OpenClaw 持久化记忆原理深度拆解:本地存储与向量数据库的局限与最优解
本文探讨了OpenClaw的持久化记忆系统原理及其优化方向。OpenClaw采用本地Markdown文件作为记忆存储,具有简单透明、可编辑的优势,但面临上下文窗口限制、检索效率低和并发写入问题。向量数据库虽能实现语义检索和海量存储,却存在chunking策略困难、精确检索不足和维护成本高的局限。作者提出分层存储的混合方案:热层(内存)处理当前会话,温层(Markdown/SQLite)存储结构化信
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
OpenClaw的持久化记忆是什么原理?本地存储和向量数据库方案各有什么局限?
一、OpenClaw的记忆设计哲学
OpenClaw的记忆系统是本地Markdown文件,这是一个刻意的设计选择,而不是偷懒。
说人话就是: 想象你有一个记事本,每次和朋友聊天后,你都会把重要的事情手写记录下来。下次见面时,你会先翻看这个记事本,回忆之前聊过什么,然后再继续对话。OpenClaw就是这样工作的——它用人类可读的Markdown文件作为"记事本",简单、透明、可直接编辑。
这种设计完全符合"个人本地部署"的定位:你的记忆就是你的文件,不需要任何额外服务,不需要网络连接,你可以随时打开、编辑、备份或删除。
OpenClaw记忆系统的核心组件
- MEMORY.md:长期记忆,存储重要决策、偏好、关键信息
- HEARTBEAT.md:定时任务指令,告诉Agent需要定期检查什么
- Sessions目录:对话历史记录,按日期和会话分类存储
- SKILL.md:技能定义文件,也是Markdown格式
Brain在每次推理前读入这些文件作为上下文,推理后把需要记住的内容写回去。整个系统对人类可读、可审计。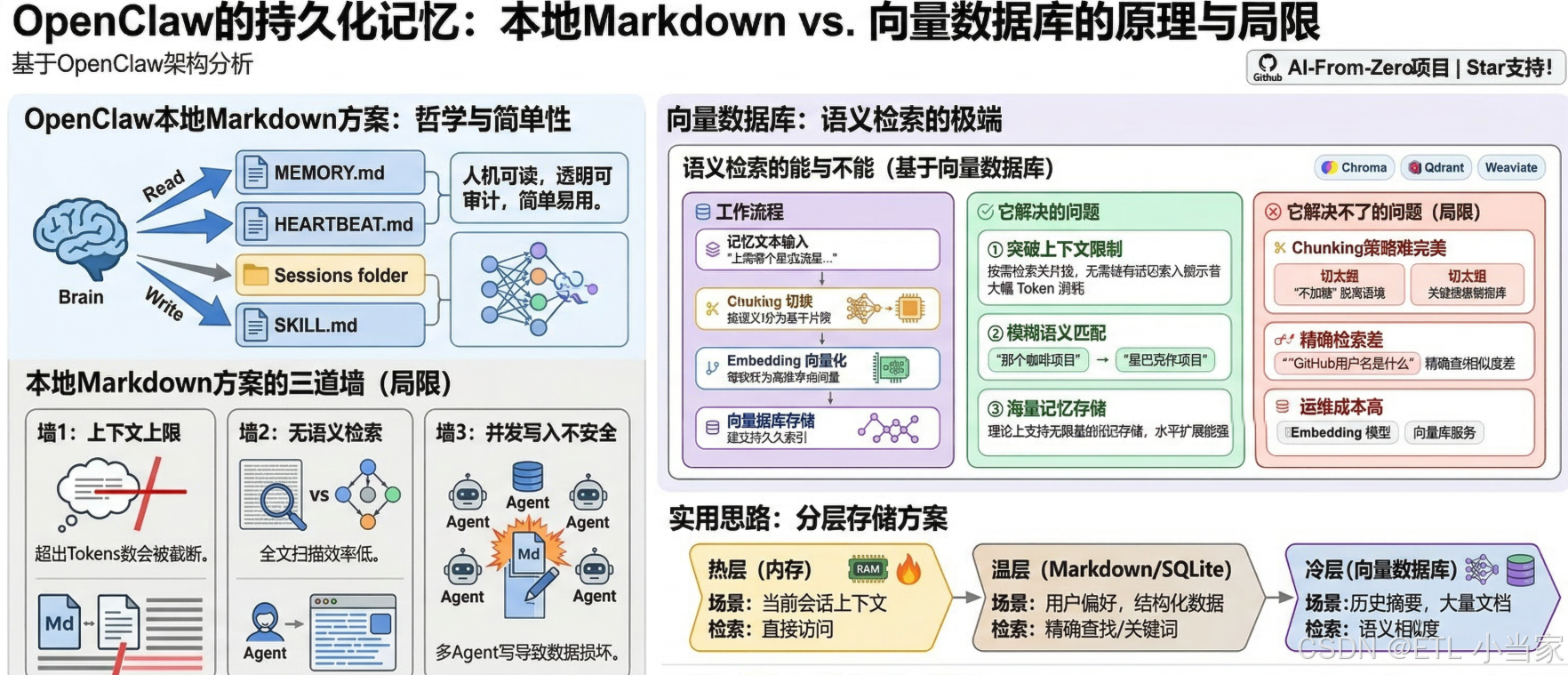
二、本地Markdown方案的三道墙
尽管Markdown方案简单优雅,但它面临着三个根本性的限制:
第一道墙:上下文窗口上限
每次推理都要把MEMORY.md和相关Session塞进提示词。当前主流LLM的上下文窗口虽已达到数十万tokens,但一个活跃使用几个月的Agent,Session历史加上积累的记忆,很容易突破这个限制。
最致命的问题是: 超出部分会被截断——而且通常是截掉最早的内容,那恰恰可能是最重要的长期偏好(比如"用户不喜欢收到周末通知")。
第二道墙:没有语义检索
Brain读进去的是全文,检索依赖LLM自己在上下文里找相关内容。如果你的记忆里有500条条目,LLM需要"阅读"全部500条才能找到相关的3条。
这不仅消耗大量tokens,还会引入注意力稀释问题——相关内容被淹没在大量无关内容中,LLM的回答质量随之下降。
第三道墙:并发写入不安全
多Agent场景下,如果两个Agent同时尝试写MEMORY.md,会产生竞争条件,导致数据损坏或丢失。Markdown文件没有事务机制,这是文件系统存储的固有局限。
| 限制类型 | 具体表现 | 影响程度 |
|---|---|---|
| 容量限制 | 上下文窗口装不下所有记忆 | 高 - 直接导致记忆丢失 |
| 检索效率 | 需要全文扫描找相关信息 | 中 - 消耗tokens,降低质量 |
