Windows利用vllm框架部署大模型(NVIDIA GPU版)
一、搭建vllm框架的环境配置由于 vLLM 主要适配 Lindux 系统而不支持 Windows,因此我们需要通过安装 WSL(Windows Subsystem for Linux,适用于 Windows 的 Linux 子系统)来运行 Ubuntu 环境。1.以管理员身份打开PowerShell或者Windows命令提示符2.直接在命令窗口输入指令 wsl --install,这个应该是最简
一、搭建vllm框架的环境配置
由于 vLLM 主要适配 Lindux 系统而不支持 Windows,因此我们需要通过安装 WSL(Windows Subsystem for Linux,适用于 Windows 的 Linux 子系统)来运行 Ubuntu 环境。
1.以管理员身份打开PowerShell或者Windows命令提示符
2.直接在命令窗口输入指令 wsl --install,这个应该是最简单安装wsl的方法,默认安装的是Ubuntu
3.重启电脑
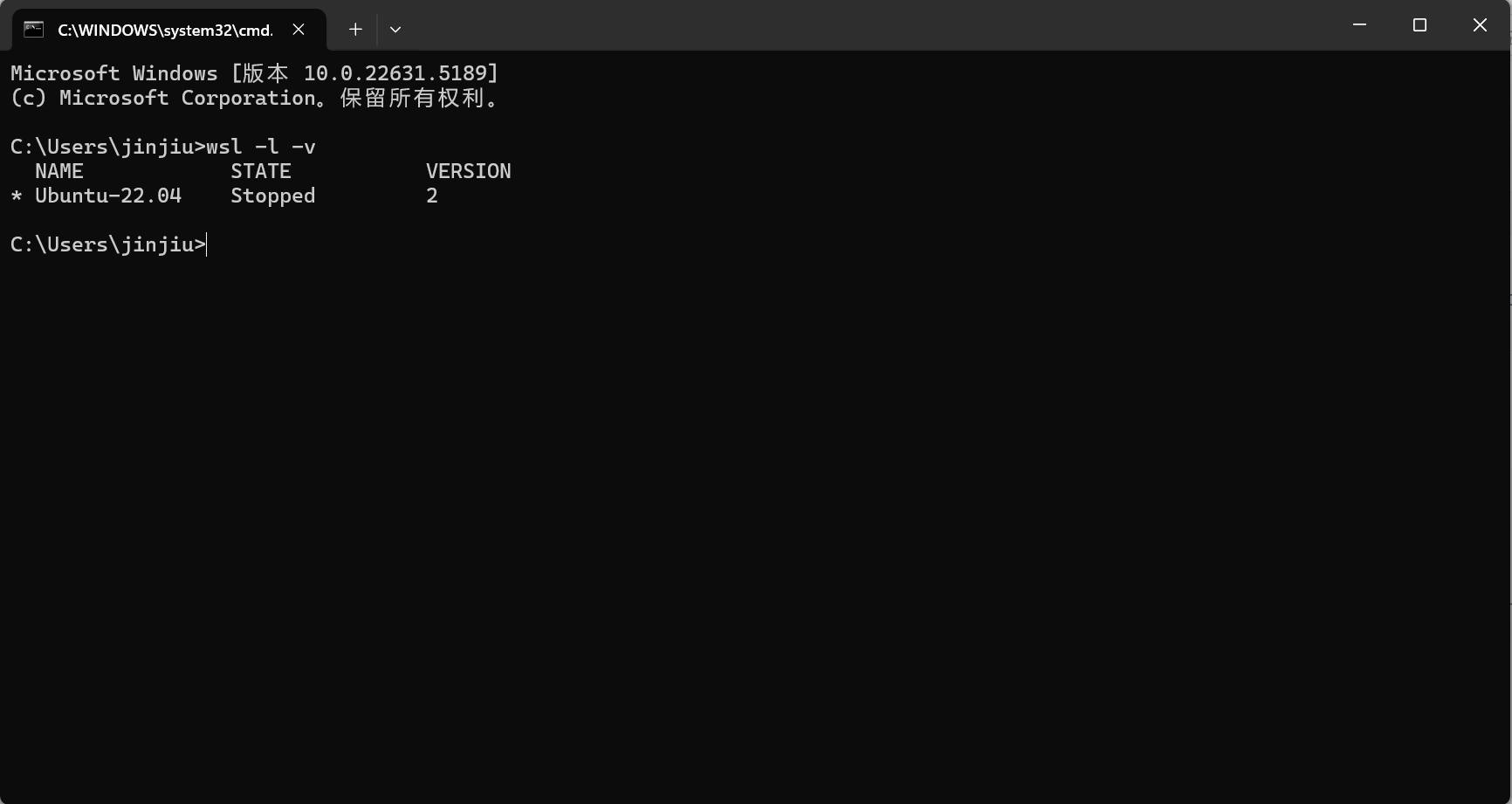
4.打开PowerShell或者Windows命令提示符,输入指令 wsl -l -v 查看wsl版本,确保安装无误
5.关闭PowerShell或者Windows命令提示符,重新以管理员身份打开
6.输入命令 wsl --user root ,这个命令是让你以root用户登录wsl,这个是让你有权限修改系统文件,后续输入命令更新软件包和下载文件不会因为权限报错,输入后前面应该有root标识

7.输入命令 sudo apt update && sudo apt upgrade 更新软件包
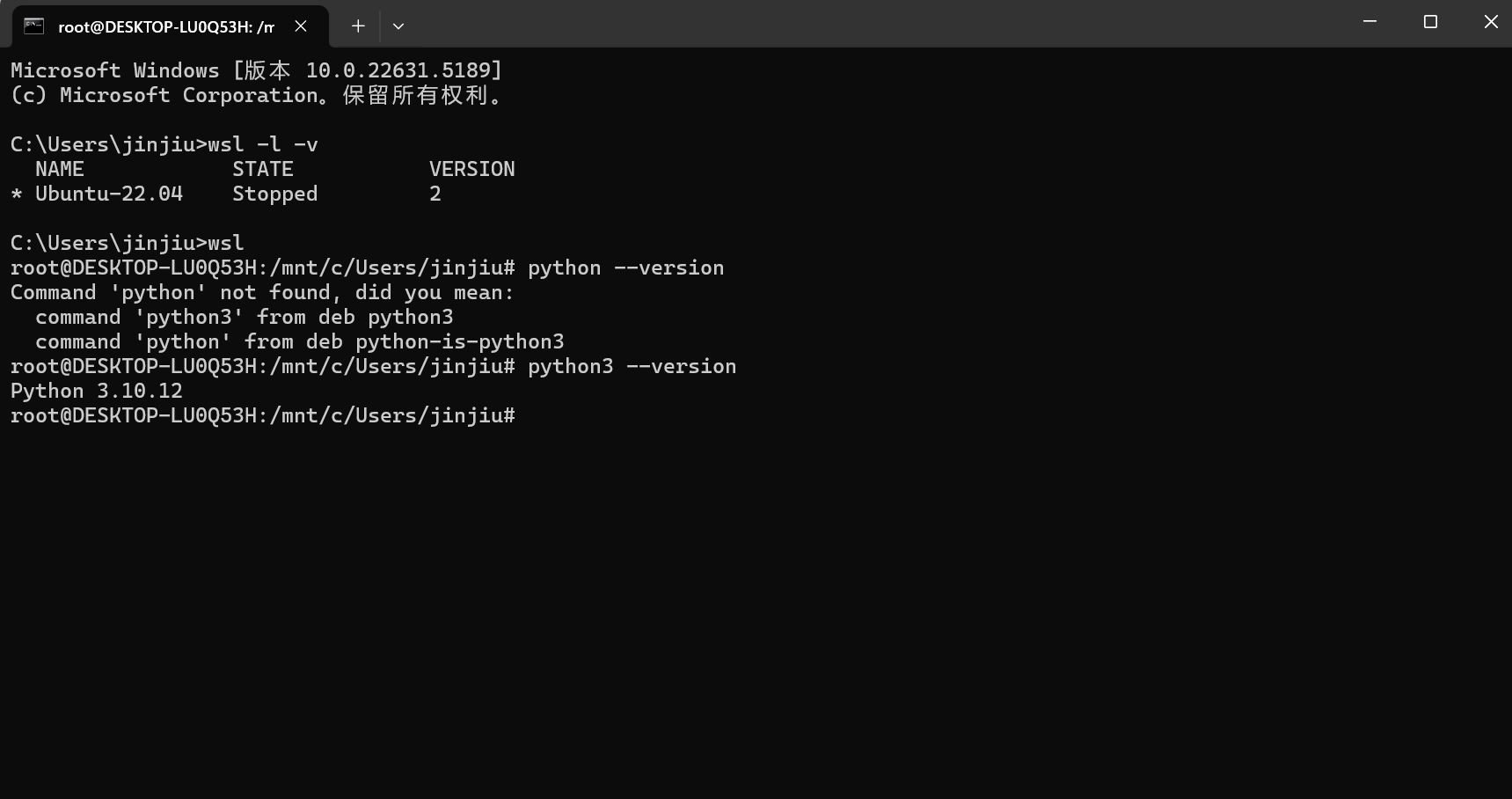
