使用Spring-ai框架,大模型应用开发
本文介绍了基于SpringAI框架的大模型应用开发实践,主要内容包括:1.智谱大模型API调用方法,包括注册账号、创建API Key和简单请求示例;2.大模型核心概念解释,如LLM、token、Temperature等参数;3.SpringAI项目环境搭建和ChatModel基础用法;4.ChatClient高级功能实现,包括角色设定、实体映射和Advisor拦截器;5.检索增强生成(RAG)技术
一. 智谱
1. 注册智谱账号并创建API key

2. 简单请求大模型Demo
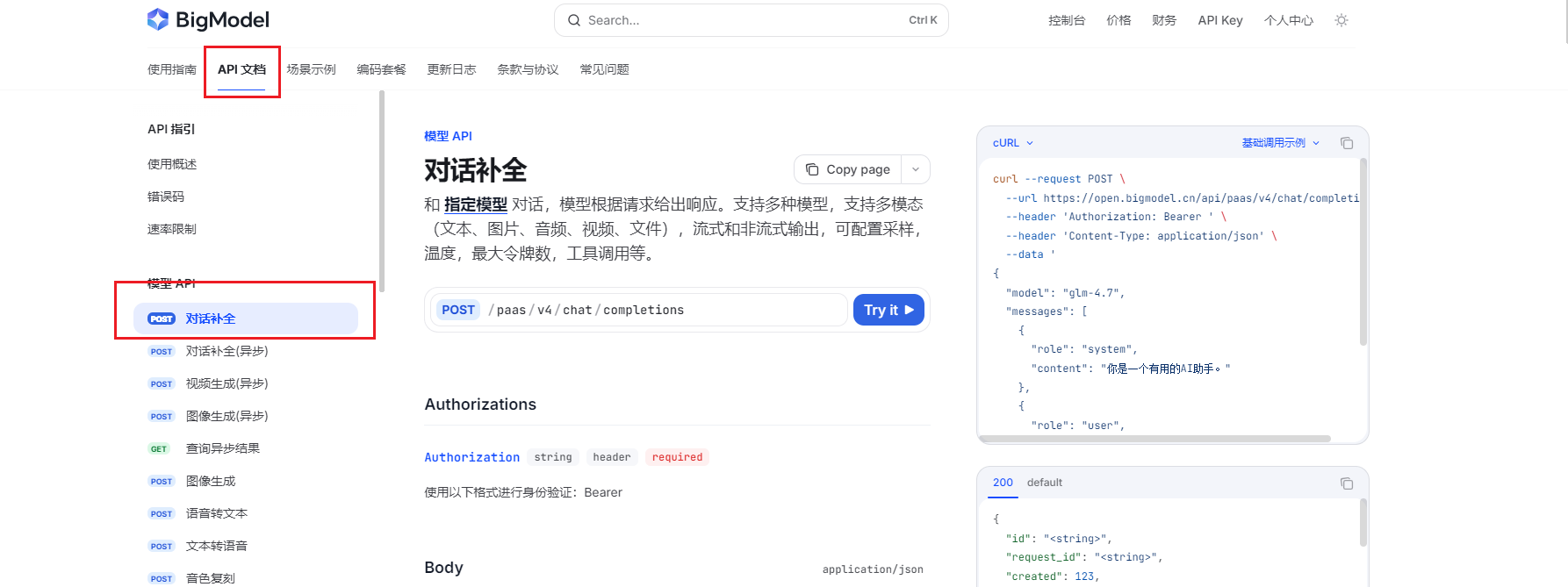
curl --request POST \
--url https://open.bigmodel.cn/api/paas/v4/chat/completions \
--header 'Authorization: Bearer you_API_key' \
--header 'Content-Type: application/json' \
--data '
{
"model": "glm-4.7",
"messages": [
{
"role": "system",
"content": "你是一个有用的AI助手。"
},
{
"role": "user",
"content": "请介绍一下人工智能的发展历程。"
}
],
"stream": false,
"temperature": 1
}
'其实这个就是通过API请求调用大模型实现问答;
二. 大模型相关概念
1. LLM
大语言模型Large Language Model;
2. token
token 是模型用来表示自然语言文本的基本单位,也是我们的计费单元,可以直观的理解为“字”或“词”。各个大模型的计算不一样;
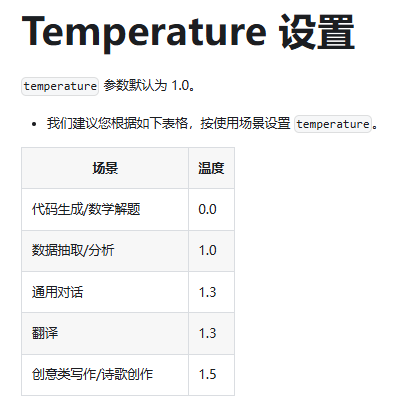
3. Temperature
大模型回复内容的发散性,值越小越确定,越大越发散。查找到deepseek的建议设置如下:
4. 流式响应
例如我们问一些AI工具时,可以看到它回复的时候是一个字一个字的返回的,这个就是流式响应,流式响应可以减少回复的等待时间,用户看到的时瞬间就有消息回复,提高用户体验;
5. 角色role
system:设定这次回复的AI角色,回复时就以设定的角色来回复内容。例如:“你是一个幽默的人”,回复的内容可以就会比较幽默一些;
user:用户消息,这个是我们发送的内容;
assistant:历史会话,请求大模型时,把历史的回答也一起传过去;
tool:调用大模型过程中,可能用到的工具
6. prompt
提示词,请求中携带的数据。在SpringAI中,prompt是message+chatOptions;

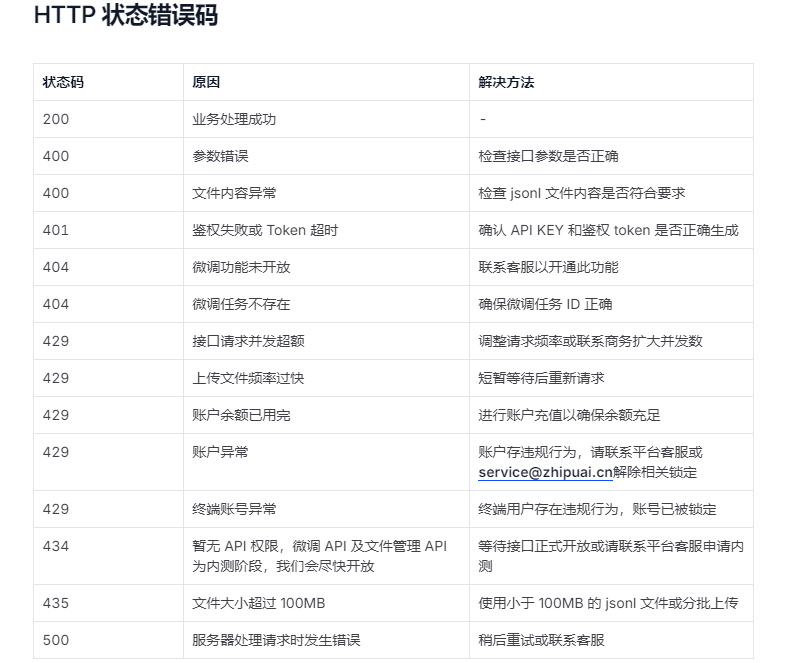
7. 错误码
当请求大模型错误时,大模型返回的错误信息,每个大模型不一样,以下是智谱的错误码
三. SpringAI
1. 项目环境
基本上SpringAI的项目环境都需要Java17+、SpringBoot3.x+;
spring-boot-dependencies3.5.10、spring-ai1.0.0、spring-ai-starter-model-zhipuai1.0.0
application.yaml
spring:
# 智谱的相关配置
ai:
zhipuai:
api-key: you_API_KEY
base-url: https://open.bigmodel.cn/api/paas
chat:
options:
model: glm-4.72. 测试环境
@RestController
@RequestMapping("/zhipu")
public class ZhipuChatController {
@Autowired
private ChatModel chatModel;
// simple
@GetMapping ("/simple")
public String simple(@RequestParam("query") String query) {
return chatModel.call(query);
}
}
结果:

四. ChatModel
1. 通过Massage传值
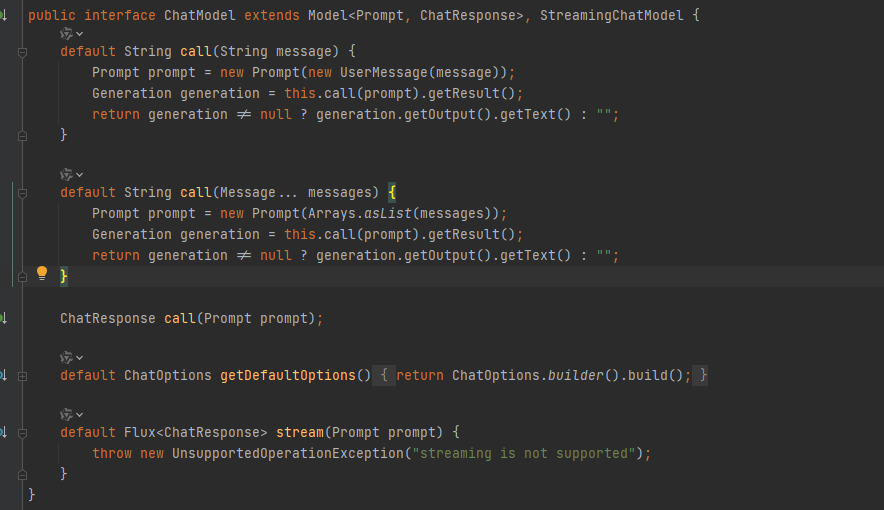
源码中,call方法除了可以传字符串,还可以传Message类型
// massage
@GetMapping ("/massage")
public String massage(@RequestParam("userQuery") String userQuery, @RequestParam("systemQuery") String systemQuery) {
Message userMessage = new UserMessage(userQuery);
