VLM强化微调 | 多模态强化学习训练 | EasyR1
本文介绍了使用EasyR1框架对Qwen3-VL模型进行强化微调的完整流程。EasyR1是LLaMA-Factory作者开发的强化学习框架,支持多种强化学习方法。文章详细说明了从代码获取、环境配置到具体训练的操作步骤,包括创建conda环境、安装依赖库、配置训练脚本等关键环节。重点展示了数学推理强化训练示例,涉及奖励函数定义、提示词格式设置和训练脚本编写。同时提供了自定义训练的建议,包括准备奖励函
在使用LLaMA-Factory完成VLM的监督微调后,使用EasyR1对VLM模型进行强化微调;
LLaMA-Factory和EasyR1都是同一个作者开发,太强了~
EasyR1支持的强化学习方法,包括下面这些:
- GRPO、DAPO
- Reinforce++、ReMax
- RLOO、GSPO 、CISPO
微调训练支持:
- Padding-free training
- Resuming from the latest/best checkpoint
- Wandb & SwanLab & Mlflow & Tensorboard tracking
本文以Qwen3-VL模型为例,使用GRPO完成强化微调,最终合并形成huggingface权重。
1、下载工程代码
开源地址:https://github.com/hiyouga/EasyR1#custom-dataset
获取EasyR1框架的工程代码,执行下面指令:
git clone https://github.com/hiyouga/EasyR1.git
cd EasyR12、使用Conda搭建训练环境(推荐)
创建Conda环境
首先创建一个Conda环境,名字为EasyR1,python版本为3.10;
然后进入EasyR1环境,执行下面命令:
conda create -n EasyR1 python=3.10
conda activate EasyR1安装依赖库
关键的依赖库和版本:
- transformers==4.57.3
- vllm==0.11.0
- numpy==1.25.0
编辑requirements.txt文件,内容如下所示:
accelerate
codetiming
datasets
flash-attn>=2.4.3
liger-kernel
mathruler
numpy==1.25.0
omegaconf
pandas
peft
pillow
pyarrow>=15.0.0
pylatexenc
qwen-vl-utils
ray[default]
tensordict
torchdata
transformers==4.57.3
vllm==0.11.0
wandb
# torch==2.8.0
# torchao==0.14.1
# torchaudio==2.8.0
# torchdata==0.11.0
# torchvision==0.23.0执行下面命令,进行依赖库安装:
pip install -r requirements.txt等待安装完成~
3、使用Docker搭建训练环境(可选)
执行下面命令,拉取镜像,启动容器环境
docker pull hiyouga/verl:ngc-th2.8.0-cu12.9-vllm0.11.0
docker run -it --ipc=host --gpus=all hiyouga/verl:ngc-th2.8.0-cu12.9-vllm0.11.04、训练前的准备工作
4.1、训练资源
训练时需要GPU,可以参考官网给出的示例:
当然还需要结合批量大小等训练参数
| Method | Bits | 1.5B | 3B | 7B | 32B | 72B |
|---|---|---|---|---|---|---|
| GRPO Full Fine-Tuning | AMP | 2*24GB | 4*40GB | 8*40GB | 16*80GB | 32*80GB |
| GRPO Full Fine-Tuning | BF16 | 1*24GB | 1*40GB | 4*40GB | 8*80GB | 16*80GB |
示例1:Qwen2.5-VL-Instruct on Geometry3k
| Size | GPU Type | Bits | Batch Size | vLLM TP | Peak Mem | Peak VRAM | Throughput | Sec per step | Actor MFU |