8.更新后输入指令 sudo apt upgrade python3 安装python,安装完成后输入python3 --version查看版本,以验证安装
9.输入指令 sudo apt install python3-pip 安装pip,后面要用pip指令安装文件
10.输入指令 sudo apt install python3-venv 安装venv用来创建虚拟环境
11.输入指令 sudo apt install build-essential 后面某些指令需要用到
12.pip默认是从官方源上下载,国内下载可能较慢甚至下载不了,可以输入指令设置从国内的镜像源下载,
从清华大学镜像源下载的指令 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
从阿里云镜像源下载的指令 pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
这是直接设置pip默认去国内镜像源下载
13.我们需要安装 NVIDIA 驱动(在 Windows 端) 和 CUDA Toolkit(在 WSL Ubuntu 端),才可让 vLLM 正常调用 GPU 进行工作。
重要前提:先在 Windows 主机上安装 NVIDIA 驱动
WSL2 的特殊架构使得Ubuntu 子系统直接使用 Windows 主机上安装的 NVIDIA 驱动。因此,在开始以下步骤之前,你必须确保:
步骤 4:配置环境变量
安装完成后,你需要将 CUDA 的二进制文件和库文件路径添加到系统环境变量中,这样系统才能找到它们。
验证安装
最后,让我们验证 CUDA 是否已正确安装。
如果以上两个命令都能正确输出信息而没有报错,恭喜你,CUDA Toolkit 已经在你的 WSL Ubuntu 中成功安装!