Message systemMessage = new SystemMessage(systemQuery);
return chatModel.call(userMessage, systemMessage);
}结果:

2. Prompt传值
// prompt
@GetMapping ("/prompt")
public String prompt(@RequestParam("userQuery") String userQuery, @RequestParam("systemQuery") String systemQuery) {
Message userMessage = new UserMessage(userQuery);
Message systemMessage = new SystemMessage(systemQuery);
// message
List<Message> messages = new ArrayList<>();
messages.add(userMessage);
messages.add(systemMessage);
// 大模型参数配置
// new ZhiPuAiChatOptions() 智谱的大模型参数设置
ChatOptions chatOptions = new ZhiPuAiChatOptions();
/**
// 如果在业务中对模型有特定的参数要求,可以在此进行设置
ZhiPuAiChatOptions chatOptions = new ZhiPuAiChatOptions();
chatOptions.setModel("glm-4.5");
chatOptions.setTemperature(0.9);
chatOptions.setMaxTokens(1024);
*/
Prompt prompt = new Prompt(messages, chatOptions);
Generation generation = chatModel.call(prompt).getResult();
return generation != null ? generation.getOutput().getText() : "";
}结果:

3. 流式调用
在前几个案例中,可以看出请求大模型回复信息时需要几十秒,这样用户体验感很不好。这个时候可以使用chatModel.stream()实现流式响应,不需要等结果都生成才回复。
// stream
@GetMapping ("/stream")
public Flux<String> stream(@RequestParam("query") String query) {
return chatModel.stream(query);
}出现乱码,修改配置
server:
servlet:
encoding:
charset: UTF-8 # UTF-8字符集
force: true # 强制使用UTF-8
enabled: true五. ChatClient
ChatModel只能用于调用大模型,但是如果需要让会话有记忆、调用工具、访问大模型前后做数据处理等等,ChatModel实现很复杂。这个时候可以使用ChatClient,它是构建在ChatModel之上,提供了除调用大模型之外的功能,例如:拦截器Advisors、模板Template、工具ToolCallbacks等,可以类似是一个简单的智能体。
1. 使用ChatClient
我们从bean容器中去获取ChatClient,发现框架并没有帮我们放在容器中,所以不能使用自动注入方式来装配ChatClient。
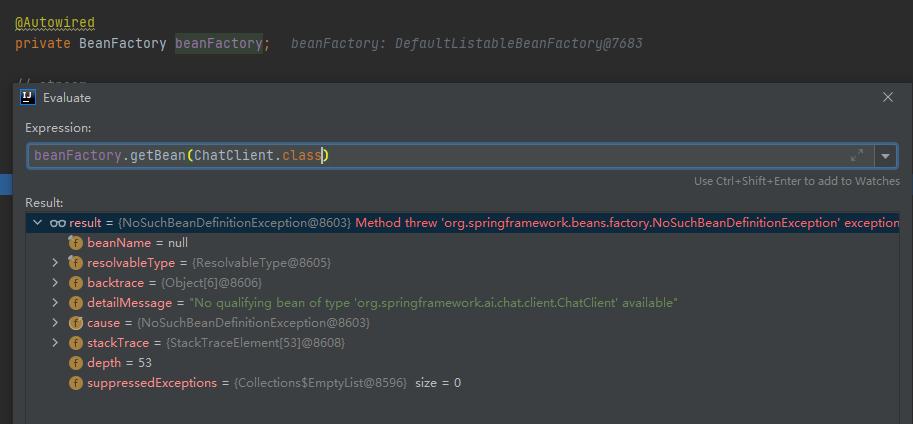
但是,框架提供了可以通过chatClientBuilder.build()创建简单的ChatClient:
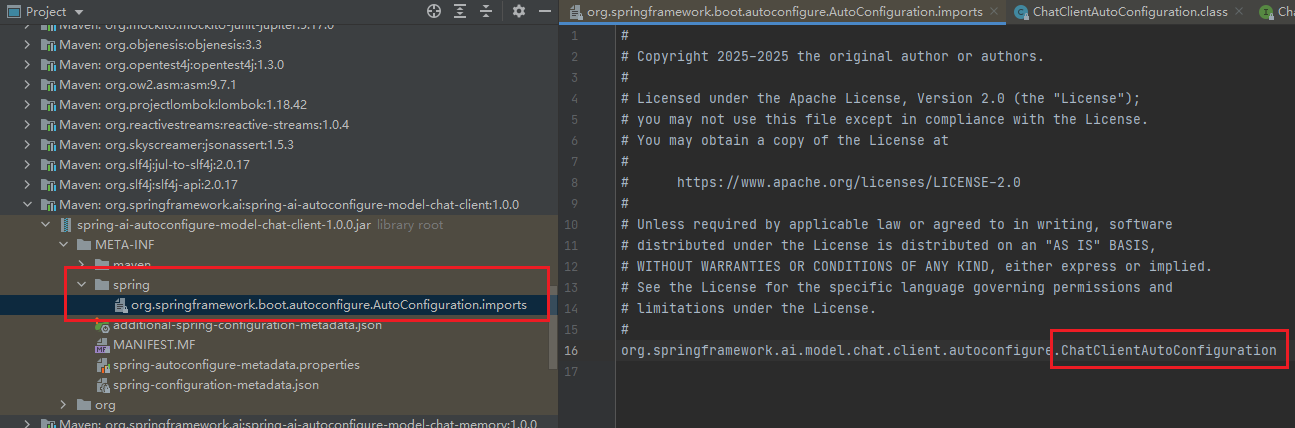
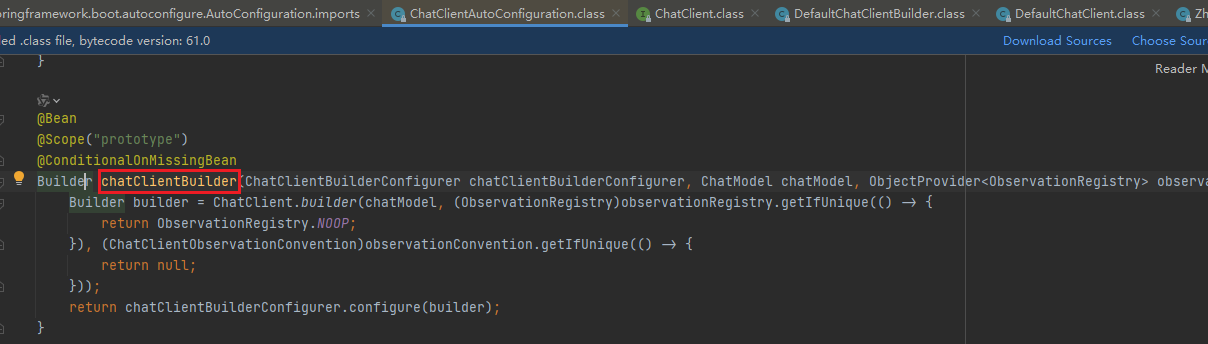
将ChatClient装配到bean容器中
@Configuration
public class ChatClientConfiguration {
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder) {
return chatClientBuilder.build();
}
}通过chatClient,调用大模型
@RestController
@RequestMapping("/zhiPuChatClient")
public class ZhipuChatClientController {
@Autowired
private ChatClient chatClient;
@RequestMapping("/simple")
public String simple(@RequestParam("query") String query) {
