深度学习的数学原理(一)—— 一元线性回归
本文通过一元线性回归案例,系统阐述了神经网络作为通用函数逼近器的基本原理。文章详细推导了梯度下降算法的数学原理,包括损失函数定义、梯度计算和参数更新公式,并指出梯度下降通常只能求得近似解。通过Python代码实现,展示了数据生成、损失函数计算、梯度下降优化及可视化分析的全过程。实验部分对比了不同学习率对收敛效果的影响,并介绍了批量梯度下降、随机梯度下降和小批量梯度下降三种优化策略的特点。该案例以直
写这个专栏,主要是为了梳理自己的学习思路。经过这么久的学习,我认为自己对人工智能的理解不够深入,仅仅停留在会用,知其然而不知其所以然,因此补充这个专栏来从底层的数学推导,结合代码来补全自己的知识框架。
本专栏主要聚焦于深度学习中最基础和常见的神经网络架构进行数学推导,结合目前深度学习的发展状况,尽可能少而精的进行介绍。
深度学习或者神经网络的本质,我认为是一个通用函数逼近器,只要有足够多的训练数据,理论上来说我们就能构造一个神经网络,通过学习数据之间隐藏的关系来完成输入到输出的映射。因此,本专栏的第一个例子并非深度学习常见入门的手写数字识别,而是用一个一元函数的回归来进行介绍。回归任务能更直观地展现 “神经网络拟合函数关系” 的核心逻辑,帮助理解参数学习、损失优化的本质,为后续复杂任务打下基础。
目标分析
已知足够多组(x,y),需要构造一个一元函数,通过学习这些 x -> y 的对应关系来求解出这个一元函数。
模型定义与训练
1. 定义一元线性回归模型
- 模型表达式:y=wx+b+ε
- 解释:x为自变量,y为因变量,w为斜率,b为截距,ε为随机噪声(模拟真实数据的误差)
- 预测目标:通过已知的(xi,yi)样本,求解最优的w∗和b∗,让预测值y^=wx+b尽可能接近真实值y
2. 构建损失函数(残差平方和)
这里要说明一下什么是损失函数:首先第一步中我们自己定义了一个模型,我们希望这个模型与这组数据对应的真实模型非常相近,对于同一个输入x,我们定义的模型和真实模型的输出肯定是有所差别的,我们希望这个差别越小越好,这样就说明我们的模型在逐渐的逼近真实模型,因此,我们就定义了这样一个损失函数,损失越小,就说明模型拟合的越好。(当然,损失函数也是多样的,这里只是用了最常见最容易理解的残差平方和来解释)
- 损失函数定义:
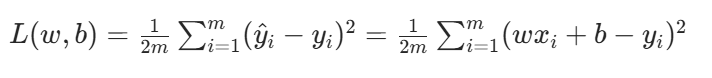
- 解释:1/2是为了求导时消去系数,不影响极值点;m是样本数量,用于平均损失
- 核心思想:最小化损失函数,即找到w和b让L(w,b)最小
3. 求解最优参数
方法 1:最小二乘法
这是我们之前学习到的一种方法,通常是在数学上求得解析解的方法

方法 2:梯度下降法
这是神经网络中最常使用的方法,原因在于我们通常用到的数据集中数据量非常大,难以求出解析解,最小二乘法因此也就不再适用

(注意:该过程实际上是批量梯度下降,每次更新参数时用到了所有样本的来更新梯度,几种常见的梯度更新策略写在文章最后)
为什么梯度下降法更新的参数可以使损失函数变小
首先我们要明确梯度下降法在做什么:不断的尝试新的w和b,使得损失函数不断减小;但是总不能随便给w和b赋值吧,那样效率太低了,因此,我们需要一种更新参数w和b的方式,既能让损失函数不断减小,同时,又能方便计算机进行操作。
梯度下降法指出,沿着梯度相反的方向进行参数更新时,损失函数下降的最快。下面进行证明
我们以单参数 w 为例(b 的推导完全同理),假设当前参数为 wt,下一轮更新后为 wt+1。
步骤 1: 损失函数的一阶泰勒展开

步骤 2: 设定参数更新规则,要求损失下降

步骤 3: 确定最优的更新方向

步骤 4: 得到参数更新公式
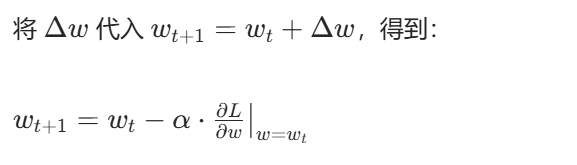
结合一元线性回归的具体梯度

每次按上述公式沿负梯度更新 w 和 b,损失函数 L(w,b) 会持续减小,直到梯度趋近于 0(此时到达最小值点),对应的 w 和 b 就是最优参数,会无限接近生成数据时的真实参数。
强调:梯度下降法大部分情况只能求出近似解
我们假设损失函数是一个一元四次函数用于举例
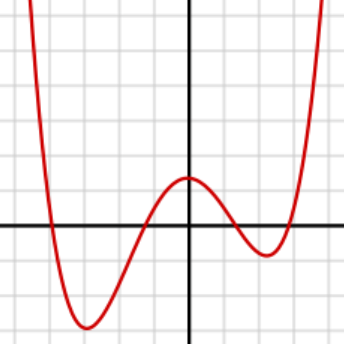
梯度下降的核心逻辑是:从当前点出发,沿着最陡的下坡方向(负梯度)一步步走。
- 如果初始点落在右侧谷的附近,梯度会引导它走到右侧的局部最小值点,然后就停在那里了,因为周围所有方向都是上坡,梯度为 0。
- 只有当初始点恰好落在左侧谷的 “吸引域” 内,梯度下降才会走到全局最小值。
