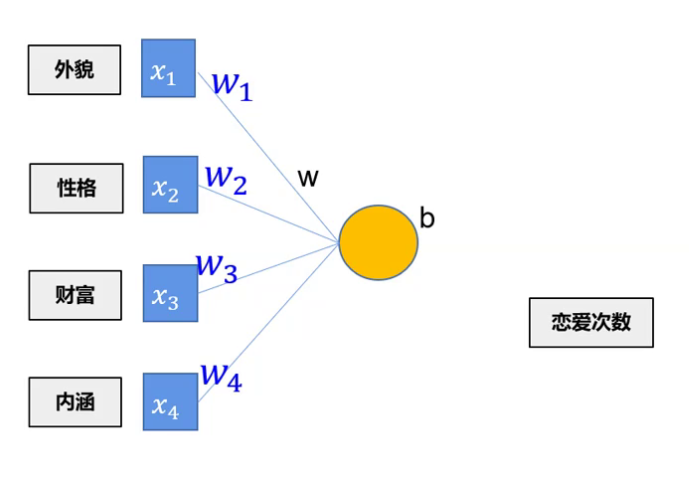
通过四个人的属性,推测出可能此人谈过多少次恋爱。但是各个因素影响程度不同,比如长得好看的往往谈的比较多,但性格好的不太一定谈的多,所以外貌权重w1相对更高。
黄色结点指的是一个神经元,其中b值为线性方程里的常数,可统一用一个常数表示
神经元与矩阵:基本公式y=wx+b
而各种输入会对各个神经元起作用后,由各个神经元再输出最终结果
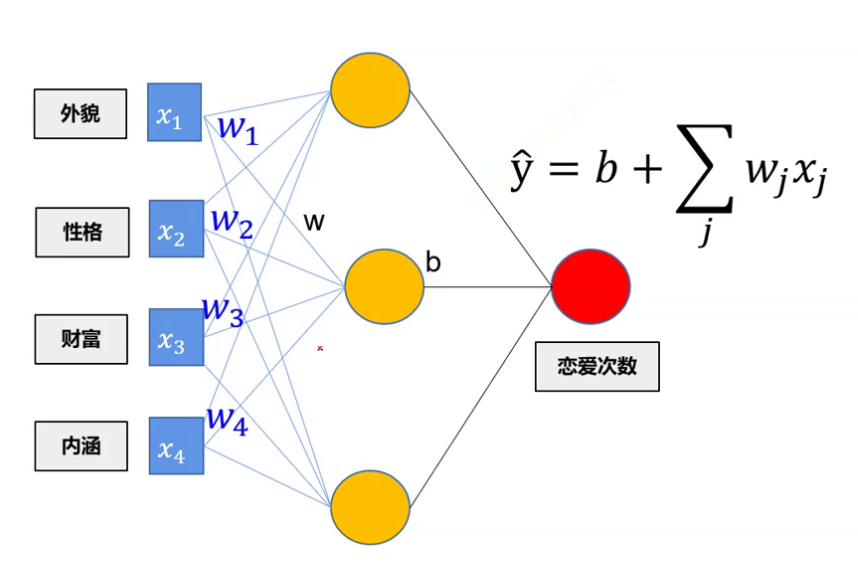
而黄色结点自身的值我们用r表示,即
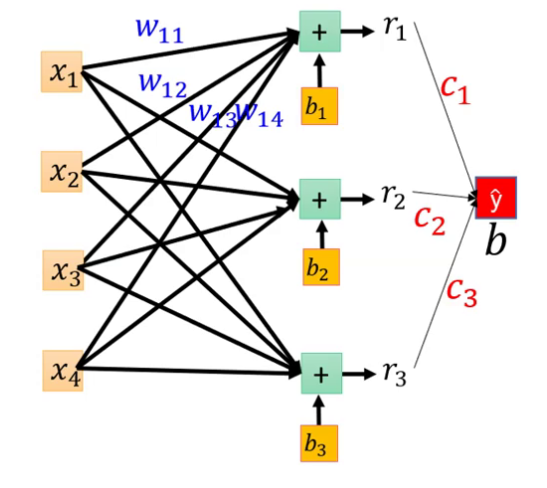
这里先不看y和c,注意到左半图,可列出方程组:
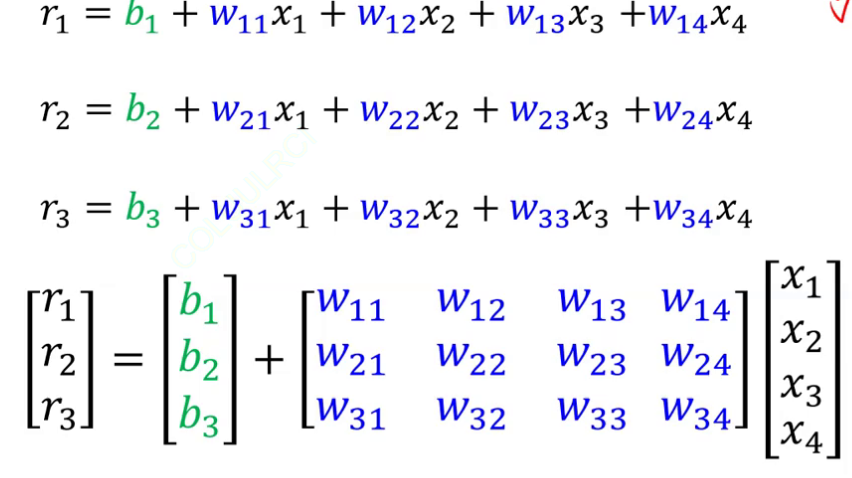
是不是和线性代数里面学的线性方程组很像,也就能写成矩阵形式。
