大模型算法(七):计算机视觉
1、计算机视觉基础
1.1.1 图像采样、图像滤波和图像增强



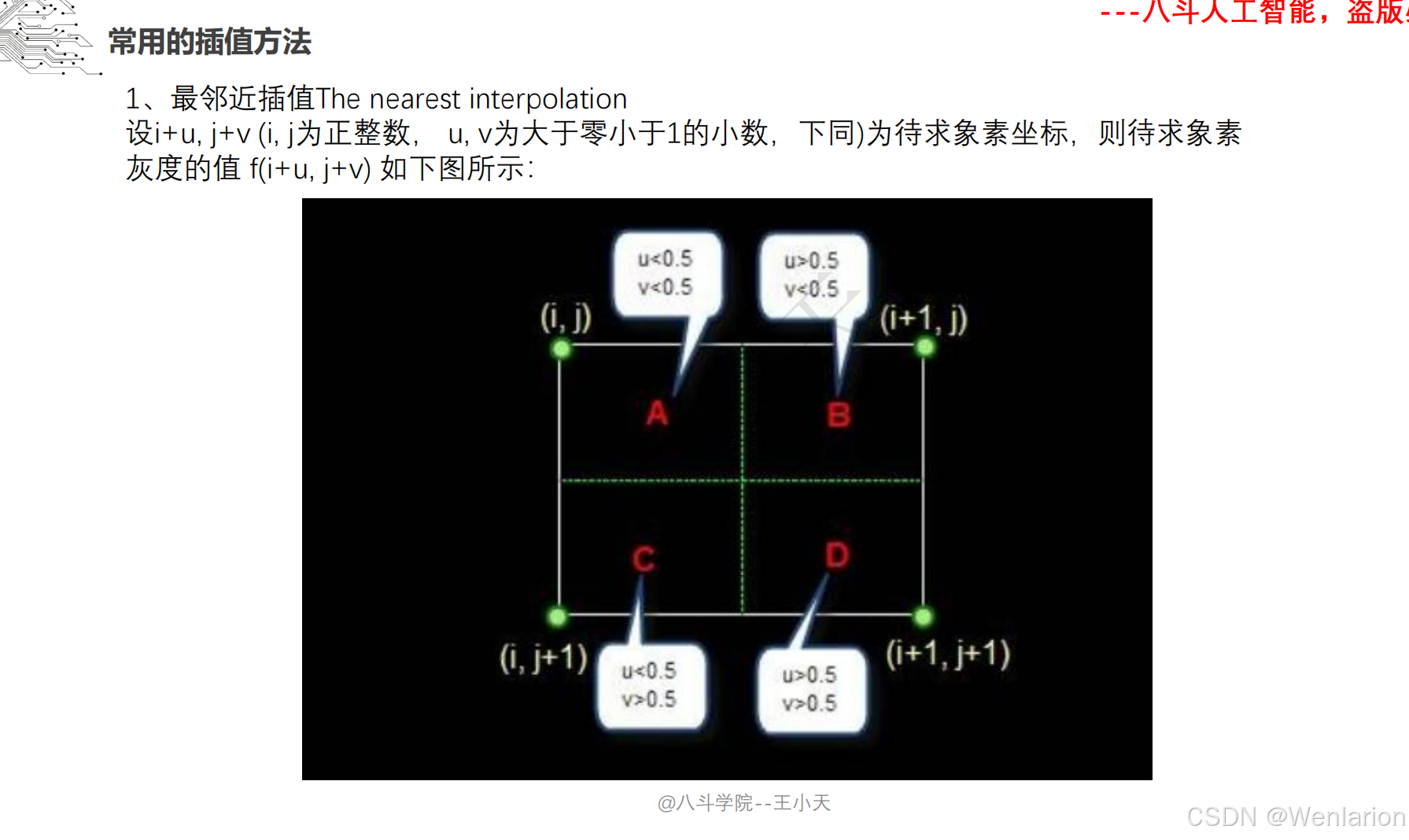
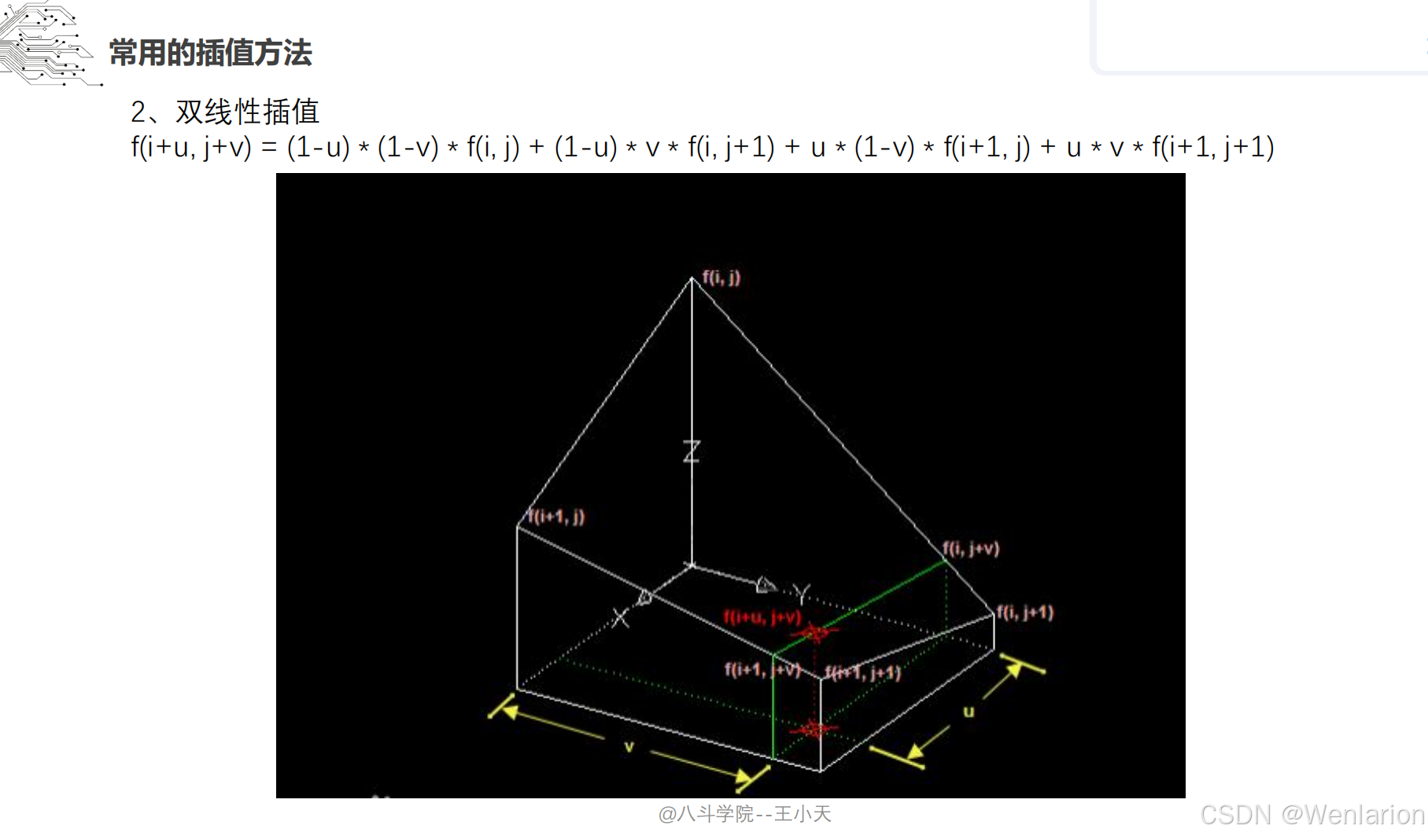
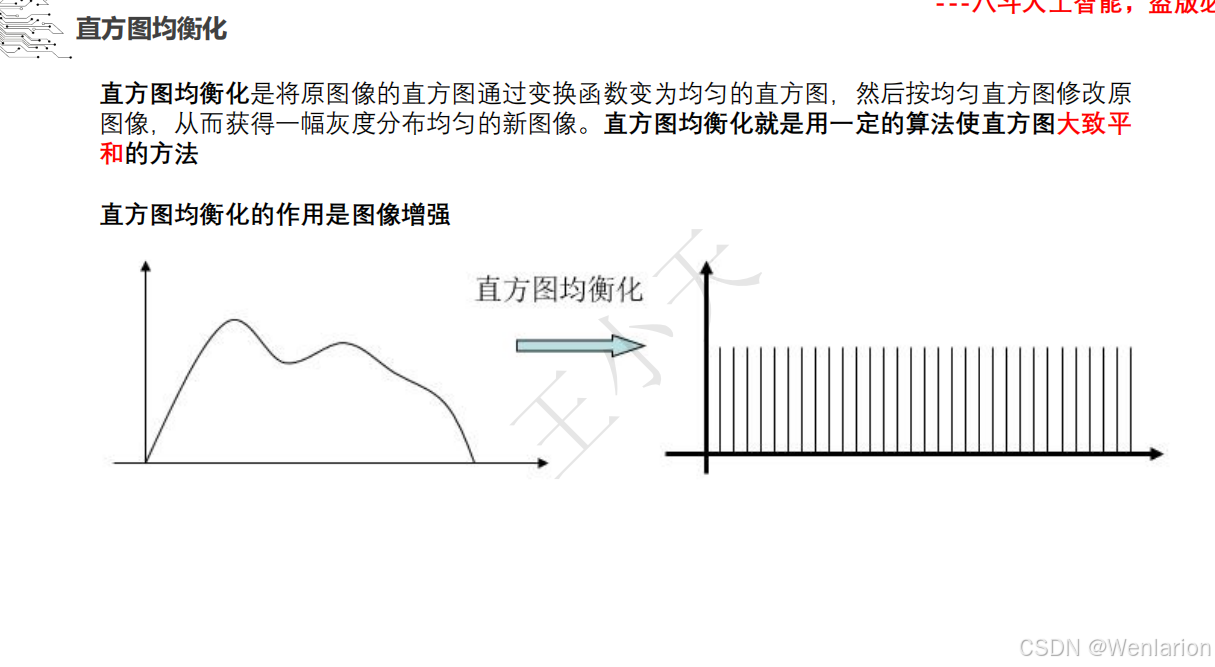




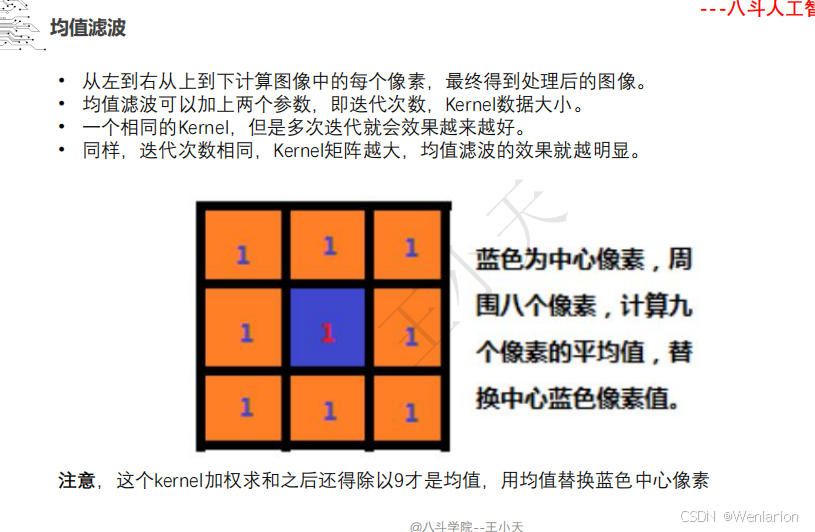

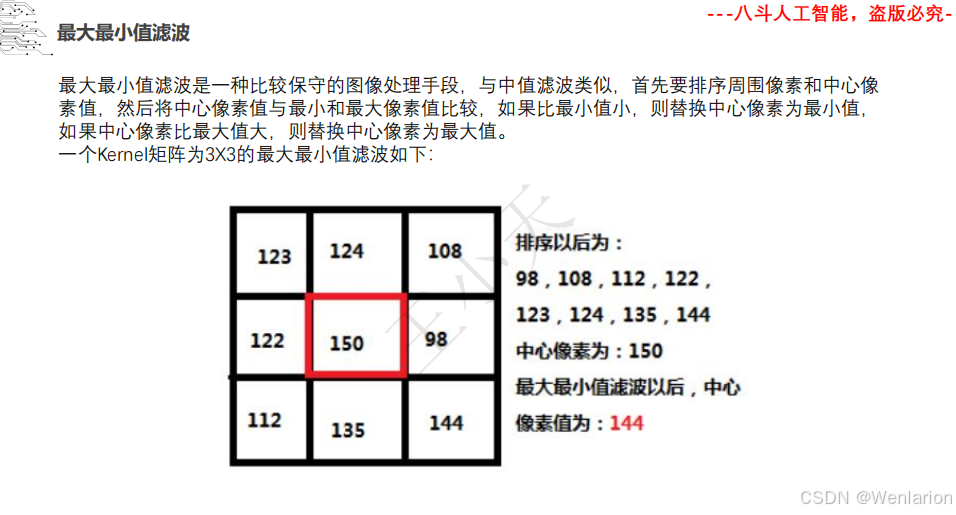
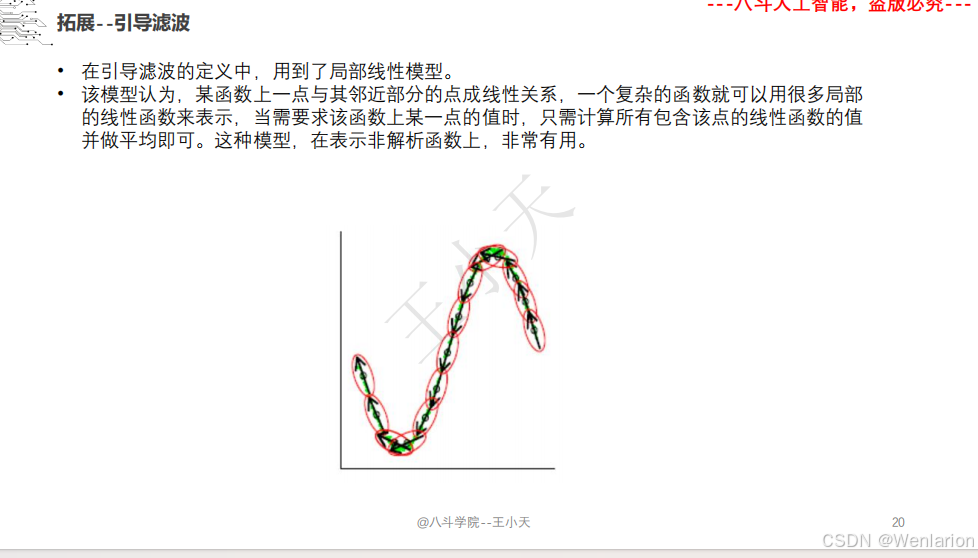





1.1.2 特征提取和特征选择


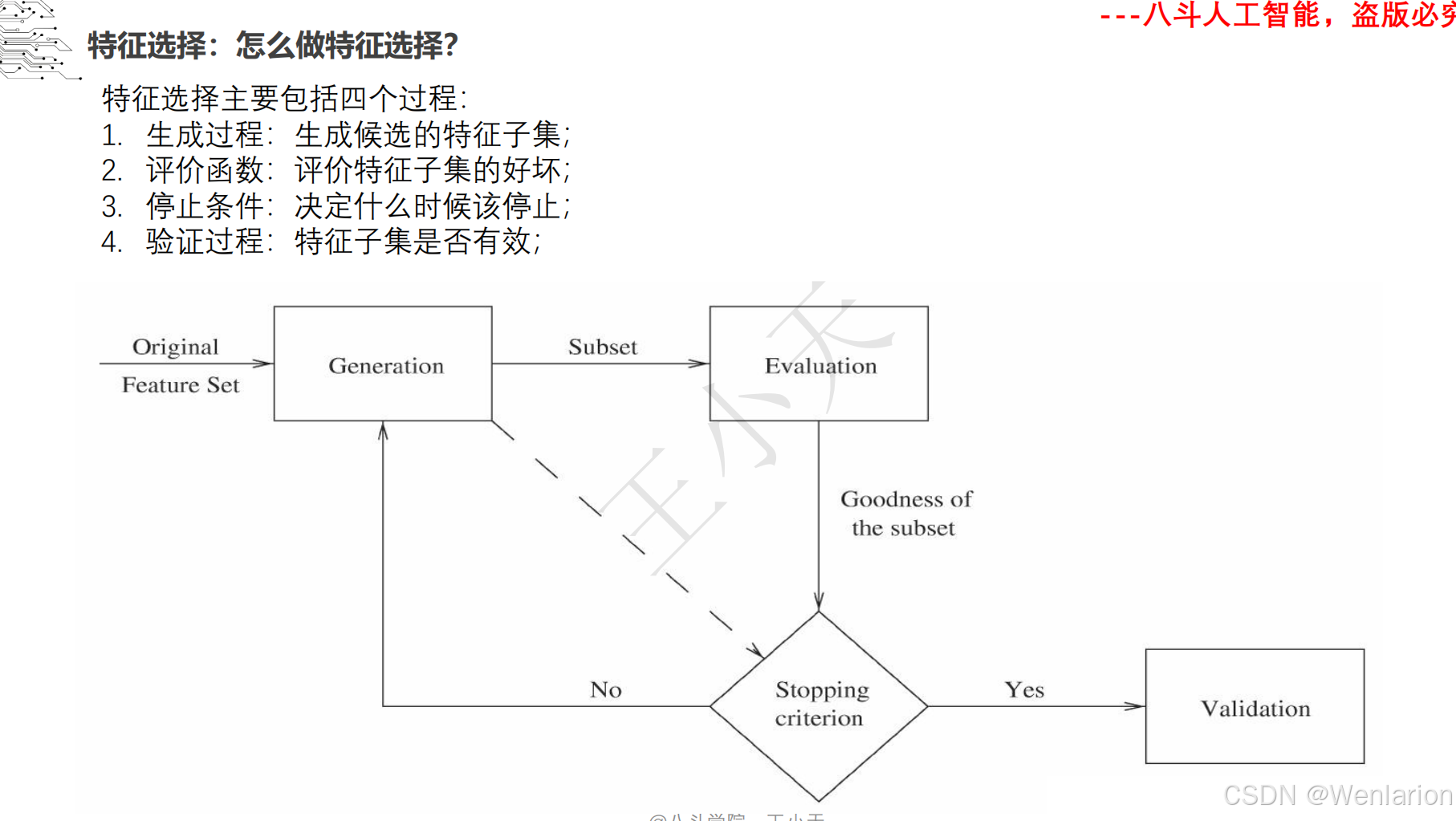




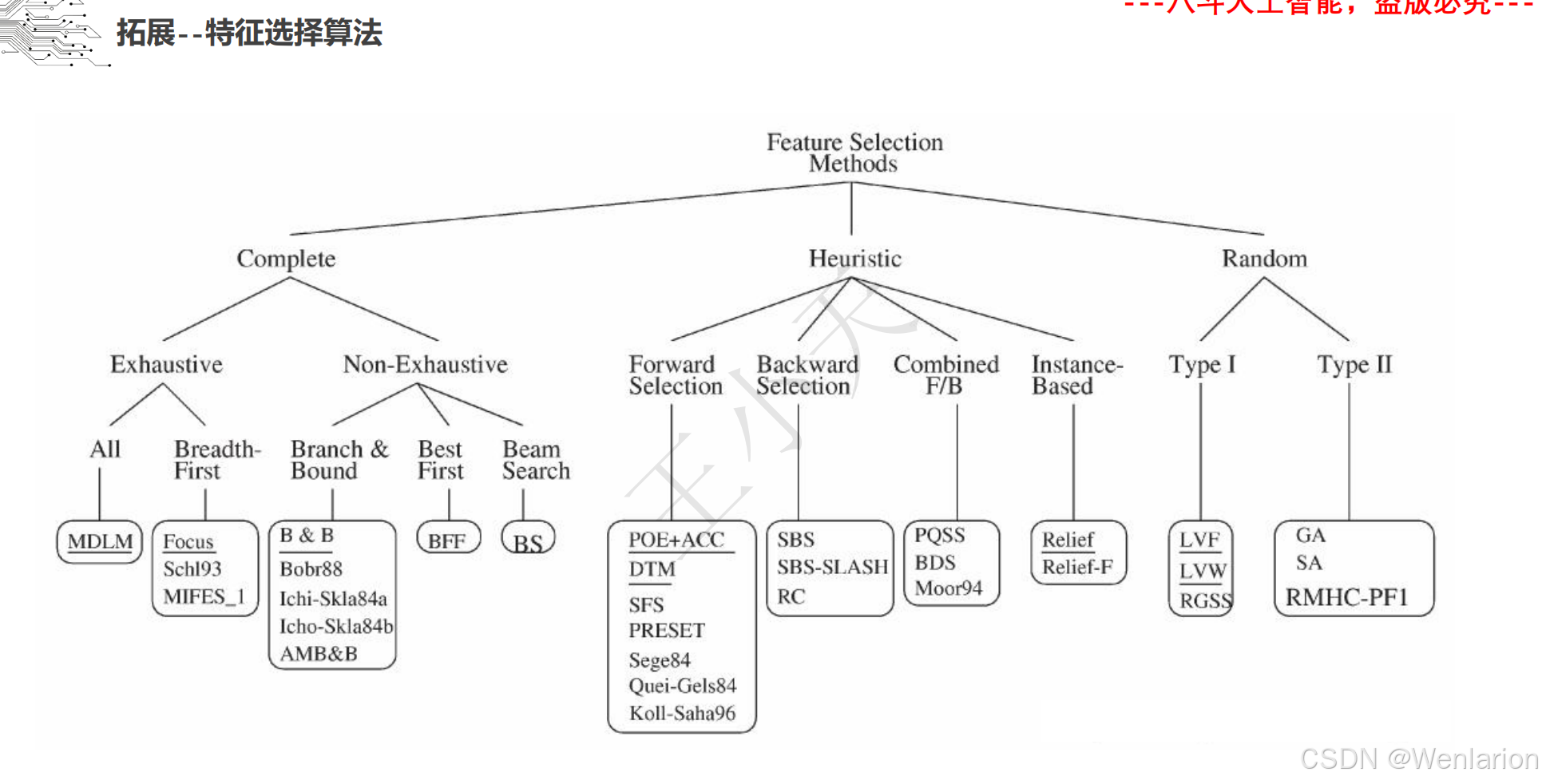






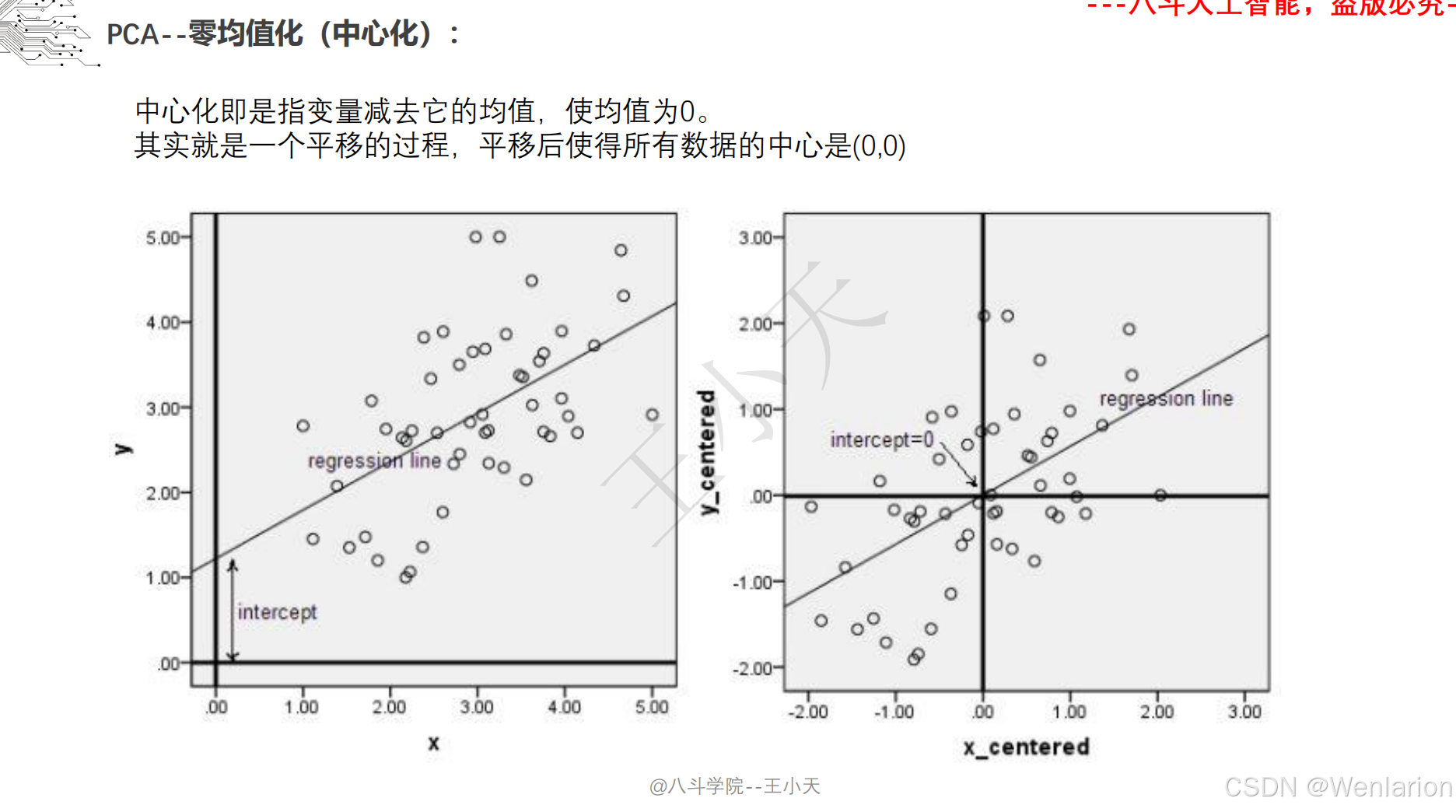
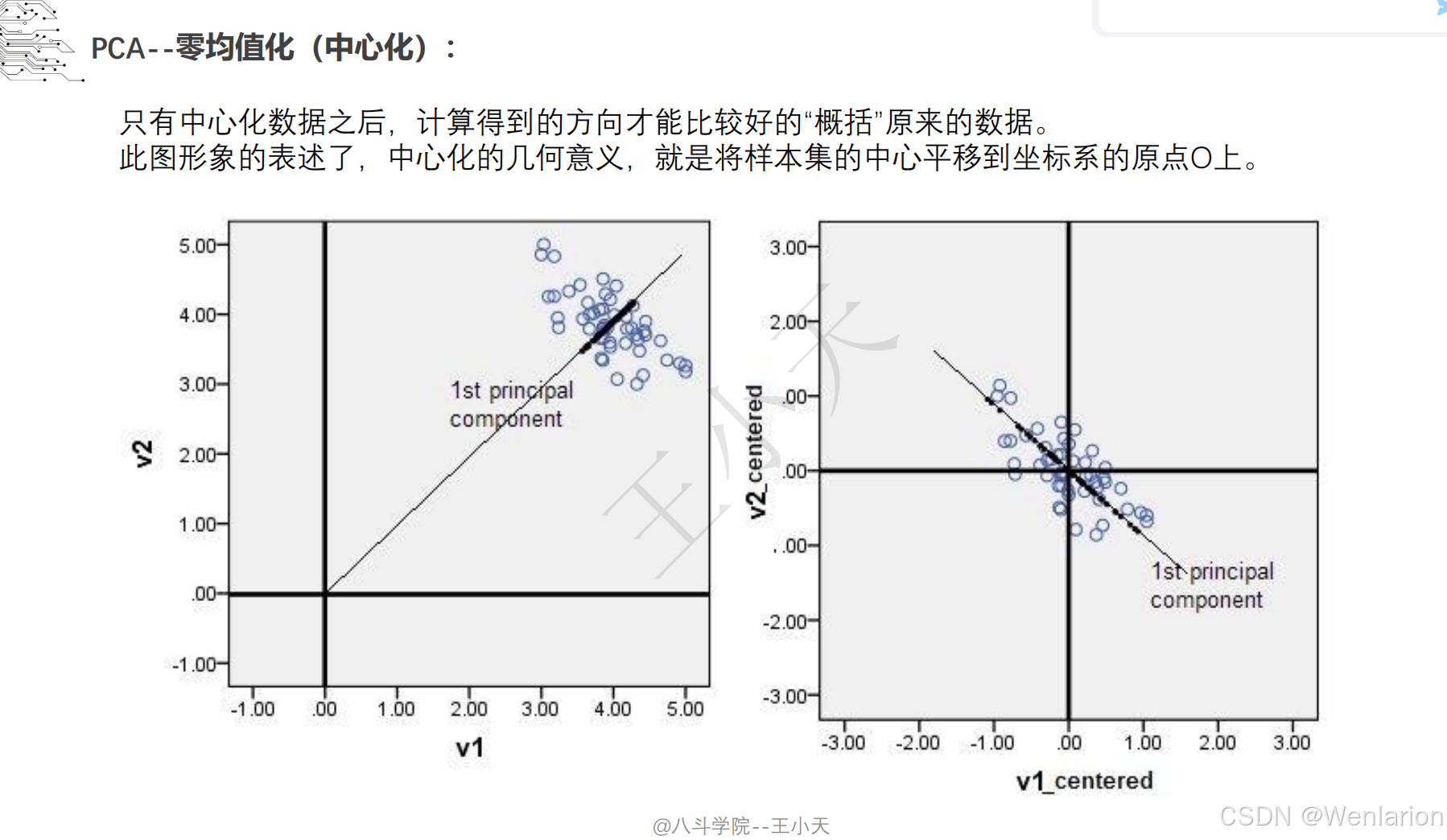


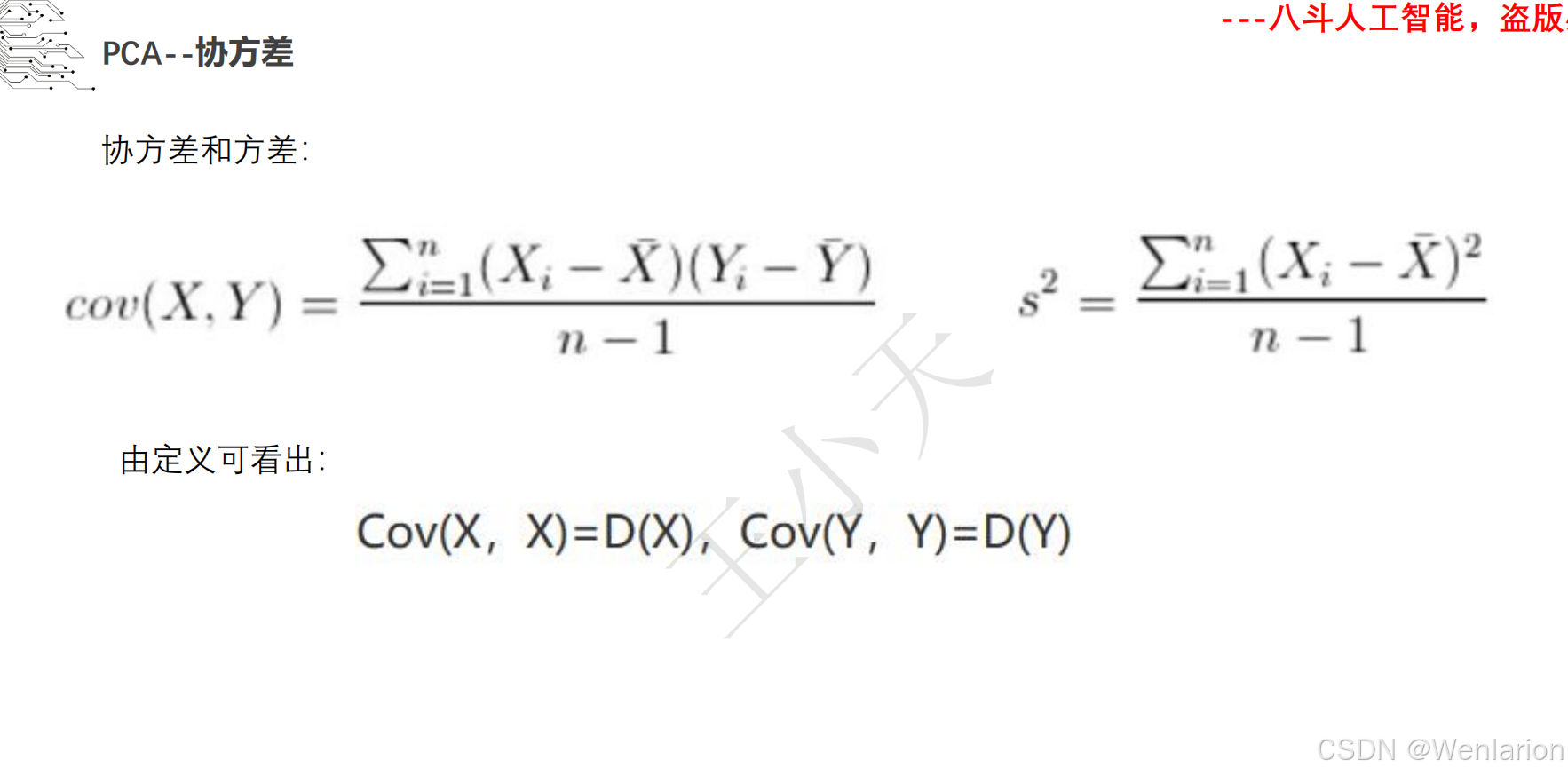

1.1.3 边缘提取










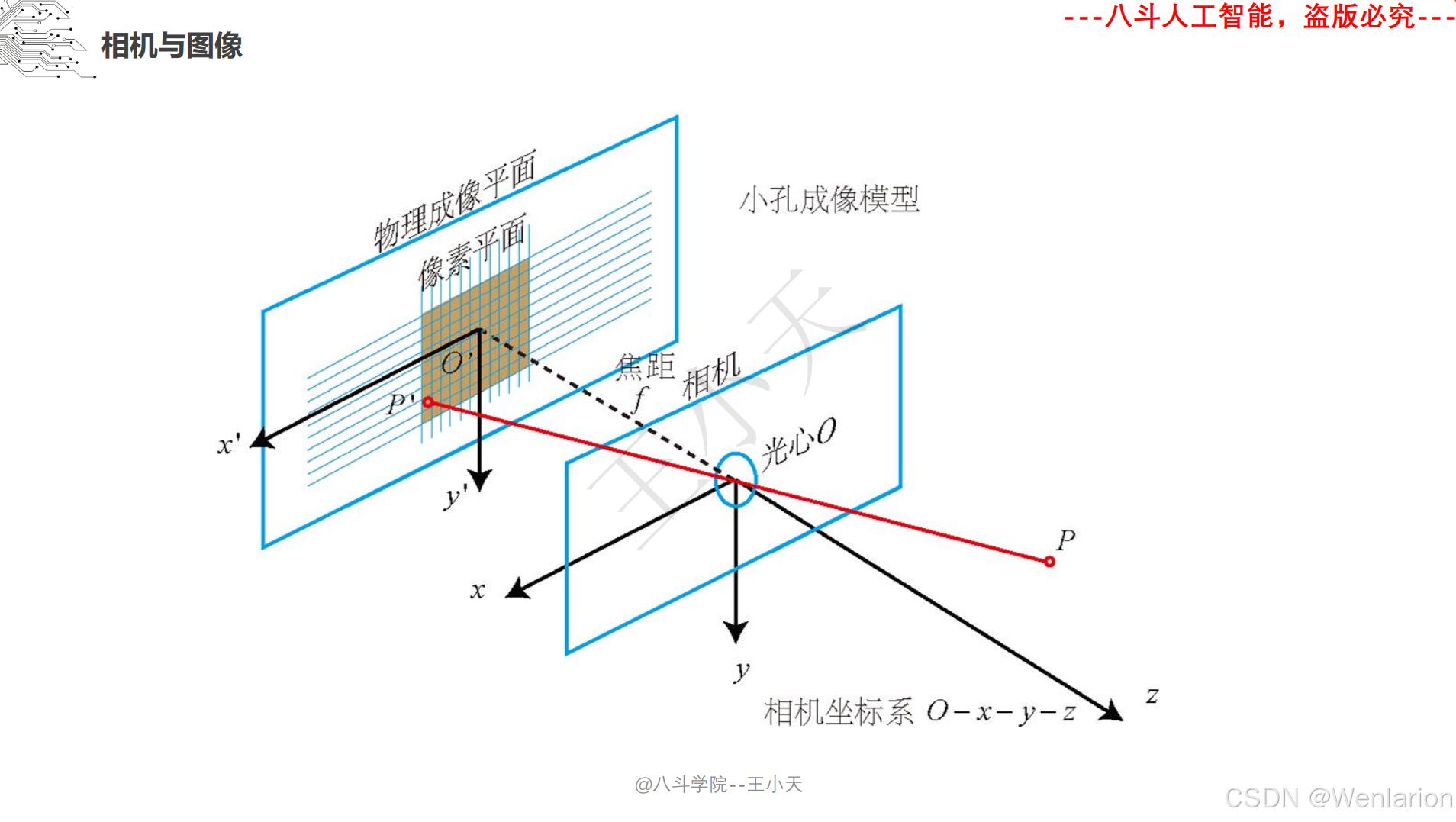
1.1.4 相机模型和畸变矫正
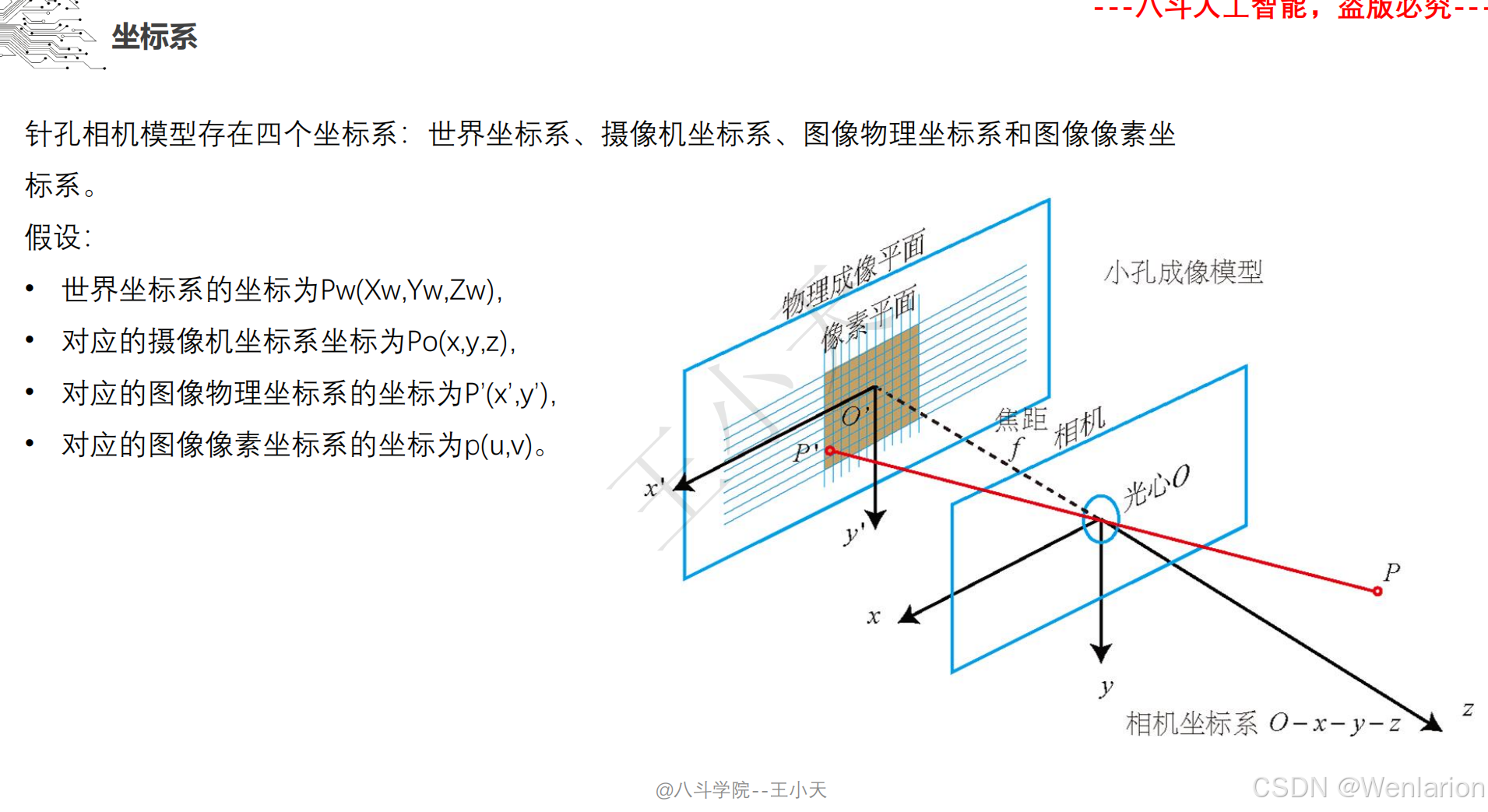
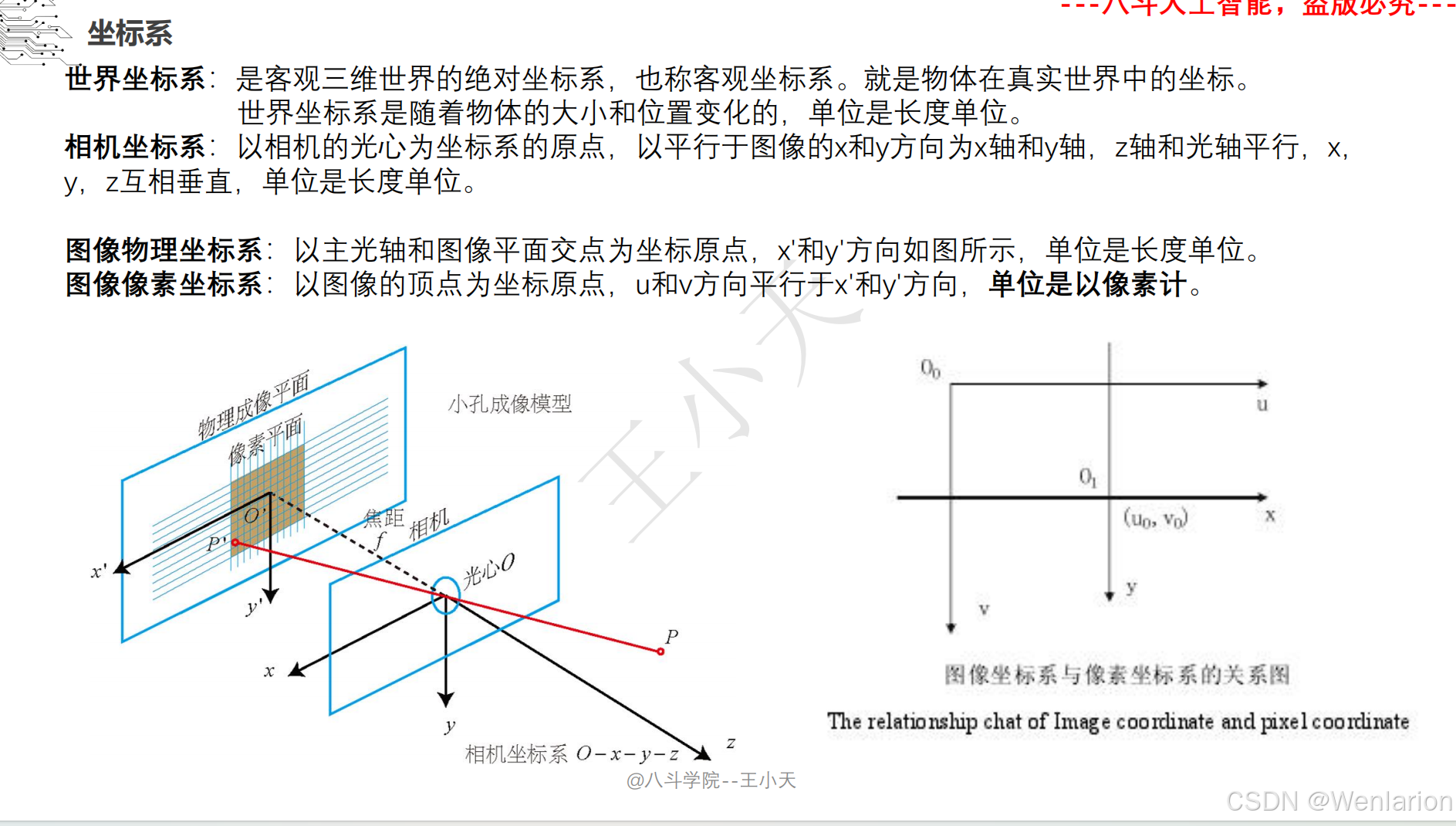
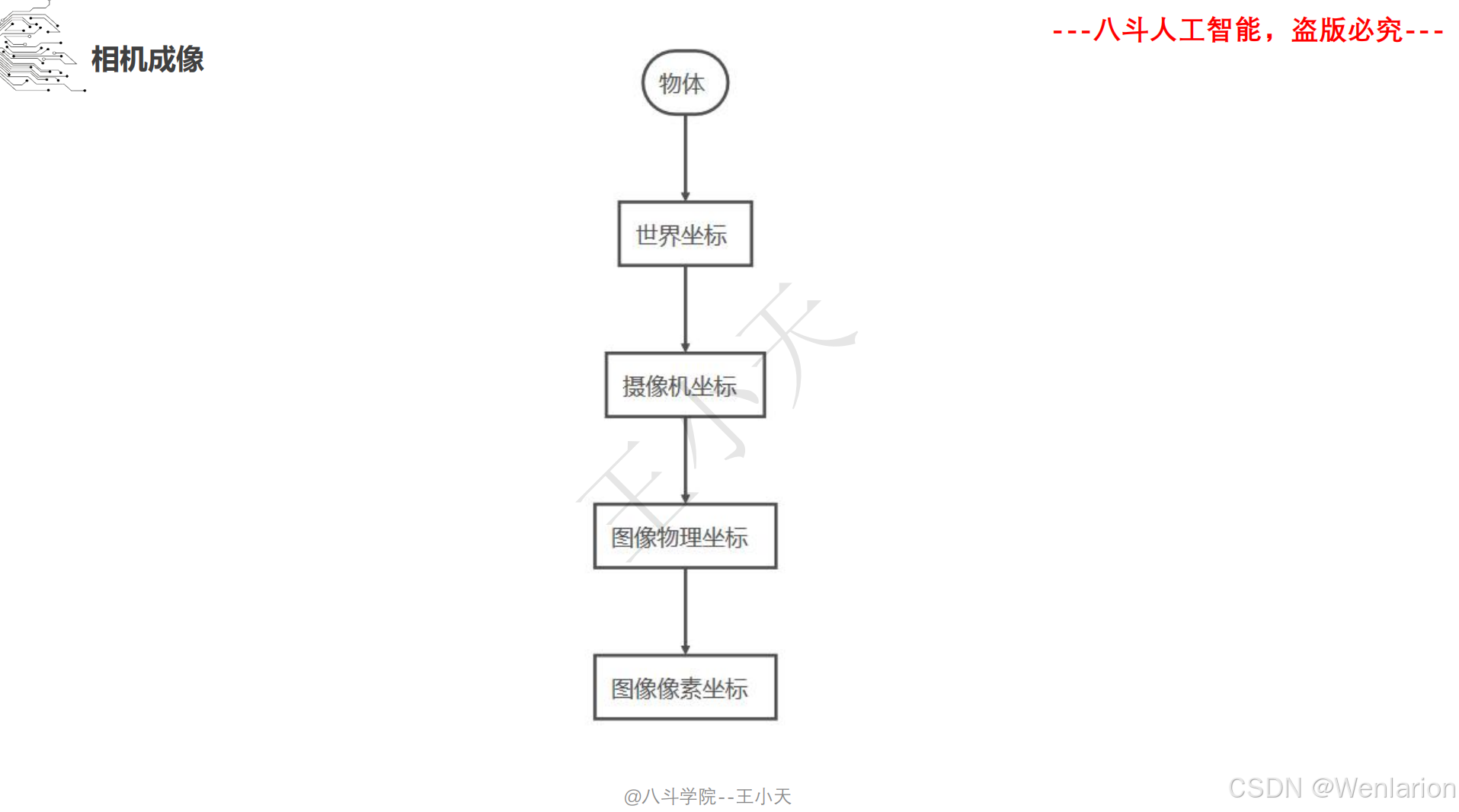

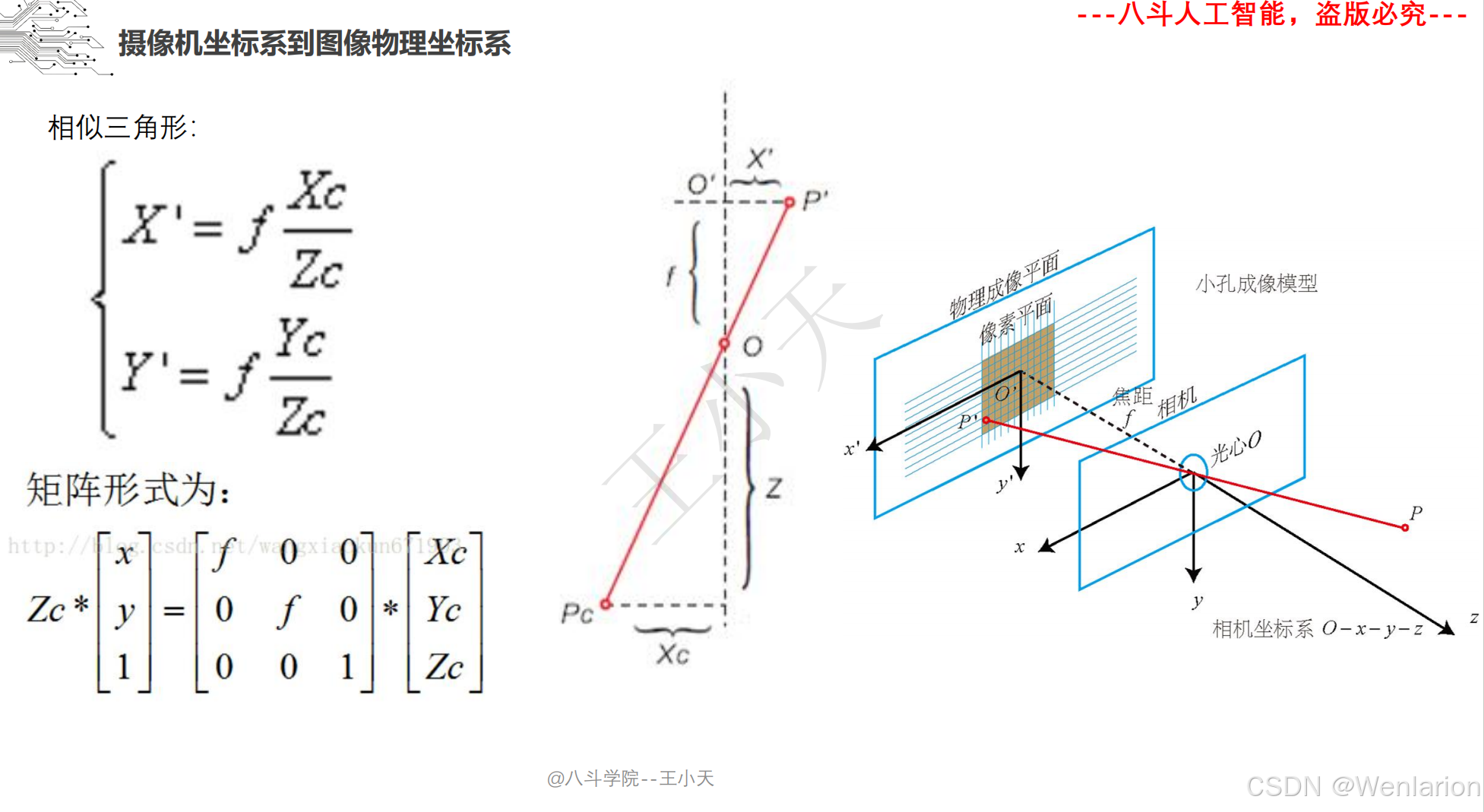
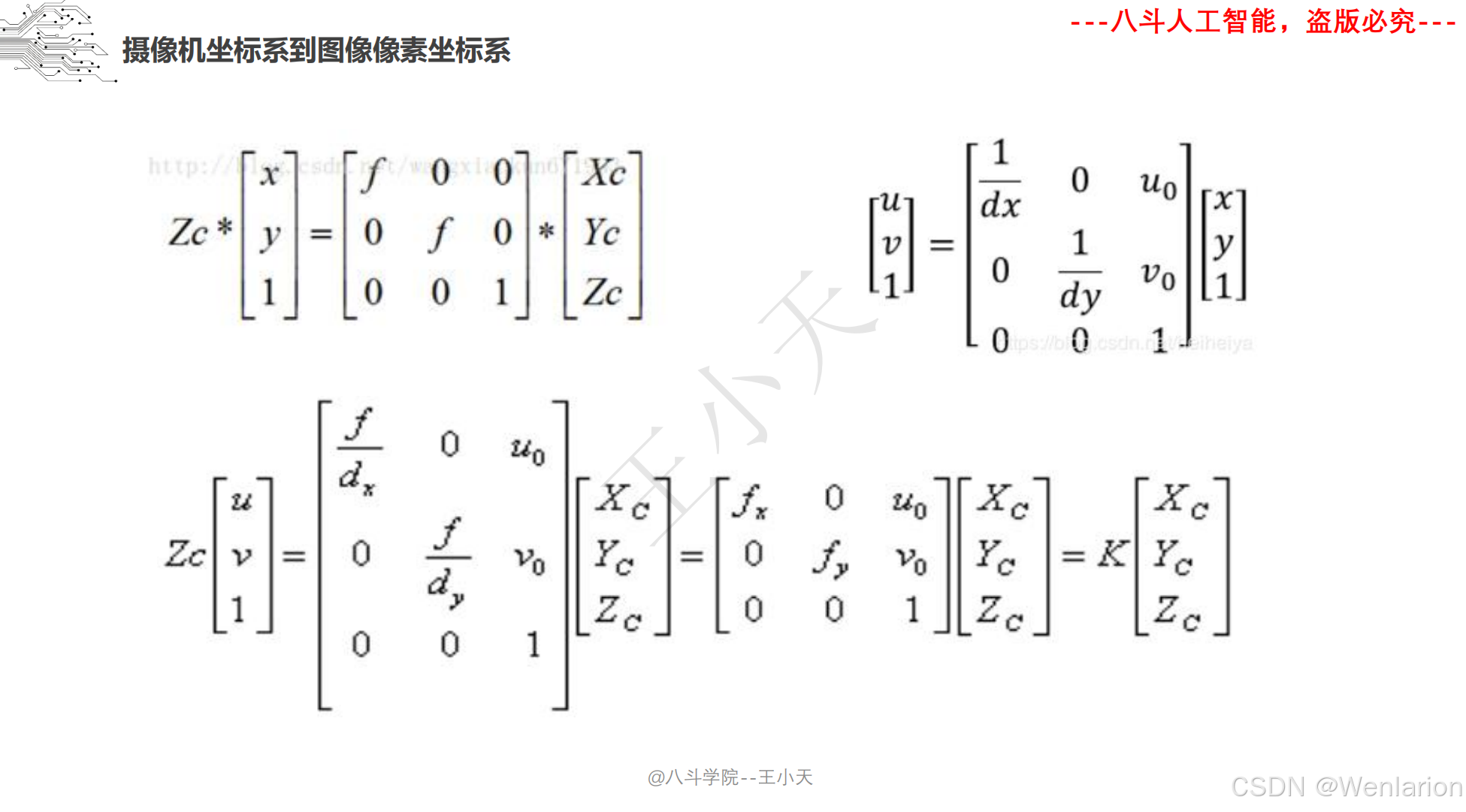
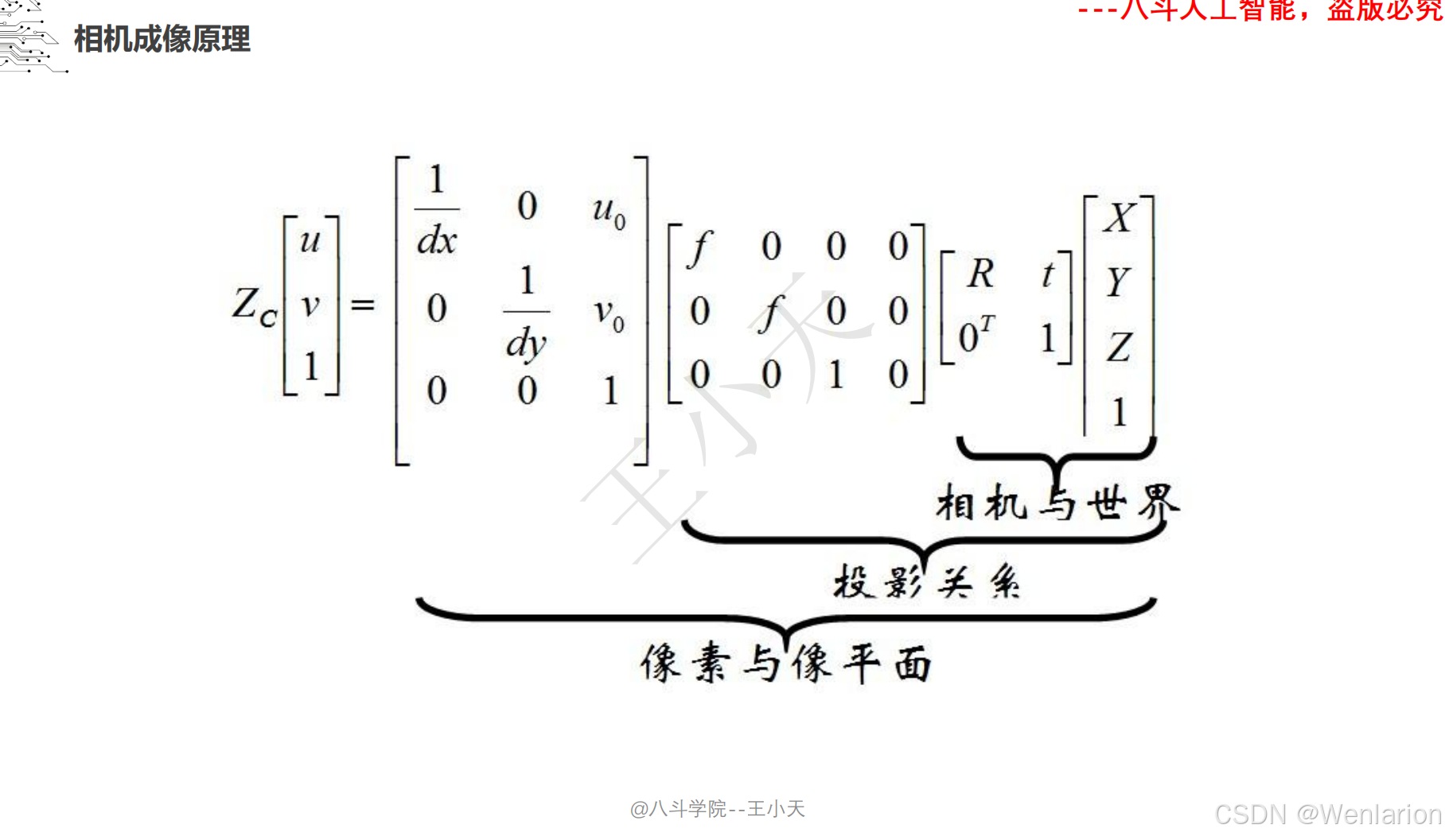

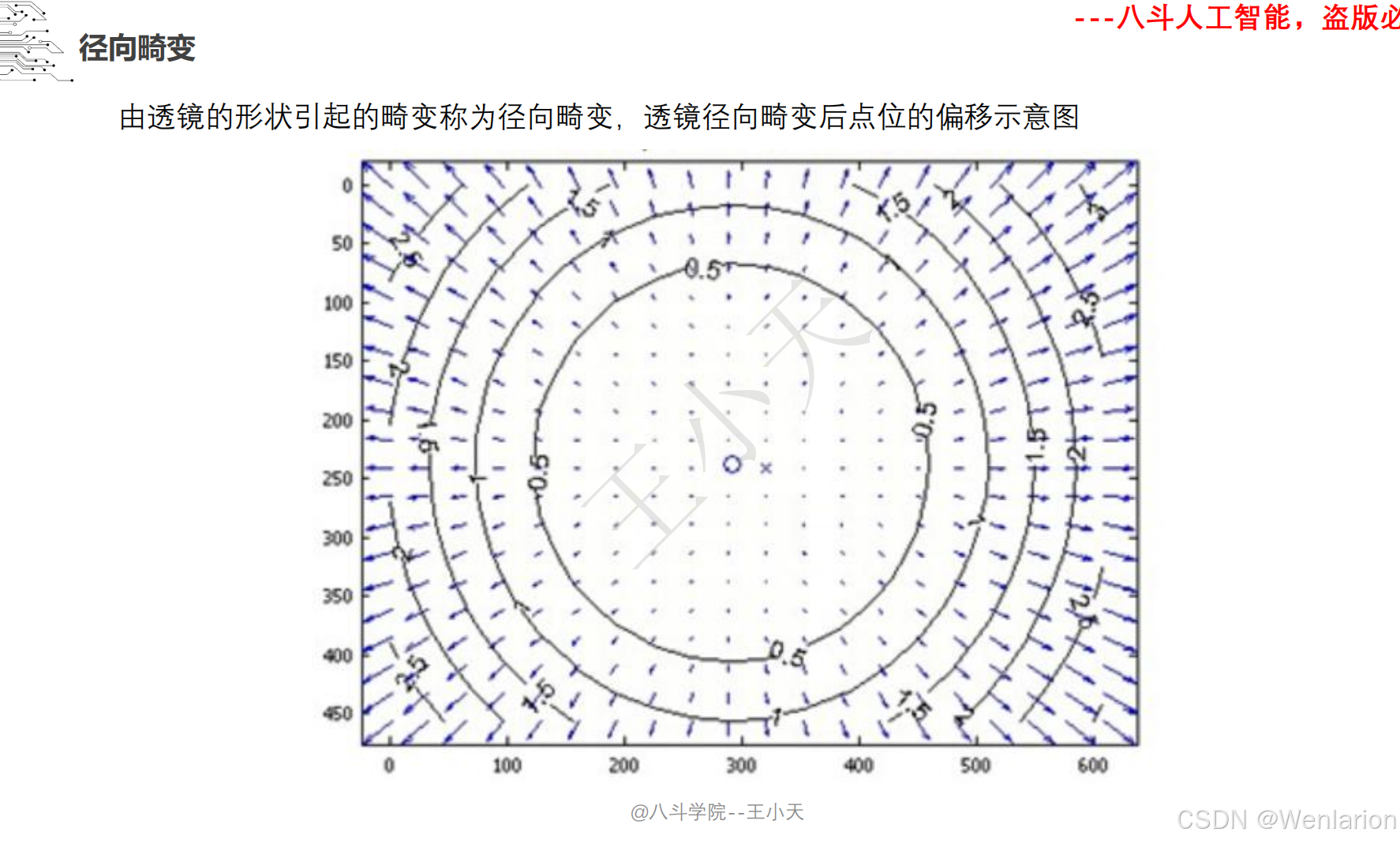
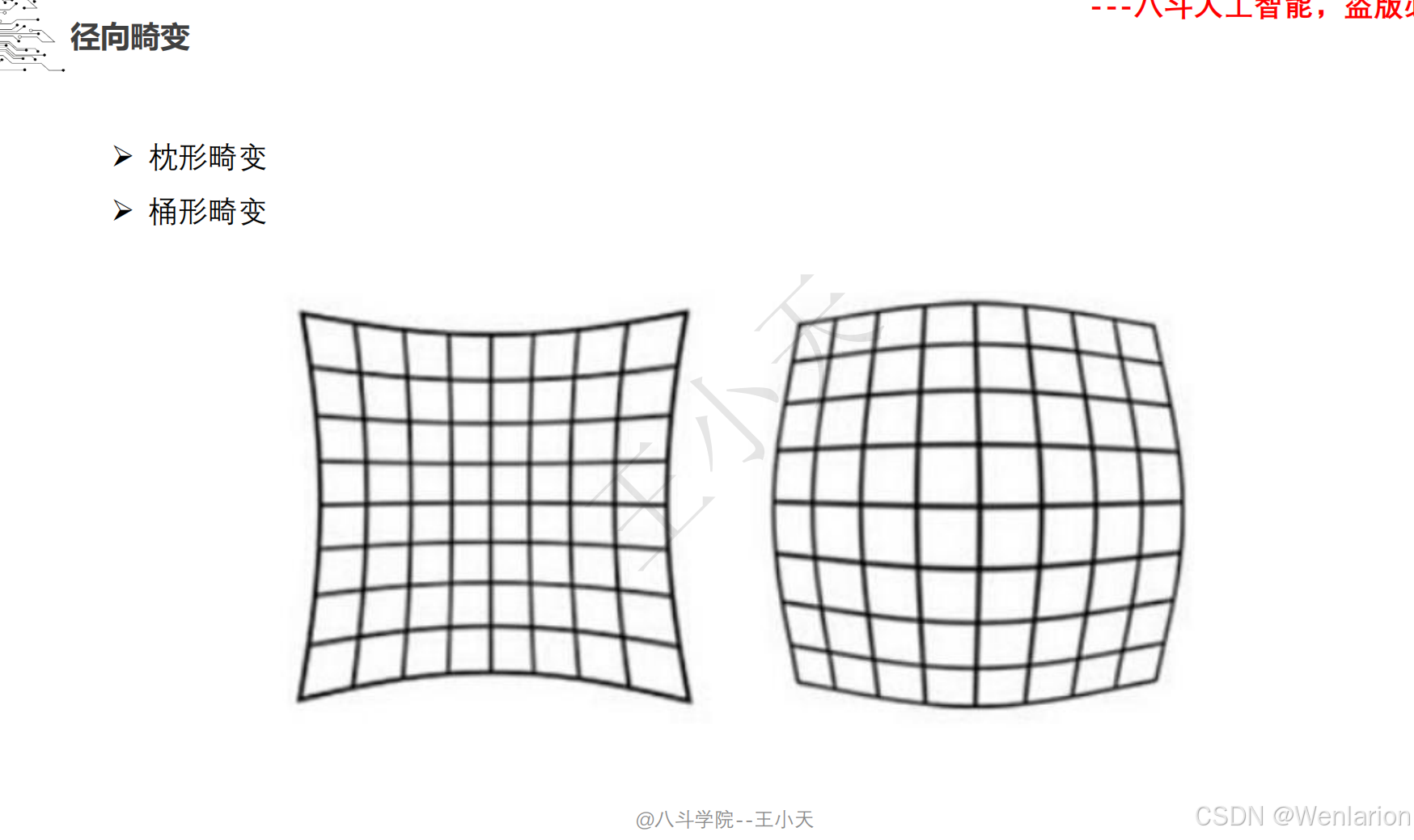


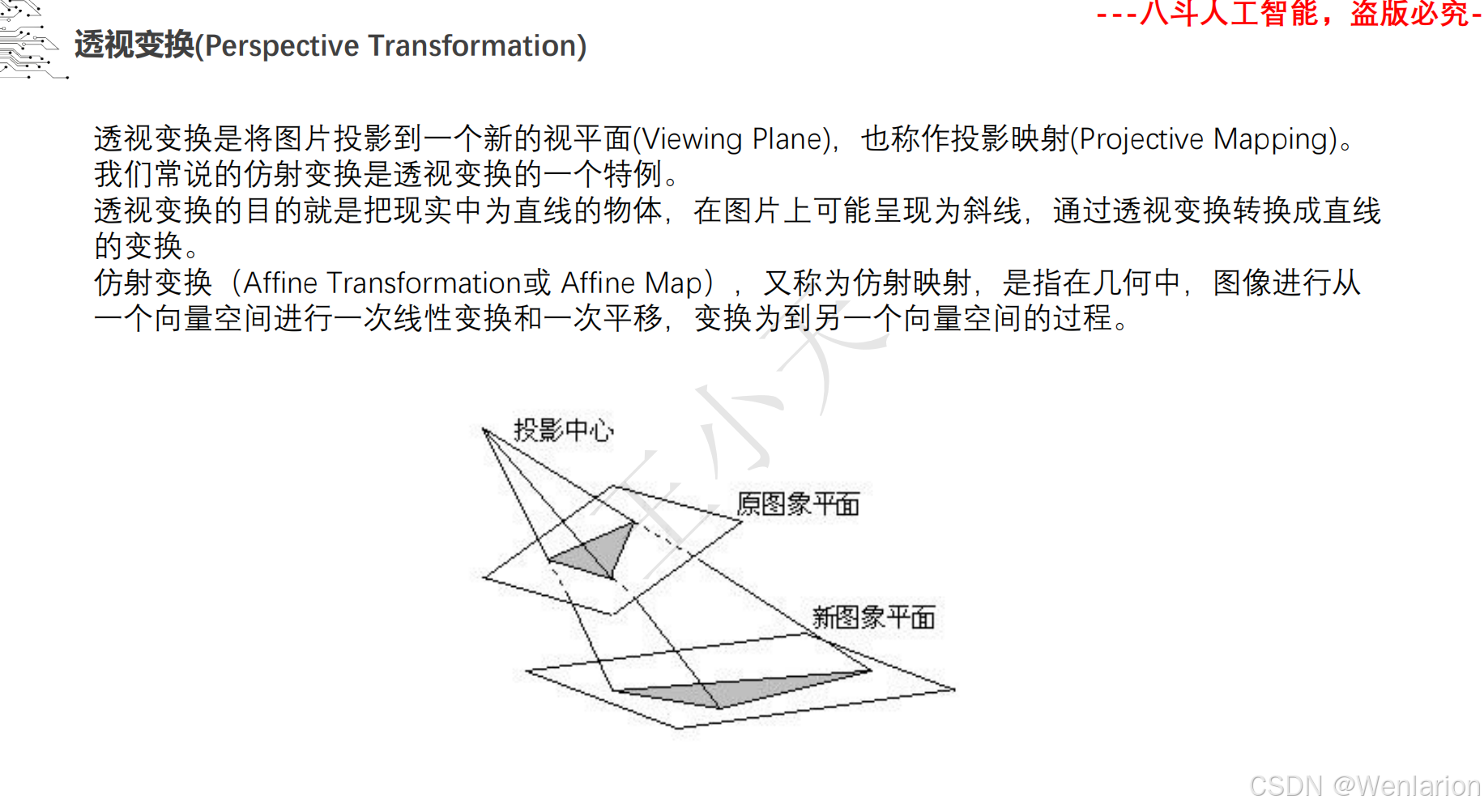

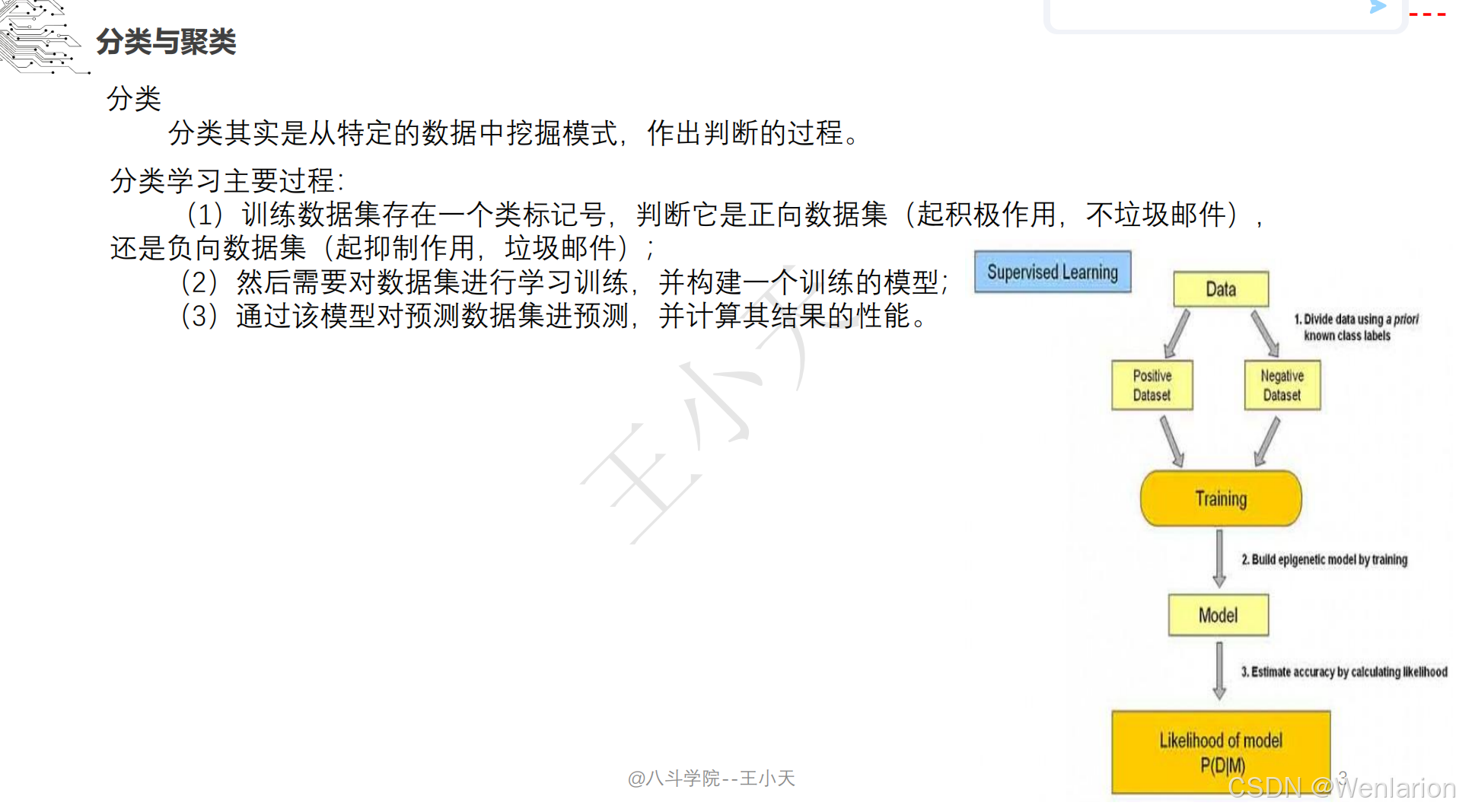
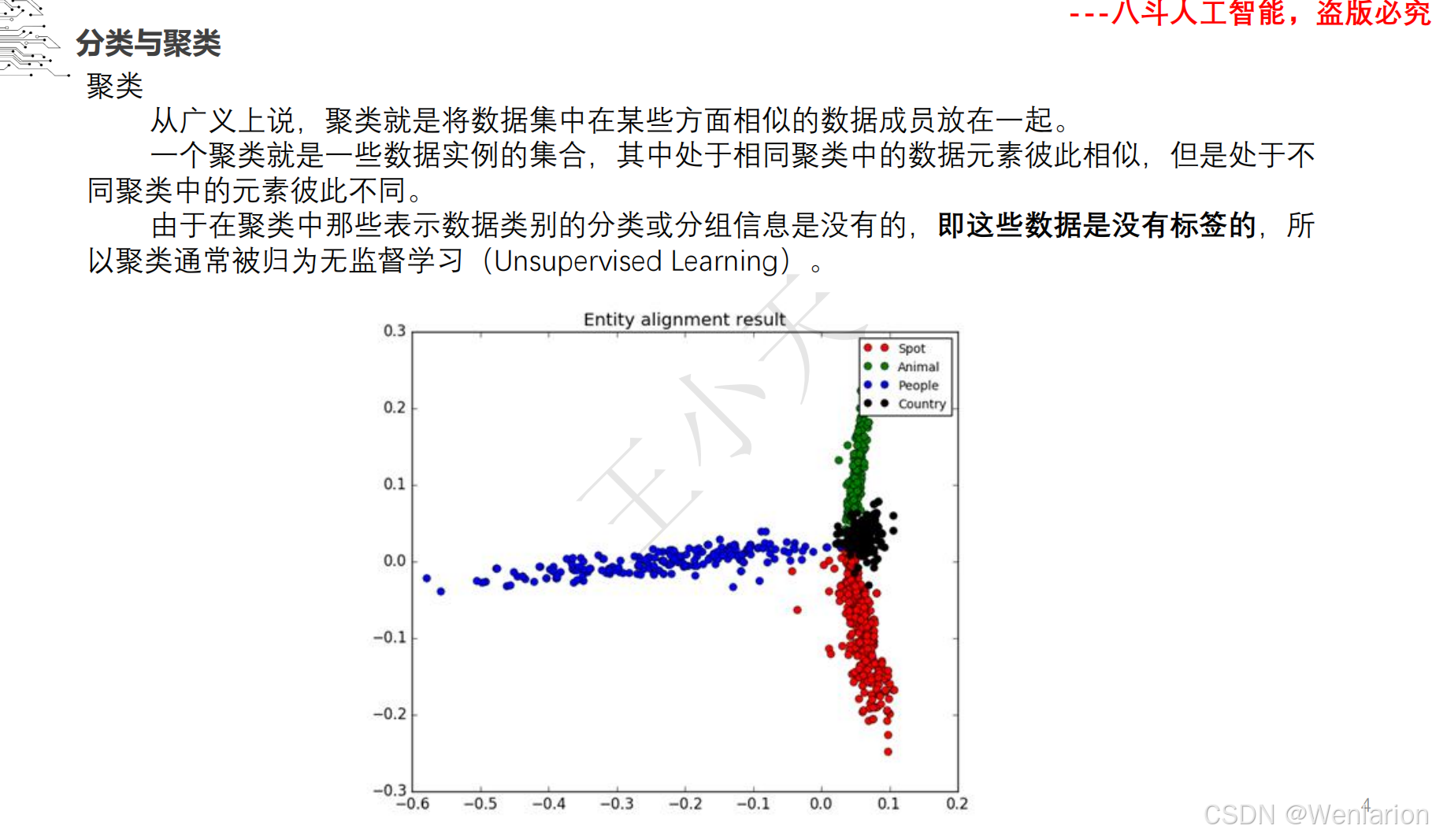
1.1.5 图像分类和聚类







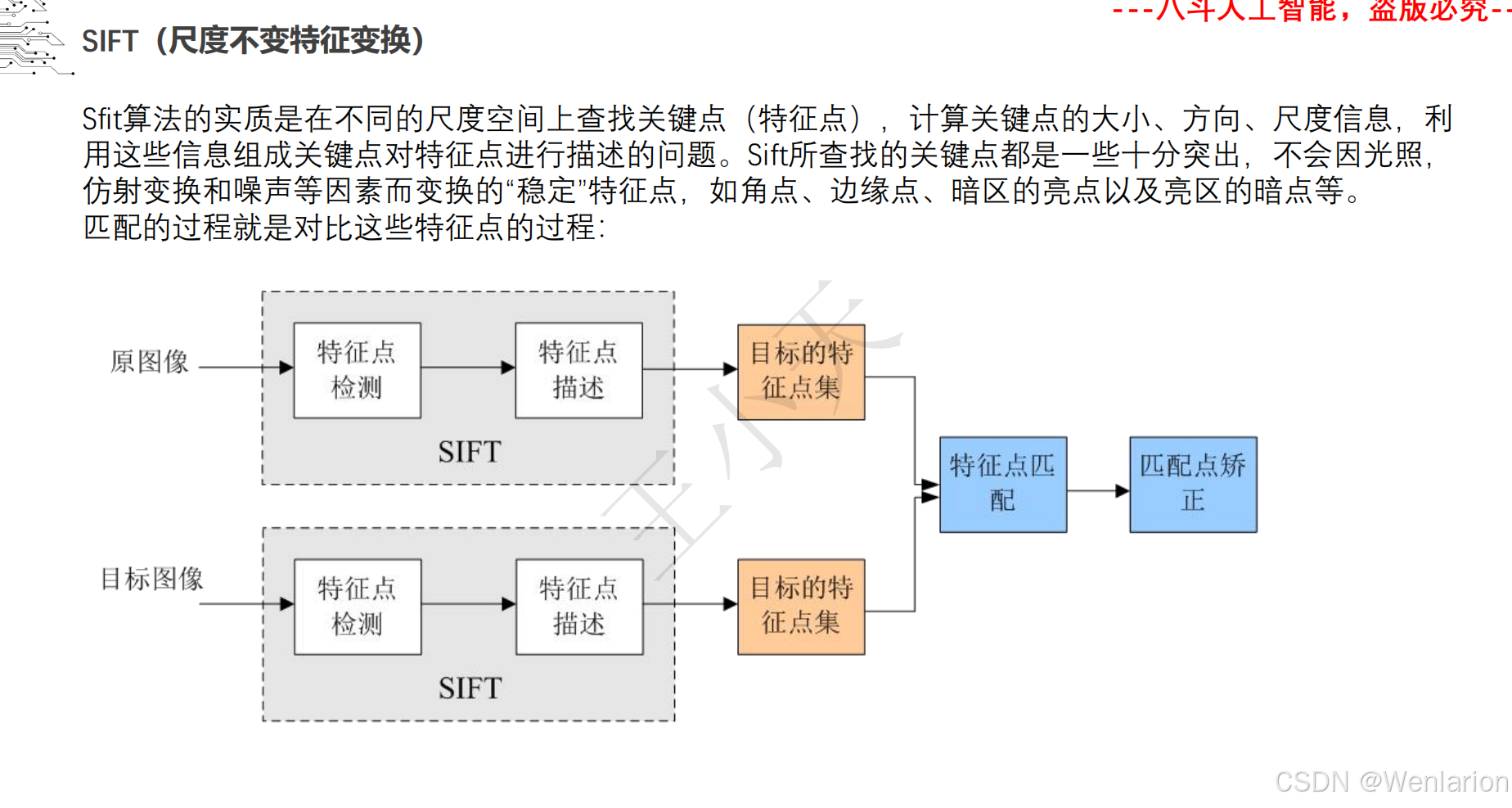
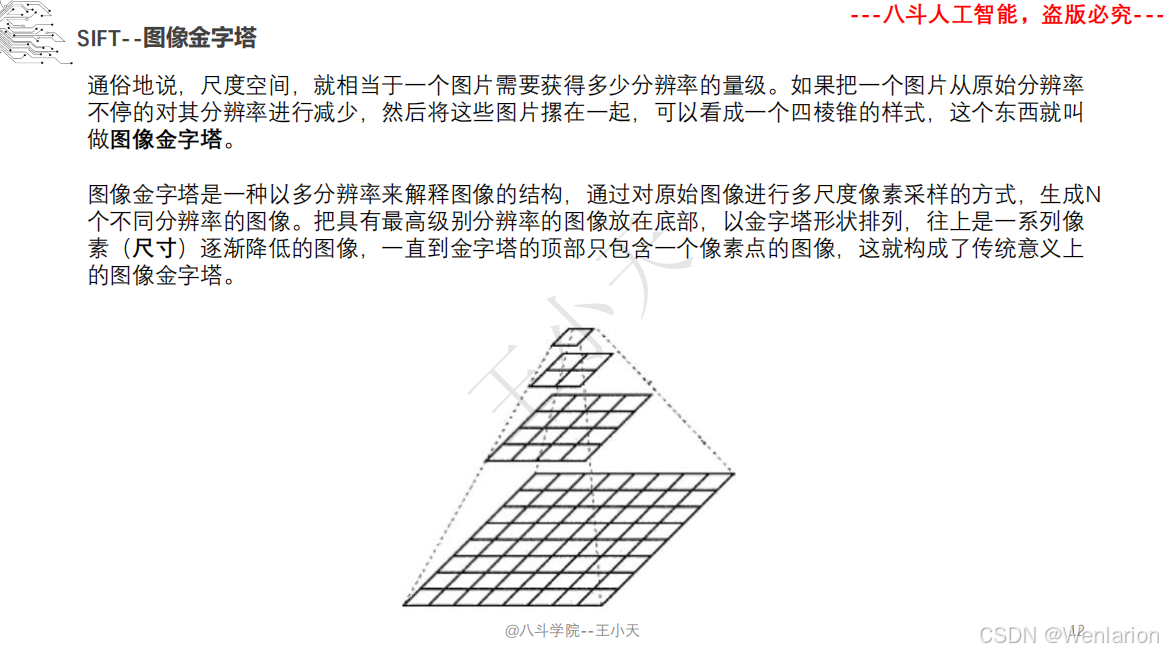
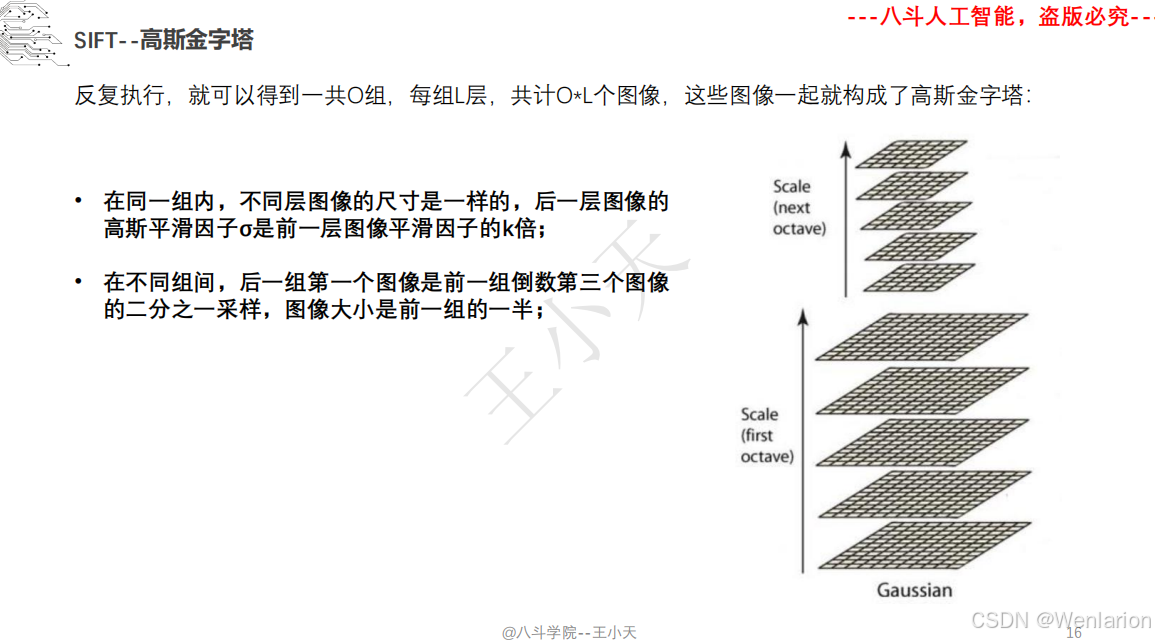
1.1.6 尺度不变特征变换-SIFT







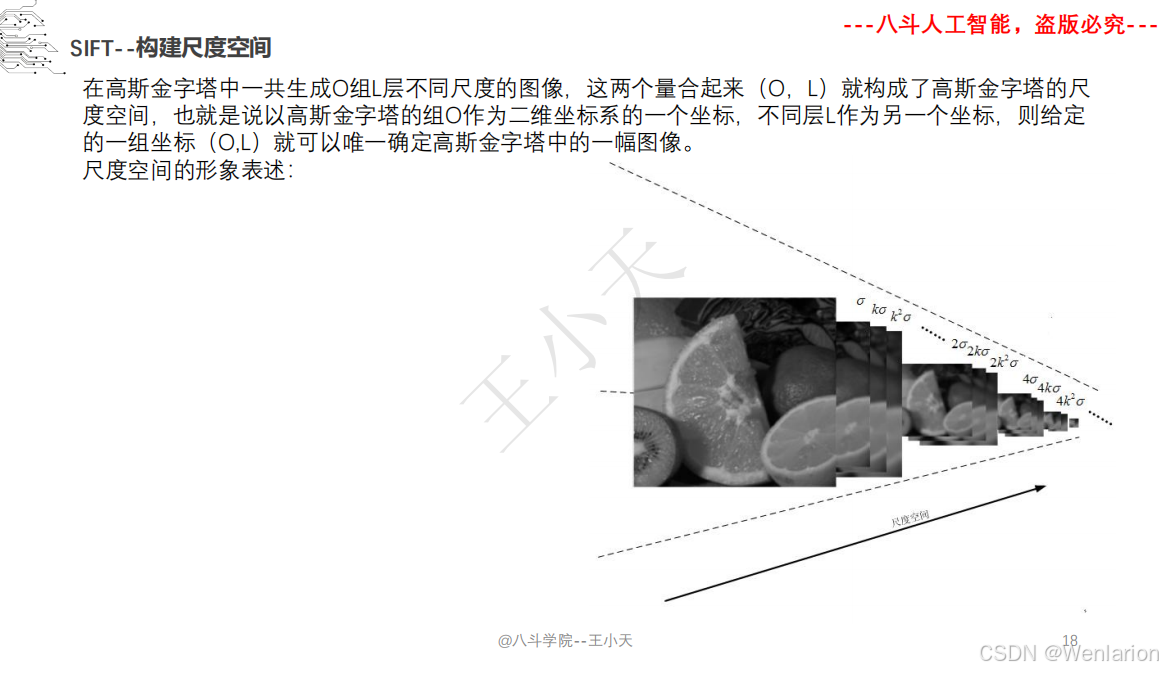


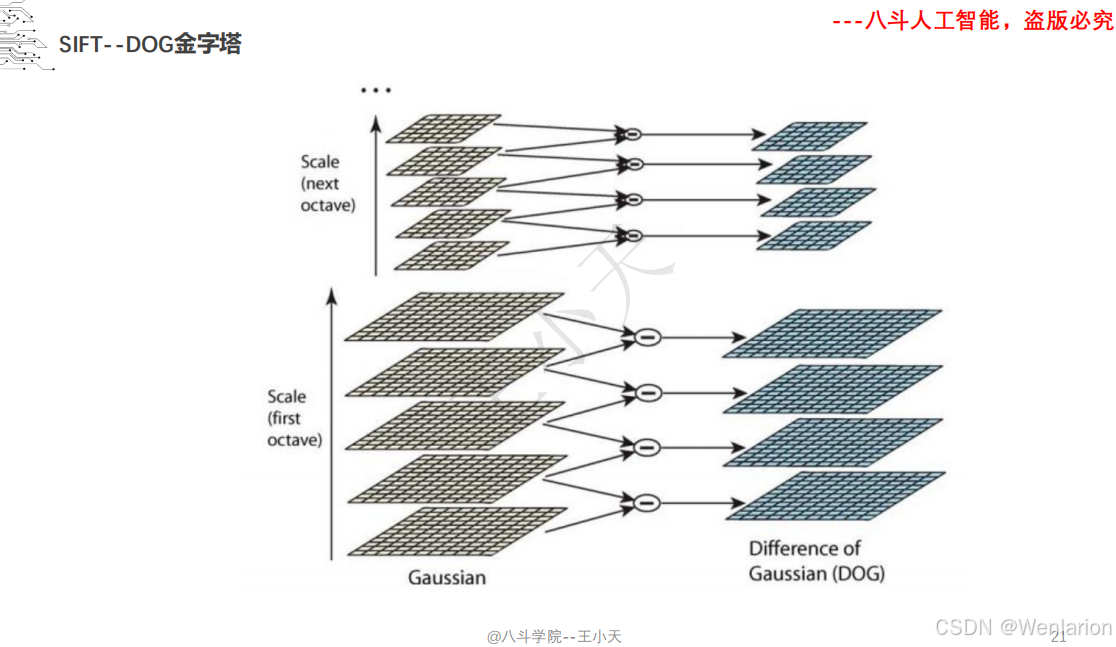
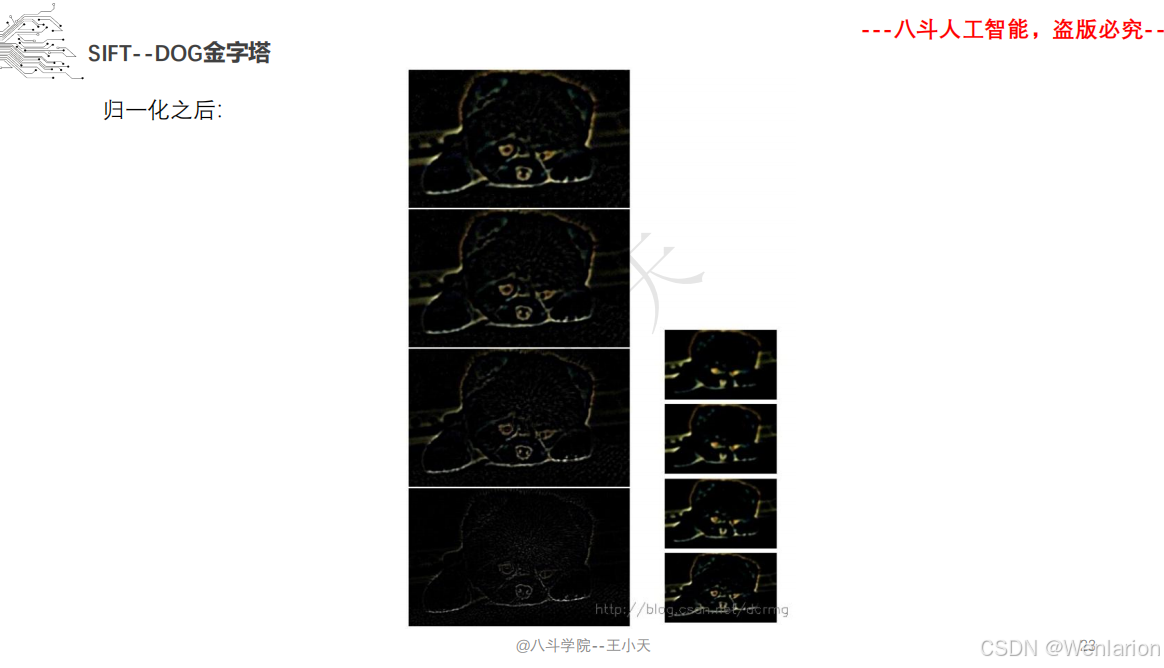
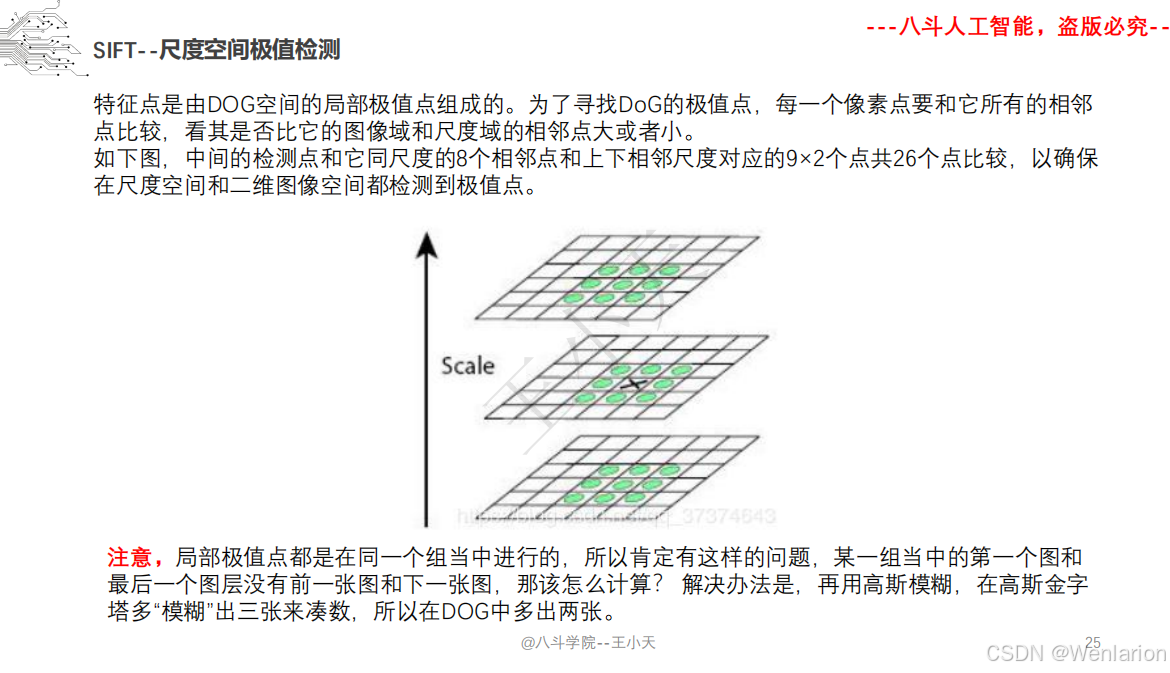


