供应链 | MSOM 论文精读:用于库存管理的整数规划强化学习——深度策略迭代方法(上)
在过去十年间,库存与供应链管理经历了显著的变革。电子商务的兴起为供应链引入了复杂性与全球化,导致物理流动日益互联。因此,管理这些供应链所需的成本不断上升。此外,COVID-19 疫情更是进一步推高了管理复杂网络的支出。根据《华尔街日报》的最新报道,美国企业的物流成本在某些年份中同比增长高达 22%. 为应对这些挑战,一个具有前景的方向是引入基于人工智能的库存管理解决方案,该类方案在管理复杂供应链方

编者按
本次解读的文章一种基于强化学习,提出了用于优化长期贴现回报问题的框架,该类问题具有组合型动作空间 (combinatorial action space) 和状态相关约束 (state dependent constraints). 这些特性在诸多运营管理问题中十分常见,例如库存补货问题,其中管理者需面对需求不确定、缺货以及产能限制,从而导致可行动作空间更为复杂。文章提出的 Programmable Actor RL (PARL) 方法采用深度策略迭代 (deep-policy iteration),借助神经网络逼近价值函数 (value function),并结合数学规划与样本平均近似 (sample average approximation),以在考虑组合动作空间与状态相关约束的前提下,求解每一步的最优动作。
方法/结果: 文章展示了该方法如何应用于复杂的库存补货问题,尤其是在解析解不可得的情形下。文章还将该算法与当前最先进的强化学习算法以及常用的补货启发式方法进行了对比测试,结果显示该算法平均在多个复杂供应链设置中相较现有方法提高最多达14.7%的表现。
管理启示: 文章发现,PARL方法相较于基准算法的表现提升,可直接归因于更优的库存成本管理,特别是在库存受限环境下。此外,在较为简单的设置中,如果最优补货策略是可解或近似已知的,发现RL算法学习到的策略能逼近最优解。最后,为了使强化学习方法更易被运营管理领域研究者使用,文章还开发了一个模块化的Python库,可用于测试RL算法在各种供应链结构下的性能(下篇详细讨论)。
1 背景介绍
在过去十年间,库存与供应链管理经历了显著的变革。电子商务的兴起为供应链引入了复杂性与全球化,导致物理流动日益互联。因此,管理这些供应链所需的成本不断上升。此外,COVID-19 疫情更是进一步推高了管理复杂网络的支出。根据《华尔街日报》的最新报道,美国企业的物流成本在某些年份中同比增长高达 22%. 为应对这些挑战,一个具有前景的方向是引入基于人工智能的库存管理解决方案,该类方案在管理复杂供应链方面展现出潜在优势。
人工智能与强化学习 (Reinforcement Learning, RL) 在多个领域取得了显著突破,包括游戏、机器人以及医疗健康。RL 提供了一种系统化框架,可在仅需极少领域知识的前提下,求解序贯决策问题。借助最先进的开源 RL 方法,研究人员可开发出能在多阶段决策问题中最大化长期回报的高效策略。因此,RL 被应用于包括供应链在内的多个领域;然而RL 在企业级运营场景中的应用仍较为有限,且面临诸多挑战。
典型的运营管理问题,如库存管理与网络收入管理,通常具有以下特征:动作空间庞大、状态依赖的动作约束清晰,且具有潜在的随机转移动态。例如,一个在供应链网络中管理库存的企业,需决定如何将库存分配至不同节点。此类问题面临多重挑战:需应对网络节点间的需求不确定性,管理一个本地可行动作集合(该集合通常具有组合特性),满足大量状态相关约束以保证可行性,并在短期回报与长期回报之间权衡取舍。
RL 方法可在真实或模拟环境中,通过采样不确定性并生成回报轨迹来进行策略学习。通过对这些轨迹的评估,RL 能够估计在短期与长期回报间实现平衡的最优动作策略。然而,运营管理问题中固有的状态相关约束下的大规模组合动作空间使得基于枚举的传统 RL 技术在计算上不可行。
文章针对上述挑战,文章引入了一种深度策略迭代方法,借助神经网络逼近价值函数——该方法结合了数学规划与样本平均近似,以在考虑组合动作空间与状态相关约束的前提下,最优地求解逐步动作选择问题。
2 相关文献综述
本次解读所选文章的文献综述内容详实,系统梳理了传统 RL 到深度 RL在库存优化中的演进路径,并涵盖了强化学习与数学规划融合方法的最新进展。鉴于该论文为近期正式发表的期刊文章,其综述具有较高参考价值,相关内容将在解读中予以体现。
文章的工作与以下不同的文献领域有关:
- 参数化策略 (parametric policies),
- 近似动态规划 (Approximate Dynamic Programming, ADP),
- 强化学习,以及
- 基于数学规划的强化学习 (MP-based RL).