根据r可以得到y
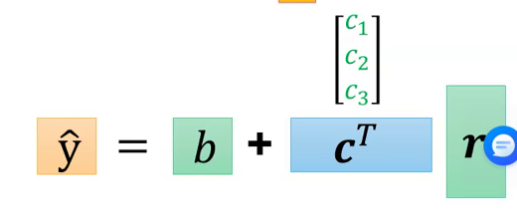
其中C又是r关于y的系数参数,b为常数
上述例子为两层神经网络且为线性,可以称为串联的神经网络,都可以简化为单层神经网络,没有必要划为多层,本质是一层。
若只有线性传递,一层与多层无区别,不管多少系数参数,对于某一个输入Xn,可统一为一个参数Wn
为此,引入激活函数(激活函数都是非线性的,则神经网络可以模拟任何非线性关系)
那么到底什么事激活函数?举两个高等数学中的简单例子

第一个不介绍,都能懂。第二个说明分段函数也能称作非线性函数
激活函数基本特征:可导
以上述二层神经网络为例,在得出第一层值r后,对r代入激活函数计算
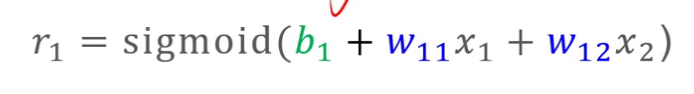
那么激活函数在神经网络里面的哪个位置起作用?
