ollama+llm+springai集成
本文详细介绍了ollama+anything+llm本地环境搭建与RAG检索增强环境的配置方法。主要内容包括:1)ollama的安装配置及模型下载;2)与SpringAI的集成验证,包括ChatClient、ChatModel、工具调用和MCPServer的实现;3)AnythingLLM的安装使用,重点讲解Workspace工作区配置和RAG文档验证;4)常用ollama命令汇总。文章指出Spr
引言
本文主要介绍 ollama+anything+llm本地环境搭建与rag检索增强环境搭建,与spring ai集成验证等内容,是一套很完整的框架体系。内容会持续更新,多多关注和留言,相互学习。
springAI框架还是一个快速迭代中版本,目前2.0里程杯版本已经开始,1.0的版本已经支持AI应用的大部分功能,做AI应用应该是足够了。因为AI模型最初的研究起源是基于python语言的,所以AI Agent智能体应用功早期的框架是也是用python写的(比如langchain),所以SpringAI发展相对比较滞后。另外一个原因是智能体应用到现在其实也还比较新,框架也在迭代(比如LangGraph替代langchain变成架构 ),SpingAI也不列外。
做AI智能体应用,个人认为在API同样成熟的条件下(或者可接受的稍微落后),大规模长期使用SpringAI我觉得是更好的选择,因为SpringAI具有天生的语言优势。Java是天生的强类型、面向对象的语言,更容易理解和维护。你看到很多讲面向对象设计思想的示例,几乎都是用的Java语言。不用脚本语言或者Go等语言原因,主要这些语言不是天生的面向对象语言,都是发现自己不好维护了之后,在想办法模拟面向对象、强类型语言特性,所以把自己搞得不论不类的,看起了来别扭。当然java也有点自己的问题,他也在模仿弱类型语言比如lambda,var关键字。这玩意使用不当也会让代码不好理解和维护,有很多新增的特性我都不轻易的用,比如接口的默认方法。scala整个语言就是语法过于复杂,实现一个东西有多种写法,让人容易记忆混乱,脑裂,当然这玩意估计都没有意识到这个问题。当时有点想干掉java的念头,不过这玩意十多年过去了,都没有成功。因为我为了研究spark源码,专门学了scala语言,两周后全忘记了,又学复习了一遍,两周没有又忘记了。现在吹的很火的TypeScript语法也是相当炸裂和scala有得一拼。很多公司都在用Go语言,吹嘘Go的优秀,我也充满了好奇得学了一把,发现那玩意就是一个多了垃圾回的C,还有指针概念,面向对象也是使用结构体模拟,反正很扯,这完全是C干的事情。Go语言更最初的选择应该都是一群搞C的,但是奇怪的是公司喜欢招java的兼职干Go(或者让你转Go),实际上Go更适合做C的搞。Python也在向强类型靠近(变量后边可以加类型)。
当语言用户和应用规模变大后,面向对象、强类型对后期维护的优势就越发明显。所以那些弱类型、非面向对对象语言都在想尽办法模拟,你却没有感觉到Java的优势,有点可悲。当然C++其实也是也是一门不错的面向对象语言,只是毕业后就转java了。rust这们语言据说性能靠近C/C++(没有GC),就是学习曲线陡峭(陡峭有点吓人),如果这玩意能变得易小学,性能变得更好、框架也成熟易用,估计会取代很多语言。
上面说了这么多,主要是想表达SpringAI更适合做大规模、长期稳定的生产应用,python还是适合做模型、研究小的应用。python生态和规范也在逐步完善,使用也需要做好工程化管理。这是很多公司都没有实际重视的问题,这又让我想到了扁鹊三兄弟的故事。
SpringAI框架主要包括:聊天客户端(chatClient)、Tools、MCPServer、MCPClient、ChatMemory、VectorStore几个主要部分。下面会对整个体系逐一介绍,虽然不是生产级别的实践场景,但也会对生产环境做出一些提示或者思考的地方。
1 ollama简介
1 Ollama 的核心优势
1 极致的易用性
一键运行: 无需手动下载几十GB的模型权重文件,无需配置复杂的 Python 环境或依赖库。只需一条命令 ollama run llama3.2 即可自动下载并启动模型。
Docker 般的体验: 它将模型权重、配置参数和运行环境打包成一个整体(Modelfile),像管理 Docker 容器一样管理 AI 模型,屏蔽了底层技术细节。
跨平台支持: 完美支持 macOS (包括 Apple Silicon M1/M2/M3)、Windows 和 Linux,且在各类硬件上都能自动优化(如自动调用 Metal, CUDA, ROCm)。
2 数据隐私与安全
完全本地化: 所有推理过程都在用户自己的设备上完成,数据永不上传云端。这对于处理敏感数据(如医疗记录、法律文档、公司代码、个人隐私)至关重要。
离线运行: 一旦模型下载完成,即可在无网络环境下使用,适合内网隔离环境、飞机上或野外作业场景。
自主可控: 用户拥有模型的完全控制权,不用担心云服务商的API封禁、服务中断或数据被用于训练。
3 零成本与无限使用
免费开源: 软件本身免费,模型多为开源协议(如 Apache 2.0, MIT),无 API 调用费用。
无限制: 没有请求次数限制(Rate Limits),没有并发数限制(仅受限于本地硬件),可以7x24小时随意调用,适合高频测试和大量生成任务。
4 强大的生态兼容性
OpenAI API 兼容: Ollama 原生模拟 OpenAI 的 API 接口 (/v1/chat/completions)。这意味着任何支持 OpenAI SDK 的应用(如 LangChain, LlamaIndex, Next.js AI SDK, 各种聊天前端)只需修改一行配置(Base URL)即可无缝切换到本地 Ollama。
丰富的模型库: 官方库收录了数百种主流模型(Llama 3, Qwen 2.5, DeepSeek, Mistral, Gemma等),且社区更新极快,新模型发布后通常几天内即可在 Ollama 上运行。
自定义模型: 支持通过 Modelfile 轻松创建自定义模型(调整系统提示词、温度参数、绑定特定工具),便于微调后的模型部署。
5 硬件自适应优化 (Hardware Optimization)
智能量化: 默认加载经过量化的 GGUF 格式模型,大幅降低显存/内存需求,使得在消费级显卡(甚至纯 CPU)上运行大模型成为可能。混合卸载: 自动判断显存大小,将模型层智能分配给 GPU 和 CPU,最大化利用现有硬件资源。
2 典型应用场景
1 个人开发者与学习者
快速原型开发: 在开发 AI 应用(如 RAG 知识库、Agent)时,先用 Ollama 本地调试逻辑,无需花费昂贵的 API 费用,调试通后再切换至生产环境。学习大模型原理: 学生和研究者可以在本地自由实验不同参数、不同架构的模型,观察输出差异,无需担心成本。代码助手: 本地运行 CodeLlama 或 Qwen-Coder,集成到 VS Code 中作为私有的编程助手,代码不泄露给第三方。
2 企业与组织
敏感数据处理: 金融、法律、医疗等行业,需要将文档、合同、病历等敏感信息输入 AI 分析,但严禁数据出域。Ollama 提供了完美的私有化解决方案。
内部知识库 (RAG): 结合向量数据库,搭建企业内部的智能问答系统,员工可查询内部文档、规章制度,数据完全留存在内网。
低成本客服/办公助手: 对于并发要求不高但需要长期运行的内部办公场景(如邮件草稿生成、会议纪要总结),使用本地服务器运行 Ollama 可大幅降低运营成本。
3 特定行业与特殊环境
离线/弱网环境: 船舶、飞机、矿山、野外科考等网络不稳定或无网络的场景,本地部署的 Ollama 可提供持续的 AI 辅助能力。
边缘计算设备: 在高性能嵌入式设备(如 NVIDIA Jetson, 高端工控机)上部署 Ollama,实现端侧智能,减少云端延迟和带宽压力。
4. 隐私倡导者与普通用户
私人助理: 搭配 OpenClaw、Dify 或 Chatbox 等前端,打造完全属于自己的“贾维斯”,记录个人日程、日记、想法,无需担心被大厂扫描画像。
内容创作: 作家、博主可使用本地模型进行头脑风暴、大纲生成,避免创意被云端模型“偷窃”或污染。
3 局限性与注意事项
虽然 Ollama 很强,但它不是万能的,以下场景不适合直接使用 Ollama:
超高并发生产环境: 如果需要每秒处理数千个请求(如面向百万用户的公网服务),Ollama 的单机性能可能不足,此时应选用 vLLM 或 TensorRT-LLM 进行集群部署。
超大模型推理: 虽然 Ollama 支持大模型,但如果模型参数量远超本地显存+内存总和(如运行 405B 模型而只有 64G 内存),速度会极慢(主要靠 CPU 跑),体验不佳。
复杂分布式训练: Ollama 主要用于推理 (Inference),不支持大规模分布式微调训练(Fine-tuning)。
4 其他部署工具参考
vLLM (最热门的高性能引擎)
核心优势: 引入了 PagedAttention 技术,显存利用率极高,吞吐量比传统框架高 24 倍以上。支持连续批处理 (Continuous Batching)、张量并行 (Tensor Parallelism)。
适用场景: 高并发在线服务、SaaS 平台、需要最大化 GPU 利用率的场景。
特点: 原生兼容 OpenAI API,生态极其丰富,几乎成为行业标准。
缺点: 配置相对 Ollama 复杂,主要依赖 NVIDIA GPU,对消费级显卡的多卡支持门槛较高。
SGLang (结构化语言生成)