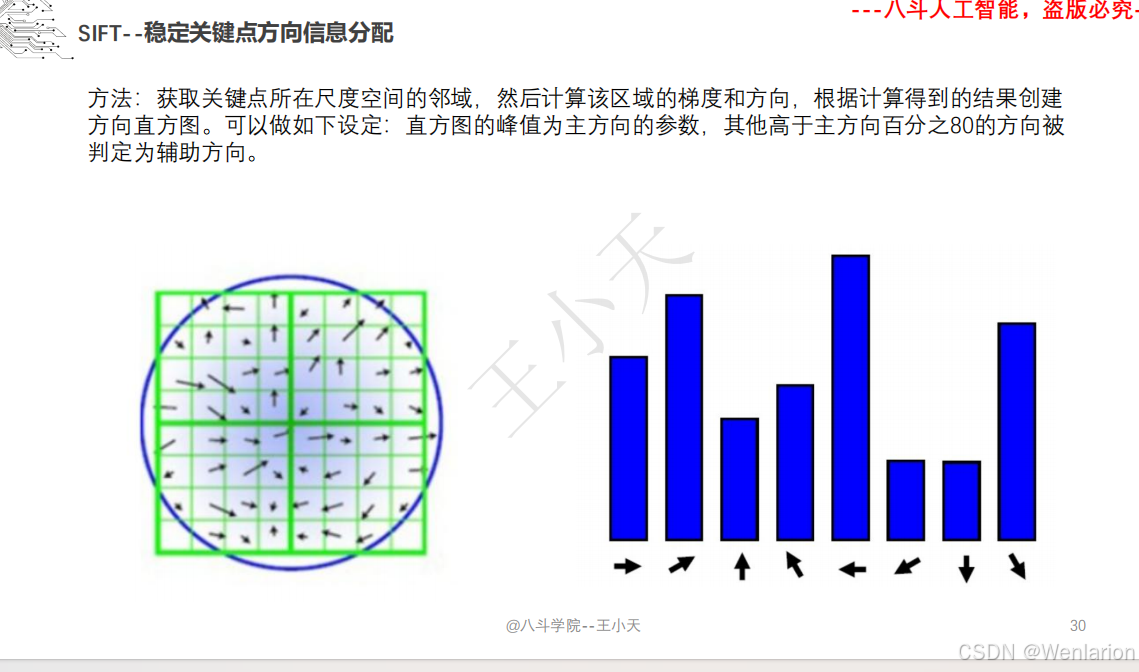


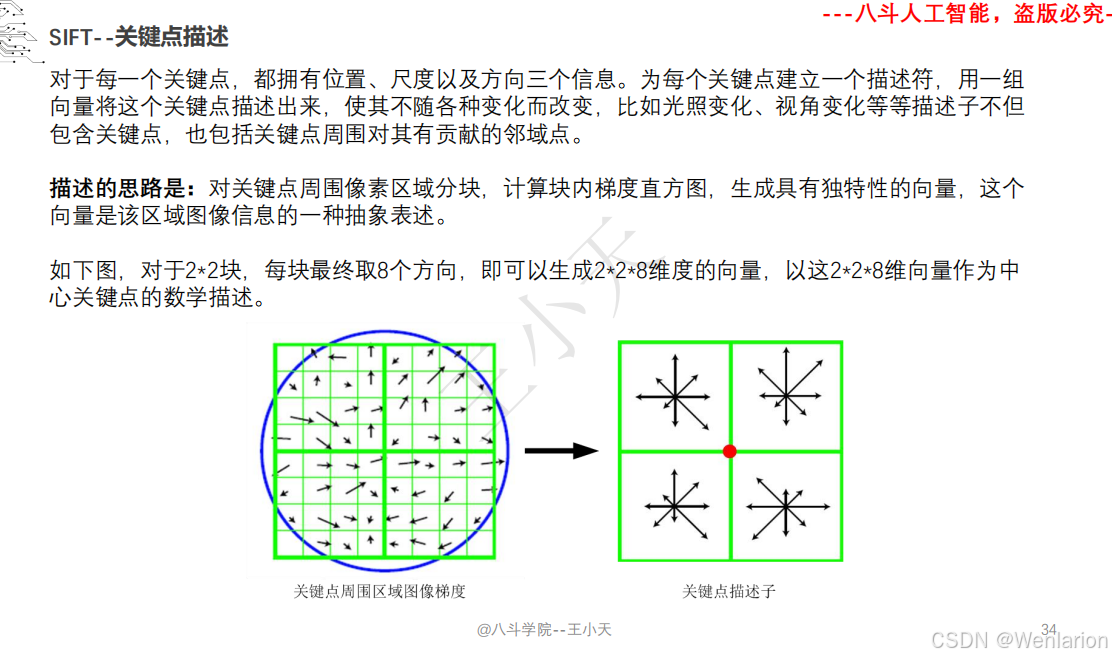
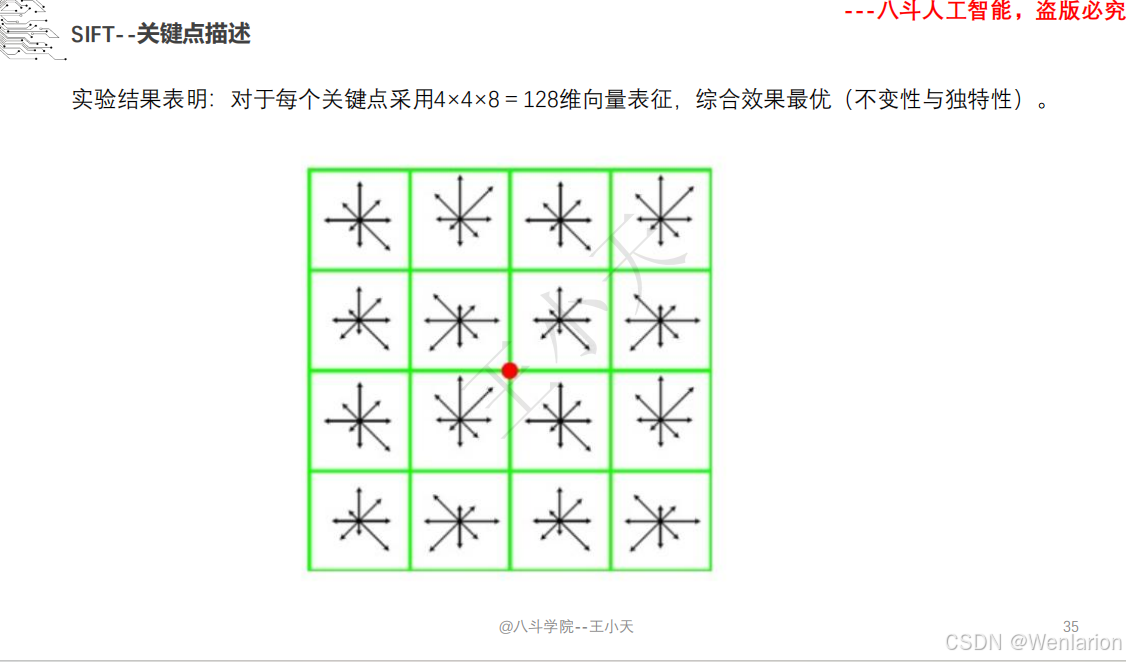



SIFT(尺度不变特征变换)的核心论文由 David G. Lowe 奠定,后续衍生出轻量化、加速与深度学习增强版本。以下按奠基论文→核心变体→加速实现分类,提供简介、论文链接、权威代码,覆盖学术复现、工程部署与实时应用。
一、SIFT 奠基论文(必读)
|
论文标题 |
发表 |
核心贡献 |
论文链接 |
官方 / 权威代码 |
|---|---|---|---|---|
|
Distinctive Image Features from Scale-Invariant Keypoints |
IJCV 2004 |
SIFT 终稿,完整定义 DoG 金字塔、关键点定位、方向赋值、128 维描述子,成为局部特征黄金标准。 |
https://doi.org/10.1023/B:VISI.0000029664.99615.94arXiv: https://arxiv.org/abs/cs/0409063 |
🔗 Lowe 官方(C/MATLAB):http://www.cs.ubc.ca/~lowe/keypoints/ |
|
Object Recognition from Local Scale-Invariant Features |
ICCV 1999 |
SIFT 首次提出,奠定尺度不变特征框架,后续 2004 年 IJCV 版为完善版。 |
同上(1999 版算法包含在官方包中) |
二、核心变体与增强(研究常用)
|
论文标题 |
发表 |
核心贡献 |
论文链接 |
代码链接 |
|---|---|---|---|---|
|
PCA-SIFT: A More Distinctive Representation for Local Image Descriptors |
CVPR 2004 |
用 PCA 降维 128 维描述子至 36 维,加速匹配且保持区分性。 |
🔗 OpenSIFT 扩展:https://github.com/robwhess/opensift(需自行添加 PCA 模块) |
|
|
SURF: Speeded Up Robust Features |
ECCV 2006 |
用积分图加速 Hessian 检测,替代 DoG,速度提升数倍,成为 SIFT 工业替代。 |
🔗 OpenCV 内置: |
|
|
RootSIFT: Thresholded Euclidean Distance vs. Chi-Squared Distance for Binary Feature Matching |
CVPR 2012 (Workshop) |
对 SIFT 描述子做 L1 归一化后开方,匹配精度显著提升,无需重新训练。 |
三、高效实现与实时部署(工程必备)
|
论文标题 |
发表 |
核心贡献 |
论文链接 |
代码链接 |
|---|---|---|---|---|
|
Popsift: a faithful SIFT implementation for real-time applications |
MMSys 2018 |
基于 CUDA 的实时 SIFT,严格遵循 Lowe 2004 标准,支持 1080p 实时流。 |
||
|
SiftGPU: A GPU Implementation of Scale Invariant Feature Transform |
VMV 2007 |
首个 GPU 加速 SIFT,支持多尺度检测与描述子生成,适合并行计算场景。 |
四、常用开源实现汇总(快速上手)
|
实现名称 |
语言 |
特点 |
适用场景 |
代码链接 |
|---|---|---|---|---|
|
OpenCV SIFT |
C++/Python |
工业级稳定实现,支持 |
快速原型、工程部署 |
🔗 官方源码:https://github.com/opencv/opencv/blob/master/modules/features2d/src/sift.dispatch.cpp |
|
OpenSIFT (Rob Hess) |
C |
最贴近 Lowe 论文的经典实现,模块化强,适合算法研究。 |
学术复现、算法调试 |
|
|
Python-SIFT |
Python |
纯 Python 轻量实现,基于 NumPy,适合教学与快速验证。 |
教学演示、小型项目 |
五、使用建议
-
学术研究:优先阅读 Lowe 2004 年 IJCV 论文,使用 OpenSIFT 或 Lowe 官方代码复现,确保与原始算法一致。
-
工程部署:直接使用 OpenCV 的
cv2.SIFT_create(),兼顾速度与稳定性;需实时处理时,选用 Popsift(CUDA)或 SiftGPU。 -
匹配优化:对 SIFT 描述子应用 RootSIFT 变换,可在不增加计算量的前提下提升匹配精度。
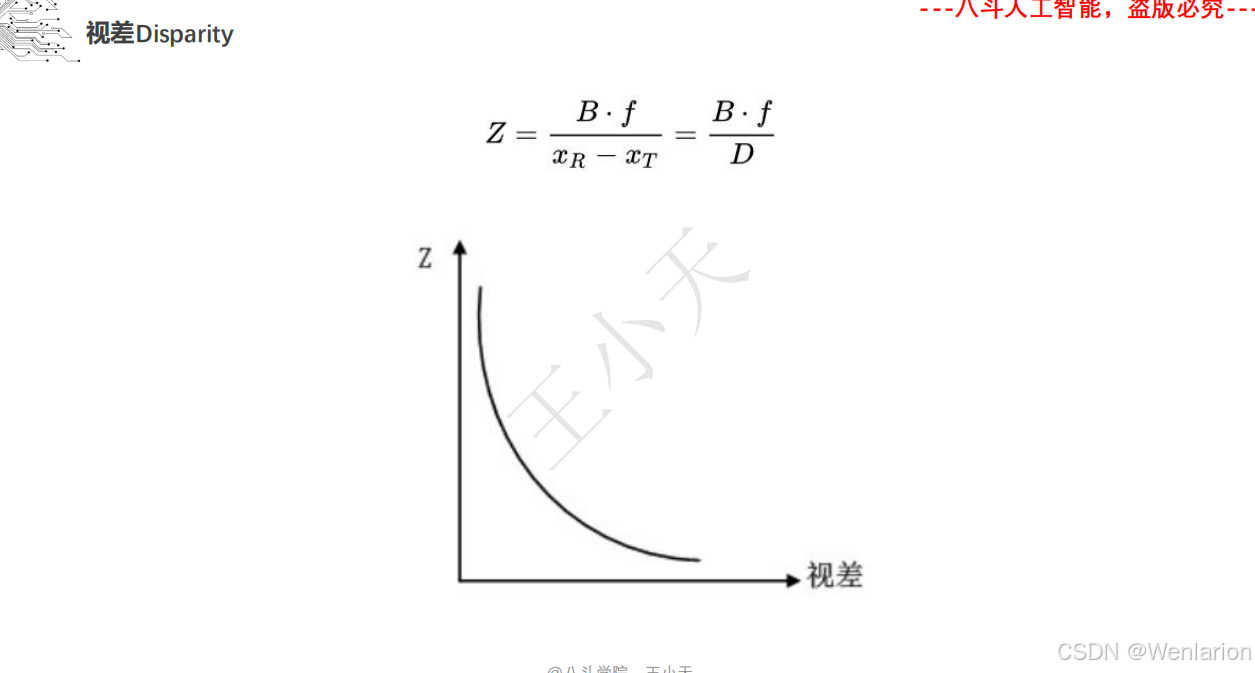
1.2 立体视觉
1.2.1 立体视觉


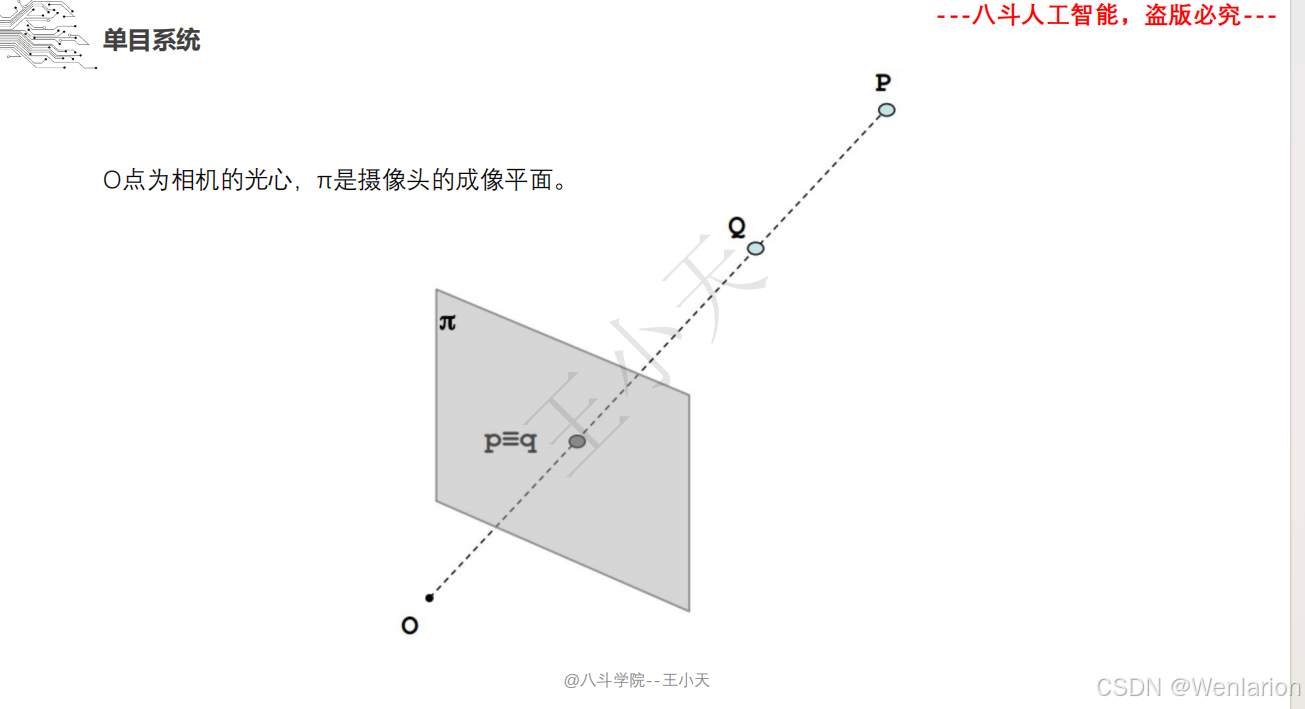
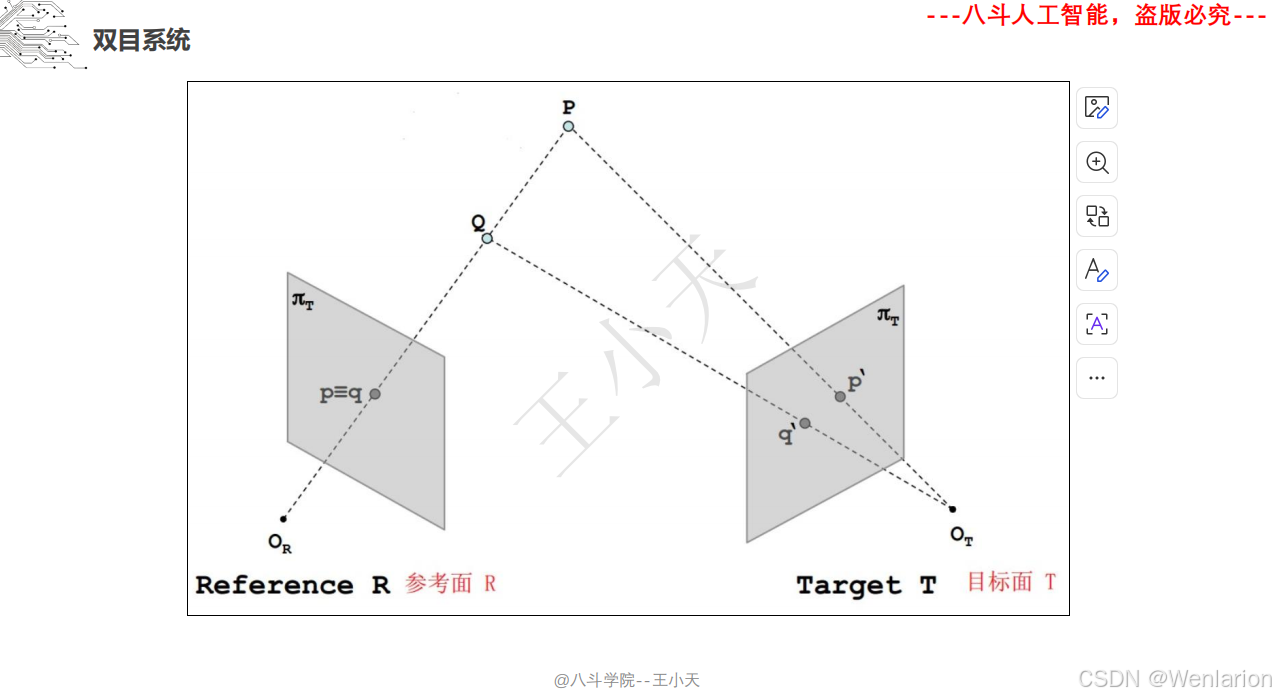
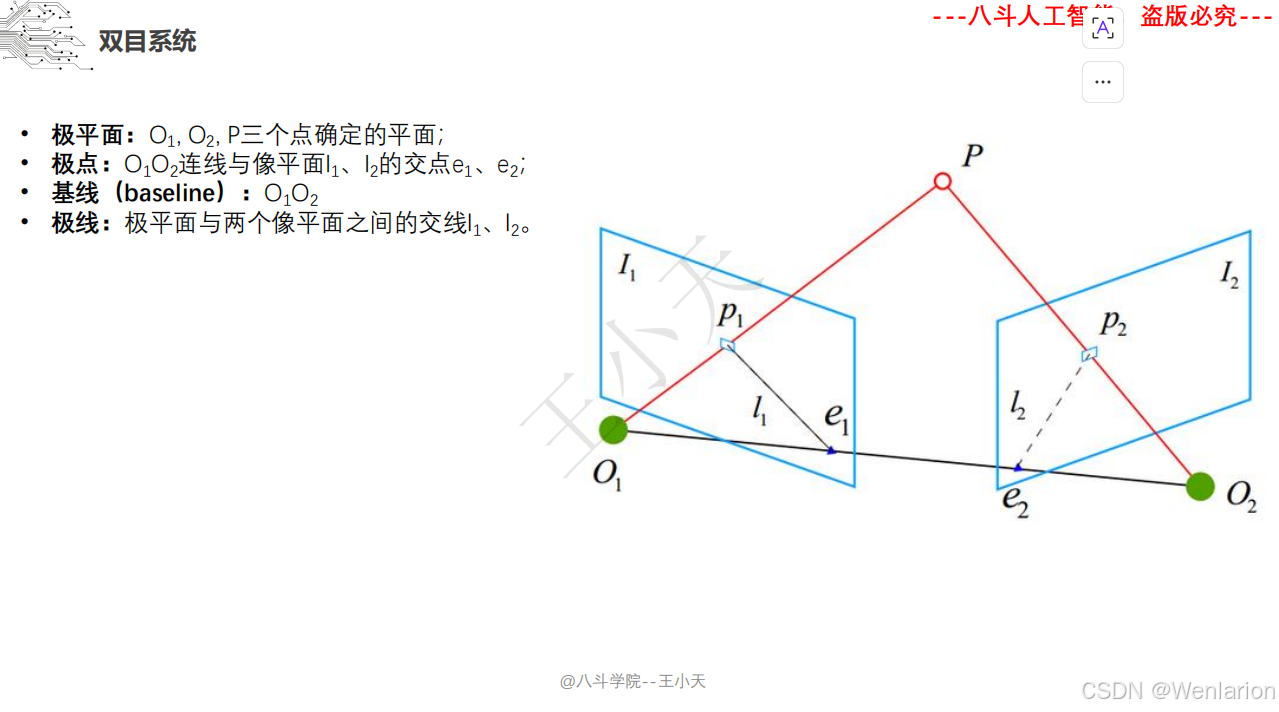
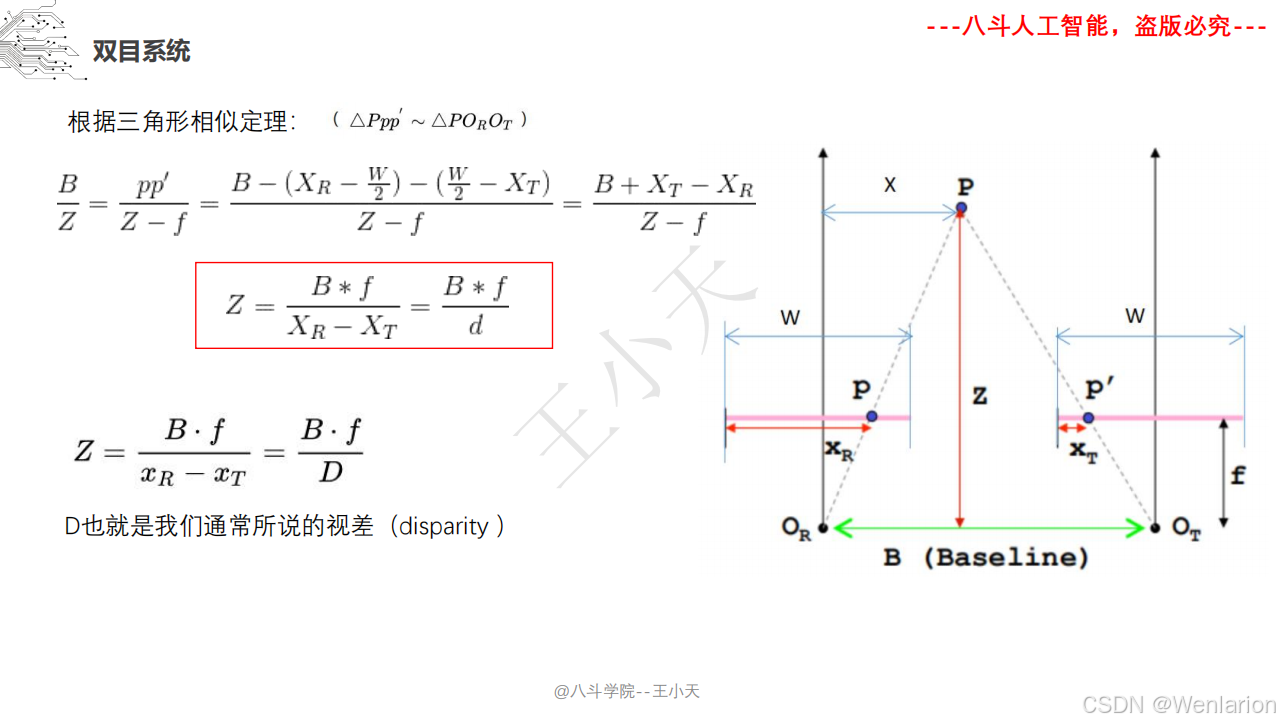
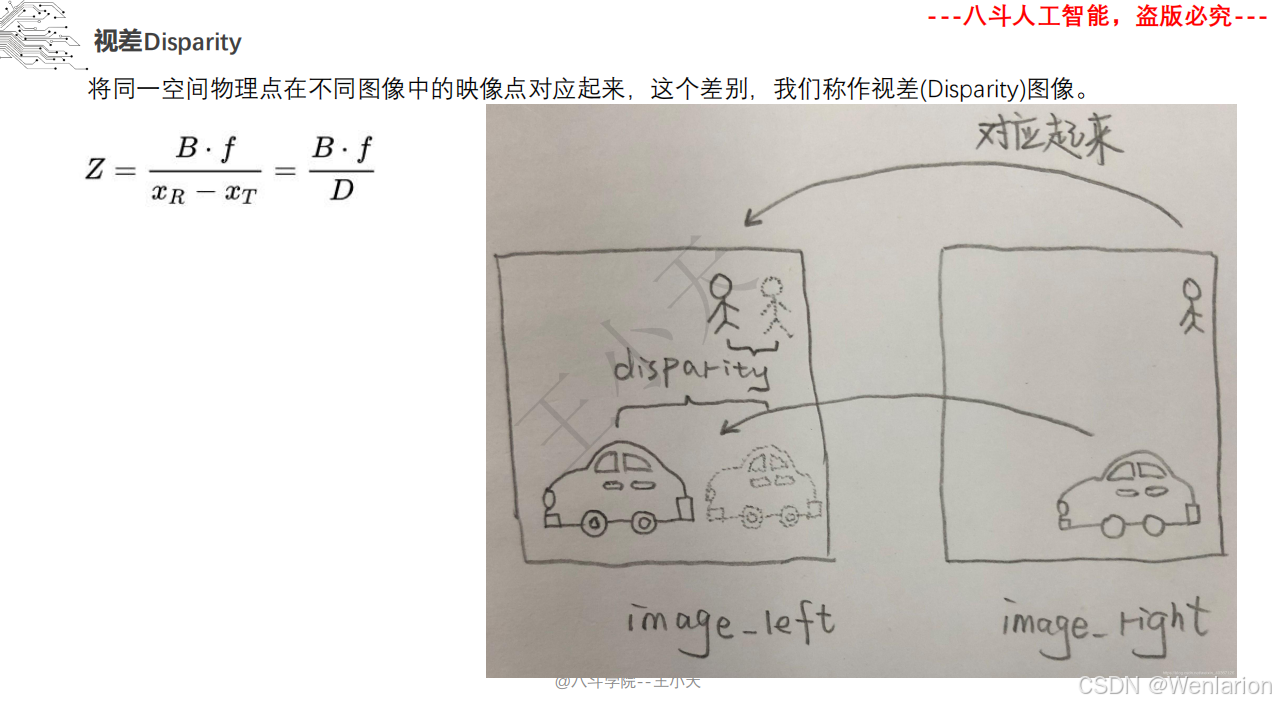
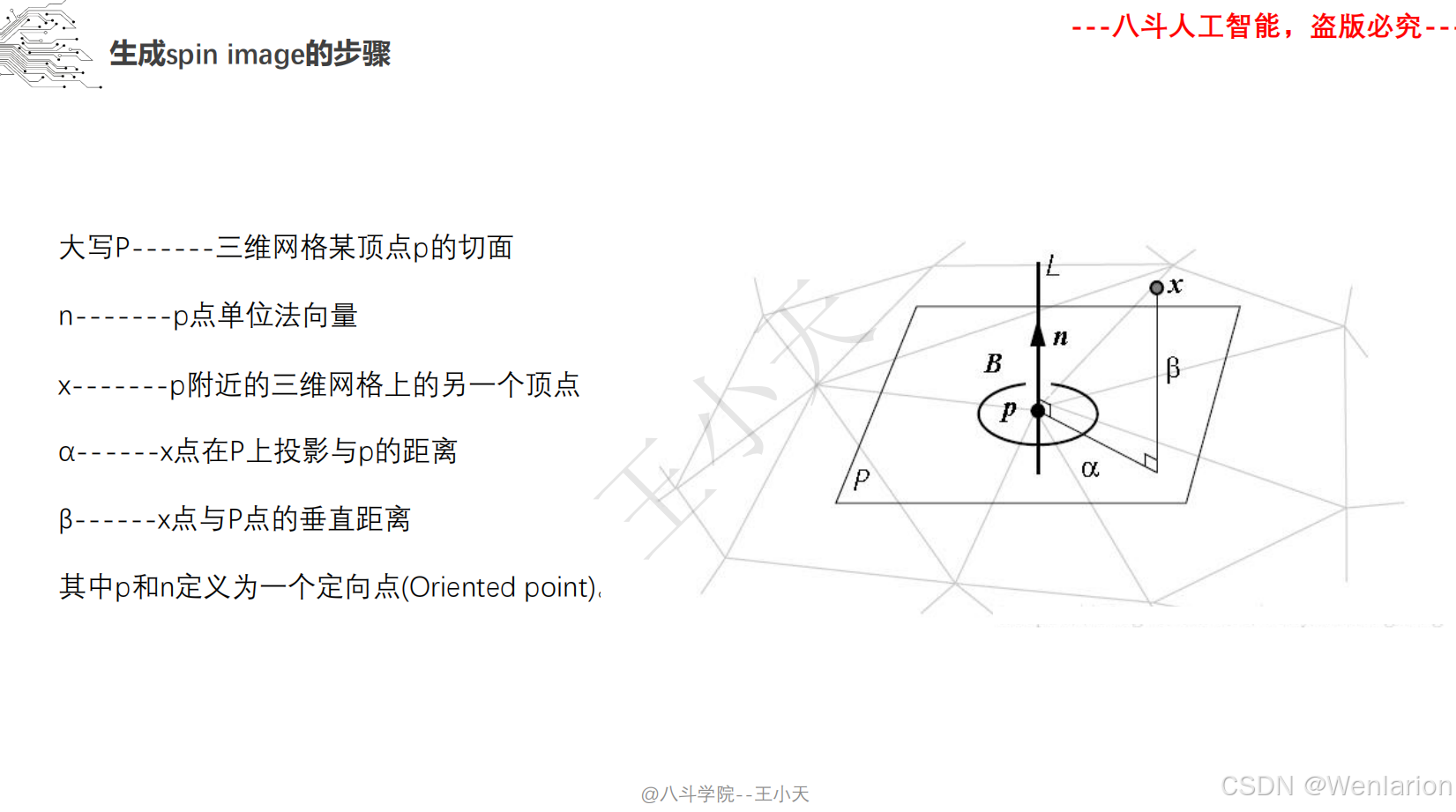
1.2.2 点云模型









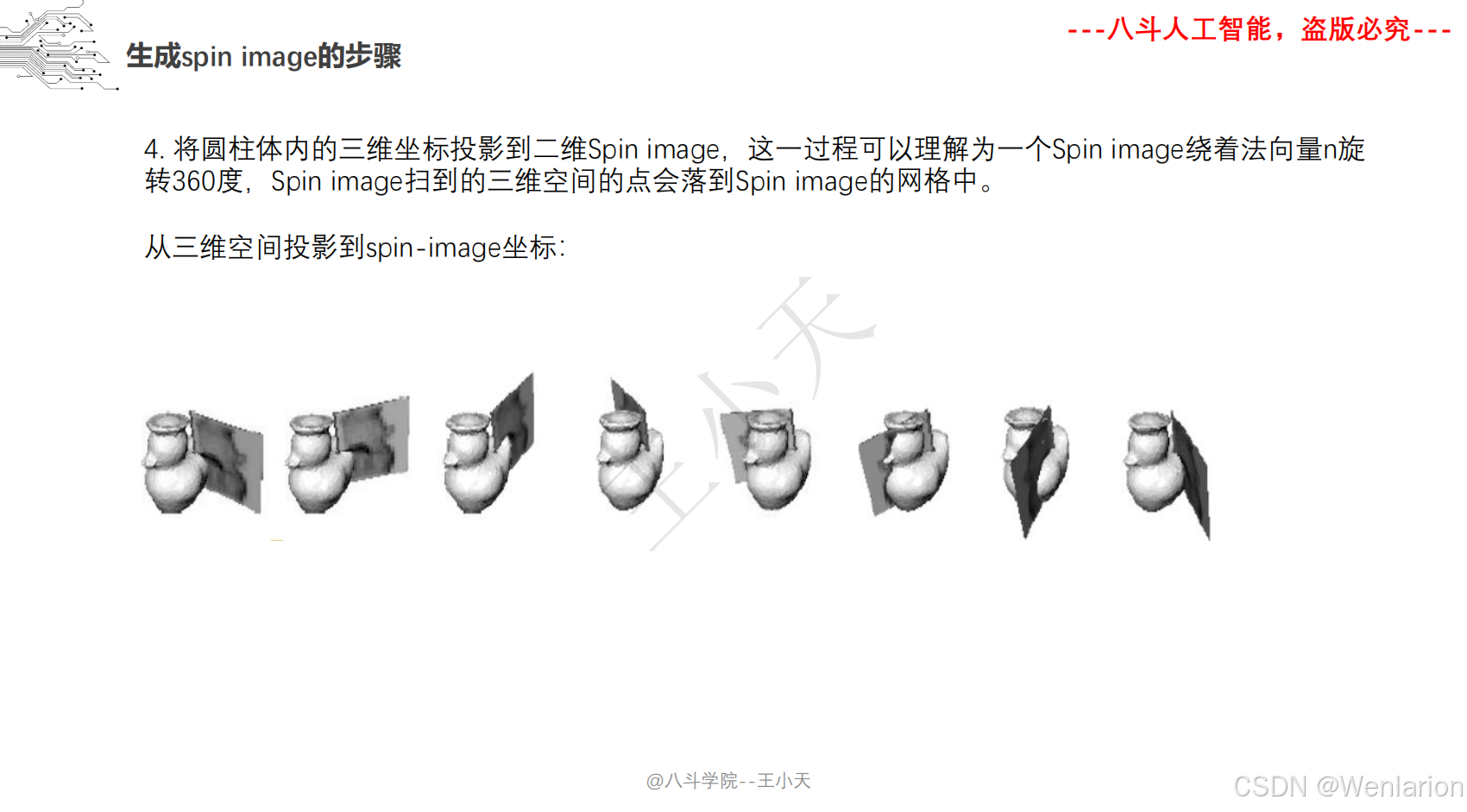

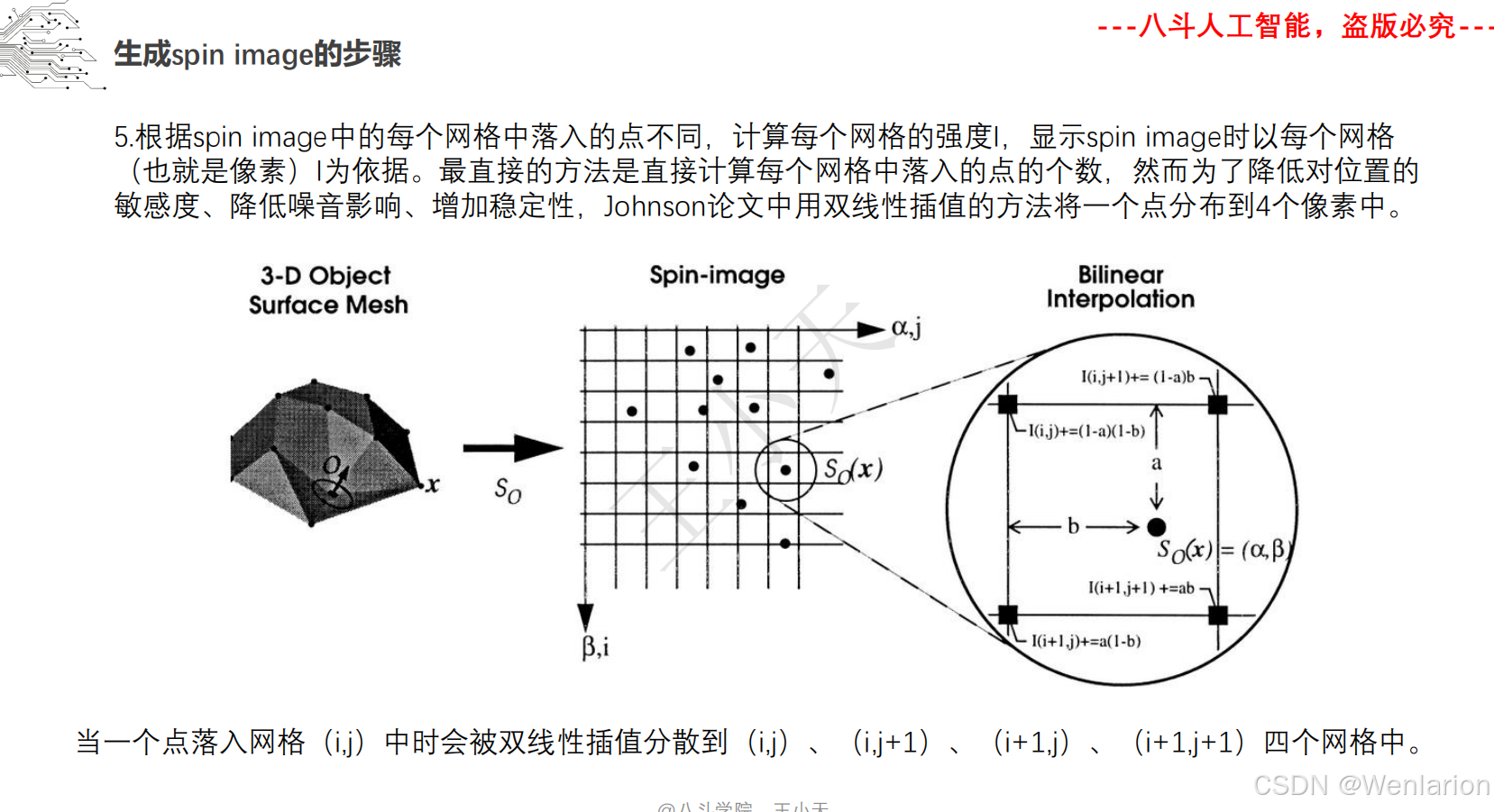
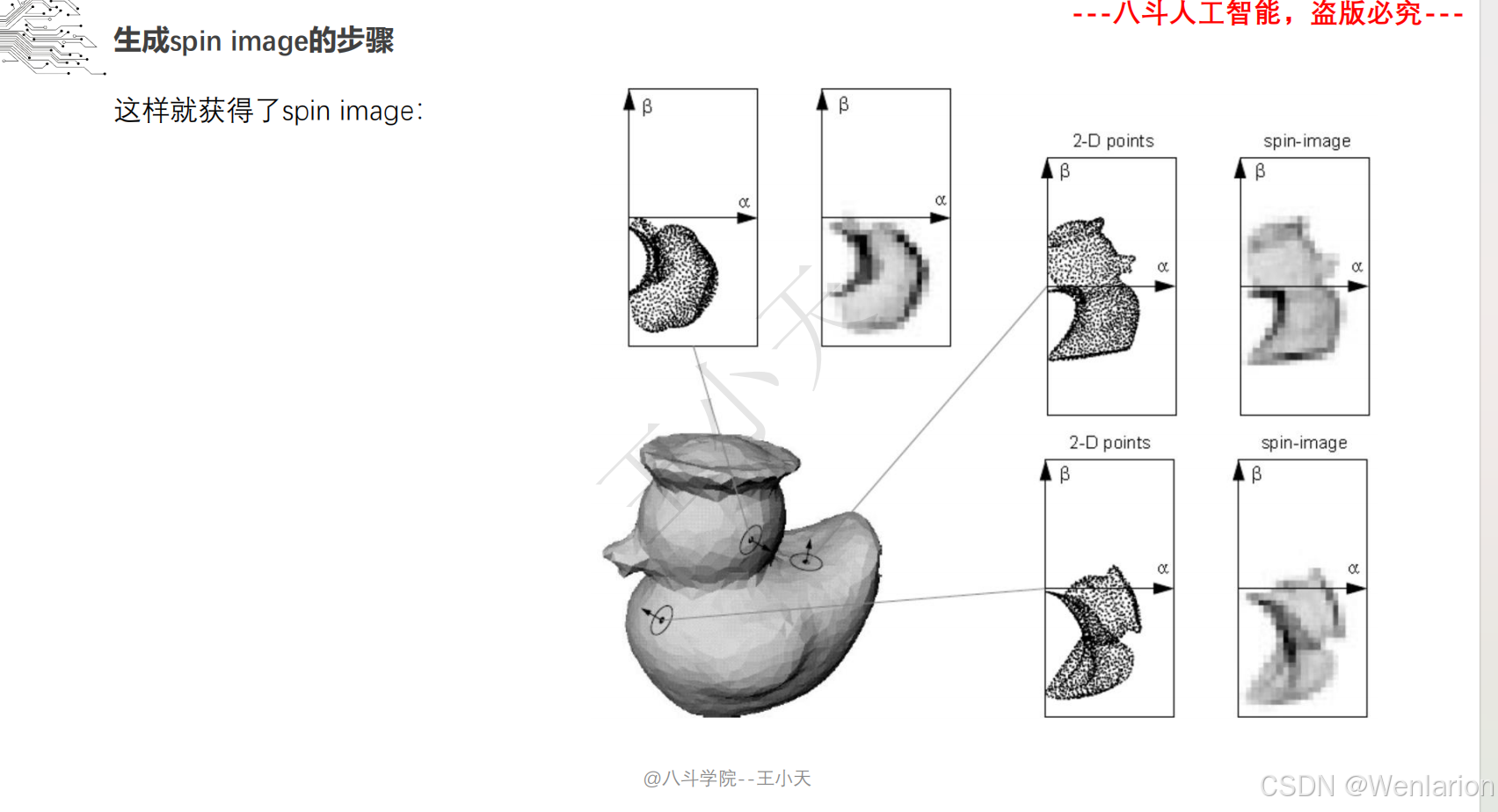

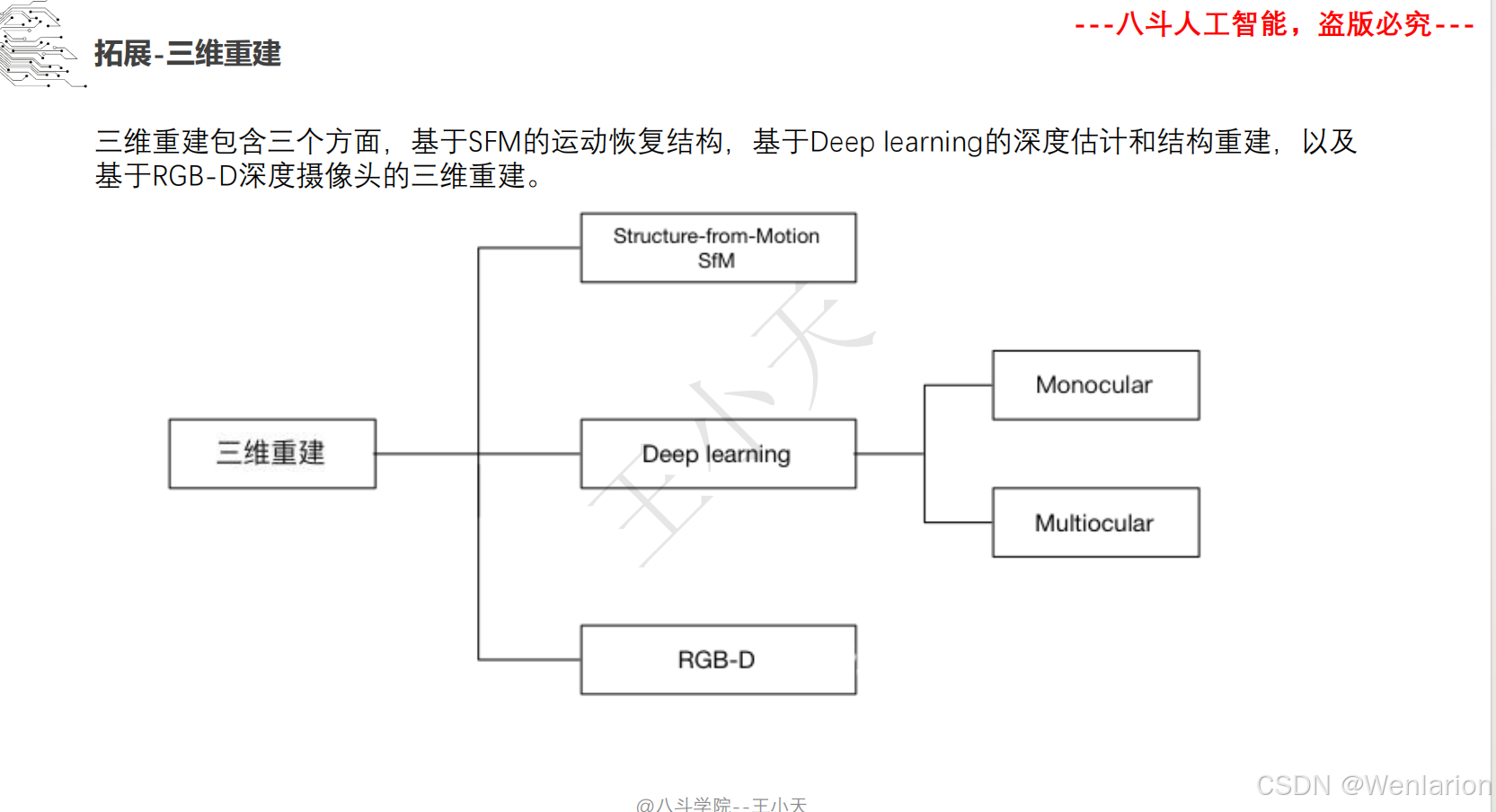

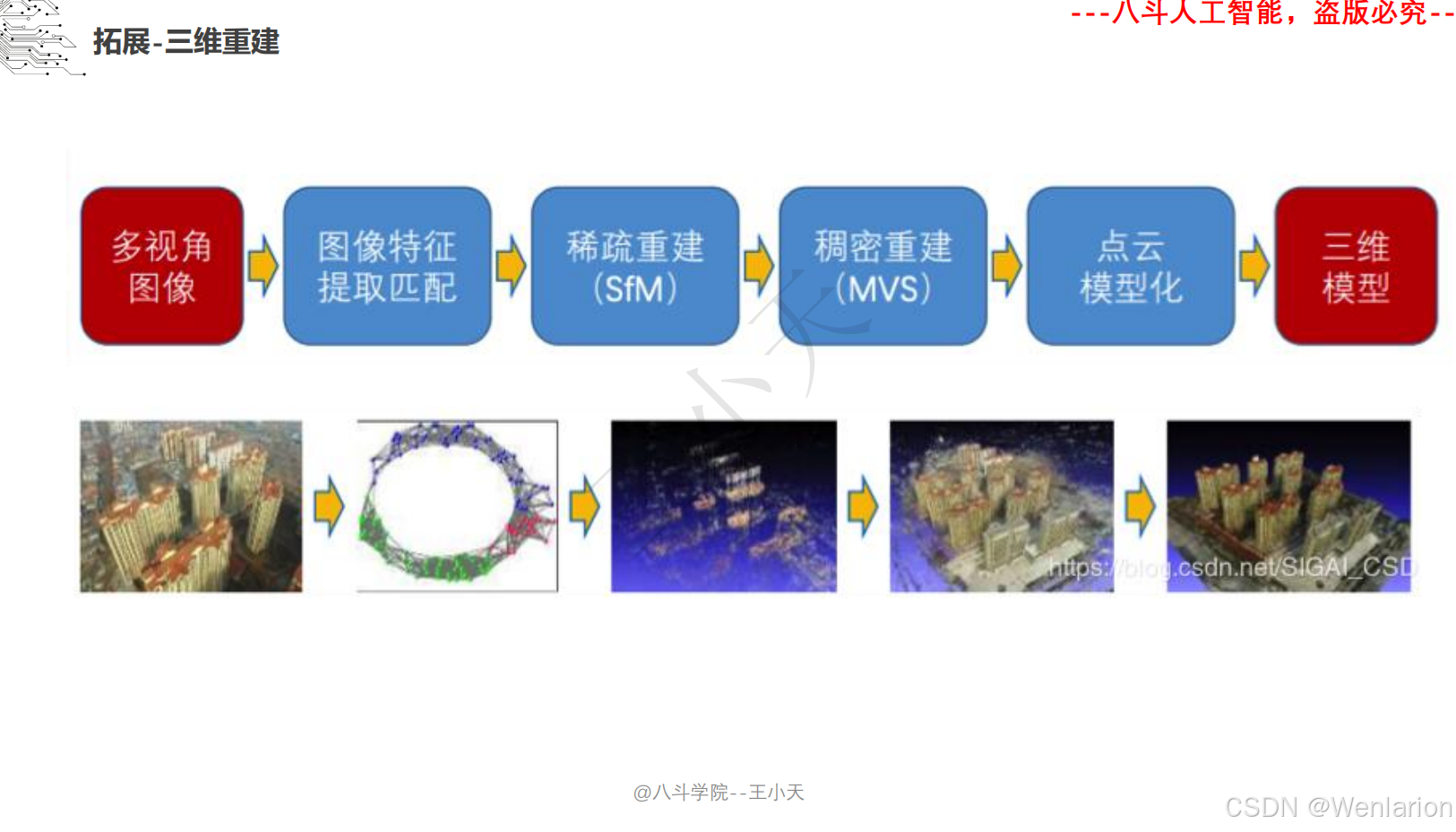
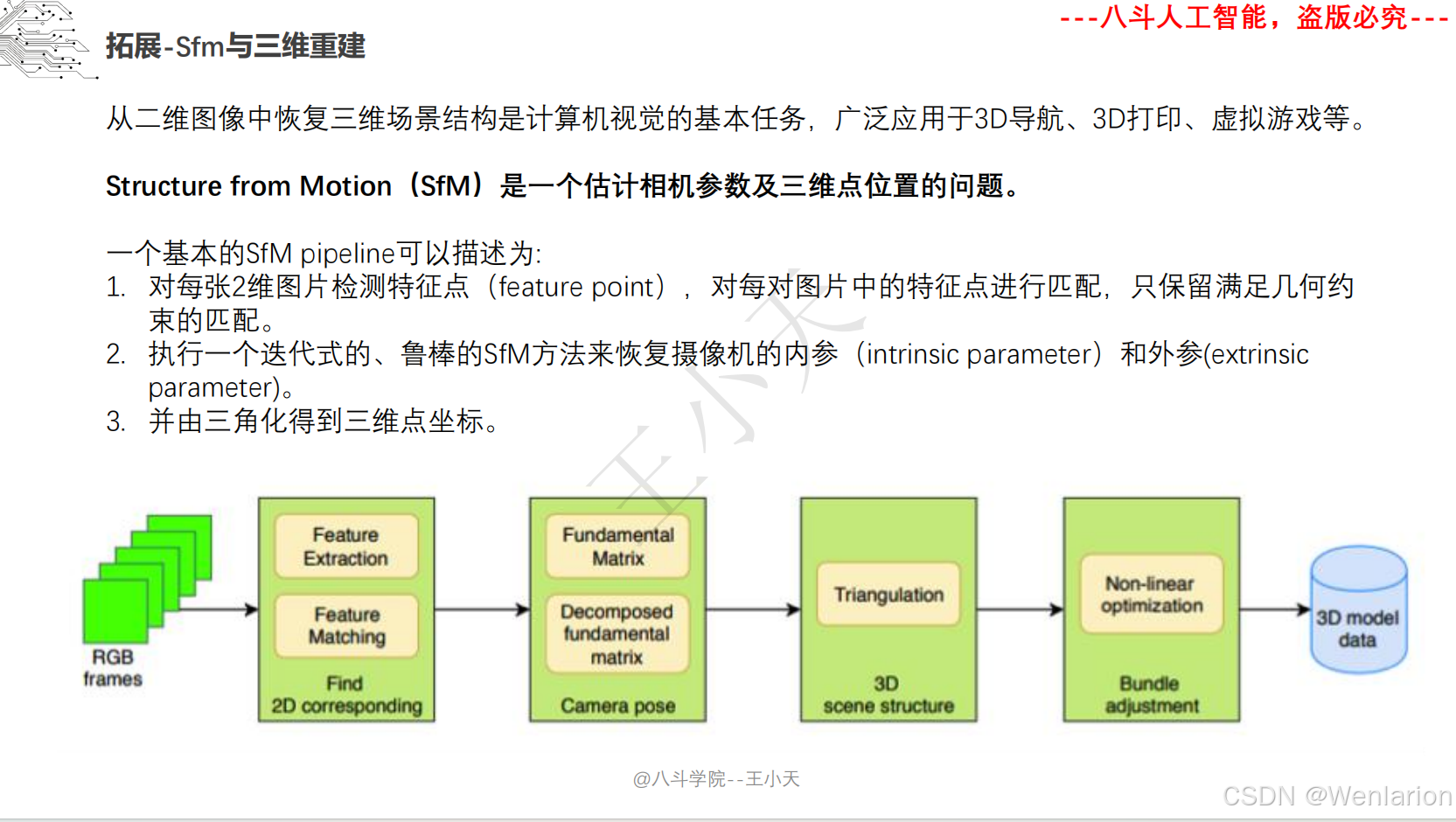

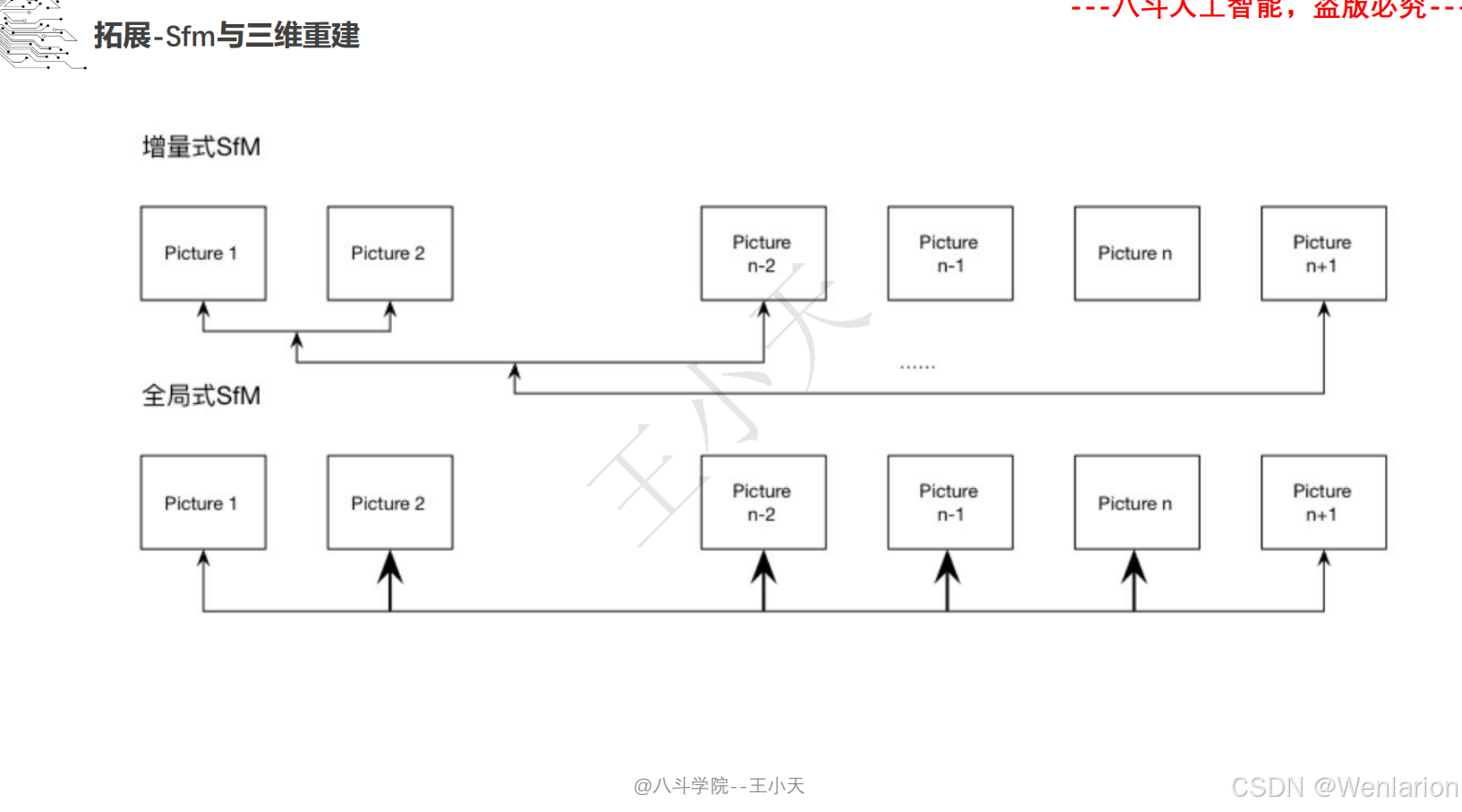
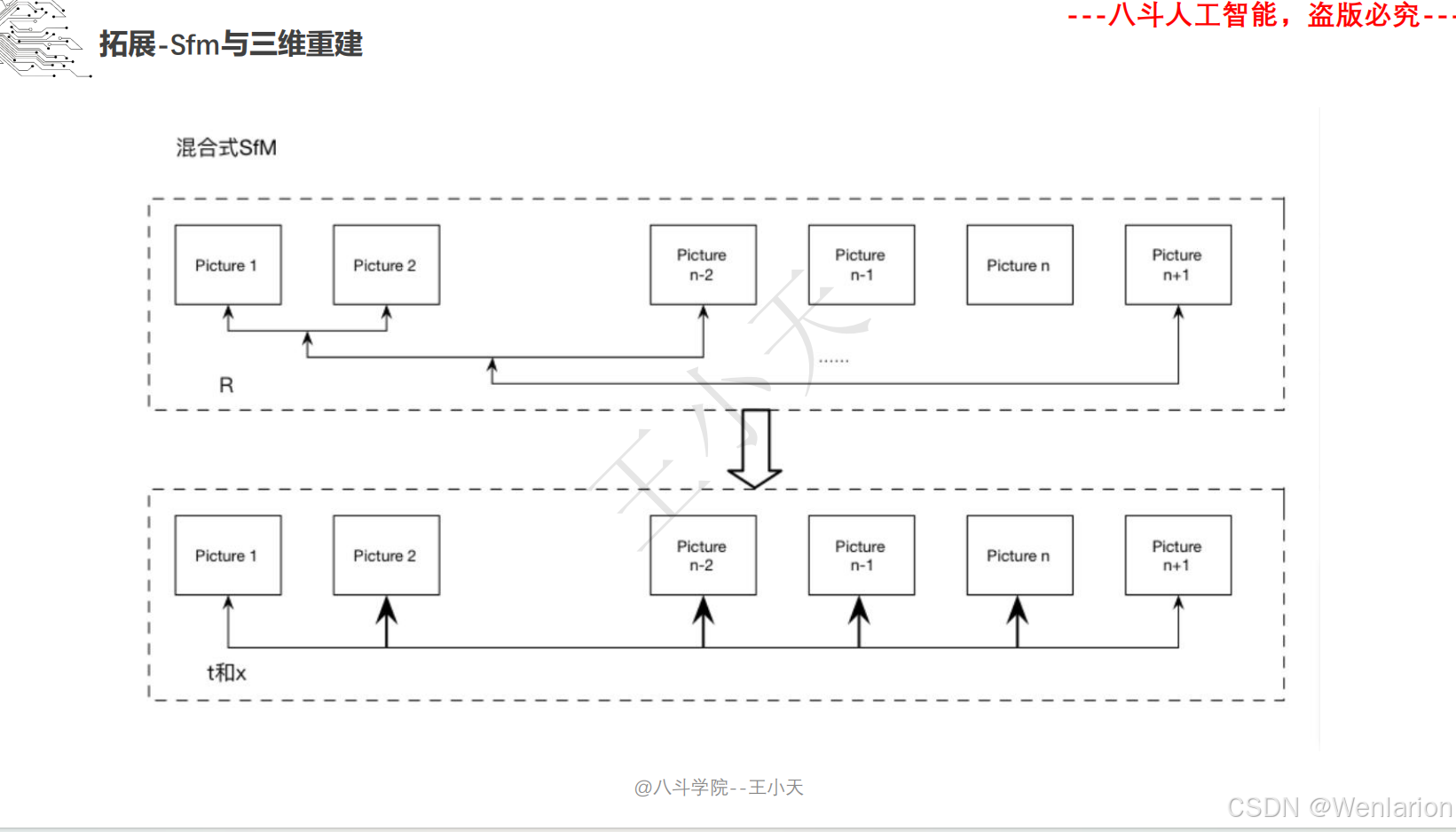
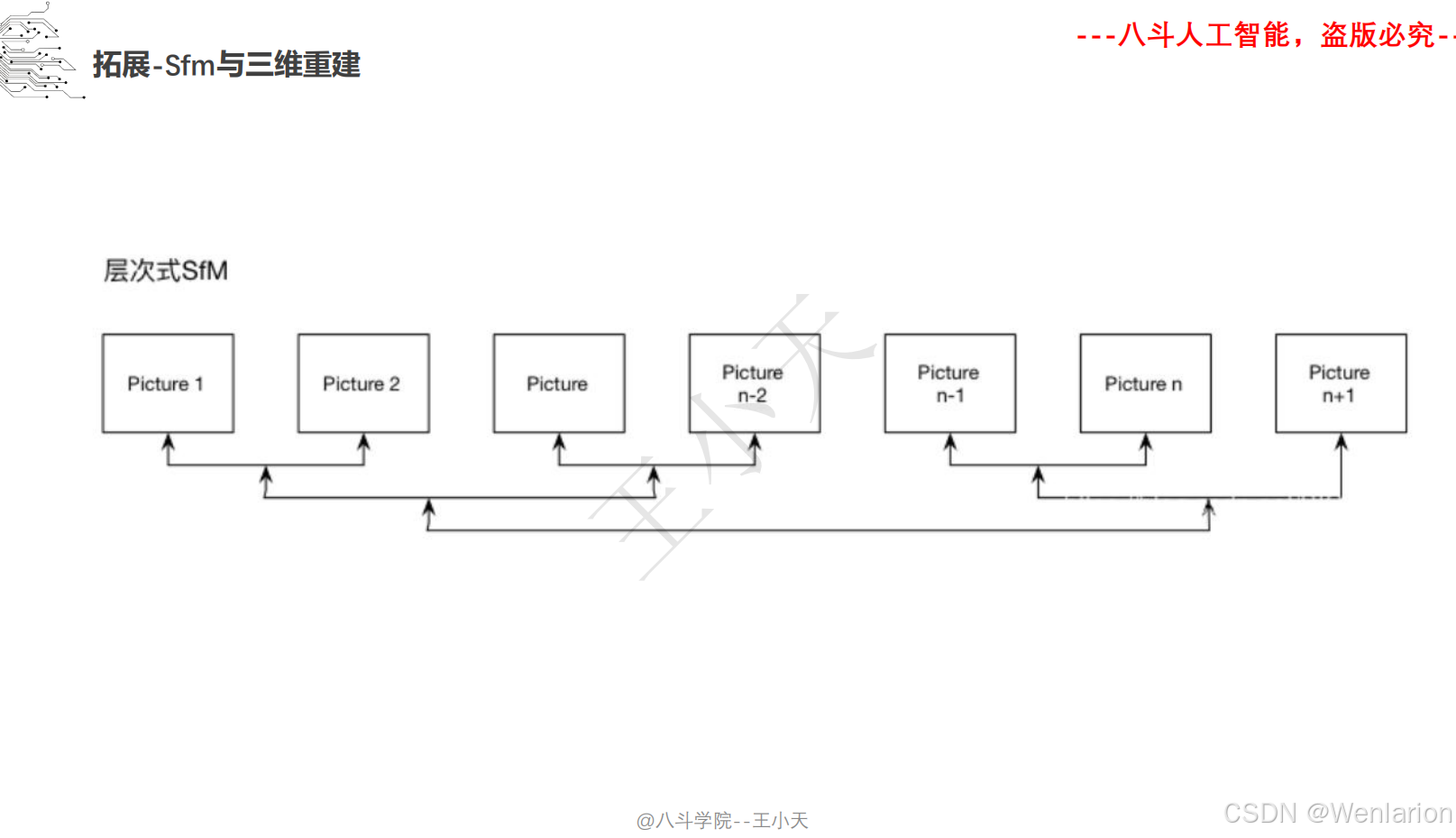
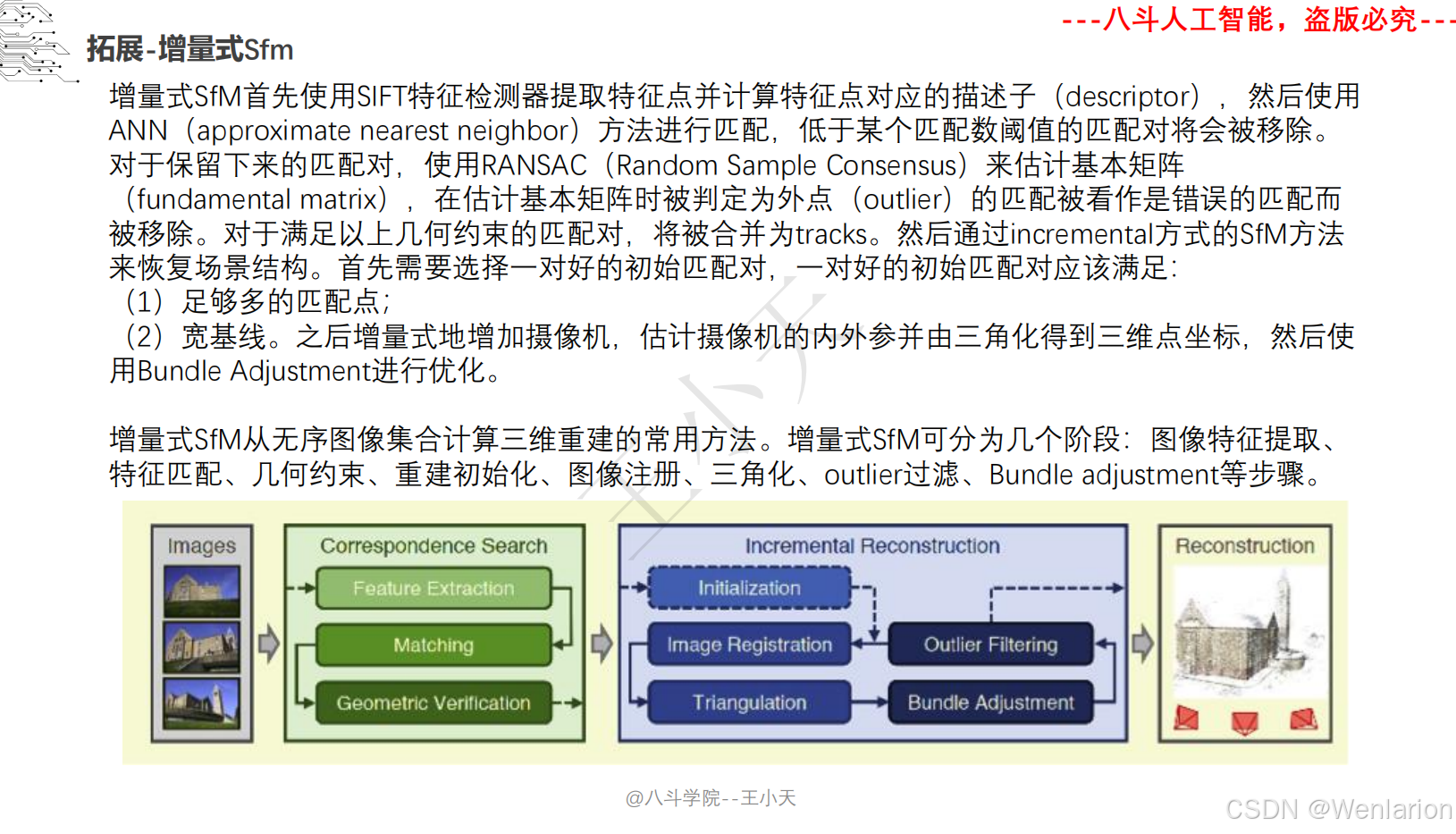


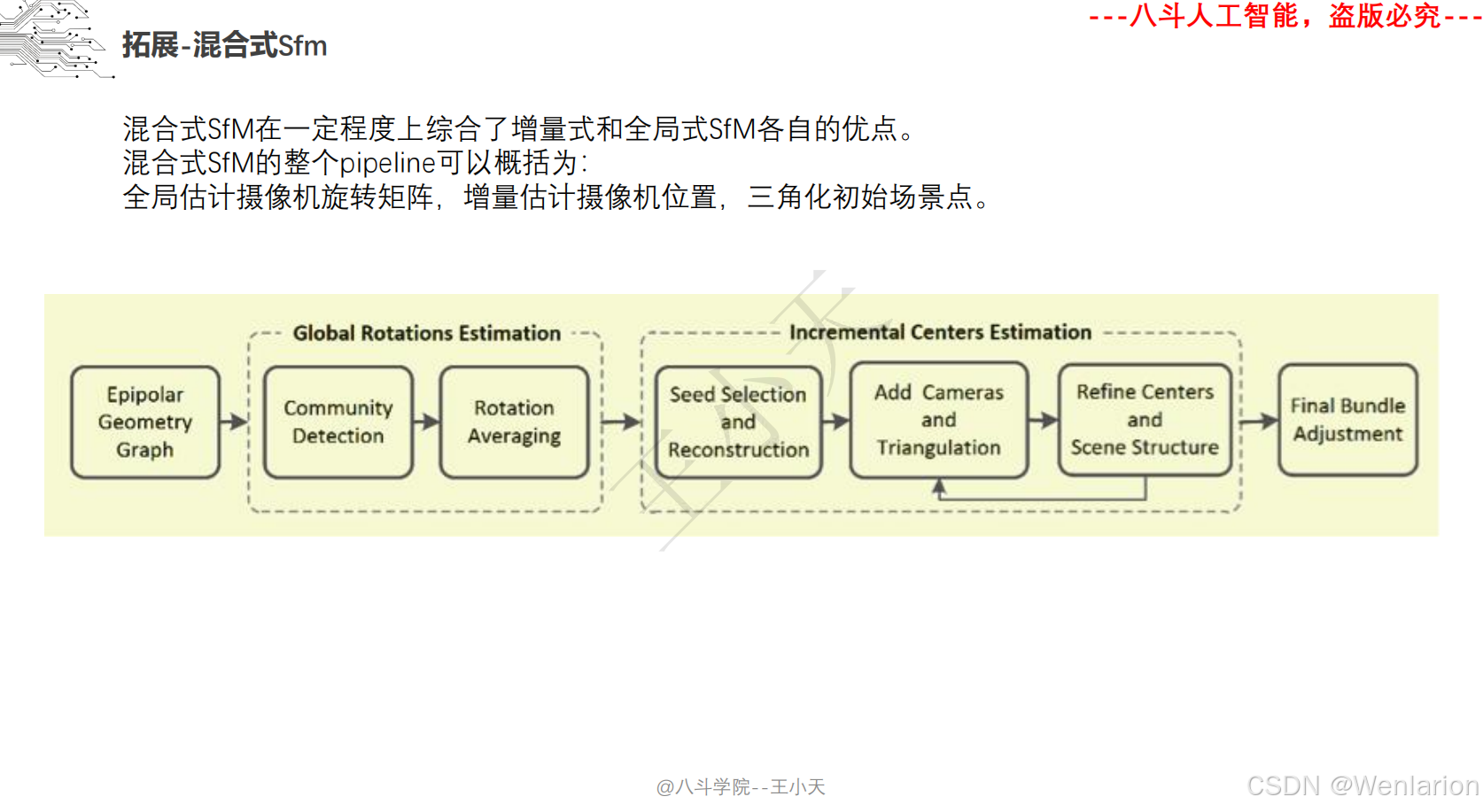




1.2.3 3D视觉代码和论文(点云进化、3D 检测 / 多模态融合、SLAM 与视觉定位)
一、2016:深度学习 3D 视觉元年(点云奠基)
1. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
-
会议 / 年份:CVPR 2017(arXiv 2016)
-
核心贡献:点云深度学习开山之作,直接处理无序点云,用对称函数保证排列不变性,统一 3D 分类、分割任务,奠定后续所有点云模型基础。
2. 3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction
-
会议 / 年份:ECCV 2016
-
核心贡献:端到端 3D 重建里程碑,统一单 / 多视图重建,用 LSTM 融合多视图信息,直接输出体素化 3D 模型。
3. Volumetric and Multi-View CNNs for Object Classification on 3D Data
-
会议 / 年份:CVPR 2016
-
核心贡献:首次系统对比体素 CNN vs 多视图 CNN,提出改进架构,成为 3D 分类基准。
4. 3D-GAN: Learning a Probabilistic Latent Space of Object Shapes via 3D Generative Adversarial Modeling
-
会议 / 年份:NeurIPS 2016
-
核心贡献:首个 3D 生成对抗网络,用体素 CNN 实现 3D 物体生成与插值。
二、2017-2019:点云进化、3D 检测爆发
5. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
-
会议 / 年份:NeurIPS 2017
-
核心贡献:PointNet 升级版,引入分层采样与分组,捕捉局部几何结构,大幅提升分割 / 检测精度。
6. VoxelNet: End-to-End Learning for Point Cloud Based 3D Object Detection
-
会议 / 年份:CVPR 2018
-
核心贡献:首个端到端纯点云 3D 检测器,将点云转为体素特征,用 3D 卷积检测,开启自动驾驶 3D 感知。
7. PointPillars: Fast Encoders for Object Detection from Point Clouds
-
会议 / 年份:CVPR 2019
-
核心贡献:工业界主流 3D 检测 backbone,将点云转为柱体(Pillar)特征,兼顾速度与精度,适配实时自动驾驶。
8. PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
-
会议 / 年份:CVPR 2020
-
核心贡献:融合点云细粒度特征 + 体素全局特征,3D 检测精度 SOTA,成为后续多模态融合基准。
9. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation
-
会议 / 年份:CVPR 2019
-
核心贡献:隐式 3D 表示里程碑,用 SDF(符号距离函数)表示连续 3D 形状,支持任意分辨率重建与生成。
三、2020:NeRF 时代开启(神经渲染革命)
10. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
-
会议 / 年份:ECCV 2020
-
核心贡献:神经辐射场开山之作,用 MLP 学习 5D 场景函数(位置 + 方向→颜色 + 密度),实现照片级新视角合成,彻底改变 3D 重建与渲染范式。
11. MVSNet: Depth Inference for Unstructured Multi-view Stereo
-
会议 / 年份:ECCV 2018
-
核心贡献:深度学习 MVS 里程碑,用可微分代价体 + 3D 卷积,端到端输出深度图,多视图重建精度大幅超越传统方法。
12. PatchmatchNet: Learned Multi-View Patchmatch Stereo
-
会议 / 年份:CVPR 2021
-
核心贡献:结合传统 PatchMatch 与深度学习,速度与精度平衡,成为 MVS 主流方案。
四、2021-2022:NeRF 加速与扩展
13. Instant NGP: Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
-
会议 / 年份:SIGGRAPH 2022
-
核心贡献:NeRF 训练速度革命,用多分辨率哈希编码,将 NeRF 训练从小时级压缩到秒级,支持实时交互。
14. Point-NeRF: Point-based Neural Radiance Fields
-
会议 / 年份:CVPR 2022
-
核心贡献:点云 + NeRF 融合,用点云显式表示 + 局部 NeRF 隐式渲染,兼顾重建质量与速度。
15. NerfAcc: Efficient Neural Radiance Field Rendering with Acceleration Structures
-
会议 / 年份:ECCV 2022
-
核心贡献:NeRF 渲染加速,引入空间划分与提前终止,渲染速度提升 10-100 倍。
16. MonoNeRF: Learning a Neural Radiance Field from One Image
-
会议 / 年份:ICCV 2021
-
核心贡献:单视图 NeRF,从单张图像预测完整 NeRF,解决稀疏视图重建难题。
五、2023:3D Gaussian Splatting(3DGS,实时渲染突破)
17. 3D Gaussian Splatting for Real-Time Radiance Field Rendering
-
会议 / 年份:SIGGRAPH 2023
-
核心贡献:3D 视觉范式转移,用显式 3D 高斯点云表示场景,基于光栅化渲染,实现实时(30+FPS)照片级渲染,彻底解决 NeRF 速度瓶颈。
18. Gaussian-SLAM: Real-Time Dense Mapping and Pose Tracking
-
会议 / 年份:CVPR 2024
-
核心贡献:3DGS+SLAM 融合,实时稠密建图与位姿跟踪,将 3DGS 推向机器人 / AR 实时应用。
19. DreamFusion: Text-to-3D using 2D Diffusion
-
会议 / 年份:ICLR 2023
-
核心贡献:文本生成 3D 里程碑,用预训练 2D 扩散模型(Stable Diffusion)监督 NeRF/3DGS 训练,实现text→3D生成。
六、2024-2026:Feed-Forward 3D 大模型(一步到位 3D 感知)
20. DUSt3R: Geometric 3D Vision Made Easy
-
会议 / 年份:CVPR 2024
-
核心贡献:端到端 3D 大模型,直接从单 / 多视图图像输出相机位姿 + 深度图 + 点云,无需姿态初始化,简化 3D 重建流程。
21. MASt3R: Masked Autoencoders Meet 3D Vision
-
会议 / 年份:ECCV 2024
-
核心贡献:DUSt3R 升级版,引入掩码自监督预训练,提升跨场景泛化与稀疏视图鲁棒性。
22. VGGT: Visual Geometry Grounded Transformer
-
会议 / 年份:CVPR 2025(最佳论文)
-
核心贡献:3D 视觉新范式,秒级输出相机参数 + 深度 + 点云 + 轨迹,支持单图 / 多图 / 百图输入,速度比 DUSt3R 快 10 倍 +。
23. LGM: Large 3D Gaussian Model
-
会议 / 年份:arXiv 2025
-
核心贡献:3D 大模型 + 3DGS 融合,直接从图像 / 文本预测 3D 高斯参数,实现零样本 3D 生成与重建。
24. UniScale: Unified Scale-Aware 3D Reconstruction
-
会议 / 年份:arXiv 2026
-
核心贡献:统一尺度感知 3D 重建,解决跨尺度(小物体→大场景)重建一致性问题,适配机器人全域感知。
七、3D 检测 / 多模态融合(自动驾驶核心)
25. BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
-
会议 / 年份:ECCV 2022
-
核心贡献:纯视觉 BEV 感知里程碑,用 Transformer 将多相机图像转为鸟瞰图,实现无 LiDAR 3D 检测,特斯拉 FSD 核心思路。
26. PETR: Position Embedding Transformation for Multi-View 3D Object Detection
-
会议 / 年份:ECCV 2022
-
核心贡献:多视图 3D 检测新范式,用位置嵌入变换直接建模 3D 空间,无需显式深度估计,速度与精度平衡。
27. OccNet: Occupancy Networks for 3D Reconstruction
-
会议 / 年份:NeurIPS 2019
-
核心贡献:** occupancy 表示里程碑 **,用二分类预测空间点是否在物体内部,支持任意拓扑 3D 重建,特斯拉 Occupancy Grid 基础。
八、SLAM 与视觉定位(机器人 / AR 核心)
28. ORB-SLAM3: An Accurate Open-Source Library for Visual, Visual-Inertial and Multi-Map SLAM
-
会议 / 年份:IEEE T-RO 2021
-
核心贡献:视觉 SLAM 集大成者,支持单目 / 双目 / RGBD / 惯性导航,多地图融合,精度与鲁棒性 SOTA,工业界标配。
29. DSO: Direct Sparse Odometry
-
会议 / 年份:IEEE T-RO 2018
-
核心贡献:直接法 SLAM 里程碑,基于像素亮度误差直接优化,无需特征提取,在低纹理场景鲁棒性强。
30. VIO-SLAM: Visual-Inertial Odometry for Robust Localization
-
会议 / 年份:ICRA 2017
-
核心贡献:视觉 - 惯性融合 SLAM,融合相机与 IMU,解决单目尺度歧义与快速运动模糊问题,无人机 / 机器人标配。
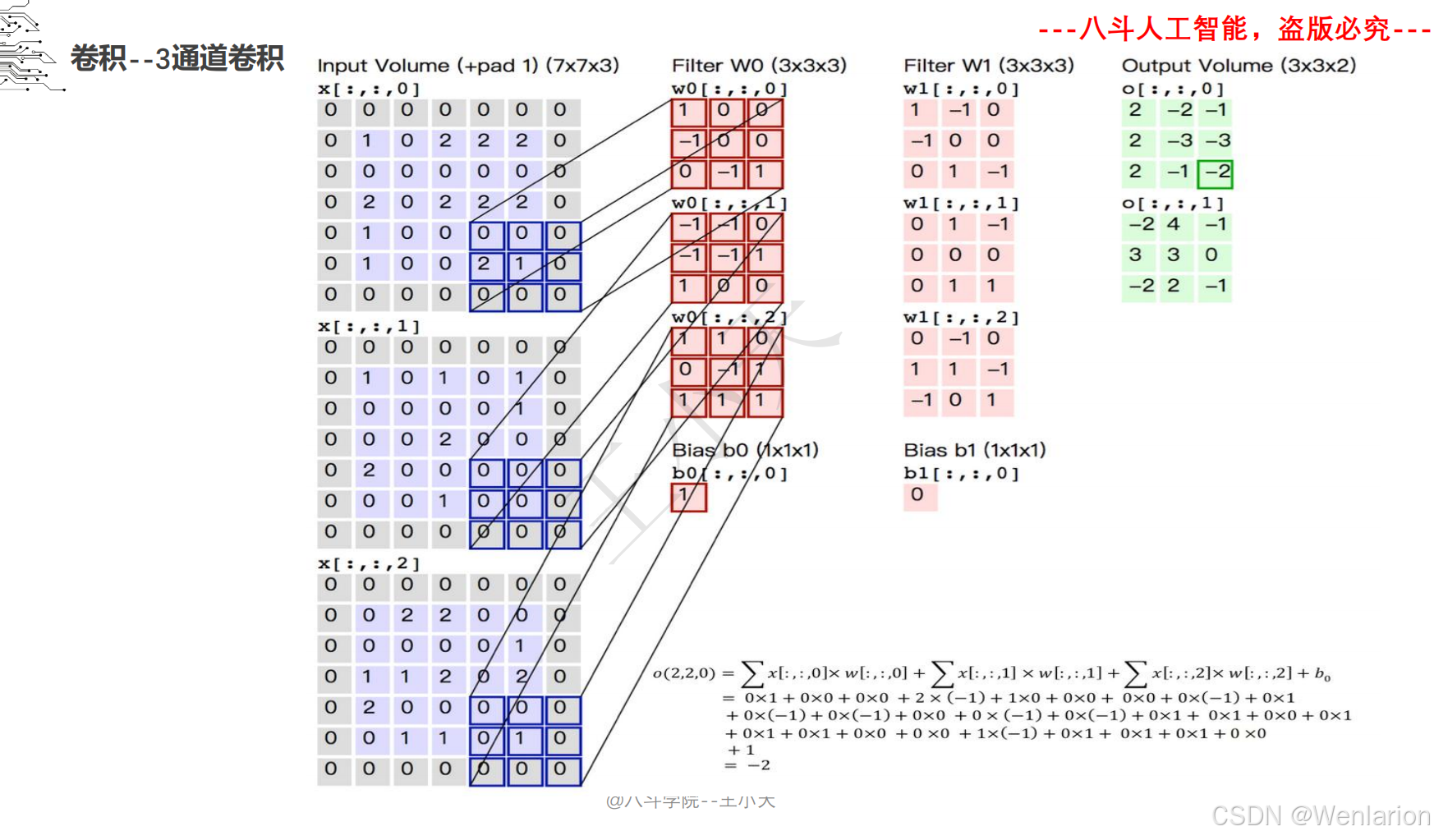
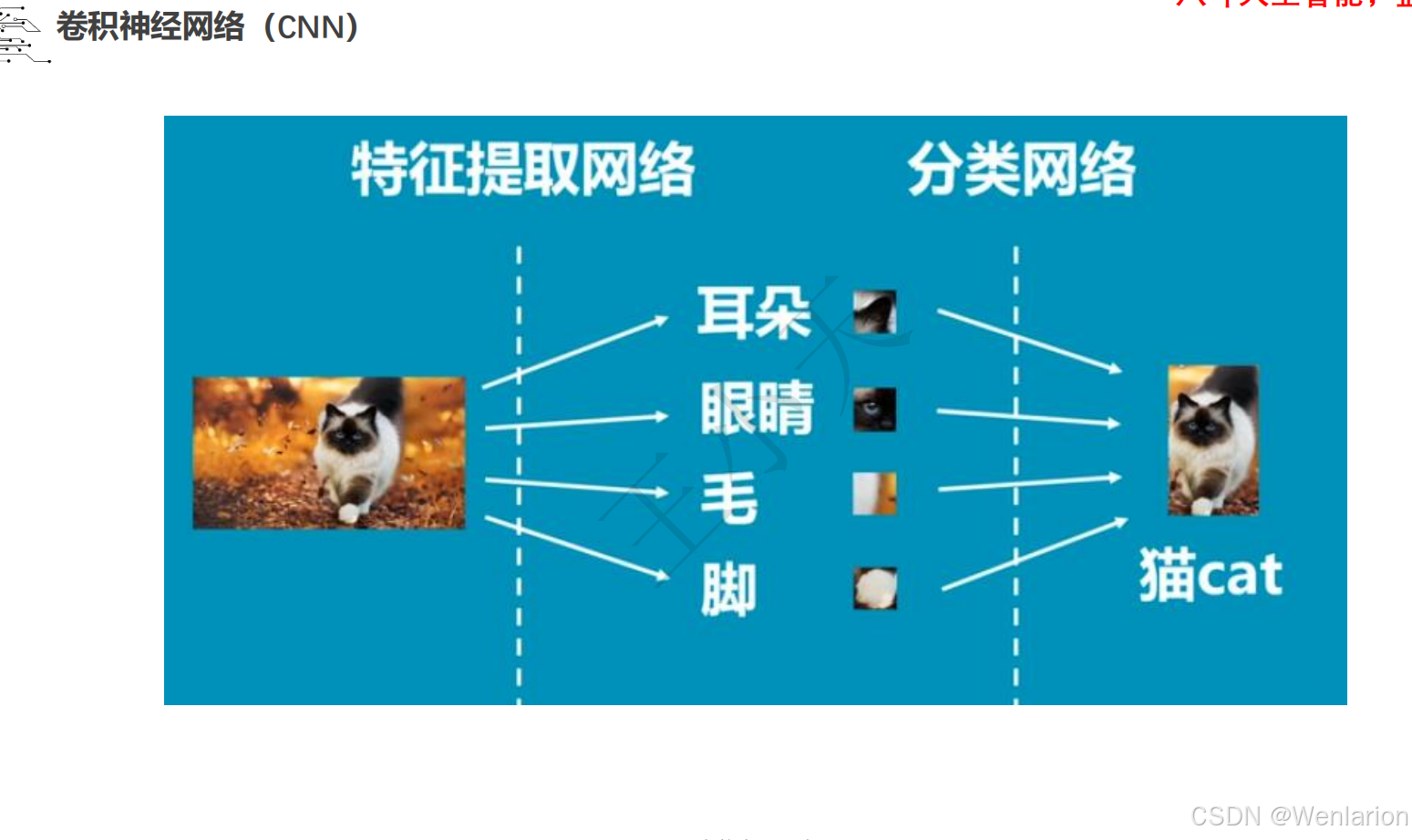
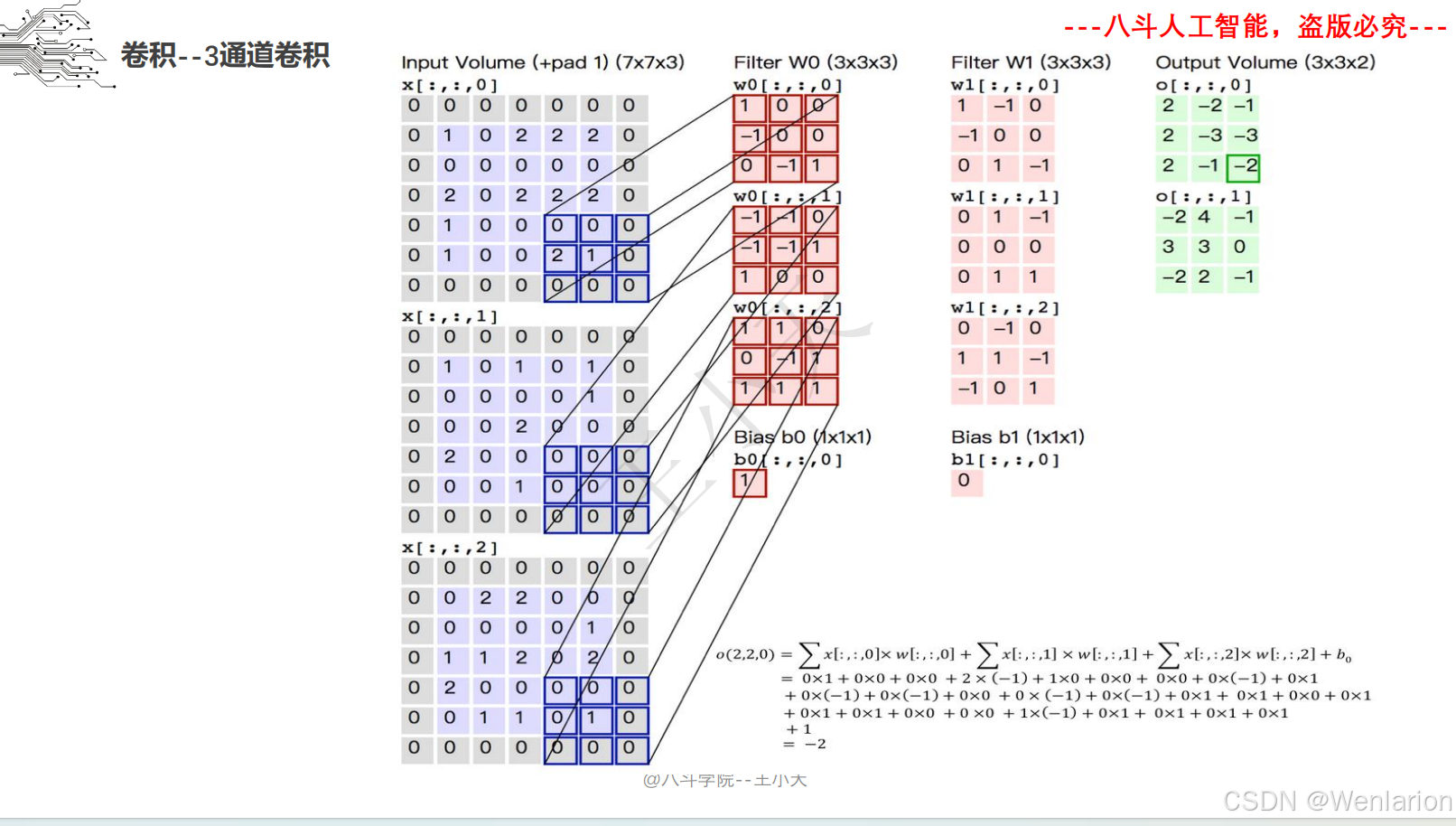
1.3 卷积神经网络





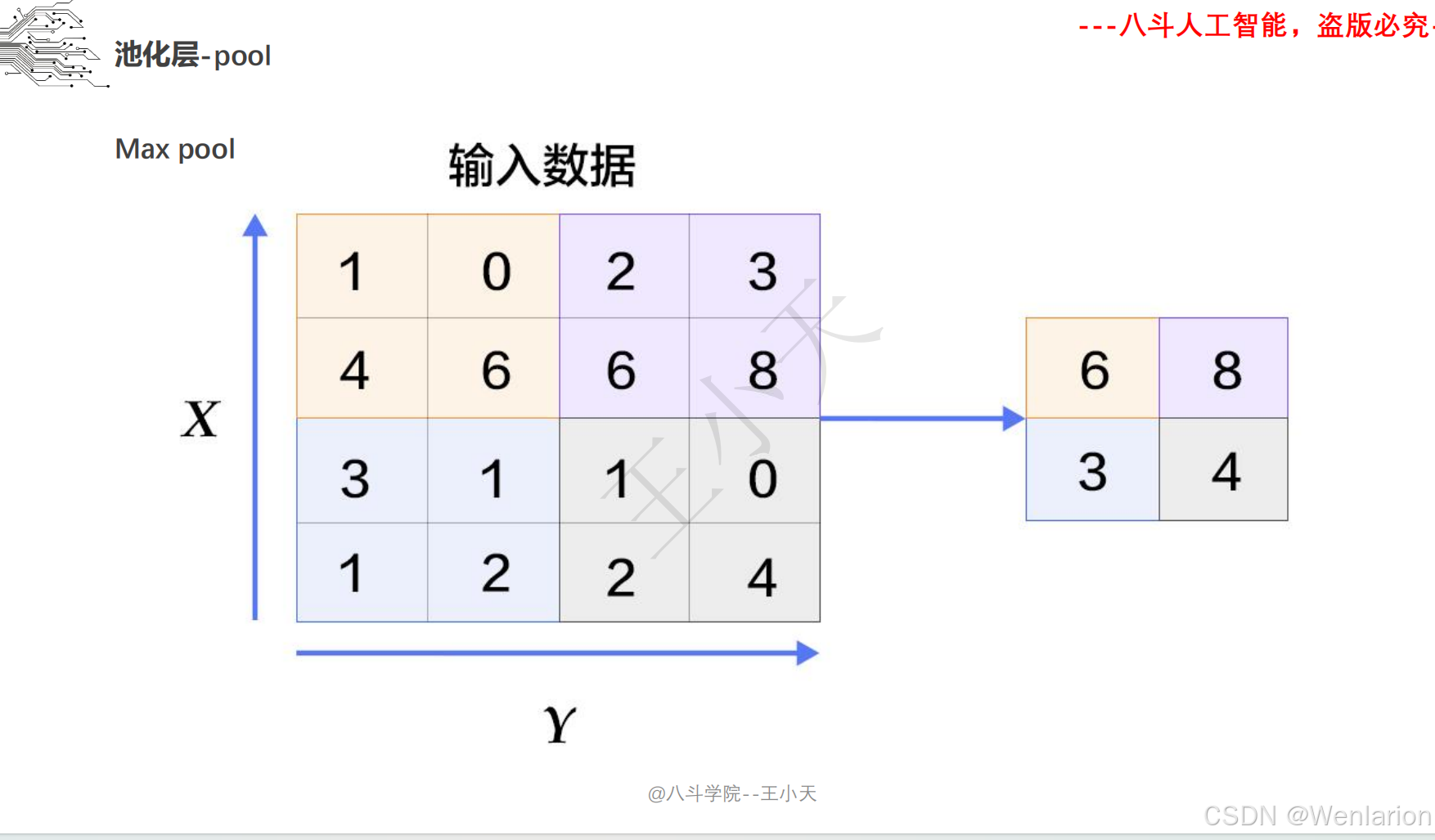
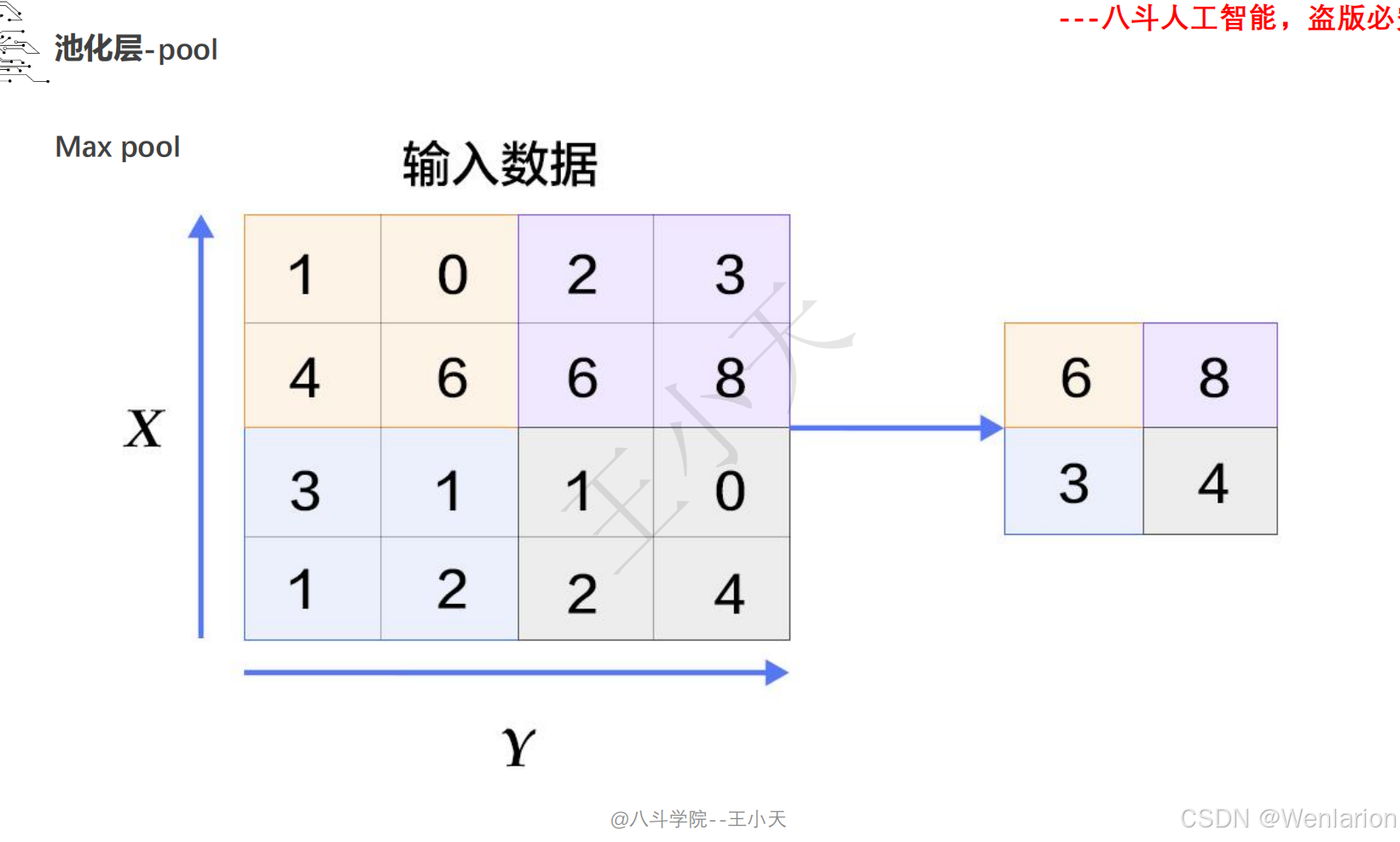