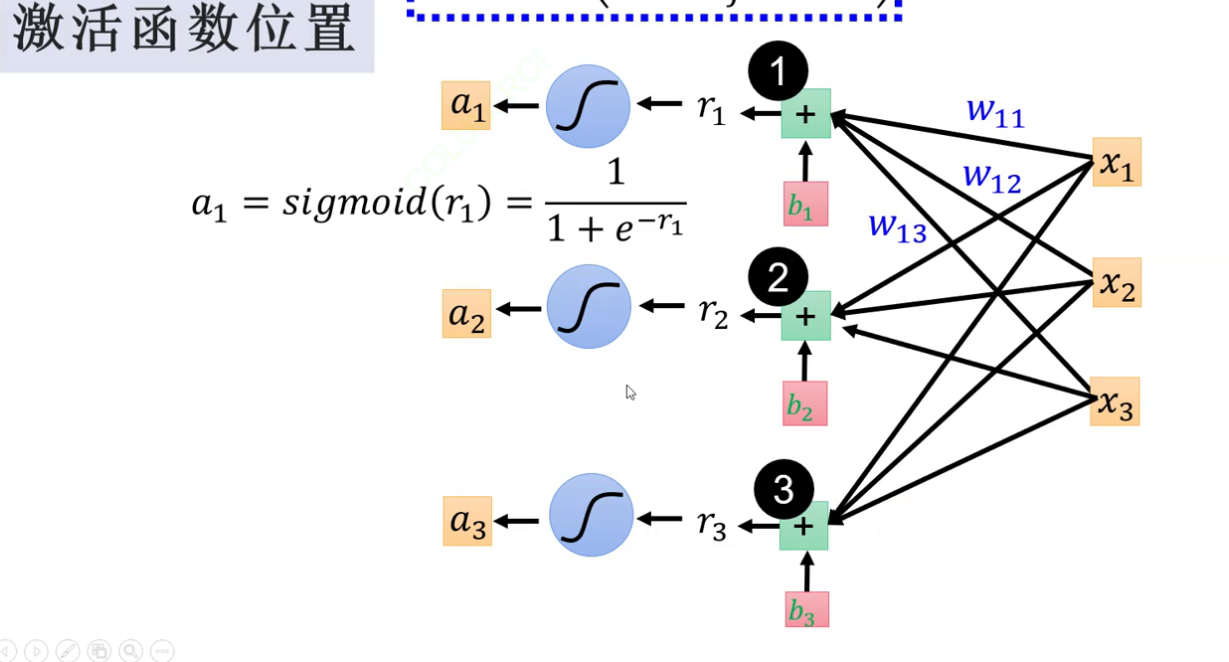
就是在计算出某层的输出后将这个输出代入激活函数再继续推进神经网络
激活函数对拟合曲线的作用效果展示图例
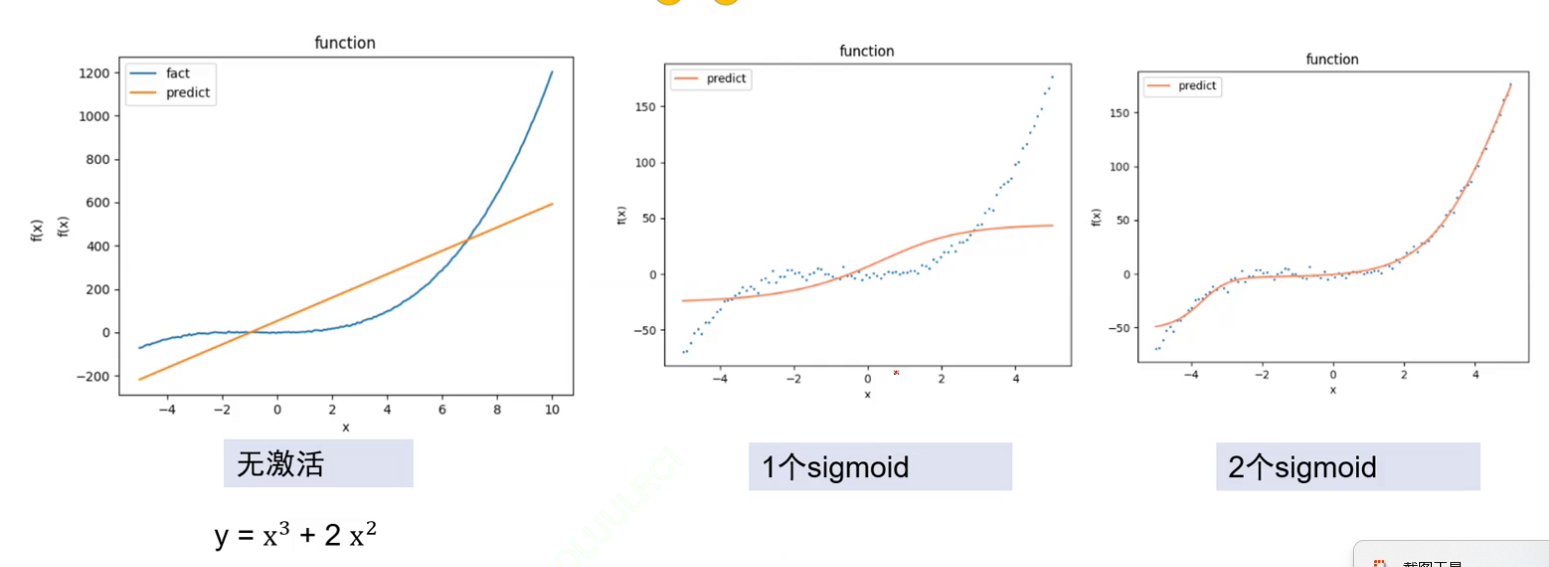
这就是激活函数对拟合非线性函数的作用
小结一下下,我们常见的神经网络
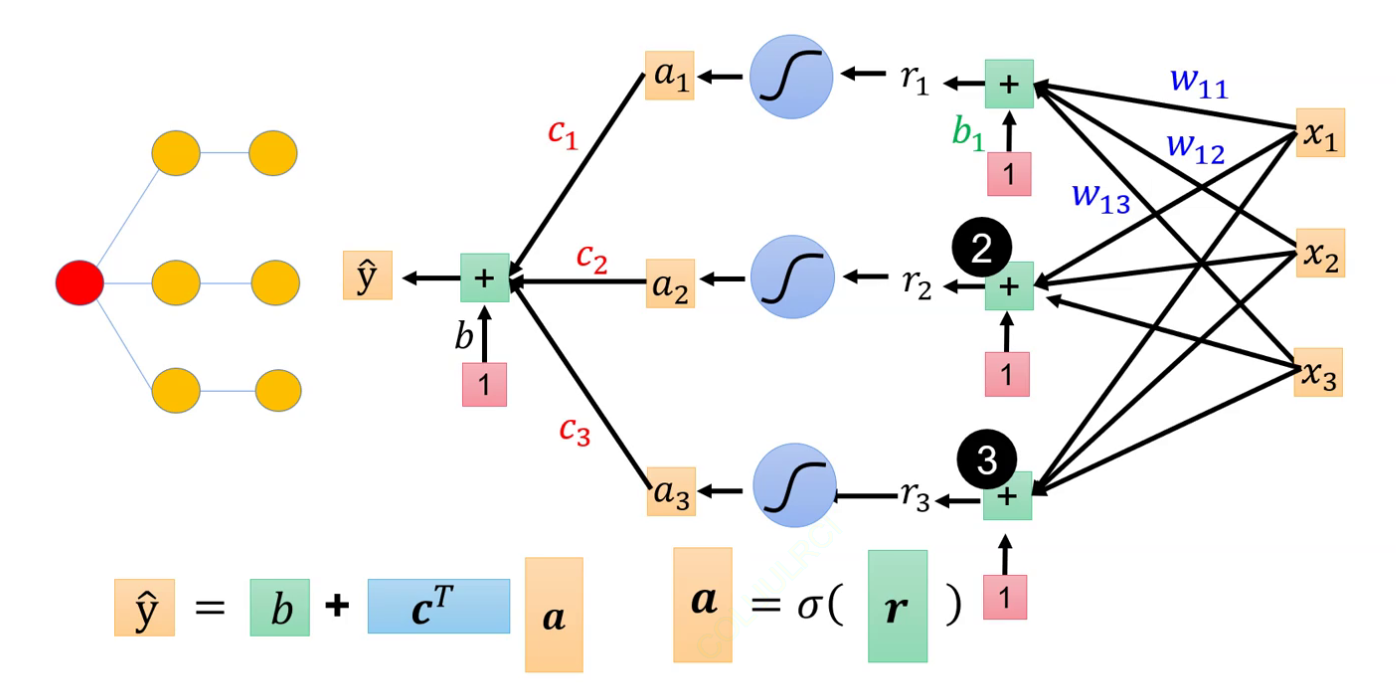
这三种表示的是同一个东西,注意最下面那个cT和![]() 指的是向量和矩阵运算
