【vllm-ascend】 MTP原理及工程适配
MTP通过并行预测多个Token,将1-token的生成,转变成multi-token的生成,在不影响输出质量的前提下提升生成吞吐量, 实现成倍的推理加速来提升推理性能。
作者:昇腾实战派
MTP通过并行预测多个Token,将1-token的生成,转变成multi-token的生成,在不影响输出质量的前提下提升生成吞吐量, 实现成倍的推理加速来提升推理性能。
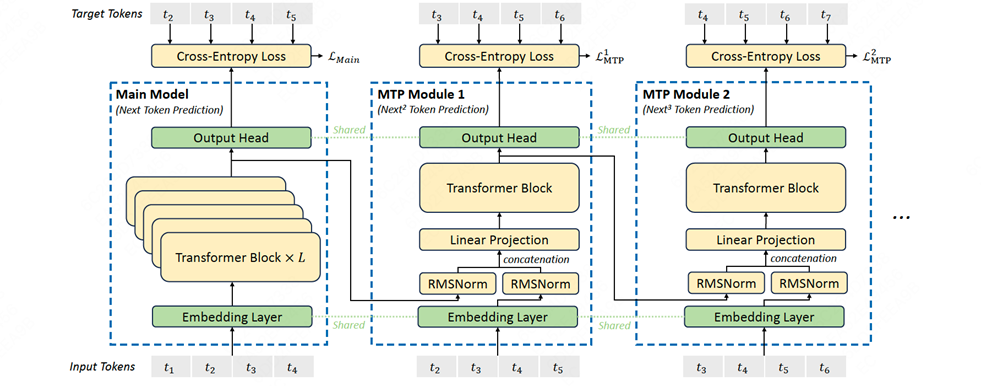
一、DeepSeek MTP模型架构
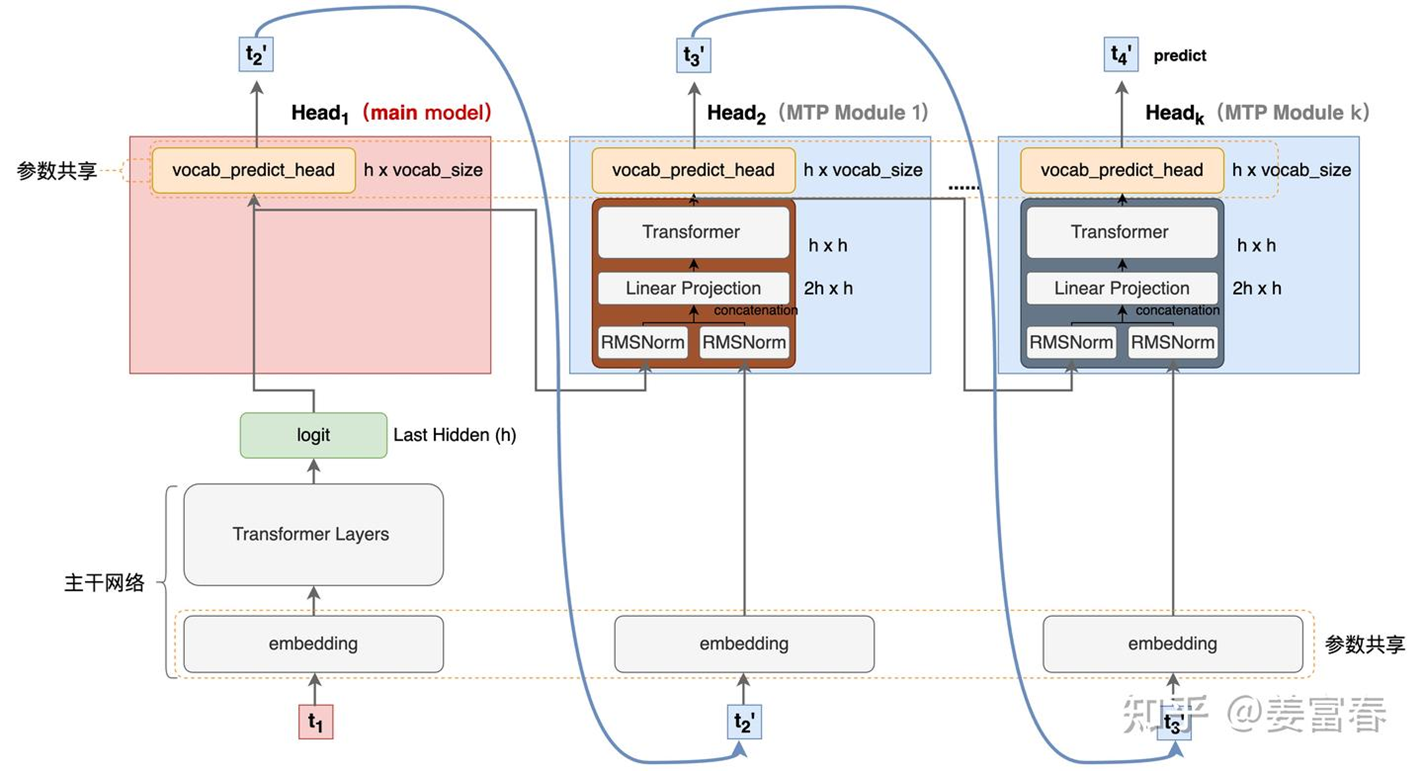
•主模型(Deepseek主干模型): 含有L层Transformers Block。 以Deepseek-V3 为例,主模型有61层Transformers Block;在推理时,其Attention 部分使用对应的前61层KV cache。
•MTP层: MTP 使用顺序模块来预测额外的令牌。每个模块包含一个共享的嵌入层、一个共享的输出头、一个 Transformer 模块和一个投影矩阵。 以Deepseek-V3 为例,MTP有1层Transformers Block;在推理时,其Attention 部分使用对应的最后1层KV cache。
•Linear Projection输入组合: 对于每个输入token,MTP 将上一轮的hidden state的和当前的token的embedding结合,通过linear projection生成新的hidden state。
•Transformer 处理: Transformer 模块处理这些组合的表示,生成当前深度的输出表示。
•输出头预测: 共享输出头使用 Transformer 模块的输出表示来计算额外预测令牌的概率分布。
•损失计算: 对于每个预测深度,计算交叉熵损失,并将所有深度的损失平均并加权,作为最终的 MTP 损失
二、MTP模型基础推理适配
MTP=1推理适配流程
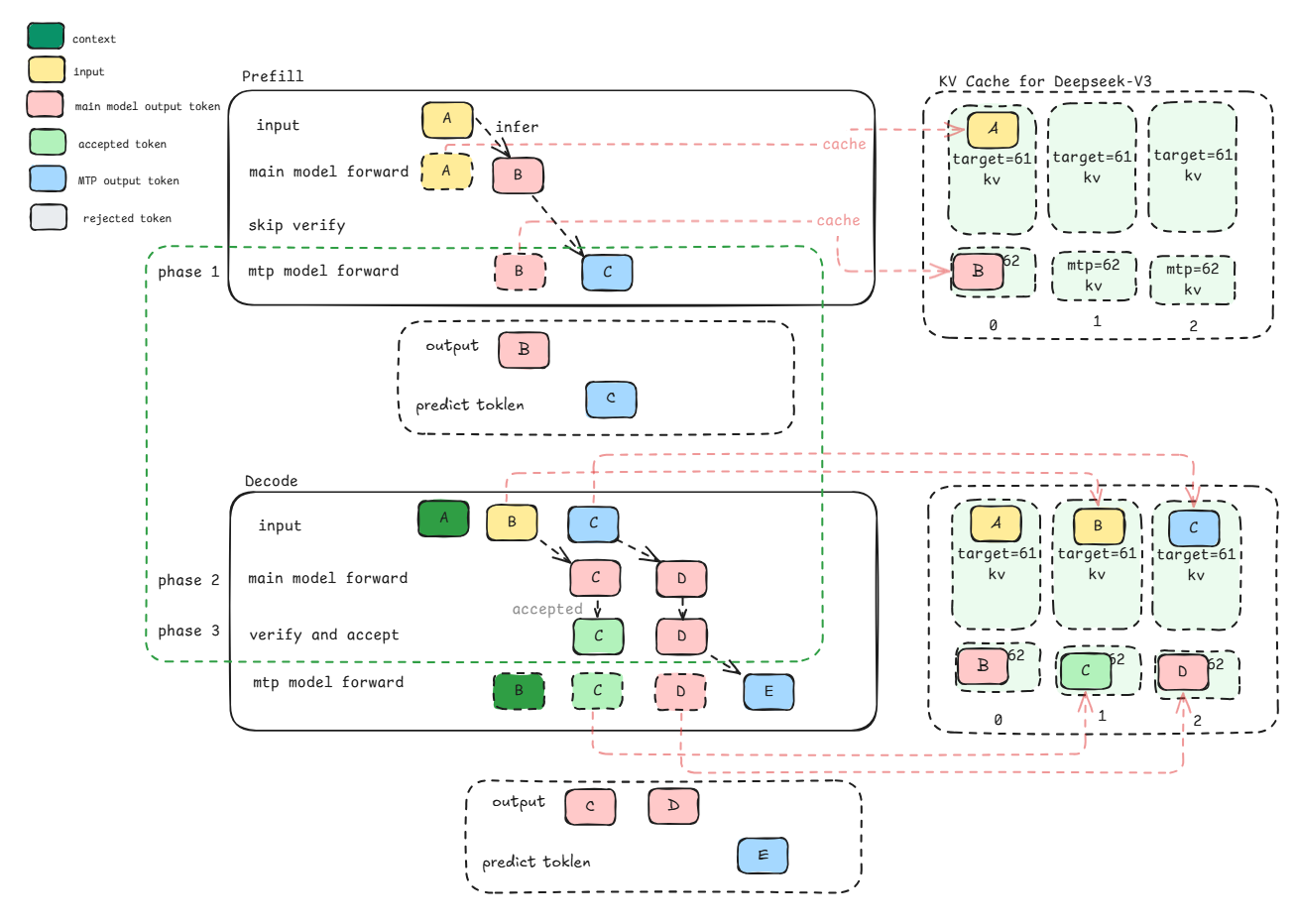
•DeepSeek V3推理有三个阶段:
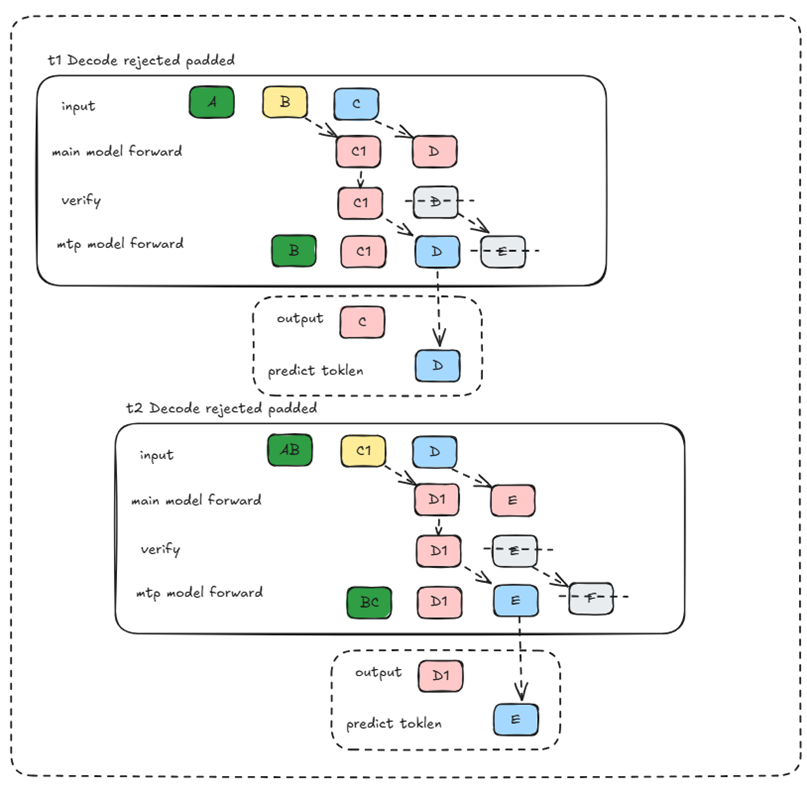
•阶段1:predict (预测),利用 k 个Head一次生成 k 个token,每个Head生成一个token。如果用到flash attention会将对应的token kv缓存至最后一层kv cache中。
•阶段2:verify(验证),将原始的序列和生成的token拼接,组成多个 Pair <sequence_input,label> ,将组装的多 Pair <sequence_input,label> 组成一个Batch,一次发给 Main Model做校验。此时主模型会每个request推理(1+mtp 草稿数量)个数的token,图中为2个token,mtp=1。
•阶段3:accept(接受): 选择 Head1 预估token与 label 一致的最长 k 作为可接受的结果。
•循环上述过程,直到生成eos终止标记。
MTP=k 推理适配流程
当MTP>1时,其基本流程与MTP=1差异不大。只是在 mtp model forward的时候循环遍历 k 遍。在vllm-ascend的当前实现中,我们选择了多个MTP模组共用同一层KV cache,因为Deepseek-V3 仅开源了一层MTP权重,使用多层KV cache的意义不大。
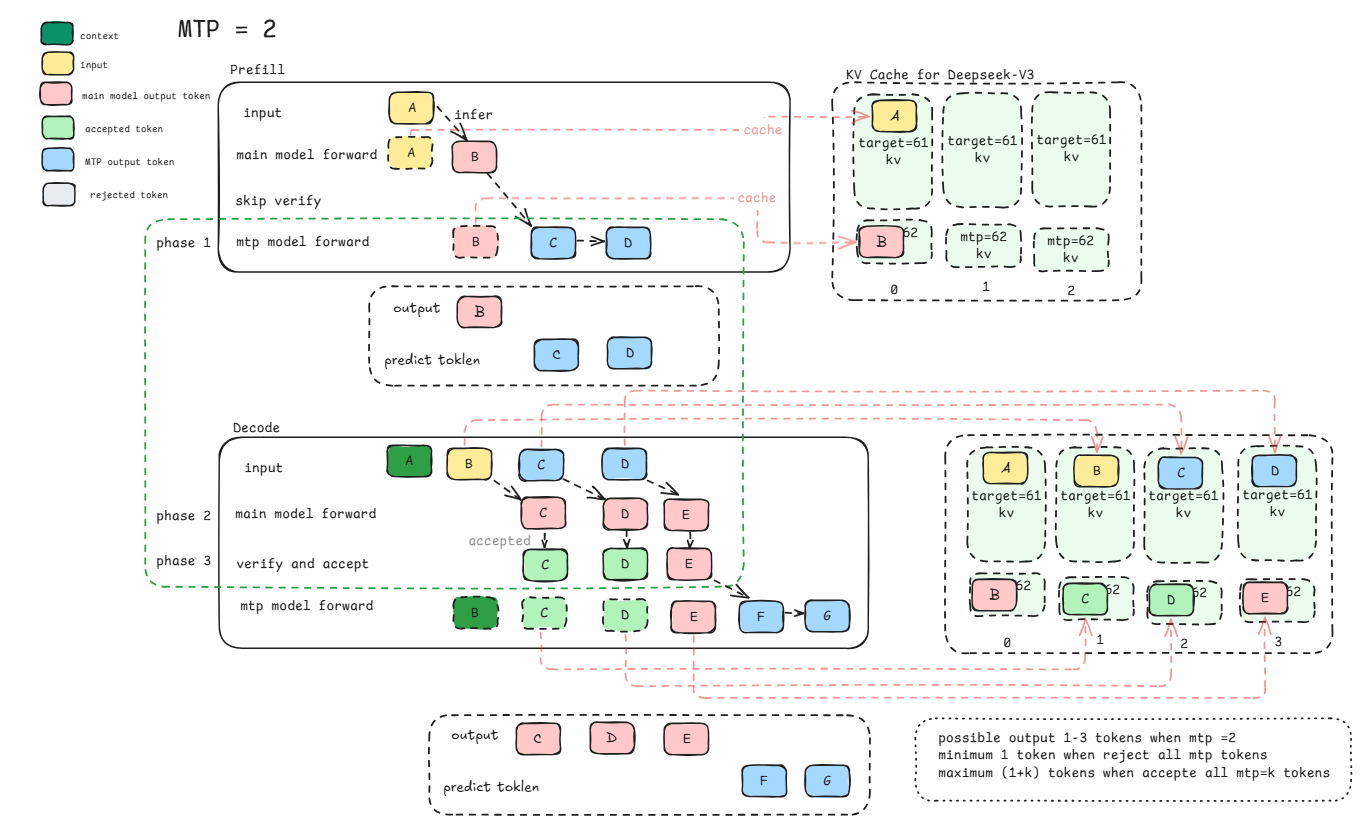
推理流程
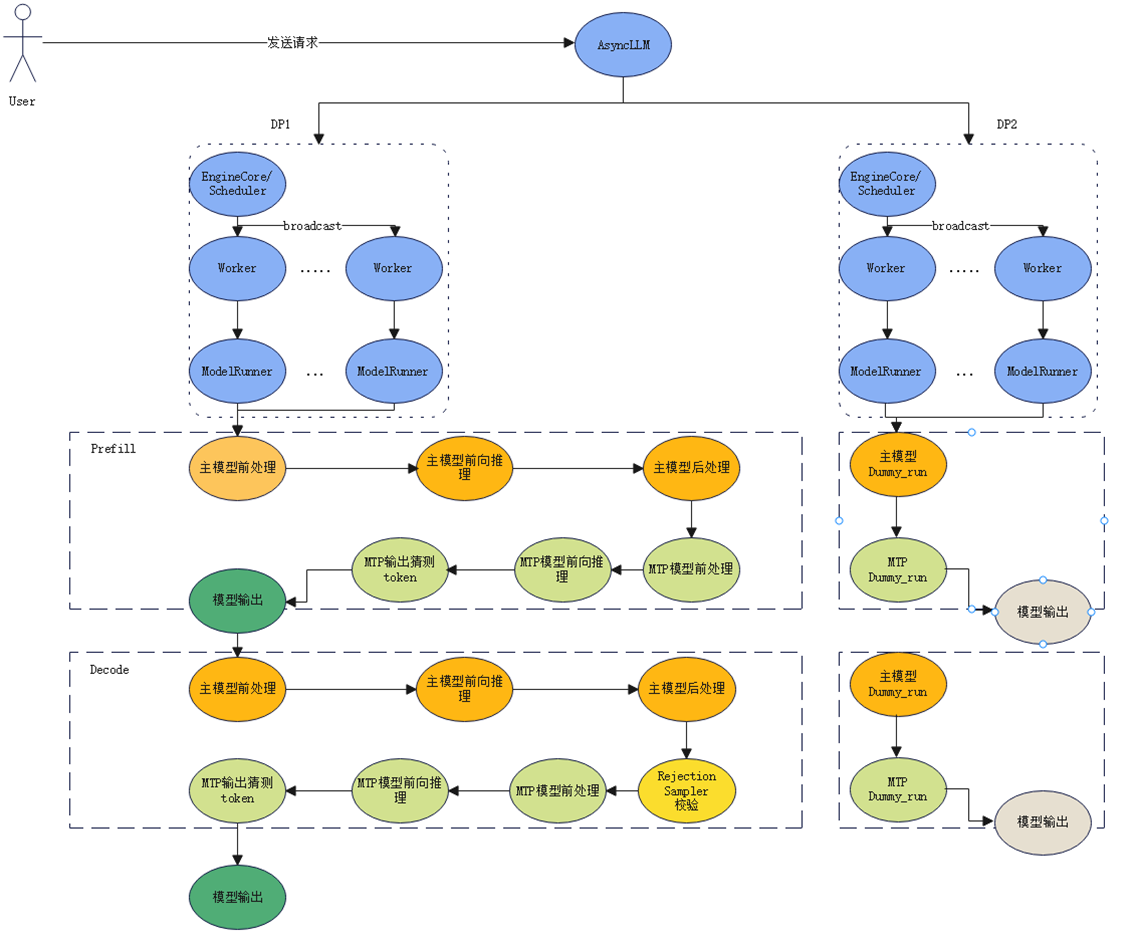
以MTP=1为例,用户发送一个请求时,该请求会被EngineCore接收并broadcast到该DP域的所有worker上。在Prefill阶段,主模型会先对该请求做预处理、前向推理、后处理,但没有校验,因为此时mtp模型还没有给出预测token。主模型的输出hidden state,及一些输入参数会给到mtp模型做预处理并做前向推理,最后MTP模型使用贪心后采样输出预测token。整个模型
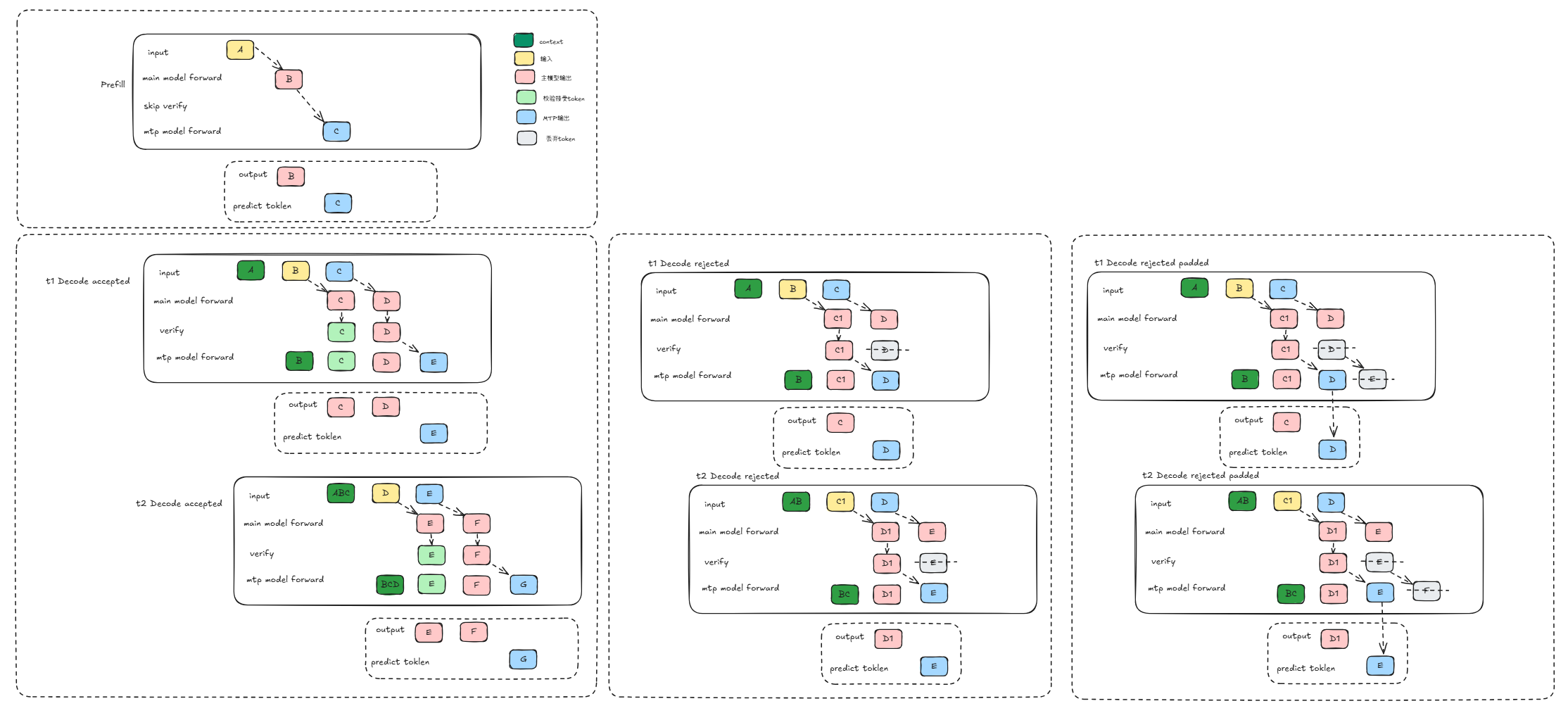
在Decode阶段,主模型会将上轮的输出token和预测token拼到一起运行(同时计算2个token),此时第一个token是绝对正确的,但第二个token不一定正确因为是基于猜测token推理出来的,我们称之为bonus token。想要确认bonus token是否可以被接受,我们有两种策略来确认,一种是较为简单的贪心策略,还有一种是随机性更大的拒绝采样策略。(贪心策略下)我们需要校验本轮主模型推理出来的token是否与上轮的mtp猜测token一致,若完全一致则接受bonus token,不一致则拒绝基于mtp猜测token推理出来的bonus token。(拒绝采样策略下)对于每一个草稿(draft)token,其是否被接受的判定基于以下不等式:
P_target / P_draft >= U
其中:
P_target: 目标模型(Target Model)为当前草稿 token 分配的概率。
P_draft: 草稿模型(Draft Model)为当前草稿 token 分配的概率。
U: 一个从 [0, 1) 区间均匀分布中采样得到的随机数。
判定逻辑:
接受 (Accept):如果 P_target / P_draft >= U 成立,则接受该草稿 token,将其作为输出。
拒绝 (Reject):如果 P_target / P_draft < U,则拒绝该草稿 token
被拒绝后的恢复采样公式
当一个 token 被拒绝后,需要从一个调整后的概率分布中重新采样一个“恢复 token”(recovered token)。这个调整后的分布 Q 的计算公式是:
Q = max(P_target - P_draft, 0)
当前MTP实现中不传入P_draft,所以默认为1,以上公式可以简化为:
接受:P_target >= U,恢复分布:Q = max(P_target - 1, 0)
若校验后bonus token被接受了,mtp模型则需要推理计算2个token(主模型原本的输出token + bonus token),若没有被接受,则只需要推理计算1个token。在图模式中,为了保证静态图,无论校验后bonus token是否被接受,我们都会推理计算2个token,但最后输出只取校验时接受的那个index,确保输出的结果是正确的。
若存在多个DP组,那么没收到请求的DP组会运行dummy_run 陪跑。陪跑的原因是因为部署dp并行的同时,往往会一同使用EP并行(专家并行),专家的权重分散在不同的卡上,有可能部分被激活需要参与计算的专家刚好当前没有收到request。我们需要这部分专家一起陪跑才能完成MoeDistributeDispatch 和MoeDistributeCombine。
流程图
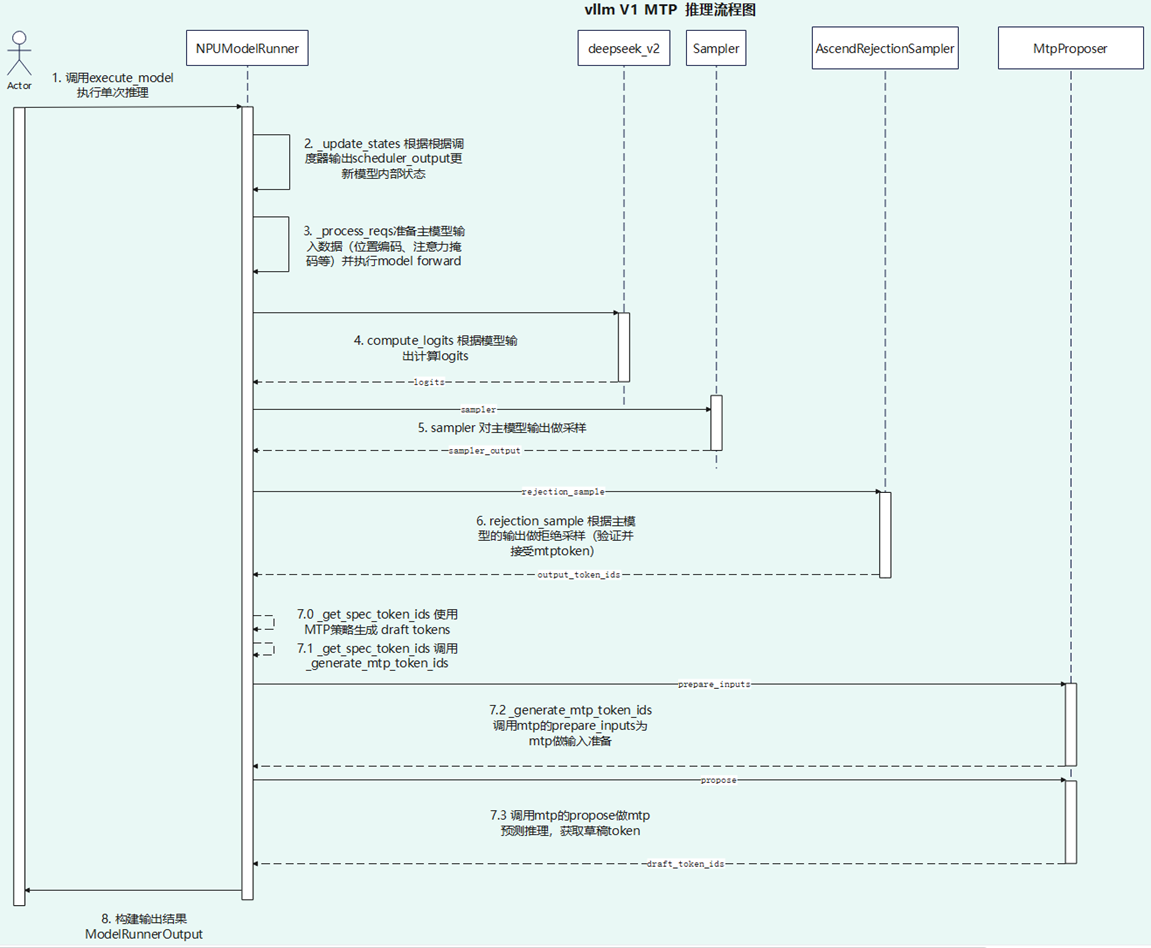
Rejection Sampler-vllm-ascend流程图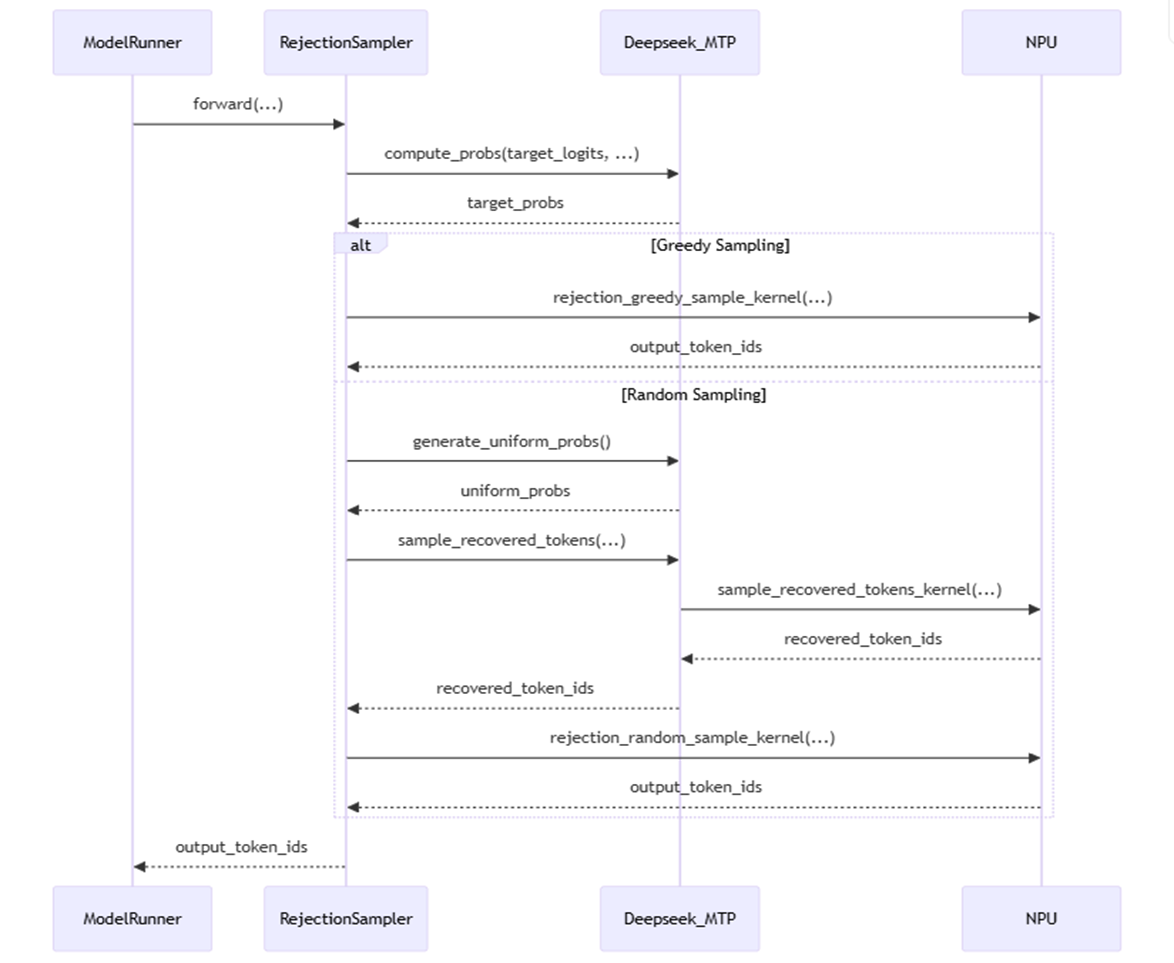
三、相关算子及图模式适配
由于 MLA 的复杂性,现在的很多 MLA 实现并不支持在 decode 单次前向计算时同时并行计算多个 Query token,为此主流推理框架有几个方案
**方案一:**比较常见的是通过Batch Expansion 进行投机解码
**方案二:**当前vllm社区会在attention部分做校验,若query token>1则会走chunked prefill算子
**方案三:**torch npu的npu_fused_infer_attention_score支持在decode阶段单次前向计算时同时并行计算多个 Query token,但限制条件比较多,具体参考说明文档
此处我会详细介绍方案一(sglang实现),方案三(vllm-ascend实现)
Batch Expansion
以 how [can, we] 举例,我们可以展开成 3 个请求:
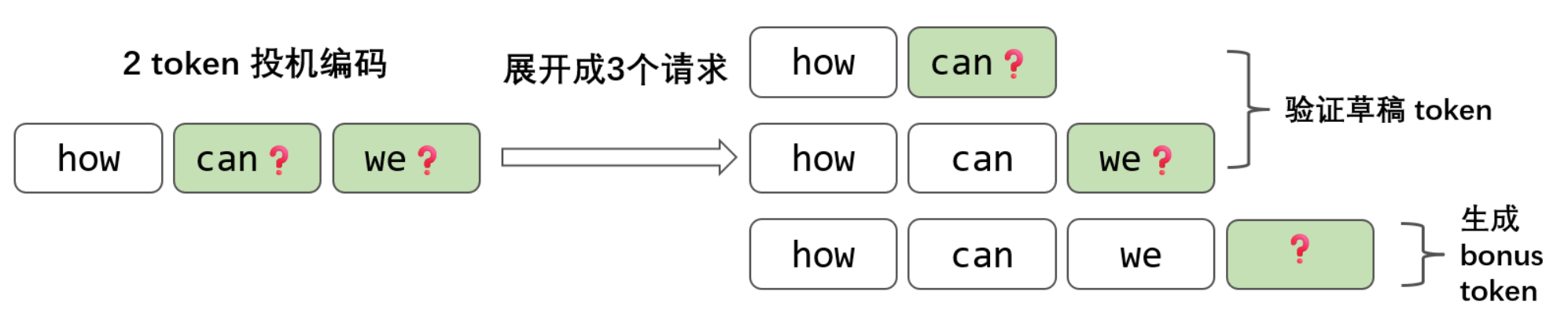
从逻辑上来看,请求变多了,但 3 个请求放到一个 batch 中可以进行并行计算,可以共享 prefix cache (如果先做 prefill 的话),这样我们依然可以拿到 p_how, p_can 和 p_we。通过并行请求也能够实现 1 次 Decode 验证多个 token。
这里要注意一个逻辑:虽然要验证 2 个 token,但是却展开成了 3 个请求。这样如果全部两个草稿模型投机推理的 token 都被接受了,那第 3 个 token 会由目标模型自己生成,这个 token 被称为 bonus token。
虽然 Batch Expansion 能解决投机编码时的并行问题,但 Batch Expansion 有一定的计算开销。在高吞吐的时候,会抵消投机编码带来的加速。更好的优化就需要 MLA 算子在单次前向计算时,同时 decode 2 个 query token,这有一定的改造成本。
npu_fused_infer_attention_score 算子适配
•开启MTP后每个request在decode时需要处理>1个token,而vllm-ascend原本并不支持decode阶段处理seq_len>1的场景。为了能在decode阶段处理seq_len>1的场景,我们需要对底层的注意力算子npu_fused_infer_attention_score算子适配TND 场景