|---|---|---|---|---|---|---|---|---|---|
| 3B | 8 * H100 80GB | AMP | 1 / 2 | 2 | 120GB | 54GB | 1800 (+600) | 120s | 8.1% |
| 7B | 8 * H100 80GB | AMP | 1 / 2 | 2 | 120GB | 68GB | 1600 (+400) | 145s | 16.0% |
| 7B | 8 * H100 80GB | AMP | 4 / 8 | 2 | 200GB | 72GB | 2000 (+600) | 120s | 23.2% |
| 7B | 8 * L20 48GB | AMP | 1 / 2 | 2 | 120GB | 42GB | 410 (+0) | 580s | 26.5% |
| 7B | 8 * H100 80GB | BF16 | 1 / 2 | 2 | 120GB | 58GB | 1600 (+320) | 145s | 16.0% |
| 32B | 8 * H100 80GB | BF16 | 1 / 2 | 8 | 260GB | 72GB | 620 (+260) | 530s | 25.8% |
示例2:Qwen3-VL-Instruct on Geometry3k
| Size | GPU Type | Bits | Batch Size | vLLM TP | Peak Mem | Peak VRAM | Throughput | Sec per step | Actor MFU |
|---|---|---|---|---|---|---|---|---|---|
| 30B-A3B | 8 * H800 80GB | BF16 | 1 / 2 | 8 | 170GB | 50GB | 80 | 4600s | 1.8% |
4.2、训练日志
如果需要更好可视化训练过程日志,建议使用wandb
wandb访问地址:https://wandb.ai/home
然后在终端登录,输入 wandb的API Key;在配置文件中,默认是开启 wandb的。
