【李宏毅深度学习笔记(一)】:深度学习基本步骤与网络架构
文章目录
-
- 1. 深度学习的三个步骤 (Three Steps for Deep Learning)
- 2. 基础架构:全连接层 (Fully Connected Layer)
- 3. 循环结构:RNN (Recurrent Neural Network)
- 4. RNN 的架构变体 (Special Architectures)
- 5. Naïve RNN 的数学定义
- 6. 进阶架构:LSTM (Long Short-Term Memory)
- 7. 简化的进阶:GRU (Gated Recurrent Unit)
- 8. 实验与分析:RNN/LSTM 在语音识别中的表现
- 9. 架构探索:LSTM 真的是最优解吗?
- 10. 特殊结构:Stack RNN
- 11. 基础架构:卷积层 (Convolutional Layer)
- 12. 卷积层的应用场景举例
- 13. 基础架构:池化层 (Pooling Layer)
- 14. 综合应用:CLDNN
1. 深度学习的三个步骤 (Three Steps for Deep Learning)
在进行任何深度学习任务时,我们都可以将其抽象为三个核心步骤。这不仅是操作流程,更是理解机器学习算法的通用框架。
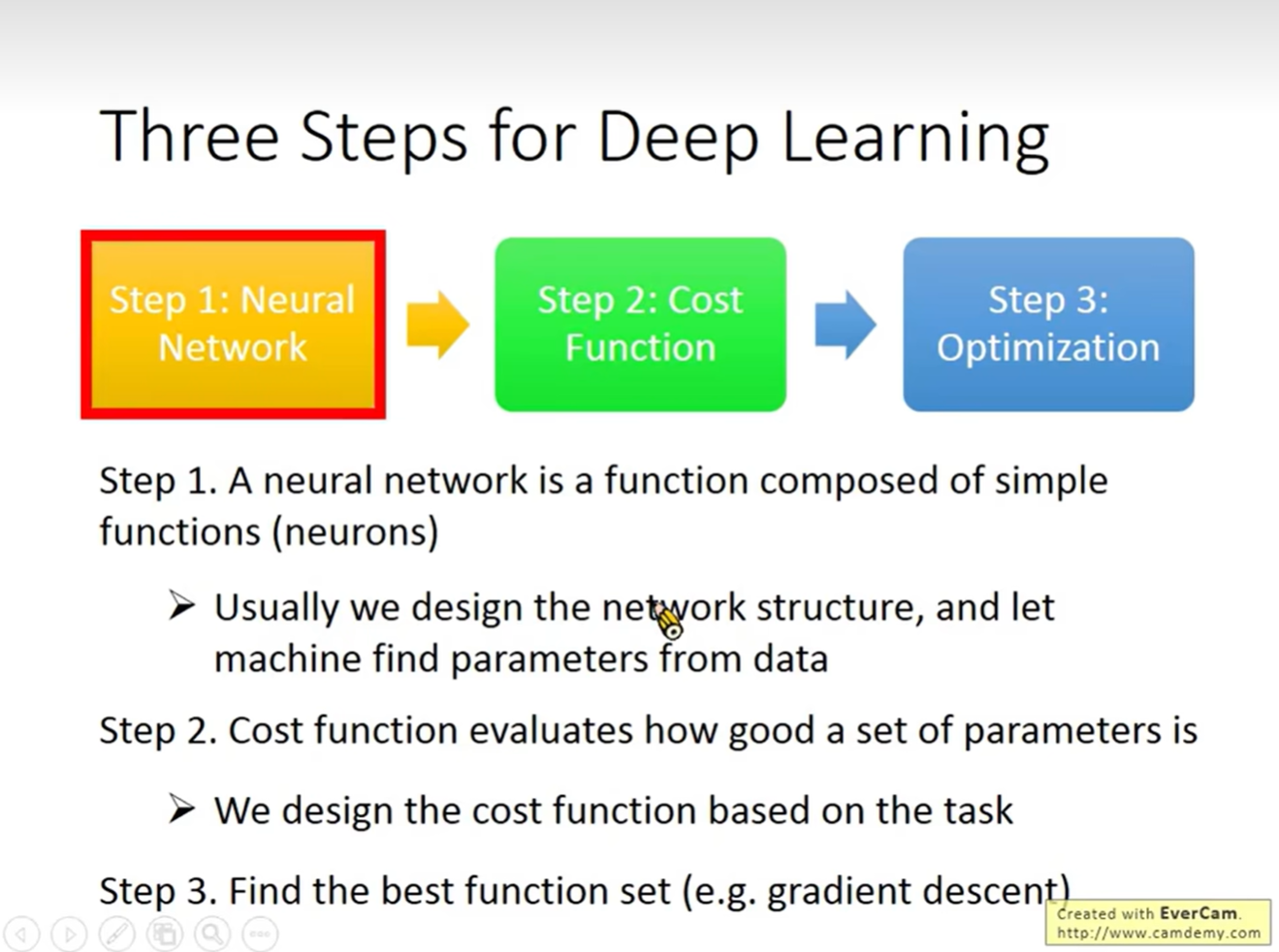
Step 1: 神经网络 (Neural Network)
这是本篇笔记的重点。我们需要定义一个 函数集合(Function Set)。
- 神经网络本质上就是一个极其复杂的函数,它由许多简单的函数(神经元/Neurons)组合而成。
- 结构设计:通常我们需要人工设计网络的结构(Structure),例如有多少层、每层有多少个神经元、神经元之间如何连接。
- 参数学习:虽然结构是人工设计的,但网络中的参数(权重 Weights 和 偏置 Biases)是由机器根据数据自动寻找的。
Step 2: 代价函数 (Cost Function)
我们需要定义一个评估标准,用来衡量某一组参数的好坏。
- 根据具体任务(如分类、回归)设计 Cost Function。
- 它告诉机器:目前的函数在处理数据时,误差有多大。
Step 3: 优化 (Optimization)
找到那个能让 Cost Function 达到最小值的“最佳函数”(即最佳参数集)。
- 最常用的方法是 梯度下降 (Gradient Descent) 及其变体。
2. 基础架构:全连接层 (Fully Connected Layer)
全连接层(Fully Connected Layer, FCL)是前馈神经网络(Feedforward Neural Network)中最基础的组件。理解它的关键在于掌握其 矩阵运算 的表示。
![![图片2]](https://i-blog.csdnimg.cn/direct/b2080af783c648f288f913b2db6975e1.png)
(注:课程大纲展示了我们将从 Basic Structure 开始,逐步深入到 CNN、RNN 以及更特殊的结构)
2.1 符号定义 (Notation)
为了准确描述网络中信号的传递,我们需要定义一套严谨的数学符号:
![![图片3]](https://i-blog.csdnimg.cn/direct/9eb7149c5dc44c3f969e06da4d6176aa.png)
![![图片4]](https://i-blog.csdnimg.cn/direct/c6a7600a8eb74c48921583f15de9fda9.png)
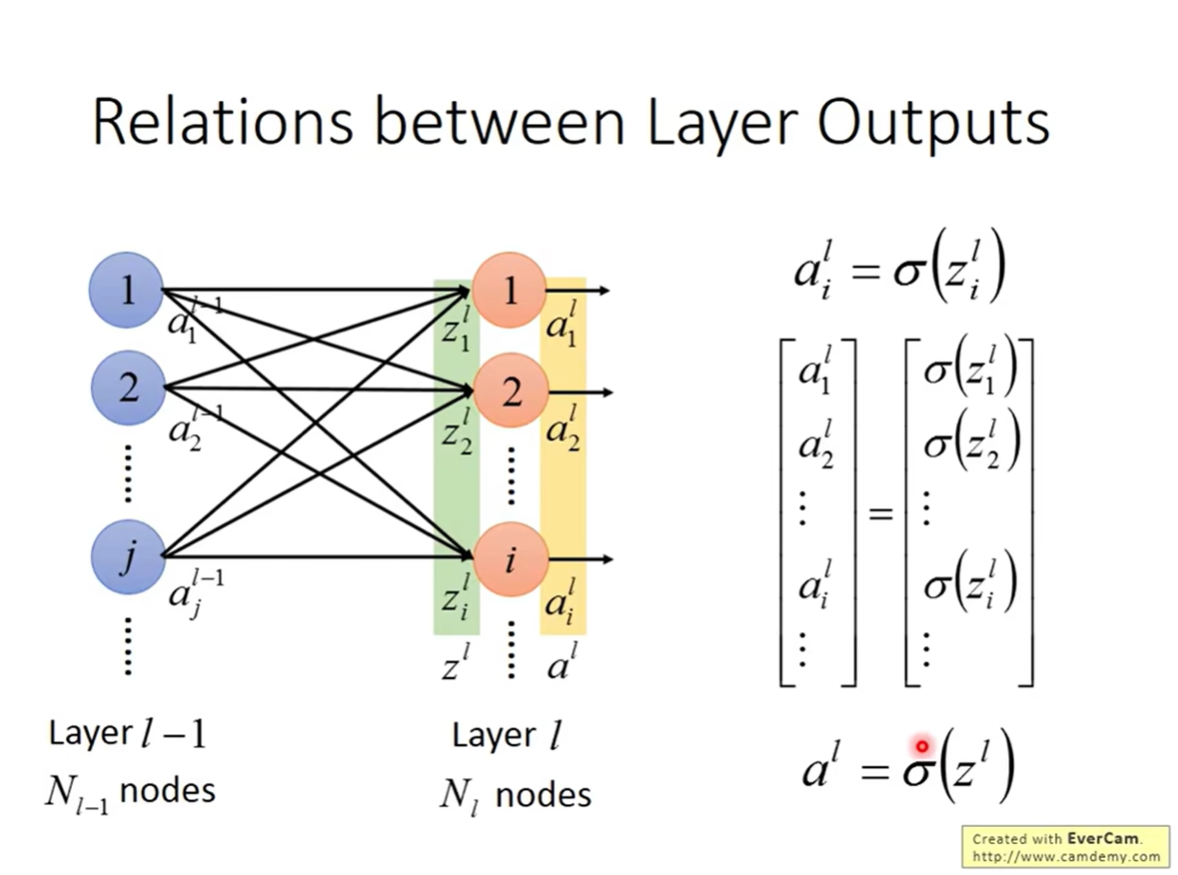
- 层级(Layer):我们用上标 l l l 表示第 l l l 层,用 l − 1 l-1 l−1 表示前一层。
- 神经元(Neuron):我们用下标 i i i 或 j j j 表示层内的第几个神经元。
- 输出(Output):
- a i l a^l_i ail:表示第 l l l 层中第 i i i 个神经元的输出值。
- a l a^l al:表示第 l l l 层所有神经元输出组成的 向量 (Vector)。
2.2 权重与偏置 (Weights & Biases)
这是全连接层参数的核心定义,也是初学者最容易搞混下标的地方。
![![图片5]](https://i-blog.csdnimg.cn/direct/3edd4a26c3624fd292ff3acfcf30d24c.png)
- 权重 (Weight) w i j l w^l_{ij} wijl:
- 表示从第 l − 1 l-1 l−1 层的第 j j j 个神经元,连接到第 l l l 层的第 i i i 个神经元的权重。
- 注意下标顺序:是 i j ij ij,即 “To” i i i, “From” j j j。之所以这样定义,是为了后续矩阵乘法时可以直接写成 W ⋅ a W \cdot a W⋅a 的形式(行对应目标神经元,列对应来源神经元)。
- 权重矩阵 W l W^l Wl:第 l l l 层的权重矩阵,其维度为 N l × N l − 1 N_l \times N_{l-1} Nl×Nl−1( N l N_l Nl 为当前层节点数, N l − 1 N_{l-1} Nl−1 为上一层节点数)。
![![图片6]](https://i-blog.csdnimg.cn/direct/ca42b591bad24db492697a79b3ec27a9.png)
- 偏置 (Bias) b i l b^l_i bil:
- 表示第 l l l 层第 i i i 个神经元的偏置值。
- 偏置向量 b l b^l bl:所有 b i l b^l_i bil 组成的列向量,维度为 N l × 1 N_l \times 1 Nl×1。
2.3 信号传播过程 (Signal Propagation)
神经元的运算可以分为两步:线性加权求和 和 非线性激活。
第一步:线性加权 (Linear Combination)
![![图片7]](https://i-blog.csdnimg.cn/direct/0043918eeb304a0ea69dfadb829f1f65.png)
对于第 l l l 层第 i i i 个神经元,其输入 z i l z^l_i zil 来源于上一层所有神经元输出 a l − 1 a^{l-1} al−1 的加权和,再加上偏置:
z i l = ∑ j = 1 N l − 1 w i j l a j l − 1 + b i l z^l_i = \sum_{j=1}^{N_{l-1}} w^l_{ij} a^{l-1}_j + b^l_i zil=j=1∑Nl−1wijlajl−1+bil
矩阵化表示(重点):
如果我们考虑第 l l l 层的所有神经元,上述标量公式可以优雅地转换为矩阵运算:
![![图片8]](https://i-blog.csdnimg.cn/direct/6202f20ead4347c1a538aee5dc22156d.png)
z l = W l a l − 1 + b l z^l = W^l a^{l-1} + b^l zl=Wlal−1+bl
- W l W^l Wl 是 N l × N l − 1 N_l \times N_{l-1} Nl×Nl−1 的矩阵。
- a l − 1 a^{l-1} al−1 是 N l − 1 × 1 N_{l-1} \times 1 Nl−1×1 的向量。
- 结果 z l z^l zl 是 N l × 1 N_l \times 1 Nl×1 的向量。
第二步:激活函数 (Activation Function)
线性变换能力有限,我们需要引入非线性。常用的激活函数有 Sigmoid ( σ \sigma σ)、ReLU 等。
a l = σ ( z l ) a^l = \sigma(z^l) al=σ(zl)
这里的 σ \sigma σ 是逐元素(element-wise)作用于向量 z l z^l zl 的每一个分量上的。
2.4 层间关系总结
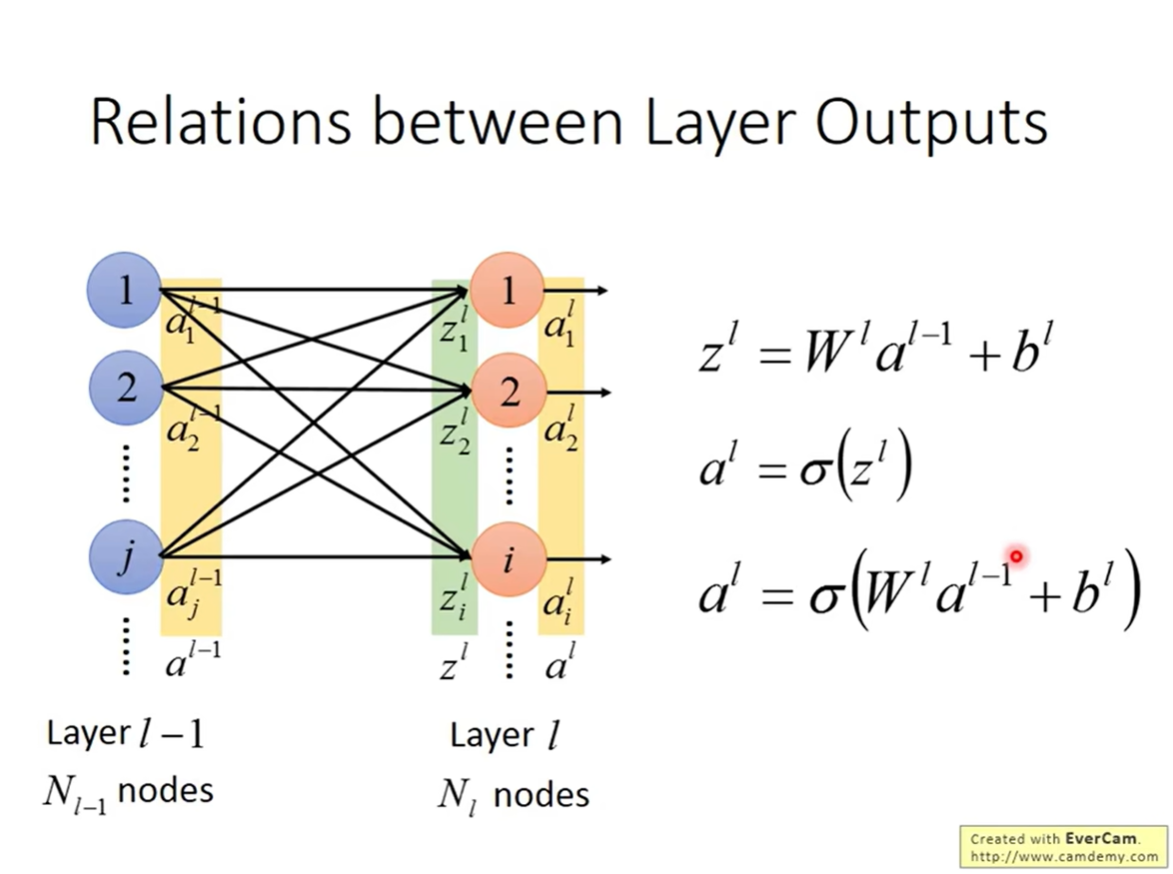
综上所述,全连接层中,相邻两层 l − 1 l-1 l−1 和 l l l 之间的关系可以浓缩为这一个公式:
a l = σ ( W l a l − 1 + b l ) a^l = \sigma( W^l a^{l-1} + b^l ) al=σ(Wlal−1+bl)
这个公式展示了深度神经网络的前向传播本质:就是不断地进行 矩阵乘法 -> 向量加法 -> 激活函数 的循环迭代。
3. 循环结构:RNN (Recurrent Neural Network)
当输入数据不再是独立的向量,而是一个 序列 (Sequence)(如文本、语音、股市曲线)时,普通的全连接网络就显得力不从心。我们需要一种能够记忆“上下文”的结构,这就是 循环神经网络。

3.1 核心思想:函数复用
RNN 的核心设计哲学是:Simplify the network by using the same function again and again.(通过反复使用同一个函数来简化网络)。
(图片12 为参考文献,展示了 LSTM 和 RNN 相关的经典论文,供进阶阅读)
![![图片12]](https://i-blog.csdnimg.cn/direct/21507fe2fff6413e9141a20eb1d0cc24.png)
3.2 RNN 的基本工作流
![![图片13]](https://i-blog.csdnimg.cn/direct/9114ec8a43ac4ebfae446aa258e19c85.png)
在 RNN 中,每一个时间步(Time Step)都使用同一个函数 f f f。
- 输入:当前时刻的输入 x t x^t xt 和 上一时刻的记忆(Hidden State) h t − 1 h^{t-1} ht−1。
- 输出:当前时刻的输出 y t y^t yt 和 更新后的记忆 h t h^t ht(即图中的 h ′ h' h′)。
- 公式描述:
h ′ , y = f ( h , x ) h', y = f(h, x) h′,y=f(h,x) - 特点:无论输入序列 x 1 , x 2 , x 3 . . . x^1, x^2, x^3... x1,x2,x3... 有多长,我们始终复用同一个函数 f f f(即同一套参数)。这意味着 RNN 的参数量不会随着序列长度的增加而增加。
4. RNN 的架构变体 (Special Architectures)
为了解决特定问题或提升性能,RNN 衍生出了多种结构。
4.1 深度 RNN (Deep RNN)
![![图片14]](https://i-blog.csdnimg.cn/direct/9a1b84b7fa6349e1846bec48a640659a.png)
Deep RNN 将“深度”的概念引入 RNN。它不仅在时间轴上展开,还在空间轴(层数)上堆叠。
- 结构:
- 第一层 RNN 处理输入 x x x,输出隐藏状态 h h h(作为下一时刻第一层的输入)和输出 y y y。
- 这个输出 y y y(或者该层的 hidden state)会作为 第二层 RNN 的输入。
- 参数:每一层的函数 f 1 , f 2 , . . . f_1, f_2, ... f1,f2,... 是不同的,但在同一层内,不同时刻使用的是相同的参数。
4.2 双向 RNN (Bidirectional RNN)
![![图片16]](https://i-blog.csdnimg.cn/direct/d05966d663cf4e42983c2708d40f9fd5.png)
痛点:单向 RNN 在 t t t 时刻只能看到 t t t 之前的信息。但在很多任务(如填空题)中,理解上下文需要同时看到“过去”和“未来”。
解决方案:
- 正向层 ( f 1 f_1 f1):从 x 1 x^1 x1 读到 x T x^T xT,生成 hidden states h 1 , h 2 , . . . h^1, h^2, ... h1,h2,...
