特征提取太6了!高效涨点!17种深度学习特征提取改进方法全面汇总
为了帮助大家更高效地选择适合的特征提取方法,快速提升模型效果,或者为寻找研究方向提供灵感,我精心整理了17种前沿的改进方法,并附上了每种方法的原文和源码。这些方法涵盖了多个技术流派,包括基于卷积神经网络(CNN)的方法、基于Transformer的方法、基于patch的方法以及基于图神经网络(GNN)的方法等,内容全面且实用。特征提取作为人工智能领域的一项关键技术。尤其是随着深度学习的兴起,这一领
·
特征提取作为人工智能领域的一项关键技术。无论是提升模型性能、降低计算复杂度、增强可解释性,还是让数据更好地适配各种学习算法,特征提取都扮演着不可或缺的角色。
尤其是随着深度学习的兴起,这一领域发生了翻天覆地的变化,传统的手工设计特征方法逐渐被智能化、自适应化的提取方式所取代,各种创新改进层出不穷。
为了帮助大家更高效地选择适合的特征提取方法,快速提升模型效果,或者为寻找研究方向提供灵感,我精心整理了17种前沿的改进方法,并附上了每种方法的原文和源码。这些方法涵盖了多个技术流派,包括基于卷积神经网络(CNN)的方法、基于Transformer的方法、基于patch的方法以及基于图神经网络(GNN)的方法等,内容全面且实用。
一、Domain Generalization for Activity Recognition via Adaptive Feature Fusion
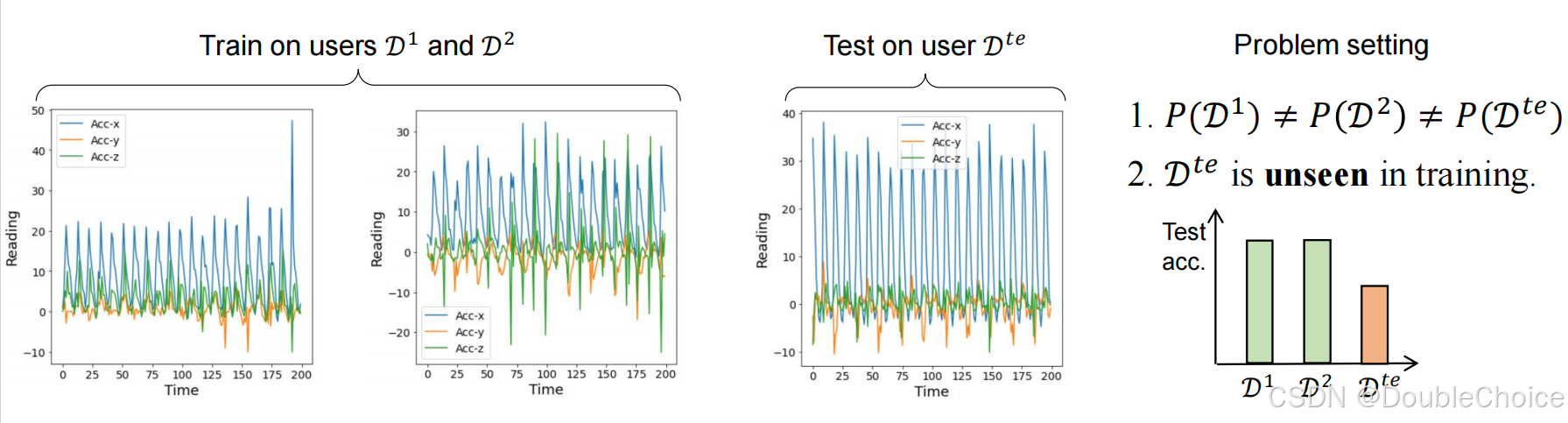
1.方法
自适应特征融合方法
1. 核心思想
-
同时学习领域不变特征和领域特定特征,通过动态融合增强模型泛化能力。 -
领域不变特征:捕捉跨领域可迁移的通用知识。 -
领域特定特征:保留各领域独特信息,防止特征退化。
2. 关键模块
-
特征提取模块:共享的卷积层提取底层特征。 -
领域特定表示模块:为每个领域设计独立的全连接层,学习领域特有特征。 -
领域不变表示模块:通过最大均值差异对齐不同领域的特征分布。 -
