基于强化学习的PMSM磁场定向控制:RL - TD3的卓越表现
基于强化学习的PMSM磁场定向控制这是关于双延迟深度确定性强化学习策略提取(RL-TD3)在速度与电流控制上的优越性与鲁棒性研究国外SCI-paper模型复现,完全可以二次改进与参考适合高校本科与研究生参考学习在电机控制领域,永磁同步电机(PMSM)因其高效、节能等优点被广泛应用。而磁场定向控制作为PMSM的经典控制策略,不断地在新技术的融入下得到优化。
基于强化学习的PMSM磁场定向控制 这是关于双延迟深度确定性强化学习策略提取(RL-TD3)在速度与电流控制上的优越性与鲁棒性研究 国外SCI-paper模型复现,完全可以二次改进与参考 适合高校本科与研究生参考学习
在电机控制领域,永磁同步电机(PMSM)因其高效、节能等优点被广泛应用。而磁场定向控制作为PMSM的经典控制策略,不断地在新技术的融入下得到优化。今天咱们就来聊聊基于强化学习的PMSM磁场定向控制,尤其是双延迟深度确定性强化学习策略提取(RL - TD3)在速度与电流控制上展现出的优越性与鲁棒性。
RL - TD3:为何是它?
深度确定性策略梯度(DDPG)是强化学习中的重要算法,但它在面对复杂环境时存在一些稳定性问题。RL - TD3就是为了解决这些问题而诞生。TD3引入了双延迟机制,有效提高了算法的稳定性和收敛性,这使得它在PMSM的速度与电流控制这种复杂任务中表现出色。
速度与电流控制的实现
咱们先来看速度控制部分的代码示例(以Python和PyTorch框架为例):
import torch
import torch.nn as nn
import torch.optim as optim
# 定义策略网络
class PolicyNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, action_dim)
def forward(self, state):
x = torch.relu(self.fc1(state))
x = torch.relu(self.fc2(x))
action = torch.tanh(self.fc3(x))
return action
# 定义价值网络
class ValueNetwork(nn.Module):
def __init__(self, state_dim, action_dim):
super(ValueNetwork, self).__init__()
self.fc1 = nn.Linear(state_dim + action_dim, 256)
self.fc2 = nn.Linear(256, 256)
self.fc3 = nn.Linear(256, 1)
def forward(self, state, action):
x = torch.cat([state, action], 1)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
value = self.fc3(x)
return value
# 假设状态维度和动作维度
state_dim = 10
action_dim = 2
