深度学习学习笔记
1、由于L1 Loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他loss中作为约束。2、在[-1,1]区间之外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题。1、在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑的问题。2、L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值。3、L用来衡量真实值y与预测值y'之间的差异性的损失结果。Smooth L1
Day10
二分类任务损失函数
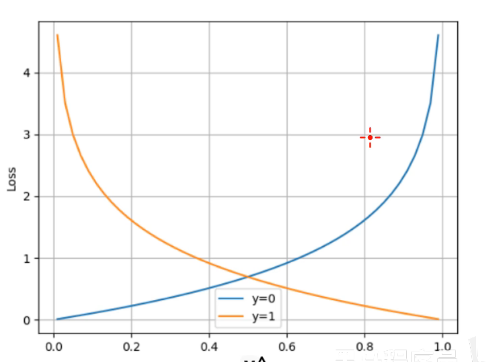
在处理二分类任务时,我们不再使用softmax激活函数,而是使用sigmoid激活函数,那损失函数也相应的进行调整,使用二分类的交叉熵损失函数:
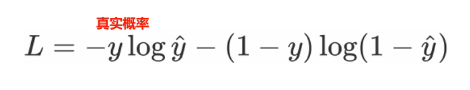
其中:
1、y是样本x属于某一个类别的真实概率(0或1)
2、y'是样本属于某一类别的概率预测
3、L用来衡量真实值y与预测值y'之间的差异性的损失结果。
在pytorch中实现时使用nn.BCELoss()
"""
案例:
演示二分类任务的损失函数
二分类任务的损失函数(BCELoss)
公式:
Loss=-ulog(预测值)-(1-y)log(1-预测值)
细节:
因为公式中没有包含Sigmoid激活函数,所以使用BCELoss的时候,还需要手动指定SIgmoid
"""
import torch
import torch.nn as nn
#1、定义函数:演示二分类任务的损失函数
def dm01():
#1、设置真实值
y_true=torch.tensor([0,1,0],dtype=torch.float)
#2、设置预测值
y_pred=torch.tensor([0.6901,0.5423,0.2639])
#3、创建二分类交叉熵损失函数
criterion=nn.BCELoss()
#4、计算损失
loss=criterion(y_pred,y_true)
print(loss)
if __name__ == '__main__':
dm01()回归任务损失函数—MAE损失函数
Mean absolute loss(MAE)也被称为L1 Loss,是以绝对误差作为距离。损失函数公式:
MAE——>L1Loss 误差绝对值之和 的平均数 L1:权重为0
MSE——>MSELoss 误差平方的 平均数 L2:权重趋近于0
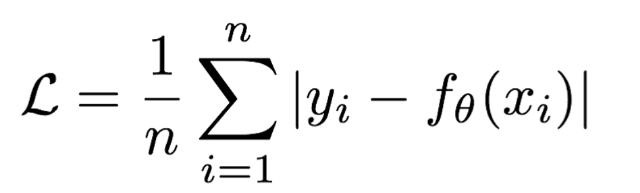
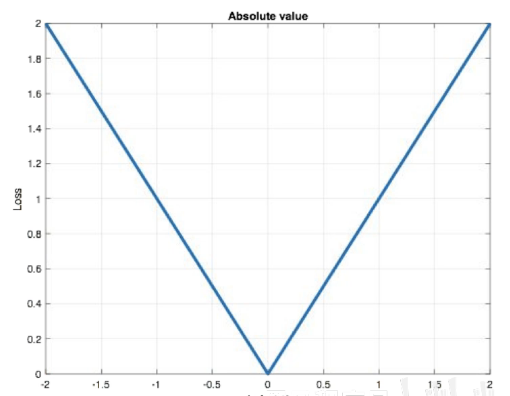
特点是:
1、由于L1 Loss具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他loss中作为约束
2、L1 loss的最大问题是梯度在零点不平滑,导致会跳过极小值
MSE损失函数
Mean Squared Loss/Quadratic Loss(MSE Loss)也被称作L2 loss,或者欧式距离,它是以误差的平方和的均值作为距离损失函数公式:
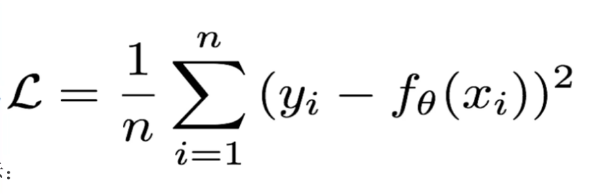
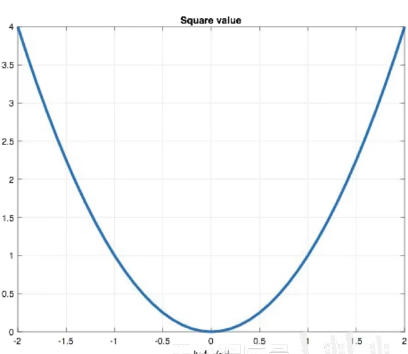
图像为:
特点是:
1、L2 loss也常常作为正则项
2、当预测值于目标值相差很大时,梯度容易爆炸
回归任务损失函数—Smooth L1损失函数
