简单快捷部署各类大模型-vllm的cli命令-可访问api接口
前期准备
1、准备合适显存的gpu服务器
可查看之前的博客中的内容:写代码的方式部署glm-4-9b-chat模型:gradio和api两种模式-CSDN博客
2、配置pip镜像
先升级依赖
python -m pip install --upgrade pip配置镜像源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple3、准备requirement文件
torch>=2.3.0
torchvision>=0.18.0
transformers==4.51.3
huggingface-hub>=0.24.0
sentencepiece>=0.2.0
jinja2>=3.1.4
pydantic>=2.8.2
timm>=1.0.7
tiktoken>=0.7.0
accelerate>=0.32.1
sentence_transformers>=3.0.1
gradio>=4.38.1 # web demo
openai>=1.35.0 # openai demo
einops>=0.8.0
pillow>=10.4.0
sse-starlette>=2.1.2
bitsandbytes>=0.43.1 # INT4 Loading
#vllm==0.8.5
vllm #最新的vllm版本
modelscope执行requirement.txt文件,安装依赖
pip install -r requirements.txt注意:一般vllm的版本最好是最新的,特别是新出的模型,有时候可能用到了新的方法,旧版本会提示,升级vllm到最新版本即可。
部署qwen3-8b模型
执行完前面步骤,环境准备好后,利用modelscope下载对应模型
指定目录为:/root/autodl-tmp/models