这就像一个人在山里找最低点:
- 如果他从右侧山坡出发,只会走到右侧的小山谷,根本不知道左侧还有一个更深的大峡谷。
- 他的 “下山” 路径完全被初始位置和局部地形决定了。
有如下情况,都会使得梯度下降法只能求出近似解
- 容易陷入局部最优:在非凸函数中,梯度下降极大概率会停在一个局部最小值,而不是全局最小值。这个局部最优解就是对全局最优解的一个近似。
- 迭代终止条件:即使在凸函数中,梯度下降也很少能精确走到理论上的极值点。通常是当梯度的模长小于一个很小的阈值(比如 10−6),或者达到最大迭代次数时就停止了,得到的是一个 “足够接近” 精确解的近似值。
- 学习率的影响:如果学习率太大,会在最小值附近震荡,永远无法精确到达;如果太小,收敛太慢,也只能在有限时间内得到一个近似。
值得庆幸的是,对于我们计算机专业,近似解就足够用了
代码
1、导入库
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from mpl_toolkits.mplot3d import Axes3D
import warnings
warnings.filterwarnings('ignore')
# 设置matplotlib参数
plt.rcParams['figure.figsize'] = (12, 8)
plt.rcParams['font.size'] = 12
plt.style.use('seaborn-v0_8')
# 设置中文字体显示
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
print("库导入完成")2、数据生成
# 设置随机种子保证结果可重现
np.random.seed(42)
# 生成数据集
m = 100 # 样本数量
true_w = 2.5 # 真实权重
true_b = 1.0 # 真实偏置
# 生成输入特征 x
x = np.random.uniform(-5, 5, m)
# 生成目标值 y = wx + b + 噪声
noise = np.random.normal(0, 0.5, m) # 添加高斯噪声
y = true_w * x + true_b + noise
# 可视化生成的数据
plt.figure(figsize=(10, 6))
plt.scatter(x, y, alpha=0.6, color='blue', label='数据点')
plt.plot(x, true_w * x + true_b, 'r-', linewidth=2, label=f'真实函数: y = {true_w}x + {true_b}')
plt.xlabel('x')
plt.ylabel('y')
plt.title('生成的数据集')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
print(f"数据集大小: {m} 个样本")
print(f"真实参数: w = {true_w}, b = {true_b}")
print(f"x 范围: [{x.min():.2f}, {x.max():.2f}]")
print(f"y 范围: [{y.min():.2f}, {y.max():.2f}]")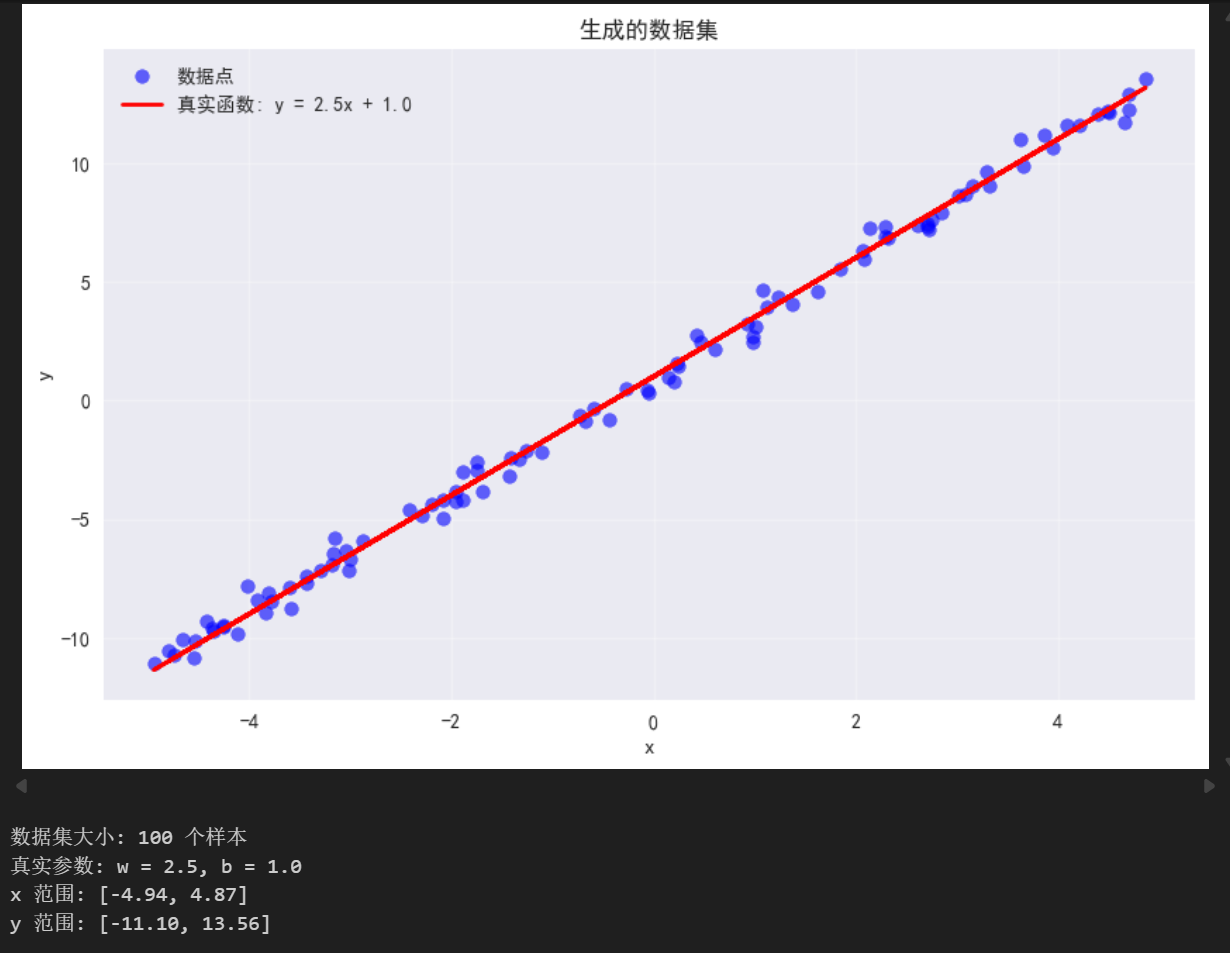
3、实现梯度下降
定义损失函数与梯度
def compute_loss(w, b, x, y):
"""
计算均方误差损失函数
参数:
w, b: 当前的参数
x, y: 数据
返回:
loss: 损失值
"""
m = len(x)
y_pred = w * x + b
loss = (1/(2*m)) * np.sum((y - y_pred)**2)
return loss
def compute_gradients(w, b, x, y):
"""
计算损失函数对参数的梯度
参数:
w, b: 当前的参数
x, y: 数据
返回:
dw, db: 梯度
"""
m = len(x)
y_pred = w * x + b
error = y - y_pred
dw = -(1/m) * np.sum(error * x)
db = -(1/m) * np.sum(error)
return dw, db
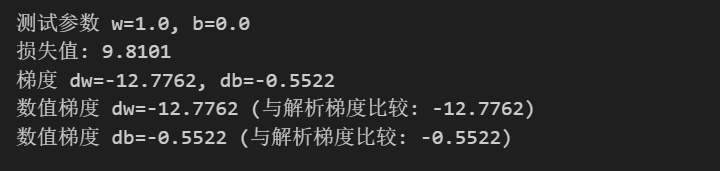
# 测试函数
w_test, b_test = 1.0, 0.0
