本地安装部署vllm并运行大模型
本文详细介绍了在WSL2环境下部署vLLM运行大语言模型的完整流程。首先需要具备NVIDIA显卡(≥4GB显存)并安装Python和WSL2。主要步骤包括:1)安装Miniconda并创建Python3.10虚拟环境;2)安装WSL2专用CUDA12.1工具包;3)通过conda安装vLLM框架;4)从魔搭社区下载Qwen3.5-0.8B模型;5)启动API服务并进行测试。整个过程涉及环境配置、依
·
一、前置条件
1、NVIDIA 独立显卡(笔记本 / 台式都行)
2、显存 ≥ 4GB(能跑小模型)
3、安装python(参考我的文章:用Python生成二维码)
4、可以进入Windows下的WSL2(参考我的文章:小龙虾OpenClaw本地部署(一):前置软件安装中的三)
二、在 WSL2 内安装 Miniconda
简介:Miniconda 是 Anaconda 的轻量级发行版,核心作用是跨平台、跨语言的包与环境管理器,专为 Python 等项目设计,主打环境隔离与依赖解析。
目的:创建并激活虚拟环境(避免python版本带来的冲突)
1、进入WSL2命令窗口,输入下面命令:
# 1. 下载Miniconda安装包(Linux版)
mkdir -p ~/miniconda3
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O ~/miniconda3/miniconda.sh
# 2. 执行安装(全程默认,最后输入yes确认)
bash ~/miniconda3/miniconda.sh -b -u -p ~/miniconda3
# 3. 初始化conda(让终端识别conda命令)
source ~/miniconda3/bin/activate
conda init bash
# 4. 重启终端(或执行source命令生效)
source ~/.bashrc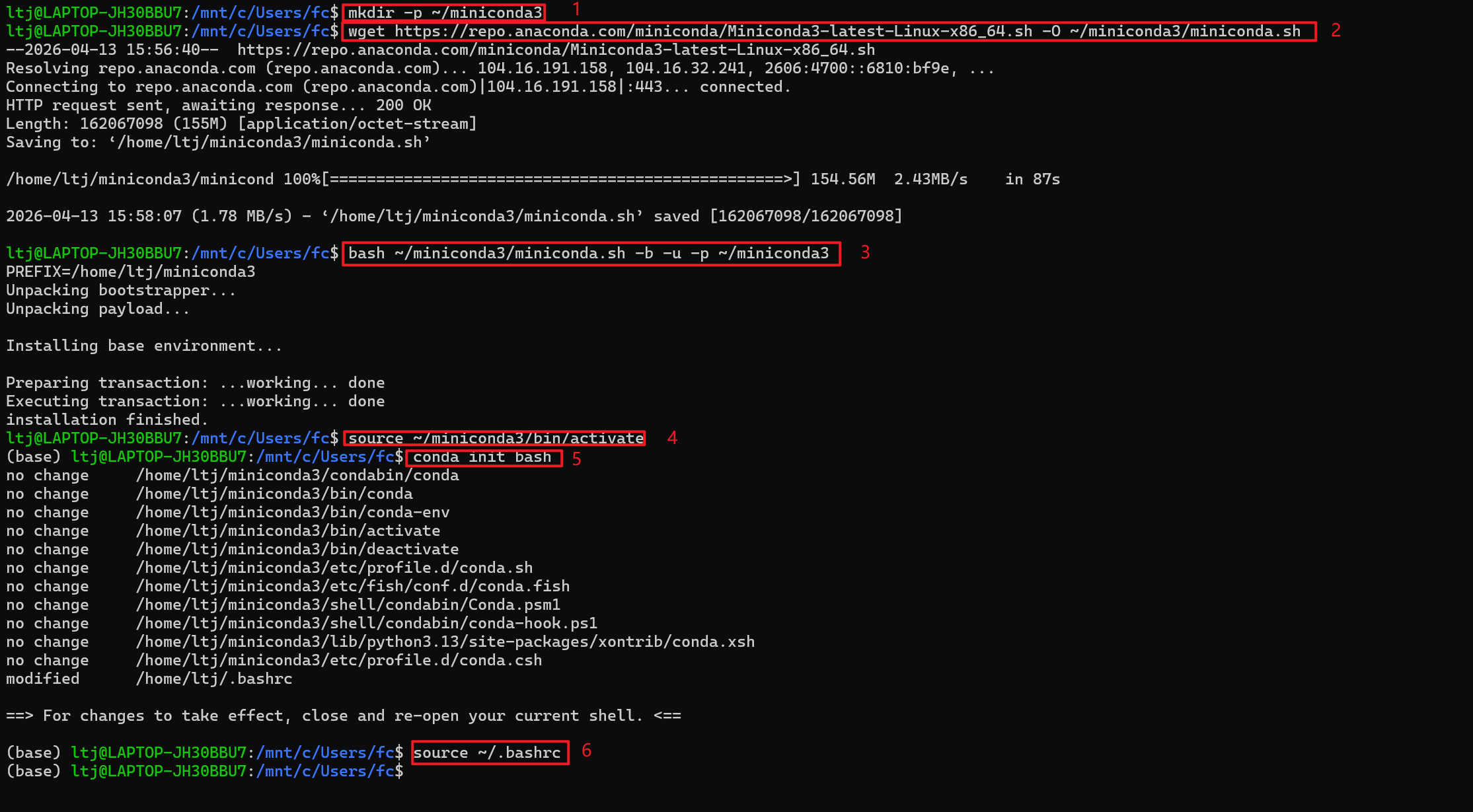
2、验证Miniconda是否安装成功
conda --version![]()
3、创建并激活虚拟环境
