昇思25天学习打卡营第1天|MindSpore实现一个简单的深度学习模型
人工智能(AI)框架已经有十余年的发展历史,四条主线驱动着AI框架不停地演进和发展:面向开发者:兼顾算法开发的效率和运行性能。面向硬件:充分发挥芯片和集群的性能。面向算法和数据:从计算规模看,需要应对模型越来越大的挑战;从计算范式看,需要处理不断涌现的新的计算负载。面向部署:需要将AI能力部署到每个设备、每个应用、每个行业。MindSpore是面向“端-边-云”全场景设计的AI框架,旨在弥合AI算
前言:
人工智能(AI)框架已经有十余年的发展历史,四条主线驱动着AI框架不停地演进和发展:
面向开发者:兼顾算法开发的效率和运行性能。
面向硬件:充分发挥芯片和集群的性能。
面向算法和数据:从计算规模看,需要应对模型越来越大的挑战;从计算范式看,需要处理不断涌现的新的计算负载。
面向部署:需要将AI能力部署到每个设备、每个应用、每个行业。
MindSpore是面向“端-边-云”全场景设计的AI框架,旨在弥合AI算法研究与生产部署之间的鸿沟。
在算法研究阶段,为开发者提供动静统一的编程体验以提升算法的开发效率;在生产阶段,自动并行可以极大加快分布式训练的开发和调试效率,同时充分挖掘异构硬件的算力;在部署阶段,基于“端-边-云”统一架构,应对企业级部署和安全可信方面的挑战。
昇思MindSpore是一个全场景深度学习框架,旨在实现易开发、高效执行、全场景统一部署三大目标。
其中,易开发表现为API友好、调试难度低;高效执行包括计算效率、数据预处理效率和分布式训练效率;全场景则指框架同时支持云、边缘以及端侧场景。
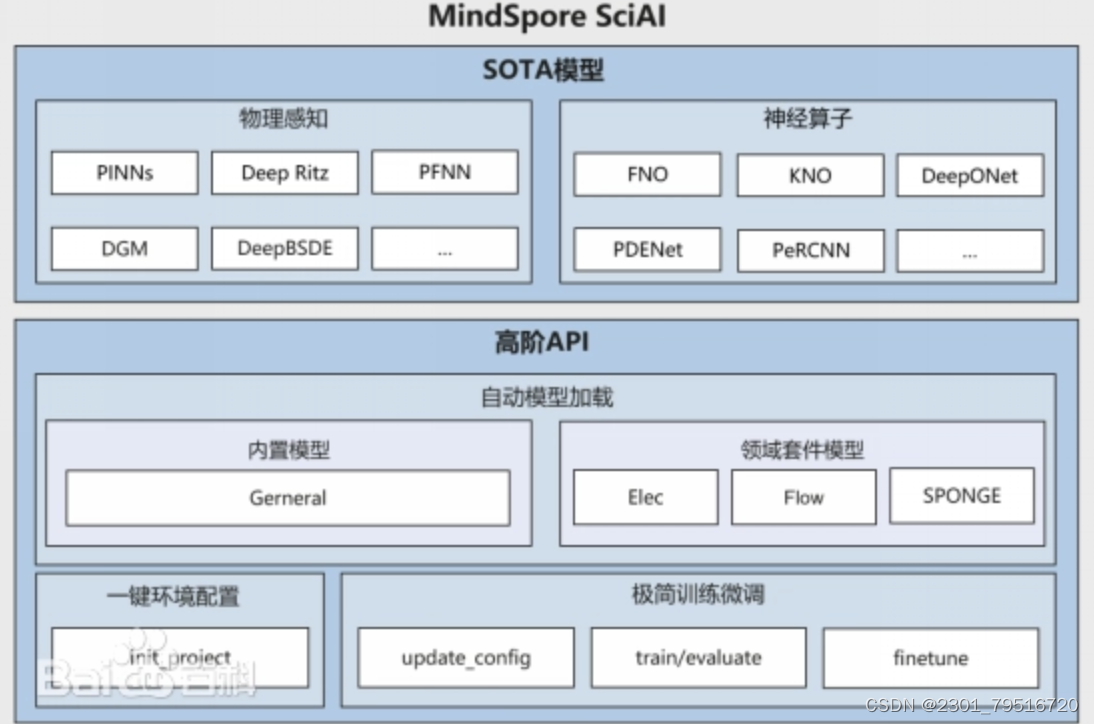
1. 设计理念:

- 支持全场景统一部署
昇思MindSpore源于全产业的最佳实践,向数据科学家和算法工程师提供了统一的模型训练、推理和导出等接口,支持端、边、云等不同场景下的灵活部署,推动深度学习和科学计算等领域繁荣发展。
- 提供Python编程范式,简化AI编程