loss_test = compute_loss(w_test, b_test, x, y)
dw_test, db_test = compute_gradients(w_test, b_test, x, y)
print(f"测试参数 w={w_test}, b={b_test}")
print(f"损失值: {loss_test:.4f}")
print(f"梯度 dw={dw_test:.4f}, db={db_test:.4f}")
# 验证梯度计算的正确性(数值梯度)
def numerical_gradient(f, x, h=1e-5):
return (f(x + h) - f(x - h)) / (2 * h)
# 对w的数值梯度
loss_w = lambda w_val: compute_loss(w_val, b_test, x, y)
dw_numerical = numerical_gradient(loss_w, w_test)
print(f"数值梯度 dw={dw_numerical:.4f} (与解析梯度比较: {dw_test:.4f})")
# 对b的数值梯度
loss_b = lambda b_val: compute_loss(w_test, b_val, x, y)
db_numerical = numerical_gradient(loss_b, b_test)
print(f"数值梯度 db={db_numerical:.4f} (与解析梯度比较: {db_test:.4f})")为了说明这部分代码,我们需要回归一下公式
1. 损失函数(均方误差 MSE,带 1/2 是为了求导消系数)
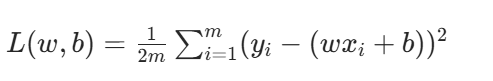
- m:样本数量
- yi:真实标签,wxi+b:预测值
- 21:求导时能消去平方的系数 2,简化计算(不影响最小值位置)
- m1:对所有样本的损失取平均,避免样本数影响梯度大小
2. 梯度(损失函数对w、b的偏导数)
对损失函数分别求w、b的偏导:
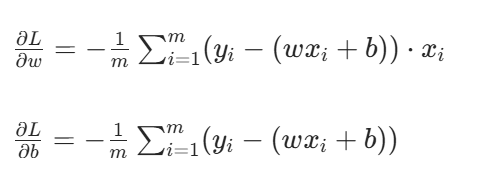
- 负号:因为求导时链式法则会把(y−y^)变成−(y^−y),最终体现为负号
- 乘以xi:对w求导时,预测值wxi+b对w的偏导是xi;对b求导时偏导是 1
输出如下
梯度下降算法实现
梯度下降的更新公式我们在之前已经推导过了
def gradient_descent(x, y, w_init=0.0, b_init=0.0, learning_rate=0.01, num_iterations=100, tolerance=1e-6):
"""
梯度下降算法实现
参数:
x, y: 数据
w_init, b_init: 初始参数
learning_rate: 学习率
num_iterations: 最大迭代次数
tolerance: 收敛阈值
返回:
w_history, b_history: 参数历史
loss_history: 损失历史
"""
w = w_init
b = b_init
w_history = [w]
b_history = [b]
loss_history = [compute_loss(w, b, x, y)]
for i in range(num_iterations):
# 计算梯度
dw, db = compute_gradients(w, b, x, y)
# 更新参数
w_new = w - learning_rate * dw
b_new = b - learning_rate * db
# 计算新损失
loss_new = compute_loss(w_new, b_new, x, y)
# 记录历史
w_history.append(w_new)
b_history.append(b_new)
loss_history.append(loss_new)
# 检查收敛
if abs(loss_new - loss_history[-2]) < tolerance:
print(f"算法在第{i+1}次迭代收敛")
break
# 更新参数
w, b = w_new, b_new
# 每10次迭代打印一次信息
if (i + 1) % 10 == 0:
print(f"迭代 {i+1}: w={w:.4f}, b={b:.4f}, loss={loss_new:.6f}")
return w_history, b_history, loss_history
# 运行梯度下降
print("开始梯度下降优化...")