①先接受服务条款(避免报错)
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
②创建vllm 的python环境(vLLM 仅支持 Python 3.9 ~ 3.11,3.10和3.11最稳定、兼容性最好)
conda create -n vllm python=3.10 -y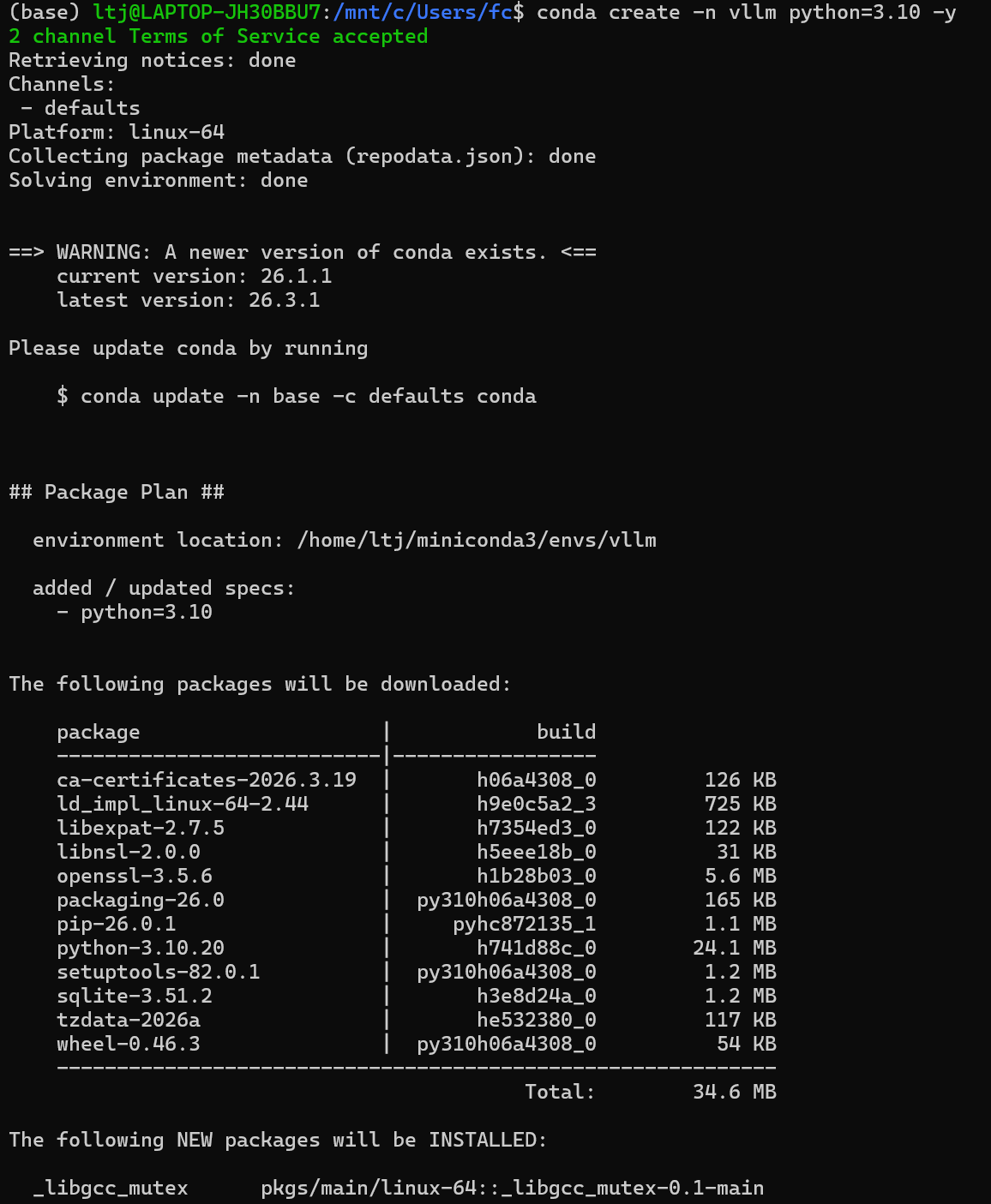
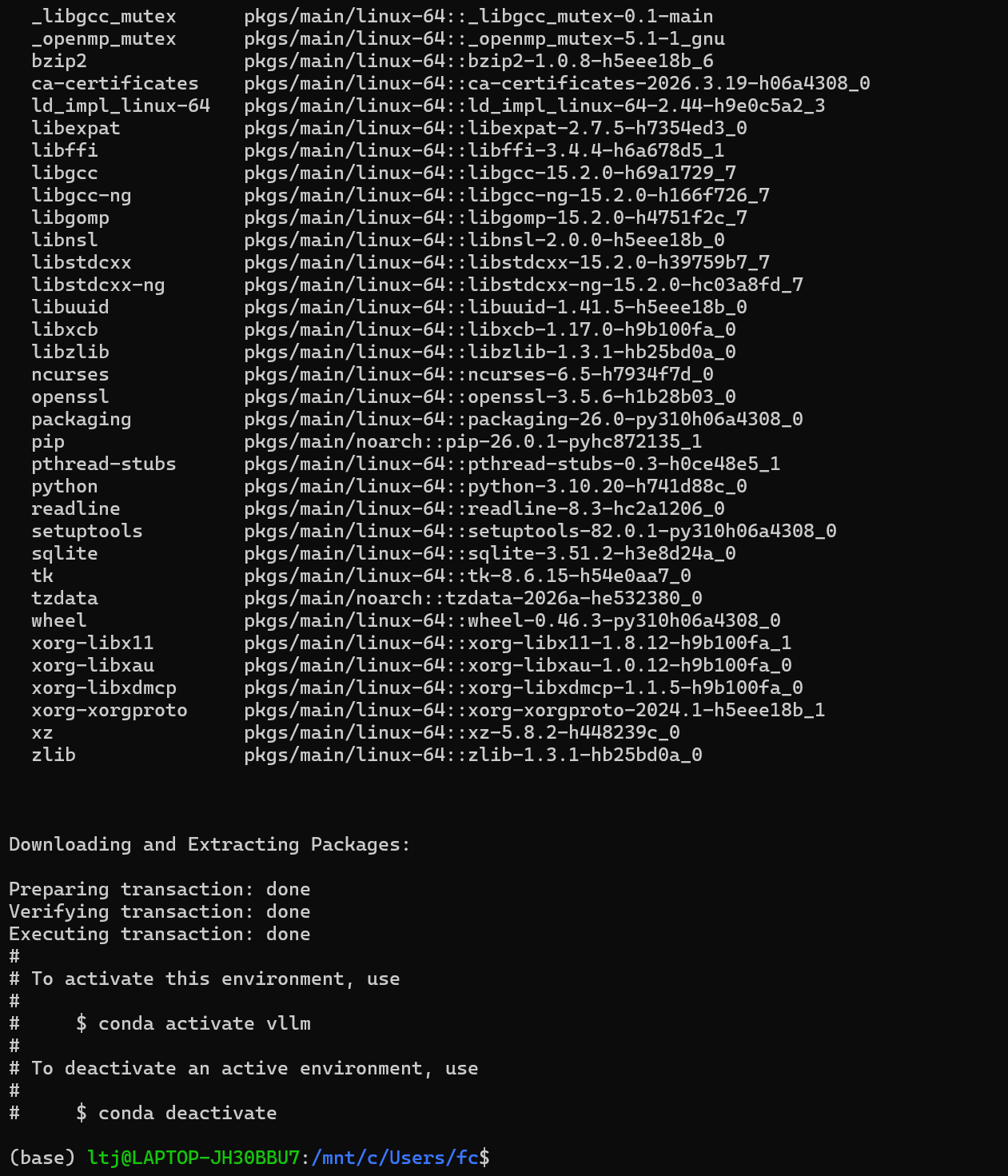
③激活环境(如果成功,你会看到前面的提示符变成:(vllm),这就表示环境创建成功。)
conda activate vllm
三、在 WSL2 内安装 WSL2 专用 CUDA 12.1(和 自己的Windows 版本对应)
注:这里可以参考我的文章:llama.cpp部署deepseek-r1-8b模型,查看一下自己Windows可以安装的版本(cmd命令:nvidia-smi)
1、在wsl2中执行下面的命令,下载WSL2 Ubuntu专用CUDA 12.1 repo包:
# 下载 CUDA 12.1 的安装源文件
wget https://developer.download.nvidia.com/compute/cuda/12.1.0/local_installers/cuda-repo-
wsl-ubuntu-12-1-local_12.1.0-1_amd64.deb
# 把刚才下载的文件安装进系统
sudo dpkg -i cuda-repo-wsl-ubuntu-12-1-local_12.1.0-1_amd64.deb
# 安装安全密钥,让系统信任 NVIDIA 的安装源,不报错、不拦截。
sudo cp /var/cuda-repo-wsl-ubuntu-12-1-local/cuda-*-keyring.gpg /usr/share/keyrings/
# 刷新软件列表告诉系统:“更新一下,我现在能装 CUDA 12.1 了”。
sudo apt-get update
# 真正安装 CUDA 12.1 工具包,这一步执行完,你的 WSL2 就有 CUDA 了,nvcc 就能用了。
sudo apt-get -y install cuda-toolkit-12-1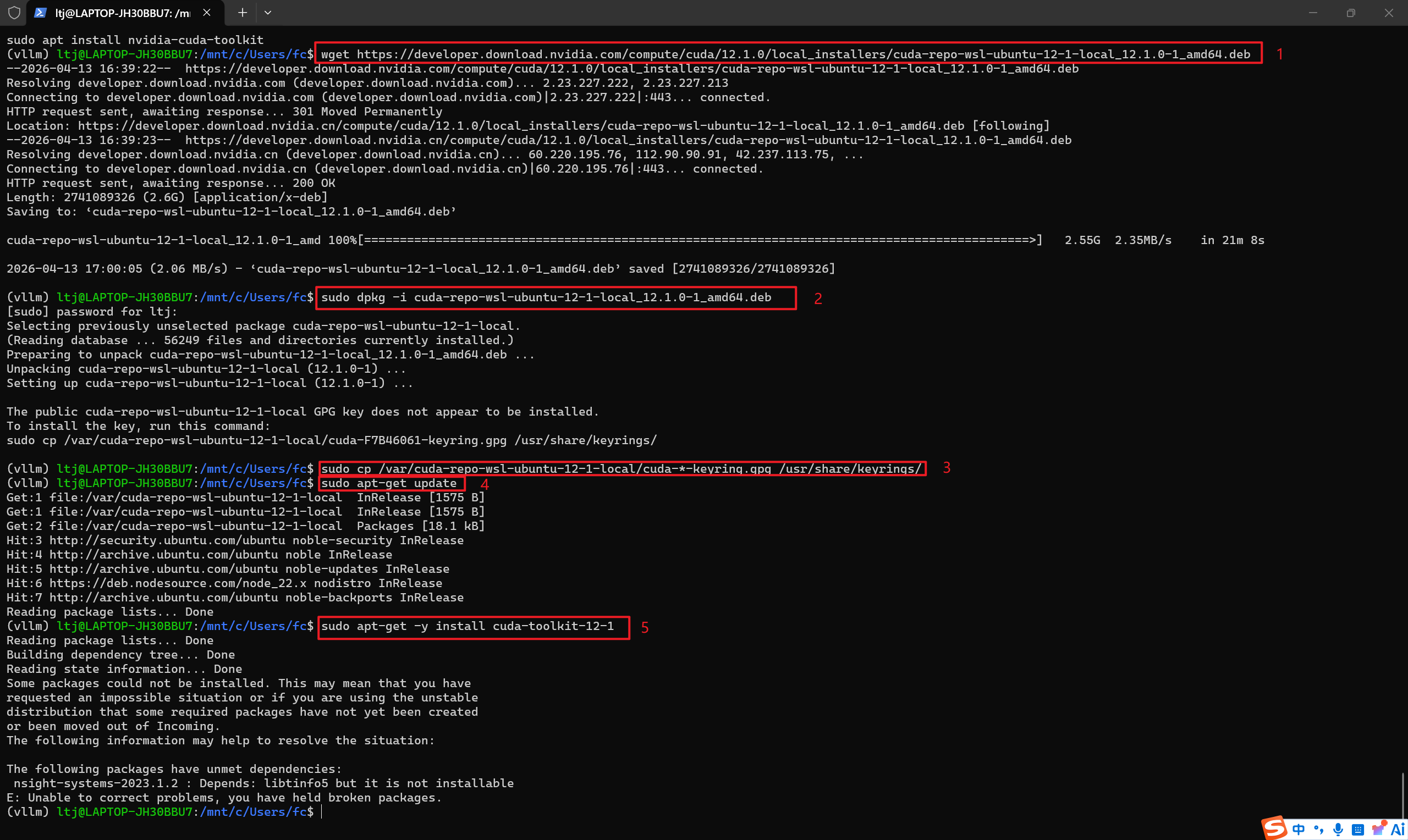
2、这里第五步出现了依赖缺失报错,不需要解决,输入:nvidia-smi,出现下面截图内容,那就代表成功了! WSL2 已经完美接管了你的显卡。
nvidia-smi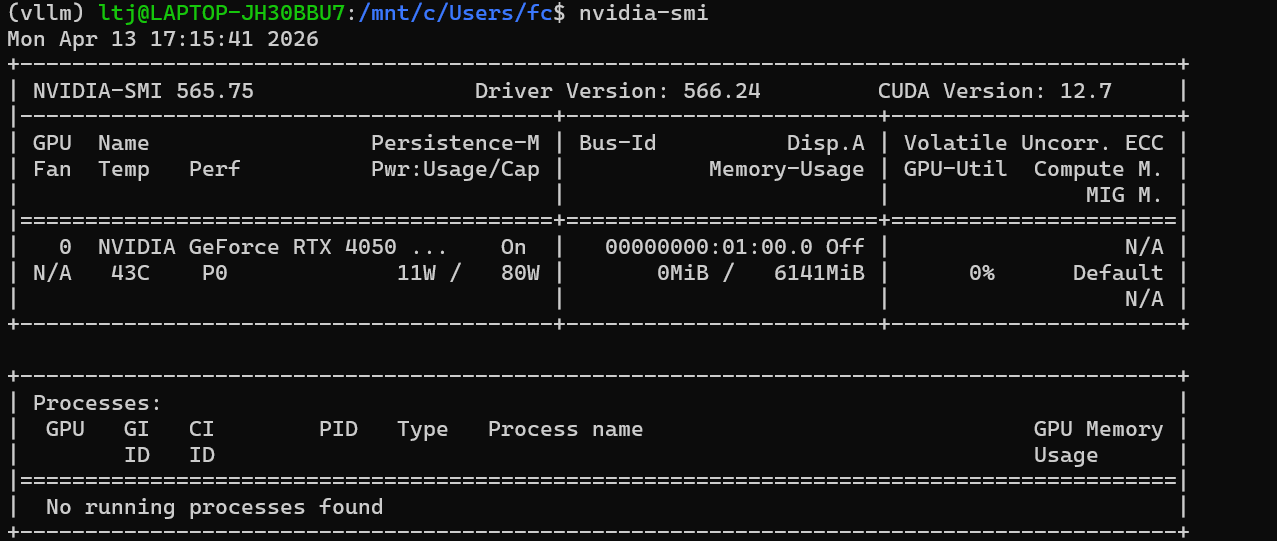
四、安装 vLLM
1、回到 vllm 虚拟环境
conda activate vllm
2、一键安装 vLLM,安装最新版 vLLM(vLLM 会自动自带匹配的 PyTorch,不需要额外安装),下面两个安装源任选一个安装,另一个备用。
# 使用清华源加速
pip install vllm -U -i https://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn
# 阿里云源安装
pip install vllm -U -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com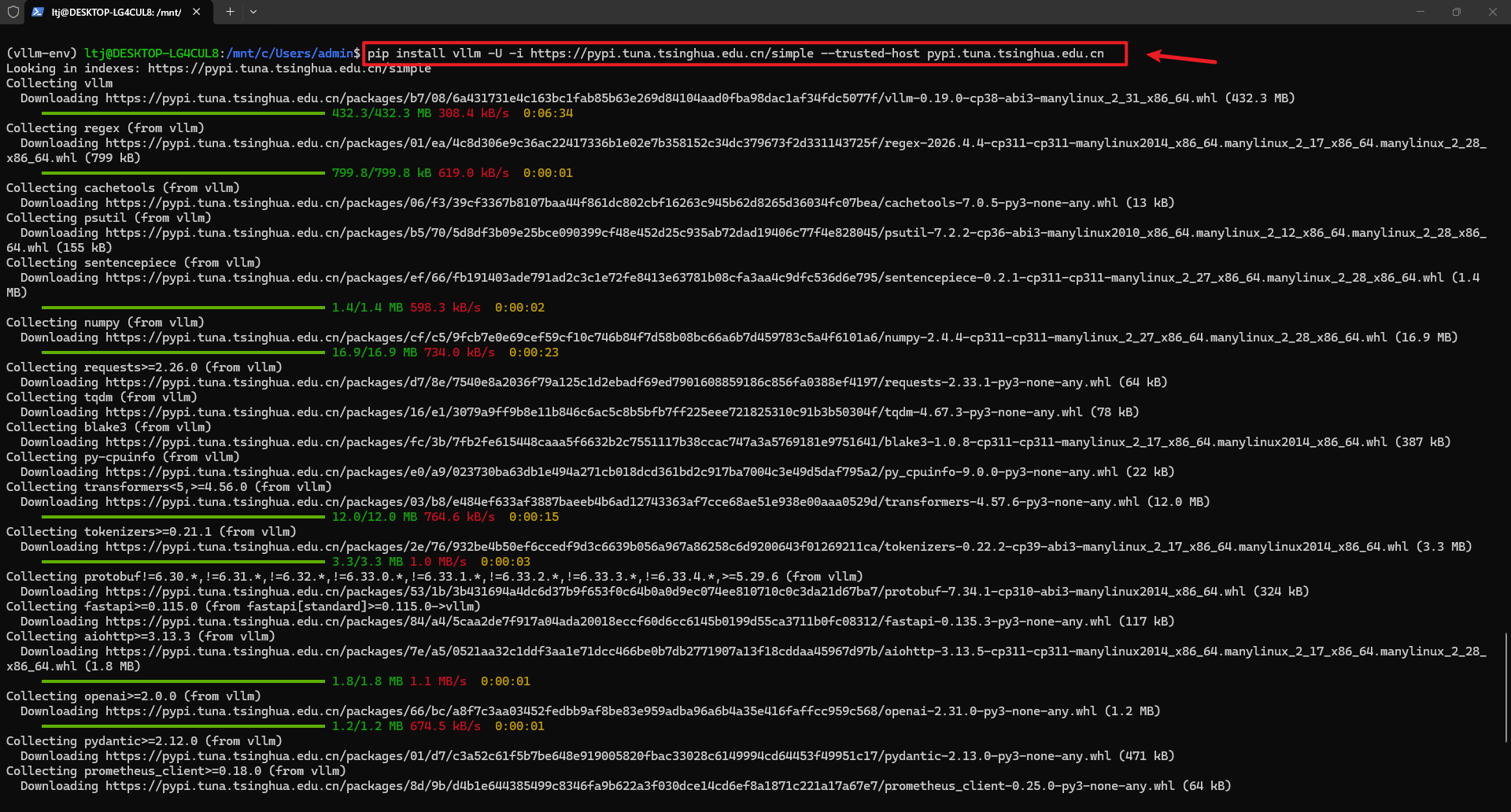
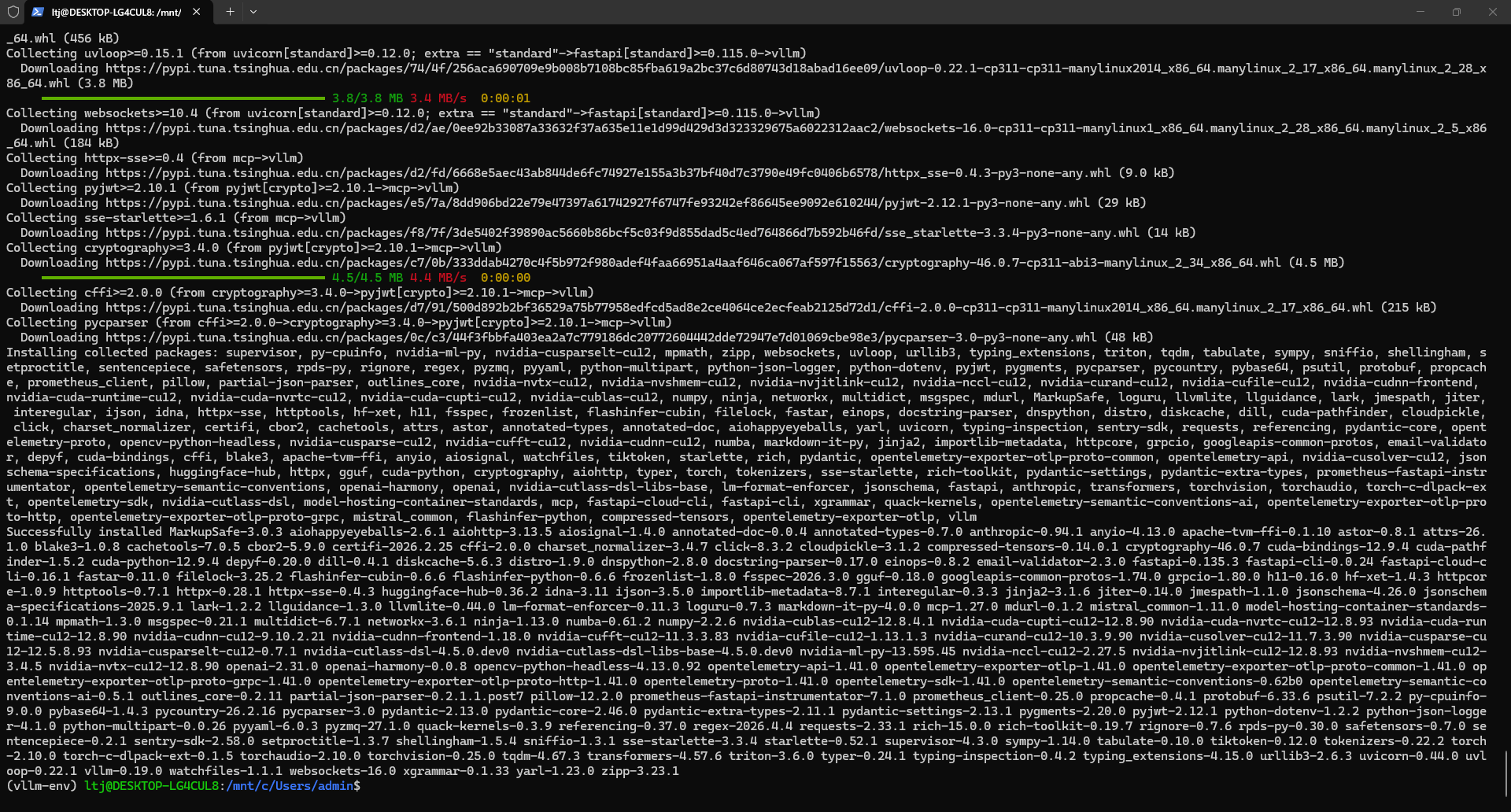
3、安装完成后,执行以下命令验证环境
# 验证 vLLM
python -c "import vllm; print('✅ vLLM 安装成功!版本:', vllm.__version__)"
# 验证 PyTorch + CUDA
python -c "import torch; print('PyTorch 版本:', torch.__version__); print('CUDA 版本:', torch.version.cuda); print('CUDA 是否可用:', torch.cuda.is_available())"
五、用vllm运行大模型(我选择了国内的魔搭社区)
1、安装魔搭工具
