【深度学习】一文搞懂卷积神经网络(CNN):从图像基础到核心组件
本文介绍了卷积神经网络(CNN)的基础知识及其核心组件。首先阐述了图像的基本概念和类型,包括二值图像、灰度图像、索引图像和RGB图像。然后重点讲解了CNN的结构,主要由卷积层、池化层和全连接层组成,并列举了其在图像分类、目标检测等领域的应用。文章详细解析了卷积层的计算过程,包括卷积核操作、Padding填充、Stride步长等关键概念,以及多通道和多卷积核的处理方式。最后给出了PyTorch中卷积
一、 图像基础知识
在深入了解卷积神经网络(CNN)之前,我们首先需要掌握一些关于图像的基础知识,因为 CNN 正是为了处理像图像这类具有网格结构的数据而设计的。
1.1 图像基本概念
图像是人类视觉的基础,是自然景物的客观反映。“图”是物体反射或透射光的分布,“像“是人的视觉系统所接受的图在人脑中所形成的印象或认识。照片、绘画、地图、X光片、卫星云图等都是图像。
在计算机中,图像由像素点组成,每个像素点的取值范围通常为 [0, 255]。像素值越接近于0,颜色越暗,接近于黑色;像素值越接近于255,颜色越亮,接近于白色。
1.2 图像基本类型
在计算机中,按照颜色和灰度的多少,图像可以分为四种基本类型。
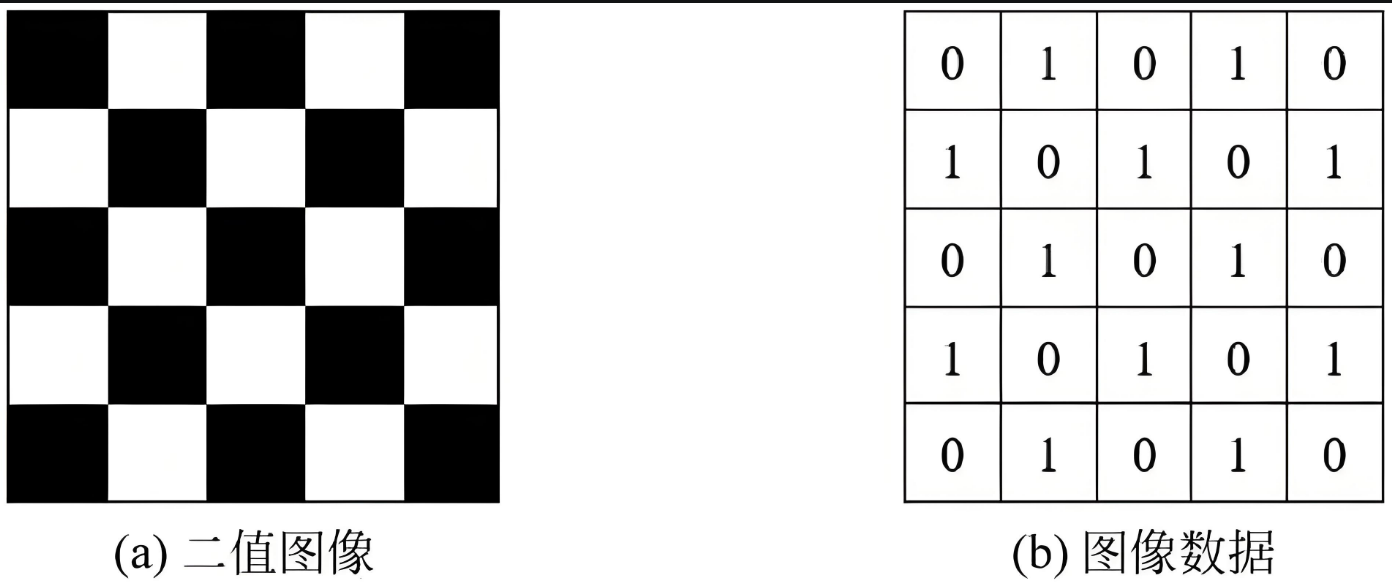
1. 二值图像 (Binary Image)
一幅二值图像的二维矩阵仅由 0 和 1 两个值构成,“0”代表黑色,“1”代表白色。由于每个像素只有两种可能,计算机中通常用1个二进制位来存储。二值图像常用于文字识别(OCR)、线条图和掩膜图像等。
2. 灰度图像 (Grayscale Image)
灰度图像矩阵元素的取值范围通常为 [0, 255],共256个灰度级。数据类型一般为8位无符号整数(uint8)。“0”表示纯黑色,“255”表示纯白色,中间的数字代表由黑到白的过渡色。
3. 索引图像 (Indexed Image)
索引图像的结构比较复杂,它包含一个图像的二维矩阵和一个颜色索引矩阵(MAP)。图像矩阵中的每个像素值(如0-255)并不直接表示颜色,而是作为索引,去颜色索引矩阵MAP中查找对应的真实颜色。MAP是一个 N x 3 的数组,每一行存储一个 [R, G, B] 颜色值。这种方式可以有效压缩图像体积。
4. 真彩色RGB图像 (True Color RGB Image)
RGB图像直接存储每个像素的颜色值。它由三个通道(Channel)组成:红(Red)、绿(Green)、蓝(Blue)。每个像素的颜色由这三个通道的值组合而成。因此,一个 M x N 的彩色图像在计算机中实际存储为三个 M x N 的二维矩阵。
