【探索实战】搞不定多集群?带你深度拆解 Kurator 云原生全栈治理:从架构拓扑到 GitOps 自动化,手把手教你玩转分布式云的一站式利器
Kurator作为分布式云原生领域的新兴力量,以其一体化的设计理念对现有集群的包容性和基于主流云原生技术栈的特点,为企业提供了实用的多云多集群管理解决方案。通过统一应用分发、统一监控和统一策略管理等核心功能,Kurator显著降低了分布式云原生环境的运维复杂度。其开放原子基金会的背景也为其在中国市场的发展提供了良好的生态基础。
【探索实战】搞不定多集群?带你深度拆解 Kurator 云原生全栈治理:从架构拓扑到 GitOps 自动化,手把手教你玩转分布式云的一站式利器
说起现在的云原生开发,大家最头疼的肯定不是怎么写一个 Dockerfile,也不是怎么起一个 K8s 集群,而是当手里的集群变多之后,那种“按下葫芦浮起瓢”的无力感。你想啊,有的集群在阿里云,有的在华为云,有的还在自家的机房,甚至还有一堆边缘节点。这时候,如果你还想搞什么统一调度、自动运维、GitOps 持续交付,那简直是大型灾难现场。
这就是 Kurator 出来的意义。简单来说,Kurator 就是要把这堆乱七八糟的集群给“策反”了,让他们乖乖听话,变成一个整体。它不是简单的套壳,而是基于像 Karmada、Volcano、KubeEdge 这些顶尖项目,在上面盖了一座通向“分布式云”的桥。今天咱们就抛开那些晦涩难懂的官方文档,用最实在的话聊聊,这玩意儿到底是怎么帮咱们解决问题的。
一、 别再乱找教程了,先跟我把这套环境给“盘”熟
咱们搞技术的,最烦的就是看了一大堆理论,结果环境半天搭不起来。Kurator 的环境搭建其实没那么玄乎,但你得先把基础打牢。
1. 源码先拉下来,这是“入坑”第一步
很多人习惯直接下载二进制包,但我建议既然要深入了解,还是直接从源码开始。咱先找个干净的 Linux 环境,找个你顺眼的目录,直接把代码拽过来。别去 GitHub 挤了,国内咱直接用 GitCode,速度嗖嗖的。
在我们开启正式篇章之前,我们先来学习下如何克隆Kurator项目吧,如下附上如何获取Kurator项目详细步骤教程:
我们可直接下载zip压缩包:
直接点击下载:
接下来,我们只需要解压即可。
拉下来之后,你会发现里面结构挺清晰的。Kurator 聪明的地方在于它把复杂的逻辑都封装进了自定义资源(CRD)里。
2. 环境里的那些“弯弯绕绕”
搭建环境的时候,你得明白,Kurator 实际上是一个“管理集群”的角色。它利用 Kurator Cluster Operator 的整体架构 来控制其他的“工作集群”。这个 Operator 就像是总司令部,它通过控制器模式,时刻盯着你定义的那些 YAML 文件。如果你想加个集群,你不用去手动装各种组件,你只需要给这个 Operator 发个指令,它就会根据架构里的定义,自动去调用底层的接口。
说白了,环境搭建不仅仅是跑个脚本,更多的是要理解这个 Operator 是怎么通过控制循环(Reconciliation Loop)来确保你的集群状态和你想的一模一样。这个过程中,它会初始化很多核心组件,比如负责多集群管理的 Karmada,还有负责资源调度的 Volcano。
二、 剥开外壳看内核:Kurator 是怎么管集群的? 🏗️
环境搭好了,咱得看看它肚子里到底卖的什么药。很多人问,这么多集群,它是怎么分得清谁是谁,还能管得井井有条的?
