使用vllm部署DeepSeek-R1-Distill-Qwen-1.5B
1.介绍
1.1 vllm
vLLM是伯克利大学LMSYS组织开源的大语言模型高速推理框架,旨在极大地提升实时场景下的语言模型服务的吞吐与内存使用效率。vLLM是一个快速且易于使用的库,用于 LLM 推理和服务,可以和HuggingFace 无缝集成。vLLM利用了全新的注意力算法「PagedAttention」,有效地管理注意力键和值。
vLLM 的特点和优势:
采用了 PagedAttention,可以有效管理 attention 的 keys、values。
吞吐量最多可以达到 huggingface 实现的24倍,文本生成推理(TGI)高出3.5倍,并且不需要对模型结构进行任何的改变。
如果想使用更简单的方式部署DeepSeek-R1-Distill-Qwen-1.5B,可以看这篇文章:
使用ollama部署DeepSeek-R1-Distill-Qwen-1.5B-CSDN博客
1.2 Deepseek
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司。推出国产大模型DeepSeek-V3和DeepSeek-R1。总参数量为671B,激活37B。
优势:
(1):开发费用超级低,训练成本约为558万美元,是美国最好的模型openAI o1开发费用的3%;
(2):与openAI o1水平相当,数学、编程和推理任务上,甚至偶尔超过了o1;
也正是因为如此,DeepSeek R1价格非常便宜,每100万个输出tokens 2.19美元,而 OpenAI o1 则需要60美元,DeepSeek R1便宜 96.4%,性能却不相上下,完全就是逆风翻盘。
DeepSeek基于 Llama 和 Qwen 从 DeepSeek-R1 中提炼出六个密集模型。 DeepSeek-R1-Distill-Qwen-32B 在各种基准测试中均优于 OpenAI-o1-mini。
