强化学习(Reinforcement Learning)——学习笔记
什么是强化学习(Reinforcement Learning)
强化学习研究的是:智能体(Agent)如何通过与环境(Environment)的交互,在试错中学习一个策略(Policy),以最大化长期累积回报(Reward)。
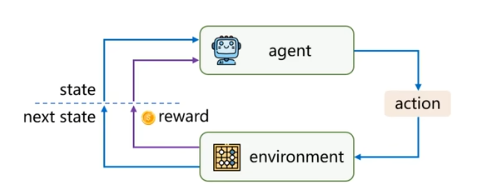
这是一个“做—反馈—再做—再改进”的学习过程。
核心要素(五要素)
| 元素 | 含义 |
|---|---|
| Agent(智能体) | 学习与决策的主体(如机器人、程序) |
| Environment(环境) | 智能体所处的世界 |
| State(状态) | 环境当前的描述 |
| Action(动作) | 智能体可以采取的行为 |
| Reward(奖励) | 环境对动作的反馈(标量) |
强化学习的目标不是“预测对不对”,而是长期奖励最大。
核心目标
强化学习的目标是训练一个策略模型 Pθ(τ),让它在动作空间里,根据当前状态 st 选择动作 at,最终让整个轨迹 τ 的期望回报最大化。
- 轨迹 τ:从游戏开始到结束的一整串 “状态 - 动作” 序列,比如马里奥从左跑到右、跳过坑、吃到金币的全过程。
- 回报 R(τ):这条轨迹上所有奖励的总和,比如吃到金币 + 100,掉坑 - 1000。
三个关键公式
①期望回报公式
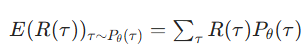
我们要计算在当前策略 Pθ 下,所有可能轨迹的回报乘以其出现概率的总和,也就是平均能拿到多少回报。我们的目标就是让这个平均值尽可能大。
②策略梯度的原始形式
![]()
这里 J(θ) 就是我们要最大化的目标函数(期望回报)。这个公式是在求目标函数对模型参数 θ 的梯度,告诉我们怎么调整参数才能让回报变大。但直接计算这个梯度在实践中非常困难。
③策略梯度的可计算形式(REINFORCE)
![]()
这是最关键的一步,它把难以计算的原始梯度,转化成了可以通过采样来估计的形式:
- 我们先让智能体玩几局游戏,采样出几条轨迹 τ。
- 对每条轨迹,计算它的总回报 R(τ)。
- 然后用这个回报去 “加权” 每一步动作的概率对数梯度 ∇θlogπθ(at∣st)。
- 最后求平均,就得到了梯度的估计值。
- 直观理解:如果一条轨迹的总回报是正的,就 “鼓励” 模型多做这条轨迹里的动作;如果是负的,就 “惩罚” 这些动作。
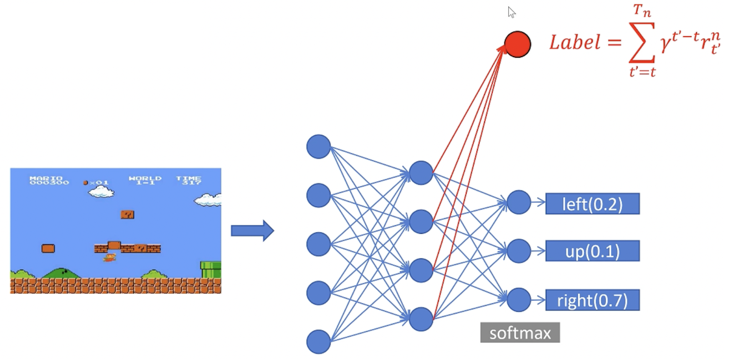
这张图展示了策略模型在大模型或深度学习中的实现方式:
- 输入是当前的游戏画面(状态 st)。
- 经过多层神经网络处理后,输出每个可能动作(left, up, right)的概率。
- 最后通过 softmax 函数,把输出变成合法的概率分布(如 right: 0.7, left: 0.2, up: 0.1),模型就根据这个概率分布来选择下一步动作。
奖励 R(τ) 的作用
R(τ) 是一个标量,我们可以根据实际场景设置它的正负和大小:
- 好动作(如吃到金币):给正的奖励(+10),增加这个动作被采样到的概率。
- 坏动作(如掉坑):给负的奖励(-10),减小这个动作被采样到的概率。
- 这就是强化学习的核心:用奖励信号来引导模型学习。
近端策略优化(PPO)算法
为什么需要 PPO?