核心优势: 由伯克利团队开发,专为复杂交互和结构化输出优化。引入了 RadixAttention,在处理多轮对话、长上下文和复杂推理链(CoT)时性能极强,往往比 vLLM 更快。
适用场景: AI Agent 开发、复杂推理任务、需要严格 JSON/代码输出的场景。
特点: 编程模型灵活,支持高效的约束解码。
TGI (Text Generation Inference) (Hugging Face 官方出品)
核心优势: 企业级稳定性,原生支持 FlashAttention 和量化。是 Hugging Face Inference Endpoints 的底层引擎。
适用场景: 需要与 Hugging Face 生态深度集成、追求稳定性的企业部署。
现状: 虽然稳定,但在极致吞吐量上近期略逊于 vLLM 和 SGLang。
TensorRT-LLM (NVIDIA 官方出品)
核心优势: 针对 NVIDIA 硬件的极致优化。通过编译优化、内核融合等技术,能在 NVIDIA GPU 上获得最低的延迟和最高的吞吐。
适用场景: 大规模生产部署、对延迟极其敏感的实时应用。
缺点: 学习曲线陡峭,模型转换过程复杂,绑定 NVIDIA 生态。
LMDeploy (商汤科技开源)
核心优势: 一站式工具包,支持自动量化、多卡部署、服务化。在中文模型(如 Qwen, InternLM)支持上非常好,性能表现优异(常与 vLLM 对标)。
适用场景: 中文大模型部署、需要量化压缩的场景。
2 ollama安装
ollama可以用来方便的部署模型,作用有点像docker。
1 下载安装文件
到ollama官网下载安装文件对应系统的安装文件,我这里是在windows上安装,所以下载OllamaSetup.exe
2 执行安装命令
这里可以直接双击exe安装,但是应用程序默认会安装的用户目录下面取,如果想改变安装路径,可以使用下面命令安装:
OllamaSetup.exe /DIR="D:\programs\ollama"
3 设置模型保存路径(可选)
点击设置可以可以修改模型保存路径
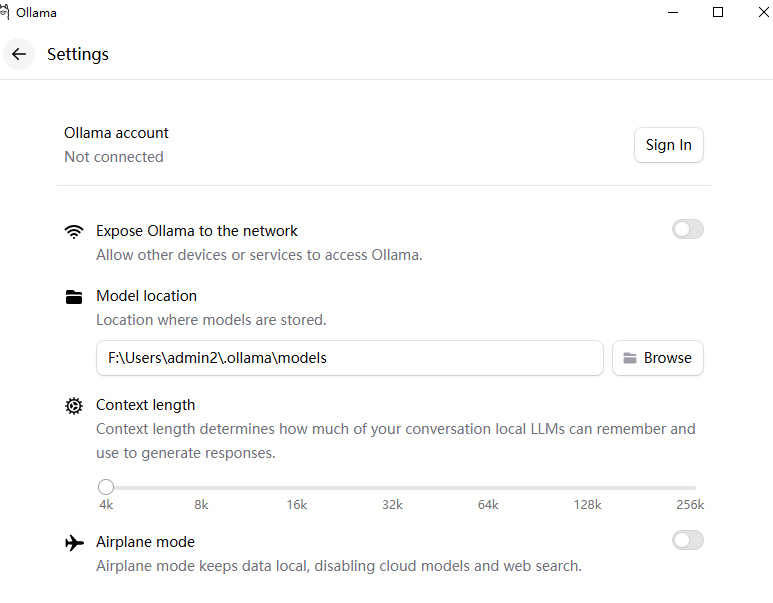
4 下载模型
选择好模型后,可以做出一个提问,就会自动下载模型了。生产级别的模型要根据实际情况做出选择。满血版成本比较高,一般的RAG不需要满血版,可能一个30B左右的模型就够了。
5 常用命令
| 命令 | 功能描述 | 示例 |
|---|---|---|
| ollama run <model> | 运行指定模型(交互式) | ollama run llama3.1 |
| echo "问题" | ollama run <model> | 非交互式运行模型 | echo "你好" | ollama run mistral |
| ollama pull <model> | 拉取模型(从仓库下载) | ollama pull qwen2:0.5b |
| ollama list | 列出本地模型 | ollama list |
| ollama rm <model> | 删除本地模型 | ollama rm gemma2 |
| ollama create <model> -f <Modelfile> | 创建自定义模型 | ollama create my-bot -f ./Modelfile |
| ollama cp <source> <new> | 复制模型 | ollama cp llama3 my-model |
| ollama show <model> | 查看模型信息 | ollama show llama3.1 |
| ollama serve | 启动API服务 | ollama serve |
| ollama ps | 列出运行中的模型 | ollama ps |
| ollama stop <model> | 停止模型服务 | ollama stop llama3.1 |
| ollama help | 显示帮助信息 | ollama help |
| ollama -v | 显示版本信息 | ollama -v |
2 springAi集成验证
使用的时候一定要主要springAI版本,因为现在API变化较快,如果不对,可能会报错
1 ChatClient集成与验证
不能使用spring 4.0以上版本,官方文档里面ollama说明没有更新,使用新版本的starter。目前只看到两个版本,应该是最近才搞出来的。deepseek-r1:8b目前不支持ToolCall,可以使用qwen3:8b,代码保持不变
|
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.5.9</version> <relativePath /> <!-- lookup parent from repository --> </parent> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-ollama-spring-boot-starter</artifactId> < <version>1.0.0-M6</version> </dependency> |
自动配置即可
|
spring.ai.ollama.base-url=http://localhost:11434 spring.ai.ollama.chat.model=deepseek-r1:8b spring.ai.ollama.chat.options.temperature=0.8 spring.ai.ollama.chat.options.top-p=0.9 spring.ai.ollama.chat.options.top-k=100 |
|
private String promp1 = "请翻译 I love You 为中文"; private final ChatClient chatClient; public TestChatClientCtl(ChatModel chatModel) { // 构造时,可以设置 ChatClient 的参数 chatClient = ChatClient.builder(chatModel) // 实现 Logger 的 Advisor .defaultAdvisors(new SimpleLoggerAdvisor()) // 设置 ChatClient 中 ChatModel 的 Options 参数 .defaultOptions(OllamaOptions.builder().topP(0.7).model("deepseek-r1:8b").build()).build(); } @ResponseBody @RequestMapping("/t1") public String t1() { return chatClient.prompt(promp1).call().content(); } |
每个厂商都有自己的api,所以官方spring ai文档有可能过时或者没有用,如果能直接调用http接口或者有更直接的依赖包。没必要用spring ai。如果对应的集api不是由接口提供者维护,可能很久都不一定有对应stater,后期升级或者维护会很麻烦,http简单直接,不依赖第三方包。
如果不需要手动配置客户端,需要排除自动配置类
//@SpringBootApplication(exclude = OllamaAutoConfiguration.class)
@SpringBootApplication
public class AiApplication {
public static void main(String[] args) {
SpringApplication.run(AiApplication.class, args);
}
}手动配置样例(如果涉及多个模型调用,就会涉及自动配置)
//@Configuration
//public class DeepseekChatModelConf {
//
// @Bean
// public ChatModel deepseekR1ChatModel() {
// /**
// * 这里假设通过OllamaServiceFactory创建ChatModel实例,具体根据实际情况调整,也可以通过自动配置注入
// * 自动注入可能会造成api不熟悉,学习适合,手动注入处理多实例就会派上用场
// */
// OllamaOptions options = OllamaOptions.builder()
// .model("deepseek-r1:8b")
// .temperature(0.8)
// .topK(50)
// .topP(0.9)
// .build();
// OllamaApi ollamaApi = new OllamaApi("http://localhost:11434");
// return OllamaChatModel.builder().defaultOptions(options).ollamaApi(ollamaApi).build();
// }
//
//
//}2 ChatModel集成与验证
ChatModel是比ChatClient更底层的东西,ChatClient是通过ChatModel构建的更上层的对象,正常情况都应该使用ChatClient
@Controller
@RequestMapping("/test1")
public class TestChatModelCtl {
@Autowired
private ChatModel chatModel;