自适应融合模块:利用域分类器生成权重,动态融合不同领域的特征。
3. 损失函数设计
-
总损失函数: -
分类损失( ):交叉熵损失。
-
领域特定损失( ):域分类器的交叉熵损失。
-
领域不变损失( ):MMD距离最小化跨领域分布差异。
-
4. 训练与推理
-
训练时:多领域数据联合优化,通过域分类器生成各领域权重。 -
推理时:基于目标数据特征自动计算领域权重,融合各领域特征进行预测。
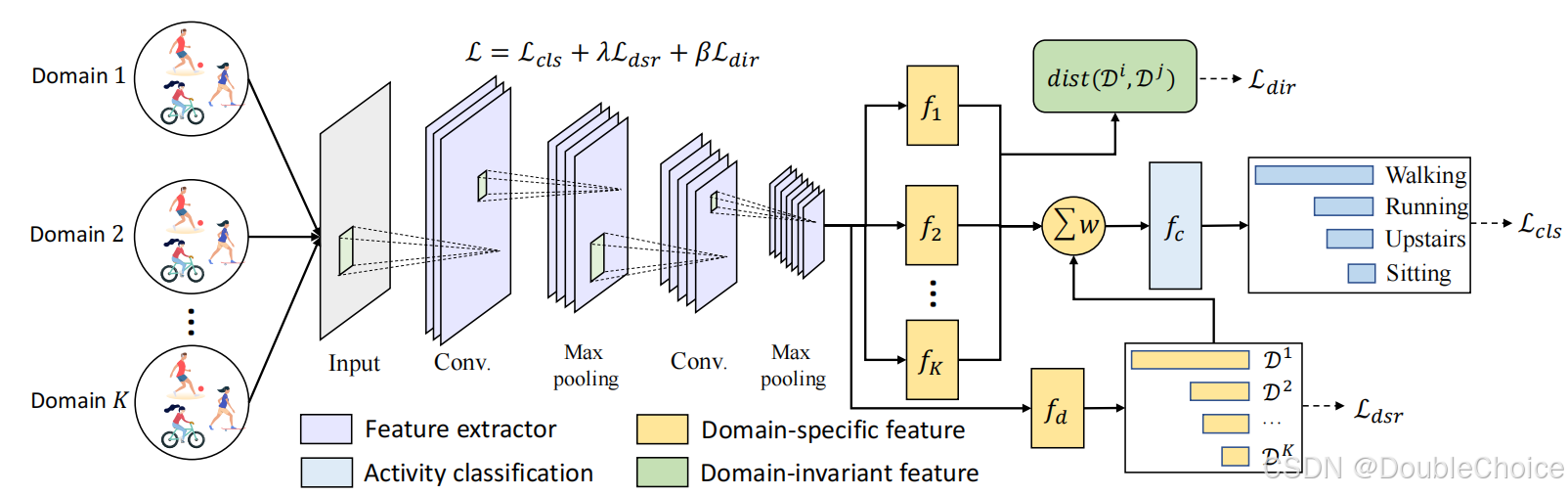
2.创新点
1. 问题定义创新
-
首次提出领域泛化活动识别问题,强调在训练阶段无法访问测试领域数据的实际场景,区别于传统领域适应和迁移学习。
2. 方法创新
-
双路径特征学习:同时建模领域不变与领域特定特征,克服单一特征表示的局限性。 -
动态特征融合机制:通过域分类器自适应调整各领域权重,实现目标领域特征的灵活组合。 -
可扩展的分布对齐:支持MMD、CORAL、对抗训练等多种分布对齐方法,框架通用性强。
3. 理论支持
-
基于领域泛化风险上界理论,证明领域特定学习最小化加权源风险,领域不变学习降低跨领域分布差异,双路径设计符合理论最优性。
4. 应用验证
-
在公开HAR数据集(DSADS/USC-HAD/PAMAP2)上平均F1提升 -
成功应用于ADHD儿童诊断,验证方法在医疗健康场景的有效性,分类精度提升2.44%。
5. 工程贡献
-
开源代码实现端到端训练,相比基线模型推理时间仅增加0.05ms,兼顾效率与性能。 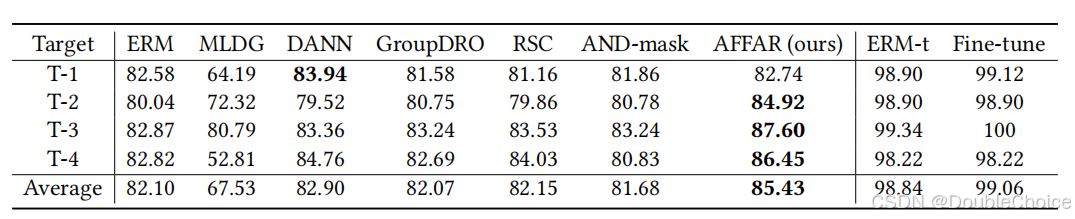
论文链接:https://arxiv.org/abs/2207.11221
Large-scale Contrastive Language-Audio Pretraining with Feature Fusion and Keyword-to-CaptionAugmentation
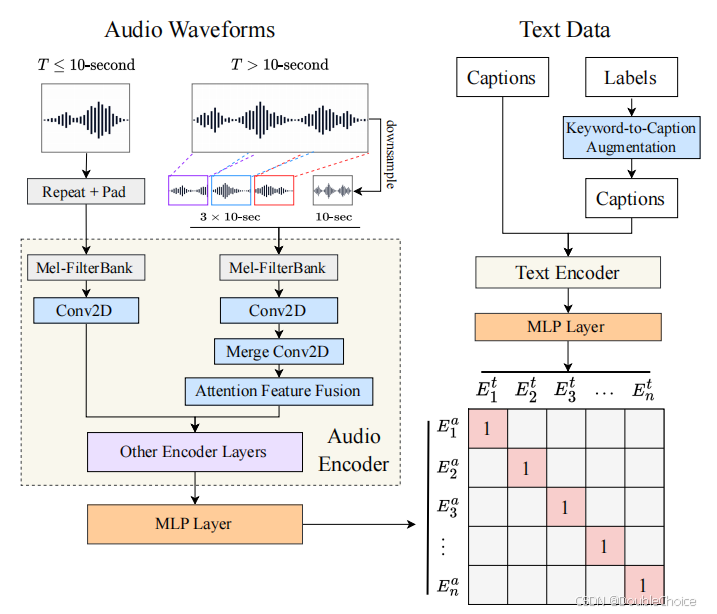