return chatClient.prompt(query).call().content();
}
}结果:

可以通过使用chatClient来定义固定配置的大模型客户端,根据不同的使用场景来调用不同的chatClient
@Configuration
public class ChatClientConfiguration {
/*
* ChatClient.Builder 的实现是DefaultChatClientBuilder,它有一个“protected final DefaultChatClientRequestSpec defaultRequest;” 导致它是有状态的(非线程安全);
* 但是,框架把他配置成多例的,所以在bean容器中以多例的形式存在;
* 关于单例和多例,其实是容器getBean()的时候,是直接从容器拿还是创建新的bean对象;
* 如果下面创建各种ChatClient对象,不是以参数传进入的,而是创建ChatClientConfiguration使用@Autowired自动注入,会发现所有ChatClient对象属性值一样,
* */
@Bean
public ChatClient chatClient(ChatClient.Builder chatClientBuilder) {
return chatClientBuilder.build();
}
@Bean
public ChatClient humorChatClient(ChatClient.Builder chatClientBuilder) {
return chatClientBuilder.defaultSystem("你是一个幽默的人").build();
}
@Bean
public ChatClient optionChatClient(ChatClient.Builder chatClientBuilder) {
DefaultChatOptions chatOptions = new DefaultChatOptions();
chatOptions.setTemperature(0.9);
chatOptions.setMaxTokens(1024);
chatOptions.setModel("glm-4.5");
return chatClientBuilder.defaultOptions(chatOptions).build();
}
}2. 返回的数据映射到Java实体上
可以给定一个结构,让AI返回按照提供的结构返回实体数据
@Data
@ToString
public class SymptomAnalysis {
private String chiefComplaint; // 主诉
private List<String> symptoms; // 症状列表
private Integer durationDays; // 持续天数
private String severity; // 严重程度(轻/中/重)
private List<String> suggestions; // 建议
private Boolean emergency; // 是否急症
}@GetMapping("/mapperEntity")
public void mapperEntity() {
SymptomAnalysis analysis = chatClient.prompt()
.user("""
分析以下症状描述:
'我头疼三天了,伴随着发热38.5度,还有咳嗽和全身酸痛。
吃了退烧药能暂时降温,但过几小时又会烧起来。
没有呼吸困难,也没有去过疫区。'
要求:返回中文
""")
.call()
.entity(SymptomAnalysis.class);
System.out.println("analysis = " + analysis);
System.out.println("analysis.getEmergency() = " + analysis.getEmergency());
System.out.println("analysis.getSymptoms() = " + analysis.getSymptoms());
System.out.println("analysis.getChiefComplaint() = " + analysis.getChiefComplaint());
System.out.println("analysis.getDurationDays() = " + analysis.getDurationDays());
System.out.println("analysis.getSeverity() = " + analysis.getSeverity());
System.out.println("analysis.getSuggestions() = " + analysis.getSuggestions());
}结果:

3. advisor
