知识图谱之——图数据库:以“关系”为核心的数据新大陆
最近,我对知识图谱产生了浓厚的兴趣。在构建知识图谱的各个环节中,最让我感到惊艳的,莫过于它的存储基石——图数据库。它和我们熟悉的MySQL、Oracle这类传统数据库截然不同,为我们理解和处理数据提供了一种全新的范式。
一、什么是知识图谱
知识图谱(Knowledge Graph),本质上是一个巨大的、富含语义的网络结构图,它由实体(节点)和关系(边)组成,旨在描述现实世界中的实体(如人、地点、事件)及其之间的丰富关系。它让机器能够“理解”数据之间的逻辑,而不仅仅是存储它们。
那么,一个随之而来的关键问题是:如何高效地存储和查询知识图谱中这种错综复杂的连接关系?传统的关系型数据库(如MySQL)在处理多层次的关联查询时,往往需要大量的JOIN操作,导致性能急剧下降,查询语句也异常复杂。正是在这样的需求下,图数据库(Graph Database) 应运而生,它以其原生处理关系的强大能力,成为了知识图谱最理想的“家园”。
二、什么是图数据库
要理解图数据库,首先要建立“图”的思维。这里的“图”并非指常见的饼图、柱状图,而是数学和计算机科学中的图论概念,即由节点和连接这些节点的边构成的网络。
1. 三元组
图数据库和知识图谱的最小知识单元是三元组,其形式为:主体 - 关系 - 客体。
-
示例1:
张三 - 认识 - 李四 -
示例2:
北京 - 是 - 中国首都 -
示例3:
刘德华 - 主演 - 无间道
这个简单的结构能够表达出极其丰富的语义信息。
2. 点与边
三元组在图数据库中具体体现为:
-
节点:代表实体。例如,一个人、一家公司、一部电影。节点可以有标签(如
Person,Movie)来分类,并且可以拥有多个属性(如name: ‘张三’,age: 28)。 -
边:代表关系。它连接两个节点,定义了它们之间的关系。边同样可以拥有方向和属性。例如,一条从“张三”指向“李四”的边,类型是
KNOWS,并且可以有一个since: 2020的属性,表示相识年份。
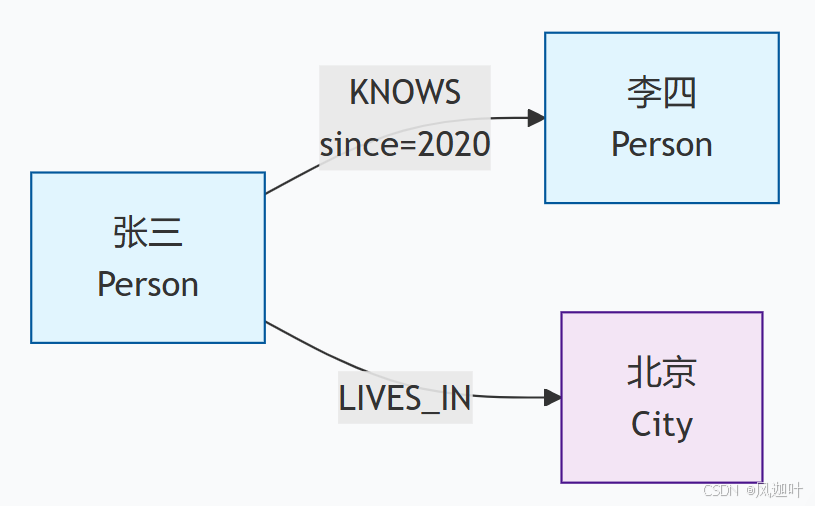
这种直观的建模方式,使得数据及其关系能够以最自然的形式被存储和呈现。
从上面的分析可以清晰的理解,图数据库,就是一种专门用来处理和查询“关系”的数据库。它不关心数据本身有多少,而是特别关心数据之间是怎么连起来的。它的核心优势是:沿着关系找东西,速度快得飞起。
三、知识图谱构建思路
构建一个知识图谱通常包含以下几个关键步骤,它是一个循环迭代的过程:
1. 知识定义与建模
明确业务边界,设计本体。即定义有哪些类型的实体(节点标签)和关系(边类型),以及它们各自拥有哪些属性。这是构建图谱的蓝图,从面向对象开发的角度理解,你可以理解为“类的定义”。
2. 知识获取
确定知识图谱主题后,收集各类数据,然后从各类数据源中提取信息。其中,数据的形式包括:
· 结构化数据:直接从业务数据库(MySQL等)中获取。
· 半结构化/非结构化数据:通过爬虫、NLP技术从文本(甚至可以是一本书)、网页中抽取实体和关系。
这里提到的实体和关系,从面向对象开发的角度理解,你可以理解为“类的实例化”。
3. 知识融合与存储
