技术视角:国外数据分析报告搜集全攻略
国外经济类、跨境电商类数据分析报告的搜集,核心是「技术工具+合规采集+数据标准化」的闭环。从前期环境搭建、数据源选型,到中期数据采集、清洗,再到后期可视化和报告生成,每一步都需兼顾实操性和合规性。后续可根据具体需求,扩展数据源(如新增东南亚电商平台、欧洲经济数据),优化技术栈(如引入AI进行数据预测),进一步提升数据搜集和分析的效率与深度。
核心逻辑:以「技术工具为支撑、合规采集为前提、数据清洗为核心、可视化呈现为目标」,打通“数据源获取→数据抓取→清洗处理→报告整合”全流程,兼顾实操性和可复用性,适配开发者、数据分析师的使用场景,全程融入代码片段、工具选型和避坑技巧。
一、前期准备:技术栈选型与环境搭建
搜集国外数据的核心痛点的是「跨境访问、反爬拦截、多格式数据解析」,因此技术栈选型需围绕“稳定、高效、可规避反爬”展开,推荐轻量易上手的组合,新手可直接复用,老手可按需扩展。
1. 核心技术栈(轻量化选型,降低入门门槛)
-
网络层:Python + Requests(基础请求)、Playwright(动态页面渲染,替代Selenium,更稳定),搭配海外代理IP池(BrightData、IPRoyal),解决跨境访问和IP封禁问题。
-
数据解析层:BeautifulSoup4(静态页面解析)、lxml(高效XML/HTML解析)、Pandas(表格数据处理),适配国外网站常见的HTML、CSV、JSON格式。
-
数据存储层:SQLite(轻量本地存储,适合小体量数据)、MySQL(批量数据存储,便于后续查询分析),避免数据丢失和重复采集。
-
可视化与报告生成层:Matplotlib/Seaborn(基础可视化)、Plotly(交互式图表)、ReportLab(自动生成PDF报告),贴合数据分析报告的呈现需求。
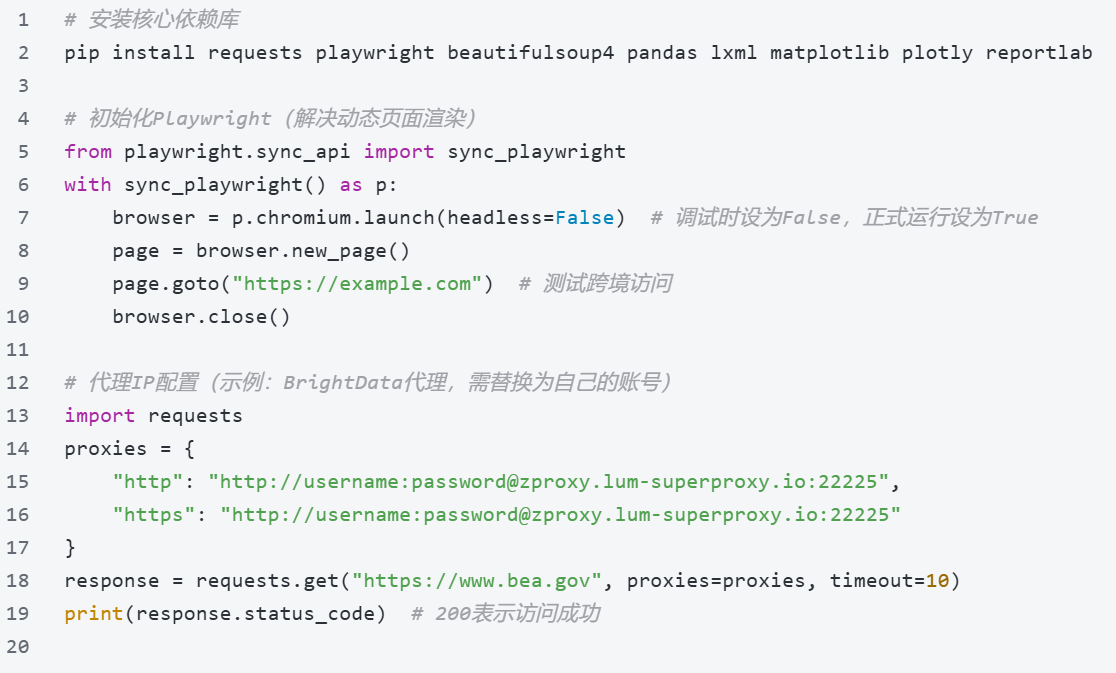
2. 环境搭建(代码可直接复制运行)
3. 前置配置要点(避坑关键)
-
代理IP需选择「静态海外IP」,避免动态IP频繁切换被网站拦截,优先选择支持多国家地区的代理,适配不同国家的经济、电商数据源。
-
请求头伪装:统一设置User-Agent、Referer,模拟真实浏览器访问,避免被识别为爬虫(示例:headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"})。
-
合规配置:提前查看目标网站的robots.txt协议,禁止爬取隐私数据、付费数据,跨境数据采集需遵守GDPR(欧盟)、CCPA(美国)等地区法规,避免法律风险。
二、核心环节:数据源分类与技术化采集
按「数据类型」拆分数据源,分别对应国外经济类、跨境电商类,每个数据源提供「技术采集方法+代码片段+避坑技巧」,兼顾免费数据源(适合个人/小团队)和付费数据源(适合企业级需求)。
第一类:国外经济类数据(宏观/微观,权威数据源优先)
核心数据源:官方统计机构、国际组织、商业数据商,优先选择提供API接口的数据源(采集效率高、数据格式规范),无API则通过爬虫采集静态/动态页面。
1. 官方统计机构数据源(免费、权威,重点推荐)
代表平台:美国经济分析局(BEA)、美国劳工统计局(BLS)、欧盟统计局(Eurostat),核心数据包括GDP、CPI、非农就业、进出口数据等,是经济类报告的核心支撑。
采集技术:API接口调用(优先)+ 网页爬取(备用)


