【探索实战】Kurator云原生平台:从架构解析到多集群统一治理的深度实践
在云原生技术快速演进的今天,企业面临着日益复杂的多集群管理挑战。随着业务规模的扩张,单一Kubernetes集群已无法满足高可用、多地域、边缘计算等场景需求。Kurator应运而生,它是一个开源的分布式云原生平台,旨在提供统一的多集群生命周期管理、应用分发、流量治理和可观测性能力。Kurator的核心价值在于将复杂的多集群操作抽象为简单的声明式API,让运维团队能够以统一的方式管理跨云、跨区域的K
【探索实战】Kurator云原生平台:从架构解析到多集群统一治理的深度实践
【探索实战】Kurator云原生平台:从架构解析到多集群统一治理的深度实践
摘要
本文深入探讨了Kurator分布式云原生平台的核心架构与实践应用。Kurator作为新一代云原生统一管理平台,致力于解决多集群环境下的资源编排、应用分发、流量治理和统一监控等关键挑战。文章从环境搭建入手,详细阐述了Kurator的核心组件架构,包括Fleet集群管理机制、Karmada多集群编排集成、KubeEdge边缘计算协同、应用分发流程以及Volcano调度器的深度整合。通过真实的代码示例和配置实践,展示了Kurator在企业级云原生场景中的应用价值。本文不仅提供了完整的技术实施路径,更从架构设计、性能优化和未来演进等维度进行了深度思考,为云原生平台的建设者提供了系统化的参考方案。
一、Kurator分布式云原生平台概述
1.1 Kurator的诞生背景与核心价值
在云原生技术快速演进的今天,企业面临着日益复杂的多集群管理挑战。随着业务规模的扩张,单一Kubernetes集群已无法满足高可用、多地域、边缘计算等场景需求。Kurator应运而生,它是一个开源的分布式云原生平台,旨在提供统一的多集群生命周期管理、应用分发、流量治理和可观测性能力。Kurator的核心价值在于将复杂的多集群操作抽象为简单的声明式API,让运维团队能够以统一的方式管理跨云、跨区域的Kubernetes集群。
Kurator并非重复造轮子,而是深度整合了CNCF生态中的优秀项目,如Karmada(多集群编排)、Istio(服务网格)、Prometheus(监控)、KubeEdge(边缘计算)等,形成了一个完整的云原生治理体系。这种整合式的设计理念,既保证了各组件的专业性,又实现了统一的管理入口。
1.2 Kurator的核心功能特性
Kurator提供了五大核心功能模块,构建了完整的云原生平台治理能力:
集群生命周期管理:支持多云环境下Kubernetes集群的自动化创建、升级、扩缩容和删除。通过声明式配置,运维人员可以快速在AWS、Azure、阿里云等多个云平台上部署标准化的Kubernetes集群,大幅降低了多云管理的复杂度。
统一应用分发:基于Karmada的多集群调度能力,Kurator实现了应用的智能分发和放置策略。支持按地域、资源、标签等多维度进行应用编排,确保应用在合适的集群中运行。同时提供了差异化配置能力,允许同一应用在不同集群中使用不同的配置参数。
统一流量治理:整合Istio服务网格,实现跨集群的流量管理、灰度发布、故障注入和熔断降级。通过VirtualService和DestinationRule的统一配置,可以实现全局的流量控制策略,保障服务的稳定性和可靠性。
1.3 Kurator的架构设计理念
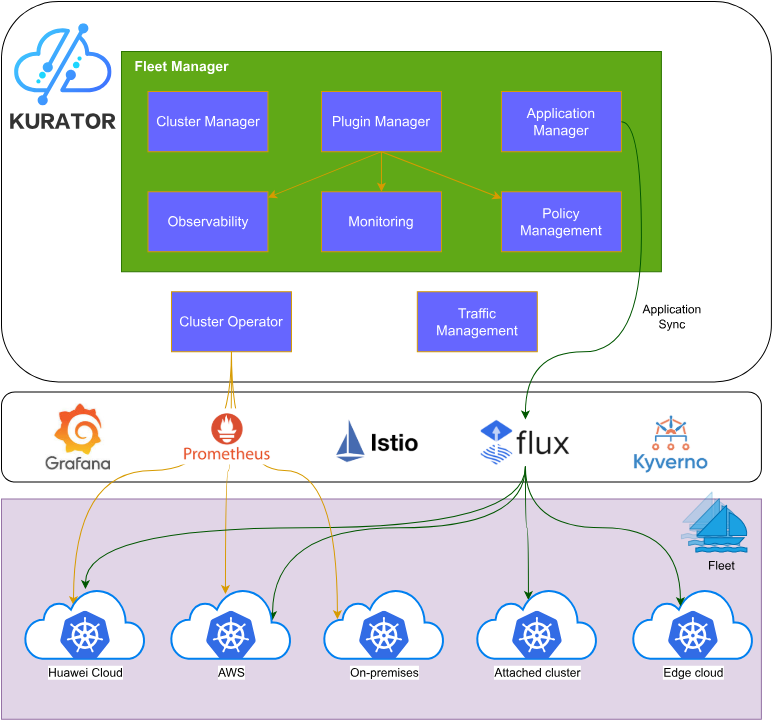
Kurator采用了分层架构设计,自底向上分为基础设施层、编排层、治理层和API层。基础设施层负责与各云平台对接,管理底层计算、存储和网络资源;编排层通过Karmada实现多集群的统一调度;治理层提供应用分发、流量管理、监控告警等高级能力;API层则向用户暴露统一的CRD接口。
这种分层设计的优势在于职责清晰、易于扩展。当需要接入新的云平台或增加新的治理能力时,只需在对应层级进行扩展,不会影响其他层的功能。同时,Kurator遵循Kubernetes的设计哲学,所有功能都通过自定义资源(CRD)和控制器(Controller)模式实现,保证了与原生Kubernetes生态的无缝集成。
1.4 Kurator与其他云原生平台的对比
相比于传统的多集群管理方案,Kurator具有以下显著优势:首先,它是一个完全开源的解决方案,避免了供应商锁定;其次,Kurator深度整合了CNCF生态,而不是自建一套封闭体系;第三,Kurator提供了端到端的云原生治理能力,而不仅仅是集群管理或应用编排。这使得Kurator成为构建企业级云原生平台的理想选择。
二、Kurator分布式云原生环境搭建实战
2.1 环境准备与前置要求
在开始Kurator环境搭建之前,需要准备以下基础环境:一台安装了Linux操作系统的服务器(推荐Ubuntu 20.04或CentOS 7.9),至少8核CPU、16GB内存和100GB磁盘空间。软件依赖包括Docker(版本20.10+)、kubectl(版本1.24+)、Helm(版本3.8+)和Kind或Minikube(用于本地测试)。
对于生产环境,建议准备至少3个Kubernetes集群,分别作为Kurator的控制面集群和两个成员集群。控制面集群承载Kurator的核心组件,成员集群用于实际的应用负载运行。每个集群应配置高可用的etcd和多个Master节点,确保系统的稳定性。