pip install modelscope -i https://pypi.tuna.tsinghua.edu.cn/simple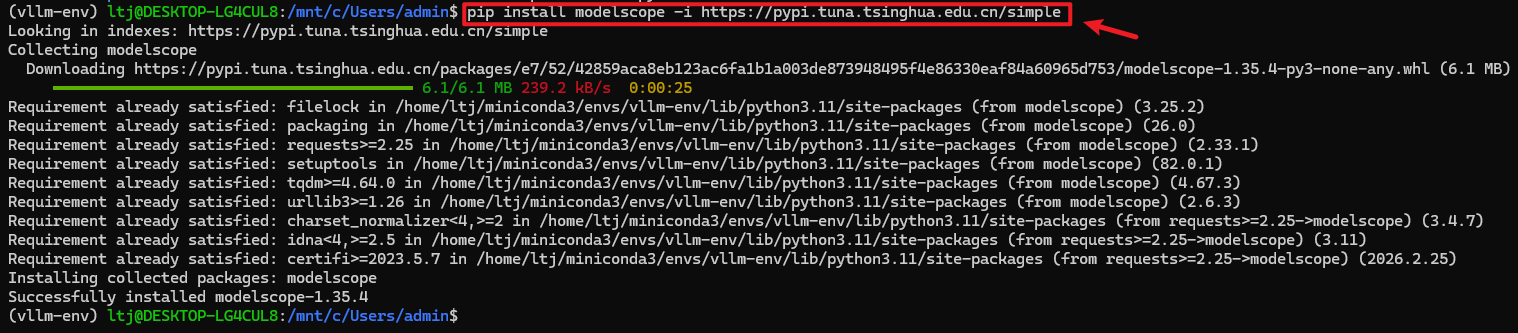
2、从魔搭下载模型到你的电脑,我选了一个Qwen3.5-08B的模型
注意:模型必须下载为 HF 格式(pytorch_model.bin 系列),vLLM 只认 Hugging Face 格式,不认其他格式。
网址:https://www.modelscope.cn/models/Qwen/Qwen3.5-0.8B
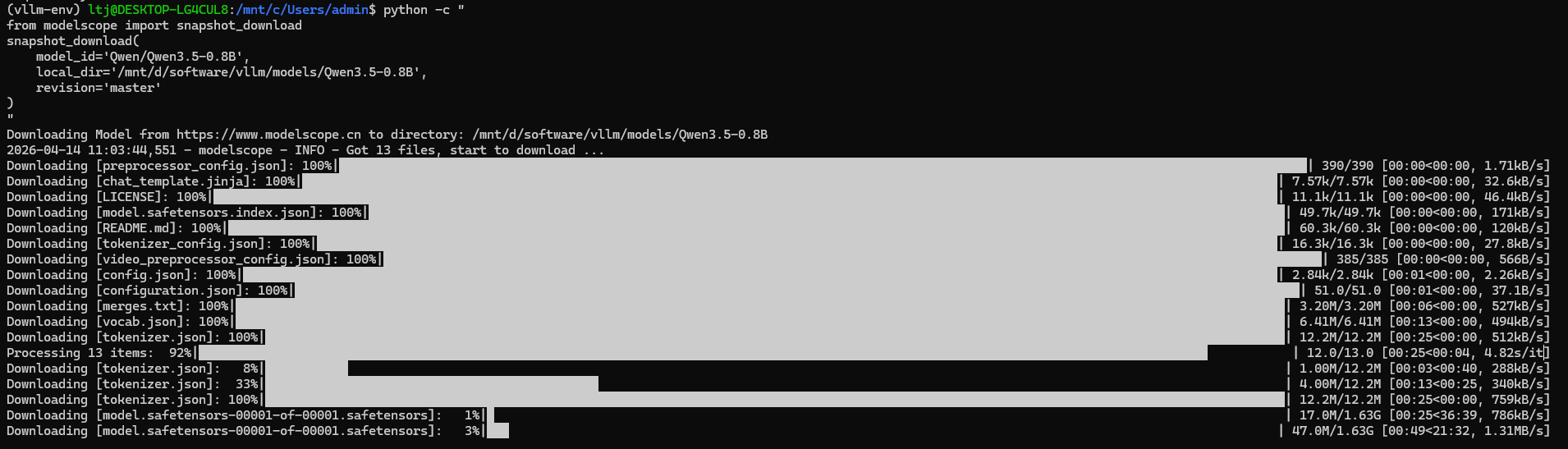
python -c "
from modelscope import snapshot_download
snapshot_download(
model_id='Qwen/Qwen3.5-0.8B',
local_dir='/mnt/d/software/vllm/models/Qwen3.5-0.8B',
revision='master'
)
"
3、用vllm启动模型文件