- 逆向层 ( f 2 f_2 f2):从 x T x^T xT 读到 x 1 x^1 x1,生成 hidden states b T , . . . b 1 b^T, ... b^1 bT,...b1。
- 最终输出: t t t 时刻的输出 y t y^t yt 由 f 3 f_3 f3 产生,它的输入同时包含正向的 h t h^t ht 和 逆向的 b t b^t bt。
y = f 3 ( h , b ) y = f_3(h, b) y=f3(h,b)
这样,网络在产生输出时,就同时拥有了整个序列的全部信息。
4.3 金字塔 RNN (Pyramidal RNN)
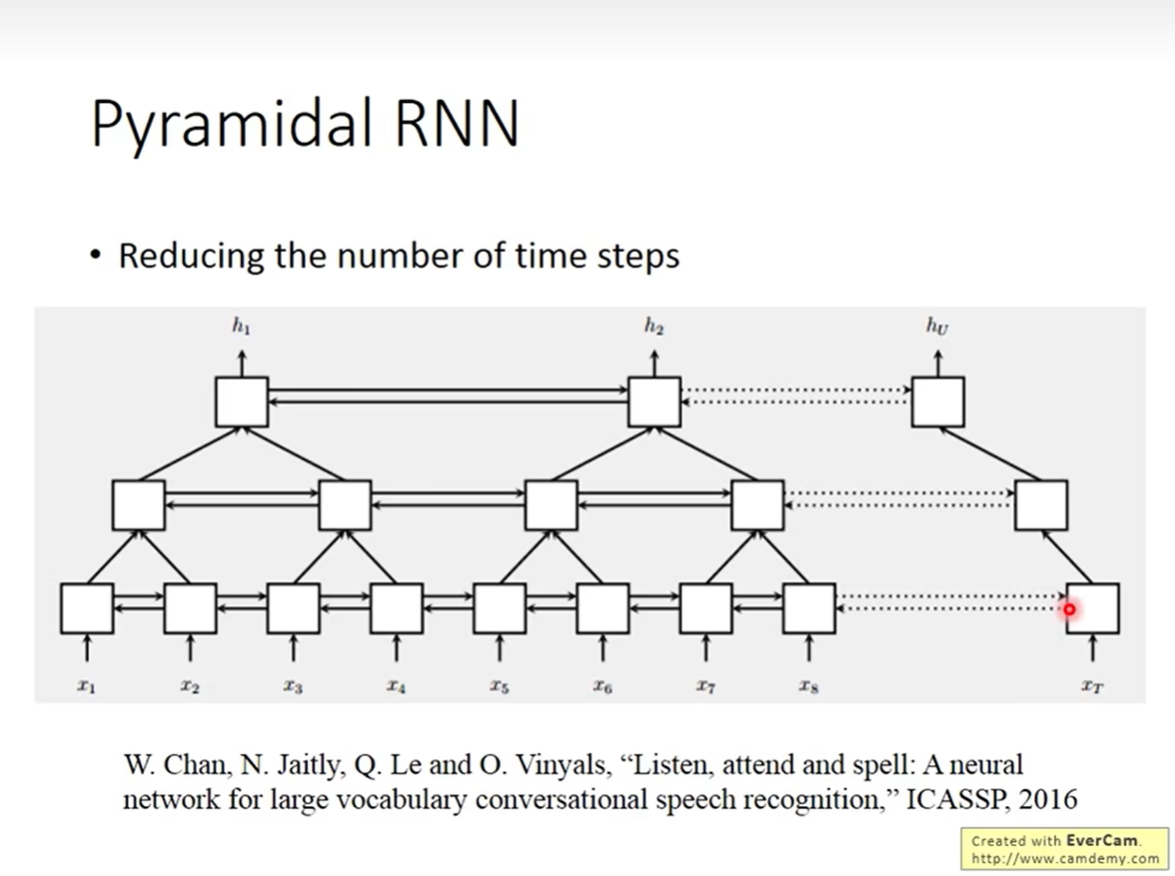
痛点:对于像语音识别这样的任务,输入序列非常长(一秒钟的音频可能包含成百上千个采样点),计算量巨大且难以捕捉极长距离的依赖。
解决方案:
- 通过层级结构减少时间步数。
- 底层 RNN 每个时间步都处理输入。
- 上一层的 RNN 可能每隔几个时间步才接收一次底层的输出(类似 CNN 中的 Stride 或 Pooling 概念)。
- 结果:越往高层,序列长度越短,网络呈现金字塔状,大大提高了计算效率并扩大了感受野。
5. Naïve RNN 的数学定义
最后,我们来看看最原始的 RNN(Naïve RNN)的具体数学公式,这通常也被称为 Elman Network。
![![图片18]](https://i-blog.csdnimg.cn/direct/67f9e0a325ac4fb3b8b2897716a7d7a2.png)
符号定义
- x x x:当前时刻输入向量。
- h h h:上一时刻的 Hidden State。
- h ′ h' h′:当前时刻更新后的 Hidden State。
- y y y:当前时刻的输出。
参数矩阵
RNN 包含三组共享权重的矩阵:
- W h W^h Wh:处理上一时刻记忆的权重。
- W i W^i Wi:处理当前输入的权重。
- W o W^o Wo:产生输出的权重。
运算公式
-
更新记忆 (Hidden Layer Update):
新的记忆 h ′ h' h′ 是由旧记忆 h h h 和新输入 x x x 共同决定的。通常会加上激活函数 σ \sigma σ(如 Tanh 或 Sigmoid)。
h ′ = σ ( W h h + W i x ) h' = \sigma ( W^h h + W^i x ) h′=σ(Whh+Wix)
(注:这里省略了偏置项,实际应用中通常会有 bias) -
计算输出 (Output Layer):
输出 y y y 仅依赖于当前的记忆 h ′ h' h′。如果是分类任务,通常通过 Softmax 函数。
y = σ ( W o h ′ ) y = \sigma ( W^o h' ) y=σ(Woh′)
通过这组公式,RNN 实现了将历史信息 h h h 一步步传递下去的功能。
6. 进阶架构:LSTM (Long Short-Term Memory)
Naïve RNN 最大的问题在于“短期记忆”,难以处理长序列中的长期依赖问题。LSTM 通过引入更复杂的内部机制来解决这一问题。
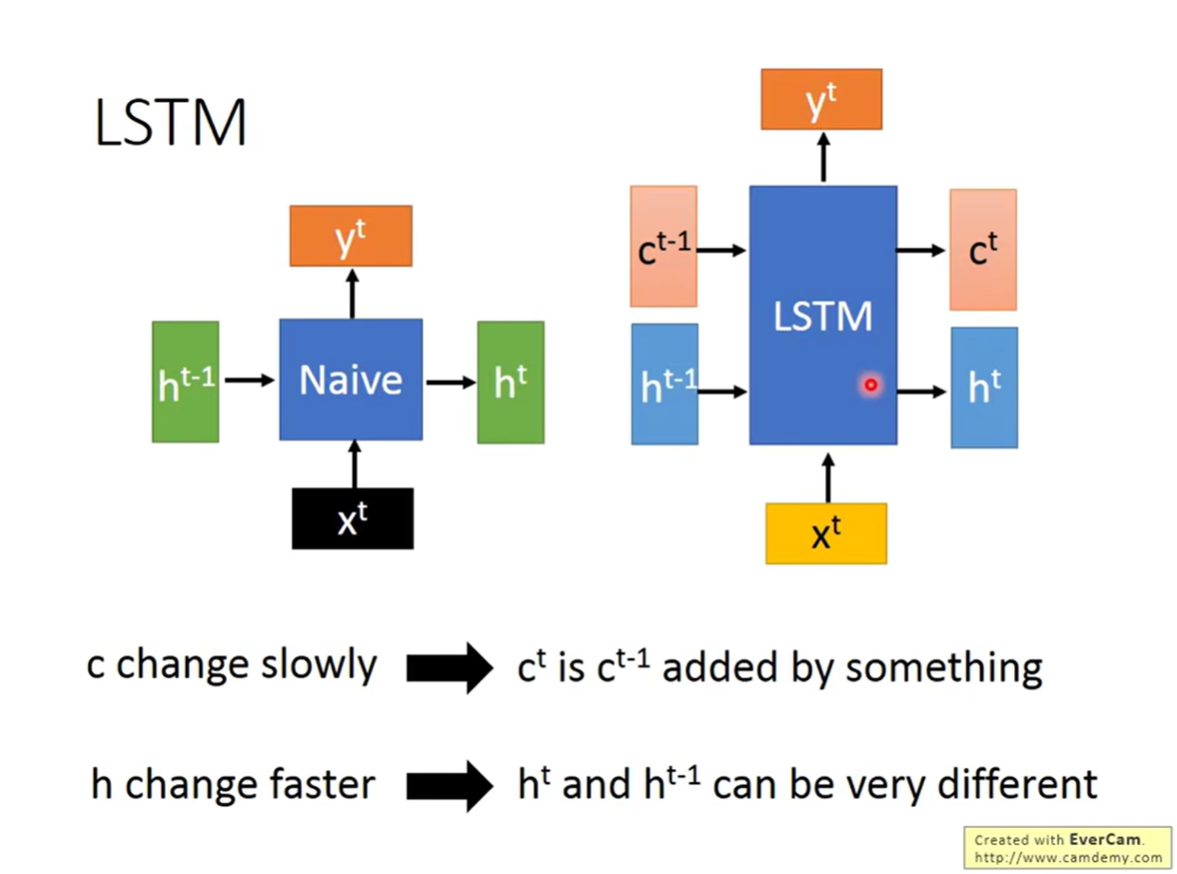
6.1 核心概念:Cell State vs Hidden State
LSTM 区分了两种状态:
- h t h^t ht (Hidden State):短期状态,变化较快,对应我们之前理解的 RNN 输出。
- c t c^t ct (Cell State):长期状态,变化较慢。
- c t c^t ct 是在 c t − 1 c^{t-1} ct−1 的基础上加上一些东西得到的(Additivity),这种加法特性使得梯度更容易长时间保留,从而解决梯度消失问题。
6.2 LSTM 的内部构造