w_history, b_history, loss_history = gradient_descent(
x, y,
w_init=0.0,
b_init=0.0,
learning_rate=0.01,
num_iterations=200
)
print("优化完成!")
print(f"最终参数: w={w_history[-1]:.4f}, b={b_history[-1]:.4f}")
print(f"最终损失: {loss_history[-1]:.6f}")
print(f"真实参数: w={true_w}, b={true_b}")
print(f"参数误差: w误差={abs(w_history[-1] - true_w):.4f}, b误差={abs(b_history[-1] - true_b):.4f}")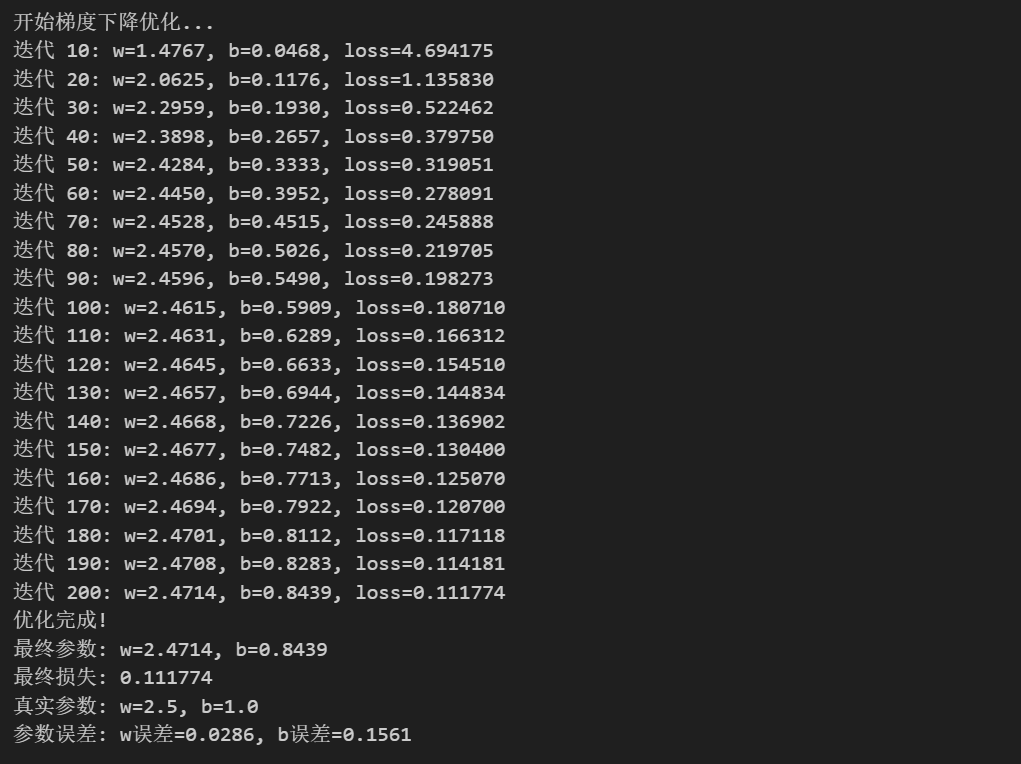
4、可视化学习过程
# 可视化损失函数收敛过程
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(loss_history, 'b-', linewidth=2)
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title('损失函数收敛过程')
plt.grid(True, alpha=0.3)
plt.yscale('log') # 使用对数尺度更好地显示收敛
plt.subplot(1, 2, 2)
plt.plot(loss_history[:50], 'r-', linewidth=2) # 只显示前50次迭代
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title('损失函数收敛过程 (前50次迭代)')
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"初始损失: {loss_history[0]:.6f}")
print(f"最终损失: {loss_history[-1]:.6f}")
print(f"损失减少: {loss_history[0] - loss_history[-1]:.6f} ({((loss_history[0] - loss_history[-1])/loss_history[0]*100):.1f}%)")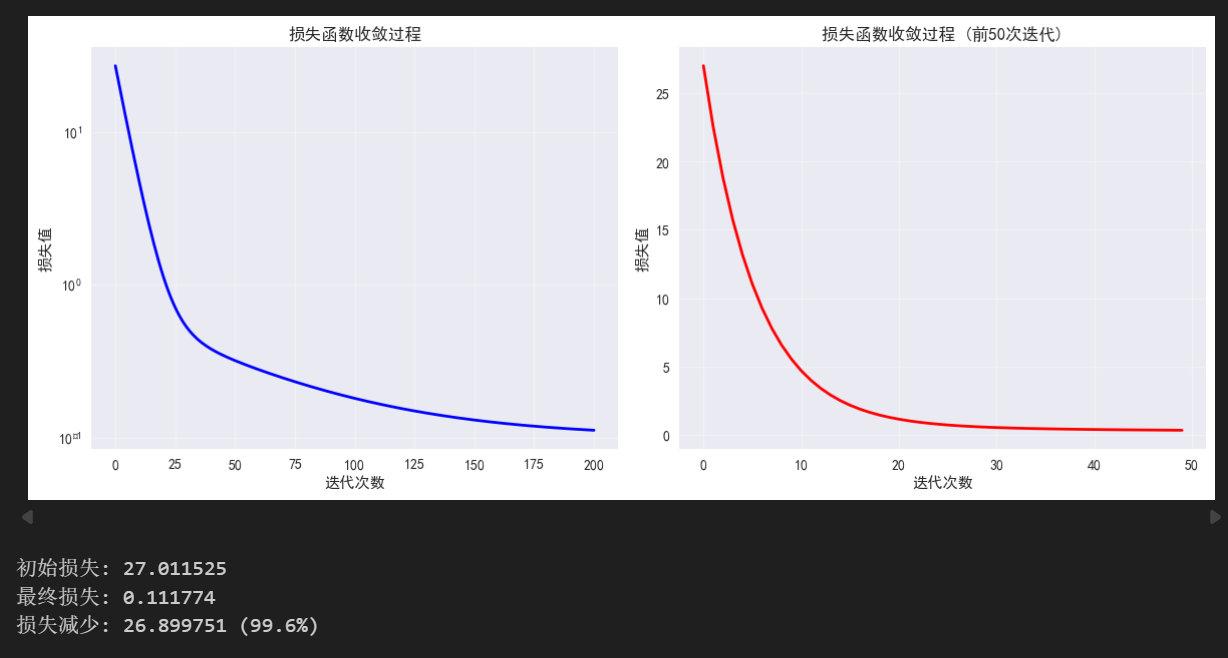
