多层神经网络
多层神经网络的背景神经网络的基本单元是神经元,多层神经元的连接形成神经网络,由输入层、隐层(多层次)、输出层组成的多层神经网络。在传统的神经网络中,采用迭代的算法来训练整个网络,随机设定初值,计算当前网络的输出,然后根据当前输出和实际样本之间的差进行反馈改变前面各层的参数,直到收敛,整体是一个梯度下降法,这就是BP神经网络,该方法在一段时间运用很广泛很火热,但是随着网络层数的增加,残差传播到最前面
目录
多层神经网络的背景
神经网络的基本单元是神经元,多层神经元的连接形成神经网络,由输入层、隐层(多层次)、输出层组成的多层神经网络。
在传统的神经网络中,采用迭代的算法来训练整个网络,随机设定初值,计算当前网络的输出,然后根据当前输出和实际样本之间的差进行反馈改变前面各层的参数,直到收敛,整体是一个梯度下降法,这就是BP神经网络,该方法在一段时间运用很广泛很火热,但是随着网络层数的增加,残差传播到最前面的层已经变得太小,梯度越来越稀疏,收敛到局部最小值等等无法克服的难题,于是神经网络走入了困境。
直到2006年,加拿大多伦多大学教授、机器学习领域的泰斗Geoffrey Hinton提出了在非监督数据上建立多层神经网络的一个有效方法,简单的说,分为两步,一是每次训练一层网络,二是调优,才解决了传统神经网络的一大痛点,于是多层神经网络再一次迎来蓬勃发展。
多层神经网络的概念
多层神经网络的结构
多层神经网络,即由多个层结构组成的网络系统,它的每一层都是由若干个神经元结点构成,该层的任意一个结点都与上一层的每一个结点相联,由它们来提供输入,经过计算产生该结点的输出并作为下一层结点的输入。第一层称为输入层,最后一层称为输出层,其他中间层称为隐藏层,整个网络中信号从输入层向输出层单向传播, 可用一个有向无环图表示多层神经网络结构如图1所示。
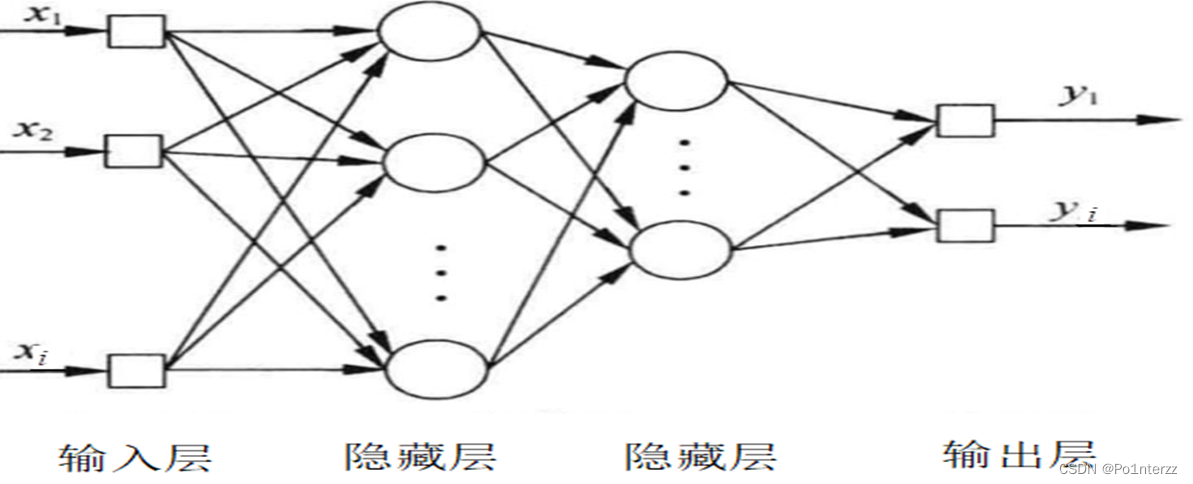
图1 多层神经网络结构
多层神经网络的数学模型



多层神经网络分类问题应用举例
在图像处理方面的一个很经典的案例就是手写数字的识别问题,本例子使用MNIST数据集,这是机器学习领域的一个经典的数据集,在20 世纪 80 年代由美国国家标准与技术研究院收集得到,训练集由来自 250 个不同人手写的数字构成,其中 50% 是高中学生,50% 来自人口普查局的工作人员,测试集也是同样比例的手写数字数据,其数据集里面包含了60000 张训练图像和 10 000 张测试图像,划分了10个类别(0-9数字)的手写数字灰度图像(标准图像是28*28像素),运用这个数据集来验证多层神经网络分类问题。
1.MNIST数据集
例子用的MNIST数据集集成在Tensorflow框架里面,因此加载Tensorflow框架,用mnist.load_data()函数获取,示例代码如下:
#加载tensorflow框架
import tensorflow as tf
mnist = tf.keras.datasets.mnist #MNIST数据集加载
#将数据集划分成训练集与测试集
(x_train_all, y_train_all),(x_test, y_test) = mnist.load_data() 这里的x_train,x_test,表示训练集和测试集x输入,这里的x是手写数字图像样本, y_train, y_test表示标签数字,取值范围是0-9,图像与标签是一一对应的。
由于图像数据灰度图像,在计算机存储里面,灰度图像即没有色彩的黑白图像,是由黑白像素组成的,像素点的数值范围是0-255,数字为0代表黑色,白色为255,由于MNIS数据集的各类图像数据有差异,一般进行归一化处理,示例代码如下:
#将Mnist数据集简单归一化
x_train_all, x_test = x_train_all / 255.0, x_test / 255.0
# 对数据集进行划分,50009个为训练集,10000个为验证集
x_train, x_valid = x_train_all[:50000], x_train_all[50000:] #验证集10000个
y_train, y_valid = y_train_all[:50000], y_train_all[50000:]
print(x_train.shape)数据集已经加载完之后,可以打印出来看看MINST数据集里面的数据是上面模样的,定义一个函数读取单张图片,示例代码如下:
#打印一张照片
import matplotlib.pyplot as plt #加载画图模快
def show_single_image(img_arr): #定义一个提取图像函数
plt.imshow(img_arr,cmap='binary') #展示图像
plt.show()
show_single_image(x_train[1])2.多层神经网络模型构建