相比于 Naïve RNN 只有一个输入(Input),LSTM 的神经元(Memory Cell)在每个时间步处理输入时,会生成 4 个不同的向量。
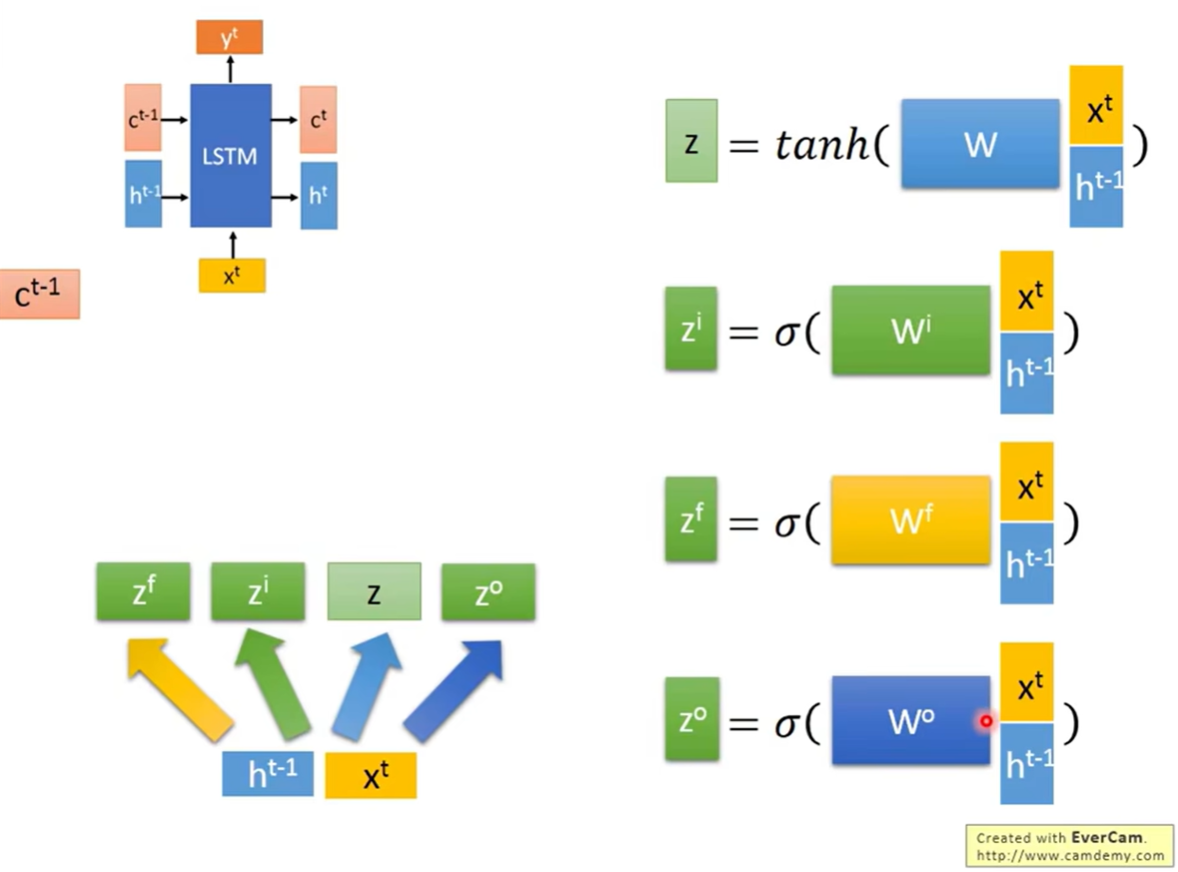
假设当前输入为 x t x^t xt,上一时刻的短期状态为 h t − 1 h^{t-1} ht−1,它们经过线性变换后,分别通过不同的激活函数,产生以下四个信号:
- z z z (Input Signal):
- 激活函数:tanh
- 作用:相当于标准 RNN 中的输入,包含了当前时刻的主要信息。
- z i z^i zi (Input Gate Signal):
- 激活函数:Sigmoid (输出 0~1)
- 作用:输入门。决定了 z z z 中的信息有多少能被“写入”到记忆单元中(1 代表完全打开,0 代表完全关闭)。
- z f z^f zf (Forget Gate Signal):
- 激活函数:Sigmoid
- 作用:遗忘门。决定了上一时刻的记忆 c t − 1 c^{t-1} ct−1 有多少需要被“遗忘”或保留。
- z o z^o zo (Output Gate Signal):
- 激活函数:Sigmoid
- 作用:输出门。决定了当前的记忆 c t c^t ct 有多少能被输出成为 h t h^t ht。
6.3 窥孔连接 (Peephole Connection)
![![图片3]](https://i-blog.csdnimg.cn/direct/8bbf76e6ef8e4dd4918b4c5336ac75c6.png)
标准的 LSTM 仅利用 x t x^t xt 和 h t − 1 h^{t-1} ht−1 来控制门控信号。但在某些实现中,会加入 Peephole 机制,即让 上一时刻的 Cell State ( c t − 1 c^{t-1} ct−1) 也参与到 z , z i , z f , z o z, z^i, z^f, z^o z,zi,zf,zo 的计算中。这使得门控机制能“看到”内部的长期记忆。
6.4 LSTM 的数学公式 (关键)
理解 LSTM 的运作流,关键在于以下两个公式:
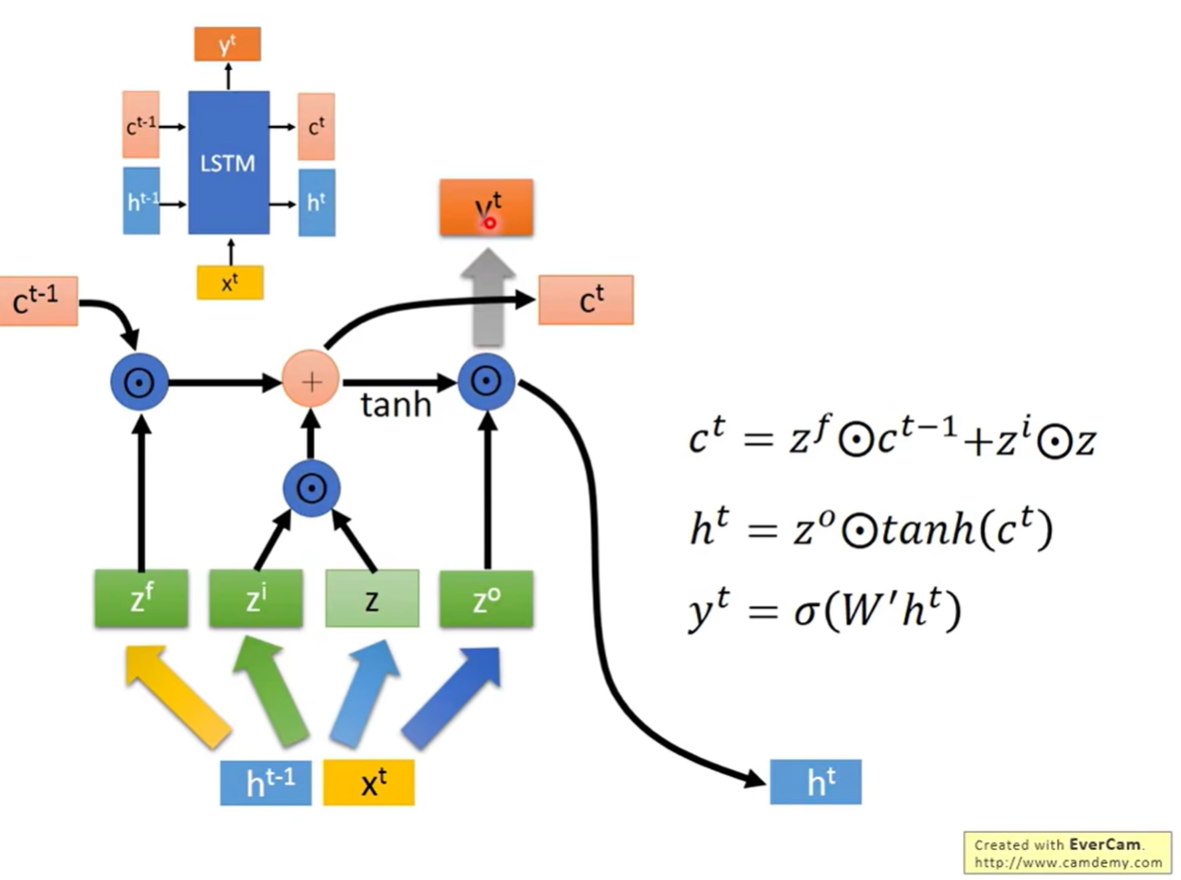
Step 1: 更新 Cell State ( c t c^t ct)
c t = z f ⊙ c t − 1 ⏟ 遗忘旧记忆 + z i ⊙ z ⏟ 写入新信息 c^t = \underbrace{z^f \odot c^{t-1}}_{\text{遗忘旧记忆}} + \underbrace{z^i \odot z}_{\text{写入新信息}} ct=遗忘旧记忆
zf⊙ct−1+写入新信息
zi⊙z
- ⊙ \odot ⊙ 代表逐元素相乘 (Element-wise product)。
- 这体现了 LSTM 的核心思想:记忆是旧记忆的衰减与新输入的叠加。
Step 2: 计算 Hidden State ( h t h^t ht) 和 输出 ( y t y^t yt)
h t = z o ⊙ tanh ( c t ) h^t = z^o \odot \tanh(c^t) ht=zo⊙tanh(ct)
y t = σ ( W ′ h t ) y^t = \sigma(W' h^t) yt=σ(W′ht)
- 当前的长期记忆 c t c^t ct 经过 tanh 激活后,被输出门 z o z^o zo 调控,形成当前的短期状态 h t h^t ht。
6.5 序列中的 LSTM
![![图片5]](https://i-blog.csdnimg.cn/direct/4571ad6c5461427c87b98d1cdc315484.png)
当我们把 LSTM 在时间轴上展开时,可以清晰地看到:
- c c c (Cell State) 像一条传送带,贯穿所有时间步,负责信息的长距离传递。
- x x x 和 h h h 在每个节点汇入,对 c c c 进行微调(遗忘或写入),并从 c c c 中读取信息生成输出。
7. 简化的进阶:GRU (Gated Recurrent Unit)
LSTM 参数较多(4 组权重矩阵),计算量大。于是有了简化版本 GRU。
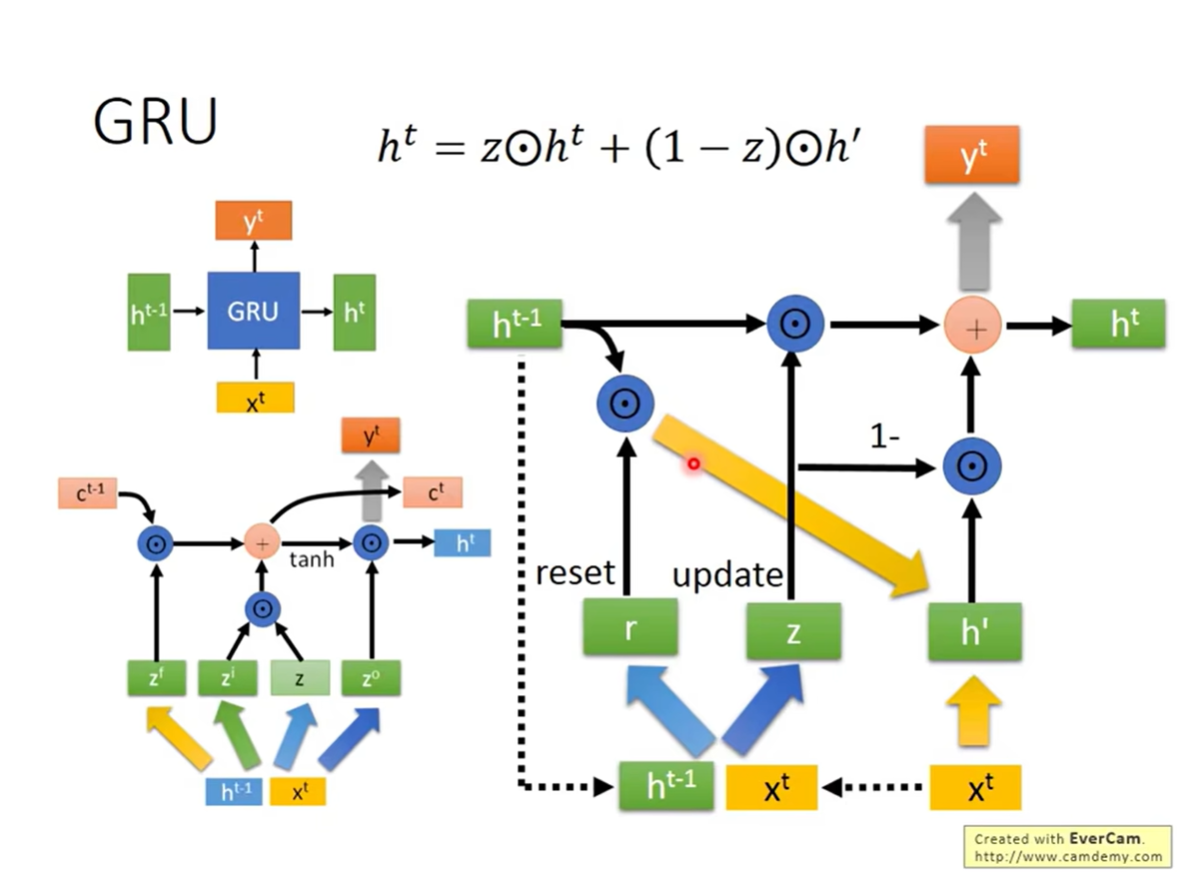
GRU 的特点
- 只有 2 个门:
- Reset Gate ( r r r):重置门,决定在计算候选状态时,是否忽略之前的状态。
- Update Gate ( z z z):更新门,它同时承担了 LSTM 中“输入门”和“遗忘门”的职责。
- 状态合并:取消了 c c c 和 h h h 的区分,统一使用 h h h。
GRU 的公式
h t = z ⊙ h t − 1 + ( 1 − z ) ⊙ h ′ h^t = z \odot h^{t-1} + (1-z) \odot h' ht=z⊙ht−1+(1−z)⊙h′
- 这里的 z z z 是 update gate。
- 公式含义:如果 z = 1 z=1 z=1,则 h t = h t − 1 h^t = h^{t-1} ht=ht−1(完全保留旧记忆,忽略新输入);如果 z = 0 z=0 z=0,则 h t = h ′ h^t = h' ht=h′(完全使用新状态)。
- 核心思想:旧记忆和新状态处于一种“此消彼长”的竞争关系。
8. 实验与分析:RNN/LSTM 在语音识别中的表现
为了验证不同架构的效果,课程使用了 TIMIT 数据集进行 Phoneme Classification(音素分类) 任务。
![![图片7]](https://i-blog.csdnimg.cn/direct/e2079e7d89a94014ac3d5575384d4075.png)
8.1 任务描述
- 输入:声学特征序列(MFCC 等)。
- 输出:每一帧(Frame)所属的音素(Phoneme)。
- 难点:由于发音的协同发音效应,同一个音素(如 “a”)在不同上下文(“apple” vs “car”)中特征不同。
8.2 单向 RNN 的局限与 Target Delay
![![图片8]](https://i-blog.csdnimg.cn/direct/547a3b6cc1744c439335925ace7cccd6.png)
- 问题:单向 RNN 在 t t t 时刻只能看到 t t t 及其之前的信息。但在语音识别中,往往需要看到后面的内容才能确定当前的音素(例如区分
c-l-a-p和c-l-i-p,读到l时需要看后面的元音)。 - Tricky Solution (Target Delay):如果不想用双向网络,可以人工将目标标签(Target Labels)向后延迟 k k k 个时间步。
- 这样,网络在输出 t t t 时刻的预测时,实际上已经读入了 t + k t+k t+k 时刻的输入数据。
8.3 实验结果对比
![![图片9]](https://i-blog.csdnimg.cn/direct/e8ed4fda435f4743b688a22e70d39a4a.png)
上图展示了分类正确率与 Target Delay 的关系:
- 架构对比:LSTM (实心方块) > RNN (空心圆) > Feedforward MLP (实心圆)。LSTM 优势明显。
- 双向 vs 单向:Bi-directional (BLSTM, 顶部横线) 效果远好于 Uni-directional,且不需要 Target Delay。
- Delay 的作用:对于单向网络,增加 Delay 能显著提升性能。
8.4 可视化分析
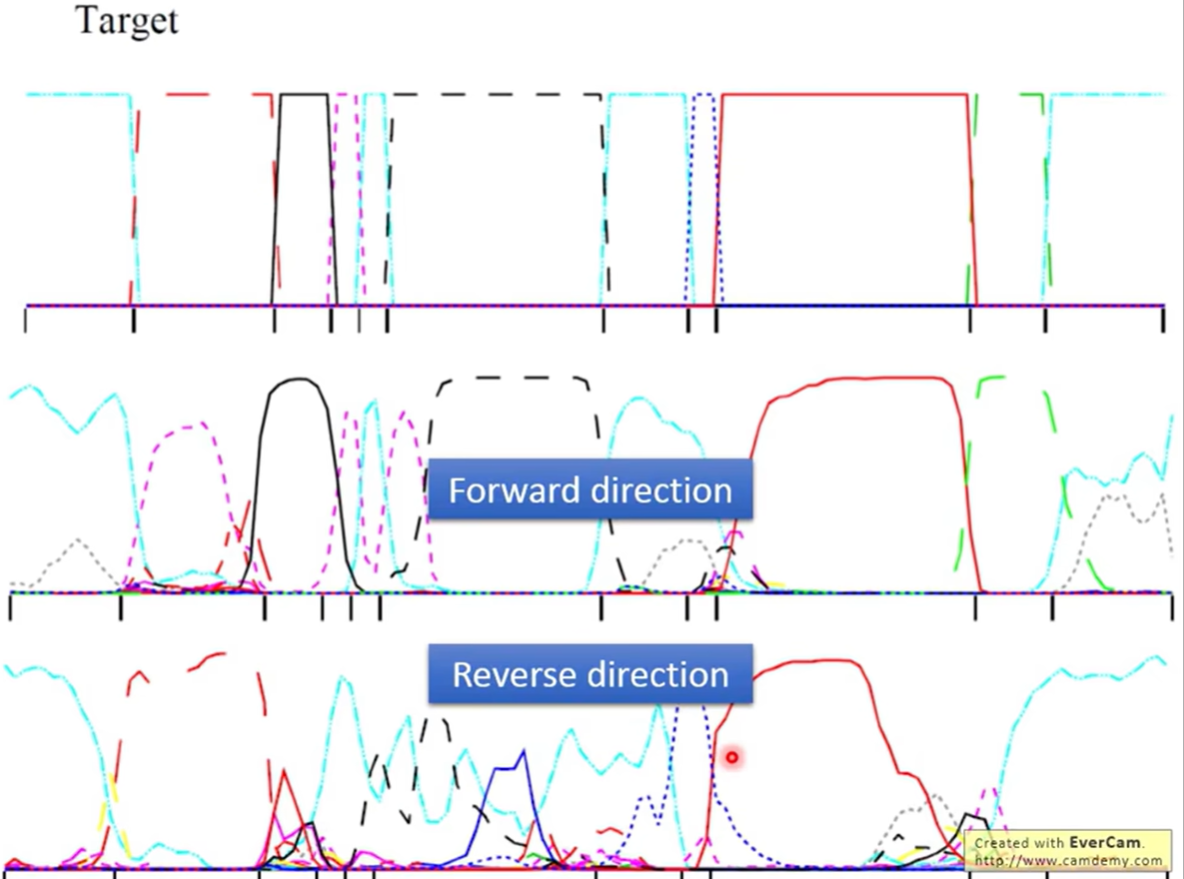