昇思MindSpore提供了Python编程范式,用户使用Python原生控制逻辑即可构建复杂的神经网络模型,AI编程变得简单。
- 提供动态图和静态图统一的编码方式
目前主流的深度学习框架的执行模式有两种,分别为静态图模式和动态图模式。静态图模式拥有较高的训练性能,但难以调试。动态图模式相较于静态图模式虽然易于调试,但难以高效执行。 昇思MindSpore提供了动态图和静态图统一的编码方式,大大增加了静态图和动态图的可兼容性,用户无需开发多套代码,仅变更一行代码便可切换动态图/静态图模式,用户可拥有更轻松的开发调试及性能体验。
在友好支持AI模型训练推理编程的基础上,扩展支持灵活自动微分编程能力,支持对函数、控制流表达情况下的微分求导和各种如正向微分、高阶微分等高级微分能力的支持,用户可基于此实现科学计算常用的微分函数编程表达,从而支持AI和科学计算融合编程开发。
- 分布式训练原生
随着神经网络模型和数据集的规模不断增大,分布式并行训练成为了神经网络训练的常见做法,但分布式并行训练的策略选择和编写十分复杂,这严重制约着深度学习模型的训练效率,阻碍深度学习的发展。MindSpore统一了单机和分布式训练的编码方式,开发者无需编写复杂的分布式策略,在单机代码中添加少量代码即可实现分布式训练,提高神经网络训练效率,大大降低了AI开发门槛,使用户能够快速实现想要的模型。
通过MindSpore的API来快速实现一个简单的深度学习模型,若想要深入了解MindSpore的使用方法。
MindSpore提供基于Pipeline的数据引擎,通过数据集(Dataset)和数据变换(Transforms)实现高效的数据预处理。在本教程中,我们使用Mnist数据集,自动下载完成后,使用mindspore.dataset提供的数据变换进行预处理。
示例代码依赖download,可使用命令pip install download安装。如本文档以Notebook运行时,完成安装后需要重启kernel才能执行后续代码。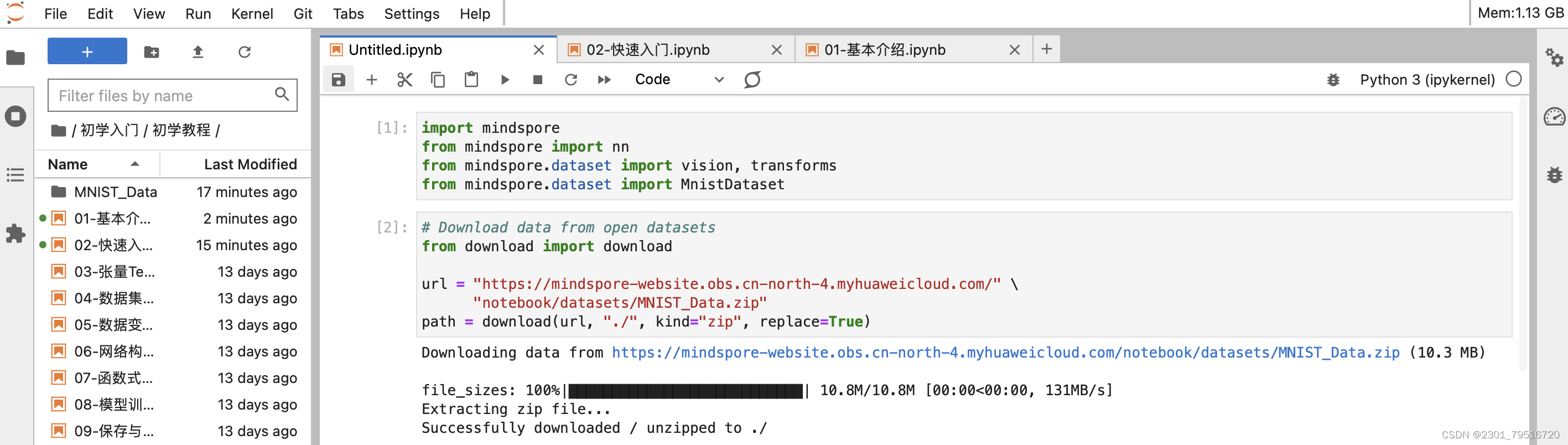