传统的策略梯度(PG)算法有一个致命缺点:
每次更新策略时,如果步子太大,模型的行为会发生剧烈波动,甚至直接崩溃。
而且,PG 算法对数据的利用率很低,每次更新都需要重新采样大量新数据。
PPO 的核心改进就是两点:
Clip 约束:限制新策略和旧策略之间的差异,防止更新过度,让训练更稳定。
重要性采样:让新策略可以 “复用” 旧策略采样的数据,大大提升了数据利用率。
公式拆解
①PG 算法的梯度公式
![]()
这是我们上一页见过的策略梯度公式,它直接用轨迹的总回报 R(τ) 来引导策略更新,但容易导致训练不稳定。
②PPO 的目标函数
![]()
这个公式看起来复杂,其实核心就是两部分:
重要性采样
这个比值表示:在当前状态下,新策略采取这个动作的概率,是旧策略的多少倍。通过这个比值,我们就可以用旧策略采样的数据来估计新策略的梯度,从而提升数据利用率。
Clip 约束(蓝色箭头)
这是 PPO 最关键的创新。它把重要性采样的比值限制在 [1−ε,1+ε] 这个小范围内(比如 ε=0.2)。如果比值超过了这个范围,就直接把它 “裁剪” 到边界上。
这样就保证了新策略和旧策略不会相差太远,防止了模型更新过度导致的崩溃。
优势函数
代表在当前状态下,采取这个动作比平均水平 “好” 多少。如果
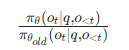
优势函数
意义
优势函数 A(s,a) 回答了一个关键问题:
在状态 s 下,执行动作 a,比 “平均水平” 要好多少?
这里的 “平均水平”,就是由 Critic(评论家)网络 提供的基线(Baseline) V(s),它代表了在状态 s 下,遵循当前策略所能获得的期望未来回报。
- 如果 A(s,a)>0:说明这个动作比平均水平好,策略应该 “鼓励” 它。
- 如果 A(s,a)<0:说明这个动作比平均水平差,策略应该 “避免” 它。
公式
(1)带基线的策略梯度(PG)公式
![]()
- Gt:从时刻 t 开始到轨迹结束的总回报。
- b(st):由 Critic 网络提供的基线,即对状态 st 的价值估计 V(st)。
- Gt−b(st):这就是最原始的优势函数,它减去了基线,消除了与动作好坏无关的 “平均回报” 部分,让梯度更新更聚焦于动作本身的优劣。
(2)PPO 目标函数中的优势 At
![]()
在 PPO 中,我们不再直接用总回报 Gt 减去基线,而是使用更精细的优势估计 At,这能让训练更加稳定。
(3)广义优势估计(GAE)
![]()
这是 PPO 中最常用的优势函数计算方法,通过超参数 λ 在 ** 偏差(Bias)和方差(Variance)** 之间做权衡:
- δtV:称为时序差分误差(TD Error),它是单步的优势估计。
- GAE 通过对未来多步的 TD 误差进行加权求和,得到一个更平滑、方差更小的优势估计。
- 当 λ=1 时,GAE 退化为蒙特卡洛估计,方差大但偏差小;当 λ=0 时,它退化为单步 TD 误差,偏差大但方差小。
PPO 算法中的熵约束
1. 四大核心模型角色
在 PPO 的训练体系中,有四个核心模型各司其职:
- 策略(Policy)模型:我们需要训练的核心模型,负责根据当前状态选择下一步动作。
- 价值(Critic)模型:负责估计未来的期望收益,为优势函数提供基线。
- 奖励(Reward)模型:负责对模型的每一步输出给出即时的奖励或惩罚信号。
- 参考(Reference)模型:作为 “锚点”,限制策略模型更新时偏离预设的行为规范(如人类偏好)太远,防止模型跑飞。
2. PPO 目标函数回顾
![]()
这个公式通过clip操作限制了新策略与旧策略的差异,是 PPO 训练稳定的基础。
3. KL 散度(熵约束)公式
![]()
- KL 散度:衡量两个概率分布之间的 “距离” 或 “差异”。在这里,它衡量的是策略模型 π 和参考模型 πref 在同一状态下动作分布的差异。
- 约束目的:确保新策略 π 不会偏离参考策略 πref 太远。这可以让模型在学习新的、更好的策略时,仍然遵守既定的行为规范(例如,保持符合人类偏好的对话风格),从而实现更稳定的学习。
作用
- 防止跑飞:通过 KL 散度约束,策略模型的更新被限制在参考模型附近,避免了因过度优化而导致的行为崩坏(如熵崩溃)。
- 稳定训练:它与 PPO 的 clip 约束相辅相成,共同构成了训练过程中的 “安全网”,让模型在探索和利用之间取得更好的平衡。
强化学习如何迁移到大模型?
