Time-R1突破视频时序定位挑战:多模态强化学习后训练框架仅用2.5K数据刷新SOTA
SOTA性能和全面实验:仅使用2.5K训练数据,Time-R1即在多个TVG下游任务上达到SOTA,在TVGBench上提升79.14%,表现优于Gemini-2.5-Pro,微调后的性能超越了专为特定任务训练的小型模型。实验表明,该方法在时序定位准确率方面取得显著提升,并且能提升模型的视频问答能力,相关技术方案(代码/模型)已在GitHub开源。为此,我们提出了TimeRFT方法,通过构建针对视
近期,以Deepseek-R1为代表的大语言模型通过强化学习后训练(RL post-training)显著提升了模型推理能力,这一技术范式正迅速向多模态领域延伸。
小米大模型Plus团队联合中国人民大学AIM3实验室在长视频时序定位(Temporal Video Grounding)任务中取得突破性进展,在长视频任务上首次验证了强化学习后训练提升多模态大模型视频推理能力的可行性。
团队提出的Time-R1(TimeZero续作)创新性地采用基于RL的多模态后训练框架,仅需2.5K规模的训练数据即刷新了该任务在7B多模态大模型上的新SOTA,为视频时序定位与推理任务开辟了新的技术路径。

01
论文信息

-
论文名称: Time-R1: Post-Training Large Vision Language Model for Temporal Video Grounding
-
论文链接: https://arxiv.org/pdf/2503.13377v2
-
论文主页: https://xuboshen.github.io/Time-R1/
-
代码链接:https://github.com/xiaomi-research/Time-R1
近期将开源所有训练数据、训练代码、测试数据、测试代码及模型权重,开源代码支持在视频定位任务TimeRFT、Charades、ActivityNet上的训练,并支持测试集如下:视频定位测试集TVGBench、Charades、ActivityNet、短视频问答测试集MVBench、TempCompass、长视频问答测试集VideoMME、EgoSchema,开源代码支持vLLM框架的加速测试。
▍核心贡献
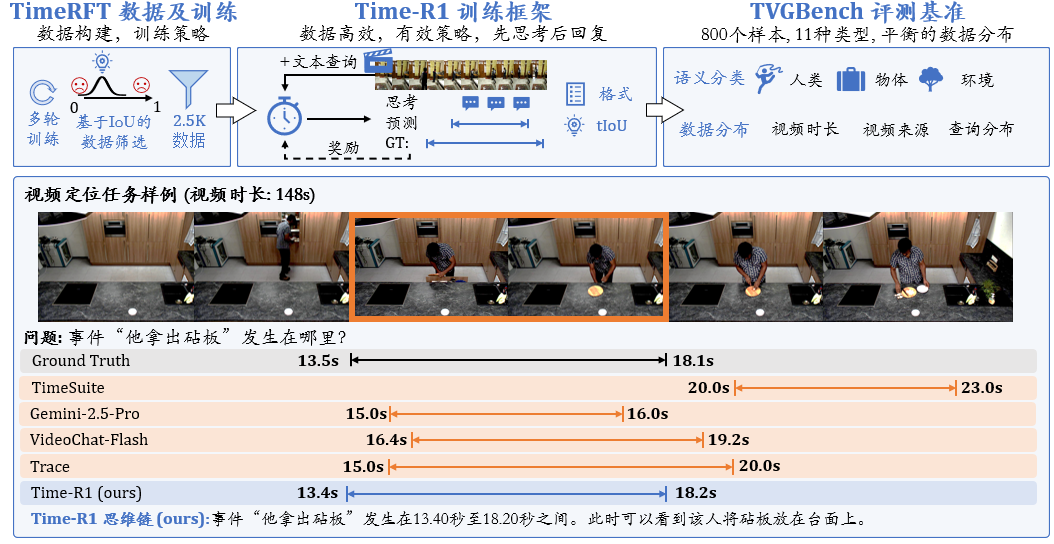
