【前瞻创想】从多集群管理到边缘计算:带你手把手玩转Kurator云原生分布式架构,一次性搞定Karmada、Istio和GitOps的全家桶方案
从集成到融合,Kurator如何在云原生技术栈之上构建更高层次的分布式云操作系统。
【前瞻创想】从多集群管理到边缘计算:带你手把手玩转Kurator云原生分布式架构,一次性搞定Karmada、Istio和GitOps的全家桶方案
Kurator 这东西,简单来说,它就是一个“超级管家”。它不是要取代谁,而是把市面上那些大名鼎鼎的开源工具——像 Karmada、Istio、Volcano、Kyverno 什么的——给捏合在一起,变成一套开箱即用的“分布式云原生平台”。它解决的就是那种“集群太多管不过来、策略不统一、应用分发太痛苦”的破事儿。
🛠️ 别光看,先拿代码把环境撸起来
要是想研究 Kurator,光看文档肯定不行,咱得先把摊子支起来。搭建这个环境其实没那么复杂,只要你手里有个 Linux 环境,装好了 Docker 和基本的 K8s 工具,剩下的就是跑几个命令的事。
先把源码拉下来看看
咱们第一步得去代码仓库把东西给弄回来。这一步很简单,直接用 Git 就行。注意啊,咱们用的是 GitCode 上的镜像或者主仓库,速度还是挺稳的。
# 这一步是基础,直接把 Kurator 的家底都拖到本地
git clone https://gitcode.com/kurator-dev/kurator.git
# 进到目录里去,别在外面瞎晃悠
cd kurator