4.3、训练数据
可以参考示例数据集,来准备自己的数据集
- 文本数据集:https://huggingface.co/datasets/hiyouga/math12k
- 图像-文本数据集:https://huggingface.co/datasets/hiyouga/geometry3k
- 多图像文本数据集:https://huggingface.co/datasets/hiyouga/journeybench-multi-image-vqa
- 文本-图像混合数据集:https://huggingface.co/datasets/hiyouga/rl-mixed-dataset
5、开启Qwen3-VL +GRPO训练
示例1,数学推理强化训练
- 配置文件:examples/config.yaml
- 奖励函数定义:examples/reward_function/math.py
- 提示词格式:examples/format_prompt/math.jinja
- 主函数:verl/trainer/main.py
bash examples/qwen3_vl_4b_geo3k_grpo.sh其中qwen3_vl_4b_geo3k_grpo.sh,内容如下所示:
#!/bin/bash
set -x
MODEL_PATH=Qwen/Qwen3-VL-4B-Instruct # replace it with your local file path
python3 -m verl.trainer.main \
config=examples/config.yaml \
data.train_files=hiyouga/geometry3k@train \
data.val_files=hiyouga/geometry3k@test \
worker.actor.model.model_path=${MODEL_PATH} \
trainer.experiment_name=qwen3_vl_4b_geo_grpo \
trainer.n_gpus_per_node=4
使用到的数据集是hiyouga/math12k,
