vllm 多卡部署推理接口无响应(hanging ),后台GPU使用率一直100%
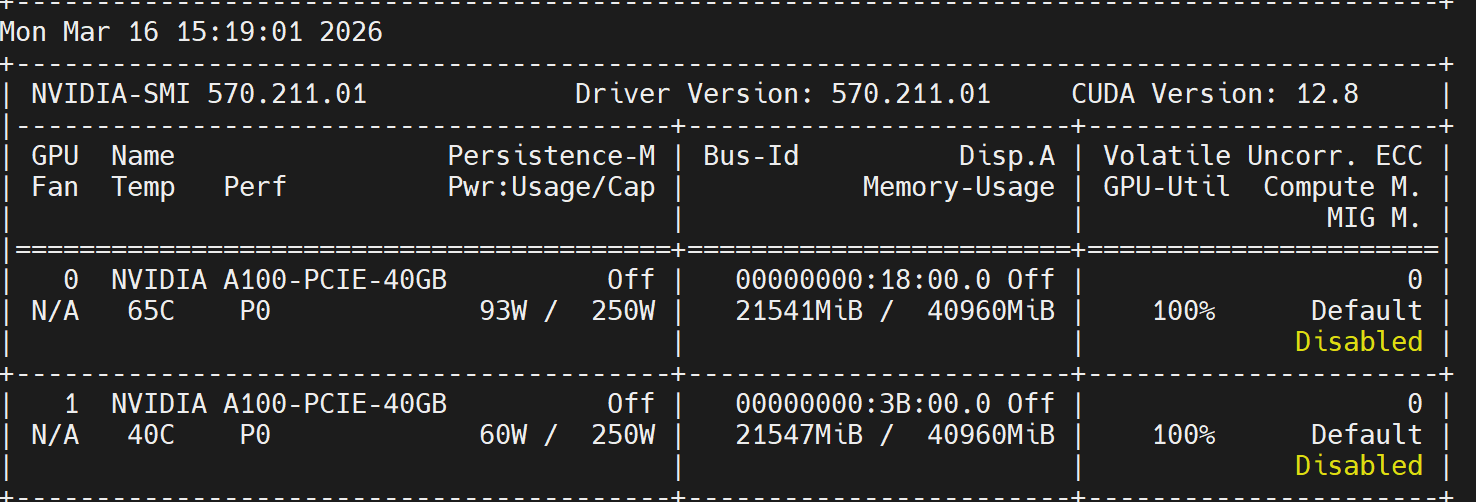
Ubuntu24.04.2物理机器 ,配置是两张A100 pcie接口(无nvlink),使用vllm0.17版本进行双卡部署32b模型,运行时出现推理接口无响应,后台GPU使用率一直100%,因此我用调小显存使用率和使用14b和1.5b小模型进行了实验,在单卡模式都可以正常运行并使用(分别指定了gpu0和1),但是加了参数–tensor-parallel-size 2后就会出现这个情况。已将共享
问题描述
Ubuntu24.04.2物理机器 ,配置是两张A100 pcie接口(无nvlink),使用vllm0.17版本进行双卡部署32b模型,运行时出现推理接口无响应,后台GPU使用率一直100%,因此我用调小显存使用率和使用14b和1.5b小模型进行了实验,在单卡模式都可以正常运行并使用(分别指定了gpu0和1),但是加了参数–tensor-parallel-size 2后就会出现这个情况。已将共享内存调到高也不起作用。
另外还可以看到如下的提示信息:
No available shared memorybroadcast block found in 60 seconds. This typically happens when some processes are hanging or doing some time-consumingwork)
问题分析
在单张显卡上正常运行,在多张显卡即使增大共享内存,使用较小参数的模型也不行,出现hanging状态。大概率是多块GPU之间通信导致的问题。英伟达多块 GPU 之间极速同步数据,依靠NCCL(NVIDIA 集合通信库)。
(base) tgkw03@tgkw03-SYS-7049GP-TRT:~$ nvidia-smi topo -m
GPU0 GPU1 CPU Affinity NUMA Affinity GPU NUMA ID
GPU0 X NODE 0-13,28-41 0 N/A
GPU1 NODE X 0-13,28-41 0 N/A
Legend:
X = Self
SYS = Connection traversing PCIe as well as the SMP interconnect between NUMA nodes (e.g., QPI/UPI)
NODE = Connection traversing PCIe as well as the interconnect between PCIe Host Bridges within a NUMA node
PHB = Connection traversing PCIe as well as a PCIe Host Bridge (typically the CPU)
PXB = Connection traversing multiple PCIe bridges (without traversing the PCIe Host Bridge)
PIX = Connection traversing at most a single PCIe bridge
NV# = Connection traversing a bonded set of # NVLinks
(base) tgkw03@tgkw03-SYS-7049GP-TRT:~$ nvidia-smi topo -p2p p
GPU0 GPU1
GPU0 X NS
GPU1 NS X
Legend:
X = Self
OK = Status Ok
CNS = Chipset not supported
GNS = GPU not supported
TNS = Topology not supported
NS = Not supported
U = Unknown