该算子会根据传入的actual_seq_lengths 和 actual_seq_lengths_kv, 计算每个request的实际Query token,和cached kv token,实现在 decode 单次前向计算时同时并行计算多个 Query token。
注意事项: npu_fused_infer_attention_score算子的TND 场景算子限制特别多,需要仔细阅读说明文档进行适配,以下是两个关键参数的说明:
- actual_seq_lengths:int类型数组,代表不同Batch中query的有效seqlen,数据类型支持int64。如果不指定seqlen可以传入None,表示和query的shape的S长度相同。
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件、Atlas A3 训练系列产品/Atlas A3 推理系列产品:
该入参中每个batch的有效seqlen应该不大于query中对应batch的seqlen。seqlen的传入长度为1时,每个Batch使用相同seqlen;传入长度大于等于Batch时取seqlen的前Batch个数。其他长度不支持。当query的input_layout为TND时,该入参必须传入,且以该入参元素的数量作为Batch值。该入参中每个元素的值表示当前Batch与之前所有Batch的seqlen和,因此后一个元素的值必须大于等于前一个元素的值,且不能出现负值。综合约束请见约束说明。- actual_seq_lengths_kv(IntArray*,计算输入):Host侧的IntArray
Atlas A2 训练系列产品/Atlas 800I A2 推理产品/A200I A2 Box 异构组件、Atlas A3 训练系列产品/Atlas A3 推理系列产品:该入参中每个batch的有效Sequence Length应该不大于key/value中对应batch的Sequence Length。seqlenKv的传入长度为1时,每个Batch使用相同seqlenKv;传入长度大于等于Batch时取seqlenKv的前Batch个数。其他长度不支持。当key/value的inputLayout为TND/NTD_TND时,综合约束请见约束说明。- TND、TND_NTD、NTD_TND场景下query、key、value输入的综合限制(节选):
- T小于等于1M;
- actualSeqLengths和actualSeqLengthsKv必须传入,且以该入参元素的数量作为Batch值。该入参中每个元素的值表示当前Batch与之前所有Batch的Sequence Length和,因此后一个元素的值必须大于等于前一个元素的值;
- 支持query每个batch的S为1-16;
Attention Mask
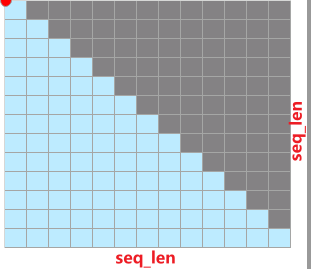
正常推理的时候我们所使用的attention mask为 [seq_len, seq_len] 大小的下三角矩阵,如下图所示
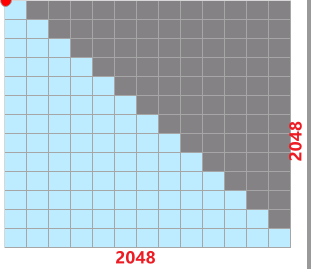
而当layout为TND时,算子强制要求需要一个[2048, 2048] 的压缩下三角矩阵
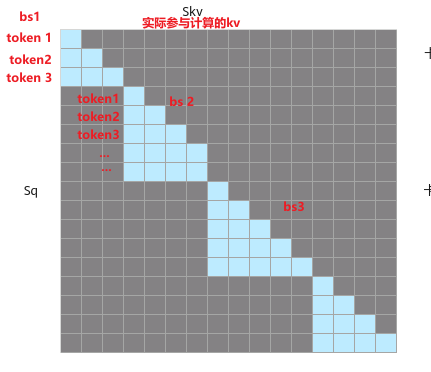
实际运行时,算子内部会自行拼接出实际需要的attention mask。(下图为我自行理解,如有错误请指正)
torchair 适配
TorchAir(Torch Ascend Intermediate Representation)是为torch_npu提供图模式能力的扩展库,支持用户使用PyTorch和torch_npu在昇腾设备上进行图模式的训练和推理。TorchAir对外提供昇腾设备的图模式编译后端,对接PyTorch的dynamo特性,将PyTorch的FX计算图转换为昇腾的GE计算图,并提供在昇腾设备上启动GE计算图编译和执行的能力。
**优点:**使用图模式可以大量减少算子下发时延,只需在模型开始推理前进行静态图模式的编译,运行过程中查询调用对应的静态图执行即可。
**弊处:**DFX定位能力较弱,及时官方给出了许多定位指导,但新手较难直接看出问题所在,需要通过不断的打点查看上下文信息并结合图dump功能才能逐步定位到根因。同时静态图的限制较多,dynamo容易误判某些入参导致动态shape,某些从config中读取不会变动的变量也需要手动标记为静态输入。
Torchair图模式适配注意点:
1、**尽量使用静态图: **将所有图的入参通过torch._dynamo.mark_static 标记为静态输入。有的时候dynamo容易误判某些入参导致动态shape,某些从config中读取不会变动的变量也需要手动标记为静态输入。这个时候就需要dump 图结构进行查看是哪一部分引入了动态shape。最后使用torch.compile对模型进行编译, 以下为示例:
# 编译静态图
config = torchair.CompilerConfig()
config.experimental_config.frozen_parameter = True
config.experimental_config.tiling_schedule_optimize = True
config.experimental_config.enable_view_optimize = \
get_ascend_config().torchair_graph_config.enable_view_optimize
torch.npu.set_compile_mode(jit_compile=False)
npu_backend = torchair.get_npu_backend(compiler_config=config)
self.torchair_compiled_model = torch.compile(
self.model,
dynamic=not self.use_sparse,
fullgraph=True,
backend=npu_backend)
# 标记入参为静态输入
torch._dynamo.mark_static(input_ids)
torch._dynamo.mark_static(positions)
torch._dynamo.mark_static(previous_hidden_states)
torch._dynamo.mark_static(attn_metadata.decode.block_table)
torch._dynamo.mark_static(attn_metadata.decode.input_positions)
if hasattr(attn_metadata.decode, "sin"):
torch._dynamo.mark_static(attn_metadata.decode.sin)
torch._dynamo.mark_static(attn_metadata.decode.cos)
torch._dynamo.mark_static(get_forward_context().mc2_mask)
torch._dynamo.mark_static(attn_metadata.slot_mapping)
torch._dynamo.mark_static(attn_metadata.decode.attn_mask)
torchair_compiled_model = self._get_torchair_lazy_compiled_model(num_tokens)
# 执行静态图
torchair_compiled_model(
input_ids=input_ids,
positions=positions,
hidden_states=previous_hidden_states,
inputs_embeds=None,
intermediate_tensors=None,
attn_metadata=attn_metadata,
kv_caches=self.runner.kv_caches[-1:],
spec_step_idx=0)
2、 **注意padding 要保持一致,**且需要考虑多DP时dummy_run的padding shape。因为上述的诸多算子限制,在torchair适配时,padding成为了严重阻塞点。
最终的padding方案为: 假设每个request在decode阶段会处理(1+k)个token,使actualSeqLengths pad到当前最大的图size。假设图大小为32, k=1,actualSeqLengths=[2,4,6,8,…,32]; actual_seq_lengths_kv 为当前实际的sequence长度,使用0进行pad, 最终为[s1, s2, s3, …, 0, 0]
然而这个假设在主模型阶段一直是对的,但在MTP阶段,由于存在部分token被拒绝的可能,MTP推理时每个request在decode阶段会处理最少1个token,最多(1+k)个token。那MTP阶段只能选择不入图,或者强制pad到(1+k)个token。我们选择了后者,无论上轮的mtp草稿token是否被接受,我们都推理(1+k)个token,最后在取hidden states时,再取对应的被接受的indices。如下图所示。