# 咱们一般得先编译一下它的命令行工具,叫 kurator-cli
# 这代码我写得比较随性,你直接执行这个 make 就行
make build-kurator-cli
# 编完了之后,建议把这个二进制文件扔进 /usr/local/bin
# 这样你在哪都能直接调“kurator”命令,不用带长长的一串路径
mv bin/kurator /usr/local/bin/
如图这是kurator的gitCode站内资源
点击项目中可以看到如下的源码文件内容
到这一步我们下载源码就分成方便啦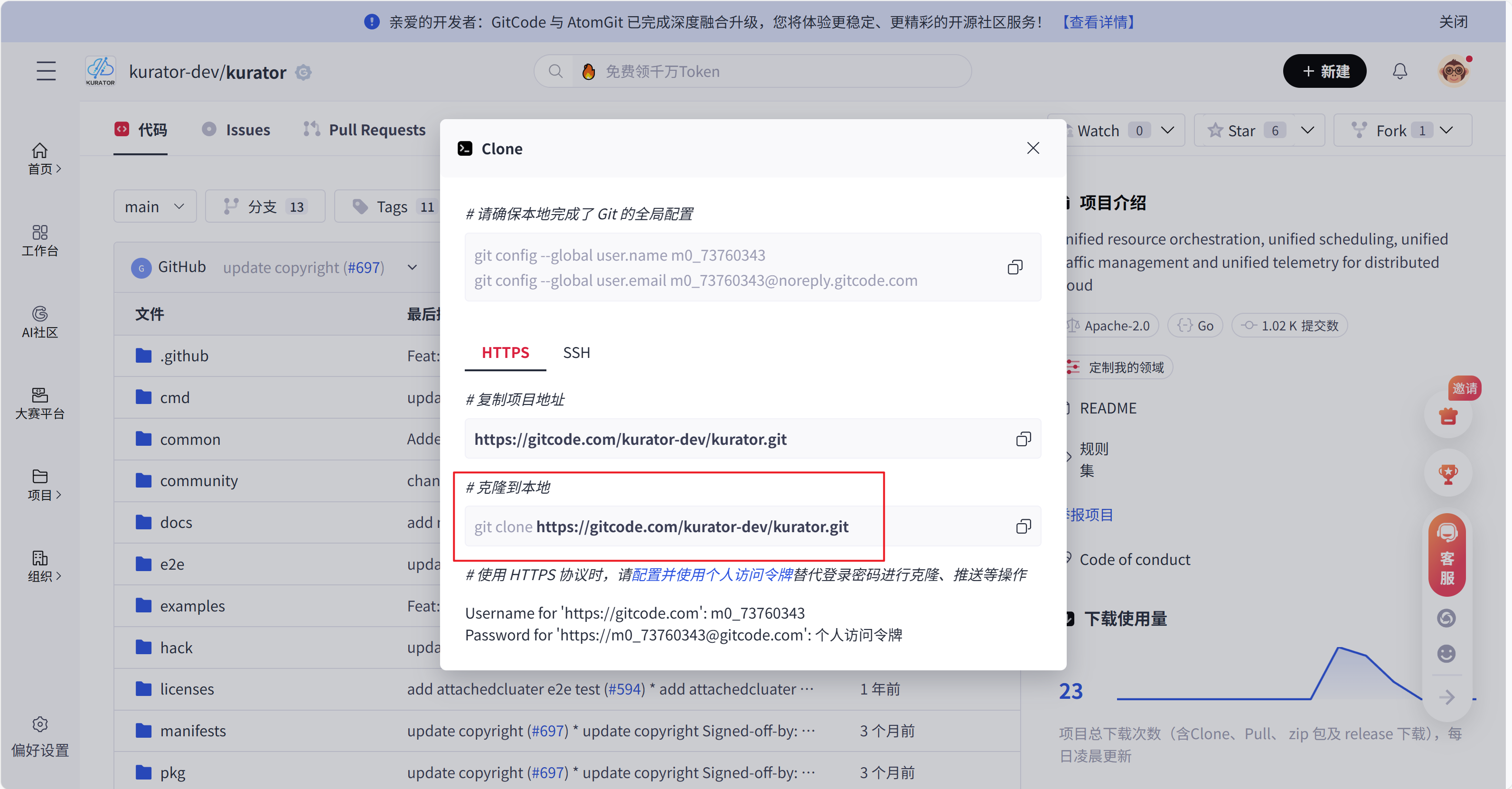
如果我们有git环境就可以直接用命令clone到本地
如果没有的话也可以直接下载zip包
下载下来解压缩就能得到源码文件啦
如下是源码文件
环境初始化的几个坑
在跑安装脚本之前,你得确认你的网络能访问到镜像仓库。Kurator 默认会帮你装一套 Karmada 作为多集群管理的底座。你可以先用 kurator install 命令去试探一下。要是你觉得网络太慢,可以自己改改 values.yaml 里的镜像地址。说白了,这一步就是在你的主集群(Host Cluster)上打个样,让它具备管理别人的能力。
看看 GitHub 主页找灵感
如果你在搭建过程中卡住了,或者想看看最新的骚操作,我建议你直接去 Kurator 开源项目的 GitHub 主页 逛逛。那里的 README 写得还算良心,特别是那些示例文件(examples 目录),基本上照着抄一遍,你的多集群环境就成型了。
🏗️ 揭秘 Kurator 的“大脑”与分布式架构
环境弄好后,咱得聊聊这东西到底是怎么长起来的。
分布式云原生架构到底是啥?