网络方面,需要确保各集群之间可以互相访问,建议使用VPN或专线连接。如果是云上环境,可以利用云厂商的VPC对等连接功能。防火墙需要开放Kubernetes API Server端口(6443)、Karmada API Server端口(5443)以及各类监控和日志组件的端口。
2.2 克隆Kurator代码仓库与初始化
首先从GitHub克隆Kurator项目代码,这是搭建环境的第一步:
# 克隆Kurator官方仓库
git clone https://github.com/kurator-dev/kurator.git
cd kurator
# 查看可用的版本标签
git tag -l
# 切换到稳定版本(例如v0.5.0)
git checkout v0.5.0
# 查看目录结构
ls -la

克隆完成后,可以看到Kurator的典型目录结构:/cmd目录包含各组件的入口程序,/pkg目录包含核心业务逻辑,/manifests目录存放部署配置文件,/examples目录提供了丰富的使用示例。建议仔细阅读README.md文件,了解项目的整体架构和快速开始指南。
在初始化阶段,还需要配置Go语言环境(版本1.20+)用于编译Kurator组件。执行go mod download下载依赖包,这一步可能需要配置GOPROXY加速下载。
2.3 使用Kind创建本地测试集群
为了快速验证Kurator的功能,我们首先使用Kind创建本地测试集群。Kind(Kubernetes in Docker)能够在Docker容器中运行Kubernetes集群,非常适合开发和测试场景。
# 安装Kind工具
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.20.0/kind-linux-amd64
chmod +x ./kind
sudo mv ./kind /usr/local/bin/kind
# 创建Kurator控制面集群
cat <<EOF | kind create cluster --name kurator-host --config=-
kind: Cluster
apiVersion: [kind.x-k8s.io/v1alpha4](http://kind.x-k8s.io/v1alpha4)
nodes:
- role: control-plane
- role: worker
- role: worker
EOF
# 创建第一个成员集群
kind create cluster --name kurator-member1
# 创建第二个成员集群
kind create cluster --name kurator-member2
# 验证集群创建成功
kind get clusters
kubectl config get-contexts
创建完成后,会生成三个独立的Kubernetes集群,每个集群都有自己的kubeconfig配置。需要注意的是Kind集群的网络配置,默认情况下各集群之间无法直接通信,需要通过端口映射或自定义网络进行配置。
2.4 安装Kurator核心组件
Kurator的核心组件包括Cluster Operator(集群管理)、Fleet Manager(舰队管理)、Application Manager(应用管理)等。推荐使用Helm进行安装,这样便于后续的升级和维护。
# 切换到控制面集群的context
kubectl config use-context kind-kurator-host
# 创建kurator-system命名空间
kubectl create namespace kurator-system
# 使用Helm安装Kurator
helm repo add kurator https://kurator-dev.github.io/helm-charts
helm repo update
helm install kurator-operator kurator/kurator-operator \
--namespace kurator-system \
--create-namespace \
--set image.tag=v0.5.0 \
--wait
# 验证安装状态
kubectl get pods -n kurator-system
kubectl get crd | grep kurator
安装过程中可能遇到的问题:镜像拉取失败时可以配置国内镜像源,或者提前将镜像推送到私有仓库;如果Pod一直处于Pending状态,检查节点资源是否充足;CRD安装失败通常是由于权限问题,确认当前用户有cluster-admin权限。
三、Kurator架构与Fleet集群管理深度解析
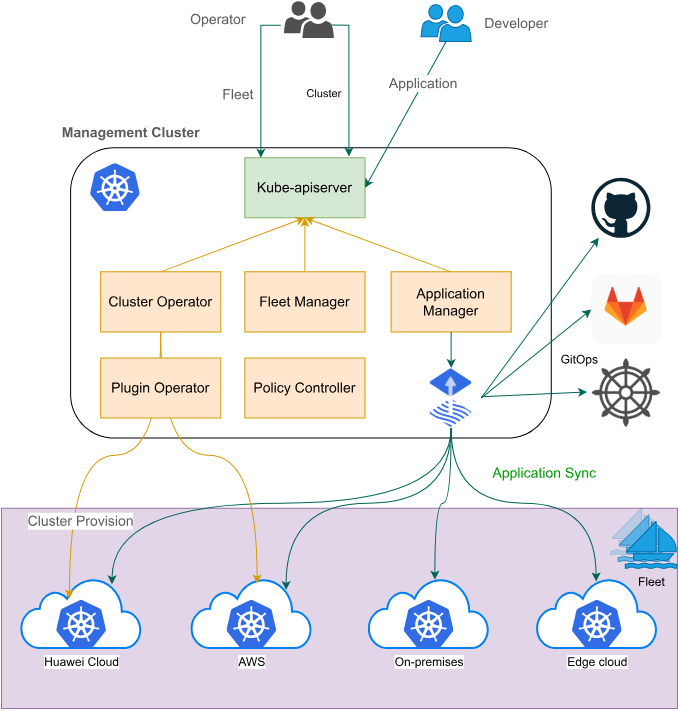
3.1 Fleet集群管理机制详解
Fleet是Kurator中的核心概念,代表一组具有相同特征或用途的Kubernetes集群的集合。通过Fleet抽象,运维人员可以将地理位置、环境类型、硬件配置等维度的集群进行逻辑分组,实现统一管理。Fleet Manager负责监控Fleet中各个集群的健康状态、资源使用情况和版本信息,为上层的应用分发和调度提供决策依据。
