深度学习笔记2:交叉熵损失函数
机器学习的优化思想

定义基本模型
提出基本模型,明确目标。基本模型就是自己设定的神经网络模型,核心重点就是求解神经网络的权重向量w。
定义损失函数
定义某个评估指标,用来衡量权重向量为w的情况下,预测结果与真实结果的差异。当真实值与预测值差异越大时,就认为神经网络学习过程中丢失了许多信息,而丢失的这部分就被形象地称为“损失”,因此,用来评估真实值与预测值之间差异的函数就称为“损失函数”。
如果损失函数的值很大,则模型在w权重情况下的预测值与真实值差异很大,表现差劲。
如果损失函数的值很小,则模型在w权重情况下的预测值与真实值差异很小,表现优秀。
因此则将问题转变为求解损失函数L(w)的最小值所对应的自变量w。
定义优化算法
目前没有学到
利用优化算法求解最佳权重w
| 模型 | 损失函数 | 优化算法 |
|---|---|---|
| 回归模型 | SSE | 最小二乘法/梯度下降法 |
| 二分类模型 | 交叉熵损失函数 | 暂时不知道 |
| 多分类模型 | 交叉熵损失函数 | 暂时不知道 |
二分类交叉熵损失函数
函数概念
交叉熵损失函数,又叫对数损失。这个损失函数被广泛地使用在任何输出结果是二分类的神经网络 中,它不止限于单层的神经网络,还可被拓展到多分类中,大多数时候,除非特殊声明为二分类,否则提到交叉熵损失函数,都默认算法的分类目标是多分类。
二分类交叉熵损失函数中,对于有m个样本的数据集而言,在全部样本上的损失可以写作如下公式:
其中单个样本的损失为:
是以自然底数为底的对数函数,表示求解出来的一组权重(在等号的右侧,
在
里)
是样本的个数
是样本
上真实的标签
是样本
上,基于参数计算出来的sigmoid函数的返回值(此时损失函数的权重
用于在这里计算)
是第
个样本各个特征的取值
交叉熵损失函数很重要!要背会公式!
tensor实现二分类交叉熵损失函数
数据准备:
import torch #导包
m=3*pow(10,3) #定义数据集的大小,3000条数据,科学写法
torch.random.manual_seed(420) #随机数种子,便于复现
X=torch.rand((m,4),dtype=torch.float32) #生成一个(3000,4)大小的随机数据集,有4个特征
w=torch.rand((4,1),dtype=torch.float32) #生成权重矩阵,形状(4,1)
y=torch.randint(low=0,high=2,size=(m,1),dtype=torch.float32) #生成标签,左开右比,0和1
zhat=torch.mm(X,w) #矩阵和矩阵相乘用mm方法,获得线性层输出zhat
sigma=torch.sigmoid(zhat) #使用sigmoid函数将线性层输出zhat映射到[0,1]区间表示编写交叉熵损失函数代码:
loss = -( y * torch.log(sigma) + (1-y) * torch.log(1-sigma))结果:
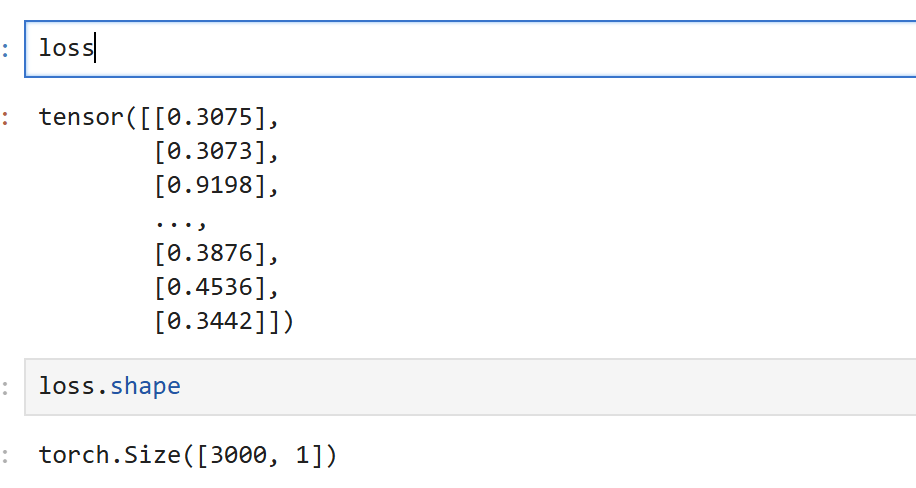