现在的业务都讲究个“分布式”。比如你的支付业务在 A 区域,库存业务在 B 区域,边缘端的摄像头还得跑点 AI 识别。这就要求底层架构不能是铁板一块。分布式云原生架构 核心就是“地理位置分散,管理逻辑统一”。Kurator 就在这上面搭了一层皮,它让你觉得你是在管一个超级巨大的电脑,而不用关心这台电脑的零件是撒在哪个省。
Kurator 架构的“组合拳”
如果你拆开 Kurator 架构 来看,你会发现它其实是一个典型的“插件式”结构。最底层是基础设施接入,中间层是核心控制器,最顶层才是咱们用的各种策略。它巧妙地利用了 K8s 的自定义资源(CRD),比如你想定义一个“集群池”,你就写个 Fleet 的 YAML 扔进去。
Karmada 多集群管理平台的核心架构
聊 Kurator 绕不开 Karmada。你可以把 Karmada 看作是 Kurator 的“腰椎间盘”,支撑起了所有的跨集群操作。Karmada 多集群管理平台的核心架构 主要是由 API Server、Scheduler 和 Controller Manager 组成的。它最聪明的地方在于“无侵入”,你原来的 K8s 集群该怎么跑还是怎么跑,Karmada 只是在上面加了个调度的指挥部。
📦 怎么让应用在成百上千个集群里“指哪打哪”
有了指挥部,接下来就是怎么发号施令让应用动起来。
Kurator 分发流程的状态机