由于这些主题本身的文献数量庞大,即使是在供应链和库存管理的特定背景下也是如此,文章挑选了其中与当前研究最为相关的部分,来介绍已有的最先进研究成果。
2.1 用于库存管理的参数化策略
库存管理一直是被广泛研究的课题,且具有悠久的研究历史。Scarf (1960) 的奠基性工作表明:对于一个单节点、由单一供应商供货、库存无限、提前期固定、订货成本包含固定与可变部分的系统,其最优策略对于延期交货需求 (backordered demand) 具有一个(s,S)(s,S)(s,S)的结构,其中SSS是指根据库存位置(即现有库存与在途库存的总和)定义的补至水平 (order-up-to level),sss则是表示当库存位置低于该阈值时触发补货的门槛。这种 (s,S)(s,S)(s,S) 策略通常被称为基本库存策略 (base stock policy). 在销售损失 (lost sales) 的需求场景中,如果实际需求超过库存,则超出的部分即为损失。在这类情形下,若提前期为正,哪怕是在单节点、由单一零售商供货的设置中,最优策略的结构也是未知的。此外,在这些销售损失场景中,基本库存策略的表现通常较差,尤其是在惩罚成本较高、库存水平高、缺货事件罕见时除外。
一般而言,最优策略依赖于完整的库存链(inventory pipeline),这与在延期交货设置中可能存在的状态空间折叠 (state-space collapse) 不同 (Levi et al. 2008). 随着提前期增长,问题复杂度呈指数增长。在这些设定下,Huh et al.(2009) 与 Goldberg et al.(2016) 分别证明了:当惩罚成本高且使用固定订货策略时,基本库存策略在提前期较大时具有渐近最优性 (asymptotic optimality). Xin (2021) 将上述结果结合,提出了一个截断基本库存策略 (capped base stock policy), 在提前期增长时保持渐近最优,且在提前期较小的情况下也具有良好的经验表现。Sheopuri et al.(2010) 进一步证明:销售损失问题是双重供货问题 (dual sourcing problem) 的一个特例,亦即每个零售节点有两个外部供应商来源。因此,基本库存策略在此类情形下通常不是最优策略。
多级网络 (Multiechelon networks) 包含多个节点、多个阶段或多个持有库存的层级,带来了额外挑战。基本库存策略仅在特定情形下才是最优,例如:延期交货需求,无固定成本,连续串行供应链,惩罚施加在需求端节点(Clark and Scarf 1960),或无法在仓库中持有库存的两级分销网络 (Federguen and Zipkin 1984). 有关多级库存模型的综述研究可参考 de Kok et al.(2018),其覆盖了多种建模假设与网络结构。
尽管 (s,S)(s,S)(s,S) 策略与状态空间折叠一起构成的基本库存策略在许多条件下并非最优,它们在实践与文献中仍广泛使用。
2.2 近似动态规划与强化学习
文章的工作也与近似动态规划 (Approximate Dynamic Programming, ADP) 这一广泛领域密切相关。ADP 主要关注求解 Bellman 方程,并在过去几十年中一直是活跃的研究方向。ADP 方法通常使用价值函数的近似表示来优化那些在计算上不可行的动态规划问题。
常见的算法可以被划分为两类:有模型方法 (model-aware) 与无模型方法 (model-agnostic).
- 有模型方法利用系统已知的动态信息(如状态转移函数与即时奖励函数)来估计 value-to-go,常见方法包括 value iteration 与 policy iteration。这些算法从对 value-to-go 的任意初始估计出发,反复迭代改进,最终收敛至未知的最优策略。原文作者推荐参考 Gijsbrechts et al.(2022) 对于基于 ADP 的库存管理方法的优秀综述。
- 无模型方法则绕过对系统动态部分或全部信息的依赖,转而在模拟环境中使用试错方式学习策略。环境提供即时奖励与状态转移信息,基于当前状态与已选动作。这一框架通常被称为强化学习 (Sutton and Barto 2018).
RL 方法又可分为两类:基于模型的强化学习 (model-based RL) 与 无模型强化学习 (model-free RL). 在基于模型的 RL 中,转移函数与最优策略是同时学习的;而在无模型 RL 中,转移函数并不被显式学习。
在经典 RL 方法中,会选择一组特征,并用这些特征的多项式函数去逼近价值函数(Van Roy et al. 1997)。此类方法最初成功有限。在本文中,文章聚焦于无模型强化学习方法。其中一种流行的无模型 RL 算法是Q-learning:每个状态-动作对的价值是通过状态轨迹与不同行动下的奖励进行估计的,最优动作由穷举搜索获得。
然而,伴随深度学习的兴起与计算能力的大幅提升,深度强化学习 (DRL) 在受欢迎程度与效果上都出现了显著回升。这种复兴主要得益于使用神经网络逼近价值函数,使特征选择与函数选择的过程自动化。该进展带来了多个算法突破,包括:策略梯度方法 (policy gradient methods)的发展,如 actor-critic 方法 (Mnih et al. 2016). 在这些方法中,神经网络被用于同时逼近价值函数与策略函数。策略通常通过一个动作网络表示,编码动作分布。
尽管 DRL 与 actor-critic 方法取得了成功,但也面临以下挑战:缺乏稳健的收敛性、对超参数的高敏感性、高样本复杂度、网络内部的函数逼近误差,导致次优策略与不准确的价值估计。为应对上述问题,研究者提出了 actor-critic 的若干变体,例如:
- 近端策略优化 (Proximal Policy Optimization, PPO),其目标是避免陷入次优解,同时仍保持策略更新过程中的显著性能提升。该方法通过约束新旧策略之间的偏差来实现改进 (Schulman et al. 2017);
- 软 actor-critic 方法 (Soft Actor-Critic, SAC),其通过熵正则化提升探索能力,从而增强对超参数的鲁棒性、防止陷入局部最优、并加速策略学习 (Haarnoja et al. 2018).
文章研究内容与上述文献互为补充。文章提供了一种系统化方法,显式考虑已知约束与即时奖励,避免在训练过程中隐式学习或推断它们。文章提出的框架潜在地帮助缓解了 DRL 所面临的已知挑战,如:降低样本复杂度、提高算法鲁棒性、降低陷入次优策略的风险、减少对策略网络函数逼近能力的依赖(该依赖可能因过拟合、欠拟合或数据采样问题造成误差,如探索不足或收敛至非最优解)。
2.3 强化学习与数学规划在库存管理中的应用
关于强化学习在多级库存管理问题中的益处,最近,越来越多的研究采用基于深度神经网络 (DNN) 的强化学习技术来求解供应链问题。Gijsbrechts et al.(2022)研究了一种基于 DNN 的 actor-critic 方法来求解库存管理问题,针对销售损失、双重供货设置与多级结构情形,实证显示其在后两者中的表现优于传统方法。Sultana et al.(2020)提出了一个多节点 actor-critic 框架 (multiagent actor-critic framework),用于在多级结构中针对大量产品的库存管理问题建模。Qi et al.(2023)则开发了一个实用的端到端深度学习方法,用于库存管理。 Hubbs et al.(2020)表明,在有限时间视野的串行供应链中,RL 方法相较于 base-stock policy 具有更优表现。关于 RL 在库存管理中的应用路线图,原文作者建议参考综述 Boute et al.(2022).