-
你的电脑拥有 NVIDIA GPU。
-
你已经在 Windows 系统(不是 WSL) 中安装了最新版的 NVIDIA GeForce Game Ready 驱动 或 NVIDIA Studio 驱动。
-
Download The Official NVIDIA Drivers | NVIDIA
 https://www.nvidia.com/en-us/drivers/去官网选择自己显卡的型号下载对应的驱动
https://www.nvidia.com/en-us/drivers/去官网选择自己显卡的型号下载对应的驱动 -
在搭建vllm框架的环境配置步骤中,我们已经下载了大部分需要的包,
添加 NVIDIA 包仓库并安装 CUDA
这是最推荐的方法,通过 NVIDIA 的官方仓库来安装,便于管理和更新。
-
下载并安装仓库密钥环包(Keyring Package)
这个包会将 NVIDIA 的官方 GPG 密钥和仓库信息添加到你的系统中。请根据你的 Ubuntu 版本选择对应的命令。-
如果您安装的是 Ubuntu 22.04 (Jammy Jellyfish) - 这是目前最常见的版本
指令1 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2204/x86_64/cuda-keyring_1.1-1_all.deb 指令2 sudo dpkg -i cuda-keyring_1.1-1_all.deb
-
如果您安装的是 Ubuntu 20.04 (Focal Fossa)