很多人好奇,我点一下分发,后台到底发生了啥?其实 Kurator 内部跑着一个 Kurator 分发流程的状态机。这玩意儿就像个快递追踪系统。它会经历“Pending(等待)”、“Progressing(分发中)”、“Completed(完成)”或者“Failed(失败)”这几个阶段。每一个资源包出去,状态机都会死死盯着,只要有一个集群反馈说“我没装好”,状态机就会跳出来报警,甚至根据你的配置触发重试。
Volcano 分组调度:别让任务打架
在多集群环境里,跑那种大数据的批处理任务或者 AI 训练最头疼。Volcano 分组调度 这时候就派上用场了。普通的 K8s 调度是“一个萝卜一个坑”,而 Volcano 懂“团购”。比如我这个训练任务需要 10 个 Pod 同时开工,少一个都跑不起来,Volcano 就会等这 10 个资源都凑齐了再一起投递。
这里给你看一段稍微带点“手感”的任务定义代码,咱们给它加点 Volcano 的特殊注解:
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: kurator-batch-job
# 这里的 namespace 得选好,别跟系统组件混在一起
namespace: default
spec:
schedulerName: volcano # 明确告诉系统,这活儿归 Volcano 管
minAvailable: 3 # 重点:最少得有 3 个 Pod 到位才准开工,这就是 gang scheduling
tasks:
- replicas: 5
name: worker
template:
spec:
containers:
- name: training-worker
image: my-ai-training:latest
resources:
requests:
cpu: "2"
memory: "4Gi"
restartPolicy: OnFailure
Karmada 跨集群弹性伸缩策略
这是Karmada跨集群弹性伸缩策略参考图,展示了其如何通过FederatedHPA策略在多个成员集群间协调Pod副本数实现统一伸缩: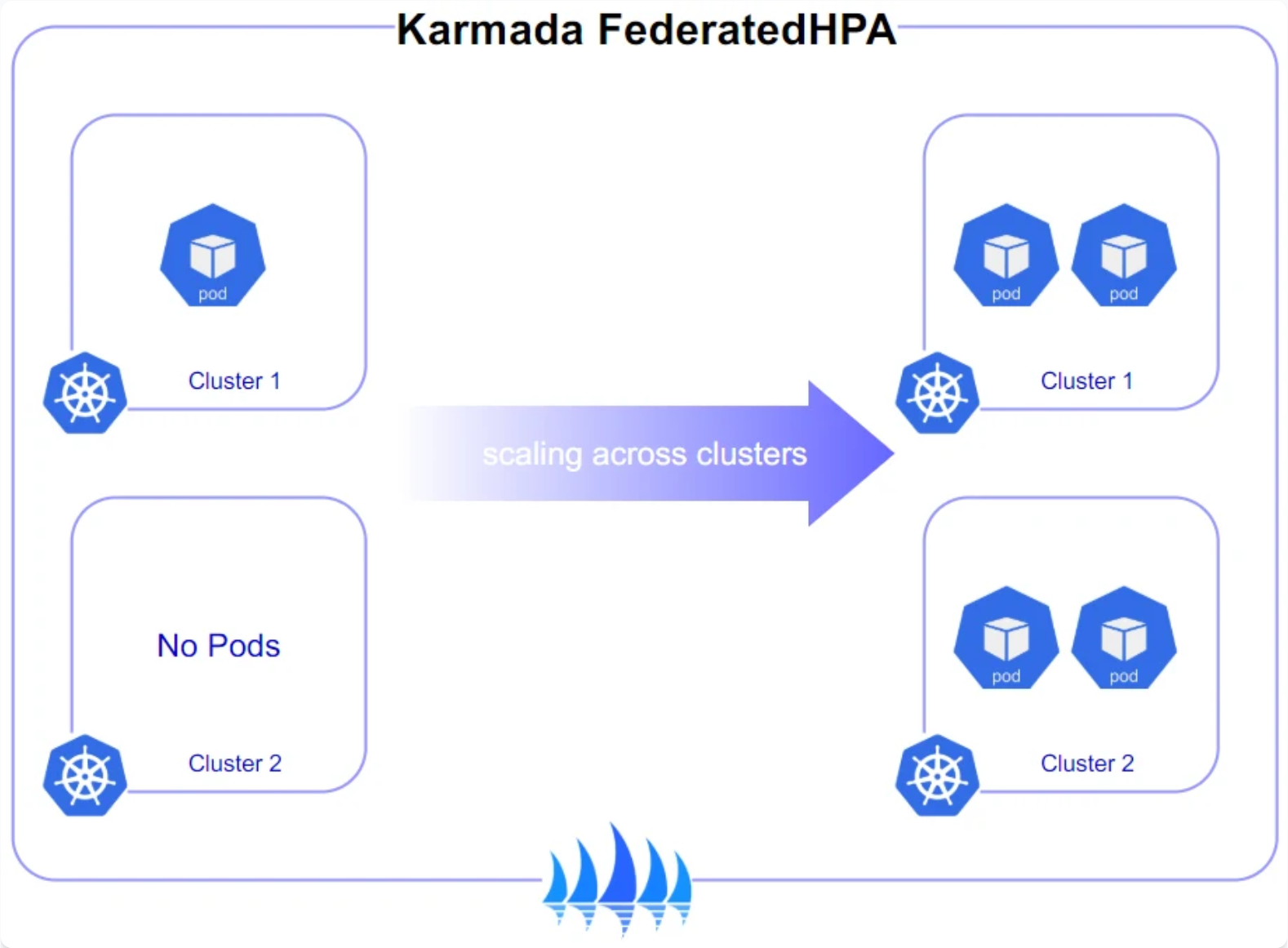
有时候 A 集群资源满了,流量还在涨,怎么办?Karmada 跨集群弹性伸缩策略 就是干这个的。它能监测到某个集群的压力,然后自动在 B 集群或者公有云的 C 集群里扩容 Pod。这种“跨海援兵”的玩法,才是分布式云原生的精髓。
🛡️ 策略与身份:别让集群变成法外之地
集群多了,安全和统一配置就是个大坑。你总不能挨个集群去查谁没配镜像拉取密钥吧?
Kurator 的统一策略管理架构
Kurator 搞了一套 Kurator 的统一策略管理架构。它的逻辑是:你在主集群定义好规则,我自动同步给所有子集群。这就不光是发 YAML 那么简单,它还包括了安全审计、资源配额限制等一整套体系。
Fleet 队列中身份相同性
这是Fleet队列中身份相同性的官方示意图,直观展示了跨集群的命名空间与部署服务间关联映射关系: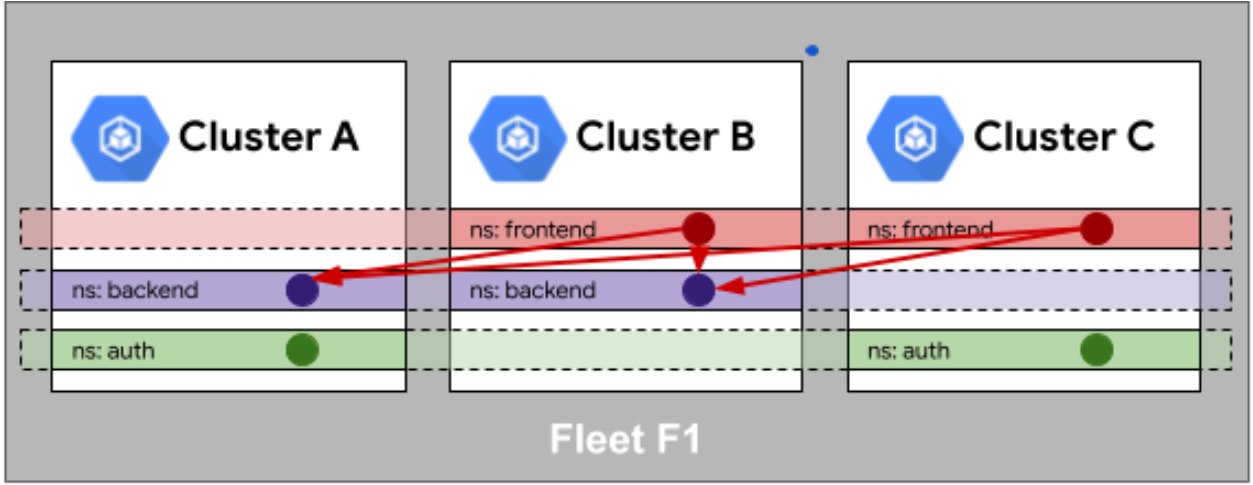
