vllm多卡部署开源模型(一)
·
背景:最近准备私有化一个语言模型,在问题理解,意图分析,数据组合等业务上,进行更好的理解,记录一下过程,还部署了一些常用的框架,前端的dify,ollama-webui等,本文以后台模型为主
1. 服务器准备
- 显卡:A800-80GB * 3卡
- 内存:300G
- CPU:42 vCPU
2. 软件环境
-
PyTorch 2.3.0
-
Python 3.12(ubuntu22.04)
-
Cuda 12.1
-
vllm
vLLM 是一个快速且易于使用的 LLM 推理和服务库
- 开源地址:https://github.com/vllm-project/vllm
- 文档地址:Welcome to vLLM! — vLLM
- 版本:0.6.5
- 安装命令
操作系统:Linux Python:3.9 - 3.12 GPU:计算能力7.0或更高(例如V100、T4、RTX20xx、A100、L4、H100等) pip install vllm- 命令示例
vllm serve "modelId" --tensor-parallel-size 1 --port=8001 # 相关参数示例 usage: vllm serve [-h] [--host HOST] [--port PORT] [--uvicorn-log-level {debug,info,warning,error,critical,trace}] [--allow-credentials] [--allowed-origins ALLOWED_ORIGINS] [--allowed-methods ALLOWED_METHODS] [--allowed-headers ALLOWED_HEADERS] [--api-key API_KEY] [--lora-modules LORA_MODULES [LORA_MODULES ...]] [--prompt-adapters PROMPT_ADAPTERS [PROMPT_ADAPTERS ...]] # --host # 主机名 # --port # 端口号 # 默认值: 8000 # --uvicorn-log-level # 可能的选择:调试、信息、警告、错误、严重、跟踪 # uvicorn 的日志级别 # 默认值:“info” # --allow-credentials # 允许凭证 # 默认值:False
-
text-embeddings-inference
是一个用于部署和提供开源文本嵌入和序列分类模型的工具包。TEI 可实现最流行模型的高性能提取,包括 FlagEmbedding、Ember、GTE 和 E5。TEI 实现了许多功能
- 开源地址:https://github.com/vllm-project/vllm
- 文档地址:Welcome to vLLM! — vLLM
- 版本:1.6.0
- docker安装