本例子用的MNIST数据集已经准备就绪,接下来就需要进行多层神经网络的构建工作。在本节书里面,运用的是tensorflow核心组件keras进行搭建网络结构,神经网络的核心组件是层( layer),一种数据处理模块(数据过滤器)。
本案例中的网络包含 4个 Dense 层,它们是全连接的神经层,第0层即输入层,由28*28=784数组层,第一二、三层都是隐藏层,最后一层输出层是 10 个 softmax 层,它将返回一个由 10 个概率值(总和为 1)组成的数组,每个概率值表示当前数字图像属于 10 个数字类别中某一个的概率。
在设计多层神经网络网络时,网络的结构配置等超参数可以按着经验自由设置,只需要遵循少量的约束即可,比如隐藏层 1 的输入节点数必须和数据的实际特征长度匹配,每层的输入层节点数与上一层输出节点数匹配,输出层的激活函数和节点数需要根据任务的具体设定进行设计,神经网络结构的自由度较大,如图6-11所示,网络结构中每层的输出节点数不一定要设计为[256,128,64,10],也可以是[256,256,64,10],[512,64,32,10]等都行,至于与哪一组超参数是最优的,这需要大量的实验尝试和各方面领域的知识积累,或者可以通过 比如AutoML 技术搜索出较优设定等等方法实现。
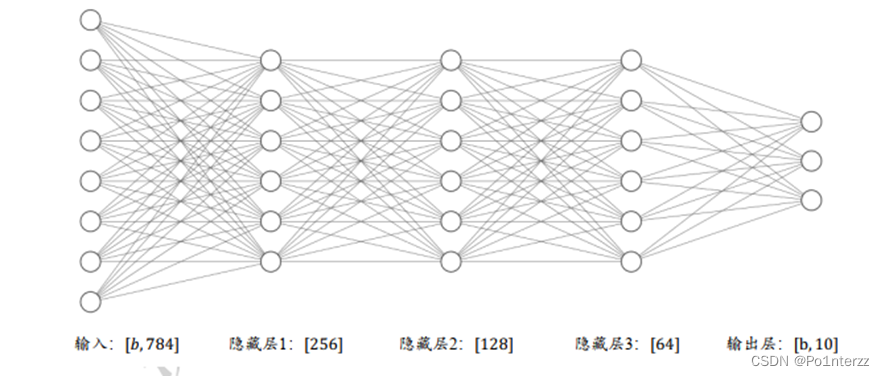
实现在tensorflow框架中实现网络层的架构,可以用层的方式实现更加简洁,先新建各个网络层,并指定各层的激活函数类型,本次实例用的是层实现方式: layers.Dense(units, activation),只需要指定输出节点数 Units 和激活函数类型即可,本例每层用的.relu激活函数,如果网络有点复制,需要考虑过拟合情况,将训练和测试的准确率差距变小,这时可以在每层添加使用dropout函数改善过拟合,或者用正则化同样可以改善过拟合作用,本例子用dropout函数实现,示例代码如下:
import tensorflow.keras as keras
from tensorflow.keras import models, layers, optimizers #序列模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), #输入层
tf.keras.layers.Dense(256, activation=tf.nn.relu), #隐藏层1
tf.keras.layers.Dropout(0.2), #百分之20的神经元不工作,防止过拟合
tf.keras.layers.Dense(128, activation=tf.nn.relu), #隐藏层2
tf.keras.layers.Dense(64, activation=tf.nn.relu), #隐藏层3
tf.keras.layers.Dense(10, activation=tf.nn.softmax) #输出层
]) 3. 模型编译步骤
多层神经网络框架建立之后,需要对模型进行编译步骤确定优化器,损失函数,训练效果中计算准确率等步骤,这里采用model.compile()实现,优化器用Adam算法,损失用交叉熵方法,示例代码如下:
#Adam算法为训练选择优化器和sparse_categorical_crossentropy为损失函数:
model.compile(optimizer='adam', #Adam算法为训练选择优化器
loss='sparse_categorical_crossentropy', #损失用交叉熵,速度会更快
metrics=['accuracy']) #计算准确率
# 打印网络参数
model.summary()4.模型训练&验证
多层神经网络模型进行编译之后,确定好各类参数之后,开始对训练集样本进行训练,获取模型的参数等,开始训练神经网络,采用的是model.fit()方法,在 Keras 中这一步是通过调用网络的 fit 方法来完成的,在训练数据上拟合(fit)模型,把训练集导入,训练次数根据需要自己定(本例为了排版需要,训练5次)。在多层神经网络模型训练完毕后,接下来需要验证一下这个模型精度如何,用model.evaluate()方法进行,示例代码如下:
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 验证模型:
loss,accuracy = model.evaluate(x_test,y_test,verbose=2)5. 完整代码
#加载tensorflow框架
import tensorflow as tf
mnist = tf.keras.datasets.mnist #MNIST数据集加载
#将数据集划分成训练集与测试集
(x_train_all, y_train_all),(x_test, y_test) = mnist.load_data()
#将Mnist数据集简单归一化