注意: 在某些图像处理库(如 OpenCV)中,通道的默认顺序是 BGR 而不是 RGB。
图像类型总结
| 图像类型 | 通道数 | 像素值范围 | 主要特点 | 常见用途 |
|---|---|---|---|---|
| 二值图像 | 1通道 | 0 或 1 | 每个像素只有黑与白两种值 | 形态学操作、二值化、轮廓检测 |
| 灰度图像 | 1通道 | 0 到 255 | 每个像素表示灰度(亮度) | 图像预处理、物体检测、人脸识别 |
| 索引图像 | 1通道 | 0 到 255(索引) | 像素值为颜色表的索引,颜色表决定实际颜色 | 存储压缩、较少颜色的图像表示 |
| RGB图像 | 3通道(R、G、B) | 0 到 255 | 每个像素由红、绿、蓝三个通道组成 | 普通彩色图像显示、图像处理与分析 |
二、 卷积神经网络(CNN)概述
2.1 什么是卷积神经网络?
卷积神经网络(Convolutional Neural Network, CNN)是深度学习在计算机视觉领域的突破性成果,它是一种专门用于处理具有类似网格结构数据(如图像、视频)的神经网络。
相比于传统全连接网络,CNN能更好地处理图像数据,因为它可以自动学习和提取图像特征,同时保留空间结构,且参数量更少。
CNN网络主要由三部分构成:卷积层、池化层和全连接层。
- (1) 卷积层(CONV):负责提取图像中的局部特征(如边缘、纹理、形状)。
- (2) 池化层(POOL):用来大幅降低参数量级(降维),并增强模型的鲁棒性。
- (3) 全连接层(FC):类似传统神经网络,将提取到的特征进行整合,用于最终的分类或回归任务。

2.2 卷积神经网络应用
- 图像分类:识别图片中的物体类别(猫、狗、汽车等)。
- 目标检测:检测图像中物体的位置和类别。
- 图像分割:将图像像素级地分成不同区域。
- 人脸识别:识别和验证图像中的人脸。
- 医学图像分析:检测医学图像中的异常(如癌症检测)。
- 自动驾驶:识别交通标志、车辆、行人。
2.3 CNN中的经典网络架构
- LeNet-5: 最早的CNN架构之一,奠定了CNN的基础。
- AlexNet: 在ImageNet竞赛中取得巨大成功,引入了ReLU激活函数、Dropout,推动了深度学习的热潮。
- VGGNet: 证明了通过堆叠小的(3x3)卷积核可以构建更深、更有效的网络。