本文为强化学习后训练多模态大模型在视频定位领域提出新的技术方向,构建可靠的基线方法,提供一套完整的训练和测试框架,达到SOTA的性能。
-
Time-R1训练框架:通过强化学习后训练提升视频时序定位能力的训练框架。
-
TimeRFT数据构建及训练策略: 包含高效训练Time-R1模型的策略及配套数据集构建方法。
-
TVGBench评测基准: 一个规模小巧但覆盖面广的小型评测基准,用于快速评估模型的TVG能力。
-
SOTA性能和全面实验:仅使用2.5K训练数据,Time-R1即在多个TVG下游任务上达到SOTA,在TVGBench上提升79.14%,表现优于Gemini-2.5-Pro,微调后的性能超越了专为特定任务训练的小型模型。此外,我们发现提升TVG能力还能进一步改善视频问答性能。
02
RL对比以往训练范式
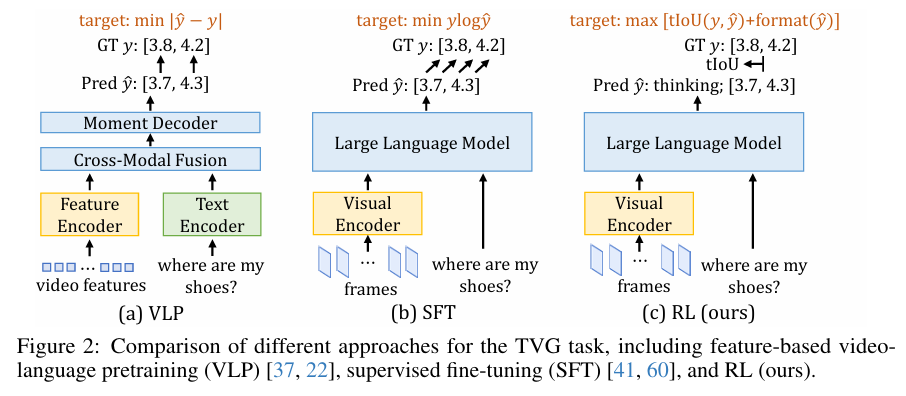
时序视频定位(Temporal Video Grounding,TVG)作为长视频理解的核心挑战之一,其任务是根据语言查询定位特定的视频时间片段。
传统视频时序定位方法通常采用基于特征的视觉语言训练范式:首先通过预训练模型(如CLIP、I3D)提取文本和视频特征,再通过特定任务的定位模型进行推理。然而,这类方法因依赖预提取特征而产生误差累积问题,且模型性能上限受限于预训练特征质量。
为突破这一局限,近期研究转向端到端的多模态大模型,这类模型可直接处理长视频和文本查询。然而需要注意的是,尽管多模态大模型(参数量达7B)的预训练数据规模达到特定领域基准数据集的100倍以上,其性能却往往逊于参数量极小的传统模型(如仅9M参数量的特征模型EaTR)。
这引出了一个关键问题:为何具备海量预训练知识的多模态大模型在视频定位任务中表现欠佳?
我们认为,多模态大模型性能瓶颈源于监督微调(SFT)过程中对假阴性样本的过度惩罚。例如,当真实时间片段为[2s, 4s]时,即使模型给出[1.9s, 3.9s]的合理预测,自回归损失仍会被不恰当地放大。这种对合理预测的过度惩罚会导致模型过拟合和泛化能力下降。
现有解决方案试图通过两种途径缓解该问题:1. 扩展词表:在词汇表中新增时间戳token,避免对数字的输出和拟合,2.添加预测头:通过附加的回归头预测时间戳。但这些方法往往以牺牲大语言模型原有的数字理解能力为代价。