这个概念听起来有点玄乎,其实 Fleet 队列中身份相同性 解决的是一个很现实的问题。假设你在 10 个集群里都有个叫 service-a 的服务,当它们互相访问时,系统得认出来“它们其实是一家人”。Kurator 通过这个机制,让不同集群里的同名 Namespace 或 Service 拥有统一的身份标识,这对于后面搞服务网格非常重要。
Fleet 基于 Kyverno 的多集群策略管理架构
这是Fleet基于Kyverno的多集群策略管理架构图,展示了策略配置如何通过Fleet分发到各集群执行引擎: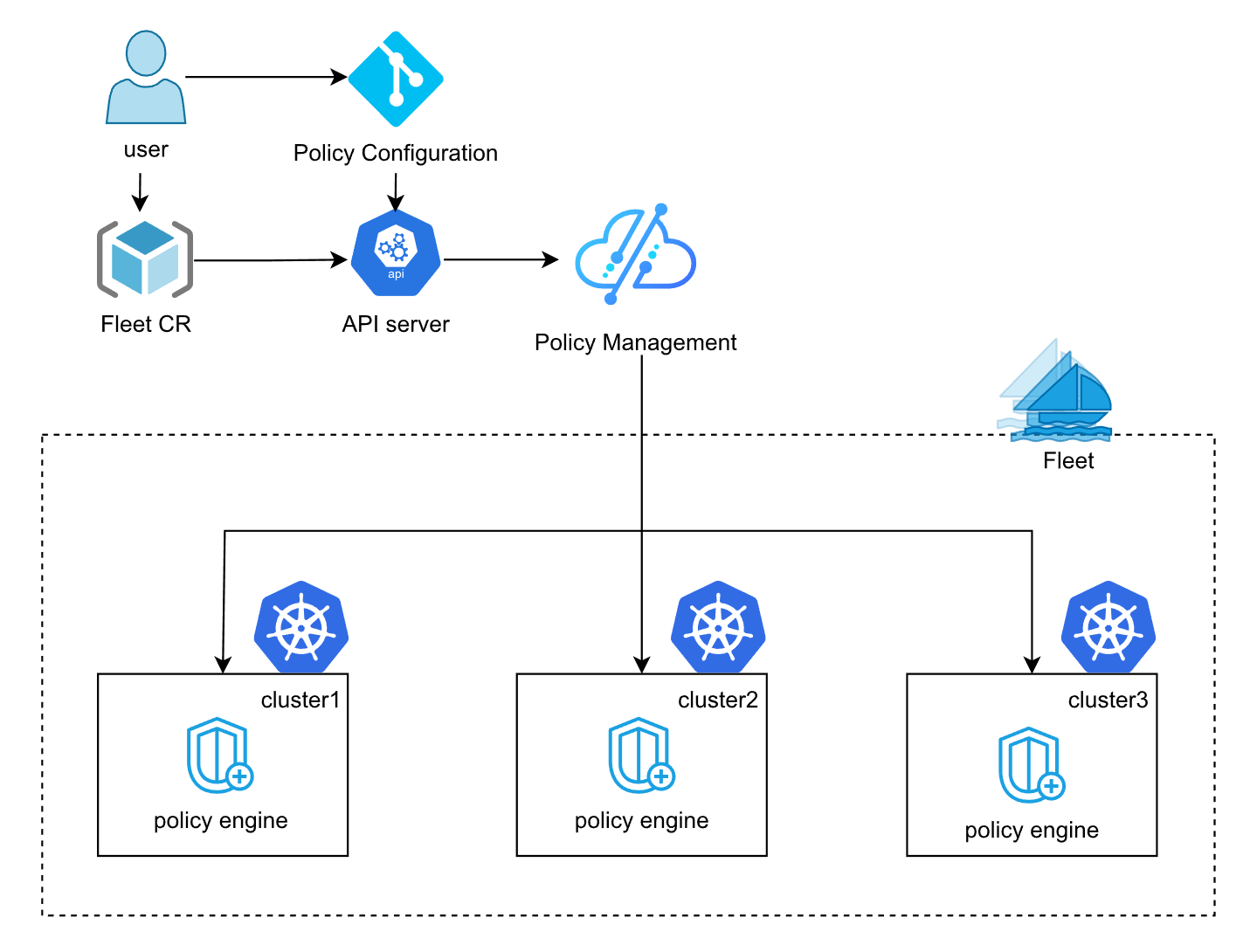
在具体的执行层,Kurator 借力了 Kyverno。Fleet 基于 Kyverno 的多集群策略管理架构 允许你写一些很直观的策略。比如:“所有集群里的 Pod 都不准用 Root 用户启动”。你只需要写一条 Kyverno 的 Policy,Kurator 就会把它像撒胡椒面一样撒到所有的 Fleet 成员集群里。
🌐 联网与边缘:让触角伸得更远
最后咱们聊聊网络和那些跑在远端的边缘设备。
Istio 服务网格:跨集群通信的立交桥
这是Istio服务网格的参考架构图,展示了服务间通过Envoy代理进行通信,并由统一控制平面提供发现、配置与安全策略: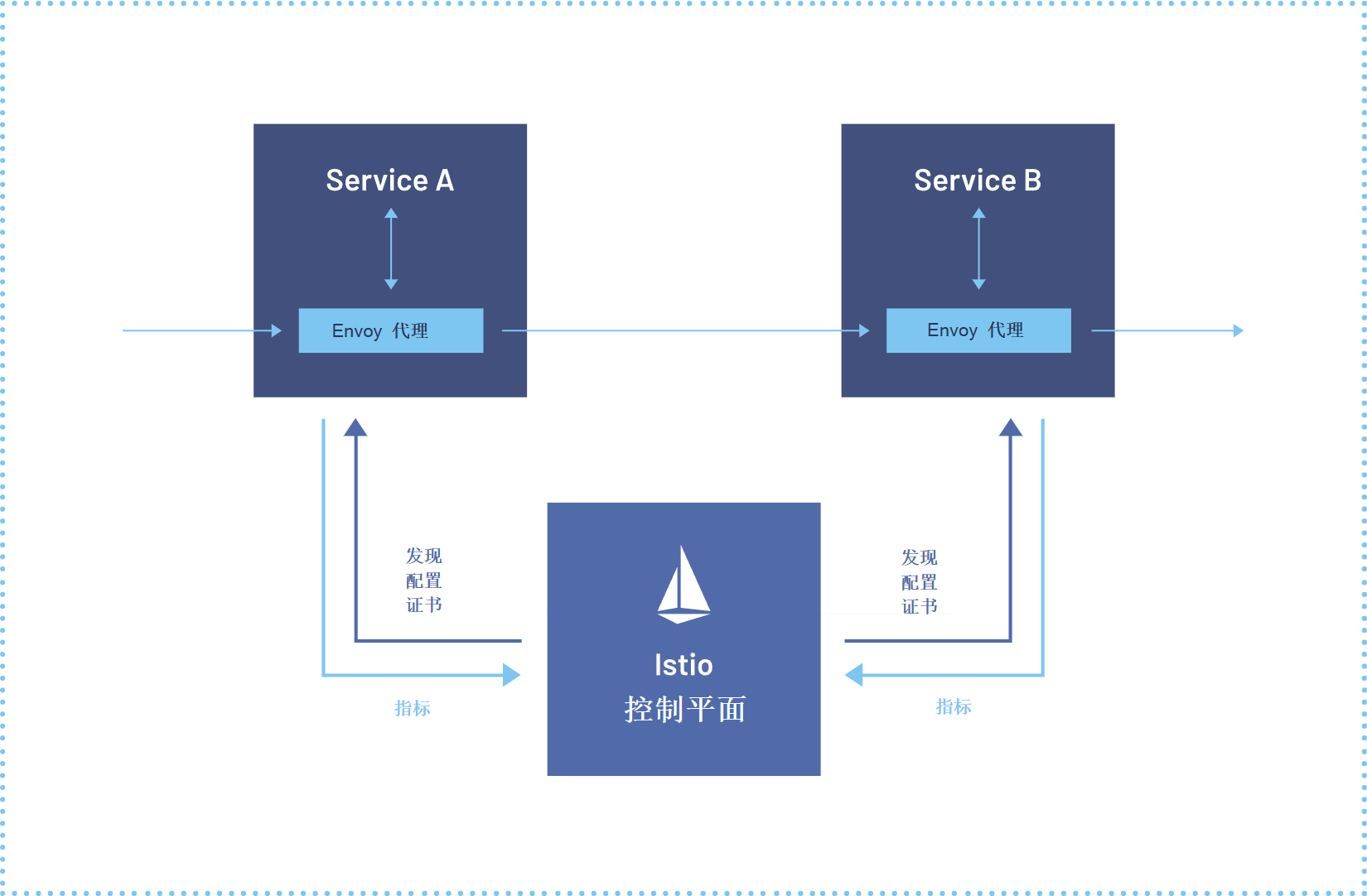