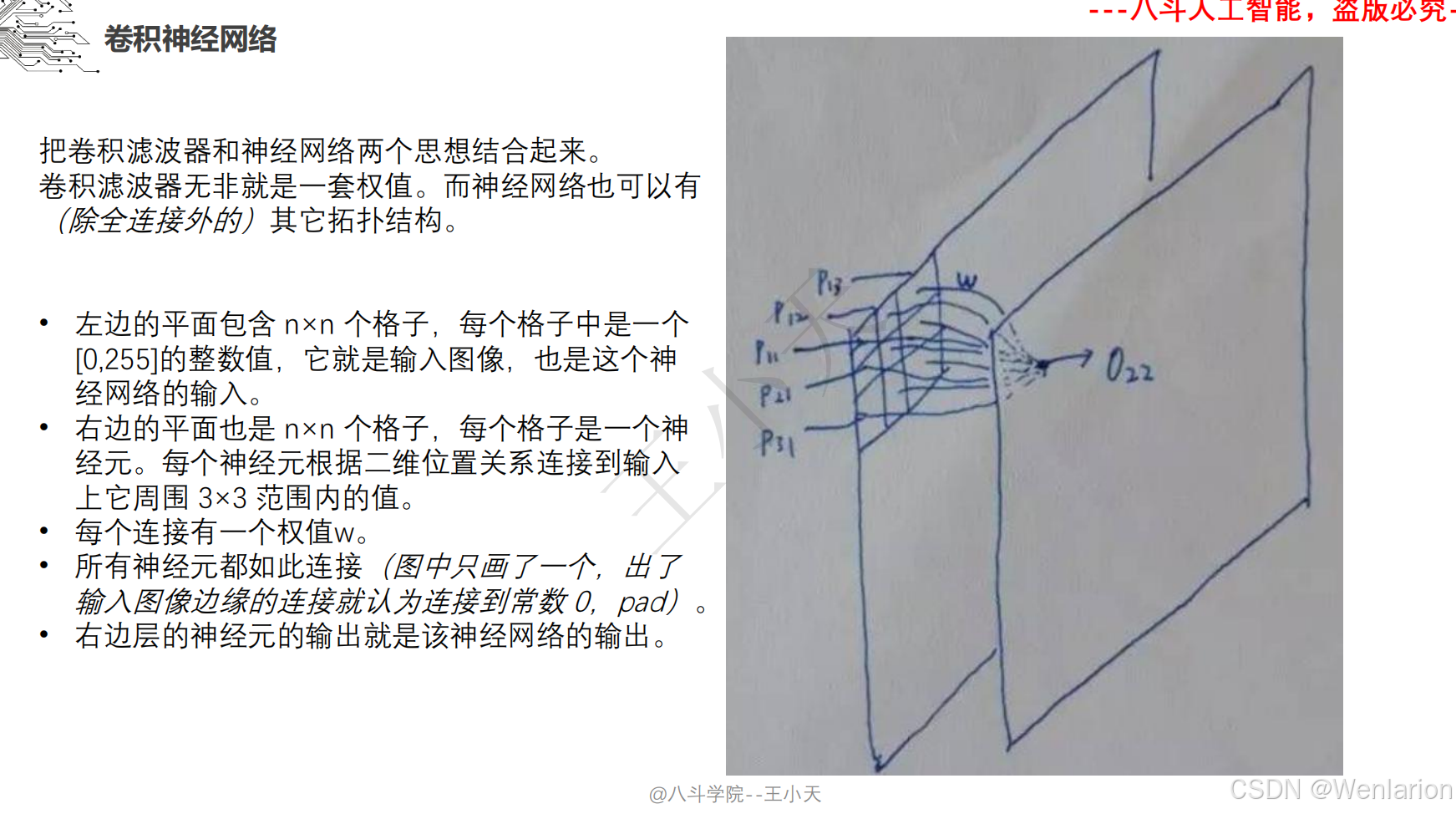
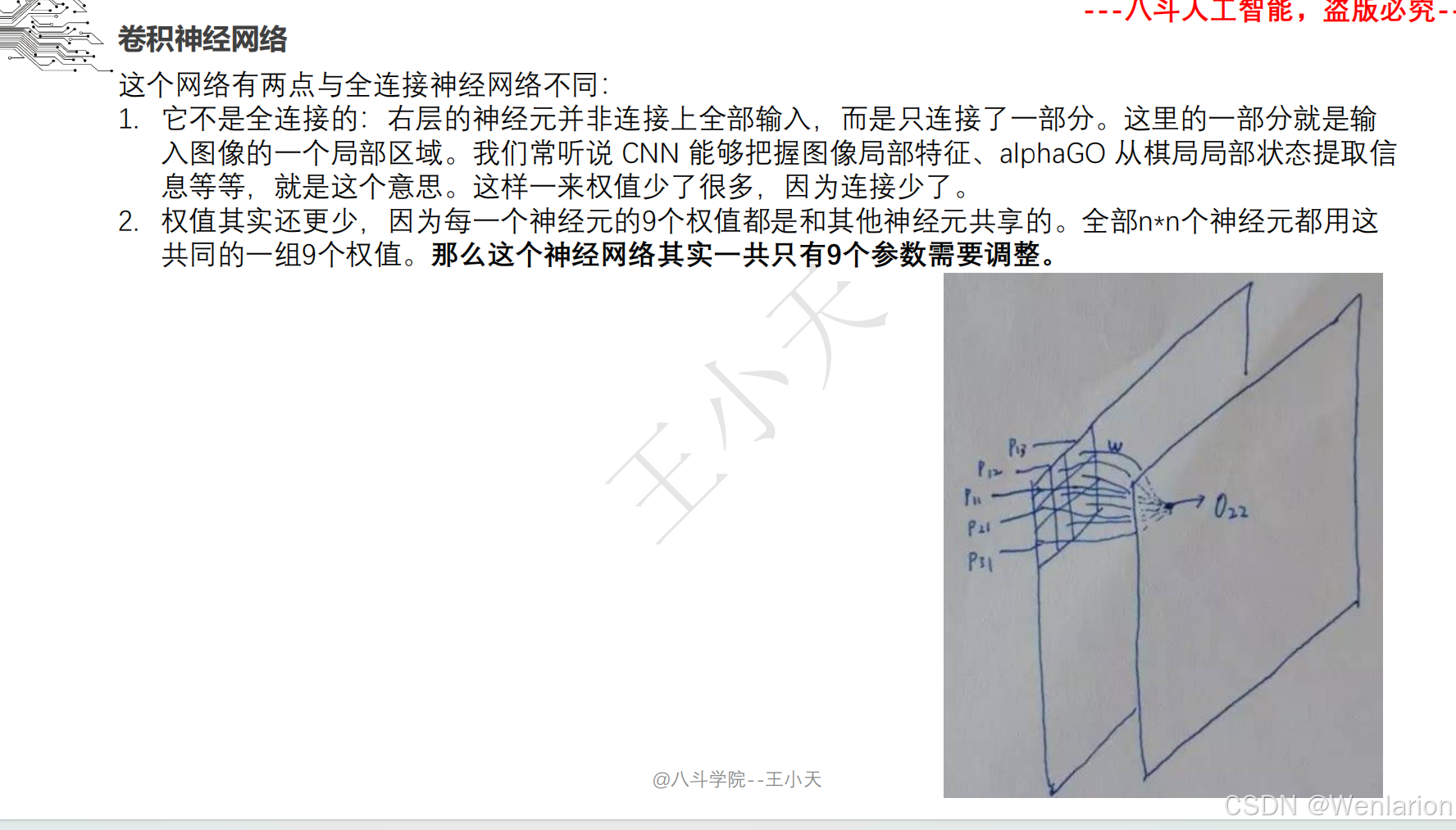

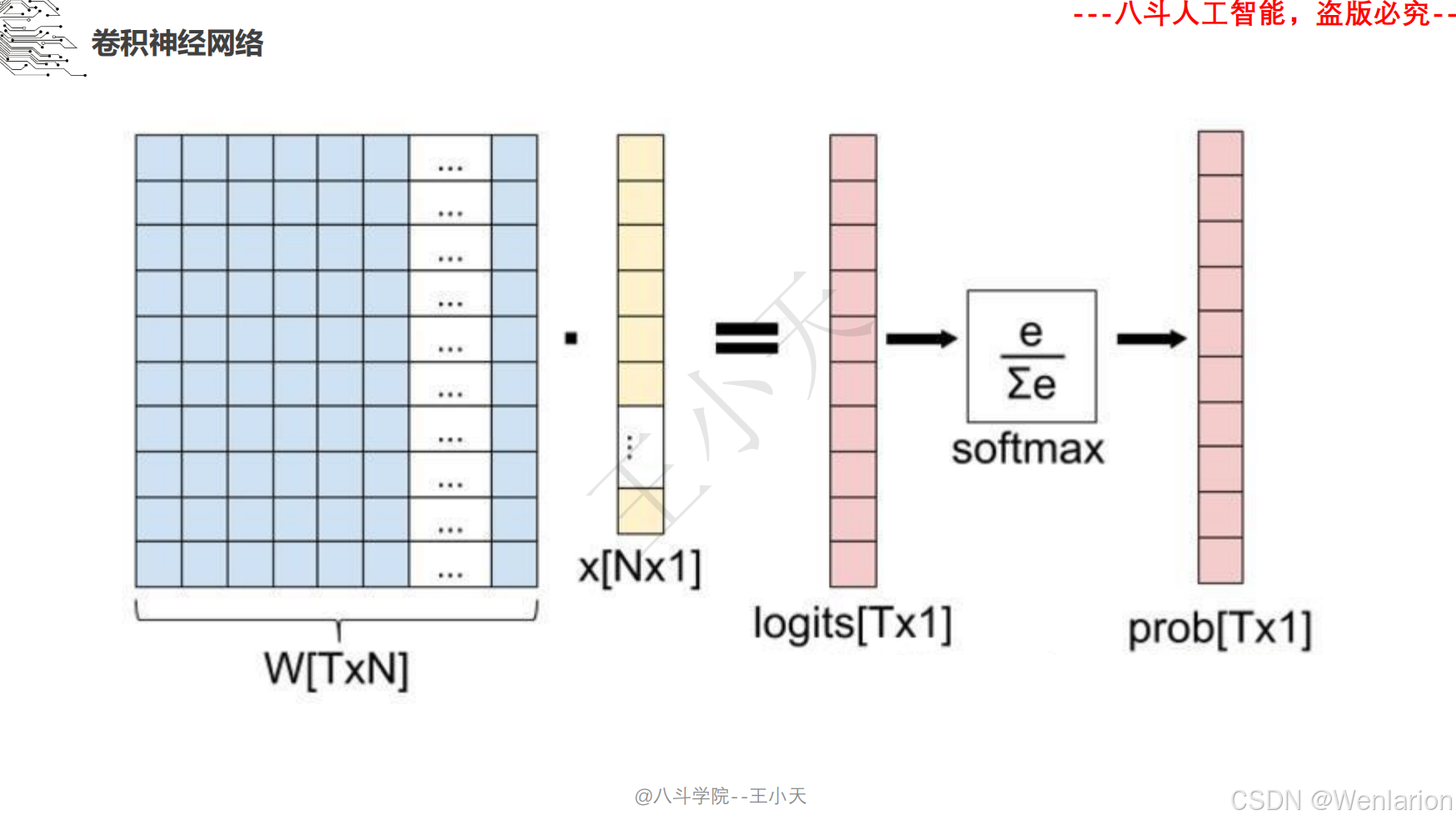

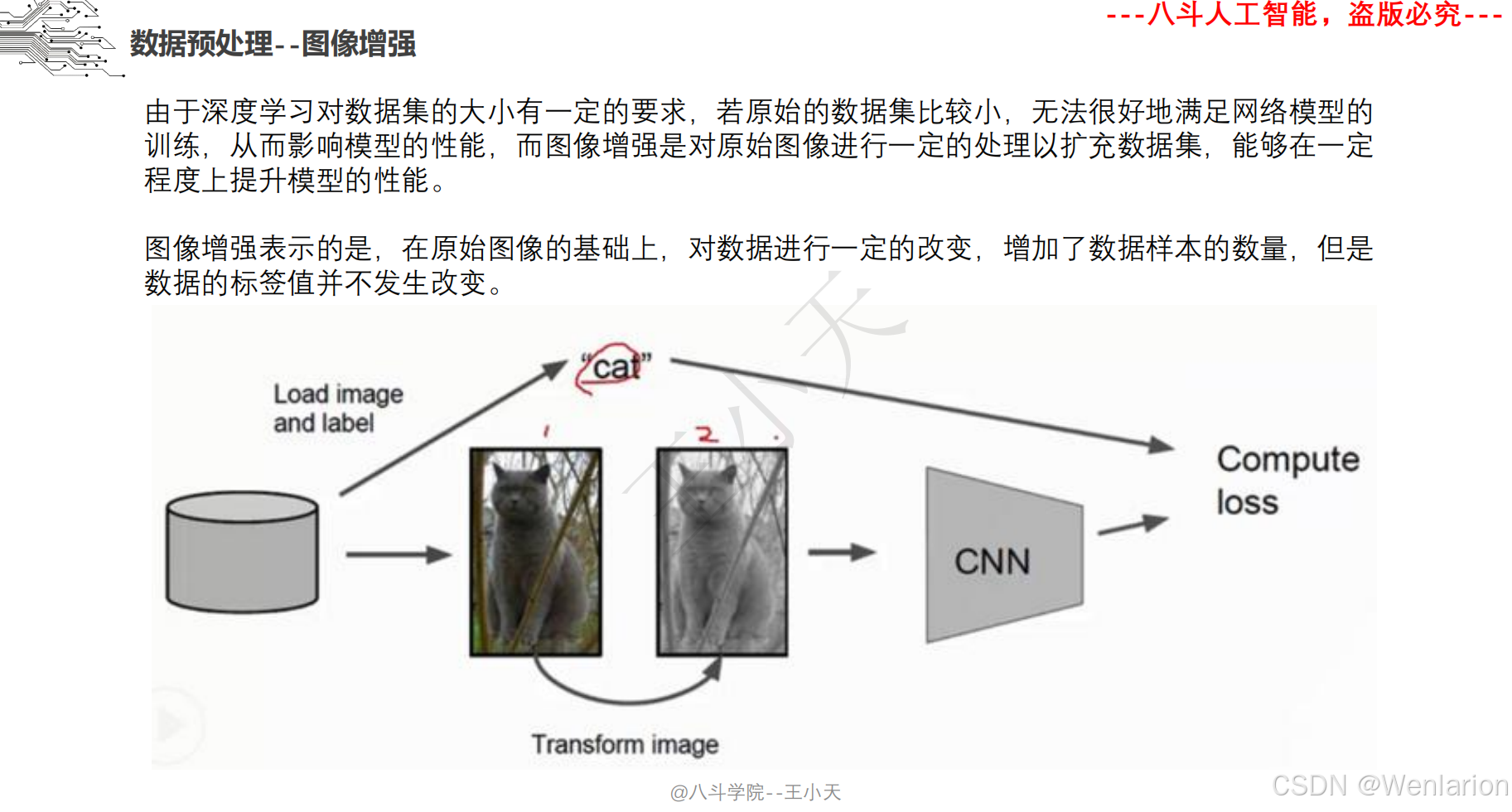


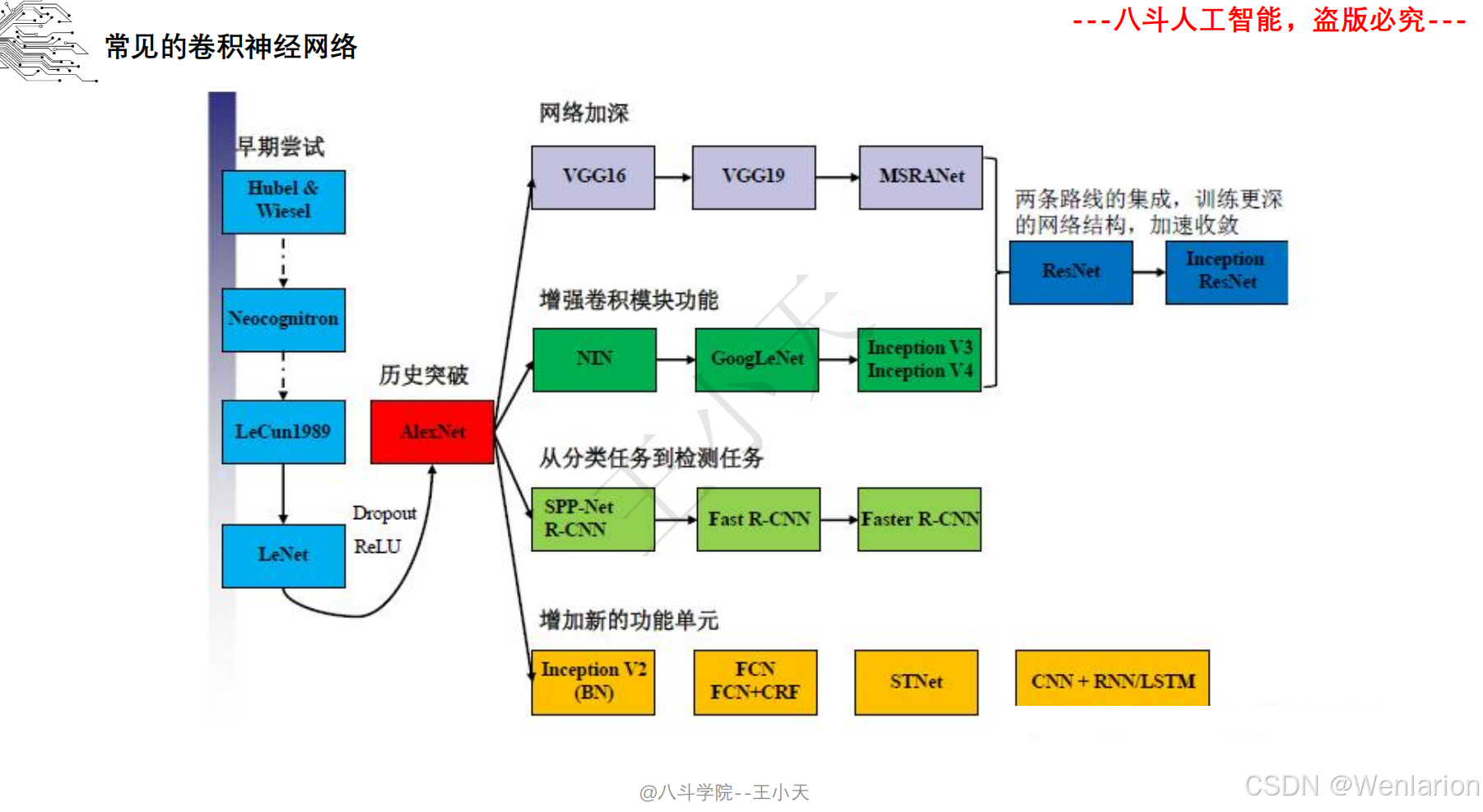
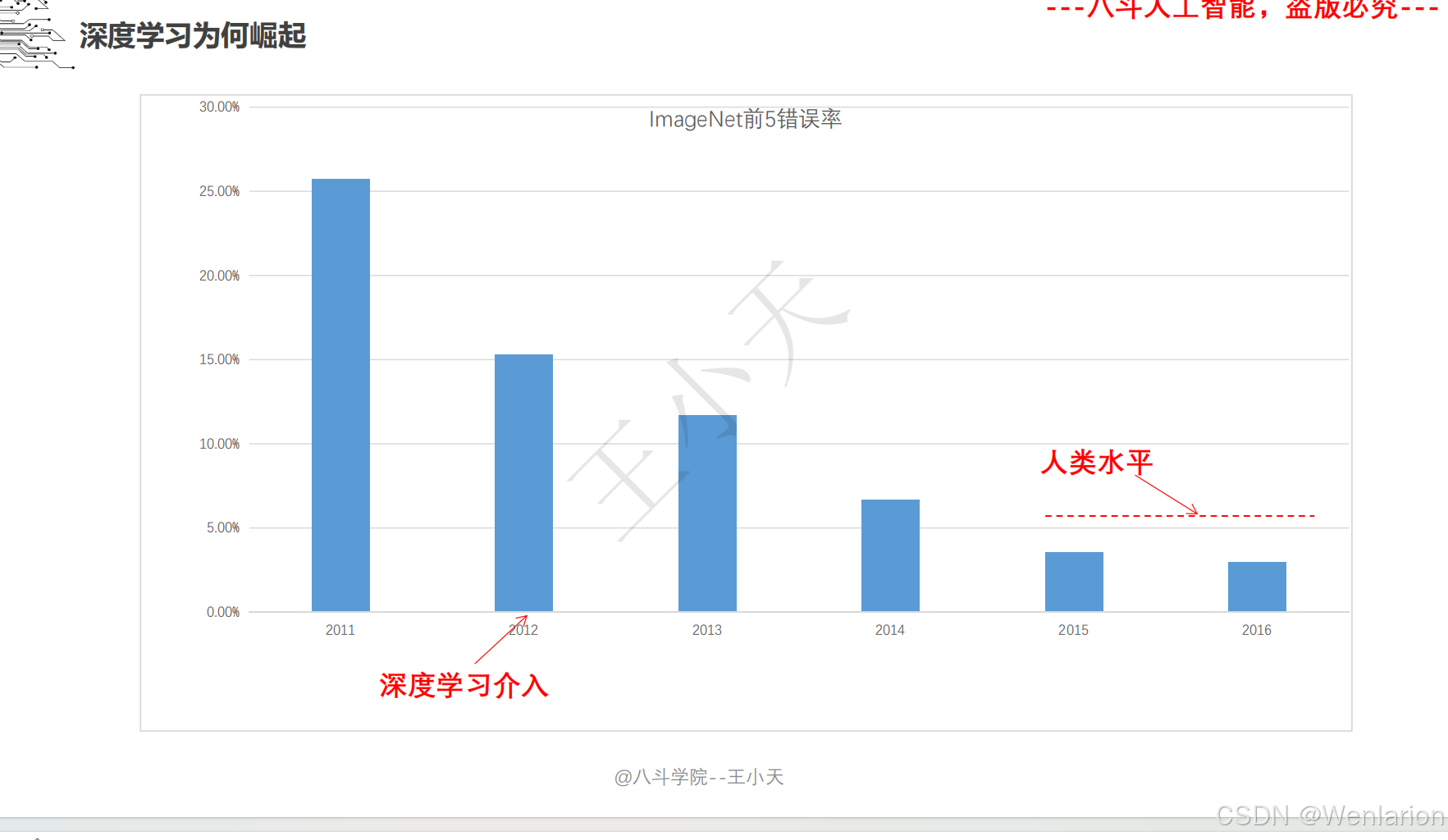

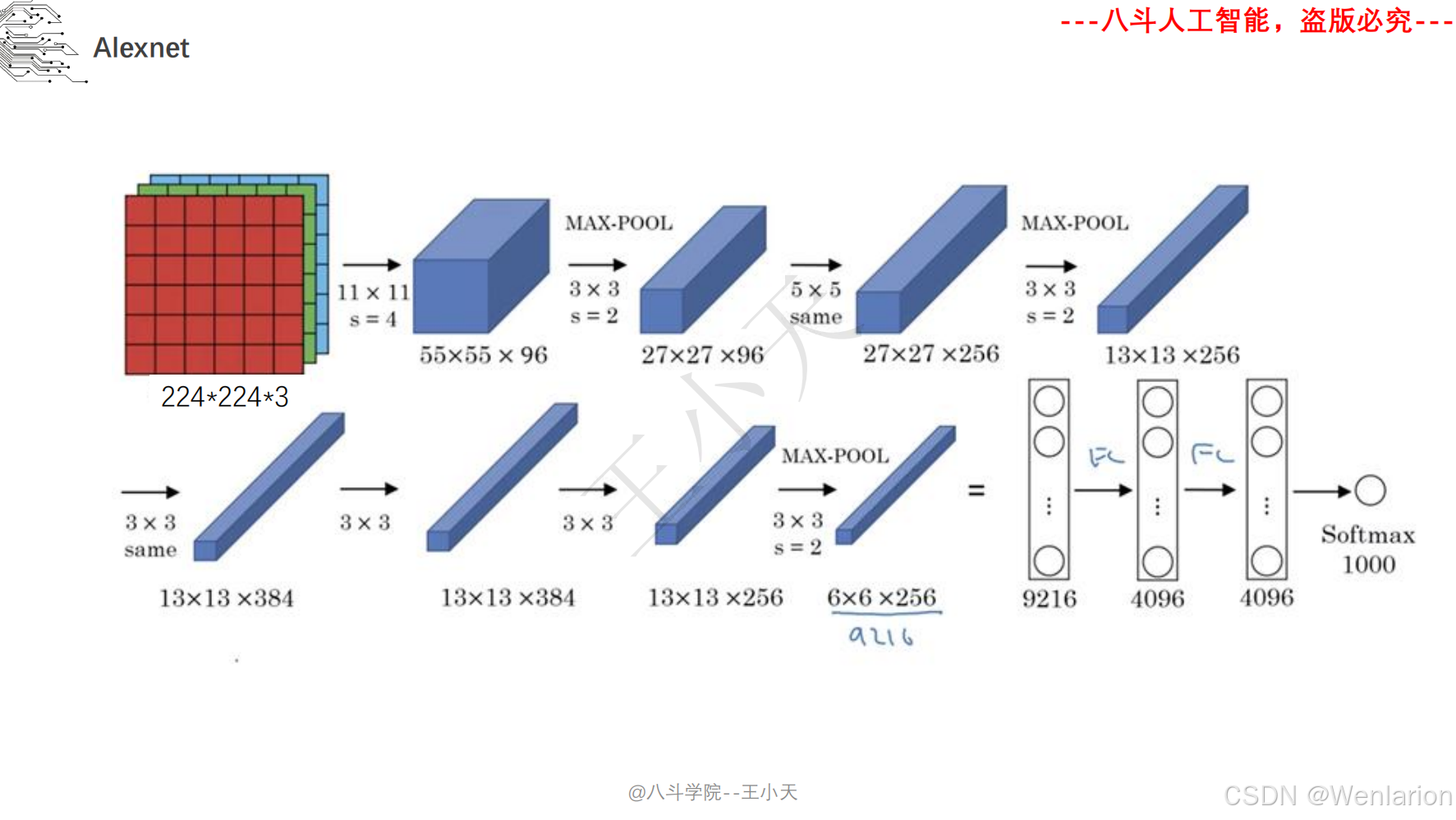
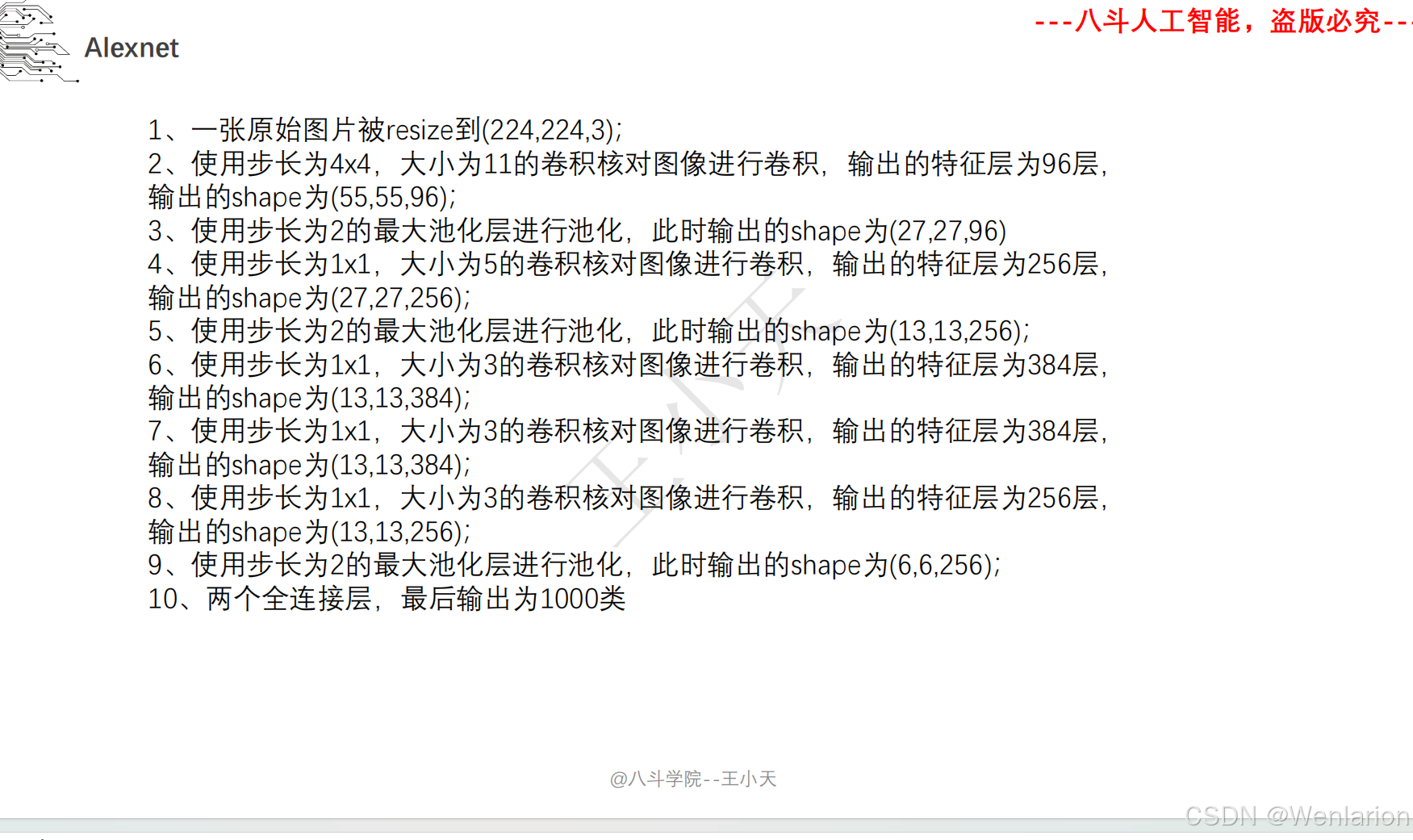

2、计算机视觉问题(图像识别、目标检测、图像分割、目标追踪、姿态估计)
2.1 图像识别问题



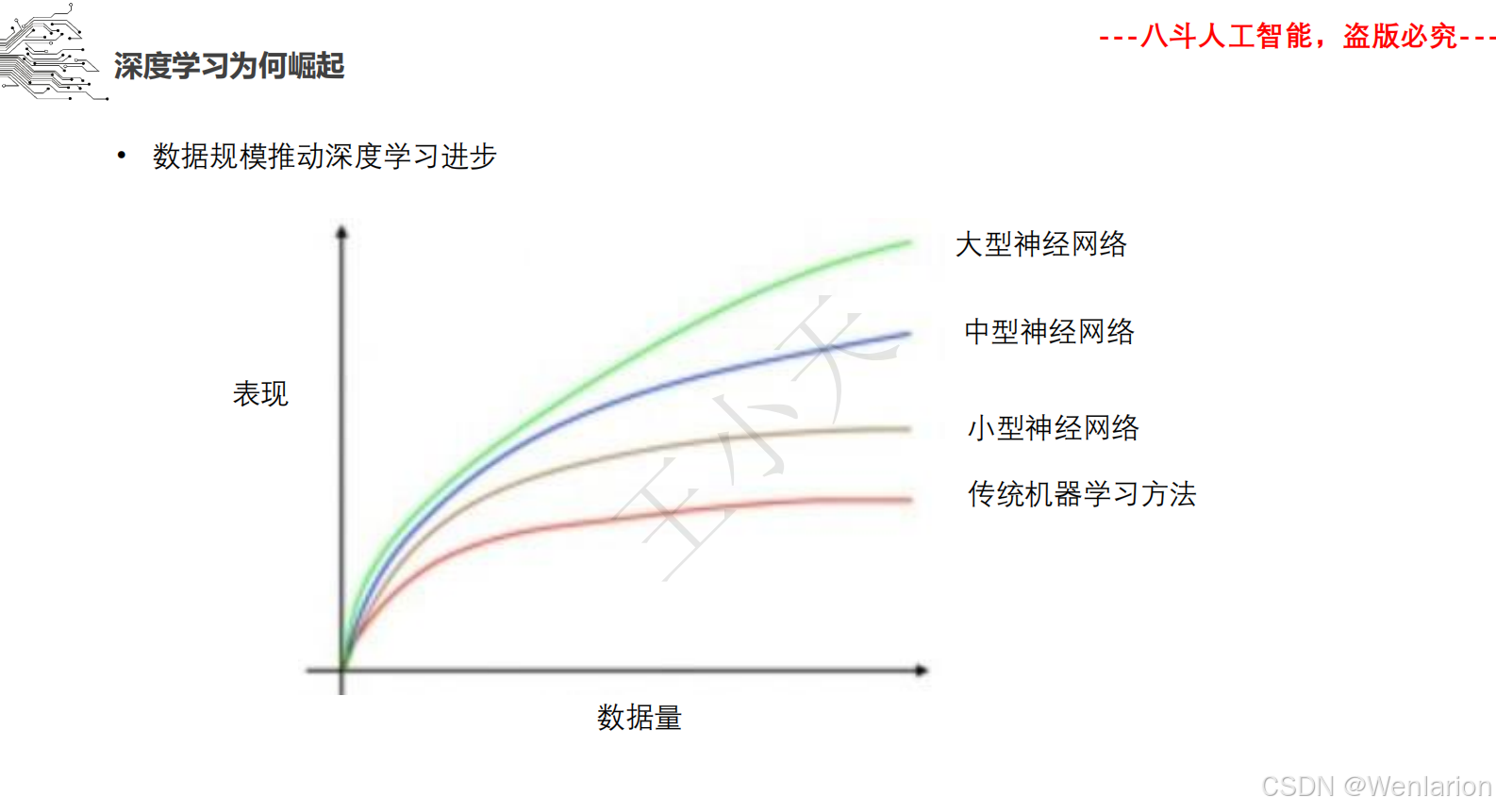
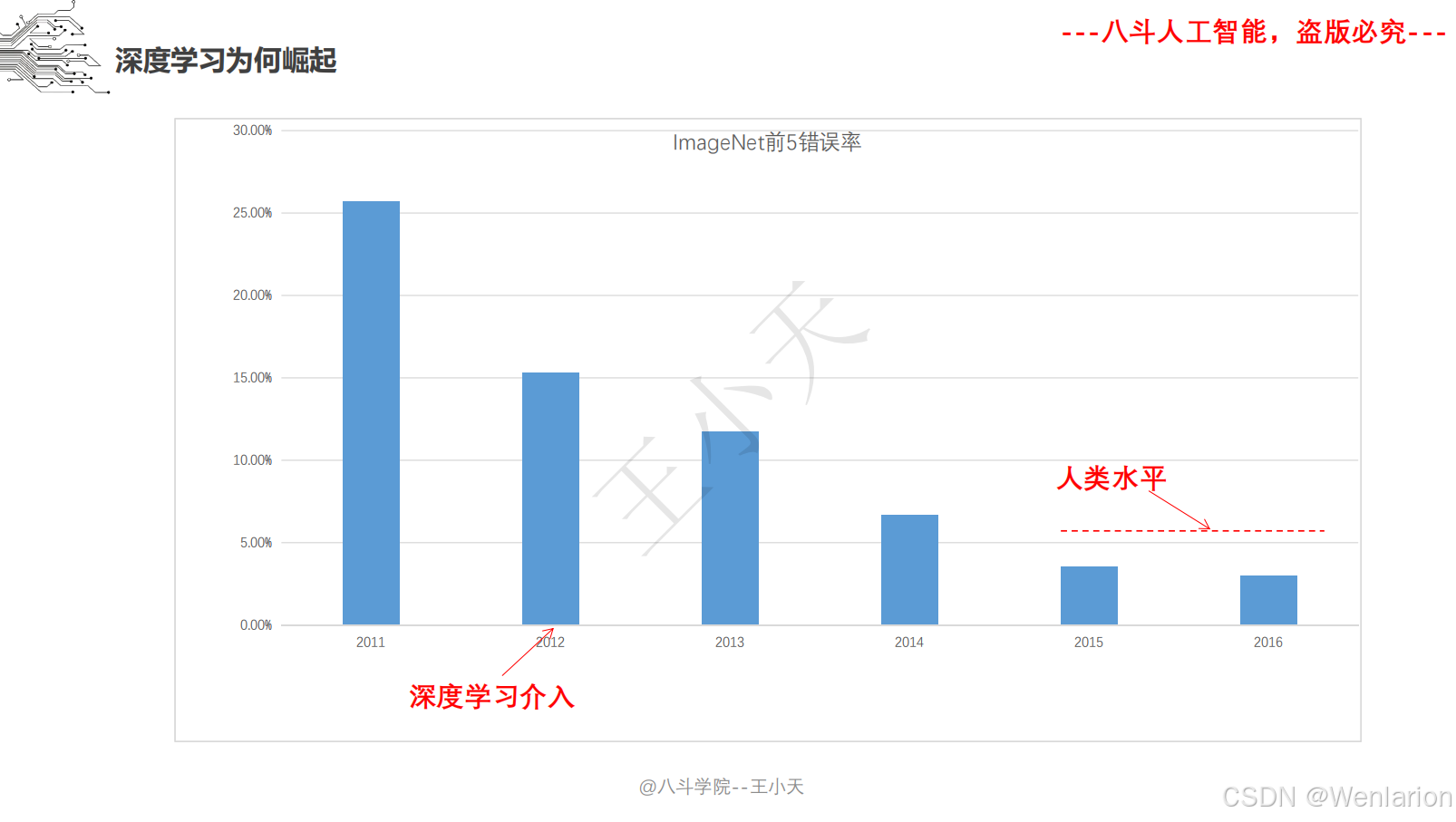

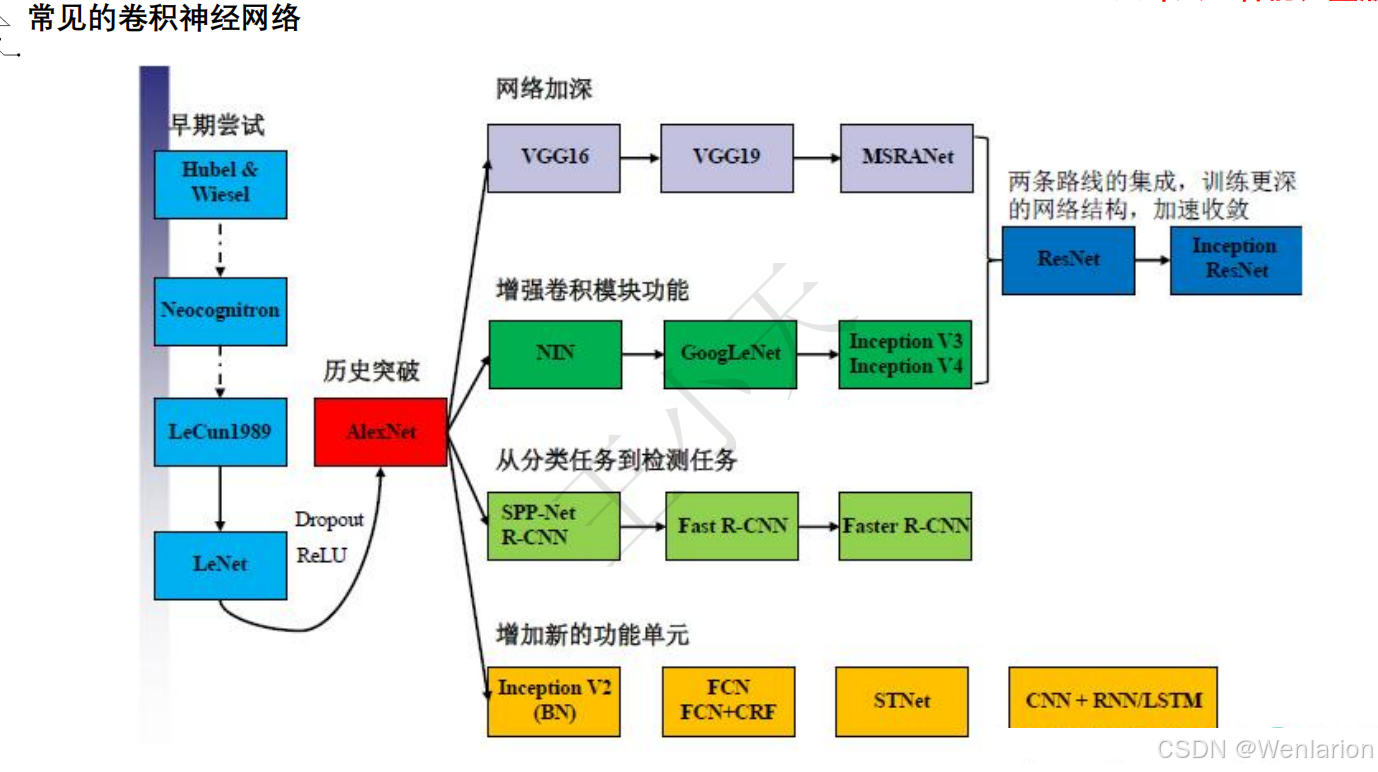
2.1.1 VGG系列

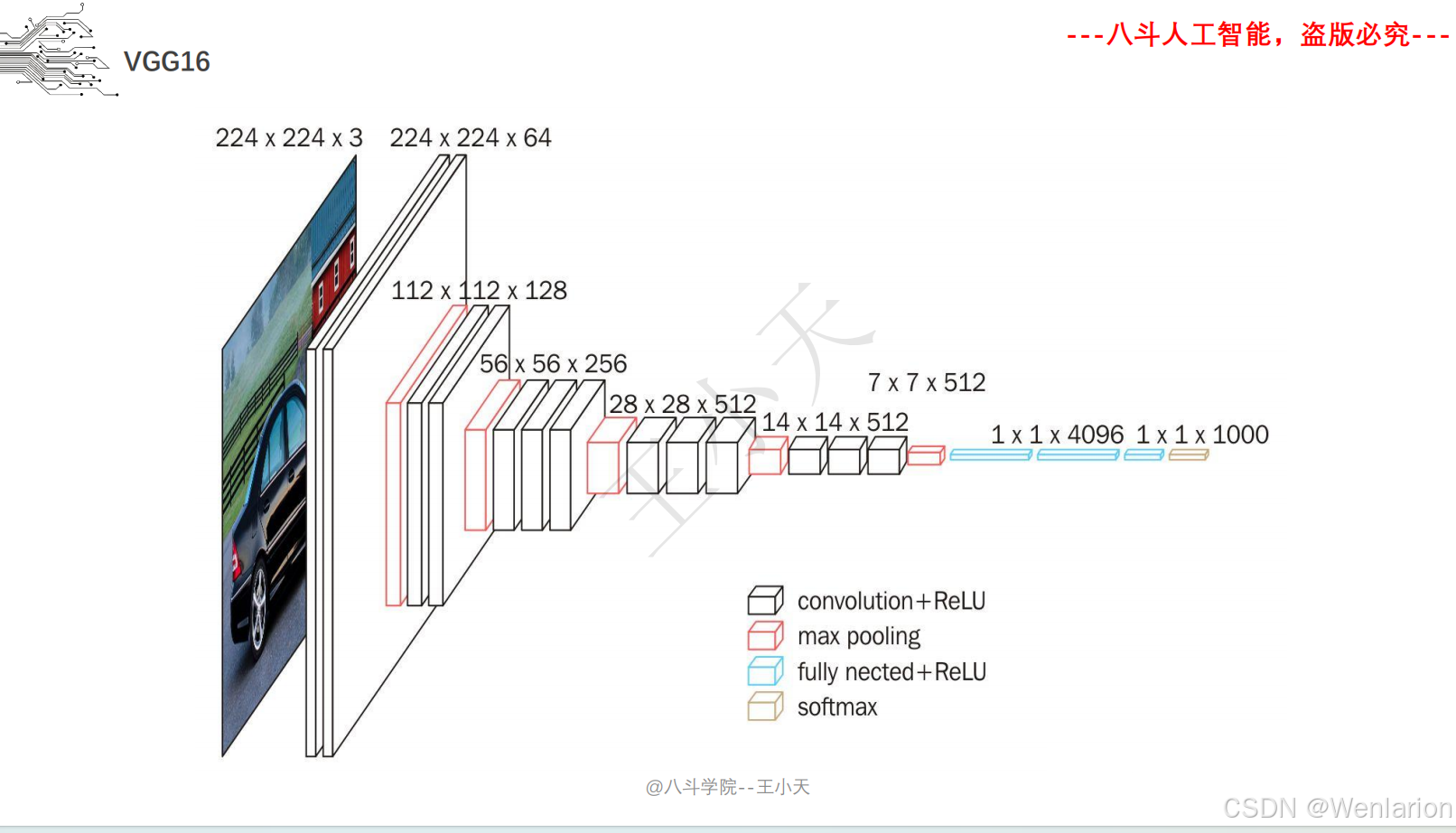



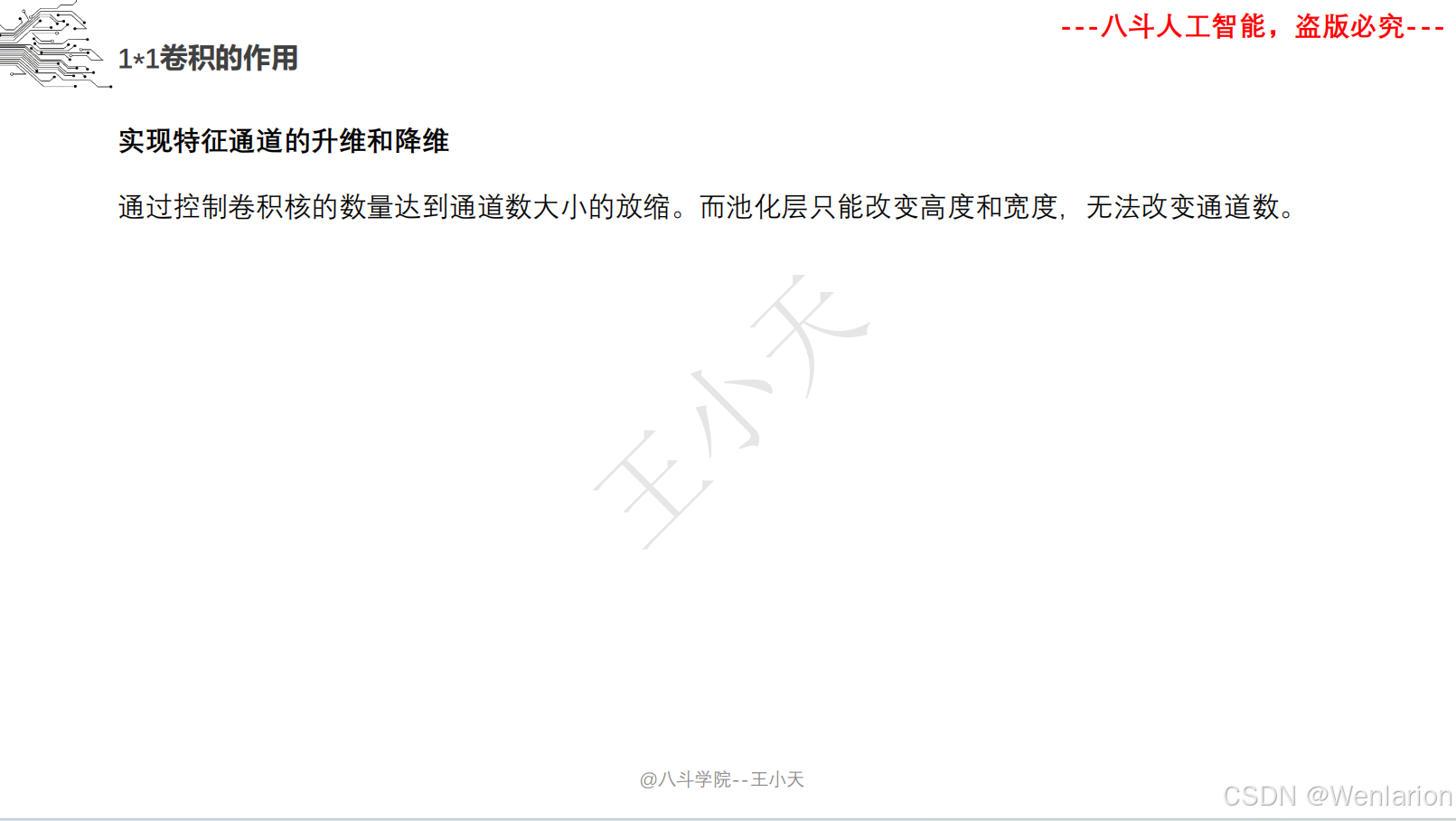
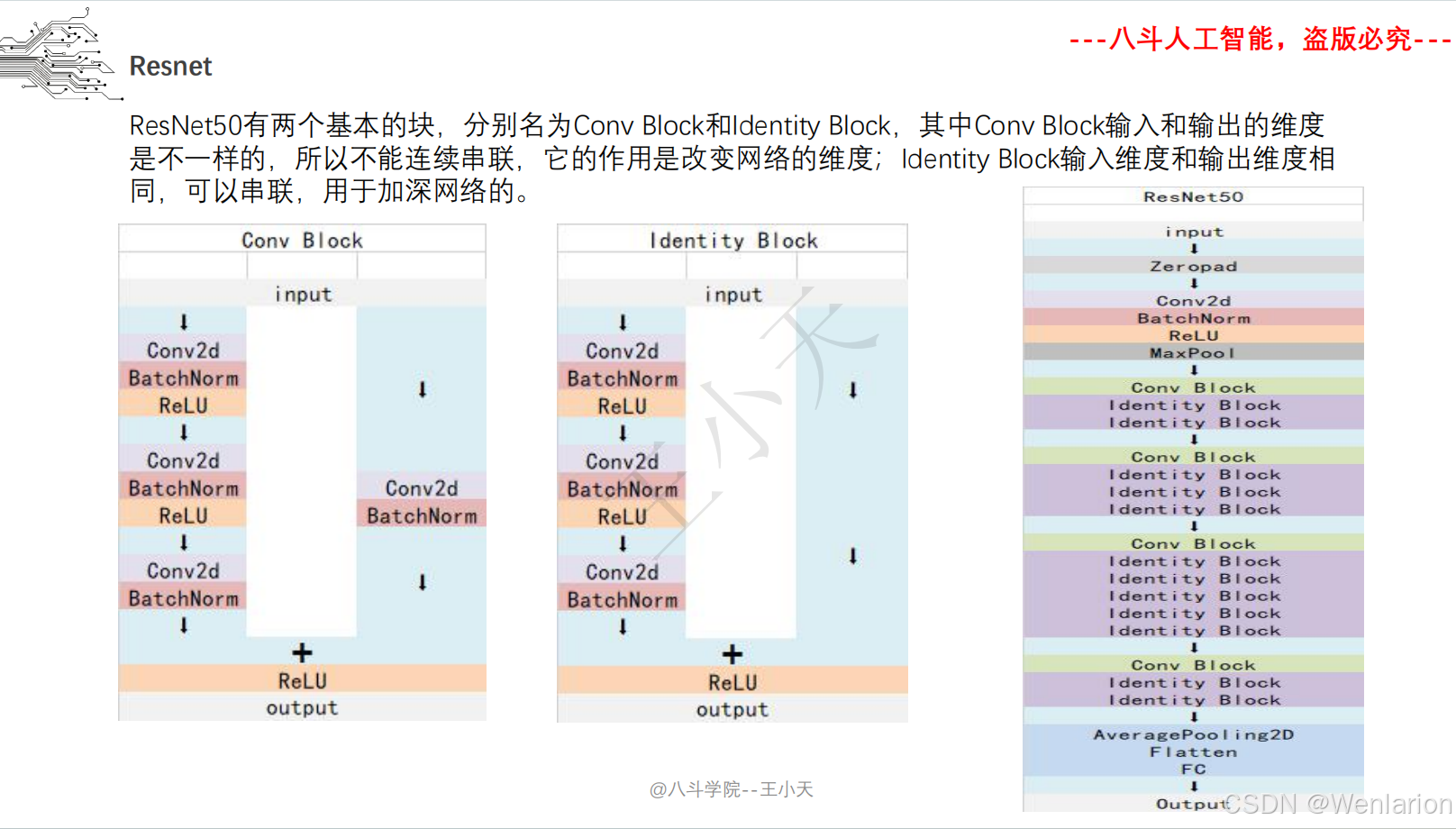
2.1.2 Resnet系列

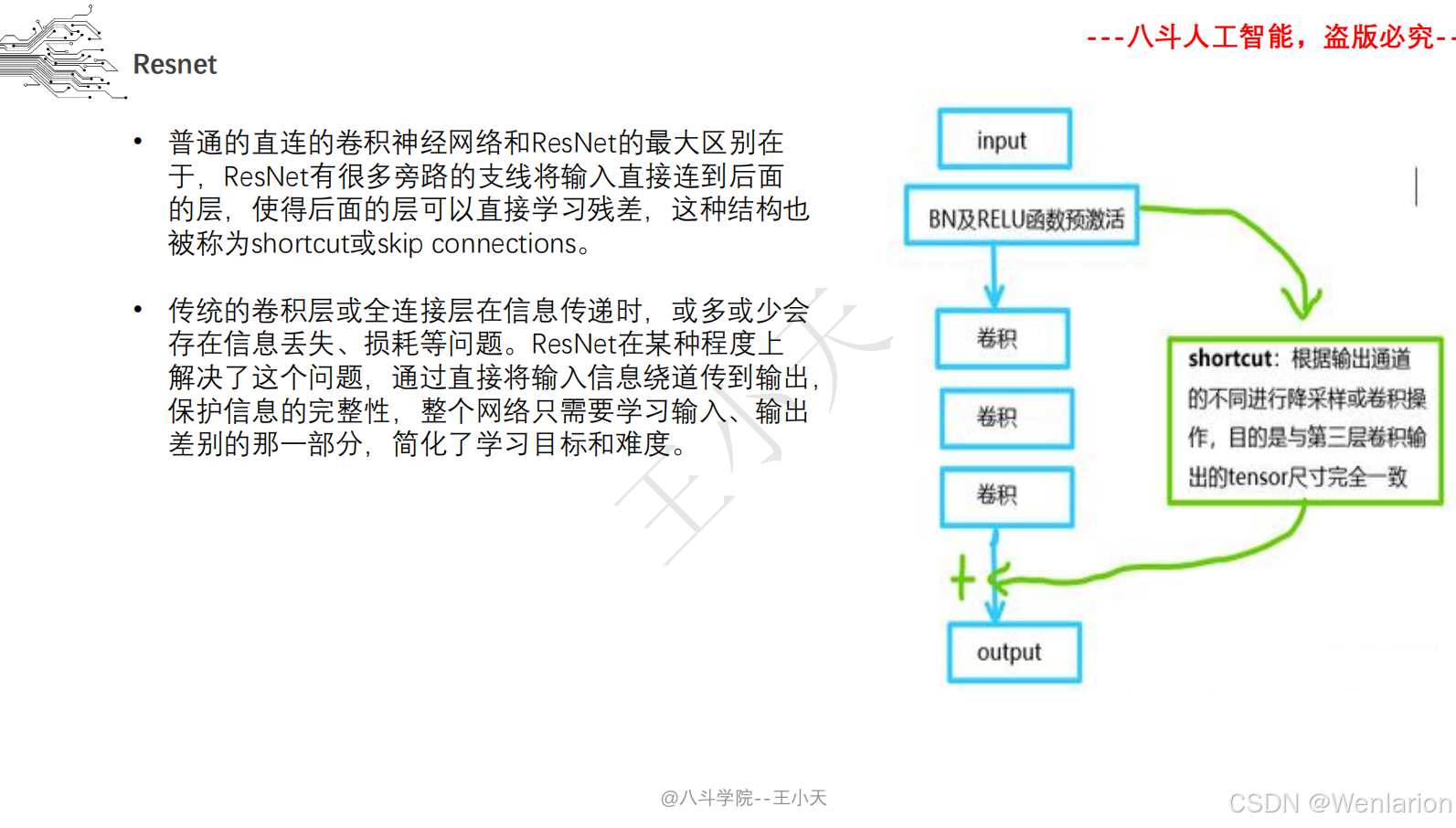

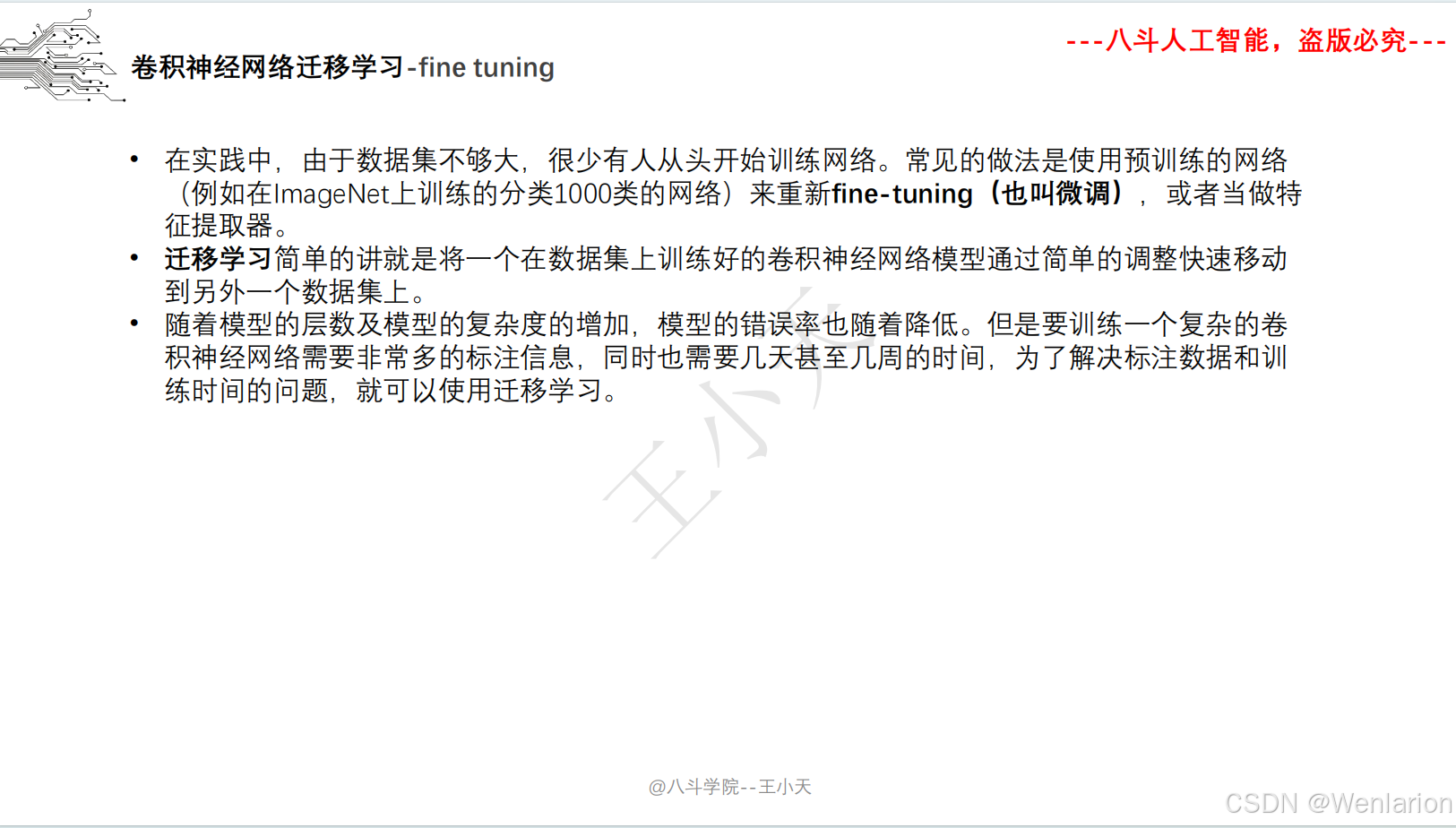
2.1.3 迁移学习 Fine tuning

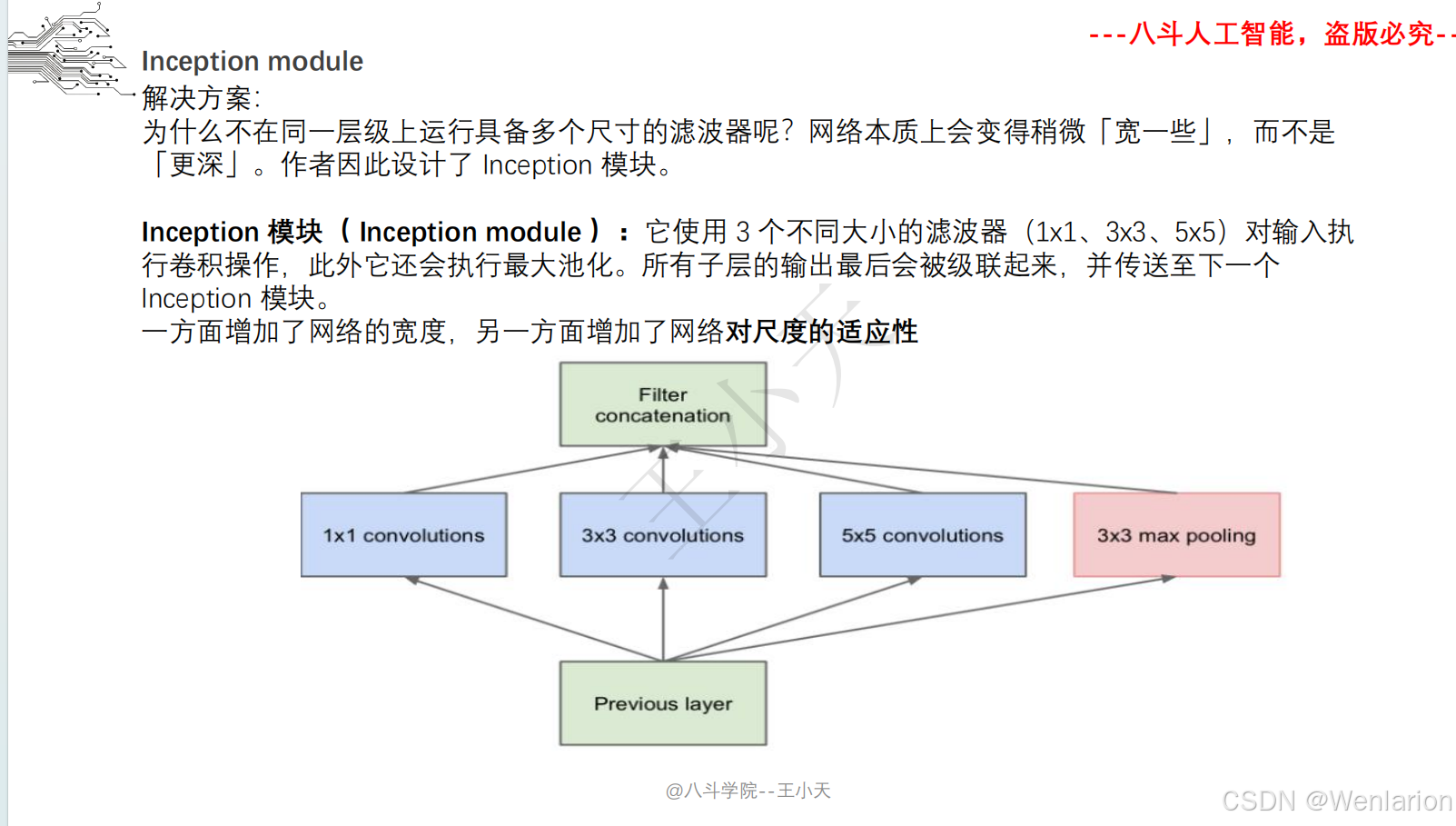
2.1.5 迁移学习 Inception系列





2.1.6 迁移学习 Mobilenet

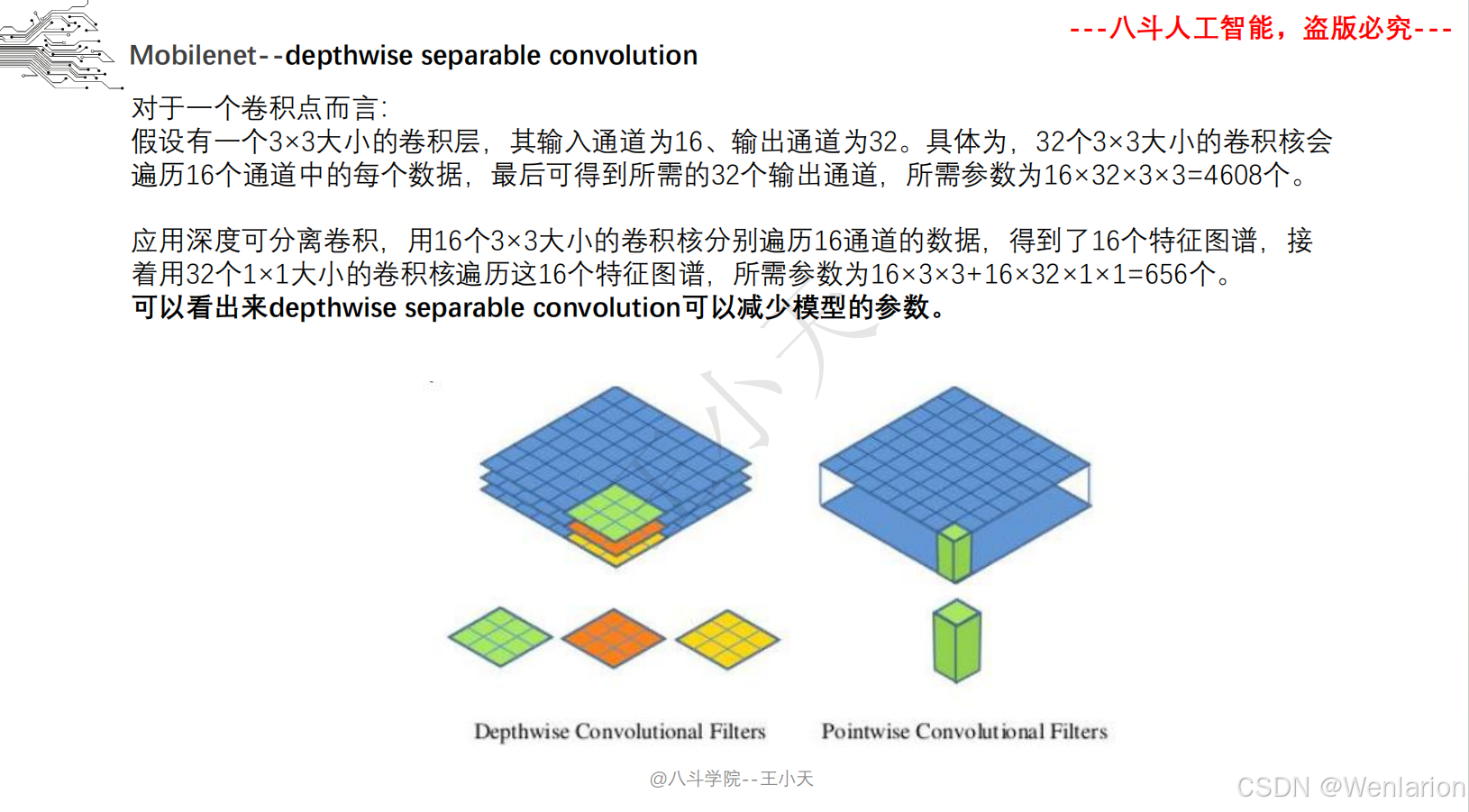
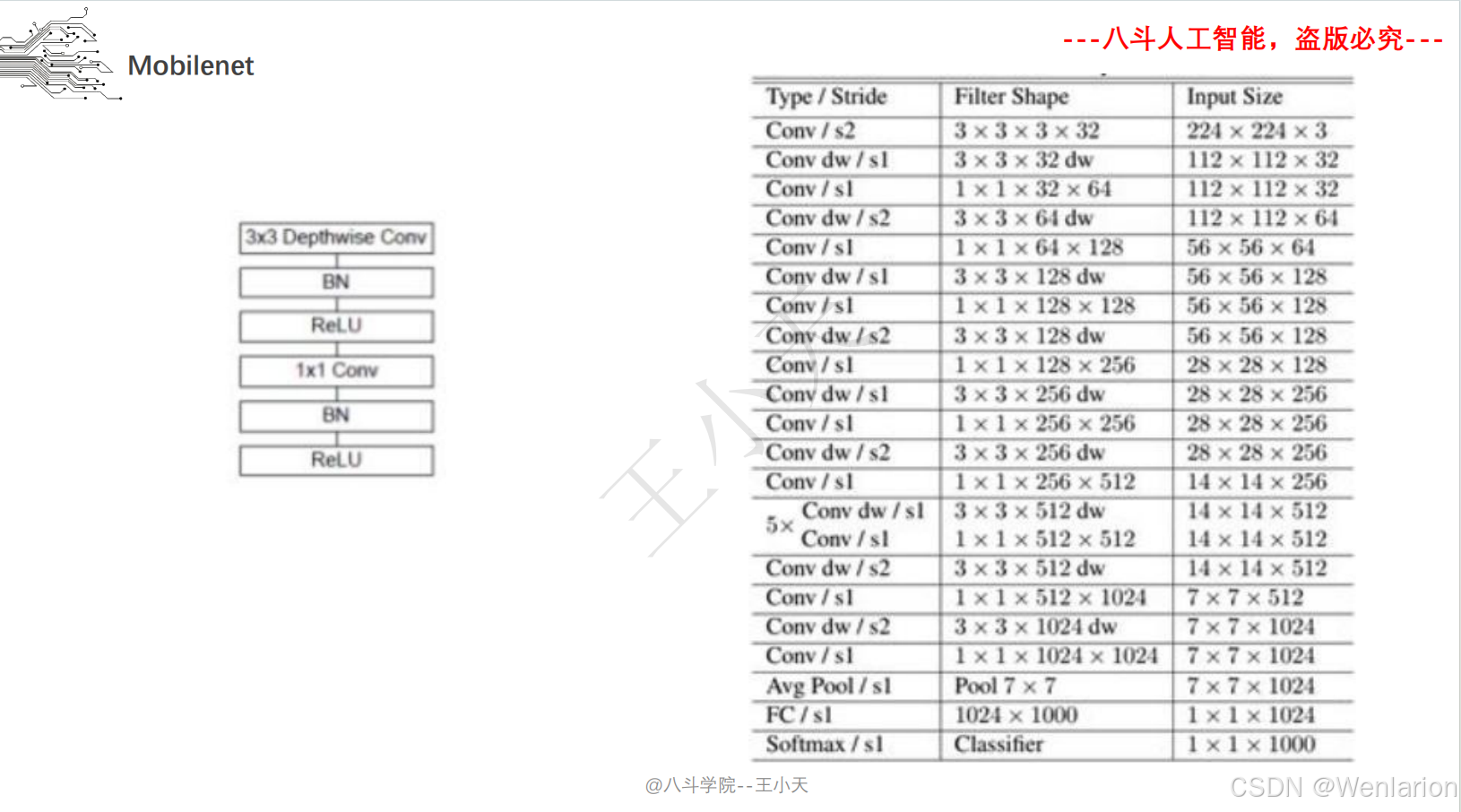
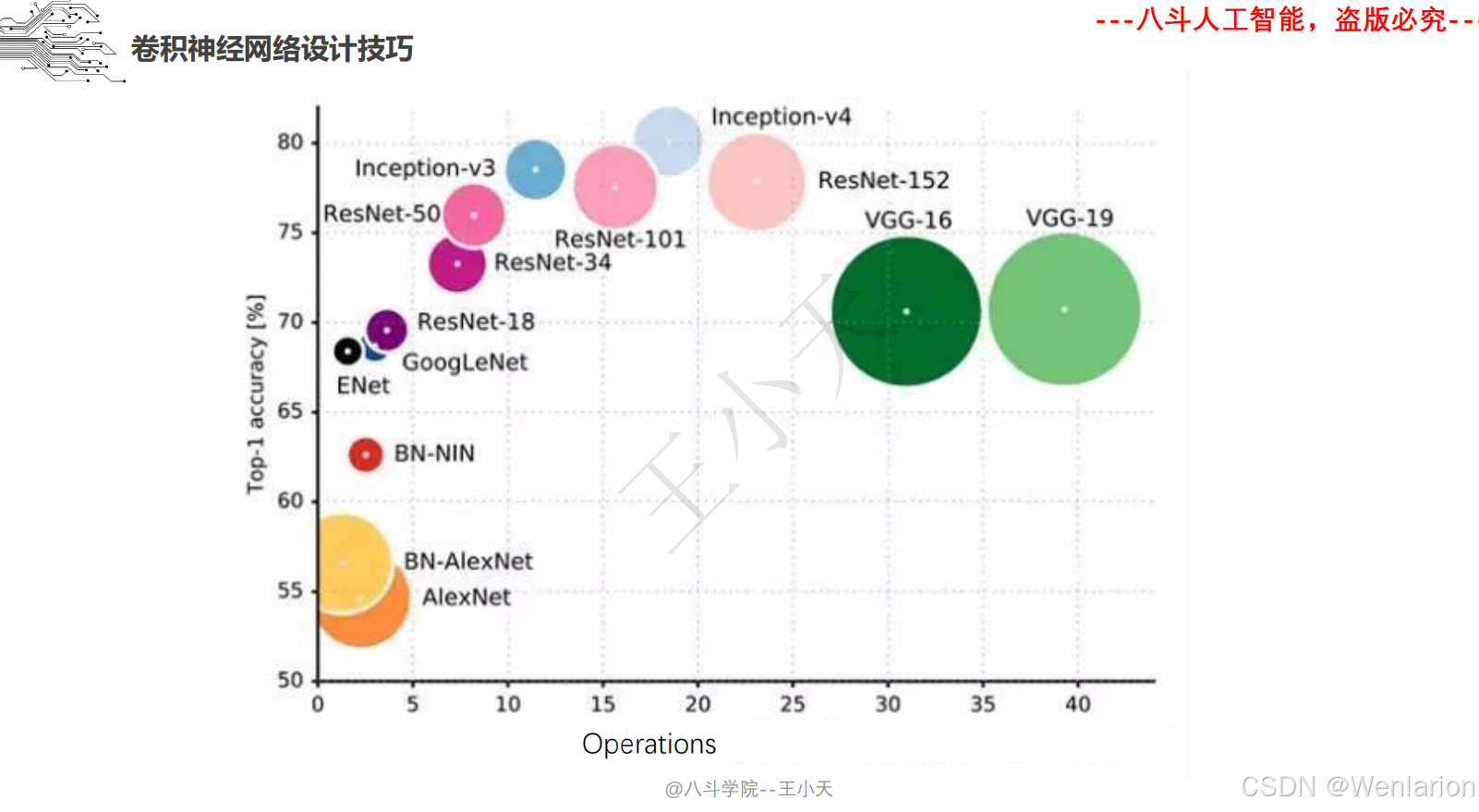
2.1.7 卷积神经网络设计技巧





图像识别论文和代码(VGG、ResNet、Inception、MobileNet 四类经典 CNN 架构)
一、VGG (Visual Geometry Group)
1. 论文简介
VGG 由牛津大学 VGG 组提出,核心贡献是证明了通过堆叠小尺寸(3×3)卷积核的深层网络,能显著提升特征提取能力。相比 AlexNet 的大卷积核(11×11、5×5),3×3 卷积核在保持感受野的同时,大幅减少参数数量,且多层小卷积的非线性拟合能力更强。VGG 的核心架构分为 VGG16(13 个卷积层 + 3 个全连接层)和 VGG19,成为后续 CNN 的基础模块。
2. 论文信息
-
标题:Very Deep Convolutional Networks for Large-Scale Image Recognition
-
发表:ICLR 2015
3. 代码地址
-
官方(Caffe):https://www.robots.ox.ac.uk/~vgg/research/very_deep/
-
主流开源实现(PyTorch):https://github.com/pytorch/vision/blob/main/torchvision/models/vgg.py
-
主流开源实现(TensorFlow/Keras):https://github.com/keras-team/keras-applications/blob/master/keras_applications/vgg16.py
二、ResNet (Residual Network)
1. 论文简介
ResNet 由何恺明等人提出,解决了深度神经网络的梯度消失 / 爆炸问题,首次将 CNN 层数推至百层甚至千层级别。核心创新是 “残差连接(Residual Connection)”:通过跳跃连接(shortcut)让网络学习 “残差映射” 而非直接映射,使得深层网络仍能稳定训练且性能提升。ResNet 在 ILSVRC 2015 竞赛中斩获分类、检测、分割三项冠军,是至今最常用的骨干网络之一。
2. 论文信息
-
标题:Deep Residual Learning for Image Recognition
-
发表:CVPR 2016 (最佳论文)
-
扩展版(ResNeXt):https://arxiv.org/abs/1611.05431(分组卷积增强)
3. 代码地址
-
官方(Torch):https://github.com/KaimingHe/deep-residual-networks
-
主流开源实现(PyTorch):https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py
-
主流开源实现(TensorFlow/Keras):https://github.com/keras-team/keras-applications/blob/master/keras_applications/resnet50.py
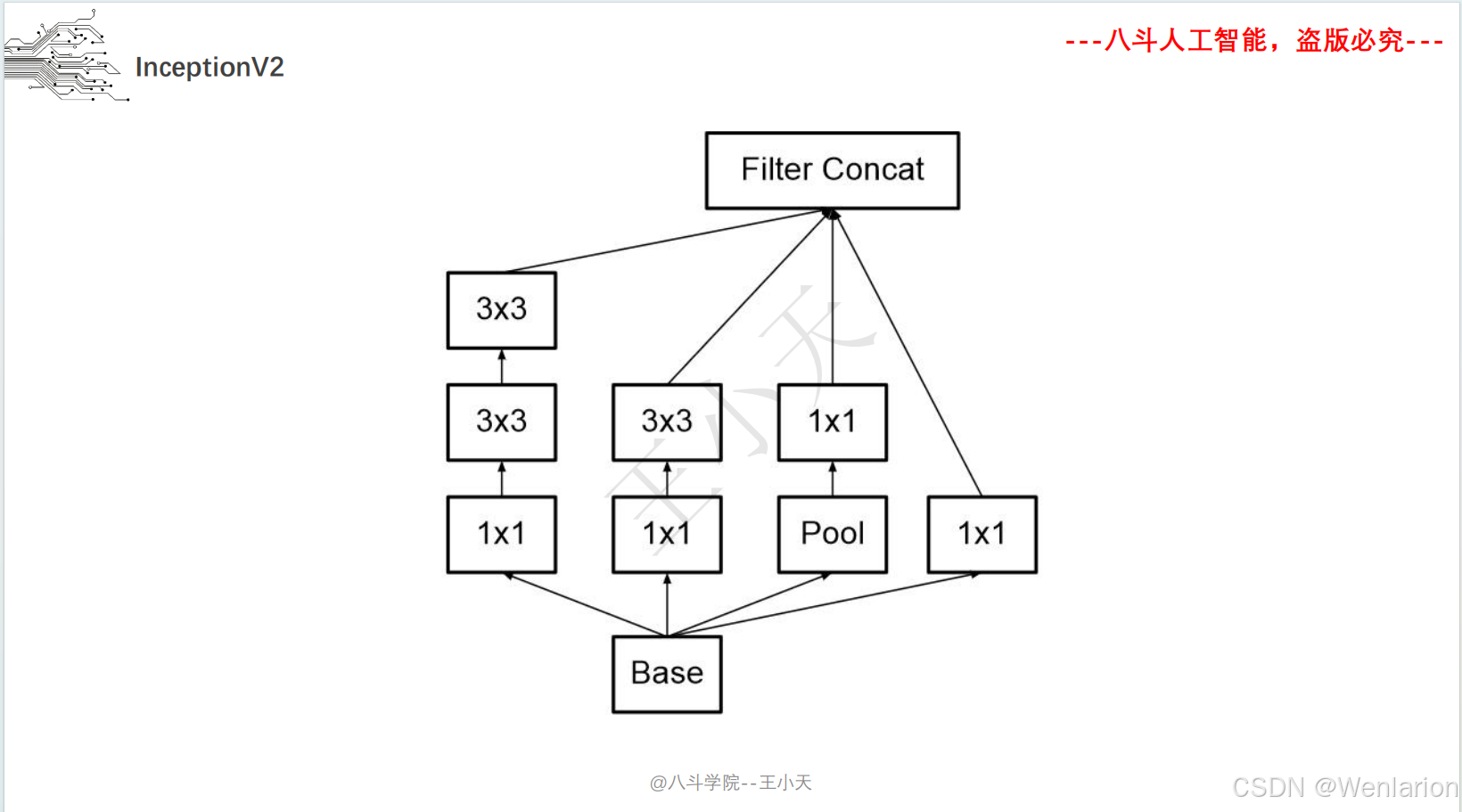
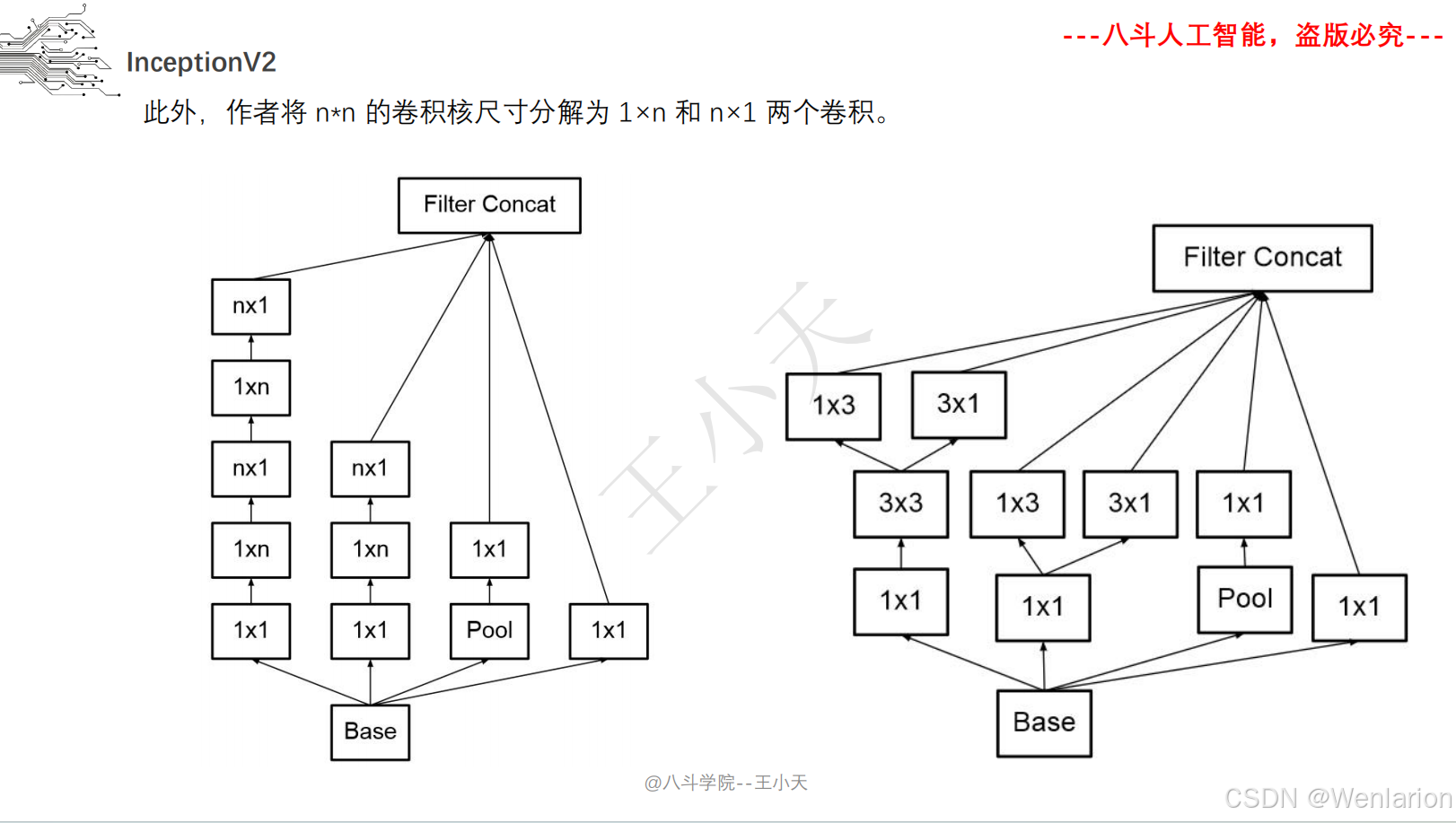
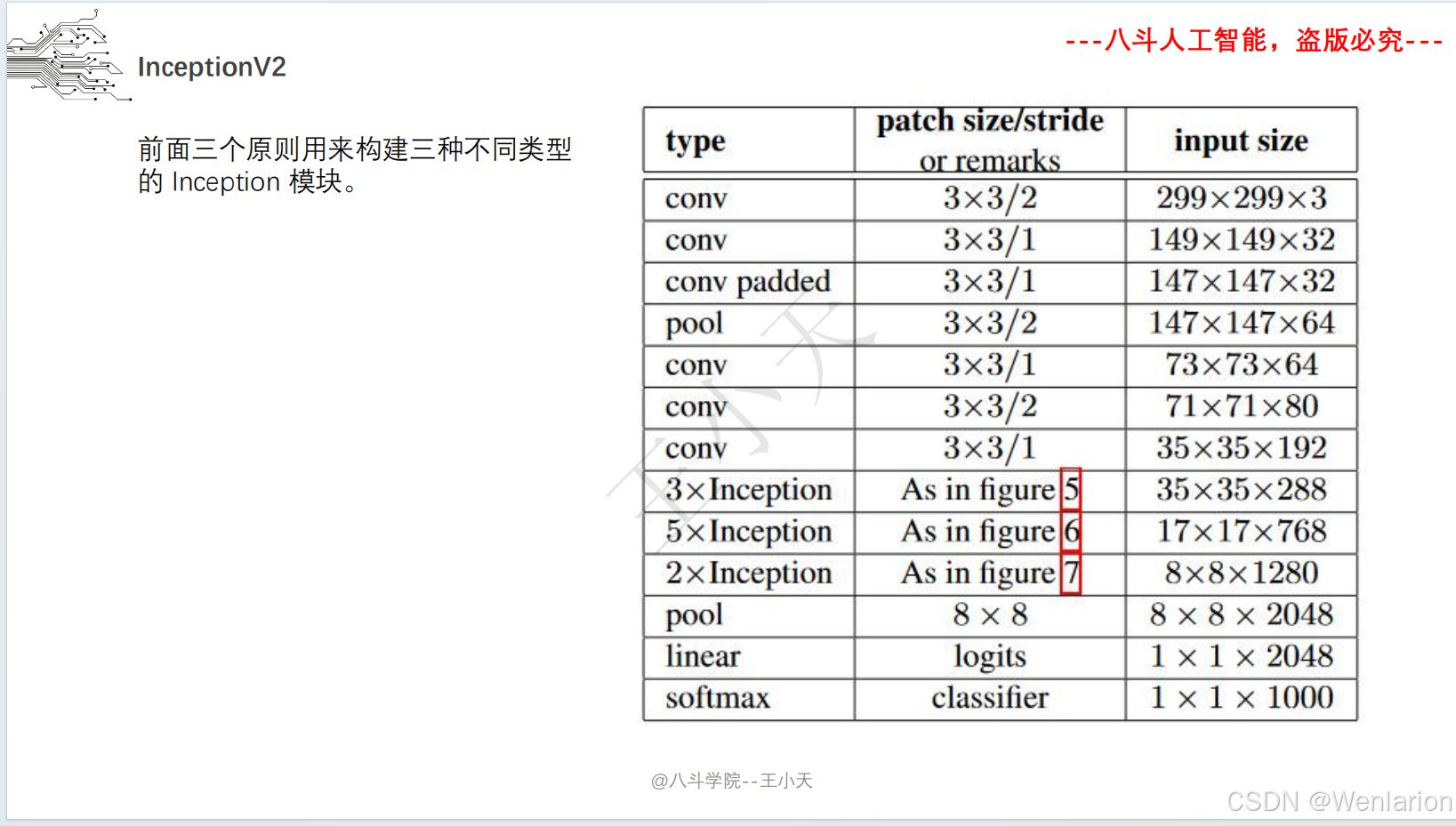
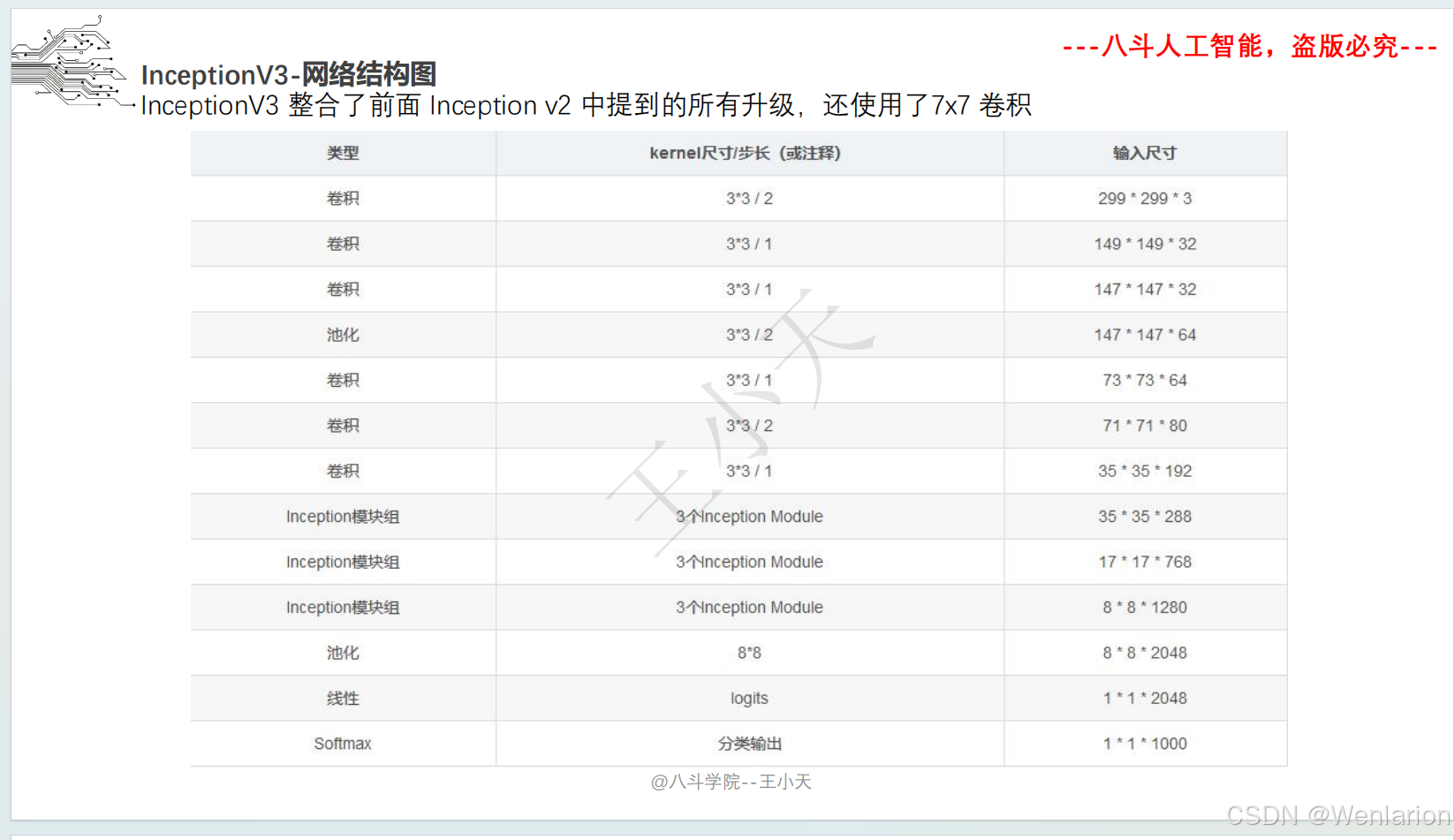
三、Inception (GoogLeNet)
1. 论文简介
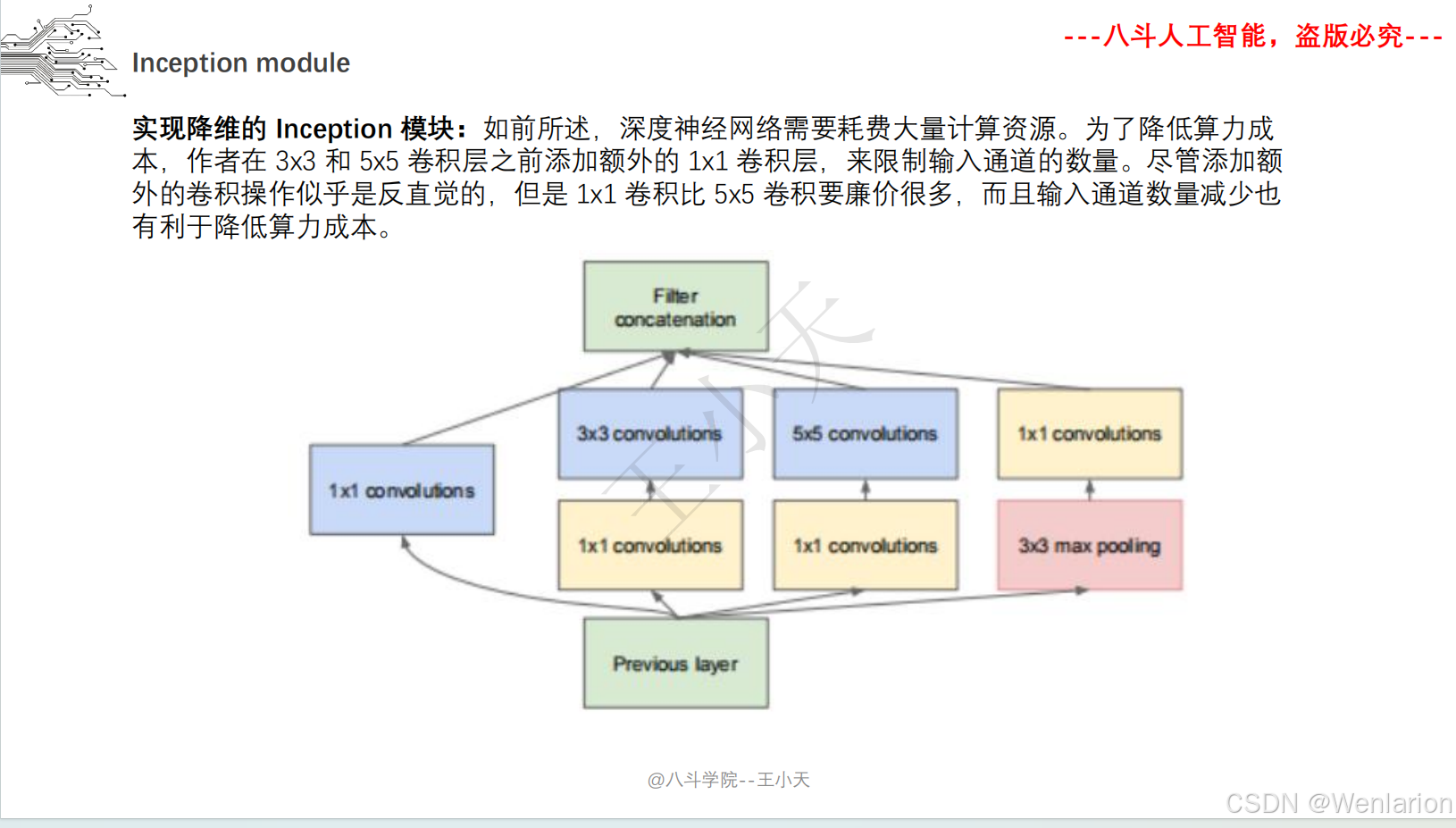
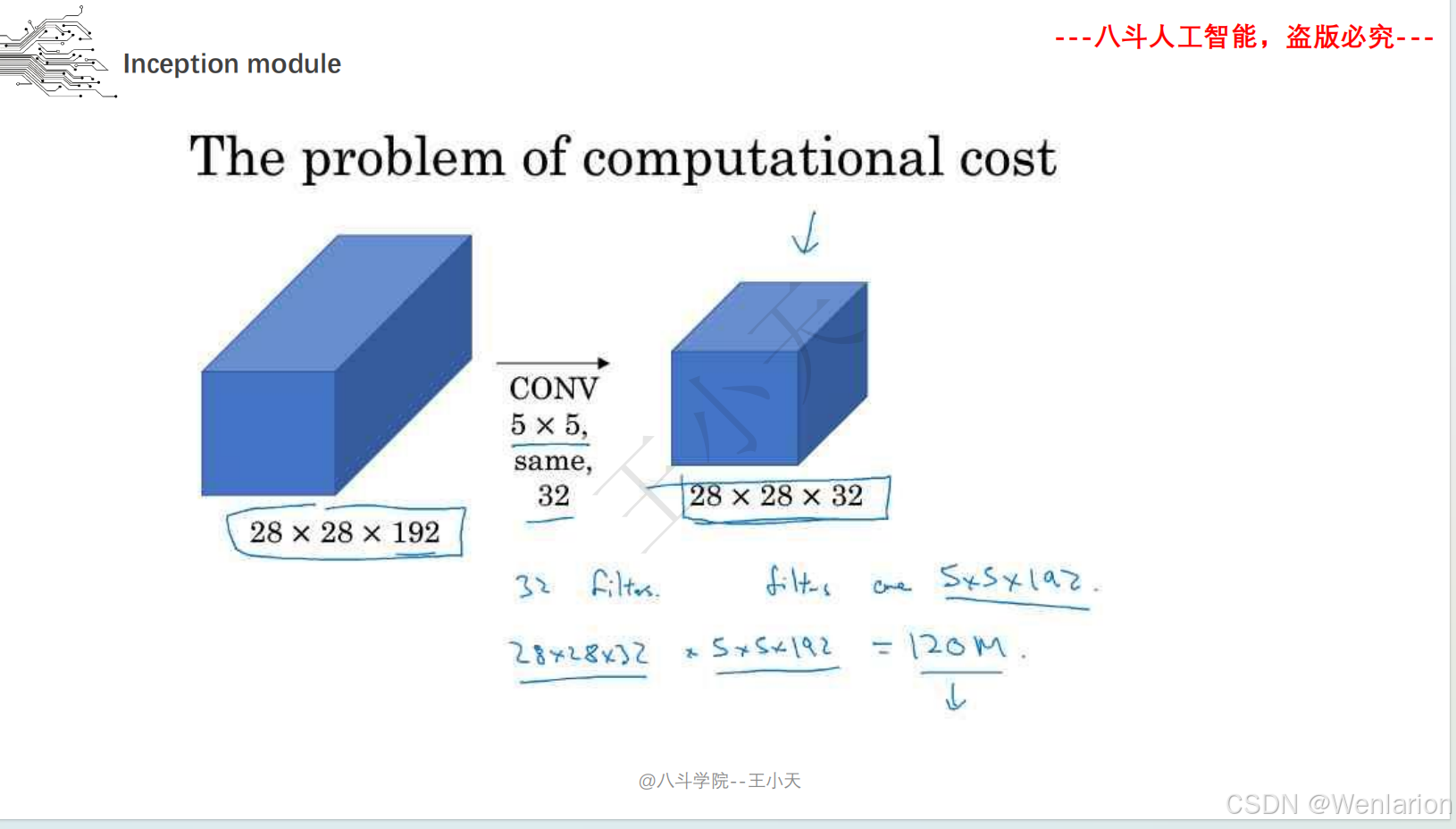
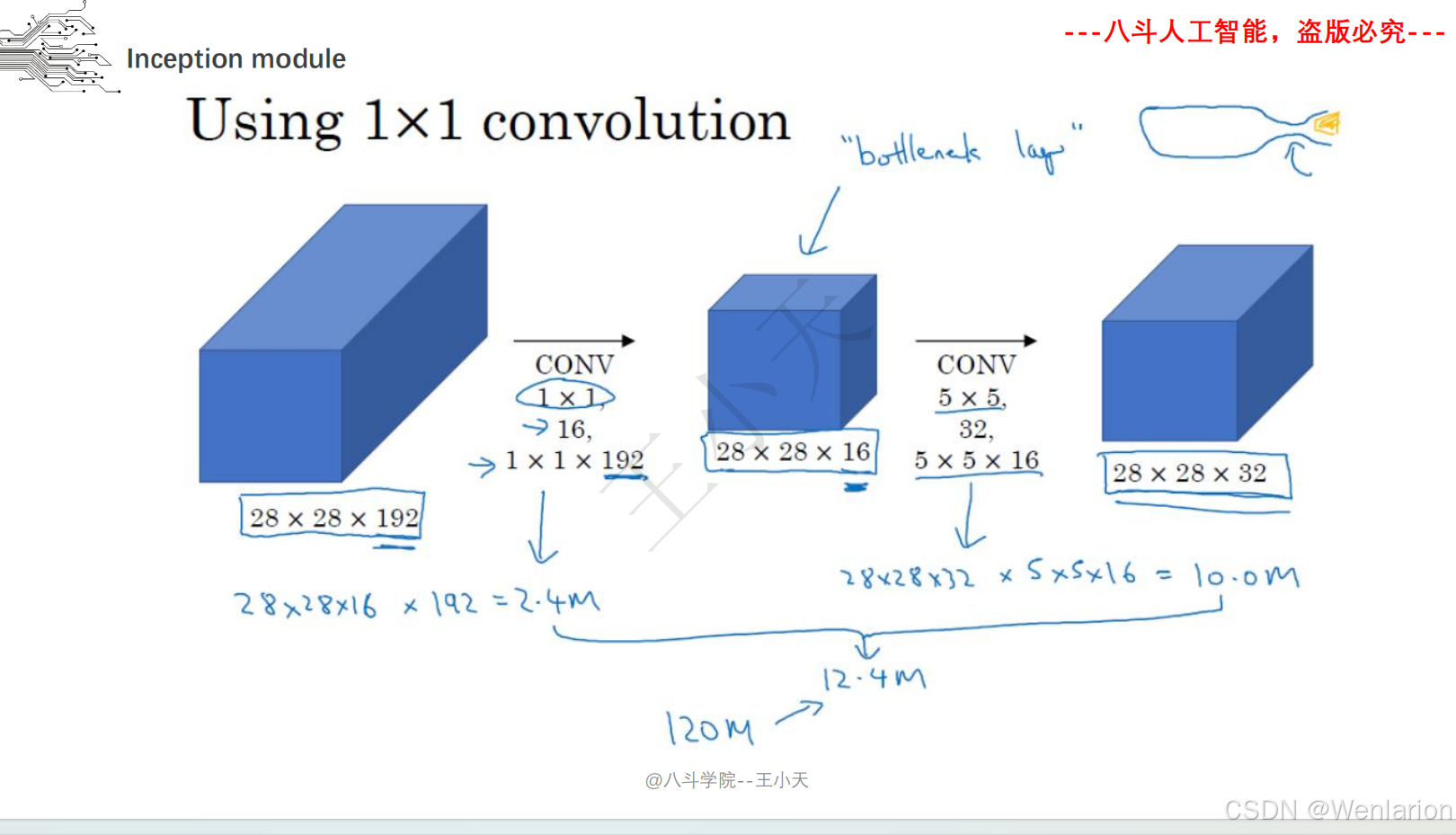
Inception(初代名为 GoogLeNet)由谷歌提出,核心目标是在不显著增加计算量的前提下提升网络宽度和多尺度特征提取能力。核心创新包括:
-
多分支卷积(1×1、3×3、5×5 卷积 + 池化并行),捕捉不同尺度特征;
-
1×1 卷积实现 “瓶颈层”,降维减少计算量;
-
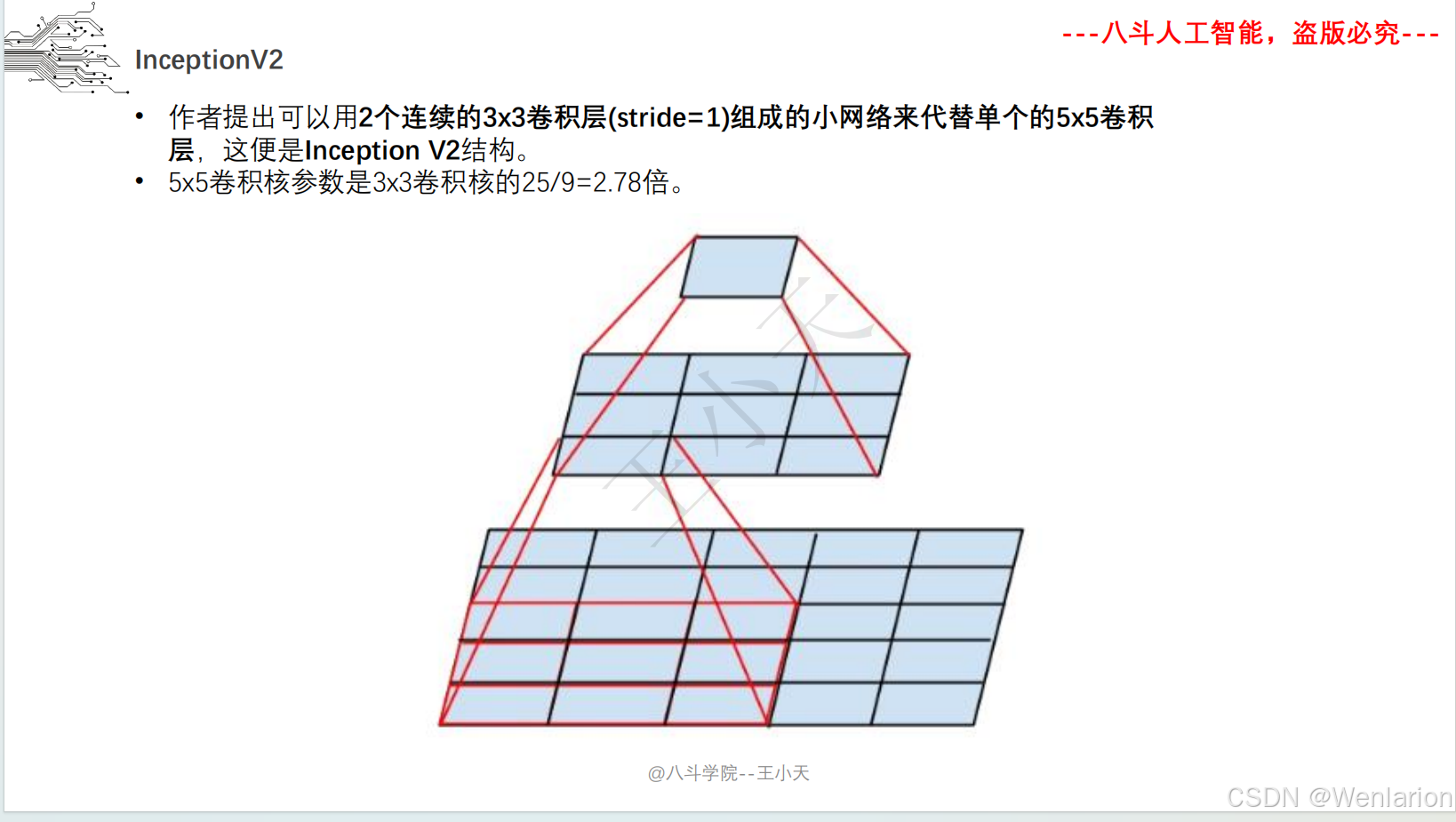
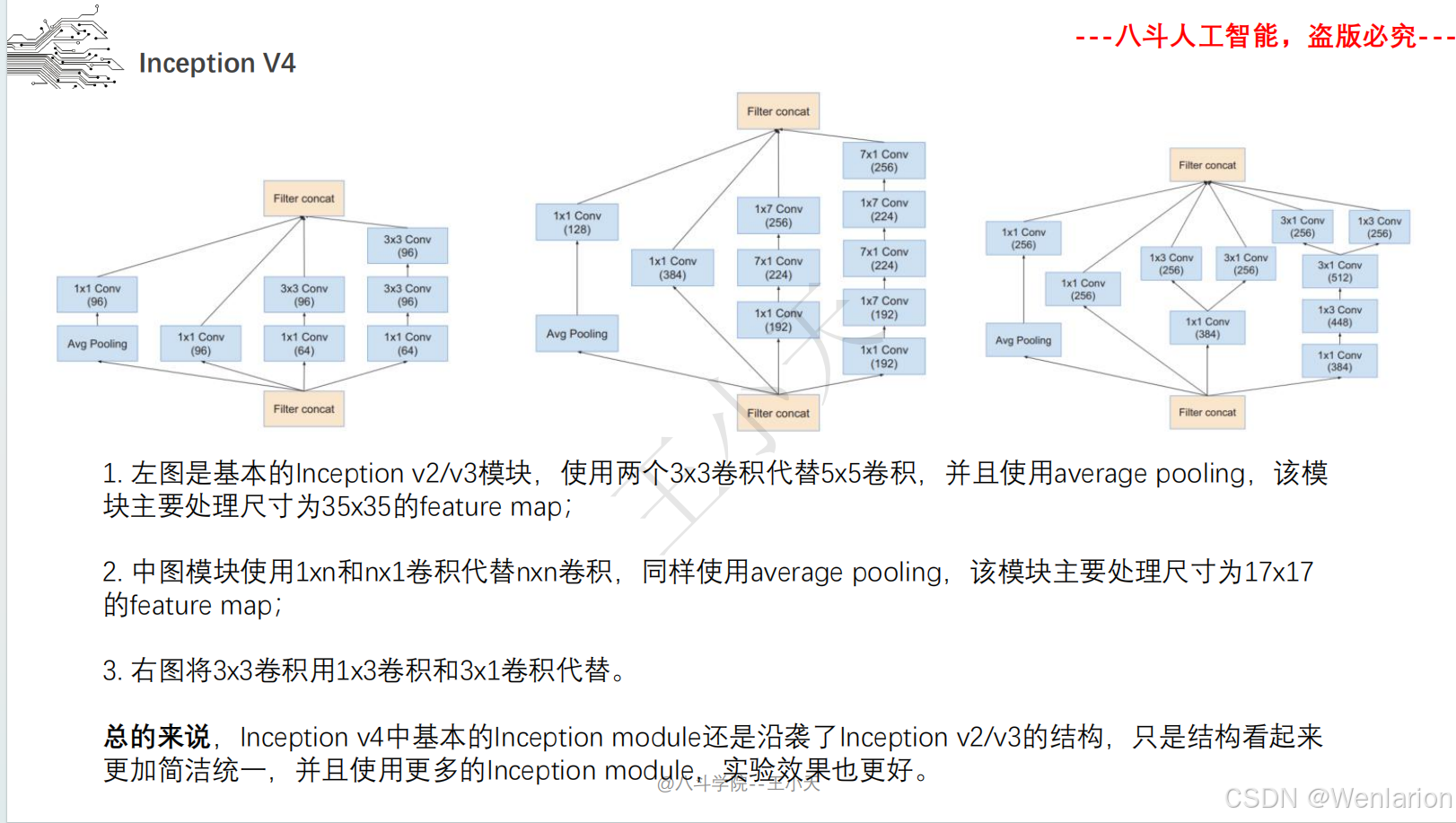
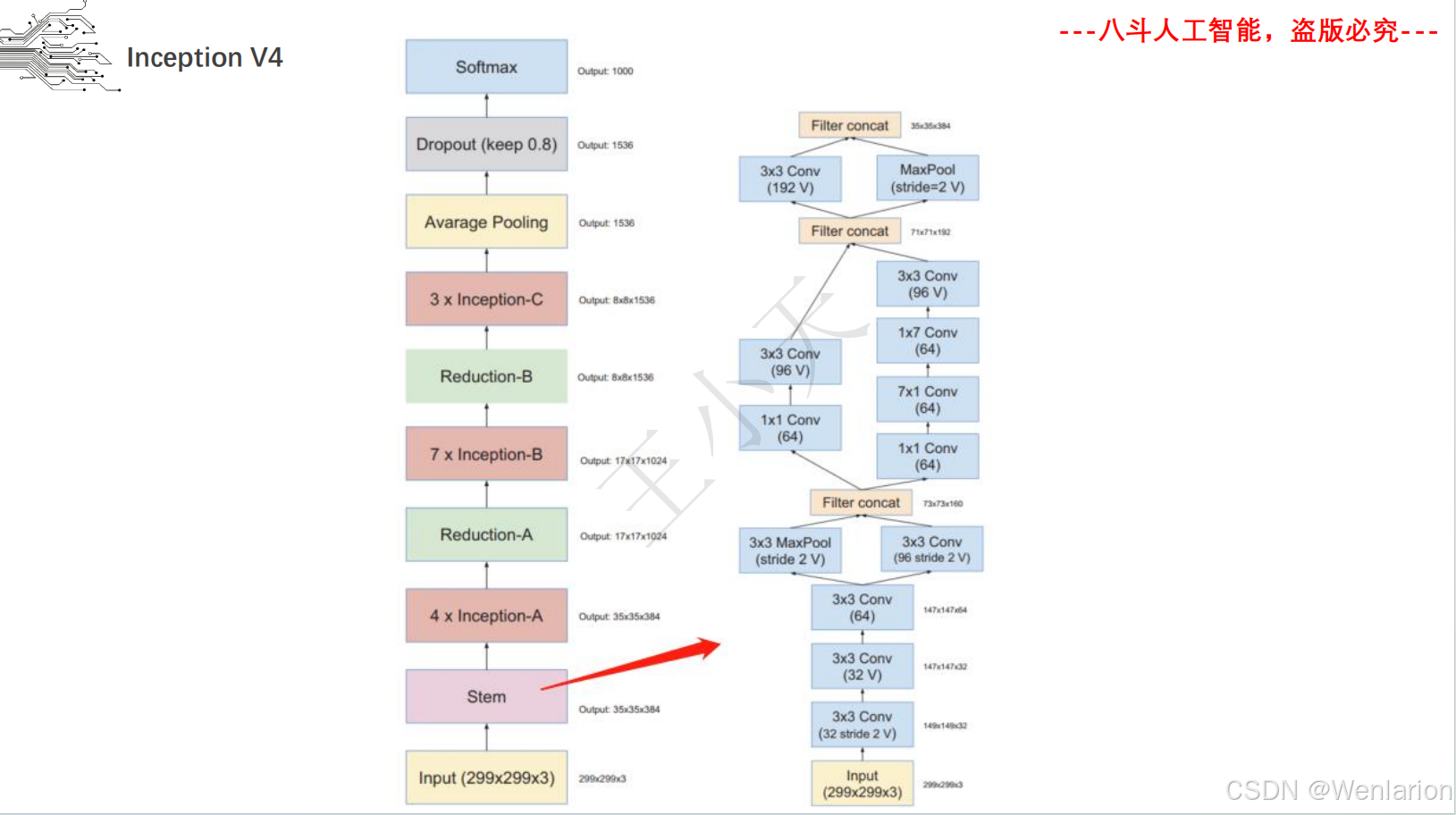
取消全连接层,用全局平均池化替代,大幅减少参数。后续迭代包括 Inception v2/v3(优化卷积核、标签平滑)、Inception v4(融合 ResNet 残差连接)。
2. 论文信息
-
初代(GoogLeNet):
-
标题:Going Deeper with Convolutions
-
发表:CVPR 2015
-
-
Inception v3:
-
标题:Rethinking the Inception Architecture for Computer Vision
-
发表:CVPR 2016
-
-
Inception v4:
-
标题:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
-
发表:AAAI 2017
-
3. 代码地址
-
主流开源实现(PyTorch):https://github.com/pytorch/vision/blob/main/torchvision/models/inception.py
-
主流开源实现(TensorFlow/Keras):https://github.com/keras-team/keras-applications/blob/master/keras_applications/inception_v3.py
-
谷歌官方实现:https://github.com/tensorflow/models/tree/master/research/slim/nets/inception
四、MobileNet
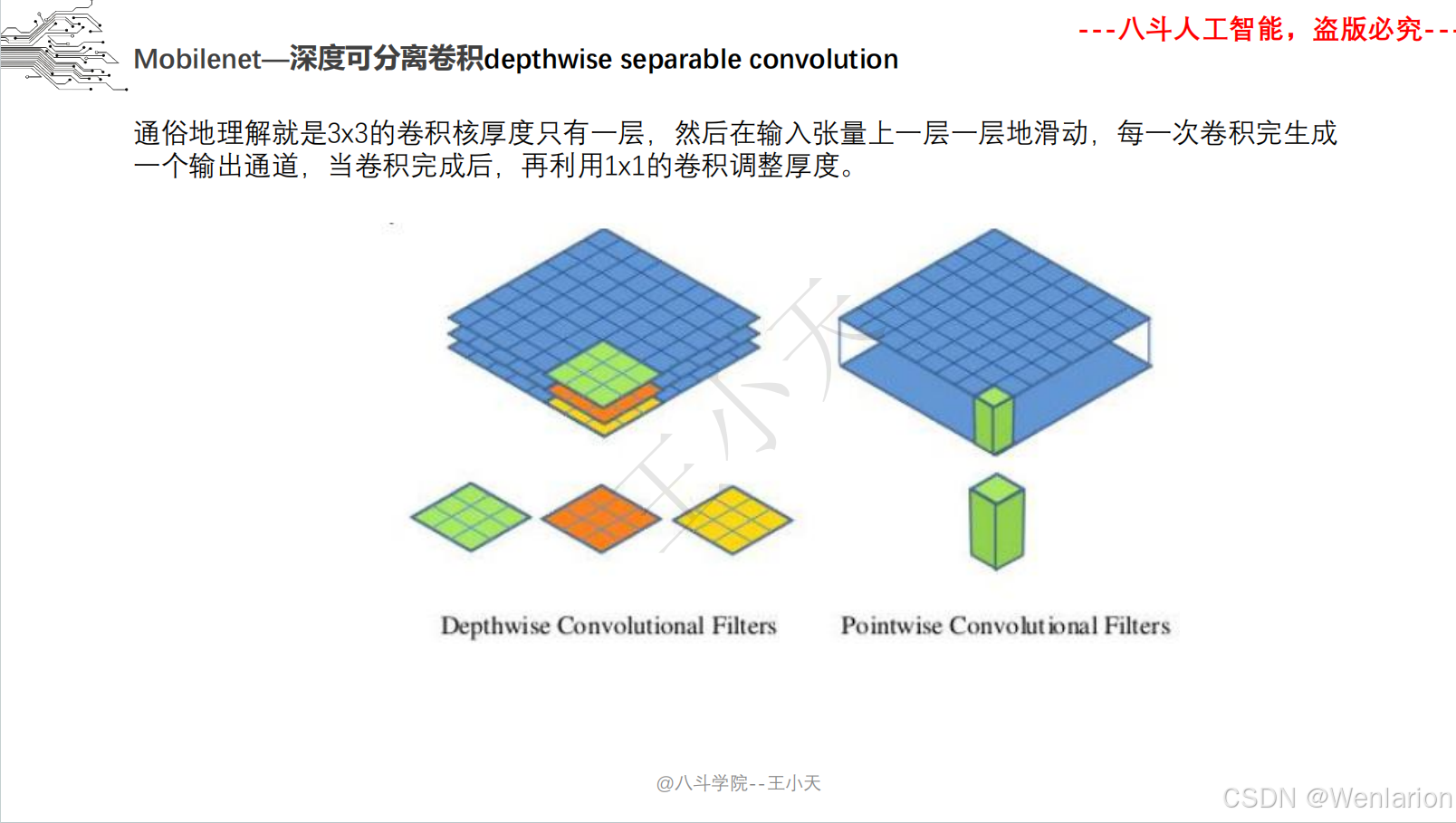
1. 论文简介
MobileNet 由谷歌提出,专为移动 / 嵌入式设备设计的轻量化 CNN,核心目标是在保证精度的前提下最小化计算量和模型大小。
-
MobileNet v1:提出 “深度可分离卷积(Depthwise Separable Convolution)”,将标准卷积拆分为深度卷积(逐通道卷积)+ 逐点卷积(1×1 卷积),计算量减少 8-9 倍;
-
MobileNet v2:引入 “逆残差连接” 和 “线性瓶颈层”,解决深度可分离卷积的特征退化问题;
-
MobileNet v3:融合 NAS(神经架构搜索)和 NetAdapt,优化激活函数(Hard-Swish)和网络结构,进一步平衡速度与精度。
2. 论文信息
-
MobileNet v1:
-
标题:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
-
发表:CVPR 2017 (Workshop)
-
-
MobileNet v2:
-
标题:MobileNetV2: Inverted Residuals and Linear Bottlenecks
-
发表:CVPR 2018
-
-
MobileNet v3:
-
标题:Searching for MobileNetV3
-
发表:ICCV 2019
-
3. 代码地址
-
谷歌官方(TensorFlow):https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
-
主流开源实现(PyTorch):https://github.com/pytorch/vision/blob/main/torchvision/models/mobilenet.py
-
轻量化部署版(ONNX/TFLite):https://github.com/onnx/models/tree/main/vision/classification/mobilenet
总结
-
VGG:核心是 “小卷积核 + 深网络”,奠定 CNN 堆叠范式,参数量大但易理解,适合学术研究基线;
-
ResNet:通过残差连接突破网络深度限制,是至今最通用的骨干网络,工业界首选;
-
Inception:多分支多尺度特征提取,兼顾精度与计算效率,启发后续 EfficientNet 等架构;
-
MobileNet:深度可分离卷积实现轻量化,专为移动端设计,是边缘设备视觉任务的核心架构。
2.2 目标检测问题
2.2.1 目标检测
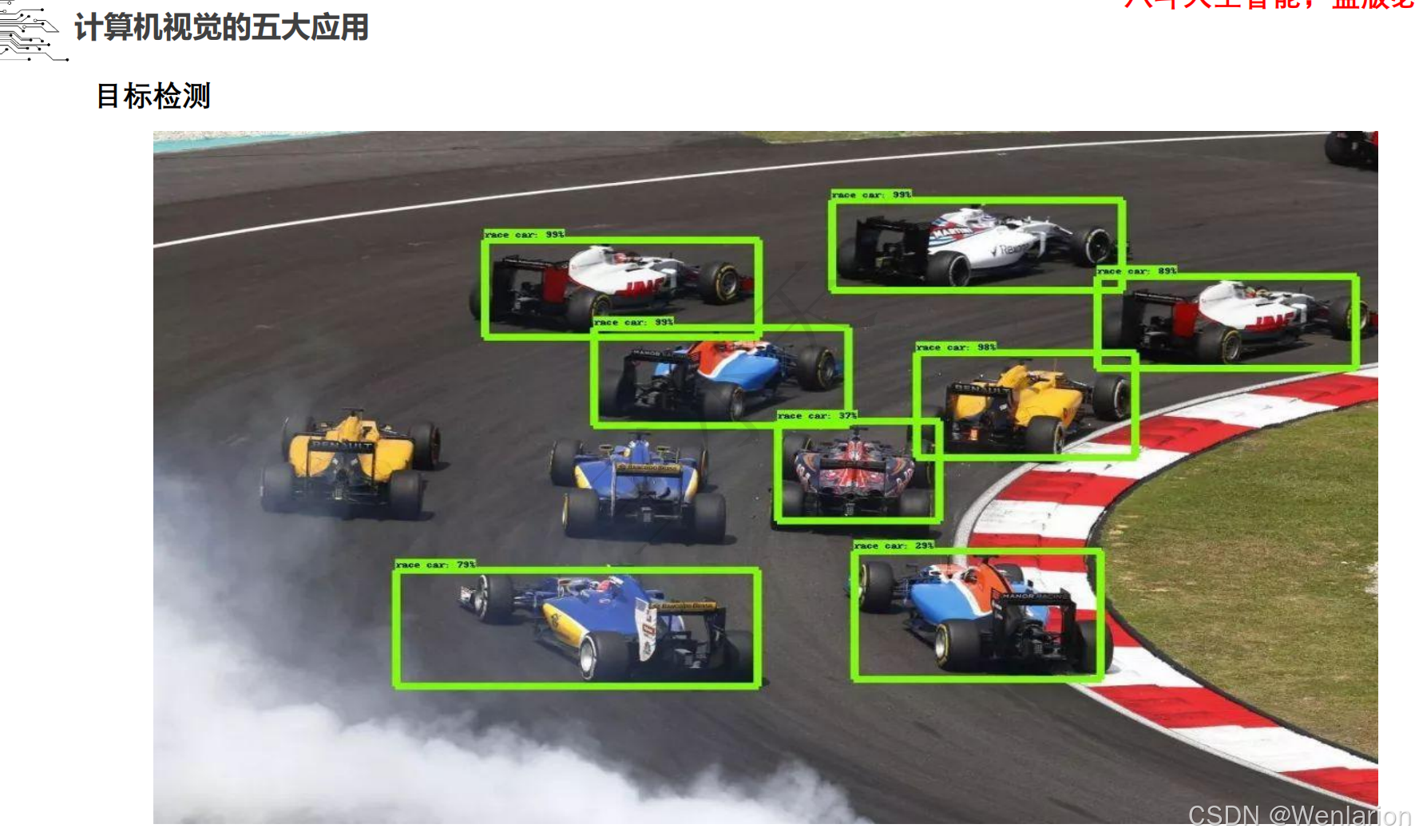