x_train_all, x_test = x_train_all / 255.0, x_test / 255.0
# 对数据集进行划分,50009个为训练集,10000个为验证集
x_train, x_valid = x_train_all[:50000], x_train_all[50000:] #验证集10000个
y_train, y_valid = y_train_all[:50000], y_train_all[50000:]
print(x_train.shape)
#打印一张照片
import matplotlib.pyplot as plt #加载画图模快
def show_single_image(img_arr): #定义一个提取图像函数
plt.imshow(img_arr,cmap='binary') #展示图像
plt.show()
show_single_image(x_train[1])
import tensorflow.keras as keras
from tensorflow.keras import models, layers, optimizers #序列模型
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), #输入层
tf.keras.layers.Dense(256, activation=tf.nn.relu), #隐藏层1
tf.keras.layers.Dropout(0.2), #百分之20的神经元不工作,防止过拟合
tf.keras.layers.Dense(128, activation=tf.nn.relu), #隐藏层2
tf.keras.layers.Dense(64, activation=tf.nn.relu), #隐藏层3
tf.keras.layers.Dense(10, activation=tf.nn.softmax) #输出层
])
#Adam算法为训练选择优化器和sparse_categorical_crossentropy为损失函数:
model.compile(optimizer='adam', #Adam算法为训练选择优化器
loss='sparse_categorical_crossentropy', #损失用交叉熵,速度会更快
metrics=['accuracy']) #计算准确率
# 打印网络参数
model.summary()
# 训练模型
model.fit(x_train, y_train, epochs=5)
# 验证模型:
loss,accuracy = model.evaluate(x_test,y_test,verbose=2)
多层神经网络回归问题应用举例
1.Auto MPG 数据集
本例子用的该数据集可以从UCI机器学习库中获取,下载的地址是:
http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data
2.数据集清洗与划分
对第一步下载好的数据集进行读写,这里使用pandas包的read_csv()函数可快速有效读取数据,由于数据众多,本例子选取气缸数(cylinders)、排量(Displacement)、马力(Horsepower)、重量(Weight)、加速(Acceleration)、车型年号(Model Year)和产地(Origin)等等属性来进行研究,示例代码如下:
# 加载画图、tensroflow等必要模块
import matplotlib.pyplot as plt #画图模块
import pandas as pd #数据读取、处理模块
import seaborn as sns #数据可视化、画各类图形
import tensorflow as tf
#下载数据
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin'] #选定需要的数据属性
data = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data",names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = data.copy() #复制数据集
print(dataset.shape)
print(dataset.tail()) #查看最后5行数据数据集导入之后,由于是一个原始状态的数据集,需要对数据进行清理缺漏、空值等,确保数据有效性,使用isna()函数判断是否有空值,用dropa()函数去除空值,同时为了保证数据值简单可用,删除这些异常值的行,示例代码如下:
#数据清洗,数据集中包括一些缺漏、空值等异常值。
dataset.isna().sum() #判断是否有空值并计算总数