private String promp1 = "请翻译 I love You 为中文";
@ResponseBody
@RequestMapping("/t1")
public String t1() {
return chatModel.call(new Prompt(promp1)).getResult().getOutput().getText();
}
}3 版本更新
现在spring ai比较成熟稳定的还是工具调用,MCP使用接口还不太友好,spring ai相关文档和资料还跟不上,新版本的spring ai已经升级到m7,ollama依赖也在变更成新版本,建议统一管理,这才是springboot应该有的样子。上面的依赖可能不都一定能查到了。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M7</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<!--修正依赖名称 -->
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>4 方法调用
早期叫函数调用,现在叫方法调用,是目前比较好用的方法。主要是分为两个步骤,工具定义,和工具注册
工具定义
public class TestTools {
@Tool(description = "Get the current date and time in the user's timezone")
public String getCurrentDateTime() {
String currentDate = LocalDateTime.now().atZone(LocaleContextHolder.getTimeZone().toZoneId()).toString();
System.out.println("call getCurrentDateTime " + currentDate);
return currentDate;
}
@Tool(description = "Set a user alarm for the given time, provided in ISO-8601 format")
public void setAlarm(String time) {
LocalDateTime alarmTime = LocalDateTime.parse(time, DateTimeFormatter.ISO_DATE_TIME);
System.out.println("Alarm set for " + alarmTime);
}
@Tool(description = "add two numbers",returnDirect=true)
public RspAdd addTwoNumber(@ToolParam(description = "first number", required = true) int firstNumber,
@ToolParam(description = "second number", required = true) int secondNumber) {
RspAdd result = new RspAdd();
StringBuilder sb = new StringBuilder();
sb.append("call tool addTwoNumber request firstNumber=").append(firstNumber);
sb.append(",secondNumber=").append(secondNumber);
System.out.println(sb.toString());
result.setResult(firstNumber+secondNumber);
result.setTip(sb.toString());
return result;
}
}工具注册
@ResponseBody
@RequestMapping("/t5")
public String t5() {
return chatClient.prompt("How much is it 1 plus 2?").tools(new TestTools()).call().content();
}5 MCPServer-SSE代码
MCP全称叫模型上下文协议,它是一个协议。当一个服务想开发给其他AI应用调用时,MCP就派上用场了。mcp协议虽然出来已久,但是spring ai 文档和api目前还跟不上节奏,变化还比较大,正在逐步规范中,需要持续关注。像阿里等大公司都开放了许多MCP服务。这个玩意使用和验证都比工具调用要复制许多。
MCP目前支持stdio,sse,stateless,streamable http(这个是新出来的,据说想替代sse,不过使用起来更复杂),下面是个sse相关代码
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.5.9</version>
<relativePath /> <!-- lookup parent from repository -->
</parent>
<groupId>test.wyp</groupId>
<artifactId>mcp.server</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>ai</name>
<description>ai test for Spring Boot</description>
<properties>
<java.version>25</java.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M7</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-server-webmvc</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
Mcp工具
@Service
public class TestTools {
@Tool(description = "add two numbers",returnDirect=true)
public RspAdd addTwoNumber(@ToolParam(description = "first number", required = true) int firstNumber,
@ToolParam(description = "second number", required = true) int secondNumber) {
RspAdd result = new RspAdd();
StringBuilder sb = new StringBuilder();
sb.append("call tool addTwoNumber request firstNumber=").append(firstNumber);
sb.append(",secondNumber=").append(secondNumber);
System.out.println(sb.toString());
result.setResult(firstNumber+secondNumber);
result.setTip(sb.toString());
return result;
}
}官网说有@McpTool,在新版本中没看到这个注解。
注册工具
@SpringBootApplication
public class McpServerApplication {
public static void main(String[] args) {
SpringApplication.run(McpServerApplication.class, args);
}
/**
* 这里可以优化一下,不使用构造器,可以使用自定义注解,然后将该注解的加入,使用构造器,多了不方便传
* 正常情况下,要作为工具使用的可以家注解或者,直接New,这个写法感觉有多余
* @param testTools
* @return
*/
@Bean
public ToolCallbackProvider toolCallbackProvider(TestTools testTools) {
return MethodToolCallbackProvider.builder()
.toolObjects(testTools)
.build();
}
}生产级别问题思考:权限验证
6 inspector工具安装
这里我使用了一个现成的工具
npx @modelcontextprotocol/inspector http://localhost:8088
或者先安装再连接
npm install -g @modelcontextprotocol/inspector
mcp-inspector http://localhost:8088
服务启动或会输出浏览器地址,将地址复制到浏览器打开,如下图
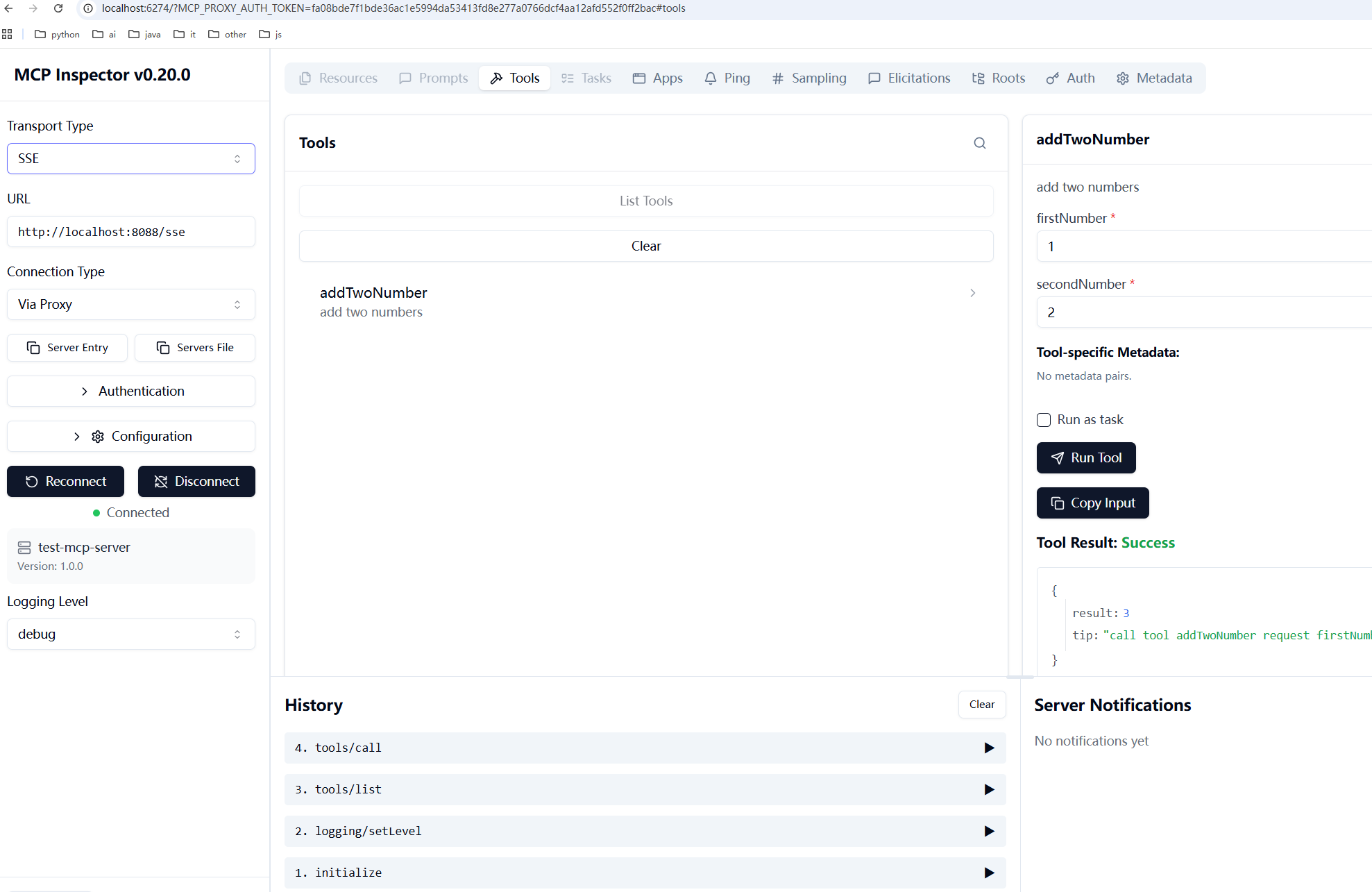
7 MCP Server验证
在Tools下看到了addTwoNumber工具,点击,然后就可以在右侧调用,如上图。验证成功,说明mcp服务正常
8 MCP Client-SSE
关键依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
<!--修正依赖名称 -->