# 可视化参数更新过程
plt.figure(figsize=(15, 5))
plt.subplot(1, 3, 1)
plt.plot(w_history, 'g-', linewidth=2, label='w')
plt.axhline(y=true_w, color='r', linestyle='--', alpha=0.7, label=f'真实w={true_w}')
plt.xlabel('迭代次数')
plt.ylabel('权重 w')
plt.title('权重参数更新过程')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 2)
plt.plot(b_history, 'orange', linewidth=2, label='b')
plt.axhline(y=true_b, color='r', linestyle='--', alpha=0.7, label=f'真实b={true_b}')
plt.xlabel('迭代次数')
plt.ylabel('偏置 b')
plt.title('偏置参数更新过程')
plt.legend()
plt.grid(True, alpha=0.3)
plt.subplot(1, 3, 3)
plt.plot(w_history, b_history, 'b-', alpha=0.7, linewidth=2)
plt.plot(w_history[0], b_history[0], 'go', markersize=8, label='起点')
plt.plot(w_history[-1], b_history[-1], 'ro', markersize=8, label='终点')
plt.plot(true_w, true_b, 'k*', markersize=12, label='真实值')
plt.xlabel('权重 w')
plt.ylabel('偏置 b')
plt.title('参数空间中的优化轨迹')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print(f"参数收敛情况:")
print(f"w: 初始={w_history[0]:.4f}, 最终={w_history[-1]:.4f}, 真实={true_w:.4f}")