dataset = dataset.dropna()由以上数据初步处理,Origin(出产地)的列数据实际上代表分类(不同国家地方),不仅仅是一个数字,所以把它转换为独热编码 (one-hot),先把Origin这一列数据拿出来,再把USA、Europe、Japan三个国家的Origin增加变成三列数据,用0-1表示,这就是one-hot编码的实质,示例代码如下:
origin = dataset.pop('Origin') #把这列取出,pop()函数移除列表中元素并赋值
dataset['USA'] = (origin == 1)*1.0 #添加USA这一列,当orgin为1的时候赋值1
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail() #倒数最后5派数据拆分训练集与测试集,82分,如下:
#拆分训练数据集和测试数据集,将数据集拆分为一个训练数据集和一个测试数据集。
train_dataset = dataset.sample(frac=0.8,random_state=0) #训练集占80%
test_dataset = dataset.drop(train_dataset.index)
print(train_dataset.shape)画图查看训练集中几对列的联合分布图,示例代码如下:
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")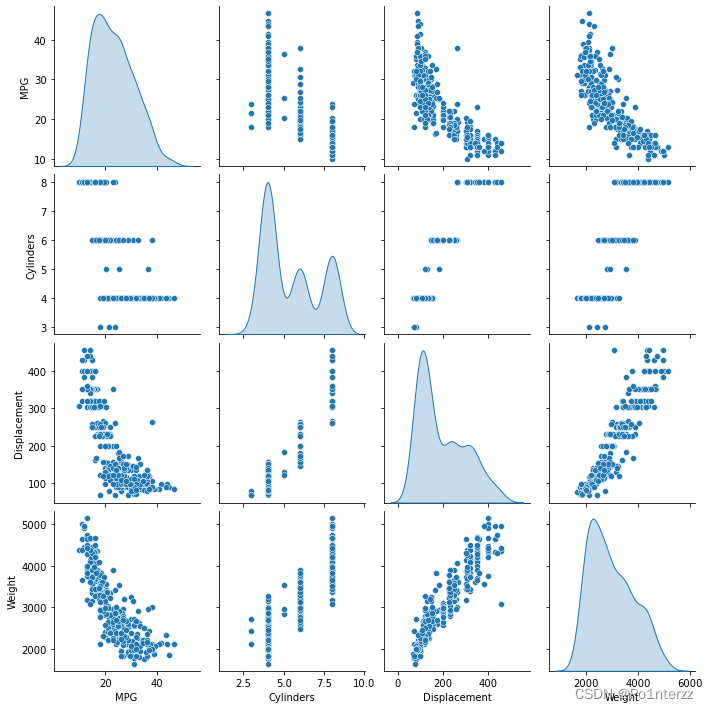 数据集的清洗、划分及其总体分布情况已经了解,接下来,对训练集和测试集的MPG标签中分离特征,这个标签是你使用训练模型进行预测的MPG值,由于上述数据的每一列的大小、范围都不一样,故有必要进行标准化处理,标准过程这里定义一个norm()函数进行,示例代码如下:
数据集的清洗、划分及其总体分布情况已经了解,接下来,对训练集和测试集的MPG标签中分离特征,这个标签是你使用训练模型进行预测的MPG值,由于上述数据的每一列的大小、范围都不一样,故有必要进行标准化处理,标准过程这里定义一个norm()函数进行,示例代码如下:
train_labels = train_dataset.pop('MPG') #训练集去掉MPG值
test_labels = test_dataset.pop('MPG')
#数据标准化
def norm(x):
return (x - train_stats['mean']) / train_stats['std'] #标准化公式
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)3.多层神经网络模型构建
所有的数据集准备工作已经就绪,接下来就到了构建模型的步骤,使用tensorflow的层模式keras.layers.Dense()方法构建多层神经网络模型,在本节里的模型里包含两个紧密相连的隐藏层,以及返回单个输出层,即3层网络,结点分布是[64,64,1],激活函数用的是relu函数,自定义RMSprop优化器,学习率是0.001,这些是按实验者的经验设置参数,模型的构建步骤包含于一个名叫 'build_model' 的函数中,示例代码如下:
def build_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
#自定义RMSprop优化器,学习率是0.001
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', #损失用mse
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
#模型实例化
model = build_model()4. 模型训练
多层神经网络模型已经构建完毕,接下来对模型运用fit()方法进行100个周期的训练,并在 history 对象中记录训练和验证的准确性,示例代码如下:
#对模型进行100个循环的训练,并在 history 对象中记录训练和验证的准确性。
history = model.fit(
normed_train_data, train_labels,
epochs=100, validation_split = 0.2, verbose=0) #verbose=0表示不输出训练记录
#输出训练的各项指标值
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
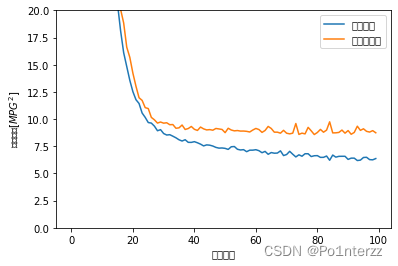
hist.tail()为了把上面的训练结果画图更直观的体现,把平均绝对误差 与均方误差的图画出来,示例代码如下:
#把训练结果用图形表示出来
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('训练次数')