1. 像看地图一样看集群资源的拓扑结构
这张图展示了集群资源的拓扑结构,清晰地呈现了从控制平面到机器部署的各个组件如何关联,比如Cluster、Control Plane和MachineDeployment之间的引用关系,帮助理解Kubernetes集群的构建逻辑: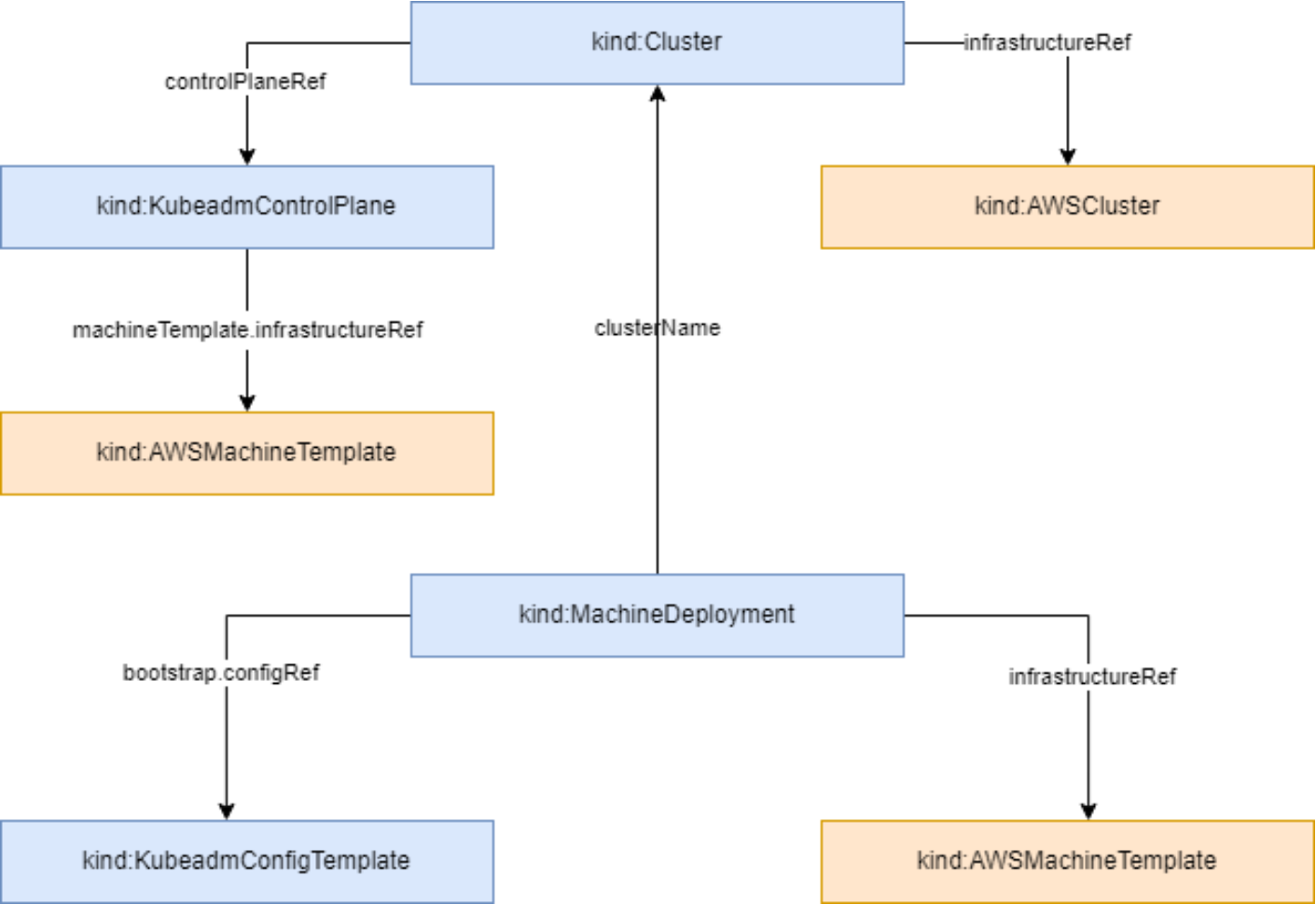
管理多集群,第一步就是得有个“视图”。集群资源的拓扑结构 这玩意儿,听着高大上,其实就是一张“关系网”。在 Kurator 里,它把每一个集群,甚至集群里的每一个节点、每一个 Pod 的归属关系都理得清清楚楚。
这种拓扑结构不是死板的,它是动态的。比如你有一个分布在三个机房的集群,Kurator 会把它们标记成不同的层级。这种清晰的层级感,让你在做调度的时候,可以非常直观地看到:我的任务是发到了核心机房,还是发到了某个偏远的边缘节点。
2. 搞定 Kurator 集群生命周期管理
这是Kurator集群生命周期管理的详细参考图,展示了从用户声明、多租户插件配置,到控制器协同工作实现异构集群统一纳管的全过程。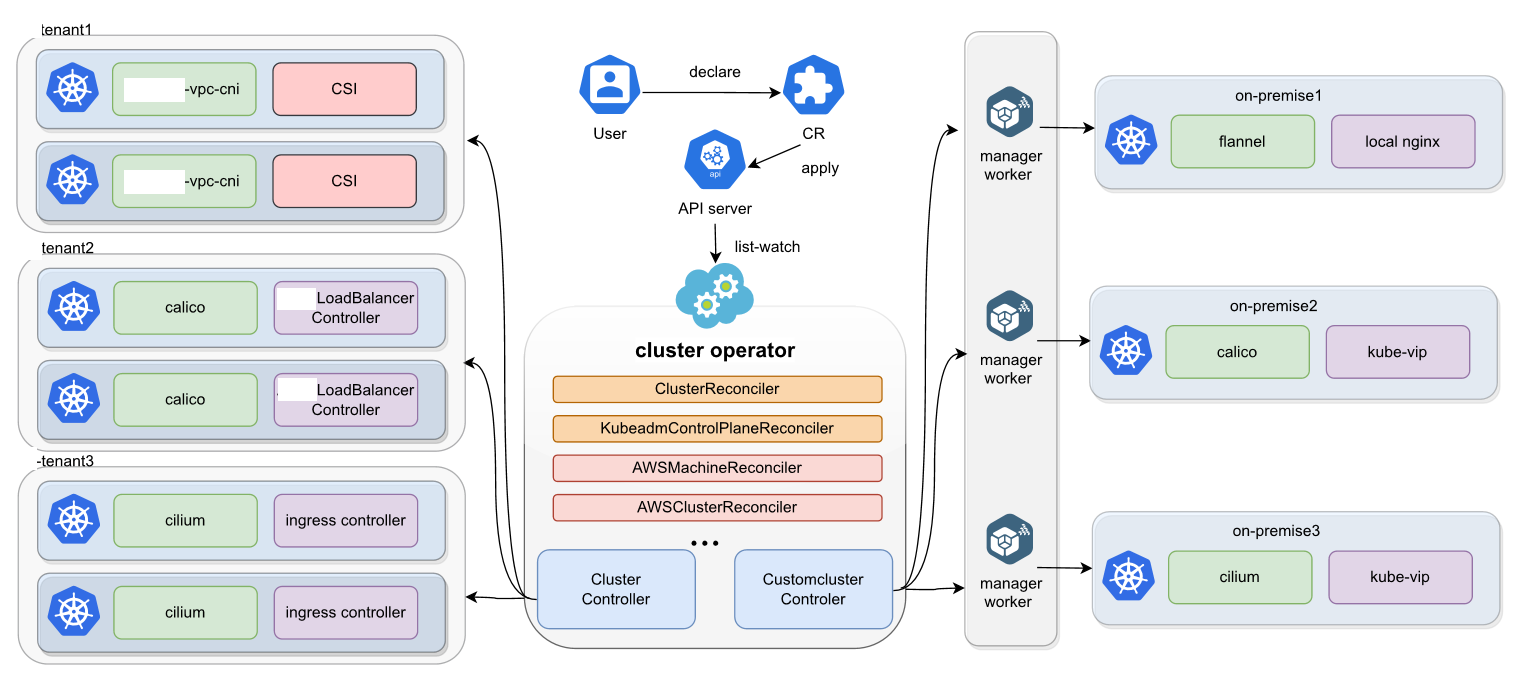
接下来就是重头戏:Kurator 集群生命周期管理。这可不是简单的“创建”和“删除”。它涵盖了从集群的预置、启动、扩缩容、升级到最后的回收。
咱以前升级个集群,那得战战兢兢,生怕哪儿配置没对。现在呢,你只需要在 Kurator 的 Cluster 资源里改个版本号。底层的生命周期控制器会自动去跑那些繁杂的工作。它会先检查你的底层基础设施是否到位,然后利用自动化脚本去更新二进制文件,最后验证集群健康度。这套流程走下来,比人工手动操作稳当得多。
3. 咱来手写一段集群定义的“小样”