- GoogLeNet (Inception): 提出了Inception模块,通过并行使用不同大小的卷积核来增加网络宽度。
- ResNet (残差网络): 引入了残差块和跳跃连接,解决了深度网络训练中的梯度消失问题。
- DenseNet (密集连接网络): 提出密集块,将每一层与前面所有层直接连接,最大化了特征重用。
三、 核心组件一:卷积层 (Convolutional Layer)
卷积层是CNN的灵魂,其核心作用是通过卷积操作自动学习和提取图像中的特征。
卷积层的主要作用:
- 特征提取:通过卷积核(滤波器)扫描输入图像,提取如边缘、角点、纹理等特征。
- 权重共享:同一个卷积核在整个输入图像上共享同一组权重,这极大地减少了模型参数量。
- 局部连接:每个神经元只与输入的一个局部区域(感受野)相连,符合图像空间局部相关的特性。
- 空间不变性:网络能够识别出图像中任何位置的相同特征,具有一定的平移不变性。
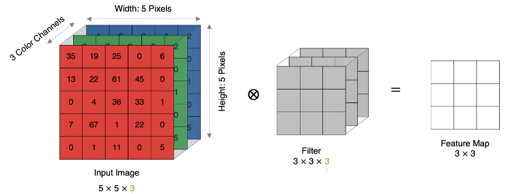
3.1 卷积计算
卷积运算的本质是滤波器(卷积核) 和输入数据的局部区域进行点积运算。
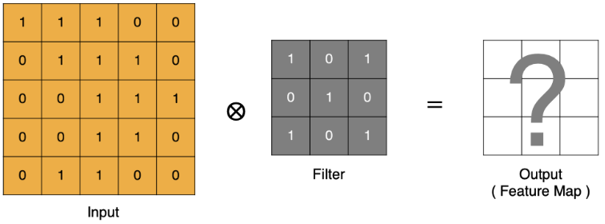
计算过程:
卷积核在输入图像上从左到右、从上到下滑动,每次滑动都覆盖一个局部区域,并将该区域的像素值与卷积核的权重进行加权求和,得到输出特征图的一个像素值。
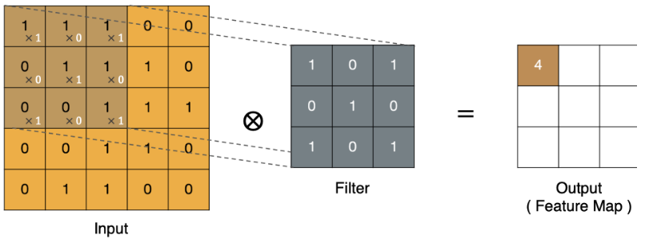
例如,左上角 4 的计算方法如下:1*1 + 0*1 + 1*1 + 0*0 + 1*1 + 1*0 + 0*0 + 0*1 + 1*1 = 4
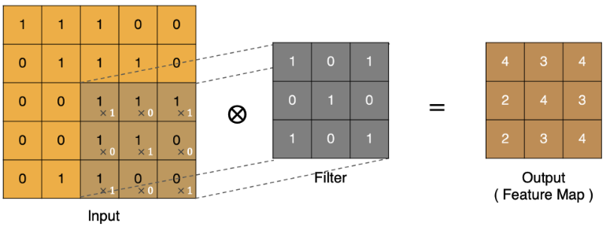
将卷积核滑过所有位置,就得到了最终的特征图(Feature Map)。
3.2 Padding (填充)
为了保持特征图的空间维度或更好地利用边缘信息,我们引入了 Padding,即在输入特征图的边界周围添加额外的像素(通常是零)。
Valid Padding: 不进行任何填充,输出尺寸会缩小。Same Padding: 添加足够的填充,使输出特征图的尺寸与输入相同。
3.3 Stride (步长)
Stride 指的是卷积核在图像上每次滑动的步长大小。步长越大,输出的特征图尺寸越小,计算量也越小。
- 步长为1 (Stride = 1):

- 步长为2 (Stride = 2):

3.4 多通道卷积计算