Fleet的设计遵循了Kubernetes的声明式API理念,通过定义Fleet CRD来描述集群组的期望状态。每个Fleet包含ClusterSelector用于自动发现和纳管符合条件的集群,支持基于标签、注解、字段等多种选择器语法。当新集群加入或现有集群状态变化时,Fleet Manager会自动更新Fleet的成员列表,实现动态的集群管理。
3.2 创建和管理Fleet资源
下面通过实际代码演示如何创建和管理Fleet资源:
apiVersion: [fleet.kurator.dev/v1alpha1](http://fleet.kurator.dev/v1alpha1)
kind: Fleet
metadata:
name: production-fleet
namespace: kurator-system
spec:
clusters:
- name: kurator-member1
kind: Attached
kubeconfig:
secretRef:
name: member1-kubeconfig
- name: kurator-member2
kind: Attached
kubeconfig:
secretRef:
name: member2-kubeconfig
clusterSelector:
matchLabels:
env: production
region: cn-east
应用此配置后,Kurator会将member1和member2两个集群纳入production-fleet进行管理。需要注意的是,kubeconfig信息存储在Secret中,确保了凭证的安全性。
# 创建集群的kubeconfig Secret
kubectl create secret generic member1-kubeconfig \
--from-file=kubeconfig=/path/to/member1-kubeconfig.yaml \
-n kurator-system
kubectl create secret generic member2-kubeconfig \
--from-file=kubeconfig=/path/to/member2-kubeconfig.yaml \
-n kurator-system
# 应用Fleet配置
kubectl apply -f production-fleet.yaml
# 查看Fleet状态
kubectl get fleet -n kurator-system
kubectl describe fleet production-fleet -n kurator-system
3.3 Fleet的高级特性与最佳实践
Fleet支持多种高级特性来满足复杂的集群管理需求。集群分组策略允许根据业务场景定义多个Fleet,比如按环境分为dev-fleet、staging-fleet、production-fleet,或按地域分为asia-fleet、europe-fleet、america-fleet。不同Fleet可以配置不同的策略和权限,实现精细化管理。
健康检查与自动恢复是Fleet Manager的重要功能。它会定期探测成员集群的API Server可用性、节点健康度和资源水位,当发现异常时触发告警并尝试自动恢复。可以通过配置健康检查参数来调整探测频率和失败阈值:
spec:
healthCheck:
enabled: true
intervalSeconds: 30
timeoutSeconds: 10
failureThreshold: 3
集群标签管理是实现智能调度的基础。Fleet Manager会自动为成员集群打上标签,标识其环境、区域、版本等信息。应用在分发时可以通过标签选择器指定目标集群,实现精准投放。
3.4 Fleet在多租户场景下的应用
在多租户环境中,Fleet可以作为资源隔离的边界。为每个租户创建独立的Fleet和Namespace,配合RBAC策略,确保租户只能访问和操作自己的集群资源。这种设计既保证了安全性,又提供了灵活性。
通过FleetBinding CRD,还可以实现Fleet之间的资源共享和借用,比如在高峰时段临时将其他Fleet的空闲集群资源借调过来。这种弹性能力对于成本优化和资源效率提升具有重要意义。
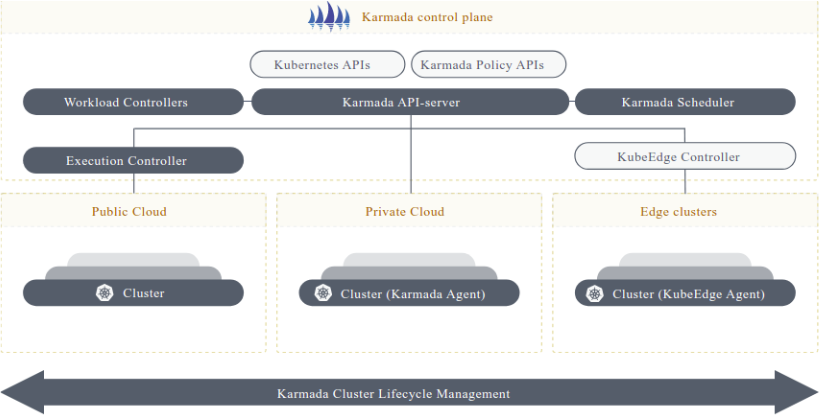
四、Karmada多集群编排集成实践
4.1 Karmada与Kurator的深度整合架构
Karmada是华为开源的多集群应用编排引擎,Kurator将其作为核心的调度底座。在架构上,Kurator的Application Manager组件与Karmada API Server深度集成,将用户的高层业务意图转换为Karmada的PropagationPolicy和ResourceBinding资源。Karmada的调度器再根据集群的实际情况,决定应用的部署位置和副本分布。
这种整合带来了显著的优势:Kurator提供了更简洁的用户界面和业务语义,而Karmada处理复杂的调度逻辑和资源同步。两者分工明确,既保证了易用性,又不损失灵活性。Kurator还扩展了Karmada的能力,增加了应用拓扑感知、依赖关系管理等高级特性。
4.2 在Kurator中部署Karmada控制面
Kurator提供了自动化脚本来部署Karmada,简化了安装过程:
# 使用Kurator提供的脚本安装Karmada
cd kurator
./hack/[deploy-karmada.sh](http://deploy-karmada.sh)
# 或者手动使用Helm安装
helm repo add karmada https://raw.githubusercontent.com/karmada-io/karmada/master/charts
helm install karmada karmada/karmada \
--namespace karmada-system \
--create-namespace \
--set apiServer.replicas=2 \
--set controllerManager.replicas=2 \
--set scheduler.replicas=2 \
--set webhook.replicas=2
# 验证Karmada组件运行状态
kubectl get pods -n karmada-system
kubectl get apiservice | grep karmada
安装完成后,Karmada会在控制面集群中创建一个独立的API Server,监听在5443端口。需要配置karmadactl工具来管理Karmada资源。
4.3 注册成员集群到Karmada
将Kubernetes集群注册到Karmada是实现多集群编排的前提:
# 使用karmadactl注册member1集群
karmadactl join member1 \
--cluster-kubeconfig=/path/to/member1-kubeconfig.yaml \
--cluster-context=kind-kurator-member1
# 注册member2集群
karmadactl join member2 \
--cluster-kubeconfig=/path/to/member2-kubeconfig.yaml \
--cluster-context=kind-kurator-member2
# 查看已注册的集群
kubectl get clusters --kubeconfig=/etc/karmada/karmada-apiserver.config
注册过程中,Karmada会在成员集群中部署karmada-agent组件,负责监听Karmada控制面的指令,并将资源同步到本地集群。同时,Karmada会收集成员集群的资源信息,构建全局的资源视图。
4.4 基于Karmada实现应用的多集群分发
下面通过一个Nginx应用的分发案例,展示Karmada的工作流程:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: default
spec:
replicas: 4
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.21
ports:
- containerPort: 80
---
apiVersion: [policy.karmada.io/v1alpha1](http://policy.karmada.io/v1alpha1)
kind: PropagationPolicy
metadata:
name: nginx-propagation
namespace: default
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx-deployment
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 3
- targetCluster:
clusterNames:
- member2
weight: 1
这个配置定义了一个总共4副本的Nginx应用,通过PropagationPolicy指定了分发策略:member1集群部署3个副本,member2集群部署1个副本,实现了按权重的智能分发。
# 应用配置
kubectl apply -f nginx-deployment.yaml --kubeconfig=/etc/karmada/karmada-apiserver.config
# 查看资源绑定情况
kubectl get resourcebinding -n default --kubeconfig=/etc/karmada/karmada-apiserver.config
# 在成员集群中验证
kubectl get pods -n default --context kind-kurator-member1
kubectl get pods -n default --context kind-kurator-member2
通过Karmada的分发机制,应用自动在多个集群中部署,并且保持配置的一致性。当某个集群出现故障时,Karmada可以自动将副本迁移到健康的集群,实现高可用。
五、KubeEdge边缘计算与Kurator协同实践

5.1 云边协同架构与Kurator的边缘扩展
KubeEdge是CNCF孵化的边缘计算项目,将Kubernetes的容器编排能力延伸到边缘侧。Kurator通过集成KubeEdge,实现了云边一体化的管理能力。在这个架构中,中心云集群运行Kurator和Karmada控制面,边缘集群通过KubeEdge接入,形成了统一的云边资源池。