Case 1: 单向 LSTM 的输出
- 上方:真实标签(Target)。
- 下方:单向 LSTM 的输出概率分布。
- 现象:可以看到输出非常不稳定,在音素边界处有剧烈波动,且对齐效果较差。
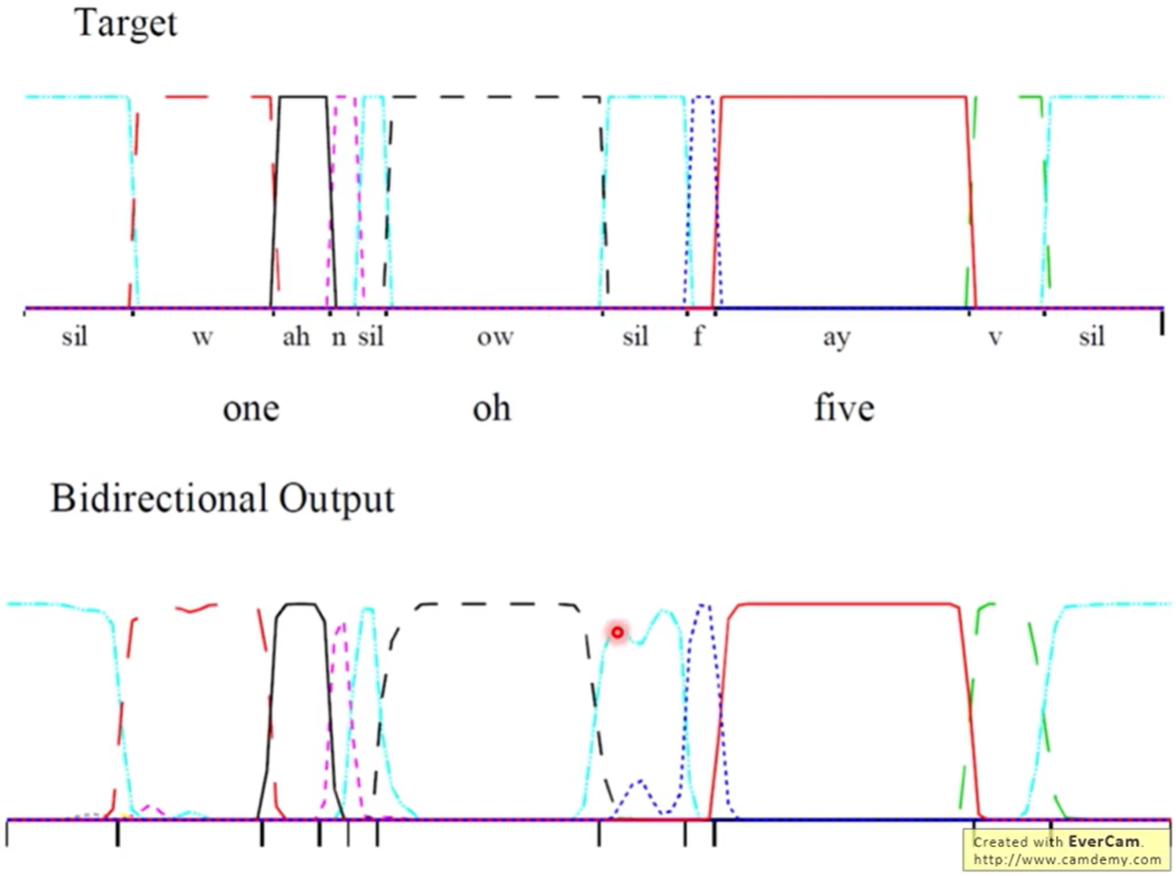
Case 2: 双向 LSTM (Bi-directional) 的输出
- 中间:Forward direction 的输出。
- 下方:Reverse direction 的输出。
- 最终结果:结合前后向信息后(图中未画出合并后的,但可推测),其对齐精度和分类置信度远高于单向网络。
8.5 学习曲线 (Learning Curve)
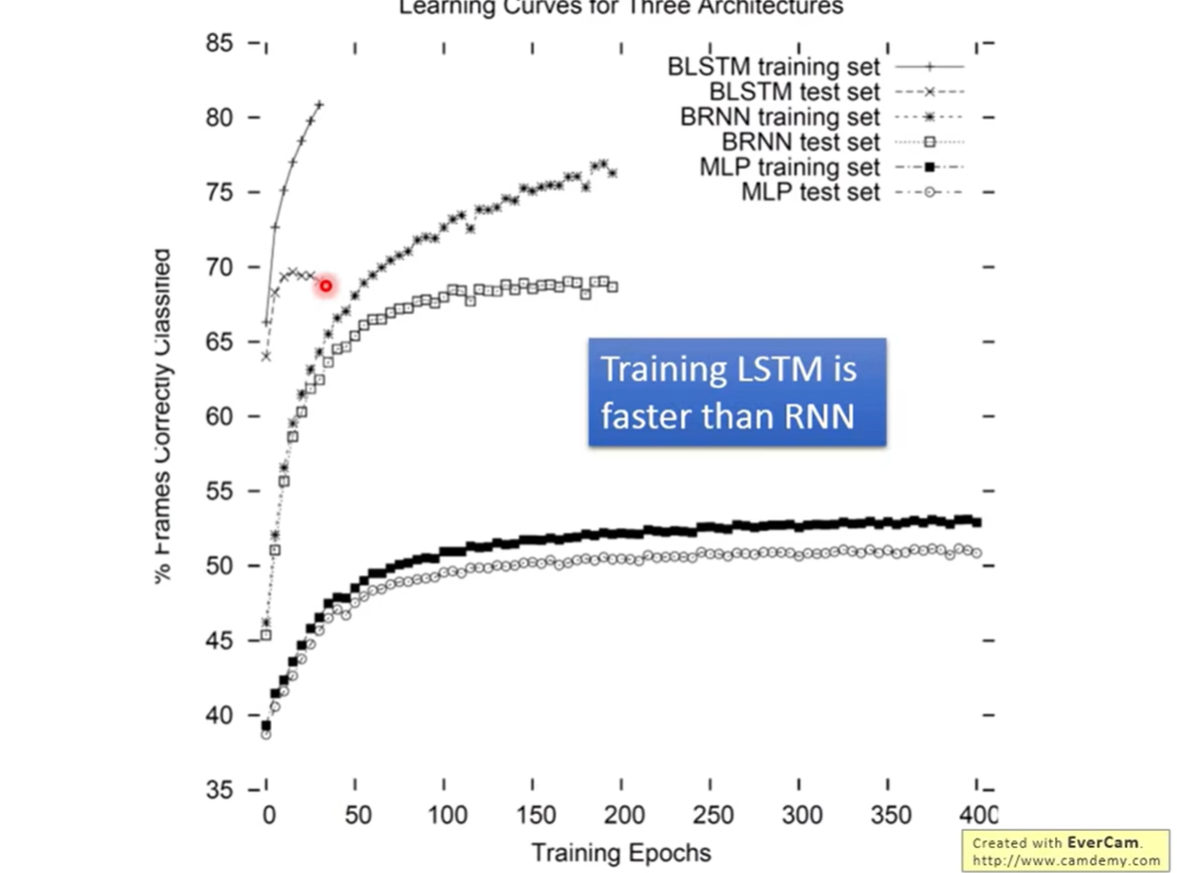
- 训练速度:LSTM(上方曲线)不仅最终效果好,其收敛速度也远快于 Naïve RNN(下方曲线)。
- 原因:这反驳了“LSTM 参数多所以难训练”的直觉。实际上,由于 LSTM 的 Cell State 通路设计解决了梯度消失问题,使得优化算法能更高效地在误差曲面上找到方向。
9. 架构探索:LSTM 真的是最优解吗?
既然 LSTM 效果这么好,它是唯一的选择吗?我们能否通过改变其内部结构(比如去掉某个门)来获得更好的效果?
9.1 LSTM: A Search Space Odyssey (Greff et al., 2016)
这篇论文系统地测试了 LSTM 的各种变体(去掉输入门 NIG、去掉遗忘门 NFG、去掉输出门 NOG 等)。
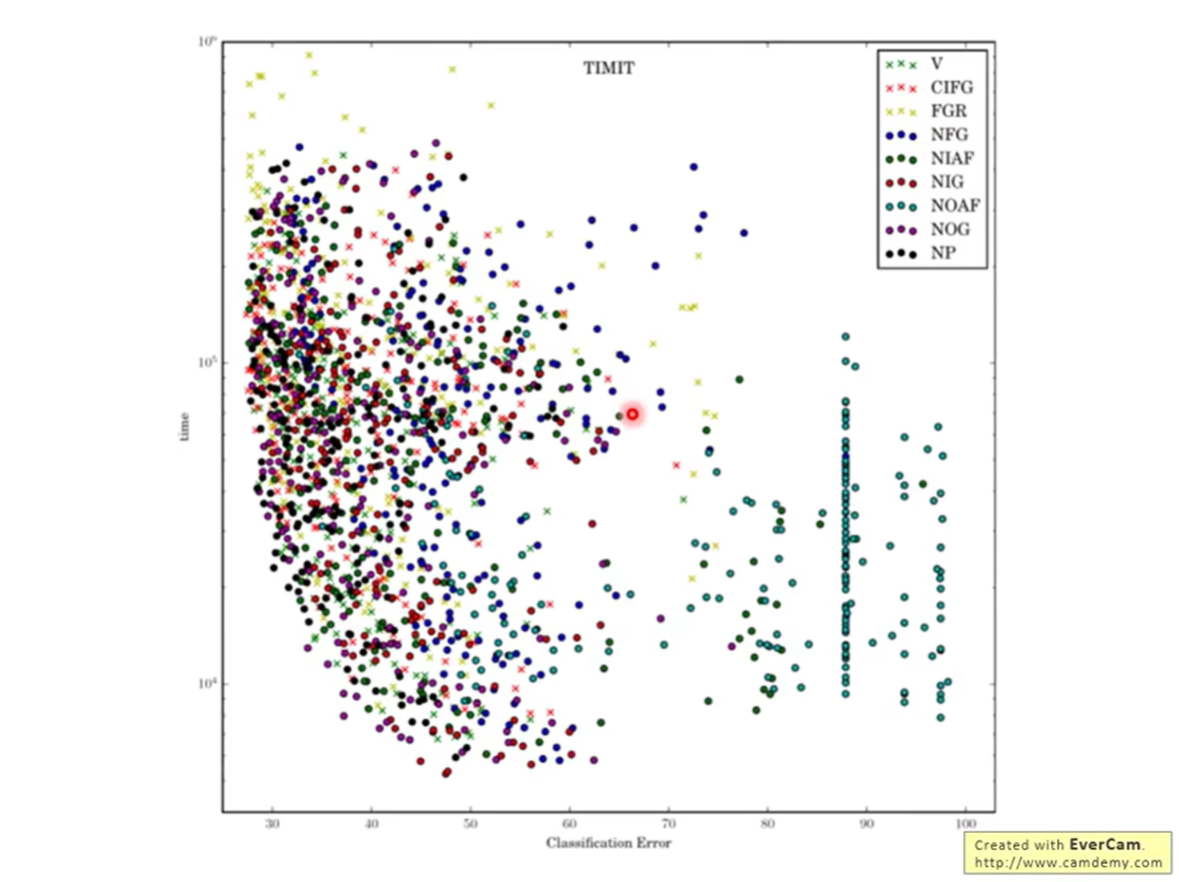
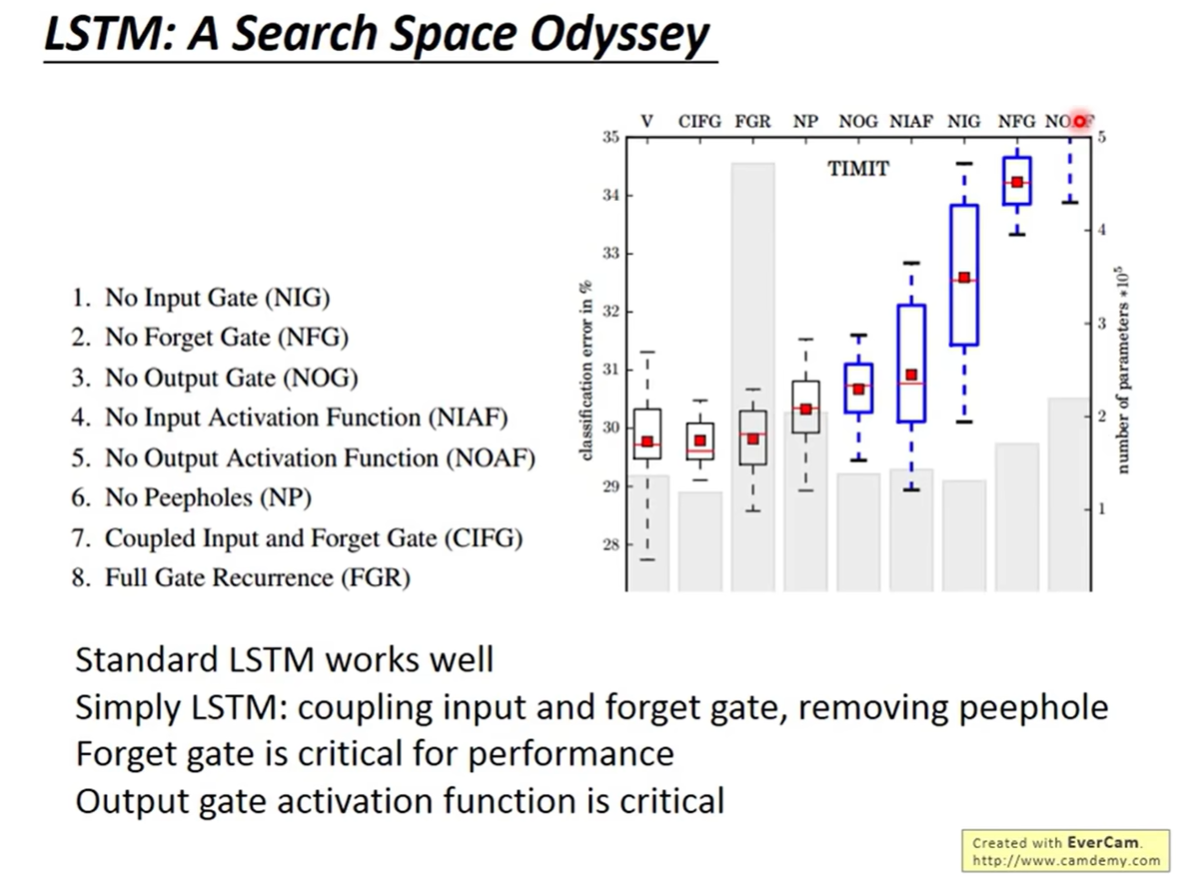
- 结论:
- Standard LSTM works well:标准的 LSTM 结构非常鲁棒,大多数变体并没有显著优于标准版。
- Forget Gate is critical:去掉遗忘门(NFG)会导致性能大幅下降(图中 NFG 的 Error 极高)。
- Output Gate bias:输出门的偏置初始化非常重要。
9.2 进化算法搜索架构 (Jozefowicz et al., 2015)
另一项研究试图通过进化算法自动搜索成千上万种 RNN 架构,试图找到超越 LSTM 的结构。
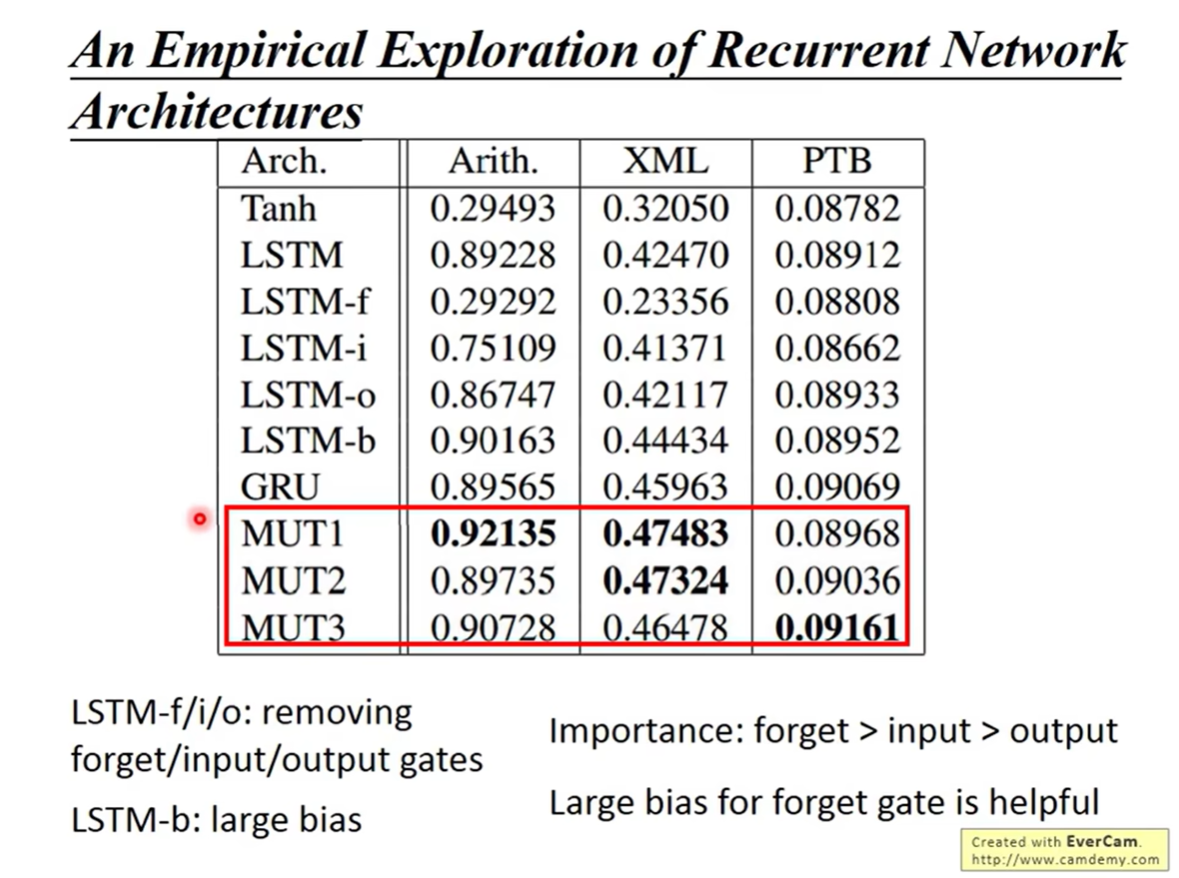
- 他们发现了三个特殊的变体:MUT1, MUT2, MUT3。
- 结果:在特定的任务(如 Arithmetic, XML 建模)上,这些自动搜索出的架构(特别是 MUT1)确实能微弱地击败 GRU 和 LSTM。
- 局限:在自然语言处理任务(PTB)上,LSTM 依然具有统治力。
9.3 MUT 系列的数学形式

上图展示了 MUT1、MUT2、MUT3 的具体公式。
- 可以看到它们在非线性激活函数(tanh/sigm)和门控操作( ⊙ \odot ⊙)的组合上做了极其复杂的尝试。
- 启示:虽然我们可以设计出无数种变体,但在通用性和可解释性上,LSTM 和 GRU 依然是目前的“黄金标准”。
10. 特殊结构:Stack RNN
在标准的 RNN 中,记忆主要由 Hidden State(或 Cell State)承担,这类似于一个未经组织的“大背包”。为了让网络具备处理更复杂逻辑(如层级结构、算法模式)的能力,研究人员引入了 栈 (Stack) 结构。
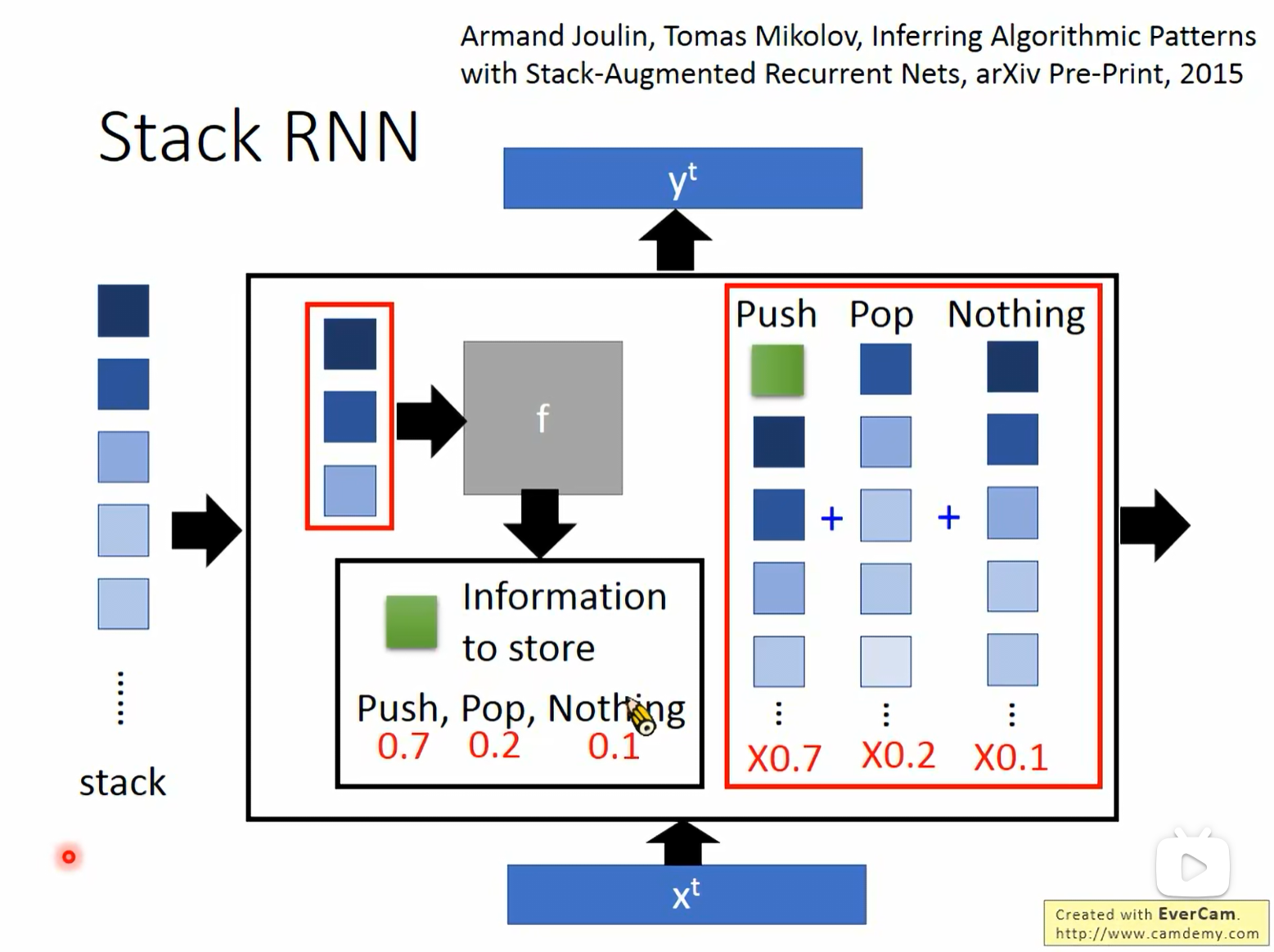
10.1 结构设计
- Stack (栈):一种先进后出(LIFO)的数据结构。
- 控制器 (Controller):即图中的 RNN/LSTM 单元。它不仅生成输出 y t y^t yt,还负责控制 Stack 的操作。
10.2 操作指令 (Instructions)