model=BAAI/bge-large-en-v1.5 volume=$PWD/data docker run --gpus all -p 8080:80 -v $volume:/data --pull always ghcr.io/huggingface/text-embeddings-inference:1.6 --model-id $model
-
Ollama Web UI Lite
Ollama Web UI Lite 是Ollama Web UI的精简版,旨在提供简化的用户界面,功能最少,复杂性降低
-
dify
Dify 是一个开源的 LLM 应用开发平台。其直观的界面结合了 AI 工作流、RAG 管道、Agent、模型管理、可观测性功能等,可以快速从原型到生产
3. 模型
Qwen2.5-72B-Instruct
大小:148GB
地址:https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/tree/main部署效果:
Qwen2.5-72B-Instruct-AWQ
大小:38.7GB
地址:https://huggingface.co/Qwen/Qwen2.5-72B-Instruct-AWQ部署效果:
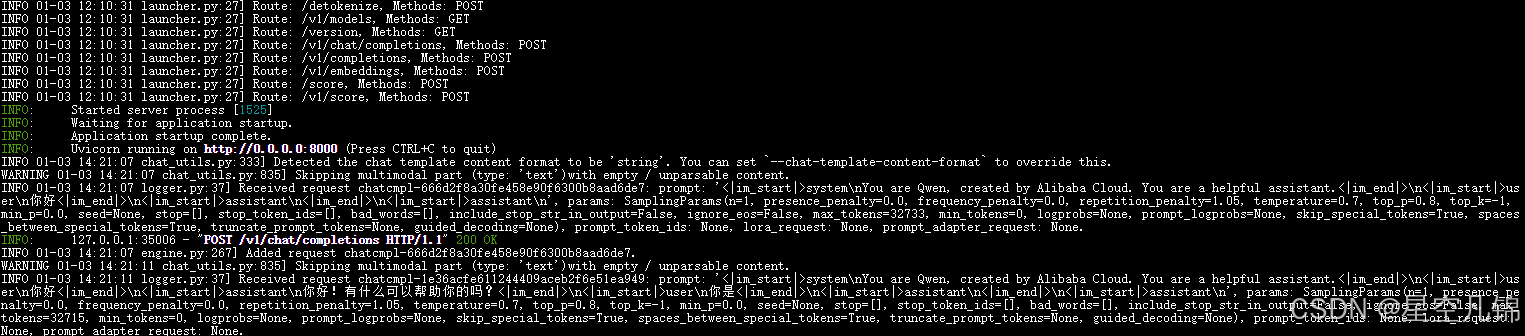
QwQ-32B-Preview
大小:61GB
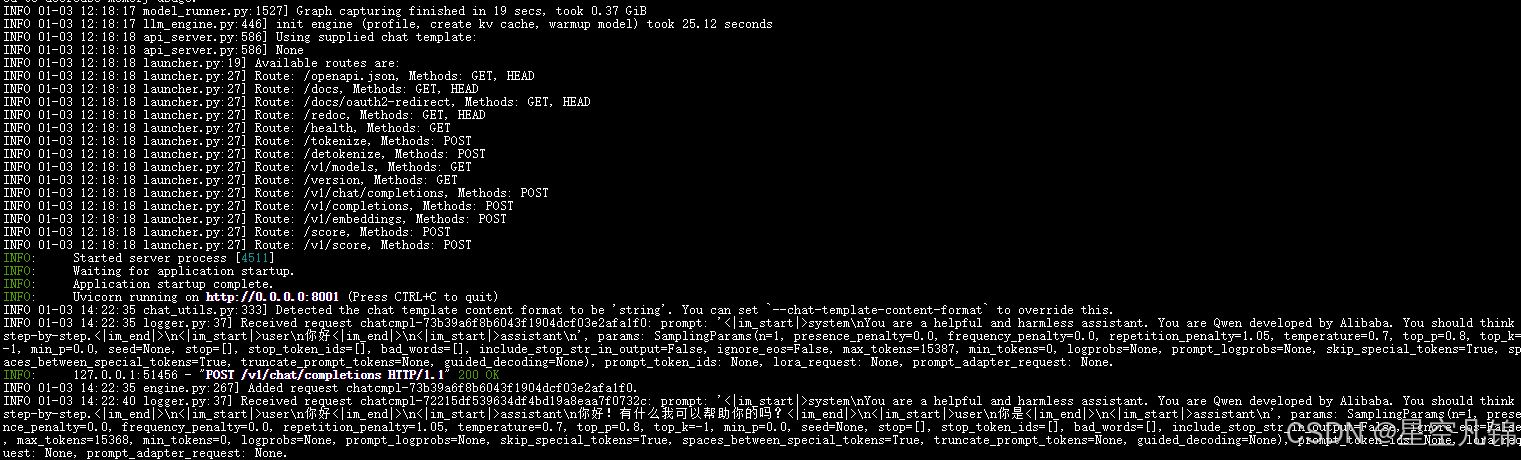
地址:https://huggingface.co/Qwen/QwQ-32B-Preview部署效果:
embedding模型