指令1 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2004/x86_64/cuda-keyring_1.1-1_all.deb 指令2 sudo dpkg -i cuda-keyring_1.0-1_all.deb
-
如果您安装的是 Ubuntu 24.04 (Noble Numbat) - 最新版本
指令1 wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb 指令2 sudo dpkg -i cuda-keyring_1.1-1_all.deb
如果不确定你的 Ubuntu 版本,可以输入
lsb_release -a查看。 -
-
更新软件包列表(以识别新添加的仓库)
bash
sudo apt update
-
安装 CUDA Toolkit
现在你可以安装 CUDA 了。建议安装最新的稳定版本(目前是 12.x),因为 vLLM 对其支持最好。bash
安装 CUDA 12.4 版本(推荐) sudo apt install -y cuda-toolkit-12-4 或者,你也可以安装 meta 包,它会自动指向最新的 12.x 版本 sudo apt install -y cuda-toolkit-12-6 或者,安装 CUDA 11.8(一些旧的库或项目可能需要) sudo apt install -y cuda-toolkit-11-8
安装过程需要下载几个 GB 的文件,请耐心等待。
-
打开你的 shell 配置文件(通常是
~/.bashrc)。bash
nano ~/.bashrc
-
在文件的最末尾,添加以下两行:
bash
export PATH=/usr/local/cuda-12.4/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-12.4/lib64:$LD_LIBRARY_PATH
注意:如果你安装的不是 12.4 版本(例如 11.8 或 12.6),请将路径中的
cuda-12.4替换为你实际安装的版本号(如cuda-11.8或cuda-12.6)。 -
保存并退出编辑器。
-
在
nano中:按Ctrl + X,然后按Y确认,最后按Enter。
-
-
让配置立即生效:
bash
source ~/.bashrc
-
检查 NVIDIA 驱动程序版本(在 WSL 内)
bash
nvidia-smi
这个命令会显示一个表格,左上角是驱动版本,右上角支持的 CUDA Version。这里显示的是你的驱动最高能支持的 CUDA 版本,只要你安装的 Toolkit 版本不高于这个值即可。例如,驱动显示支持 CUDA 12.4,你安装了 CUDA 12.4 Toolkit,这就是兼容的。
-
检查 CUDA 编译器版本
bash
nvcc --version
这个命令会输出你刚刚安装的
nvcc(CUDA 编译器)的具体版本号,它应该与你安装的 Toolkit 版本(如 12.4)一致。
二、搭建vllm框架
由于下载软件包默认会到c盘,为了防止占用c盘内存,需要把后续下载的包下至d盘
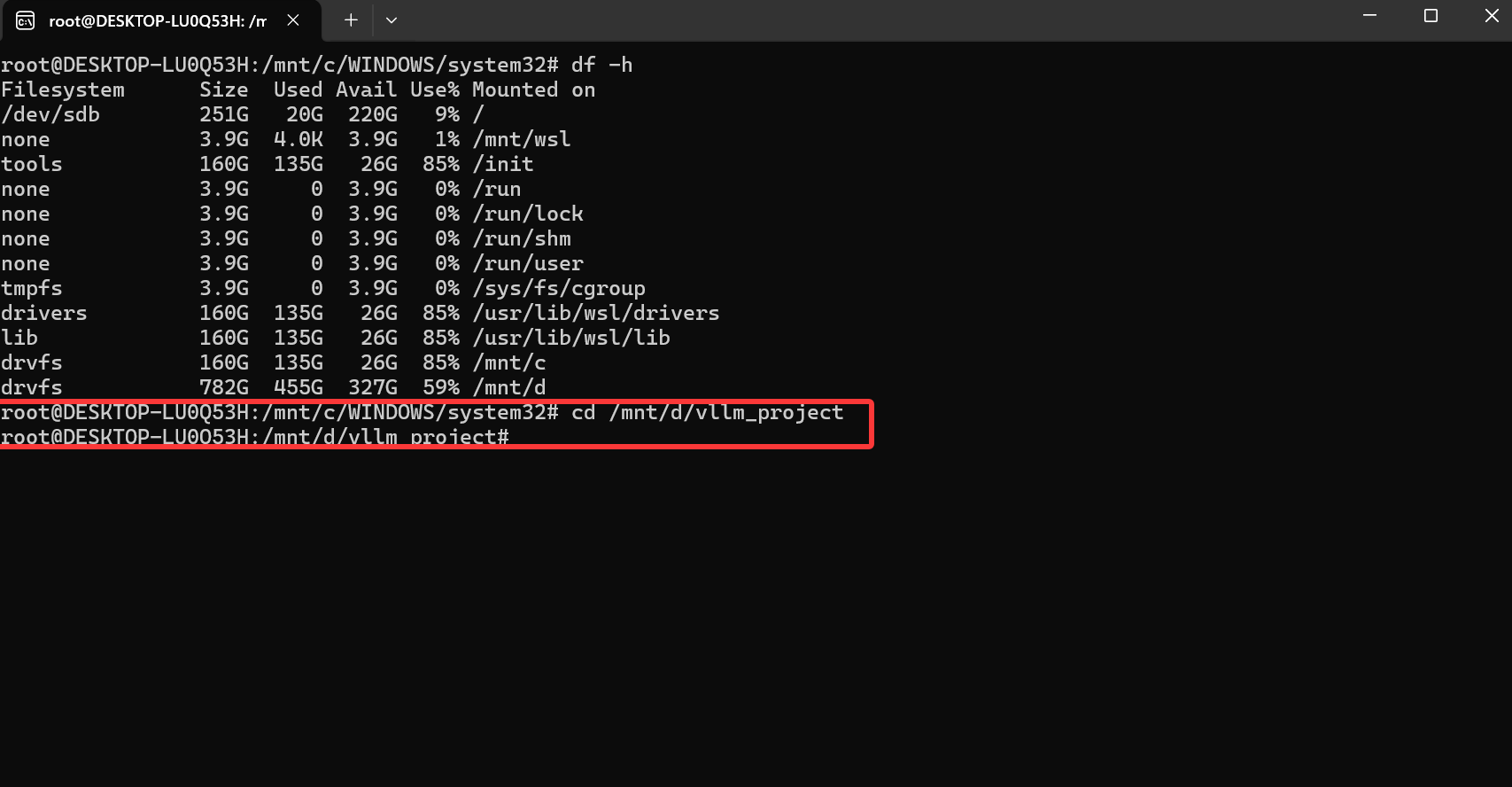