Kurator的EdgeCluster CRD专门用于管理边缘集群,它在标准的Fleet机制基础上,增加了边缘特有的属性,如网络模式、设备管理、边缘自治等。通过Kurator的统一接口,运维人员可以像管理云端集群一样管理边缘节点,大大降低了边缘计算的使用门槛。
5.2 部署KubeEdge云端组件
在Kurator控制面集群中部署KubeEdge的CloudCore组件:
# 下载keadm工具
wget https://github.com/kubeedge/kubeedge/releases/download/v1.15.0/keadm-v1.15.0-linux-amd64.tar.gz
tar -zxvf keadm-v1.15.0-linux-amd64.tar.gz
sudo cp keadm /usr/local/bin/
# 初始化CloudCore
keadm init --advertise-address="192.168.1.10" --kubeedge-version=1.15.0
# 查看CloudCore运行状态
kubectl get pods -n kubeedge
CloudCore负责与边缘节点的EdgeCore通信,处理云边消息路由和元数据同步。部署时需要指定advertise-address为云端可被边缘访问的IP地址。
5.3 注册边缘节点并纳入Kurator管理
在边缘节点上部署EdgeCore,并将其注册到Kurator:
# 在云端获取token
keadm gettoken
# 在边缘节点执行join命令
keadm join --cloudcore-ipport=192.168.1.10:10000 \
--token=<your-token> \
--kubeedge-version=1.15.0
# 在云端验证边缘节点已加入
kubectl get nodes
边缘节点加入后,会在Kubernetes集群中显示为一个特殊的Node,打上了edge标签。接下来创建EdgeCluster资源将其纳入Kurator管理:
apiVersion: [cluster.kurator.dev/v1alpha1](http://cluster.kurator.dev/v1alpha1)
kind: EdgeCluster
metadata:
name: edge-location-1
namespace: kurator-system
spec:
provider: kubeedge
region: edge-cn-shanghai
nodeSelector:
matchLabels:
[node-role.kubernetes.io/edge](http://node-role.kubernetes.io/edge): ""
deviceProfiles:
- name: temperature-sensor
protocol: modbus
5.4 边缘应用的统一分发与管理
Kurator支持将应用同时分发到云端集群和边缘集群,并根据边缘的特点进行优化配置:
apiVersion: [apps.kurator.dev/v1alpha1](http://apps.kurator.dev/v1alpha1)
kind: Application
metadata:
name: iot-data-collector
namespace: default
spec:
source:
imageRegistry:
url: [docker.io/myorg/iot-collector:v1.0](http://docker.io/myorg/iot-collector:v1.0)
syncPolicies:
- destination:
fleet: production-fleet
placement:
clusterAffinity:
matchLabels:
cluster-type: cloud
overrides:
- path: /spec/replicas
value: 3
- destination:
edgeCluster: edge-location-1
placement:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: [node-role.kubernetes.io/edge](http://node-role.kubernetes.io/edge)
operator: Exists
overrides:
- path: /spec/replicas
value: 1
- path: /spec/template/spec/resources/limits/memory
value: 512Mi
这个配置展示了差异化部署策略:云端集群部署3副本,边缘节点部署1副本且限制内存使用。Kurator会根据目标环境自动应用相应的配置覆盖。
六、Kurator统一应用分发流程深度剖析
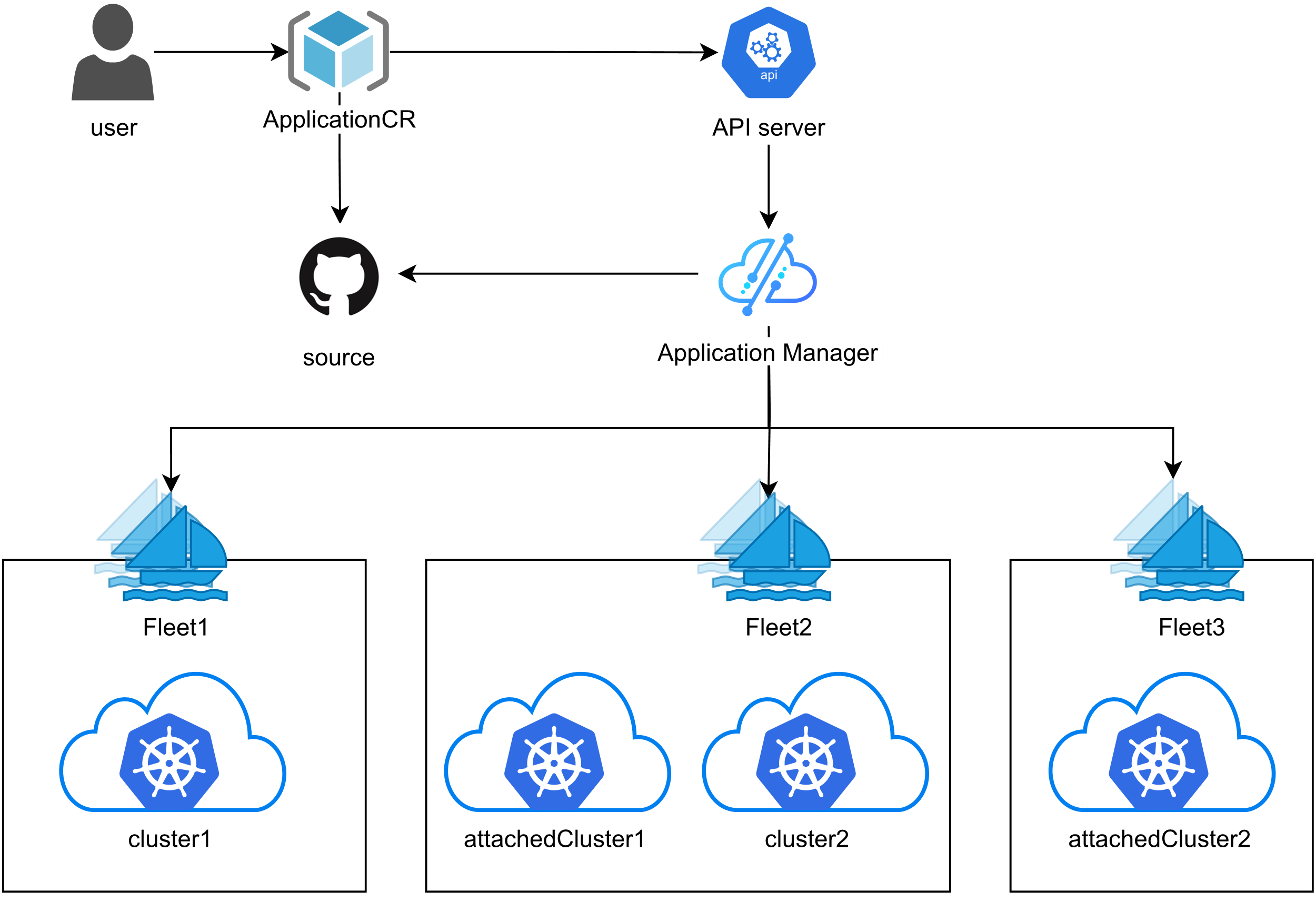
6.1 应用分发的声明式模型
Kurator的应用分发基于声明式模型,用户只需描述应用的期望状态和分发策略,无需关心具体的执行细节。Application CRD是分发流程的核心,它包含了应用的源信息、目标集群、配置覆盖、依赖关系等完整定义。
