探索基于强化学习的自适应PID参数控制方法
基于强化学习的自适应PID参数控制方法该模型使用matlab运行,DDPG算法框架控制,可以将模型换成自己的,做强化学习控制器仿真。在控制系统的领域里,PID控制犹如一位默默坚守的老将,一直以来都发挥着重要作用。然而,传统PID参数一旦设定,在面对复杂多变的工况时,往往就显得力不从心。而借助强化学习来实现自适应的PID参数控制,无疑为这一经典控制策略注入了新的活力。
基于强化学习的自适应PID参数控制方法 该模型使用matlab运行,DDPG算法框架控制,可以将模型换成自己的,做强化学习控制器仿真。
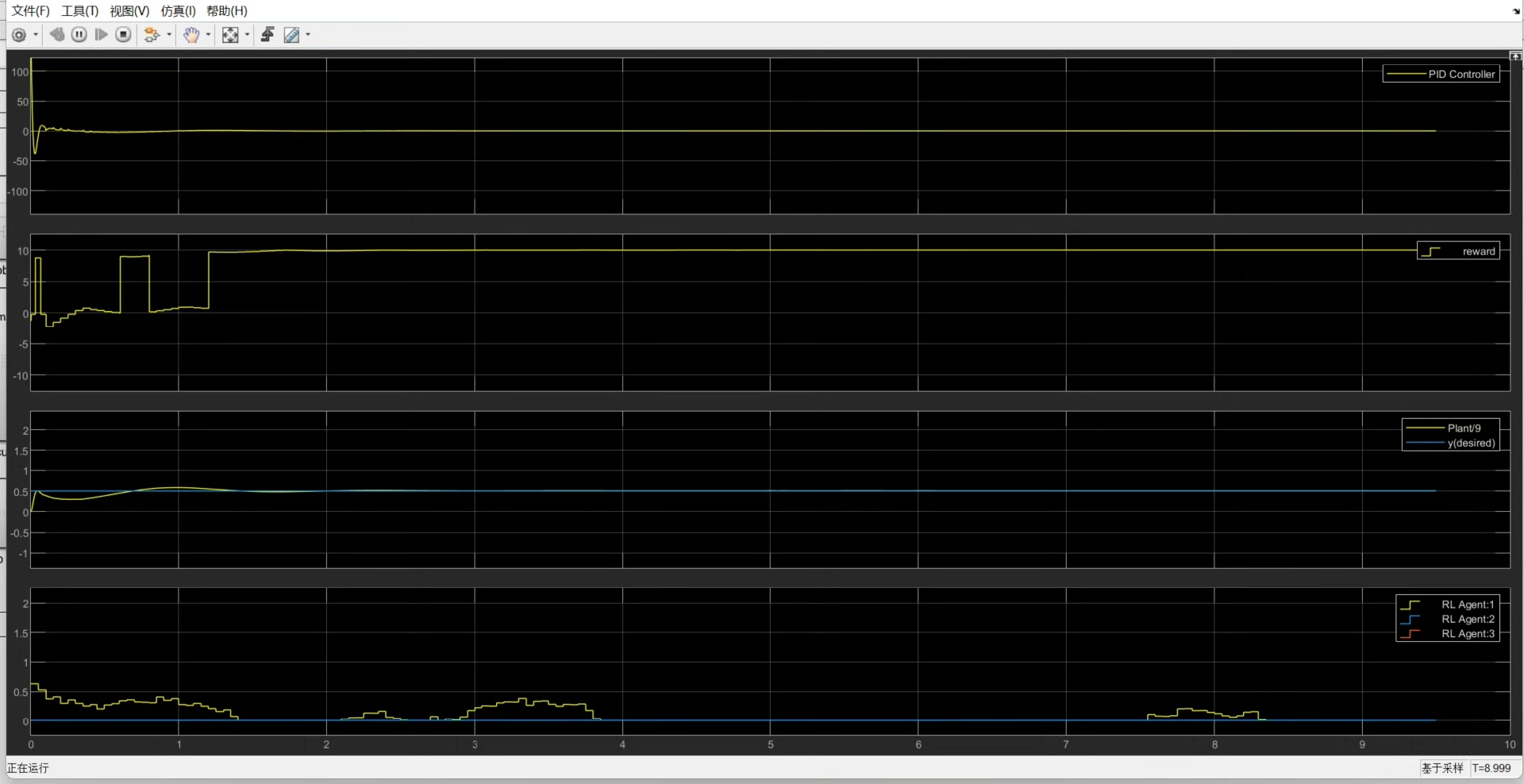
在控制系统的领域里,PID控制犹如一位默默坚守的老将,一直以来都发挥着重要作用。然而,传统PID参数一旦设定,在面对复杂多变的工况时,往往就显得力不从心。而借助强化学习来实现自适应的PID参数控制,无疑为这一经典控制策略注入了新的活力。
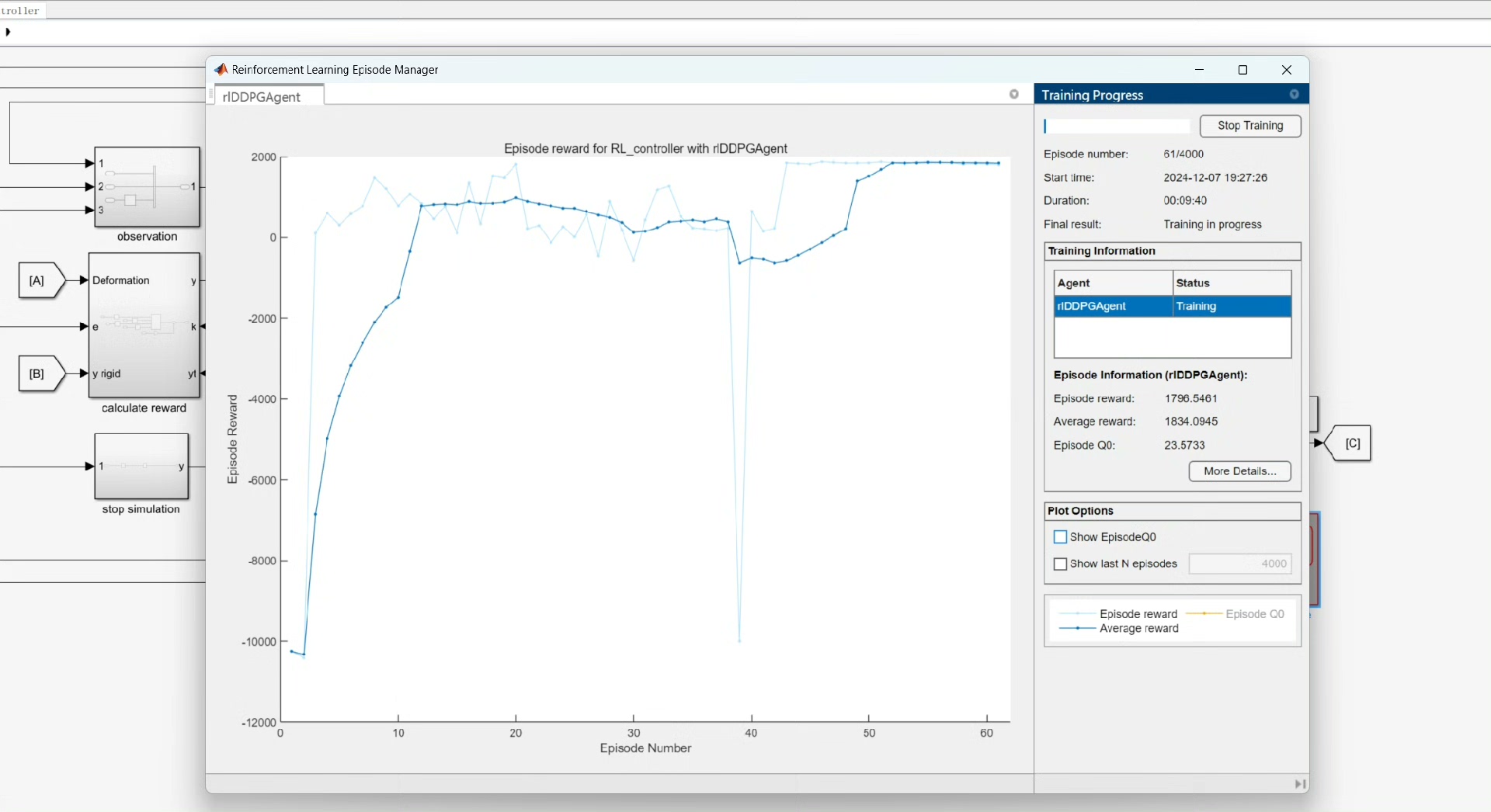
本文将探讨基于强化学习,特别是以DDPG算法框架为基础,在Matlab环境下运行的自适应PID参数控制方法,并且还会提及将模型替换为自定义模型,进行强化学习控制器仿真的相关内容。
DDPG算法框架与PID控制的结合
DDPG(Deep Deterministic Policy Gradient)是一种适用于连续动作空间的强化学习算法,它结合了深度神经网络强大的函数逼近能力和确定性策略梯度的高效性。在自适应PID参数控制场景中,我们可以把PID控制器的三个参数Kp(比例系数)、Ki(积分系数)、Kd(微分系数)当作可调整的动作,通过强化学习让智能体学习到最优的参数组合,以适应不同的系统状态。