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-mcp-client</artifactId>
</dependency>配置
#服务端口
server.port=8090
spring.application.name=mcp-client
spring.ai.mcp.client.enabled=true
spring.ai.mcp.client.type=SYNC
spring.ai.mcp.client.name=my-mcp-client
spring.ai.mcp.client.version=1.0.0
spring.ai.mcp.client.request-timeout=30s
spring.ai.mcp.client.sse.connections.server1.url=http://localhost:8088
spring.ai.mcp.client.toolcallback.enabled=true
#spring.ai.mcp.client.sse.connections.my-mcp-server.url=http://localhost:8088
#spring.ai.mcp.client.sse.connections.my-mcp-server.sse-endpoint=/sse
#spring.ai.mcp.client.sse.connections.my-mcp-server.message-endpoint=/message
#spring.ai.mcp.client.sse.connections.my-mcp-server.connection-timeout=5000
#spring.ai.mcp.client.sse.connections.my-mcp-server.read-timeout=30000
#logging.level.org.springframework.ai=DEBUG
#logging.level.org.springframework.ai.mcp=DEBUG
# 模型配置
#spring.ai.ollama.chat.model=deepseek-r1:8b
spring.ai.ollama.chat.model=qwen3:8b
spring.ai.ollama.chat.options.temperature=0.8
spring.ai.ollama.chat.options.top-p=0.9
spring.ai.ollama.chat.options.top-k=100代码
@Controller
@RequestMapping("/test1")
public class TestCtl {
private final ChatClient chatClient;
public TestCtl(ChatModel chatModel,ToolCallbackProvider tools) {
// 构造时,可以设置 ChatClient 的参数
chatClient = ChatClient.builder(chatModel).defaultTools(tools).build();
}
@ResponseBody @RequestMapping("/t1")
public String t1() {
System.out.println("call /test1/t1");
return chatClient.prompt("How much is it 1 plus 2?").call().content();
}
@ResponseBody @RequestMapping("/t2")
public RspAdd t2() {
System.out.println("call /test1/t2");
RspAdd result = chatClient.prompt("How much is it 1 plus 2?").call().entity(RspAdd.class);
return result;
}
}
这里目前遇到一个问题,t2不调用工具,如果要执行调用工具流程,需要先调用content,再entity,这像一个bug,修改后代码如下:
@ResponseBody @RequestMapping("/t2")
public RspAdd t2() {
System.out.println("call /test1/t2");
// 确保工具调用逻辑
CallResponseSpec callResponse = chatClient.prompt("How much is it 1 plus 2?").call();
// 强制触发工具调用,这看起来非常多余,也不连贯,看起来像bug
callResponse.content();
RspAdd result = callResponse.entity(RspAdd.class);
return result;
}跟踪了一下代码,发现底层代码基本都是一样的,都是调用doGetObservableChatResponse和getContentFromChatResponse,这个细节估计只能铜通过断点调试了。
1 McpServer权限验证
应为mcp是基于http协议的,所以这个问题就相当好解决了。一种是引入springsecurity,另一种是自己定义拦截器。一个新的业务,我建议自己实现交互协议,springSecurity使用上过于复杂。早期看过一些源码(好像是2.0版本源码),springSecurity因为要兼容以前版本代码,所以看起来的很混乱,有些是不必要的并没有去除。所以不系统中可能出现不同的用法,不好管理。能处理好维护问题,如果能满足要求,就可以集成springSecurity。
2 用户输入过滤
用户输入过滤这个估计不太好做,容易漏洞、所以让用户输入任意内容的地方都容易被注入,过滤不当容易影响正常使用
3 用户响应
这个也是不太好做,与输入类似
3 AnythingLLM
可以作为完全的本地使用者,不需要任何开发。
| 维度 | Dify | FastGPT | AnythingLLM | Cherry Studio |
|---|---|---|---|---|
| 部署方式 | 服务端 (Docker/K8s) | 服务端 (Docker/云) | 桌面端 / Docker (All-in-One) | 纯桌面客户端 (Win/Mac/Linux) |
| 上手难度 | ⭐⭐⭐ (需理解概念) | ⭐⭐⭐⭐ (中文友好,直观) | ⭐⭐⭐⭐⭐ (一键启动) | ⭐⭐⭐⭐⭐ (安装即用) |
| 工作流编排 | ⭐⭐⭐⭐⭐ (极强,支持循环/递归) | ⭐⭐⭐⭐ (强,节点丰富,易上手) | ❌ (不支持) | ❌ (不支持) |
| RAG 能力 | ⭐⭐⭐⭐⭐ (混合检索/Rerank/多路) | ⭐⭐⭐⭐⭐ (中文分词/QA拆分优化) | ⭐⭐⭐ (基础向量检索) | ⭐⭐ (轻量级检索) |
| 模型管理 | 需外接 (Ollama/Xinference/API) | 需外接 (Ollama/Xinference/API) | 内置管理 (可自动下载 Embed/LLM) | 聚合连接 (支持数百种 API) |
| 多用户/权限 | ⭐⭐⭐⭐⭐ (企业级团队协作) | ⭐⭐⭐⭐ (团队/空间管理) | ⭐⭐⭐⭐ (工作区隔离) | ❌ (单用户本地) |
| API/集成 | ⭐⭐⭐⭐⭐ (原生 API/插件/多渠道) | ⭐⭐⭐⭐⭐ (API/嵌入/微信钉钉) | ⭐⭐ (有限) | ❌ (仅本地使用) |
| 中文优化 | ⭐⭐⭐ (通用) | ⭐⭐⭐⭐⭐ (针对中文文档深度优化) | ⭐⭐⭐ (依赖所选模型) | ⭐⭐⭐ (依赖所选模型) |
| 主要场景 | 复杂 Agent、SaaS 应用、企业中台 | 中文客服、内部知识助手、快速落地 | 离线私有库、个人/小团队保密文档 | 个人对话、多模型切换、轻办公 |
更具实际需求选择,主要考虑安装运维、性能、支持模型供应商、以及功能组件几个方方面,目前AnythingLLM支持的供应商看起来不太丰富,也没找到重排序配置,只是安装相对简单方便。
1 安装
下载anythingllm然后点击安装文件安装,配置过程中选择ollama和对应的模型,最后勾选运行即可
2 Workspace(工作区)
一个独立的 AI 对话环境,可以绑定特定用户组,实现细粒度权限隔离。核心属性:
| id:唯一标识。 name:工作区名称。 slug:URL 友好标识。 openAiPrompt:系统提示词。 openAiTemp:温度参数。 similarityThreshold:相似度阈值。 chatProvider:聊天提供商。 |
|
openAiTemp: 1. 温度值范围 |
|
是一个介于 0 到 1 之间的浮点数,用于衡量文档与用户问题的语义相似度。通过设定阈值,过滤低相关性文档,提升回答的准确性和聚焦度。 |
功能:
支持多用户协作与权限隔离,例如“财务制度”Workspace 只对财务部门开放
将私有文档转化为可对话的知识库,支持多格式文档(Word/PDF/图片等)
3 Thread
工作区内的一个独立对话线程,用于管理用户与 AI 的交互历史。核心属性:
| id:聊天会话 ID。 workspaceId:所属工作区 ID。 prompt:用户输入。 response:AI 响应。 user_id:用户 ID。 thread_id:线程 ID。 include:是否包含在历史中。 feedbackScore:反馈评分。 chatMode:聊天模式。 vectorSearchMode:向量搜索模式 |