在每个时间步,网络会计算三种操作的概率分布:
- Push (压栈):将新的信息存入栈顶。
- Pop (出栈):从栈顶取出信息并删除。
- Nothing (无操作):保持栈的状态不变。
例如,图中显示的概率分布为 Push: 0.7, Pop: 0.2, Nothing: 0.1,则网络大概率执行压栈操作。这种结构使得 RNN 具备了类似计算机程序的逻辑处理能力,特别适合处理如括号匹配、代码解析等任务。
11. 基础架构:卷积层 (Convolutional Layer)
全连接层(Fully Connected Layer)虽然通用,但在处理图像或长序列时参数量过大。为了简化网络,我们基于对任务的 先验知识 (Prior Knowledge) 引入了卷积层。
![![图片2]](https://i-blog.csdnimg.cn/direct/9dfa1c4a4dd8405f971862975cb548bb.png)
11.1 特性一:稀疏连接 (Sparse Connectivity)与感受野 (Receptive Field)
在全连接层中,每个神经元都要连接上一层的所有输出。而在卷积层中,每个神经元只关注输入的一小部分区域,这个区域称为 感受野 (Receptive Field)。
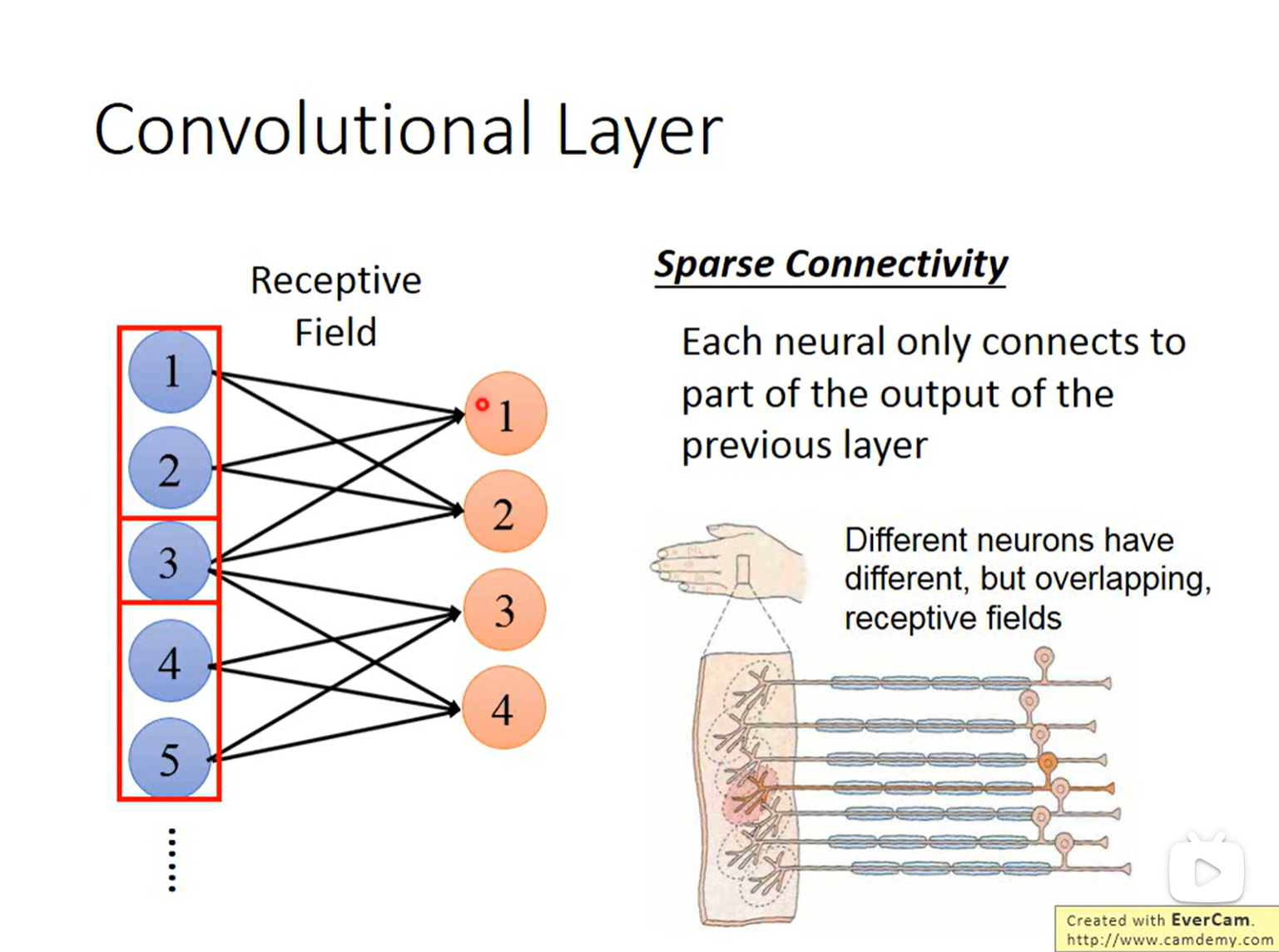
- 生物学启发:这类似于人类视觉系统,视网膜上的细胞只对视野中的局部区域有反应。
- 连接方式:如图所示,Layer l l l 的神经元 1 仅连接 Layer l − 1 l-1 l−1 的输入 1, 2, 3。
11.2 特性二:参数共享 (Parameter Sharing)
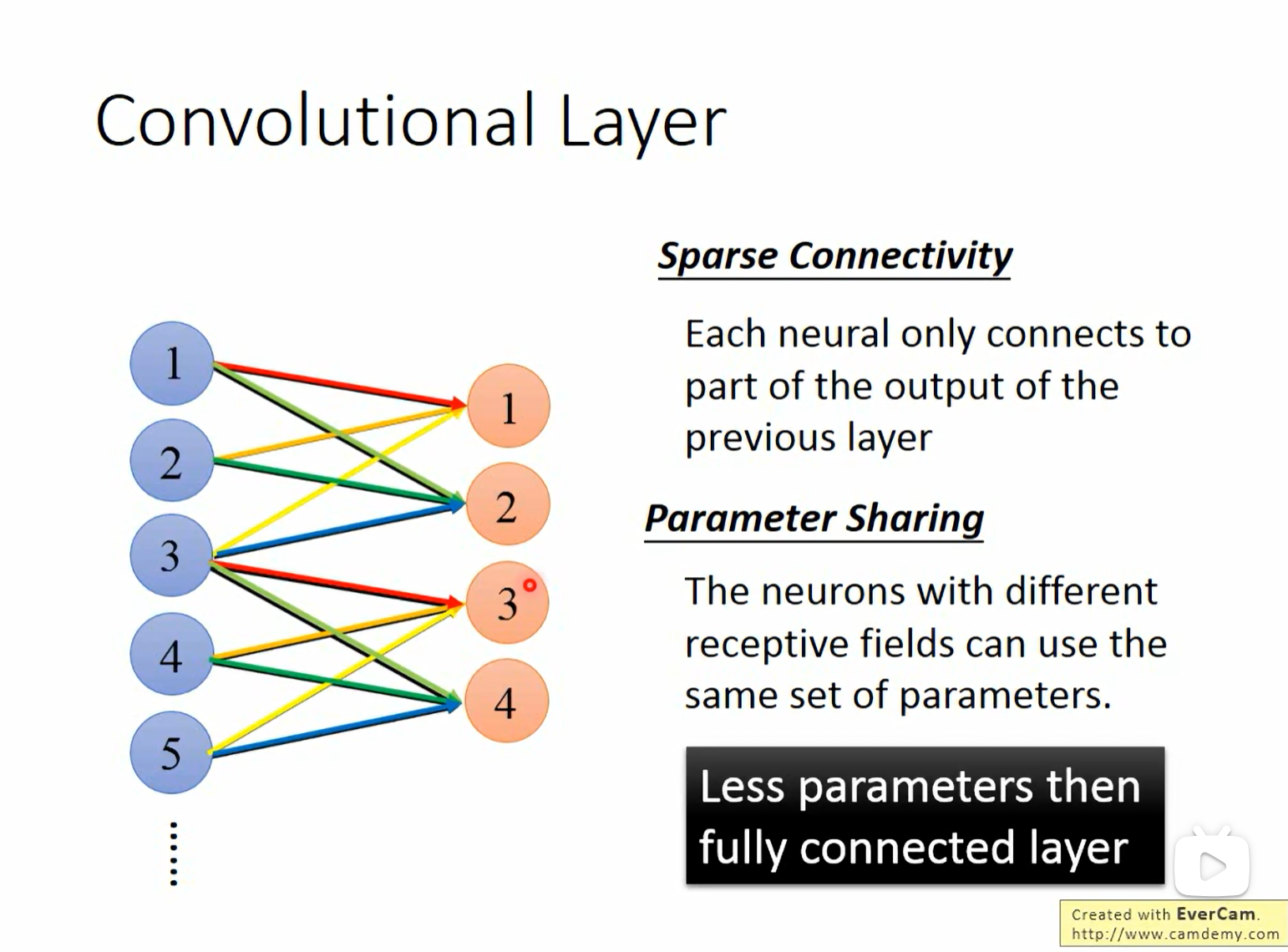
- 动机:不同的神经元虽然关注不同的感受野,但它们可能都在寻找同一种特征(例如,都在寻找“垂直边缘”)。
- 机制:既然功能相同,我们就可以让不同感受野的神经元 共享同一组参数 (Weights)。
- 图中的 Layer l l l 的神经元 1 和神经元 3 使用的是同一组颜色(红、绿、蓝)的连接权重。
- 效果:参数量远少于全连接层。
11.3 滤波器 (Filter) 与 步长 (Stride)
上述的“共享参数”在数学上就等价于 滤波器 (Filter) 或 卷积核 (Kernel)。
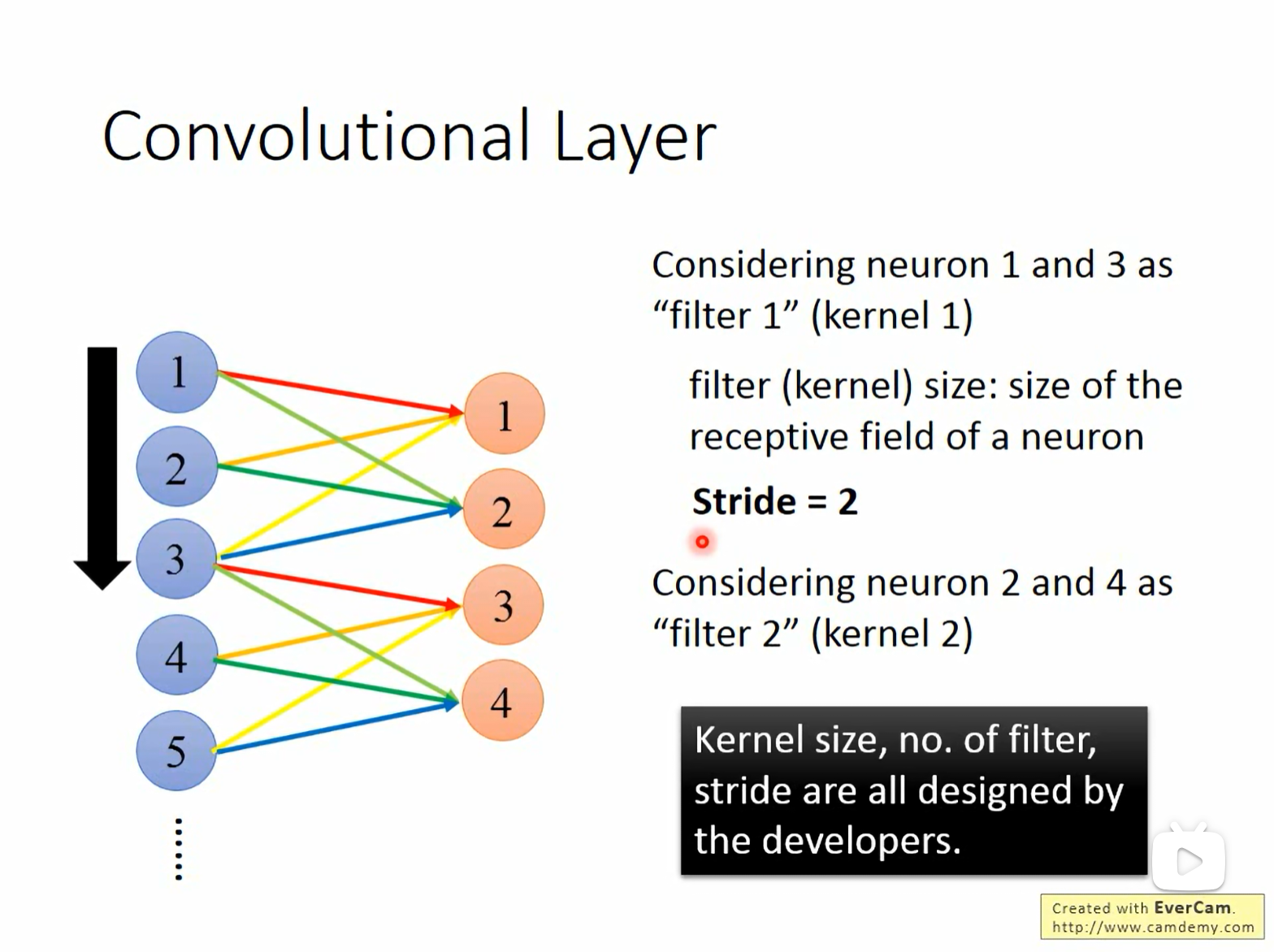
- 滤波器 (Filter):一组权重的集合。例如 Kernel 1 处理神经元 1 和 3 的感受野,Kernel 2 处理神经元 2 和 4 的感受野。
- 步长 (Stride):感受野移动的距离。图中 Stride = 2,意味着感受野从 [1,2,3] 移动到了 [3,4,5]。
- 设计权:Kernel size (感受野大小)、Filter 数量、Stride 均由开发者根据任务设计。
12. 卷积层的应用场景举例
12.1 一维信号 + 单通道 (1D Signal, Single Channel)
场景:音频波形、股票曲线。
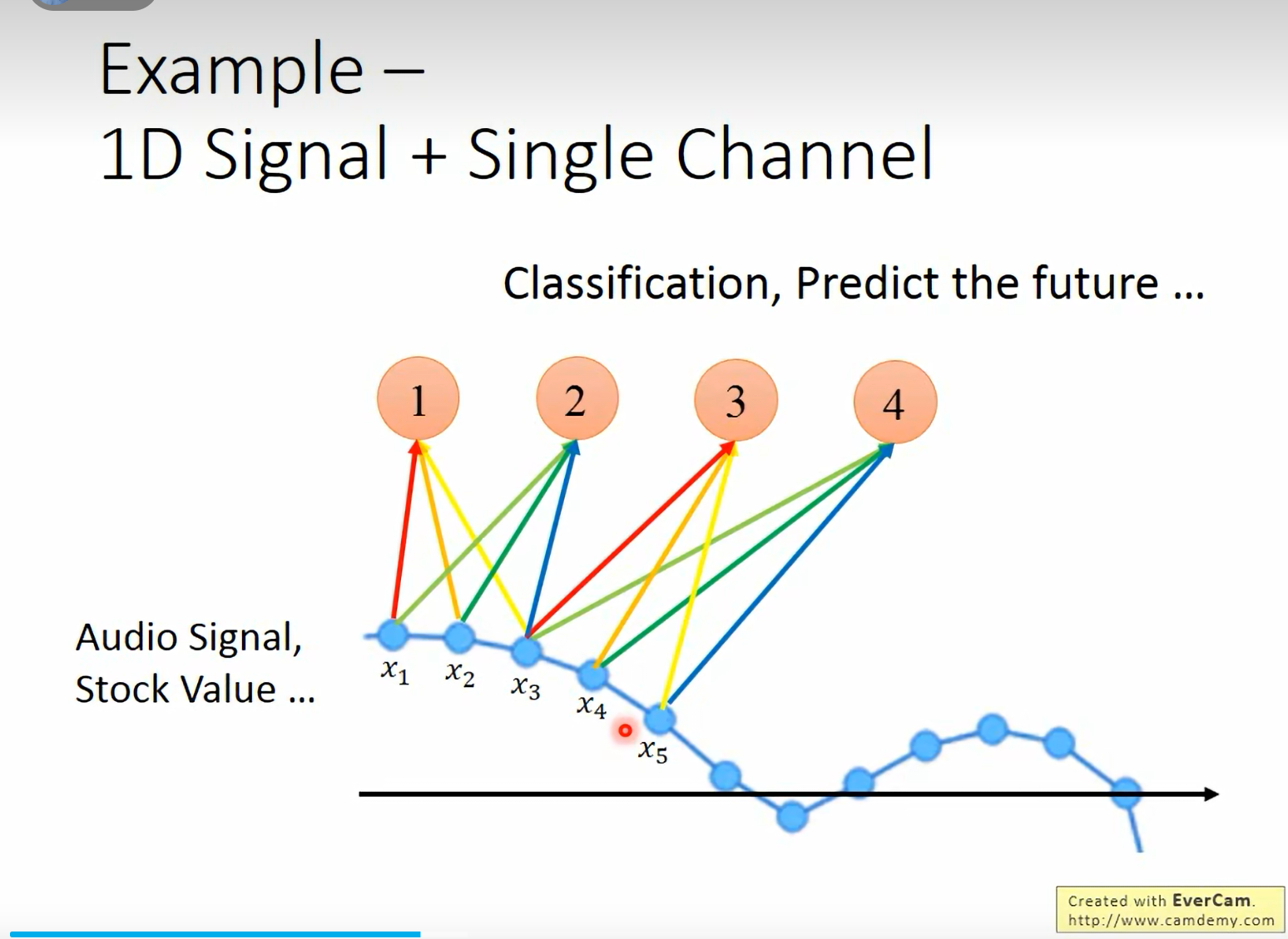
- 输入是一维的时间序列。
- 滤波器在时间轴上滑动。
- 每个神经元的感受野覆盖一小段连续的时间点。
12.2 一维信号 + 多通道 (1D Signal, Multi-Channel)
场景:自然语言处理(NLP)中的文本,每个词被表示为一个向量 (Word Vector)。
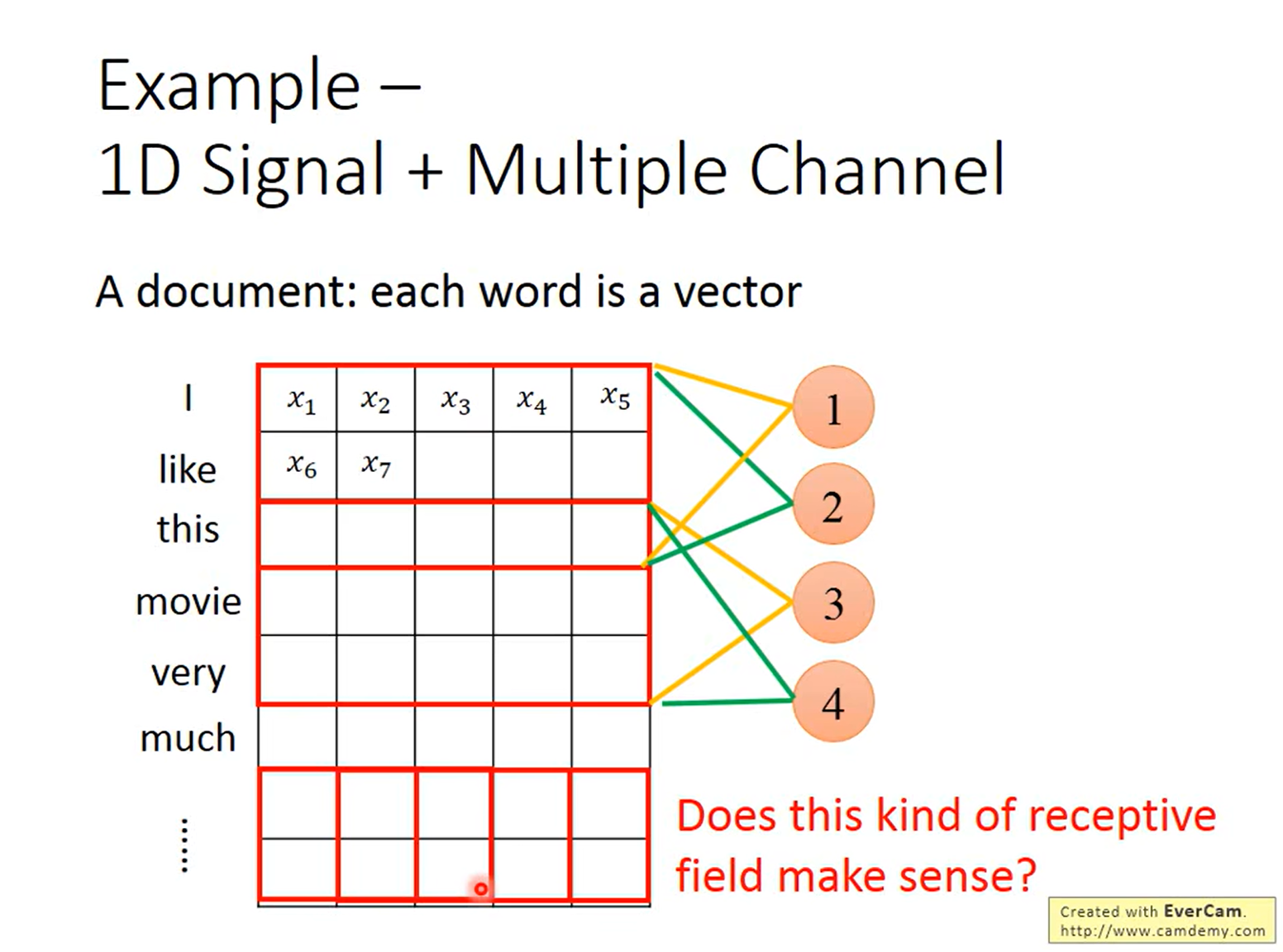
- 结构:文档是一系列词向量。
- 感受野疑问:图中展示的感受野只覆盖了词向量的一部分维度(例如前两维)。
- 思考:Does this kind of receptive field make sense?