python -m vllm.entrypoints.openai.api_server \
--model /mnt/d/software/vllm/models/Qwen3.5-0.8B \
--trust-remote-code \
--gpu-memory-utilization 0.9 \
--host 0.0.0.0 \
--port 8000 \
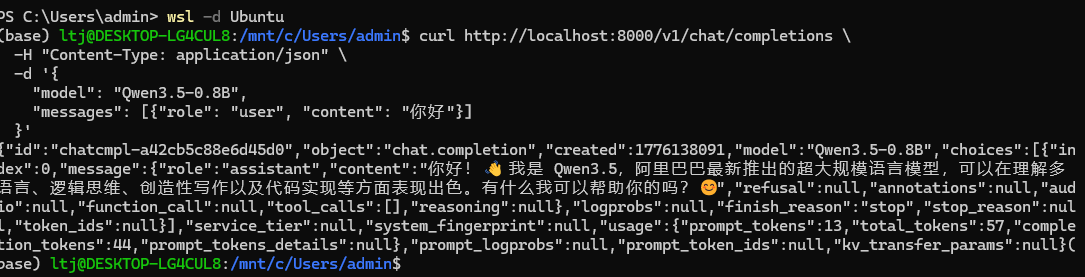
--served-model-name Qwen3.5-0.8B4、测试是否成功,在wsl2的Ubuntu中输入下面的命令:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen3.5-0.8B",
"messages": [{"role": "user", "content": "你好"}]
}'回复内容,说明成功了!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)