【专栏二:深度学习07】-【一张图讲清楚:损失函数怎么选(MSE vs 交叉熵)】
文章目录
前言
在训练模型的时候,我们一定会用到“损失函数”。
但很多人其实是这样理解的:
- MSE:算误差
- 交叉熵:也是算误差
于是很容易产生一个问题:既然都是算误差,那随便用一个不就行了吗?
但现实是:选错损失函数,模型可能根本学不动。
这篇文章,我们用一张图,把这个问题彻底讲清楚。
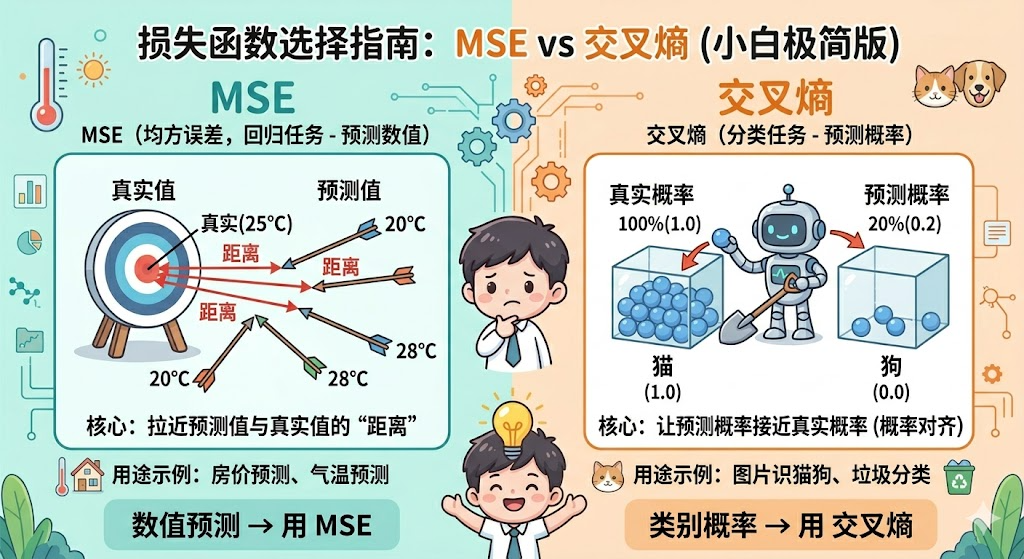
这张图其实已经给出了一个非常重要的结论:
- 数值预测 → 用 MSE
- 类别概率 → 用交叉熵
一、损失函数到底在干嘛?
在训练过程中,模型每做一次预测,都会和真实答案做一次对比。
这个“差距”,就是损失函数(Loss)。换句话说:损失函数就是模型的“评分标准”。
而我们前面讲过,模型每一次 Iteration,其实都在做一件事:让这个 Loss 变小。
所以本质上:
损失函数决定了模型“怎么学”。
二、MSE:在看“距离”
我们先看图的左半部分,MSE-均方误差做的事情非常直观:计算预测值和真实值之间的距离。
一个具体例子
假设真实温度是:25°C
模型预测了:20°C、 28°C
那么误差分别是: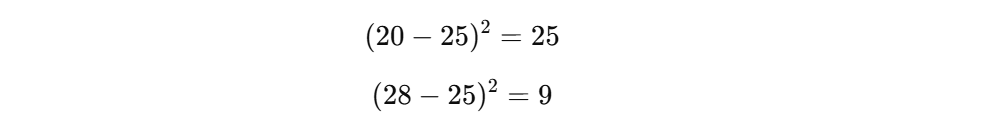
不管是高了还是低了,MSE 都只是关心一件事:离得远不远。
用公式看更清楚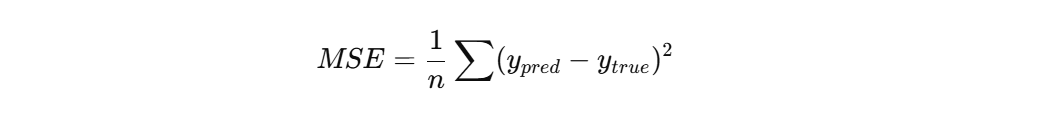
通俗一点说就是:预测值离真实值越远,惩罚越大。
一句话总结
MSE 本质是在衡量“差多少”。
适用场景
- 房价预测
- 温度预测
- 销量预测
这些都是:
连续数值问题(回归问题)
三、交叉熵:在看“你有多确定你是对的”
再看图的右半部分。
这里的任务已经变了:不再是预测一个具体数值,而是判断类别。
比如:这张图片是“猫”还是“狗”。
分类问题的本质
真实答案是:
- 猫 → 1
- 狗 → 0
模型输出的不是“一个数值”,而是:
- 猫的概率:0.2
- 狗的概率:0.8
问题就变成了:你预测的概率,和真实概率差多少?