- 在 NLP 中,通常我们的卷积核宽度会覆盖 整个词向量的维度 (Full embedding dimension),只在“词序”方向上滑动。因为词向量的内部维度通常是作为一个整体表达语义的,切分维度进行卷积在文本中较少见,但在某些特定的信号处理中可能存在。
12.3 二维信号 + 多通道 (2D Signal, Multi-Channel)
场景:彩色图像 (RGB)。
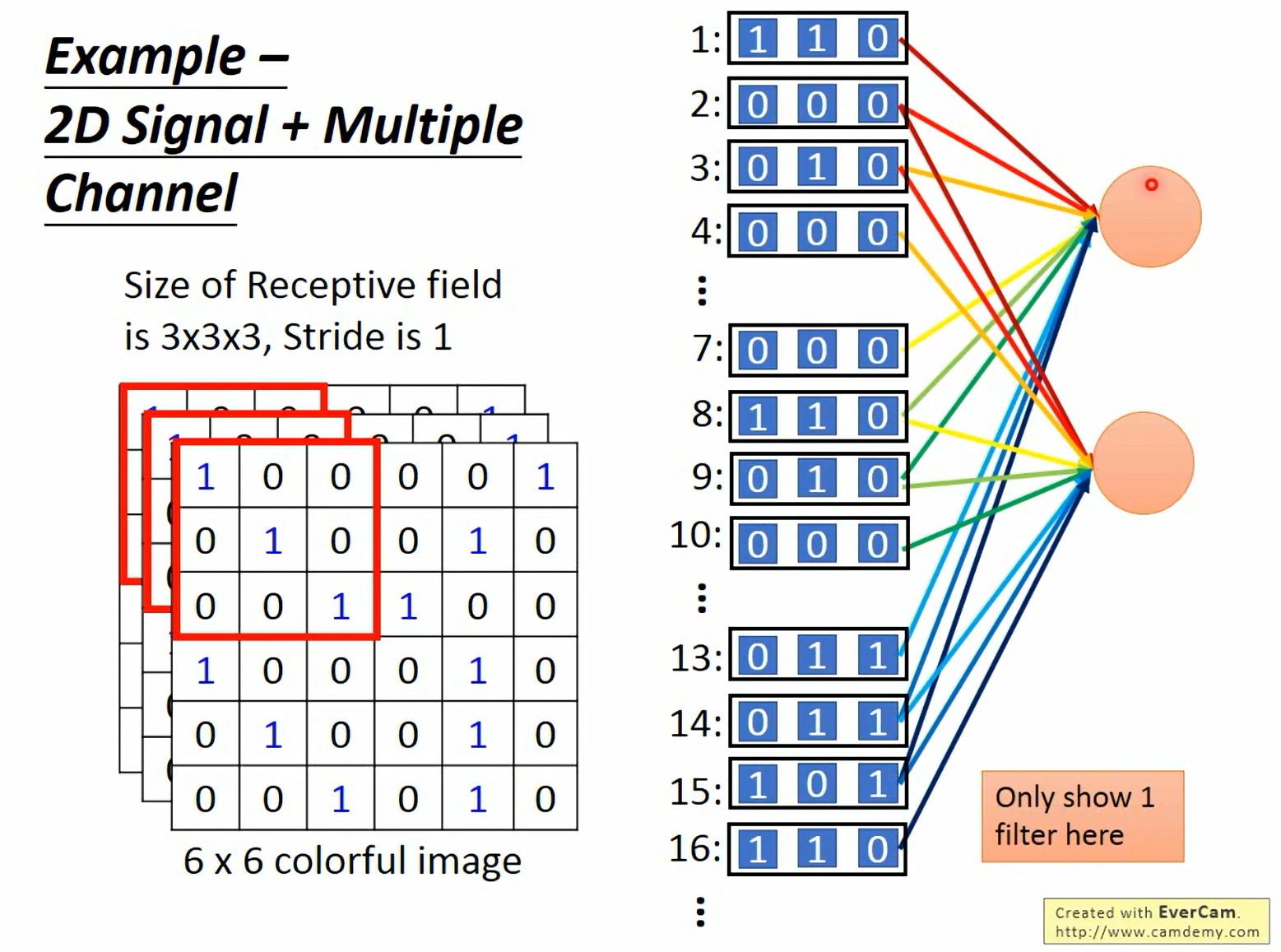
- 输入: 6 × 6 6 \times 6 6×6 的图像,有 3 个通道(RGB)。
- 感受野: 3 × 3 × 3 3 \times 3 \times 3 3×3×3。注意,虽然我们在空间上说是 3 × 3 3 \times 3 3×3,但实际上卷积核的深度必须匹配输入的通道数(这里是 3)。
- 输出:每个 Filter 会生成一张 Feature Map。如果有 2 个 Filter,输出就是 2 个通道。
12.4 零填充 (Zero Padding)
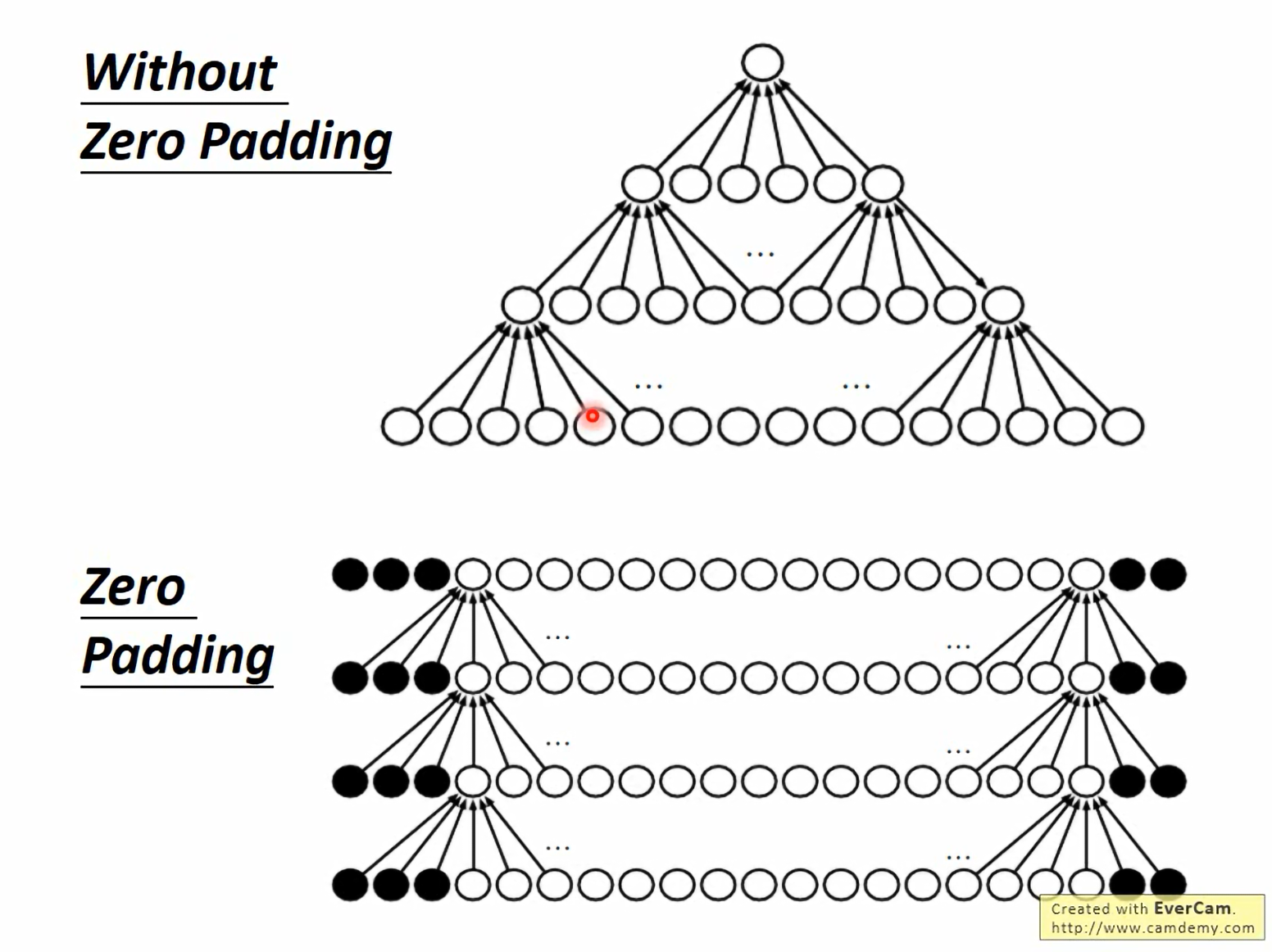
- 不填充 (Without Zero Padding):每次卷积后,特征图尺寸会变小(类似金字塔结构),深层网络会导致信息丢失过快。
- 零填充 (Zero Padding):在输入边缘补 0,使得卷积后的输出尺寸与输入保持一致,有利于构建更深的网络。
13. 基础架构:池化层 (Pooling Layer)
池化层的核心作用是 下采样 (Subsampling),即在保留关键信息的同时减少数据维度。
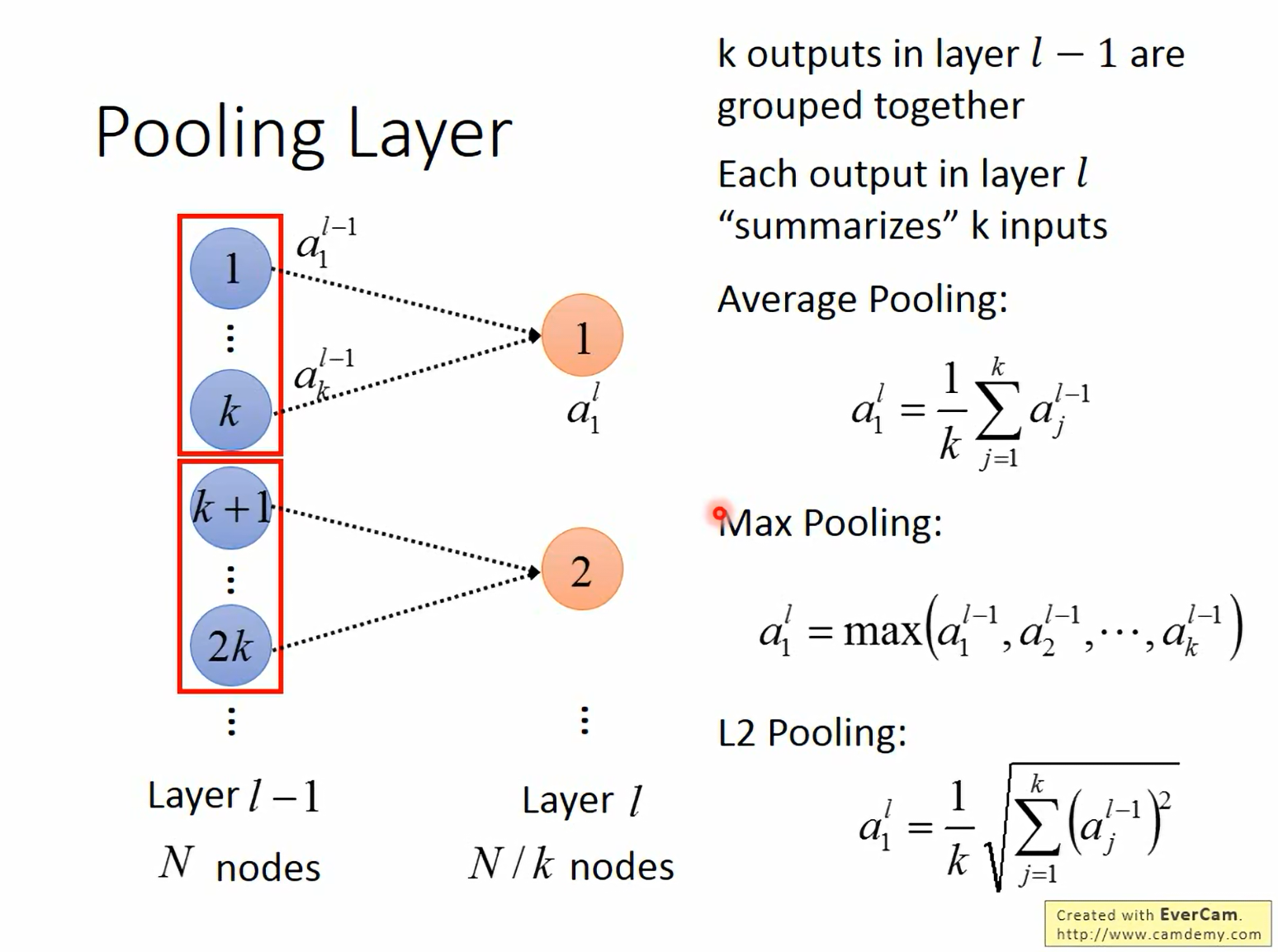
13.1 常见操作
- Max Pooling:取感受野内的最大值。
a 1 l = max ( a 1 l − 1 , a 2 l − 1 , … , a k l − 1 ) a^l_1 = \max(a^{l-1}_1, a^{l-1}_2, \dots, a^{l-1}_k) a1l=max(a1l−1,a2l−1,…,akl−1) - Average Pooling:取感受野内的平均值。
13.2 分组逻辑 (Grouping)
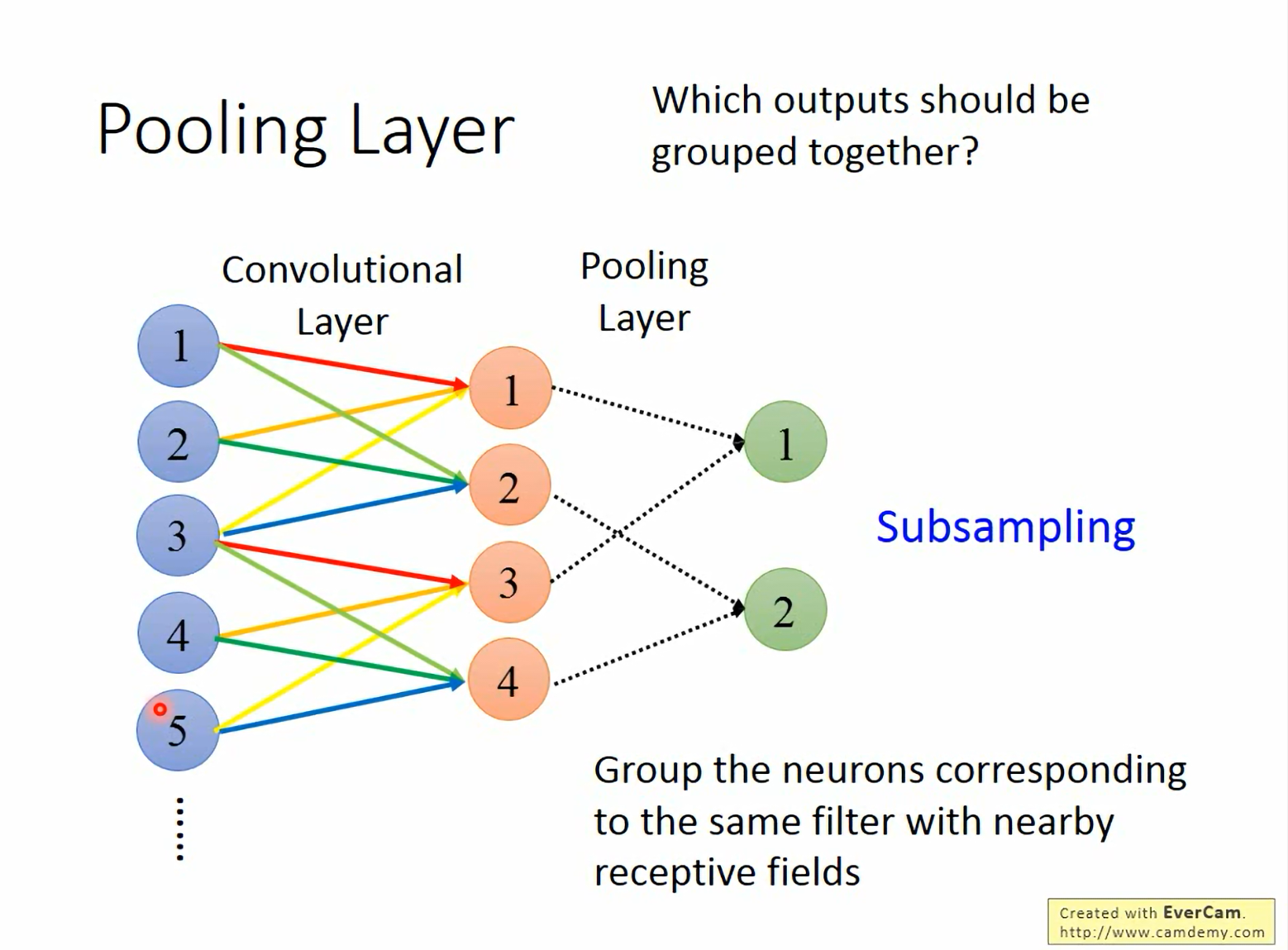
- Pooling 的对象:我们通常将 同一个 Filter 生成的、位置相邻的 输出值归为一组。
- 物理意义:这表示我们要在局部区域内寻找最显著的特征,而不关心它具体的像素级位置(平移不变性)。
13.3 对比:Maxout Network
这是一个容易混淆的概念。
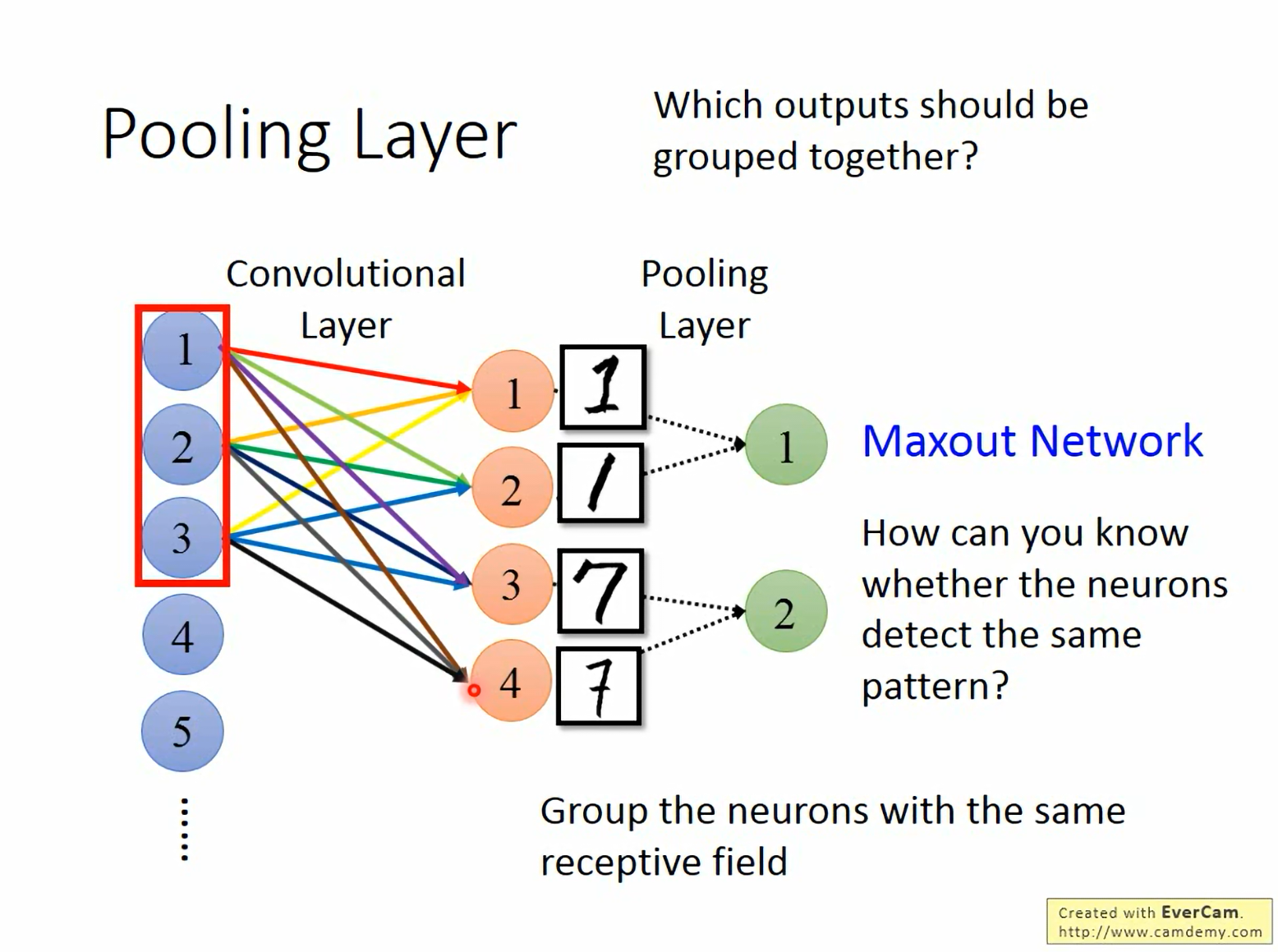
- Pooling Layer:在 Spatial(空间) 维度上操作。
- 分组对象:Same Filter, Nearby Receptive Fields.