所以在入图后,mtp阶段的计算资源使用是要比不入图时高一些的,但相较于图模式带来的算子下发时延减少而言,这点损耗并不止的一提。
3、 DFX定位
a)图结构dump功能: 查看每个arg的shape是否有-1存在,有则存在动态shape需要定位其存在的原因
b)图内Tensor打印功能:仅在图可编译且可执行时打印,打印方式为:torchair.ops.npu_print(“str", torchTensor)
Aclgraph 适配
以下是官方描述:
PyTorch原生框架默认以Eager模式运行,即单算子下发后立即执行,每个算子都需要经历如下流程:Host侧Python API->Host侧C++层算子下发->Device侧算子Kernel执行,每次Kernel执行之前都要等待Host侧下发逻辑完成。因此在单个算子计算量过小或Host性能不佳场景下,很容易产生Device空闲时间,即每个Kernel执行完后都需要一段时间去等待下一个Kernel下发完成。
为了优化Host调度性能,CUDA提供了一种GPU图模式方案,称为CUDA Graph。其本质是Device调度策略,省略了算子Host调度过程,以提升图模式执行效率,该方案详细介绍请参见官网Accelerating PyTorch with CUDA Graphs。借鉴CUDA Graph,TorchAir提供了NPU图模式方案,称为aclgraph,将算子Kernel下沉到Device执行,以实现NPU上图模式执行效率提升。
本功能就是TorchAir提供的aclgraph图模式开关,当用户网络存在Host侧调度问题时,建议开启此模式。
Aclgraph 其实与上述的torchair图差别不是特别大,主要差异点在于定位和提供底层能力的组件不同。Aclgraph主要对标Cudagraph,所有的api设计和cudagraph对齐,更有益于生态发展和迁移。其图下沉原理和cudagraph一致,由RTS提供对等CUDA的graph capture&replay的能力,而torchair则由GE提供的图模型能力。在后续的选择上,vllm-ascend也会更倾向于选择aclgraph。
优点:
- 可以选择分图模式与整图模式,如果部分模块不适合入图可以在该模块的前后加入断图功能,用单算子运行该模块,其他部分仍然使用图模式运行。(vllm社区最开始提供的cudagraph就是在attention前后加入了断图功能,每当运行到attention时会走单算子。这一层attention后的操作到下一层attention前的操作会被捕获成一张图来重放执行。现在vllm已经支持整图模式,vllm-ascend也在支持的路上)
- aclgraph后续将会像cudagraph一样,支持Inductor自动融合图,就不需要像torchair一样手动融合图。
弊处:
- aclgraph 的DFX定位能也比较弱,或者说图模式的定位都不是很容易。虽然官方提供了切换
aot_eager后端的定位手段,但有的时候默认后端的表现和aot_eager后端的表现并不完全一致 - 当前的图捕获数量依赖于 NPU 的资源配置,尤其是显存和流数。不同的模型架构和并行配置会影响资源的分配。目前能捕获的形状非常少,导致无法覆盖大部分实际推理场景,填充步长过大,造成计算性能浪费。25年Q3会进行流规格改造,从现有的2048流改为65535流,可以较大程度上缓解资源不足的问题。在改造完成之前,可以通过手动调整
cudagraph_capture_sizes来覆盖业务上关键的形状。
适配流程:
- 确保对需要使用aclgraph的模型使用了装饰器
@support_torch_compile, 这个装饰器由vllm封装,最终会调用torch.compile - 在
set_ascend_forward_context中设置对应的aclgraph_runtime_mode和batch_descriptor - 运行时不开启
enforce_eager, 则会默认运行aclgraph模式。框架内部已大量集成了aclgraph的适配,一般情况下不会遇到什么问题,如果遇到问题,需要根据报错解决问题。
DFX定位:
- 切换
aot_eager后端, 使用eager模式执行。
在vllm/vllm/compilation/wrapper.py的TorchCompileWrapperWithCustomDispatcher.__init__中
compiled_callable = torch.compile(
self.forward, fullgraph=True, backend="enforce_eager", options=options
)
四、MTP PD分离