| 并发安全 | 多Agent写入可能导致数据损坏 | 低 - 单Agent场景不明显 |
三、向量数据库:另一个极端
向量数据库(如Chroma、Qdrant、Weaviate)代表了记忆系统的另一个方向:语义检索。
核心思想是把记忆切成语义块,用embedding模型把每块转成高维向量,检索时把问题也向量化,找最近邻。这让"我上周提到的那个项目名叫什么"这类语义查询变得高效。
向量数据库能解决什么?
- 突破上下文限制:不再需要把所有记忆塞进提示词
- 语义匹配:理解"那个咖啡项目"指的是"星巴克合作项目"
- 海量存储:理论上可以支持无限量的记忆存储
但向量数据库解决不了什么?
Chunking策略很难做对
记忆切成多大的块?按句子切还是按段落切?
- 切得太细:语义不完整("不加糖"脱离了"咖啡"上下文)
- 切得太粗:检索精度下降(重要内容被淹没在大块文本中)
精确信息检索不如全文搜索
“我的GitHub用户名是什么”——这是一个精确查找,向量相似度搜索在这类问题上并不比全文匹配更好,有时候还更差。
向量数据库擅长模糊语义匹配,不擅长精确键值查找。
需要额外维护成本
一个embedding模型、一个向量数据库服务、chunking pipeline——这些对于"个人本地Agent"来说是不小的运维负担,和OpenClaw的定位有些违和。
四、更实用的混合思路:分层存储
实践中,最合理的方案往往不是二选一,而是分层存储:
记忆分层
├── 热层(内存):当前会话上下文,随用随销
├── 温层(Markdown / SQLite):结构化长期记忆,精确查找
└── 冷层(向量数据库):历史摘要、大量文档,语义检索
分层存储的具体实现
| 层级 | 存储方式 | 适用场景 | 检索方式 |
|---|---|---|---|
| 热层 | 内存 | 当前对话上下文 | 直接访问 |
| 温层 | Markdown/SQLite | 用户偏好、账号信息、待办事项 | 精确查找/关键词匹配 |
| 冷层 | 向量数据库 | 历史对话摘要、项目背景、文档内容 | 语义相似度检索 |
在OpenClaw中的实际应用
这个思路在OpenClaw的当前架构下做局部改造是可行的:
- Brain在每次Session结束时生成摘要,并向量化存入冷层
- 下次相关话题出现时先检索冷层,把相关片段注入上下文
- 而不是把全部Session历史一股脑塞进去
这样做的好处是:
- 记忆有效容量从"上下文窗口大小"扩展到"向量库容量上限"
- 检索精度在结构化信息上保持精确,在语义信息上保持灵活
- 系统复杂度只在必要时增加,保持核心简单性
五、核心结论:没有完美的方案
两种方案都没有完美答案。理解它们各自在什么场景下失效,比知道哪个"更好"更重要。
- 如果你的记忆主要是结构化的个人信息(日程、偏好、待办),Markdown方案可能更合适
- 如果你需要处理大量非结构化文档和历史对话,向量数据库的价值更大
- 如果你两者都需要,分层存储是最实用的折中方案
OpenClaw的Markdown设计体现了"简单即美"的哲学,但在实际使用中,我们需要根据自己的需求选择合适的记忆策略。毕竟,好的工具应该适应用户,而不是让用户适应工具。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)