通过执行以上命令行可以发现GPU之间无NVLink通信,且不支持p2p。另外根据英伟达官方文(https://docs.nvidia.com/maxine/triton/1.0.0/Appendicies/PCIeMultiGPUSystems.html)档可知:在采用 PCIe 拓扑的裸机 Linux 系统中,不支持启用 IOMMU 的点对点内存复制。建议在启用 IOMMU 时将其设置为直通模式(通过配置 Linux 内核参数iommu=pt实现)。
验证当前 IOMMU 状态
sudo dmesg | grep -e DMAR -e IOMMU
[citation:7][citation:8][citation:9]
如果有输出(例如 IOMMU enabled),说明 IOMMU 已开启。如果没有任何输出,则说明 IOMMU 处于关闭状态。
问题解决
1、启动模型时需要添加环境变量NCCL_P2P_DISABLE=1,强制NCCL禁用P2P通信。
p2p(Peer-to-Peer,点对点)模式在NVLink和某些PCIe连接场景下会生效。默认情况下系统是NCCL_P2P_DISABLE=0,开启p2p。笔者这里不支持,设置NCCL_P2P_DISABLE=1,强制NCCL禁用P2P通信。
export NCCL_P2P_DISABLE=1
CUDA_VISIBLE_DEVICES=0,1 vllm serve /home/user/llm/Qwen2.5-1.5B-Instruct --served-model-name Qwen2.5-1.5B-Instruct --dtype auto --api-key token-abc123 --tensor-parallel-size 2 --gpu-memory-utilization 0.2
2、关闭iommu, iommu(vt-d)会导致nccl hang。
在设置环境变量NCCL_P2P_DISABLE=1后,通信依然不行。需要关闭iommu,编辑:/etc/default/grub。设置 GRUB_CMDLINE_LINUX=“intel_iommu=on iommu=pt” 或者关闭GRUB_CMDLINE_LINUX=“intel_iommu=off”。重启系统。sudo update-grub, sudo reboot。
- 彻底关闭 IOMMU/VT-d
- 方法:在 BIOS 中禁用该功能,或者在 Linux 的 GRUB 内核启动命令行中添加
amd_iommu=off(AMD 平台)或intel_iommu=off(Intel 平台)。 - 优点:彻底消除冲突,NCCL 可以无阻碍地使用 P2P 进行通信,性能最佳。
- 缺点:系统安全性降低,并且无法在宿主机上利用 IOMMU 进行 GPU 透传(PCIe Passthrough)来创建虚拟机。
- 方法:在 BIOS 中禁用该功能,或者在 Linux 的 GRUB 内核启动命令行中添加
- 使用 IOMMU Passthrough 模式(推荐折衷方案)
- 方法:在 GRUB 内核启动命令行中添加
iommu=pt。 - 原理:此模式告诉内核,对于能够直接进行 DMA 的设备,IOMMU 只进行必要的 PCIe 设备分组,但不进行地址重映射。这样既满足了虚拟化对设备分组的基本需求,又避免了地址转换对 P2P 通信的性能干扰。
- 效果:Cisco 等厂商的官方文档明确指出,添加
iommu=pt可以解决 NCCL 关于系统不稳定或挂起的警告。
- 方法:在 GRUB 内核启动命令行中添加
在虚拟化环境中部署多GPU时,务必开启IOMMU;在物理机运行AI训练任务追求最高性能时,应考虑使用iommu=pt绕过IOMMU干预,恢复GPU间的直接通信能力。
愿我都能在各自的领域里不断成长,勇敢追求梦想,同时也保持对世界的好奇与善意!

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 8
8 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)