SpringAI中拦截器组件,在ChatClient调用大模型过程中做功能的增强。类似于SpringMVC中的拦截器,可以在不修改业务代码情况下增强功能。例如:日志记录、对话记忆、敏感词过滤、失败重试等等。
Advisor有两个子接口CallAdvisor和StreamAdvisor,对应两种不同的大模型回复,其中子类SafeGuardAdvisor和SimpleLoggerAdvisor没有final修饰,可以继承。
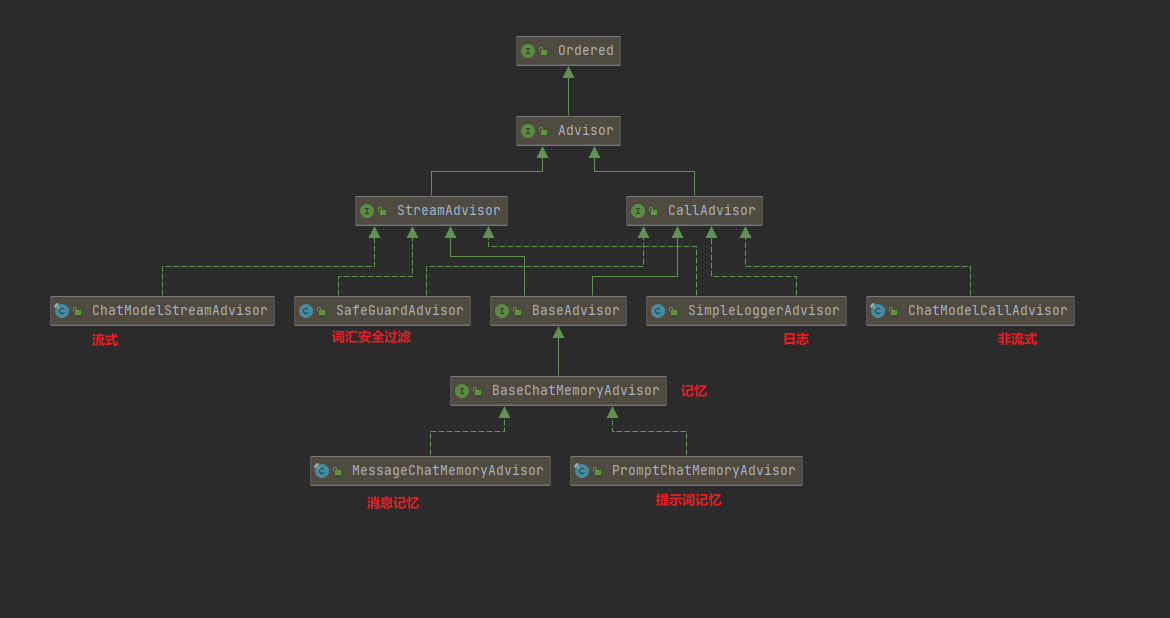
除了提供的增强,也可以自定义Advisor:
public class MyAdvisor implements BaseAdvisor {
// 请求大模型之前
@Override
public ChatClientRequest before(ChatClientRequest chatClientRequest, AdvisorChain advisorChain) {
return null;
}
// 请求大模型之后
@Override
public ChatClientResponse after(ChatClientResponse chatClientResponse, AdvisorChain advisorChain) {
return null;
}
// 设置拦截器的顺序
@Override
public int getOrder() {
return 0;
}
}4. chatClient调用chatModel过程
. 以call()为例, chatClient.prompt(query).call().content()
① 调用call()时,将chatModel封装成advisor;
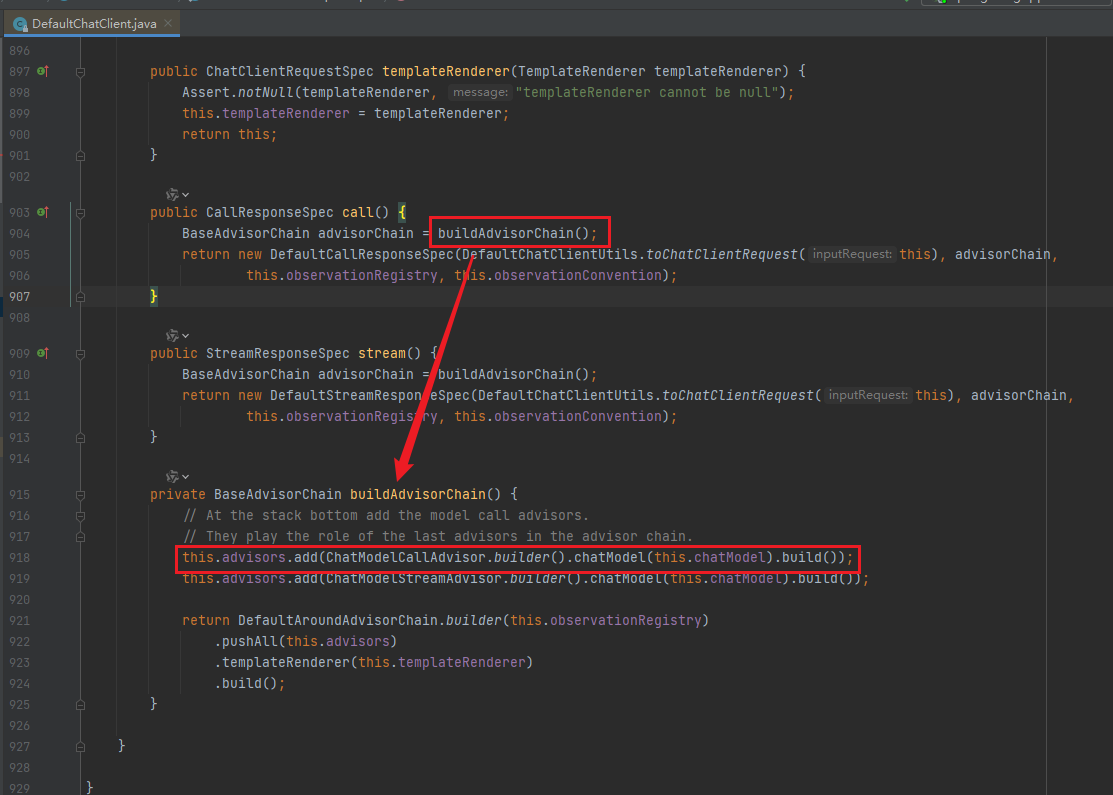
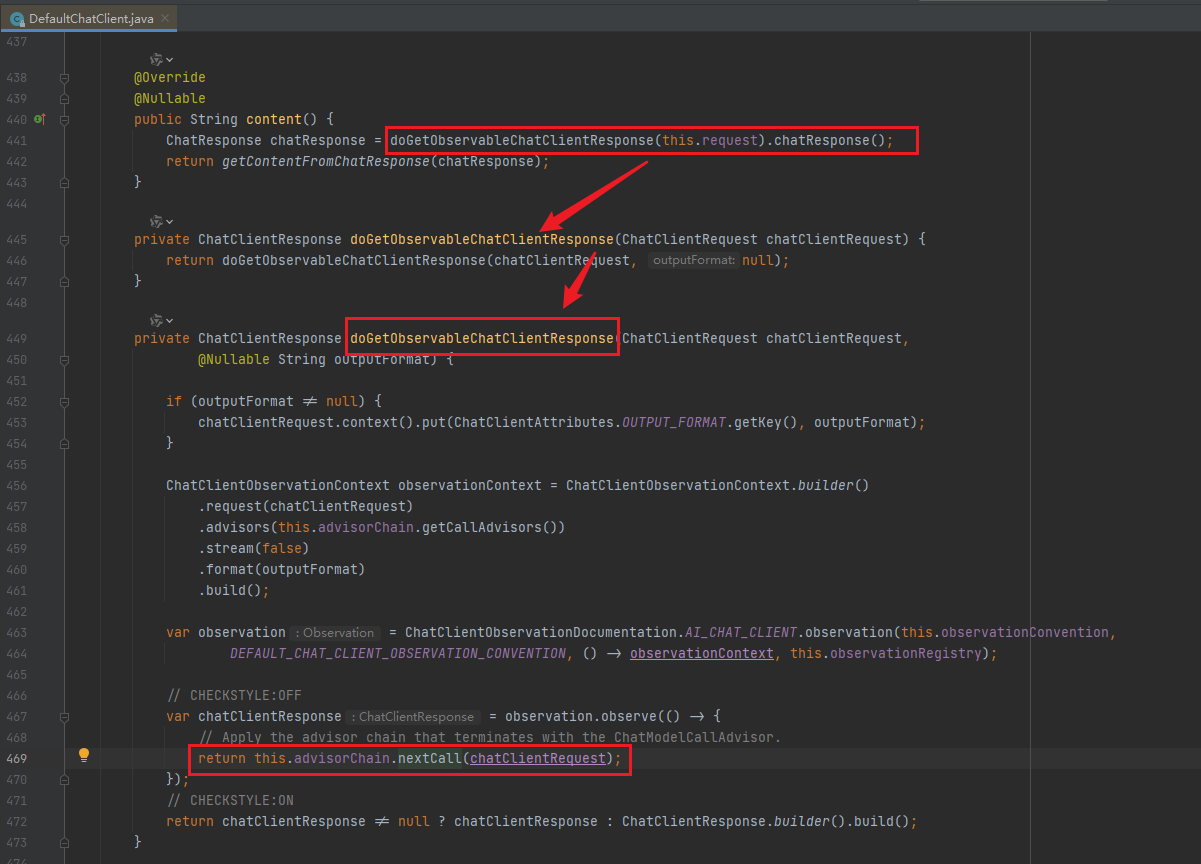
② 当调用content()时才开始调用大模型;
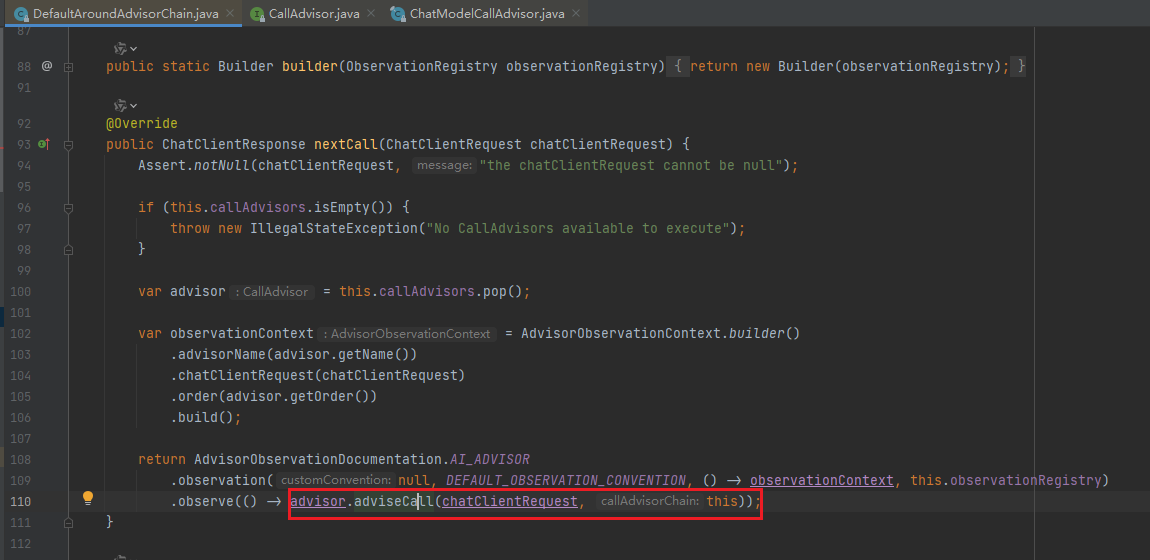
③ 调用doGetObservableChatClientResponse方法,通过执行advisorChain的nextCall方法
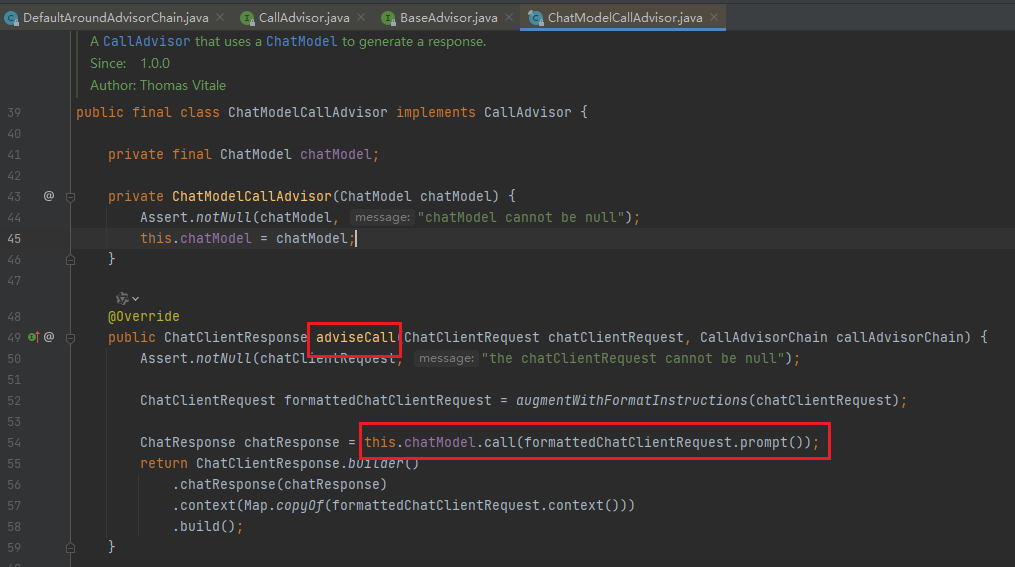
④ 根据不同的advisor调用对应的adviseCall,如果是ChatModelCallAdvisor,就会执行chatModel的call方法,调用大模型。
六. 检索增强生成RAG
全称 Retrieval-Augmented Generation,叫做“检索增强生成”。用户提问的问题先通过外部知识库检索出相关的知识,再将问题和上下文(相关知识)传给大模型,大模型整合信息再回答问题。
通过RAG,可以解决大模型的两个主要问题:
① 知识局限性,大模型是通过大量数据训练出来的,但可能涉及到新的领域知识它将无法获悉,例如一个公司的内部系统的使用等。对于这个问题,可以自行训练一个大模型,但是成本比较高;
② 幻觉现象,当大模型遇到自己不会的领域,它还是会回复问题,这个就会导致回复的信息“牛头不对马嘴”;
所以,可以通过建立知识库,把问题的相关上下文发给大模型,要求大模型按照该上下文整合回复问题。
1. RAG的工作流程
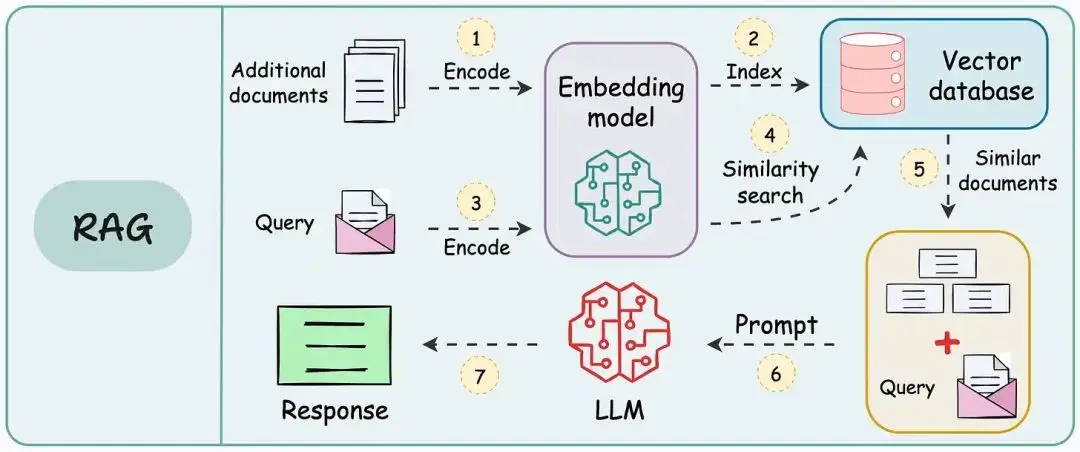
2. 相关概念
① 向量(vector):一串数字,用于表示在多维空间中的一个坐标点;
eg:[0.001,-0.034,0.89,0.008,-0.7838] 五维空间中的一个点
② 嵌入(Embedding):根据嵌入模型,将现实事物(文件、图片、音频等等)转为向量的过程;
③ 向量数据库(vectorDatabase):用于存储向量和搜索的数据库;
④ 索引(index):提高检索效率的数据结构;
⑤ 距离度量:判断向量之间的关系;
3. 环境准备
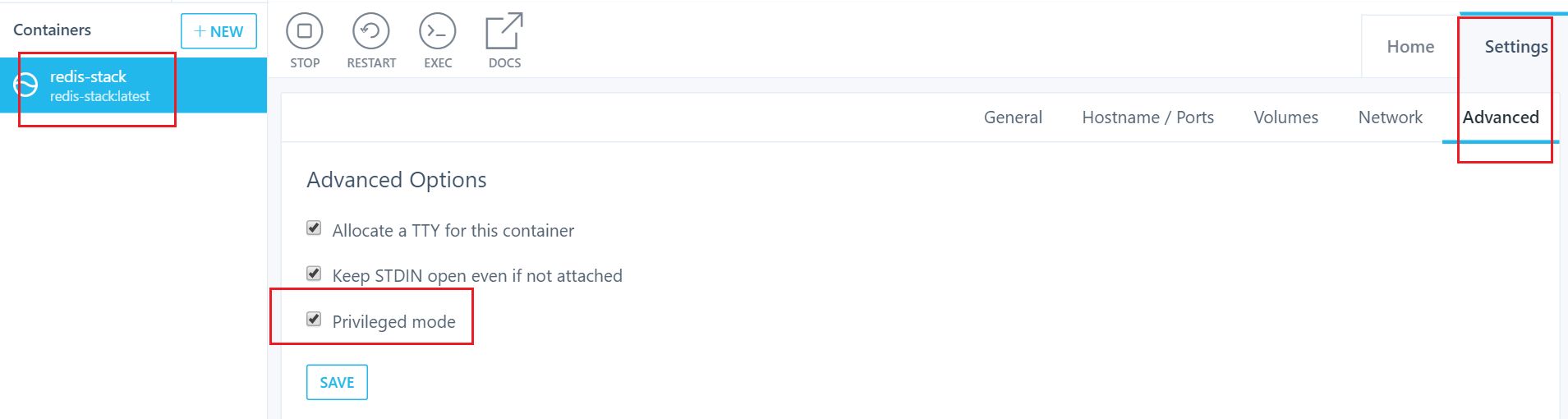
① 使用redis-stack作为向量数据库
redis-stack不能在Windows系统中直接部署,只能借助docker容器部署。其中,Windows版本比较低,使用了Toolbox,但是遇到了部署的redis-stack不能访问,可以直接修改privilege mode = true,在真实开发环境不建议这么修改,会有安全问题。
② 项目环境
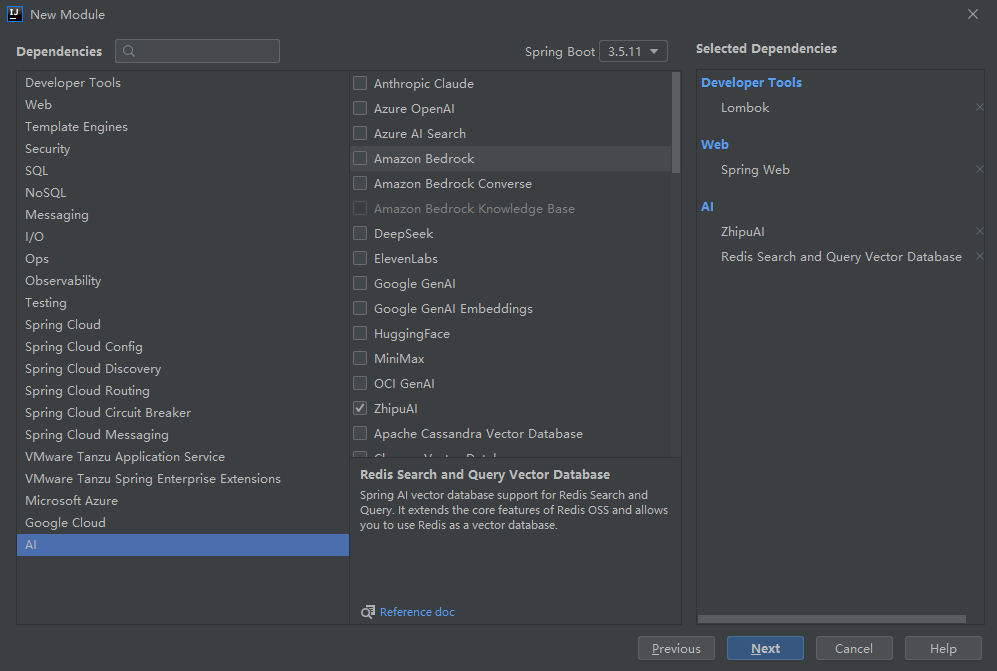
spring-boot-dependencies3.5.10、spring-ai1.0.0、spring-ai-starter-model-zhipuai1.0.0、spring-ai-advisors-vector-store1.0.0、spring-ai-starter-vector-store-redis1.0.0
application.yaml
spring:
# Spring AI 配置
ai:
zhipuai:
api-key: you_API_KEY
chat:
options:
model: glm-4.7
embedding:
options:
model: embedding-3 # 嵌入模型
dimensions: 256 # 维度
# 向量存储配置
vectorstore:
redis:
# 开启redis-stack的向量索引结构,使具备向量搜索引擎能力,不然和普通redis一样的。
# 没开启,后续相似性搜索会报错
initialize-schema: true
# 索引名称,默认 default-index
index-name: springai_rag_index
# 向量键值的前缀,默认 default:
prefix: 'springai_rag:'
# 向量数据库配置
data:
redis:
host: 192.168.99.104
port: 63794. 案例:公司制度检索增强
@Configuration
public class ChatClientConfiguration {
@Bean
public ChatClient handbookChatClient(ChatClient.Builder chatClientBuilder, VectorStore vectorStore){
// 获取知识库数据配置
VectorStoreDocumentRetriever vectorStoreDocumentRetriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore) // redis向量库
.topK(5) // 最多返回多少条结果
.similarityThreshold(0.5) // 相似度阈值
.build();
// rag增强
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(vectorStoreDocumentRetriever)
.build();
return chatClientBuilder
// 系统角色
.defaultSystem("现在你是公司的制度助手,请根据上下文简明回答问题")
// 增强
.defaultAdvisors(retrievalAugmentationAdvisor)
.build();
}
}
@RestController
@RequestMapping("/handbook")
public class HandbookController {
// 向量数据库
@Autowired
public VectorStore vectorStore;
@Autowired
public ChatClient handbookChatClient;
/**
* 按章节结构切分知识库
*/
@GetMapping("/loadStructuredKnowledgeBase")
public void loadStructuredKnowledgeBase() throws Exception {
ClassPathResource resource = new ClassPathResource("handbook.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(resource.getInputStream()));
List<Document> documents = new ArrayList<>();
StringBuilder currentChunk = new StringBuilder();
String currentChapter = "总则";
String currentSection = "";
String line;
while ((line = reader.readLine()) != null) {
line = line.trim();
if (line.isEmpty()) continue;
// 简单的规则识别:识别章节标题 (你可以根据实际文本格式调整正则)
if (line.matches("^第[一二三四五六七八九十]+章.*")) {
// 遇到新章节,先把上一章的内容存起来
if (currentChunk.length() > 0) {
documents.add(createDocument(currentChunk.toString(), currentChapter, currentSection));
currentChunk.setLength(0);
}
currentChapter = line;
currentSection = "";
} else if (line.matches("^\\d+\\.\\d+.*")) {
// 遇到小节 (如 2.1, 3.2)
if (currentChunk.length() > 200) { // 如果当前片段已经够长,先存盘