分发流程包括三个关键阶段:准备阶段,Application Controller解析用户配置,验证应用定义的合法性,获取镜像摘要等元数据;调度阶段,根据placement策略选择目标集群,调用Karmada调度器计算最优的副本分布;同步阶段,将应用资源推送到各个目标集群,并持续监控其运行状态。
6.2 实现GitOps风格的应用分发
Kurator支持从Git仓库拉取应用定义,实现GitOps工作流:
apiVersion: [apps.kurator.dev/v1alpha1](http://apps.kurator.dev/v1alpha1)
kind: Application
metadata:
name: demo-app
namespace: default
spec:
source:
gitRepository:
url: https://github.com/myorg/app-manifests.git
ref:
branch: main
path: ./kubernetes
interval: 5m
syncPolicies:
- destination:
fleet: production-fleet
syncOptions:
autoSync: true
prune: true
selfHeal: true
启用autoSync后,Kurator会定期从Git仓库同步最新配置,自动更新运行中的应用。prune选项确保删除仓库中已移除的资源,selfHeal选项则会修复用户手动修改的资源,始终保持与Git仓库的一致性。
6.3 多环境配置管理与差异化部署
实际业务中,同一应用在不同环境往往需要不同的配置参数。Kurator提供了强大的配置覆盖机制:
apiVersion: [apps.kurator.dev/v1alpha1](http://apps.kurator.dev/v1alpha1)
kind: Application
metadata:
name: backend-service
spec:
source:
kustomization:
path: ./base
syncPolicies:
- destination:
fleet: dev-fleet
kustomization:
overlay: ./overlays/dev
overrides:
- select:
kind: Deployment
name: backend
patches:
- path: /spec/replicas
value: 1
- path: /spec/template/spec/containers/0/env
value:
- name: ENV
value: development
- name: LOG_LEVEL
value: debug
- destination:
fleet: production-fleet
kustomization:
overlay: ./overlays/prod
overrides:
- select:
kind: Deployment
name: backend
patches:
- path: /spec/replicas
value: 10
- path: /spec/template/spec/containers/0/env
value:
- name: ENV
value: production
- name: LOG_LEVEL
value: info
通过Kustomize的overlay机制结合Kurator的patch能力,可以灵活管理多环境配置,避免重复定义。
6.4 应用依赖关系与部署顺序控制
复杂应用往往包含多个组件,组件之间存在依赖关系。Kurator的ApplicationSet提供了依赖管理能力:
apiVersion: [apps.kurator.dev/v1alpha1](http://apps.kurator.dev/v1alpha1)
kind: ApplicationSet
metadata:
name: microservices-stack
spec:
applications:
- name: mysql-db
source:
helmRepository:
url: https://charts.bitnami.com/bitnami
chart: mysql
version: 9.3.4
- name: redis-cache
source:
helmRepository:
url: https://charts.bitnami.com/bitnami
chart: redis
version: 17.3.7
- name: backend-api
dependencies:
- mysql-db
- redis-cache
source:
imageRegistry:
url: [myregistry.com/backend:v2.0](http://myregistry.com/backend:v2.0)
- name: frontend-web
dependencies:
- backend-api
source:
imageRegistry:
url: [myregistry.com/frontend:v2.0](http://myregistry.com/frontend:v2.0)
syncPolicy:
destination:
fleet: production-fleet
ApplicationSet会根据dependencies字段确定部署顺序,确保数据库和缓存先部署完成并进入Ready状态后,再部署依赖它们的后端服务。
七、Volcano调度器与Kurator的深度整合
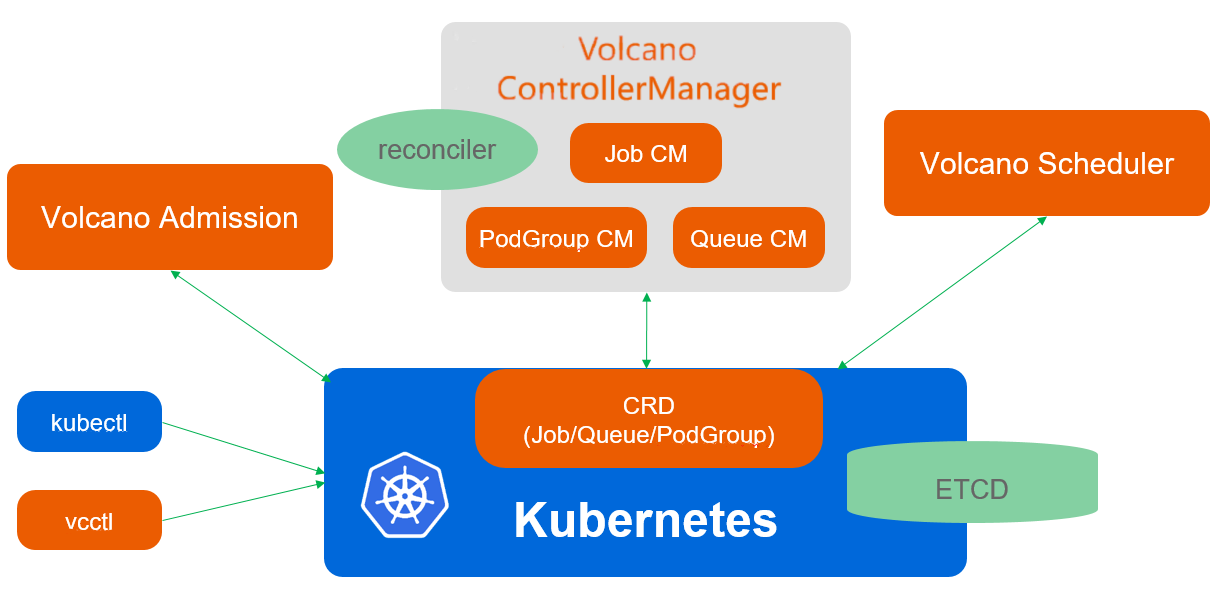
7.1 Volcano调度架构概述
Volcano是CNCF的批处理和AI训练场景调度器,提供了丰富的调度算法和资源管理能力。Kurator集成Volcano是为了增强批量作业和高性能计算场景的调度能力。在多集群环境中,Volcano的gang scheduling(组调度)、队列管理、资源预留等特性尤为重要。
Volcano的架构包括三个核心组件:volcano-scheduler实现各类高级调度算法,volcano-controller-manager管理Job、Queue等自定义资源的生命周期,volcano-admission提供准入控制和资源配额校验。Kurator将Volcano部署在各成员集群中,并通过全局策略协调跨集群的作业调度。
7.2 在Kurator环境中部署Volcano
为Kurator管理的集群批量部署Volcano:
# 创建Volcano部署配置
cat > volcano-addon.yaml <<EOF
apiVersion: [apps.kurator.dev/v1alpha1](http://apps.kurator.dev/v1alpha1)
kind: ClusterAddon
metadata:
name: volcano-addon
namespace: kurator-system
spec:
targetFleets:
- production-fleet
addon:
name: volcano
version: v1.8.0
helmChart:
repo: https://volcano-sh.github.io/helm-charts
chart: volcano
values:
scheduler:
replicas: 2
image:
repository: volcanosh/vc-scheduler
tag: v1.8.0
controller:
replicas: 2
EOF
# 应用配置,Kurator会自动在fleet中的所有集群安装Volcano
kubectl apply -f volcano-addon.yaml
# 验证部署状态
kubectl get clusteraddon volcano-addon -n kurator-system
7.3 配置多集群批量作业调度策略
Volcano的Queue资源用于作业队列管理和资源配额分配:
apiVersion: [scheduling.volcano.sh/v1beta1](http://scheduling.volcano.sh/v1beta1)
kind: Queue
metadata:
name: ai-training-queue
spec:
weight: 100
capability:
cpu: "100"
memory: 500Gi
[nvidia.com/gpu](http://nvidia.com/gpu): "20"
reclaimable: true
---
apiVersion: [batch.volcano.sh/v1alpha1](http://batch.volcano.sh/v1alpha1)
kind: Job
metadata:
name: distributed-training
spec:
minAvailable: 4
schedulerName: volcano
queue: ai-training-queue
tasks:
- replicas: 4
name: worker
template:
spec:
containers:
- name: trainer
image: tensorflow/tensorflow:2.11.0-gpu
command:
- python
- /app/[train.py](http://train.py)
resources:
limits:
[nvidia.com/gpu](http://nvidia.com/gpu): 1
memory: 8Gi
requests:
[nvidia.com/gpu](http://nvidia.com/gpu): 1
memory: 8Gi
restartPolicy: OnFailure
这个配置定义了一个分布式训练任务,需要4个GPU节点。minAvailable指定了gang scheduling的最小副本数,只有当4个Pod都可以被调度时,任务才会启动,避免了资源死锁。
7.4 跨集群资源池化与统一调度
Kurator的全局调度器可以将多个集群的资源池化,实现统一调度:
apiVersion: [apps.kurator.dev/v1alpha1](http://apps.kurator.dev/v1alpha1)
kind: GlobalJob
metadata:
name: big-data-processing