MNIST数据集目录结构如下:
MNIST_Data
└── train
├── train-images-idx3-ubyte (60000个训练图片)
├── train-labels-idx1-ubyte (60000个训练标签)
└── test
├── t10k-images-idx3-ubyte (10000个测试图片)
├── t10k-labels-idx1-ubyte (10000个测试标签)
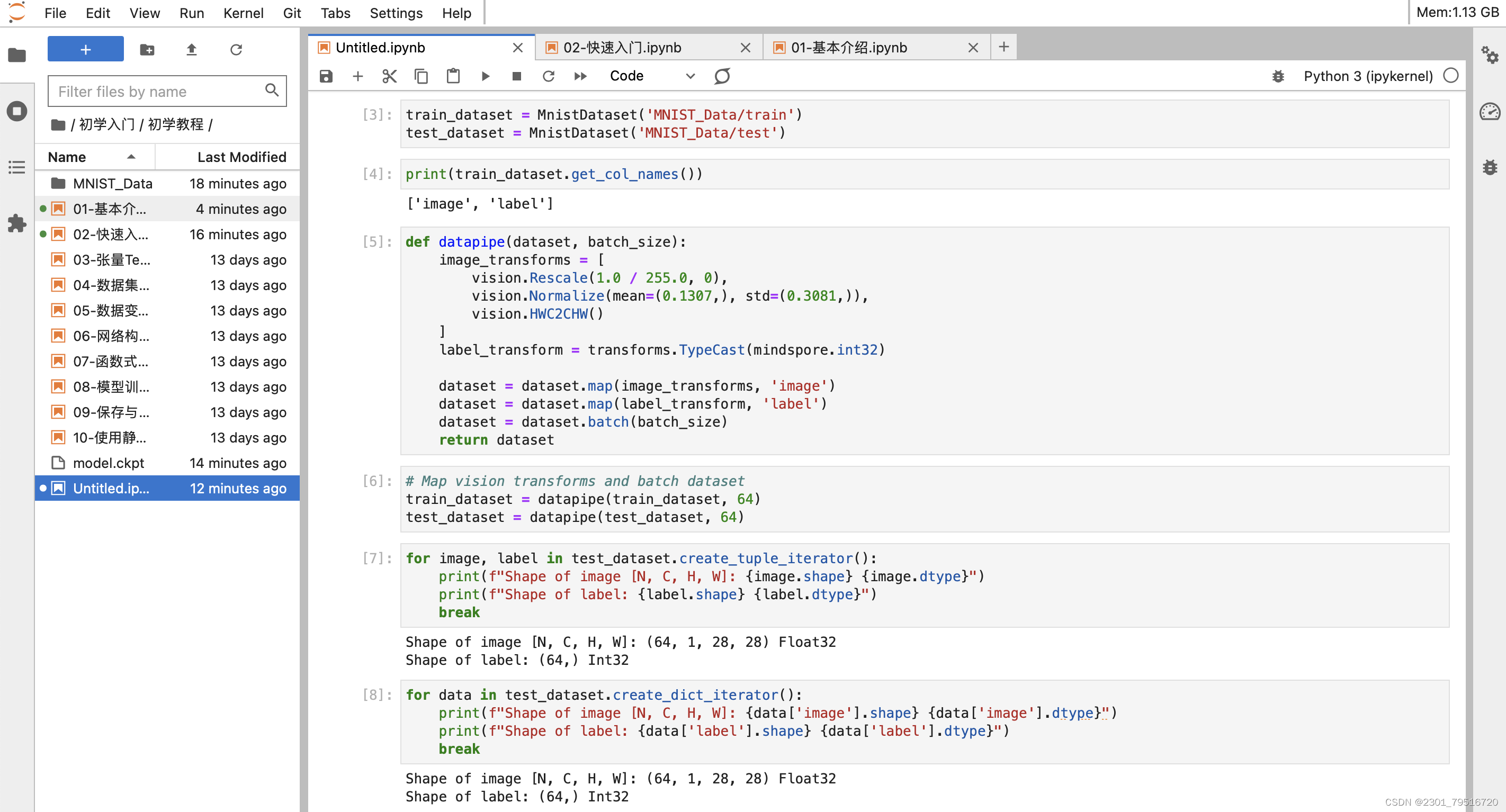
数据下载完成后,获得数据集对象。
打印数据集中包含的数据列名,用于dataset的预处理,MindSpore的dataset使用数据处理流水线(Data Processing Pipeline),需指定map、batch、shuffle等操作。这里我们使用map对图像数据及标签进行变换处理,然后将处理好的数据集打包为大小为64的batch。