受近期大语言模型强化学习后训练成功案例的启发,我们探索了将强化学习作为解决视频时序定位任务的解决方案。与监督微调不同,强化学习可直接优化任务特定指标(如交并比IoU),从而缓解自回归损失的刚性惩罚问题,并鼓励模型生成合理的时间戳预测。本研究提出基于强化学习的Time-R1框架,通过高效后训练多模态大模型,成功突破了视频定位任务的性能瓶颈。
03
方法细节
▍Time-R1训练框架
1.基于GRPO训练框架目标
强化学习的训练目标是优化模型让模型能够获得更高的奖励R(o),同时加入KL散度来约束模型参数更新不要离原有模型参数差距太大。
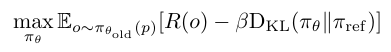
-
保留KL散度: 实验表明保留KL散度能使模型产生有用且可读的思维链。尽管完全舍弃KL散度可带来微小的性能提升,但这会导致模型放弃思考过程而直接输出答案。为平衡性能与可解释性,最终选择保留KL散度。
-
为了提升模型的推理和泛化能力,我们冻结视觉编码器,并全量微调大语言模型,来激活大语言模型的推理能力。
2.奖励(Reward)函数设计 r(o)
强化学习的优势是让模型能够直接面向最终的评价指标进行优化,从而改善性能,因此我们的奖励设计遵循这样的原则进行,同时加入先思考后回复的模式来改善模型可解释性和性能。
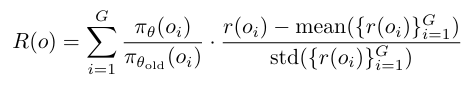
-
时间戳感知IoU(tIoU):视频时序定位任务主要采用交并比(IoU)来评估预测片段[t_s, t_e]与真实标注[t'_s, t'_e]之间的匹配质量,其计算公式为:
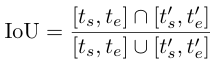
优化交并比本质上会促使多模态大模型的预测允许一定误差范围,这种方法引导多模态大模型更关注事件在可能时间范围内的语义理解,而非像监督微调那样严格要求时间点精确对齐。
然而,标准交并比在某些场景下可能无法准确反映时间对齐的质量。例如,当真实时间跨度为 [0, 30](即整个视频时长)时,任何覆盖超过 30% 视频的预测都会产生大于 0.3 的IoU值。像 [10, 25] 这样的预测会得到 0.5 的 IoU,尽管时间戳错误却仍被高估质量。
为解决这一问题,我们引入时间戳感知交并比(tIoU)作为修正指标。tIoU 在标准 IoU 基础上增加了时间戳偏差惩罚项,其定义为:
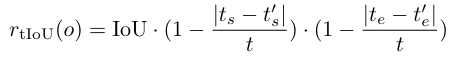
-
格式奖励: 训练模型遵循先思考后回复的格式输出:思考过程应包含在"<think>"与"</think>"标签之间,最终答案应包含在"<answer>"与"</answer>"标签之间。format:"<think>...</think><answer><ts to te></answer>"
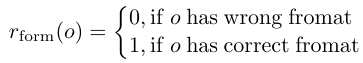
-
奖励混合: 格式奖励为二元值(0或1),tIoU取值范围为0到1。最终奖励设置为二者之和。
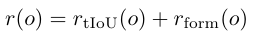
▍TimeRFT训练策略与数据集构建
由于强化学习训练的计算成本较高,我们探索了数据高效的策略以降低样本需求。为此,我们提出了TimeRFT方法,通过构建针对视频时序定位任务的数据集,并设计强化学习友好的微调策略,旨在提升模型泛化能力的同时,尽可能减少训练数据开销。
1.TimeRFT数据筛选:
-
初始数据收集: 我们从多个互联网视频数据集中收集训练视频,包括YT-Temporal、DiDeMo、QuerYD、InternVid和HowTo100M。并利用VTG-IT、TimeIT、TimePro、HTStep以及LongVid等标注数据集获取时序定位标注,最终构建了包含33.9万条时序定位样本的数据集。
-
数据筛选: 为避免训练过程中受过难或过易样本干扰,我们使用Qwen2.5-VL-7B模型对样本通过IoU来标记难易程度,并基于均值为 0.3、标准差为 0.2 的正态分布筛选样本,精选出2.5K核心训练数据,用于高效训练。
2.TimeRFT训练策略
-
难样本筛选采样: 我们采用多轮训练(multi-epoch)机制,每轮训练后动态剔除简单样本(即模型预测 IoU > 0.7 的数据),从而保持数据整体难度,降低对易样本的过拟合风险。
-
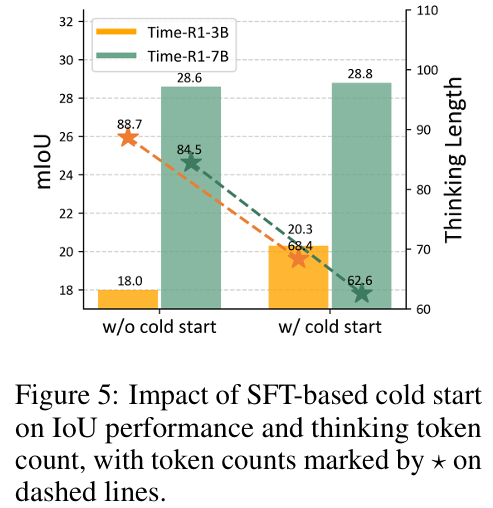
冷启动策略: 对于较小规模模型(如 3B),直接进行强化学习训练往往导致生成内容逻辑混乱或推理步骤虚构,且训练初期文本长度控制困难,影响稳定性。为此,我们引入冷启动策略,即先使用少量格式规范、内容合理的思维链示例对模型进行微调,引导其生成与视频内容紧密关联的推理过程,从而提升推理质量并稳定训练流程。