2. 国际组织数据源(免费、跨国家,适合跨国经济分析)
代表平台:国际货币基金组织(IMF)、经济合作与发展组织(OECD)、国际清算银行(BIS),核心数据包括全球经济展望、跨境贸易数据、汇率数据等,适合宏观经济报告。
采集技术:SDMX API接口 + 数据解析(IMF/OECD均支持SDMX协议)


3. 商业数据商数据源(付费、高质量,适合深度分析)
代表平台:FRED(美联储经济数据库,部分免费)、Trading Economics、CEIC,核心数据包括实时经济指标、预测数据、另类数据等,适合需要高精度数据的报告。
采集技术:官方API接口(需付费/注册),以FRED为例(免费版足够个人使用)

第二类:跨境电商类数据(平台/市场/竞品,贴合业务需求)
核心数据源:跨境电商平台、第三方电商数据工具、社交媒体/搜索引擎,核心数据包括商品销量、竞品信息、市场趋势、用户行为等,采集重点是「规避反爬、保证数据时效性」。
1. 跨境电商平台数据源(核心,直接反映市场动态)
代表平台:亚马逊(Amazon)、eBay、Shopify,核心数据包括商品排名(BSR)、销量、价格、用户评价等,无官方公开API,需通过爬虫采集(需严格遵守平台规则)。
采集技术:Playwright动态爬取(解决JS渲染)+ 代理IP轮换