plt.ylabel('平均绝对误差 [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='训练误差')
plt.plot(hist['epoch'], hist['val_mae'],
label = '测试集误差')
plt.ylim([0,5])
plt.legend()
plt.figure()
plt.xlabel('训练次数')
plt.ylabel('均方误差[$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='训练误差')
plt.plot(hist['epoch'], hist['val_mse'],
label = '测试集误差')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history) #把平均绝对误差 与均方误差的图画出来 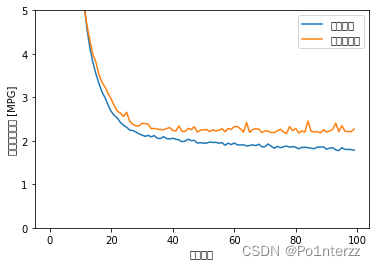
5. 模型验证
多层神经网络模型已经训练好,可以使用测试集,泛化模型,看看的效果如何,用.evaluate()方法来实现;最后,运用已经训练好的模型,预测验证一下测试集中的数据预测 MPG 值,画出预测图来表示,使用.predict()方法实现。示例代码如下:
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
print("测试集的平均绝对误差是: {:5.2f} MPG".format(mae))
test_predictions = model.predict(normed_test_data).flatten()
# 画图表示
plt.scatter(test_labels, test_predictions)
plt.xlabel('真实值 [MPG]')
plt.ylabel('预测值 [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
plt.plot([-100, 100], [-100, 100])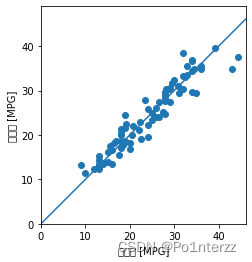
6. 完整代码
# -*- coding: utf-8 -*-
"""
Created on Mon May 20 20:22:42 2024
@author: 86150
"""
# 加载画图、tensroflow等必要模块
import matplotlib.pyplot as plt #画图模块
import pandas as pd #数据读取、处理模块
import seaborn as sns #数据可视化、画各类图形
import tensorflow as tf
#下载数据
column_names = ['MPG','Cylinders','Displacement','Horsepower','Weight',
'Acceleration', 'Model Year', 'Origin'] #选定需要的数据属性
data = pd.read_csv("http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data",names=column_names,
na_values = "?", comment='\t',
sep=" ", skipinitialspace=True)
dataset = data.copy() #复制数据集
print(dataset.shape)
print(dataset.tail()) #查看最后5行数据
#数据清洗,数据集中包括一些缺漏、空值等异常值。
dataset.isna().sum() #判断是否有空值并计算总数
dataset = dataset.dropna()
origin = dataset.pop('Origin') #把这列取出,pop()函数移除列表中元素并赋值
dataset['USA'] = (origin == 1)*1.0 #添加USA这一列,当orgin为1的时候赋值1
dataset['Europe'] = (origin == 2)*1.0
dataset['Japan'] = (origin == 3)*1.0
dataset.tail() #倒数最后5派数据
#拆分训练数据集和测试数据集,将数据集拆分为一个训练数据集和一个测试数据集。
train_dataset = dataset.sample(frac=0.8,random_state=0) #训练集占80%
test_dataset = dataset.drop(train_dataset.index)
#也可以查看总体的数据统计:
train_stats = train_dataset.describe()