- 强化学习场景:在一次完整的轨迹(Trajectory)中,智能体根据之前的动作(Action),不断生成下一个动作,直到达到终点。
- 大模型场景:在一次文本采样(Sampling)中,大模型根据之前生成的 Token,不断生成下一个 Token,直到输出完整的内容。
| 强化学习概念 | 大模型对应概念 |
|---|---|
| 智能体 (Agent) | 大模型本身 |
| 动作空间 (Action Space) | 模型的词表库(Vocabulary) |
| 动作选择 (Action Selection) | 下一个 Token 的选择(Next token prediction) |
| 状态 (State) | 模型目前已经输出的所有 Token(Context) |
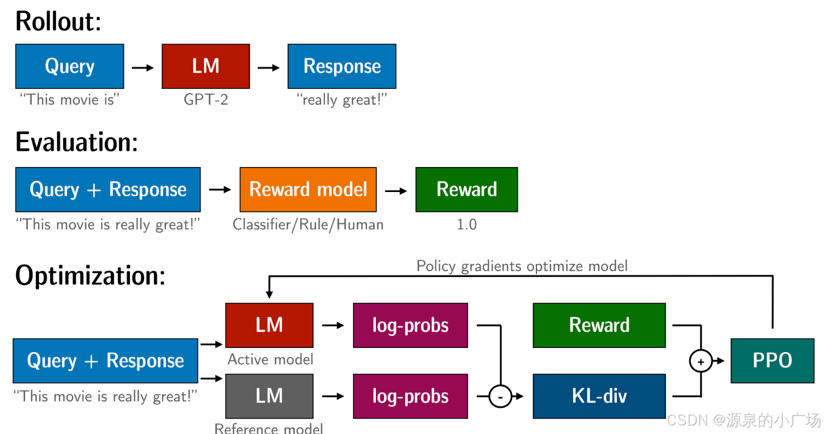
大模型PPO的流程,采样(Rollout)即生成token的过程,每生成一个token,奖励模型会对其进行评价,同时参考模型会约束防止走偏,最后输出完价值模型给出最终奖励。
PPO缺点:涉及流程太复杂,还需要额外训练一个奖励函数和价值函数,价值函数需要专门构建数据集。
GRPO
1. 核心改进
GRPO 保留了 PPO “限制更新幅度” 的思想,但做了两个关键简化:
-
绝对奖励 → 相对排序
- PPO:依赖奖励模型给出的绝对分数(如 0.8、0.9)。
- GRPO:不再关心绝对分数,而是对同一查询下生成的多个回复进行组内排序,用相对好坏来引导学习。
-
Critic 网络 → 组内统计量
- PPO:需要单独训练一个 Critic 网络来估计价值函数,计算优势。
- GRPO:直接用组内奖励的均值和标准差来计算相对优势,彻底抛弃了 Critic 网络。
2. 优势函数的计算
GRPO 的优势函数定义为:
![]()
- ri:第 i 条生成结果的奖励。
- mean(r):同一组内所有生成结果的奖励均值。
- std(r):同一组内所有生成结果的奖励标准差。
这个公式的含义是:衡量某条生成结果的奖励,比组内平均水平 “好” 或 “差” 了多少个标准差。这样做的好处是:
- 消除了不同批次、不同奖励尺度的影响,让训练更稳定。
- 完全不需要 Critic 网络,大幅降低了训练成本和复杂度。
3. GRPO 目标函数
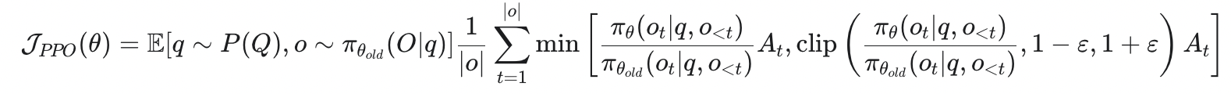
流程:一次采样,critic模型和reward模型算出优势A, policy模型和ref模型算出重要性采样值和熵惩罚,进行优化
这个公式可以拆解为三部分:
- 重要性采样:
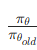 ,用于复用旧策略的数据。
,用于复用旧策略的数据。 - Clip 约束:和 PPO 一样,限制策略更新的幅度,防止训练崩溃。
- KL 散度惩罚:
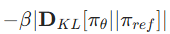 ,确保新策略不会偏离参考策略太远,保持行为一致性。
,确保新策略不会偏离参考策略太远,保持行为一致性。
优势函数:不再需要critic模型计算期望收益,直接通过计算组内的每条输出的奖励进行相对奖励
流程:多次采样,采样结果根据reward函数或者模型得到组内相对优势, policy模型和ref模型算出重要性采样值和熵惩罚,进行优化
GRPO应用的前提是有明确的奖励方式,无论是策略性的奖励函数reward function或者训练好的奖励模型reward model。所以GRPO 的设计使其特别适用于以下几类对齐任务
1)具备可靠奖励信号的领域 奖励模型(RM)可用:如数学推理(MATH)、代码生成(HumanEval)、常识问答(BoolQ)等已有成熟 RM 的任务; 可程序化评估:如答案正确性、格式合规性、执行通过率等可自动打分的指标; 组合奖励设计:通过多维度奖励(如逻辑性 + 简洁性 + 安全性)缓解 Reward Hacking。
(2)需要模型探索多样解法的任务 开放性推理:如多步数学证明、算法设计、科学解释等,存在多种合理路径; 创意生成:如故事续写、广告文案、诗歌创作,需在约束下保持多样性; 错误修正与反思:结合反思机制(如 SRPO),模型可学习自我诊断与迭代优化。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)