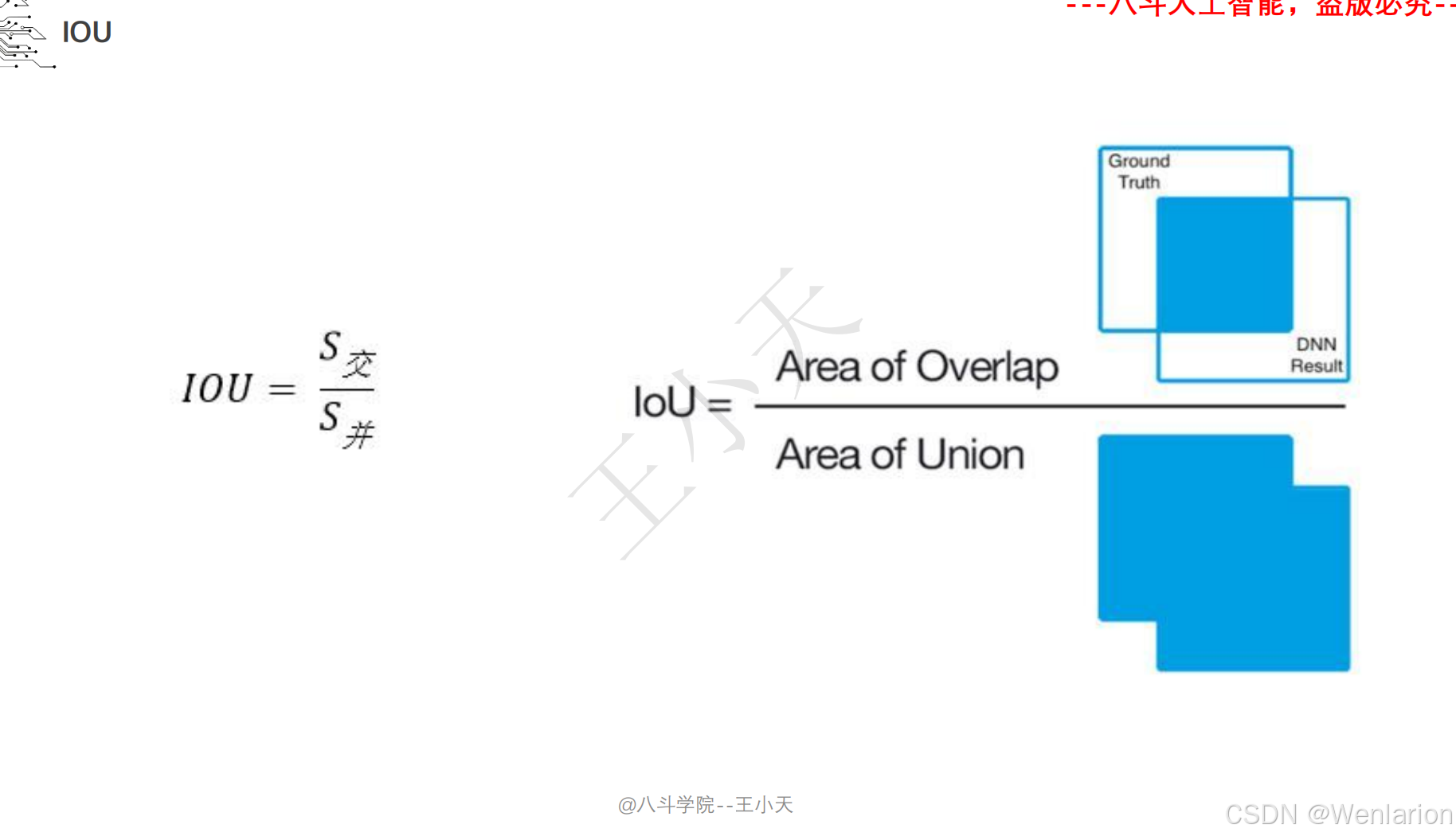
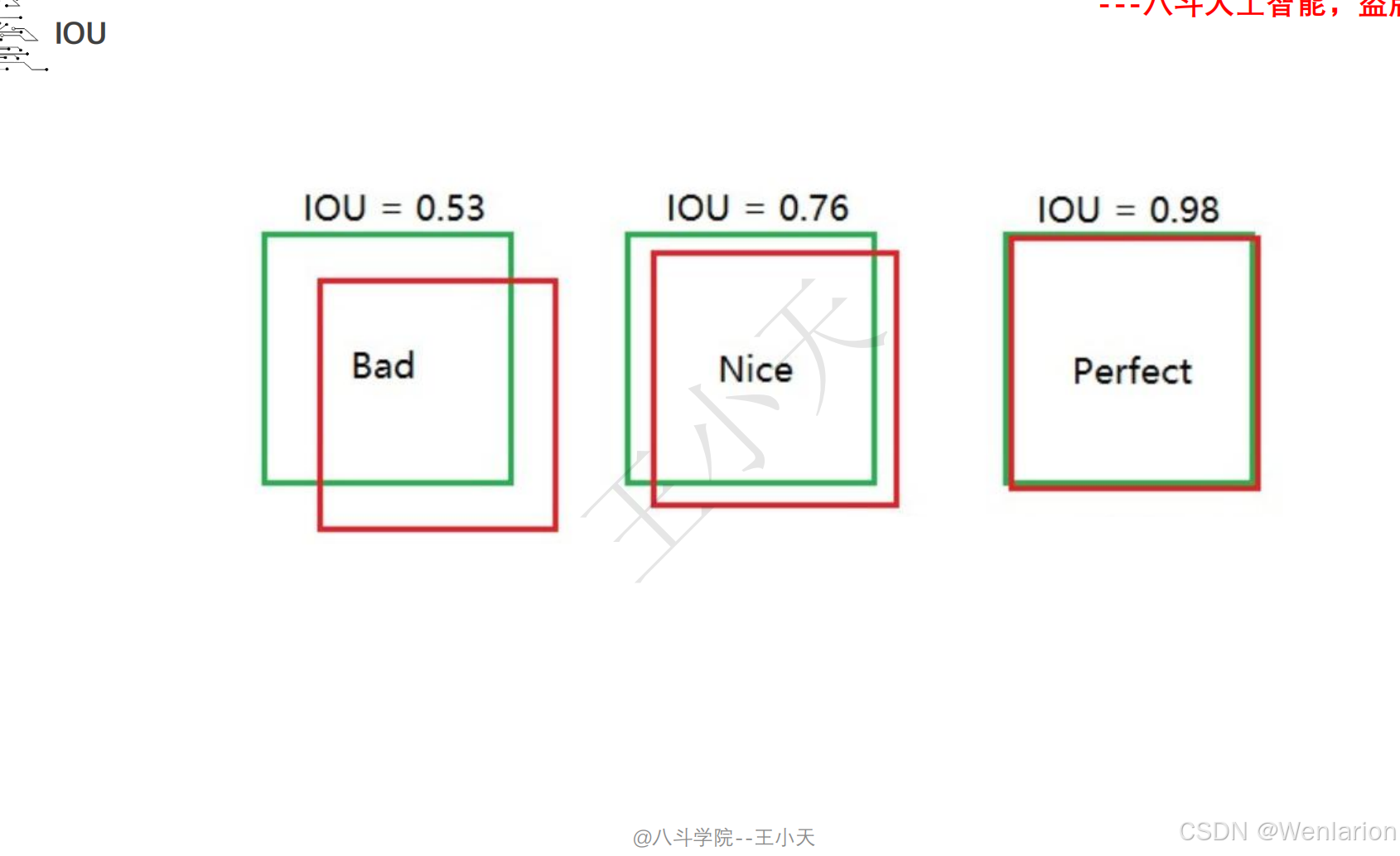




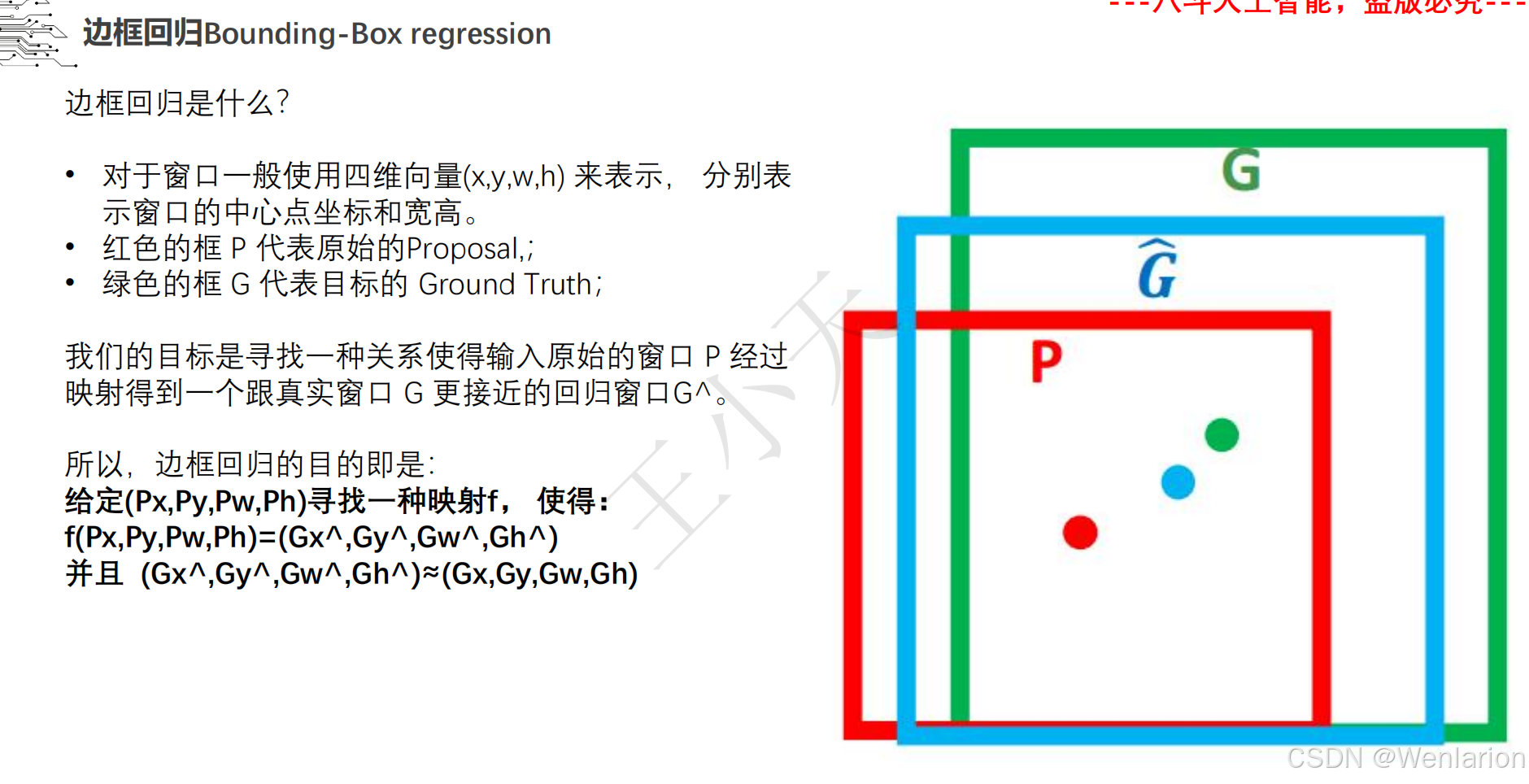


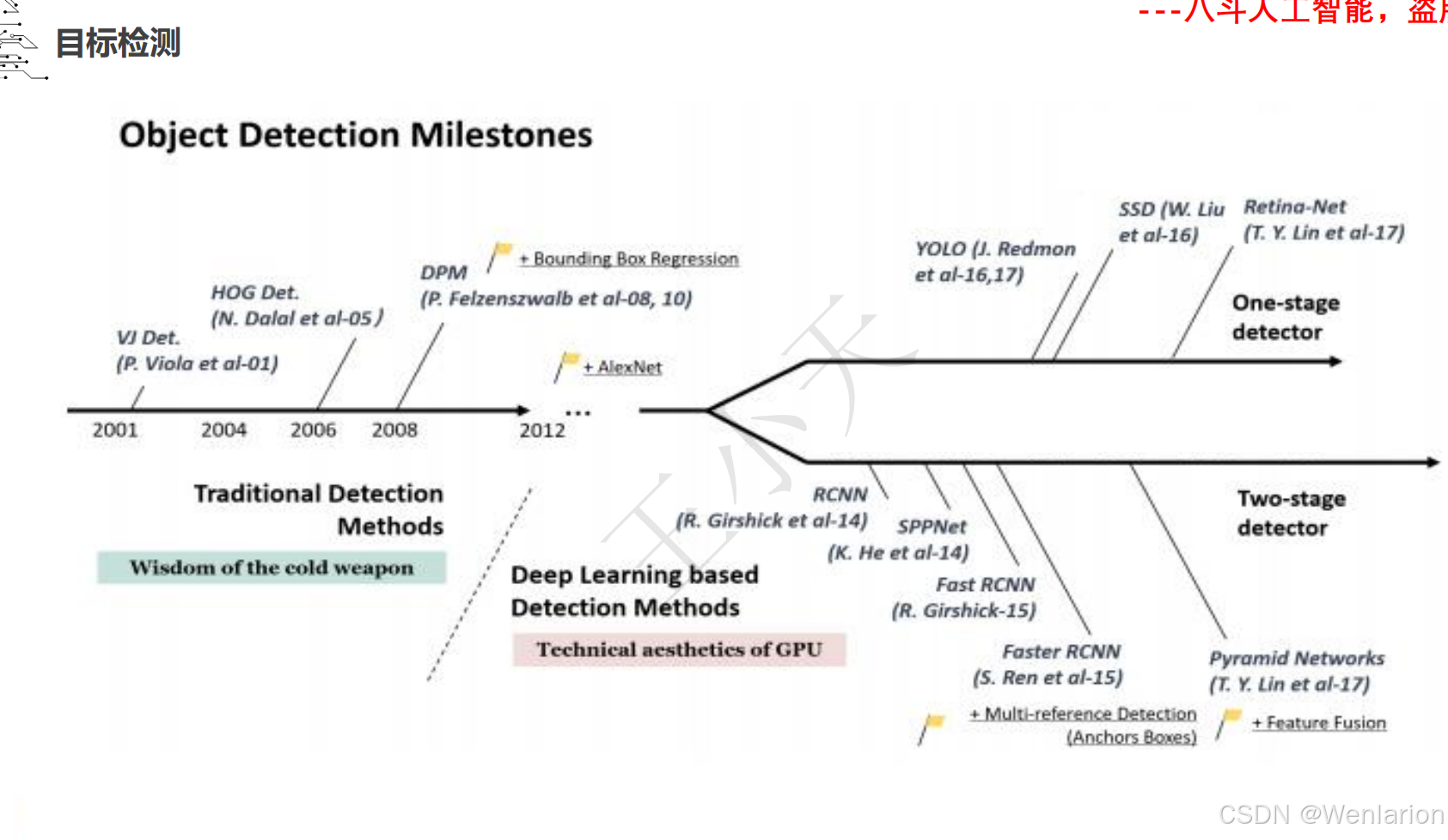

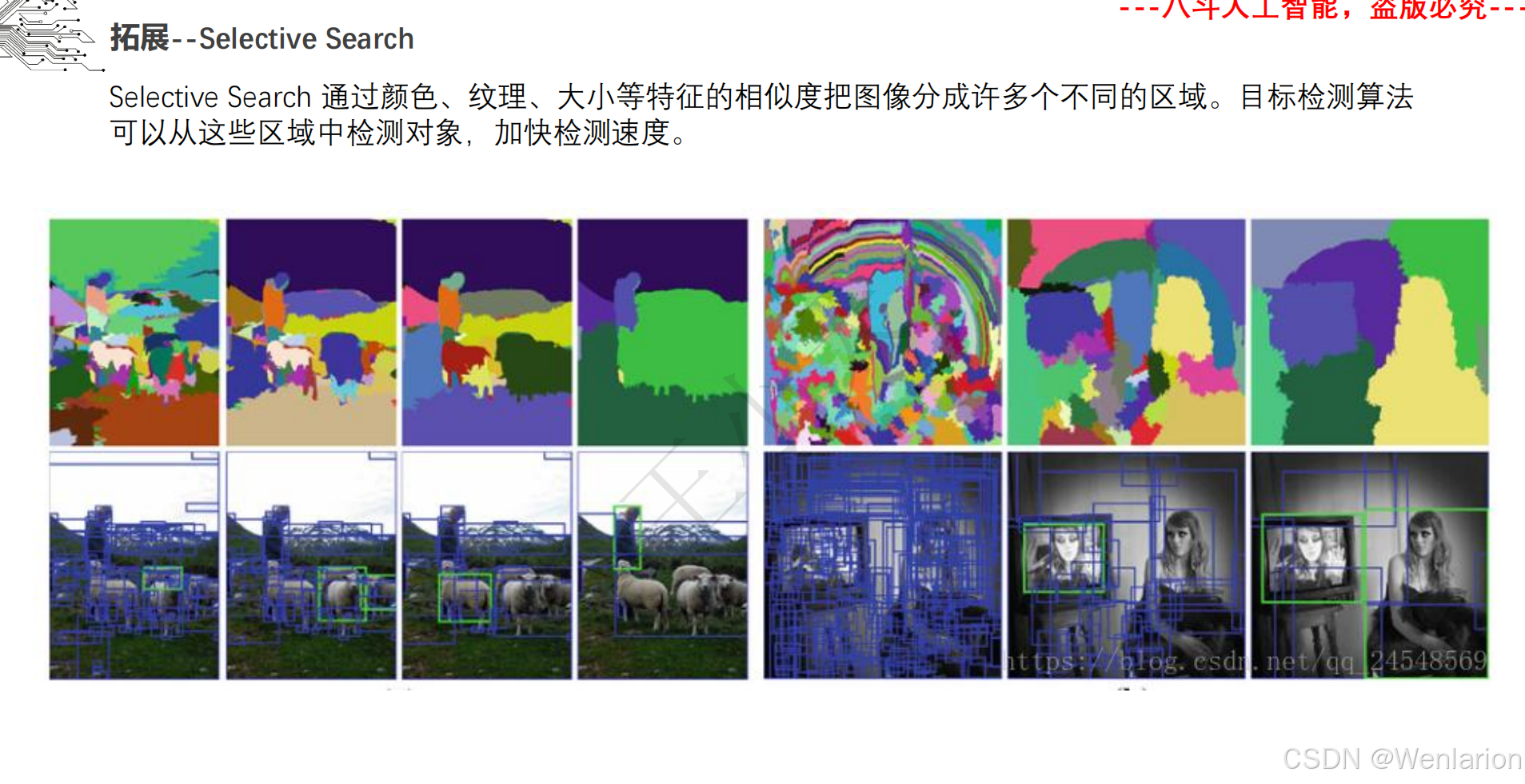


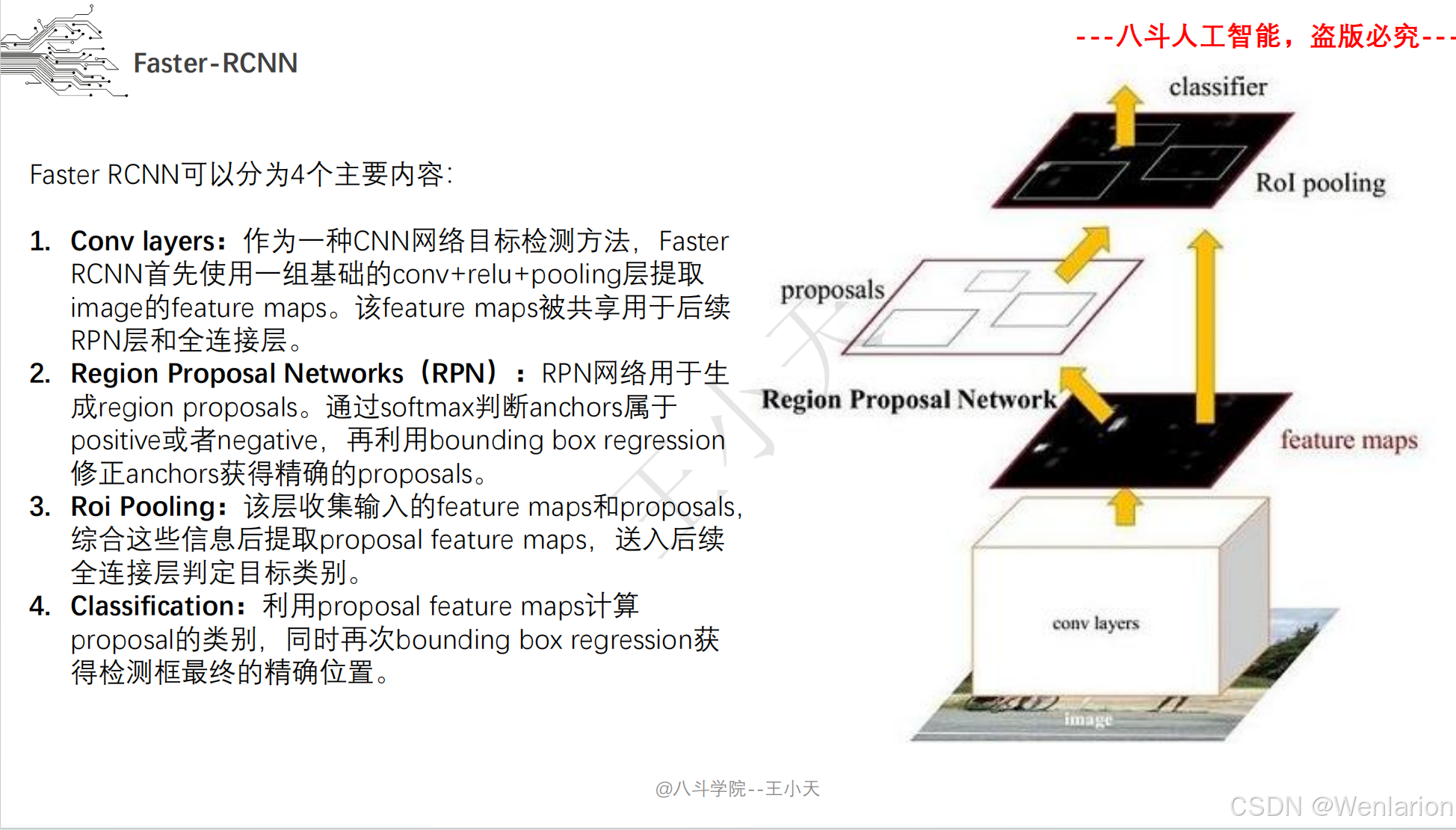
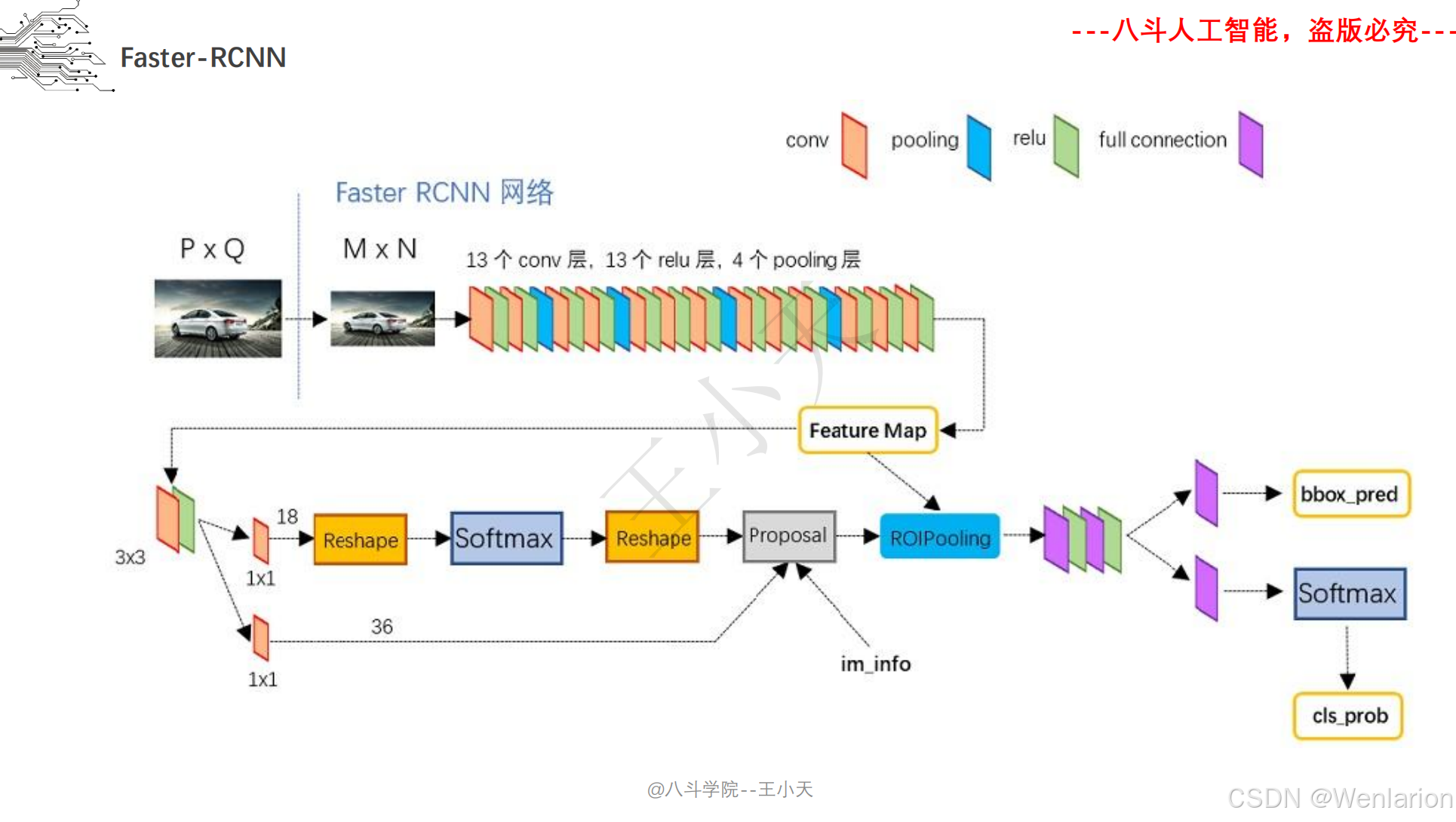
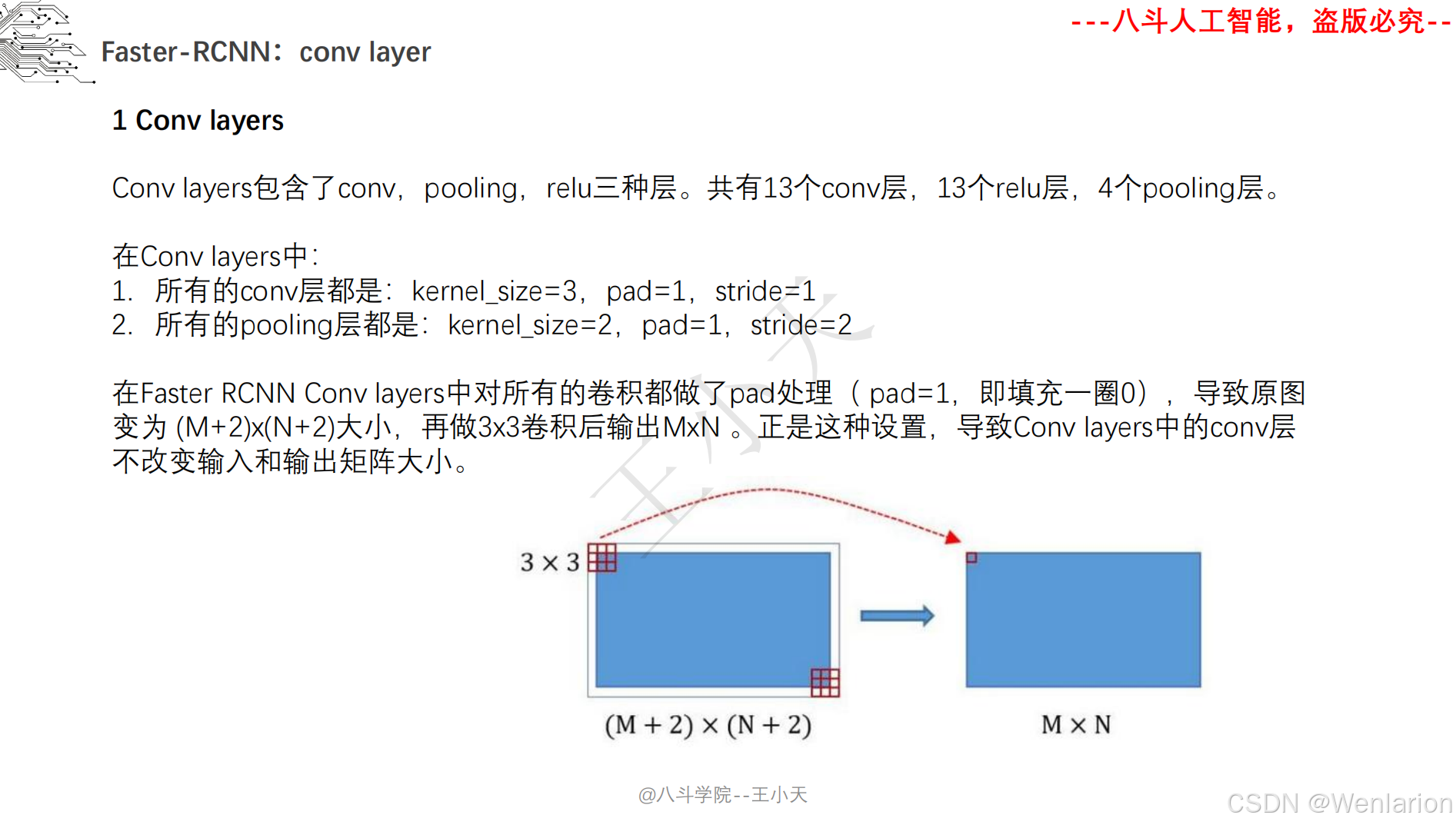

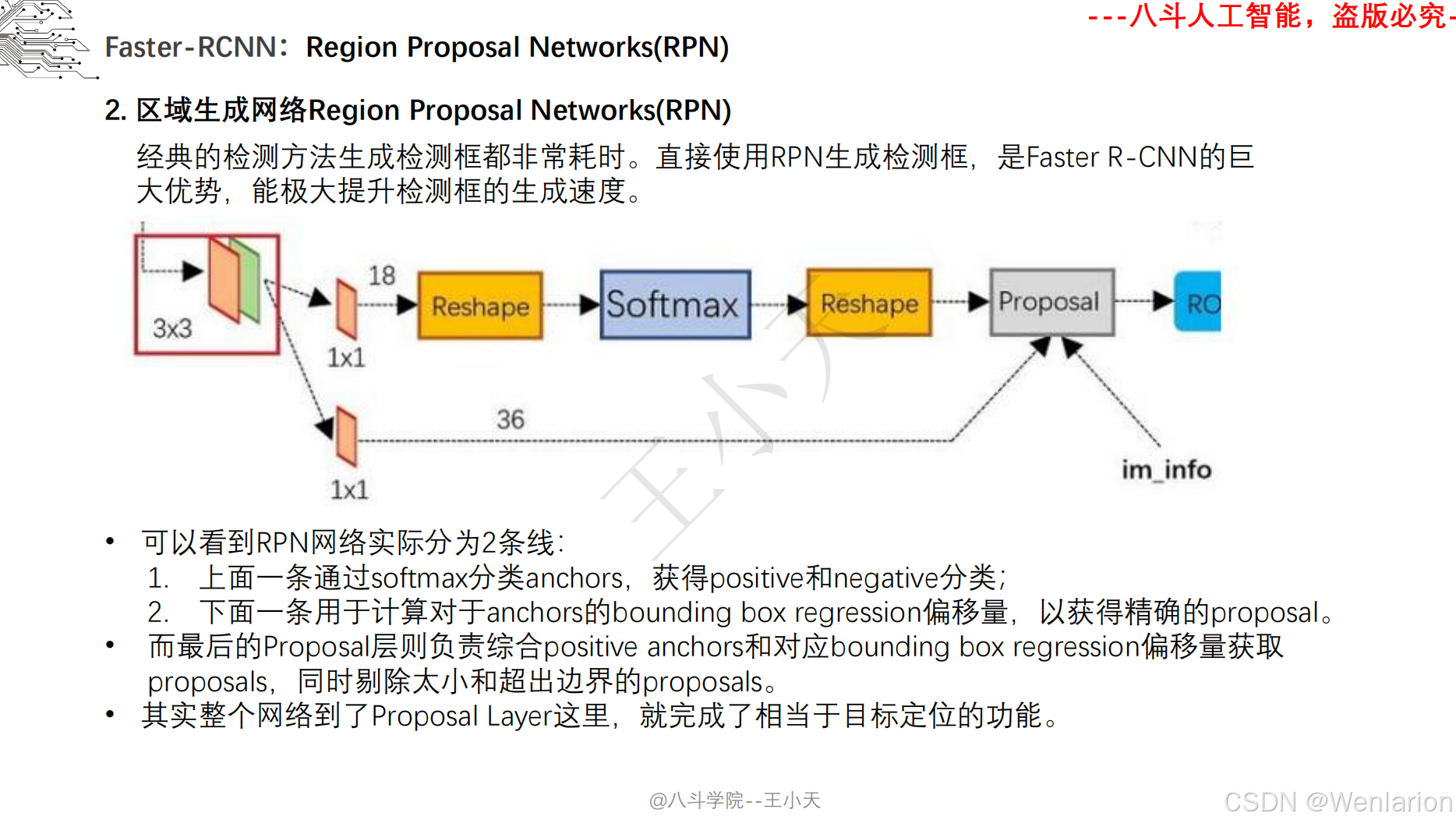
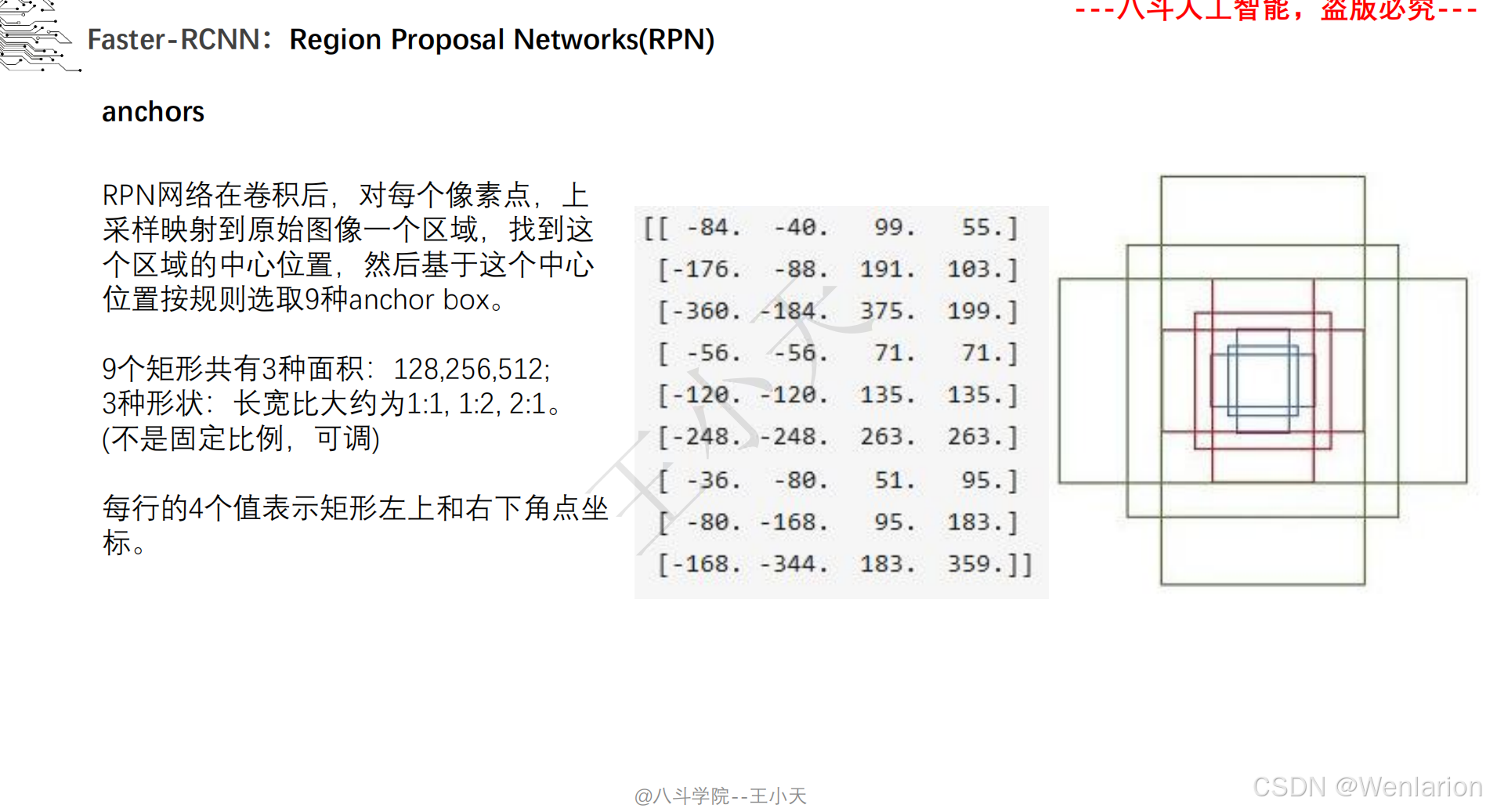

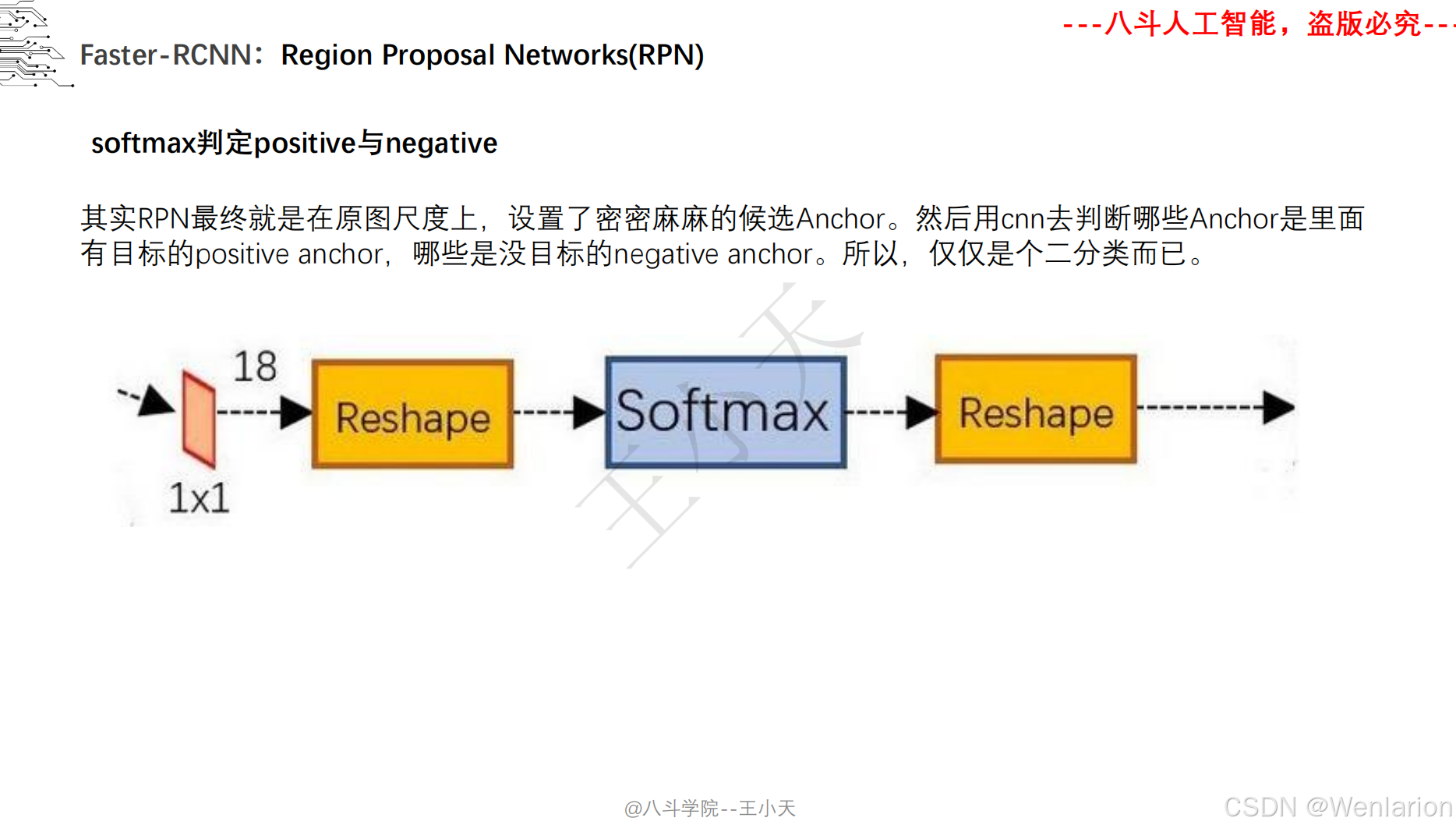
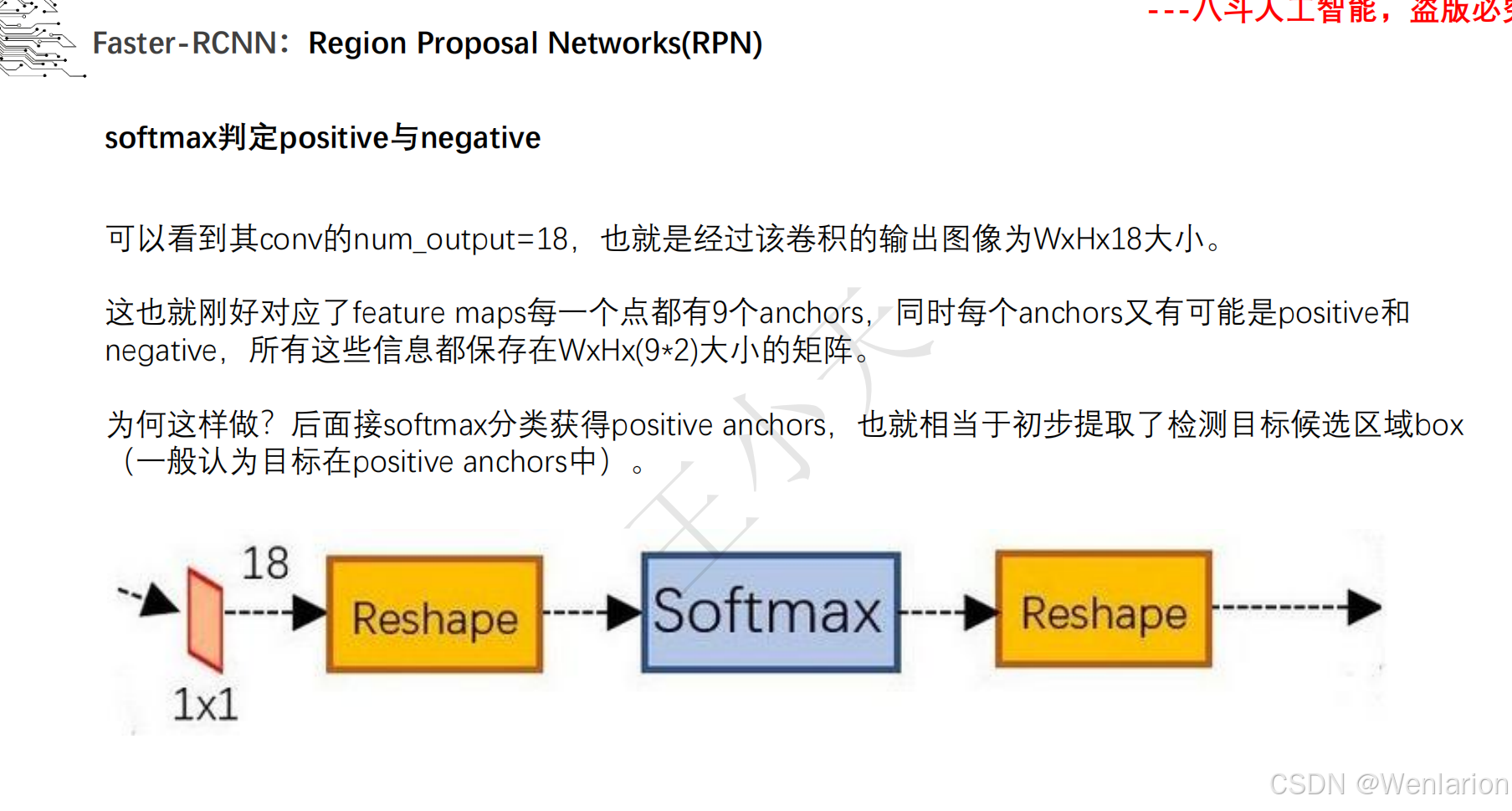
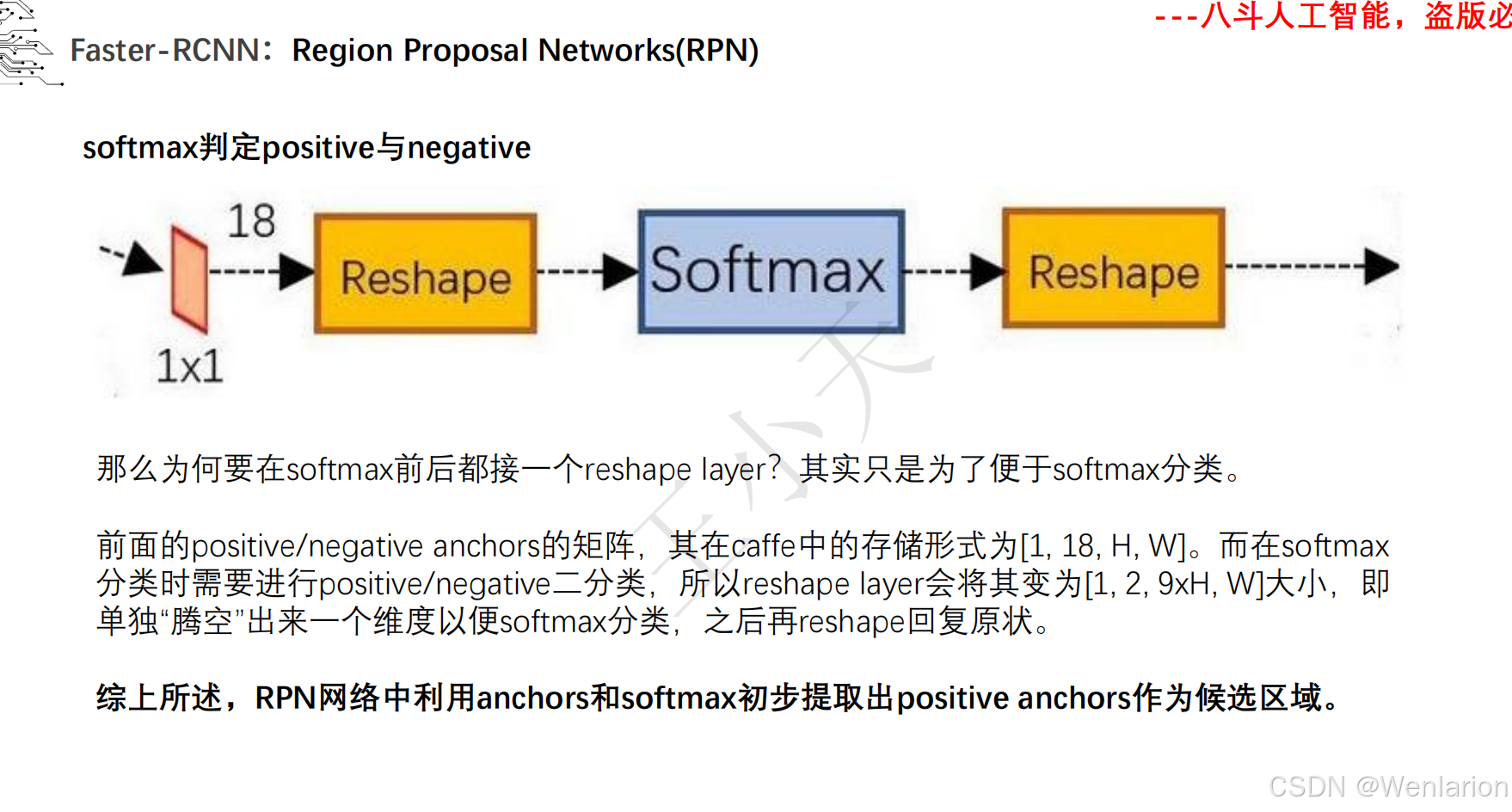




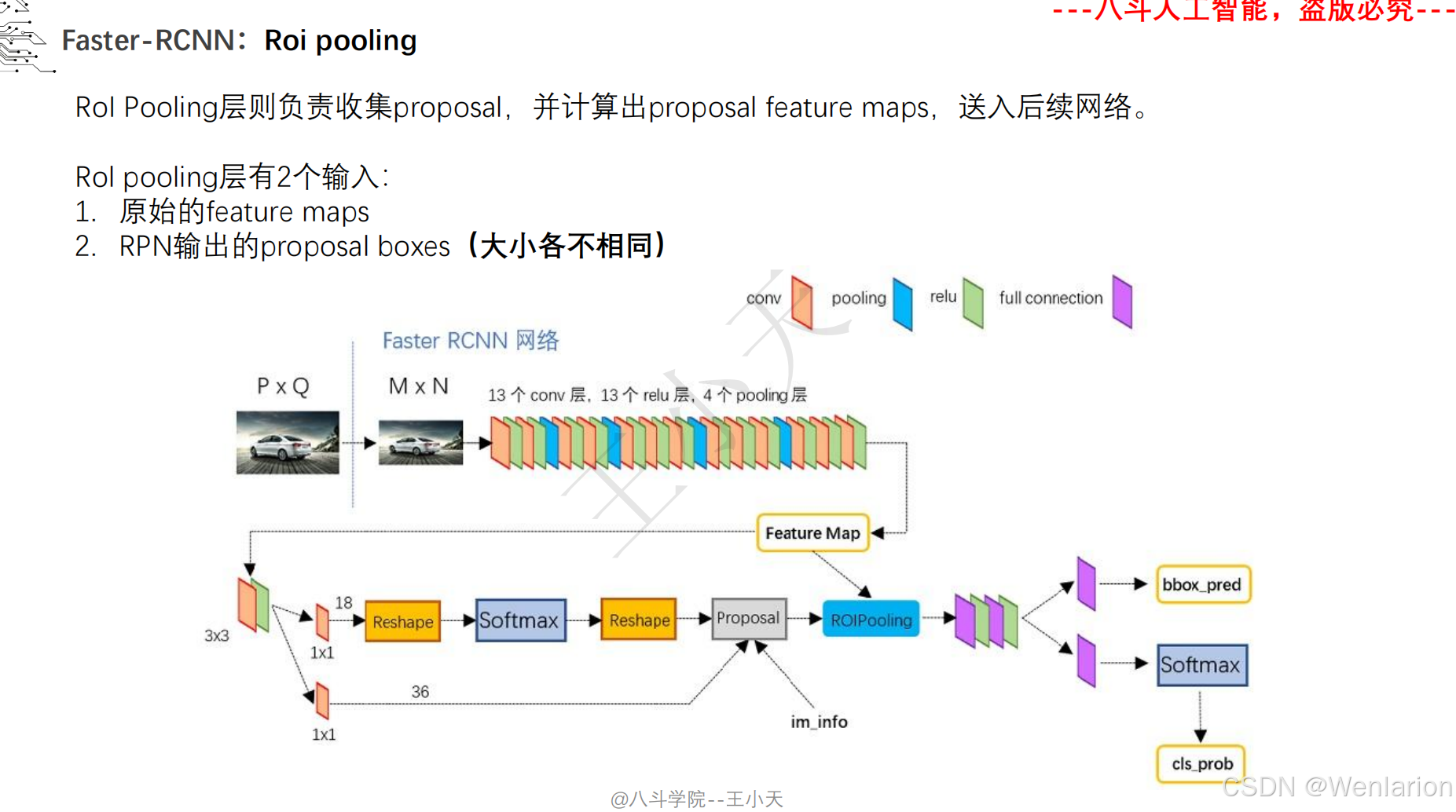


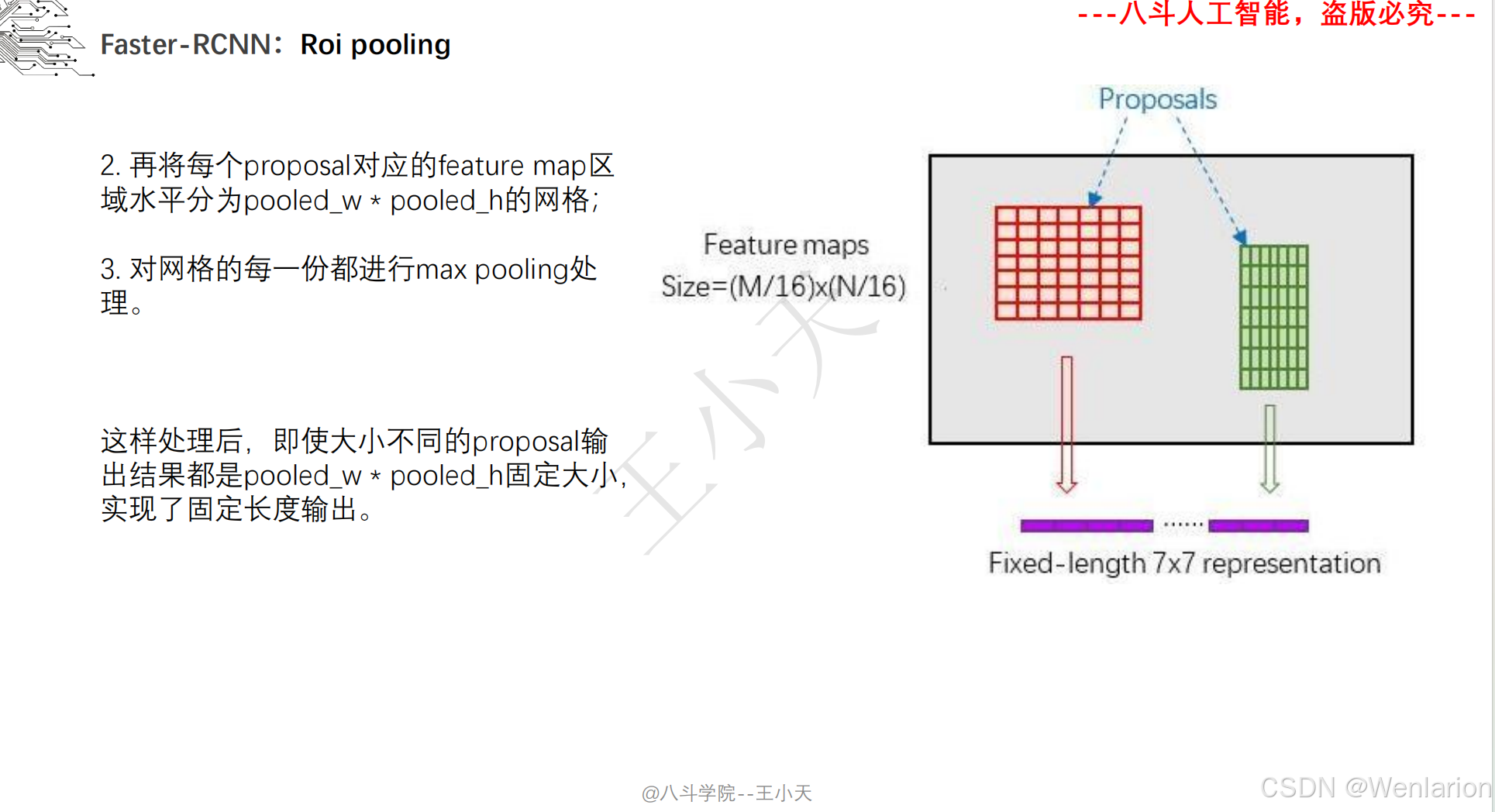
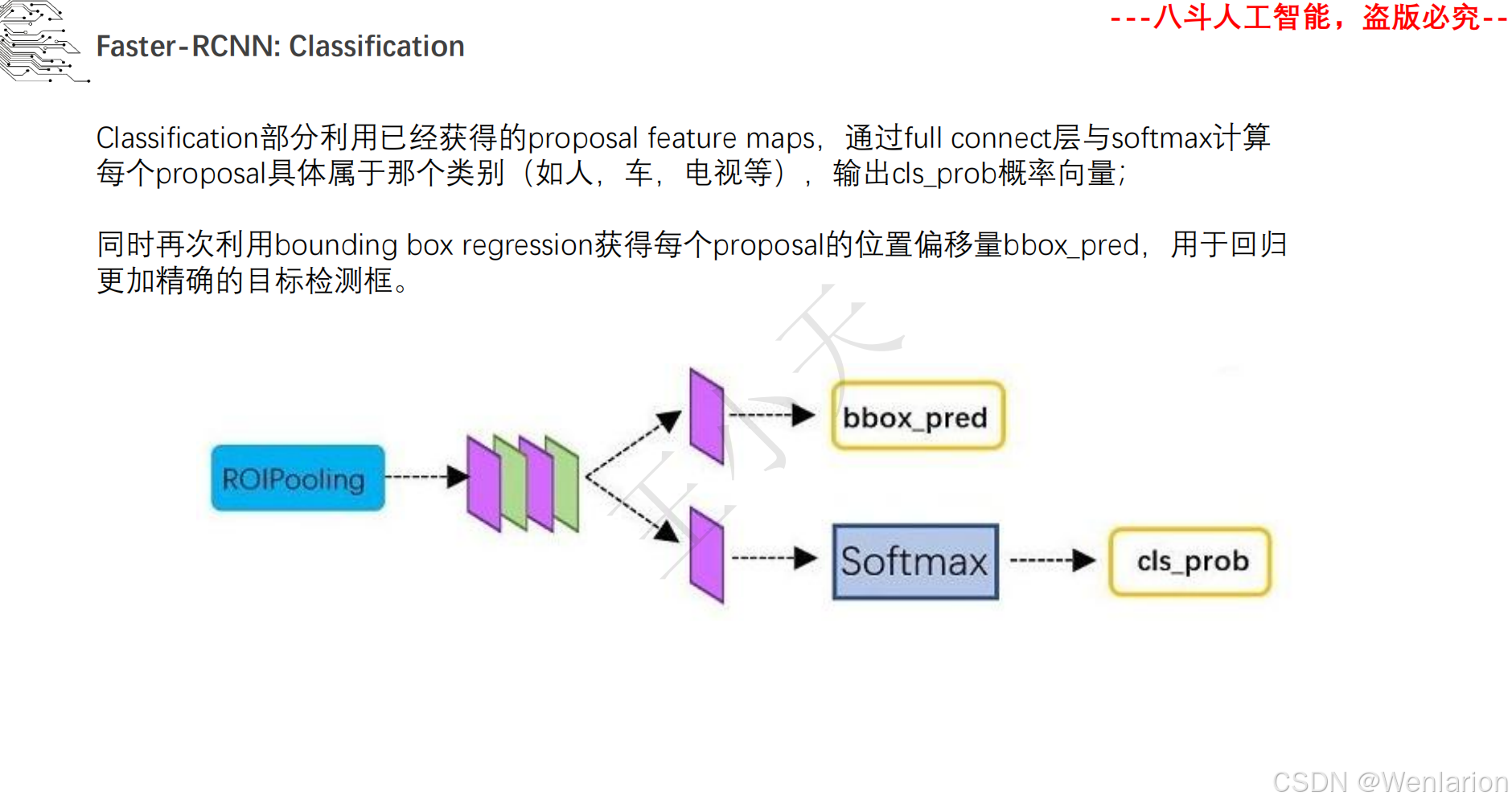

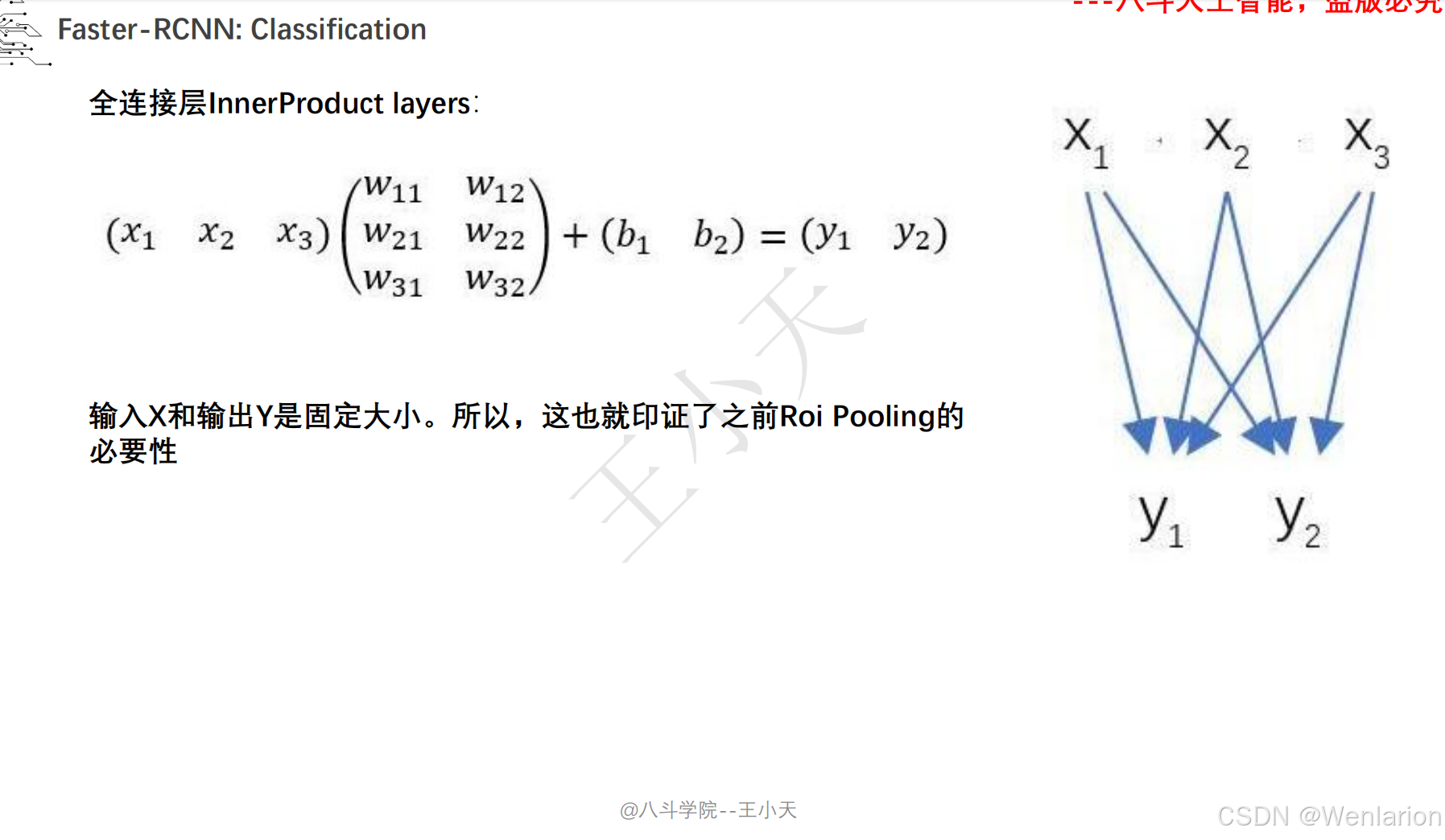
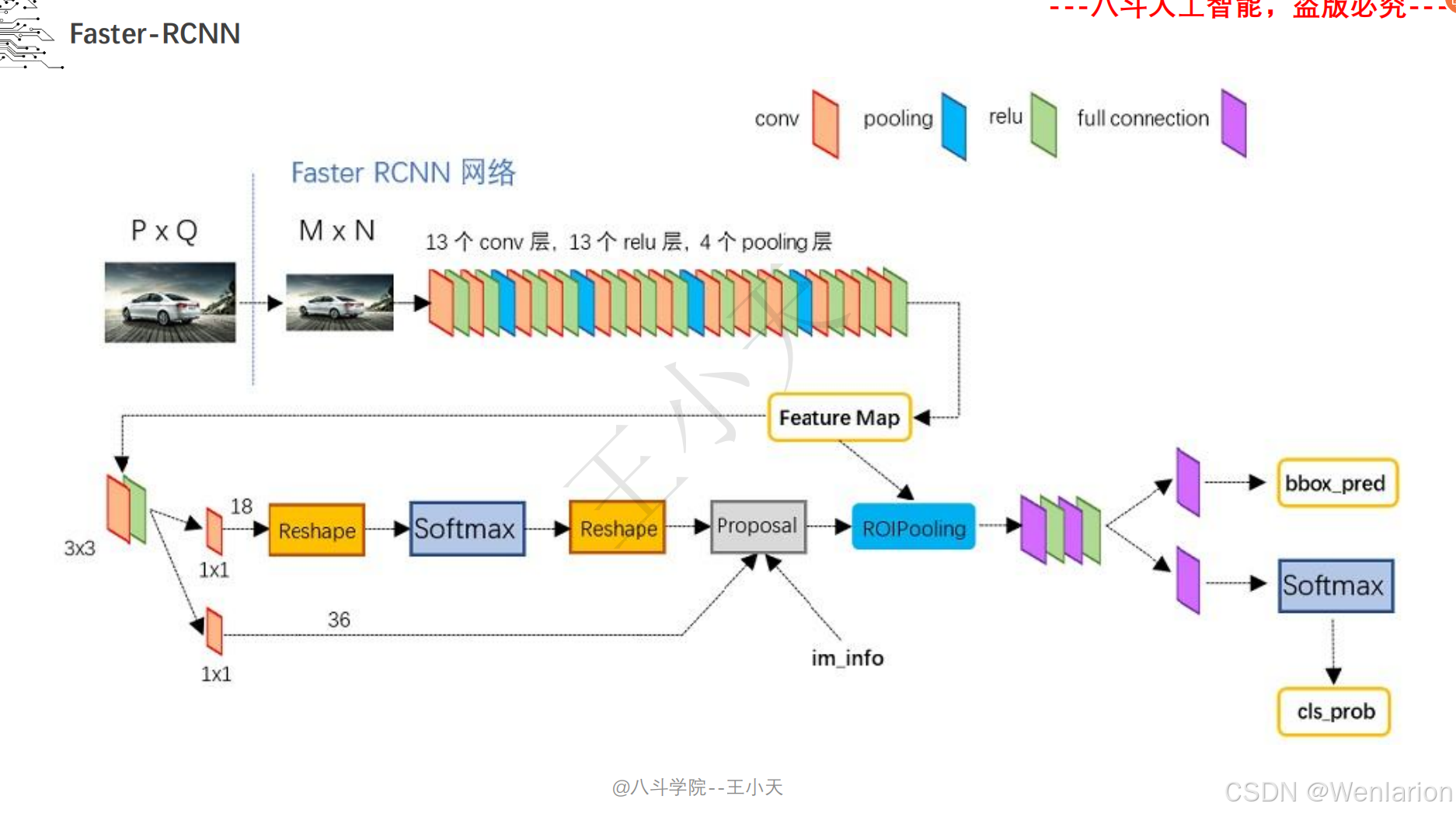
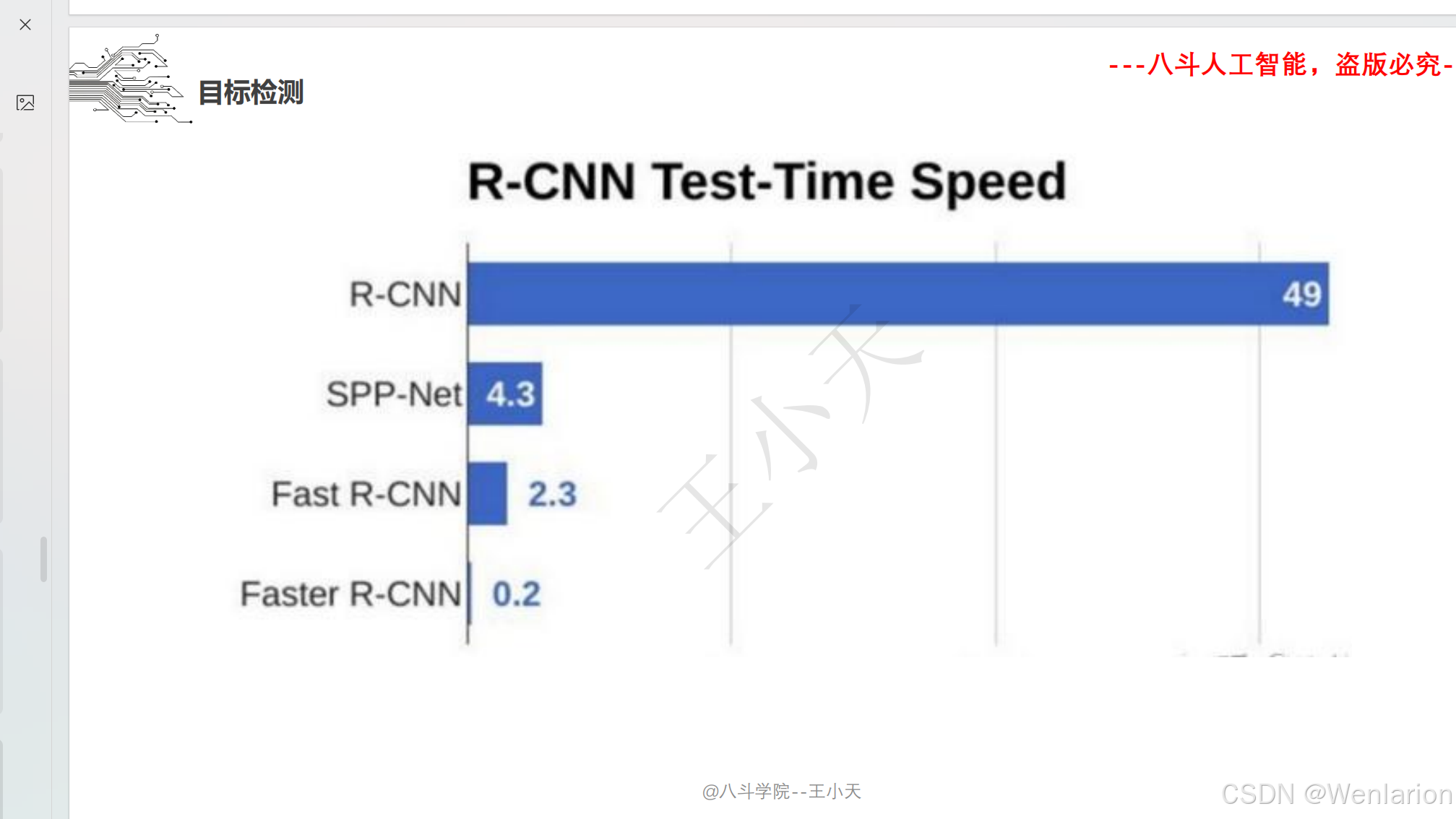