Matlab代码实现示例
下面是一个简单的Matlab代码框架,展示如何基于DDPG实现自适应PID参数控制(此处为简化示意,实际应用需更完善细节):
% 初始化环境参数
env = rlFunctionEnv(@envFunction);
% envFunction为自定义的环境函数,用于定义系统状态、奖励等
% 定义智能体结构
actorOpts = rlRepresentationOptions('LearnRate',1e-4);
criticOpts = rlRepresentationOptions('LearnRate',1e-3);
agent = ddpgAgent(env,actorOpts,criticOpts);
% 训练智能体
maxepisodes = 100;
maxsteps = 1000;
trainingOpts = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'Verbose',false,...
'Plots','training-progress');
trainResults = train(agent,env,trainingOpts);代码分析
- 环境初始化:
rlFunctionEnv(@envFunction)创建了一个基于自定义函数envFunction的强化学习环境。在这个函数里,我们需要明确系统的状态变量,比如当前的误差、误差变化率等,以及根据当前状态给予智能体的奖励值。奖励函数的设计至关重要,它要能够引导智能体朝着优化PID参数,使系统达到更好控制效果的方向学习。例如,如果系统输出更接近目标值,那么奖励可以设置为较大的正数,反之则给予负数奖励。 - 智能体结构定义:
actorOpts和criticOpts分别设置了演员网络(负责生成动作,即PID参数)和评论家网络(负责评估动作价值)的学习率。学习率决定了智能体在学习过程中参数更新的步长,合适的学习率能够保证智能体既不会因为更新过快而错过最优解,也不会因为更新过慢而导致学习效率低下。 - 训练智能体:
train函数启动了智能体的训练过程。MaxEpisodes和MaxStepsPerEpisode分别设定了最大训练 episodes 数和每个 episode 的最大步数。在训练过程中,智能体不断与环境交互,根据环境反馈的奖励来调整自身策略,逐渐学习到最优的PID参数控制策略。
模型替换与强化学习控制器仿真
在实际应用中,我们可能需要将现有的模型替换为自己的模型进行强化学习控制器仿真。这其实并不复杂,关键在于确保新模型能够提供与强化学习算法兼容的接口。
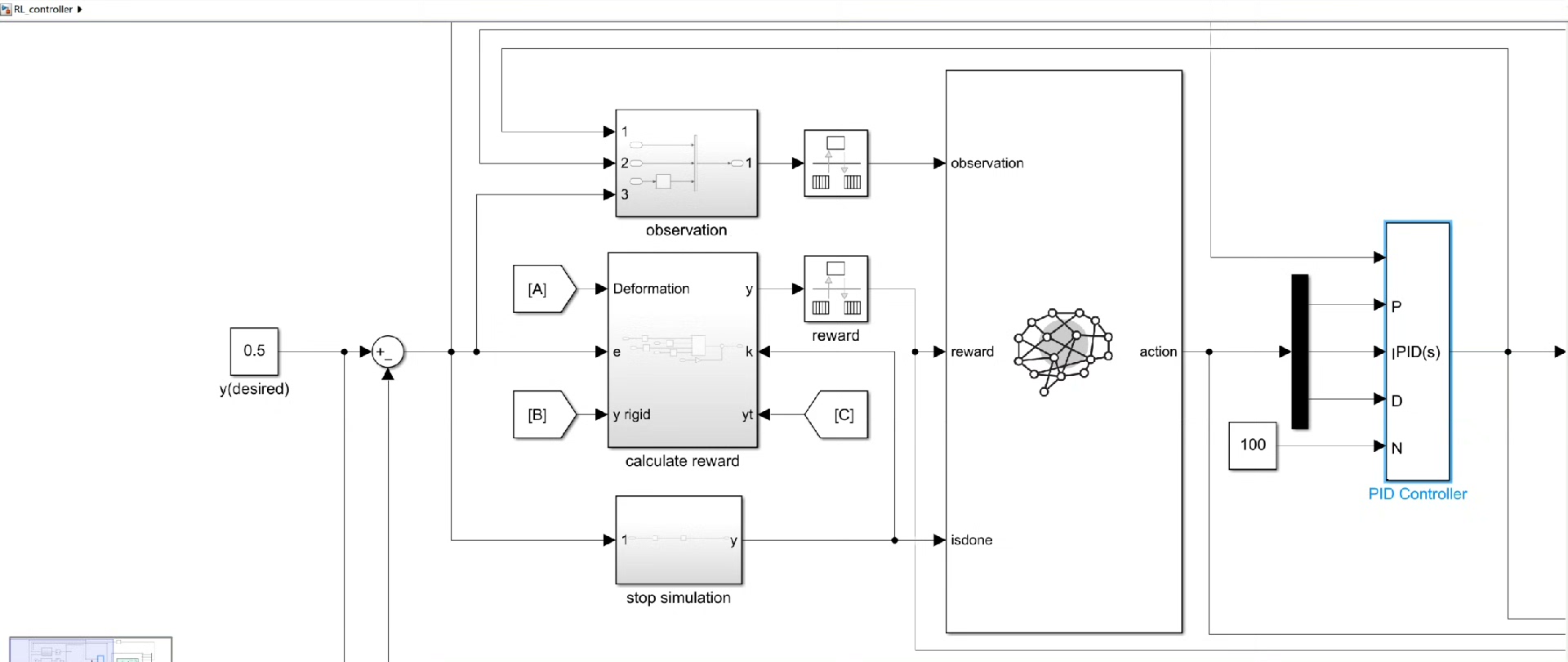
假设我们有一个自定义的动态系统模型,其状态转移方程和输出方程与原模型不同。我们首先需要修改 envFunction 函数,使其能够根据新模型的特性正确计算状态转移和奖励。例如,如果新模型的状态变量维度发生了变化,那么我们在 envFunction 中获取和处理状态变量的代码也需要相应调整。
function [state, reward, done] = envFunction(state, action)
% 假设新模型有不同的状态转移方程
new_state = new_state_transition(state, action);
% new_state_transition为自定义的新模型状态转移函数
% 根据新模型计算奖励