1.打开wsl,要明确 Windows 系统中 D 盘在 Ubuntu 里的挂载位置。一般而言,Windows 分区会被挂载到/mnt/d目录。你可以通过以下命令查看磁盘挂载情况: df -h
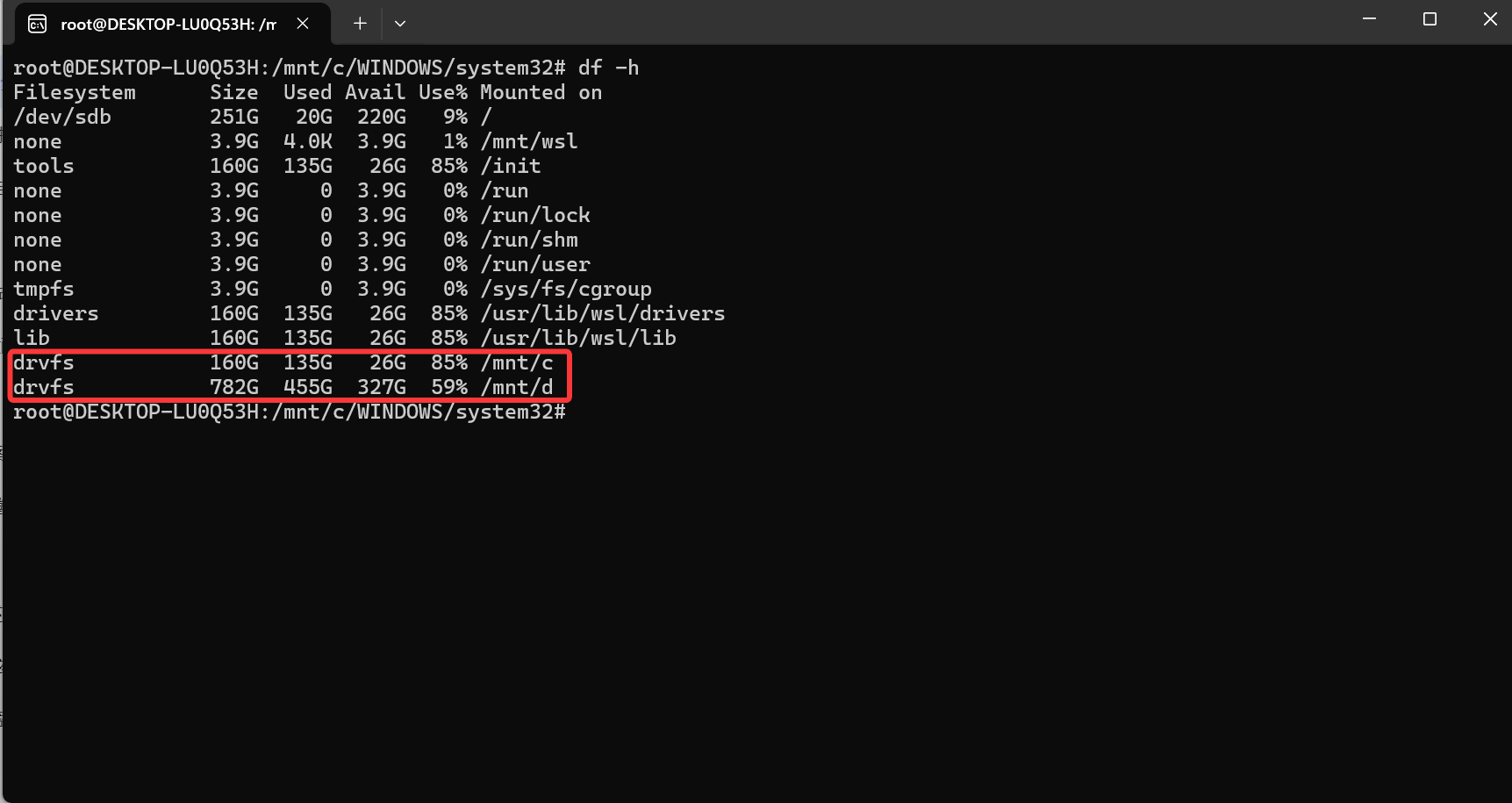
框内上面是你的 Windows C: 盘在 WSL2 中的标准挂载位置
下面是你的Windows D: 盘在 WSL2 中的标准挂载位置
如果不是你可以复制去找ai教你怎么改,因为我默认是这个,我也不知道怎么修改
2. 在 D 盘创建虚拟环境
输入指令 cd /mnt/d 打开d盘
输入指令 mkdir vllm_project 创建名为vllm_project的文件夹,方便管理文件
输入指令cd vllm_project 打开文件夹
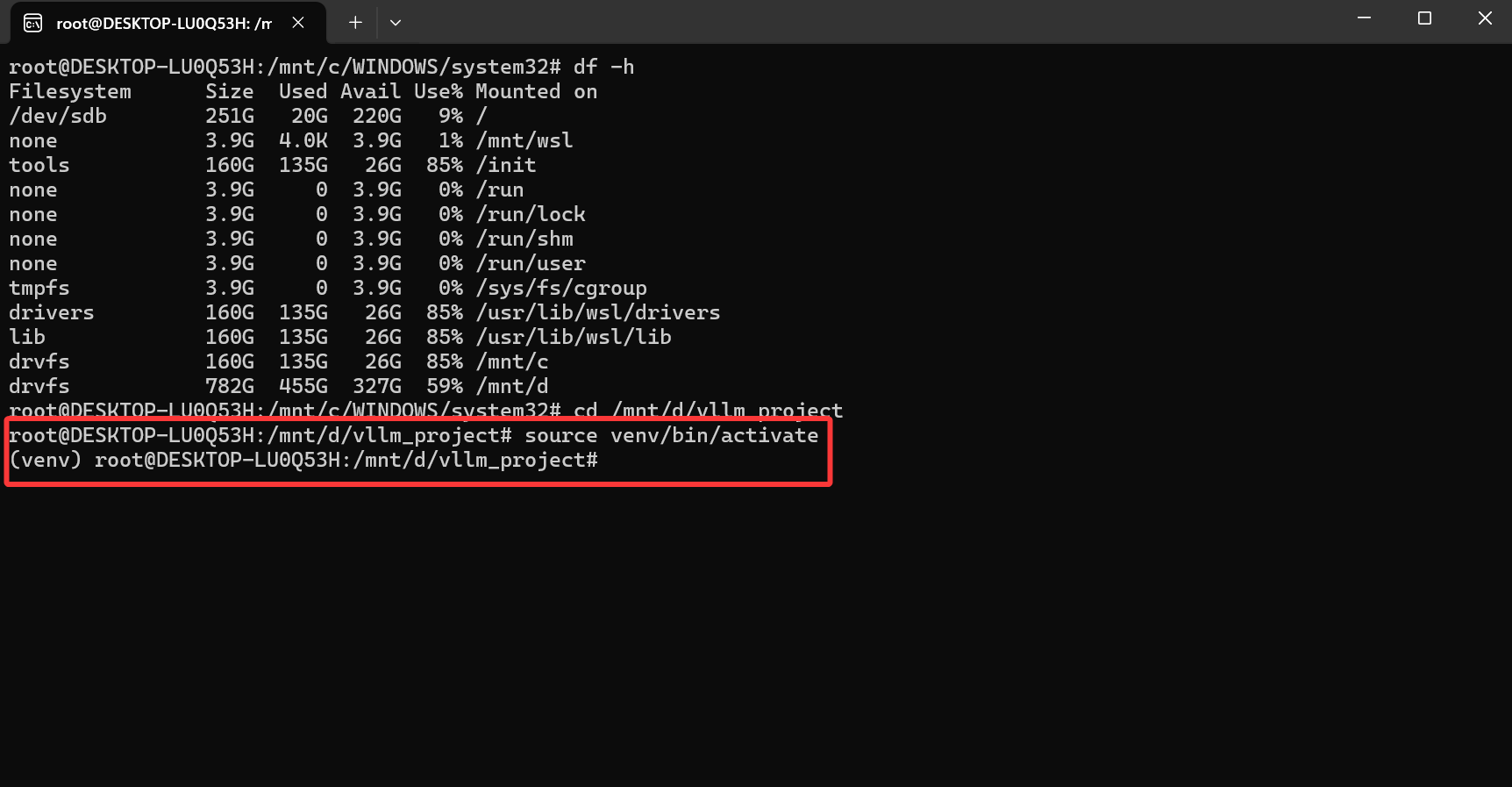
输入指令 python3 -m venv venv 创建名为venv的虚拟环境
输入指令 source venv/bin/activate 激活虚拟环境
3.安装vllm框架
在虚拟环境中输入指令 pip install vllm 安装vLLM的稳定版本
到此vllm框架安装完毕
后续打开流程:
打开cmd
输入wsl
打开d盘cd /mnt/d/vllm_project
打开虚拟环境source venv/bin/activate
三、接入大模型
由于从Hugging Face上下载模型太麻烦,国内访问需要VPN,所以我用的是阿里云的model scope下载的
使用 ModelScope 镜像下载模型
