强化学习·价值学习-MC,TD和Q-learning算法
本文介绍了强化学习中的价值学习方法,包括蒙特卡洛(MC)、时序差分(TD)和Q-learning算法。MC方法在完整序列结束后更新V-value,而TD方法每一步都更新。Q-learning通过更新Q-value实现更高效学习,采用贪心策略选择最优动作,属于off-policy方法。文章还讨论了on-policy与off-policy的区别,并通过数值例子和代码实现展示了Q-learning的具体
文章目录
价值学习方法
更新的是V-value或Q-value。
策略函数是价值的结果
- 策略函数一般是Greedy或者eplison-Greedy策略。 π ( a ∣ s ) : a ∗ = arg max a Q ( s , a ) \pi(a|s):a^*=\arg\max_a{Q(s,a)} π(a∣s):a∗=argmaxaQ(s,a)
Greedy策略:始终选择使得Q-value或者V-value的最大的动作。
eps:控制探索和利用的比例,防止陷入局部最优解。
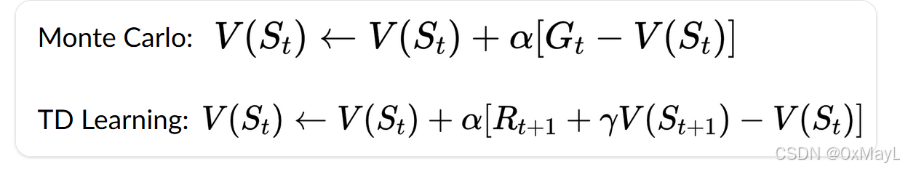
蒙特卡洛(MC)
核心思想
learning at the end of the episode,只在一次完整的序列结束后才更新V-value。
实现
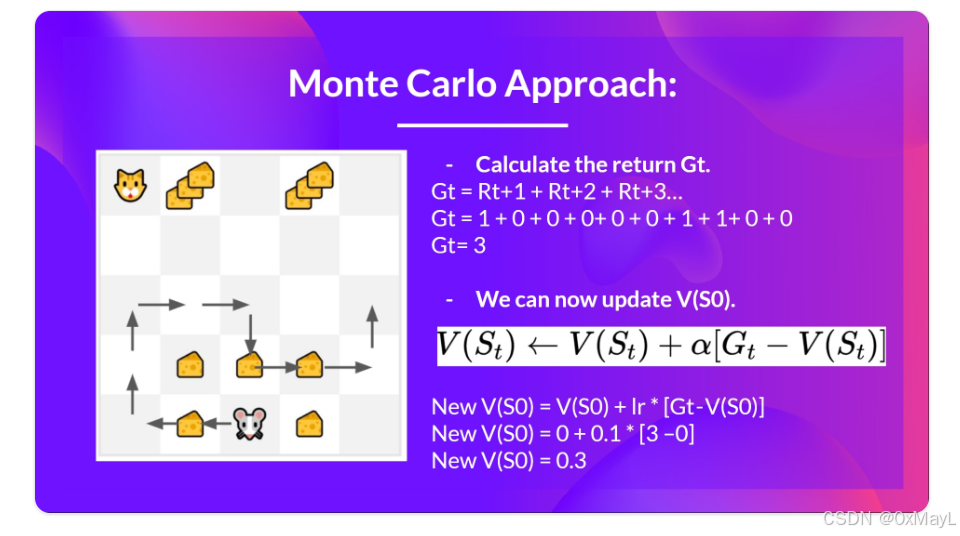
更新公式如下:
- α \alpha α:学习率
- G t − V ( S t ) G_t-V(S_t) Gt−V(St):类似深度学习中的梯度,我们需要"向上"更新新的V-value。
- G t G_t Gt表示未来的累积奖励,必须在一个完整序列结束后才能知道。

数值例子
时序差分(TD)
核心思想
每一步更新一遍V-value。
实现
- 一开始对于所有V-value初始化为0
- 对于当前时刻的状态 s t s_t st,使用公式更新 v t + 1 ( s t ) v_{t+1}(s_t) vt+1(st)
- 对于其他状态(没有被当前时刻选中的状态),其V-value保持不变。