为了让大家更有体感,我这儿准备了一个简化版的集群定义 YAML。你看看,是不是就像是在填表一样简单?
# 这是一个非常基础的集群资源定义,就像是给你的新集群领个“准生证”
apiVersion: clusters.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: my-new-app-cluster
namespace: kurator-system
spec:
# 这里定义了基础设施的提供方,比如是在本地还是在云上
infrastructure:
provider: kind
# 这里的配置决定了集群长什么样
controlPlane:
version: v1.25.3
replicas: 3
# 这部分就是告诉 Operator,我要什么样的节点
workers:
- name: standard-node-pool
replicas: 5
machineType: t3.medium
三、 多集群调度的“最强大脑”:Karmada 与 Volcano 的合体 🧠
集群多了,任务往哪儿发?这就要靠调度引擎了。Kurator 直接集成了 Karmada,这绝对是目前多集群管理界的“天花板”。
1. 深度拆解 Karmada 多集群管理平台的总体架构
这是Karmada多集群管理平台的总体架构图,展示了其控制平面如何通过各类控制器实现策略分发与跨集群资源协同: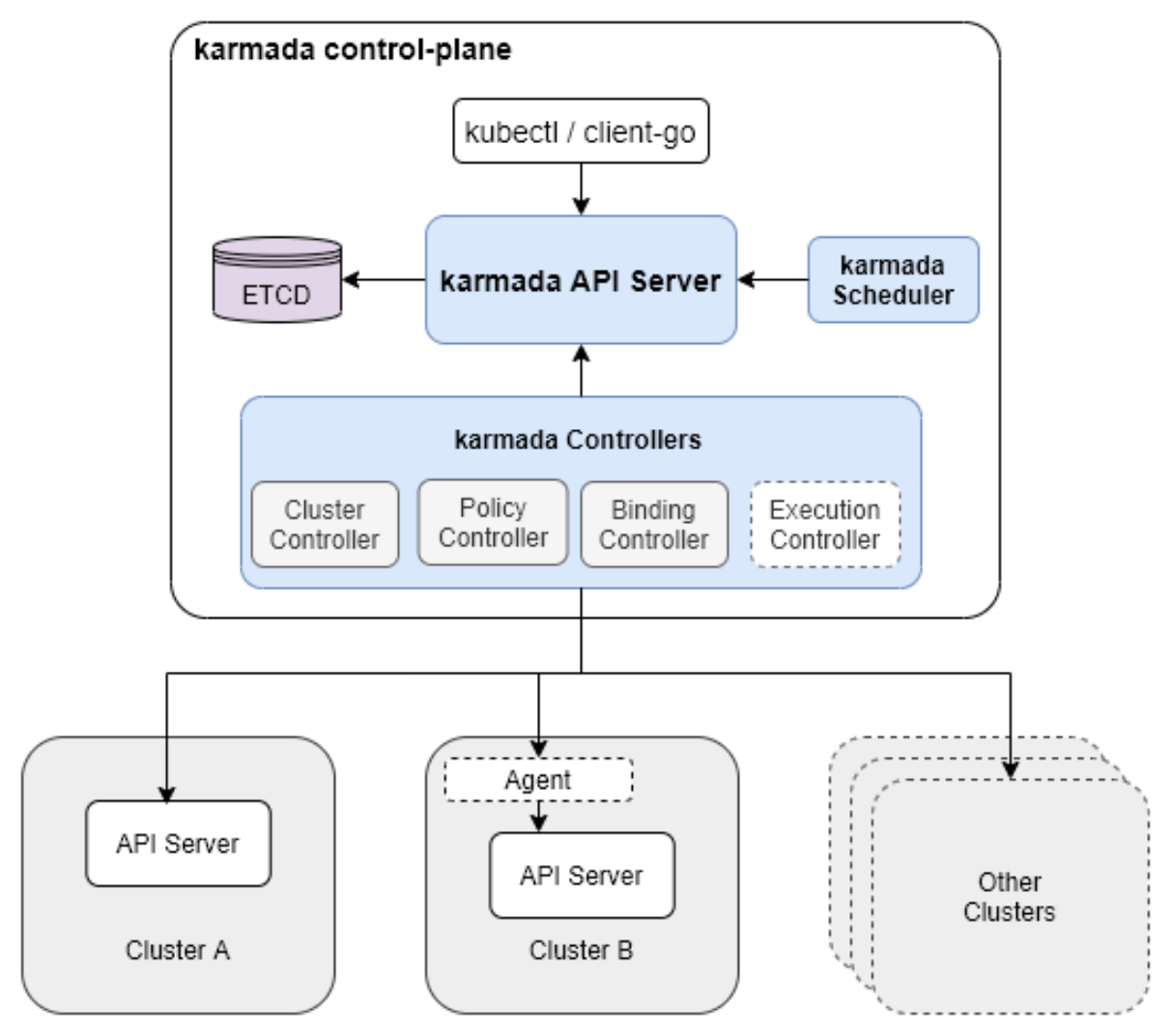
Karmada 多集群管理平台的总体架构 其实挺有意思的。它有个核心叫 API Server,但这个 API Server 和原生 K8s 的不一样,它是专门为了多集群设计的。它下面带着一堆 Controller,有的负责资源分发,有的负责状态汇总。