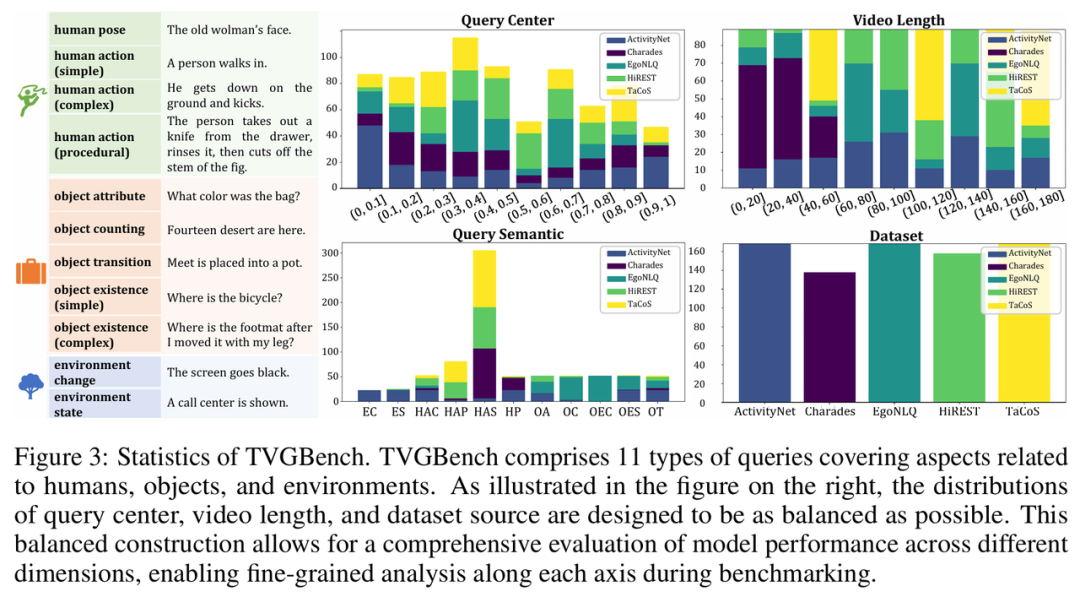
▍TVGBench评测基准构建
鉴于现有视频定位评测基准规模较大,评估多模态大模型的效率较低,我们构建了一个小而全面的评测基准TVGBench,共包含800 个样本,以提升评测效率的同时保证任务覆盖的广度与代表性。
该基准从主流视频定位评测集(包括Charades-STA、ActivityNet-Captions、HiREST、EgoNLQ和TaCoS)中,依据视频时长、数据集类型和查询中心三个维度进行均匀采样。我们预先定义并构建了11种查询类型,确保评测具有广泛性和针对性。
具体而言,查询类型划分为三大类:关于人类、物体、环境的语义查询,并进一步细化如下:
-
人类:1. 人体姿态:“一位妇人的脸庞”;2. 人类动作(简单文本查询):“一个人走进门”;3. 人类动作(复杂文本查询):“他到达平地并踢了一脚”;4. 人类动作(步骤性文本查询):“那人从抽屉里取出一把刀,冲洗干净后切掉了无花果的蒂”。
-
物体:5. 物体属性:“那个包的颜色是什么”;6. 物体计数:“这里有14个甜点”;7. 物体形态变化:“肉被放进了锅里”;8. 物体位置(简单文本查询):“自行车在哪里”;9. 物体位置(复杂文本查询):“我用脚挪过之后,脚垫去哪儿了”
-
环境:10. 环境变化:“屏幕变黑了”;11. 环境状态:“展示了一个电话中心大楼”
04
实验结果
实验设置:如无说明,基座模型均基于Qwen2.5-VL-7B。输入视频以1秒2帧的速率采样,并动态限制最大的视频输入为2.8M个像素点。举例而言,一个50秒的视频会输入100帧,每帧大约为96*96*3的分辨率。
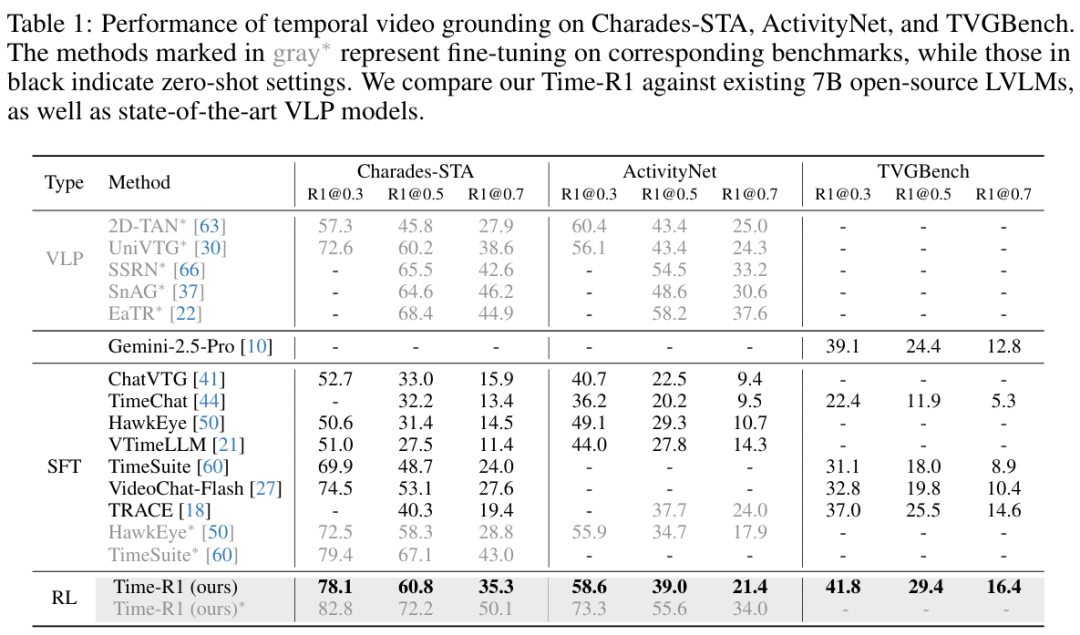
1.视频定位(TVG)性能。尽管我们仅使用2.5K条训练样本,Time-R1在多个主流视频时序定位基包括Charades,ActivityNet,TVGBench上全面超越现有所有轻量级开源模型,达到新SOTA。例如在Charades上相对VideoChat-Flash在R1@0.7提升27.8%;在ActivityNet上相较于VTimeLLM在R1@0.7上提升49.6%;在TVGBench上相较于TRACE在R1@0.7上提升12.3%。值得强调的是,Time-R1在部分任务上性能超越了如Gemini-2.5-Pro这样可能有几十倍参数量差距的闭源模型。此外,在下游任务上进行进一步微调后,其性能可超越多个以往传统方法。