MTP 会让 PD 分离变得更复杂。当前主流框架有两种方案:
方案一:Prefill 节点做 MTP Prefill:P 节点做完 DeepSeek-V3 Prefill 以后,保留最后一层所有 token(除了第 1 个,即index 0)的 hidden states,采样生成的第一个 token,获得 tokenid,然后将这些输入到 MTP Module 1 做 Prefill。
最后将
**1) **DeepSeek-V3 61 层的 KV Cache;
2) DeepSeek-V3 MTP 的 KV Cache;
3) DeepSeek-V3 生成的第一个 tokenid;
4) DeepSeek-V3 MTP 生成的第一个草稿 tokenid 和概率;这 4 部分传给 D 节点。
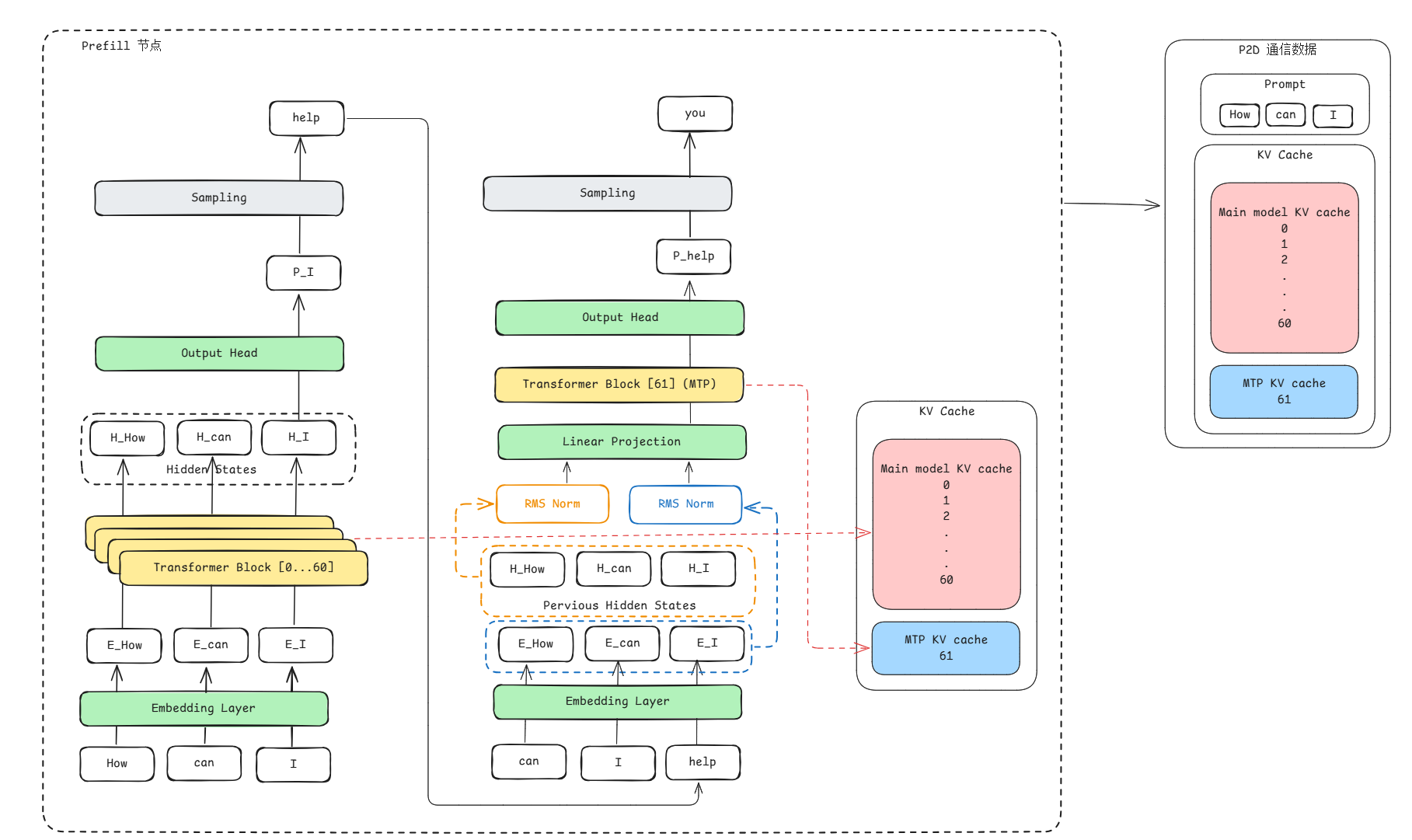
方案二:Prefill 节点不做 MTP Prefill:P 节点做完 DeepSeek-V3 Prefill 以后,把:1) DeepSeek-V3 61 层的 KV Cache; 2) 最后一层所有 token(除了第 1 个,即index 0)的 hidden states;3)所有 token (除了第 1 个,即 index 0)的 embedding。这 3 部分传给 D 节点。D 节点将生成第一个 token 的 hidden states 经过 LM Head 计算和采样获得 tokenid,然后对 MTP 进行 Prefill。
VLLM方案:
然而,由于VLLM的当前框架限制,Prefill 节点只能给 Decode节点传输KV Cache,无法传输token id,即使我们选择了方案一,我们也无法获取主模型token和MTP token,只能在D节点上使用已有的prompt和kv cache走decode算子推理第一个token。所以P节点仅仅只给D节点传输:
**1) **DeepSeek-V3 61 层的 KV Cache;
2) DeepSeek-V3 MTP 的 KV Cache;
3) 用户输入的prompt
整体流程如下:
但是如此一来,上个章节中对npu_fused_infer_attention_score(简称FIA) 的假设就不成立了,无法做到“每个request在decode阶段会处理(1+k)个token”,因为D节点在收到由P节点发送的请求时只会在decode阶段会处理1个token。那么就需要重新设计图模式的padding逻辑(单算子和piecewise aclgraph不受影响)。
如果我们针对这一情况单独写一个分支,那么正在运行的decode请求和刚刚接收到的decode请求就无法组batch计算。但如果不分开计算的话,又容易违反FIA的诸多限制。其中最容易违反的就是
- “支持query每个batch的S为1-16
- len(actualSeqLengths) == len(actual_seq_lengths_kv), 且入图后host list中的值可以变动,但长度不可变动
- actualSeqLengths的最后一个元素需要等于总token数。例如grpah是32,那么actualSeqLengths的最后一位一定要是32。
最典型的例子就是假设最大可执行的请求数16, MTP=1的情况下,编译后的graph是32, TND场景下,token数(T)为32,按原先预设的actualSeqLengths=[2,4,6,8,…,32], actual_seq_lengths_kv=[s1, s2, s3, …, s15, s16]
此时,若P节点同时发送16个处理好的请求给到D节点,D节点的actualSeqLengths需变更为[1,2,3,4,5,…,16], 否则会出现精度问题。但是这就违反了上述的第3条限制。
最终PD分离,针对FIA算子的整图padding策略为:
在编译静态图时,将静态图编译的比实际可运行的reqeust大一些,增加空位给FIA算子进行pad。还是上面的例子,我们期望最大可执行的请求数是16,但是我们把执行图扩大一些,实际可执行的最大请求数可能是18,那么最终graph将变成36。这样即使P节点同时发送16个处理好的请求给到D节点,D节点也可以在最后两个空位做padding, 同时考虑到上述的条件1,将剩下的token均分保证每个batch不超过16。最终两个关键入参为:actualSeqLengths=[1,2,3,4,5,…,16, 26, 36], actual_seq_lengths_kv=[s1, s2, s3, …, s15, s16, 0, 0]。这样最后两个request每轮都不会参与实际计算。
五、MTP代码
支持MTP torchair:[V1] MTP supports torchair