4 准本RAG文档内容和验证
text.txt内容如下
问题:张三和李四是什么亲属关系?
答案:张三和李四夫妻关系首先提问(此时没有把上面的文本嵌入AnythinLLM向量数据库):

上传数据到AnythinLLM向量数据库保存后再次提问:

看,回答正确。
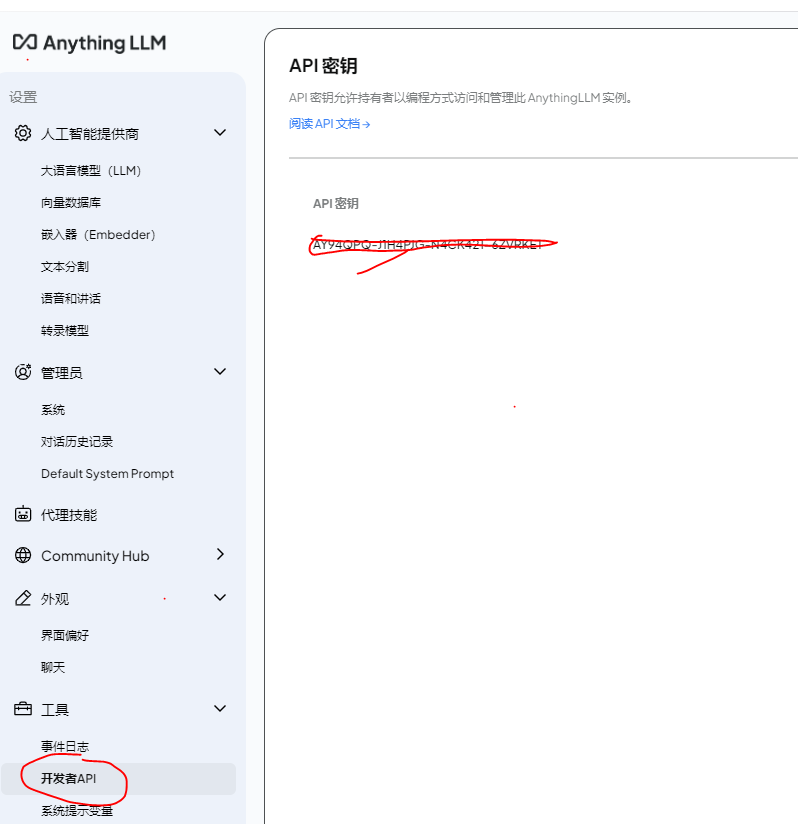
5 权限
桌面版没有看到有设置用户权限的地方,下面是配置api调用接口的地方
6 聊天接口调用
在上一步中点击开发者API,可以找到如下界面:
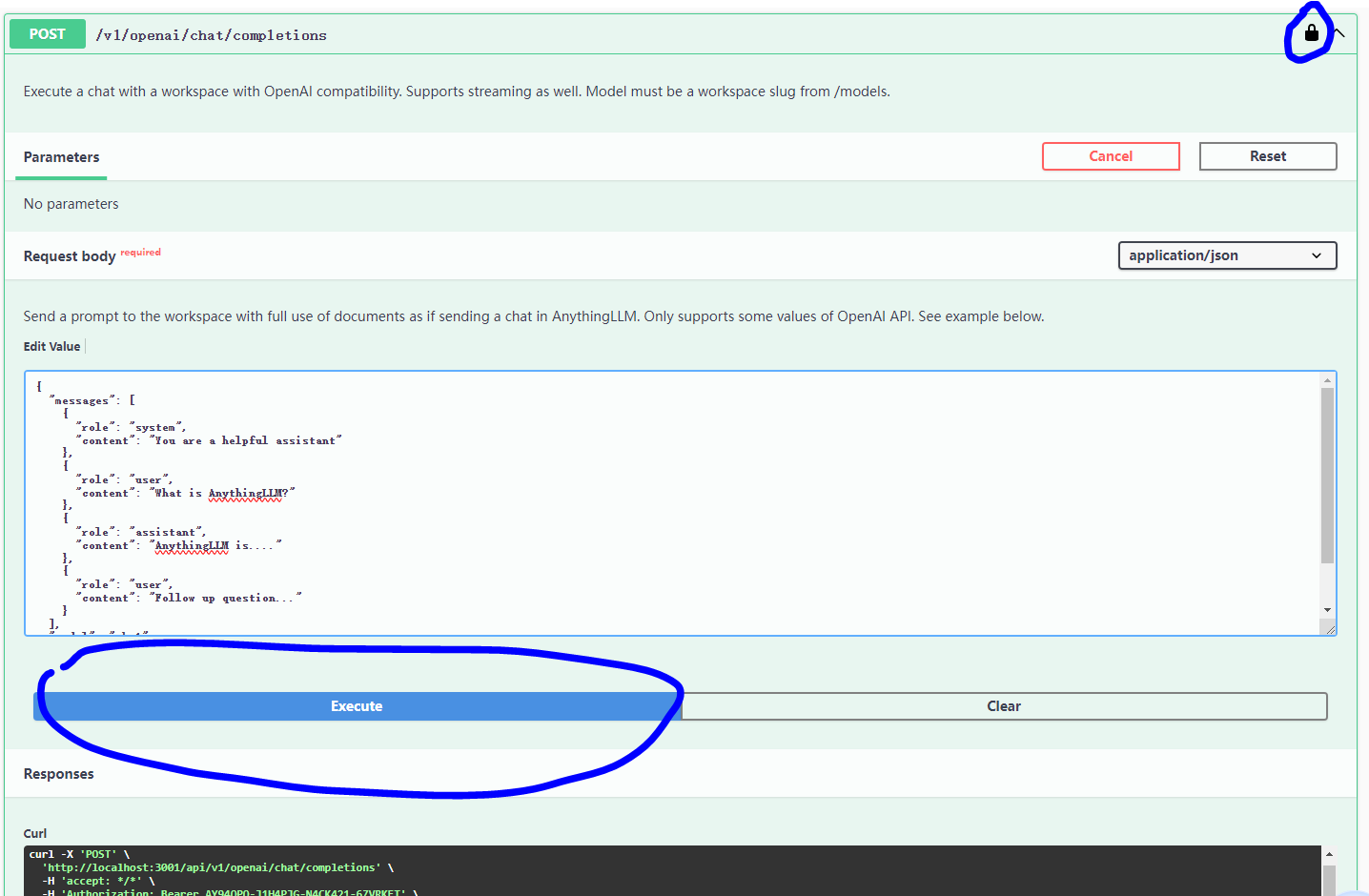
有锁的地方设置上一个图中的认证密钥,请求体中model填写存在授权的的workspace,stream改成false。然后就可以点击excute,发送请求,就可以在response看到响应。
下面是postman搞得例子:
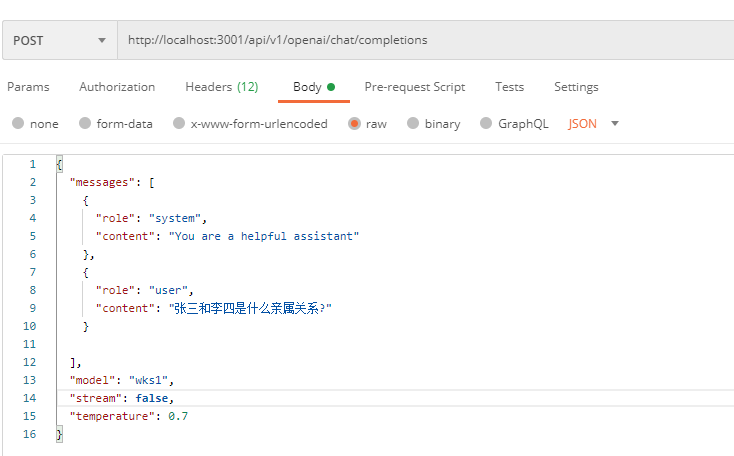

发现的问题
有时候思考的时候显示的是英文内容,这有点恶心。你问的是中文,它直接用英文回答你。
7 生产思考
少数人使用,不涉及开发,减少开发成本。如果想做一些使用方面的改造,可以调用对应接口。
4 向量数据库
下面列举几种常用的向量数据库。同样如何选择还是看需求,以及可以承受的资源和运维成本。本地研究的话选择功能齐全,安装简便的即可。
| 产品名称 | 类型 | 核心优势 | 主要劣势 | 适用场景 | 推荐指数 (2026) |
|---|---|---|---|---|---|
| Milvus | 专用开源/云原生 | 企业级首选。支持亿级数据规模,分布式架构,高可用,功能最全(多租户、权限、复杂过滤)。 | 架构较重,部署运维复杂(依赖 Etcd, MinIO 等),小数据量杀鸡用牛刀。 | 大规模生产环境、企业级知识库、高并发推荐系统。 | ⭐⭐⭐⭐⭐ |
| Qdrant | 专用开源 | 性能与易用性平衡。Rust 编写,速度极快,内存占用低。原生支持复杂的 Payload 过滤,API 设计友好。 | 超大规模(十亿级)集群经验略少于 Milvus,社区生态稍小。 | 中大型生产环境、对延迟敏感的场景、需要复杂元数据过滤的 RAG。 | ⭐⭐⭐⭐⭐ |
| Weaviate | 专用开源 | AI 原生特性。内置模块化向量模块(可直接调用 HuggingFace 等模型),支持 GraphQL,原生支持混合搜索(BM25+ 向量)。 | 资源消耗相对较高,学习曲线略陡(GraphQL)。 | 需要快速原型开发、混合搜索场景、图数据库结合场景。 | ⭐⭐⭐⭐ |
| Chroma | 专用开源 | 开发者体验最佳。极简 API,Python 优先,默认本地存储(SQLite + HN SW),无需额外部署服务器。 | 不适合生产环境。分布式支持弱,性能和扩展性有限,主要用于本地调试和小规模应用。 | 本地开发、PoC 验证、小型个人项目、嵌入式应用。 | ⭐⭐⭐ (仅限开发) |
| Pinecone | 云托管 (SaaS) | 全托管服务。零运维,Serverless 架构,自动扩缩容,SLA 保障,全球低延迟。 | 成本高,数据存储在云端(可能有合规顾虑),自定义能力受限。 | 快速上线产品、无运维团队初创公司、对稳定性要求极高的商业应用。 | ⭐⭐⭐⭐ (预算充足时) |
| pgvector | 传统 DB 扩展 | 架构最简单。PostgreSQL 插件,无需引入新组件,支持 SQL 关联查询,事务一致性。 | 性能不如专用库(尤其是高维高并发场景),索引构建慢,大规模下内存压力大。 | 已有 PG 架构的小规模应用、对数据一致性要求极高、数据量<千万级。 | ⭐⭐⭐⭐ (中小规模) |
| Redis | 传统 DB 扩展 | 极速读写。基于内存,适合实时性要求极高的场景(如实时推荐)。 | 成本高(内存贵),持久化能力相对弱,大规模向量检索功能不如专用库丰富。 | 缓存层向量检索、实时特征匹配、小规模高频访问。 | ⭐⭐⭐ |
| FAISS | 检索库 (非 DB) | 算法基准。Meta 开源,提供最强的底层索引算法(HNSW, IVF 等),性能极致。 | 不是数据库。无 CRUD 操作,无持久化,无权限管理,需自行封装开发。 | 作为底层引擎集成到自研系统中、离线批处理任务。 | ⭐⭐ (仅作为底层库) |
从上面看Milvus和Qdrant是生产级别首先,Chroma是开发实验首选,下面再补充两个
| 维度 | LanceDB | Astra DB |
|---|---|---|
| 核心定位 | 嵌入式 / Serverless 向量数据湖 | 企业级全球分布式向量数据库 (SaaS) |
| 底层技术 | Lance 格式 (列式存储,基于 Parquet 优化) | Apache Cassandra (宽列存储) + Vector Search |
| 存储后端 | 本地磁盘 或 对象存储 (S3, GCS, Azure Blob) | DataStax 专有云 (基于 Cassandra 的全球集群) |
| 架构模式 | 无服务器 (Serverless) 计算与存储完全分离,无常驻进程 |
托管集群 (Managed Cluster) 多区域自动复制,高可用架构 |
| 部署方式 | 库嵌入 (Library)pip install lancedb,代码即数据库 |
云服务 (SaaS) 在 DataStax 控制台创建实例,通过 API 连接 |
| 扩展性 | 存储无限 (依赖 S3 容量) 计算弹性 (按需启动) |
全球水平扩展 自动分片,支持跨区域读写 |
| 一致性模型 | 最终一致性 (支持版本控制/时间旅行) | 可调一致性 (Tunable Consistency) 可配置为强一致或最终一致 |
| 查询延迟 | 中等 (50ms - 200ms+) 受限于对象存储 (S3) 的网络 IO |
低且稳定 (< 50ms) 内存优化,全球边缘节点加速 |
| 并发能力 | 中低 适合批量处理或中低并发在线服务 |
极高 专为高并发企业级负载设计 |
| 主要优势 | ✅ 成本极低 (S3 存储费几乎忽略不计) ✅ 零运维 (无服务器管理) ✅ 多模态原生 (高效存图片/视频二进制) ✅ 数据湖集成 (直接查 S3 现有数据) |
✅ 企业级 SLA (99.99% 可用性) ✅ 全球分布 (数据自动同步到多地) ✅ 慷慨的免费层 (通常 5GB+ 免费) ✅ 成熟生态 (Cassandra 生态 + Vector) |
| 主要劣势 | ❌ 延迟较高 (不适合微秒级实时检索) ❌ 并发瓶颈 (不适合数千 QPS) ❌ 社区相对年轻 |
❌ 成本随流量增长 (高并发下费用较高) ❌ 学习曲线 (需理解 Cassandra 数据模型) ❌ 数据锁定 (专有云,迁移成本高) |
| 典型应用场景 | 🔹 离线/批处理分析 ( nightly build) 🔹 海量数据归档检索 (TB 级知识库) 🔹 多模态应用 (图像/视频检索) 🔹 个人/初创项目 MVP |
🔹 全球性企业应用 (跨国用户低延迟访问) 🔹 关键业务系统 (金融、电信等高可用要求) 🔹 快速原型到生产 (免费层直接用于生产) 🔹 混合负载 (向量 + 文档 + 宽表) |
| 成本模型 | 按存储量 + 计算时长付费 (若自建则仅需付 S3 存储费,极便宜) |
按请求数 + 存储量 + 节点数付费 (有免费层,超出后按用量计费) |
| Spring AI 集成 | ⭐⭐⭐ (主要通过 Python/JS SDK,Java 支持发展中) | ⭐⭐⭐⭐⭐ (官方深度集成,支持 LangChain & Spring AI) |
5 SpringAI消息类型
提示词可以消息发出方分为用户、系统、助手、工具消息。这个可能会有变化,需要关注枚举类

| 概念 | 核心 Java 类型 | 说明 |
|---|---|---|
| 用户消息 | org.springframework.ai.chat.messages.UserMessage |
代表用户的输入提示词 (Prompt)。 |
| 系统消息 | org.springframework.ai.chat.messages.SystemMessage |
代表系统指令 (System Prompt),设定人设。 |
| 助手消息 | org.springframework.ai.chat.messages.AssistantMessage |
代表 AI 生成的回复内容。 |
| 通用消息 | org.springframework.ai.chat.messages.Message |
上述三者的父接口。 |
| 提示词 | org.springframework.ai.chat.prompt.Prompt |
包含消息列表和可选参数(如 Temperature, TopK)的请求对象。 |
| 聊天响应 | org.springframework.ai.chat.ChatResponse |
包含 AI 回复、元数据(Usage, Model Name)的响应对象。 |
| 生成结果 | org.springframework.ai.chat.Generation |
ChatResponse 中的具体生成内容单元。 |
| 内容类型 | org.springframework.ai.chat.messages.Content |
消息内容的抽象,支持文本、图像等多模态。 |
6 SpringAI+RAG