当输入有多个通道时(如RGB图像),卷积核也必须有相同的通道数。计算时,卷积核的每个通道分别与输入图像的对应通道进行卷积,然后将所有通道的卷积结果按位相加,得到一个单通道的输出特征图。
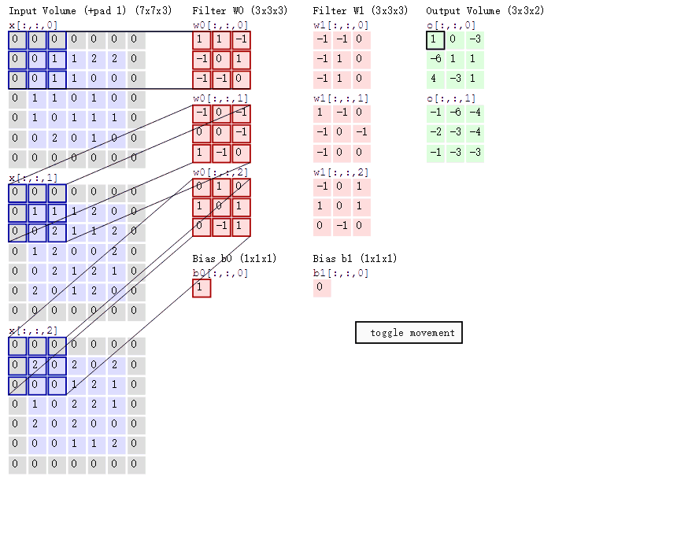
3.5 多卷积核卷积计算
一个卷积层通常包含多个卷积核,每个卷积核负责提取一种特征。如果有 K 个卷积核,就会生成 K 个特征图,这些特征图堆叠在一起,形成下一层的输入。
3.6 特征图大小计算
输出特征图的大小 N 的计算公式为:
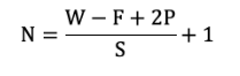
其中:
W: 输入图像大小F: 卷积核大小S: 步长 (Stride)P: 填充大小 (Padding)
3.7 PyTorch卷积层API
conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
"""
参数说明:
in_channels: 输入通道数,RGB图片一般是3
out_channels: 输出通道,也可以理解为卷积核kernel的数量
kernel_size:卷积核的高和宽设置,一般为3,5,7...
stride:卷积核移动的步长
整数stride:表示在所有维度上使用相同的步长 stride=2 表示在水平和垂直方向上每次移动2个像素
元组stride: 允许在不同维度上设置不同的步长 stride=(2, 1) 表示在水平方向上步长为2,在垂直方向上步长为1
padding:在四周加入padding的数量,默认补0
padding=0:不进行填充。
padding=1:在每个维度上填充 1 个像素(常用于保持输出尺寸与输入相同 padding=输入形状大小-输出形状大小)。
padding='same'(从 PyTorch 1.9+ 开始支持):让输出特征图的尺寸与输入保持一致。PyTorch会自动计算需要的填充量。stride必须等于1,不支持跨行,因为计算padding时可能出现小数
padding=kernel_size-1:Full Padding 完全填充
"""
四、 核心组件二:池化层 (Pooling Layer)
除了卷积层,CNN还有一个关键的降维组件——池化层。它通常位于卷积层之后,用于减小特征图的尺寸。
池化层的主要作用:
- 降维和减少计算量:通过减少特征图的尺寸,显著降低后续层的计算消耗。
- 提高鲁棒性:使模型对输入图像的微小位移、缩放或旋转不那么敏感,增强泛化能力。
- 防止过拟合:通过减少模型参数和复杂度,有助于防止过拟合。
- 抽象特征:保留最重要的特征,提取更抽象、更高层次的表示。