支持MTP + chunkedprefill:[v0.9.1] MTP supports V1 scheduler
支持MTP piecewise Aclgraph:pr1、pr2
支持MTP+PD的torchair图模式padding:pr1、pr2
六、MTP 开启方式
online
开启mtp:--speculative-config '{"num_speculative_tokens": 1, "method":"deepseek_mtp"}'
v0.9.1分支 使用v1 scheduler:"ascend_scheduler_config":{"enabled":false}
**main分支 **使用 v0 scheduler: "ascend_scheduler_config":{"enabled":true}
**main分支 **9月开始支持使用 v1 scheduler: "ascend_scheduler_config":{"enabled":false}
**main分支 **10月开始支持使用 num_speculative_tokens >1
主线代码示例
python -m vllm.entrypoints.openai.api_server \
--model="/weights/DeepSeek-R1_w8a8/" \
--trust-remote-code \
--max-model-len 40000 \
--tensor-parallel-size 4 \
--data_parallel_size 4 \
--max-num-seqs 16 \
--no-enable-prefix-caching \
--enable_expert_parallel \
--served-model-name deepseekr1 \
--speculative-config '{"num_speculative_tokens": 1, "method":"deepseek_mtp"}' \
--quantization ascend \
--host 0.0.0.0 \
--port 1234 \
--additional-config '{"torchair_graph_config":{"enabled":true,"graph_batch_sizes":[16]},"enable_weight_nz_layout":true}' \
--gpu_memory_utilization 0.9
offline
mtp 相关配置: speculative_config={ "method": "deepseek_mtp", "num_speculative_tokens": 1, }
v0.9.1分支 使用v1 scheduler:"ascend_scheduler_config": { "enabled": False},
**main分支 **使用 v0 scheduler: "ascend_scheduler_config": { "enabled": True },
**main分支 **9月开始支持使用 v1 scheduler: "ascend_scheduler_config": { "enabled": False},
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
# Create a sampling params object.
sampling_params = SamplingParams(max_tokens=16, temperature=0)
# Create an LLM.
llm = LLM(
model="/home/data/DeepSeek-R1_w8a8/",
tensor_parallel_size=16,
max_num_seqs=16,
gpu_memory_utilization=0.9,
distributed_executor_backend="mp",
enable_expert_parallel=True,
speculative_config={
"method": "deepseek_mtp",
"num_speculative_tokens": 1,
},
trust_remote_code=True,
enforce_eager=False,
max_model_len=2000,
additional_config = {
'torchair_graph_config': {
'enabled': True,
"graph_batch_sizes": [16],
'enable_multistream_shared_expert': False,
},
}
)