documents.add(createDocument(currentChunk.toString(), currentChapter, currentSection));
currentChunk.setLength(0);
}
currentSection = line;
currentChunk.append(line).append("\n");
} else {
// 普通正文,追加到当前片段
currentChunk.append(line).append("\n");
}
}
// 处理最后一个片段
if (currentChunk.length() > 0) {
documents.add(createDocument(currentChunk.toString(), currentChapter, currentSection));
}
// 存入 Redis
vectorStore.add(documents);
System.out.println("结构化切分完成,共 " + documents.size() + " 个片段");
}
/**
* 创建 Document 对象,并附上元数据
*/
private Document createDocument(String content, String chapter, String section) {
Map<String, Object> metadata = new HashMap<>();
metadata.put("chapter", chapter); // 存入章节信息
metadata.put("section", section); // 存入小节信息
return new Document(content, metadata);
}
@GetMapping("/ragAsk")
public Flux<String> ragAskQuestion(@RequestParam("question") String question) {
return handbookChatClient.prompt()
.user(question)
.stream()
.content();
}
}结果:


七. 模型上下文协议MCP
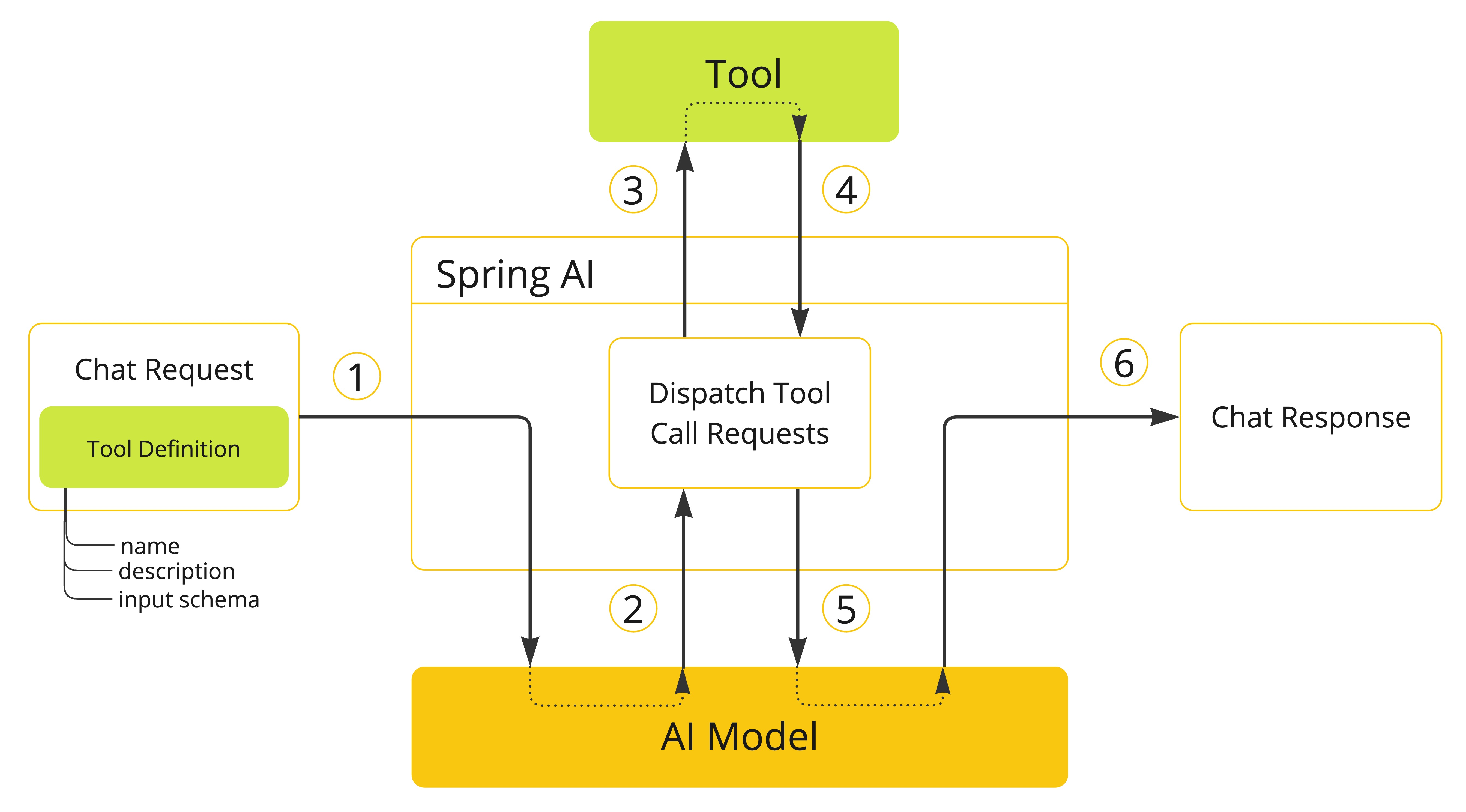
全称Model Context Protocol,模型上下文协议。AI应用与外部工具(MCP服务)进行数据交互的协议。在此之前,不同的大模型应用要调用不同的工具方式不一样,就需要写不同的调用逻辑,有了这个协议,切换不同AI大模型应用,不需要修改调用的方式。
为什么要调用外部的工具呢?这是因为大模型只能理解人类的自然语言,并且根据训练的数据做回复。如果询问一些大模型没有训练的东西,例如问当地天气怎么样?获取本地数据库数据等等这些它将回答不了,对于这种情况,我们就需要借助外部工具服务,然后大模型根据是否需要调用工具获取数据,再做回复。
可以类比,大模型就是一个“语言大脑”,我们可以和他做交流。但是,如果问他闻到什么味道,听到什么声音,他是不知道的。我们可以给这个“语言大脑”装上“鼻子”、“耳朵”这些“工具”,那么,他就可以感受到外界的这些信息,然后他再结合对语言的处理回复你。
1. 优点
① 外部工具可插拔。根据项目需要,增减MCP服务,使用方便;
② 简化开发。引入一个MCP服务,可以引入该服务中提供的全部Tool,并且多个项目可以复用同一个MCP服务,减少重复代码开发;
③ MCP 服务生态丰富。在一个MCP广场可以看到已经封装了5万多个MCP服务,另外,也可以根据协议,自己封装MCP服务提供给其他项目使用。
2. 相关概念
使用MCP过程
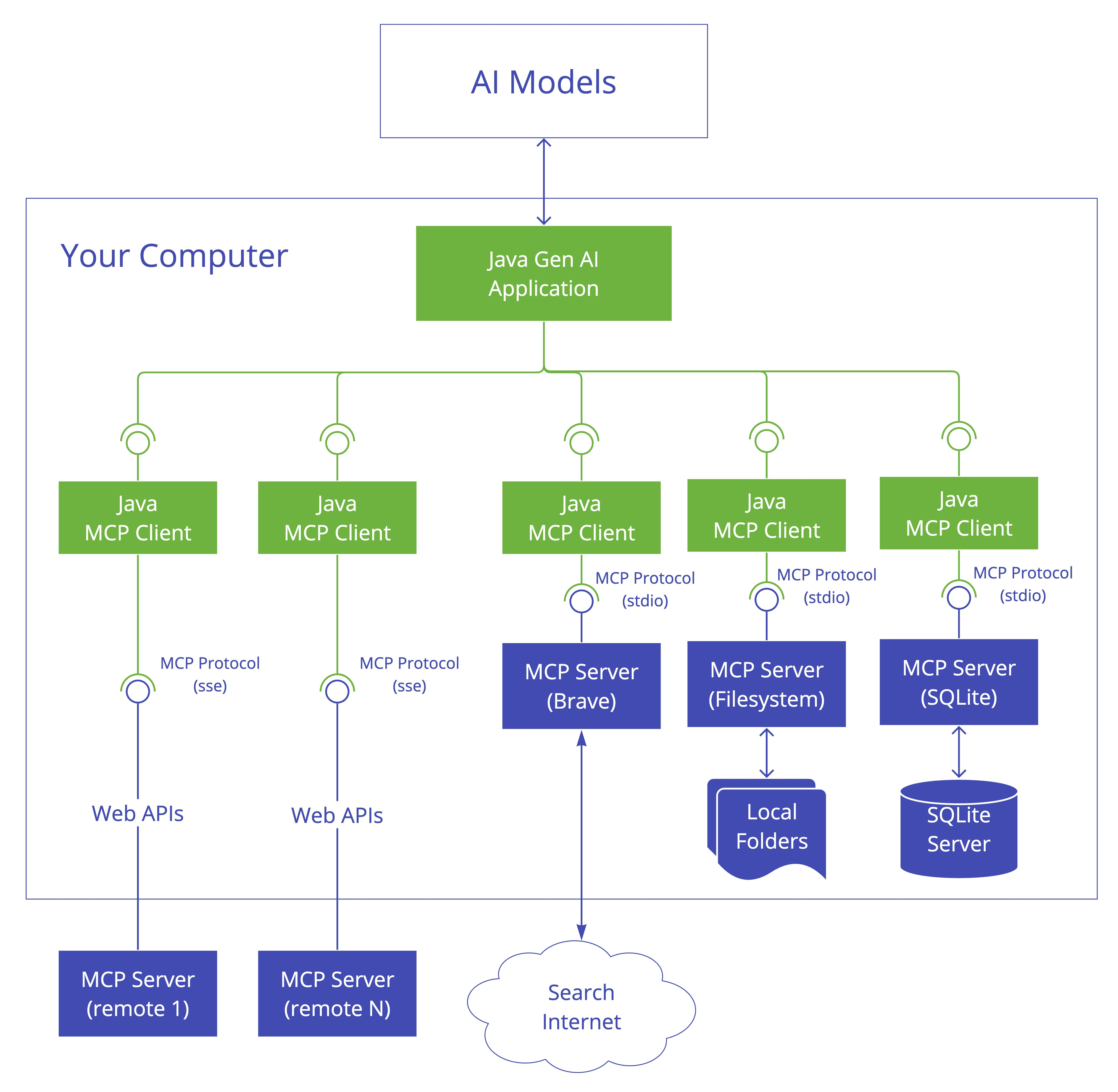
① MCP Host:应用程序,例如Cursor、springAI项目,可以接受用户提问,调用大模型;
② MCP Server:提供服务,一个MCP服务中可能有多个工具,是一个工具箱
③ MCP Client:使用服务,通过mcp协议,使用MCP服务;
④ SSE:Server-Sent Events服务器发送事件,服务器向客户端单向推送数据;
⑤ STDIO:Standard Input/Output标准输入输出
3. MCP服务链接
. https://cloud.tencent.com/developer/mcp
4. 环境准备
框架
<!-- MCP Client-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>申请高德地图服务key(https://console.amap.com/dev/key/app)
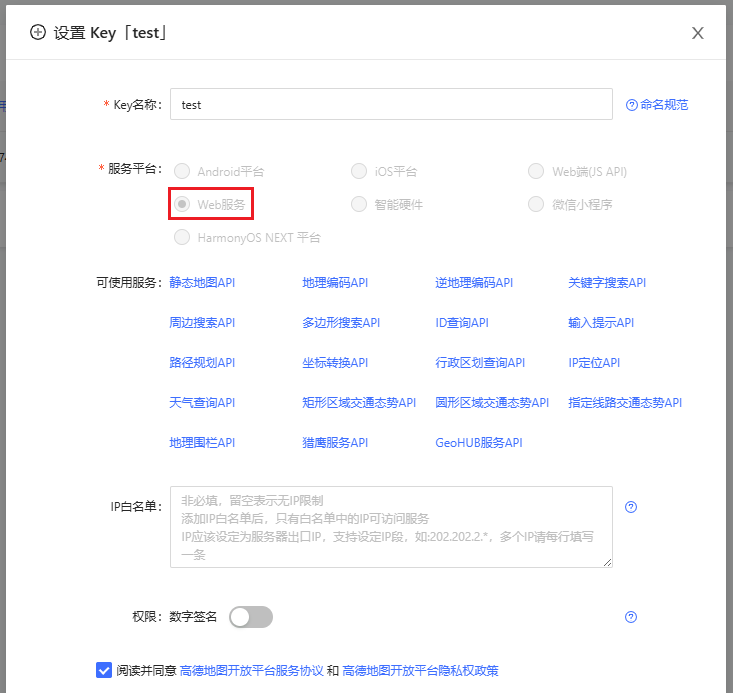
案例需要使用到node,所以电脑需要装node平台,版本需要16以上。
5. 案例
stdio方式是项目启动时候把相关包一起下载下来,本地部署;
sse方式是通过url请求远程服务;
① STDIO方式
application.yaml
..省略其他..