指的是向量和矩阵运算
注意:a不是参数,只是某层的一个中间运算结果,c那种才是参数
那么现在了解了多层神经网络和激活函数,回顾一下(一)里面的单层模型训练过程,推广到多层训练过程:
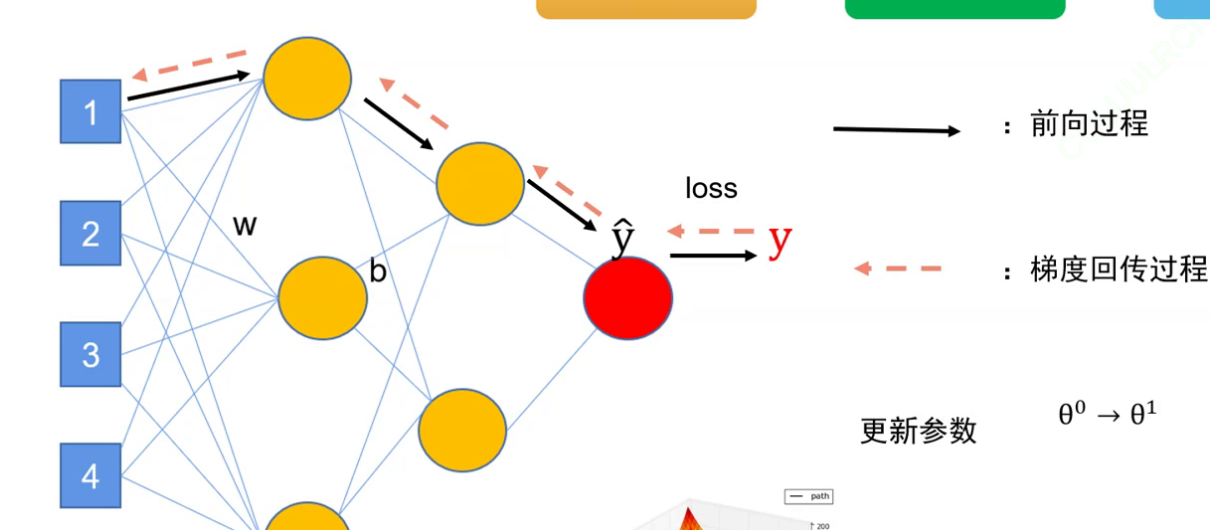
先是自己定义的模型计算出y^,再根据定义的损失函数loss进行梯度回传,逐步对参数求偏导,找到更好的参数使得loss更小。这就叫梯度下降
那么聊了那么多乱七八糟的理论知识,该上手实践一下代码了
我们以一个简单的幂函数为例来实操