python 执行这个脚本命令
from modelscope import snapshot_download
#下载qwen3-8b模型
model_dir = snapshot_download('Qwen/Qwen3-8B', cache_dir='/root/autodl-tmp/models', revision='master')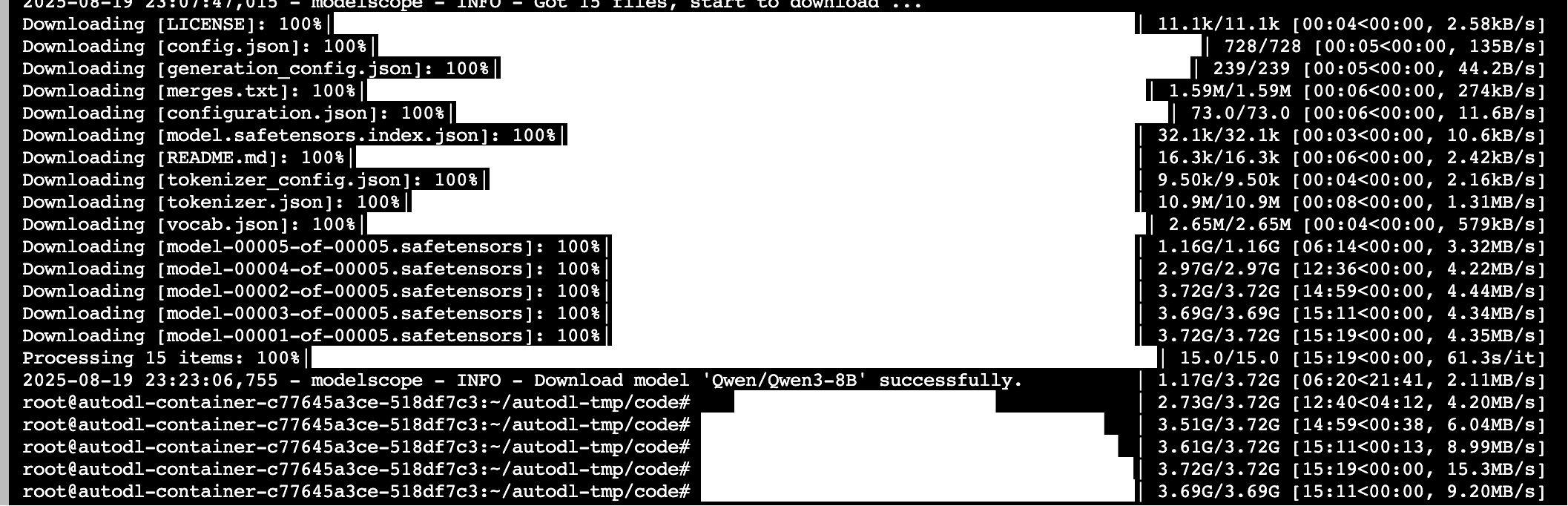
提示100%下载完成
查看指定目录:/root/autodl-tmp/models,是否存在文件跟魔塔社区中一致
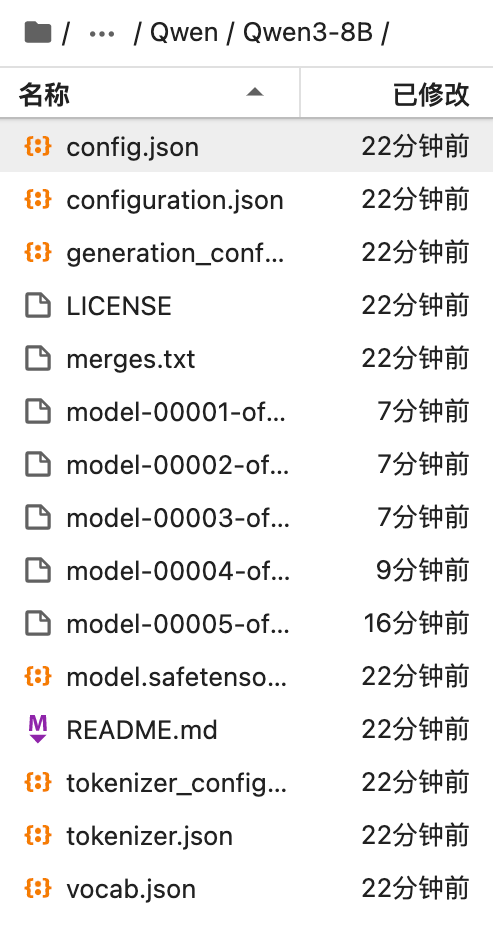
确认下载成功后,接下来可利用vllm的cli命令,帮我们启动模型,顺便绑定本地fastapi服务,开放接口
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/Qwen/Qwen3-8B \
--served-model-name qwen3-8b \
--max-model-len 8k \
--host 0.0.0.0 \
--port 6006 \
--dtype bfloat16 \
--gpu-memory-utilization 0.8 \
--enable-auto-tool-choice \
--tool-call-parser hermes \
--enable-reasoning \
--reasoning-parser deepseek_r1 \--model:指定的模型文件目录地址,要跟下载好的一致
--served-model-name:模型名称,后面调用api指定model参数要用到,名字随便起
--max-model-len:上下文长度,由于这里使用自己的,指定小点,越大占用的显存越高