Smooth L1说的是光华之后的L1。损失函数公式:
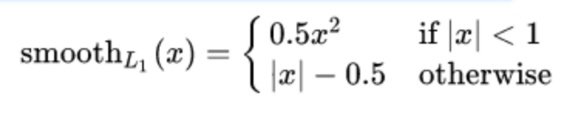
其中:x=f(x)-y为真实值和预测值的差值
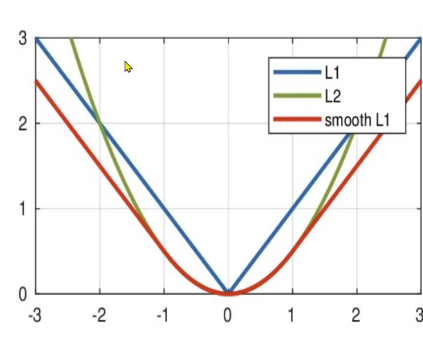
从右图可以看出,该函数实际上是一个分段函数
1、在[-1,1]之间实际上就是L2损失,这样解决了L1的不光滑的问题
2、在[-1,1]区间之外,实际上就是L1损失,这样就解决了离群点梯度爆炸的问题
"""
案例:
演示 回归任务的损失函数的介绍
回归任务常用损失函数如下:
MEA: Mean Absolute Error,平均绝对误差
公式
误差绝对值之和/样本总数
类似于L1正则化,权重可以降维0,数据会变得稀疏
弊端:
在0点不平滑,可能错过最小值
MSE:Mean Squared Error,均方误差
公式:
误差平方之和 / 样本总数
弊端:
如果误差过大,可能存在梯度爆炸情况 W新=W旧-学习率*梯度
Smooth L1:
就是基于MAE和MSE的综合:在[-1,1]是L2(MSE),其他段是L1
这样既解决了L1不平滑问题(0点不可导,可能错过最小值)
又解决了L2(MSE)的 梯度爆炸问题
"""
from importlib.metadata import requires
import torch
import torch.nn as nn
#1、定义函数,演示:MAE损失函数
def dm01():
#1、设置真实值
y_true=torch.tensor([2.0,2.0,2.0],dtype=torch.float)
#2、设置预测值
y_pred=torch.tensor([1.0,1.0,1.9],requires_grad=True)
#3、创建MAE损失函数对象
criterion=nn.L1Loss()
# criterion=nn.MSELoss()
# criterion=nn.SmoothL1Loss()
#4、计算损失
loss=criterion(y_pred,y_true)
print(loss)
#2、定义函数,演示MSE损失函数
def dm02():
#1、设置真实值
y_true=torch.tensor([2.0,2.0,2.0],dtype=torch.float)
#2、设置预测值
y_pred=torch.tensor([1.0,1.0,1.9],requires_grad=True)
#3、创建MAE损失函数对象
#criterion=nn.L1Loss()
criterion=nn.MSELoss()
# criterion=nn.SmoothL1Loss()
#4、计算损失
loss=criterion(y_pred,y_true)
print(loss)
#3、定义函数,演示:Smooth L1损失函数
def dm03():
#1、设置真实值
y_true=torch.tensor([2.0,2.0,2.0],dtype=torch.float)
#2、设置预测值
y_pred=torch.tensor([1.0,1.0,1.9],requires_grad=True)
#3、创建MAE损失函数对象
#criterion=nn.L1Loss()
#criterion=nn.MSELoss()
criterion=nn.SmoothL1Loss()
#4、计算损失
loss=criterion(y_pred,y_true)
print(loss)
#4、测试
if __name__ == '__main__':
dm03()
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)