与上述研究不同,文章采用基于数学规划的强化学习 actor 架构,并展示其在库存管理场景中相较传统深度强化学习方法的优势。最近的研究也将数学规划方法用于 DNN 驱动的 RL 设置中,特别是在面对 large action spaces 的优化问题。已有多项研究表明,训练好的ReLU 网络 (Rectified Linear Unit, ReLU) 可以被转化为一个 MIP 问题。 文章在前述复杂性基础上进一步考虑了奖励的不确定性(uncertain rewards)。
3 模型
3.1 模型介绍
考虑一个无限期、离散时间的贴现马尔可夫决策过程(Markov Decision Process, MDP),其定义如下:状态空间S\mathcal{S}S,状态s∈Ss \in \mathcal{S}s∈S;动作空间A(s)\mathcal{A}(s)A(s),动作a∈A(s)a \in \mathcal{A}(s)a∈A(s);不确定随机变量D∈RdimD \in \mathbb{R}^{\text{dim}}D∈Rdim,具有上下文相关的概率分布P(D=d∣s)P(D = d \mid s)P(D=d∣s);奖励函数R(s,a,D)R(s, a, D)R(s,a,D);初始状态分布β\betaβ;折扣因子γ\gammaγ;状态转移函数s′=T(s,a,d)s' = \mathcal{T}(s, a, d)s′=T(s,a,d),其中 s′s's′ 表示下一个状态。一个静态策略 (stationary policy) π∈Π\pi \in \Piπ∈Π 被定义为一个条件分布π(⋅∣s)\pi(\cdot \mid s)π(⋅∣s),表示在状态sss下选择动作的分布,则策略π\piπ的期望回报为:
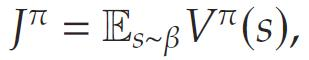
其中,价值函数 Vπ(s)V^{\pi}(s)Vπ(s) 定义为:
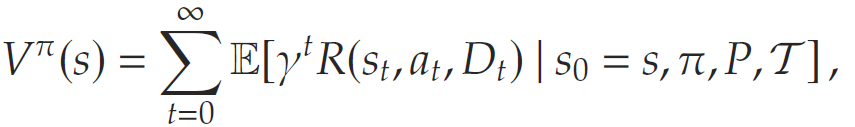
其中,期望是对即时奖励与状态转移进行的联合期望。能够最大化长期期望贴现回报的最优策略定义为:
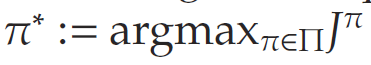
根据 Bellman 原理,最优策略是以下递推方程的唯一解:
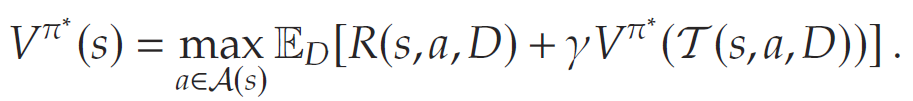
直接该式在计算上是不可行的。文章采用一种混合方法:使用模型来决定即时奖励,而 value-to-go 函数则通过在模拟环境中的试错 (trial-and-error) 方式、在无模型设定下学习得到。
3.2 算法
文章提出了一个基于蒙特卡洛模拟的策略迭代框架 (Monte Carlo simulation-based policy-iteration framework),其中学习得到的策略是某个数学规划模型的结果,称之为 PARL。与基于强化学习的方法常见的做法一样,该框架假设可以访问一个仿真环境,该环境在给定一个动作和当前状态的前提下,能够生成状态转移与奖励。
PARL 的初始化是采用随机策略。初始策略将通过引入学习得出的评论器(即价值函数)在多个轮次中被迭代改进。在第jjj轮迭代中,策略πj−1\pi_{j-1}πj−1被用于生成NNN条样本路径,每条路径长度为TTT. 在每一个时间步,每条路径由如下三元组组成:状态stns_t^nstn、奖励RtnR_t^nRtn、下一状态st+1ns_{t+1}^nst+1n,它们由环境生成。这些三元组随后用于估计值函数V^θπj−1\hat{V}_{\theta}^{\pi_{j-1}}V^θπj−1,即 value-to-go 函数。该 value-to-go 函数使用神经网络表示,并由参数θ\thetaθ参数化,该参数是通过解决某个问题学习得到的。
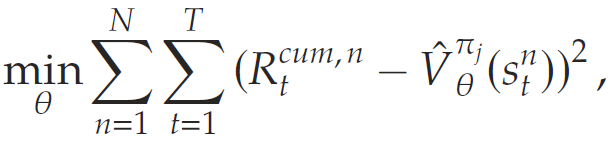
其中,目标变量 Rtcum,n:=∑i=tTγi−tRinR_t^{\text{cum}, n} := \sum_{i=t}^T \gamma^{i - t} R_i^nRtcum,n:=∑i=tTγi−tRin 表示在第nnn条样本路径中,从时刻ttt起累计的贴现奖励,该路径由模拟策略πj−1\pi_{j-1}πj−1生成。一旦估计出了V^\hat{V}V^,就可以通过该训练好的 value-to-go 函数构造出新的策略,其表达为:
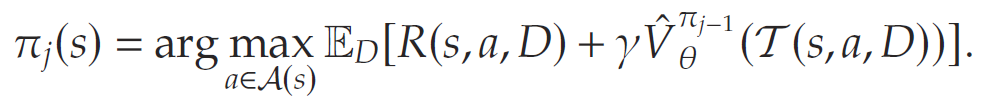
该问题与原问题类似,不同之处在于,真实的 value-to-go 被一个近似的 value-to-go 所取代。由于每次迭代都会产生一个更新后的、改进的策略,将其称为一个策略迭代方法。接下来,文章讨论如何求解该问题以在每一次迭代中获得一个更新的策略。该问题的求解具有挑战性,主要有两个原因。首先,V^θπj−1\hat{V}_{\theta}^{\pi_{j-1}}V^θπj−1是一个神经网络,这使得基于枚举的方法在操作空间较大且具有组合性质的情况下变得不可行。其次,该目标函数需要在不确定性 DDD的分布下求期望,而这在许多场景中是分析上不可解的。
3.3 通过神经网络进行优化
首先关注最大化问题 (2) 中目标函数的问题。为了简化该问题,首先考虑需求 DDD 是确定性已知为ddd的情形。此时,
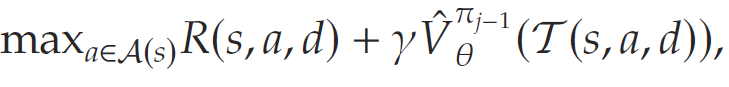
其中移除了对不确定需求DDD的期望操作。注意,决策变量aaa是作为输入传递给价值估计函数 V^\hat{V}V^. 因此,对aaa的优化等价于对一个神经网络进行优化,这并非易事。采用基于数学规划的方法来求解该问题。首先,假设价值函数是一个训练好的、具有KKK层的前馈 ReLU 网络,以状态sss为输入,并满足以下关系,对所有 k=2,…,Kk = 2, \dots, Kk=2,…,K:
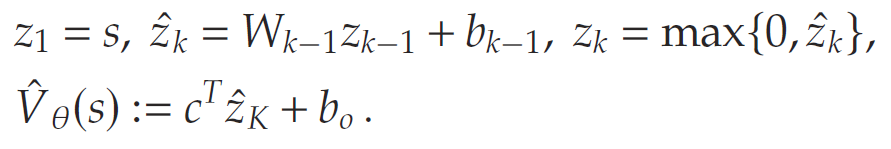
其中θ=(c,(Wk,bk)k=1K−1+b0)\theta = \left(c, {(W_k, b_k)}_{k=1}^{K-1} + b_0\right)θ=(c,(Wk,bk)k=1K−1+b0)表示待前往价值函数估计器 (value-to-go estimator) 的参数。具体而言,WkW_kWk和 bkb_kbk 分别是第 kkk 层的乘性权重和偏置,而ccc和b0b_0b0分别是输出层的权重和偏置(见图1)。
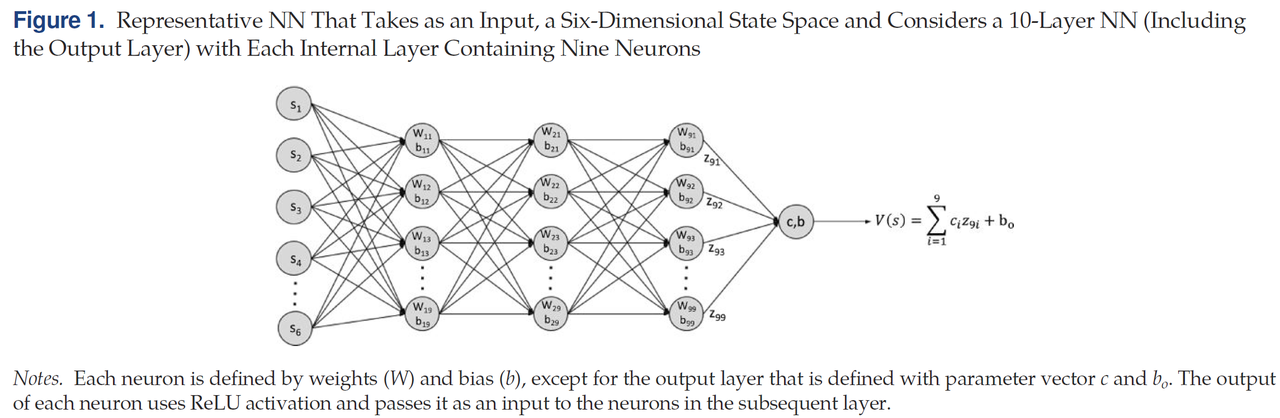
最后,z^k\hat{z}_kz^k和 zkz_kzk 分别表示第kkk层神经元激活前后的数值。每个神经元的 ReLU 激活函数允许使用二进制变量和大-M 约束来构建一个简洁的数学规划表示。为使内容完整,文章在此简要介绍这些步骤。考虑一个具有参数 (w,b)(w, b)(w,b) 的神经网络中的神经元。例如,在第kkk层,神经元iii的参数为 (Wki,bki)(W_k^i, b_k^i)(Wki,bki). 假设输入 x∈[l,u]x \in [l, u]x∈[l,u] 是有界的,那么该神经元的输出zzz可通过求解以下数学规划问题获得:
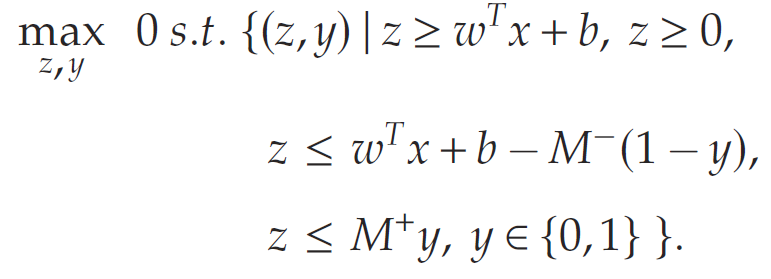
将该约束集合简洁地记作 P(w,b,x)\mathbb{P}(w, b, x)P(w,b,x). 这里, M+=maxx∈[l,u](wTx+b)M^+ = \max_{x \in [l, u]} (w^T x + b)M+=maxx∈[l,u](wTx+b),而 M−=minx∈[l,u](wTx+b)M^- = \min_{x \in [l, u]} (w^T x + b)M−=minx∈[l,u](wTx+b),分别是对于任意可行输入 xxx,该神经元的最大和最小输出。注意,M+M^+M+和M−M^-M−可以通过分析www的每个分量的符号来轻松计算。例如,设:
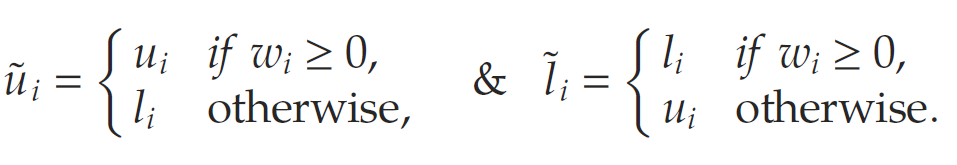
则根据代数推导,有 M+=w⊤u~+bM^+ = w^\top \tilde{u} + bM+=w⊤u~+b 且 M−=w⊤l~+bM^- = w^\top \tilde{l} + bM−=w⊤l~+b. 从有界输入状态sss出发,可以通过组合每个神经元在其前一层输出上的 max{0,M+}\max\{0, M^+\}max{0,M+} 和 max{0,M−}\max\{0, M^-\}max{0,M−},构建出后续层的上下边界。记每一层kkk的上下边界为[lk,uk][l_k, u_k][lk,uk].