这里我把springAI版本换成了1.1.2 ,SpringAI现在接口变化比较块,还不稳定。使用Chroma向量数据库
1 依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-chroma</artifactId>
</dependency>2 配置
#Chroma向量数据库相关配置,这里可能是有bug必须加http
spring.ai.vectorstore.chroma.client.host=http://192.168.1.10
spring.ai.vectorstore.chroma.client.port=8000
# --- Chroma 存储集合配置 ---
#配置成true并不会自动创建,需要手动处理
spring.ai.vectorstore.chroma.initialize-schema=true
#default: SpringAiTenant
spring.ai.vectorstore.chroma.tenant-name=SpringAiTenant
#default: SpringAiDatabase
spring.ai.vectorstore.chroma.database-name=SpringAiDatabase
#default: SpringAiCollection
spring.ai.vectorstore.chroma.collection-name=SpringAiCollection3 运行Chroma服务
这玩意不太推荐,没有管理不太方便,没界面
docker run -d -p 8000:8000 chromadb/chroma
4 手动创建集合
并不会自动创建,需要手动创建
curl -X POST "http://localhost:8000/api/v2/tenants" \
-H "Content-Type: application/json" \
-d '{
"name": "SpringAiTenant"
}'
curl -X POST "http://localhost:8000/api/v2/tenants/SpringAiTenant/databases" \
-H "Content-Type: application/json" \
-d '{
"name": "SpringAiDatabase"
}'
curl -X POST "http://localhost:8000/api/v2/tenants/SpringAiTenant/databases/SpringAiDatabase/collections" \
-H "Content-Type: application/json" \
-d '{
"name": "SpringAiCollection",
"metadata": {
"description": "Created via Chroma v2 API"
},
"get_or_create": true
}'
5 插入文档
整个有 个比较难搞的事情是文档容的检查,需要评估是否需要做一些特殊拦截和过滤
System.out.println("call /test1/t4");
String ragTest = "问题:张三和李四是什么亲属关系? 答案:张三和李四夫妻关系";
Map<String,Object> metaData = new HashMap<>();
metaData.put("category", "a");
vectorService.addDocument(ragTest,metaData)使用下面命令先查到集合ID
curl -X GET "http://localhost:8000/api/v2/tenants/SpringAiTenant/databases/SpringAiDatabase/collections"然后使用上面查到的ID替换下面命令的ID,插损数据是否插入成功
curl -s -X POST "http://localhost:8000/api/v2/tenants/SpringAiTenant/databases/SpringAiDatabase/collections/797e91e3-8c34-4ce7-b294-0c9eb3eebdb4/get" \
-H "Content-Type: application/json" \
-d '{
"include": ["documents", "metadatas"],
"limit": 5
}'结果类似,说明插入成功
{
"ids": [
"bdc5d205-d081-4f18-8064-5c00d76b1359",
"eb28b6d2-b5e6-4190-bf58-2cf7ea43c19d"
],
"embeddings": null,
"documents": [
"问题:张三和李四是什么亲属关系? 答案:张三和李四夫妻关系"
],
"uris": null,
"metadatas": [
{
"category": "a"
},
{
"category": "a"
}
],
"include": [
"documents",
"metadatas"
]
}6 检索增强
1 手动查询模式
String prompt = "张三是已婚人士吗? 如果不知道,请直接回答不知道";
List<Document> context = vectorService.search(prompt,similarityThreshold);
// 将检索到的 Document 内容提取并拼接成字符串
String contextContent = context.stream()
.map(Document::getText)
.collect(Collectors.joining("\n---\n"));
// 构造系统提示词:明确告诉 AI 只能依据上下文回答
String systemInstruction = """
你是一个基于知识库问答的助手。
请严格根据提供的【上下文信息】来回答用户的问题。
- 如果【上下文信息】中包含答案,请直接回答。
- 如果【上下文信息】中不包含答案,或者你不确定,请直接回答“不知道”,不要编造信息。
【上下文信息】:
%s
""".formatted(contextContent);
// 3. 生成阶段 (Generation)
// 构建消息列表:系统消息 + 用户消息
Message systemMessage = new SystemMessage(systemInstruction);
Message userMessage = new UserMessage(prompt);
// 调用大模型并获取结果
String response = chatClient.prompt()
.messages(List.of(systemMessage, userMessage))
.call()
.content();
System.out.println(response);问题和答案的检索信息
{
"id": "4d936f03-82f8-4f85-a84a-f1f6901253c1",
"text": "问题:张三和李四是什么亲属关系? 答案:张三和李四夫妻关系",
"media": null,
"metadata": {
"category": "a",
"distance": 0.66865456
},
"score": 0.33134543895721436
}查询的时候如果相似度设置比score高的话就查不出来,所以相似度,需要设置得低一些。问题是“张三是已婚人士吗? 如果不知道,请直接回答不知道”,这个看起来会有点迷糊,这明明就是问题答案,应该相似度很高才对呀。所以这里就需要明确一点了,向量检索相似度是计算向量得之间的距离。我们之所以觉得相似度很高,是因为我们无意识中进行了部分逻辑推理。现在AI的流程是先根据从向量数据库查询相似数据,然后再作为上下文和问题一起发给LLM进行推理,所以只要把查到的数据和问题一起发给模型,是能给出正确的结论的。如果相似度设置比score高的话,就查不出文档,缺失了上下文,就无法推理。你可能就会抱怨明明几乎有100%知识答案,缺不能保证能给出正确答案。这应该也是相似度计算一个缺陷吧。毕竟相似度模型不会设计的过于复杂,不然就没有LLM的事情干了。
要解决上面的问题,目前知道有重排序和多路召回。实际上就是在数据送入大模型前,加入和数据整合和更强的逻辑推理。代价当然是更耗时了。当你遇到像“夫妻”vs“已婚”这种需要推理才能关联的场景时,普通的 Embedding 模型往往表现不佳(如你看到的 0.33 分)。而专门的 Rerank 模型通常在大规模相关性数据集上经过微调,专门擅长处理这种隐含的逻辑推导关系
2 使用QuestionAnswerAdvisor
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>String prompt = "张三是已婚人士吗? 如果不知道,请直接回答不知道";
var qaAdvisor = QuestionAnswerAdvisor.builder(vectorService.getVectorStore())
.searchRequest(SearchRequest.builder().similarityThreshold(similarityThreshold).topK(6).build())
.build();
// 调用大模型并获取结果
String response = chatClient.prompt(prompt).advisors(qaAdvisor)