数据集链接:https://huggingface.co/datasets/hiyouga/math12k
首次运行需要下载模型权重,和配置wandb的API key
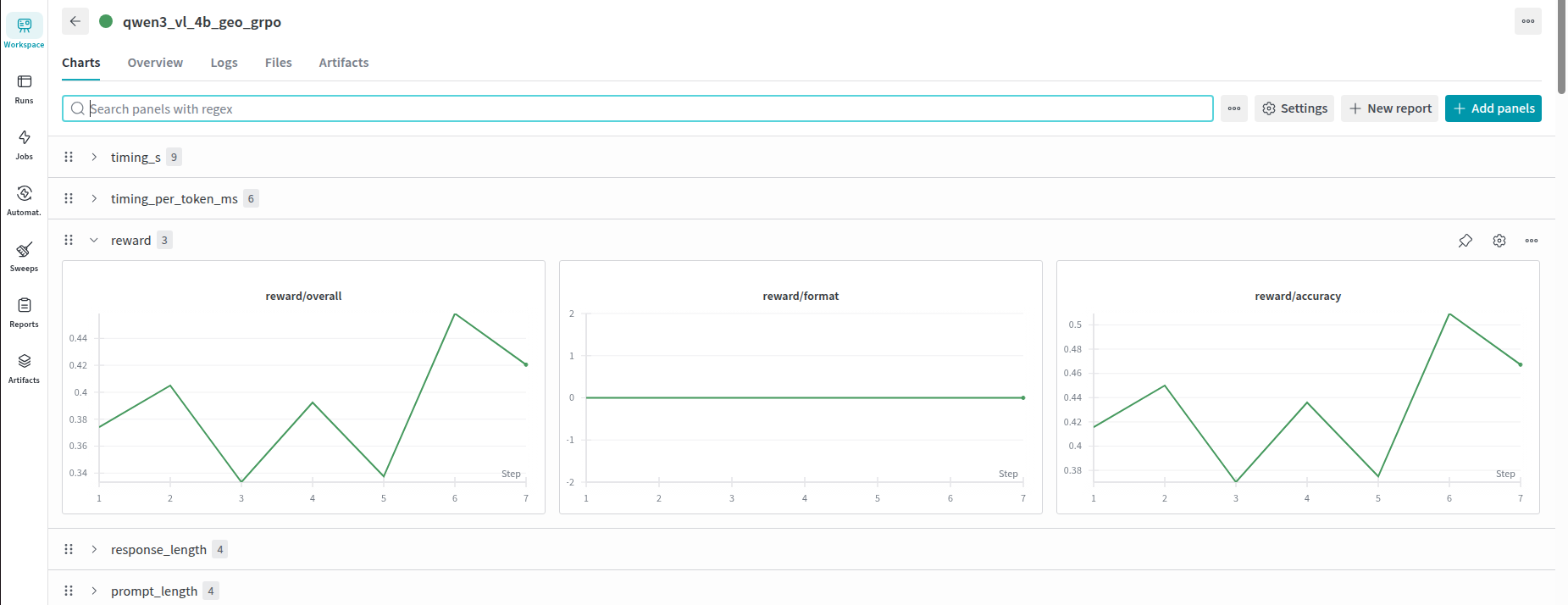
然后就可以查看训练过程了:
示例2,训练自己的模型和数据集
前提工作准备:
- 需要自定义奖励函数,然后放在examples/reward_function/xxxx.py
- 需要自定义提示词格式,这个需要和奖励函数获取模型输出,然后解析结果对应上,不然训练时奖励值可能一直为0!!!
- 修改配置文件examples/config.yaml,指定模型路径(可以给全局路径)、奖励函数、提示词代码、训练名称等参数、批量大小等
训练时,还是用到“verl/trainer/main.py”主函数,这个不用怎么改
新将一个sh脚本,修改对应配置,然后执行训练
bash examples/qwen3_vl_4b_geo3k_grpo_VLM.sh训练过程中,登录wandb能看到训练信息:
wandb访问地址:https://wandb.ai/home
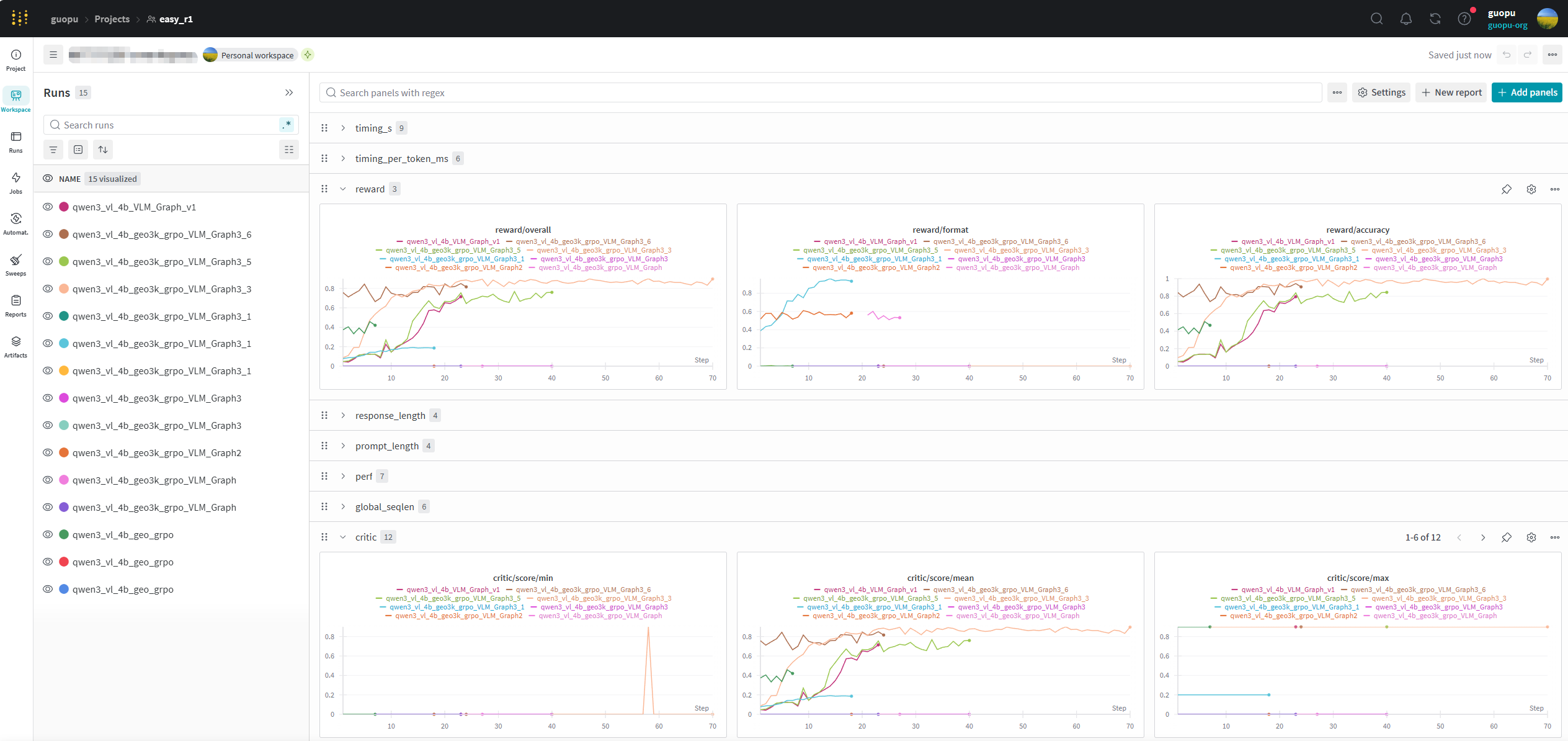
然后找到对应的训练名称,能看训练时的奖励函数变化
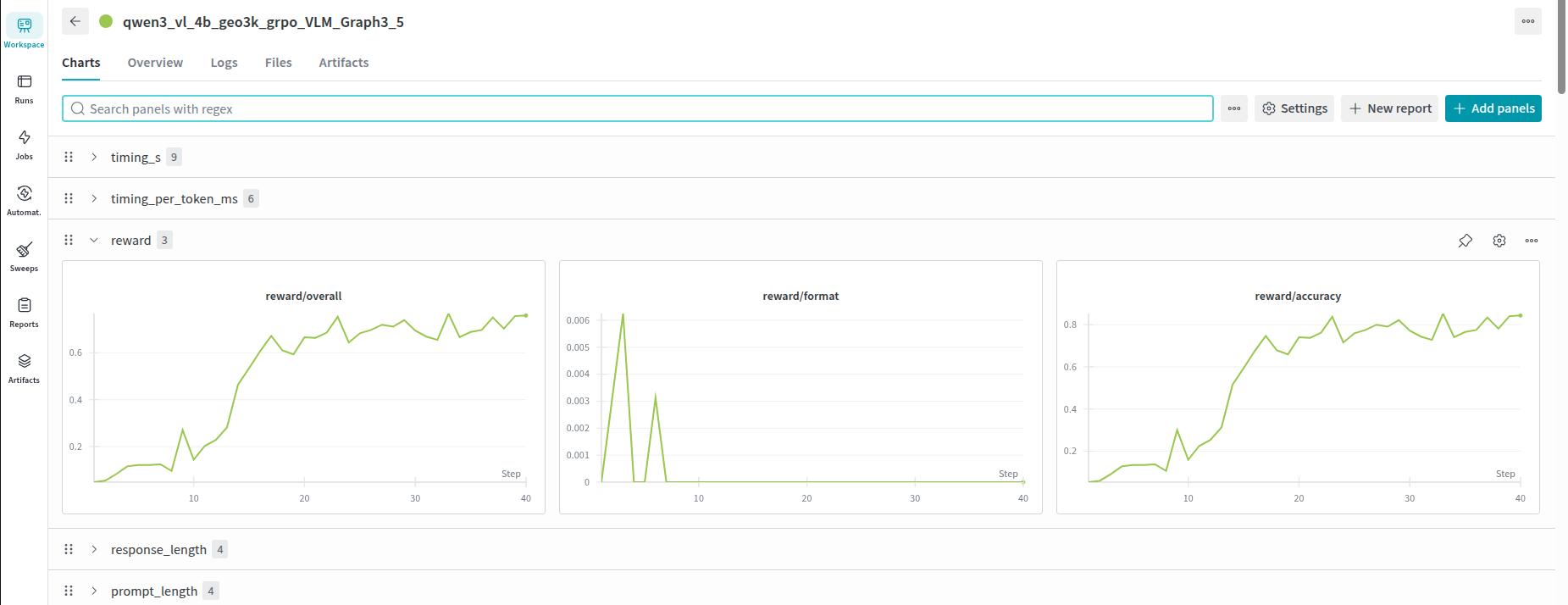
查看验证集的奖励变化和输出内容:
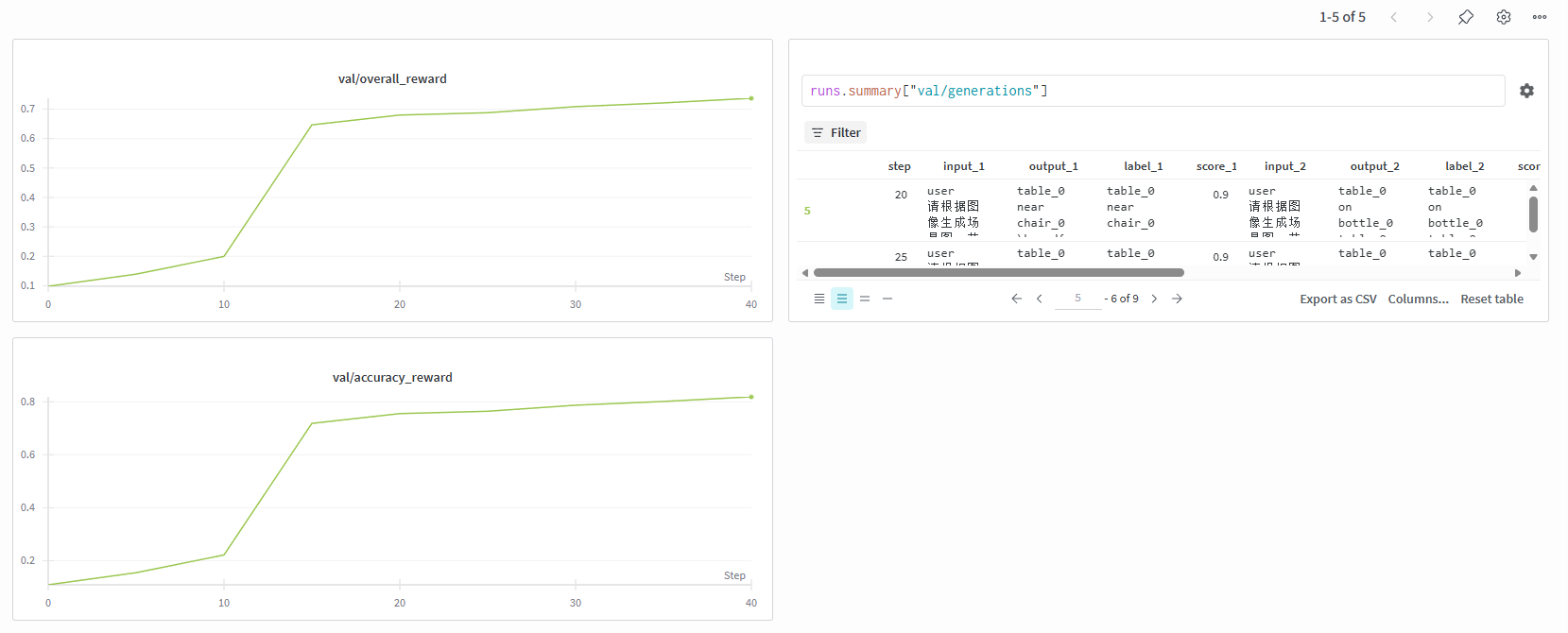
6、合成Hugging Face模型权重
强化微调后,需要用下面的命令,合成Hugging Face格式的模型权重
python3 scripts/model_merger.py --local_dir checkpoints/easy_r1/exp_name/global_step_40/actor后面模型推理,可以按照Hugging Face格式的权重去直接使用。
分享完成~

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 28
28 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)