该用于估计 value-to-go 的神经网络的数学规划重构在我们的方法中至关重要。尤其是因为还能将即时奖励用决策aaa直接表示,而任一状态下的可行动作集合又是一个多面体,所以可以利用整数规划的机制来求解。
3.4 在大动作空间下最大化期望奖励
问题 (2) 中的目标函数涉及对不确定性 DDD 的期望运算。注意,不确定性DDD同时影响即时奖励以及通过转移函数影响的 value-to-go 值。
由于 DDD通常服从连续分布,并且我们使用了一个基于神经网络(NN)的 value-to-go 近似器,因此评估该期望可能会非常困难。为了解决这个问题,我们采用了 SAA(Sample Average Approximation)方法。
令d1,d2,…,dηd_1, d_2, \dots, d_\etad1,d2,…,dη 表示η\etaη个对不确定性DDD的独立采样值。那么,SAA 将期望近似为:
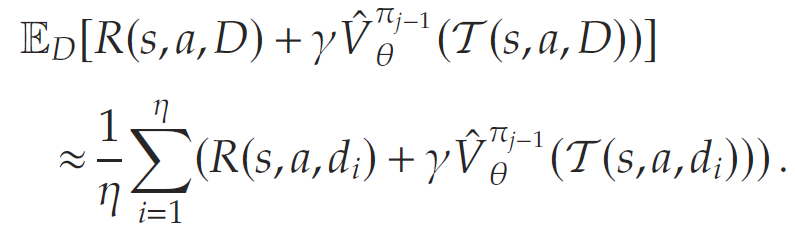
于是,
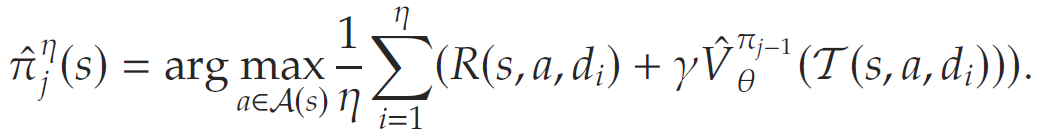
命题1 考虑 PARL 算法在第 jjj次迭代中,使用一个 ReLU 网络的 value function 估计值 V^πj−1θ(s)\hat{V}^{\pi_{j-1}}\theta(s)V^πj−1θ(s),该网络是在某一固定策略 πj−1\pi_{j-1}πj−1下训练得到的。 假设 πj\pi_jπj和 π^jη\hat{\pi}^\eta_jπ^jη分别是定义的最优策略,以及其对应的 SAA 近似下的最优策略。则对于所有状态sss,有limη→∞π^jη(s)=πj(s)\lim_{\eta \to \infty} \hat{\pi}_j^{\eta}(s) = \pi_j(s)limη→∞π^jη(s)=πj(s).
随后文章提出算法1 如下。
对于每一个 J\mathcal{J}J个 epoch(外层循环迭代)(第2行),运行当前策略(即使用优化方法和当前价值网络来计算动作)执行若干步。具体而言,我们在 NNN个随机 episode 上运行(第3行),每个 episode 包含 TTT步(第4行),以收集一批轨迹,轨迹由动作和状态-奖励对(state, reward)元组组成。
注意,在每一个 episode 中,基于定义计算轨迹中每个状态的折扣累计回报 (discounted cumulative rewards),该定义使用了折扣因子以及从该状态观察到的未来回报(第5行)。这将提供状态和累计回报的样本,这些样本分别作为输入和输出,用于训练价值神经网络:一个神经网络用来预测给定状态的价值(即累计折扣回报),从而可以用这些样本按照标准方式进行训练和更新。
通过标准的随机梯度下降方法训练价值网络参数,训练若干次更新 epoch (神经网络训练的 epoch),使用的是这批收集到的数据(第7行)。这就是标准的神经网络训练方式,其中每个外层 epoch jjj都会用新的一批轨迹更新当前价值网络的参数;也就是说,这些参数会在初始化后,随着每次策略运行产生的新轨迹不断更新。
最后,(第8行)定义了由基于当前价值网络的随机优化方法得到的更新策略。该策略基于当前状态输入而来。
请注意,只在需要时计算该策略,即当我们需要针对某一具体状态评估策略时才会进行计算。
另外还需注意,该策略在第4行中被隐式地使用,以执行当前策略;也就是说,对于每个状态,必须使用当前策略来选择下一个动作。
最后,正如强化学习中常见的做法一样,我们使用 ε\varepsilonε-greedy 策略(Sutton and Barto 2018)以确保在训练价值网络时具备一定的探索性。

4 在库存管理中的应用
现在描述PARL在库存管理问题中的应用。考虑一家公司管理单一产品在零售网络(也称为节点)中的库存补货和配送决策,目标是在满足客户需求的同时实现利润最大化,特别是考虑以下因素:(i) 运输成本,(ii) 仓储限制,以及 (iii) 未满足需求导致的销售损失。
这些问题难以求解 (notoriously difficult to solve),且关于最优策略结构的研究结果较少。然而强化学习,特别是PARL方法,可用于为这些问题生成高性能策略。
4.1 模型与系统动态
企业的供应链网络由一组节点Λ\LambdaΛ构成,各节点索引为lll. 这些节点可代表仓库、配送中心或零售商店。供应链网络中的每个节点既可生产库存单位(用随机变量DipD_{i}^{p}Dip表示),也可产生需求(用随机变量DidD_{i}^{d}Did表示)。各节点生产的库存可存储于本地或转运至供应链其他节点。对于节点lll,OlO_{l}Ol表示能向该节点发货的上游节点集合。在任何时刻,各节点可根据现有库存满足需求。我们假设未满足的需求将永久流失(即销售损失)。
企业的目标是通过优化供应链节点间的不同履约决策来实现收益最大化(或成本最小化)。任一节点的履约既可通过供应链节点间的转运完成,也可通过外部供应商实现。从节点lll到l′l'l′的每次转运具有确定的前置时间Lll′≥0L_{ll'} \geq 0Lll′≥0,并关联固定成本Kll′K_{ll'}Kll′与可变成本Cll′C_{ll'}Cll′. 固定成本可能与运输车辆的租赁相关,而可变成本可能与节点间的物理距离有关。每个节点存在单位库存持有成本hlh_lhl,不同节点售出的库存单位产生利润plp_lpl.接下来我们将详细讨论系统动态。为简化表述,时间周期ttt的依赖关系在此隐去。
- 每个周期ttt,企业观测供应链所有节点的库存管道向量III. 节点的库存管道向量存储现有库存及将从上流节点到达的库存。按照惯例,记Il0I_{l}^{0}Il0为节点的现有库存。
- 企业制定转运决策xl,l′x_{l,l'}xl,l′,表示从节点l′l'l′向lll转运的库存量,并为节点lll产生转运成本(tsc).