可使用create_tuple_iterator 或create_dict_iterator对数据集进行迭代访问,查看数据和标签的shape和datatype。
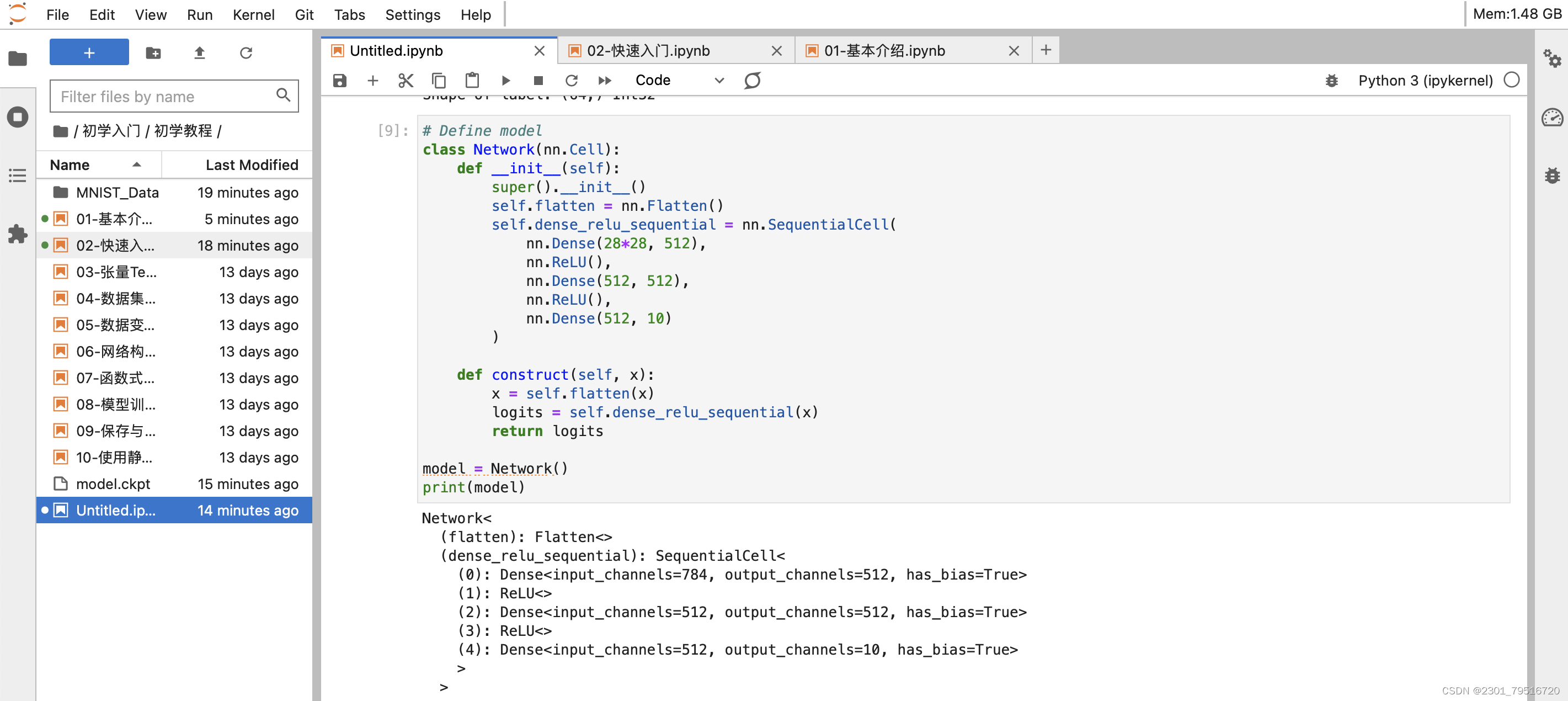
网络构建,mindspore.nn类是构建所有网络的基类,也是网络的基本单元。当用户需要自定义网络时,可以继承nn.Cell类,并重写__init__方法和construct方法。__init__包含所有网络层的定义,construct中包含数据(Tensor)的变换过程。
模型训练
在模型训练中,一个完整的训练过程(step)需要实现以下三步:
- 正向计算:模型预测结果(logits),并与正确标签(label)求预测损失(loss)。
- 反向传播:利用自动微分机制,自动求模型参数(parameters)对于loss的梯度(gradients)。
- 参数优化:将梯度更新到参数上。
MindSpore使用函数式自动微分机制,因此针对上述步骤需要实现:
- 定义正向计算函数。