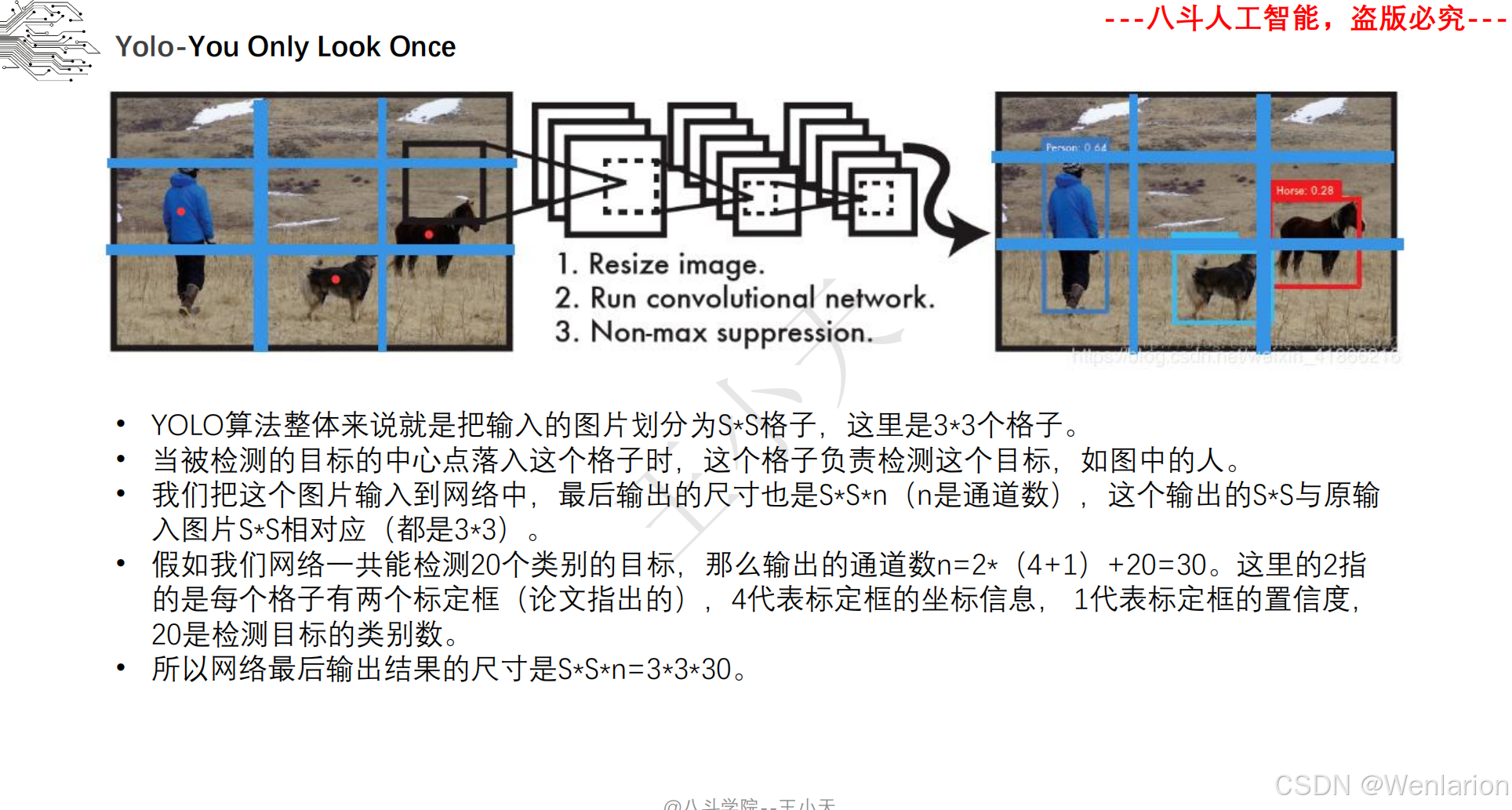




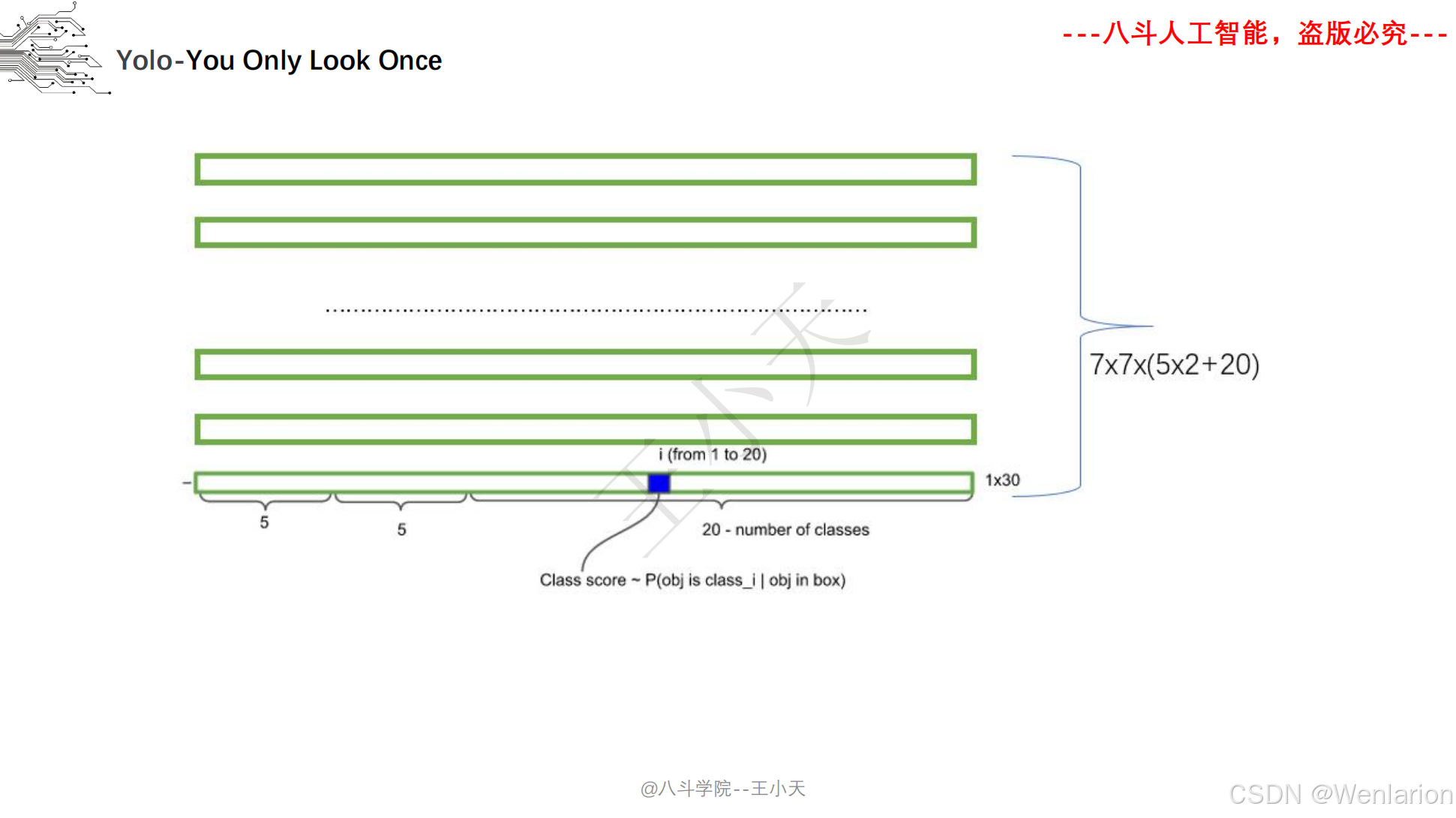
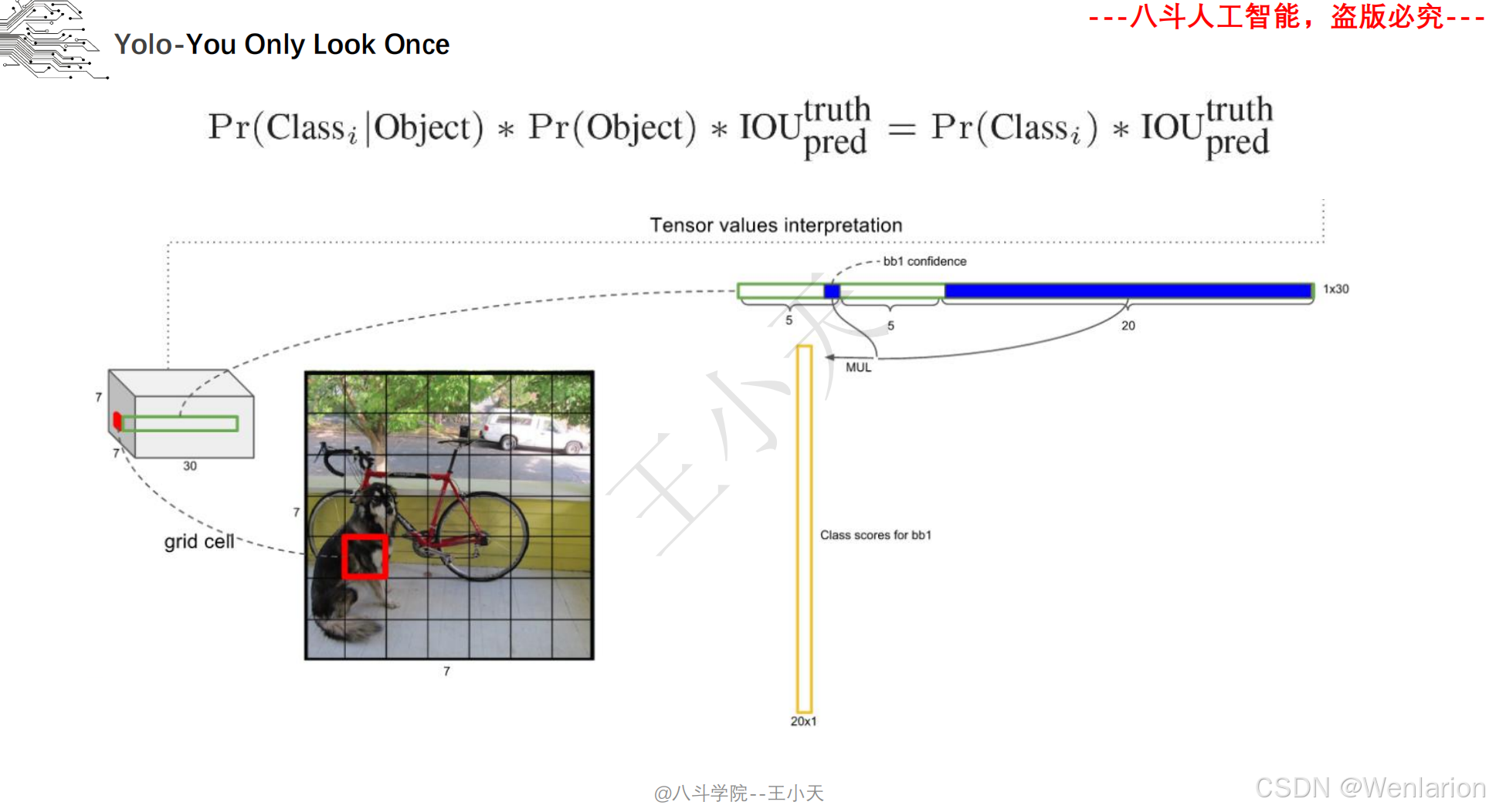
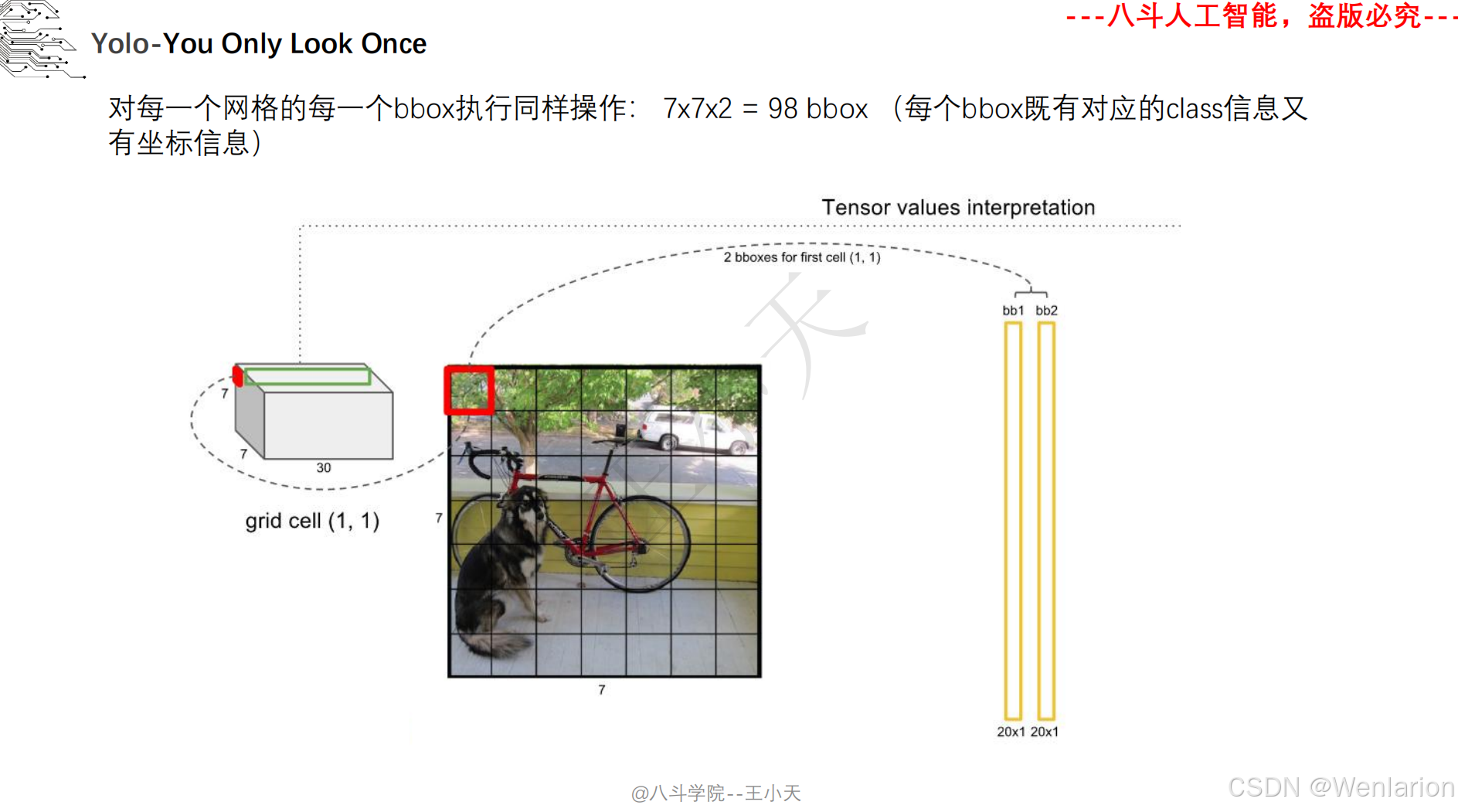
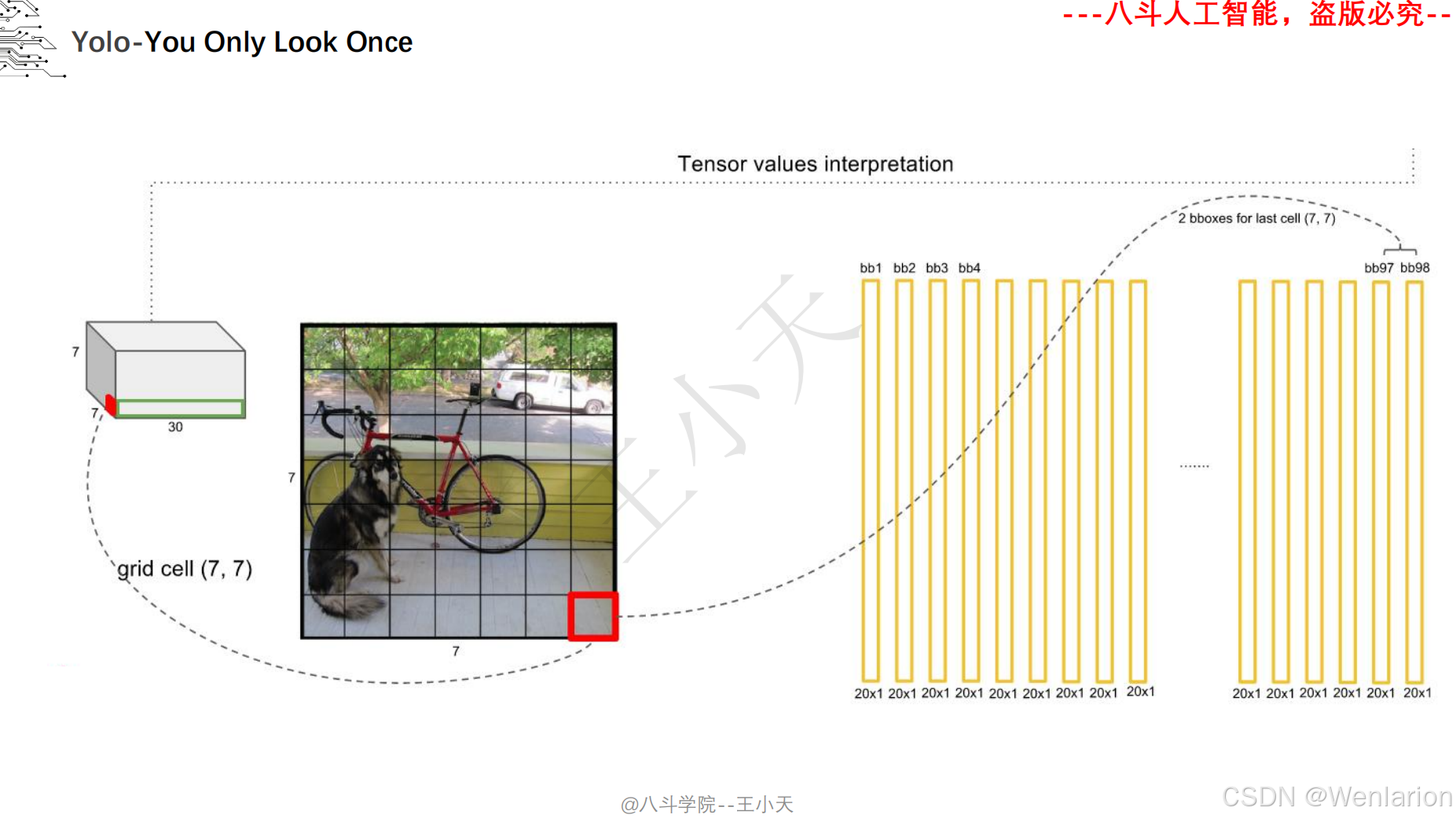
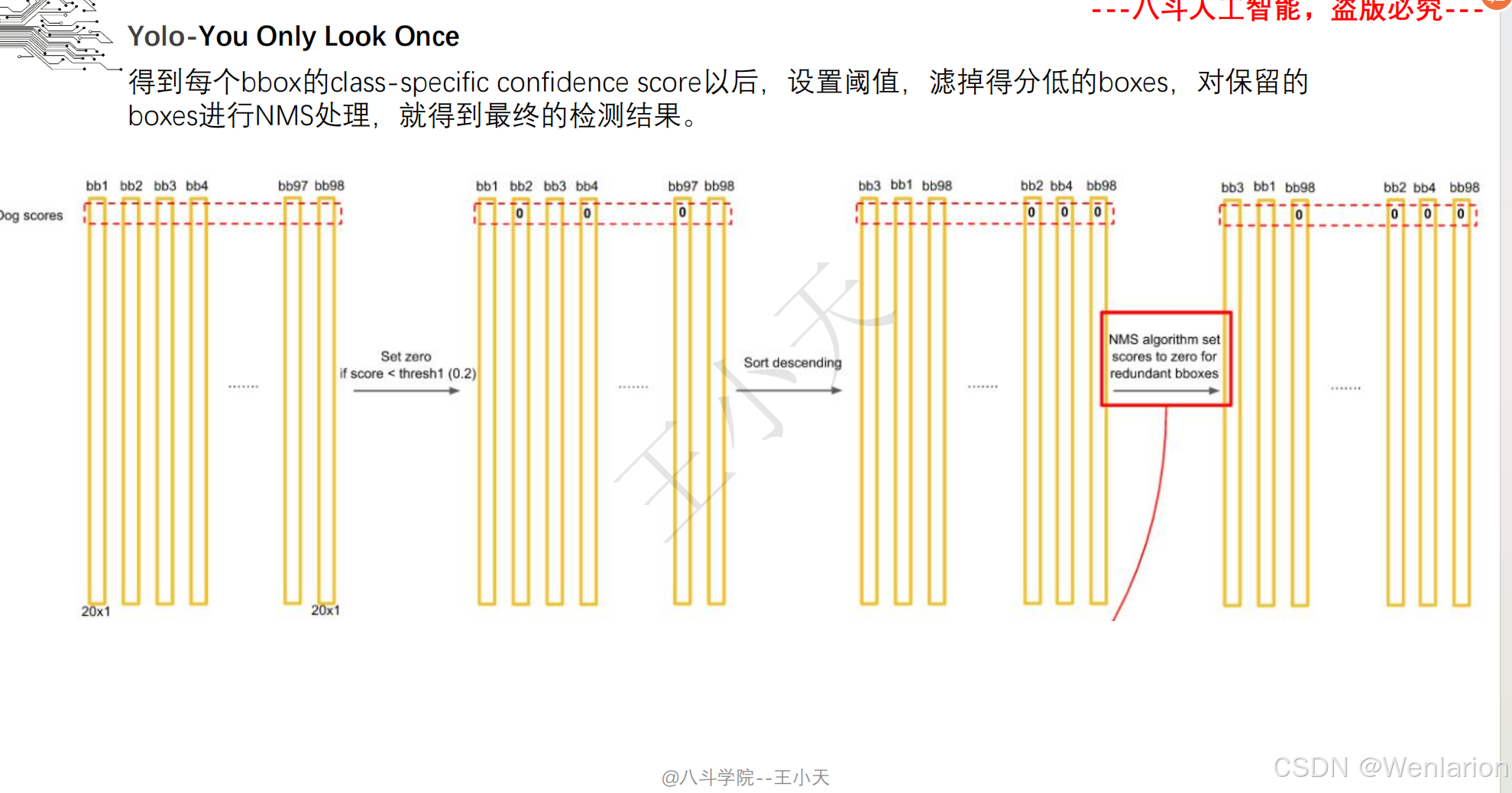
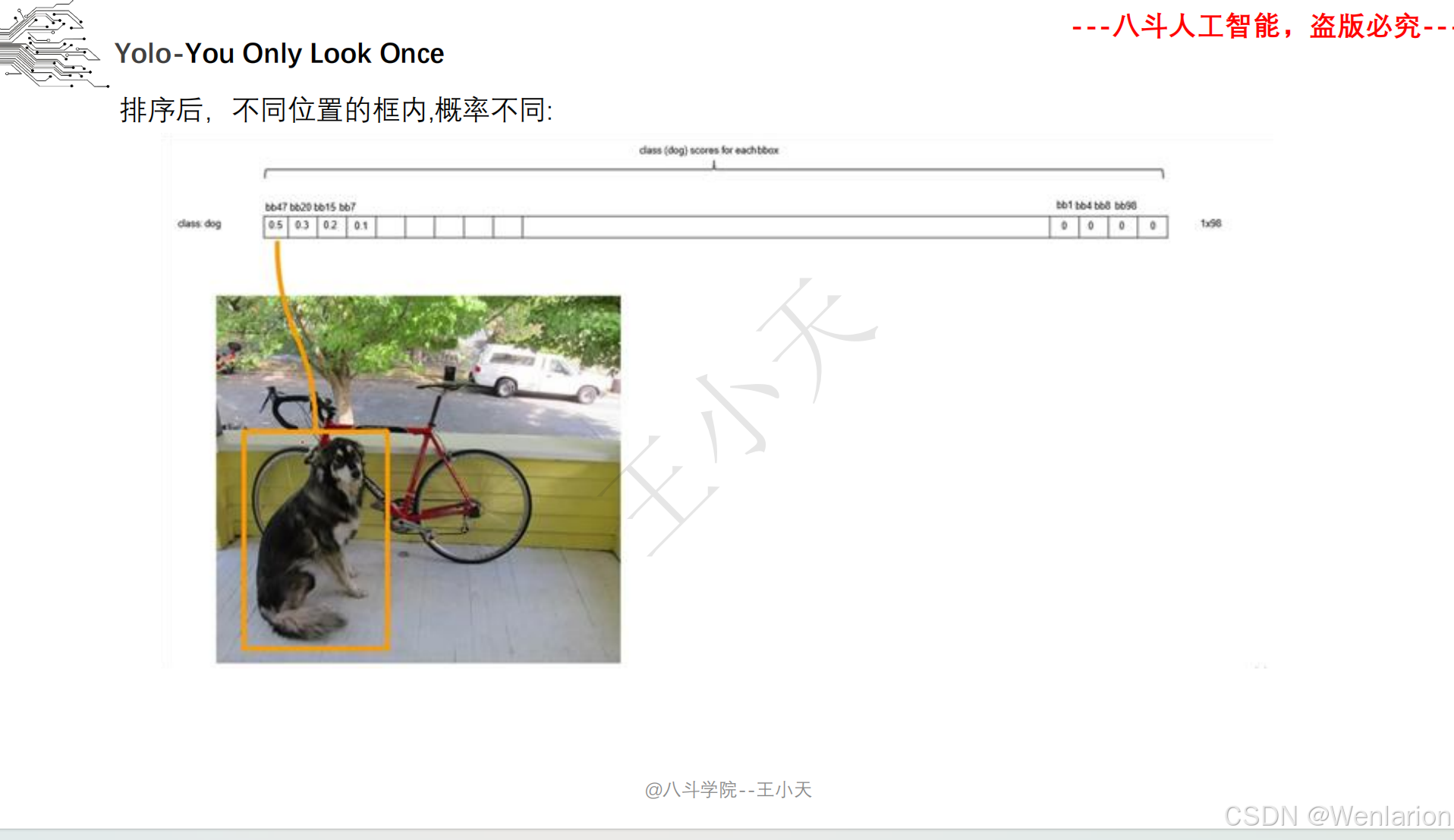
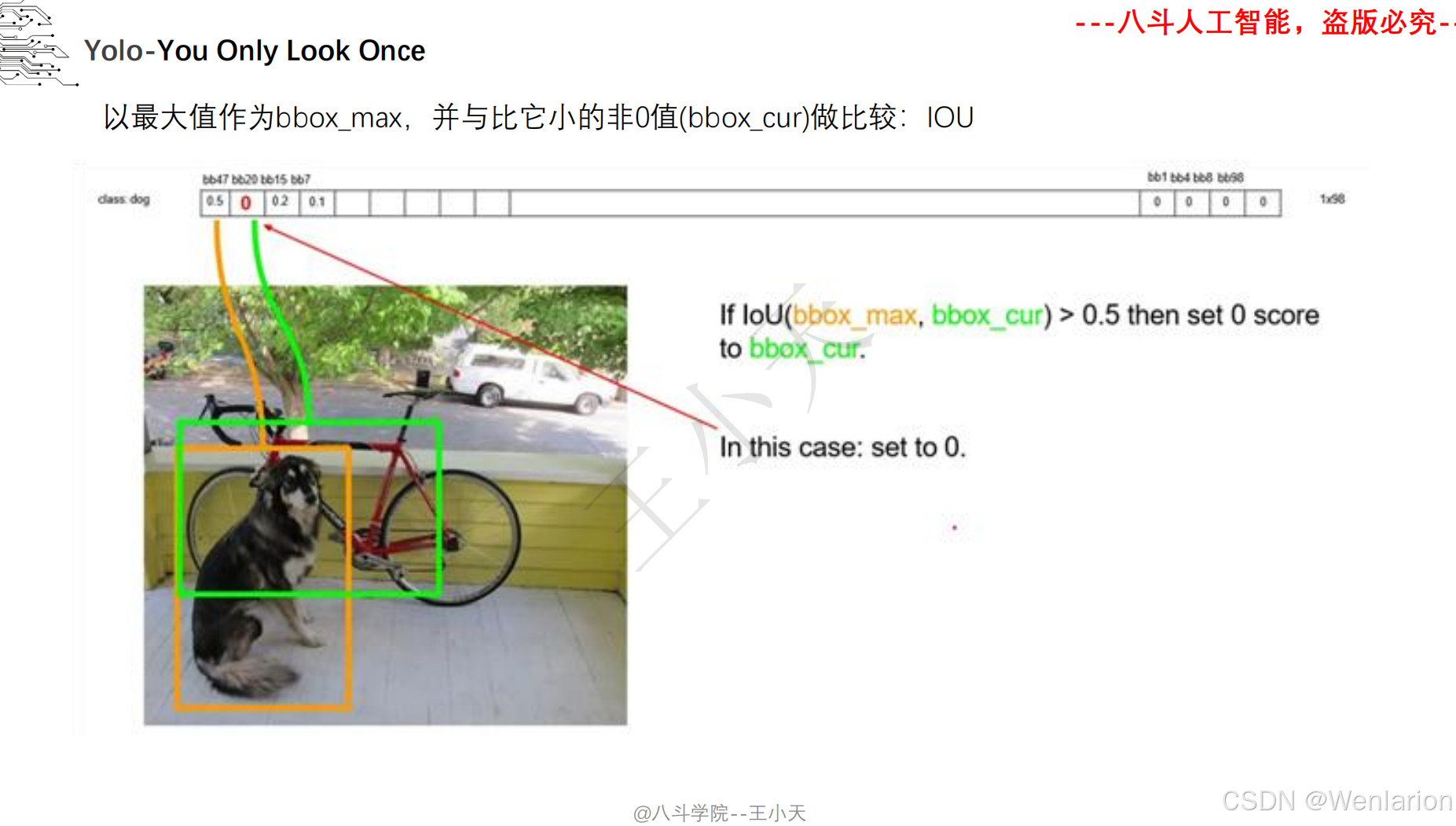
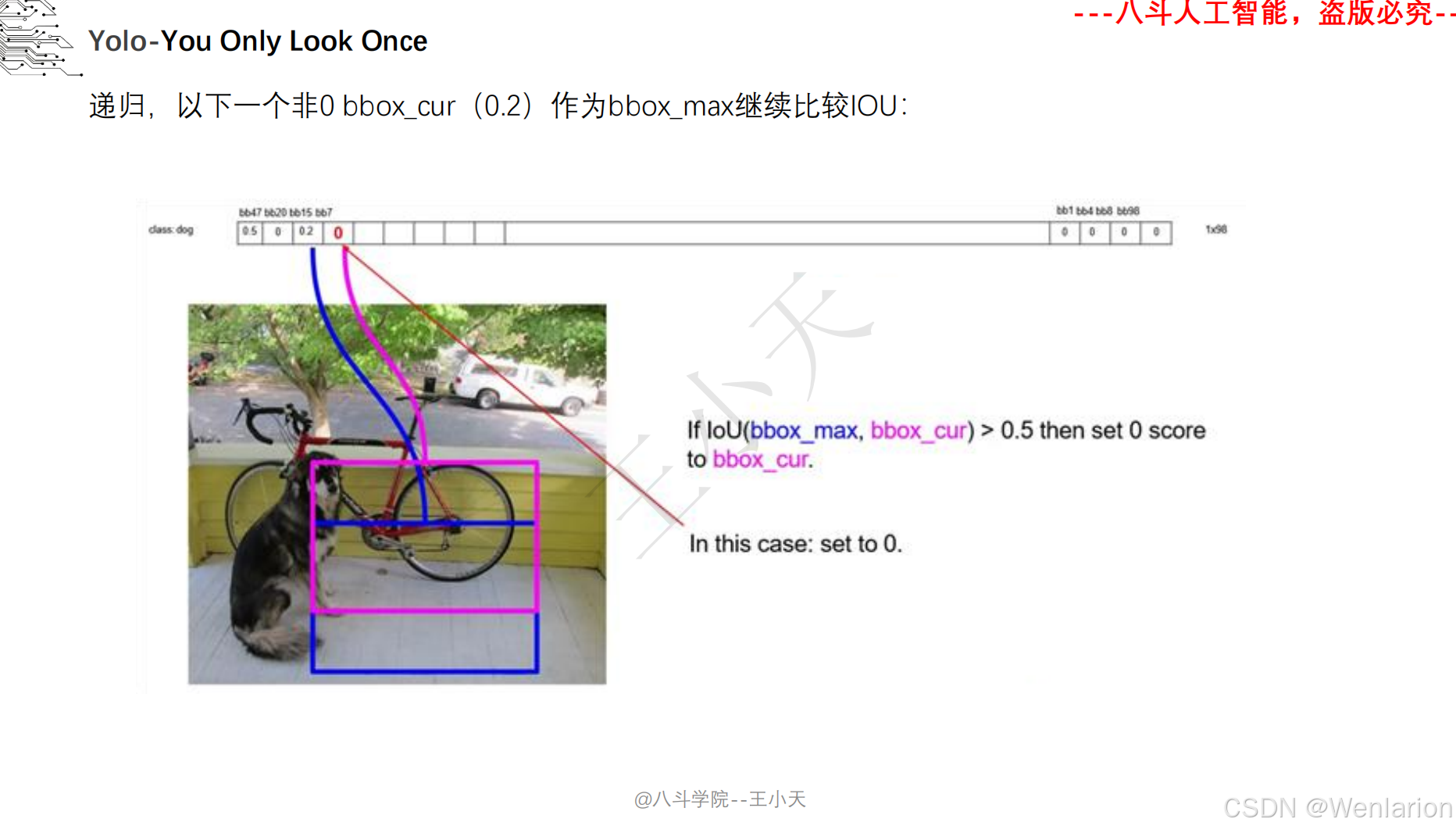
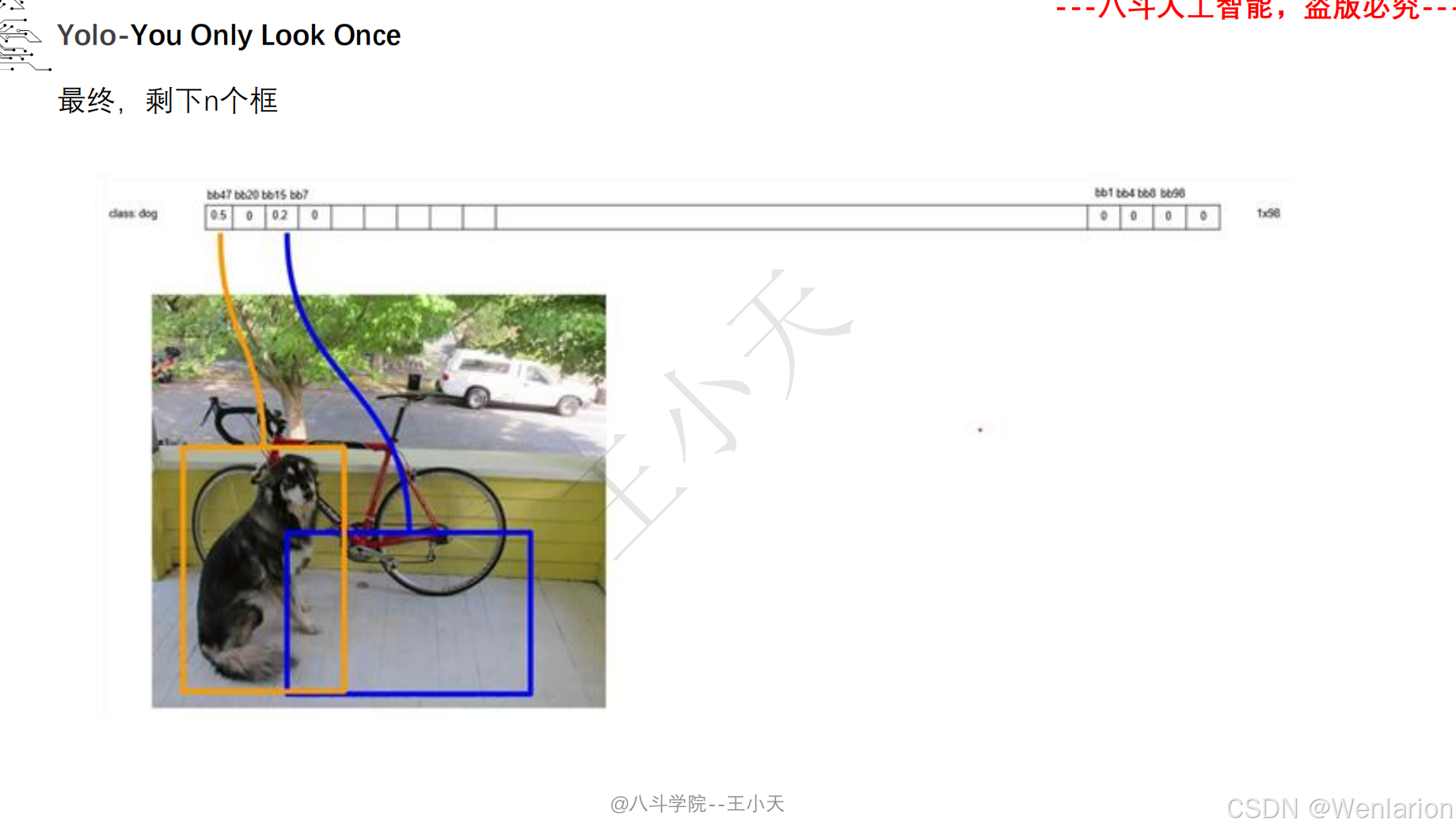
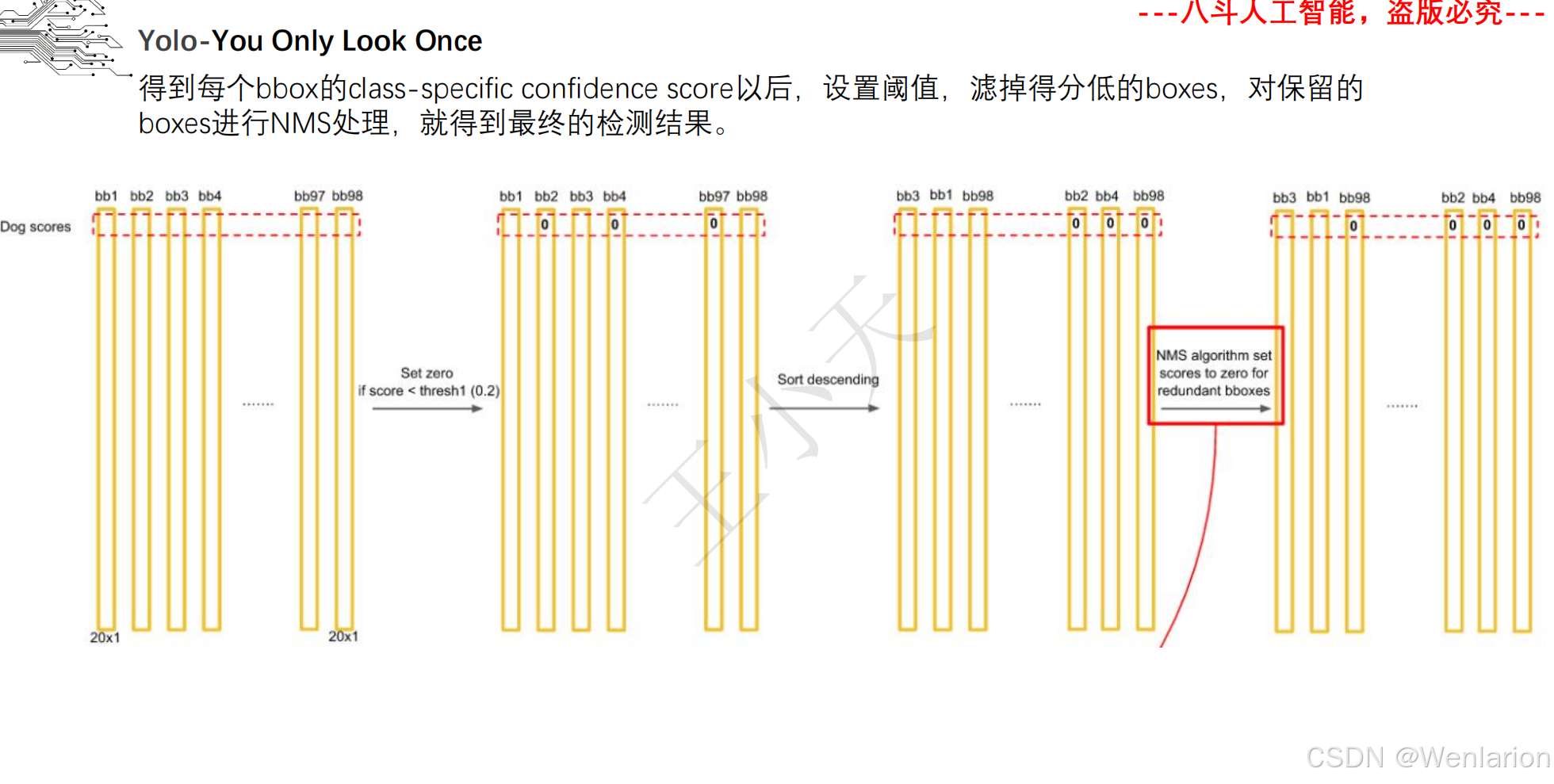
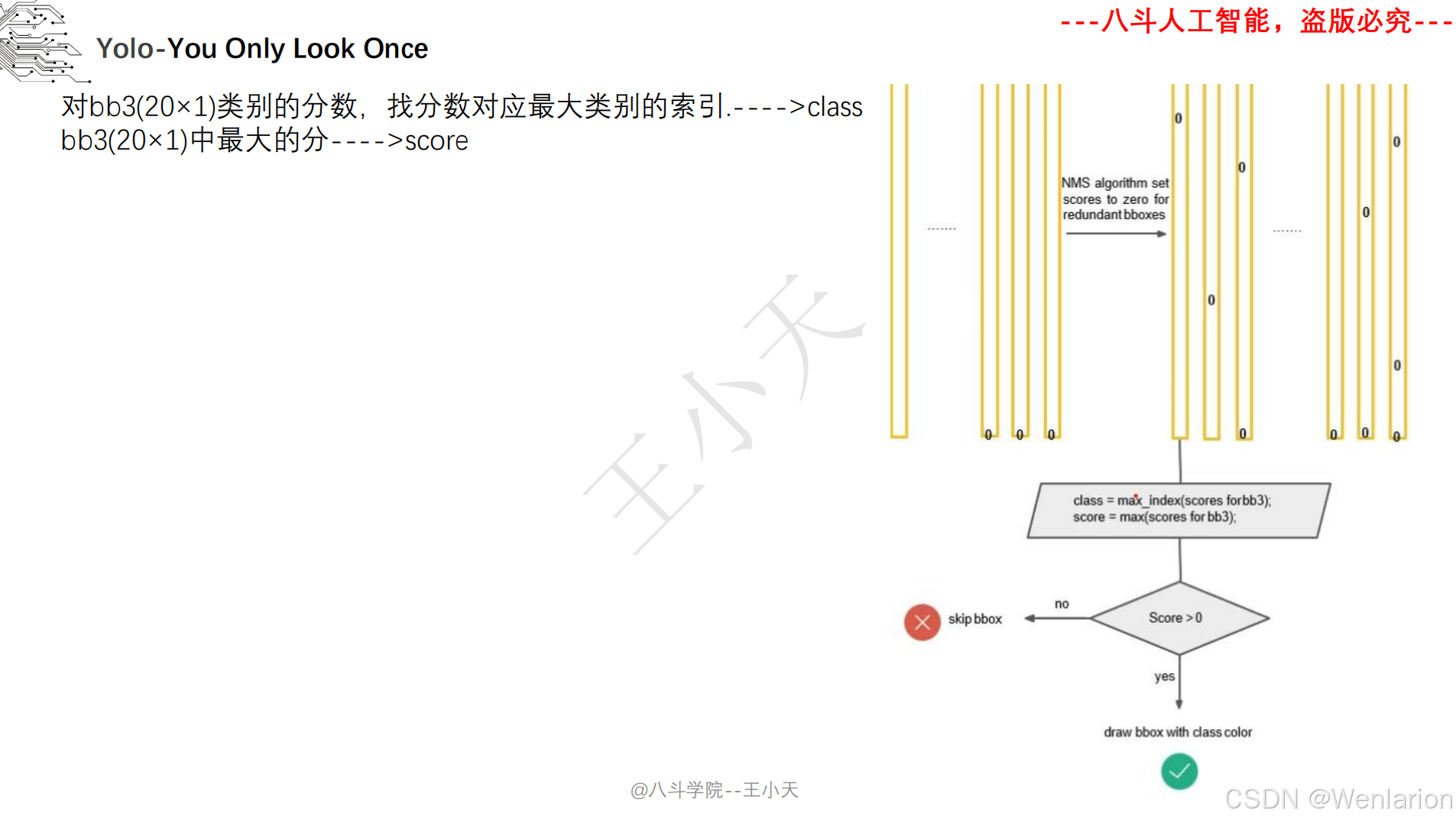
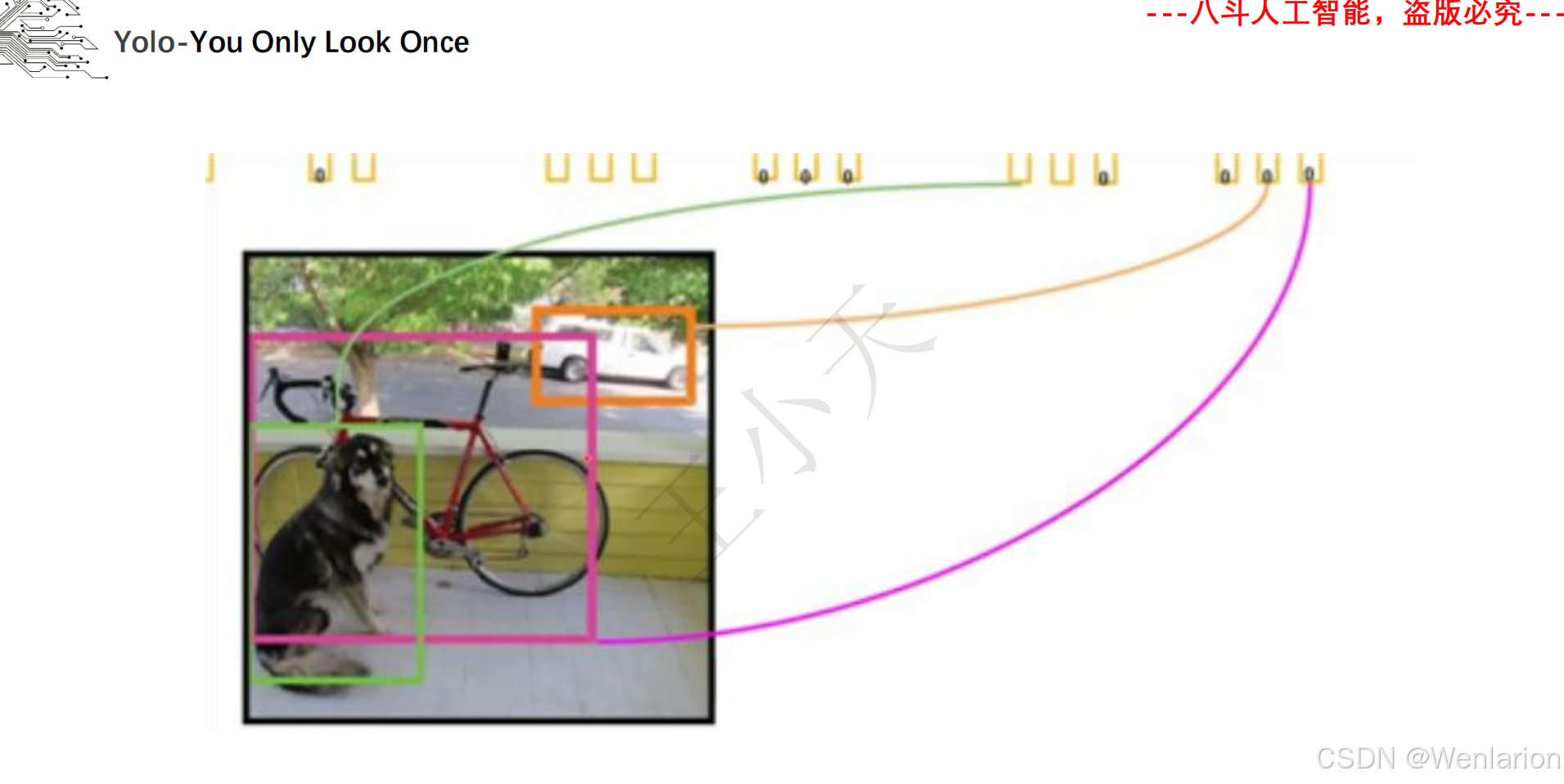
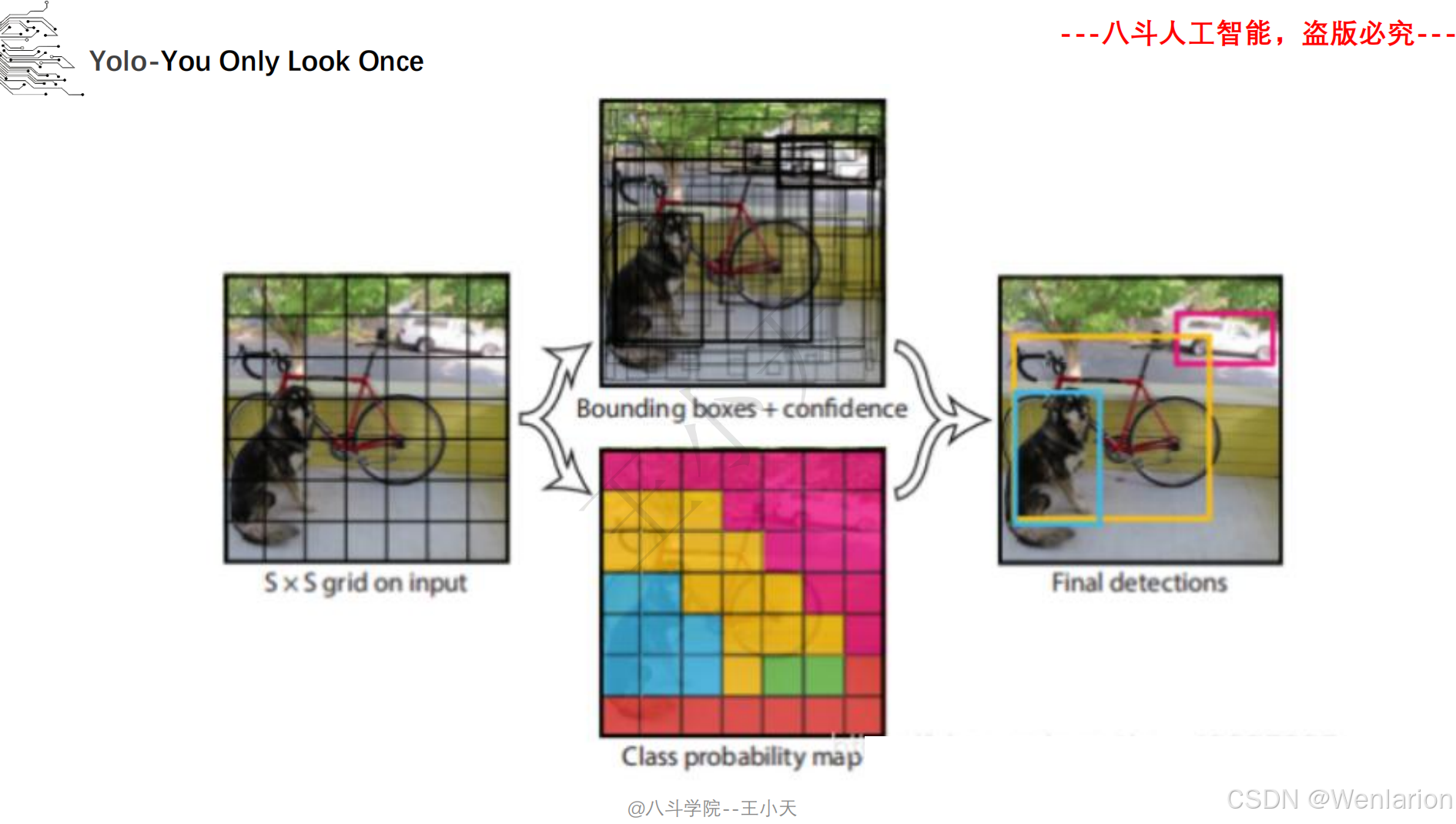

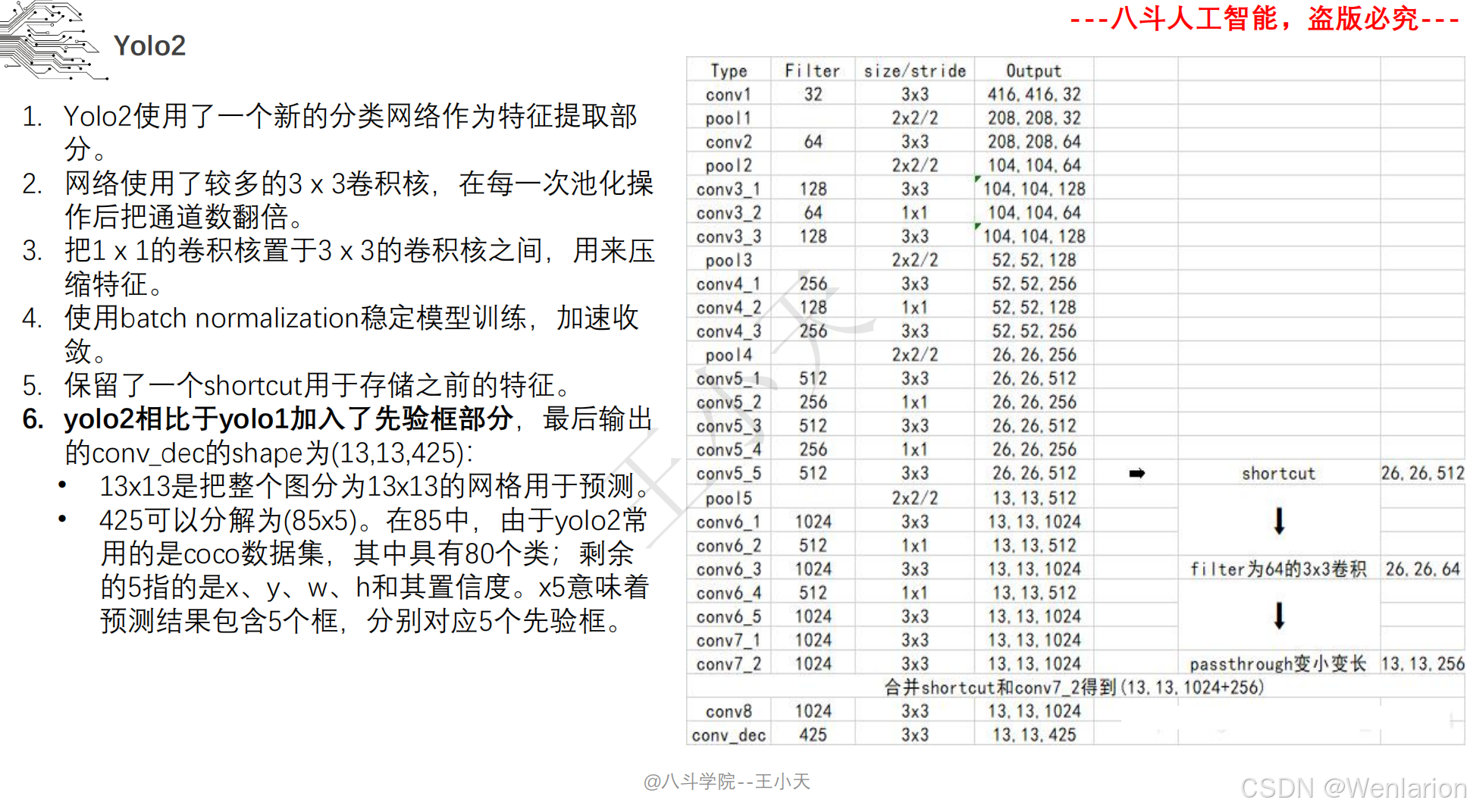
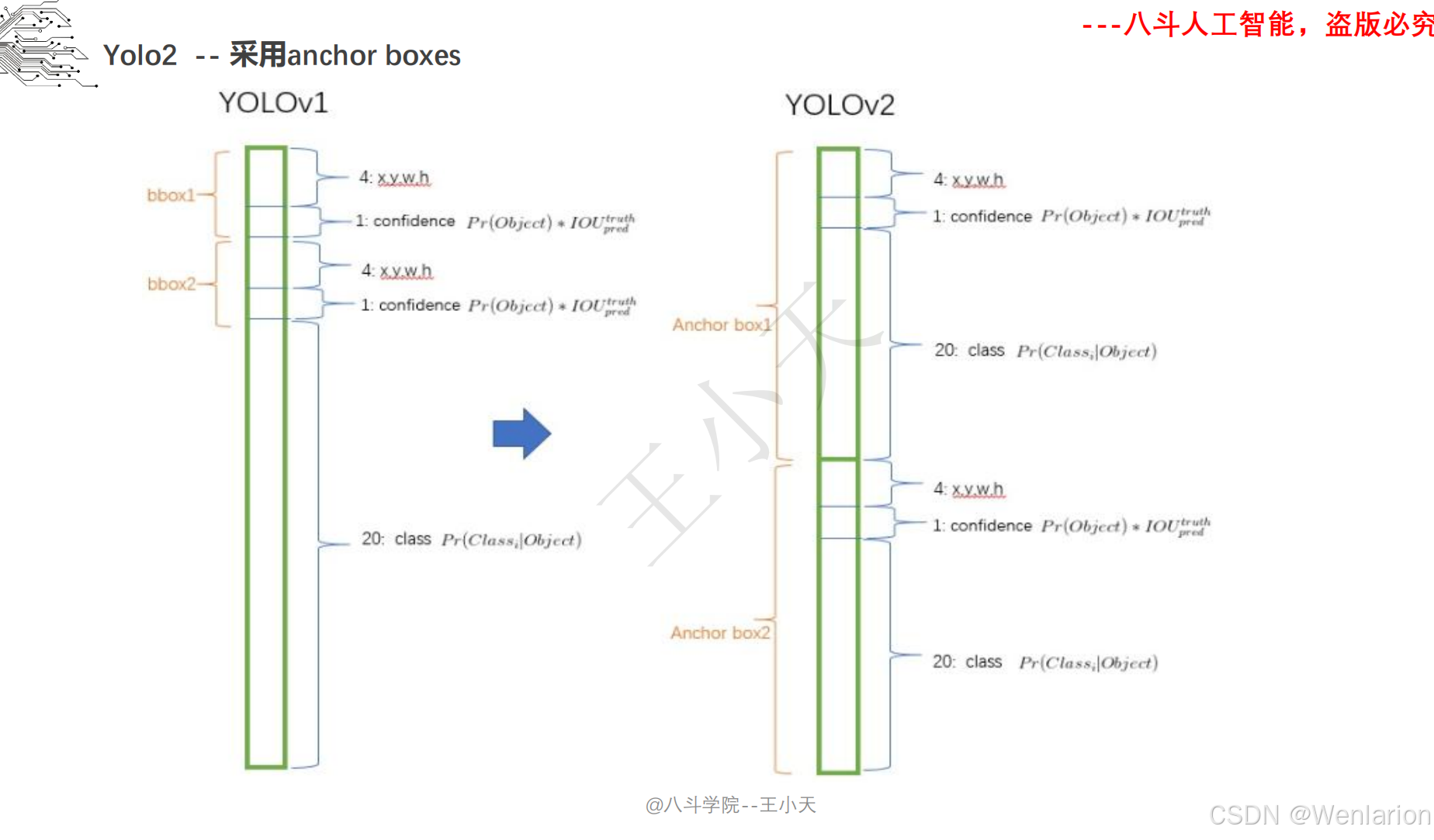

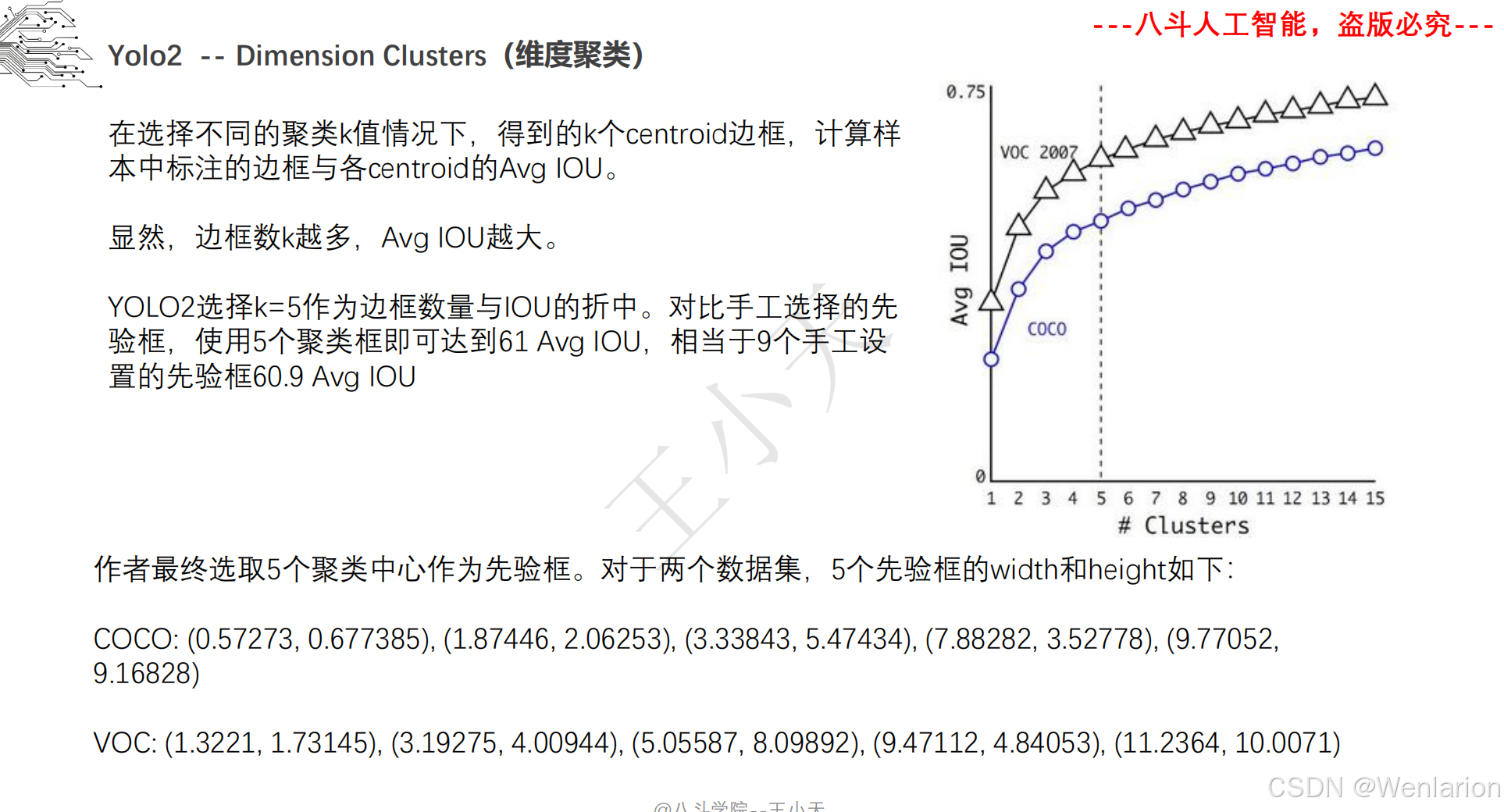
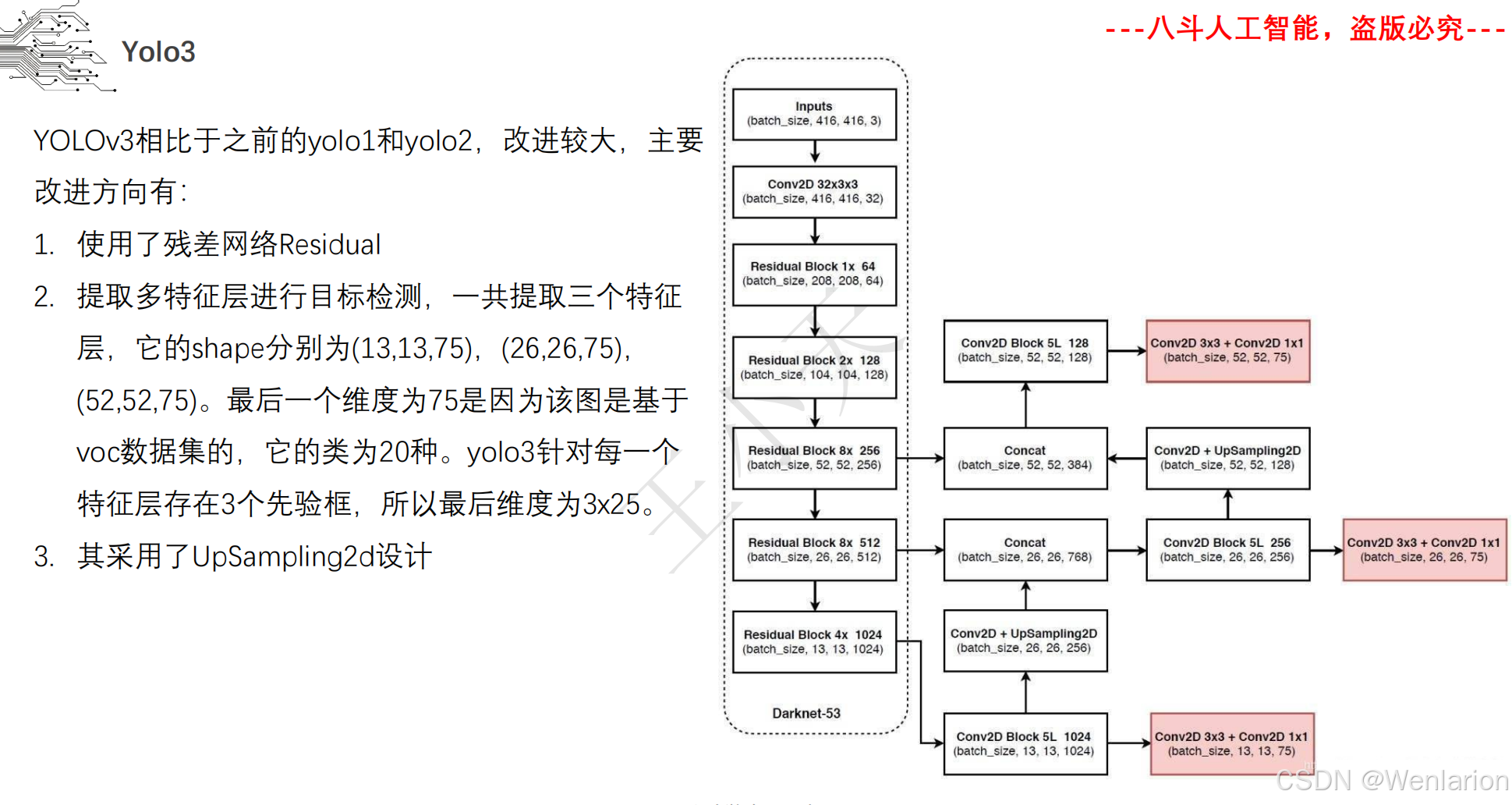


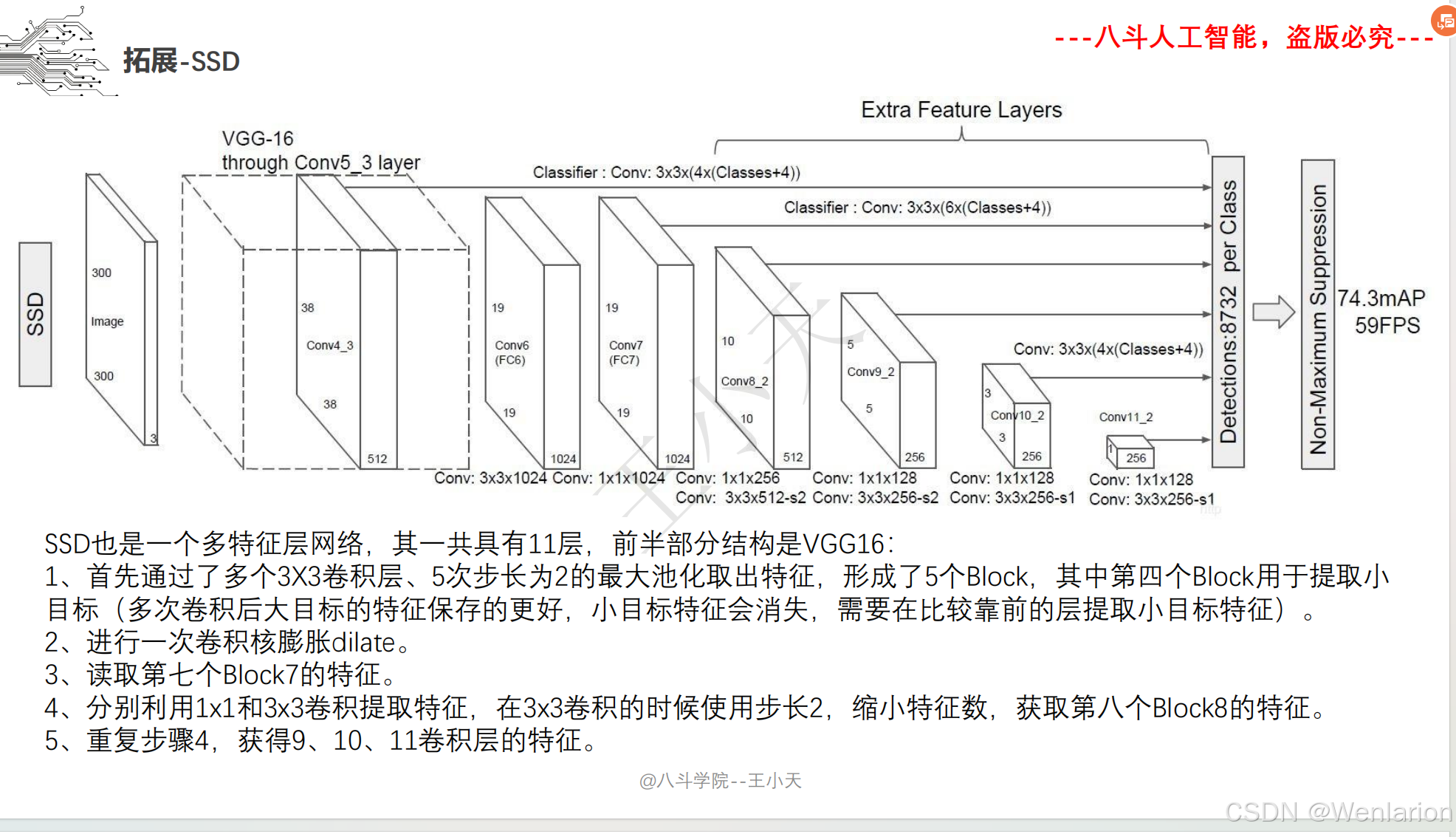
目标检测论文和代码(两阶段检测、单阶段检测、无锚框检测、轻量化 / 实时检测、Transformer 基检测)
一、两阶段目标检测(Two-Stage Detection)
核心特点
分 ** 候选区域生成(Stage1)+ 精细检测分类(Stage2)** 两步,先生成包含目标的候选框,再对候选框做分类和边框回归,精度高、鲁棒性强,是高精度检测的基础框架,缺点是推理速度相对较慢。
1. R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation
-
发表:CVPR 2014(两阶段检测开山之作,开启 CNN 目标检测时代)
-
核心简介:首次将 CNN 引入目标检测,打破传统手工特征(HOG/SIFT)的局限。先通过 ** 选择性搜索(Selective Search)** 生成约 2000 个候选区域,再将每个候选区域缩放至固定尺寸,输入 AlexNet 提取特征,最后用 SVM 做分类、线性回归做边框修正。相比传统方法,检测精度提升超 50%,奠定了两阶段检测 “候选框 + 特征提取 + 分类回归” 的核心框架。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2014/papers/Girshick_Rich_Feature_Hierarchies_2014_paper.pdf | arXiv→https://arxiv.org/pdf/1311.2524.pdf
-
代码地址:官方 MATLAB→https://github.com/rbgirshick/rcnn | PyTorch 复现→https://github.com/ruotianluo/rpn-pytorch
2. Fast R-CNN: Fast Region-based Convolutional Network for object detection
-
发表:ICCV 2015(R-CNN 核心改进,大幅提升速度和精度)
-
核心简介:解决 R-CNN重复提取特征、速度慢、训练繁琐的问题。提出ROI 池化(Region of Interest Pooling),将整张图像输入 CNN 提取一次特征,再从特征图上对候选框提取固定尺寸特征,实现特征共享;同时将 “分类 SVM + 回归器” 替换为多任务损失层(分类 + 边框回归联合训练),端到端训练大幅提升效率,推理速度比 R-CNN 快 200 + 倍。
-
论文 PDF:ICCV 官方→https://openaccess.thecvf.com/content_iccv_2015/papers/Girshick_Fast_R-CNN_2015_paper.pdf | arXiv→https://arxiv.org/pdf/1504.08083.pdf
-
代码地址:官方 MATLAB→https://github.com/rbgirshick/fast-rcnn | PyTorch 复现→https://github.com/chenyuntc/simple-faster-rcnn
3. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
-
发表:NIPS 2015(两阶段检测经典基线,工业界高精度检测标配)
-
核心简介:解决 Fast R-CNN候选框生成依赖选择性搜索(速度慢、非端到端)的问题,提出区域提议网络(RPN,Region Proposal Network)。将 RPN 与 CNN 骨干融合,直接从特征图上生成候选框,实现候选框生成 + 特征提取 + 检测分类全流程端到端训练;RPN 通过 ** 锚框(Anchor)** 机制实现多尺度 / 多宽高比目标检测,成为后续检测模型的核心设计。Faster R-CNN 首次让两阶段检测接近实时,成为至今仍在使用的高精度检测基线。
-
论文 PDF:NIPS 官方→https://proceedings.neurips.cc/paper_files/paper/2015/hash/14bfa6bb148775a0fe0b7e807fb479097-Abstract.html | arXiv→https://arxiv.org/pdf/1506.01497.pdf
-
代码地址:官方 Torch→https://github.com/rbgirshick/py-faster-rcnn | PyTorch 经典实现→https://github.com/jwyang/faster-rcnn.pytorch
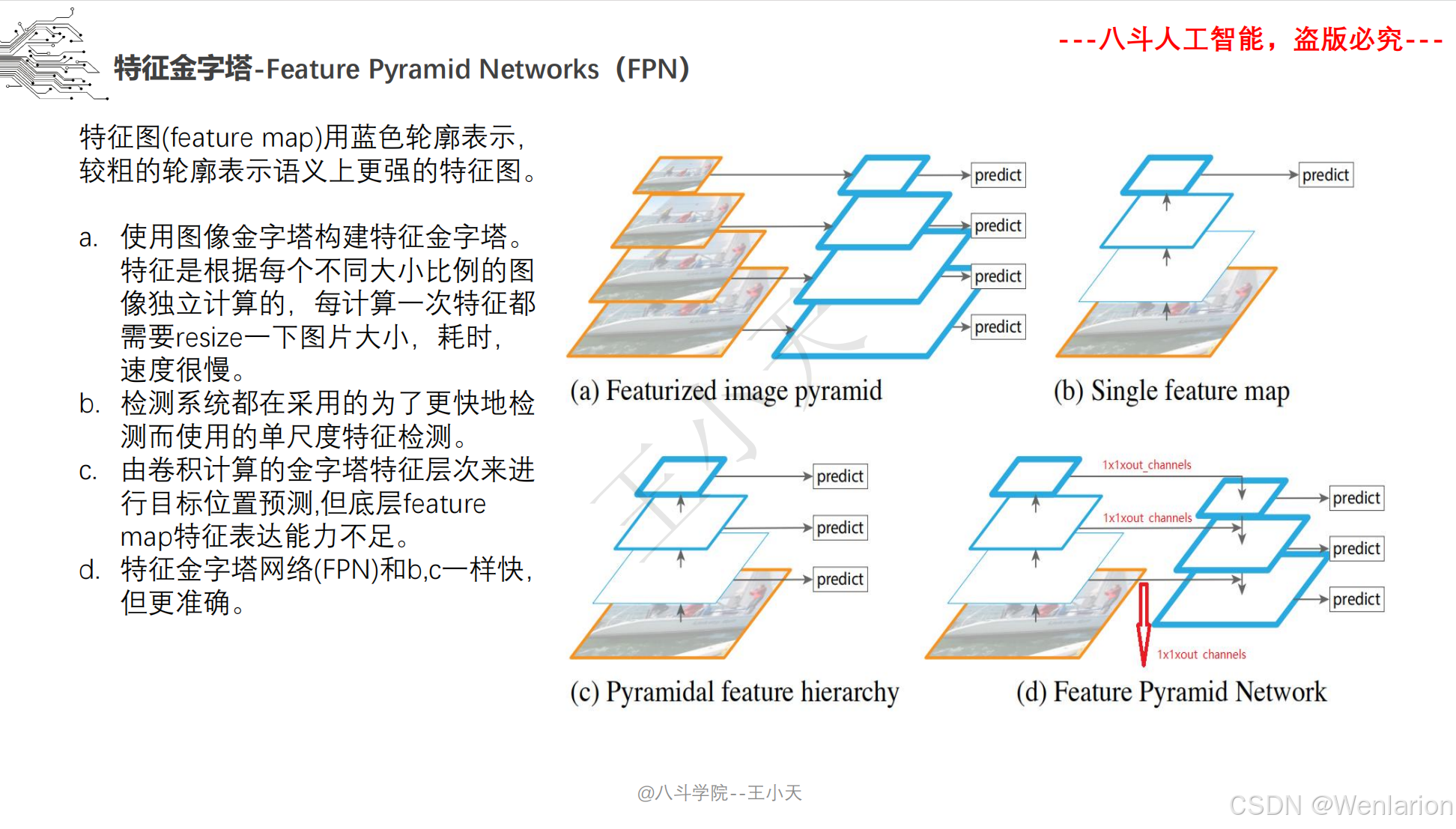
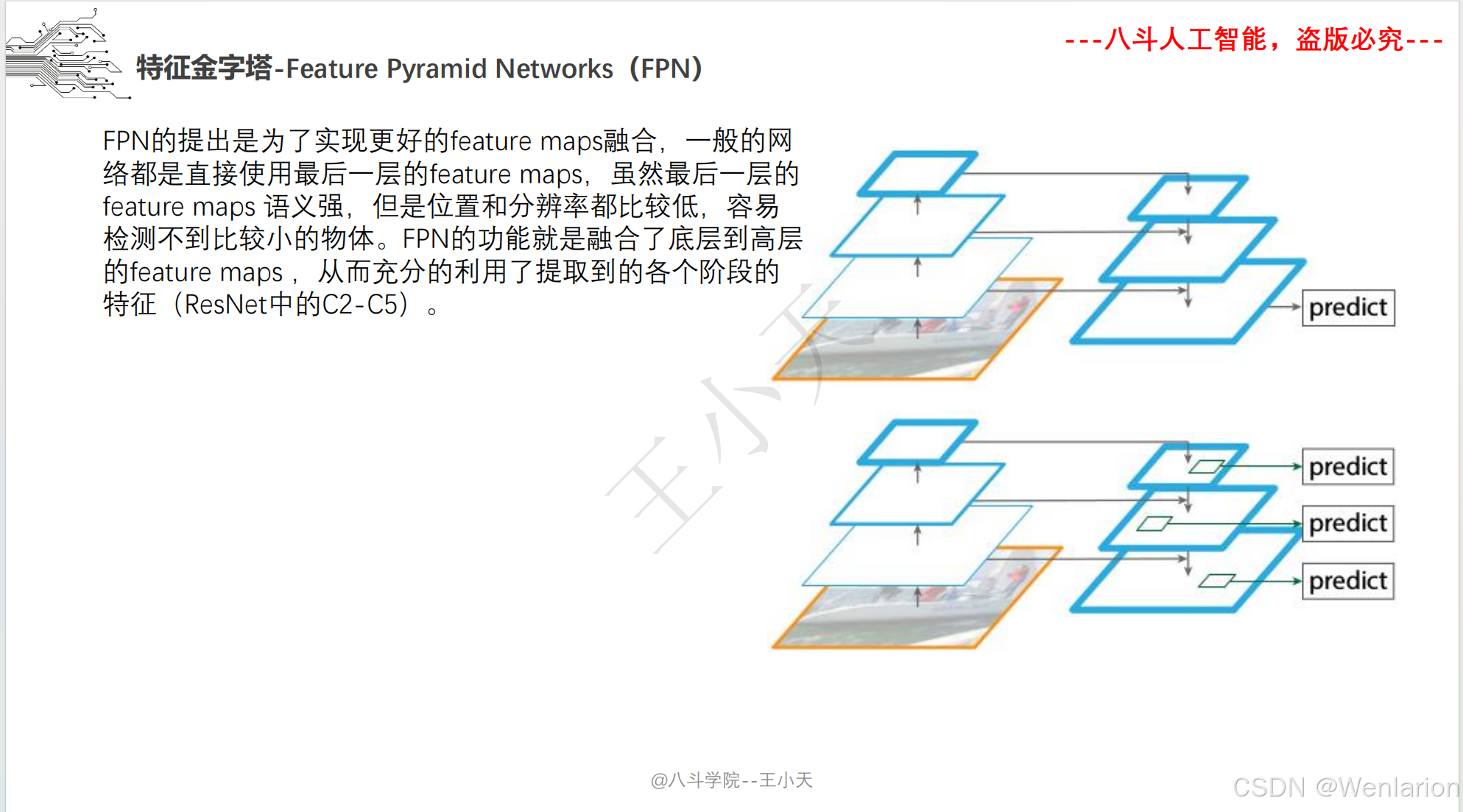
4. FPN: Feature Pyramid Networks for Object Detection
-
发表:CVPR 2017(特征金字塔核心架构,解决多尺度目标检测痛点)
-
核心简介:解决传统检测模型多尺度目标检测精度低的问题,提出特征金字塔网络(FPN)。基于 CNN 骨干的多层特征图,构建自顶向下的上采样 + 横向连接的金字塔结构,融合浅层高分辨率细节特征(适合小目标)和深层低分辨率语义特征(适合大目标),生成多尺度、强表达的融合特征图。FPN 并非独立检测模型,而是通用特征提取模块,被后续几乎所有检测模型(Faster R-CNN/YOLO/SSD)集成,是多尺度检测的标配。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2017/papers/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.pdf | arXiv→https://arxiv.org/pdf/1612.03144.pdf
-
代码地址:官方 PyTorch→https://github.com/facebookresearch/Detectron | 集成版→https://github.com/jwyang/faster-rcnn.pytorch/tree/pytorch-1.0/fpn
二、单阶段目标检测(One-Stage Detection)
核心特点
摒弃候选区域生成,直接从特征图上回归目标框和类别,单网络端到端推理,速度快、流程简单,兼顾精度与实时性,是工业界落地的主流选择,核心代表为 YOLO 和 SSD 系列。
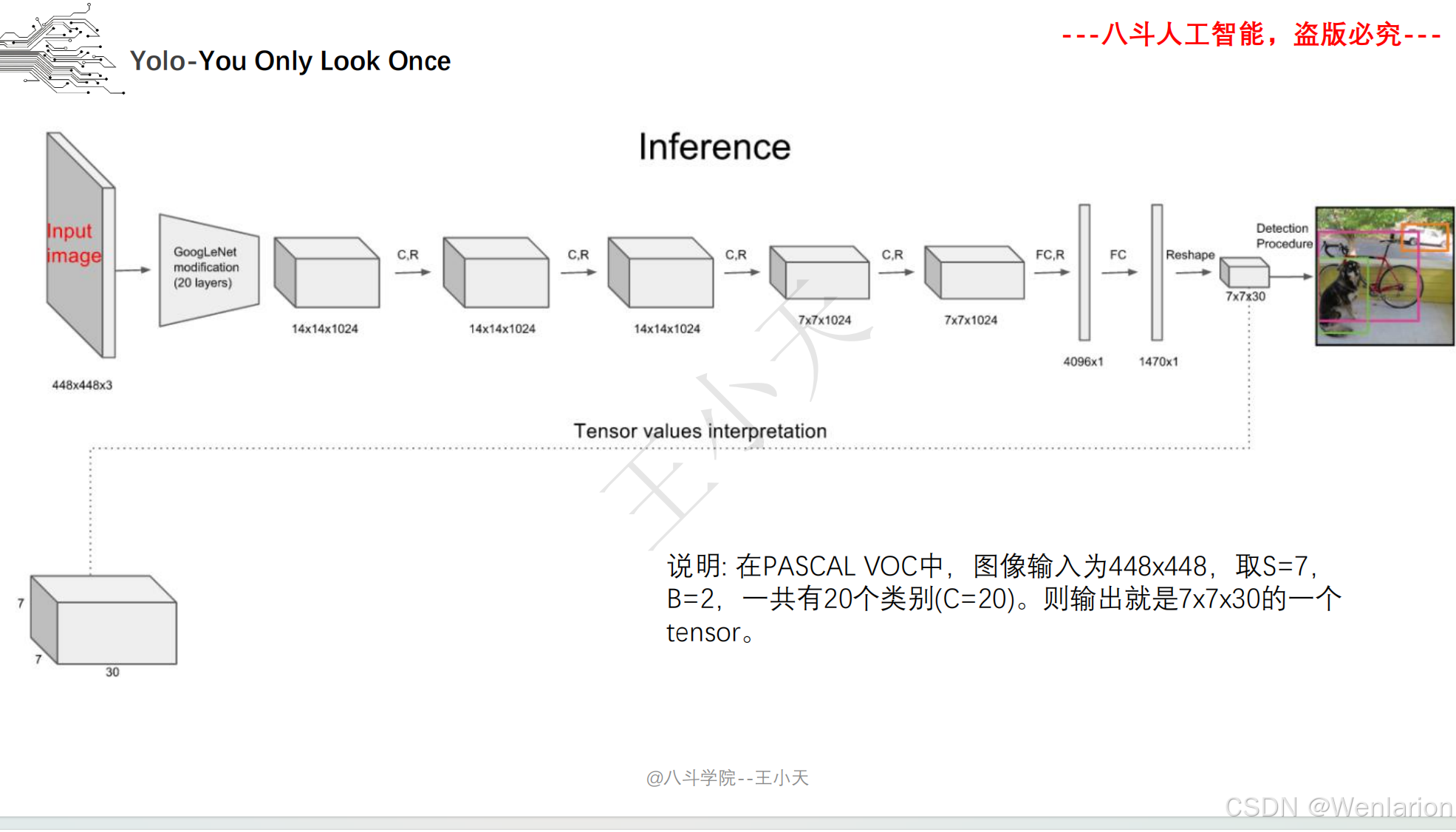
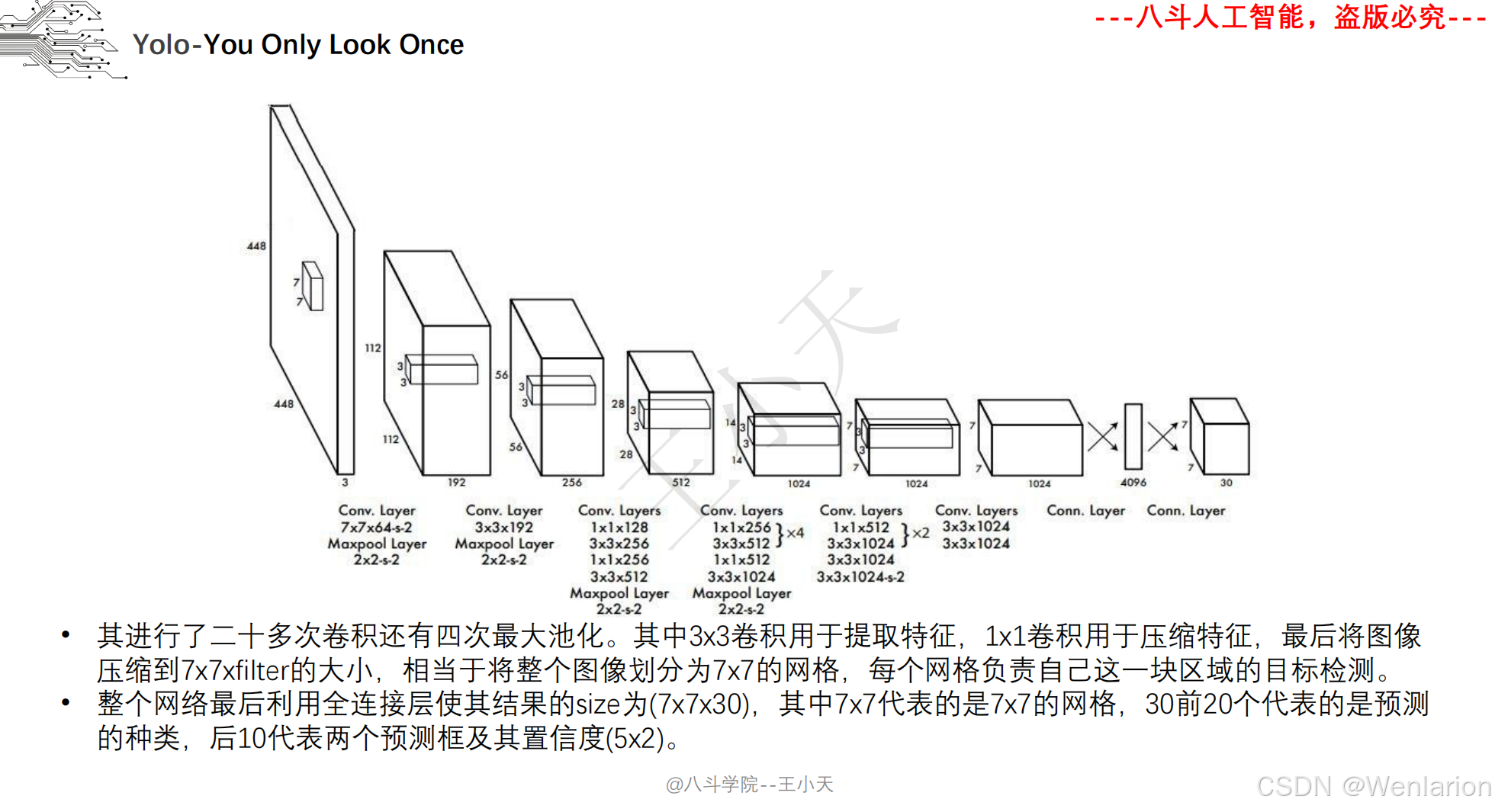
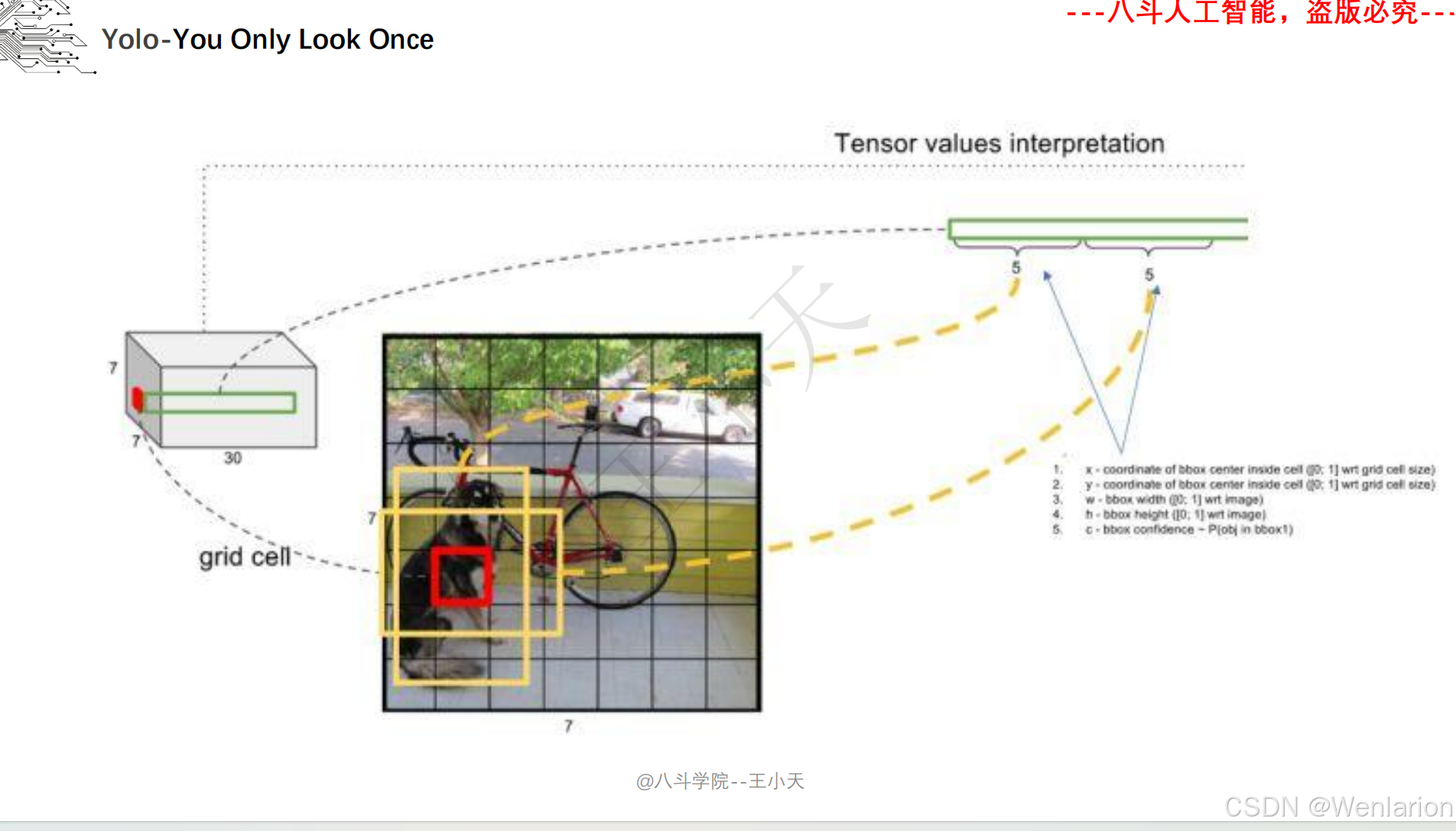
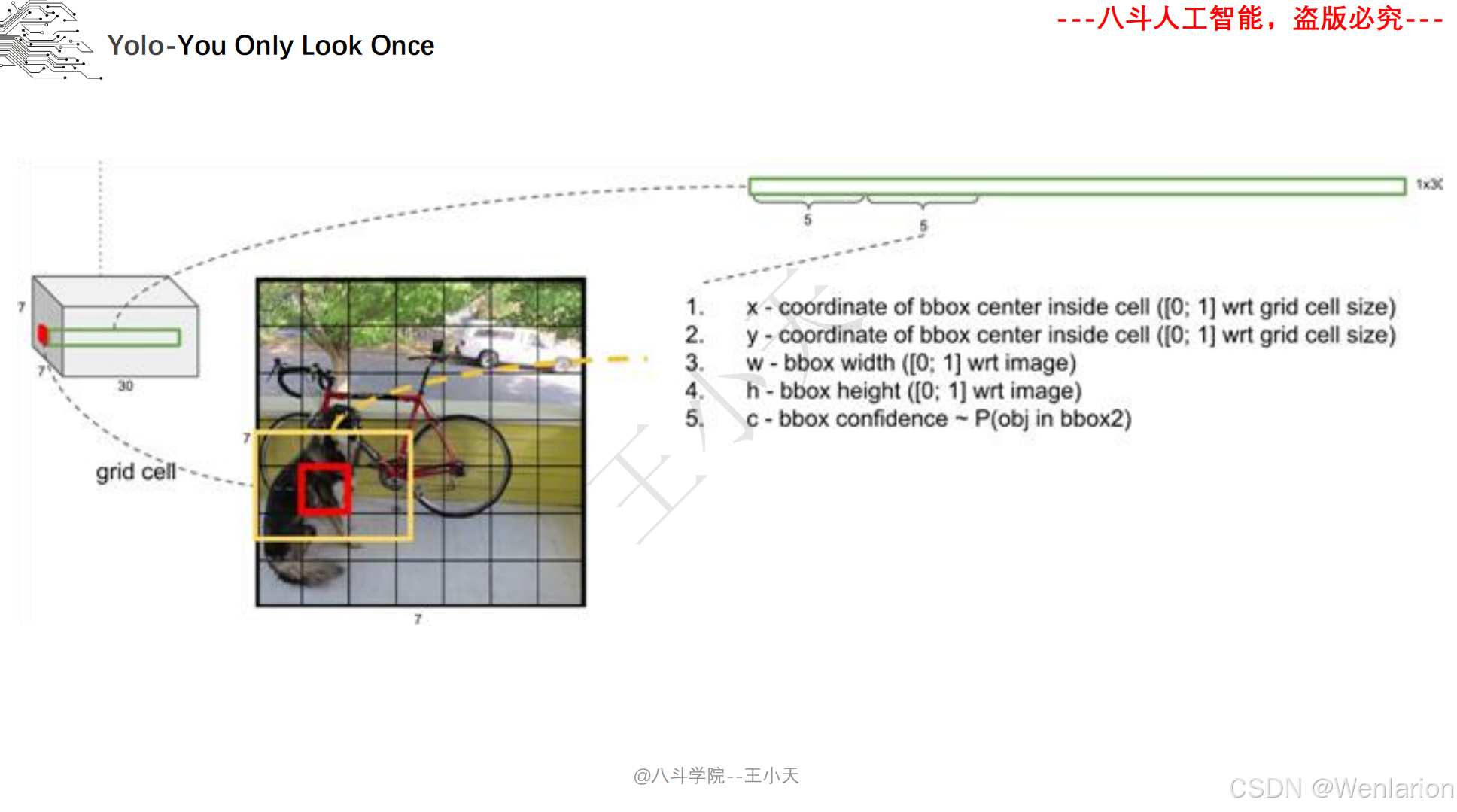
1. YOLOv1: You Only Look Once: Unified, Real-Time Object Detection
-
发表:CVPR 2016(单阶段检测开山之作,开启实时检测时代)
-
核心简介:首次提出单阶段检测思想,将目标检测建模为直接的回归问题,打破两阶段检测的流程限制。将图像划分为 S×S 网格,每个网格负责预测中心落在该网格内的目标,输出目标的边界框、置信度、类别概率,整张图像仅需一次 CNN 推理(YOLO=You Only Look Once)。推理速度达45 FPS(快速版 67 FPS),虽小目标检测精度略低于 Faster R-CNN,但首次实现实时端到端检测,奠定了单阶段检测的核心框架。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2016/papers/Redmon_You_Only_Look_CVPR_2016_paper.pdf | arXiv→https://arxiv.org/pdf/1506.02640.pdf
-
代码地址:官方 C++/CUDA→https://github.com/pjreddie/darknet | PyTorch 复现→https://github.com/ayooshkathuria/pytorch-yolo-v1
2. SSD: Single Shot MultiBox Detector
-
发表:ECCV 2016(单阶段多尺度检测经典,平衡精度与速度)
-
核心简介:融合 YOLO 的单阶段回归和 Faster R-CNN 的锚框机制,解决 YOLOv1小目标检测精度低、定位不准的问题。在 CNN 骨干的多层特征图上分别做检测,浅层特征检测小目标、深层特征检测大目标;引入锚框(MultiBox)实现多尺度 / 多宽高比目标匹配,同时用硬负样本挖掘提升训练效率。SSD 在 PASCAL VOC 数据集上精度媲美 Faster R-CNN,推理速度达59 FPS,是早期单阶段检测中精度与速度平衡的标杆。
-
论文 PDF:ECCV 官方→https://www.ecva.net/papers/eccv_2016/papers/ECCV2016_119.pdf | arXiv→https://arxiv.org/pdf/1512.02325.pdf
-
代码地址:官方 Caffe→https://github.com/weiliu89/caffe/tree/ssd | PyTorch 复现→https://github.com/amdegroot/ssd.pytorch
3. YOLOv3: An Incremental Improvement
-
发表:arXiv 2018(工业界经典实时检测模型,落地首选)
-
核心简介:YOLO 系列的里程碑改进版,大幅提升精度且保持实时性。引入FPN 特征金字塔实现多尺度检测,解决小目标检测痛点;用Darknet-53作为骨干网络,替代 YOLOv2 的 Darknet-19,提升特征提取能力;采用多标签分类替代 Softmax,支持目标多类别标注;引入锚框聚类,让锚框更适配数据集。YOLOv3 在 COCO 数据集上 mAP 提升至 57.9%,推理速度达30 FPS,成为工业界落地最广泛的实时检测模型,至今仍被大量使用。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1804.02767.pdf
-
代码地址:官方 Darknet→https://github.com/pjreddie/darknet | PyTorch 复现→https://github.com/ultralytics/yolov3
4. YOLOv5: YOLOv5 🚀 - State-of-the-Art Object Detection
-
发表:GitHub 2020(工业界主流实时检测模型,易用性拉满)
-
核心简介:YOLO 系列的工程化极致优化版,无正式论文但工业界落地率第一。采用CSPNet作为骨干,减少计算量同时提升特征融合能力;设计自适应锚框计算、自适应图片缩放,适配不同数据集和输入尺寸;集成Mosaic 数据增强、CIoU 损失,提升训练效率和定位精度;提供多个尺度版本(s/m/l/x),兼顾移动端(YOLOv5s)和服务器端(YOLOv5x)。YOLOv5 推理速度快(YOLOv5s 达 140 FPS)、训练便捷、部署友好,是当前工业界实时检测的首选模型。
-
论文 / 文档:GitHub 官方说明→https://github.com/ultralytics/yolov5/wiki
-
代码地址:官方 PyTorch→https://github.com/ultralytics/yolov5
5. YOLOv8: YOLOv8 🚀 - NEW State-of-the-Art Object Detection
-
发表:GitHub 2023(YOLO 最新版,融合检测 / 分割 / 姿态识别)
-
核心简介:YOLO 系列的新一代旗舰版,实现检测、实例分割、人体姿态识别多任务统一。替换骨干为C2f 模块,提升特征提取和融合效率;优化检测头为无锚框(Anchor-Free)设计,简化模型流程;采用Task-Aligned Assigner任务对齐分配策略,提升分类与定位的一致性;支持多平台无缝部署(PyTorch/ONNX/TensorRT/OpenVINO)。YOLOv8 在精度和速度上全面超越 YOLOv5,成为当前单阶段检测的 SOTA 落地模型。
-
论文 / 文档:GitHub 官方说明→https://github.com/ultralytics/ultralytics/wiki
-
代码地址:官方 PyTorch→https://github.com/ultralytics/ultralytics
三、无锚框目标检测(Anchor-Free Detection)
核心特点
摒弃传统的锚框(Anchor)机制,直接从特征图上预测目标的中心点、宽高、关键点等信息,解决锚框带来的超参数敏感、计算量大、正负样本不平衡问题,模型更简洁、泛化能力更强。
1. CornerNet: Detecting Objects as Paired Keypoints
-
发表:CVPR 2018(无锚框检测开山之作,开创关键点检测思路)
-
核心简介:首次提出无锚框检测的核心思想,将目标检测建模为关键点检测问题。把目标框的左上角和右下角两个角点作为关键点,通过关键点检测网络预测所有角点,再通过角点配对生成目标框;引入角池化(Corner Pooling),提升角点检测的精度;无需锚框设计,彻底摆脱锚框超参数调优。CornerNet 在 COCO 数据集上精度超越 SSD,证明了无锚框检测的可行性,开启了无锚框检测的新方向。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2018/papers/Law_CornerNet_Detecting_Objects_CVPR_2018_paper.pdf | arXiv→https://arxiv.org/pdf/1808.01244.pdf
-
代码地址:官方 PyTorch→https://github.com/princeton-vl/CornerNet
2. CenterNet: Objects as Points
-
发表:CVPR 2019(无锚框检测经典基线,简洁高效)
-
核心简介:简化 CornerNet 的角点配对思路,提出中心点检测的无锚框框架,将目标检测建模为单关键点预测。把每个目标表示为中心点,同时从中心点的特征图上回归目标的宽高、3D 尺寸、姿态等信息,无需角点配对,模型更简洁;支持2D 检测、3D 检测、人体姿态识别多任务统一,推理速度达142 FPS。CenterNet 是无锚框检测的经典基线,结构简单、精度高,后续众多无锚框模型均基于其改进。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_CVPR_2019/papers/Duan_CenterNet_Objects_as_Points_CVPR_2019_paper.pdf | arXiv→https://arxiv.org/pdf/1904.07850.pdf
-
代码地址:官方 PyTorch→https://github.com/xingyizhou/CenterNet | 轻量版→https://github.com/smallcorgi/CenterNet-better
3. FCOS: Fully Convolutional One-Stage Object Detection
-
发表:ICCV 2019(无锚框 + 单阶段融合,工业界易落地)
-
核心简介:将无锚框思想与单阶段检测结合,提出全卷积单阶段无锚框检测框架,兼容 FPN 等现有模块。直接在特征图的每个像素点上预测目标框(以该像素为框内点),通过 ** 中心度(Centerness)** 分数过滤低质量框,解决多尺度目标的分配问题;无需锚框,可直接集成到 Faster R-CNN/SSD 等模型中,改造成本低。FCOS 在精度上媲美 Faster R-CNN,推理速度更快,是工业界易落地的无锚框检测模型。
-
论文 PDF:ICCV 官方→https://openaccess.thecvf.com/content_ICCV_2019/papers/Tian_FCOS_Fully_Convolutional_One-Stage_Object_Detection_ICCV_2019_paper.pdf | arXiv→https://arxiv.org/pdf/1904.01355.pdf
-
代码地址:官方 PyTorch→https://github.com/tianzhi0549/FCOS | Detectron2 集成版→https://github.com/aim-uofa/AdelaiDet
四、轻量化 / 实时目标检测(移动端 / 边缘端)
核心特点
针对手机、嵌入式设备、自动驾驶、实时监控等落地场景,通过轻量化骨干、模型剪枝、量化、深度可分离卷积等手段,在保证一定精度的前提下,大幅减少模型参数量和计算量,实现高帧率(20+ FPS)、低显存推理。
1. MobileNet-SSD: SSD with MobileNet Backbone
-
发表:ICLR 2017(移动端实时检测开山之作)
-
核心简介:将 SSD 与MobileNetv1 轻量化骨干结合,专为移动端设计。MobileNetv1 采用深度可分离卷积(Depthwise Separable Convolution),将标准卷积拆分为深度卷积和逐点卷积,参数量和计算量仅为 AlexNet 的 1/100;基于 MobileNetv1 搭建 SSD 检测框架,在移动端实现实时检测(15+ FPS)。MobileNet-SSD 是移动端检测的经典基线,后续所有轻量化检测模型均基于深度可分离卷积改进。
-
论文 PDF:MobileNetv1→https://arxiv.org/pdf/1704.04861.pdf | SSD 适配→https://arxiv.org/pdf/1512.02325.pdf
-
代码地址:TensorFlow→https://github.com/tensorflow/models/tree/master/research/object_detection | PyTorch→https://github.com/marvis/pytorch-mobilenet-ssd
2. YOLO-Lite: A Real-Time Object Detection Algorithm Optimized for Mobile Devices
-
发表:arXiv 2018(超轻量 YOLO,适配低性能移动端)
-
核心简介:针对低性能移动端(如入门级手机、单片机)做极致轻量化,基于 YOLOv2 改进。采用超轻量骨干(仅 10 层卷积),移除冗余的卷积层和池化层;用深度可分离卷积替换标准卷积,参数量仅1.0MB;简化检测头,减少输出通道数。YOLO-Lite 推理速度达200+ FPS(PC 端)、30+ FPS(移动端),精度略低但满足低性能设备的实时检测需求。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1811.05588.pdf
-
代码地址:官方 TensorFlow→https://github.com/ultralytics/yolov3/tree/master/models/yololite | PyTorch 复现→https://github.com/ppriyank/YOLO-Lite
3. NanoDet: Ultra-Fast and Lightweight Object Detector
-
发表:arXiv 2020(移动端无锚框轻量检测 SOTA)
-
核心简介:专为移动端设计的无锚框轻量检测模型,兼顾速度和精度。采用ShuffleNetV2作为轻量化骨干,搭配PANet做特征融合;设计超轻量检测头(仅 3 层卷积),无锚框设计减少计算量;参数量仅0.98MB,推理速度达120 FPS(麒麟 990),精度超越 MobileNet-SSD、YOLO-Lite。NanoDet 支持ONNX/TensorRT/NCNN移动端部署,是当前移动端轻量检测的首选模型。
-
论文 PDF:arXiv→https://arxiv.org/pdf/2011.09020.pdf
-
代码地址:官方 PyTorch→https://github.com/RangiLyu/nanodet | 移动端部署→https://github.com/RangiLyu/nanodet-ncnn
4. YOLOv5s/YOLOv8s: 轻量版 YOLO
-
发表:GitHub 2020/2023(工业界移动端主流,平衡精度与速度)
-
核心简介:YOLOv5/YOLOv8 的轻量版(s 版),是工业界移动端落地的主流选择。采用轻量化 CSPNet/C2f 骨干,参数量仅7.2M/6.8M;支持模型量化(FP16/INT8)、剪枝,进一步适配移动端;推理速度达40+ FPS(麒麟 990),精度远超 NanoDet、MobileNet-SSD,实现移动端精度与速度的最优平衡。
-
文档地址:YOLOv5→https://github.com/ultralytics/yolov5/wiki | YOLOv8→https://github.com/ultralytics/ultralytics/wiki
-
代码地址:YOLOv5→https://github.com/ultralytics/yolov5 | YOLOv8→https://github.com/ultralytics/ultralytics
五、Transformer 基目标检测(Transformer-Based Detection)
核心特点
将 NLP 领域的Transformer引入目标检测,通过自注意力(Self-Attention)机制建模图像的全局特征依赖,解决传统 CNN感受野有限、全局特征建模能力弱的问题,在复杂场景(遮挡、多目标)下精度更高,是当前目标检测的前沿方向。
1. DETR: End-to-End Object Detection with Transformers
-
发表:ECCV 2020(Transformer 基检测开山之作,端到端检测)
-
核心简介:首次将 Transformer 成功应用于目标检测,提出端到端的检测框架(DETR=Detection Transformer),摒弃传统的锚框、NMS 等手工设计。将图像特征和可学习的目标查询(Object Queries)输入 Transformer,通过解码器的自注意力直接输出目标的类别和边界框,无需后处理(NMS);用二分图匹配实现目标与查询的一一对应,解决正负样本分配问题。DETR 实现了真正的端到端检测,开启了 Transformer 基检测的新时代。
-
论文 PDF:ECCV 官方→https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123460044.pdf | arXiv→https://arxiv.org/pdf/2005.12872.pdf
-
代码地址:官方 PyTorch→https://github.com/facebookresearch/detr
2. Faster DETR: Faster DETR with Conditional Spatial Encoding and Dual Attention
-
发表:ICCV 2021(DETR 改进版,提升推理速度)
-
核心简介:解决 DETR训练收敛慢、推理速度慢的问题,对 Transformer 架构做针对性优化。提出条件空间编码(Conditional Spatial Encoding),增强特征的空间表达能力;设计双注意力机制(Dual Attention),减少注意力计算量;引入小批量训练策略,让模型收敛速度提升 3 倍。Faster DETR 在精度上媲美 DETR,推理速度提升 2 倍,让 Transformer 基检测更接近实时。
-
论文 PDF:ICCV 官方→https://openaccess.thecvf.com/content/ICCV2021/papers/Chen_Faster_DETR_With_Conditional_Spatial_Encoding_and_Dual_Attention_ICCV_2021_paper.pdf | arXiv→https://arxiv.org/pdf/2103.09460.pdf
-
代码地址:官方 PyTorch→https://github.com/cheind/faster-detr
3. YOLOv9: YOLO with Transformers
-
发表:arXiv 2024(YOLO 与 Transformer 融合,落地级 Transformer 检测)
-
核心简介:将Transformer 与 YOLO 的工程化优势结合,提出YOLOv9,实现精度与速度的双重突破。设计C2f-Transformer 混合骨干,融合 CNN 的局部特征提取能力和 Transformer 的全局特征建模能力;提出自适应任务对齐(ATA),提升分类与定位的一致性;支持多尺度、多平台部署,在 COCO 数据集上 mAP 达53.6%,推理速度达60 FPS。YOLOv9 是工业界落地级的 Transformer 基检测模型,兼顾前沿性和实用性。
-
论文 PDF:arXiv→https://arxiv.org/pdf/2402.13616.pdf
-
代码地址:官方 PyTorch→https://github.com/WongKinYiu/yolov9
六、目标检测必备工具库与经典数据集
1. 主流工具库(封装经典 / 最新模型,开箱即用,支持训练 / 部署)
|
工具库 |
核心优势 |
代码地址 |
|---|---|---|
|
MMDetection |
国内主流,PyTorch 框架,集成所有经典 / 最新检测模型(Faster R-CNN/YOLO/DETR),支持自定义数据集 |
|
|
Detectron2 |
Facebook 官方,PyTorch 框架,主打两阶段 / 实例分割,Faster R-CNN/DETR 官方实现 |
|
|
Ultralytics |
YOLOv5/YOLOv8/YOLOv9 官方库,PyTorch 框架,训练 / 部署一体化,支持多平台无缝导出 |
|
|
TensorFlow Object Detection API |
TensorFlow 框架,适合工业界部署,集成 MobileNet-SSD/Faster R-CNN 等 |
https://github.com/tensorflow/models/tree/master/research/object_detection |
2. 经典数据集(覆盖通用 / 专用场景,模型训练与评估的基准)
|
数据集 |
适用场景 |
目标数量 / 类别 |
官网地址 |
|---|---|---|---|
|
PASCAL VOC 2007/2012 |
通用场景检测 |
约 20k 张图 / 20 类 |
|
|
MS COCO |
通用场景检测 / 分割 / 姿态 |
约 330k 张图 / 80 类 |
|
|
Cityscapes |
城市场景检测(车辆 / 行人 / 道路) |
约 5k 张图 / 30 类 |
|
|
UA-DETRAC |
交通场景车辆检测 |
约 140k 张图 / 1 类 |
|
|
Wider Face |
人脸检测(多尺度 / 遮挡) |
约 32k 张图 / 1 类 |
2.2.2 人脸检测