-
安装 ModelScope 库(在 Ubuntu 终端执行)
pip install modelscope
-
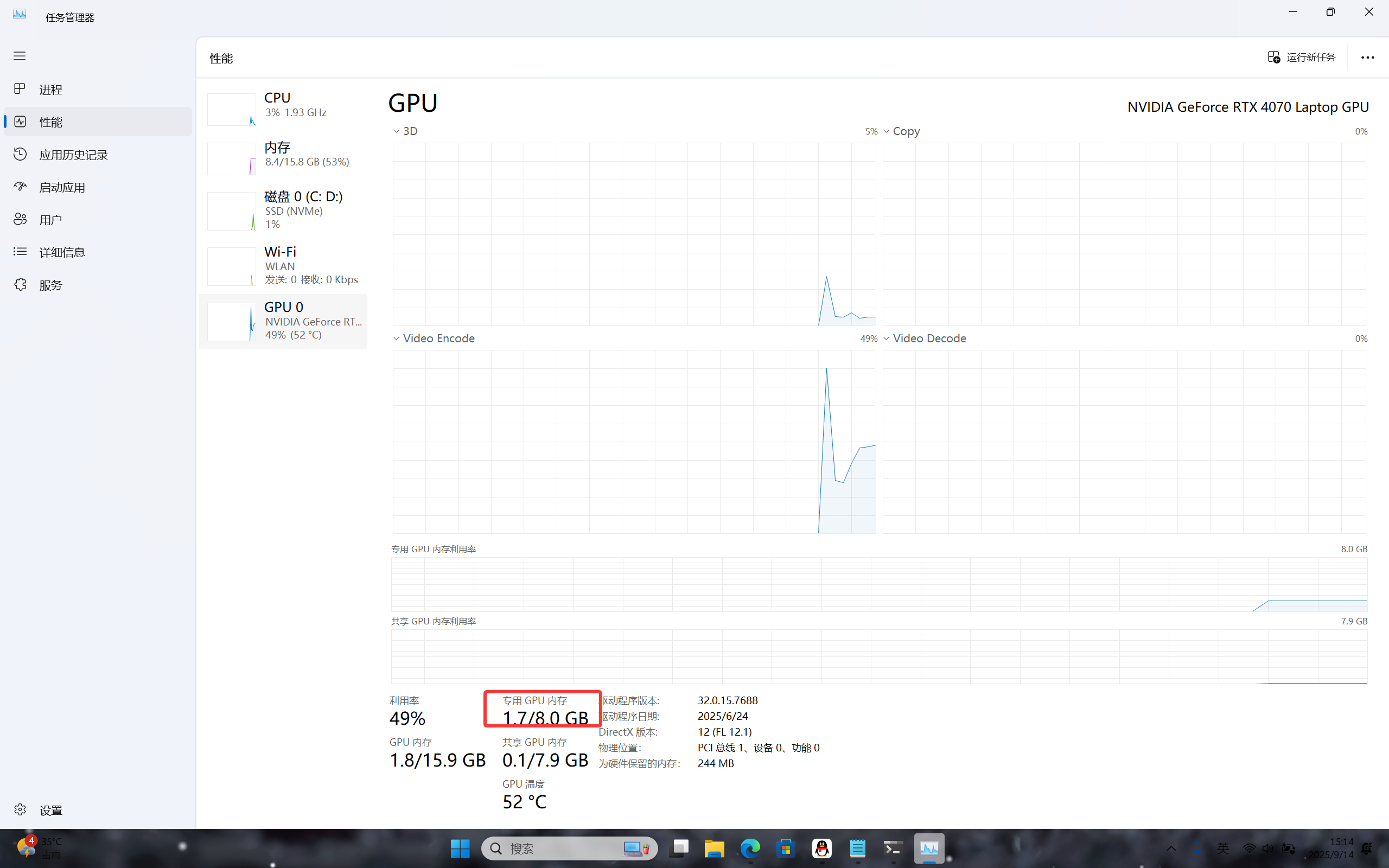
下载模型,这个需要根据自己电脑专用gpu空闲内存的大小下载,由于vllm启动需要占gpu显存,建议下载的模型占用内存不要太极限,不然跑不起来。
-
我这里以Qwen2.5-7B 模型为例 mkdir -p /mnt/d/vllm_project/models 创建模型的文件夹
-
下载模型前往 模型库首页 · 魔搭社区 官网
-
搜索自己需要的模型
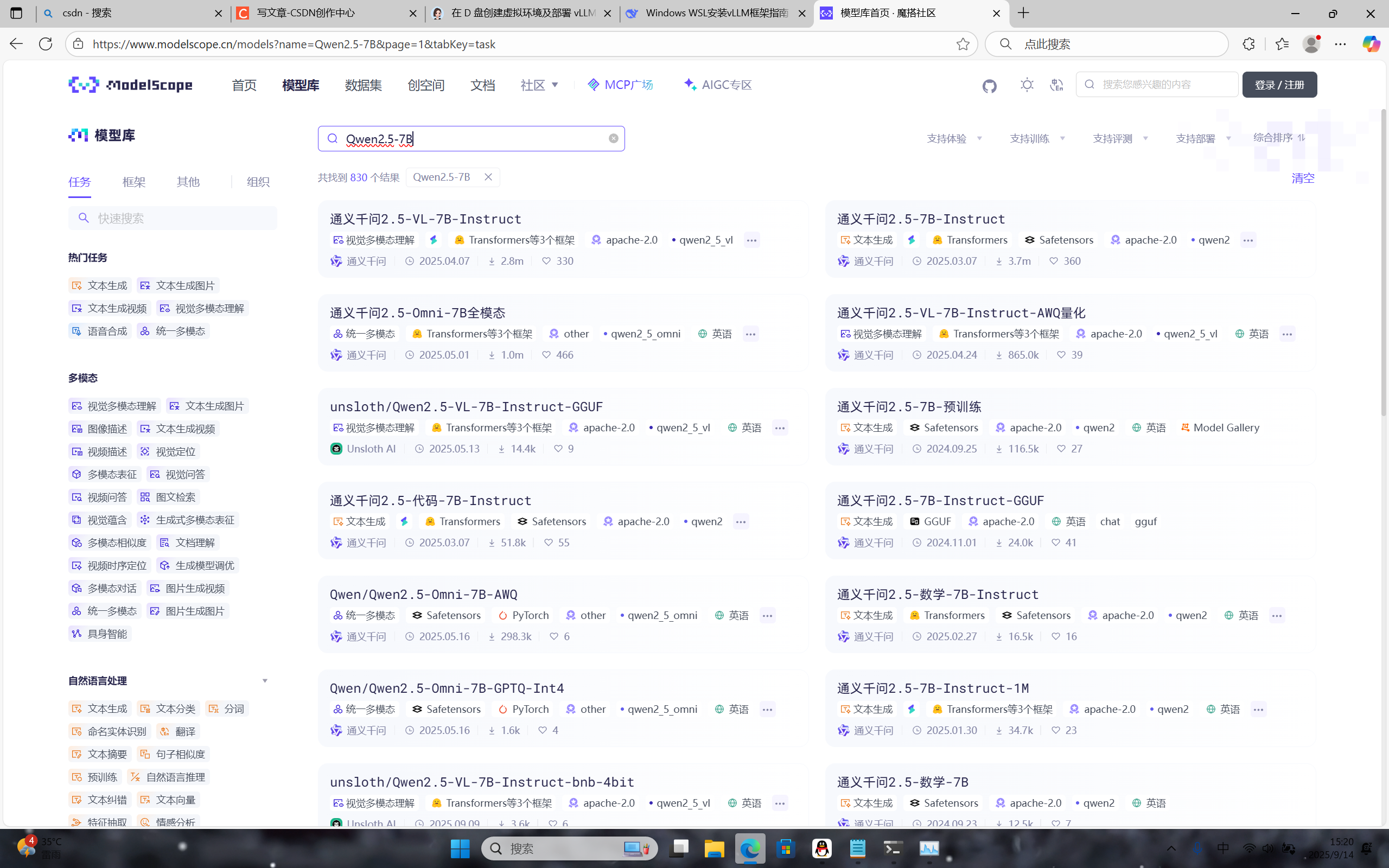
-
点击进入后点击下载模型
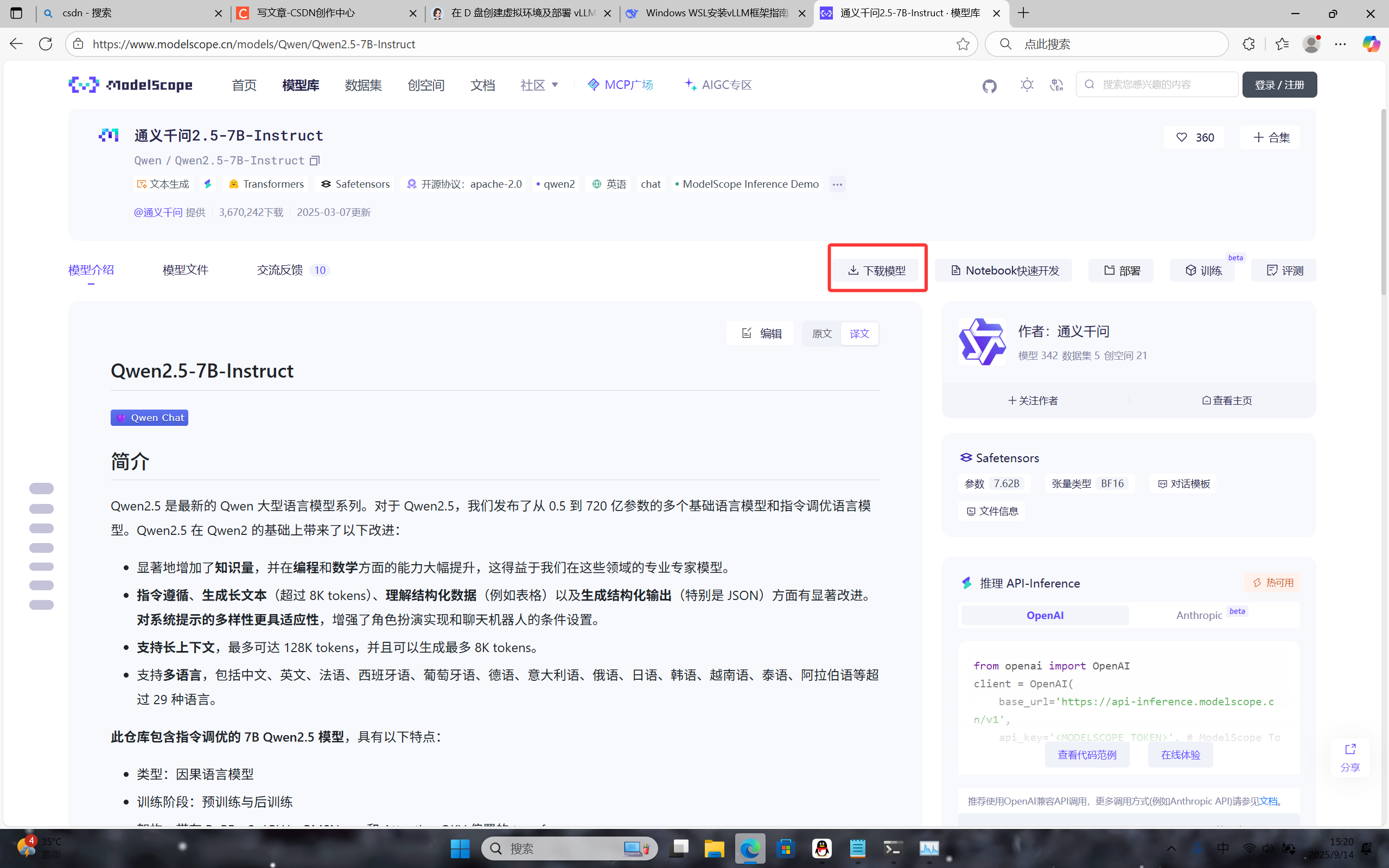
-
这里下载教程也很详细,我们前面已经进行了第一步,接下来直接进行第二步就行,下载到上面创建的模型文件夹
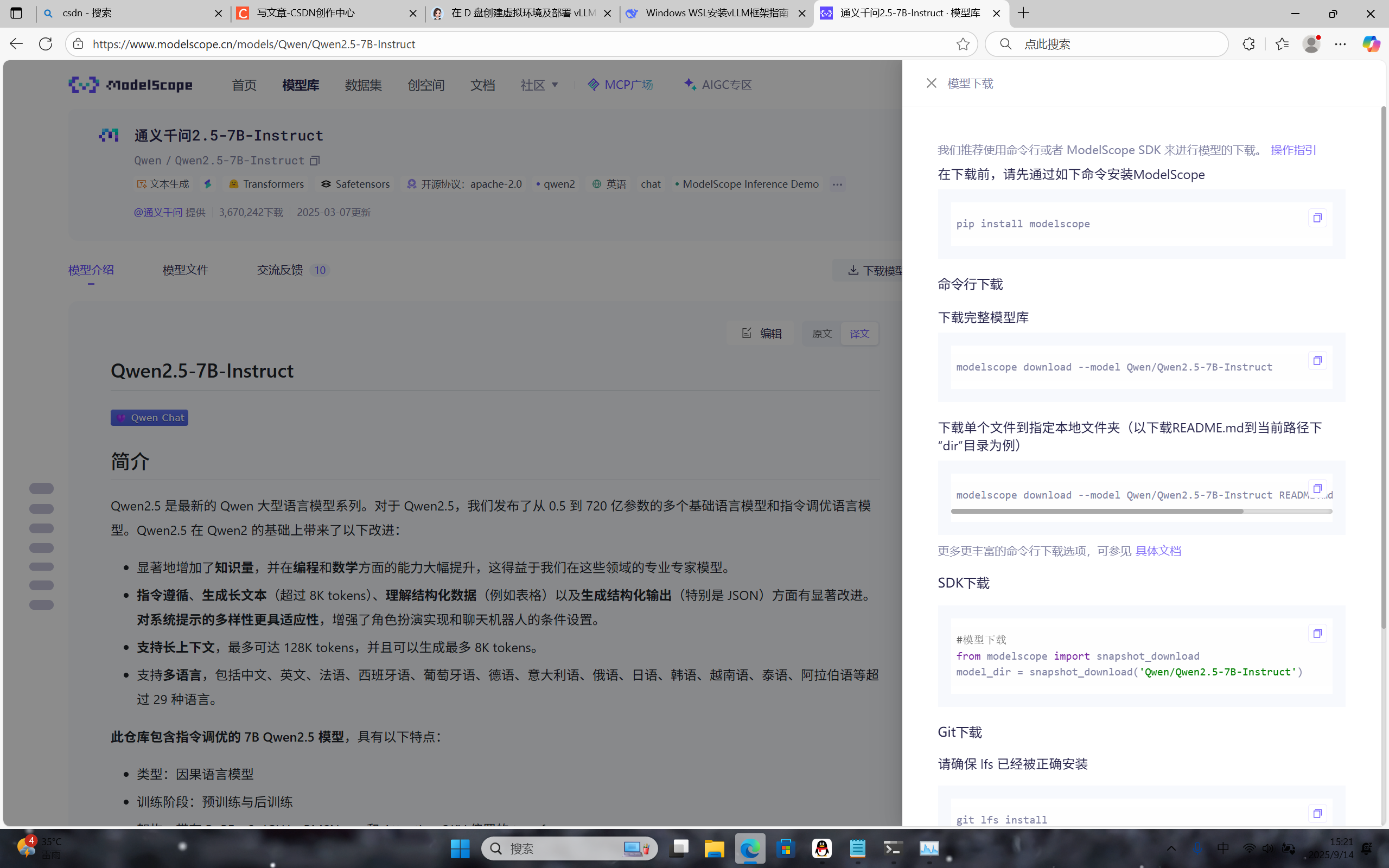
-
通过api调用服务: vllm serve /mnt/d/vllm_project/models/qwen2.5-7b --trust-remote-code --gpu-memory-utilization 0.8 --max-model-len 1024 --swap-space 2 --quantization awq --port 8000 这个指令仅供参考,这个模型我已经删除了,这个指令是我根据记忆写的可能不对
-
命令解释:
vllm serve:
这是使用 vLLM 框架来启动模型服务的命令。/mnt/d/vllm_project/models/qwen2.5-7b:
此为模型路径,表明要加载的模型存放在该位置。vllm启动模型是要模型的存储路径且要wsl格式的--host 0.0.0.0:
该参数用于设置服务器监听的地址。--port 8000:
此参数用于设置服务器监听的端口号,客户端需要通过这个端口来连接模型服务。--gpu-memory-utilization 0.15:
该参数控制分配给模型的 GPU 内存比例。0.15 表示只使用 15% 的 GPU 内存,这样做可以避免模型占用过多 GPU 资源,从而为其他任务留出运行空间。--max-model-len 4096:
此参数设置了模型能够处理的最大输入长度,单位为 token。最大就是模型支持的最大token数,越多vllm要占用的gpu显存就越大,如果设置的超过模型最大token数,模型可能就会胡言乱语。 -
服务启动成功应该输出这个
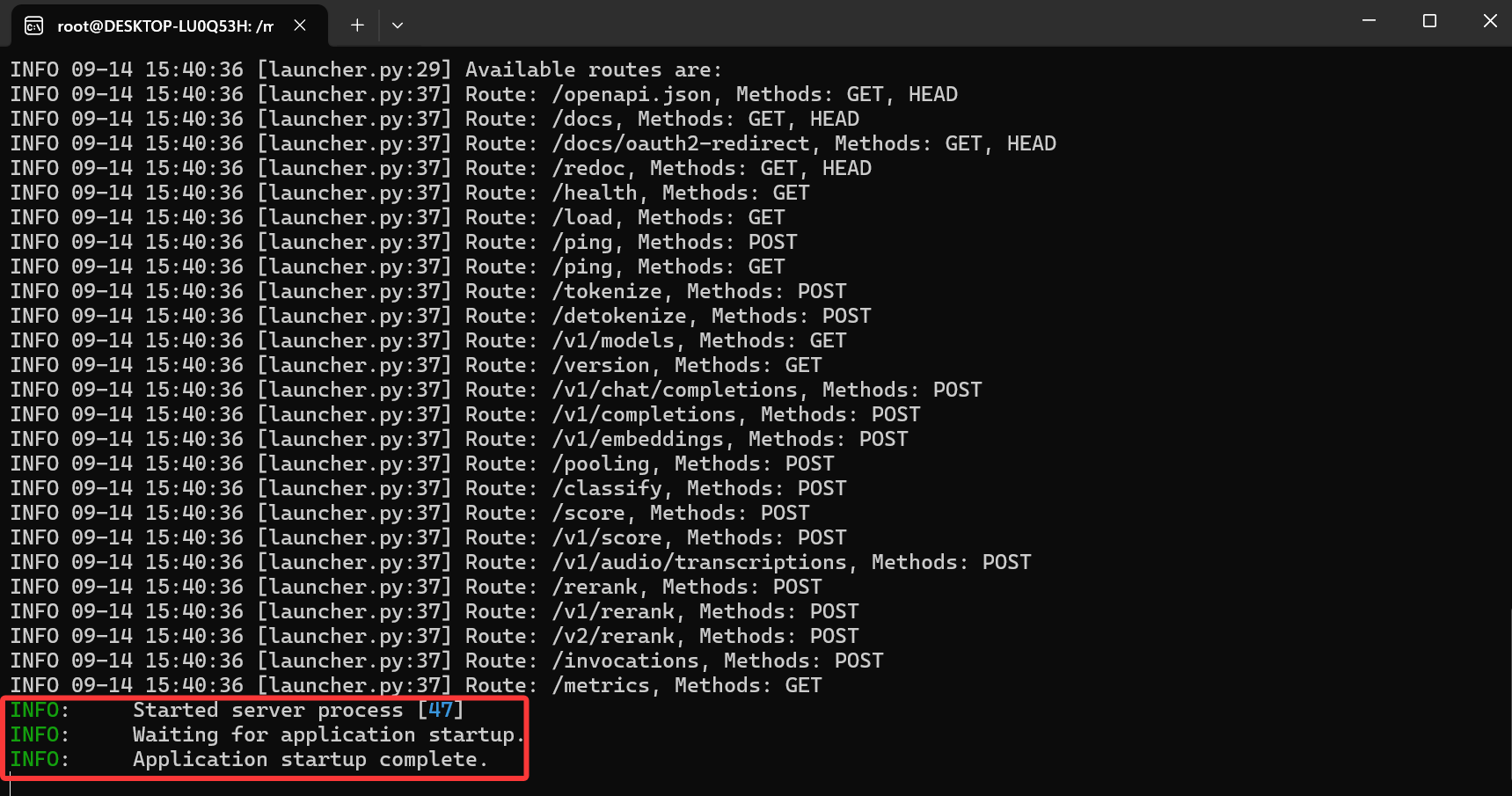
-
调用服务,直接把cmd中的复制丢给ai让它用python利用gradio创建一个ai对话界面就可以了
四、由于离我部署的时间太长了,过程又复杂导致这篇写得很乱,过程中遇到什么问题完全可以复制丢给ai来帮你提出切实可行的解决办法,ai是绝对可以帮你解决的,因为我部署的时候就是有问题就找豆包和deepseek,问题两头来回扔解决的。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)