深度学习——目标检测,语义分割和实例分割的 RCNN, Fast RCNN, FasterRCNN+RPN, Mask RCNN(初步)
一.RCNN(Region-CNN)目标检测的奠基算法步骤:Step1:提取候选区域Step2:用CNN提取特征Step3:用SVM分类Step4:检测框回归提出原因:作者说HOG和SIFI提取特征已经过时了,CNN用来提取特征非常好存在的疑问:结果有点歪...
一.RCNN(Region-CNN)
- 目标检测的奠基算法
- 步骤:
Step1:提取候选区域
Step2:用CNN提取特征
Step3:用SVM分类
Step4:检测框回归
- 提出原因:作者说HOG和SIFI提取特征已经过时了,CNN用来提取特征非常好
- 存在的疑问:
- 结果有点歪怎么办:boundding-box regression——先把脸补齐再圈出正确的框
- 为什么不用softmax直接分而用SVM:效果好呗~
二.Fast-RCNN
- 目标检测颠覆R-CNN的算法
- 步骤:
Step1:选框
Step2:用CNN提取特征(与上不同的是,这次作用于整个图)
Step3:把候选框映射到特征图上得到ROI
Step4:ROI pooling,把ROI调成同样的大小
Step5:提取ROI特征,做分类,做回归
- 与RCNN的不同:
(1)CNN是作用在整张图上,而非候选框上
(2)简单:整个过程一气呵成,而非像RCNN先提取特征,再SVM,再检测框回归。
(3)速度快:训练快9倍,测试快213倍
(4)准确:mAP比RCNN高
- 问题:
(1)ROI是如何与特征图映射的:
大小相同:一一映射
大小不同:
已知:原图候选框:(x,y,w,h)
特征图ROL:(rx,ry,rw,rh)