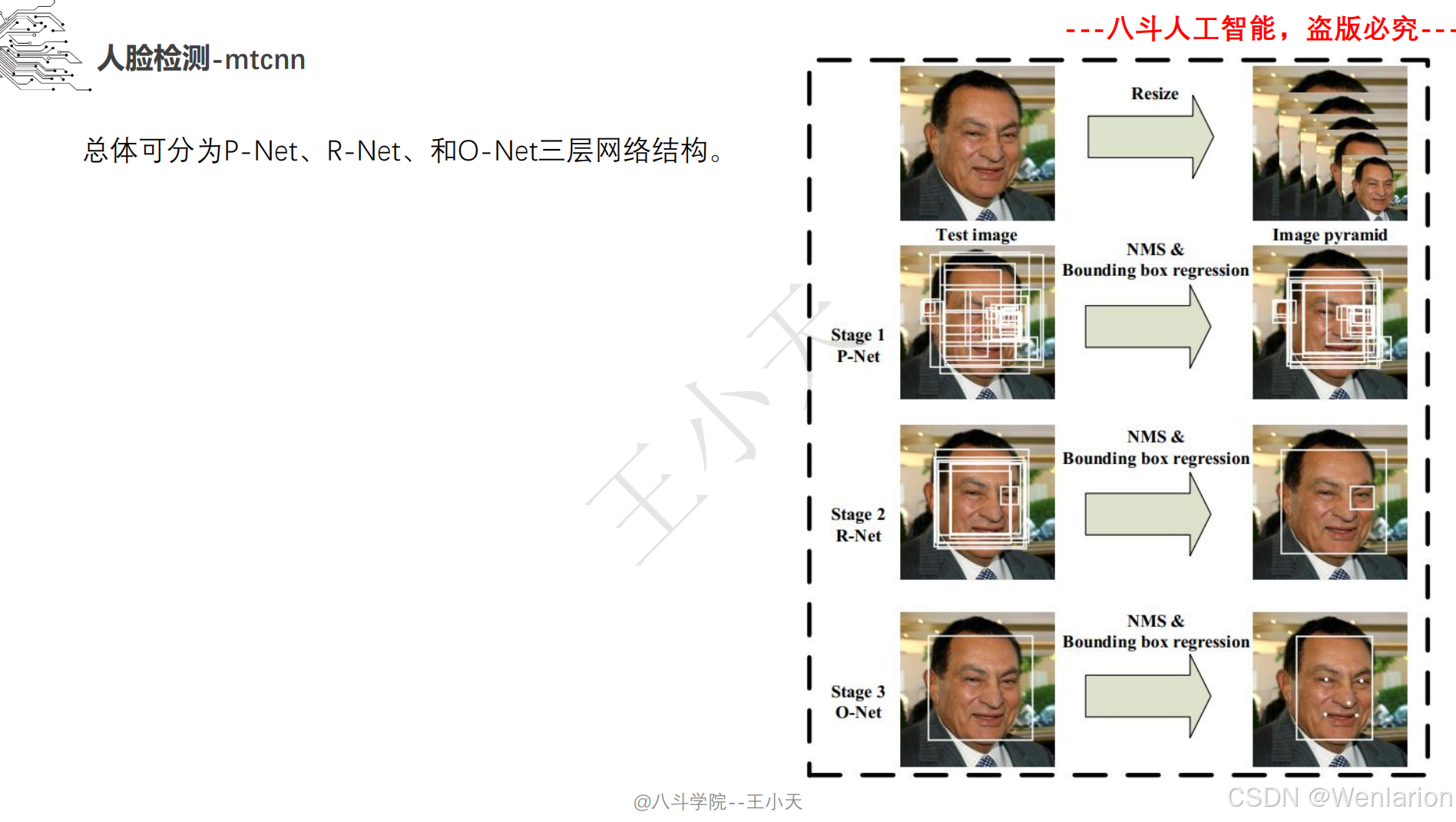
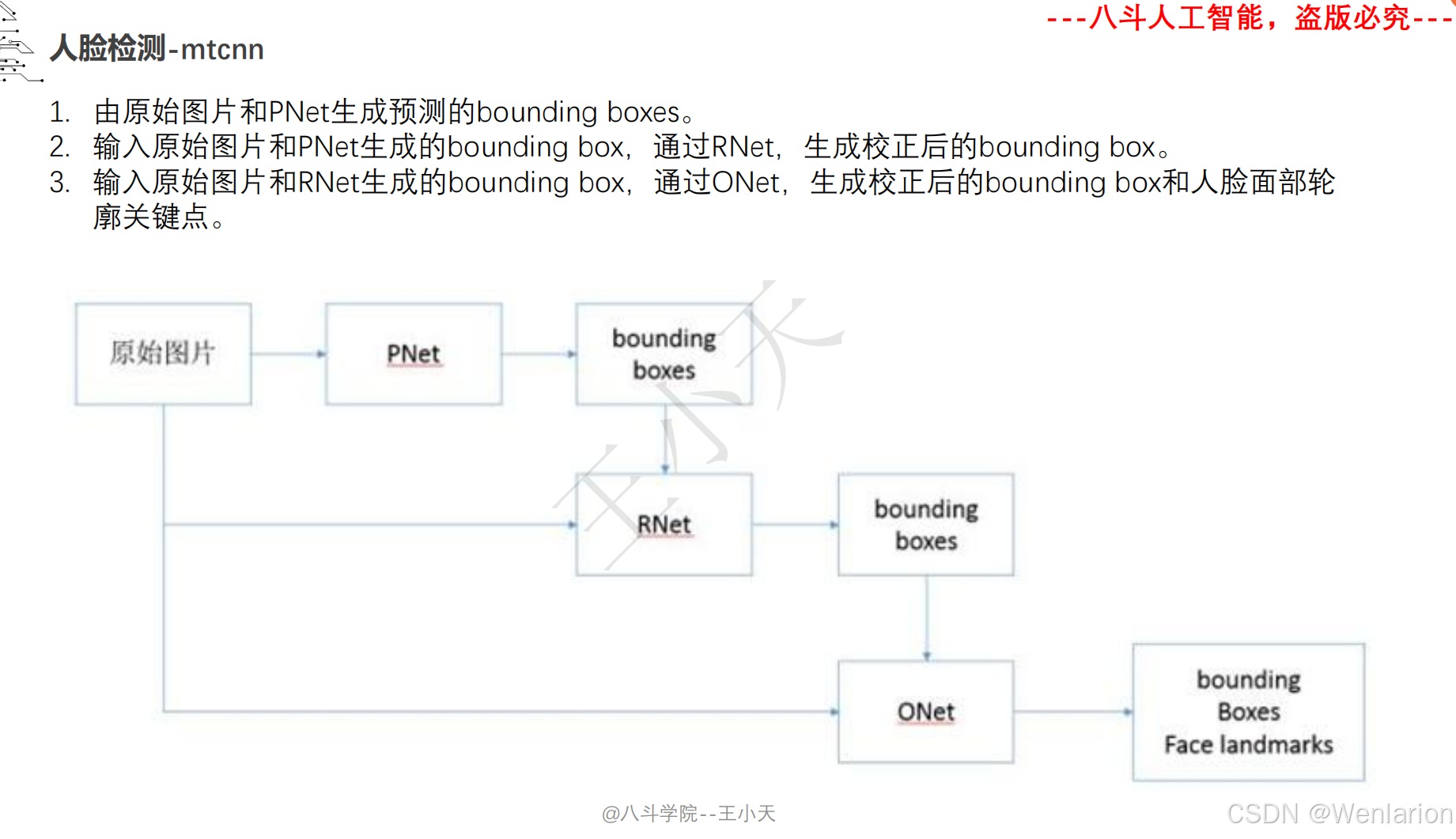







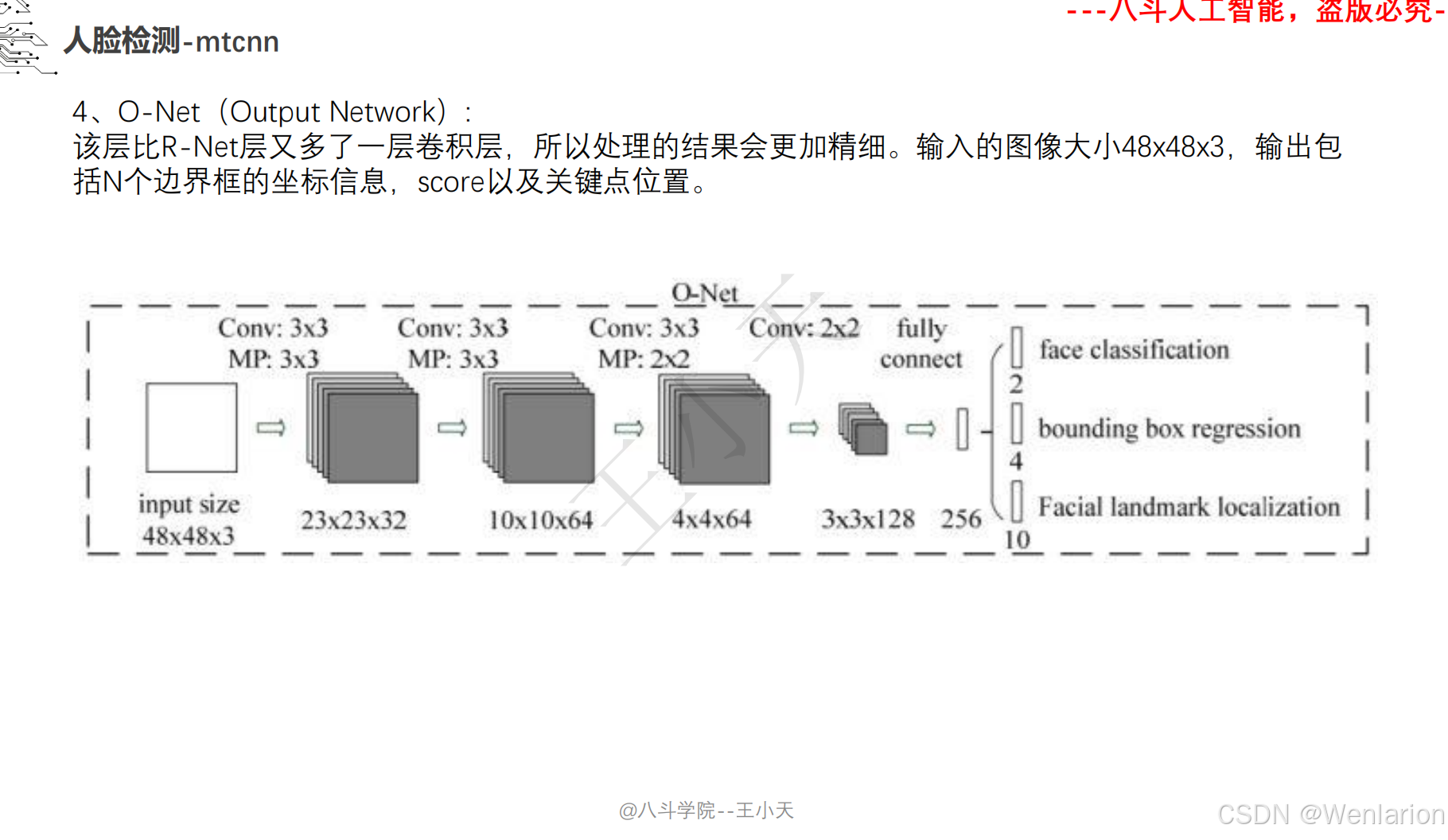


人脸检测(经典传统方法、深度学习基础框架、轻量级 / 实时检测、高精度 / 复杂场景检测)
一、经典传统方法(深度学习前标杆,奠定人脸检测基础)
核心特点
基于手工特征 + 分类器实现,无需深度网络训练,计算量小、易部署,是深度学习人脸检测的基础,核心解决人脸特征建模、多尺度 / 姿态鲁棒性问题。
1. Viola-Jones: Rapid Object Detection using a Boosted Cascade of Simple Features
-
发表:CVPR 2001(人脸检测开山之作,传统方法天花板)
-
核心简介:首个实时人脸检测算法,开创 “特征提取 + 级联分类器” 的检测框架,至今仍被 OpenCV 内置为基础人脸检测器。提出哈尔特征(Haar-like Features) 快速描述人脸纹理特征(如眼黑比脸颊暗、鼻梁比两侧亮);用积分图将哈尔特征计算复杂度从 O (n²) 降至 O (1),大幅提升速度;设计Adaboost 级联分类器,层层过滤背景区域,仅对疑似人脸区域做精细检测,实现 CPU 端实时人脸检测(15+ FPS)。该算法奠定了目标检测 “快速筛选 + 精细验证” 的核心思想,后续所有检测算法均受其启发。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2001/papers/Viola_Rapid_Object_Detection_Using_2001_paper.pdf | 原版→https://www.cs.cmu.edu/~efros/courses/LBMV07/Papers/viola-cvpr-01.pdf
-
代码地址:OpenCV 内置实现→https://docs.opencv.org/4.x/d7/d8b/tutorial_py_face_detection.html | 手动复现→https://github.com/parulnith/Viola-Jones-Face-Detector
2. DPM-Human: Deformable Part Models for Human Detection
-
发表:CVPR 2008(形变部件模型,解决人脸姿态变化痛点)
-
核心简介:将可形变部件模型(DPM) 应用于人脸检测,解决 Viola-Jones 对人脸姿态 / 形变鲁棒性差的问题。将人脸分解为根部件(整个人脸)+ 局部部件(眼睛、鼻子、嘴巴),分别建模各部件的特征和相对位置;允许局部部件在一定范围内形变,适配人脸的侧脸、抬头、低头等姿态变化;用 HOG 特征做部件特征描述,SVM 做分类,大幅提升非正面人脸的检测精度。DPM 是传统人脸检测中姿态鲁棒性最强的算法,为后续深度学习人脸检测的多部件 / 关键点建模提供思路。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2008/papers/Felzenszwalb_Deformable_Part_Models_2008_paper.pdf | arXiv→https://arxiv.org/pdf/0803.2873.pdf
-
代码地址:官方 MATLAB→https://www.cs.uchicago.edu/~pff/latent/ | Python 复现→https://github.com/rbgirshick/dpm-caffe
二、深度学习基础框架(开启人脸检测深度学习时代,经典基线)
核心特点
将 CNN 引入人脸检测,替代传统手工特征,大幅提升检测精度;针对人脸尺度小、分布密、姿态多样的特点,优化通用目标检测框架,奠定深度学习人脸检测的核心架构。
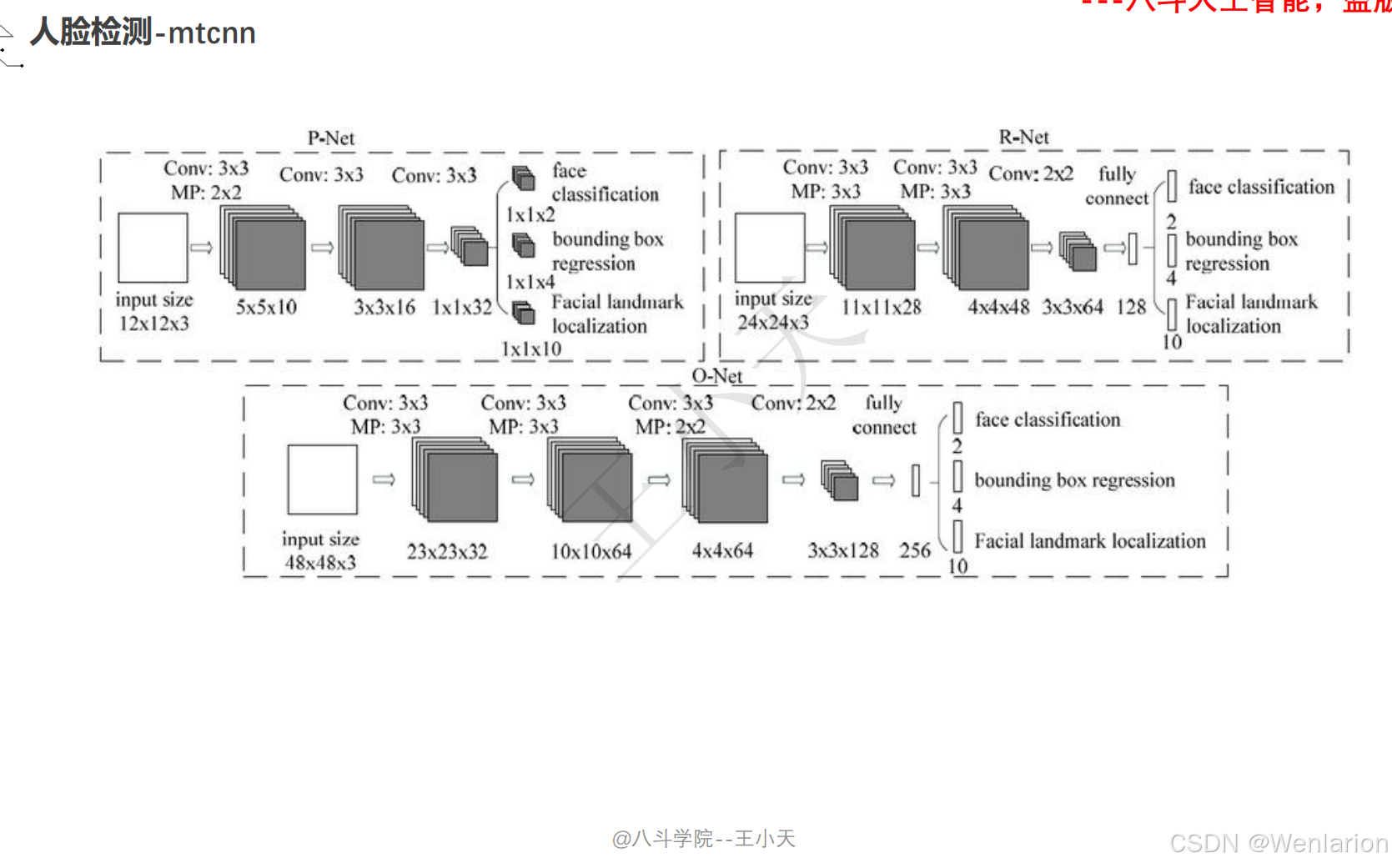
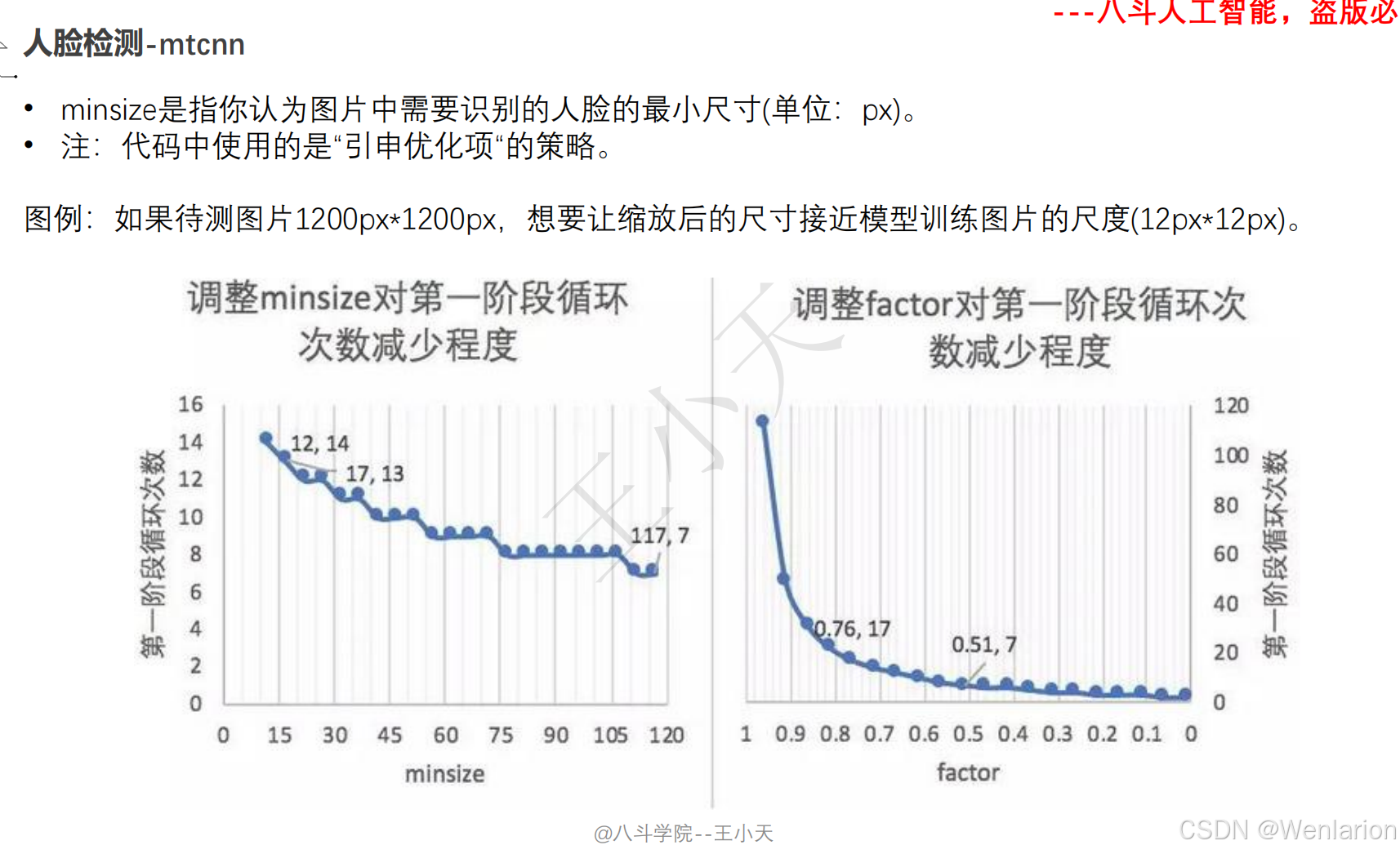
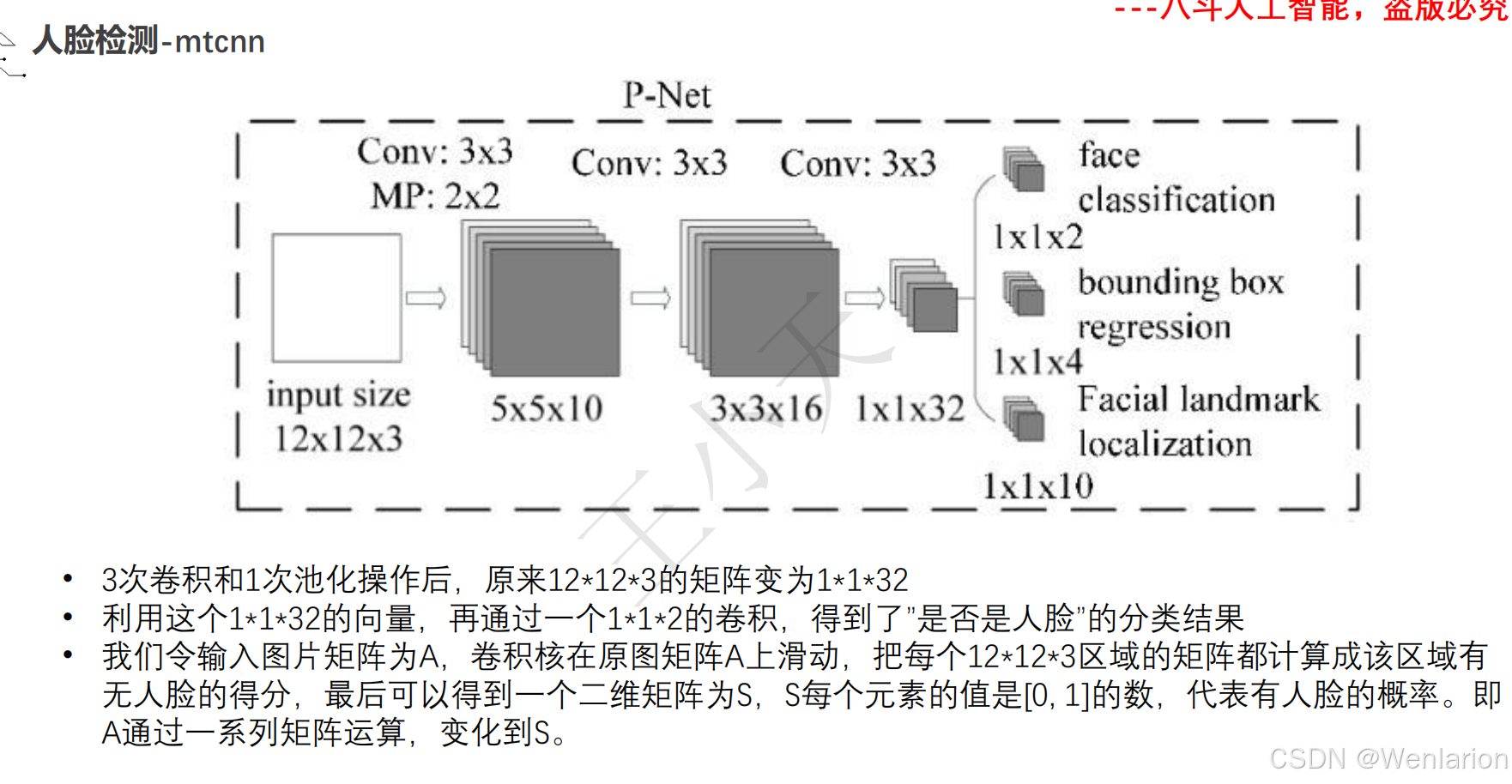
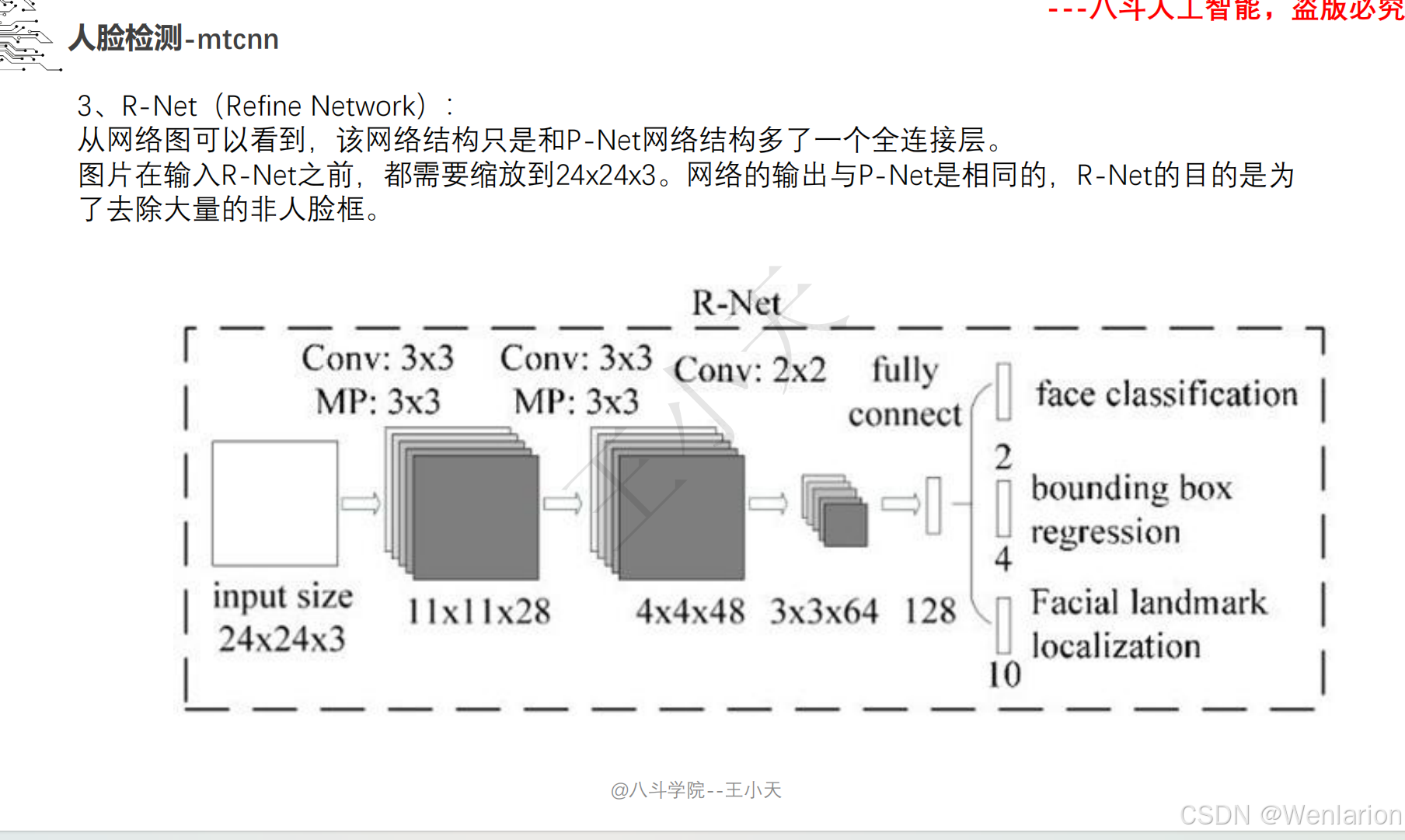
1. MTCNN: Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
-
发表:ICCV 2016 Workshop(深度学习人脸检测经典基线,工业界入门首选)
-
核心简介:首个端到端多任务人脸检测框架,融合人脸检测 + 关键点对齐,解决通用检测模型对小人脸 / 模糊人脸检测精度低的问题。设计三级级联卷积网络(P-Net→R-Net→O-Net),层层筛选 + 精细检测:P-Net 快速生成人脸候选框,R-Net 过滤假阳性框并修正位置,O-Net 输出最终人脸框和 5 个人脸关键点(眼睛、鼻子、嘴巴);将人脸分类、边框回归、关键点回归作为多任务联合训练,提升模型鲁棒性。MTCNN 轻量、速度快(CPU 端 20+ FPS)、对小人脸 / 侧脸检测效果好,是工业界落地最广泛的基础人脸检测器,至今仍被用于人脸对齐、人脸验证的前置步骤。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1604.02878.pdf | ICCV Workshop→https://www.cv-foundation.org/openaccess/content_iccv_2016_workshops/w12/papers/Kan_Joint_Face_Detection_2016.pdf
-
代码地址:官方 Caffe→https://github.com/kpzhang93/MTCNN_face_detection_alignment | PyTorch 复现→https://github.com/TropComplique/mtcnn-pytorch | OpenCV 封装→https://github.com/ipazc/mtcnn
2. Face R-CNN: Face Detection using Region Proposal Networks
-
发表:arXiv 2017(两阶段人脸检测经典,高精度基线)
-
核心简介:将 Faster R-CNN 适配人脸检测任务,提出专用的人脸区域提议网络(Face RPN),解决通用检测模型对人脸尺度适配性差的问题。针对人脸尺度分布特点,重新设计锚框(Anchor) 尺度和宽高比(以小尺度锚框为主);在 RPN 和检测头中加入人脸姿态分支,适配正面 / 侧脸 / 大角度人脸;用 ResNet+FPN 作为骨干网络,融合多尺度特征,提升小人脸检测精度。Face R-CNN 是两阶段人脸检测的经典基线,精度远超 MTCNN,适合对精度要求高的非实时场景。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1708.03982.pdf
-
代码地址:PyTorch 实现→https://github.com/chengyangfu/face-rcnn | Caffe 实现→https://github.com/ShuangLI59/Face-R-CNN
三、轻量级 / 实时人脸检测(移动端 / 边缘端,适配落地场景)
核心特点
针对手机、嵌入式设备、实时监控、人脸打卡等落地场景,通过轻量化骨干、模型压缩、级联精简等手段,在保证检测精度的前提下,实现低计算量、高帧率、低显存推理,核心适配移动端实时检测、大流量视频流检测。
1. RetinaFace: Single-stage Dense Face Localisation in the Wild
-
发表:CVPR 2020(实时人脸检测 SOTA,工业界落地首选)
-
核心简介:单阶段人脸检测的里程碑模型,兼顾实时性、高精度、多任务,解决复杂场景下(遮挡、小人脸、大角度姿态)人脸检测的痛点。基于 RetinaNet 单阶段框架,设计多尺度特征金字塔,专门优化小人脸特征提取;提出上下文增强模块(Context Enhancement Module),提升遮挡人脸的检测精度;支持人脸检测、关键点回归(5/106 点)、姿态估计多任务联合训练;提供轻量版(MobileNetV2 骨干) 和高精度版(ResNet50 骨干),轻量版在移动端实现30+ FPS,精度远超 MTCNN。RetinaFace是当前工业界落地最广泛的人脸检测模型,被广泛应用于人脸识别、人脸打卡、直播美颜等场景。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_CVPR_2020/papers/Deng_RetinaFace_Single-Stage_Dense_Face_Localisation_in_the_Wild_CVPR_2020_paper.pdf | arXiv→https://arxiv.org/pdf/1905.00641.pdf
-
代码地址:官方 MXNet→https://github.com/deepinsight/insightface/tree/master/RetinaFace | PyTorch 复现→https://github.com/biubug6/Pytorch_Retinaface | 移动端部署→https://github.com/DefTruth/lite.ai.toolkit
2. Ultra-Lightweight Face Detector (ULFD)
-
发表:ICASSP 2020(超轻量人脸检测,适配低性能移动端)
-
核心简介:专为低性能移动端(入门级手机、单片机、嵌入式设备) 设计的超轻量人脸检测器,解决 RetinaFace 轻量版仍需较大计算量的问题。采用自定义超轻量骨干网络(仅由深度可分离卷积和池化层构成),参数量仅1.0MB(RetinaFace-MobileNetV2 为 2.7MB);设计轻量级多尺度检测头,仅保留核心的分类和回归分支,移除冗余模块;针对人脸检测任务做极致的模型剪枝和量化,在保证小人脸检测精度的前提下,实现移动端 100+ FPS推理。ULFD 是低性能边缘设备的首选人脸检测器,适合人脸门禁、低成本监控等场景。
-
论文 PDF:ICASSP 官方→https://ieeexplore.ieee.org/document/9054645 | arXiv→https://arxiv.org/pdf/1909.10903.pdf
-
代码地址:官方 PyTorch→https://github.com/imistyrain/Ultra-Light-Fast-Generic-Face-Detector-1MB | ONNX 移动端部署→https://github.com/DefTruth/ulfd-onnx
3. BlazeFace: Sub-millisecond Neural Face Detection on Mobile GPUs
-
发表:CVPR 2019 Workshop(谷歌官方,移动端亚毫秒级检测)
-
核心简介:谷歌为移动端 GPU设计的实时人脸检测器,实现亚毫秒级(<1ms) 人脸检测,适配 AR、直播美颜等对延迟要求极高的场景。提出BlazeNet 轻量级骨干,由深度可分离卷积 + 瓶颈块构成,专为移动端 GPU 的并行计算优化;设计锚框重采样策略,针对人脸尺度分布优化锚框数量,减少计算量;采用单阶段检测框架,仅输出人脸框和关键点,推理速度达移动端 GPU 1000+ FPS。BlazeFace 是移动端低延迟人脸检测的标杆,被集成到谷歌 AR Core、TensorFlow Lite 中,是工业界低延迟场景的首选。
-
论文 PDF:CVPR Workshop→https://openaccess.thecvf.com/content_CVPRW_2019/papers/DFU/Kaiser_BlazeFace_Sub-Millisecond_Neural_Face_Detection_on_Mobile_GPUs_CVPRW_2019_paper.pdf | arXiv→https://arxiv.org/pdf/1907.05047.pdf
-
代码地址:TensorFlow Lite 官方→https://github.com/tensorflow/models/tree/master/research/object_detection/models/blazeface | PyTorch 复现→https://github.com/hollance/BlazeFace-PyTorch
四、高精度 / 复杂场景人脸检测(解决遮挡 / 小人脸 / 大姿态,学术 SOTA)
核心特点
针对野生场景(in the wild) 中的人脸检测痛点:小人脸(如远距人脸)、重度遮挡(口罩 / 墨镜 / 手挡)、大角度姿态(90° 侧脸 / 仰头)、密集人脸,通过特征增强、注意力机制、多任务融合、无锚框设计等手段,实现超高检测精度,适合对精度要求极高的场景(如安防监控、人脸检索、刑侦识别)。
1. PyramidBox: A Context-Assisted Single Shot Face Detector
-
发表:ECCV 2018(密集 / 小人脸检测 SOTA,上下文增强标杆)
-
核心简介:专为密集人脸、小人脸设计的高精度检测器,解决传统模型对密集人脸漏检、小人脸检测精度低的问题。提出金字塔锚框(Pyramid Anchor),在多尺度特征图上生成适配人脸尺度的锚框,提升小人脸覆盖度;设计上下文增强模块(Context Module),融合人脸周围的上下文信息,区分密集人脸和背景;引入半监督学习,利用未标注的密集人脸数据提升模型泛化能力。PyramidBox 在 WIDER FACE 数据集(人脸检测最权威数据集)的 Hard 子集上刷新 SOTA,是密集 / 小人脸检测的经典模型。
-
论文 PDF:ECCV 官方→https://www.ecva.net/papers/eccv_2018/papers_ECCV/papers/Wei_Liu_PyramidBox_A_Context-Assisted_ECCV_2018_paper.pdf | arXiv→https://arxiv.org/pdf/1803.07737.pdf
-
代码地址:官方 Caffe→https://github.com/PaddlePaddle/models/tree/develop/PaddleCV/face_detection/pyramidbox | PyTorch 复现→https://github.com/liuwei16/PyramidBox-Pytorch
2. CenterFace: Joint Face Detection and Alignment Using Face as Point
-
发表:arXiv 2019(无锚框人脸检测经典,高精度 + 实时)
-
核心简介:将无锚框检测思想引入人脸检测,提出以人脸中心点为核心的检测框架,解决锚框带来的超参数敏感、密集人脸框重叠问题。将每个人脸表示为中心点,从中心点特征图上直接回归人脸框的宽高、关键点坐标,无需锚框匹配;设计多尺度中心点检测,适配不同尺度的人脸;融合人脸检测、关键点对齐多任务,模型结构简洁,精度媲美 PyramidBox,推理速度达GPU 端 200+ FPS。CenterFace 是无锚框人脸检测的经典基线,兼顾高精度和实时性,适合密集人脸、小人脸检测场景。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1911.03599.pdf
-
代码地址:官方 PyTorch→https://github.com/Star-Clouds/CenterFace | C++/OpenCV 部署→https://github.com/jiangxinyang227/CenterFace-CPP
3. MaskedFace-RCNN: Face Detection and Segmentation for Masked Faces
-
发表:ICIP 2020(口罩遮挡人脸检测标杆,疫情场景专用)
-
核心简介:专为口罩遮挡人脸设计的高精度检测器,解决传统模型对口罩人脸漏检、定位不准的问题。基于 Mask R-CNN 两阶段框架,增加口罩分割分支,联合训练人脸检测、口罩分割、关键点回归三任务;通过口罩分割结果增强遮挡人脸的特征表达,让模型聚焦于未被遮挡的区域(眼睛、额头);重新设计锚框和样本分配策略,适配口罩人脸的框形变化。MaskedFace-RCNN 在口罩人脸数据集上检测精度达98%+,是疫情场景下人脸检测的首选模型,也为重度遮挡人脸检测提供了思路。
-
论文 PDF:ICIP 官方→https://ieeexplore.ieee.org/document/9190709 | arXiv→https://arxiv.org/pdf/2007.09082.pdf
-
代码地址:官方 PyTorch→https://github.com/aqeelanwar/MaskedFace-RCNN | 轻量版→https://github.com/akashmalla/Masked-Face-Detection
4. FAN: Face Attention Network for Facial Landmark Detection and Face Detection
-
发表:CVPR 2019(注意力机制人脸检测,遮挡 / 大姿态鲁棒)
-
核心简介:将注意力机制引入人脸检测,提出人脸注意力网络(FAN),解决传统模型对遮挡、大角度姿态人脸鲁棒性差的问题。设计空间注意力模块,让模型自动关注人脸的关键区域(如眼睛、鼻子),弱化遮挡区域的特征影响;引入通道注意力模块,筛选对人脸检测最有效的特征通道;融合人脸检测和关键点检测,通过关键点的位置信息辅助人脸框的回归,提升大姿态人脸的检测精度。FAN 在大角度姿态、重度遮挡人脸场景下的鲁棒性远超 RetinaFace,是复杂场景人脸检测的 SOTA 模型。
-
论文 PDF:CVPR 官方→https://openaccess.thecvf.com/content_CVPR_2019/papers/Bulat_Face_Attention_Network_for_Facial_Landmark_Detection_CVPR_2019_paper.pdf | arXiv→https://arxiv.org/pdf/1904.01778.pdf
-
代码地址:官方 PyTorch→https://github.com/1adrianb/face-alignment(集成检测 + 关键点)
五、人脸检测必备工具库、数据集与评估指标
1. 主流人脸检测工具库(封装经典模型,开箱即用,支持训练 / 部署)
|
工具库 |
核心优势 |
代码地址 |
|---|---|---|
|
InsightFace |
国内主流人脸算法库,集成 RetinaFace、PyramidBox 等 SOTA 模型,支持检测 / 对齐 / 识别一体化 |
|
|
OpenCV |
轻量易用,内置 Viola-Jones、MTCNN 等基础检测器,适合快速开发和轻量部署 |
|
|
Dlib |
C++/Python 跨平台,内置 HOG+SVM 人脸检测器和关键点检测器,精度高、鲁棒性强 |
|
|
PaddleFace |
百度飞桨人脸库,集成轻量 / 高精度人脸检测模型,支持移动端部署 |
2. 经典人脸检测数据集(权威基准,覆盖通用 / 复杂场景)
|
数据集 |
核心特点 |
样本量 / 人脸数 |
官网地址 |
|---|---|---|---|
|
WIDER FACE |
人脸检测最权威数据集,覆盖野生场景,分 Easy/Medium/Hard 子集(Hard 含遮挡 / 小人脸 / 大姿态) |
32k 张图 / 393k 个人脸 |
|
|
FDDB |
经典人脸检测数据集,以侧脸 / 模糊人脸为主,侧重姿态鲁棒性评估 |
2k 张图 / 5k 个人脸 |
|
|
AFLW |
大角度姿态人脸数据集,覆盖 0°~180° 人脸姿态,适合姿态鲁棒性训练 |
25k 张图 / 25k 个人脸 |
https://www.tugraz.at/institute/icg/research/team-bischof/lrs/downloads/aflw/ |
|
MAFA |
口罩遮挡人脸数据集,含各种口罩遮挡类型(半遮 / 全遮),适合遮挡人脸检测 |
30k 张图 / 35k 个人脸 |
3. 核心评估指标(人脸检测专用,区别于通用目标检测)
-
AP(Average Precision):通用检测指标,衡量精度 - 召回率曲线下面积,WIDER FACE 主指标为AP@0.5(IOU 阈值 0.5);
-
Recall(召回率):衡量模型对人脸的检出能力,重点关注 Hard 子集的召回率(小人脸 / 遮挡人脸);
-
FPS(帧 / 秒):衡量推理速度,分CPU/FPGA/ 移动端 GPU不同硬件的速度;
-
关键点检测误差:对多任务模型,用归一化均方误差(NME) 评估关键点对齐精度。
2.3 图像分割问题

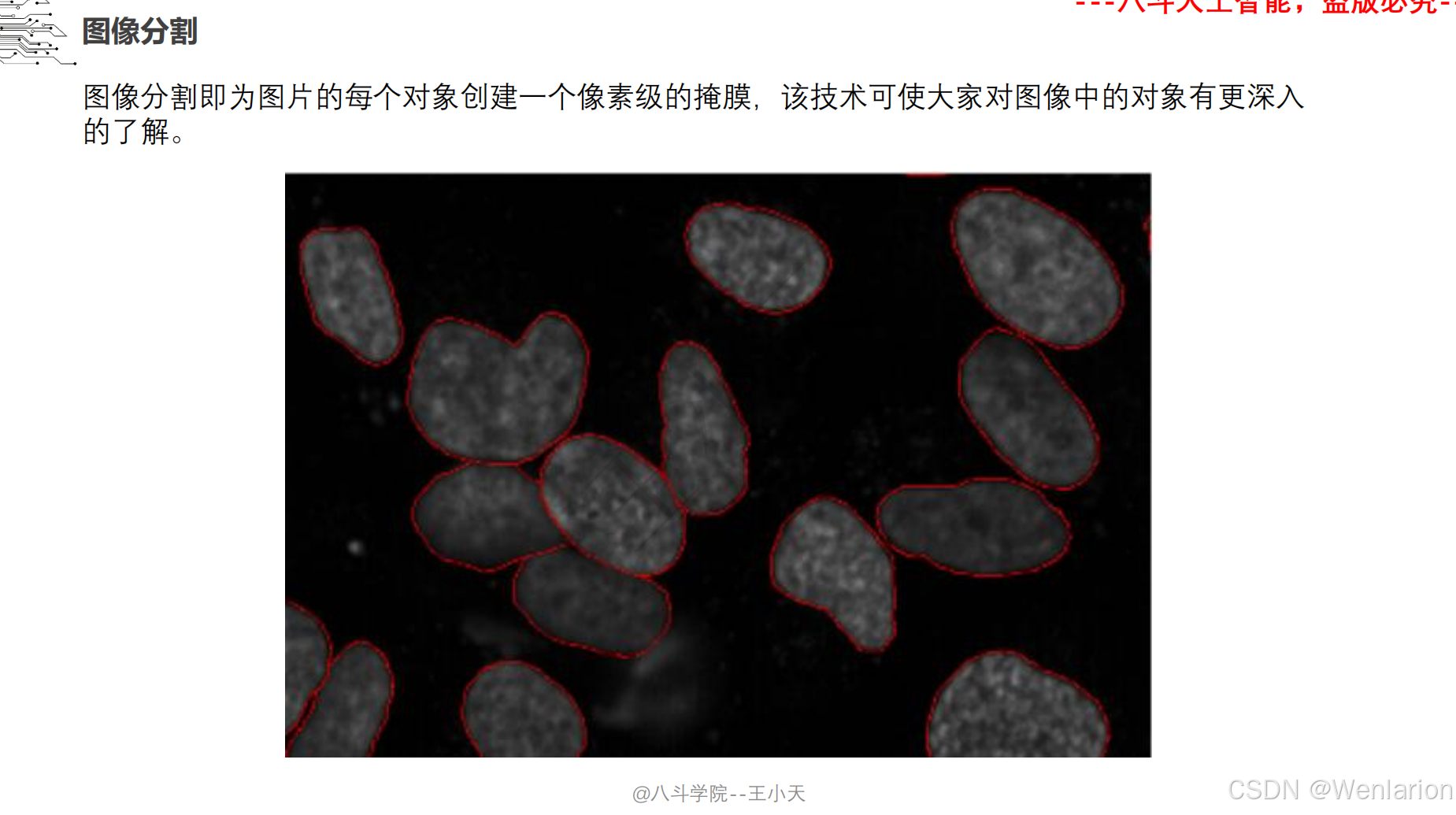

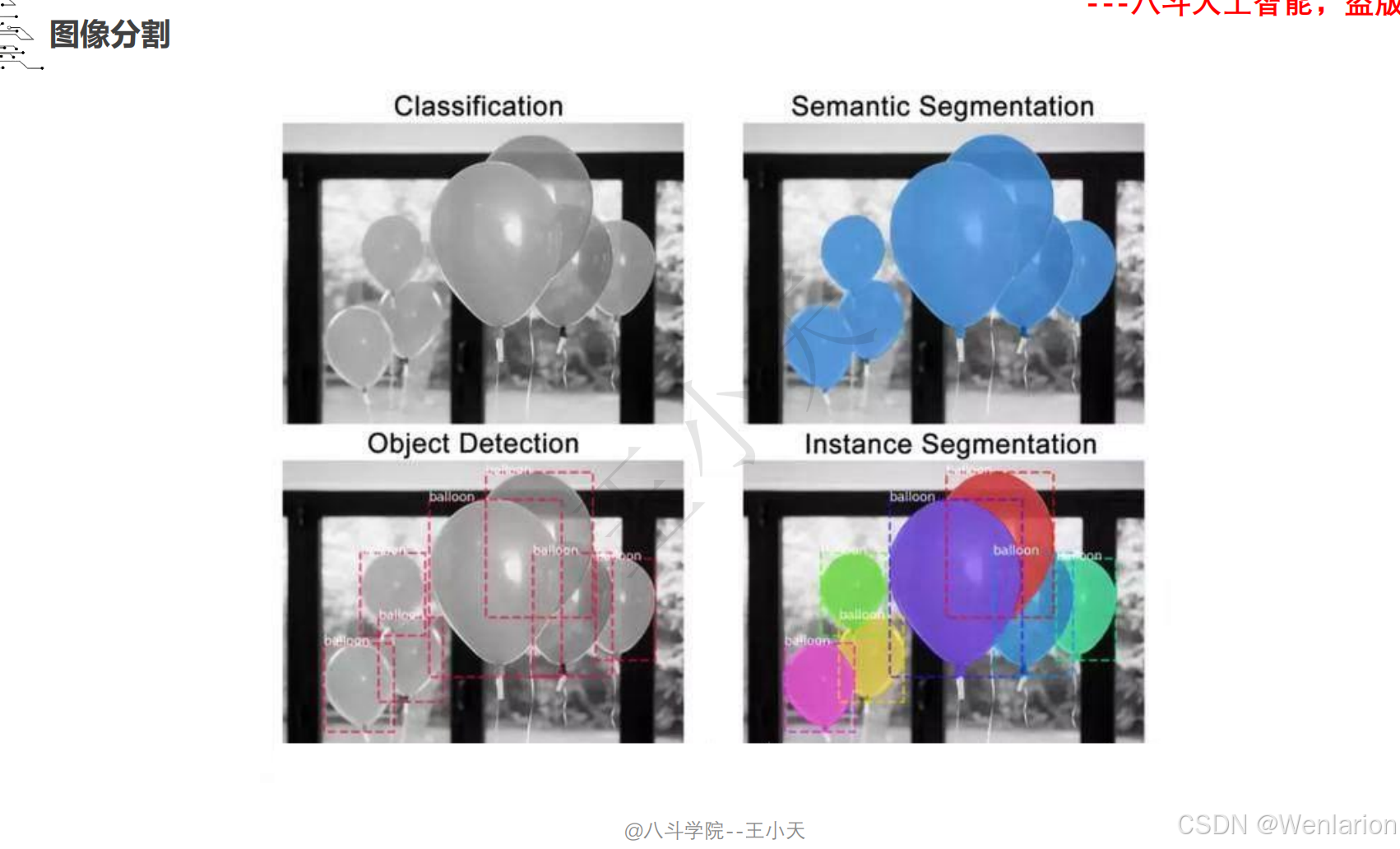
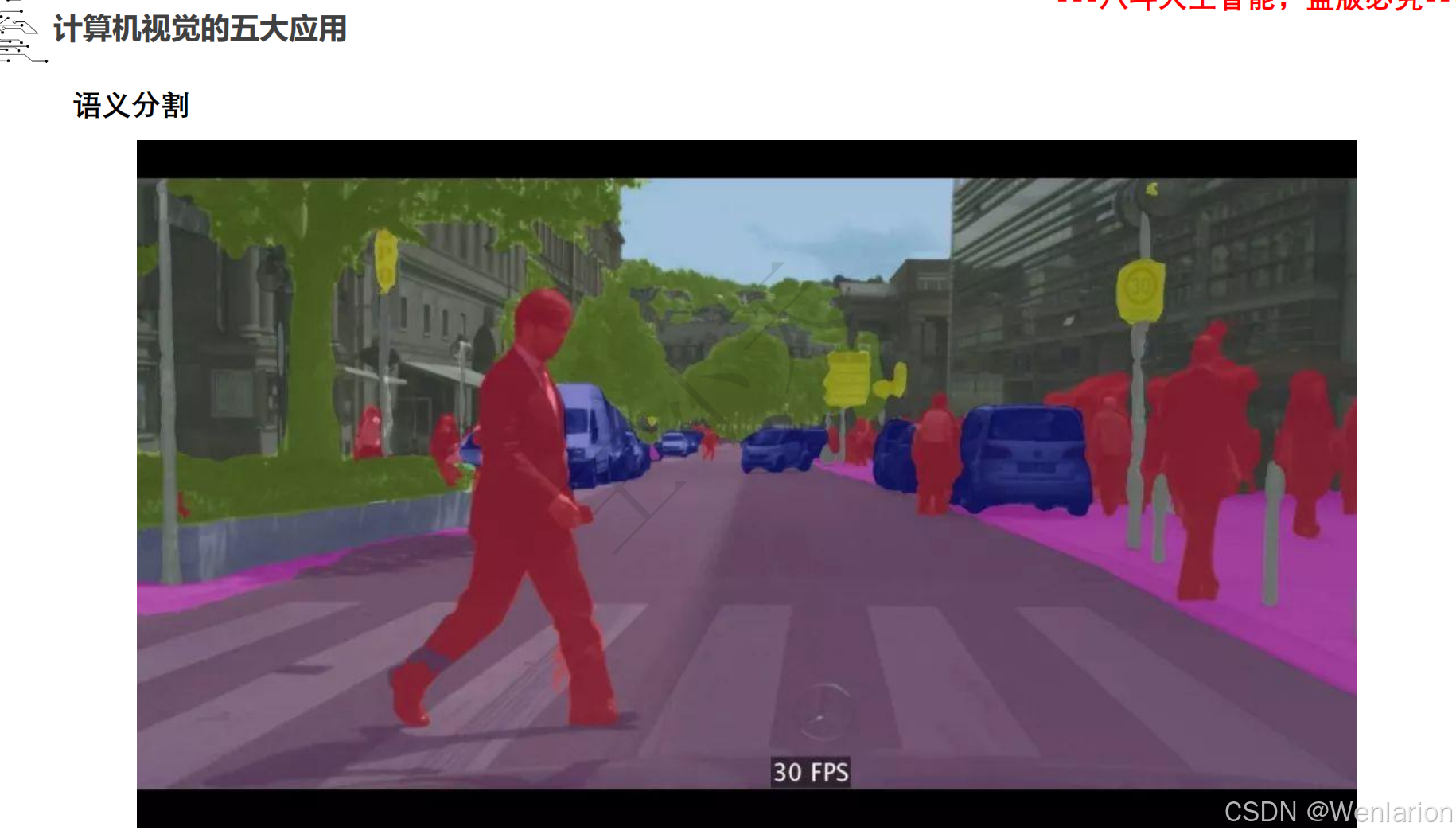
2.3.1 语义分割
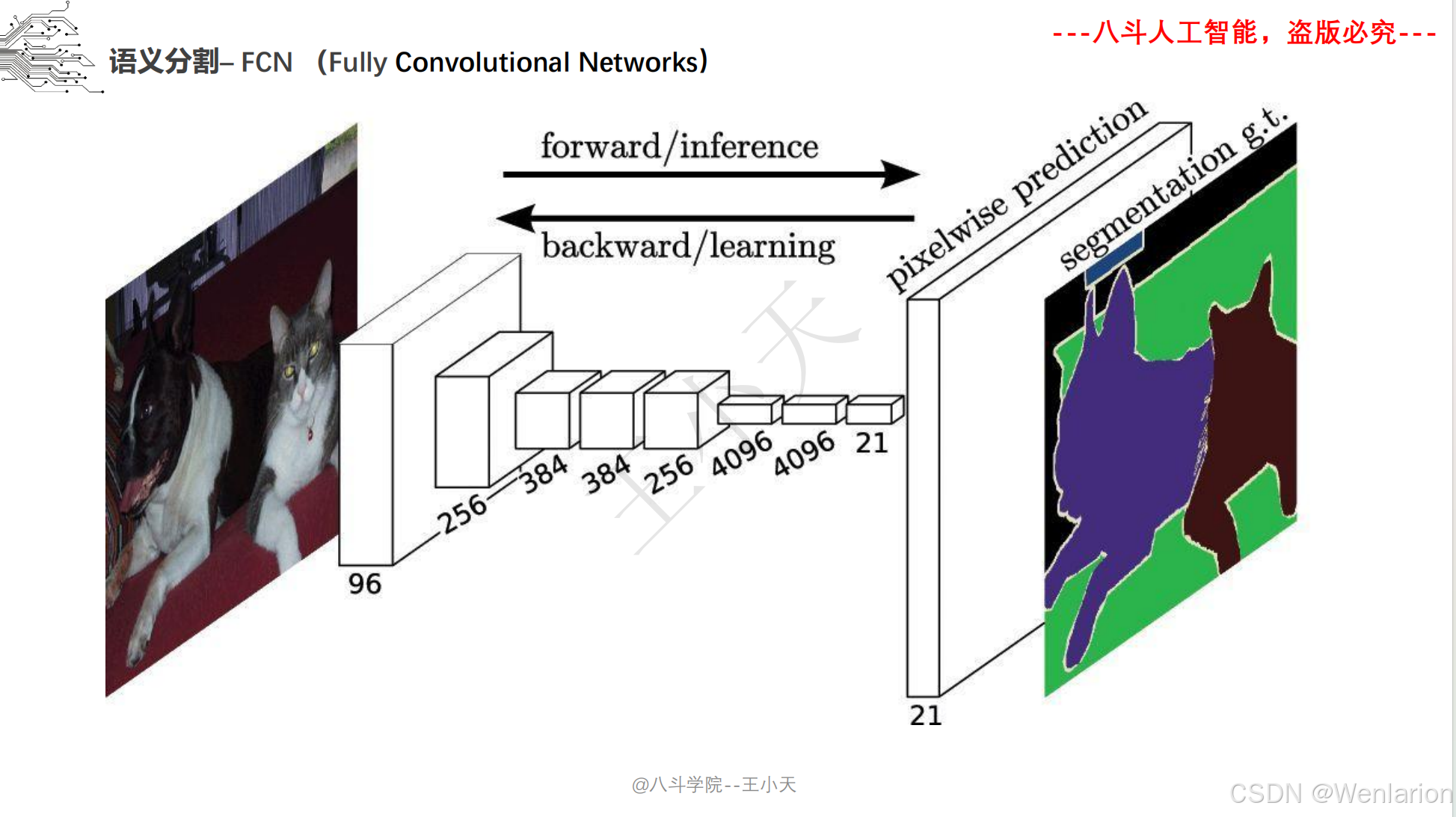
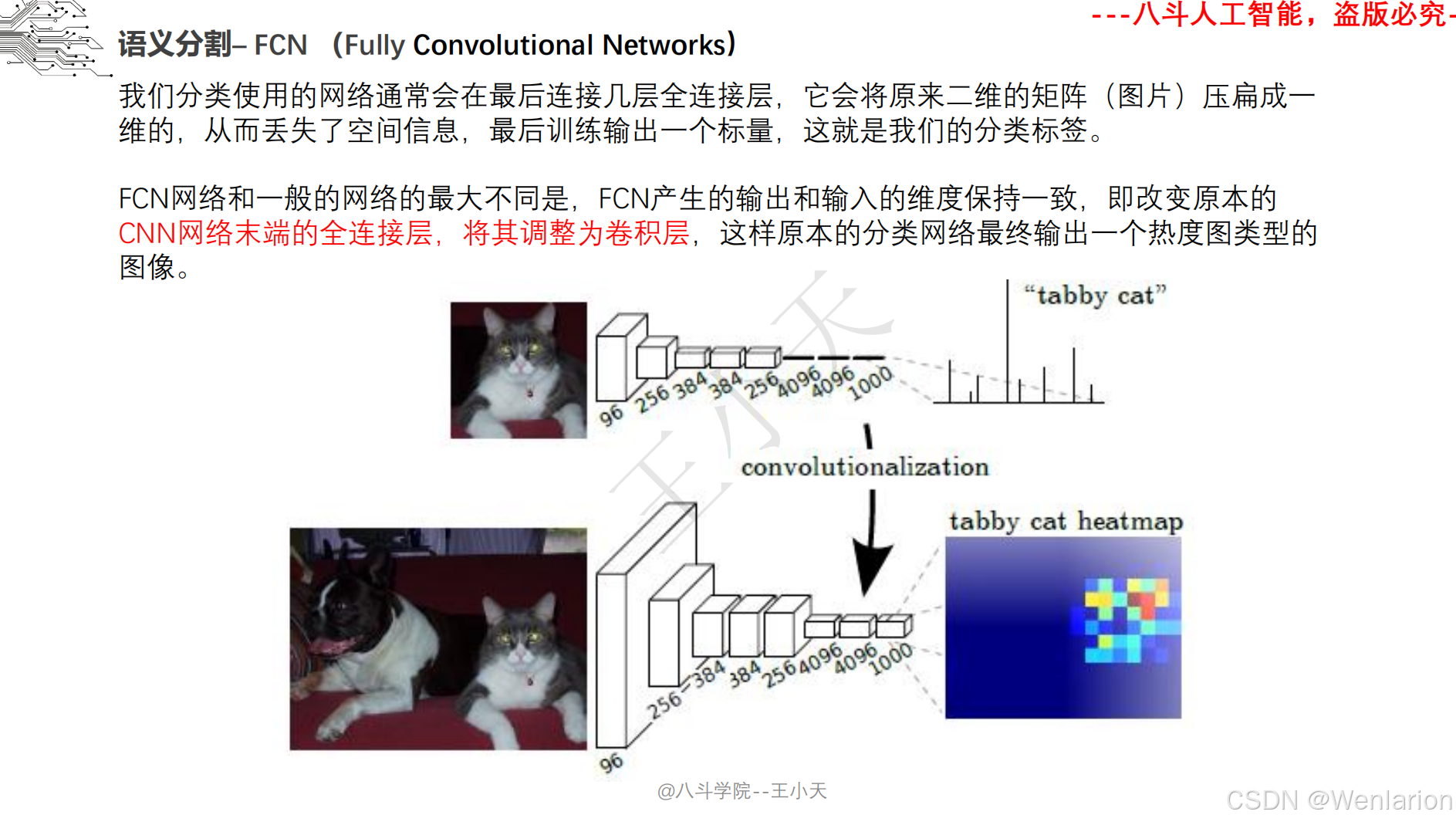





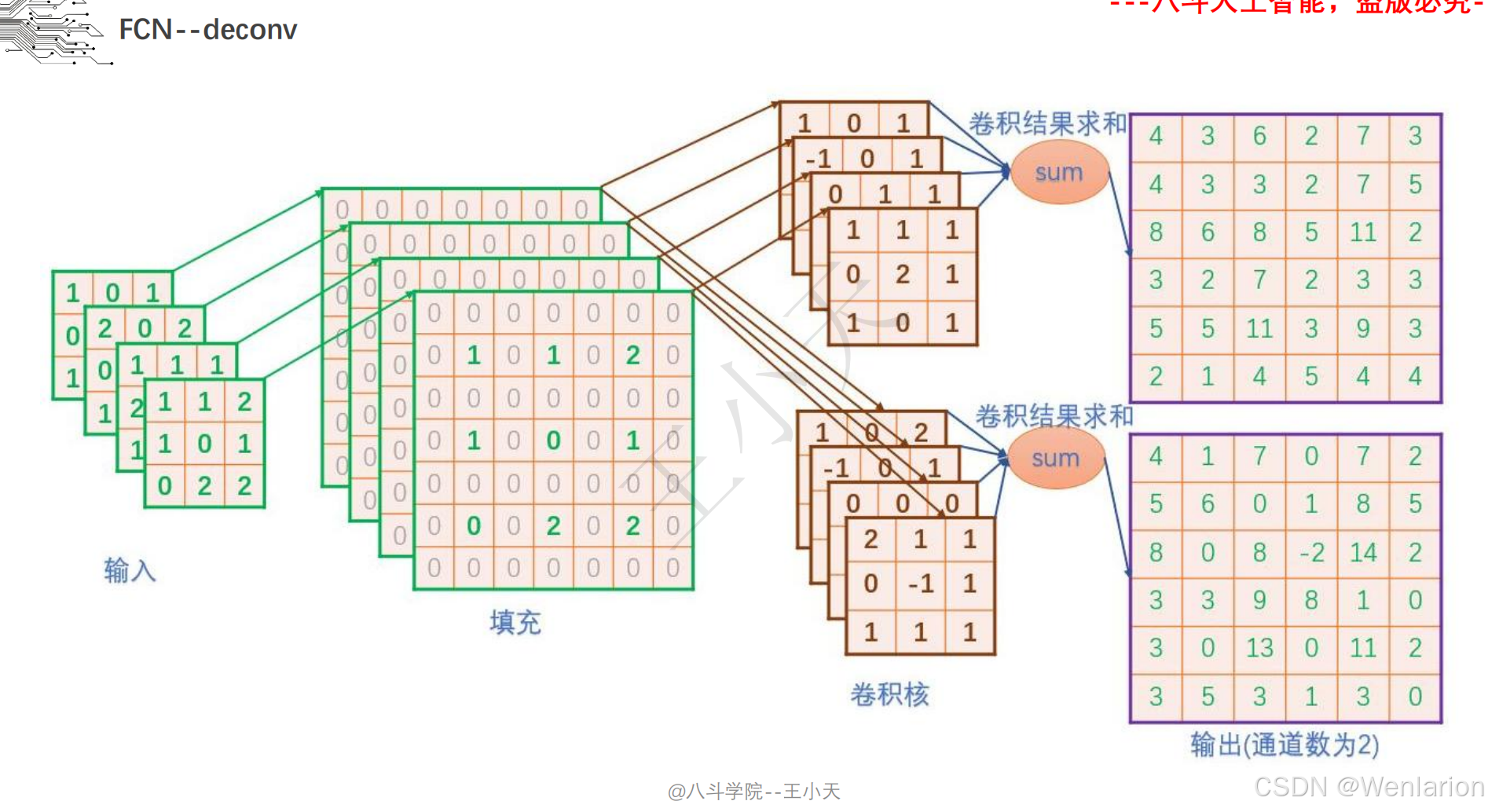


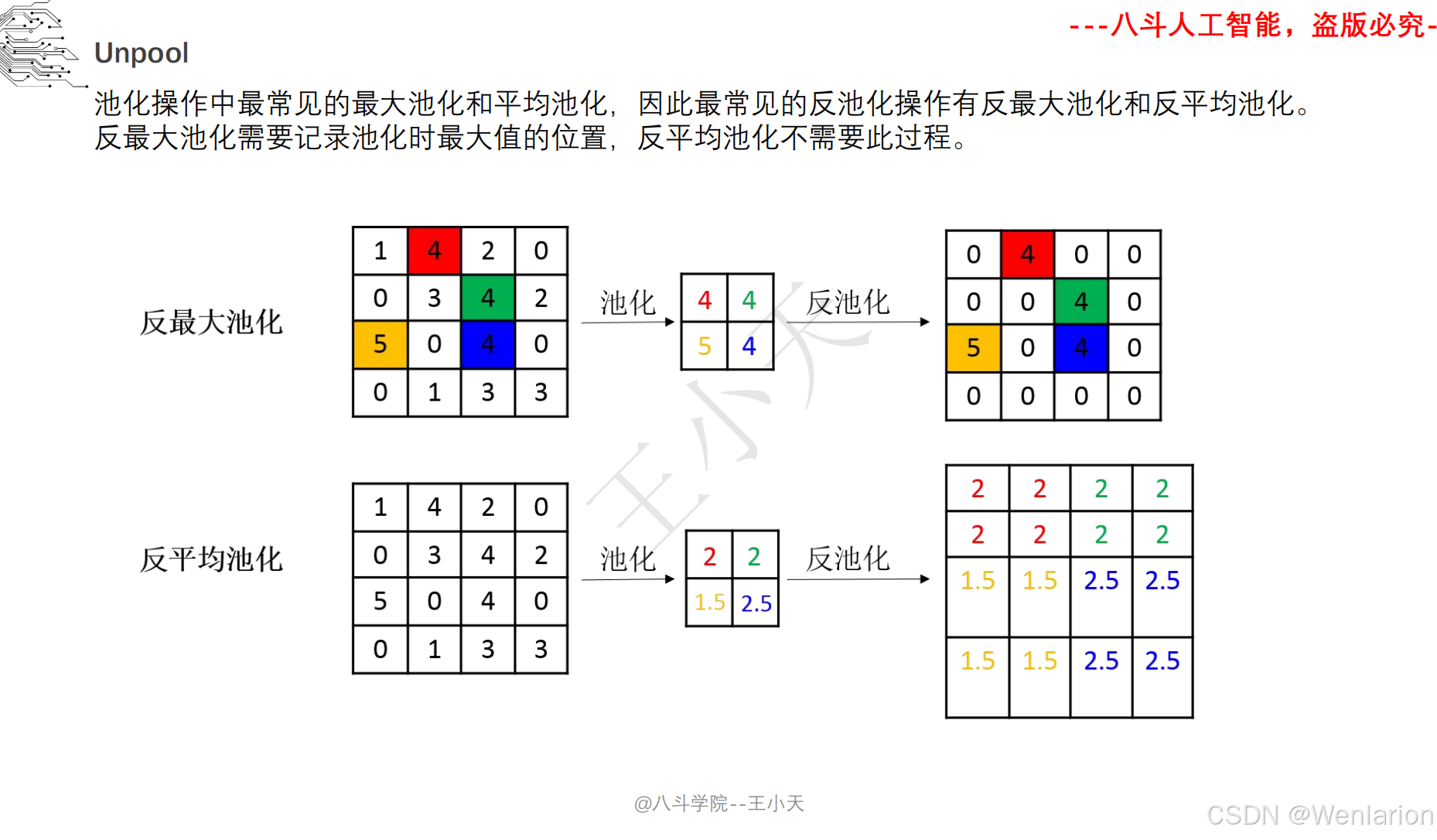
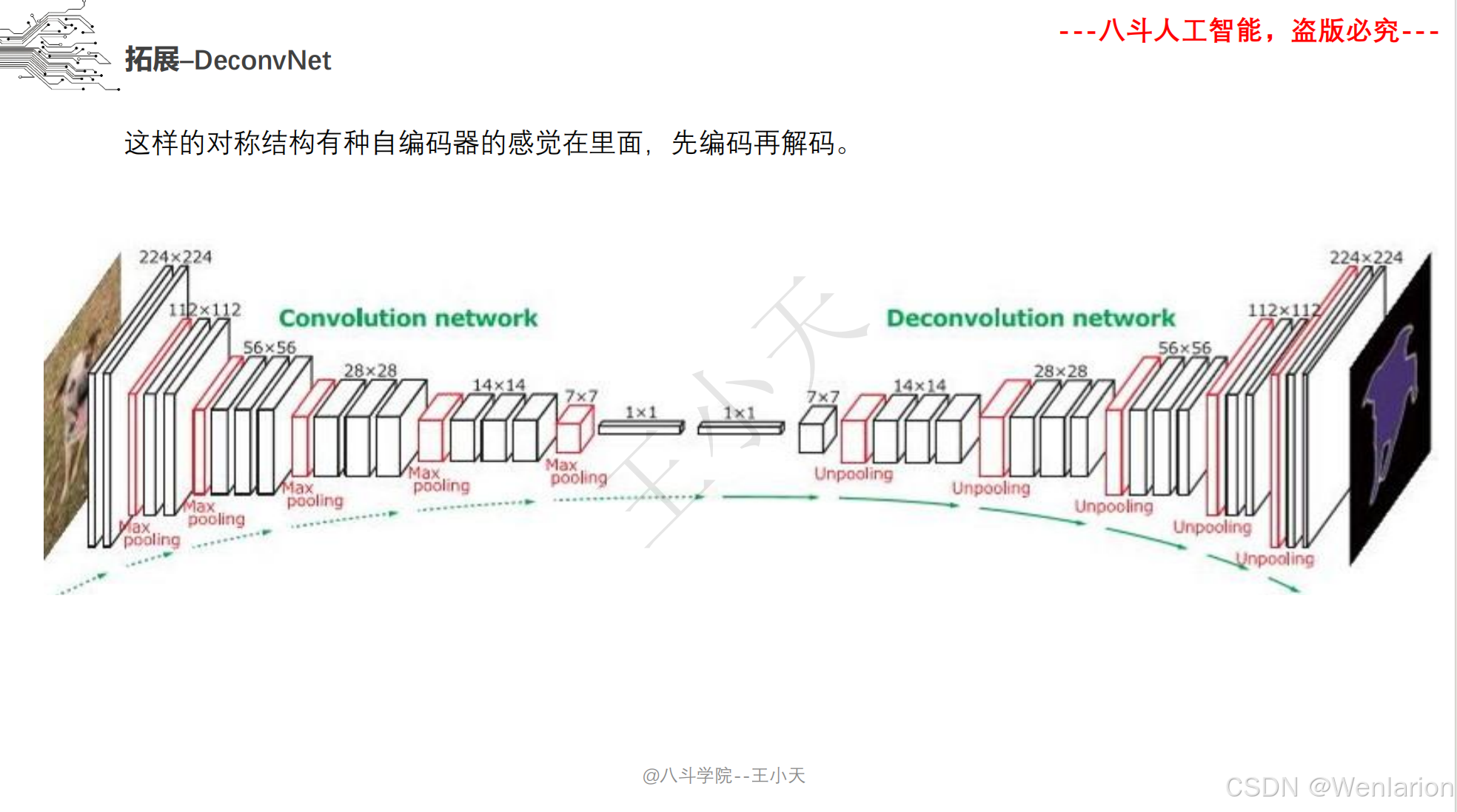
2.3.2 实例分割



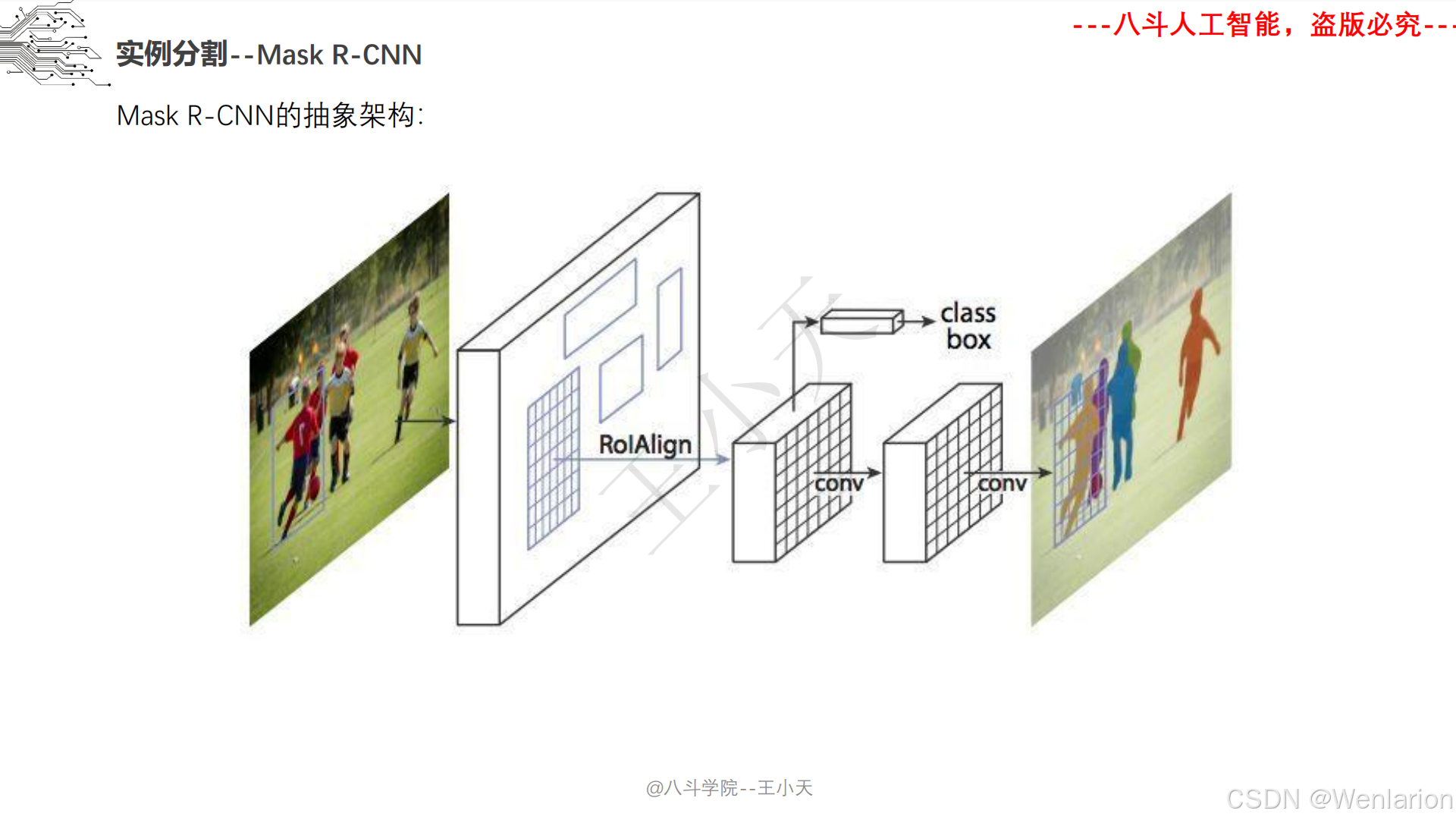
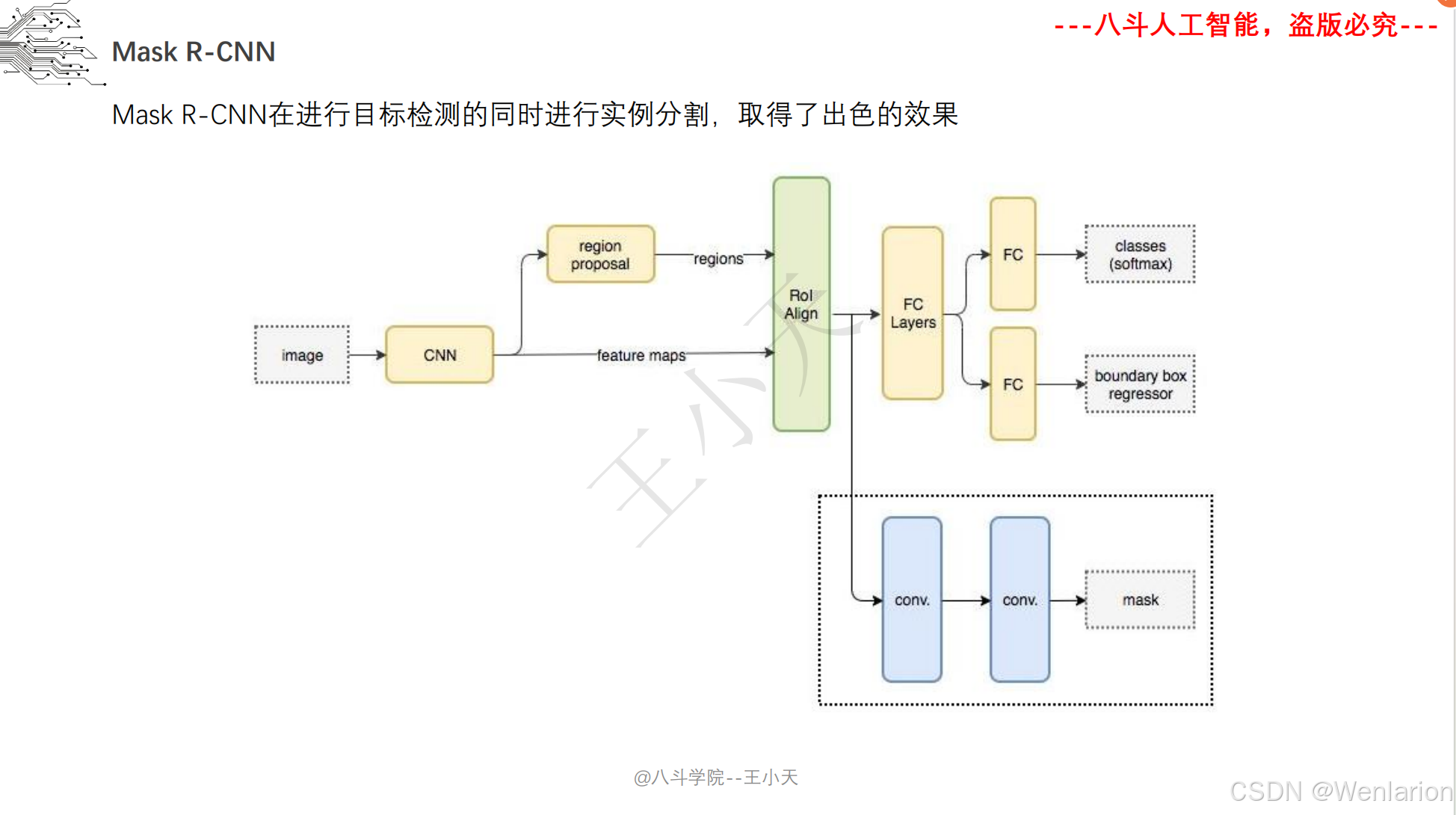
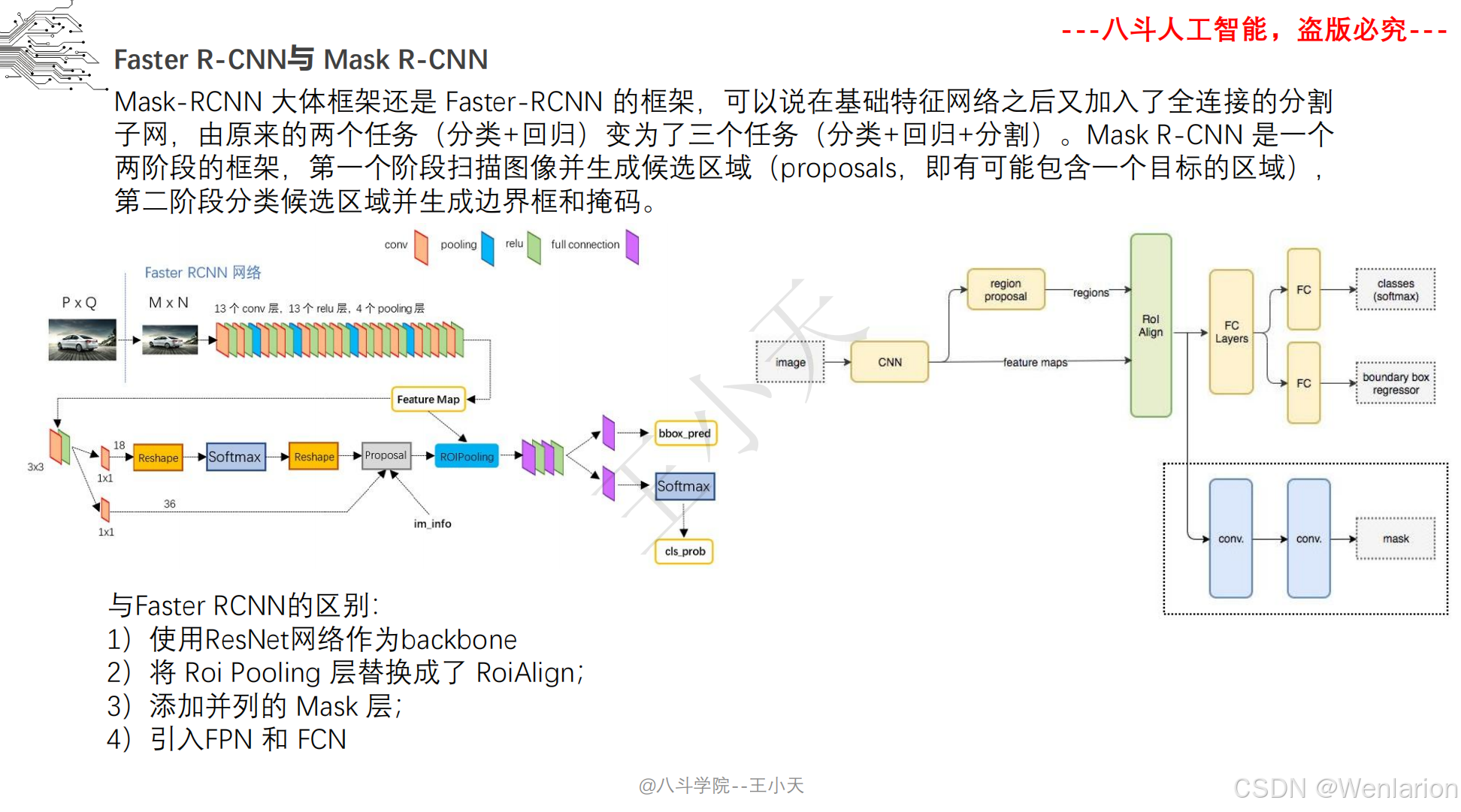