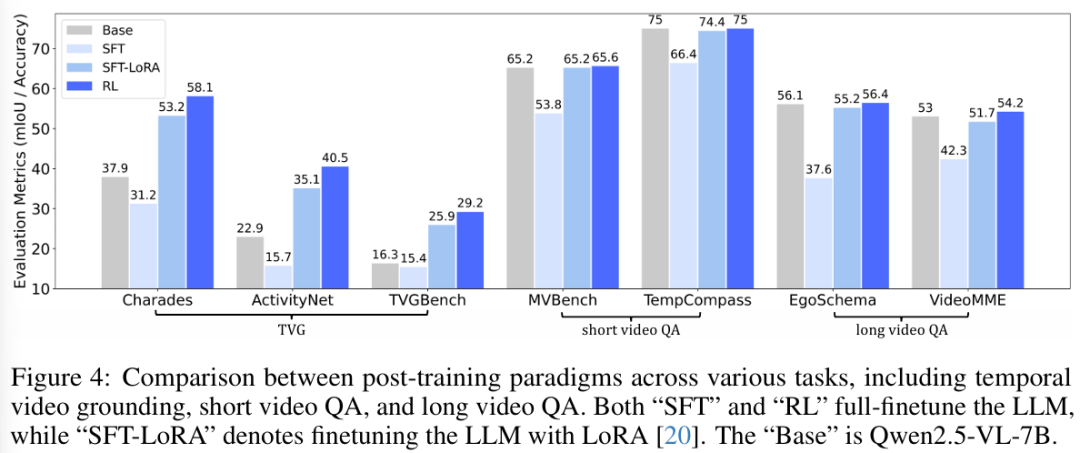
2.短/长视频理解(MCQ)性能。值得注意的是,Time-R1模型未使用任何多选题(MCQ)类型数据进行训练的前提下,依然在短视频与长视频问答评测基准上展现出性能提升,优于两种设置的监督微调(SFT)基线模型。并且,监督微调的训练对多选题的性能会造成一定损失,验证了强化学习在多模态理解任务中相较 SFT 的潜在优势。
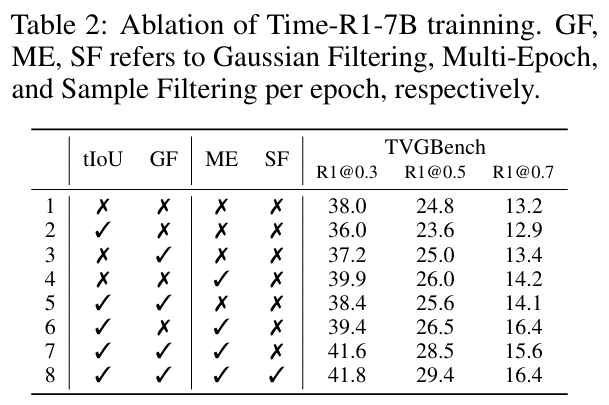
3.消融实验:如表2所示,初始数据筛选(GF)与多轮训练(ME)均能独立提升模型性能,其中ME带来的增益将R1@0.7指标从第1行的13.2提升至第4行的14.2。值得注意的是,当结合tIoU reward与ME训练时(第6行),R1@0.7显著提升到16.4。随着更多组件的引入性能持续优化,最终达到R1@0.3为41.8,R1@0.5为29.4与R1@0.7指标16.4的峰值表现。
而对于冷启动来说,如图5所示,冷启动机制不仅更好地提升了模型(尤其是3B模型)的性能,还控制了两种模型生成的token数量。我们认为这得益于冷启动对幻觉生成的抑制作用——这种现象在性能较弱的模型中往往更为显著。
▍更多的样例展示

蓝色是Time-R1的预测结果,红色是Qwen2.5-VL模型的预测结果。


05
总结
本研究针对多模态大模型在长视频理解任务中的时序定位瓶颈,创新性地提出基于强化学习的后训练优化方案。
本文提出Time-R1训练框架、TimeRFT数据构建及训练策略,以及TVGBench评测基准,首次系统性探索了基于规则的强化学习后训练范式在长视频时序定位中的应用价值。
实验表明,该方法在时序定位准确率方面取得显著提升,并且能提升模型的视频问答能力,相关技术方案(代码/模型)已在GitHub开源。尽管本研究的时序推理已取得阶段性突破,长视频的理解、定位与推理仍处于发展阶段,未来还存在广阔的探索空间。
END



腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)