loss所表示的矩阵表示,随机数据集中每一个样本,在二分类数据上的交叉熵损失。这个值越大,说明模型预测该样本与真实标签的差异越大。
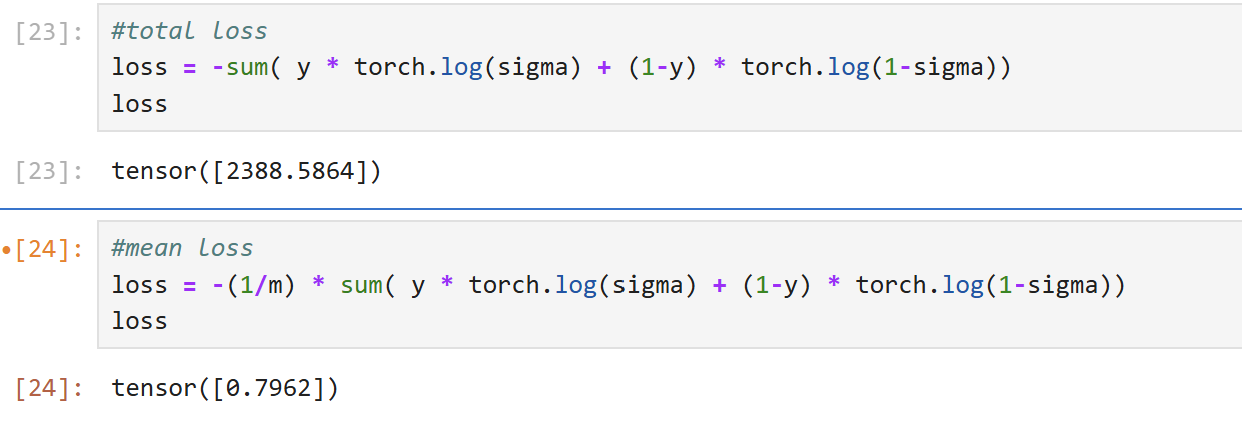
总损失和平均损失如下:
加餐
普通sum方法和torch.sum方法的区别:
数据准备
import torch
import time #计算两个方法所用的时间长短
m=3*pow(10,6) #重设数据量为300万条数据
X=torch.rand((m,4),dtype=torch.float32)
w=torch.rand((4,1),dtype=torch.float32)
y=torch.randint(low=0,high=2,size=(m,1),dtype=torch.float32)
zhat=torch.mm(X,w)
sigma=torch.sigmoid(zhat)
两种sum方法计算
sum:
start=time.time() #捕获开始计算的时间
loss = -(1/m) * sum( y * torch.log(sigma) + (1-y) * torch.log(1-sigma))
now=time.time() #捕获结束计算的时间
print(now - start)torch.sum
start=time.time() #捕获开始计算的时间
loss2 = -(1/m) * torch.sum( y * torch.log(sigma) + (1-y) * torch.log(1-sigma))
now=time.time() #捕获结束计算的时间
print(now - start)结果:
| sum方法花费时间 | torch.sum方法花费时间 |
|---|---|
| 12.658 | 0.028 |
结论:除了加减乘除,应该尽量避免使用任何Python原生的计算方法。如果可能的话, 让PyTorch处理一切,对于张量对象,PyTorch有专门计算张量的方法,使得计算效率快几千上万倍。
PyTorch中的类实现二分类交叉熵损失函数
通过使用nn模块中的类调用交叉熵损失函数:
class:BCELoss、BCEWithLogitsLoss
两个函数所需要输入的参数不同:
BCELoss中只有交叉熵函数,没有sigmoid层,因此需要输入sigma与真实标签y,且顺序不能变化,sigma必须在前。
BCEWithLogitsLoss内置了sigmoid函数与交叉熵函数,它会自动计算输入值的sigmoid值,因此需要输入zhat与真实标签y,且顺序不能变化,zhat必须在前。
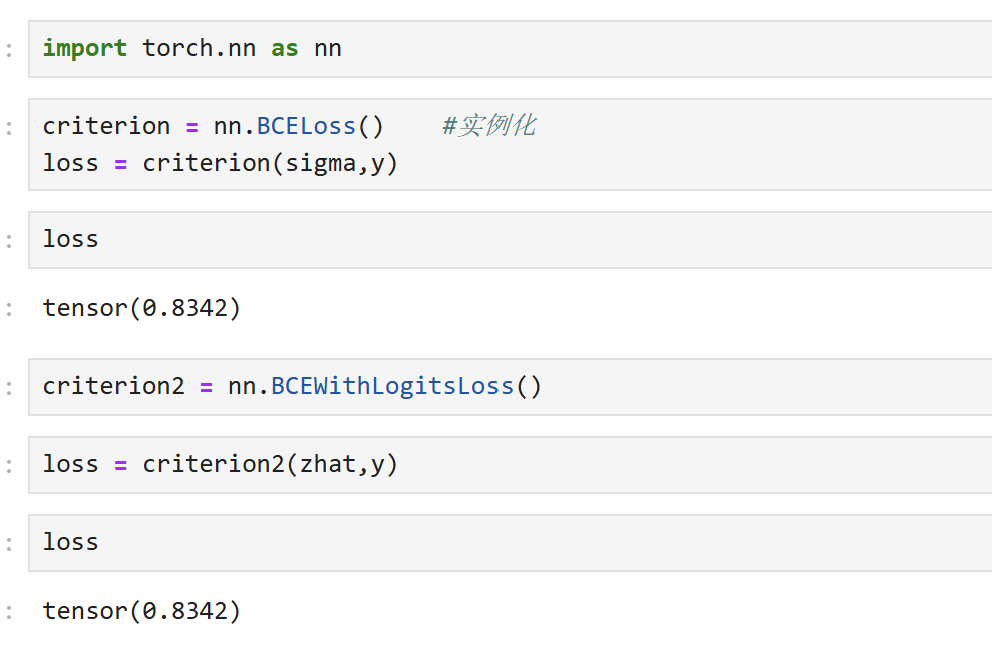
截图所用的sigma和zhat已经在前面的实验中提前计算得出。
根据PyTorch官方的公告,他们更推荐使用BCEWithLogitsLoss这个 内置了sigmoid函数的类。内置的sigmoid函数可以让精度问题被缩小(因为将指数运算包含在了内 部),以维持算法运行时的稳定性,即是说当数据量变大、数据本身也变大时,BCELoss类产生的结果 可能有精度问题。所以,当我们的输出层使用sigmoid函数时,我们就可以使用BCEWithLogitsLoss作为损失函数。