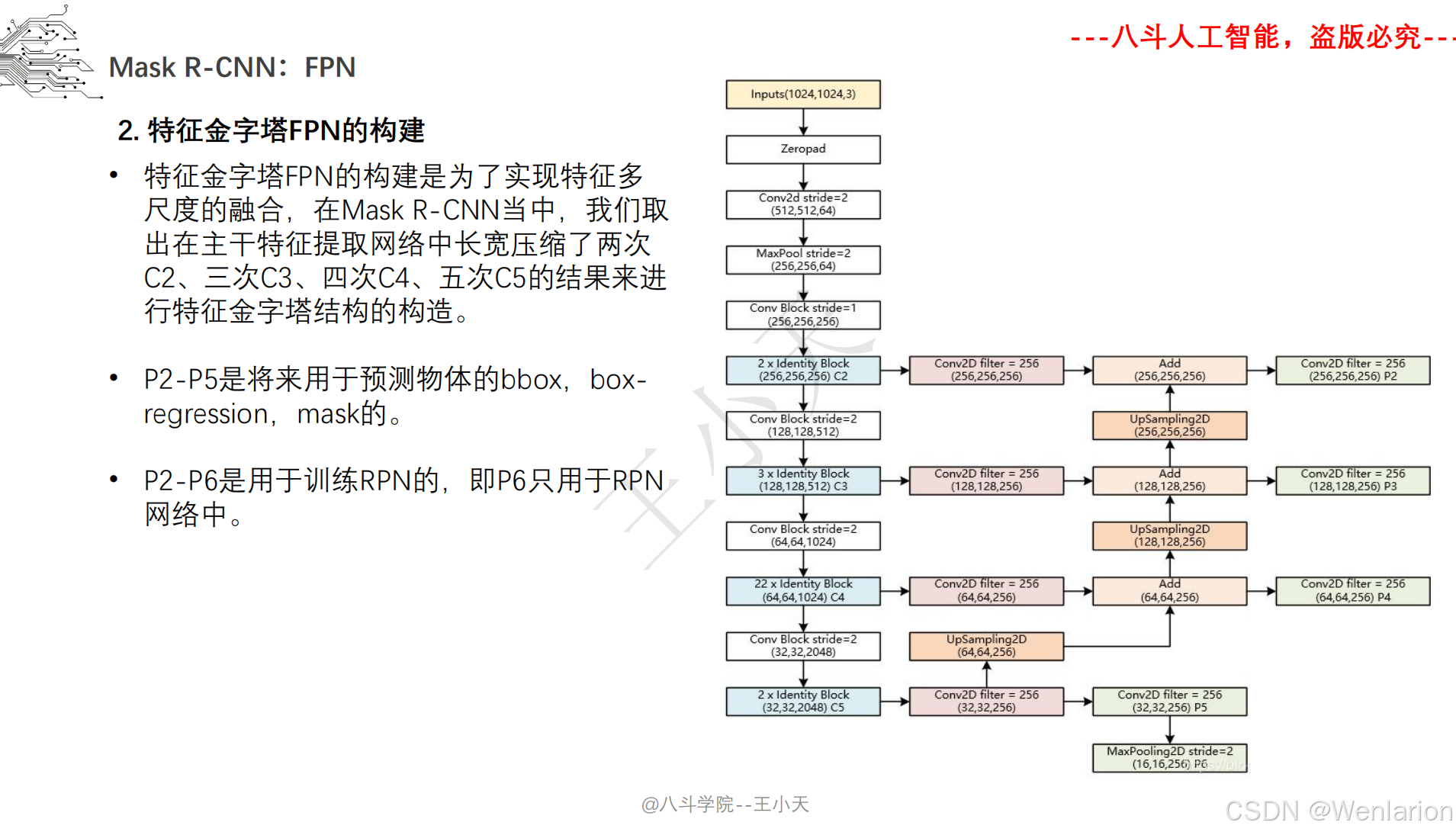


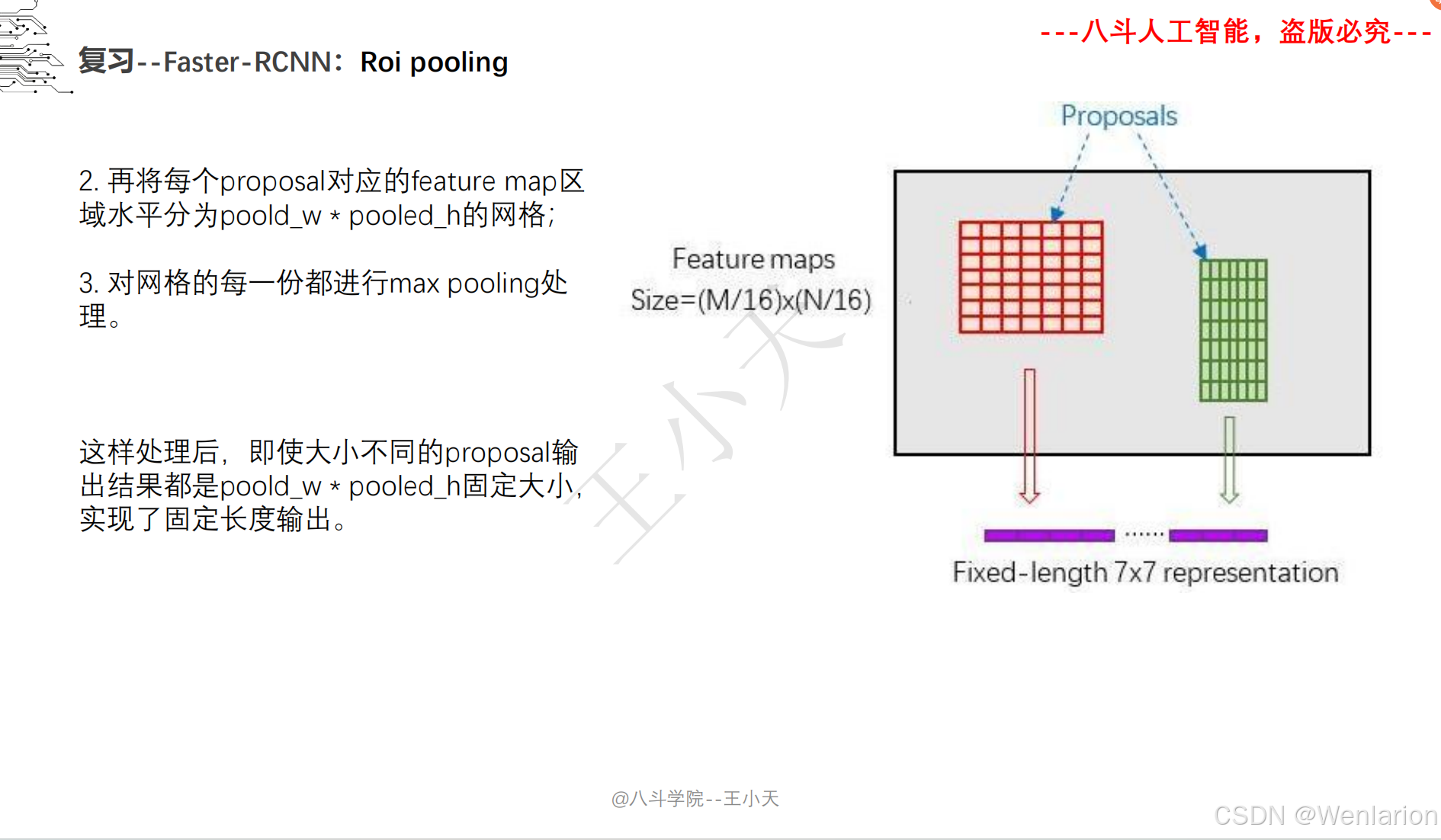
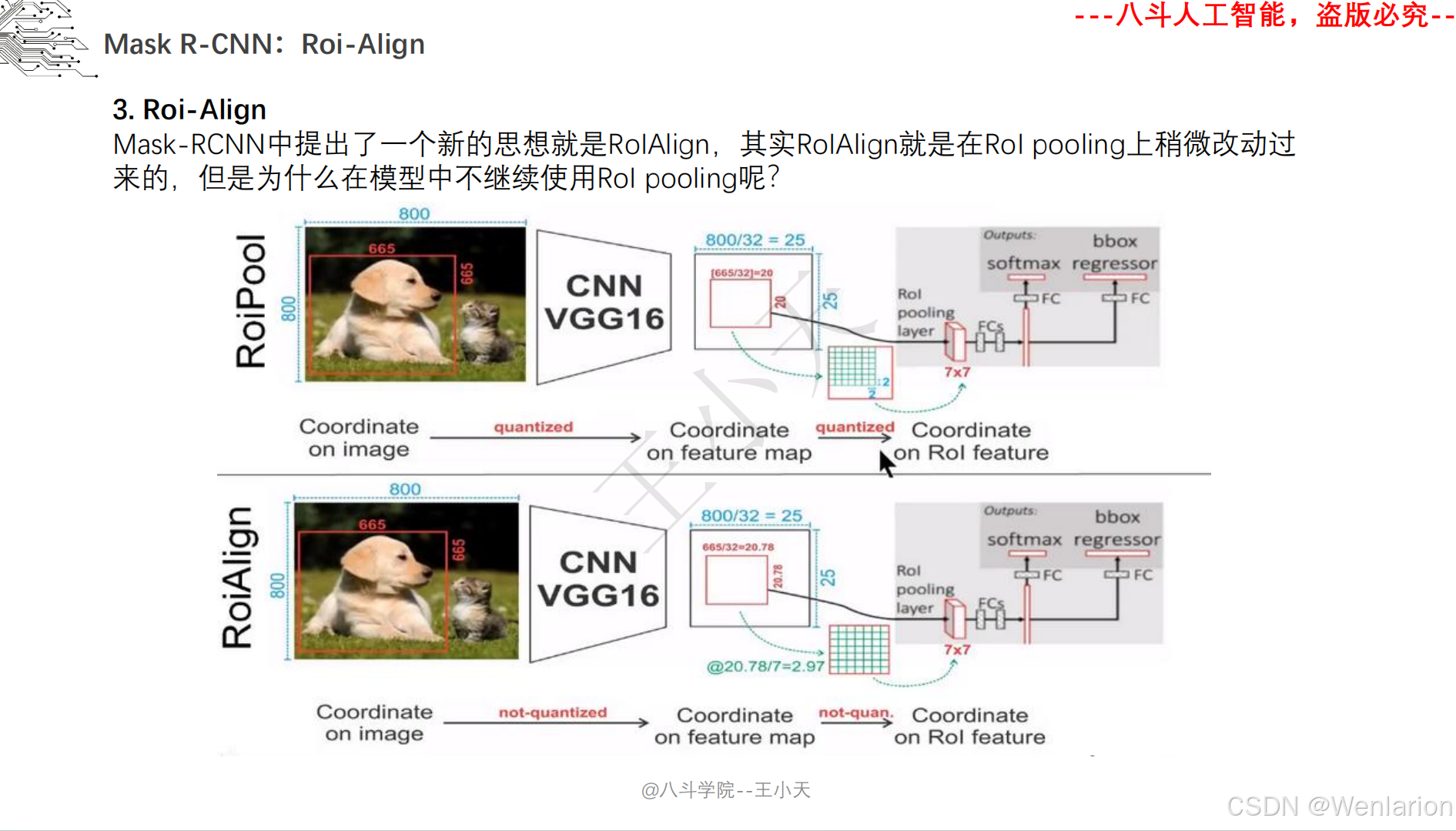
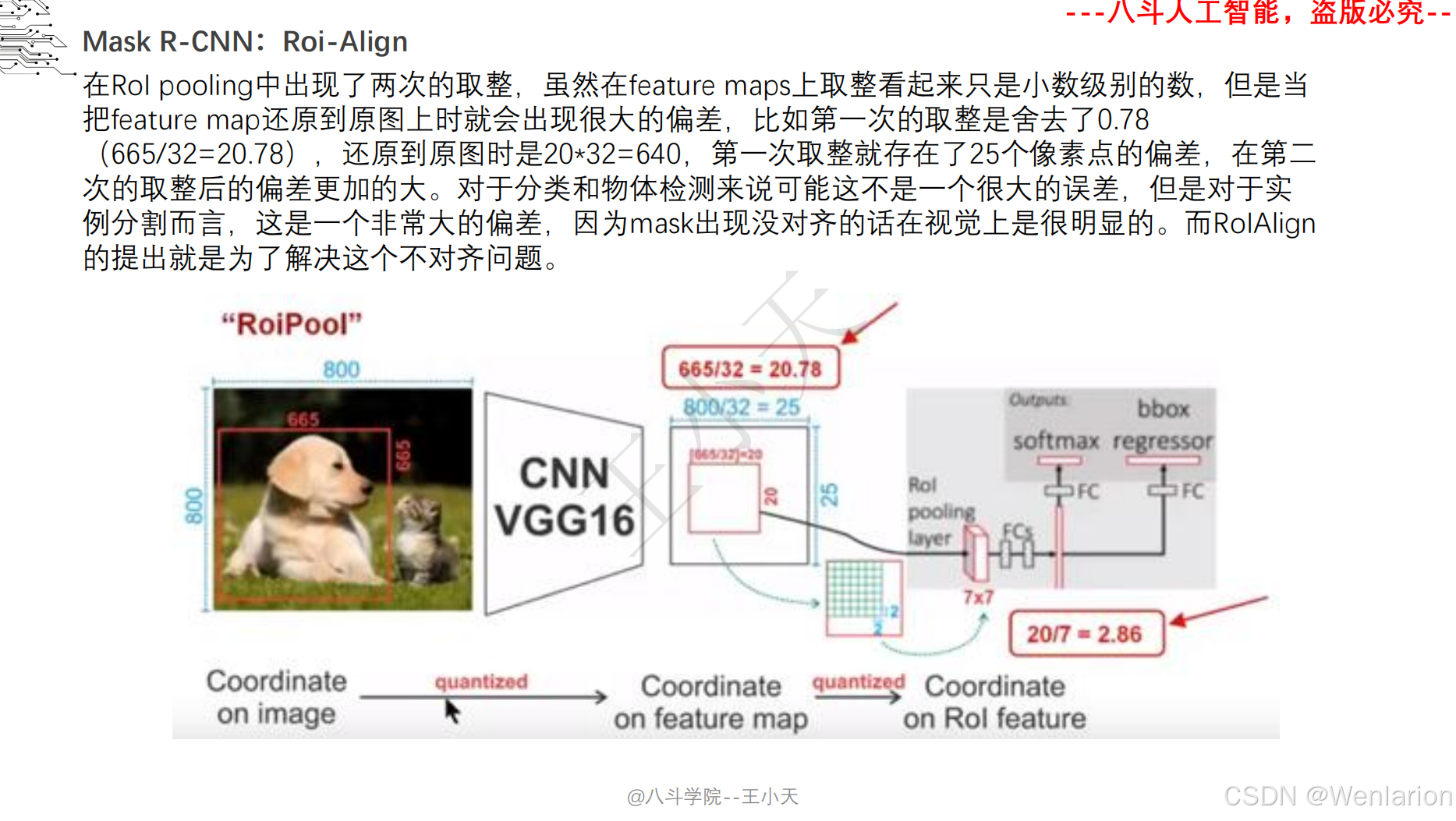
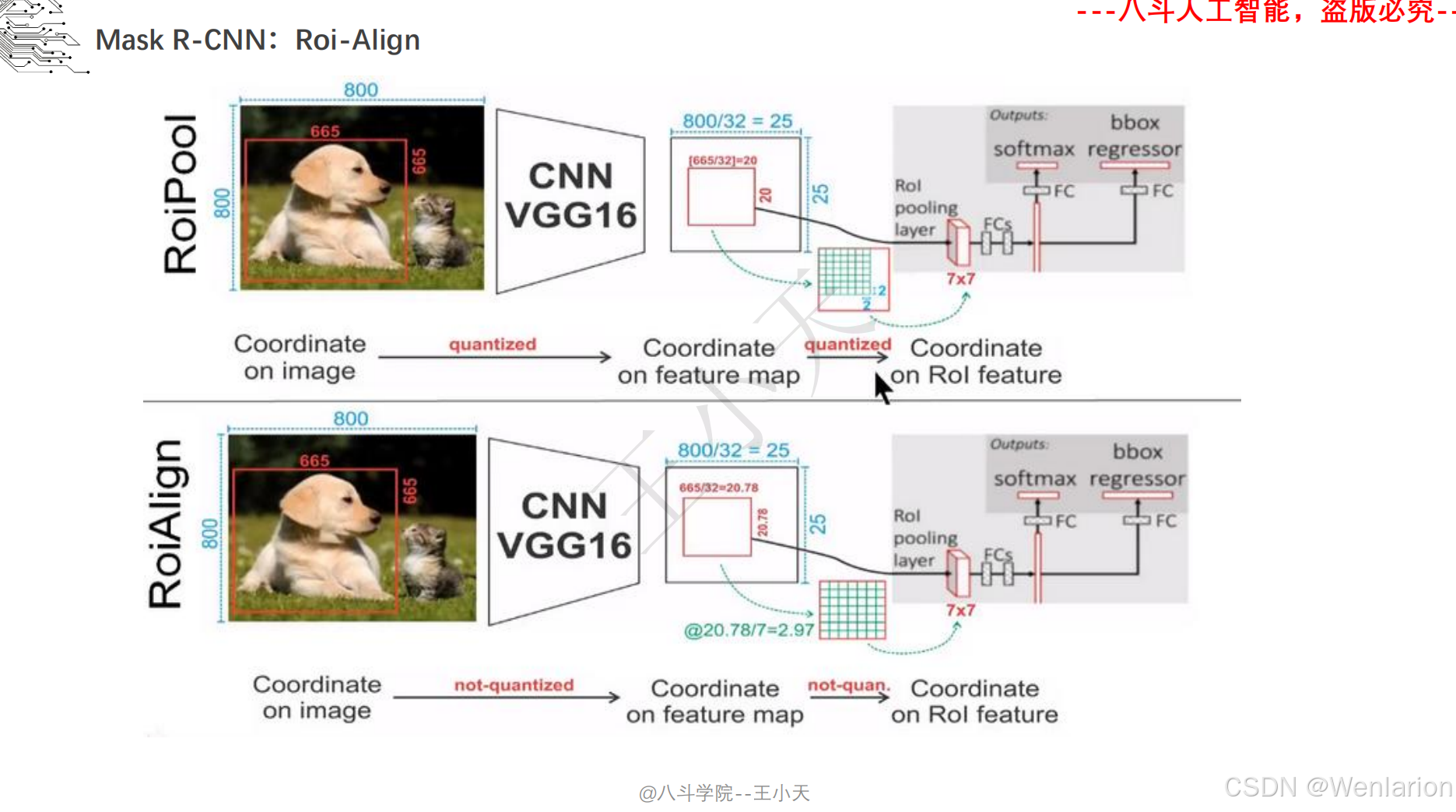

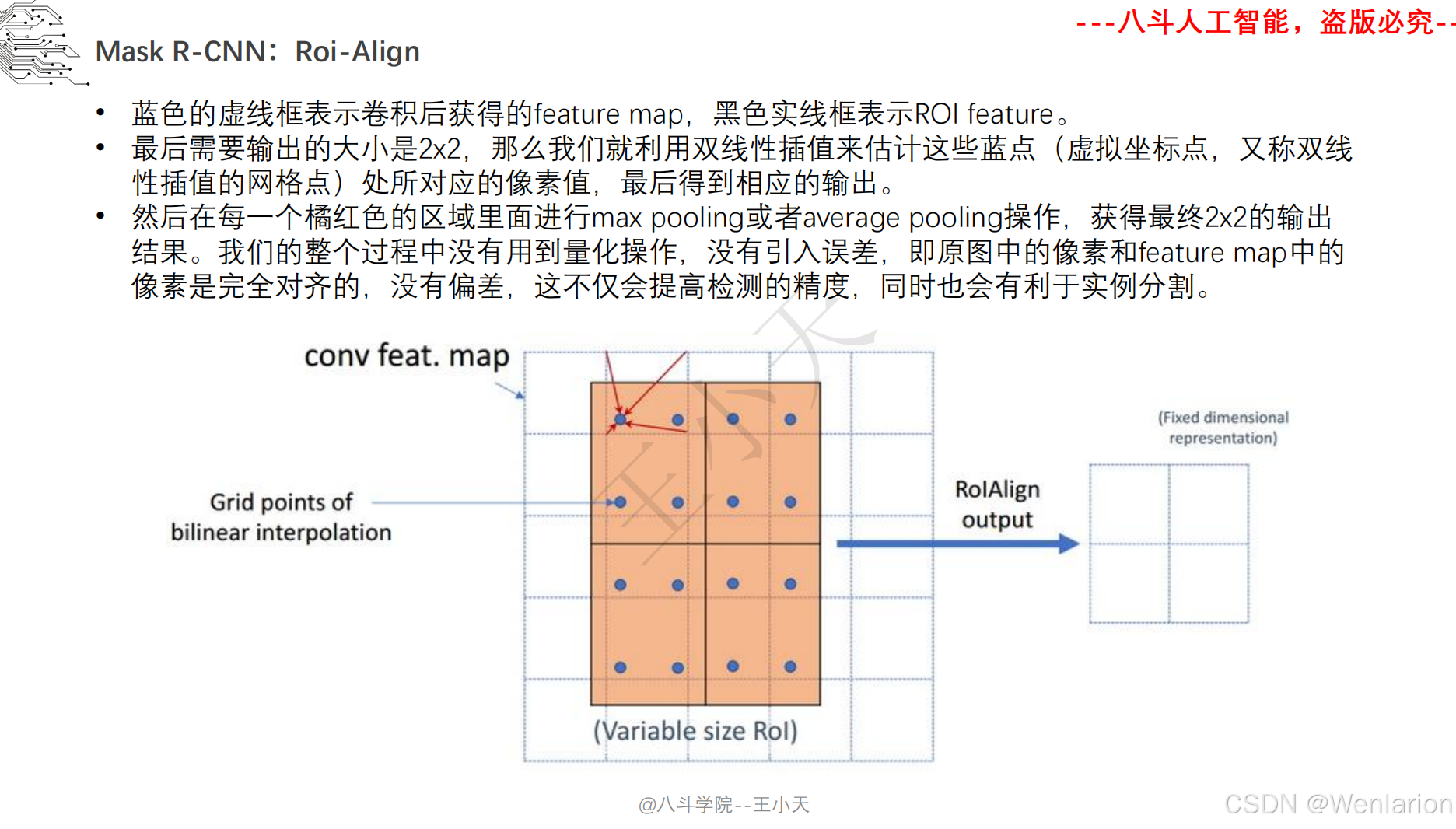
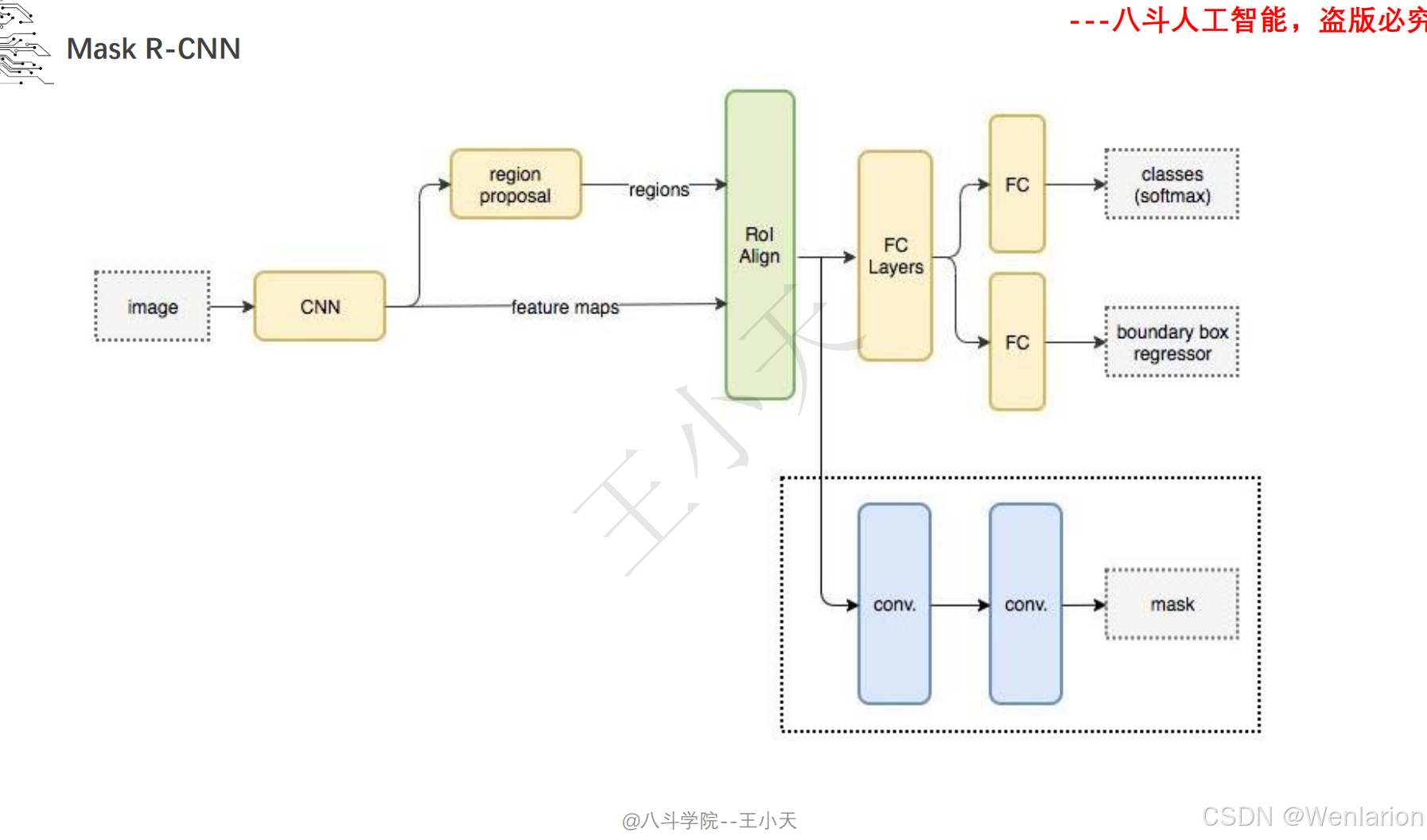


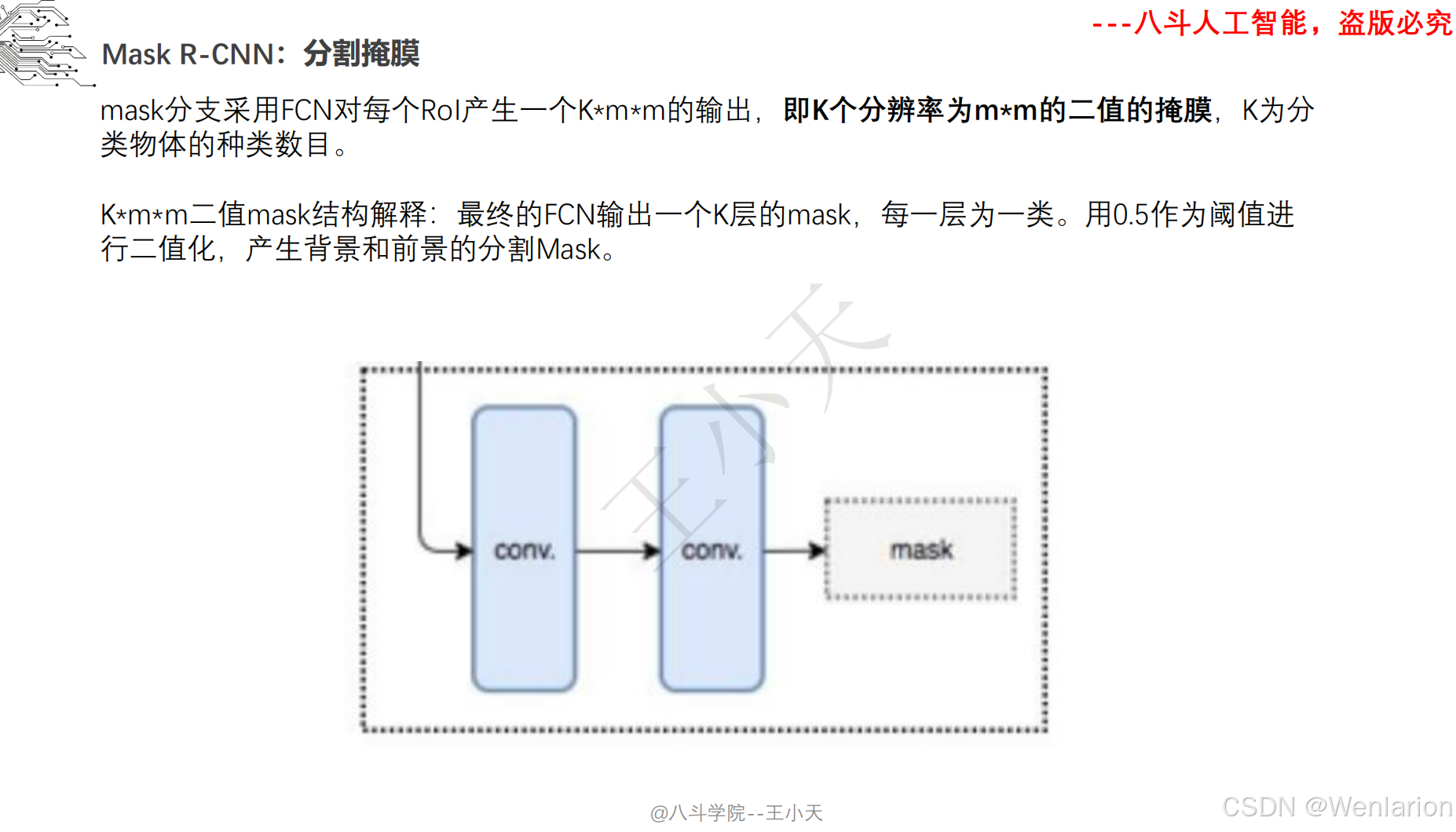
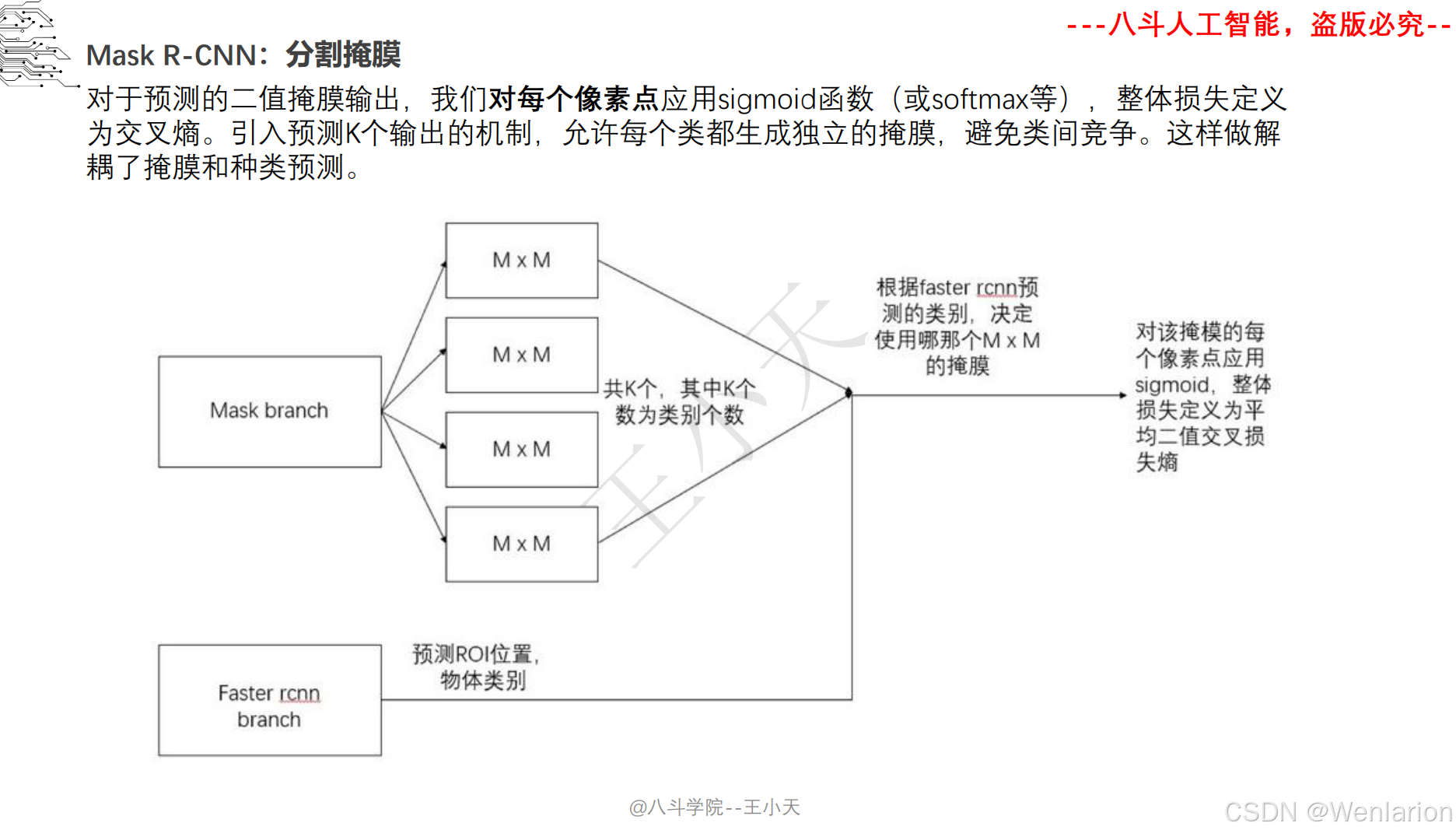




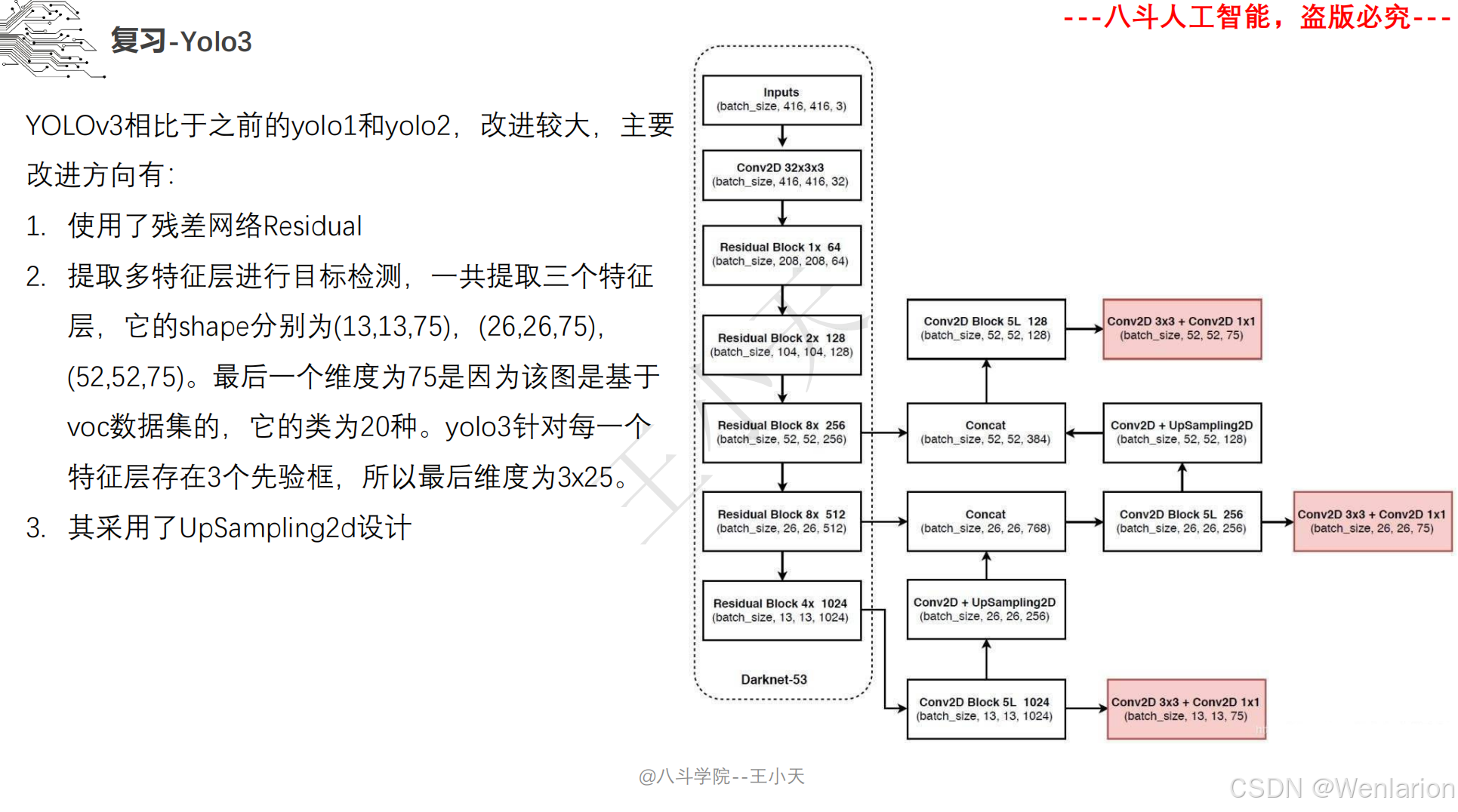
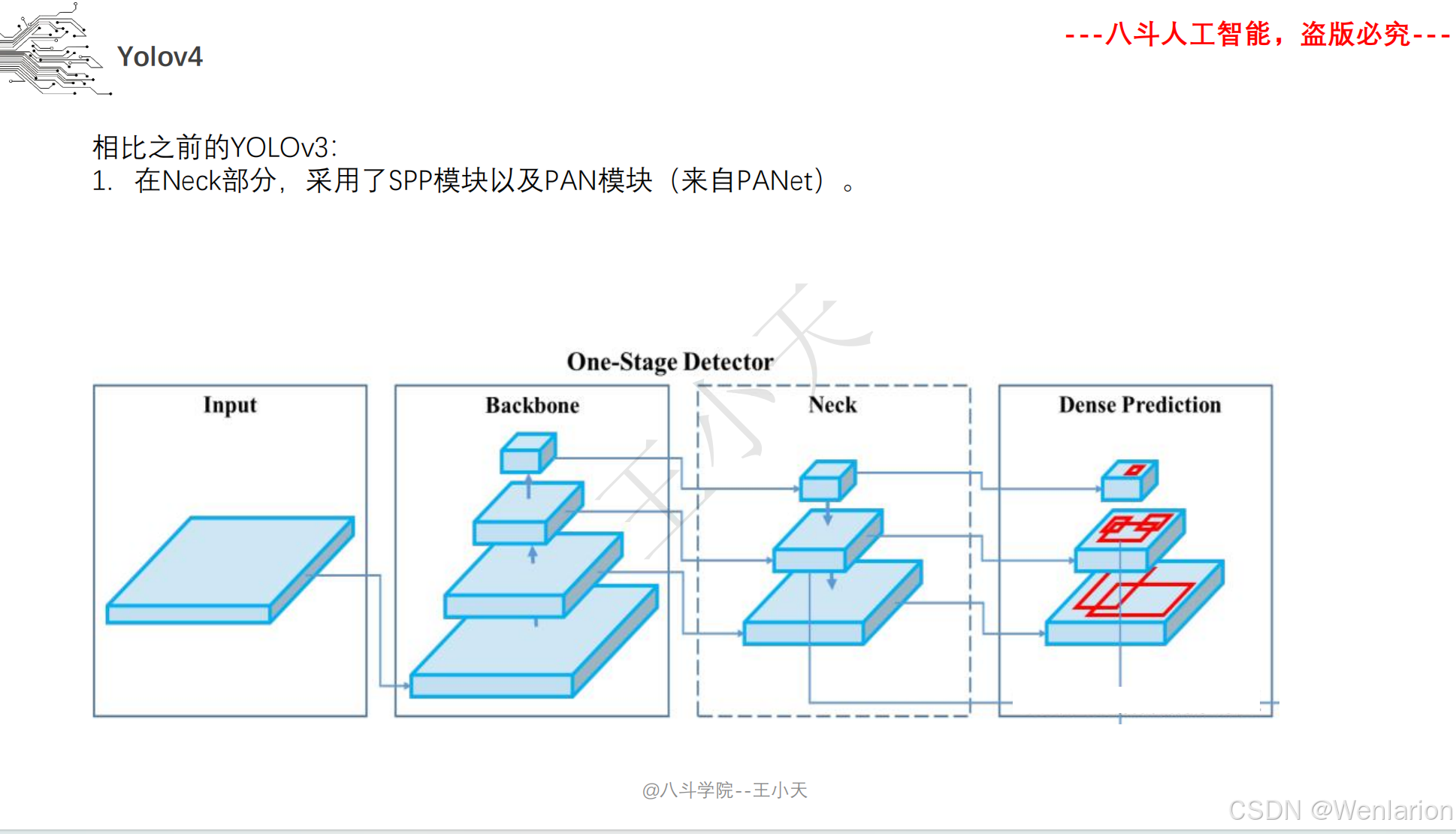
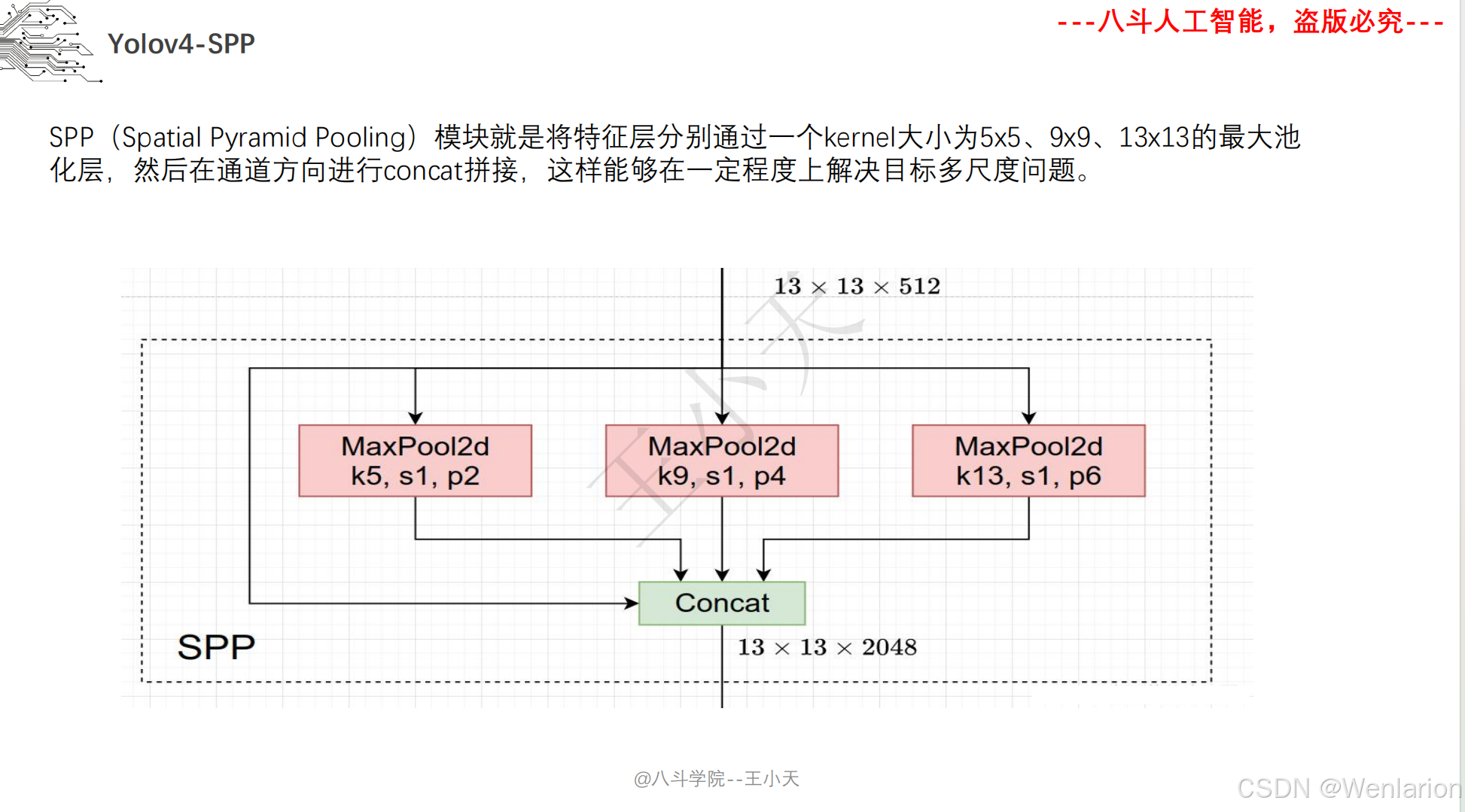
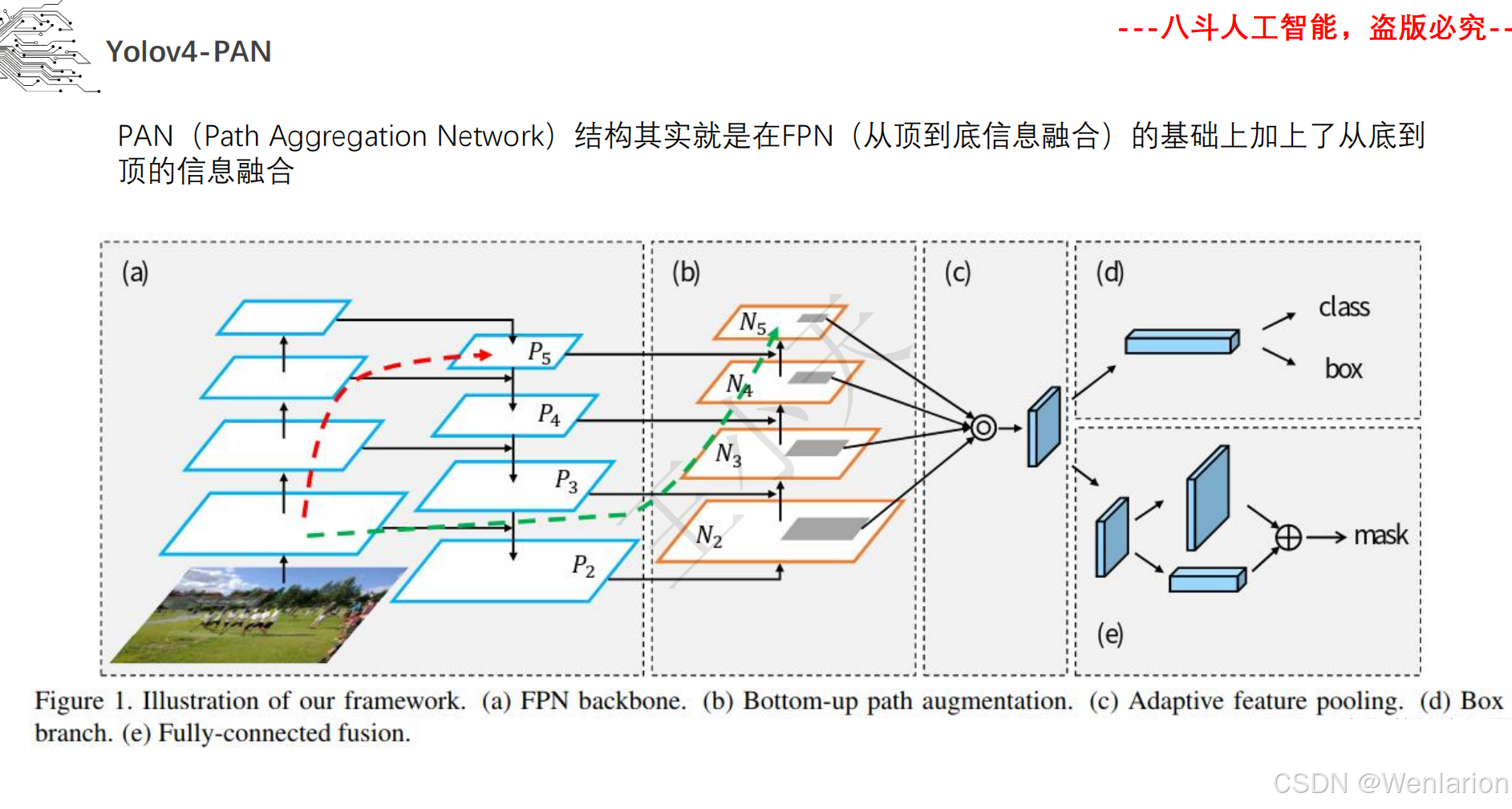
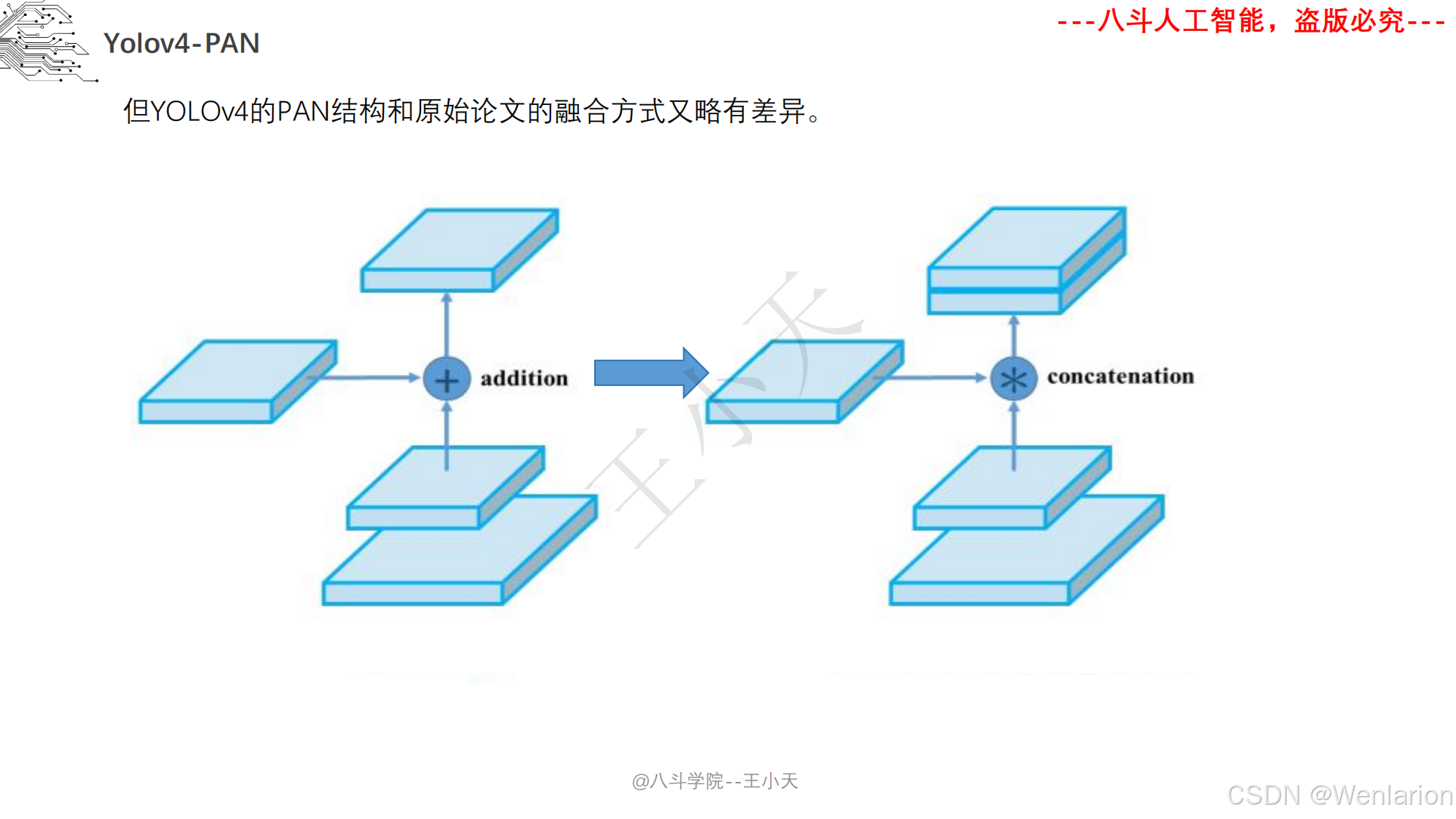
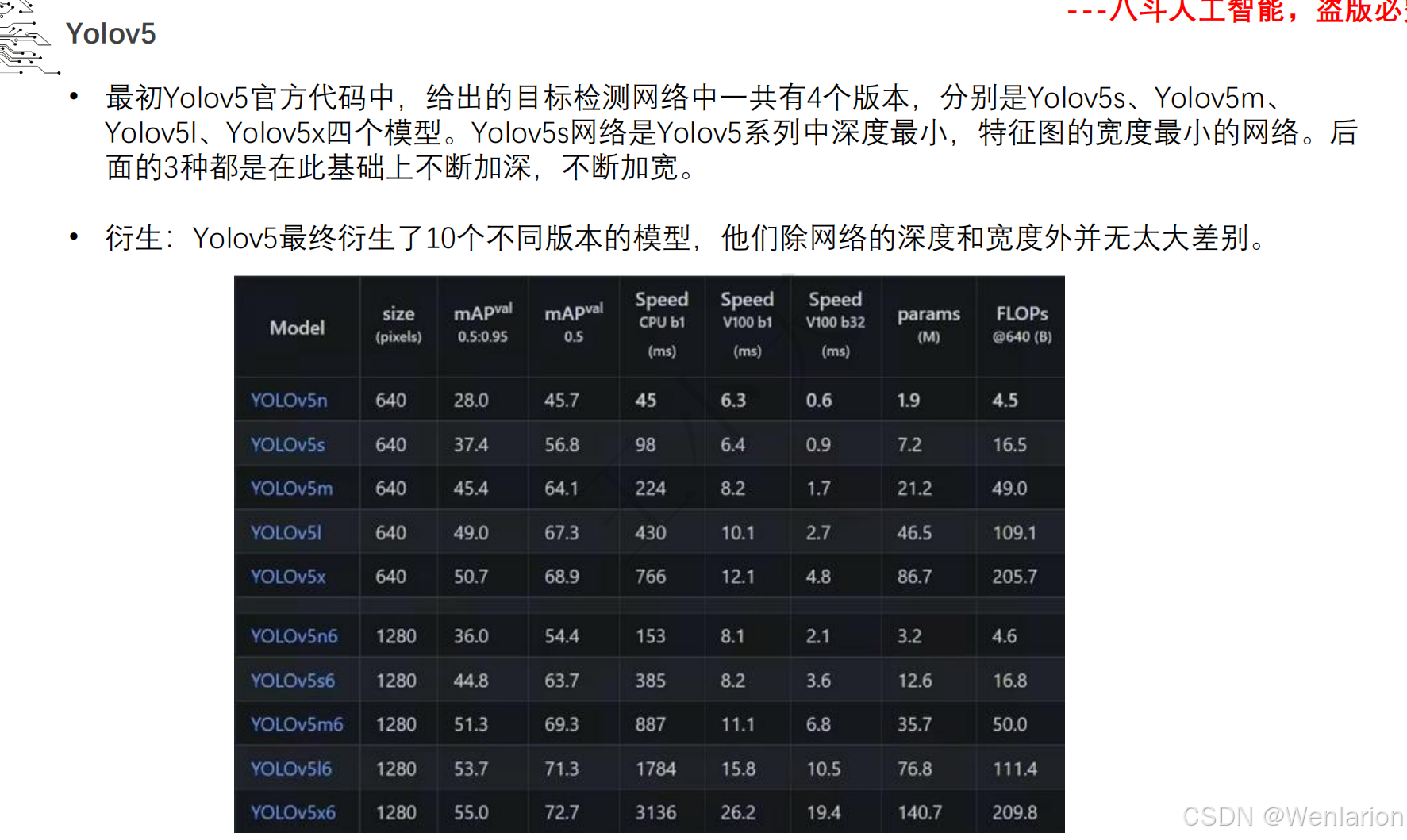
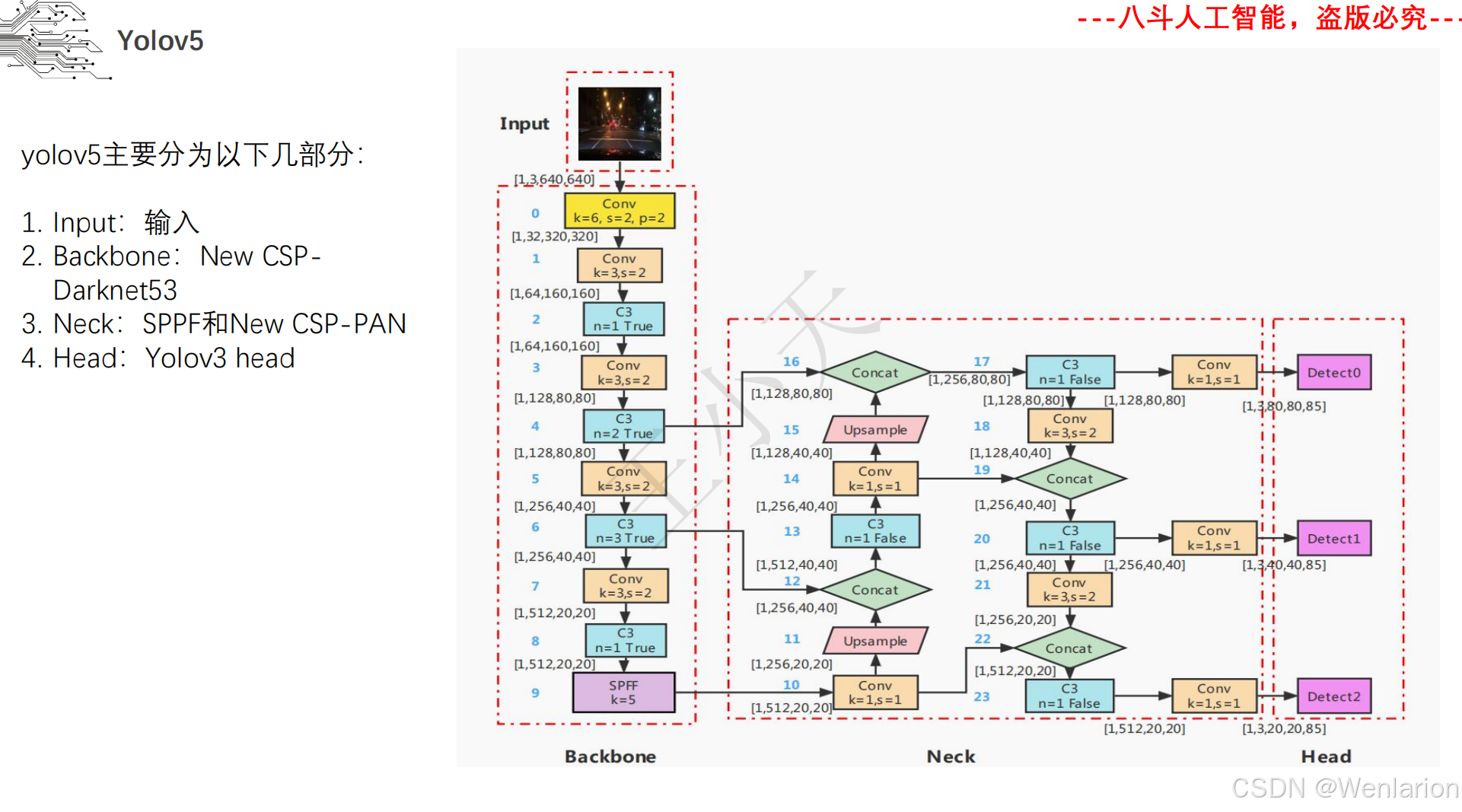
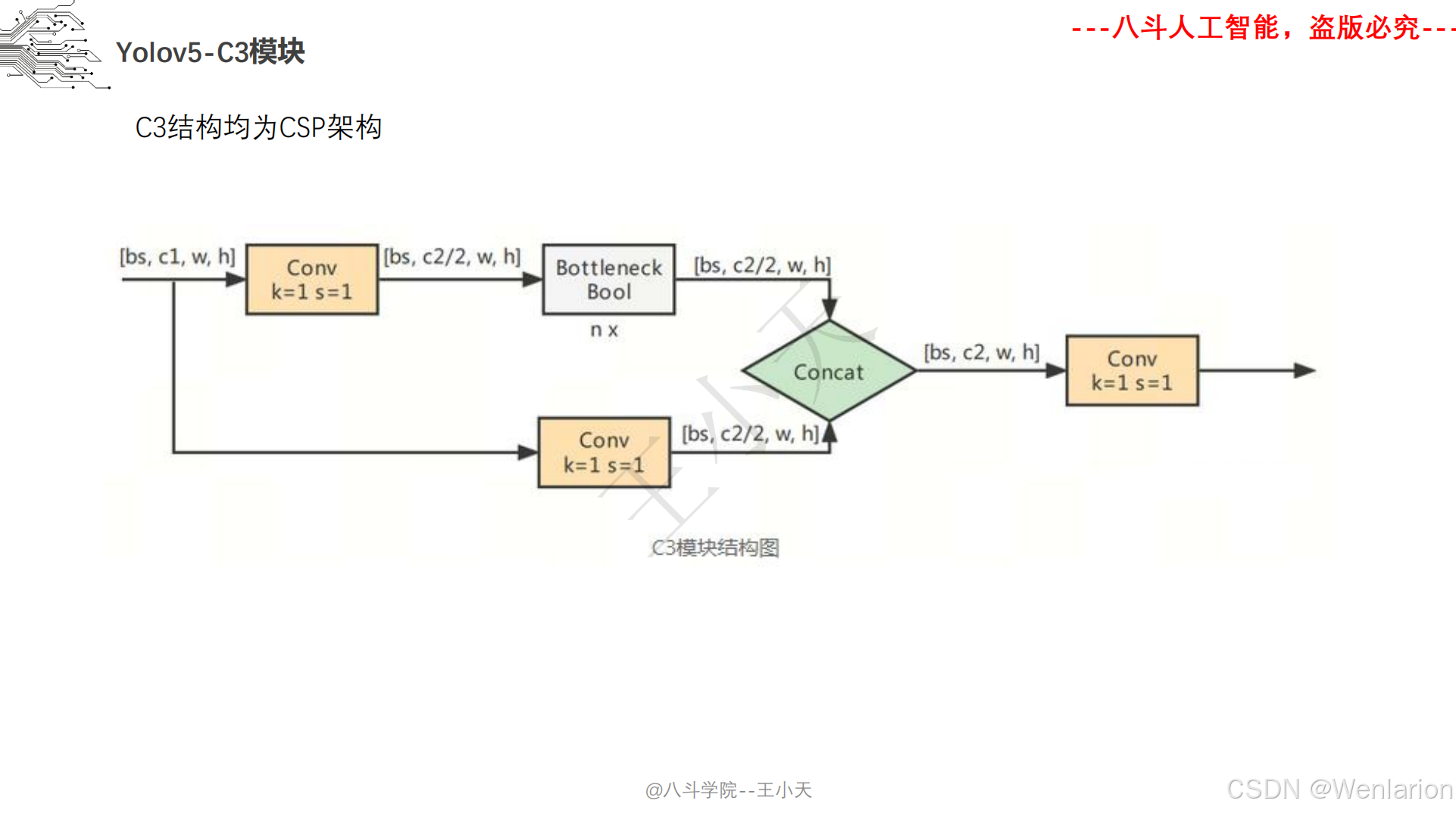
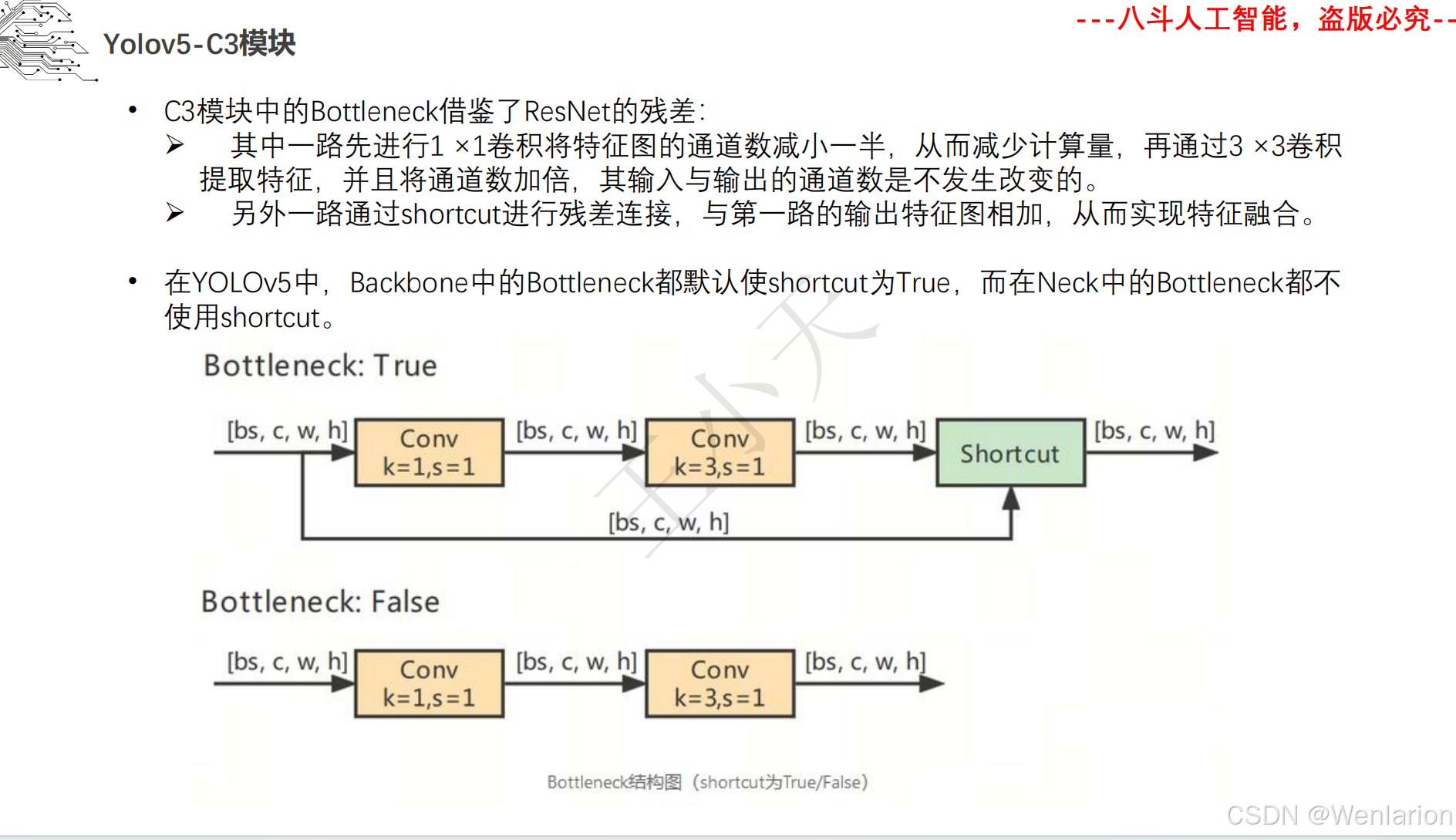
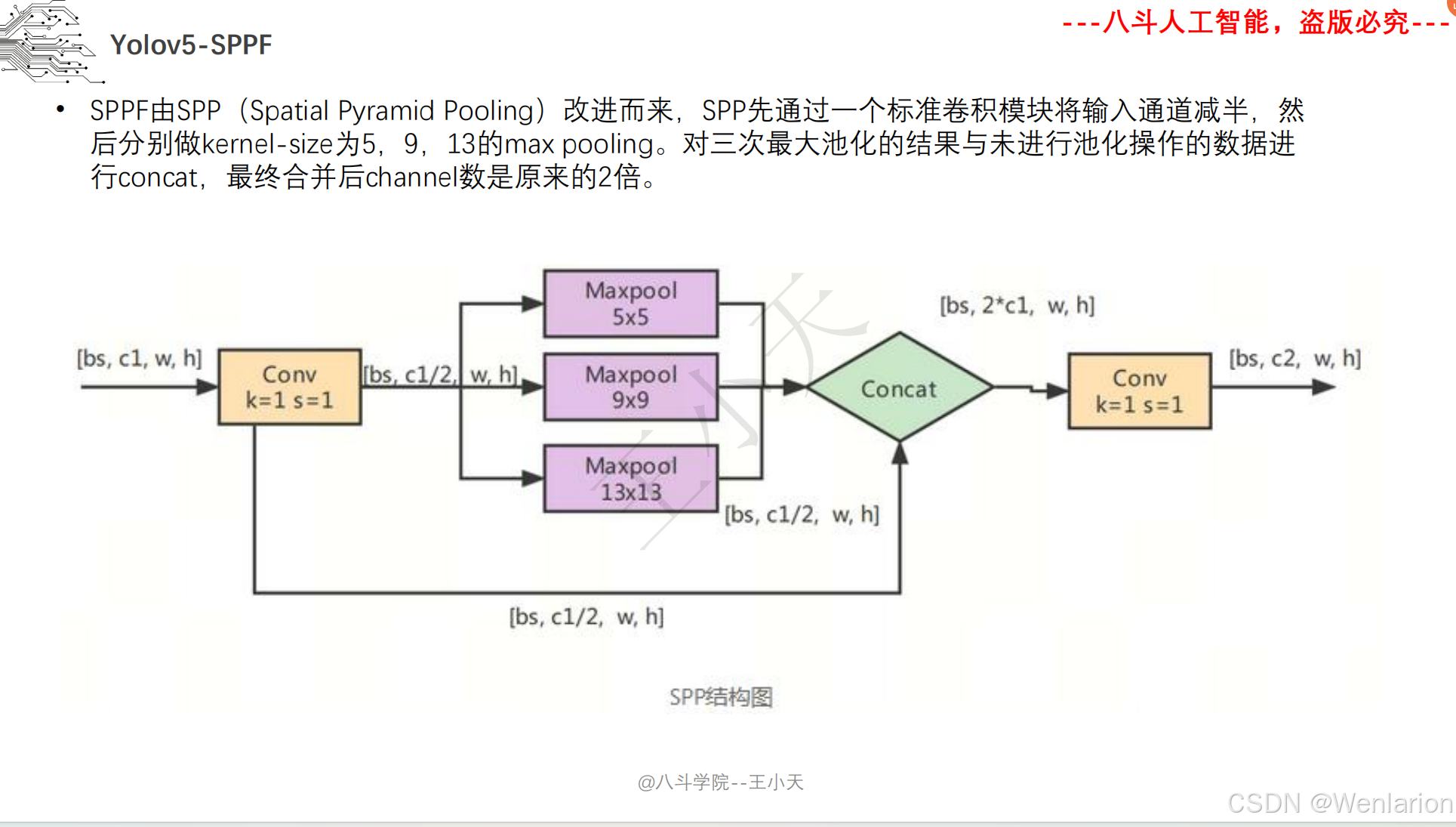
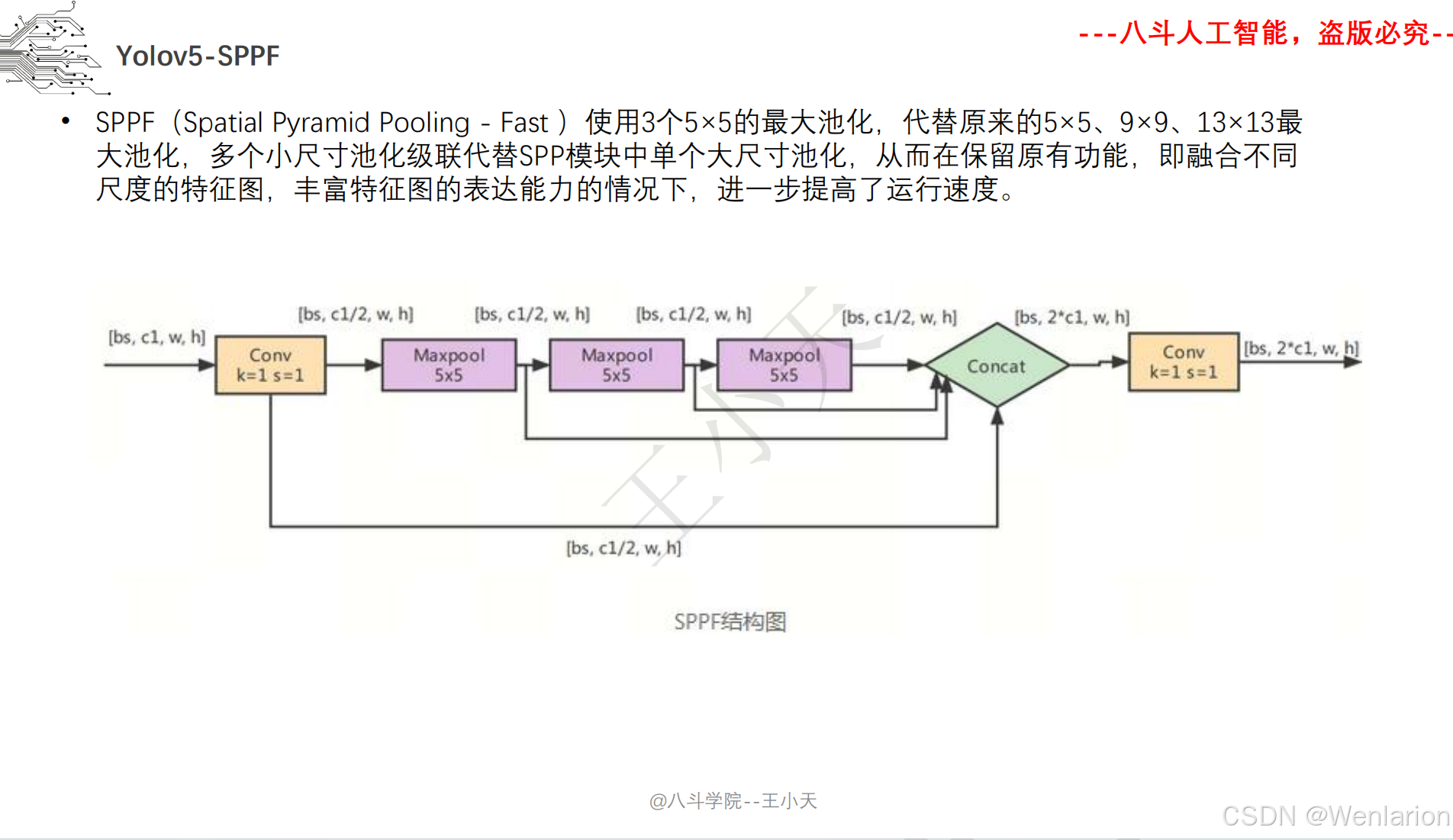
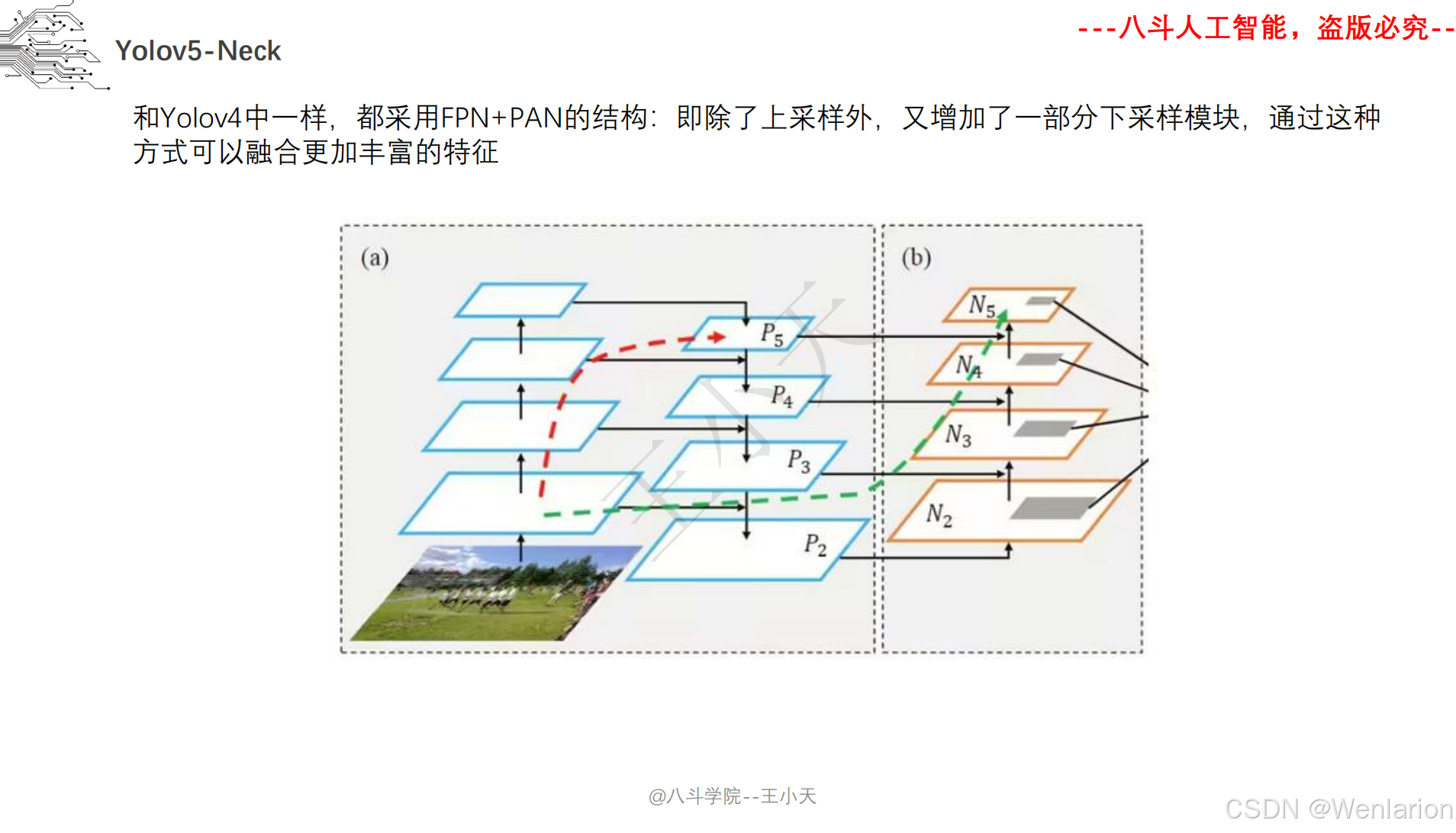
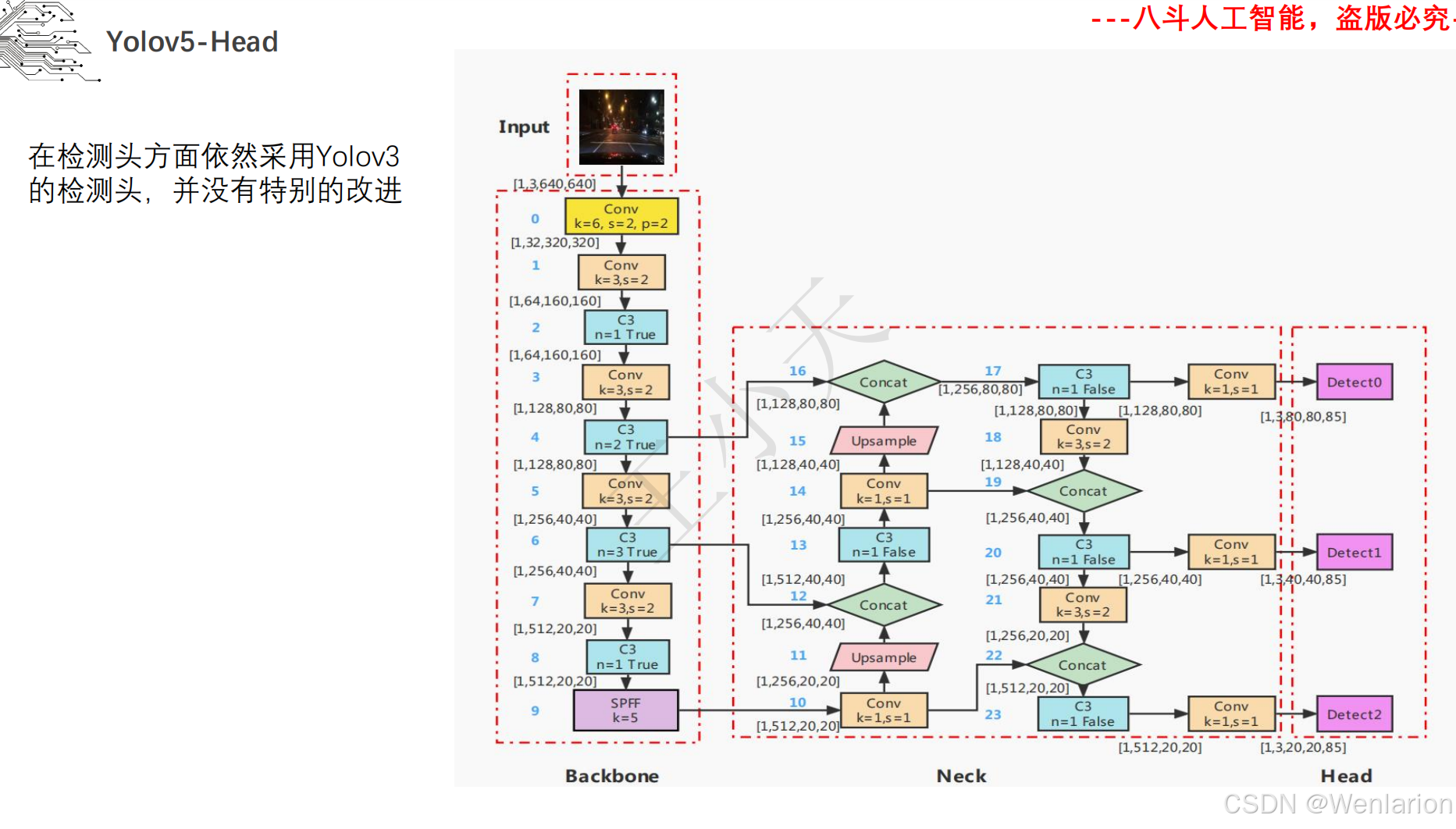

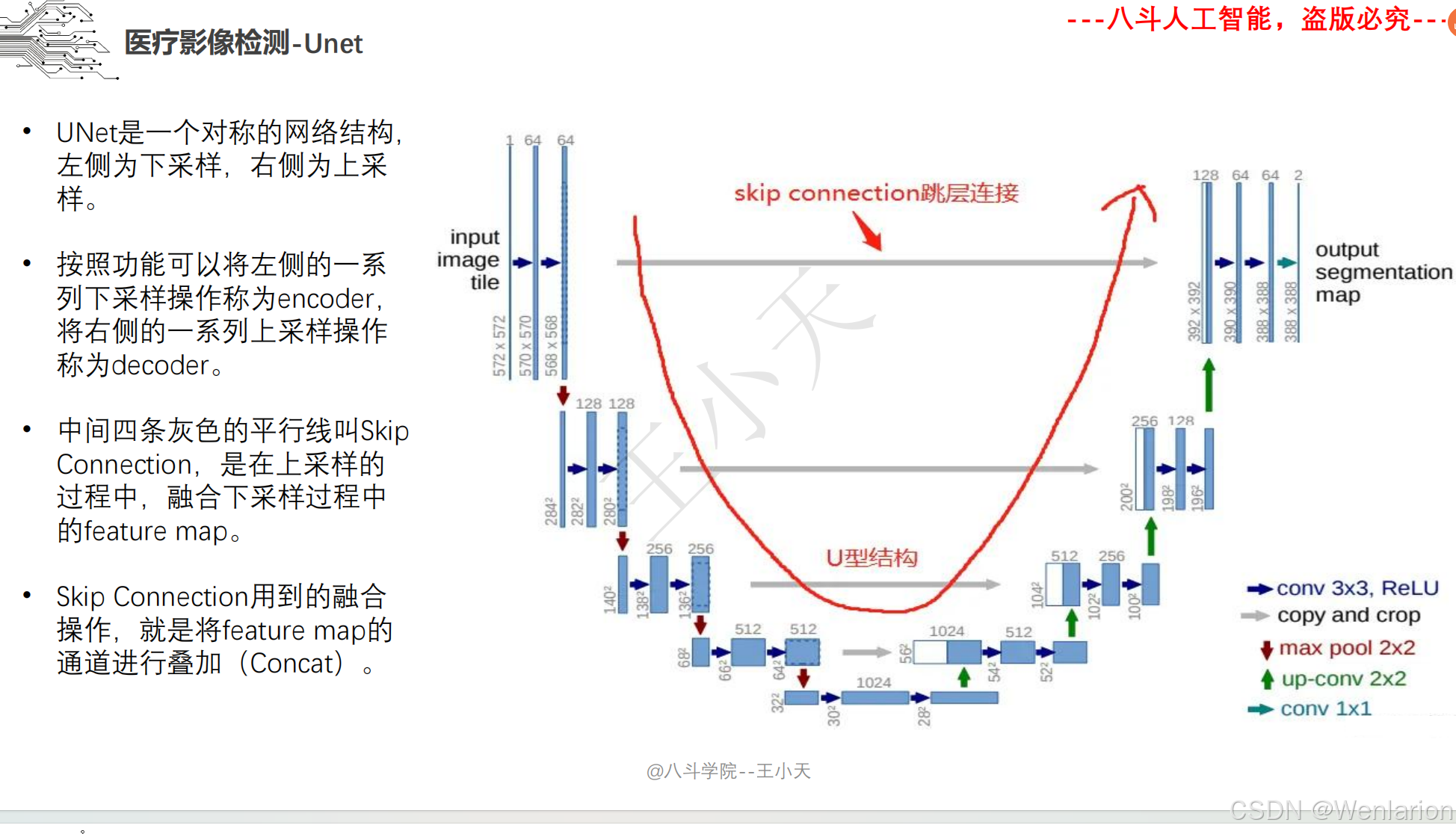

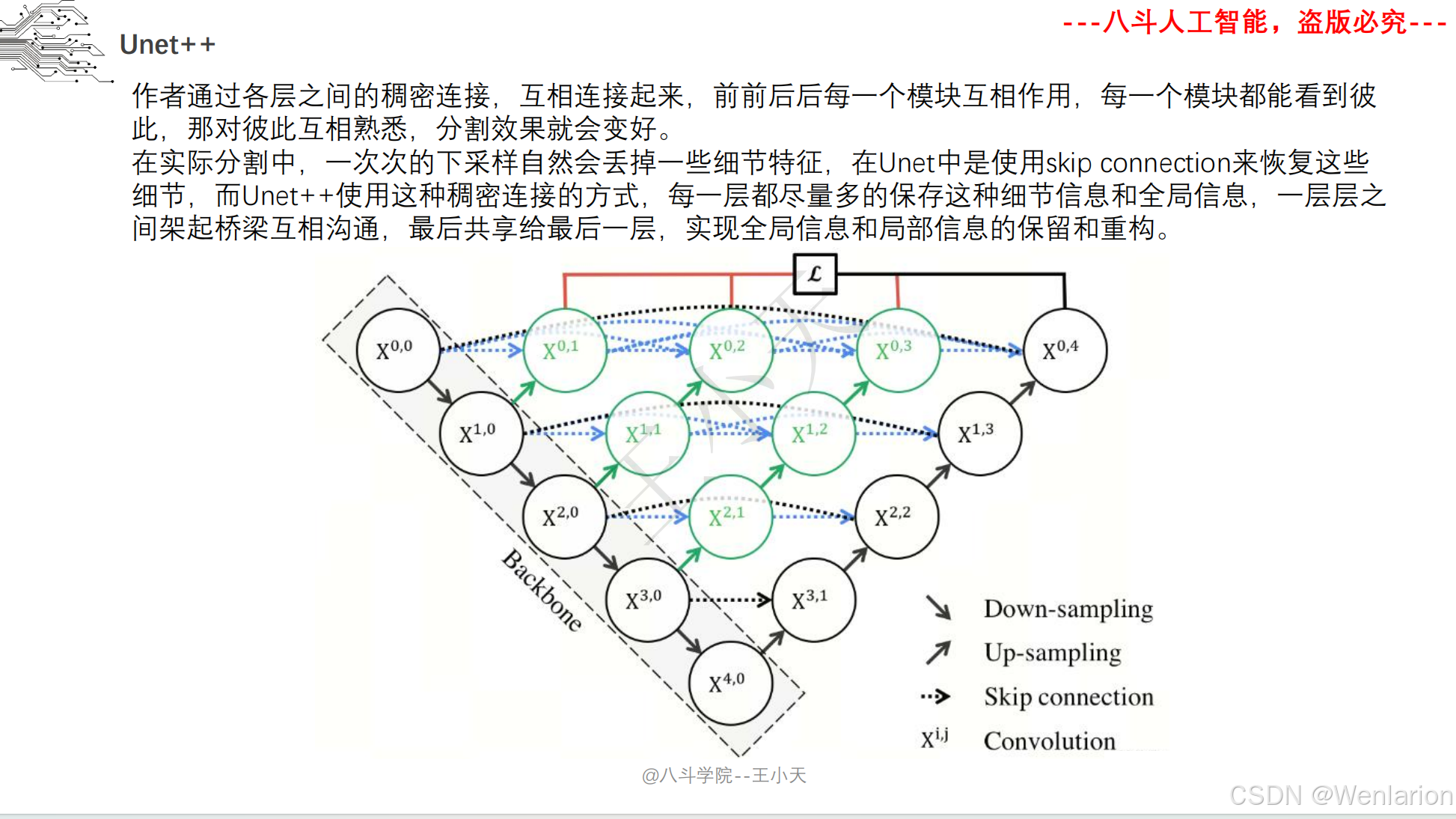
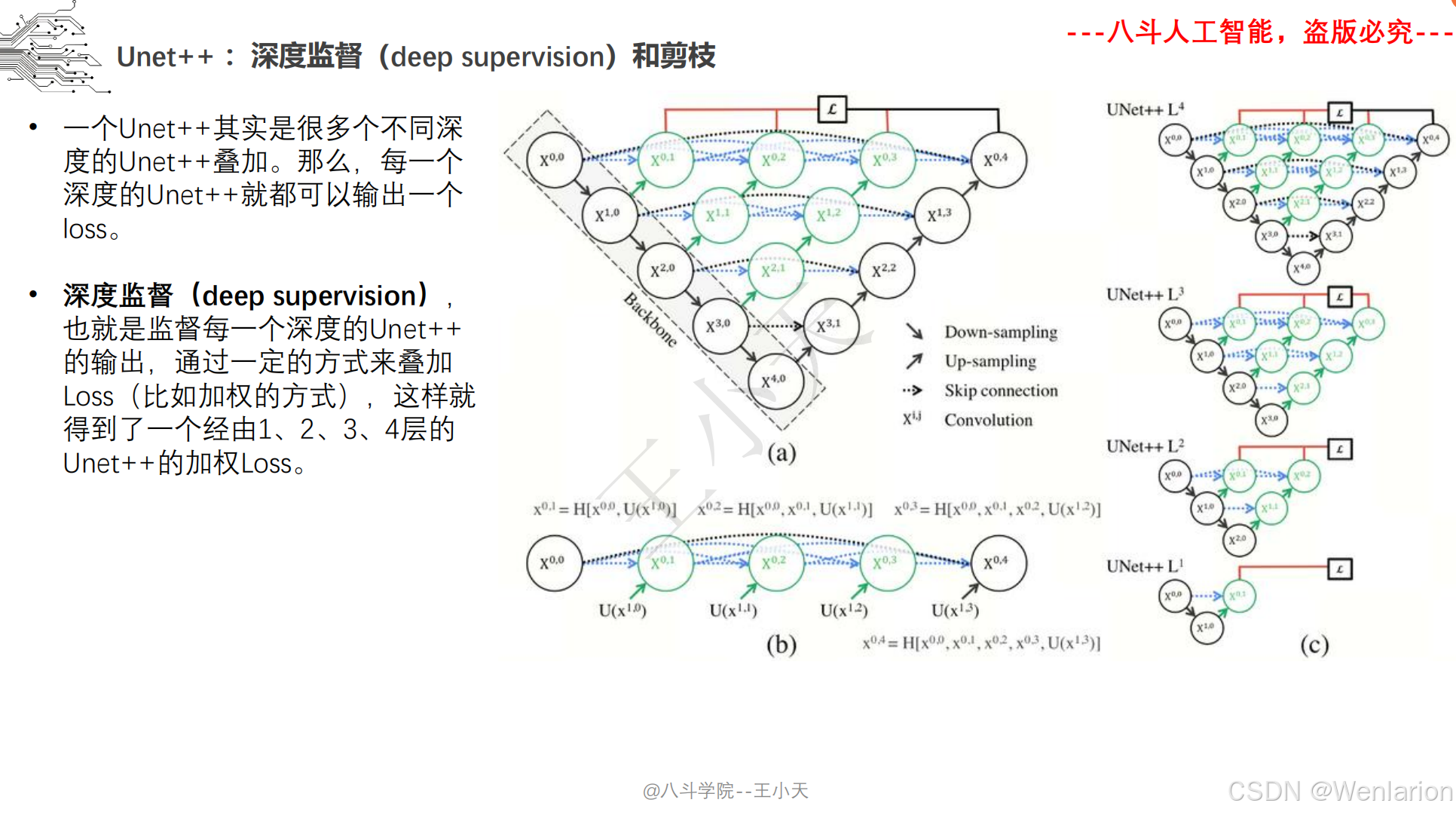
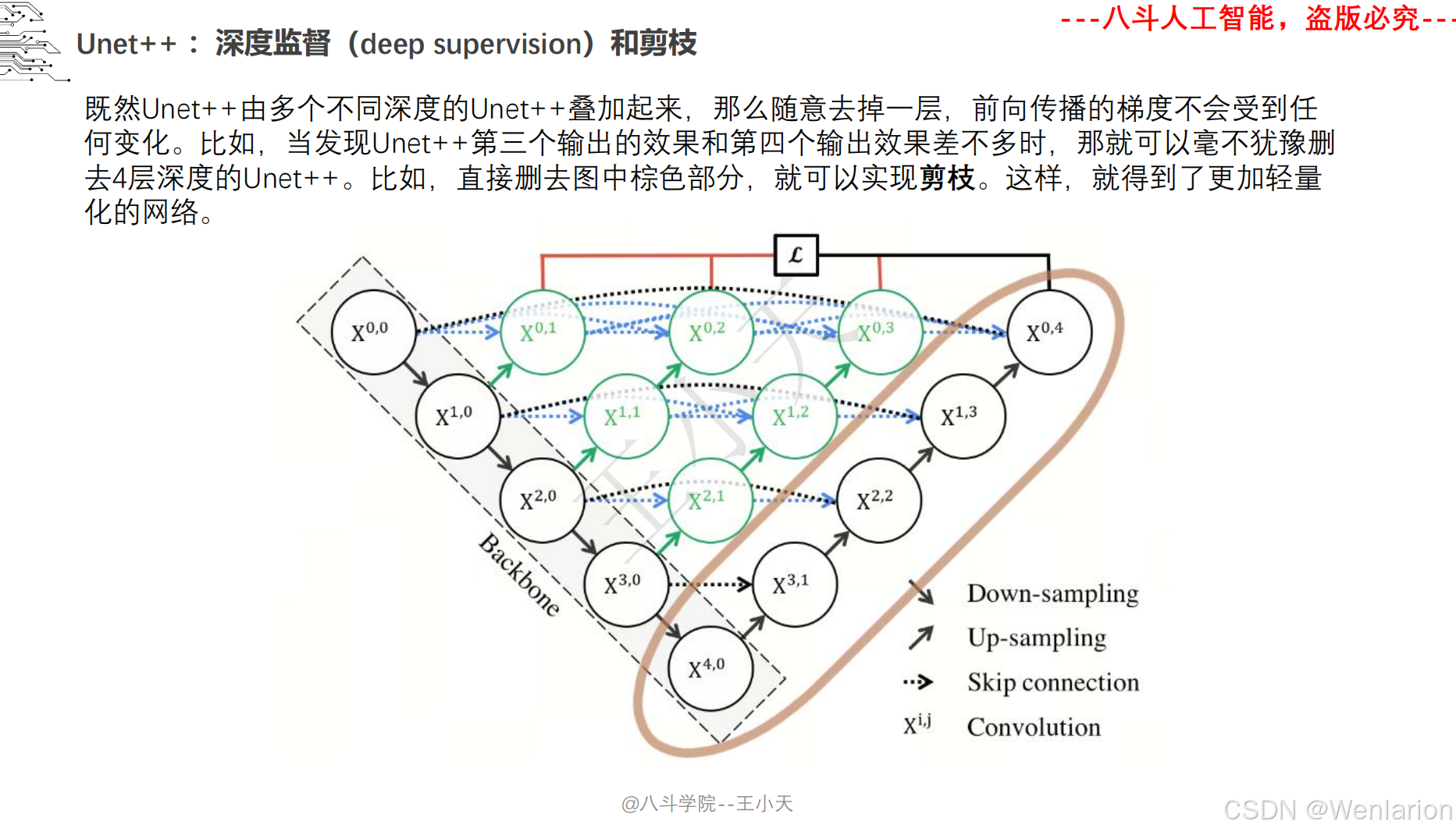
图像分割论文和代码(语义分割、实例分割、全景分割、轻量化 / 实时分割)
一、语义分割(Semantic Segmentation)
核心任务
将图像像素划分为语义类别(如人、车、树、道路),不区分同一类别的不同实例(如所有行人都标为 “人”),是图像分割的基础任务。
1. FCN: Fully Convolutional Networks for Semantic Segmentation
-
发表:CVPR 2015(经典开山之作)
-
核心简介:首次将 CNN 全面应用于语义分割,打破传统 CNN 全连接层的空间信息丢失问题,提出全卷积网络架构。将 CNN 最后的全连接层替换为卷积层,通过 ** 反卷积(转置卷积)实现特征图上采样恢复图像尺寸,引入跳级连接(Skip Connection)** 融合浅层细节特征与深层语义特征,解决分割边缘模糊问题。FCN 奠定了现代语义分割的核心框架,后续所有分割模型均基于全卷积思想改进。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1411.4038.pdf | CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2015/papers/Long_Fully_Convolutional_Networks_2015_paper.pdf
-
代码地址:官方 Torch→https://github.com/shelhamer/fcn.berkeleyvision.org | PyTorch 复现→https://github.com/usuyama/pytorch-fcn
2. U-Net: Convolutional Networks for Biomedical Image Segmentation
-
发表:MICCAI 2015(生物医学分割标杆,通用场景同样适用)
-
核心简介:针对生物医学图像样本少、细节要求高的特点,设计对称的 U 型架构。左侧为下采样编码路径(提取语义特征),右侧为上采样解码路径(恢复空间细节),通过跳跃连接直接融合编码层的高分辨率特征与解码层特征,大幅提升小目标、细纹理的分割精度。U-Net 参数量小、训练效率高,不仅成为生物医学图像分割的标配模型,也广泛应用于遥感、工业检测等小样本分割场景。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1505.04597.pdf | MICCAI 官方→https://link.springer.com/chapter/10.1007/978-3-319-24574-4_28
-
代码地址:官方 Torch→https://github.com/milesial/Pytorch-UNet | 多版本实现→https://github.com/usuyama/pytorch-unet
3. DeepLab v3+: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
-
发表:ECCV 2018(工业界主流语义分割模型)
-
核心简介:DeepLab 系列的终极版本,融合空洞卷积(Atrous Convolution)、空间金字塔池化(ASPP)、Encoder-Decoder三大核心思想。用空洞卷积扩大感受野且不丢失分辨率,ASPP 模块从多尺度提取语义特征,Encoder-Decoder 架构融合浅层细节特征,同时引入深度可分离卷积减少计算量。模型在 PASCAL VOC、Cityscapes 等数据集上实现精度与速度的均衡,成为工业界语义分割的首选基线。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1802.02611.pdf | ECCV 官方→https://www.ecva.net/papers/eccv_2018/papers_ECCV/papers/Liang-Chieh_Chen_Encoder-Decoder_With_Atrous_ECCV_2018_paper.pdf
-
代码地址:官方 TensorFlow→https://github.com/tensorflow/models/tree/master/research/deeplab | PyTorch 复现→https://github.com/jfzhang95/pytorch-deeplab-xception
4. HRNet-Semantic-Segmentation
-
发表:CVPR 2019(高分辨率特征分割标杆)
-
核心简介:将 HRNet 的全程高分辨率特征表示思想应用于语义分割,解决传统模型下采样导致的空间细节丢失问题。从高分辨率特征图出发,并行连接不同分辨率特征分支,通过跨分支融合持续增强高分辨率特征的表达能力,无需额外上采样恢复细节,分割边缘精度远超 FCN、DeepLab。该模型成为高精度语义分割的主流骨干,也适配实例分割、姿态识别等任务。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1904.04514.pdf | CVPR 官方→https://openaccess.thecvf.com/content_CVPR_2019/papers/Sun_High-Resolution_Representations_for_Labeling_CVPR_2019_paper.pdf
-
代码地址:官方 PyTorch→https://github.com/HRNet/HRNet-Semantic-Segmentation
二、实例分割(Instance Segmentation)
核心任务
不仅划分语义类别,还区分同一类别的不同实例(如区分图像中第 1 个、第 2 个行人),融合 “目标检测 + 语义分割”,是比语义分割更精细的任务。
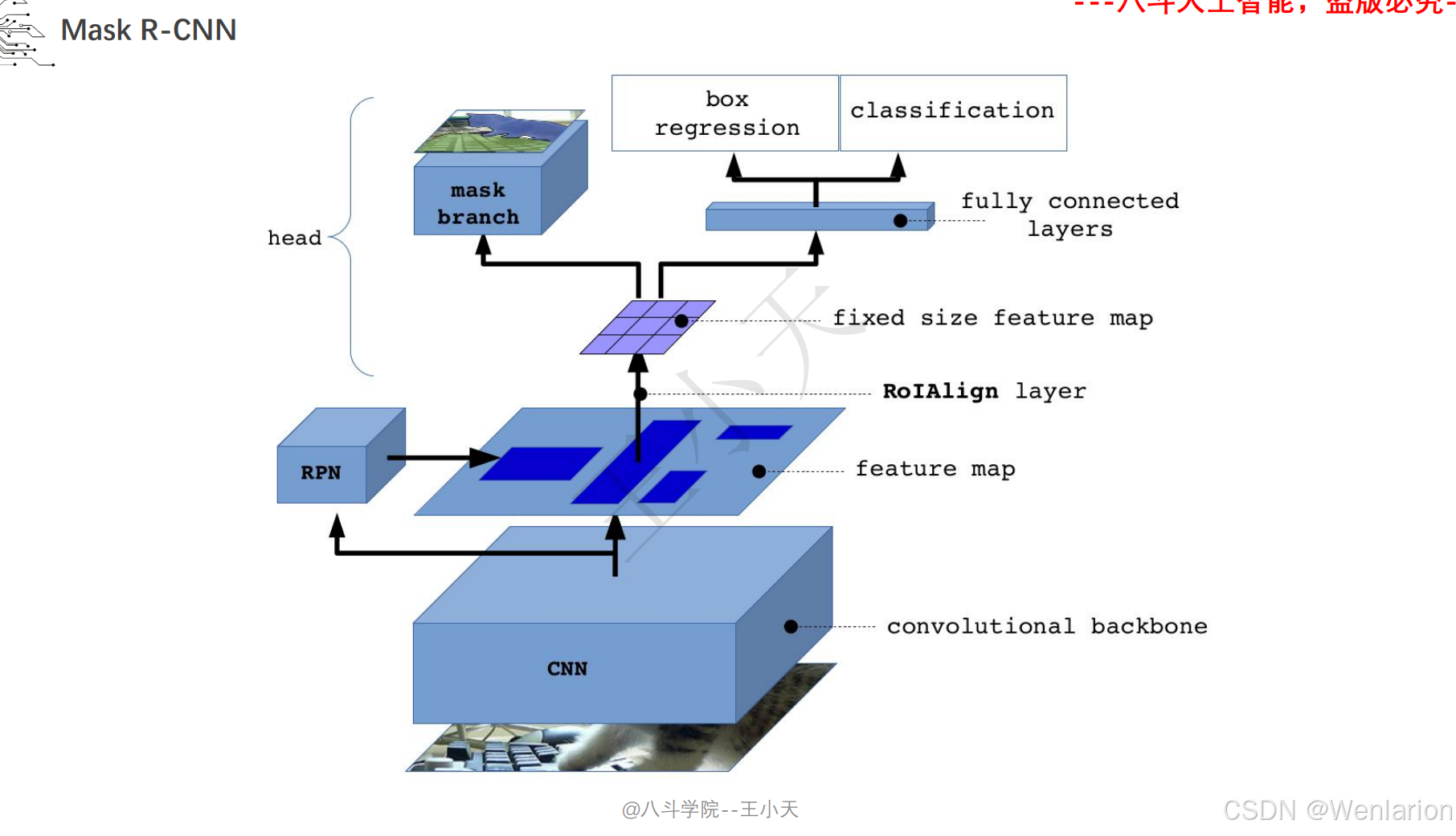
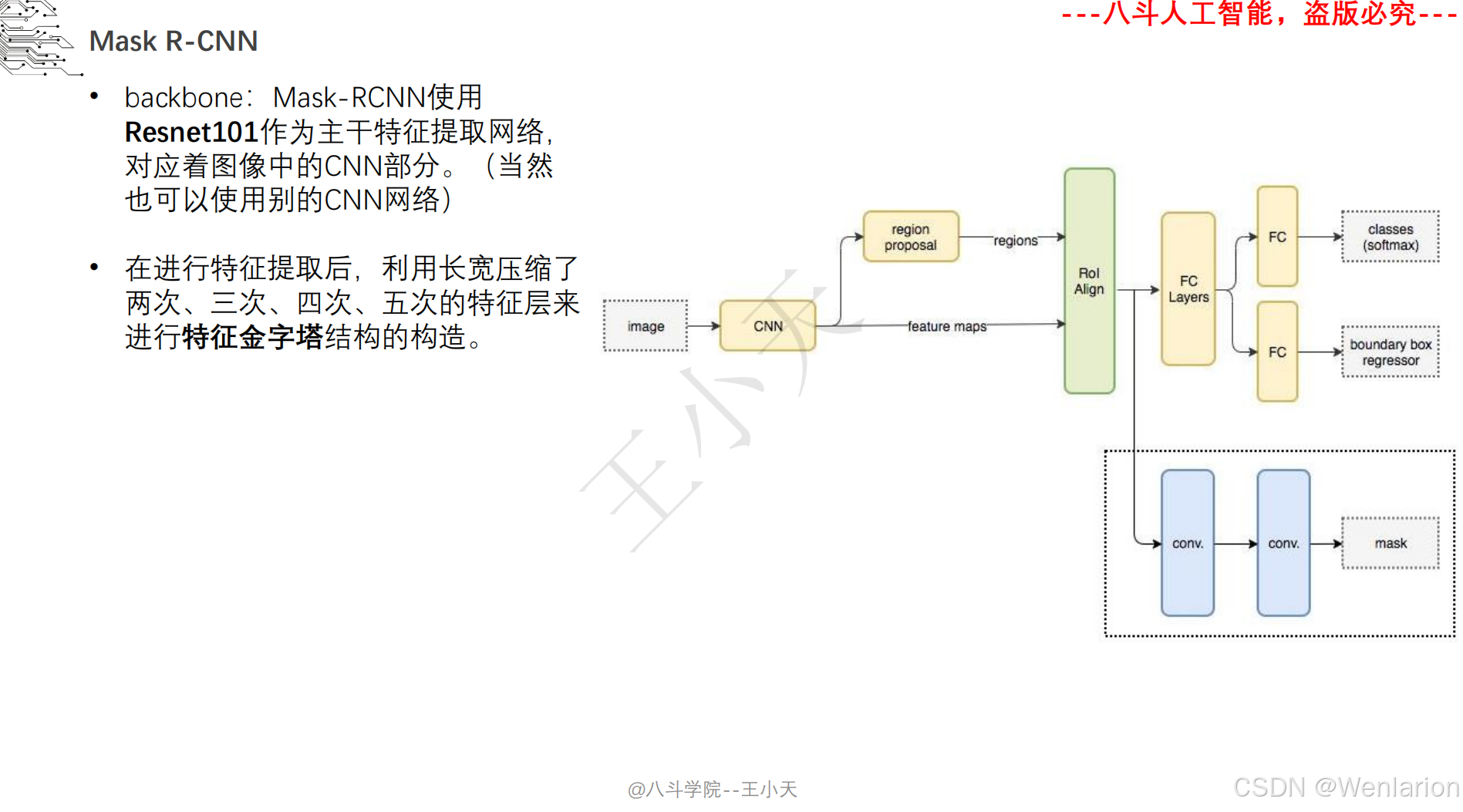
1. Mask R-CNN
-
发表:ICCV 2017(实例分割开山之作,经典基线)
-
核心简介:在 Faster R-CNN 基础上增加掩码(Mask)预测分支,实现 “目标检测 + 实例分割” 端到端训练。Faster R-CNN 负责检测目标框并分类,新增的全卷积掩码分支对每个检测到的目标框内像素做语义分割,生成实例级掩码,且掩码分支与检测分支共享骨干特征,不额外增加大量计算量。Mask R-CNN 奠定了实例分割的两阶段架构基础,后续所有实例分割模型均基于其改进。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1703.06870.pdf | ICCV 官方→https://openaccess.thecvf.com/content_ICCV_2017/papers/He_Mask_R-CNN_ICCV_2017_paper.pdf
-
代码地址:官方 Detectron2→https://github.com/facebookresearch/detectron2 | PyTorch 复现→https://github.com/matterport/Mask_RCNN
2. YOLACT: Real-Time Instance Segmentation
-
发表:ICCV 2019(首个实时单阶段实例分割模型)
-
核心简介:打破 Mask R-CNN 两阶段架构的速度限制,提出单阶段实例分割框架,实现实时推理(30+ FPS)。将实例分割拆分为全局掩码生成 + 实例掩码预测两步:先通过卷积层生成一组固定数量的原型掩码,再为每个检测到的目标预测掩码系数,将系数与原型掩码加权融合得到实例掩码,同时完成目标检测与分类。YOLACT 大幅提升实例分割速度,成为边缘端 / 实时场景的首选。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1904.02689.pdf | ICCV 官方→https://openaccess.thecvf.com/content_ICCV_2019/papers/Bolya_YOLACT_Real-Time_Instance_Segmentation_ICCV_2019_paper.pdf
-
代码地址:官方 PyTorch→https://github.com/dbolya/yolact
3. SOLO: Segmenting Objects by Locations
-
发表:ECCV 2020(创新单阶段实例分割,无锚框设计)
-
核心简介:提出无锚框(Anchor-Free)的实例分割新思路,将实例分割建模为“位置分类 + 语义分割”。根据目标的空间位置将图像划分为网格,每个网格负责分割一个实例,通过预测目标的类别掩码和中心区域,直接生成实例掩码,无需目标检测框的辅助。SOLO 简化了实例分割流程,精度媲美 Mask R-CNN,速度优于 YOLACT,后续改进版 SOLOv2 成为单阶段实例分割的 SOTA。
-
论文 PDF:SOLO→https://arxiv.org/pdf/1912.04488.pdf | SOLOv2→https://arxiv.org/pdf/2003.10152.pdf
-
代码地址:官方 MMDetection→https://github.com/WXinlong/SOLO | 独立实现→https://github.com/aim-uofa/AdelaiDet
三、全景分割(Panoptic Segmentation)
核心任务
融合语义分割(处理 stuff 类别,如道路、天空,无实例区分)+ 实例分割(处理 thing 类别,如人、车,有实例区分),对图像中所有像素进行类别 + 实例的统一标注,是图像分割的高级任务,更贴近人类视觉的完整理解。
1. Panoptic FPN
-
发表:CVPR 2019(全景分割开山之作,基线框架)
-
核心简介:首次提出全景分割的正式定义和评估指标,基于 FPN(特征金字塔)设计首个全景分割框架。共享 FPN 骨干特征,分别构建实例分割分支(处理 thing)和语义分割分支(处理 stuff),通过像素融合策略将两个分支的结果合并,解决同一像素的类别冲突问题。Panoptic FPN 奠定了全景分割的双分支融合架构,成为后续所有全景分割模型的基准。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1901.02446.pdf | CVPR 官方→https://openaccess.thecvf.com/content_CVPR_2019/papers/Kirillov_Panoptic_FPN_CVPR_2019_paper.pdf
-
代码地址:官方 Detectron2→https://github.com/facebookresearch/detectron2 | PyTorch 复现→https://github.com/chenhao2345/Panoptic-FPN
2. Mask2Former: Masked-attention Mask Transformer for Universal Image Segmentation
-
发表:CVPR 2022(通用分割 SOTA,适配全景 / 语义 / 实例分割)
-
核心简介:提出基于 Transformer 的通用图像分割框架,统一处理语义、实例、全景分割任务。引入掩码注意力(Masked-Attention),将分割建模为掩码预测任务,通过查询向量(Query)与图像特征交互,直接生成每个实例 / 类别的掩码,无需传统的检测框或网格划分。Mask2Former 在所有分割任务上均刷新 SOTA,成为当前全景分割的首选模型,也标志着 Transformer 在分割任务中的主流应用。
-
论文 PDF:arXiv→https://arxiv.org/pdf/2112.01527.pdf | CVPR 官方→https://openaccess.thecvf.com/content/CVPR2022/papers/Kirillov_Mask2Former_Masked-Attention_Mask_Transformer_for_Universal_Image_Segmentation_CVPR_2022_paper.pdf
-
代码地址:官方 Detectron2→https://github.com/facebookresearch/Mask2Former | MMGeneration→https://github.com/open-mmlab/mmsegmentation/tree/master/configs/mask2former
四、轻量化 / 实时图像分割(移动端 / 边缘端)
核心需求
针对手机、嵌入式设备、自动驾驶等实时推理场景,在保证一定精度的前提下,大幅减少模型参数量和计算量,实现高帧率(20+ FPS)分割。
1. MobileNetV3-Segmentation
-
发表:ICCV 2019(轻量化语义分割标杆)
-
核心简介:将 MobileNetV3 的轻量化骨干与 DeepLab v3 + 的 Encoder-Decoder 架构结合,用深度可分离卷积和高效通道注意力(SE)替换标准卷积,在减少参数量(仅为 DeepLab v3 + 的 1/10)的同时,保留多尺度特征提取能力。模型在 Cityscapes 数据集上实现70+ mIoU,推理速度达50+ FPS,成为移动端语义分割的主流骨干。
-
论文 PDF:MobileNetV3→https://arxiv.org/pdf/1905.02244.pdf | 分割适配→https://arxiv.org/pdf/1801.04381.pdf
-
代码地址:TensorFlow→https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet | PyTorch→https://github.com/tonylins/pytorch-mobilenet-v3
2. Fast-SCNN: Fast Semantic Segmentation Network
-
发表:ICCV 2019 Workshop(专为实时分割设计的轻量架构)
-
核心简介:提出轻量级 Encoder-Decoder 架构,针对实时分割做极致优化。Encoder 采用快速空间金字塔池化(Fast SPP)和深度可分离卷积,大幅减少计算量;Decoder 采用轻量级上采样融合,仅恢复关键细节特征。模型参数量仅1.2M,在 1080P 图像上推理速度达123 FPS,精度略低于 MobileNetV3 但速度更优,适配对帧率要求极高的边缘端场景(如无人机、实时监控)。
-
论文 PDF:arXiv→https://arxiv.org/pdf/1902.04502.pdf
-
代码地址:官方 PyTorch→https://github.com/Tramac/Fast-SCNN.pytorch | TensorFlow→https://github.com/tensorflow/models/tree/master/research/deeplab
3. PP-LiteSeg: A Superior Real-Time Semantic Segmentation Model
-
发表:NeurIPS 2022(工业界实时分割 SOTA,百度飞桨)
-
核心简介:专为工业界实时场景设计,融合轻量级骨干、多尺度特征融合、高效解码三大优化。采用 PP-LCNet 轻量化骨干,引入轻量级金字塔融合模块(LFPM)实现多尺度特征提取,设计对称解码结构快速恢复空间细节,同时支持动态调整模型尺度(从超轻量到高精度)。模型在移动端(麒麟 990)实现40+ FPS,精度超越 MobileNetV3、Fast-SCNN,成为工业界实时语义分割的首选。
-
论文 PDF:arXiv→https://arxiv.org/pdf/2204.02681.pdf
-
代码地址:官方 PaddlePaddle→https://github.com/PaddlePaddle/PaddleSeg/tree/release/2.6/configs/pp_liteseg | PyTorch 复现→https://github.com/whai362/PP-LiteSeg
五、图像分割必备工具库与数据集
1. 主流分割工具库(封装经典 / 最新模型,开箱即用)
-
MMSegmentation(PyTorch,国内主流):https://github.com/open-mmlab/mmsegmentation(支持语义 / 全景分割,集成所有经典模型)
-
Detectron2(PyTorch,Facebook):https://github.com/facebookresearch/detectron2(主打实例 / 全景分割,Mask R-CNN、Mask2Former 官方实现)
-
PaddleSeg(PaddlePaddle,百度):https://github.com/PaddlePaddle/PaddleSeg(轻量化分割优势明显,PP-LiteSeg 官方实现)
-
Segmentation Models PyTorch(PyTorch,轻量封装):https://github.com/qubvel/segmentation_models.pytorch(快速调用 FCN、U-Net、DeepLab 等)
2. 经典数据集(覆盖通用 / 专用场景)
|
任务类型 |
数据集名称 |
适用场景 |
官网地址 |
|---|---|---|---|
|
语义分割 |
PASCAL VOC 2012 |
通用场景(20 类) |
|
|
语义分割 |
Cityscapes |
城市场景(道路、车辆、行人等) |
|
|
语义分割 |
ADE20K |
室内场景(150 类) |
|
|
实例分割 |
COCO Instance Segmentation |
通用场景(80 类) |
|
|
全景分割 |
COCO Panoptic Segmentation |
通用场景 |
|
|
医学分割 |
BraTS |
脑肿瘤分割 |
|
|
遥感分割 |
DeepGlobe |
遥感图像分割 |
https://competitions.codalab.org/competitions/18468 |
2.4 目标追踪问题