1.方法
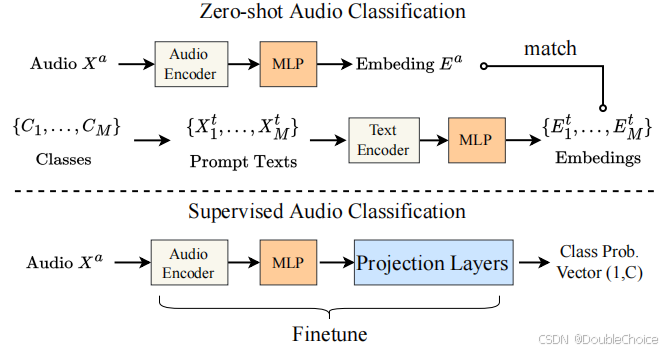
1. 对比学习语言-音频预训练框架
-
采用双编码器架构:音频编码器与文本编码器并行处理多模态输入 -
通过对比损失函数对齐音频-文本嵌入空间 -
引入两层MLP投影层将不同模态特征映射到统一维度
2. 特征融合机制
-
开发分层次特征处理架构处理变长音频: -
短音频采用重复填充策略 -
长音频通过下采样获取全局特征,随机切片获取局部特征 -
使用注意力特征融合模块动态结合全局-局部特征
-
3. 关键词到描述的增强技术
-
基于T5模型将原始标签扩展为自然语言描述 -
加入去偏置处理 -
构建模板化文本提示实现零样本分类
4. 多阶段训练策略
-
采用渐进式数据扩展:从55K到630K再到250万样本 -
混合使用专业音频数据集与网络爬取数据 -
支持不同粒度的监督信号
2.创新点
1. 数据集创新
-
发布当前最大公开音频-文本数据集LAION-Audio-630K -
整合8个异构数据源,涵盖4325小时音频 -
提出关键词到描述的自动化标注增强流程
2. 模型架构创新
-
首创音频领域的特征融合机制,突破传统固定长度输入限制 -
验证transformer-based音频编码器在对比学习中的优越性 -
开发动态温度参数学习策略优化对比损失尺度
3. 训练方法创新
-
实现跨数据集联合训练范式 -
提出分阶段渐进式扩展训练策略 -
开发高效的长音频处理方案
4. 应用创新
-
首次在音频领域实现零样本分类的SOTA性能 -
验证对比学习特征在监督任务中的迁移优势 -
建立多任务评估基准 -
在文本到音频检索任务中指标提升18.7% 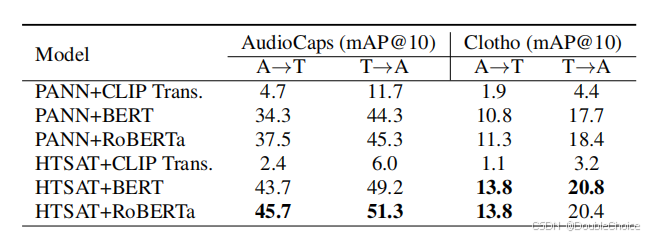
论文链接:https://arxiv.org/abs/2211.06687

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)