数值例子
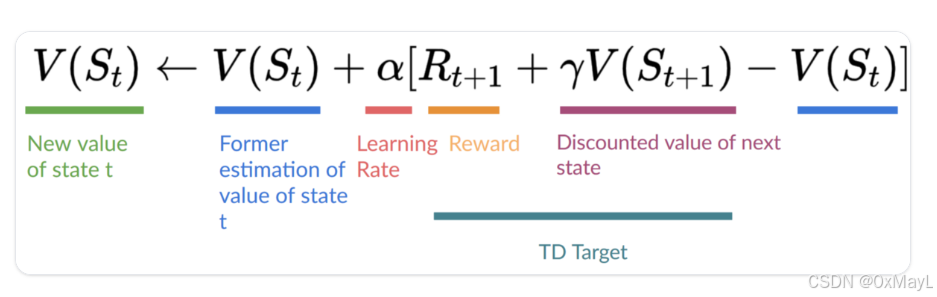
- s_0表示我们处于起点,s_1表示我们吃掉第一个奶酪。
- R_1+s_1表示我们新的估计,也叫做TD Target。
- 新的估计和原始估计的差值代表一种"梯度",表示更新方向。

Q-learning
定义
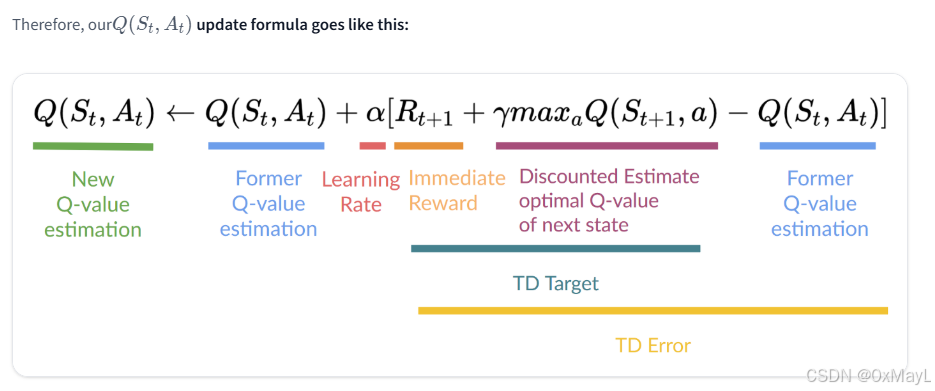
- 与TD算法关键的区别在于:这次我们要更新的是Q-value,一个动作和状态的元组( V ( S t + 1 ) → Q ( S t + 1 , A t + 1 ) ) V(S_{t+1})\rightarrow Q(S_{t+1},A_{t+1})) V(St+1)→Q(St+1,At+1))),需要事先考虑随机变量 A t + 1 A_{t+1} At+1的取值。
- 我们在进行step之后,并不知道下一次状态选择哪一个动作,因此这里我们可以采取一些策略:可以保持与policy π \pi π一致,可以选择其他的策略,一般Q-learning选择贪心策略,即选择最优的Q-value估计。
算法
- 在当前状态 s t s_t st,首先根据policy π \pi π得到动作 a t a_t at。
- 然后我们转移到下一个状态 s t + 1 s_{t+1} st+1得到即刻奖励 r t + 1 r_{t+1} rt+1。
- 我们现在有四个元组 ( s t , a t , s t + 1 , r t + 1 ) (s_t,a_t,s_{t+1},r_{t+1}) (st,at,st+1,rt+1)
- 需要确定 Q ( s t + 1 , A t + 1 ) Q_(s_{t+1},A_{t+1}) Q(st+1,At+1),通常我们遍历所有的 A t + 1 A_{t+1} At+1选择最大Q-value的动作: max a ′ Q ( s t + 1 , a ′ ) \max_{a'}Q(s_{t+1},a') maxa′Q(st+1,a′)作为我们估计的Q-value。
- 根据TD算法的公式对现有状态的Q-value进行更新。
- 注意:其他状态的Q-value保持不变。