--host:配置成0.0.0.0,代表任何一台机器都可以访问,如果配置成127.0.0.1,则只能在部署模型的服务器本机上调用
--port:模型访问的端口号
--dtype:模型权重和激活的数据类型: auto, half, float16, bfloat16, float, float32
○ “auto” 将对 FP32 和 FP16 模型使用 FP16 精度,对 BF16 模型使用 BF16 精度。
○ “half” 表示 FP16。推荐用于 AWQ 量化。
○ “float16” 与 “half” 相同。
○ “bfloat16” 在精度和范围之间取得平衡。
○ “float” 是 FP32 精度的简写。
○ “float32” 表示 FP32 精度。
默认值:“auto”
--gpu-memory-utilization:用于模型执行器的 GPU 内存的比例,范围为 0 到 1。例如,值为 0.5 表示 50% 的 GPU 内存利用率。如果未指定,将使用默认值 0.9。这是一个按实例限制,仅适用于当前的 vLLM 实例。如果您在同一 GPU 上运行另一个 vLLM 实例,则无关紧要。例如,如果您在同一 GPU 上运行两个 vLLM 实例,则可以将每个实例的 GPU 内存利用率设置为 0.5。
默认值:0.9
--enable-auto-tool-choice:为支持的模型启用自动工具选择。使用--tool-call-parser 指定要使用的解析器。(一般支持工具调用的都需要配置打开)
默认值:False
--tool-call-parser:根据您使用的模型选择工具调用解析器。这用于将模型生成的工具调用解析为 OpenAI API 格式。--enable-auto-tool-choice 需要此参数。
--enable-reasoning是否为模型启用 reasoning_content(推理内容)。如果启用,模型将能够生成 reasoning content(推理内容)。