你把任务发给 Karmada,它不会直接去干活,它会看你设定的策略。这时候,Karmada 调度引擎 就发挥作用了。它会计算:哪个集群现在最空闲?哪个集群离用户最近?哪个集群的成本最低?然后把你的 Deployment 或者 Service 准确地推送到目标集群的 API Server 上。
2. 调度界的一把好手:Volcano 调度器工作流
这是Volcano调度器工作流的详细参考图,展示了从Job提交到Pod调度的完整流程及其可插拔的插件机制: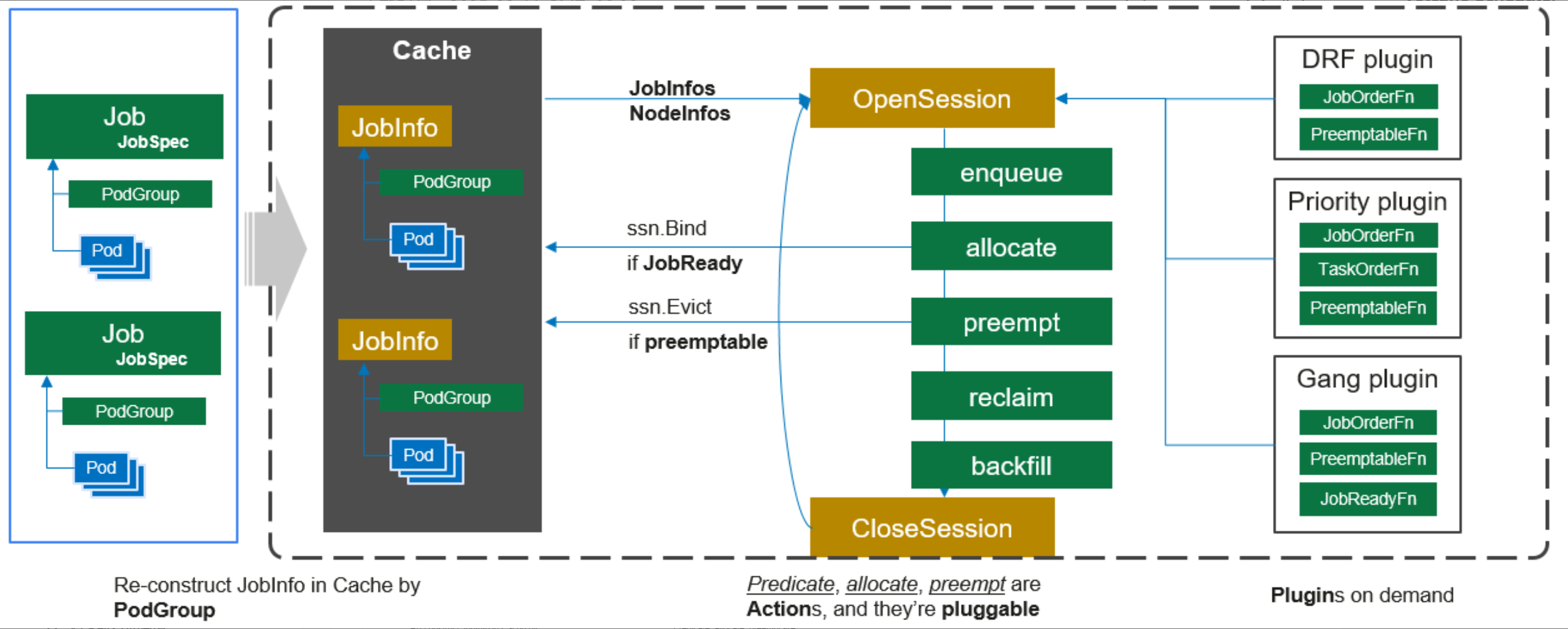
如果说 Karmada 是管“大方向”的,那 Volcano 调度器工作流 就是管“细活”的。当任务落到具体的某个集群里,如果这个任务是高性能计算或者是大数据批处理,原生的 K8s 调度器可能就有点吃力了。
Volcano 的工作流非常讲究。它支持 Gang Scheduling(成组调度),意思就是:如果你这组任务里有一个起不来,那其他的也先别起,省得浪费资源。它会经历“入队、缓存、调度、执行”这一整套严密的流程。在 Kurator 的体系下,Volcano 能够跨越集群边界,感知到全局的资源压力,确保你的 AI 模型训练或者大数据作业能跑在性能最好的机器上。
3. 分级优化策略:大集群和小集群待遇不一样
这是针对不同集群规模的分级优化策略参考图,展示了从小型到大型集群在资源配置、调度与网络等方面逐级深入的调优方案: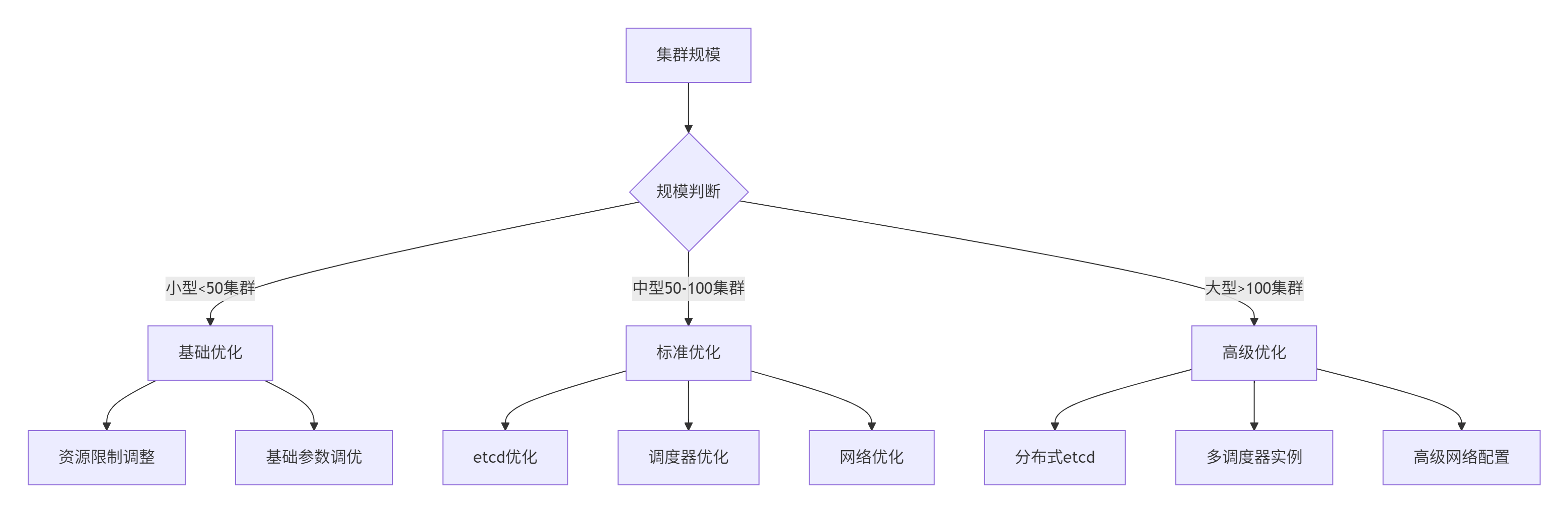
你可能想过,我管 5 个集群和管 500 个集群,方法能一样吗?这就是 针对不同集群规模的分级优化策略。Kurator 会根据集群的规模自动切换管理模式。