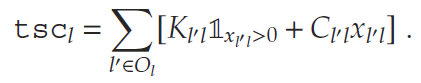
- 各节点的可用现有库存将根据以下因素更新:(a) 运出的库存单位,(b) 从其他节点到达的库存单位,以及 © 本节点生产的库存单位。用 Il0I_{l}^{0}Il0表示这一中间过程的现有库存,其计算公式为:
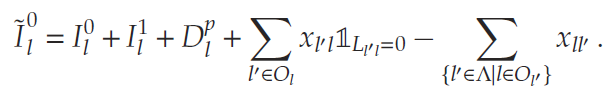
- 各节点的随机需求 DidD_{i}^{d}Did实现后,企业从中间现有库存履行需求,产生的销售收益为:rsl=plmin{Did,Il0}rs_{l} = p_{l}\min\{D_{i}^{d}, I_{l}^{0}\}rsl=plmin{Did,Il0}
- 超出节点容量的过剩库存将被折价处理,且企业需为剩余库存支付持有成本。公司将产生持有-回收成本 (hsc) 如下:
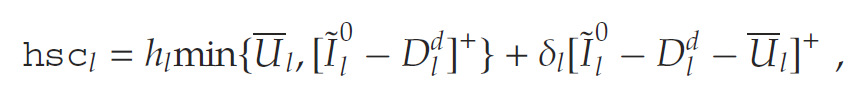
其中Πl\Pi_lΠl表示节点lll的存储容量。为简化表示,我们定义Il0:=min{Πl,[Il0−Dld]+}I_l^0 := \min\{\Pi_l, [I_l^0 - D_l^d]^+\}Il0:=min{Πl,[Il0−Dld]+}.
6. 最后,在时间周期结束时进行库存轮换:
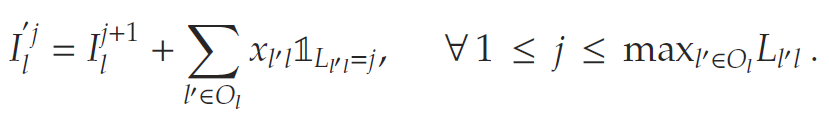
轮换后的库存将成为下一时间周期的库存管道向量,即:$I_{t+1} = I_t’ $.
该补货问题的利润最大化问题可表述为马尔可夫决策过程。具体而言:状态空间sss为库存管道向量III, 动作空间由可行动作集合定义, 转移函数 TTT 由下一状态方程组定义(其依赖于需求 DidD_i^dDid 的分布), 每个状态的奖励为当期利润减去库存持有成本与转运成本。我们可以用贝尔曼递归表示该优化问题。设:
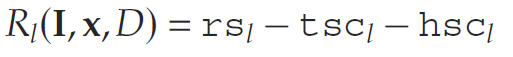
将各节点的收益表示为库存管道向量、转运决策以及随机需求和生产的函数。那么,供应链在每个时间周期内产生的总收益为:
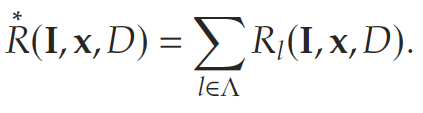
类似地,
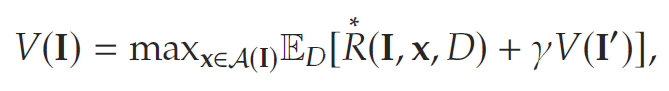
其中I′I'I′是III、xxx和DDD的隐式函数。如前所述,该库存补货问题与第2节所述一般问题形式完全相同,可通过贝尔曼递归求解,但该方法的计算复杂度较高。
4.2 库存管理中的PARL应用
在库存管理中,PARL求解的问题为
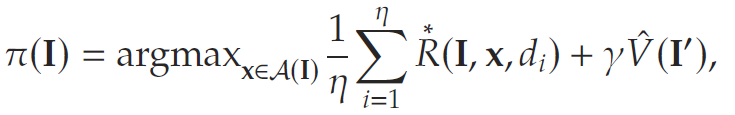
其中,如前所述,下一状态I′I'I′是当前状态、行动和需求实现的函数。所有符号定义的简明表格概述请参见附录A中的表EC.1。下面文章将该问题表述为整数规划形式:
首先,考虑到采用销售损失库存设定,定义辅助变量salisa_{li}sali表示节点III在需求样本iii下的销售数量。此时约束条件:sali≤dlid且sali≤Ili0sa_{li} \leq d_{li}^{d} \quad \text{且} \quad sa_{li} \leq I_{li}^{0}sali≤dlid且sali≤Ili0
确保销售数量不超过现有库存和需求量。需要注意的是,在考虑折扣奖励且价格/成本时不变的情况下,由于销售变量的存在,未来周期不存在库存对冲机会,因此实际销售量将严格等于需求与库存的最小值。
同时定义辅助变量BliB_{li}Bli表示节点lll在需求样本iii下的折价处理数量。相应的约束条件为:
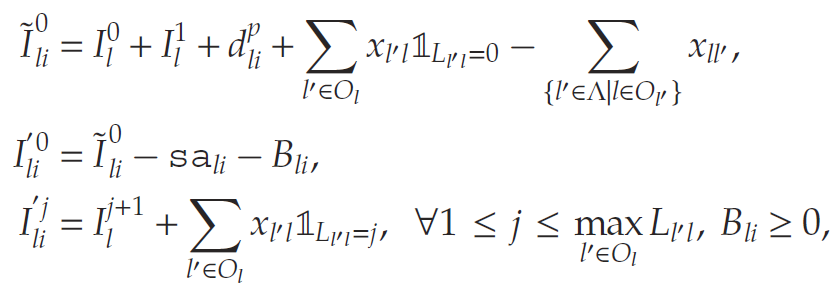
用于描述每个需求实现对应的状态转移。最终,目标函数包含两个组成部分:即时奖励和未来价值。根据辅助变量表示的即时奖励可写作:
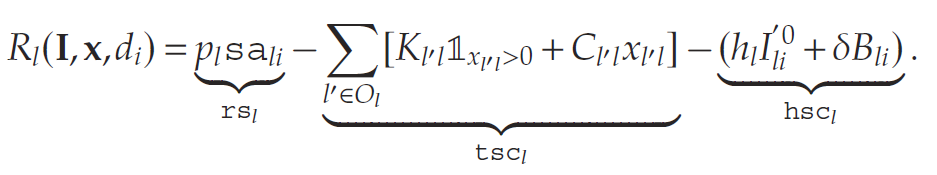
需注意,g1/2g_{1/2}g1/2为二元变量,用于建模订货固定成本。令Ii′I_i'Ii′表示第iii个需求实现下的下一状态。假设用于估计未来价值的神经网络(NN)包含Ψ\PsiΨ个全连接层,其中每层具有NkN_kNk个神经元(采用ReLU激活函数)和一个输出层。定义neujk\text{neu}_{jk}neujk为第kkk层第jjj个神经元,则在第iii个需求实现下,第一层神经元的输出可表示为:
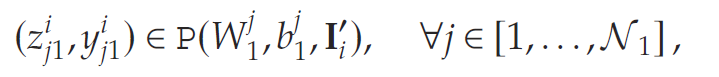
(根据前文定义,式(3)中的P(⋅,⋅,⋅)P(\cdot,\cdot,\cdot)P(⋅,⋅,⋅)表示用于描述对应神经元输出的混合整数规划 (MIP) 约束集)。该层的输出将作为下一层的输入。因此,令Zi1:=[z11,z21,…,zN11]Z_i^1 := [z_{11}, z_{21}, \ldots, z_{N_11}]Zi1:=[z11,z21,…,zN11]表示第1层的输出向量,则第iii个需求实现下第2层各神经元的输出可表示为:
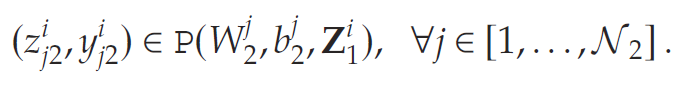
继续迭代计算
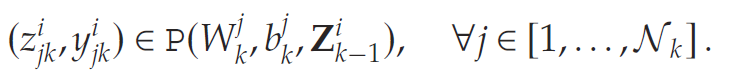
最终,设ccc和b0b_0b0分别表示输出层的权重向量与偏置项,则未来价值的表达式为:V(Ii′)=cTZΨ+b0V(I_i') = c^T Z_{\Psi} + b_0V(Ii′)=cTZΨ+b0, 其中V(Ii′)V(I_i')V(Ii′)是决策变量xxx的隐式函数,因为xxx会影响下一状态I′I'I′的转移。基于该价值函数近似,每期的库存履约问题可表述为:
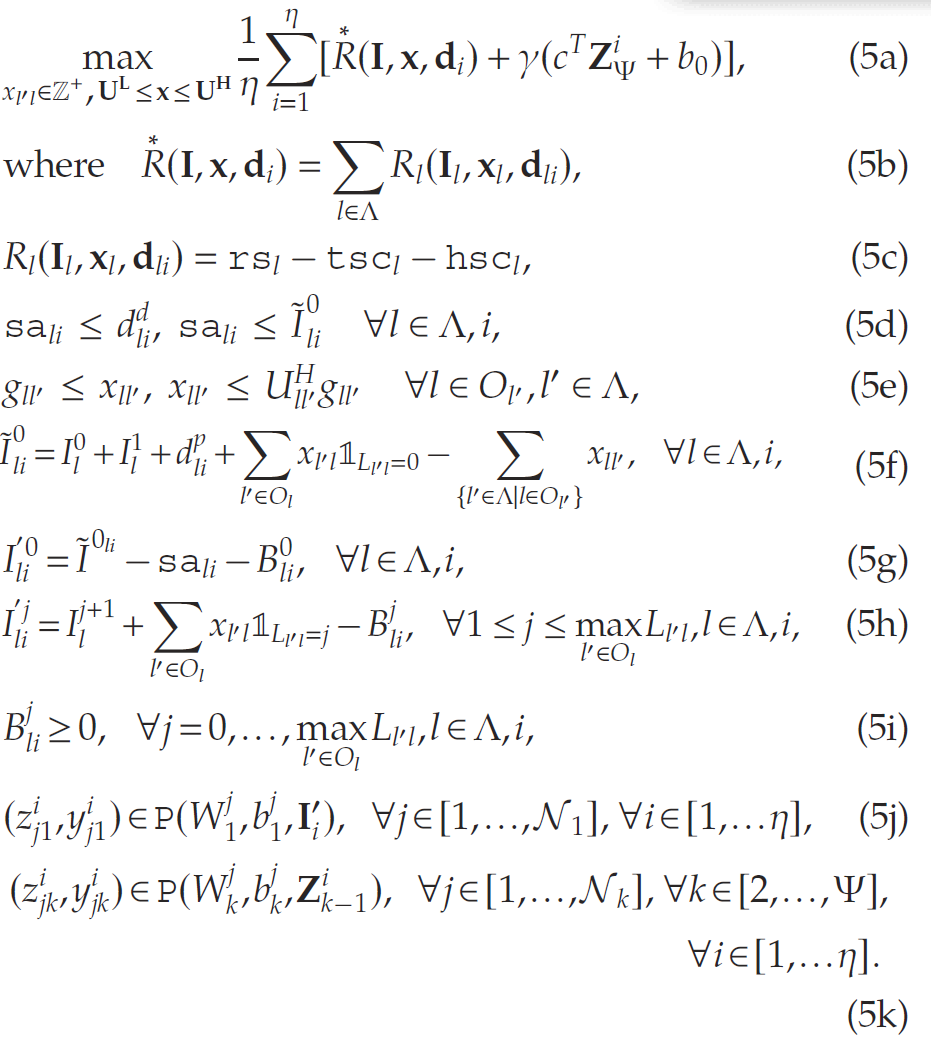
(基于Q学习的替代方法):需要说明的是,本文提出的PARL方法基于价值函数估计V^(s)\hat{V}(s)V^(s)来优化行动。作为替代方案,可考虑求解以下问题:
πj(s)=argmaxa∈A(s)Qπj−1(s,a)\pi_j(s) = \arg\max_{a \in A(s)} Q^{\pi_{j-1}}(s,a)πj(s)=arga∈A(s)maxQπj−1(s,a)
其中Qπj−1(s,a)Q^{\pi_{j-1}}(s,a)Qπj−1(s,a)表示在状态sss下选择行动aaa的预期折现奖励估计。未采用Q学习方法主要基于以下原因:
首先,估计Q值所需的更大规模神经网络存在显著缺陷。假设供应链网络为全连接结构,且中央规划者每期需决策节点间的运输量,则行动决策a∈R∣Λ∣2a \in \mathbb{R}^{|\Lambda|^2}a∈R∣Λ∣2. 此时Q函数近似神经网络的输入层规模将达∣I∣+∣Λ∣2|\mathbf{I}| + |\Lambda|^2∣I∣+∣Λ∣2,而文章提出的价值函数方法输入层规模仅为∣I∣|\mathbf{I}|∣I∣,显著更小。需注意输入空间越大,深度神经网络(DNN)的近似规模就越大。由于整数变量数量随网络规模线性增长,为保证计算可行性应优先选择较小网络。
其次,在Q学习方法中,除非每个行动步求解两个优化问题,否则无法直接建模即时奖励信息。
我们将在下篇继续解读文章的算例和开源程序部分,敬请关注。
参考文献
Boute RN, Gijsbrechts J, van Jaarsveld W, Vanvuchelen N (2022) Deep reinforcement learning for inventory control: A roadmap. Eur. J. Oper. Res. 298(2):401–412.
Clark AJ, Scarf H (1960) Optimal policies for a multi-echelon inventory problem. Management Sci. 6(4):475–490.
de Kok T, Grob C, Laumanns M, Minner S, Rambau J, Schade K (2018) A typology and literature review on stochastic multiechelon inventory models. Eur. J. Oper. Res. 269(3):955–983.
Federgruen A, Zipkin P (1984) Approximations of dynamic, multilocation production and inventory problems. Management Sci. 30(1):69–84.
Gijsbrechts J, Boute RN, Van Mieghem JA, Zhang D (2022) Can deep reinforcement learning improve inventory management? Performance on dual sourcing, lost sales and multiechelon problems. Manufacturing Service Oper. Management 24(3): 1349–1368.
Goldberg DA, Katz-Rogozhnikov DA, Lu Y, Sharma M, Squillante MS (2016) Asymptotic optimality of constant order policies for lost sales inventory models with large lead times. Math. Oper. Res. 41(3):898–913.
Haarnoja T, Zhou A, Abbeel P, Levine S (2018) Soft actor-critic: Offpolicy maximum entropy deep reinforcement learning with a stochastic actor.