.call()
.content();这种方式不建议使用,没发使用重排序和多路召回
3 使用RetrievalAugmentationAdvisor
1.1.2没有发现直接重排api支持,可能后的处理documentPostProcessors里面
Advisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorService.getVectorStore())
.build())
//目前来看在这里实现重排,没有发现其他方法
.documentPostProcessors(List.of())
.build();
String response = chatClient.prompt()
.advisors(retrievalAugmentationAdvisor)
.user(prompt)
.call()
.content();7 生产级别问题思考
1 多路召回
向量、关键词(BM25,ES)。实际上这个可能性有点小,你要多路召回,那么数据入库的是就要入库两份。这个需要考虑成本,性能。可以用并发查询减小延迟,最终时间却决于最慢的那个。
2 重排序
一般只有使用多了召回才会使用到重排序,代价就是增加了延迟和、也要选择排序模型。
springAI目前没有提供明显的重排序API,可以在documentPostProcessors中实现。
3 上下文压缩
重排序相当于已经做了上下文压缩了,可以在重排序中一同处理
4 嵌入模型选择
数据源:文件内容(多种语言、表格、图片)、文件格式(pdf、图片等)、是否需要清洗(大量非结构化文本估计清洗苦难)
模型:模型尺寸、特性(需要根据数据做出选择)、硬件需求、性能。
5 文件分块
SpringAI 也有支持
RecursiveCharacterTextSplitter (最推荐)
原理:按照字符递归切分。优先按段落 (\n\n) 切,如果还太长就按行 (\n) 切,再长按空格 ( ) 切,最后按字符切。
优点:能尽量保持语义的完整性(不会把句子从中间切断),是 RAG 场景下的标准选择。
适用:通用文本、Markdown、代码。
TokenCountTextSplitter
原理:基于 Token 数量切分(需要配置 Tokenizer,如 Tiktoken)。
优点:精确控制每个块的 Token 数,确保绝对不超过 Embedding 模型的上限。
缺点:可能会在句子中间切断,破坏语义连贯性。
ParagraphTextSplitter / LineTextSplitter
原理:简单粗暴地按段落或行切分。
适用:结构非常规范的文本。
另一个也可以自定义分割器,比如在每个分块上加上章节标题、每个分块预先生成问题等
6 查询重写
问题拆分(MultiQueryExpander生成多个子问题 ),问题精确化、问题抽象化。如果有多个结果,需要去重(ConcatenationDocumentJoiner)和重排序
7 RAG评估
需要准备Q(Question)、A(Answer,人工给出的准确答案)对检查模型输出,尽量多样化,达到预期指标就可以投产了运行了。对模型使用Q提问之后,对模型输出和A做比较(整个比较是做相似比表,没法做等于判断的,所以这里主要还是使用模型自动化判断),就是测试验证的主要逻辑。
模型评估目前比较流行的RAGAS,是python写的,所以需要使用pyhon环境,并不是什么难事,工作量还是主要再验证数据集的准备上。
RAGAS 将 RAG 流程拆解为 检索 (Retrieval) 和 生成 (Generation) 两个主要阶段,并提供了一系列指标来分别衡量它们的性能。
1 检索阶段评估指标 (Retrieval Metrics)
| 指标名称 (英文) | 指标名称 (中文) | 核心定义与衡量目标 | 是否需要标准答案 (Ground Truth) | 关键作用与优化方向 |
|---|---|---|---|---|
| Context Precision | 上下文精确度 | 衡量相关文档在检索结果中的排名位置。理想情况下,所有相关文档应排在无关文档之前。 | ❌ 否 (需标准答案推导相关信息) |
优化排序:确保最关键的证据出现在上下文的最前端,减少 LLM 被后半段噪音干扰的概率(Lost in the Middle 现象)。 |
| Context Recall | 上下文召回率 | 衡量检索到的上下文中包含多少标准答案中的关键信息。即:是否漏掉了回答问题所需的重要片段。 | ✅ 是 | 防止遗漏:诊断检索系统是否“漏抓”了关键证据。如果低,说明需要扩大检索范围 (Top-K)、优化切片策略 (Chunk Size) 或更换 Embedding 模型。 |
| Context Relevancy | 上下文相关性 | 衡量检索到的内容中,有多少比例是真正与问题相关的,剔除无关的废话或噪音。 | ❌ 否 (仅需 Question + Context) |
提升纯净度:评估检索结果的“信噪比”。高分意味着上下文紧凑、无冗余,有助于降低 Token 成本并提高生成质量。 |
| Context Entities Recall | 上下文实体召回率 | 专门衡量检索到的上下文中包含的关键实体(人名、地名、专有名词等)占标准答案中实体的比例。 | ✅ 是 | 事实覆盖:针对事实密集型任务的细粒度评估,确保回答所需的具体事实依据(实体)已被检索到。 |
2 生成阶段评估指标 (Generation Metrics)
| 指标名称 (英文) | 指标名称 (中文) | 核心定义与衡量目标 | 是否需要标准答案 (Ground Truth) | 关键作用与优化方向 |
|---|---|---|---|---|
| Faithfulness | 忠实性 (事实一致性) |
最核心指标。衡量生成的答案是否完全源自检索到的上下文,是否存在“幻觉”(编造上下文中没有的信息)。 | ❌ 否 (仅需 Context + Answer) |
监控幻觉:低分意味着模型在“胡说八道”,即使答案看起来是对的,但依据不足。需调整 Prompt 强调“仅依据上下文”或更换更严谨的模型。 |
| Answer Relevancy | 答案相关性 | 衡量生成的答案是否直接、明确地回答了用户的问题,是否存在答非所问、冗余或含糊其辞。 | ❌ 否 (仅需 Question + Answer) |
确保针对性:防止模型虽然引用了正确的上下文,但生成的回复偏离了用户意图或过于啰嗦。需优化生成阶段的 Prompt 指令。 |
| Answer Semantic Similarity | 答案语义相似度 | 衡量生成的答案与标准答案在语义向量空间上的相似程度,而非简单的文字匹配。 | ✅ 是 | 语义对齐:评估回答的“意思”是否正确。即使措辞不同,只要核心含义一致即可得高分。适合评估开放式问答。 |
| Answer Correctness | 答案正确性 | 综合指标,结合语义相似度和事实匹配度,全面评估答案与标准答案的一致性。 | ✅ 是 | 最终验收:给出一个最终的“对错”判定分数,适合用于测试集的整体效果宏观监控和回归测试。 |
还有一种可行的办法就是将模型输出给给出的答案做相似性评分,可以可以不用python工具
8 模型微调
如果还不达标,可以采用模型微调,全量训练很少用,代价很大
RAFT (Retrieval-Augmented Fine-Tuning) 是一种专门为了优化 RAG(检索增强生成) 系统而设计的微调技术。它由 Berkeley AI Research (BAIR) 等机构在 2024 年提出,核心思想是:“不要只教模型知识,要教模型如何使用检索到的文档。
传统的微调(SFT)通常直接给模型 (问题,答案),这会导致模型依赖其内部参数记忆(Parametric Memory),忽略外部检索内容,或者在面对检索到的无关噪音时产生幻觉。
而 RAFT 通过构造特殊的训练数据,强迫模型学会“阅读、筛选、推理”检索到的上下文。
| 特性 | 标准 RAG | 标准 Fine-Tuning | RAFT (Retrieval-Augmented Fine-Tuning) |
|---|---|---|---|
| 知识来源 | 外部数据库 (实时) | 模型参数 (静态) | 模型学会了如何结合外部数据库 |
| 更新成本 | 低 (更新数据库即可) | 高 (需重新训练) | 中 (更新数据库 + 偶尔增量微调) |
| 抗幻觉能力 | 中 (依赖模型理解力) | 低 (容易编造) | 高 (强制模型依据检索内容) |
| 处理噪声 | 弱 (容易被误导) | N/A | 强 (专门训练忽略无关文档) |
| 适用场景 | 知识频繁变化 | 风格迁移、固定知识 | 高精度领域问答、复杂文档分析 |
如果需要微调,可以使用相关微调工具和测评工具,这个就要苦难一些了,不过只要不涉及动手写神经网络,只是调用工具的话难度不会太大,搞几个就知道套路了。
模型微调会增加转悠能力,但是可能影响通用能力,如果不能同时满足,可以拆分模型。
是否可以自建模型,如果建立模型,这个代价可能会非常大,要能支持SpringAI集成。
如果不熟悉,模型的微调应该交给相关专业团队处理,对于一个庞大复杂的技术体系,没有时间和经历的话不要浪费精力(很多东西对于一般人来说要没有一年半载时搞不透的)。
是否需要微调,很多时候需主要是关注模型的能力,实在拿不准就用测试说话,开源的许多通用模型都是经过了一些主要行业数据投喂的。如果业务太依赖与准确性,就需要考虑是使用模型是否合理,毕竟LLM就是通过概率计算处理的。
9 没有上下文怎么办
转人工还是、提示抱歉、或者说请提供更多信息或者换个提问方式?