2. 第三方电商数据工具(高效、合规,适合企业级需求)
代表平台:Shopify Analytics、Helium 10(亚马逊专用)、SimilarWeb(流量分析)、Google Analytics,核心数据包括店铺流量、转化率、竞品营销策略等,支持API接口调用,合规性更高。
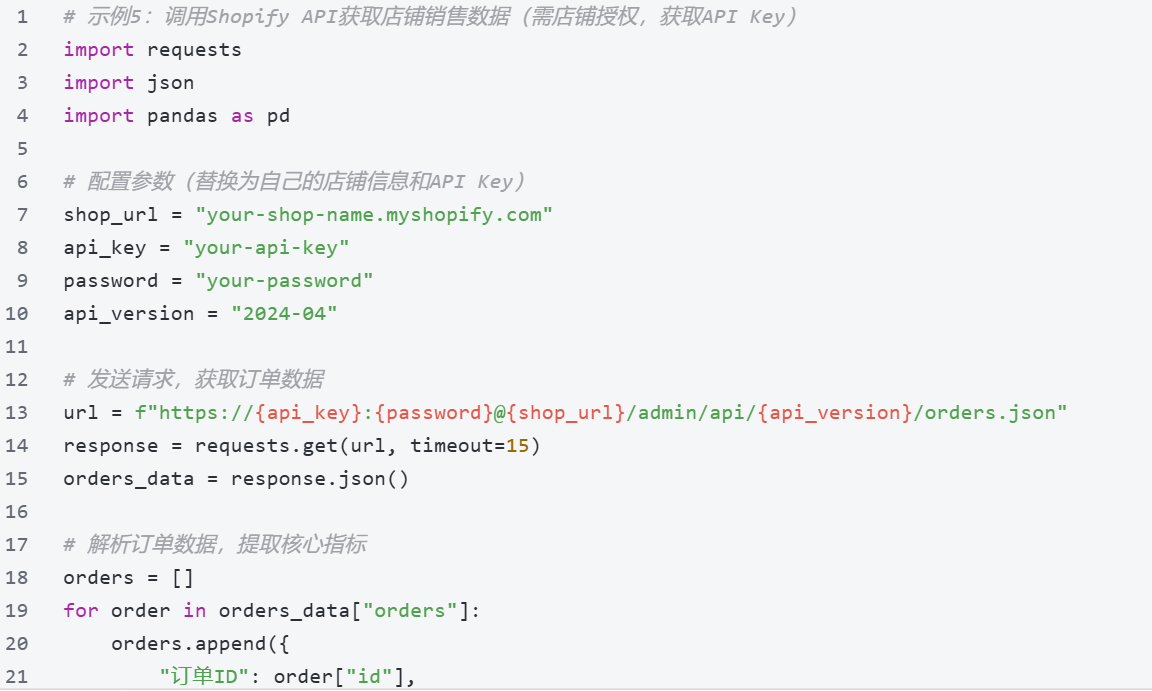
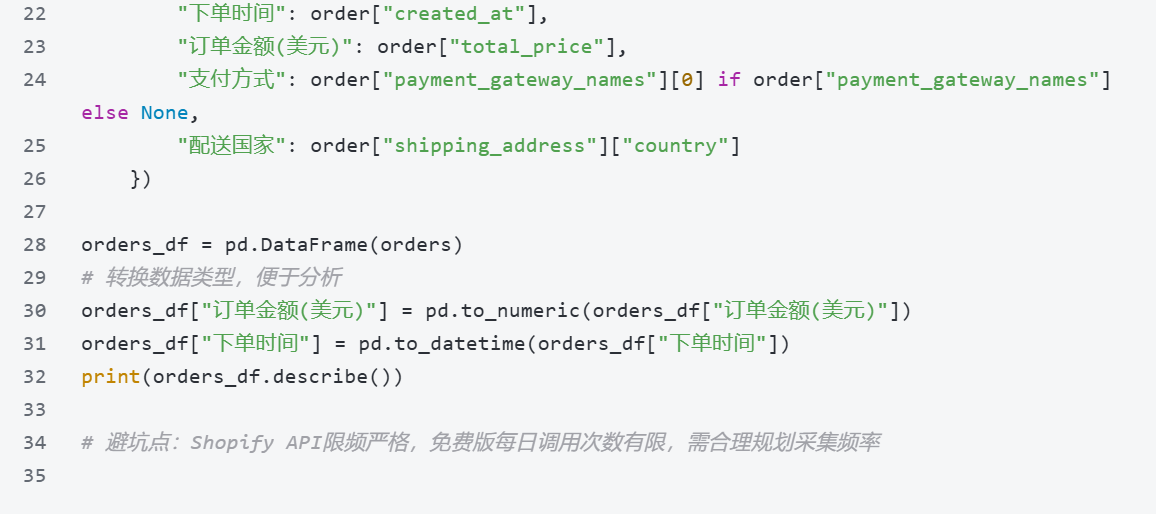
采集技术:API接口调用(需注册/付费),以Shopify Analytics为例
3. 社交媒体/搜索引擎数据源(补充,挖掘用户需求)
代表平台:TikTok、Instagram、Google Trends,核心数据包括热门商品趋势、用户搜索热度、舆情反馈等,用于补充电商报告的用户需求分析。
采集技术:API接口 + 关键词挖掘,以Google Trends为例


三、关键步骤:数据清洗与标准化(报告核心,避免数据失真)
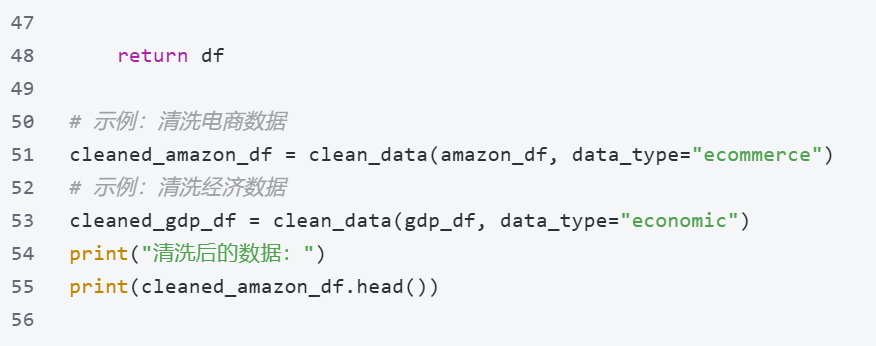
国外数据的痛点是「格式不统一、存在缺失值、单位不一致」(如经济数据有不同货币单位,电商数据有不同时间格式),需通过技术手段标准化,为后续报告撰写和可视化奠定基础,以下是核心操作。


四、收尾环节:数据可视化与报告生成
搜集数据的最终目的是生成数据分析报告,需通过技术手段实现「可视化图表生成+自动化报告输出」,以下是核心实现方法,兼顾美观性和实用性,适合直接用于CSDN博客分享或工作汇报。
1. 数据可视化(核心图表,贴合报告需求)
针对经济类、电商类数据的不同特点,推荐对应的可视化图表,代码示例如下:


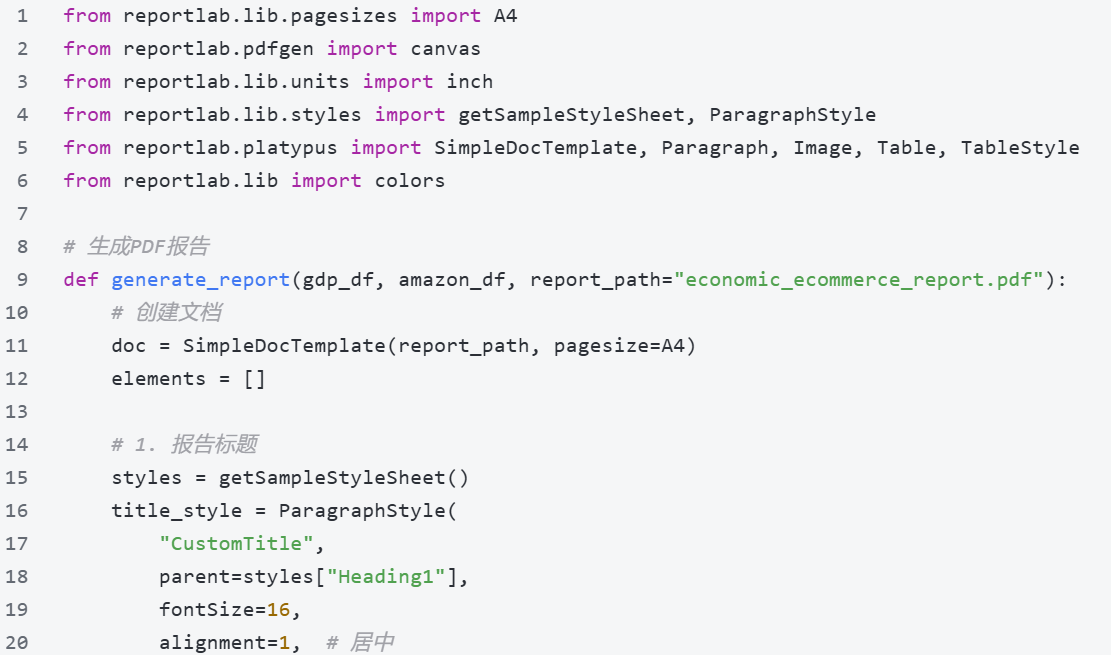
2. 自动化报告生成(ReportLab,高效输出PDF报告)
通过ReportLab库,将清洗后的数据、可视化图表自动整合为PDF报告,无需手动排版,适合批量生成报告,代码示例如下:



五、技术避坑与优化建议
1. 核心避坑点(高频问题,必看)
-
反爬拦截:避免使用单一IP、高频请求,优先用API接口;爬虫需伪装浏览器,设置随机休眠时间(1-3秒),动态页面必须用Playwright,避免Requests无法获取数据。
-
数据合规:不爬取付费数据、隐私数据,遵守robots.txt协议和地区法规(GDPR/CCPA),避免法律风险;商业数据商API需按规则调用,不破解、不滥用。
-
数据失真:清洗时重点处理缺失值、异常值,统一单位和格式;经济数据注意修订版(如BEA的初值、修正值),避免用错误版本的数据。
-
跨境访问:必须使用海外代理IP,优先选择静态IP,避免动态IP被识别为恶意访问;测试时先验证IP有效性,避免浪费时间。
2. 技术优化建议(提升效率,适配不同需求)
-
批量采集优化:用多线程(threading)或异步(aiohttp)提升采集效率,注意控制并发数,避免给目标网站造成压力。
-
数据存储优化:大规模数据可使用MongoDB存储非结构化数据(如用户评论),MySQL存储结构化数据,便于后续查询和分析。
-
自动化优化:用Airflow搭建定时任务,实现数据定时采集、清洗、报告生成,适合长期跟踪数据趋势。
-
代码复用:将常用的采集、清洗函数封装为工具类,后续可直接调用,减少重复开发(示例:封装代理请求函数、数据清洗函数)。
六、总结
国外经济类、跨境电商类数据分析报告的搜集,核心是「技术工具+合规采集+数据标准化」的闭环。从前期环境搭建、数据源选型,到中期数据采集、清洗,再到后期可视化和报告生成,每一步都需兼顾实操性和合规性。
后续可根据具体需求,扩展数据源(如新增东南亚电商平台、欧洲经济数据),优化技术栈(如引入AI进行数据预测),进一步提升数据搜集和分析的效率与深度。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)