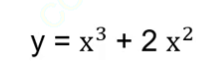
重点看这么一个函数
nn.Linear(in_features=1,out_features=100), # Linear modelfeature就是我们的输入值,1指一个输入计算中间的100个中间值
就是我们神经网络的计算过程,看图更好理解:
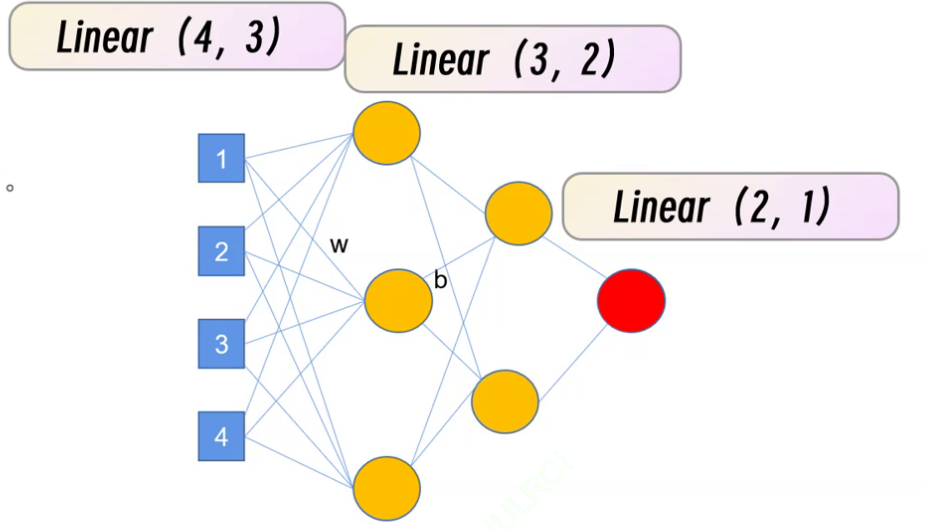
linear(x,r)x是输入,r是输出
上一层的输出一定是下一层的输入
ok现在来看看结果,如果不采用激活函数会发生什么?