交叉熵的核心目标是:让预测概率尽可能接近真实概率。
举个最关键的例子
真实标签:猫(1)
模型预测:
- 情况1:0.9
- 情况2:0.6
- 情况3:0.1
这三种情况的区别在于:
- 0.9:很接近正确
- 0.6:有点模糊
- 0.1:严重错误
交叉熵的特点是:预测越接近 0(但真实是 1),惩罚会急剧变大。
一句话总结
交叉熵不是在看“差多少”,而是在看:你有多确定你是对的。
适用场景
- 图像分类(猫/狗)
- 文本分类
- 垃圾邮件识别
这些都是:概率分类问题
四、核心对比:MSE vs 交叉熵
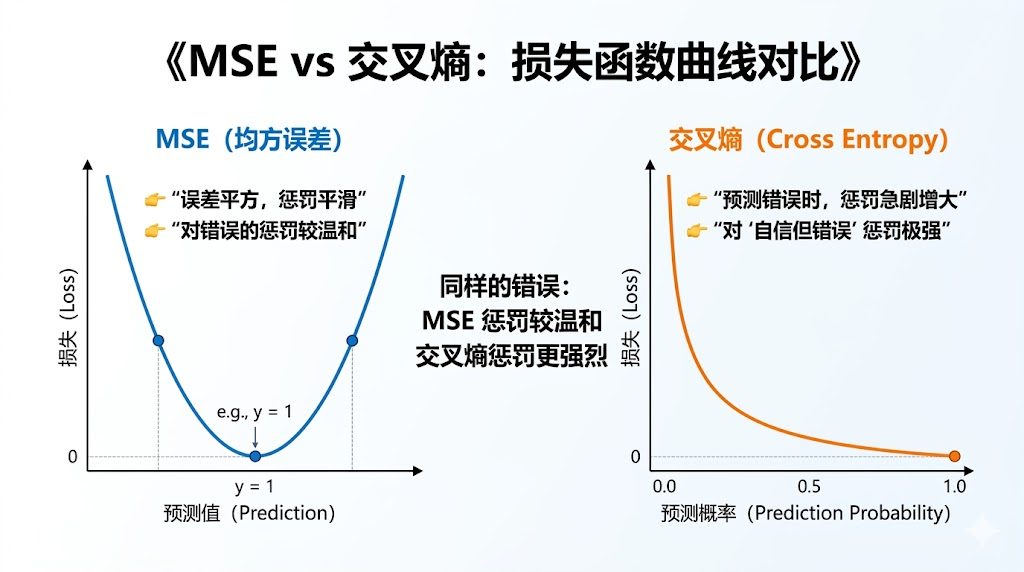
我们用同一个例子对比一下,真实标签 = 1(是猫)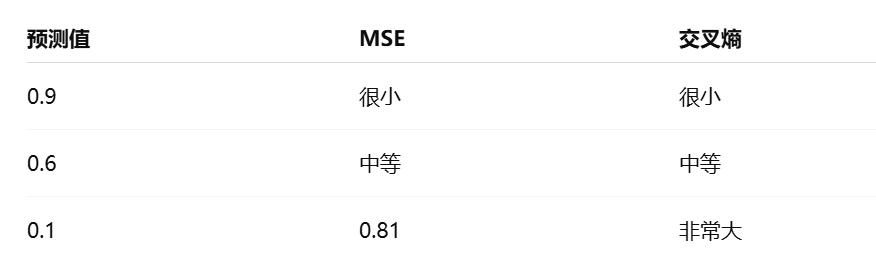
可以看到一个非常关键的差异:
- MSE 的惩罚是“平滑的”
- 交叉熵的惩罚是“陡峭的”
换句话说:
- MSE 比较温和
- 交叉熵更严格
五、为什么分类任务不用 MSE?
这才是最关键的一步。
原因1:优化目标不一样
- MSE 在做:最小化“数值距离”
- 交叉熵在做:最大化“概率正确性”
而分类问题,本质上是:概率问题,而不是距离问题。
原因2:对错误的惩罚不同
- MSE:错误也惩罚,但不够“狠”
- 交叉熵:越自信但越错,惩罚越大
这会带来一个重要影响:模型在交叉熵下,更容易被“拉回正确方向”。
六、把前面的知识串起来
我们前面讲过:
- Batch
- Iteration
- 梯度下降
现在可以把它们全部串起来,每一次 Iteration,模型都会:
- 做一次预测
- 计算 Loss
- 根据 Loss 更新参数
而这个 Loss,就是我们这里讲的:MSE 或 交叉熵
也就是说:损失函数不仅是“算误差”,而是决定模型怎么更新参数。
损失函数决定了模型“怎么学”,而不是只是“算误差”。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)