Off-policy和On-policy
选择动作时的策略(例如Greedy和eplison-Greedy)是否与更新时的策略(Greedy)一致。
例如:Q-learning使用贪心策略更新Q-value的估计,但是Saras选择eps-贪心策略,确保与动作选择一致。因此前者是off-policy(与policy不一致),后者是on-policy(与policy)一致。
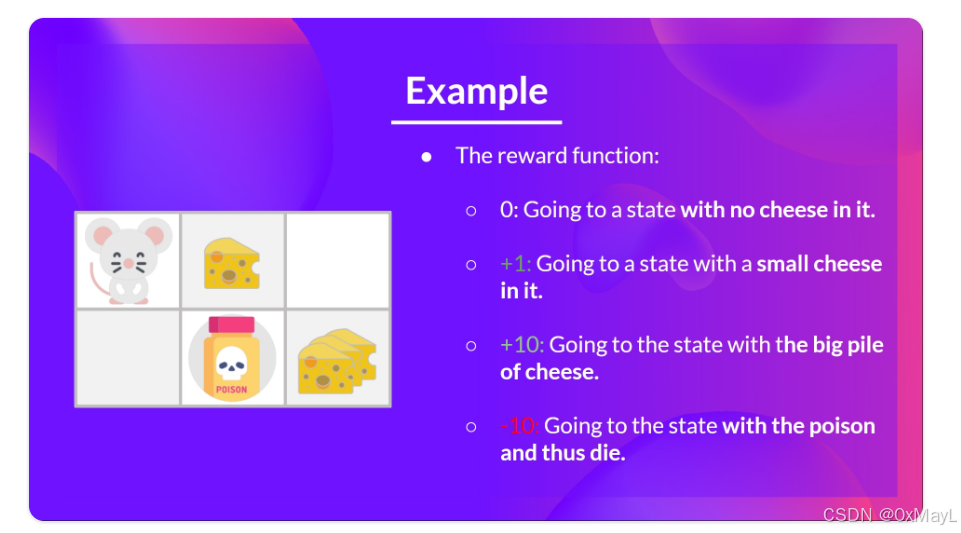
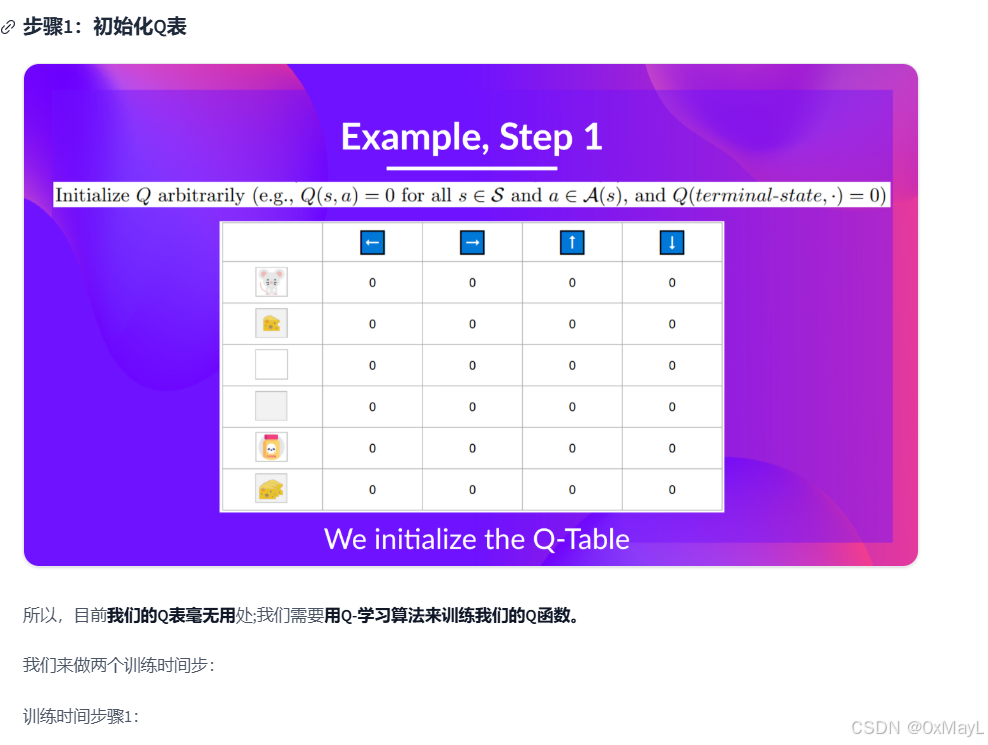
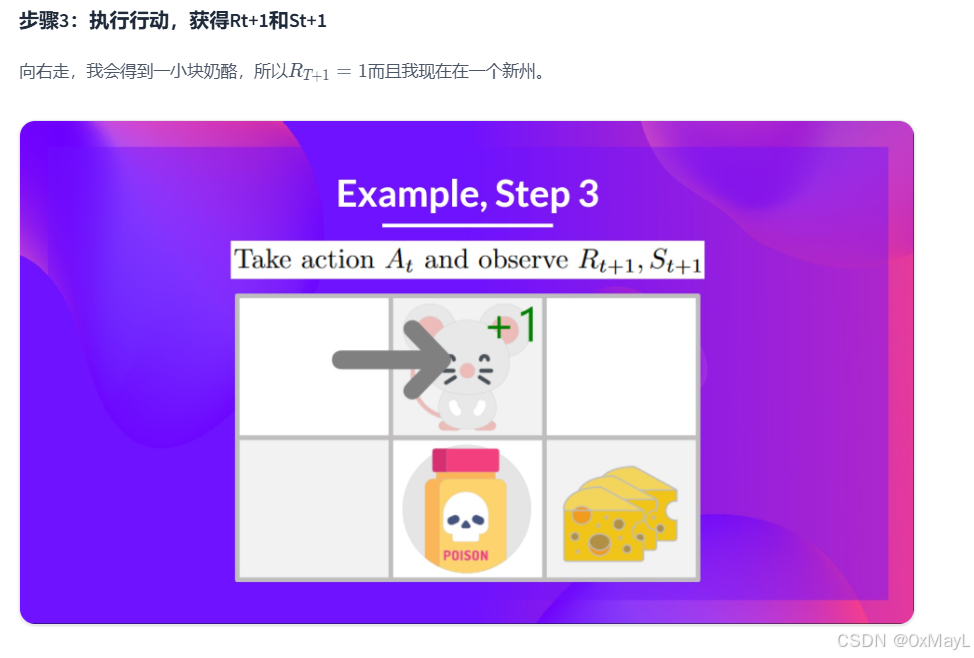
数值例子