print(f"b: 初始={b_history[0]:.4f}, 最终={b_history[-1]:.4f}, 真实={true_b:.4f}")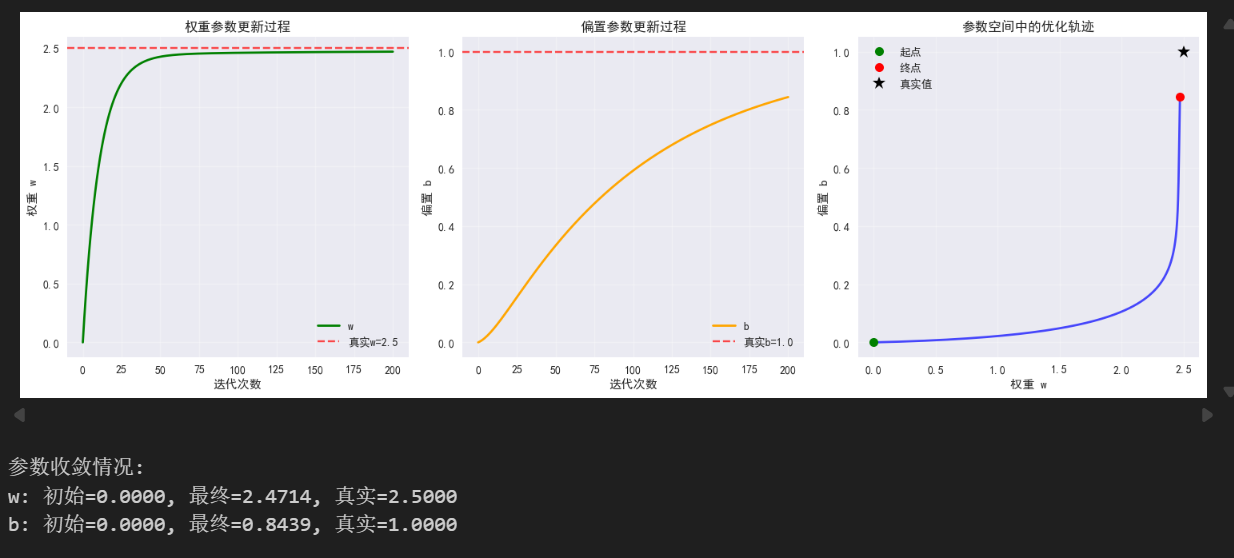
# 可视化最终拟合结果
plt.figure(figsize=(12, 8))
# 绘制数据点
plt.scatter(x, y, alpha=0.6, color='blue', label='数据点', s=50)
# 绘制真实函数
x_line = np.linspace(x.min(), x.max(), 100)
plt.plot(x_line, true_w * x_line + true_b, 'r-', linewidth=3, label=f'真实函数: y = {true_w}x + {true_b}')
# 绘制学习到的函数
plt.plot(x_line, w_history[-1] * x_line + b_history[-1], 'g--', linewidth=3,
label=f'学习结果: y = {w_history[-1]:.3f}x + {b_history[-1]:.3f}')
# 突出显示几个中间结果
for i in [10, 50, len(w_history)//2]:
if i < len(w_history):
plt.plot(x_line, w_history[i] * x_line + b_history[i], 'gray', alpha=0.3,
label=f'迭代{i}次' if i == 10 else None)
plt.xlabel('x', fontsize=14)
plt.ylabel('y', fontsize=14)
plt.title('梯度下降法回归结果', fontsize=16)
plt.legend(fontsize=12)
plt.grid(True, alpha=0.3)
# 添加参数信息文本框
textstr = f'最终参数:\nw = {w_history[-1]:.4f} (真实: {true_w})\nb = {b_history[-1]:.4f} (真实: {true_b})\n损失: {loss_history[-1]:.6f}'
plt.text(0.02, 0.98, textstr, transform=plt.gca().transAxes, fontsize=10,