# Generate texts from the prompts.
# llm.start_profile()
outputs = llm.generate(prompts, sampling_params)
# llm.stop_profile()
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
七、性能收益
MTP主要的主要作用是使用更多的计算资源来缩短平均decode时延(TPOT),以下是MTP在eager和aclgraph场景下的表现, MTP=1的TPOP计算公式为 ITL/(1+接受率), 整体时延缩短了1.28倍。
| original ITL/TPOP | mtp ITL | MTP TPOP(@85% accept rate) | acceleration | |
|---|---|---|---|---|
| eager | 247.6ms | 356.7ms | 192.8ms | 1.284 x |
| aclgraph | 106.5ms | 153.1ms | 82.75ms | 1.287 x |
在多机PD分离,大EP场景下,同样取的了差不多1.3倍的收益:
4机A3,2P1D; P:dp2、tp8、ep16 ;D:dp32、tp1、ep32
| original tpop | mtp ITL | mtp tpop | acceleration | |
|---|---|---|---|---|
| 大EP torchair | 68.37 | 95.49 | 51.46 | 1.32 x |
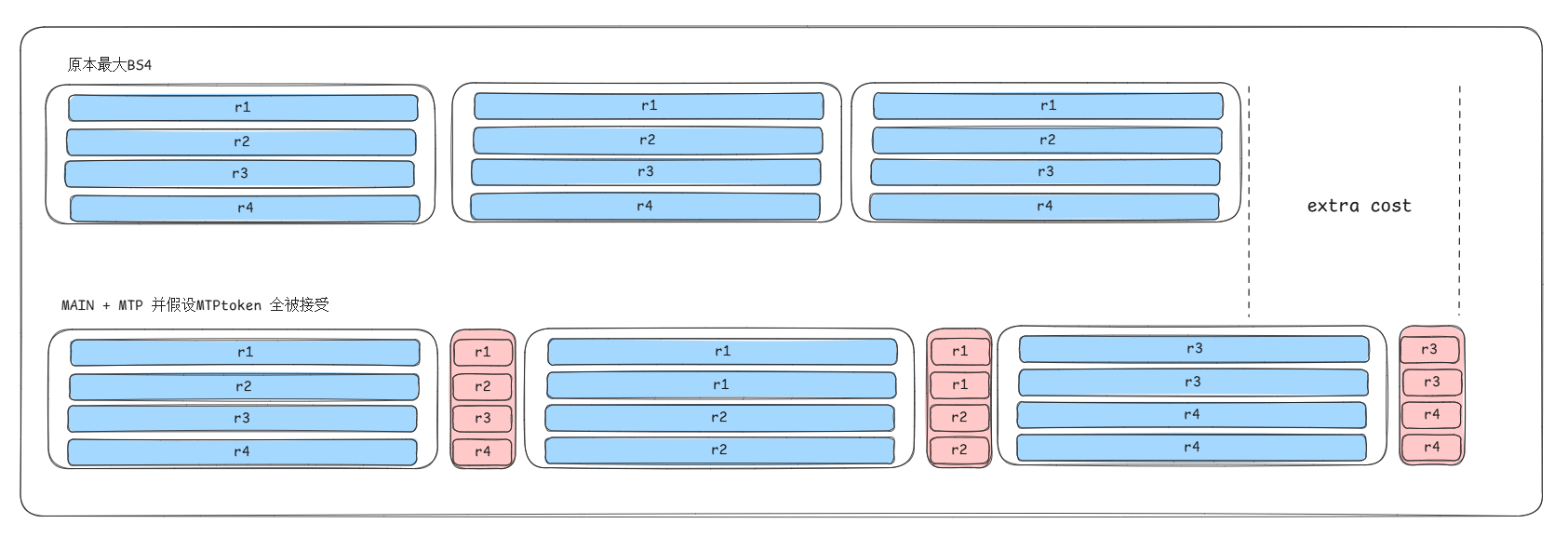
MTP的收益主要来源于小模型的快速推理。相比于主模型,小模型单次推理速度可能是原来的1/20,而使用小模型的代价仅仅是一点点额外的小模型输入准备、小模型推理及校验三个模块的overhead。只要这些overhead*(1-接受率)小于原本主模型单次推理时延,那么我们就可以获取一定量的性能加速。在草稿token被接受的情况下,原本推理4个token需要4个step,现在只需要2个step就可以得到正确结果。需要注意的是,MTP的使用是基于拥有冗余算力的基础上的,在小batch场景下mtp的收益较为明显,可能有30%-40%+的加速,取决于实际场景的接受率;在大batch场景(仍有冗余计算资源)下可能支持有10%-20%+的性能加速。
Full Attention场景的MLA无论是否使用MTP,其KV Cache的搬运量相同。因此MTP能够提高计算访存比,从而提高算力利用率。
需要注意的是,MTP并不是什么场景都适合使用的,因为MTP的使用会带来额外的显存压力和计算资源的使用,在不计时延只追求最求最大吞吐的场景下,最大吞吐反而会下降。简单的原因就是,在相同的计算资源的情况下,算力是恒定的,显存可能因为mtp的引入变小的同时,可并行处理的请求数却下降了, 而且仍然需要承担mtp带来的overhead。哪怕我们假设接受率为100%,还是会因为额外多了小模型推理的部分资源占用,导致整体吞吐不如不加mtp。
八、注意事项
当前在PD分离场景下,P节点只传输KV cache和promp,并不会传输主模型推理的token+mtptoken,所以D节点在第一轮推理的时候使用promp的最后一个token进行推理,同时不带mtp token。然后D节点在计算padding的时候并没有办法分辨这一情况,所以当前仅支持一张图编译,多张图可能存在选错图的大小。在设置"graph_batch_sizes"时仅设置一个数字,例如:[16]
online示例:--additional-config '{"torchair_graph_config":{"enabled":true,"graph_batch_sizes":[16]},"enable_weight_nz_layout":true}' \
offline 示例:
additional_config = {
'torchair_graph_config': {
'enabled': True,
"graph_batch_sizes": [16],
'enable_multistream_shared_expert': False,
},
}
九、后续优化及展望
-
归一泛化,当前由于之前为了极致优化,将MTP与常规eagle写成了两个文件,后续考虑归一泛化,减少新模式的适配工作量。
-
Triton算子加速,当前rejection sampler部分因开发时,triton算子支持度不够,使用了单算子形式,性能相较于triton算子大幅劣化,计划于Q4将这部分算子替换回社区的triton算子,当前已基于triton-ascend 穿刺成功。
-
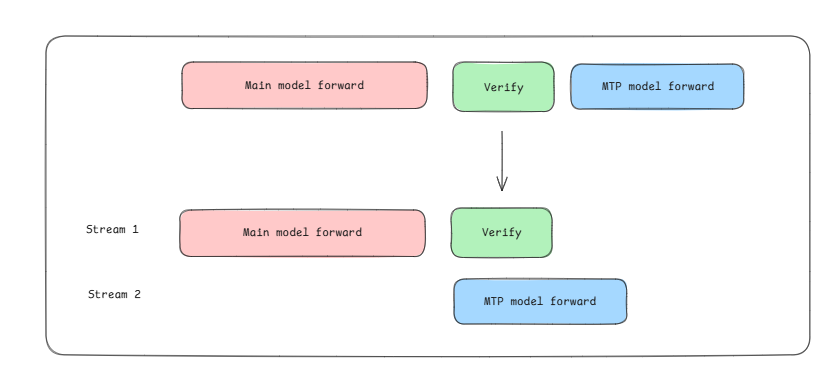
投机并行加速, 实现草稿模型推理和主模型校验的计算掩盖,草稿模型在实现padding后,可以不用等待主模型的验证,避免浪费计算资源。
-
投机解码校验优化算法, 由token-by-token校验 -> block-wise联合校验 / 概率联合校验, 提升校验通过的长度期望值,将在Q4实现。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)