将获取的知识进行清洗和整合。关键任务是实体链接(也有人称之为:实体对齐),即判断不同来源的“Steve Jobs”和“乔布斯”是否指向同一实体,消除歧义。最后,将处理好的三元组数据存入图数据库。
4. 知识应用与可视化
利用图查询语言(如Cypher、nGQL)对图谱进行查询、推理和分析。并将结果通过图谱可视化、智能问答、推荐系统等方式呈现给最终用户。
四、主流图数据库概览
当前,图数据库领域有多种产品,主要可分为原生图数据库(存储和计算引擎均为图专用)和非原生图数据库(基于其他存储引擎构建图处理层)。我找了以下的一些产品,分析理解了一下,也参考了一些书籍,汇总成下面这个表格,供大家参考:
| Neo4j | Dgraph | NebulaGraph | JanusGraph | |
| 首次发布 | 2007年 | 2016年 | 2019年 | 2017年 |
| 开发语言 | Java | Go | C++ | Java |
| 主要特点 | 历史悠久、生态成熟的原生图数据库,使用 Cypher 查询语言。适用于社交网络、推荐系统、欺诈检测等 | 原生的分布式图数据库,部署简单,复杂查询性能好。使用GraphQL+-like语法,适用于知识图谱等场景 | 国产开源分布式图数据库,对中文场景有优化。适合处理千亿顶点、万亿边的超大规模图 | 开源的分布式图数据库,可与 HBase、Cassandra 等大数据组件集成。使用 Gremlin,擅长处理超大规模图数据 |
| 拥有专为图数据设计的自定义存储引擎和计算引擎。其存储格式、事务处理、查询执行都是围绕图模型从头构建的,是原生图的典型代表。 | 虽然底层使用键值存储(BadgerDB),但 BadgerDB 是 Dgraph 团队专门为 Dgraph 研发的嵌入式存储引擎。其整个分布式架构和查询处理都是为 GraphQL-like 的图查询设计的。 | 虽然底层使用 RocksDB 作为单机存储引擎,但其分布式存储层(Meta、Storage)和计算层(Graph)是专为图场景设计和深度优化的。它并非简单地在 RocksDB 之上加一个接口,因此被视为原生分布式图数据库。 | 它本身是一个图计算引擎层,依赖外部的存储后端(如 HBase、Cassandra)和索引后端(如 ElasticSearch)。存储和计算分离,其架构不是原生的。 | |
| 属性图模型 | 完整的属性图模型 | 不完整的属性图模型,更接近于RDF存储 | 完整的属性图模型 | 完整的属性图模型 |
| 架构 | 单机/集群 | 分布式 | 分布式 | 分布式 |
| 存储后端 | 自定义文件格式 | 键值数据库BadgerDB | 键值数据库RocksDB | HBase、Cassandra、BerkeleyDB |
| 物理存储 | KV | KV | KV | KCV |
| 高可用性 | 不支持 | 支持 | 支持 | 支持 |
| 一致性协议 | 无 | RAFT | RAFT | HBase:Paxos;Cassandra:基于多数派(Quorum-based) |
| 跨数据中心复制 | 不支持 | 支持 | 不支持 | 支持 |