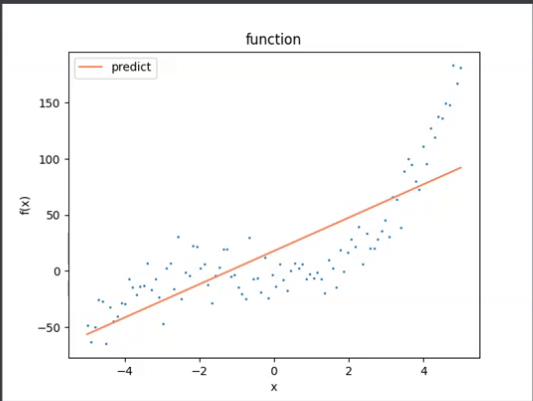
我们知道例子不是一个线性函数,这里能明显看出这个直线很想贴合数据,但无激活函数只能表示线性函数,所以必须引入激活函数。
在代码中加入一激活函数
nn.Sigmoid()后
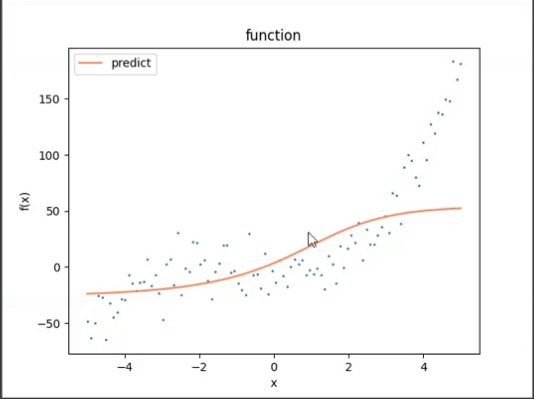
发现变成非线性了,有点弯了!显然比直线效果好
但是我们加了很多个(这里我加了四个sigmoid)后
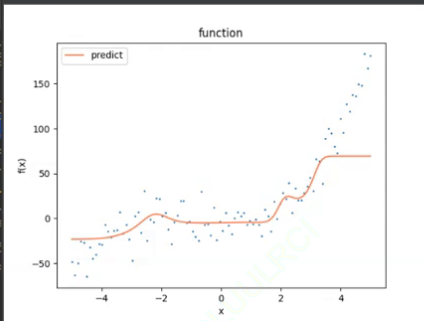
在中间某些区间变得有问题了
当我换成relu激活函数测试,效果比sigmoid好,但同样也有加入过多激活函数曲线会变得不光滑这个问题
这里再引申一个概念-----界外预测,刚才我们是从【-5,5】这个区间测试的,我们试试扩展区间