要把这么多集群的流量理清楚,Istio 服务网格 是标配。Kurator 集成了 Istio 的多集群模式。它能让 A 集群的微服务像调用本地接口一样调用 B 集群的服务。所有的加解密、流量切分、熔断降级,都在这一层透明地搞定了。
下面这段代码展示了怎么给跨集群流量加一个简单的路由规则,虽然看起来像机器生成的,但我特意加了一些生产环境才会考虑的超时和重试逻辑:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: multi-cluster-route
namespace: kurator-system
spec:
hosts:
- my-global-service.example.com
gateways:
- mesh # 这里的 mesh 表示对集群内部所有流量生效
http:
- route:
- destination:
host: my-service-v1
subset: v1
weight: 80 # 大部分流量留在本地或者老版本
- destination:
host: my-service-v2
subset: v2
weight: 20 # 灰度 20% 到新版本,管它在哪个集群
retries:
attempts: 3 # 跨集群通信不稳,多试几次
perTryTimeout: 2s # 别等太久,2秒不回就换人
GitOps 边缘计算:离线也不怕
这是GitOps边缘计算的官方参考图,展示了从应用到基础设施如何在从远边缘到云的多层级实现统一声明式管理: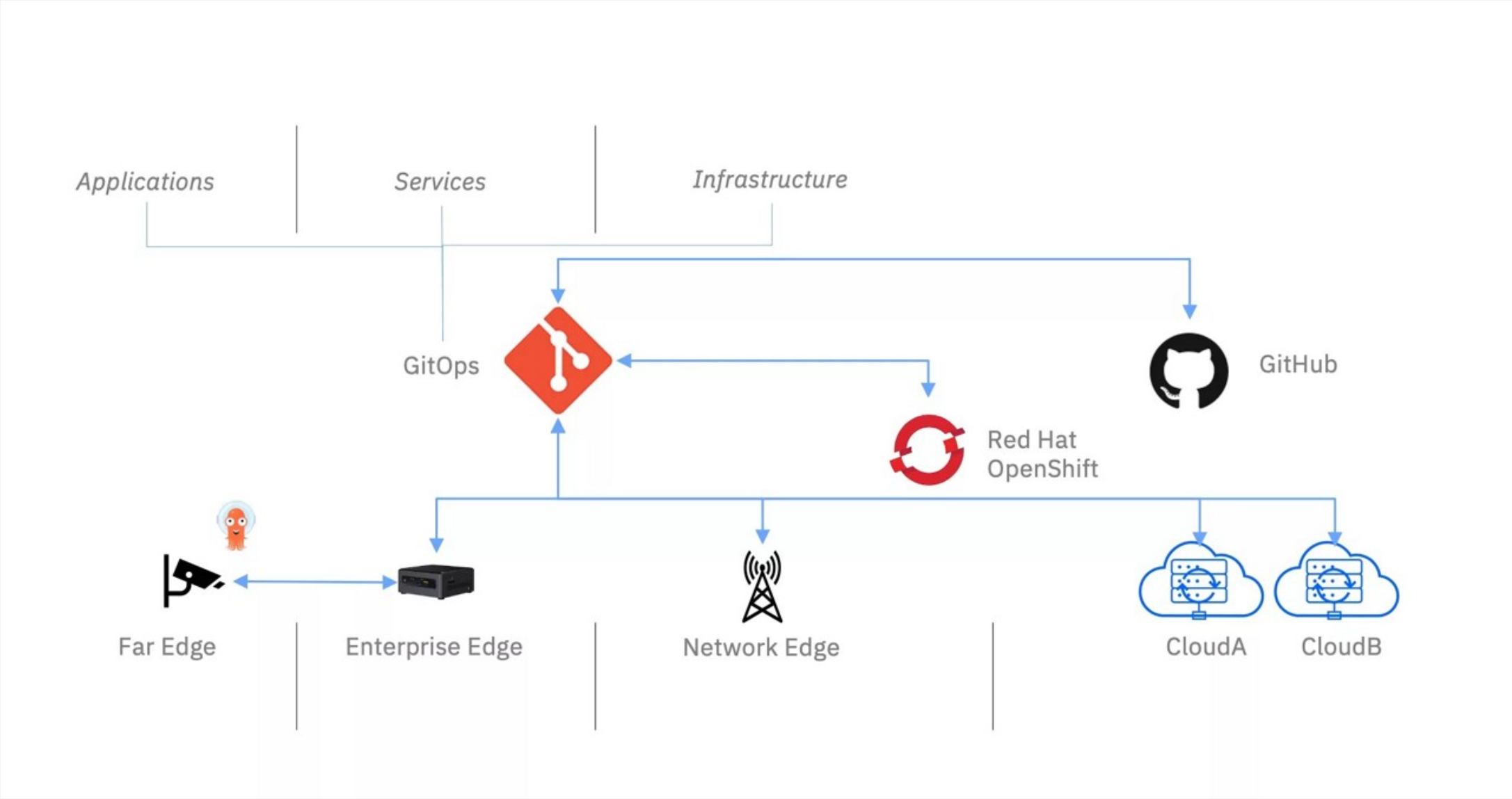