不同参数
二分类交叉熵的类们也有参数reduction,默认是”mean“,表示求解所有样本平均的 损失,也可换为”sum”,要求输出整体的损失。以及,还可以使用选项“none”,表示不对损失结果做任 何聚合运算,直接输出每个样本对应的损失矩阵。
criterion2 = nn.BCEWithLogitsLoss(reduction = "mean") #平均损失
criterion2 = nn.BCEWithLogitsLoss(reduction = "sum") #整体损失
criterion2 = nn.BCEWithLogitsLoss(reduction = "none") #不对损失结果做任何运算,直接输出损失矩阵多分类交叉熵损失函数
PyTorch实现多分类交叉熵损失函数,有两种方法:
调用logsoftmax和NLLLoss实现
import torch
m=3*pow(10,3) #3000条数据
torch.random.manual_seed(420)
X=torch.rand((m,4),dtype=torch.float32)
w=torch.rand((4,3),dtype=torch.float32)
y=torch.randint(low=0,high=3,size=(m,),dtype=torch.float32)
zhat=torch.mm(X,w)logsm = nn.LogSoftmax(dim=1)
logsigma = logsm(zhat)
logsigma
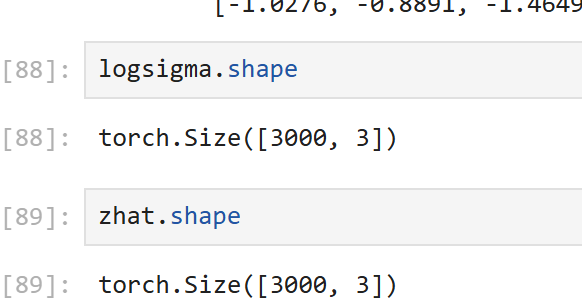
得到的logsigma矩阵,形状与zhat(模型的原始输出,未经过激活函数)相同,每个元素代表 “该样本属于对应类别的对数概率”。由于 Softmax 的输出是 (0,1) 之间的概率,取 log 后,logsigma 的值一定是负数(因为 log(x) 在 0<x<1 时为负)。
criterion = nn.NLLLoss() #实例化
#由于交叉熵损失需要将标签转化为独热形式,因此不接受浮点数作为标签的输入,需要定义y为int型,使用long
#对NLLLoss而言,需要输入logsigma
criterion(logsigma,y.long()) #获取平均损失,可在上方实例化时修改参数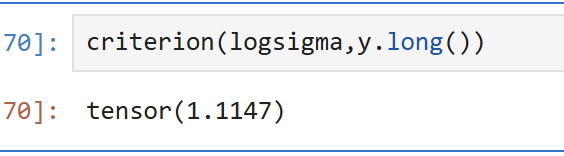
直接调用CrossEntropyLoss
criterion = nn.CrossEntropyLoss()
#对打包好的CorssEnrtopyLoss而言,只需要输入zhat
criterion(zhat,y.long())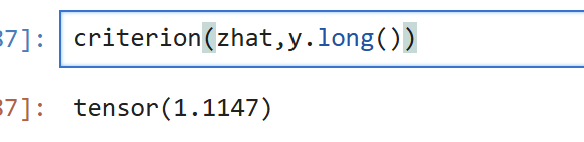
与其他损失函数一致,CrossEntropyLoss也有参数reduction,可以设置为mean、sum以及None。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)