policy = PolicyNetwork(state_dim, action_dim)
target_policy = PolicyNetwork(state_dim, action_dim)
value1 = ValueNetwork(state_dim, action_dim)
value2 = ValueNetwork(state_dim, action_dim)
target_value1 = ValueNetwork(state_dim, action_dim)
target_value2 = ValueNetwork(state_dim, action_dim)
policy_optimizer = optim.Adam(policy.parameters(), lr=3e - 4)
value1_optimizer = optim.Adam(value1.parameters(), lr=3e - 4)
value2_optimizer = optim.Adam(value2.parameters(), lr=3e - 4)在这段代码里,我们定义了策略网络PolicyNetwork和价值网络ValueNetwork。策略网络根据输入的状态输出一个动作,这里通过多层全连接神经网络来实现。价值网络则是评估状态 - 动作对的价值,将状态和动作连接起来作为输入,经过几层全连接层输出一个价值。
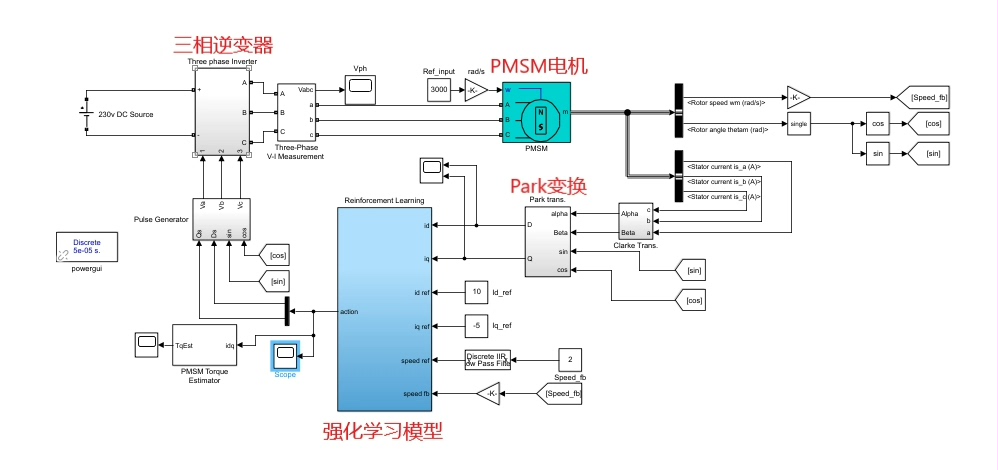
在电流控制方面,思路类似,但状态和动作的定义会有所不同,需要根据电流控制的具体需求来调整网络结构和参数。
优越性与鲁棒性体现
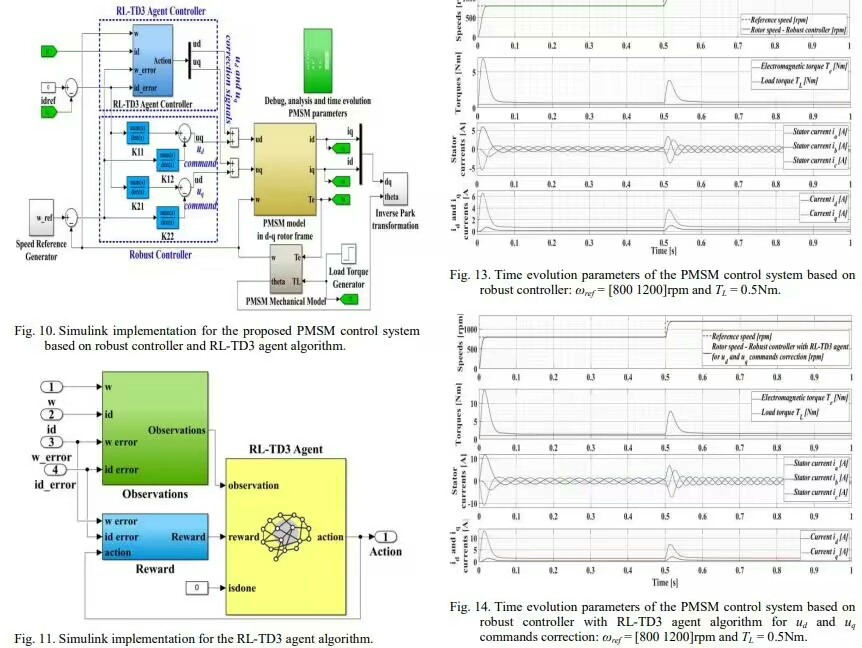
RL - TD3在PMSM速度与电流控制上的优越性体现在它能够更快地收敛到较好的控制策略。相比于传统控制方法,它不需要精确的电机模型,能够自适应地学习到最优控制策略。
基于强化学习的PMSM磁场定向控制 这是关于双延迟深度确定性强化学习策略提取(RL-TD3)在速度与电流控制上的优越性与鲁棒性研究 国外SCI-paper模型复现,完全可以二次改进与参考 适合高校本科与研究生参考学习
鲁棒性则表现在面对电机参数变化、负载扰动等情况时,RL - TD3依然能够保持较好的控制性能。比如说,当电机的转动惯量突然变化,传统控制方法可能会出现较大的波动,而RL - TD3通过不断学习,可以快速调整控制策略,维持稳定的速度和电流输出。
国外SCI - paper模型复现及拓展
这次研究是基于国外SCI论文模型的复现。这不仅为我们提供了一个验证算法有效性的机会,而且完全可以在此基础上进行二次改进。对于高校本科和研究生来说,这是一个绝佳的学习与实践素材。通过复现模型,可以深入理解强化学习在PMSM控制中的应用原理,掌握相关算法的实现细节。
而二次改进则可以从很多方面入手,比如尝试不同的网络结构、调整超参数,甚至结合其他控制算法进一步提升性能。这不仅能加深对知识的理解,还可能创造出更优秀的控制策略。
总之,基于强化学习的PMSM磁场定向控制,尤其是RL - TD3算法,为电机控制领域带来了新的活力,值得大家深入研究和探索。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)