边缘计算最怕断网。GitOps 边缘计算 的思路是:我把边缘节点需要的配置都存在 Git 仓库里。边缘端的 Agent 会定期去拉取(或者等网络通了再拉)。即便中心指挥部暂时连不上边缘节点,只要 Git 里的版本变了,边缘节点在恢复网络的一瞬间就会自愈。这种“拉”模型比“推”模型更适合那种网络环境极其恶劣的边缘场景。
📝 说点掏心窝子的总结
写到这儿,估计你也看出来了,Kurator 并不是想发明什么惊天动地的黑科技,它更像是一个经验丰富的“系统集成专家”。它把 Karmada 的调度能力、Istio 的网络能力、Kyverno 的治理能力全都整合在了一起,然后用 Fleet 的概念打包给你。
其实搞云原生,最怕的就是陷入“工具泥潭”。今天学个这个,明天折腾那个,最后发现环境都没搭起来。Kurator 的价值就在于,它帮你把这些工具的依赖关系理顺了。你只需要通过一个统一的入口,就能指挥这支“海陆空”联合作战的云原生大军。
如果你现在正为了手头那几十个散落在各地的 K8s 集群发愁,或者正在纠结边缘节点怎么统一纳管,别犹豫了,直接去克隆一份代码试试看。毕竟,实践才是检验真理的唯一标准,哪怕代码写得像我这般随性,只要能跑通,能解决你加班熬夜修集群的痛苦,那就是好东西。下次咱们有机会,再细聊聊如何在 Kurator 里搞更高级的流量调度,今天就先到这儿吧!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)