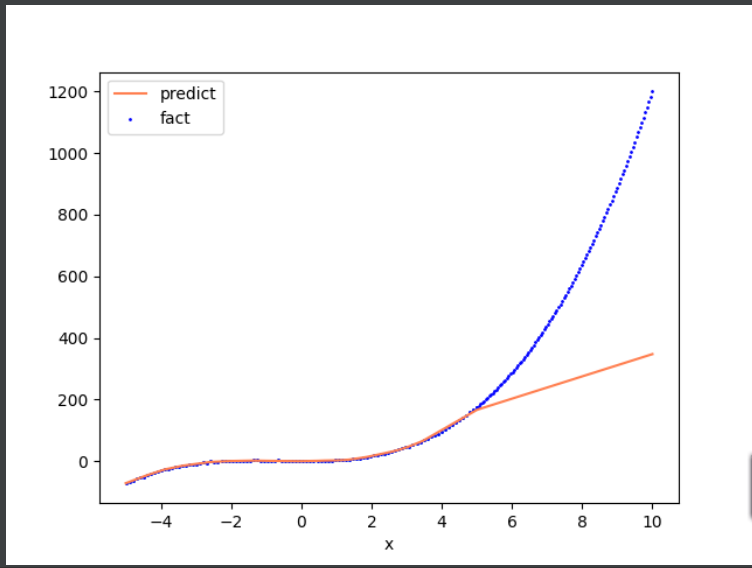
发现并不准确(这是只是提一嘴界外预测,详细后面再聊)
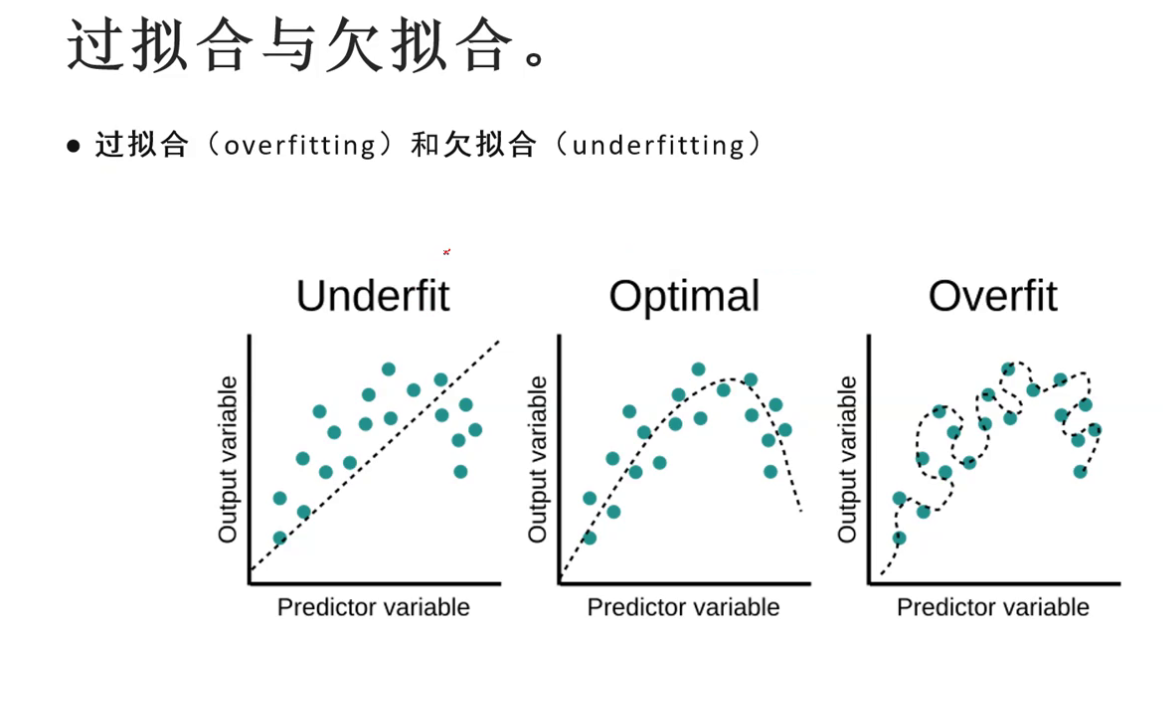
过拟合与欠拟合
刚刚我们无激活函数时,一条直线显然无法表示我们的数据,叫欠拟合。
而加入太多激活函数,导致拟合曲线弯弯绕绕的也远离真实函数,叫过拟合。
给个图好理解:
参数量的计算!(比较重要)
一个全连接的参数量计算,比如linear(30,60)那么共有30个输入,60个神经元
对应30*60个w加上60个b,共1860个参数
可能整理有点乱,但这是零基础能够看得懂的部分了,大概了解我们深度学习到底是个什么东西就行,这才能对我们为什么这么写代码才有些了解。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)