reward = calculate_reward(new_state);
% calculate_reward为自定义的基于新模型状态计算奖励的函数
% 判断是否结束当前episode
done = check_termination(new_state);
% check_termination为自定义的判断结束条件函数
state = new_state;
end代码分析
- 状态转移:
newstatetransition函数实现了自定义模型的状态转移逻辑。它接收当前状态state和智能体采取的动作action(即PID参数),并返回新的状态。这部分代码需要根据新模型的数学描述精确实现,以保证强化学习能够基于正确的系统动态进行学习。 - 奖励计算:
calculate_reward函数根据新模型的状态计算奖励值。与前面提到的类似,奖励函数要紧密结合新模型的控制目标,鼓励智能体学习到对新模型有效的PID参数。 - 结束条件判断:
check_termination函数用于判断当前episode是否应该结束。这可能基于新模型的某些特定条件,比如系统是否达到稳定状态,或者是否超出了允许的误差范围等。
通过以上步骤,我们就能够基于强化学习实现自适应PID参数控制,并灵活地替换模型进行强化学习控制器仿真,为各种复杂系统的控制提供更智能、更有效的解决方案。
希望本文的内容能为你在相关领域的研究和实践提供一些启发,让我们一起在强化学习与控制工程结合的道路上不断探索前行!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 28
28 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)