| 事务 | 完全的ACID | 基于Omid修改版的分布式事务 | 不支持分布式事务 | BerkeleyDB:完全的ACID支持;HBase和Cassandra:BASE,通过锁和两阶段提交增强一致性 |
| 分区策略 | 不支持分区 | 自动分区,自动再平衡,再平衡时拒绝写入和更新 | 哈希(取模)静态分区,分区数设定后不能更改 | 随机分区,支持显式指定分区策略 |
| 分区方法 | 不支持分区 | 根据边标签(谓词)分区 | 根据顶点id分区,每条边存储两次 | 根据顶点id分区,每边存储两次 |
| 大数据平台集成 | Spark | 不支持 | Spark、Flink | Spark、Hadoop、Giraph |
| 顶点标签 | 0个或多个 | 0个 | 1个或多个 | 0个或1个 |
|
顶点间相同标签 的多条边 |
顶点对之间支持多条相同标签的边 | 不支持 | 顶点对之间支持多条相同标签的边 | 支持,且支持多种约束条件(ONE2ONE、ONE2MANY等) |
| 查询语言 | Cypher,通过插件可支持Gremlin、GraphQL等 | GraphQL | nGQL | Gremlin,通过插件可支持openCypher |
| 全文检索 | 内置 | 内置 | ElasticSearch | ElasticSearch、Solr、Lucene |
| 多个图 | 一个实例只能有一个图 | 一个集群只能有一个图 | 支持创建任意意图 | 支持创建任意意图 |
| 属性图模式 | 可选模式约束 | 无模式 | 强制模式约束 | 无模式,可选模式约束,强制模式约束 |
| 客户端协议 | HTTP、BOLT | HTTP、gRPC、Protocol Buffer | HTTP | HTTP、WebSockets |
| 客户端语言 | Java、.NET、JavaScript、Python、Go | Java、JavaScript、Go、Python、.Net | Python、Java、Go、C++ | Java、Python、C#、Go、Ruby、Rust |
这个表格,我基本还原了书本原作者的内容,仅做了部分扩充。结合上表,再从国产信创、开源协议、性能、架构、生态、依赖性与成本(包括学习成本)等角度分析,最终选择了NebulaGraph,并构建了一些简单的应用实例。
目前已经完成初步搭建与测试,其性能和易用性符合我们的预期,不仅解决了当下的技术问题,更为未来的业务发展选定了清晰的方向和可靠的技术底座。下图是其中的一个测试图谱样例:
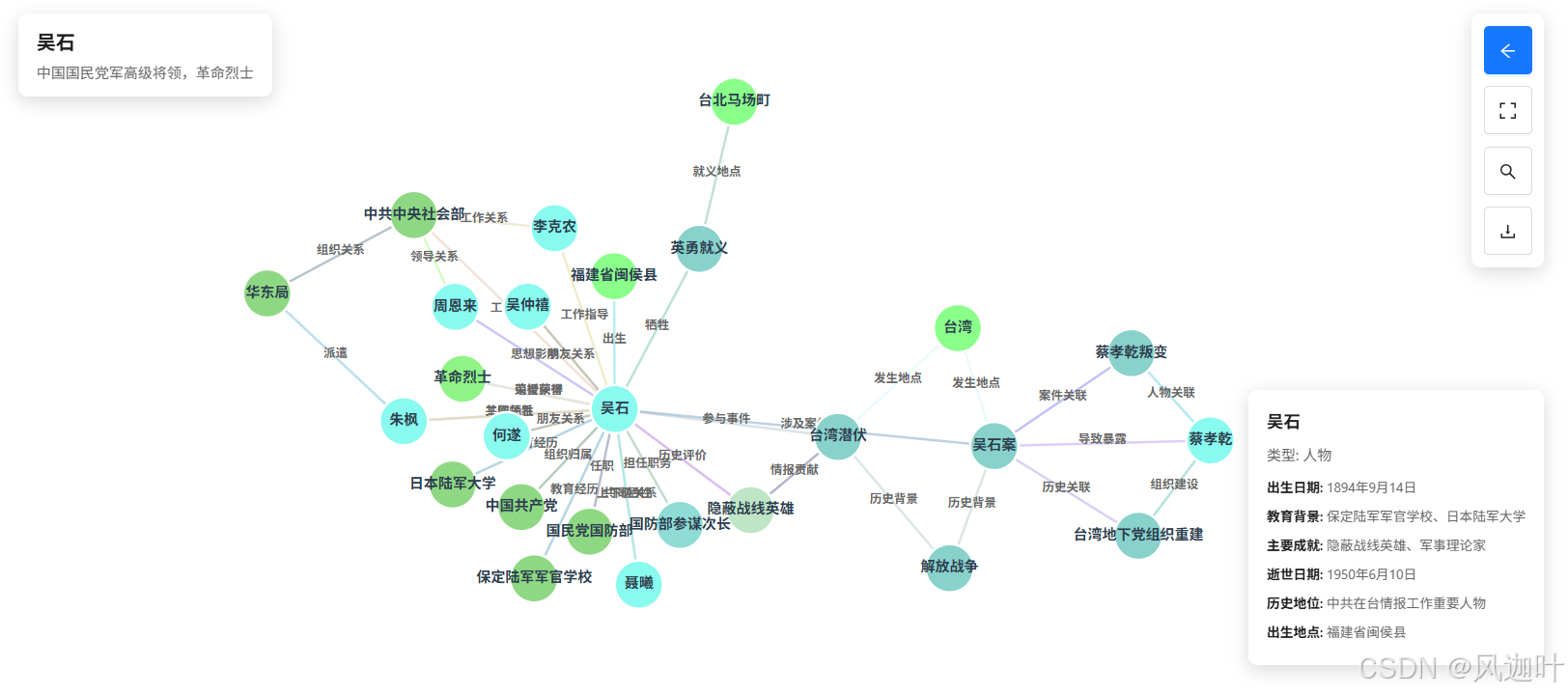
未来,还将探索其在实时推荐、网络分析等更多领域的应用,持续释放数据的关联价值,产出更多有价值的成果,请大家拭目以待!
五、结语
图数据库以其“关系为中心”的核心思想,完美地契合了知识图谱对复杂关系管理和挖掘的需求。它不仅是存储技术的革新,更是一种思维方式的转变。随着人工智能从感知智能走向认知智能,能够理解和处理逻辑关系的知识图谱与图数据库,必将扮演越来越重要的角色。 希望本文能为您打开一扇通往图数据世界的大门。
现在,不妨您也选择一个图数据库,从构建一个属于自己的小型知识图谱开始吧!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)