则:rx=x*(特征图宽/原图宽)
ry=y*(特征图高/原图高)
rw=w*(特征图宽/原图宽)
rh=h*(特征图高/原图高)
(2)ROI Pooling是怎样一种操作:把不同的特征图映射到同样的大小。(通过原图和Pooling后的尺寸确定bin的大小)
(3) 全链接如何使用SVD加速:原来的全链接相当于矩阵的乘法,而SVD相当于矩阵分解。将大矩阵分解成小矩阵做乘法的好处就是,减少计算量,减少参数个数,加快运算。
三.Faster R-CNN
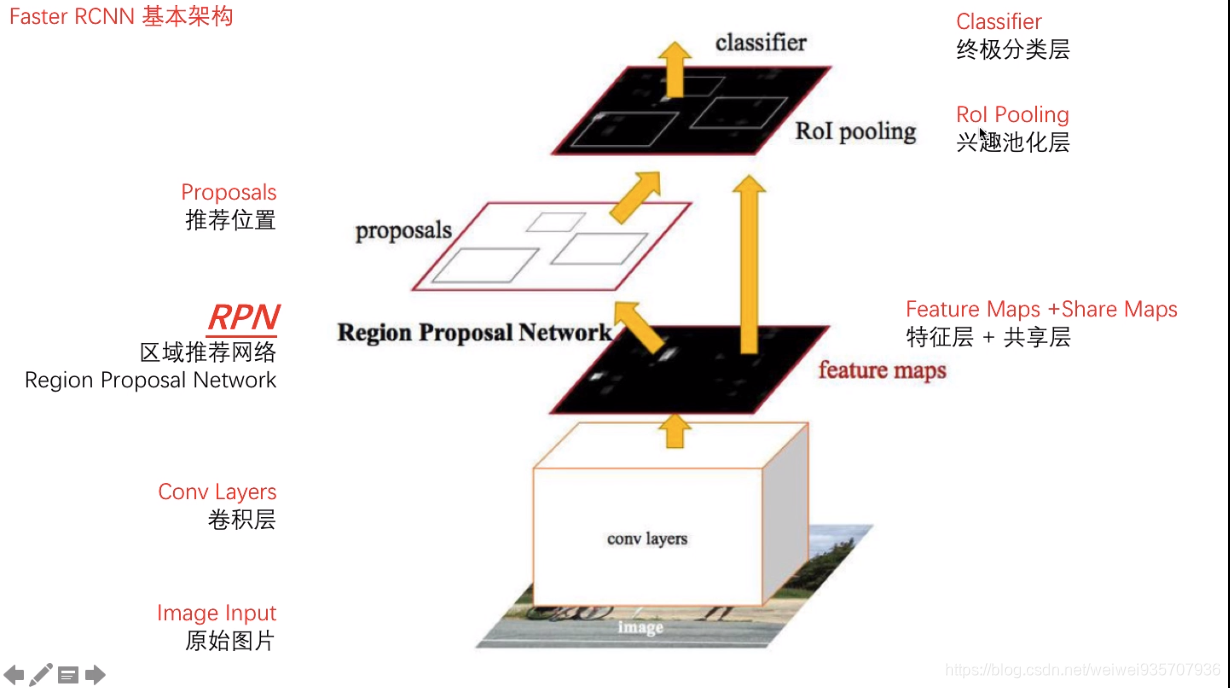
-
物体检测最通用的方法之一
-
与Fast R-CNN的不同:在候选框部分也使用神经网络。即整个过程只需要一个网络。
-
RPN——Region Proposal Networks:候选框网络
-
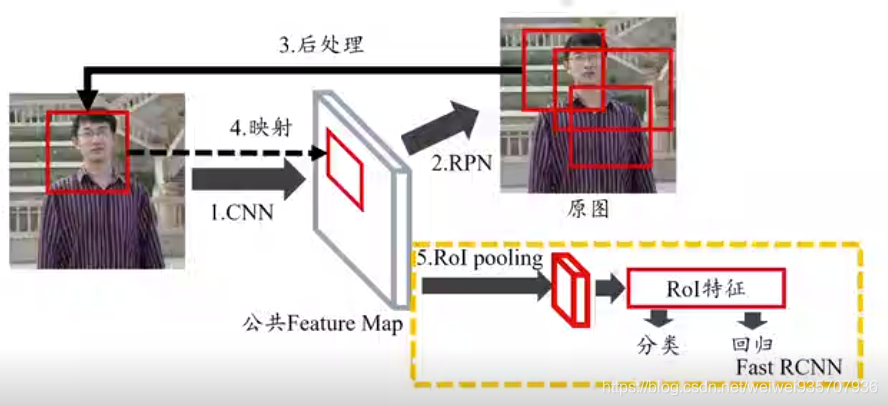
过程:
Step1:图片送入CNN得特征
Step2:特征送RPN得候选框
Step3:候选框进行后处理
(下同Fast R CNN)
Step4:经CNN得特征图(和前面的特征图是同一张图,称为:公共特征图)
Step5:经RoI Pooling 得同样大小特征图
Step6:由特征图进行分类,回归
- 训练:
(1)交替训练:
1)先训练RPN
2)再训练Fast RCNN( 不共享)
3)fine-tune
(2)一起训练
(3)基于坐标的一起训练?
- FPN——Featurized image pyramid:图像金子塔,用于解决检测框尺寸无法满足要求的情况。
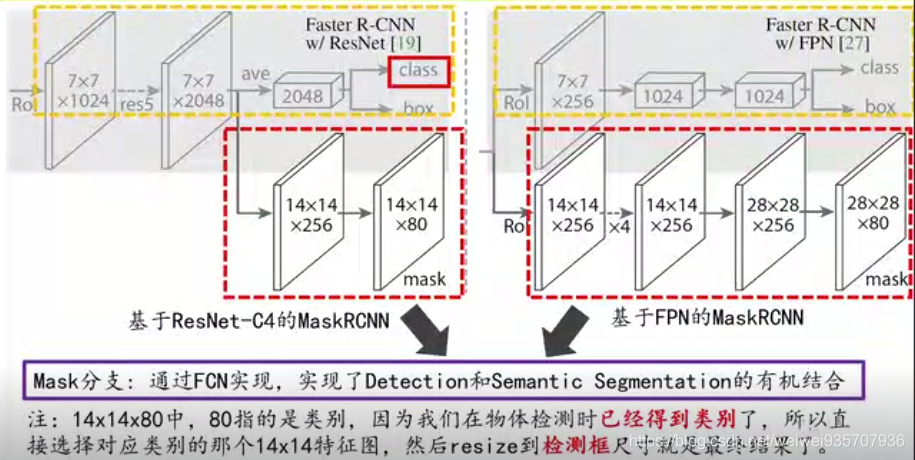
四.Mask R-CNN