spring:
ai:
mcp:
client:
# 本地服务器方式
stdio:
servers-configuration: classpath:/mcpServerConfig.json # 加载类路径下配置文件
toolcallback:
enabled: truemcpServerConfig.json
{
"mcpServers": {
"amap-maps": {
"command": "cmd", // Windows系统要使用cmd
"args": [
"/c", // command是cmd,需要加
"npx", // 使用node下载包,还支持python、mvn等等,看MCP服务提供方对包的定义
"-y", // npx命令的配置项,下载包过程中一路yes
"@amap/amap-maps-mcp-server" // 高德地图MCP包
],
"env": {
"AMAP_MAPS_API_KEY": "<you_key>" // 需要提供使用高德地图服务的key
}
}
}
}
业务代码
@Configuration
public class ChatClientConfiguration {
@Bean
public ChatClient mapChatClient(ChatModel chatModel, ToolCallbackProvider toolCallbackProvider) {
return ChatClient.builder(chatModel)
.defaultSystem("你是地图小助手,关于地图问题请调用地图工具")
.defaultToolCallbacks(toolCallbackProvider)
.build();
}
}@RestController
@RequestMapping("/mapClient")
public class MapController {
@Autowired
private ChatClient mapChatClient;
@GetMapping("/map")
public String mapPage(@RequestParam("question") String question) {
return mapChatClient.prompt()
.user(question)
.call()
.content();
}
}运行日志

第一条日志:“STDERR Message received: Amap Maps MCP Server running on stdio”表示MCP服务包下载下来了;
第二条日志:获取到了该MCP服务的toolList
Server response with Protocol: 2024-11-05, Capabilities: ServerCapabilities[completions=null, experimental=null, logging=null, prompts=null, resources=null, tools=ToolCapabilities[listChanged=null]], Info: Implementation[name=mcp-server/amap-maps, version=0.1.0] and Instructions null
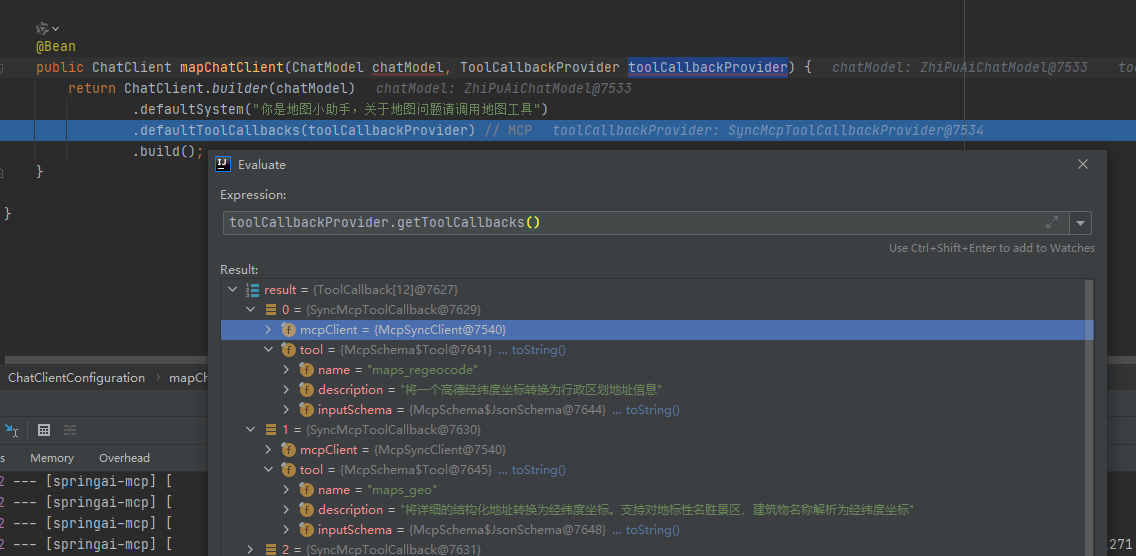
可以看到注册了12个地图服务tool
结果:
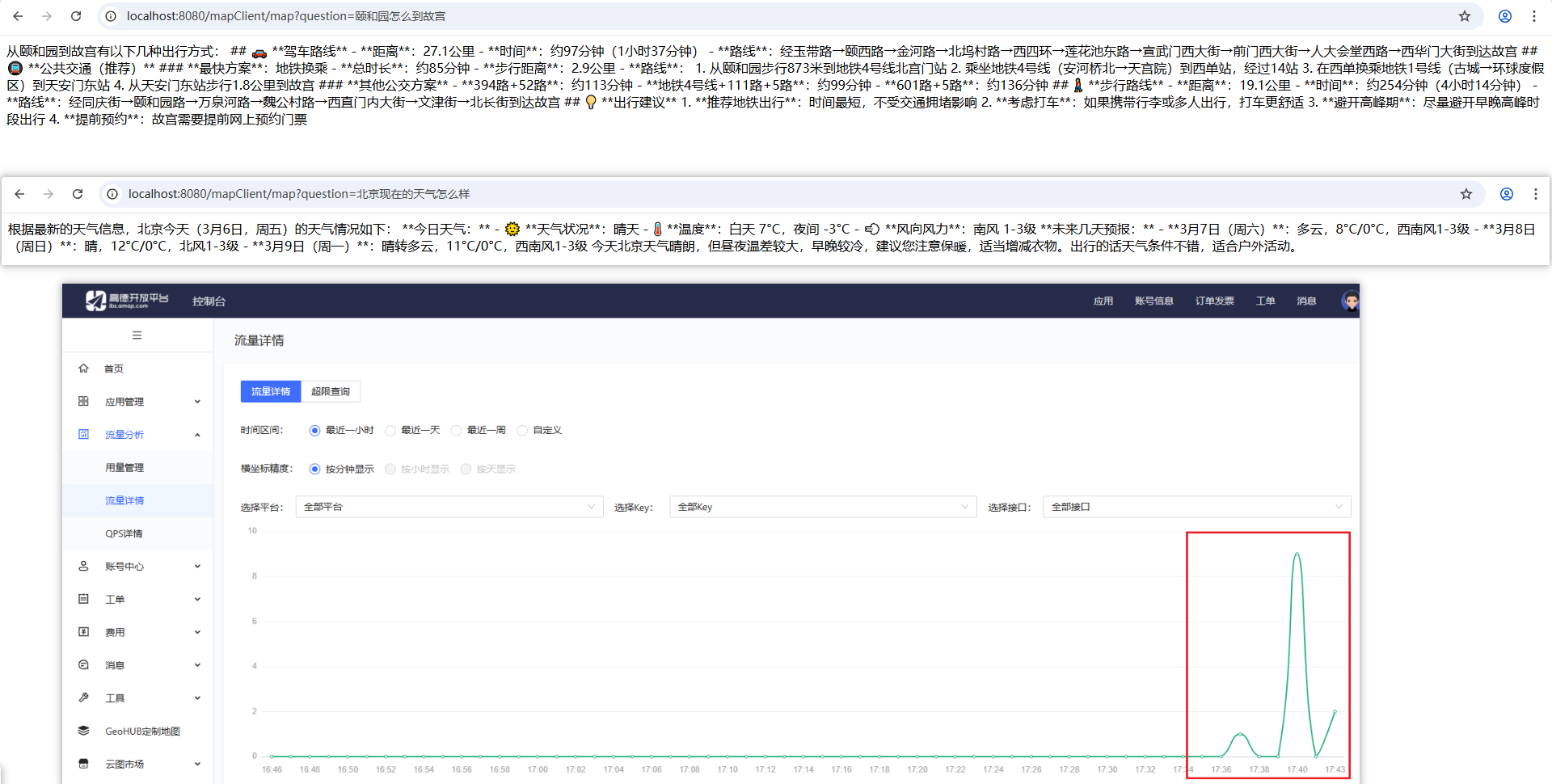
可以看到真实调用了高德服务回复用户问题。大模型根据用户提问,分析用户意图,发现需要调用工具,触发调用对应工具获取数据,再由大模型整合回复。和Tool Calling形式差不多。
② SSE方式
application.yaml
spring:
ai:
mcp:
client:
# 本地服务器方式
# stdio:
# servers-configuration: classpath:/mcpServerConfig.json
# toolcallback:
# enabled: true
# 远程url调用
sse:
connections:
# 高德地图
amap-map: # 名字随便起
url: https://mcp.amap.com
sse-endpoint: /sse?key=<you_key>
# 需要分开写,不要写成url: https://xxxxxx/sse?key=xxx,sse-endpoint为空
# 不然到时候回调工具报Invalid key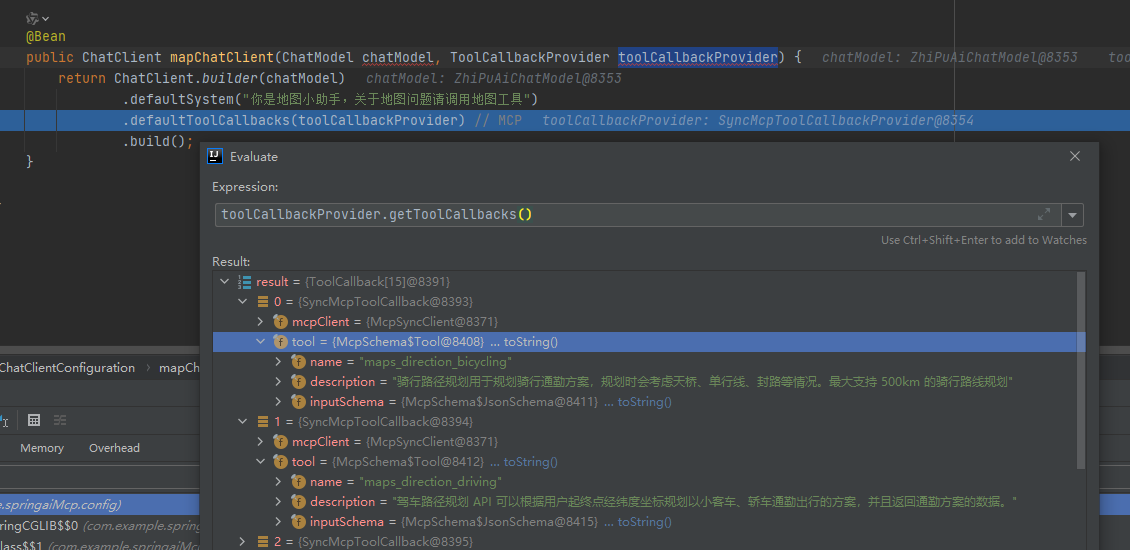
其他可以不用改,运行看到15个tool。可能这种方式可以实时获取,比stdio多了几个tool
八. springai-alibaba - Graph工作流编排
阿里云推出的可以用于工作流编排和多智能体协作的框架。例如,目前大模型很多类,各有各的优势,那么可以让这些大模型连接在一起,按照规定的流程分别调用大模型来处理自己擅长的事情。
1. 相关概念
① StateGraph状态图:定义整个工作流的蓝图;
② Node节点:工作流中的执行单元,执行具体的业务;
③ Edge边:连接节点,决定流程的走向;
④ OverAllState全局状态:保存整个工作流过程的数据,一个Map集合;
⑤ KeyStrategy键策略:工作流执行过程中产生的数据的合并策略;
⑥ CompiledGraph编译图:状态图的实例;
2. 环境准备
pom.xml
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-graph-core</artifactId>
</dependency>
<!-- 阿里百炼 Alibaba Bailian -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-zhipuai</artifactId>
</dependency>application.yaml
spring:
# 其他省略
ai:
zhipuai:
api-key: you_key
chat:
options:
model: glm-4.7
dashscope:
api-key: you_key3. 案例:模拟具有不同优势的大模型联合工作
@Configuration
public class GraphConfiguration {
private static final String ZHI_PU_NODE = "zhipuNode";
private static final String BAILIAN_NODE = "bailianNode";
@Bean
public ChatClient dashscopeChatClient(DashScopeChatModel dashscopeChatModel) {
return ChatClient.builder(dashscopeChatModel)
.defaultSystem("你是一个内容执行专家。请根据以下规划完成任务")
.build();
}
@Bean
public ChatClient zhiPuChatClient(ZhiPuAiChatModel zhiPuAiChatModel){
return ChatClient.builder(zhiPuAiChatModel)
.defaultSystem("你是一个任务规划助手。请分析用户输入并提取关键任务点")
.build();
}
@Bean
public CompiledGraph simpleGraph(@Qualifier("dashscopeChatClient") ChatClient dashscopeChatClient, @Qualifier("zhiPuChatClient") ChatClient zhiPuChatClient) throws GraphStateException {
// 1. 定义状态图中保存数据策略
// ReplaceStrategy: 替换策略,用于新值替换旧值
// AppendStrategy:追加策略,用于List类型