Dy J, Krause A, ed. Proc. 35th Internat. Conf. Machine Learn., Proceedings of Machine Learning Research, vol. 75 (PMLR, New York), 1861–1870.
Hubbs CD, Perez HD, Sarwar O, Sahinidis NV, Grossmann IE, Wassick JM (2020) Or-gym: A reinforcement learning library for operations research problems. Preprint, submitted August 14, https://arxiv.org/abs/2008.06319.
Huh WT, Janakiraman G, Muckstadt JA, Rusmevichientong P (2009) Asymptotic optimality of order-up-to policies in lost sales inventory systems. Management Sci. 55(3):404–420.
Levi R, Janakiraman G, Nagarajan M (2008) A 2-approximation algorithm for stochastic inventory control models with lost sales. Math. Oper. Res. 33(2):351–374.
Mnih V, Badia AP, Mirza M, Graves A, Lillicrap T, Harley T, Silver D, et al. (2016) Asynchronous methods for deep reinforcement learning.
Balcan MF, Weinberger KQ, eds. Proc. 33rd Internat. Conf. Machine Learn. (Proceedings of Machine Learning Research (PMLR), Cambridge, MA), 1928–1937.
Scarf H (1960) The optimality of (s, s) policies in the dynamic inventory problem. Optimal Pricing, Inflation, and the Cost of Price Adjustment (MIT Press, Cambridge, MA), 49–56.
Schulman J, Wolski F, Dhariwal P, Radford A, Klimov O (2017) Proximal policy optimization algorithms. Preprint, submitted July 20, https://arxiv.org/abs/1707.06347.
Sheopuri A, Janakiraman G, Seshadri S (2010) New policies for the stochastic inventory control problem with two supply sources. Oper. Res. 58(3):734–745.
Sultana NN, Meisheri H, Baniwal V, Nath S, Ravindran B, Khadilkar H (2020) Reinforcement learning for multi-product multi-node inventory management in supply chains. Preprint, submitted June 7, https://arxiv.org/abs/2006.04037.
Sutton RS, Barto AG (2018) Reinforcement Learning: An Introduction (MIT Press, Cambridge, MA).
Qi M, Shi Y, Qi Y, Ma C, Yuan R, Wu D, Shen ZJ (2023) A practical end-to-end inventory management model with deep learning. Management Sci. 69(2):759–773.
Xin L (2021) Understanding the performance of capped basestock policies in lost-sales inventory models. Oper. Res. 69(1): 61–70.

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)