- 作用:语义分割,主要用来生成Mask(刚好和物体轮廓对齐的区域)
- 将其作为分类问题,每个像素点都有一个类别。要分割示例处是一类,背景作为一类。最后可以得到一个score map的分数图(用sigmoid分类)。
- 难点:同类别无法分割,变成语义分割。
- FCN:用以解决Semantic Segmentation
- Mask R-CNN 和 Faster R-CNN的不同:
(1)没有使用RoI Pooling,使用RoI Align
(2)最后的输出结果多了一个Mask
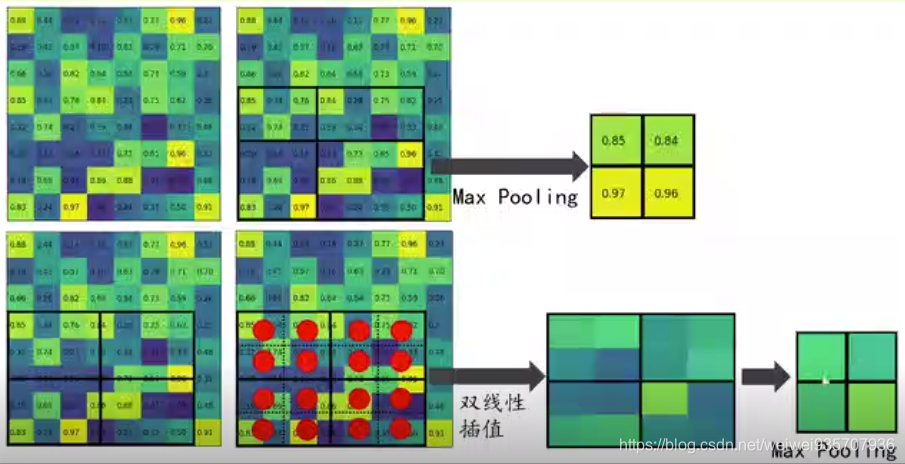
- RoI Align:
(1)平移不变性:物体怎么移动结果都不变——全链接,全局Pooling
平移等价性:物体如何移动,结果如何移动——卷积 和 FCN
(2)双线性插值:
- 结构:
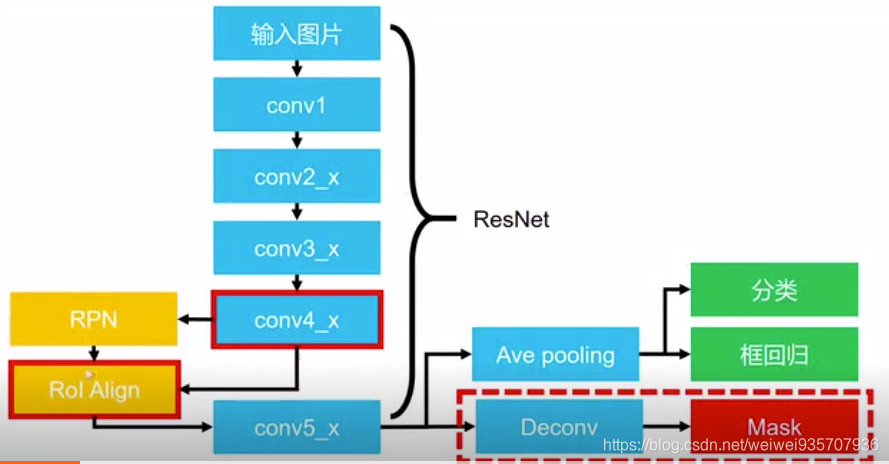
- 训练:(即传说中的 one stage 和 two stage)

- 损失函数:(使用sigmoid的原因是,这个问题近似是二分类问题)

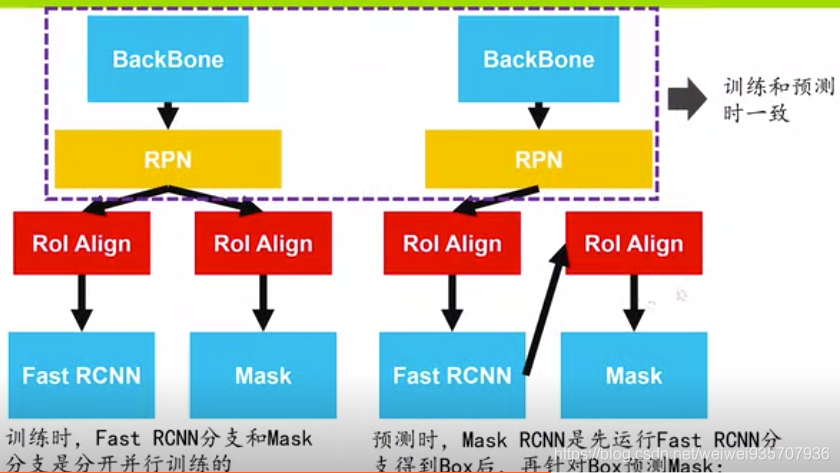
- 预测(训练和预测使用网络的顺序不同)
- 更灵活的操作
(1)加入关键点之后,可以进行人体关键点的检测。(??十分巧妙)
(2)它的backbone也更加灵活,需要精度用ResNet,需要速度用:Inception,squeezeNet,MobileNet
(3)Mask部分也可以替换成专门的。
参考:公众号懒人学AI

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)