对于小规模集群,它追求的是响应速度和极致的简单;而对于那种成百上千节点的巨型集群,它会开启“联邦模式”或者“代理模式”。这时候,它会减少心跳频率,采用更高效的压缩算法来传输状态数据,甚至会引入多级缓存。这种分级的艺术,保证了系统在任何压力下都不会“罢工”。
四、 自动化运维的终极奥义:GitOps 与 蓝绿发布 🚀
手动改 YAML 终究是不够优雅的。真正的专家,都是玩自动化的。
1. 像写代码一样搞运维:GitOps 流水线的操作流程
这是GitOps工作流的官方参考图,展示了从代码提交到镜像构建,最终由GitOps控制器实现集群自动部署的完整流程: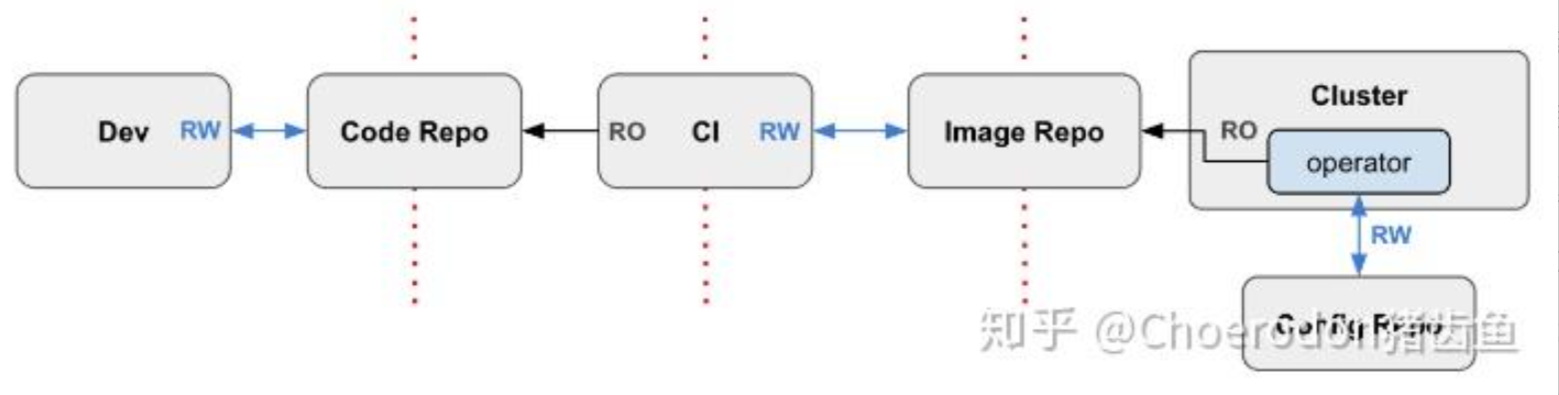
GitOps 流水线的操作流程 在 Kurator 里被简化成了三步:提交、同步、确认。说白了,你的 Git 仓库就是你的“真理来源”。
当你把一个新的 Deployment 配置文件 push 到 Git 仓库时,Kurator 的 GitOps 控制器会立刻捕捉到这个变动。它会对比 Git 里的配置和集群里的实际状态,发现不一样后,就开始自动同步。你不需要打开控制台去点点点,所有的变动都有迹可循,想回滚也只是一个 git revert 的事儿。
2. 稳如泰山:在 Kurator 中配置蓝绿发布
发布新版本最怕什么?怕上线就崩。所以咱得用 Kurator 中配置蓝绿发布。
这里的逻辑是:你可以同时跑两个版本的应用,一个叫“蓝色版本”(旧的),一个叫“绿色版本”(新的)。Kurator 会帮你接管流量。你可以先让 10% 的流量去试探一下绿色版本,如果没问题,再慢慢增加。最酷的是,这整个过程可以通过一段简单的流量控制策略来搞定。
3. 咱们手搓一段蓝绿发布的流量切换代码
虽然我们可以用很多复杂的工具,但有时候最直接的配置反而最清晰。看下面这段“手感十足”的流量切换定义:
# 这是一个模拟蓝绿流量分配的配置,看着复杂,其实逻辑很直观
apiVersion: traffic.kurator.dev/v1alpha1
kind: TrafficSplit
metadata:
name: app-rolling-out
spec:
service: my-cool-app
# 这里就是精髓所在:按比例分流
backends:
- name: my-cool-app-v1 # 这是老版本,蓝军
weight: 80
- name: my-cool-app-v2 # 这是新版本,绿军
weight: 20
# Kurator 会根据这个权重,自动去修改底层多集群网关的路由规则
五、 跨越边界的连接:从中心到边缘的统一迁移 🌐
现在的应用早已不局限在中心机房了,很多时候我们需要把触角伸向边缘。
1. 边缘计算的利器:KubeEdge 架构的工作流程
这是KubeEdge架构的工作流程参考图,展示了云端控制器如何通过CloudHub与边缘节点通信,实现应用下发和设备管理的完整协同链路: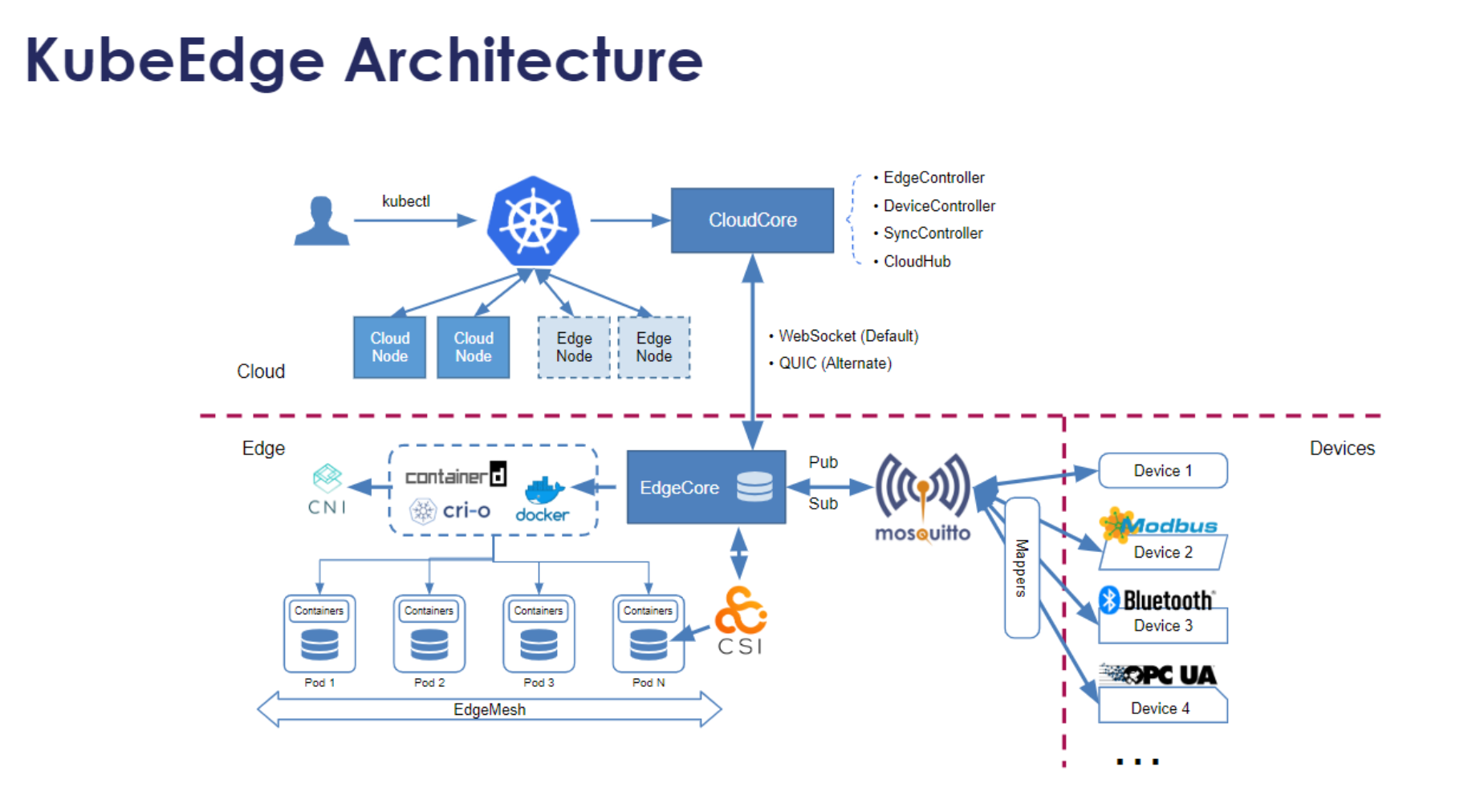
KubeEdge 架构的工作流程 主要是为了解决边缘节点网络不稳定、资源有限的问题。Kurator 集成了 KubeEdge,让你可以像管理云端节点一样管理路边的摄像头或者工厂里的工控机。
它的工作流程是这样的:云端有个 EdgeController 负责发号施令,边缘侧有个 EdgeCore 负责接旨。即便网络断了,边缘侧的节点也能根据之前的“圣旨”继续跑任务,等网络一恢复,立刻同步状态。这种“断连自治”的能力,是边缘计算的刚需。
2. 搬家不再难:Kurator 的统一迁移流程