// MergeStrategy: 合并策略,用于Map类型
KeyStrategyFactory keyStrategyFactory = () -> Map.of(
"userInput", new ReplaceStrategy(),
"zhipuOutput", new ReplaceStrategy(),
"bailianOutput", new ReplaceStrategy()
);
// 2. 创建状态图
StateGraph stateGraph = new StateGraph("multiModelGraph", keyStrategyFactory);
// 3. 添加状态图的节点
stateGraph.addNode(ZHI_PU_NODE, AsyncNodeAction.node_async((OverAllState state) -> {
Map<String, Object> stateData = state.data();
Object userInput = stateData.get("userInput");
System.out.printf("%s节点执行大模型前状态:%s%n", ZHI_PU_NODE, stateData);
String zhipuOutput = zhiPuChatClient.prompt().user(userInput.toString()).call().content();
// state.input(Map.of("zhipuOutput", zhipuOutput)); // 在keyStrategyFactory中有这个key的才会添加进去
state.updateState(Map.of("zhipuOutput", zhipuOutput)); // key不在keyStrategyFactory中的key,可以添加进去,默认策略KeyStrategy.REPLACE
System.out.printf("%s节点执行大模型后状态:%s%n", ZHI_PU_NODE, stateData);
return state.data();
}));
stateGraph.addNode(BAILIAN_NODE, AsyncNodeAction.node_async((state) -> {
Map<String, Object> stateData = state.data();
Object userInput = stateData.get("userInput");
Object zhipuOutput = stateData.get("zhipuOutput");
System.out.printf("%s节点执行大模型前状态:%s%n", BAILIAN_NODE, stateData);
String userContent = String.format("规划内容:%s, 原始需求:%s", zhipuOutput, userInput);
String bailianOutput = dashscopeChatClient.prompt().user(userContent).call().content();
state.updateState(Map.of("bailianOutput", bailianOutput));
System.out.printf("%s节点执行大模型后状态:%s%n", BAILIAN_NODE, stateData);
return state.data();
}));
// 4. 添加状态图的边
// start --> zhipuNode --> bailianNode --> end
stateGraph.addEdge(StateGraph.START, ZHI_PU_NODE);
stateGraph.addEdge(ZHI_PU_NODE, BAILIAN_NODE);
stateGraph.addEdge(BAILIAN_NODE, StateGraph.END);
// 5. 生成状态图
return stateGraph.compile();
}
}
@RestController
@RequestMapping("/graph")
public class GraphController {
@Autowired
public CompiledGraph simpleGraph;
@GetMapping("/simpleGraph")
public String simpleGraph(@RequestParam("question") String question) {
Optional<OverAllState> overAllStateOpt = simpleGraph.call(Map.of("userInput", question));
System.out.println("overAllStateOpt.toString() = " + overAllStateOpt.toString());
return overAllStateOpt.get().data().get("bailianOutput").toString();
}
}结果:
日志打印:
zhipuNode节点执行大模型前状态:{userInput=我喜欢喝北京豆汁儿,在北京哪里最正宗}
zhipuNode节点执行大模型后状态:{zhipuOutput=基于用户输入“我喜欢喝北京豆汁儿,在北京哪里最正宗”,为您提取的关键任务点如下:**1. 任务目标**
* 寻找北京地区被公认为口味“最正宗”的豆汁儿店铺。**2. 关键任务点**
* **信息检索:** 搜索北京知名的老字号小吃店,重点锁定以经营豆汁儿为特色的店铺。
* **筛选与验证:** 根据历史口碑、老字号资质及本地食客评价,筛选出“正宗”指数最高的候选店铺(如锦馨、护国寺、尹三豆汁等)。
* **信息汇总:** 提取筛选出的店铺的具体名称、详细地址(分店信息)及营业状态。
* **结果输出:** 将整理好的推荐清单清晰地呈现给用户。, userInput=我喜欢喝北京豆汁儿,在北京哪里最正宗}
bailianNode节点执行大模型前状态:{zhipuOutput=基于用户输入“我喜欢喝北京豆汁儿,在北京哪里最正宗”,为您提取的关键任务点如下:**1. 任务目标**
* 寻找北京地区被公认为口味“最正宗”的豆汁儿店铺。**2. 关键任务点**
* **信息检索:** 搜索北京知名的老字号小吃店,重点锁定以经营豆汁儿为特色的店铺。
* **筛选与验证:** 根据历史口碑、老字号资质及本地食客评价,筛选出“正宗”指数最高的候选店铺(如锦馨、护国寺、尹三豆汁等)。
* **信息汇总:** 提取筛选出的店铺的具体名称、详细地址(分店信息)及营业状态。
* **结果输出:** 将整理好的推荐清单清晰地呈现给用户。, userInput=我喜欢喝北京豆汁儿,在北京哪里最正宗}
bailianNode节点执行大模型后状态:{bailianOutput=根据您的需求“我喜欢喝北京豆汁儿,在北京哪里最正宗”,我们已完成信息检索、老字号资质....中间省略...我,立刻为您定制 👇, zhipuOutput=基于用户输入“我喜欢喝北京豆汁儿,在北京哪里最正宗”,为您提取的关键任务点如下:**1. 任务目标**
* 寻找北京地区被公认为口味“最正宗”的豆汁儿店铺。**2. 关键任务点**
* **信息检索:** 搜索北京知名的老字号小吃店,重点锁定以经营豆汁儿为特色的店铺。
* **筛选与验证:** 根据历史口碑、老字号资质及本地食客评价,筛选出“正宗”指数最高的候选店铺(如锦馨、护国寺、尹三豆汁等)。
* **信息汇总:** 提取筛选出的店铺的具体名称、详细地址(分店信息)及营业状态。
* **结果输出:** 将整理好的推荐清单清晰地呈现给用户。, userInput=我喜欢喝北京豆汁儿,在北京哪里最正宗}


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 18
18 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)