- 使用value_and_grad通过函数变换获得梯度计算函数。
- 定义训练函数,使用set_train设置为训练模式,执行正向计算、反向传播和参数优化。
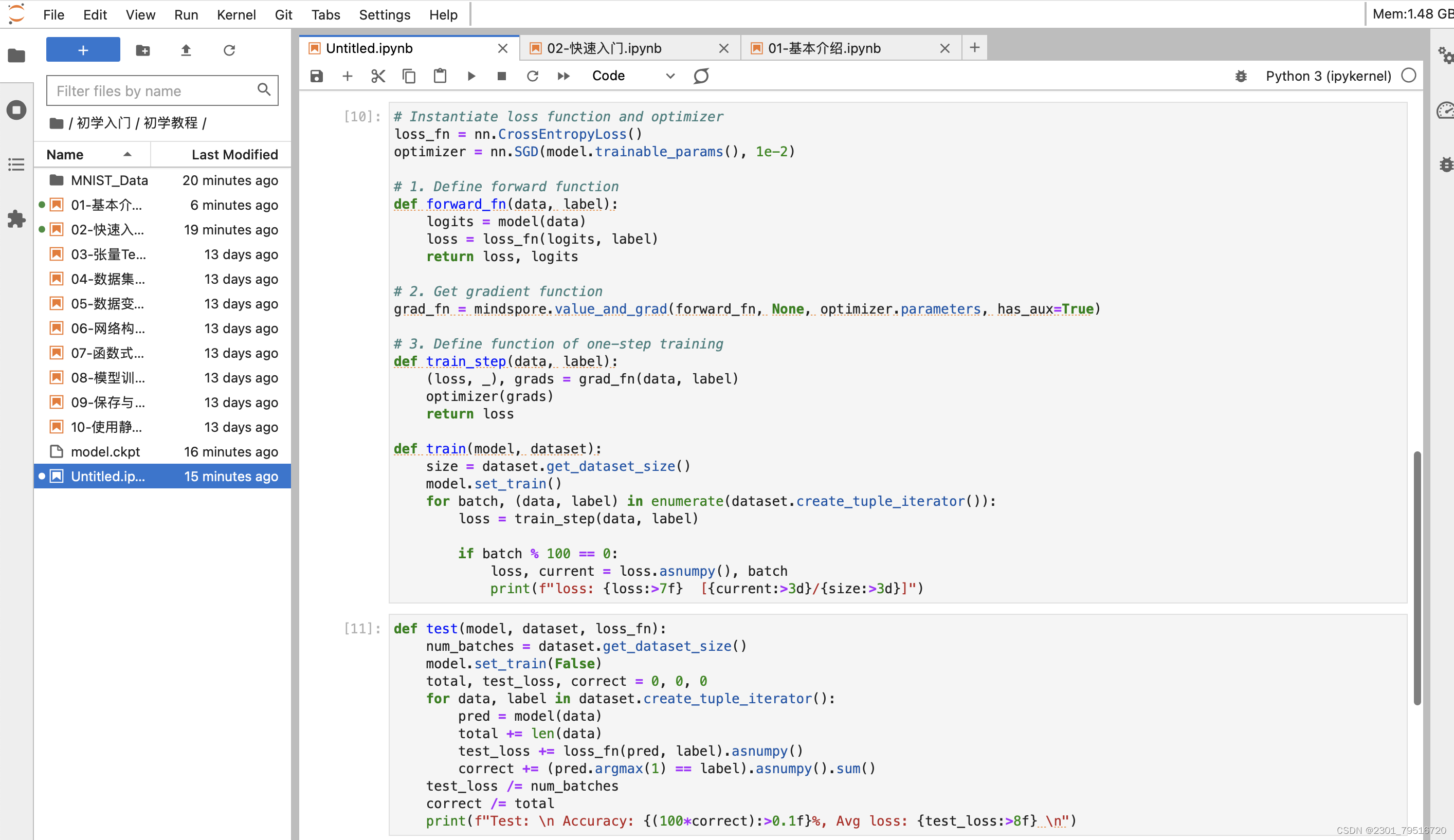
训练过程需多次迭代数据集,一次完整的迭代称为一轮(epoch)。在每一轮,遍历训练集进行训练,结束后使用测试集进行预测。打印每一轮的loss值和预测准确率(Accuracy),可以看到loss在不断下降,Accuracy在不断提高。
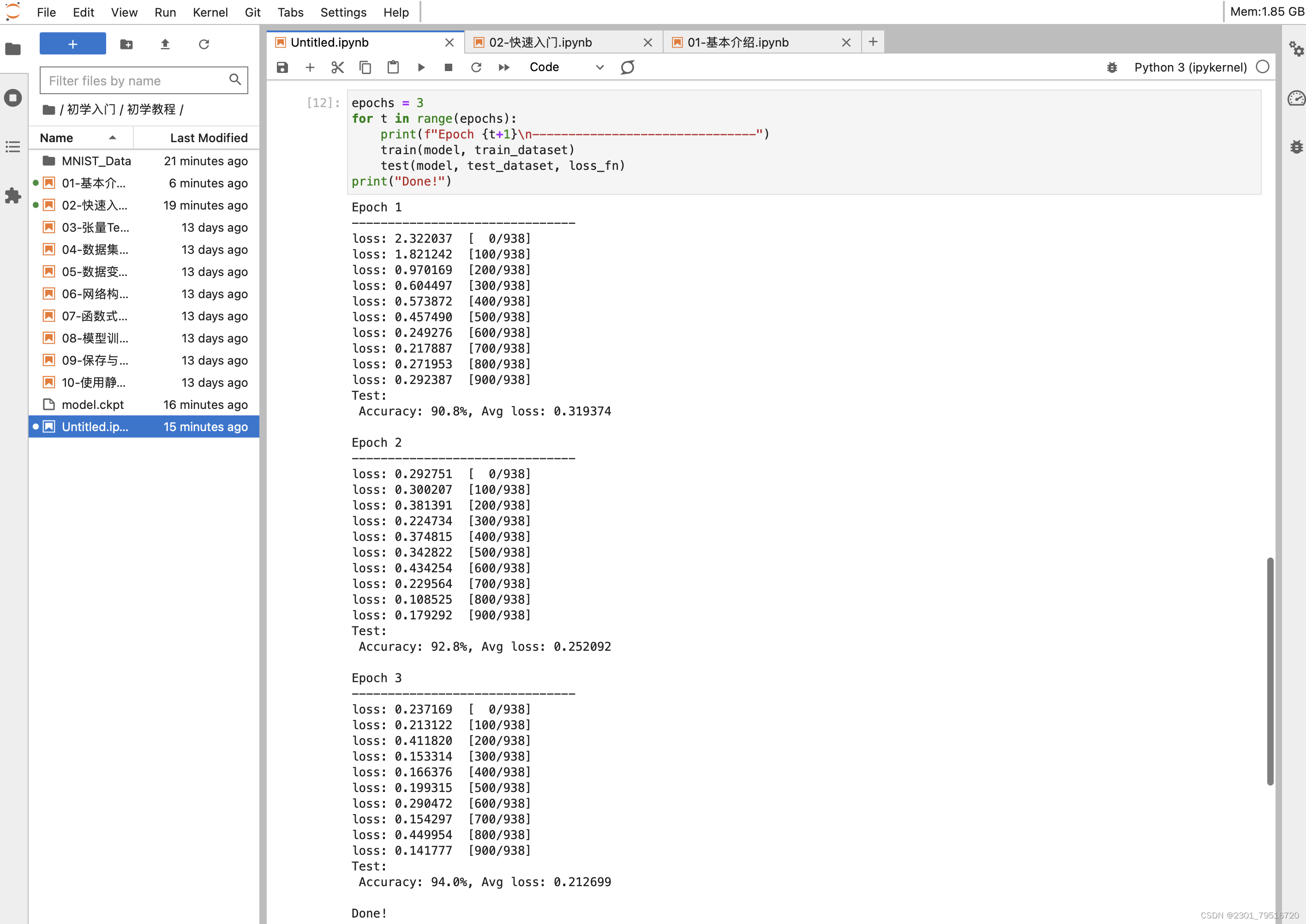
保存模型
模型训练完成后,需要将其参数进行保存。
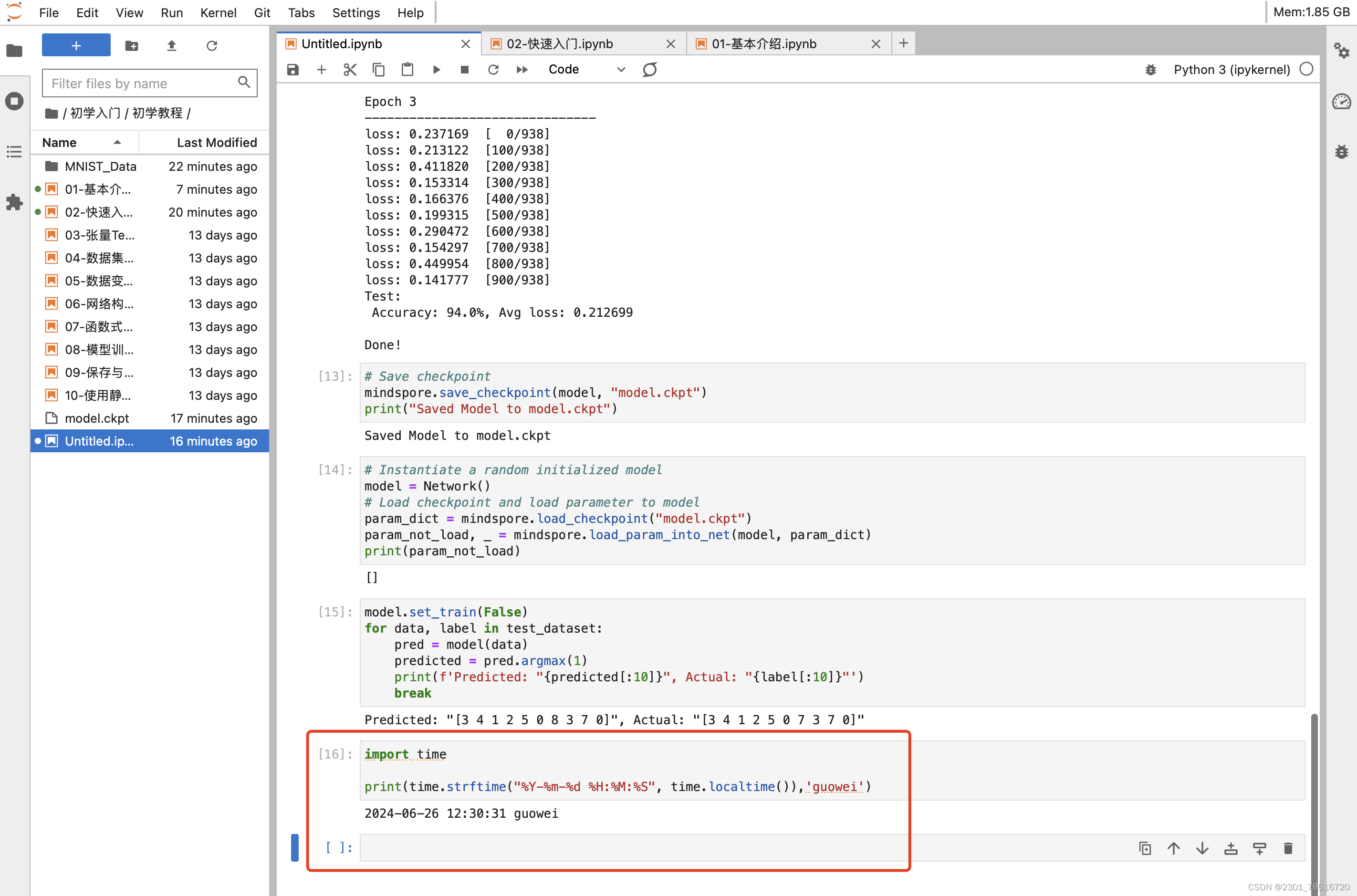
加载模型
加载保存的权重分为两步:
- 重新实例化模型对象,构造模型。
- 加载模型参数,并将其加载至模型上。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)