train_stats.pop("MPG")
train_stats = train_stats.transpose()
#img
sns.pairplot(train_dataset[["MPG", "Cylinders", "Displacement", "Weight"]], diag_kind="kde")
train_labels = train_dataset.pop('MPG') #训练集去掉MPG值
test_labels = test_dataset.pop('MPG')
#数据标准化
def norm(x):
return (x - train_stats['mean']) / train_stats['std'] #标准化公式
normed_train_data = norm(train_dataset)
normed_test_data = norm(test_dataset)
#建立3层网络,结点[64,64,1],激活函数用的是relu函数
def build_model():
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=[len(train_dataset.keys())]),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(1)
])
#自定义RMSprop优化器,学习率是0.001
optimizer = tf.keras.optimizers.RMSprop(0.001)
model.compile(loss='mse', #损失用mse
optimizer=optimizer,
metrics=['mae', 'mse'])
return model
#模型实例化
model = build_model()
model.summary()
#对模型进行100个循环的训练,并在 history 对象中记录训练和验证的准确性。
history = model.fit(
normed_train_data, train_labels,
epochs=100, validation_split = 0.2, verbose=0) #verbose=0表示不输出训练记录
#输出训练的各项指标值
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
#把训练结果用图形表示出来
def plot_history(history):
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
plt.figure()
plt.xlabel('训练次数')
plt.ylabel('平均绝对误差 [MPG]')
plt.plot(hist['epoch'], hist['mae'],
label='训练误差')
plt.plot(hist['epoch'], hist['val_mae'],
label = '测试集误差')
plt.ylim([0,5])
plt.legend()
plt.figure()
plt.xlabel('训练次数')
plt.ylabel('均方误差[$MPG^2$]')
plt.plot(hist['epoch'], hist['mse'],
label='训练误差')
plt.plot(hist['epoch'], hist['val_mse'],
label = '测试集误差')
plt.ylim([0,20])
plt.legend()
plt.show()
plot_history(history) #把平均绝对误差 与均方误差的图画出来
loss, mae, mse = model.evaluate(normed_test_data, test_labels, verbose=2)
print("测试集的平均绝对误差是: {:5.2f} MPG".format(mae))
test_predictions = model.predict(normed_test_data).flatten()
# 画图表示
plt.scatter(test_labels, test_predictions)
plt.xlabel('真实值 [MPG]')
plt.ylabel('预测值 [MPG]')
plt.axis('equal')
plt.axis('square')
plt.xlim([0,plt.xlim()[1]])
plt.ylim([0,plt.ylim()[1]])
plt.plot([-100, 100], [-100, 100])

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 36
36 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)