verticalalignment='top', bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.8))
plt.show()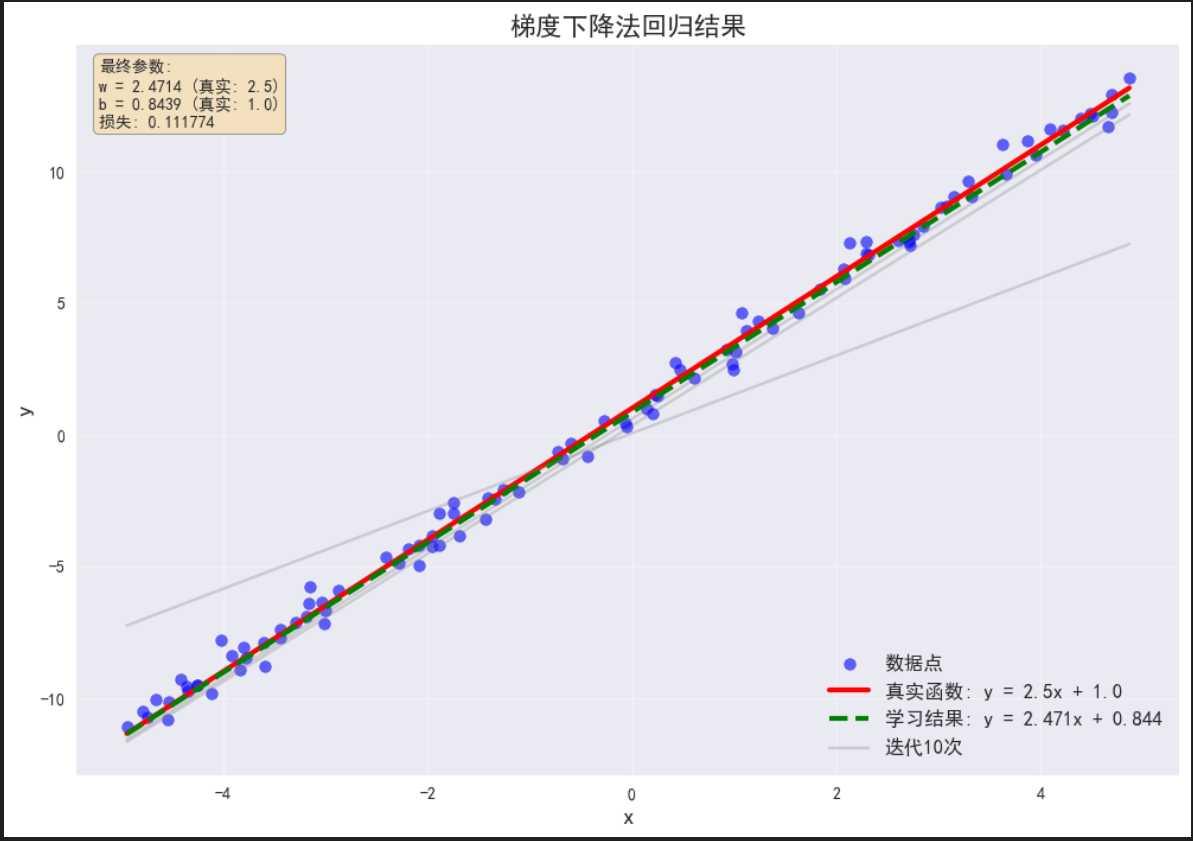
学习率的选择
对于深度学习来说,学习率α(即每一步更新的长度)的选择是至关重要的,下面我们通过代码来显示不同学习率的影响
# 实验不同学习率
learning_rates = [0.001, 0.01, 0.05, 0.1, 0.5]
results_lr = {}
plt.figure(figsize=(15, 10))
for i, lr in enumerate(learning_rates):
print(f"\n测试学习率: {lr}")
# 运行梯度下降
w_hist, b_hist, loss_hist = gradient_descent(
x, y, w_init=0.0, b_init=0.0,
learning_rate=lr, num_iterations=100
)
results_lr[lr] = {
'w_final': w_hist[-1],
'b_final': b_hist[-1],
'loss_final': loss_hist[-1],
'iterations': len(loss_hist) - 1
}
# 绘制损失收敛曲线
plt.subplot(2, 3, i+1)
plt.plot(loss_hist, linewidth=2, label=f'lr={lr}')
plt.xlabel('迭代次数')
plt.ylabel('损失值')
plt.title(f'学习率 {lr} 的收敛')
plt.grid(True, alpha=0.3)
plt.legend()
if len(loss_hist) > 50:
plt.yscale('log')
plt.tight_layout()
plt.show()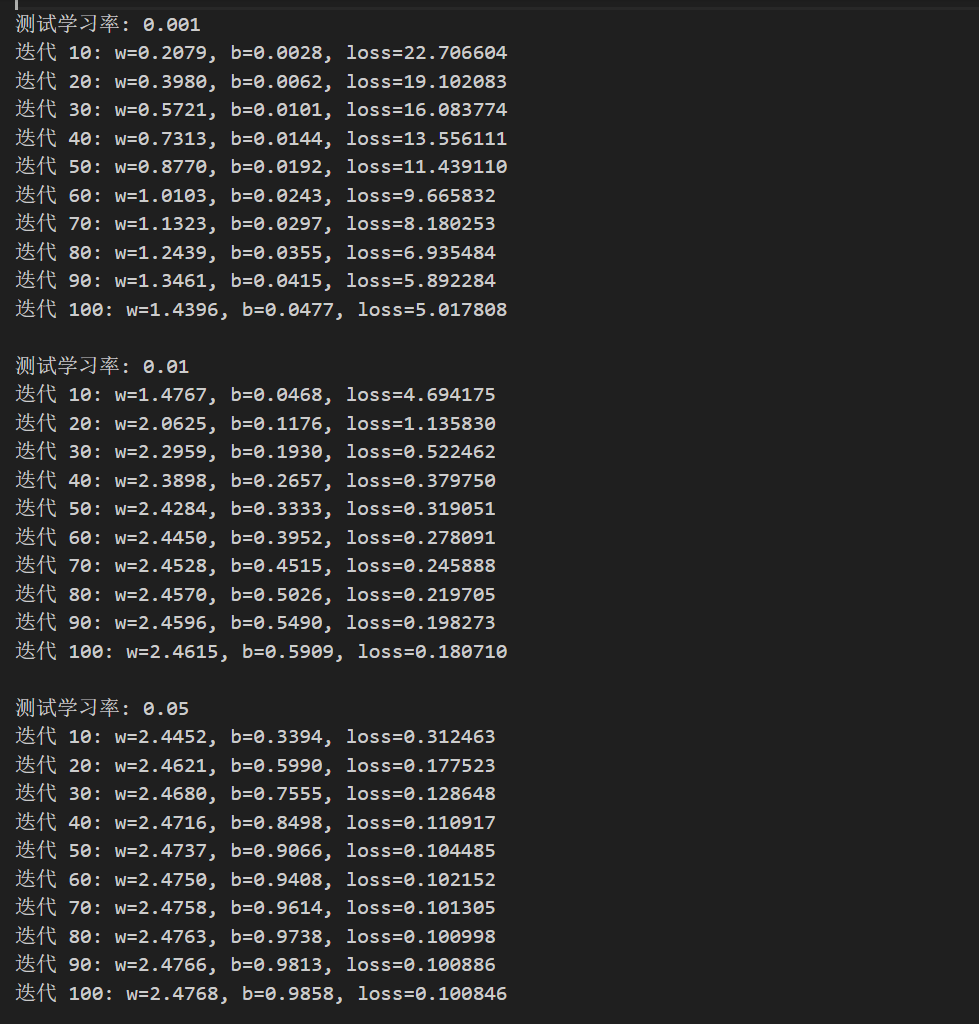
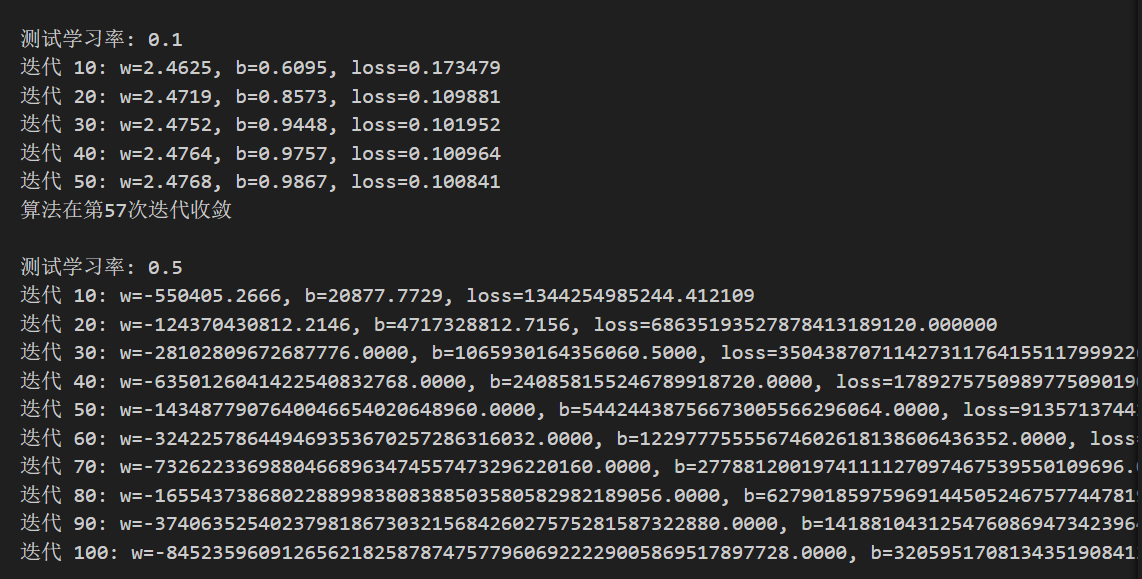
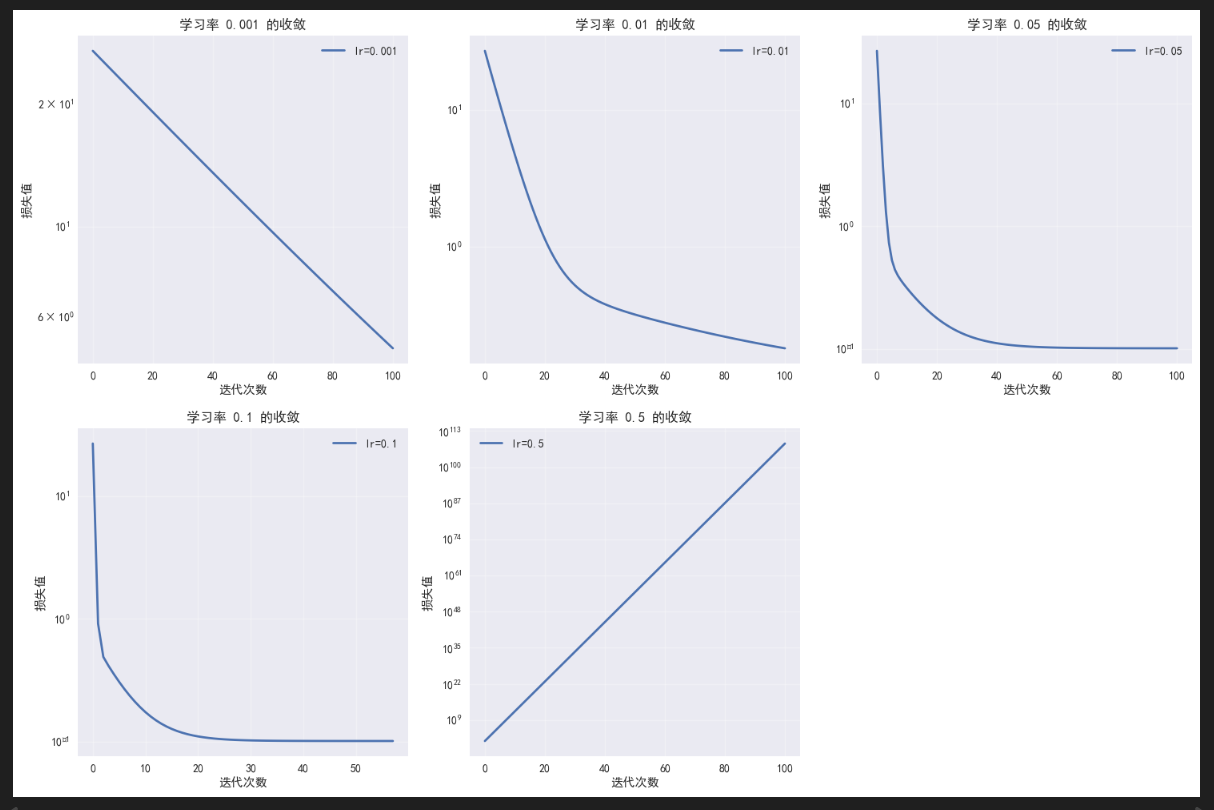
可以明显看到,学习率太小(如图1),会导致收敛到迭代的次数显著增高,增加训练成本
学习率太大(如图2),会导致一次迈过的步子太大,跳过了最优解,参数在最优解周围反复更新而始终无法达到,造成无法收敛。