默认值:False
--reasoning-parser可选选项:deepseek_r1, granite
根据您正在使用的模型选择 reasoning parser(推理解析器)。这用于将 reasoning content(推理内容)解析为 OpenAI API 格式。--enable-reasoning 需要此项。
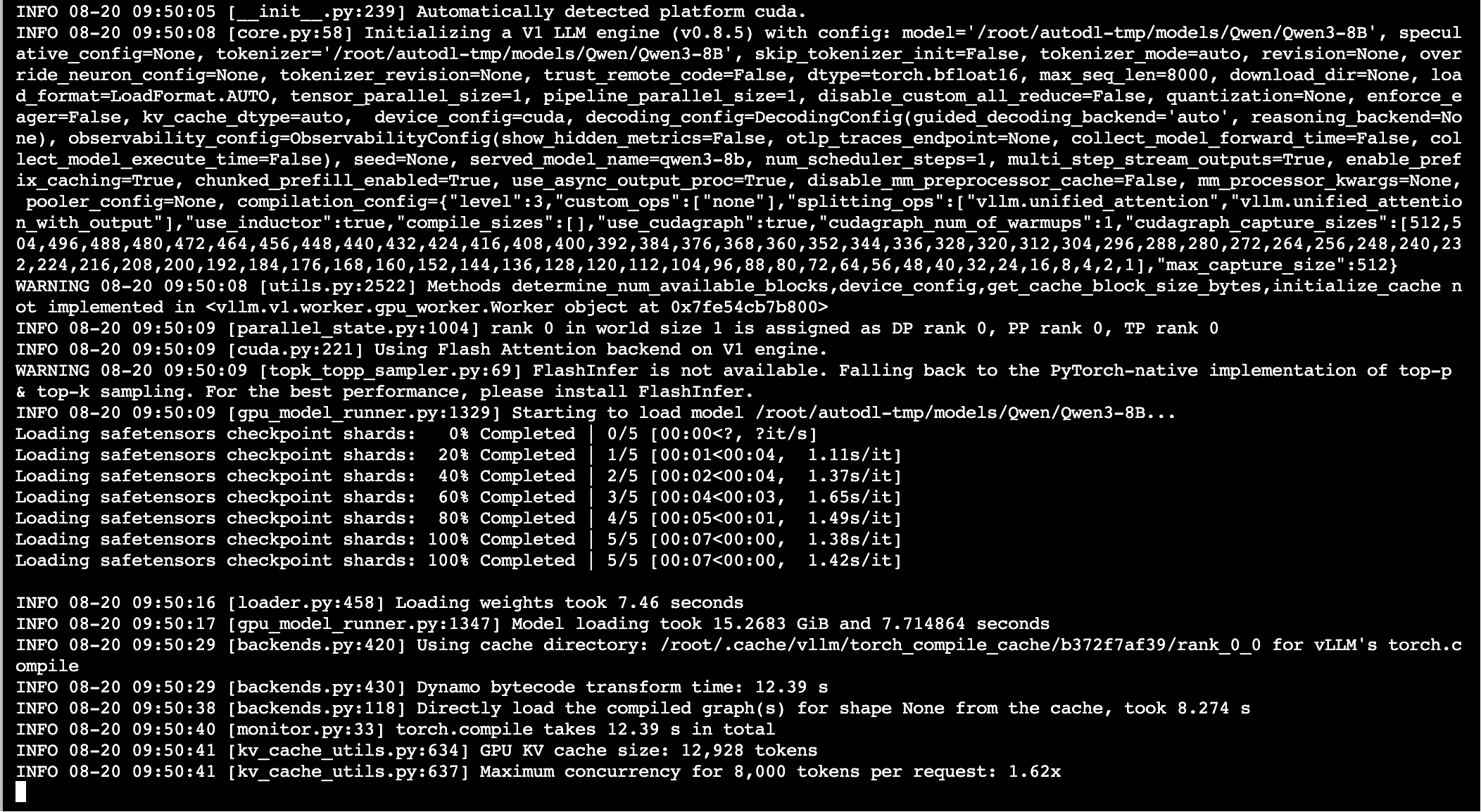
在服务器中执行完cli命令,等待模型启动成功后,即可调用api(如果是算力云,需要端口映射到本地)
启动需要点时间,大概两三分钟,这样就代表启动成功
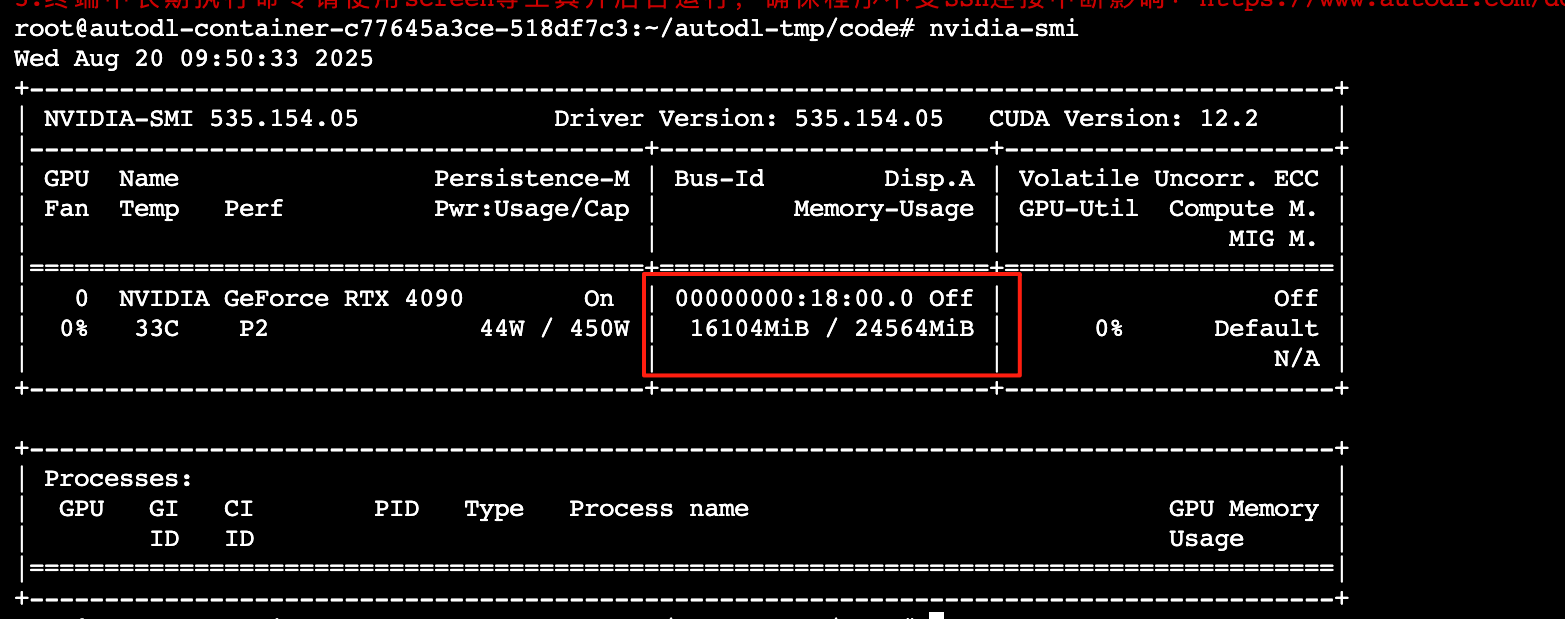
输入 nvidia-smi,查看显卡情况,启动已经占用了16G左右,算是正常
接下来就可以访问接口地址了,接下来就可以愉快地调用了
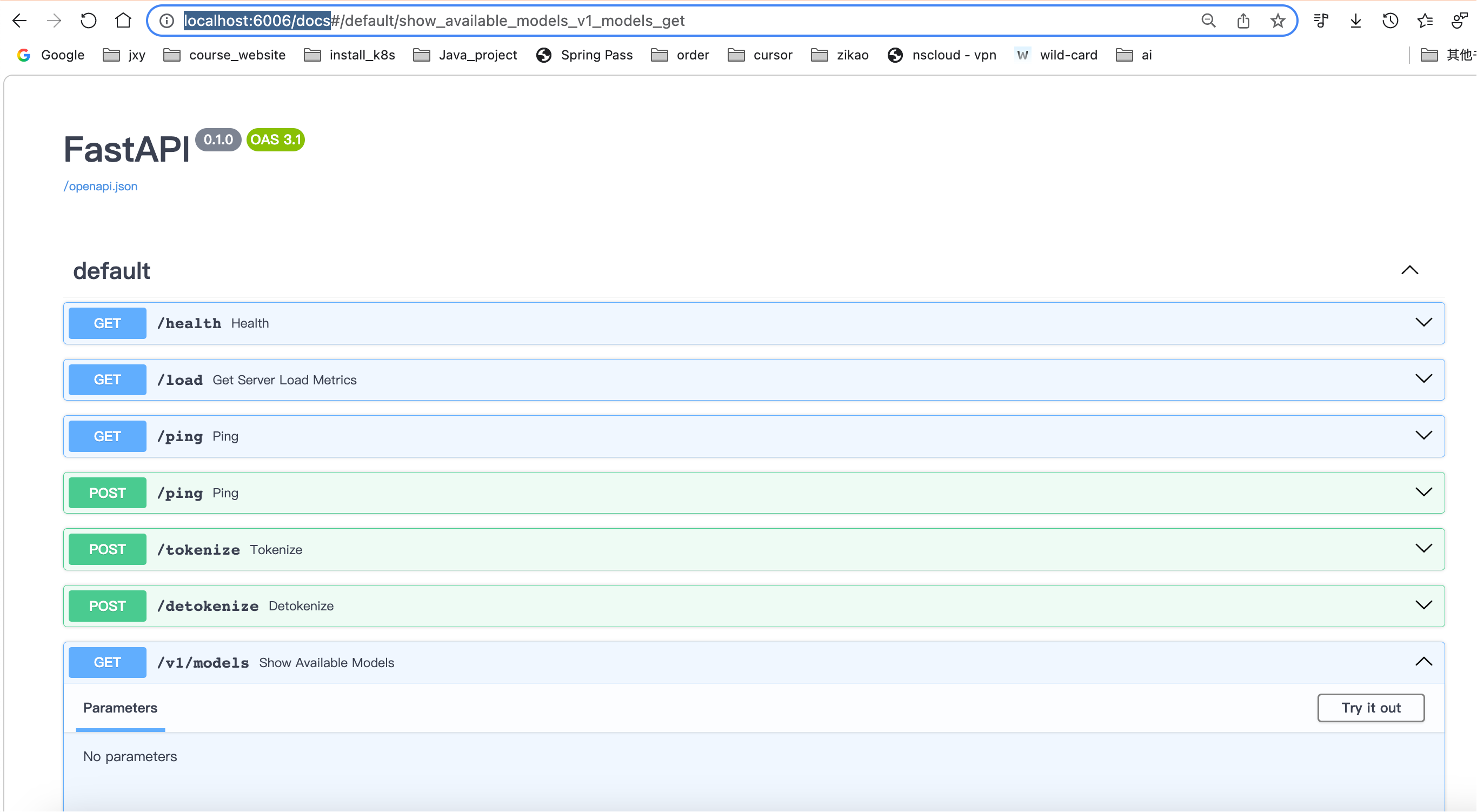
部署deepseek模型
参考前面的步骤
下载模型命令:
from modelscope import snapshot_download
#下载qwen3-8b模型
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', cache_dir='/root/autodl-tmp/models', revision='master')下载完成后,执行vllm-cli命令,参数就是在前面的qwen一样的命令上进行稍微改动而已:
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/deepseek-ai/DeepSeek-R1-0528-Qwen3-8B \
--served-model-name ds-qwen3-8b \
--max-model-len 8k \
--host 0.0.0.0 \
--port 6006 \
--dtype bfloat16 \
--gpu-memory-utilization 0.8 \
--enable-auto-tool-choice \
--tool-call-parser hermes启动成功后即可访问api接口
部署多模态大模型-Qwen2.5-Omni-3B
这是一个支持多模态的大模型,测试玩玩,所以跑了最小的3B模型,如果要想开源的性能最好的多模态大模型,推荐使用通义千问2.5VL系列,占的显存要求就比较大了,跟普通的文本大模型不一样。
1、下载大模型:
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen2.5-Omni-3B', cache_dir='/root/autodl-tmp/models', revision='master')2、下载完后使用vllm的cli命令启动后即可
python -m vllm.entrypoints.openai.api_server \
--model /root/autodl-tmp/models/Qwen/Qwen2___5-Omni-3B \
--served-model-name qwen-omni-3b \
--max-model-len 16k \
--host 0.0.0.0 \
--port 6006 \
--dtype float16 \
--gpu-memory-utilization 0.8
腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 20
20 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)