spec:
jobTemplate:
apiVersion: [batch.volcano.sh/v1alpha1](http://batch.volcano.sh/v1alpha1)
kind: Job
spec:
minAvailable: 10
schedulerName: volcano
tasks:
- replicas: 10
name: processor
template:
spec:
containers:
- name: spark
image: spark:3.3.1
placement:
spreadConstraints:
- maxSkew: 2
topologyKey: cluster
whenUnsatisfiable: DoNotSchedule
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: ScheduleAnyway
GlobalJob会在多个集群中分配任务副本,spreadConstraints确保副本在集群和可用区维度的均匀分布。当某个集群资源不足时,Volcano会自动将任务调度到其他集群,实现了资源的高效利用。
八、Kurator未来发展方向与展望

8.1 AI驱动的智能调度与优化
随着云原生与AI技术的深度融合,Kurator的未来版本将引入AI驱动的智能调度能力。通过机器学习模型分析历史的资源使用数据、应用性能指标和成本信息,预测应用的资源需求和运行模式,从而实现更精准的调度决策。例如,根据应用的访问峰谷特征,自动调整副本分布和资源配额;基于成本模型,在满足SLA的前提下选择最经济的集群和节点类型。
Kurator还计划集成AIOps能力,通过异常检测算法识别性能瓶颈和潜在故障,提前触发弹性伸缩或故障迁移。这种主动式的运维模式将大幅提升系统的可靠性和运维效率。
8.2 增强的边缘计算与IoT集成
边缘计算是Kurator重点发展的方向。未来将进一步增强与KubeEdge、OpenYurt等边缘项目的集成,支持更多类型的边缘设备接入。计划中的EdgeMesh功能将提供边缘节点之间的直接通信能力,减少云边流量和延迟。EdgeAI功能则支持将AI推理模型部署到边缘侧,实现本地化的实时决策。
IoT设备管理也是重要的扩展点。Kurator将提供设备影子、设备孪生等概念,统一管理海量的IoT设备,并实现设备数据与云原生应用的无缝集成。
8.3 多云成本优化与FinOps实践
在多云环境中,成本管理是企业关注的重点。Kurator计划引入FinOps功能,实时收集各云平台的资源使用和账单数据,提供统一的成本视图和分析报告。结合策略引擎,可以实现成本驱动的调度决策,比如在保证性能的前提下,优先使用Spot实例或选择价格更低的区域部署应用。
成本预测和预算告警功能将帮助企业更好地规划云资源支出。Kurator还将提供成本优化建议,如识别闲置资源、推荐合适的实例类型等,助力企业降本增效。
8.4 安全增强与合规性管理
云原生安全是Kurator持续加强的领域。未来版本将集成更多安全工具,如Falco(运行时安全)、Trivy(镜像扫描)、OPA(策略引擎),构建纵深防御体系。Kurator将提供统一的安全策略管理界面,支持跨集群的安全配置一致性校验和自动修复。
在合规性方面,Kurator将支持多种行业标准和监管要求,如SOC2、ISO27001、等保等。通过自动化的合规性检查和审计日志,帮助企业满足监管要求,降低合规风险。
8.5 开放生态与社区建设
Kurator致力于构建开放的云原生生态。通过标准化的插件接口,第三方厂商和开发者可以方便地扩展Kurator的功能,比如接入新的云平台、增加自定义调度算法、集成特定的运维工具等。Kurator将建立活跃的开源社区,鼓励用户贡献代码、分享实践经验、参与技术讨论。
未来,Kurator还计划推动多集群管理标准的制定,与CNCF的其他项目紧密合作,共同推动云原生技术的发展和普及。
总结
本文从实践角度深入剖析了Kurator云原生平台的架构设计与应用场景。从环境搭建到核心组件部署,从Fleet集群管理到Karmada多集群编排,从KubeEdge边缘计算到Volcano批量调度,我们全面展示了Kurator在分布式云原生领域的能力和价值。
Kurator的核心优势在于其开放性、可扩展性和深度的生态集成。它不是简单的功能堆砌,而是有机整合了CNCF生态的优秀项目,形成了端到端的云原生治理解决方案。通过声明式API和GitOps工作流,Kurator极大地简化了多集群管理的复杂度,让运维团队能够以一致的方式管理跨云、跨区域、跨边缘的Kubernetes环境。
在实践中,我们也看到了Kurator在统一应用分发、差异化配置管理、智能调度等方面的强大能力。这些能力不仅提升了运维效率,更为企业的数字化转型提供了坚实的技术底座。随着AI、边缘计算、FinOps等新技术的融入,Kurator将持续演进,引领云原生技术的下一个十年。
对于云原生从业者而言,深入学习和实践Kurator,不仅能够掌握前沿的技术趋势,更能培养系统化的架构思维和工程能力。希望本文的分享能够为大家的云原生之旅提供有价值的参考。让我们共同期待Kurator在云原生领域创造更多的可能性。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)