- bert-base-chinese
大小:1.59GB
地址:https://huggingface.co/google-bert/bert-base-chinese- 部署效果
由于服务器的原因,安装GPU启动环境失败,只能在CPU上运行了,如果服务器不是docker中安装的liunx安装GPU环境是没问题的- 运行命令
text-embeddings-router --model-id bert-base-chinese --port 8091

rerank模型
- bge-reranker-large
大小:6.27GB
地址:https://huggingface.co/BAAI/bge-reranker-large- 部署效果
- 运行命令
text-embeddings-router --model-id bge-reranker-large --port 8090

系统性能
GPU
显存
CPU
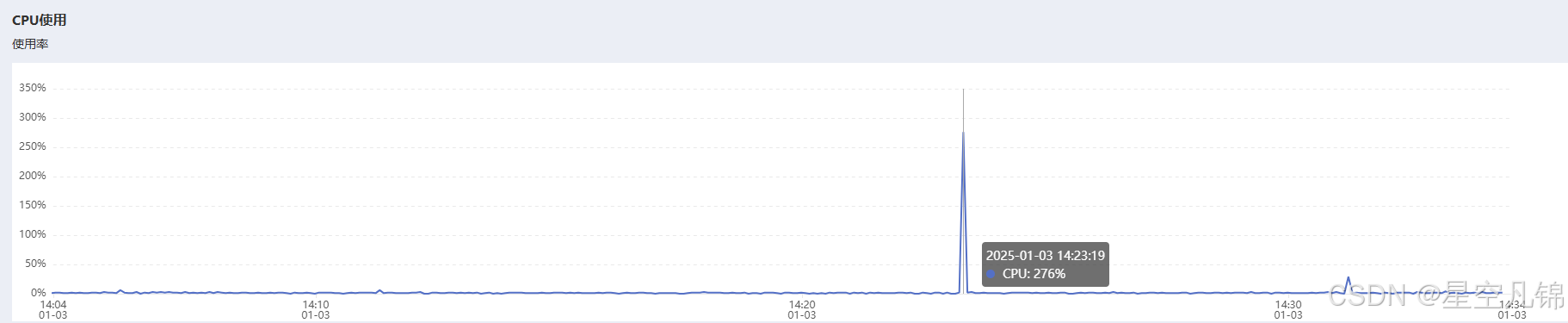
内存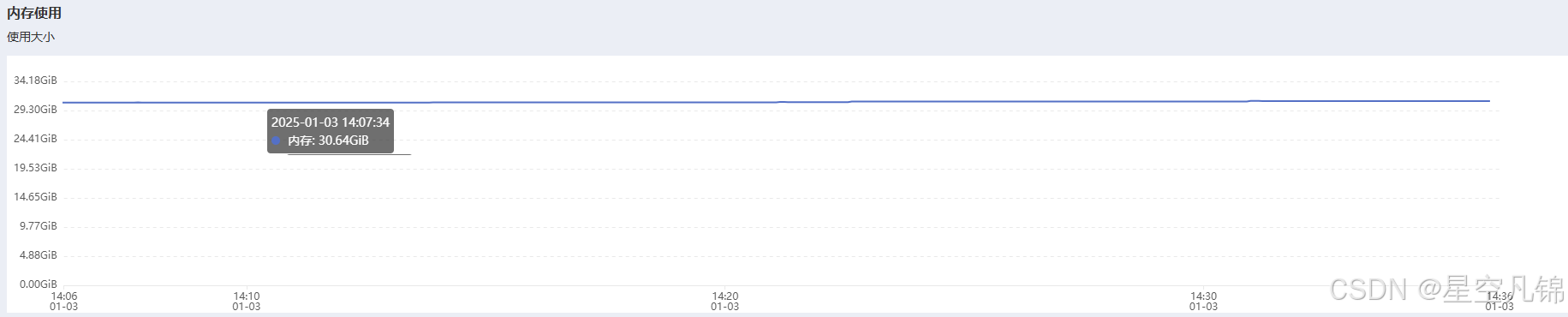
最终效果
dify

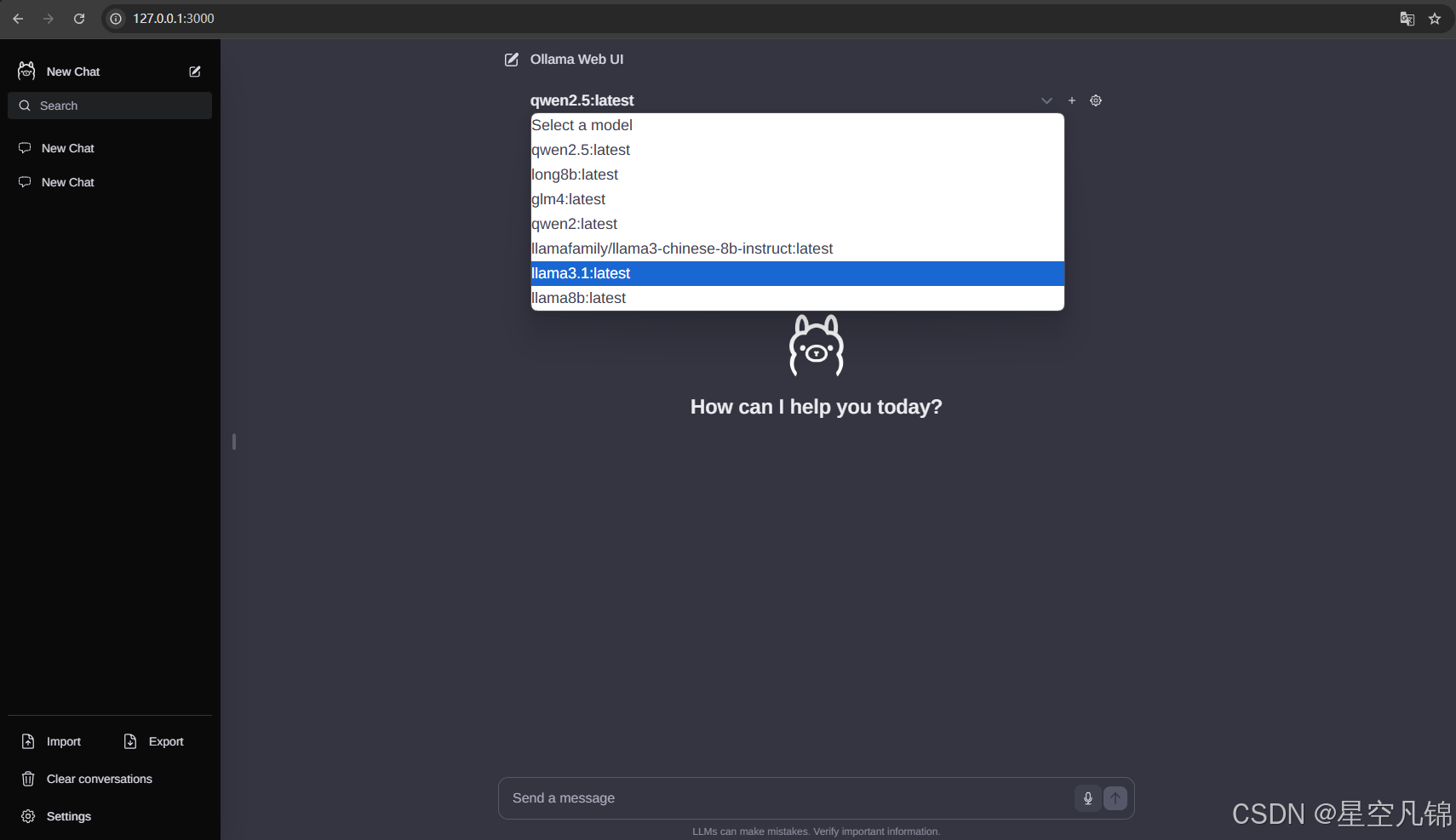
ollama-webui-lite
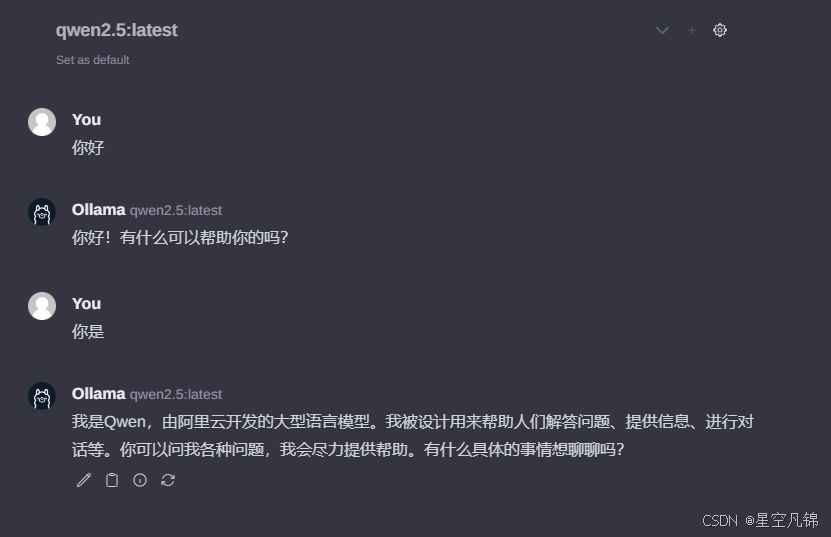
python

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)