这张图展示了Kurator的统一迁移流程,用户只需要创建一个自定义资源,后面就由系统自动完成备份、上传、下载和恢复,把数据从源集群平滑迁移到多个目标集群,整个过程简单又高效: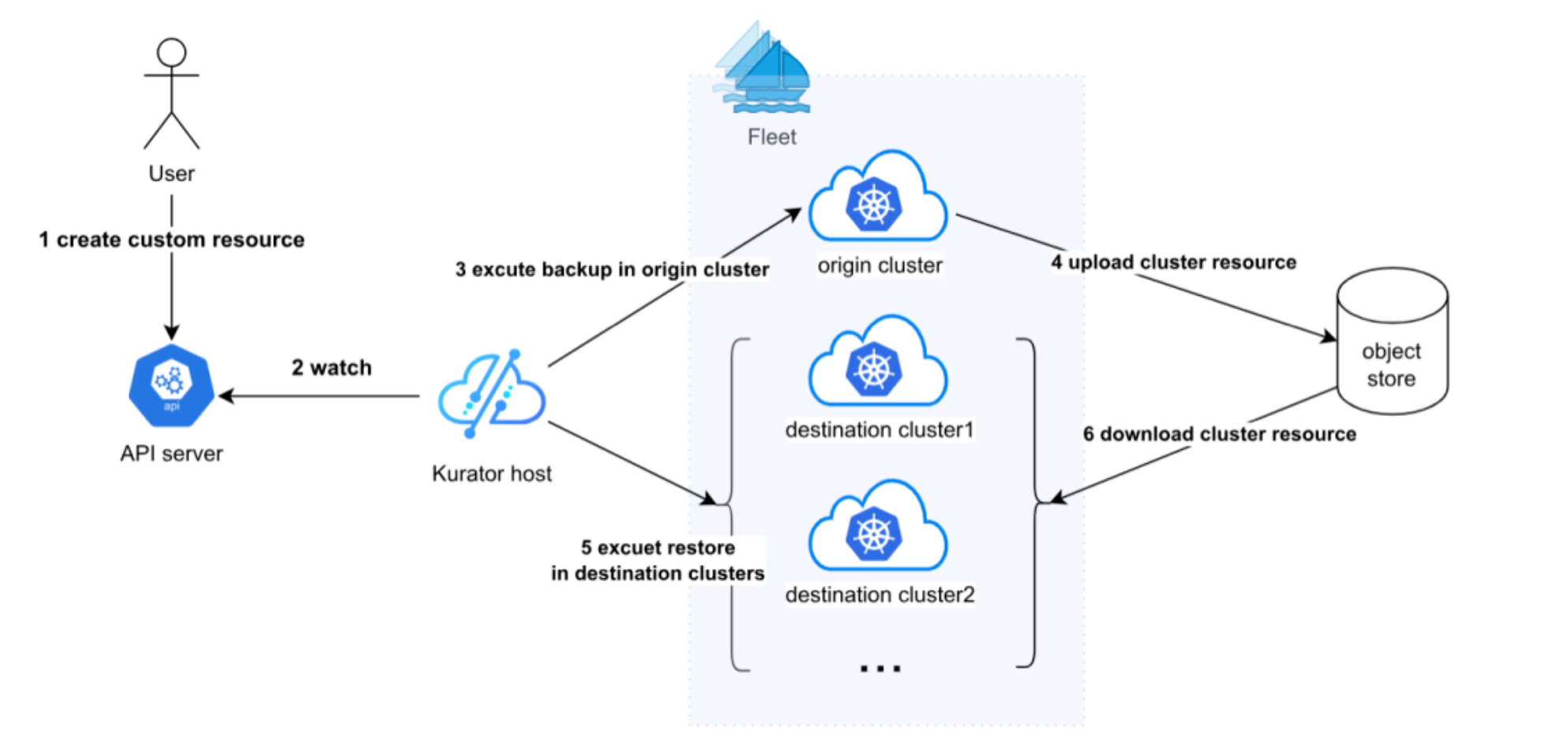
有时候我们需要把一个老集群里的应用搬到新集群,或者从 A 云迁到 B 云。Kurator 的统一迁移流程 就派上用场了。
它不是粗暴地 copy 镜像。它会先扫描你源集群的应用依赖,包括 ConfigMap、Secret 甚至是持久化卷的数据。然后,它会在目标集群里重建这些环境,最后通过镜像同步工具把代码搬过去。最厉害的是,它能保证在搬家过程中,对外服务的 IP 或者域名尽可能保持平滑切换,让用户几乎感知不到你在后台搞“大动作”。
3. 身份证明:Fleet 集群注册机制
那么多集群要进来,总得有个“户口”。Fleet 集群注册机制 就是干这个的。当你有一个新集群想要加入 Kurator 的管理范围时,你得先把它注册到一个 Fleet(舰队)里。
注册过程会自动交换证书,建立安全的通信隧道。一旦注册成功,这个集群就成了 Fleet 的一员,可以统一接收 GitOps 指令,统一参与调度。这就像是给你的船队装上了全球定位系统,不管船在哪儿,总调度台都能一眼看到。
六、 总结与展望:Kurator 核心价值的全景路线 🗺️
聊了这么多,大家心里应该对 Kurator 有个底了。其实,看一个开源项目好不好,不仅要看它现在能干什么,还要看它的远景。
1. 咱们最后看一眼:Fleet 注册的“手动档”代码
为了让你感觉真的是在一步步操作,咱们最后来看一段注册集群时的配置片段。这通常是你把一个现有的 K8s 集群“上缴”给 Kurator 时要填写的资料。