4.1 池化层计算
池化操作在一个窗口(Pooling Window)内进行,最常见的两种类型是:
1. 最大池化 (Max Pooling)
取池化窗口内的最大值作为输出。这种方法能更好地保留纹理特征。
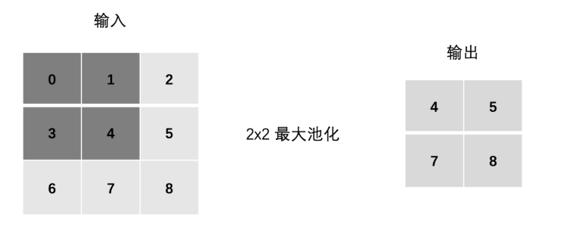
2. 平均池化 (Avg Pooling)
取池化窗口内所有值的平均值作为输出。这种方法能更好地保留背景信息。
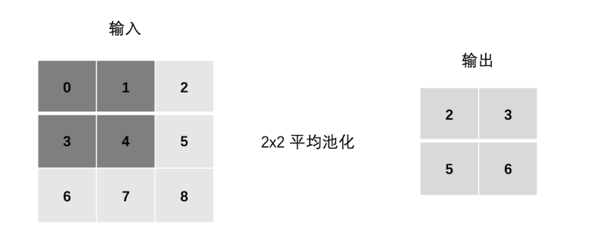
4.2 Padding与Stride
池化层同样具有 Padding 和 Stride 参数,其作用和计算方式与卷积层类似。
- Padding in Pooling:
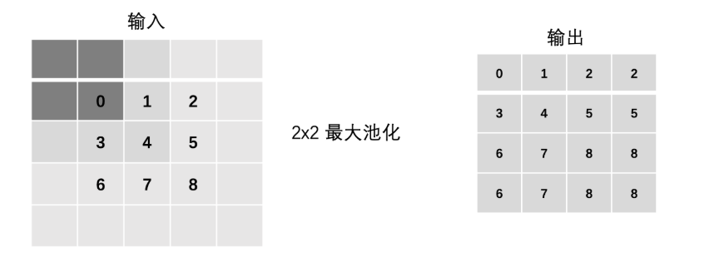
- Stride in Pooling:

4.3 多通道池化计算
池化层在处理多通道输入时,与卷积层有本质区别:
池化操作在每个通道上是独立进行的。
这意味着池化层不会改变输入的通道数。如果输入有 C 个通道,经过池化后,输出仍然是 C 个通道,只是每个通道的宽度和高度变小了。
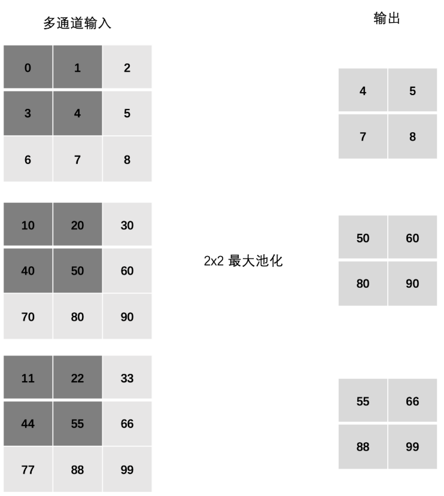
4.4 PyTorch池化层API
# 最大池化
nn.MaxPool2d(kernel_size=2, stride=2, padding=1)
# 平均池化
nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
"""
参数说明:
kernel_size:核的高和宽设置,一般为3,5,7...
stride:核移动的步长
padding:在四周加入padding的数量,默认补0
"""
希望这篇博客能帮助您全面理解卷积神经网络的基础知识。从图像的基本概念到CNN的两大核心组件——卷积层和池化层,我们一步步揭开了它的神秘面纱。
五、参考资料
本文核心知识点均提炼自 B 站黑马程序员 的精品课程,老师讲得非常详细,大家一定要去支持!
课程名称: AI大模型《神经网络与深度学习》全套视频课程,涵盖Pytorch深度学习框架、BP神经网络、CNN图像分类算法及RNN文本生成算法

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 34
34 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)