性能狂提!LSTM+强化学习,学会顶会顶刊发到手软!
LSTM与强化学习的结合在时序决策任务中展现出显著优势,最新研究聚焦于OpenRAN网络切片管理和量子混合架构等创新应用。加州大学团队提出的RL-LSTM模型有效提升动态环境适应性,而OpenRAN研究中LSTM预测与分布式DRL的结合使网络性能提升7.7%。同时,量子-LSTM混合模型在欺诈检测中准确率达95.33%,优于传统方法。当前研究趋势包括领域定制化架构设计、多模态时序关联挖掘和轻量化模
LSTM搭上强化学习的快车,最近在学术圈里彻底火了!ICML 2025上,加州大学团队提出的RL-LSTM模型,直接把时序决策任务的性能拉满,不仅精度大幅提升,还解决了传统LSTM在动态环境中的适应性问题。LSTM本身擅长处理序列数据,强化学习则能根据环境反馈动态调整策略,两者的结合让模型在复杂场景下更加智能。
想发论文可以关注以下几个方向:一是针对金融交易、智能交通等特定领域的时序决策任务,设计定制化的LSTM+强化学习架构;二是探索多模态数据中的时序关联,挖掘更丰富的特征;三是将强化学习与轻量级LSTM模型结合,提高模型的实时性和适应性。
为了帮助大家更好地开展研究,我特意整理了8篇LSTM结合强化学习的相关论文,都是顶会顶刊成果,部分论文附上了代码便于大家复现,全部论文PDF版+开源代码,工种号 沃的顶会 扫码回复 “LS强化” 领取全部论文+开源代码。
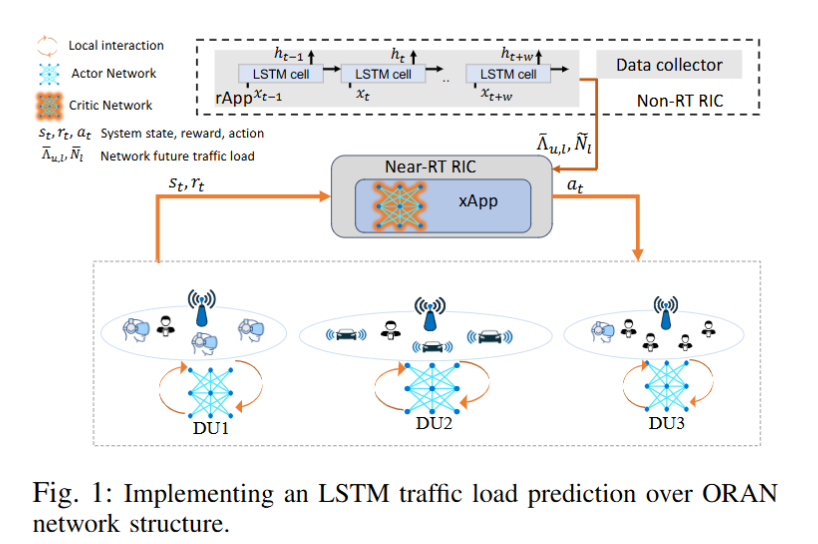
Open RAN LSTM Traffic Prediction and Slice Management using Deep Reinforcement Learning
文章解析
文章针对Open RAN网络切片管理难题,提出结合动态深度强化学习(DRL)和长短期记忆网络(LSTM)的方法。用LSTM预测流量,为DRL决策提供信息,经仿真实验验证,该方法能提升网络性能,减少服务质量(QoS)违规情况。
创新点
首次将RNN预测与分布式DRL方法结合用于Open RAN网络切片,利用LSTM预测流量辅助决策。
采用分布式DRL方法,通过多个分布在不同位置的智能体利用集体知识和经验优化训练过程。
引入基于LSTM的rApp预测网络流量负载,为xApp中的RL智能体提供额外信息,增强决策能力。
研究方法
构建Open RAN网络模型,定义无线通信模型和优化问题,将其建模为马尔可夫决策过程,运用Soft Actor-Critic算法求解。
设定包含不同切片、分布式单元和用户的仿真场景,对比有、无LSTM预测信息时的网络性能。
使用Python生成模拟环境数据集训练LSTM模型,采用PyTorch的演员-评论家方法实现DRL算法。
研究结论
基于LSTM预测的分布式DRL方法相比无预测的方法,最终回报值最多可提高7.7%,在注重长期规划的场景中表现更优。
该方法在减少SLA违规的同时,还能提高用户吞吐量。
研究表明利用基于LSTM的预测信息对Open RAN网络切片管理有效,为网络切片优化提供了新方向。
SPAT:Sensitivity-based Multihead-attention Pruning on Time Series Forecasting Models
文章解析
文章提出融合经典LSTM网络与变分量子电路的混合量子 - 经典神经网络架构,用于信用卡欺诈检测。经数据预处理和模型训练评估,该模型在准确率等指标上优于经典LSTM,且训练效率较高,为欺诈检测提供新方法。
创新点
构建结合经典LSTM与变分量子电路的混合架构,利用量子特性提升特征表示能力。
采用AngleEmbedding编码技术和强纠缠层,增强模型表达能力,有效捕捉数据中的复杂模式。
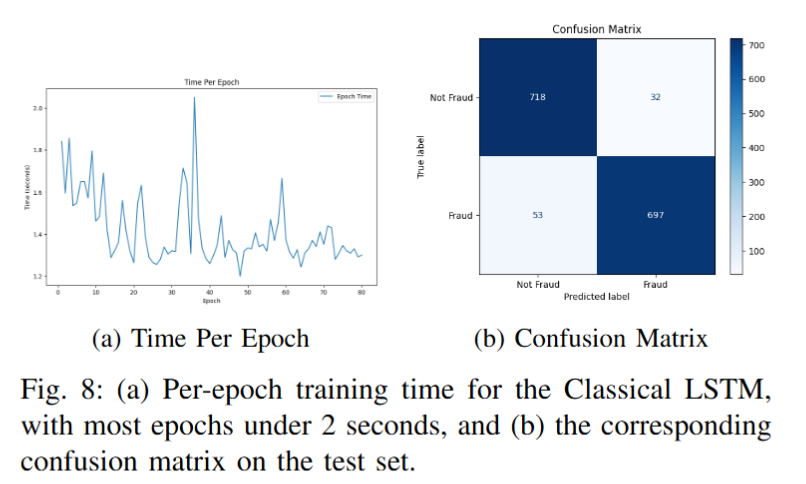
训练效率高,在CPU上使用默认模拟器,每轮训练时间在45 - 65秒,优于同类模型。
研究方法
对信用卡交易数据进行清洗、编码、平衡和归一化等预处理,构建包含LSTM、降维层和量子层的模型。
以经典LSTM模型为基准,对比两者在相同数据集上的性能表现。
使用PyTorch和PennyLane库进行模型实现,采用BCEWithLogitsLoss损失函数和Adam优化器训练模型。
研究结论
混合量子模型训练准确率达99.69%,测试准确率为95.33%,在召回率和F1分数等指标上优于经典LSTM模型。
增加数据集规模可提升模型性能,但更大的量子比特配置会增加计算成本。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)