# 别看只有几行,这是建立信任的关键
apiVersion: fleet.kurator.dev/v1alpha1
kind: ClusterRegistration
metadata:
name: register-office-cluster
spec:
# 这里引用的是你那个集群的 kubeconfig,也就是它的“身份证”
secretRef:
name: office-cluster-kubeconfig
# 把它分到哪个组里,方便以后按组群发命令
labels:
region: china-north
env: production
2. 未来的路:Kurator 核心价值的全景路线
Kurator 核心价值的全景路线 其实非常明确:它要打造一个“分布式云操作系统”。从最底层的异构集群接入,到中间层的多集群调度优化,再到最上层的自动化运维和应用治理,它想让复杂的分布式系统变得像用单机电脑一样简单。
它一直在迭代,比如未来会加入更智能的 AI 调度算法,能根据电费波动自动切换计算节点;或者更深度的服务网格集成,让多集群之间的通信像在同一个机房一样快。
说实话,云原生这条路挺卷的,但像 Kurator 这样能把这么多顶尖开源项目整合得这么顺手的,确实不多见。如果你正被多集群、跨云运维搞得焦头烂额,不妨按我说的,先 git clone 下来跑一跑,没准儿你会发现,以前那些让你熬夜的难题,其实也就是写几个 YAML 就能搞定的事。
怎么样?关于 Kurator,你还有哪些地方觉得没听透?或者说你在多集群管理上还有啥别的槽想吐?咱们评论区接着聊!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 21
21 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)