- Maxout Network:在 Channel(通道) 维度上操作。
- 分组对象:Same Receptive Field, Different Filters.
- 它是在同一位置上,从不同的 Filter 输出中取最大值。这相当于学习了一种分段线性的激活函数。
14. 综合应用:CLDNN
在实际的高级任务中,我们往往不仅仅使用单一结构,而是将卷积层、LSTM 和全连接层组合使用。这里以 Google 的 CLDNN (Convolutional, Long Short-Term Memory, Deep Neural Network) 为例,该模型用于处理原始音频波形(Raw Waveform)。
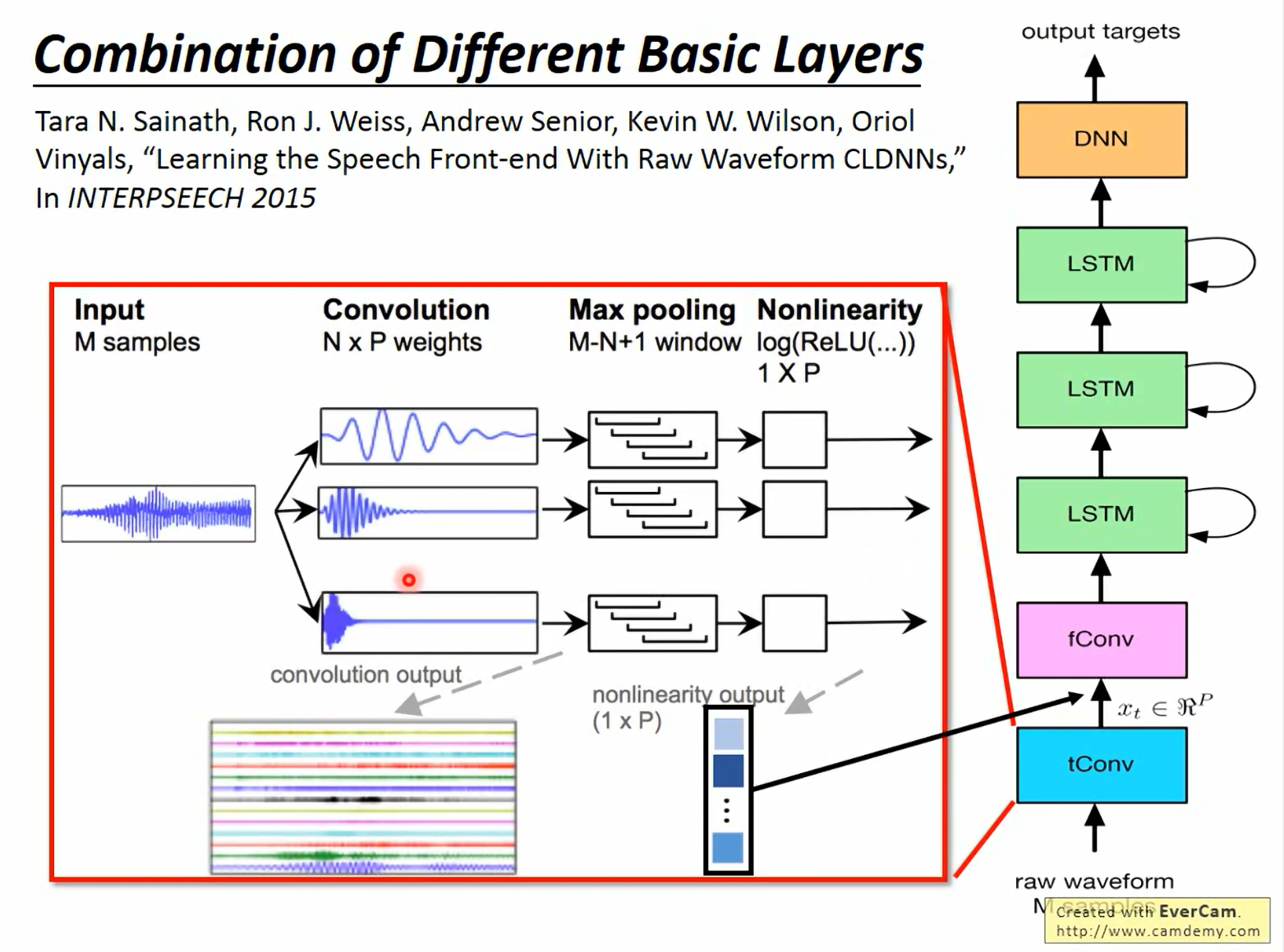
14.1 架构流程
- Input:原始波形 (Raw Waveform),不再是手工提取的 MFCC 特征。
- tConv (Time Convolution):
- 在时间域上进行卷积。
- 作用:相当于一个可学习的滤波器组 (Filter Bank),自动提取频谱特征。
- fConv (Frequency Convolution):
- 在 tConv 输出的“频谱”上,沿着频率轴进行卷积。
- 作用:为了消除不同说话人音高不同带来的影响(频率平移不变性)。
- LSTM:
- 处理 fConv 的输出序列。
- 作用:捕捉长距离的时间依赖关系。
- DNN (Fully Connected):
- 作用:最后的高层特征整合与分类。
14.2 深入理解 fConv
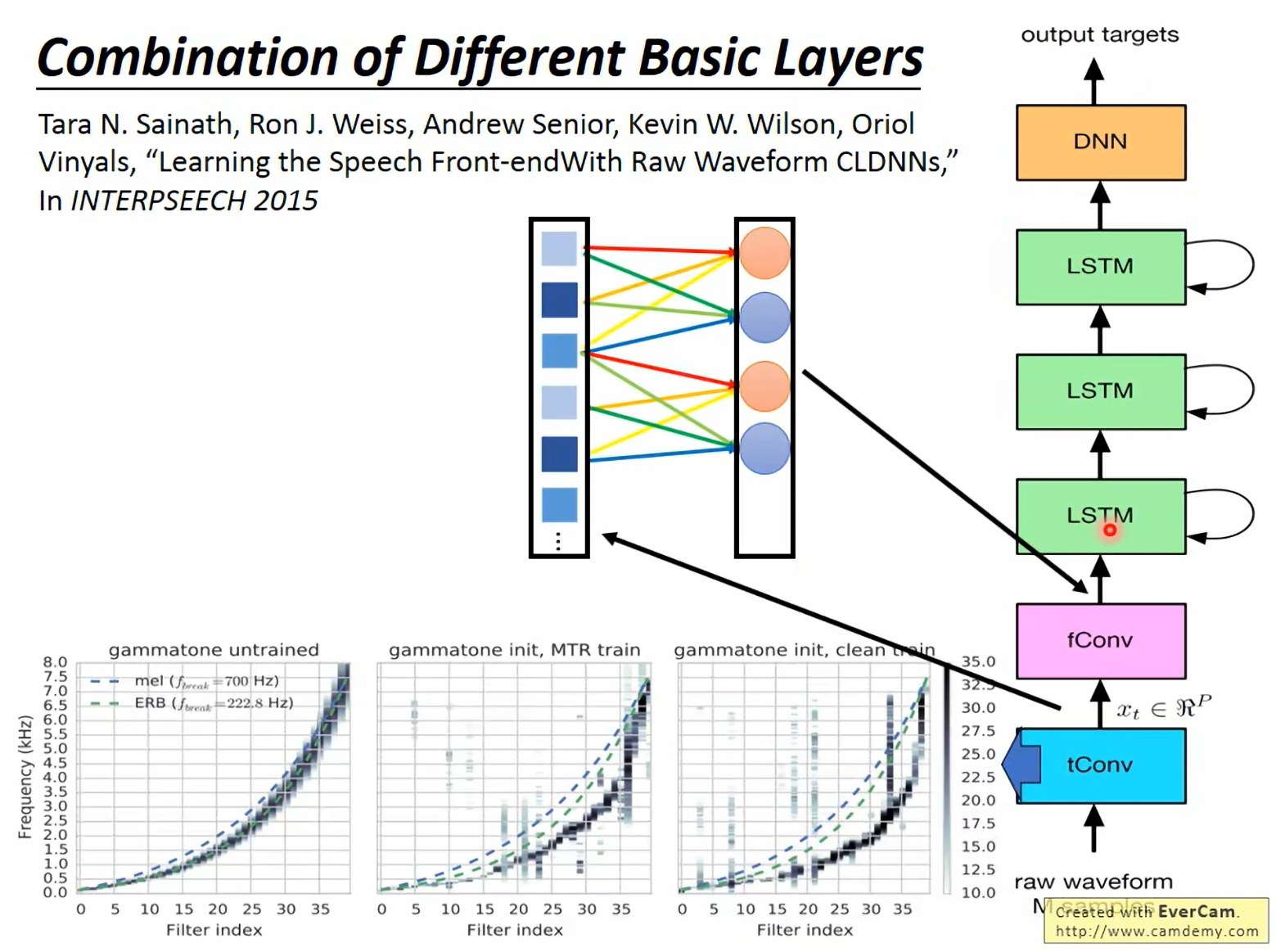
- Frequency Domain:tConv 的输出可以看作是一张声谱图。
- Frequency Convolution:滤波器在频率轴上滑动。这意味着无论通过 tConv 提取的 Formant(共振峰)在哪个频段,fConv 都能将其提取出来。这对于解决 Vocal tract length normalization (VTLN) 问题非常有效。
14.3 完整结构图解
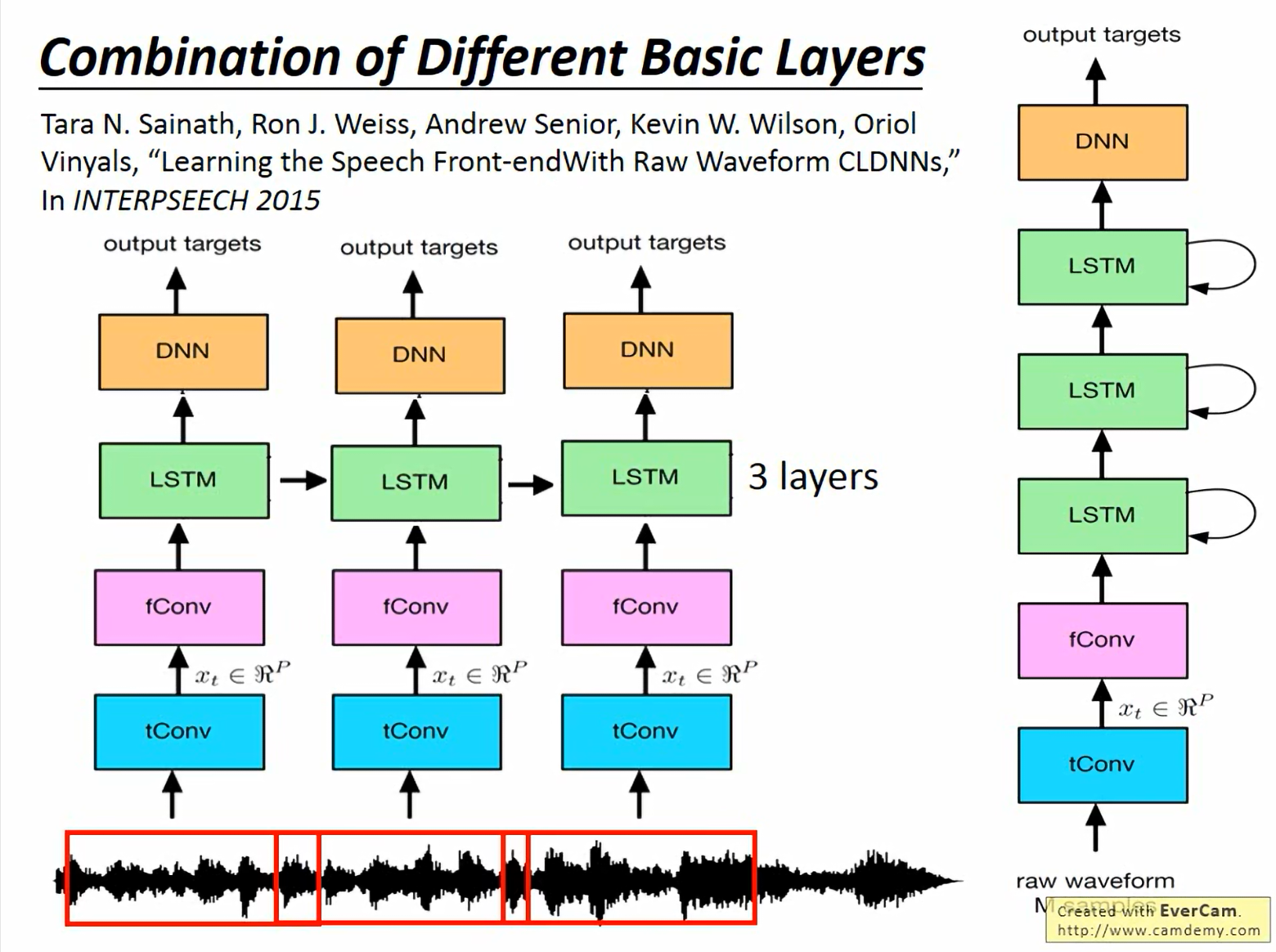
这个复杂的结构展示了深度学习架构设计的精髓:
- 用 Conv 提取局部特征(时域和频域)。
- 用 LSTM 处理序列上下文。
- 用 DNN 进行最终决策。
- Raw Waveform 的输入证明了端到端学习(End-to-End Learning)的潜力:让神经网络自己去学习如何处理声音信号,而不是依赖人工设计的特征。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)