代码实现

The training loop goes like this:
For episode in the total of training episodes:
Reduce epsilon (since we need less and less exploration)
Reset the environment
For step in max timesteps:
Choose the action At using epsilon greedy policy
Take the action (a) and observe the outcome state(s') and reward (r)
Update the Q-value Q(s,a) using Bellman equation Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
If done, finish the episode
Our next state is the new state
- 实现起来就是两个for循环,第一个for循环遍历每一个完整动作序列,第二个for循环遍历每一个动作。
- 然后根据公式采取行动,更新之前状态的Q表即可!
def train(n_training_episodes, min_epsilon, max_epsilon, decay_rate, env, max_steps, Qtable):
for episode in tqdm(range(n_training_episodes)):
# Reduce epsilon (because we need less and less exploration)
epsilon = min_epsilon + (max_epsilon - min_epsilon)*np.exp(-decay_rate*episode)
# Reset the environment
state, info = env.reset()
step = 0
terminated = False
truncated = False
# repeat
for step in range(max_steps):
# Choose the action At using epsilon greedy policy
action = epsilon_greedy_policy(Qtable, state, epsilon)
# Take action At and observe Rt+1 and St+1
# Take the action (a) and observe the outcome state(s') and reward (r)
new_state, reward, terminated, truncated, info = env.step(action)
# Update Q(s,a):= Q(s,a) + lr [R(s,a) + gamma * max Q(s',a') - Q(s,a)]
Qtable[state][action] = Qtable[state,action] + learning_rate * (reward + gamma * np.max(Qtable[new_state,:])-Qtable[state,action])
# If terminated or truncated finish the episode
if terminated or truncated:
break
# Our next state is the new state
state = new_state
return Qtable
Deep Q-learning
Q-learning只适合状态数较少的情况,如果对应星际入侵这种游戏,那么状态空间太大,不适合使用表格法的方法更新Q-value.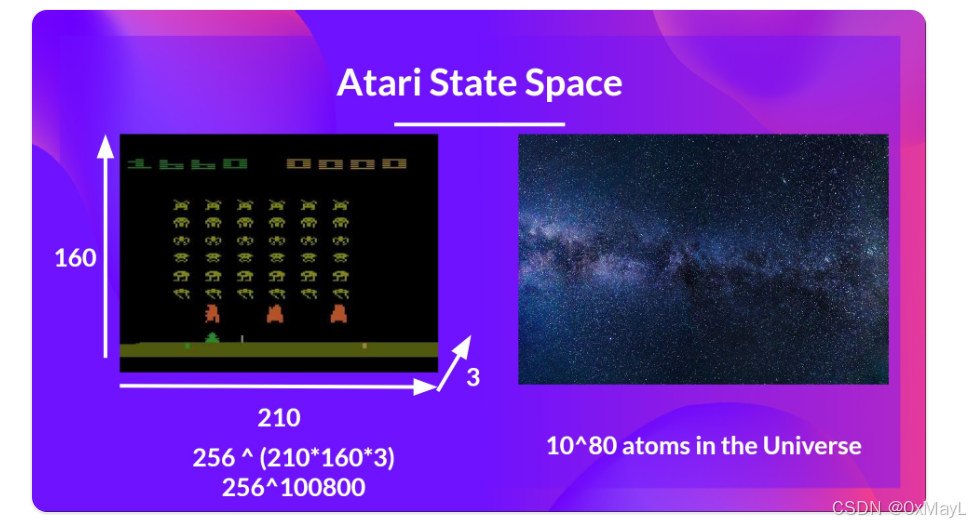
使用神经网络Q-Network来接受状态(这时候状态不一定是像素,而是一张图片,甚至是抽象的东西),然后输出对应动作的Q值(就是一个n_action维度的向量)。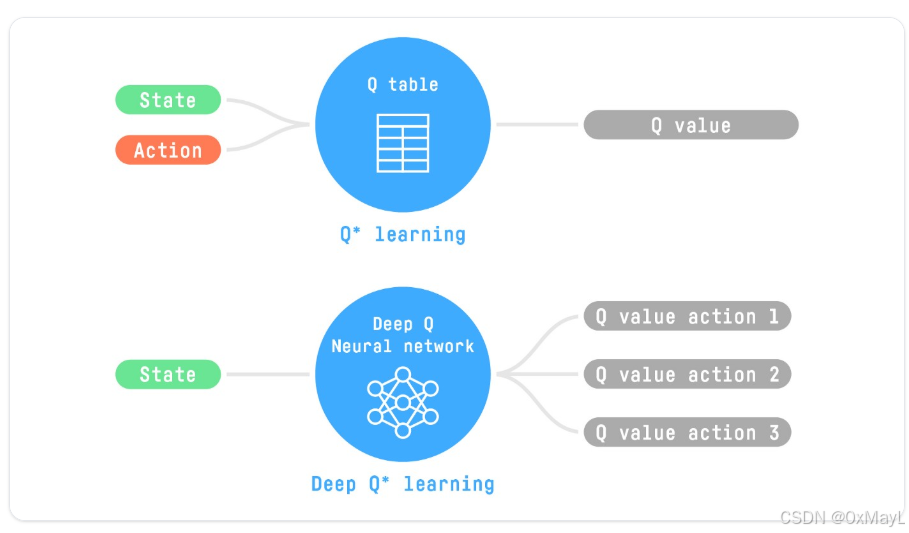
数据处理
- 简单来说就是对画面进行简化处理,降低状态,同时提供运动信息。

实现
- 我们有两个网络:Q-Network和Q-Target。
- Q-Network用于表示当前对于状态s,给定a下的经验估计
- Q-Target表示对于未来状态s’的经验估计


这并不是与Q-Learning相比的唯一区别。深度Q学习训练可能存在不稳定性,主要原因是结合了非线性Q值函数(神经网络)和自助法(即用现有估计值更新目标,而非实际完整回报)。
为了帮助我们稳定培训,我们实施了三种不同的解决方案:
- 体验重玩以更高效地利用经验。
- 固定Q目标以稳定训练。
- 双深度Q学习,用于处理Q值高估的问题。
经验回放
- 解决了状态之间相关性比较强的问题

固定Q-Target
- 我们对于Q-Target一无所知,我们通常使用Q-Network的参数来对齐Q-Target,问题是Q-Target的参数变化会随着Q-Network而变化,这就导致了训练时候的更新路径震荡和不确定。
- 解决方法:没固定C个step才更新一次Q-target,分为软更新(加权平滑)和硬更新(直接赋值)。

双重Q-Network


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)