10 响应
响应内容是否需要做一些拦截过滤处理
7 聊天历史
1 内存模式
spring ai 聊天历史默认使用内存存储(InMemoryChatMemoryRepository) 和消息窗口存储 (MessageWindowChatMemory) 实现历史会话管理。
List<Message> history = chatMemory.get(conversationId);
for(Message msg:history) {
IO.println(msg.getMessageType().getValue()+":"
+msg.getMetadata().get("id")+":"
+msg.getText()
);
}
String response = chatClient.prompt(question).call().content();
int id = count.incrementAndGet();
Message userMessage = UserMessage.builder().text(question).metadata(Map.of("id",id)).build();
Message astMsg = AssistantMessage.builder().content(response).properties(Map.of("id",id)).build();
chatMemory.add(conversationId, List.of(userMessage,astMsg));2 mysql
依赖+数据库配置
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-chat-memory-repository-jdbc</artifactId>
</dependency>
<dependency>
<groupId>com.mysql</groupId>
<artifactId>mysql-connector-j</artifactId>
<scope>runtime</scope>
</dependency>spring.datasource.url=jdbc:mysql://localhost:3306/spring_ai_db?useSSL=false&serverTimezone=UTC&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=root
spring.datasource.driver-class-name: com.mysql.cj.jdbc.Driver
spring.ai.chat.memory.repository.jdbc.initialize-schema=always public TestCtl(toolCallback,ChatMemoryRepository repository) {
this.chatMemory = MessageWindowChatMemory.builder()
.chatMemoryRepository(repository) // 注入 MySQL 仓库
.maxMessages(6) // 设置最大消息数
.build();
}
3 生产级别问题思考
如果数据量大了该怎么选择,保存多少条操作会有性能问题吗、可能需要重写chaMemory的repository
8 MCP
前面已经介绍过sse,这里在详细研究一个这三个协议具体使用情况。
| 特性 | stdio (标准输入/输出) | SSE (Server-Sent Events) (旧版 HTTP 标准,现已被弃用/替代) |
Streamable HTTP (新版 HTTP 标准,推荐) |
|---|---|---|---|
| 通信机制 | 基于进程的标准输入 (stdin) 和标准输出 (stdout) 进行文本流通信。 |
双向分离: 1. 客户端通过 POST 发送请求。2. 服务端通过独立的 SSE 连接 ( GET /sse) 推送响应。 |
单连接双向流: 在一个 HTTP 连接上,既支持客户端发送请求,也支持服务端流式返回响应(利用 HTTP/1.1 Chunked 或 HTTP/2 流)。 |
| 连接方向 | 单向管道(客户端写 stdin,读 stdout),但在逻辑上构成双向对话。 | 双通道:需要维护两个独立的 HTTP 连接(一个用于请求,一个用于长轮询/事件流)。 | 单通道:只需一个 HTTP 端点,即可处理请求和流式响应。 |
| 协议版本状态 | 标准 (Standard) 始终支持,最基础的模式。 |
已弃用 (Deprecated) 在 2024-11-05 版本中定义,2025-03-26 版本中被 Streamable HTTP 取代。 |
标准 (Standard) 2025-03-26 版本引入,当前的首选 HTTP 传输方式。 |
| 数据格式 | UTF-8 编码的 JSON-RPC 消息,以换行符分隔。 | JSON-RPC over HTTP POST + JSON-RPC over SSE stream。 | JSON-RPC over HTTP (支持流式分块传输)。 |
| 通道名称 | 方向 | HTTP 方法 | 连接类型 | 作用 | 对应配置 |
|---|---|---|---|---|---|
| 通道 A:请求通道 | 客户端 → 服务端 | POST |
短连接 (通常) | 客户端发送具体的 JSON-RPC 请求(如“调用工具 X”)。服务端收到后通常立即返回 202 Accepted,表示“收到了”,而不直接返回结果。 |
message-endpoint |
| 通道 B:事件通道 | 服务端 → 客户端 | GET |
长连接 (SSE) | 服务端通过此连接持续推送数据。包括: 1. 对通道 A 请求的最终结果。 2. 服务端主动发起的通知 (Notifications)。 3. 握手信息。 |
sse-endpoint |
1 这两个通道是如何协作的?
假设客户端要调用一个耗时很长的工具(例如“生成代码”):
发起请求:客户端通过 通道 1 (POST /message) 发送调用请求。
立即确认:服务端收到请求,启动后台任务,并立即通过 通道 1 返回 202 Accepted(告诉客户端“别等了,请求已受理”),然后关闭这次 POST 连接。
持续监听:客户端一直保持着 通道 2 (GET /sse) 的连接不断开。
推送进度:服务端在后台处理时,通过 通道 2 推送一条通知:{ "method": "notifications/progress", "params": { "percent": 50 } }。
推送结果:任务完成后,服务端再次通过 通道 2 推送最终结果:{ "result": "...code..." }。
客户端接收:客户端从 通道 2 的流中解析出这些消息,完成整个交互。
2 这种模式的优缺点
优点:
兼容性好:基于标准的 HTTP GET (SSE) 和 POST,能穿过大多数防火墙和代理。
实时性:服务端可以随时推送消息,无需客户端轮询。
缺点:
连接管理复杂:客户端必须同时维护两个连接。如果 通道 2 (SSE) 断了,即使 通道 1 正常,客户端也收不到结果;反之亦然。
状态同步难:需要确保两个连接属于同一个会话上下文。
资源消耗:每个客户端都需要占用两个 TCP 连接(其中一个长期占用)
平时使用的是ChatClient,底层已经使用封装McpClient,不然就要自己写发送请求和匹配等待结果,会很麻烦。
// 1. 配置时,框架自动在后台启动了上面的所有逻辑
McpClient client = McpClient.builder()
.transport(new SseMcpTransport(...))
.notificationHandler(this::myHandler) // 只需要关心业务逻辑
.build();
// 2. ChatClient 使用时,完全感知不到底层通道
String result = chatClient.prompt()
.tools(client.asToolCallbackProvider()) // 自动绑定
.user("帮我查天气")
.call()
.content();1 MCP-SSE
sse代码前面已经有示例,因为sse协议是一个客户端有两个请求端点配置
spring.ai.mcp.client.sse.connections.mcp-server1.sse-endpoint=/sse
spring.ai.mcp.client.sse.connections.mcp-server1.message-endpoint=/message这个配置起初使用的时候也是感觉怪怪的,实际上构成了两个单项通道。
2 MCP-STDIO
STDIO直接只能支持本地基于标准输入输出使用,一般是开发使用、或者想IDE这种本地插件使用
3 MCP-Streamable
1 首先在服务端要启用协议配置
spring.ai.mcp.server.protocol=STREAMABLE
spring.ai.mcp.server.type=SYNC差异:SYNC 阻塞线程直到完成;ASYNC 立即释放线程,后台跑完再回写。
选择:95% 的情况保持默认(SYNC)即可。只有当你遇到“慢工具阻塞服务器”的性能瓶颈,并且愿意将代码改为异步风格时,才需要关注 ASYNC
注意:这里的ASYNC是服务端异步处理请求,但是此时链接还没有释放,服务异步处理完毕之后,会把结果通过前面的连接写会客户端,所以从客户端侧看,还是阻塞的(这个是可以写代码验证的)。
服务端端点默认是/mcp,客户端;连接配置如下
spring.ai.mcp.client.name=my-mcp-client
spring.ai.mcp.client.version=1.0.0
spring.ai.mcp.client.toolcallback.enabled=true
#mcp-server1 streamable-http
spring.ai.mcp.client.streamable-http.connections.mcp-server1.enabled=true
spring.ai.mcp.client.streamable-http.connections.mcp-server1.url=http://localhost:8088
spring.ai.mcp.client.streamable-http.connections.mcp-server1.endpoint=/mcp
服务有时候需要调用客户端模型,需要配置下采样处理器
@Component
public class SamplingHandler {
@McpSampling(clients = "llm-server")
public CreateMessageResult handleSamplingRequest(CreateMessageRequest request) {
// Process the request and generate a response
String response = generateLLMResponse(request);
return CreateMessageResult.builder()
.role(Role.ASSISTANT)
.content(new TextContent(response))
.model("gpt-4")
.build();
}
}目前服务支持的注解有@McpTool @McpResource @McpPrompt @McpComplete 。@McpTool是注解注册在chatClient,让模型识别调用的,其他注解触发逻辑还需要研究一下,目前还没查到相关信息。
4 版本与注解问题
1.1.2 版本使用MCP开头的注解是能自动扫描的到,但是使用@Tool注解的工具需要做如下处理
@Bean
public ToolCallbackProvider toolCallbackProvider(TestTools testTools) {
return MethodToolCallbackProvider.builder()
.toolObjects(testTools)
.build();
}所以不建议使用@Tool注解。1.1.2 般的mcp需要如下改写
//早期版本可以
// this.chatClient = ChatClient.builder(chatModel).defaultTools(tools).build();
//1.1.2 远程需要按下面写,本地@注解用后面一个方法注册
this.chatClient = ChatClient.builder(chatModel).defaultToolCallbacks(toolCallback).defaultTools(LocalTools)目前来看RAG和MCP工具使用基本没有啥问题

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)