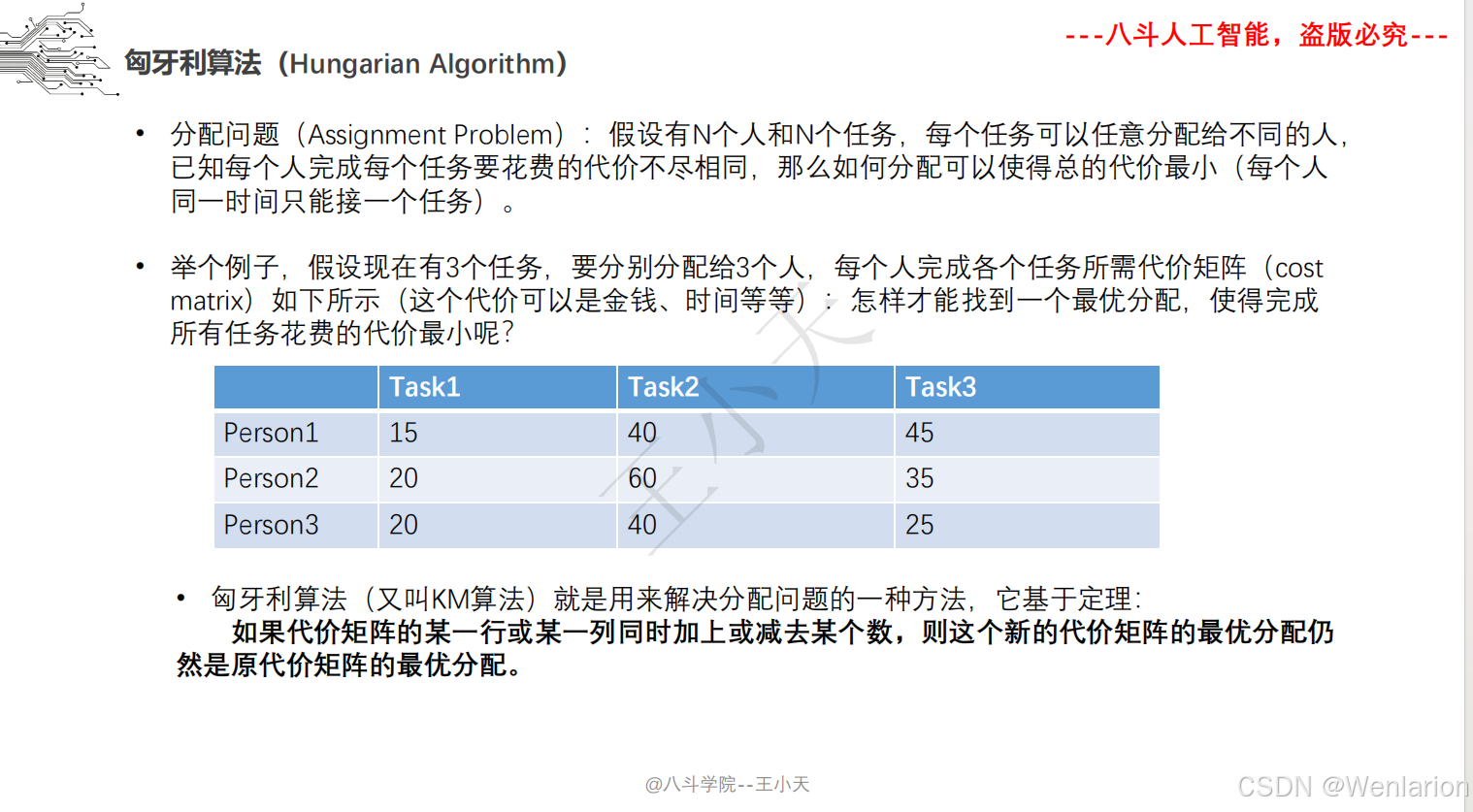

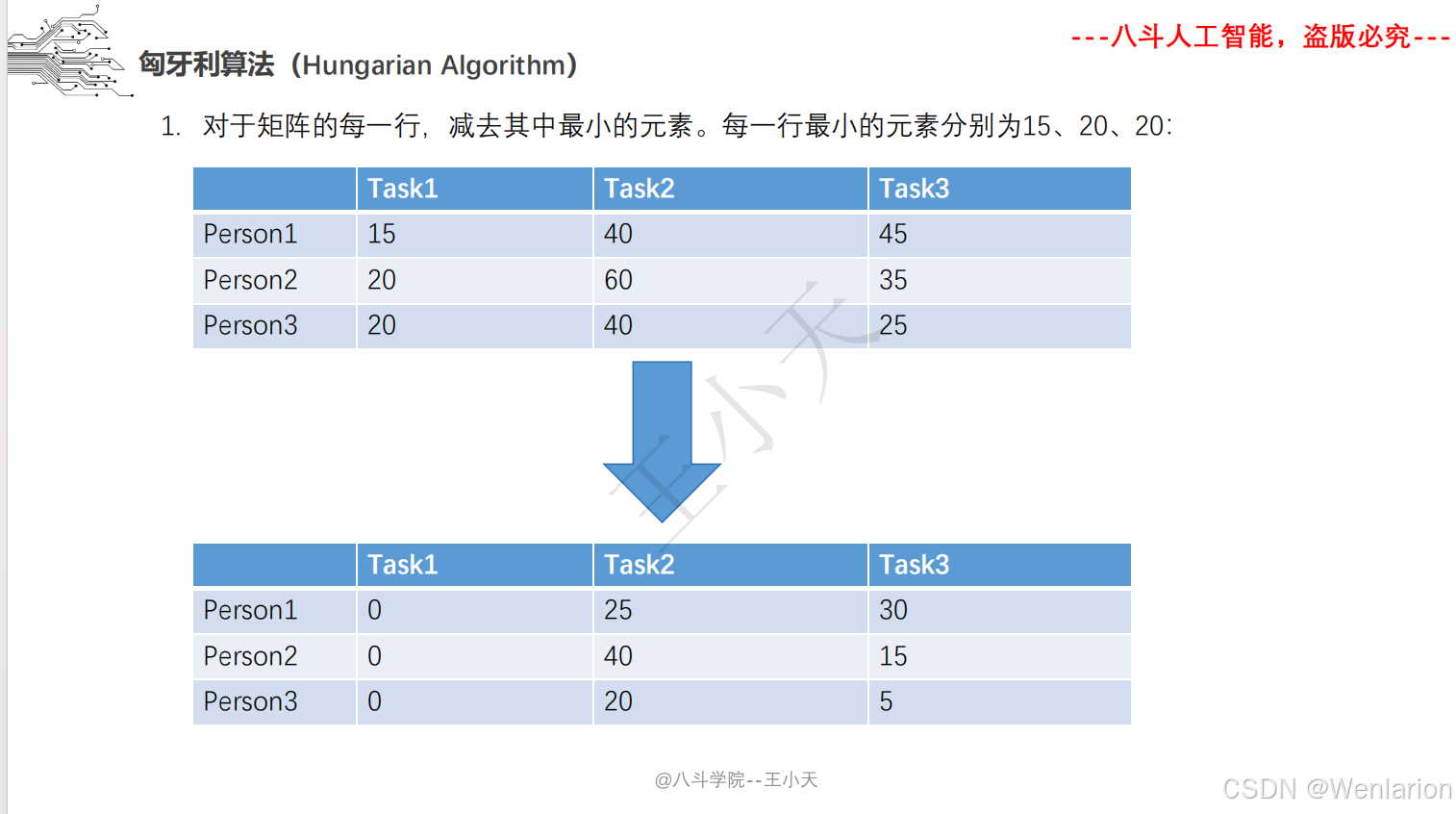
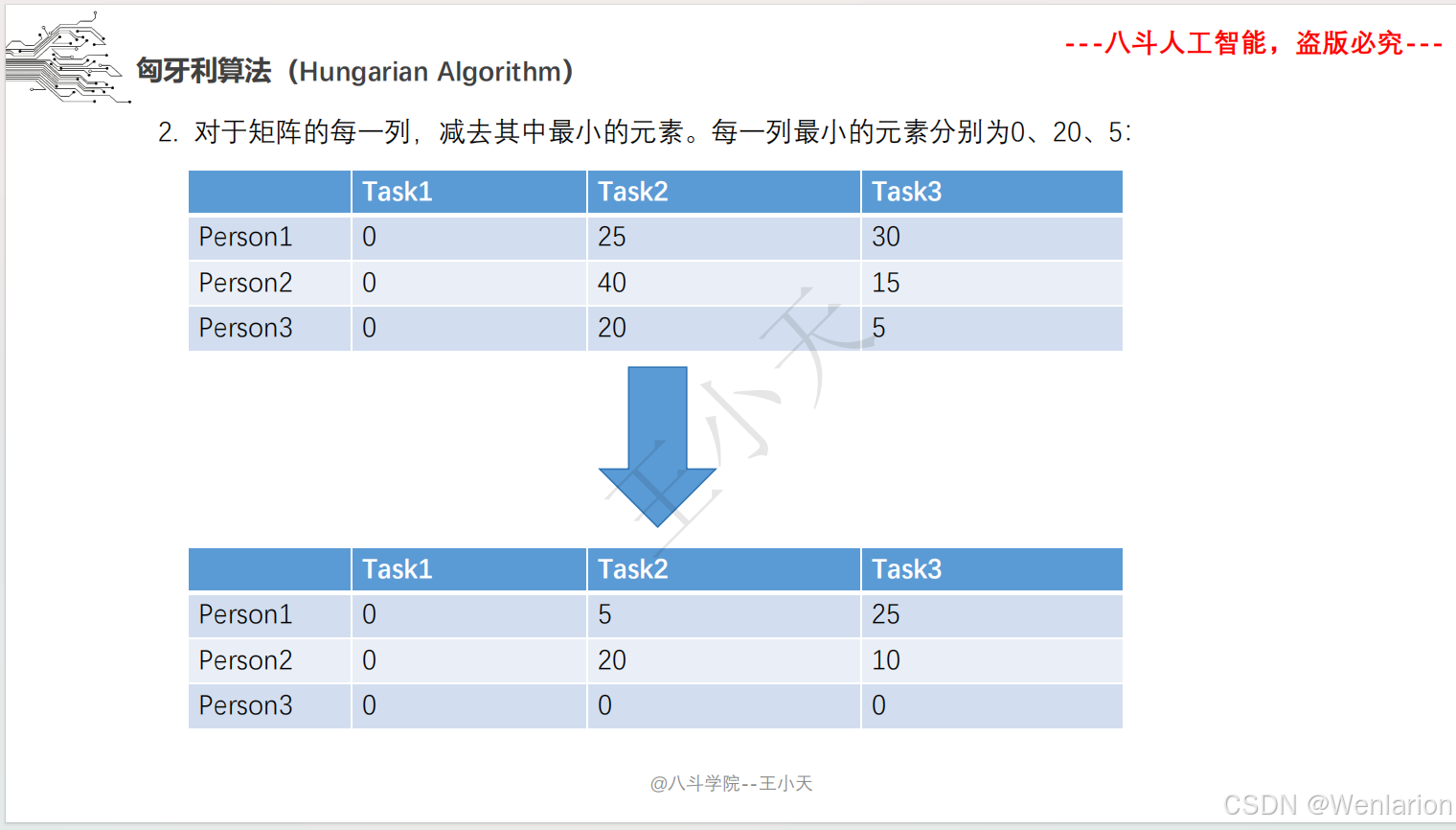
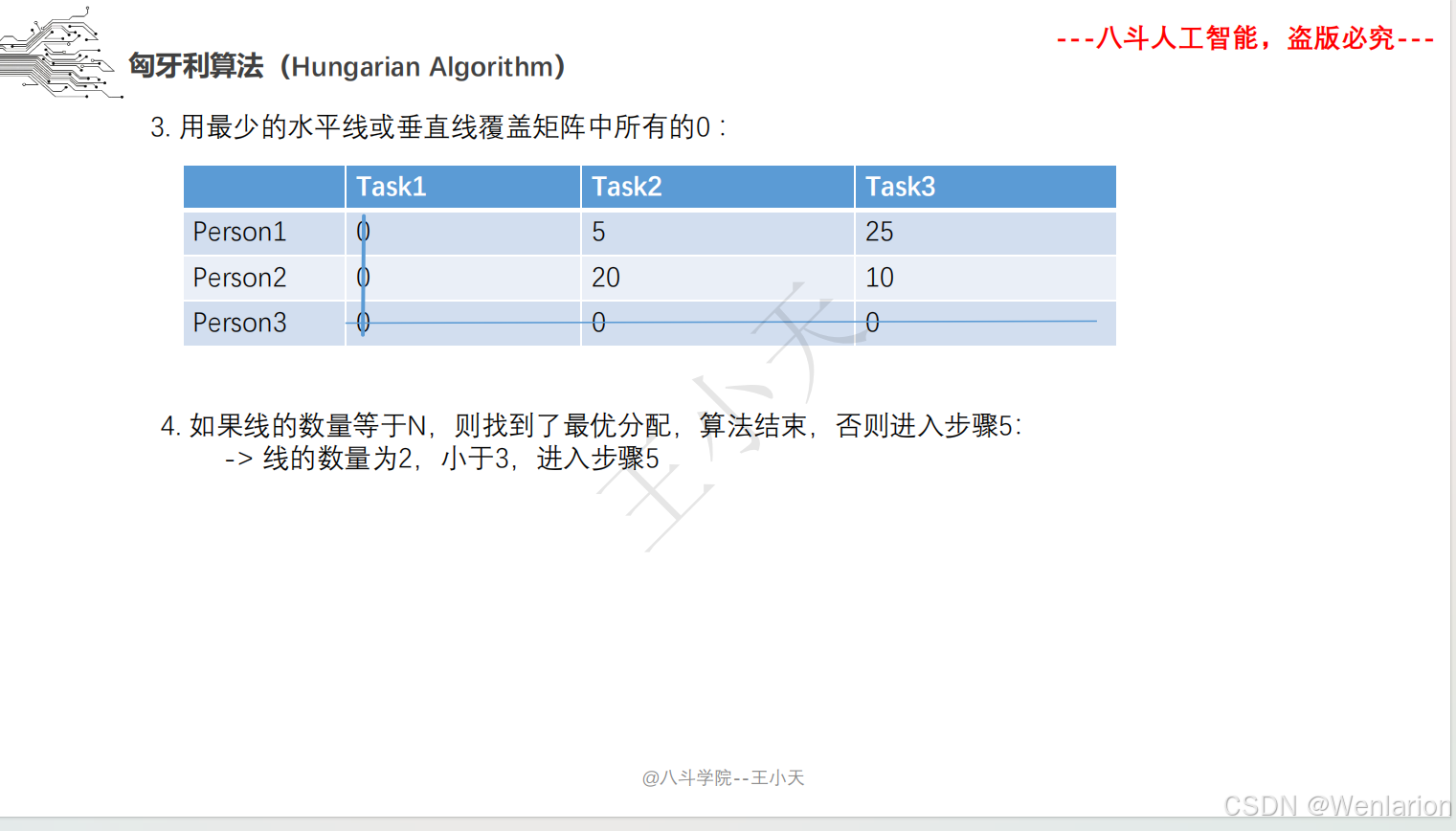
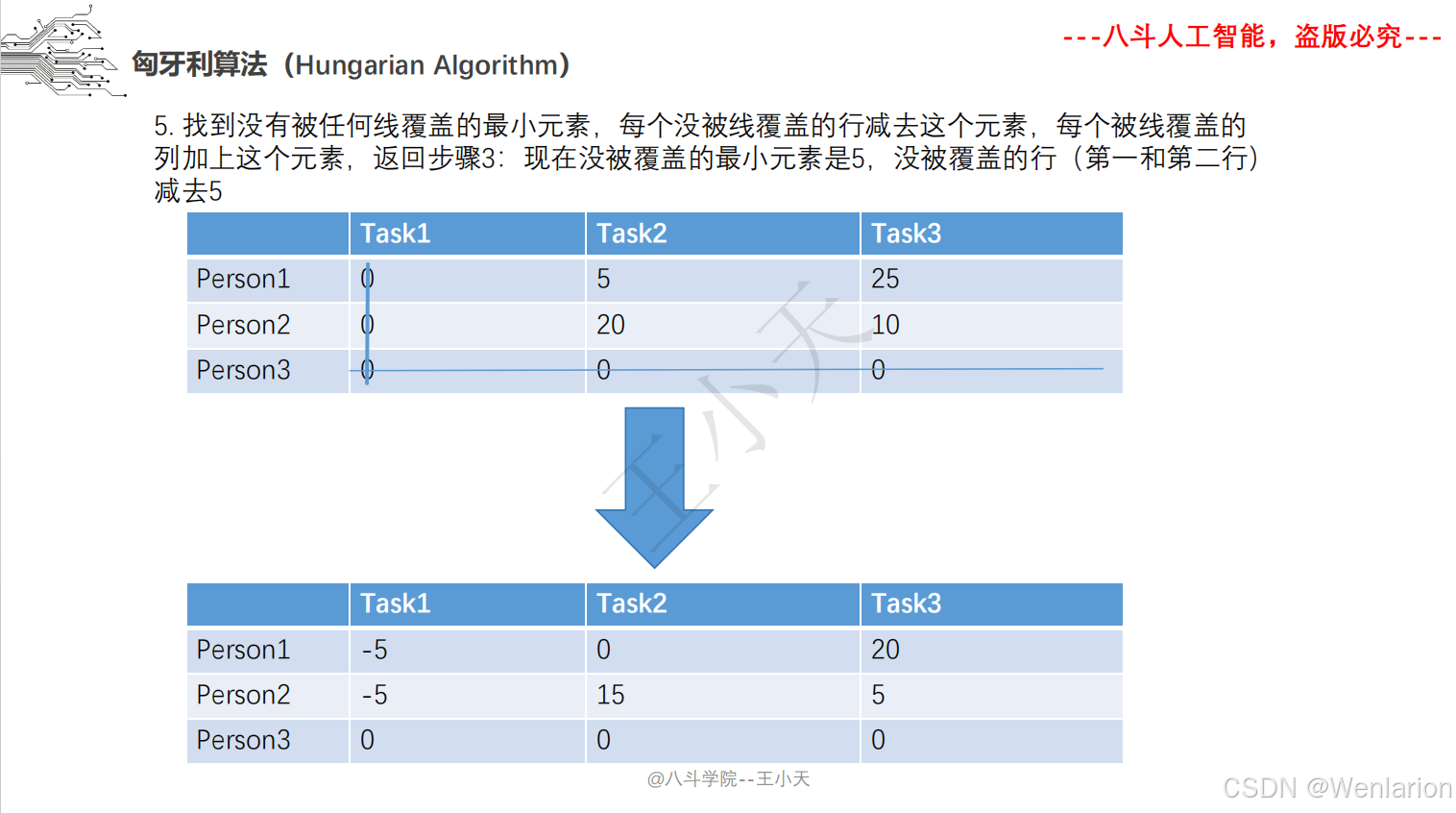
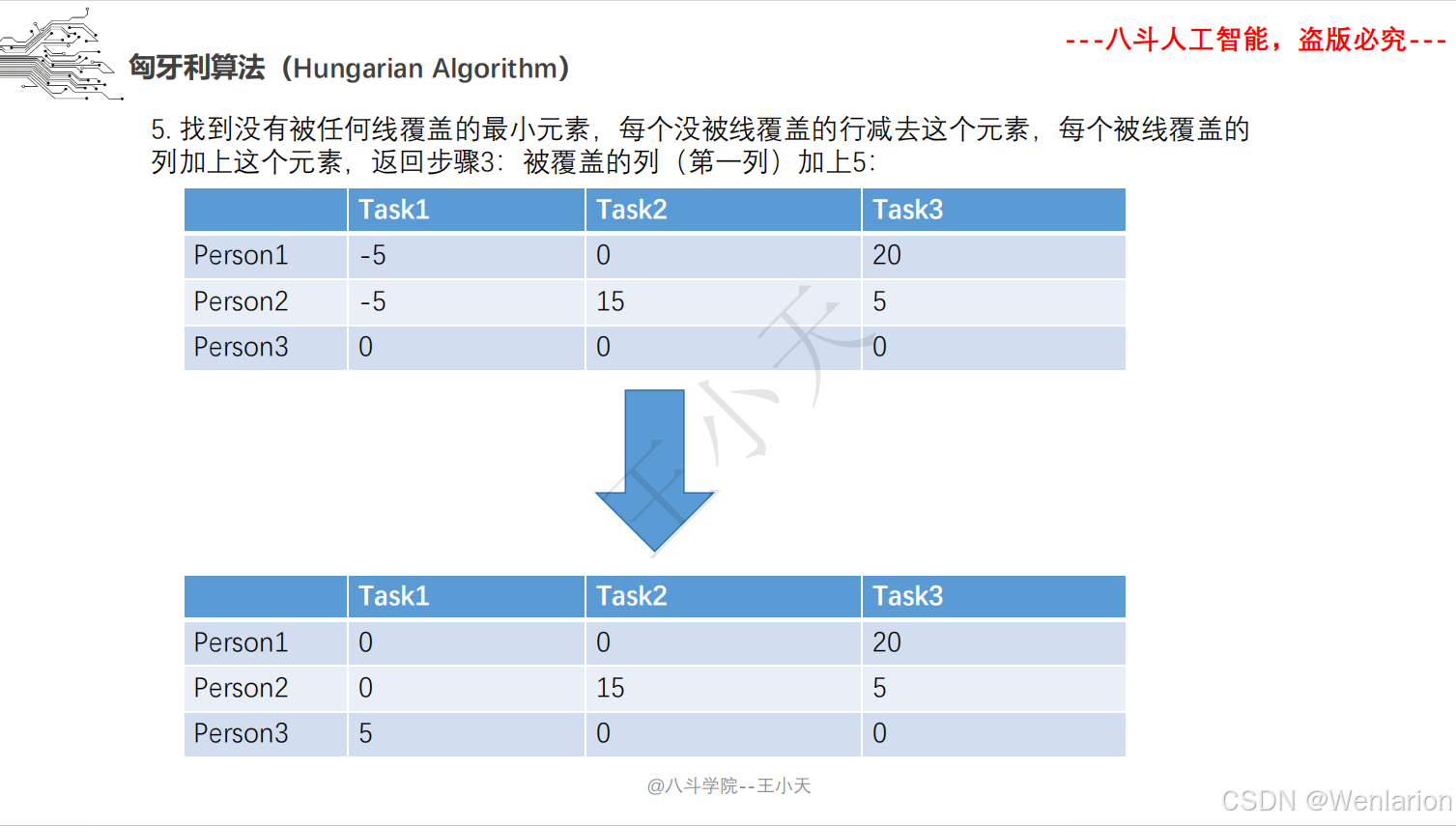
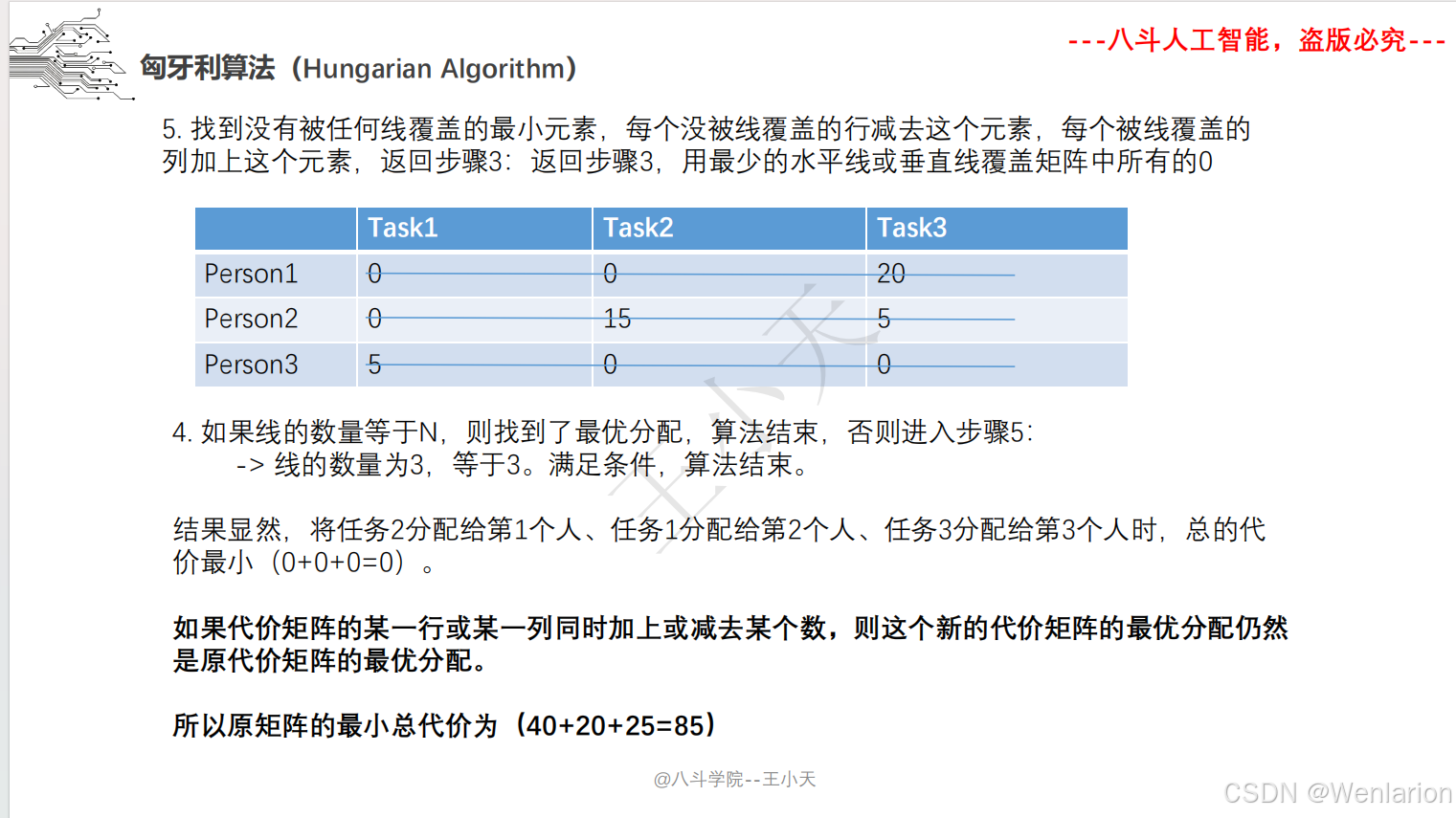
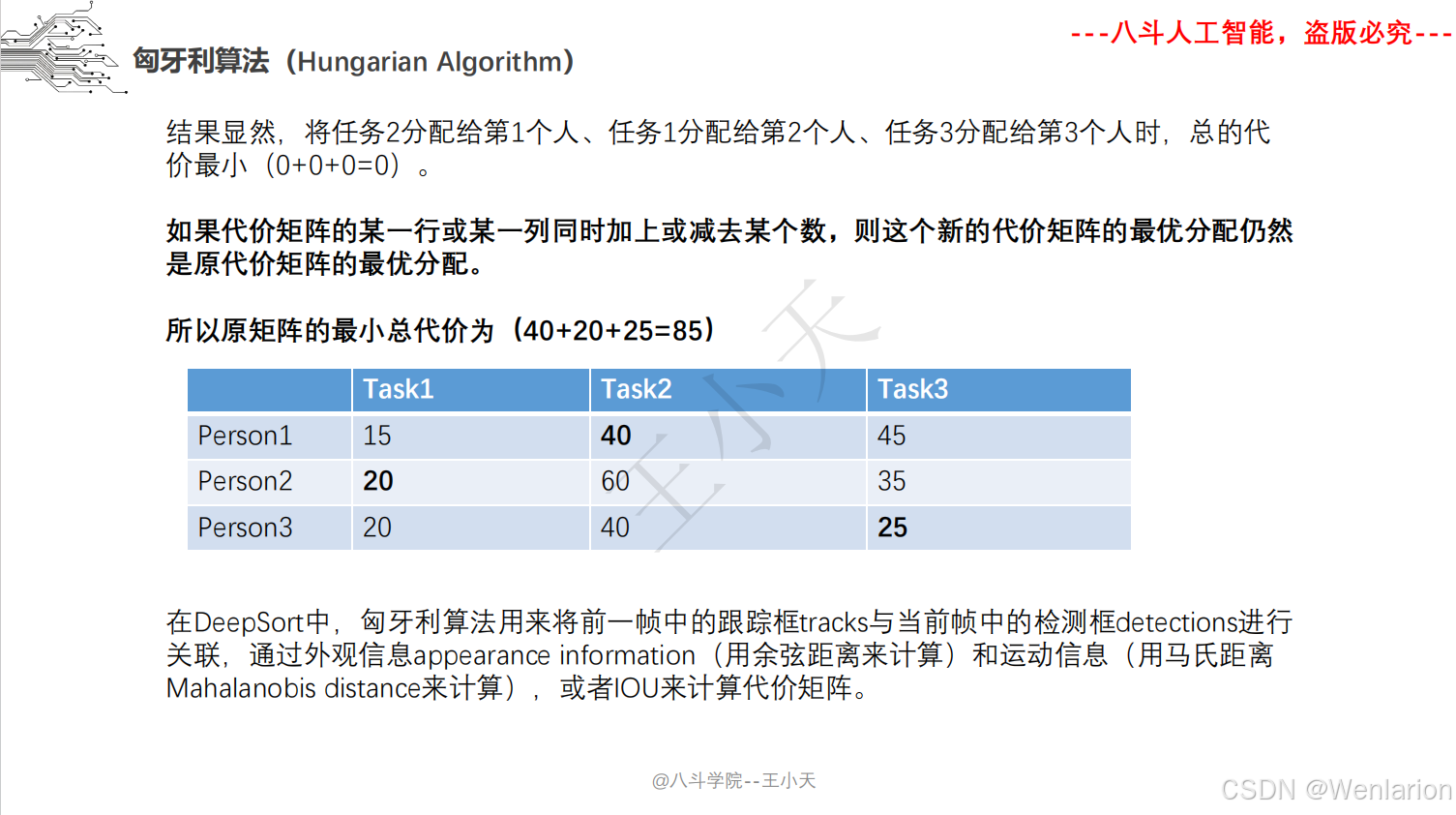





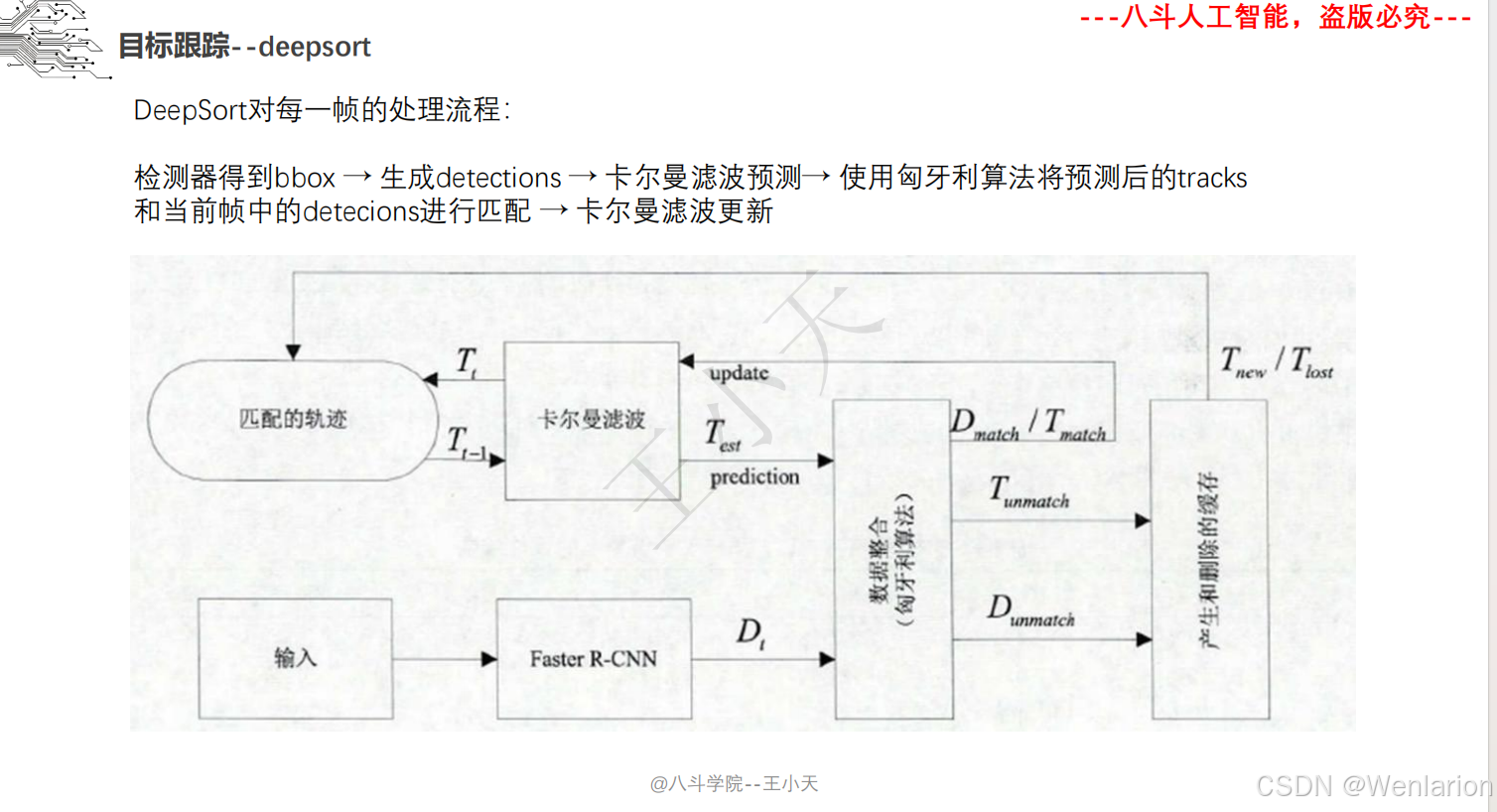
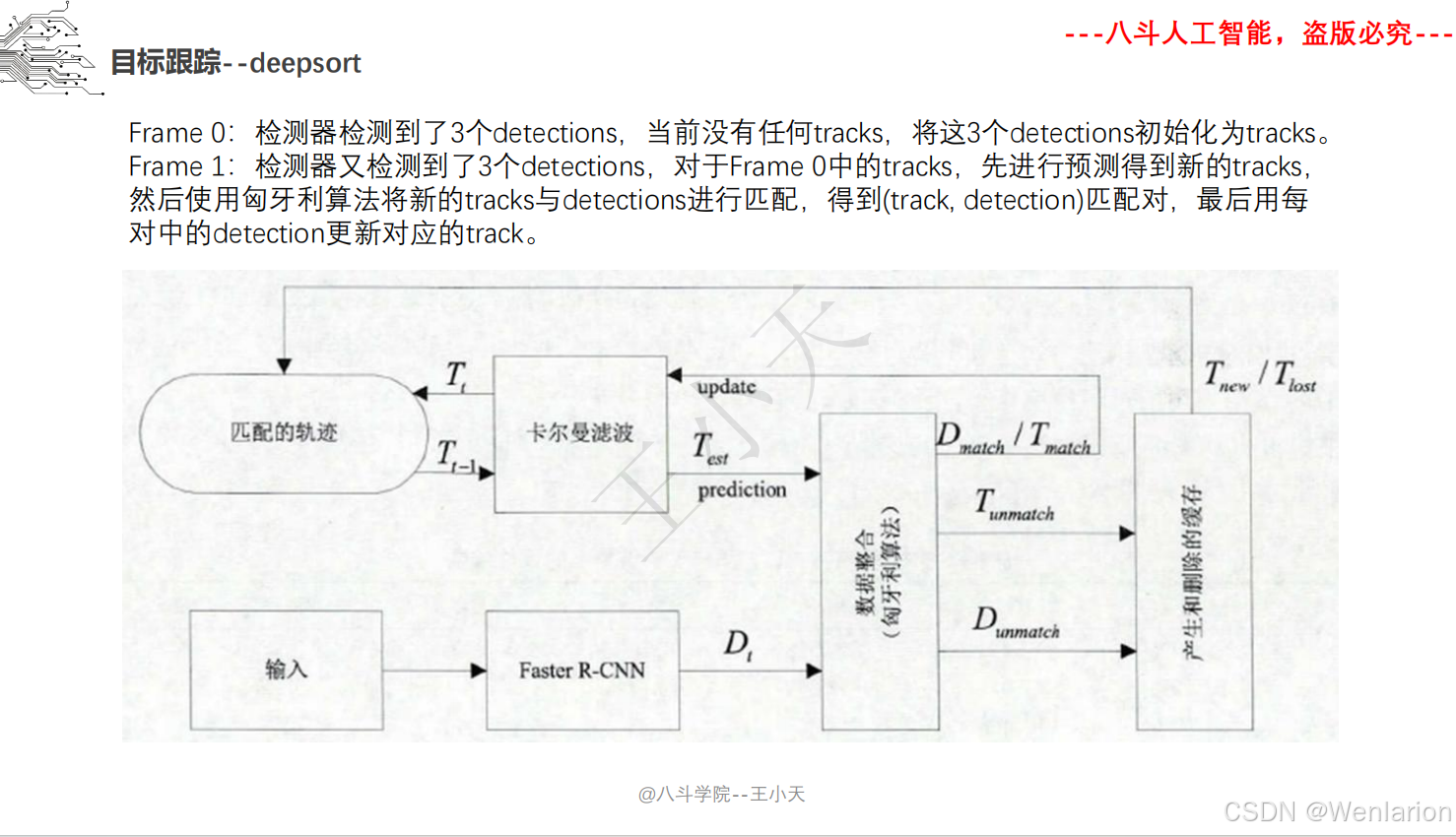
目标追踪相关论文和代码(单目标跟踪(SOT)、多目标跟踪(MOT)、联合检测跟踪(JDE))
一、单目标跟踪(SOT):跟踪视频中单个指定目标
1. MOSSE: Visual Object Tracking using Adaptive Correlation Filters
-
发表:CVPR 2010
-
核心简介:相关滤波跟踪的开山之作,首次将最小平方误差输出和(MOSSE)引入跟踪,用快速傅里叶变换(FFT)实现实时、轻量的目标跟踪。仅用单帧初始化,通过自适应更新滤波器应对目标形变,速度达600+ FPS,奠定了后续 KCF、CSRT 等相关滤波算法的基础。
-
论文:https://www.cs.colostate.edu/~vision/publications/bolme_cvpr10.pdf
2. KCF: High-Speed Tracking with Kernelized Correlation Filters
-
发表:TPAMI 2015
-
核心简介:在 MOSSE 基础上引入核技巧,将线性相关滤波扩展到非线性空间,大幅提升跟踪精度;同时用循环矩阵采样减少计算量,速度保持300+ FPS,成为实时单目标跟踪的经典基线,被 OpenCV 内置为标准跟踪器。
3. SiamRPN: High Performance Visual Tracking with Siamese Region Proposal Network
-
发表:CVPR 2018
-
核心简介:孪生网络 + 区域提议(RPN)的里程碑,将跟踪建模为模板 - 搜索区域匹配 + 目标框回归。用孪生网络提取目标与搜索区域特征,RPN 生成候选框并回归精确位置,首次在单目标跟踪中实现端到端训练 + 实时 + 高精度,开启孪生跟踪时代。
4. SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
-
发表:CVPR 2019
-
核心简介:解决 SiamRPN 无法使用深层网络(如 ResNet-50)的问题,提出深度孪生网络 + 多层特征融合,引入深度互相关提升特征匹配能力,在 OTB、VOT 等数据集上刷新 SOTA,成为孪生跟踪的主流架构。
5. SiamMask: A Framework for Fast Online Object Tracking and Segmentation
-
发表:CVPR 2019
-
核心简介:跟踪 + 分割一体化,在孪生网络中加入掩码分支,同时输出目标框与像素级掩码,实现实例级跟踪。速度达55 FPS,兼顾精度与实时性,适用于需要精确目标轮廓的场景。
二、多目标跟踪(MOT):同时跟踪视频中多个目标(行人 / 车辆等)
1. SORT: Simple Online and Realtime Tracking
-
发表:ICIP 2016
-
核心简介:轻量多目标跟踪的极简基线,仅用卡尔曼滤波 + 匈牙利算法实现跟踪。卡尔曼滤波预测目标位置,匈牙利算法做检测框与跟踪目标的 IOU 匹配,无外观特征、代码仅 300 行,速度达260 FPS,成为后续 DeepSORT、ByteTrack 等的基础框架。
2. DeepSORT: Simple Online and Realtime Tracking with a Deep Association Metric
-
发表:ICIP 2017
-
核心简介:在 SORT 基础上加入深度表观特征,解决 SORT 仅靠 IOU 匹配易 ID 切换的问题。用预训练 CNN 提取目标外观特征,结合马氏距离 + 余弦距离做数据关联,大幅提升ID 保持能力,成为工业界最常用的多目标跟踪器。
3. ByteTrack: Multi-Object Tracking by Associating Every Detection Box
-
发表:ECCV 2022
-
核心简介:突破传统 “只保留高置信度检测” 的局限,提出关联所有检测框的策略。对低置信度检测框,通过与跟踪轨迹匹配恢复真实目标、过滤背景,解决遮挡导致的轨迹断裂问题;在 MOT17/20 上实现80+ MOTA、30 FPS,成为当前MOT 的 SOTA 基线。
4. BoT-SORT: Robust Associations Multi-Pedestrian Tracking
-
发表:arXiv 2022
-
核心简介:优化 DeepSORT 的关联策略,用IoU + 外观特征 + 运动信息的加权匹配,引入轨迹平滑与相机运动补偿,提升复杂场景(拥挤 / 遮挡)下的鲁棒性;速度与精度均衡,适配自动驾驶、视频监控等场景。
三、联合检测与跟踪(JDE):单网络同时完成检测 + 跟踪,端到端推理
1. JDE: Towards Real-Time Multi-Object Tracking
-
发表:ECCV 2020
-
核心简介:首个单阶段联合检测 + 跟踪框架,在 YOLOv3 基础上增加表观特征分支,同时输出目标框、类别与 ID 特征。实现检测 + 特征提取 + 关联一体化,无需单独训练外观模型,速度达22 FPS,开启 JDE 时代。
2. FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
-
发表:ECCV 2020
-
核心简介:解决 JDE 中检测与重识别(ReID)特征冲突的问题,提出公平特征学习。用共享骨干 + 分离检测 / ReID 头,平衡检测定位精度与 ID 区分能力,在 MOT17 上实现73.7 MOTA、30 FPS,成为 JDE 的经典改进模型。
3. TransTrack: Tracking with Transformers
-
发表:CVPR 2022
-
核心简介:Transformer 首次应用于多目标跟踪,用 Transformer 建模帧间目标关联,无需显式数据关联算法。将跟踪建模为目标查询匹配,直接输出目标 ID 与位置,简化流程,在复杂场景下 ID 保持能力更强。
四、工具库与数据集
1. 跟踪工具库
-
PySOT(SOT):https://github.com/STVIR/pysot(SiamRPN++ 等实现)
-
MOTChallenge(MOT 基准):https://motchallenge.net/
-
OpenCV Trackers:https://github.com/opencv/opencv_contrib/tree/master/modules/tracking
2. 常用数据集
-
SOT:OTB100、VOT2023、LaSOT、GOT-10k
-
MOT:MOT17、MOT20、CrowdHuman、UA-DETRAC
2.5 姿态估计问题

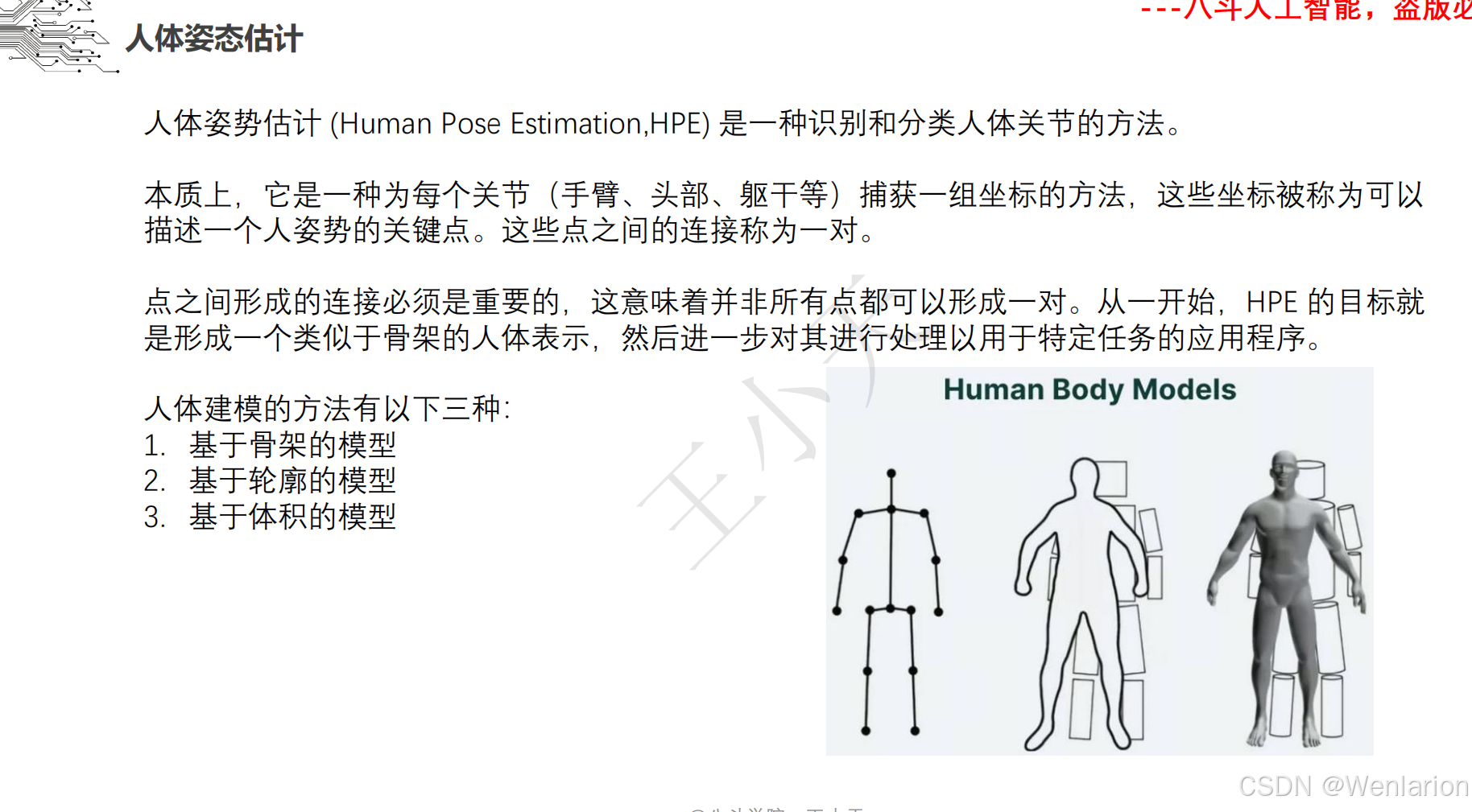


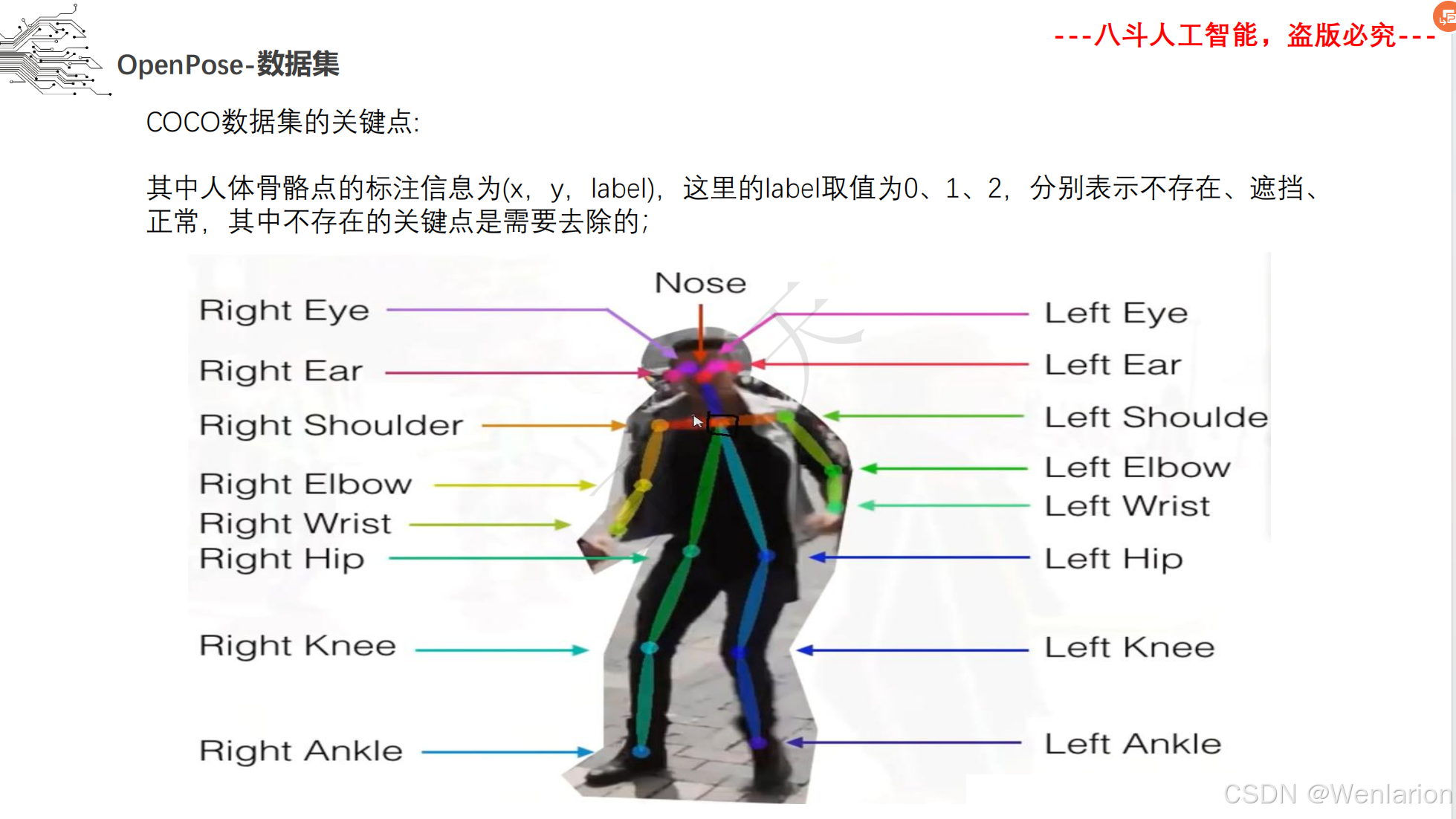

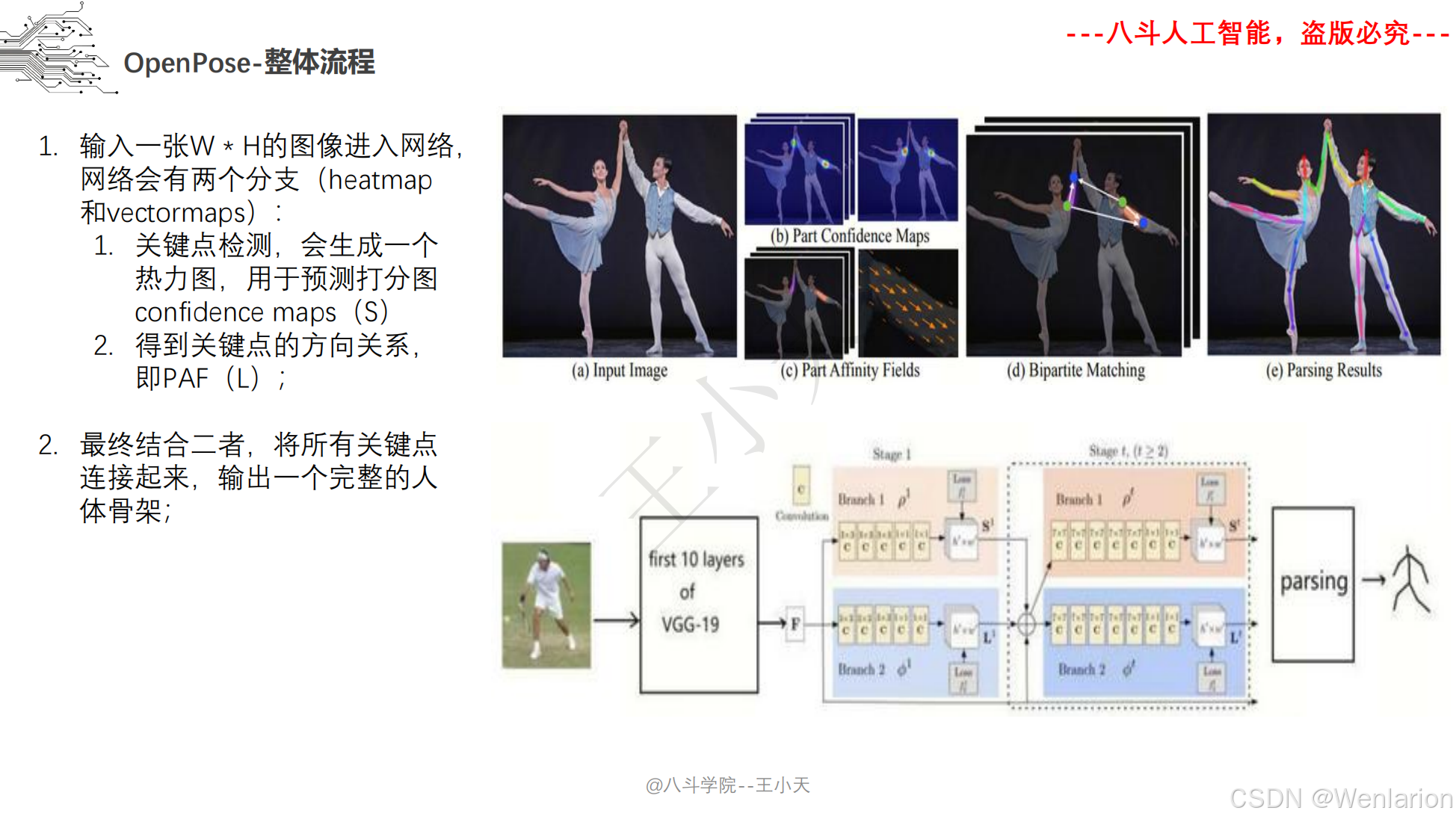
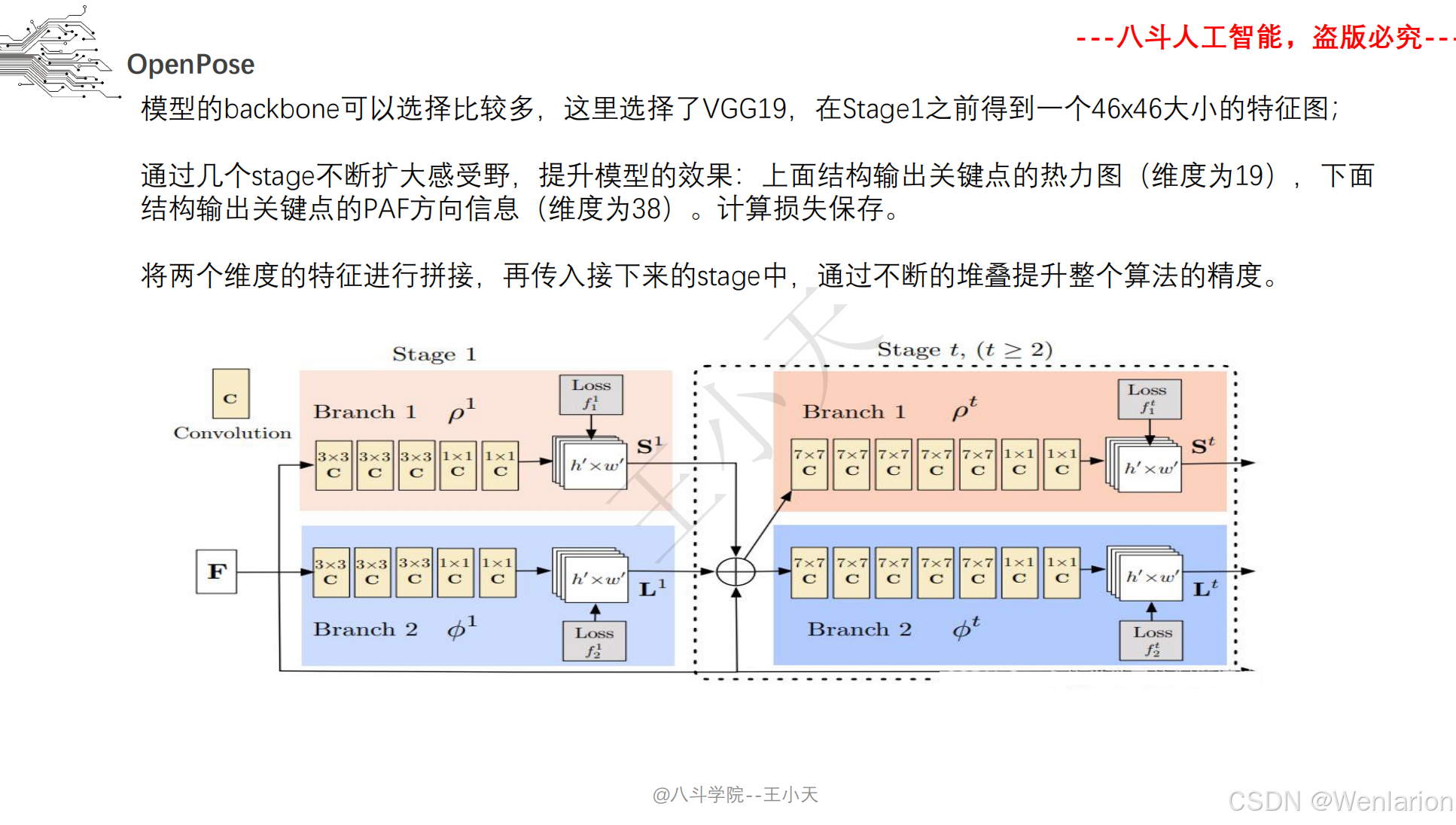


人体姿态识别相关论文和代码(2D 自下而上→2D 自上而下→3D 姿态识别→实时 / 轻量化)
一、2D 人体姿态识别(自下而上)
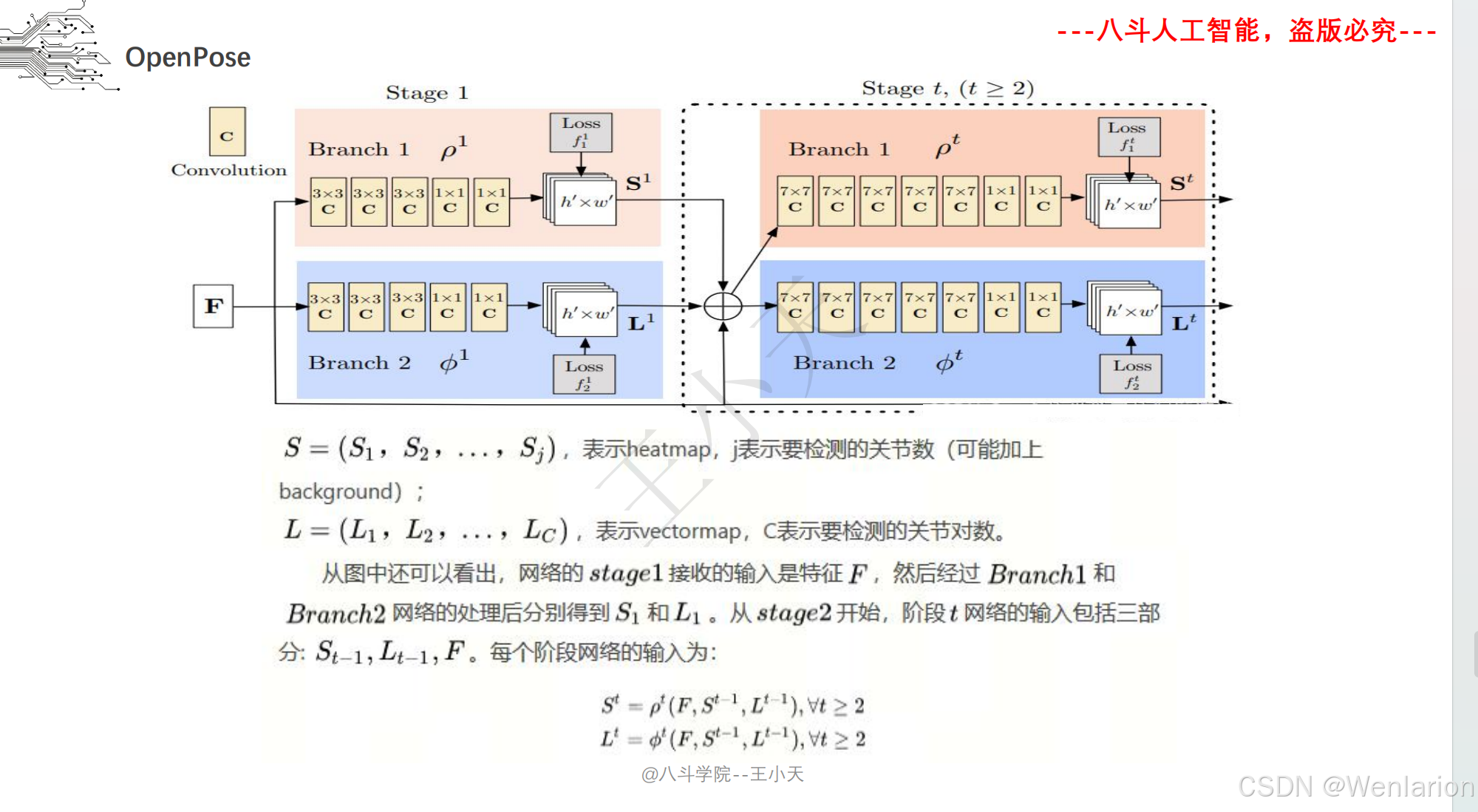
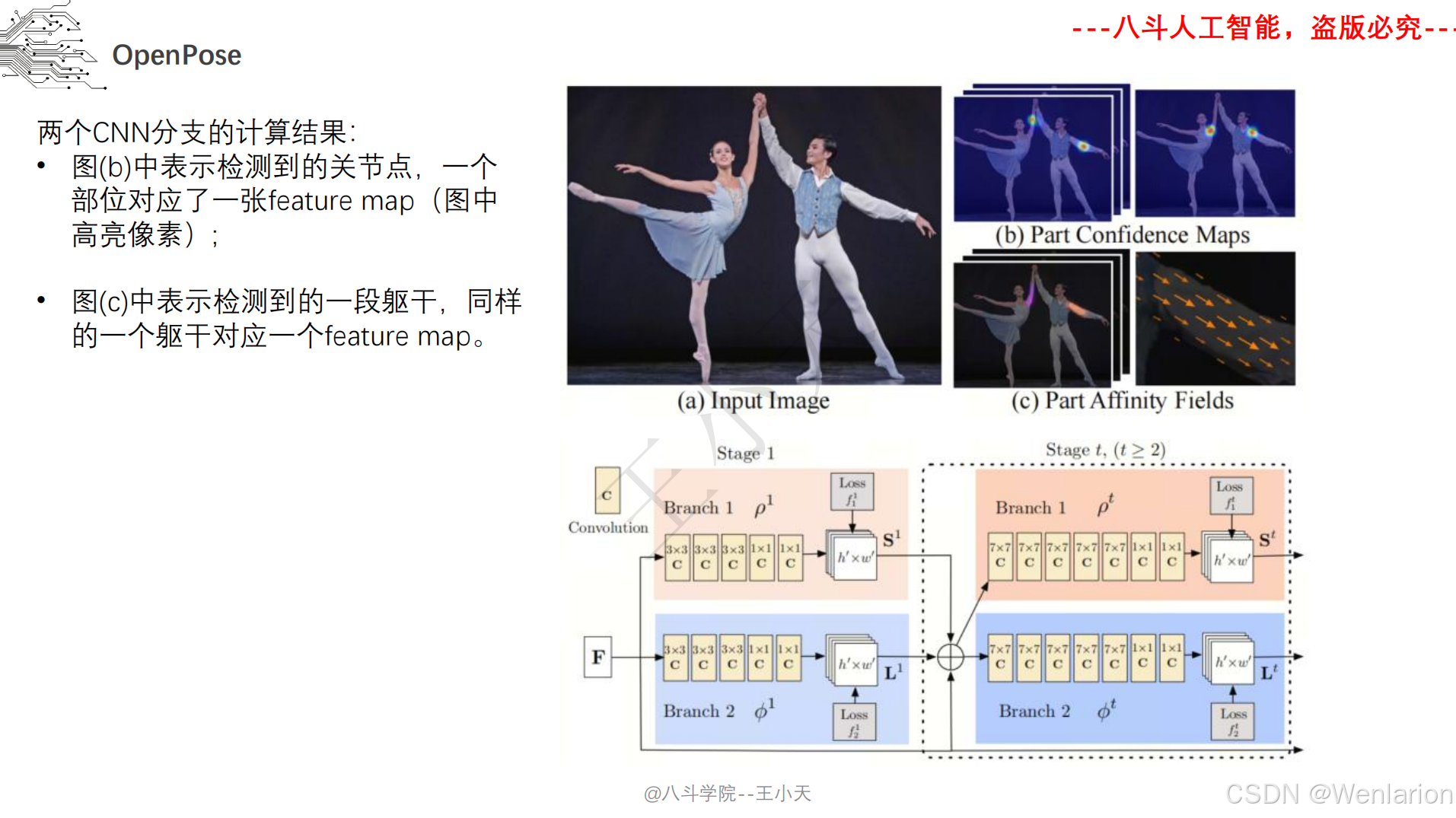
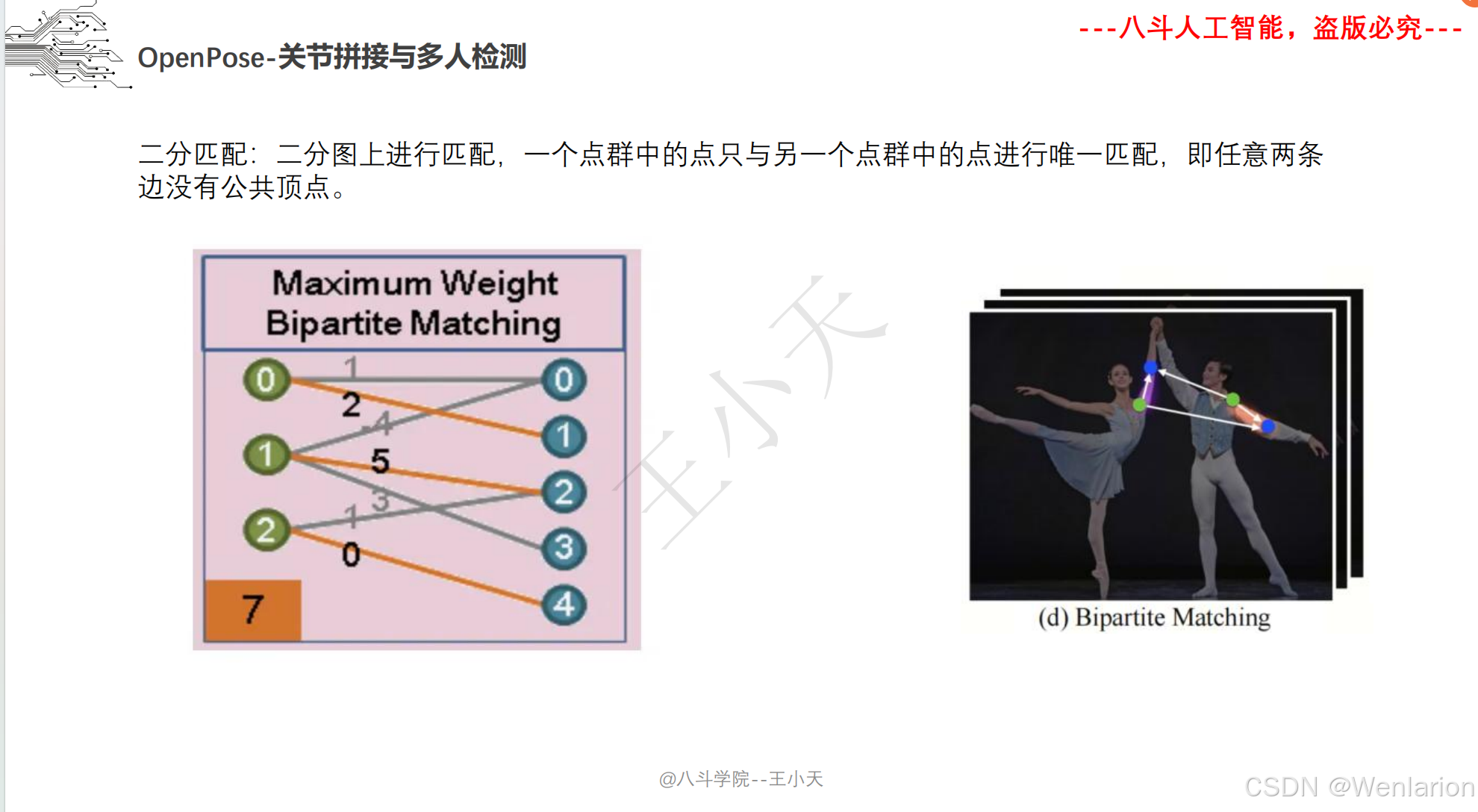
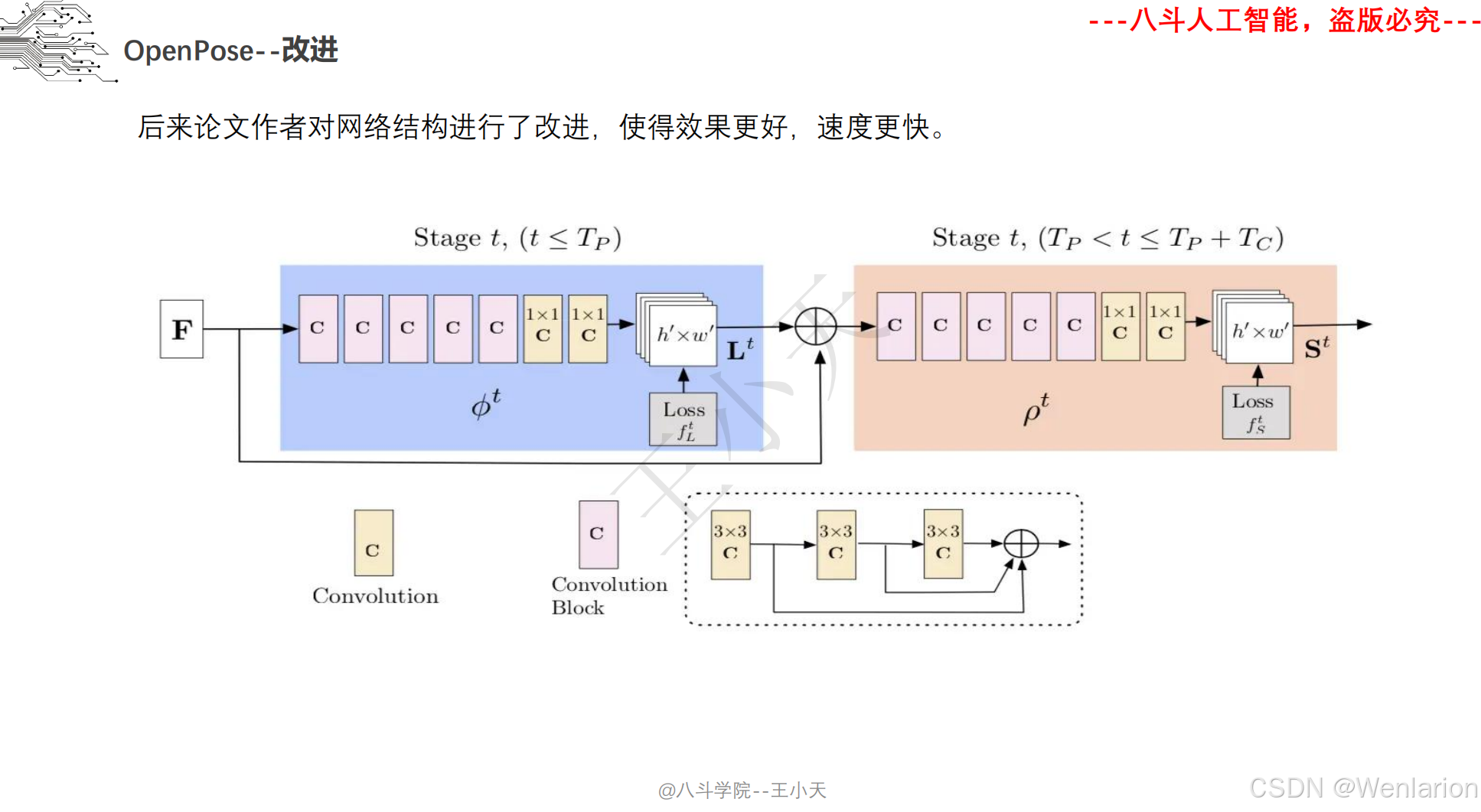
1. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields
-
发表:CVPR 2017
-
核心简介:首个落地的实时多人 2D 姿态识别框架,解决了传统方法无法高效处理多人姿态、关键点匹配混乱的问题。提出Part Affinity Fields (PAF,部分亲和域),通过连续的向量场建模人体关键点之间的关联关系,实现从关键点检测到人体分组的端到端推理;同时采用多阶段卷积网络,兼顾检测精度和实时性(CPU/GPU 均能运行),成为自下而上方法的开山之作,后续多数自下而上模型均基于其思想改进。
-
PDF 下载:arXiv→https://arxiv.org/pdf/1812.08008.pdf | CVPR 官方→https://openaccess.thecvf.com/content_cvpr_2017/papers/Cao_Realtime_Multi-Person_2D_CVPR_2017_paper.pdf
-
代码地址:https://github.com/CMU-Perceptual-Computing-Lab/openpose
2. Associative Embedding: End-to-End Learning for Joint Detection and Grouping
-
发表:NIPS 2017
-
核心简介:提出关联嵌入(Associative Embedding) 新思路,解决自下而上方法中 “关键点检测与人体分组分离” 的问题,实现端到端的多人姿态识别。为每个检测到的人体关键点分配一个嵌入向量,同一人体的关键点向量相似度高,不同人体的向量相似度低,通过向量聚类自动完成关键点分组;无需额外的分组后处理,简化了模型流程,同时提升了推理速度,该嵌入思想被后续众多自下而上模型借鉴。
-
代码地址:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch(集成在 HRNet 官方库中)
二、2D 人体姿态识别(自上而下)
1. Simple Baselines for Human Pose Estimation and Tracking
-
发表:ECCV 2018
-
核心简介:打破当时 “姿态识别模型必须设计复杂模块” 的误区,提出极简的自上而下基线模型,以 ResNet 为骨干网络,搭配反卷积层做上采样恢复关键点热力图,无任何复杂的定制化模块。实验证明该简单架构在 COCO、MPII 数据集上性能媲美当时的复杂模型,成为后续所有自上而下姿态模型的基准框架;同时提出姿态跟踪的简单思路,实现视频中人体姿态的连续估计,为后续模型改进提供了清晰的对比基线。
-
代码地址:https://github.com/microsoft/human-pose-estimation.pytorch
2. Deep High-Resolution Representation Learning for Human Pose Estimation (HRNet)
-
发表:CVPR 2019
-
核心简介:解决传统 CNN 在特征提取中 “高分辨率特征逐步丢失” 的问题,提出全程高分辨率特征表示网络。不同于传统网络 “下采样降维→上采样恢复” 的流程,HRNet 从高分辨率特征图出发,并行连接不同分辨率的特征分支,通过跨分支融合不断增强高分辨率特征的表达能力,让模型始终保留人体关键点的精细空间信息。该架构在 COCO 数据集上刷新当时 SOTA,成为 2D 姿态识别的主流骨干网络,后续被广泛应用于目标检测、分割等计算机视觉任务。
-
PDF 下载:arXiv→https://arxiv.org/pdf/1902.09212.pdf | CVPR 官方→https://openaccess.thecvf.com/content_CVPR_2019/papers/Sun_Deep_High-Resolution_Representation_Learning_for_Human_Pose_Estimation_CVPR_2019_paper.pdf
-
代码地址:https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
3. HigherHRNet: Scale-Aware Representation Learning for Bottom-Up Human Pose Estimation
-
发表:CVPR 2020
-
核心简介:将 HRNet 的高分辨率特征思想适配到自下而上方法,解决自下而上模型对不同尺度人体(如大 / 小人)检测精度低的问题。提出尺度感知的特征表示,在 HRNet 基础上增加多尺度特征融合模块,同时设计自适应的关键点检测头,针对不同尺度的人体特征做针对性检测;相比 OpenPose,在多人、多尺度场景下精度大幅提升,成为自下而上 2D 姿态识别的 SOTA 模型。
-
代码地址:https://github.com/HRNet/HigherHRNet-Human-Pose-Estimation
4. ViTPose: Simple Vision Transformer Baselines for Human Pose Estimation
-
发表:NeurIPS 2022
-
核心简介:首次将 Vision Transformer(ViT)成功应用于人体姿态识别,打破此前姿态模型依赖 CNN 骨干的局限。提出适配姿态任务的 ViT 架构,通过调整 patch 大小、增加特征上采样模块,解决 ViT 对精细空间信息捕捉不足的问题;同时设计简单的热力图解码头,在 COCO、MPII 等数据集上超越当时所有 CNN 基姿态模型,为姿态识别开辟了Transformer 基模型的新方向,后续众多 ViT 姿态模型均基于其改进。
三、3D 人体姿态识别
1. 3D Human Pose Estimation in Video with Temporal Convolutions and Semi-Supervised Training
-
发表:CVPR 2019
-
核心简介:针对单张图片 3D 姿态估计易受视角、遮挡影响的问题,提出基于视频的 3D 姿态估计模型(VideoPose3D)。采用 “2D 检测→3D 提升” 的两阶段思路,先通过 2D 姿态模型提取视频中每一帧的 2D 关键点,再利用时序卷积网络(TCN) 建模视频帧间的时间关联,从时序特征中恢复 3D 姿态;同时引入半监督训练,利用未标注的视频数据提升模型泛化能力,在 Human3.6M、MPI-INF-3DHP 数据集上实现 SOTA,成为视频 3D 姿态估计的经典基线。
2. Simple Baselines for 3D Human Pose Estimation
-
发表:ICCV 2019 Workshop
-
核心简介:为 3D 姿态估计提供极简的单图基线模型,解决当时 3D 姿态模型架构复杂、难以复现的问题。采用 “2D 关键点特征→3D 坐标回归” 的直接思路,以 ResNet 提取 2D 关键点的空间特征,通过全连接层直接回归 3D 姿态坐标,无任何复杂的时序或几何约束模块;实验证明该简单模型在单图 3D 姿态估计任务上性能媲美复杂模型,成为单图 3D 姿态识别的基准框架,后续模型均以其为对比基线。
3. HMR: Human Mesh Recovery from a Single Image
-
发表:ICCV 2019
-
核心简介:突破传统 3D 姿态识别 “仅回归关键点坐标” 的局限,提出从单张图片恢复 3D 人体网格(Human Mesh Recovery) 的方法。将人体表示为参数化的 SMPL 网格模型,模型直接回归 SMPL 的形状、姿态参数,从而生成完整的 3D 人体网格,而非孤立的关键点;同时引入对抗训练提升网格的真实感,实现从 “关键点级” 到 “网格级” 的 3D 人体理解,成为 3D 人体网格恢复的开山之作。
4. PARE: Part Attention Regressor for 3D Human Body Estimation
-
发表:CVPR 2021
-
核心简介:针对 HMR 等模型在人体局部遮挡、复杂姿态下精度低的问题,提出基于部分注意力的 3D 人体网格回归模型(PARE)。引入部位注意力机制(Part Attention),让模型自动关注人体未被遮挡的部位,弱化遮挡部位的特征影响;同时设计多任务学习框架,联合回归 3D 关键点、人体网格和相机参数,提升模型的鲁棒性;在遮挡、复杂姿态场景下,网格恢复精度远超 HMR,成为当时 3D 人体网格估计的 SOTA 模型。
四、实时 / 轻量化人体姿态识别(移动端 / 边缘端)
1. Lite-HRNet: A Lightweight High-Resolution Network
-
发表:CVPR 2021
-
核心简介:针对 HRNet 参数量大、无法部署在移动端的问题,提出HRNet 的轻量化版本,在保留高分辨率特征思想的前提下,大幅减少参数量和计算量。通过深度可分离卷积替换 HRNet 中的标准卷积,同时设计轻量级的跨分辨率特征融合模块,在减少计算量的同时保留高分辨率特征的表达能力;相比 HRNet,参数量减少 80% 以上,推理速度提升 5 倍,在移动端实现高精度的实时 2D 姿态识别,成为边缘端姿态识别的主流骨干。
2. MobilePose: Real-Time Pose Estimation for Mobile Devices
-
发表:arXiv 2018
-
核心简介:首个专为移动端设计的实时姿态识别模型,解决传统姿态模型(如 OpenPose)计算量过大、无法在手机等嵌入式设备运行的问题。以轻量级的 MobileNet 为骨干网络,替换 OpenPose 中的 VGG 骨干,同时简化 PAF 特征提取模块,在保证基本识别精度的前提下,将模型参数量和计算量降至移动端可承受范围;支持 iOS/Android 端的实时推理,为移动端姿态识别的落地奠定基础。
-
代码地址:https://github.com/CMU-Perceptual-Computing-Lab/mobilepose
3. YOLO-Pose: Enhancing YOLO for Multi Person Pose Estimation Using Object Keypoint Similarity Loss
-
发表:CVPR 2022 Workshop
-
核心简介:将 YOLO 的目标检测思想与姿态识别融合,提出一站式的实时多人姿态识别模型,解决传统自上而下方法 “检测 + 姿态” 两步推理速度慢的问题。在 YOLOv5 的基础上,增加关键点预测头,将人体检测和关键点回归融合在一个网络中,实现单阶段端到端的多人姿态估计;同时引入Object Keypoint Similarity (OKS) 损失,适配姿态任务的标签分布,相比 OpenPose 推理速度提升 10 倍以上,在桌面端 / 边缘端均能实现实时(30+FPS)多人姿态识别。
-
代码地址:https://github.com/TexasInstruments/edgeai-yolov5/tree/pose
五、工具库与数据集
1. MMPose
2. Detectron2
3. 常用数据集
-
COCO Keypoints: https://cocodataset.org/#keypoints-2017
六、论文下载通用方法(免费)
1. arXiv(最常用)
-
格式:
https://arxiv.org/pdf/[论文编号].pdf
2. CVF Open Access(CVPR/ICCV)
-
格式:
https://openaccess.thecvf.com/content_[会议]/papers/[论文名].pdf
3. ECCV
-
格式:
https://www.ecva.net/papers/[会议]/papers/[论文名].pdf
4. NeurIPS
-
格式:
https://proceedings.neurips.cc/paper_files/paper/[年份]/hash/[哈希值]-Paper.pdf
5. PapersWithCode(一站式)
-
搜索论文标题,直接获取论文 + 代码链接
2.6 缺陷检测问题
目前的缺陷检测主要分为两大类:
-
有监督检测 (Supervised):需要大量缺陷样本标注,常用目标检测(YOLO系列)和分割网络。
-
无监督/半监督异常检测 (Unsupervised/Semi-supervised):当前研究热点。仅需正常样本训练,通过重构或特征分布来判断异常,解决工业界“缺陷样本少”的痛点。
一、核心开源资源库 (强烈推荐)
在深入研究具体算法前,建议先收藏以下汇总资源库,它们包含了绝大多数主流算法的论文和代码链接。
-
Awesome Defect Detection
-
简介:汇集了表面缺陷检测的学术论文、开源工具、算法汇总及数据集(涵盖PCB、钢材、织物等)。
-
地址:https://github.com/tomhardy3dvisionworkshop/awesomedefectdetection
-
-
Anomalib (Intel开源库)
-
简介:目前最完善的工业异常检测库之一,集成了PatchCore, FastFlow, SPADE, CFA等20+种SOTA算法,支持训练、评估和部署。
-
二、经典与SOTA无监督异常检测算法 (重点)
这类算法是目前工业界落地的首选,因为它们不需要大量的缺陷标注数据。
1. PatchCore (CVPR 2022) - 当前标杆
-
论文标题: Towards Total Recall in Industrial Anomaly Detection
-
简介: 解决了“冷启动”问题(仅用正常样本训练)。核心思想是提取预训练网络(如ResNet)的局部Patch特征,构建一个记忆库 (Memory Bank)。测试时,通过计算查询图像特征与记忆库中正常特征的最近邻距离来判定异常。它在MVTec AD数据集上长期占据榜首,检测精度和定位能力极强。
-
论文地址: arXiv:2106.08265
-
官方代码: https://github.com/amazon-science/patchcore-inspection
-
PyTorch复现: https://github.com/shanglianlm0525/CvPytorch (搜索PatchCore部分)
2. FastFlow (2021/2022)
-
论文标题: FastFlow: Unsupervised Anomaly Detection and Localization via 2D Normalizing Flows
-
简介: 提出了一种基于2D归一化流 (Normalizing Flows) 的方法。它直接在2D特征图上建模正常数据的概率分布,避免了将特征展平为1D向量导致的空间信息丢失。推理速度快,能生成像素级的异常热力图。
-
论文地址: arXiv:2111.07677
3. SPADE (CVPR 2021)
-
论文标题: Sub-Image Anomaly Detection with Deep Pyramid Correspondences
-
简介: 开创了像素级异常检测的先河。利用预训练网络提取多尺度特征,通过寻找测试图像子区域与正常样本库中对应区域的最佳匹配(Correspondence),计算重构误差或特征差异来定位异常。
-
论文地址: arXiv:2005.02357
-
代码地址: 通常包含在Anomalib库中,或参考早期实现 https://github.com/xiahaifeng1995/PaDiM-SpaDE-FastFlow-Pytorch (非官方维护,仅供参考)
4. PaDiM (ICPR 2021)
-
论文标题: PaDiM: a Patch Distribution Modeling Framework for Anomaly Detection and Localization
-
简介: 假设正常图像的Patch特征服从多元高斯分布。训练时估计每个空间位置的均值和协方差矩阵;测试时计算马氏距离。方法简单高效,是PatchCore出现之前的SOTA。
-
论文地址: arXiv:2011.08785
5. CFA / Coupled-Hypersphere (2022)
-
论文标题: CFA: Coupled-Hypersphere-Based Feature Adaptation for Target-Oriented Anomaly Localization
-
简介: 针对特征分布适配问题,提出耦合超球体模型,更好地适应目标域的特征分布,提升了对微小缺陷的定位能力。
-
代码地址: 建议直接在 Anomalib 中调用,或搜索相关复现仓库。
6. WinClip (CVPR 2023) - CLIP赋能
-
论文标题: WinClip: Zero-/Few-Shot Anomaly Classification and Segmentation
-
简介: 利用大模型 CLIP 的零样本/少样本能力。无需训练(或极少训练),通过滑动窗口裁剪图像并利用CLIP的文本 - 图像匹配能力来判断是否包含“缺陷”语义。适合跨品类快速部署。
-
论文地址: arXiv:2305.10760
-
代码地址: https://github.com/zqhang/WinClip (或搜索官方实现)
三、有监督检测算法 (传统深度学习)
如果您拥有充足的缺陷标注数据,以下目标检测和分割网络依然是工业界的主力:
表格
|
算法类型 |
代表模型 |
特点 |
代码/资源 |
|---|---|---|---|
|
目标检测 |
YOLO v8/v9/v10 |
速度极快,适合实时产线检测,对明显缺陷效果好。 |
|
|
目标检测 |
Faster R-CNN |
精度高,适合小目标缺陷,但速度较慢。 |
|
|
语义分割 |
U-Net / DeepLabV3+ |
像素级分割,能精确勾勒缺陷形状。 |
|
|
实例分割 |
Mask R-CNN |
同时完成检测与精细分割。 |
四、常用数据集
研究和测试算法通常使用以下公开数据集:
-
MVTec AD (Most Popular): 工业异常检测的基准数据集,包含15个类别(地毯、螺丝、胶囊等),涵盖多种缺陷类型。
-
下载:MVTec官网
-
-
VisA: 包含更多复杂物体和多尺度缺陷的数据集。
-
Neu-Defect / Steel Defect: 针对特定行业(如钢材表面)的数据集,常在Kaggle或特定论文附录中找到。
五、总结与建议
-
入门首选: 直接运行 Anomalib 库,它内置了PatchCore, FastFlow, PaDiM等算法,文档齐全,能快速复现SOTA结果。
-
高精度需求: 优先尝试 PatchCore 或 WinClip (如果有预训练大模型资源)。
-
实时性需求: 考虑 FastFlow 或有监督的 YOLO 系列(如果有标注数据)。
-
最新趋势: 关注基于 Diffusion Model (扩散模型) 和 Vision Transformer (ViT) 的异常检测方法(如DiAD, SimpleNet等),这些是2023-2025年的研究前沿。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)