不过现在,有比较成熟的学习率选择工具,后续会进行介绍。
梯度更新策略
1. 批量梯度下降(Batch Gradient Descent, BGD)
- 样本使用量:每次迭代用全部m个样本计算梯度(B=m);
- 梯度公式:
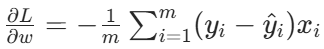 ;
; - 通俗理解:把所有数据看完,计算一个 “全局平均梯度”,再更新一次参数。
2. 随机梯度下降(Stochastic Gradient Descent, SGD)
- 样本使用量:每次迭代用1 个随机样本计算梯度(B=1);
- 梯度公式:
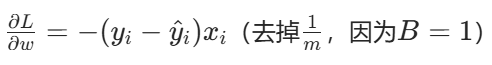 ;
; - 通俗理解:看一个样本,就立刻算梯度、更参数,“见一个学一个”。
3. 小批量梯度下降(Mini-Batch Gradient Descent, MBGD)
- 样本使用量:每次迭代用部分样本(比如 32/64/128 个) 计算梯度(1<B<m);
- 梯度公式:
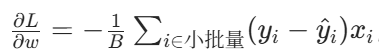 ;
; - 通俗理解:把数据分成若干小批次,看一批学一批,是 BGD 和 SGD 的折中。
总结对比
| 维度 | 批量梯度下降(BGD) | 随机梯度下降(SGD) | 小批量梯度下降(MBGD) |
|---|---|---|---|
| 每次迭代样本数 | 全部m个 | 1 个(随机选) | B个(如 32/64,随机选) |
| 梯度计算 | 全局准确梯度 | 单个样本的噪声梯度 | 局部近似梯度(噪声适中) |
| 收敛速度 | 慢(每次迭代计算量太大) | 快(单次计算量极小,但震荡) | 快(平衡计算量和速度) |
| 收敛曲线 | 平滑,稳步向最优值靠近 | 剧烈震荡,围绕最优值波动 | 轻微震荡,快速收敛到最优值附近 |
| 计算效率 | 低(样本多则单次迭代慢) | 高(单次迭代极快) | 高(利用 GPU 并行计算小批量) |
| 是否易陷入局部最优 | 是(梯度太 “平滑”,易卡在局部) | 否(噪声梯度易跳出局部最优) | 否(噪声适中,兼顾探索与利用) |
| 实际应用 | 极少(仅样本量极小时用) | 少(基础版 SGD 已被优化版替代) | 深度学习主流(PyTorch/TensorFlow 默认) |

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)