2. 环境配置
V100-32GB
PyTorch 2.5.1
Python 3.12(ubuntu22.04)
Cuda 12.4
Triton==3.0.0
transformers==4.46.3
safetensors==0.4.5
vllm==0.6.6
3. DeepSeek-R1-Distill-Qwen-1.5B模型下载
3.1下载网址
https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
3.2 下载后存放目录
/LLM/DeepSeek-R1-Distill-Qwen-1.5B
4. 启动api server服务
4.1 写启动脚本api_server.sh
python -m vllm.entrypoints.openai.api_server
--model /LLM/DeepSeek-R1-Distill-Qwen-1.5B
--served-model-name deepseek-qwen-1.5b
--dtype=half
--tensor-parallel-size 1
--max-model-len 1000
4.2 启动脚本api_server.sh
sh api_server.sh
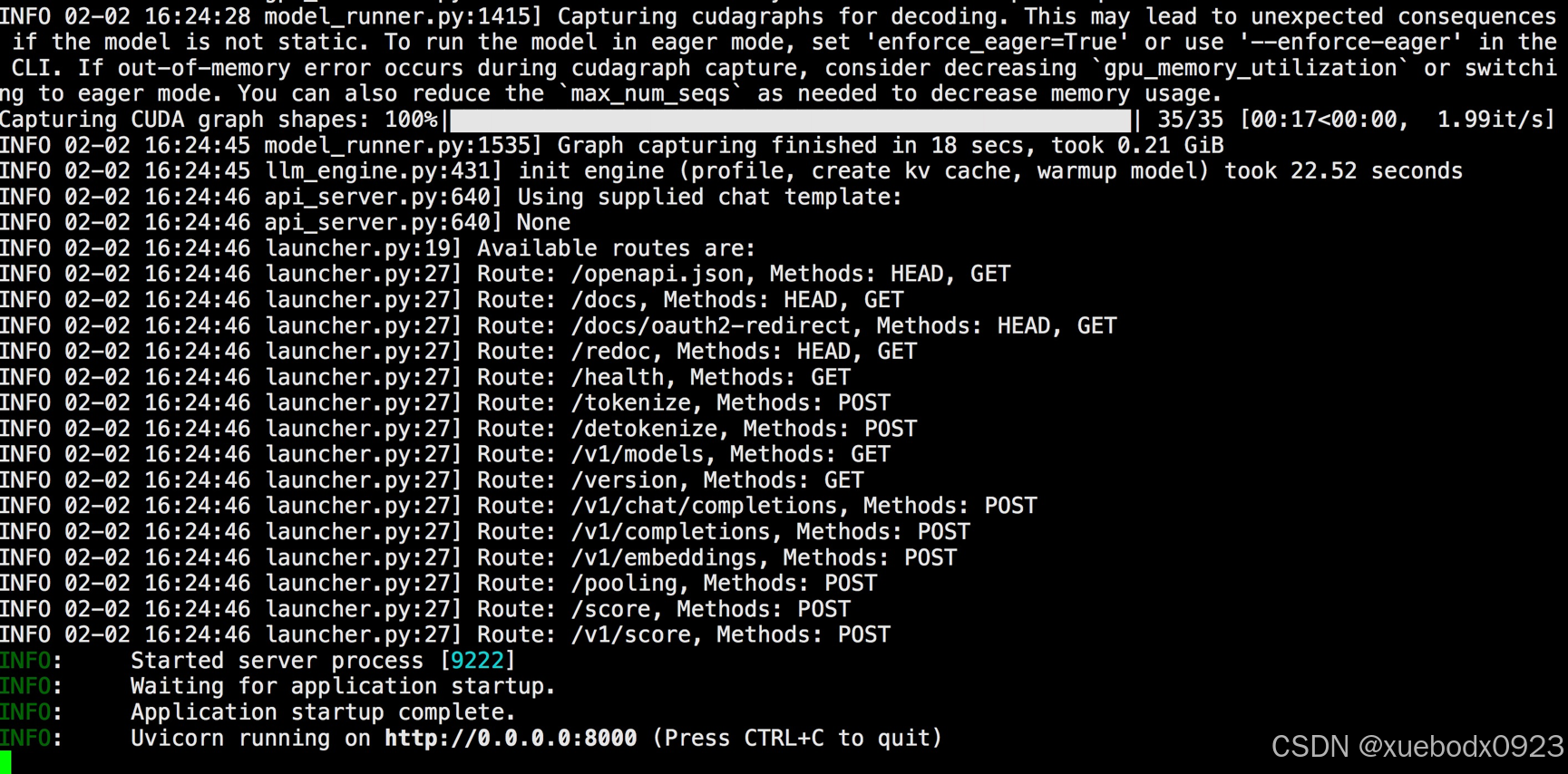
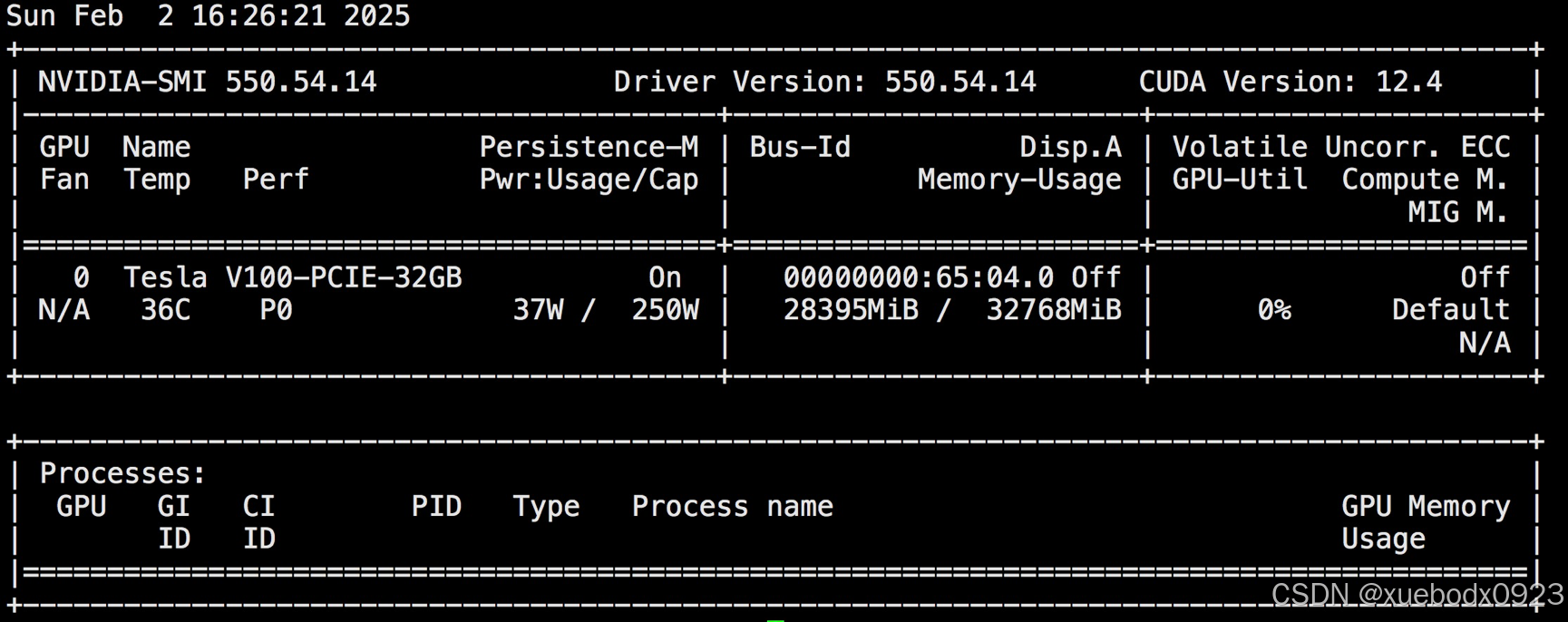
GPU用了28G:
4.3 小模型显存占用过高的分析,以及降低显存的方法
从模型启动信息model weights take 3.35GiB; non_torch_memory takes 0.23GiB; PyTorch activation peak memory takes 1.39GiB; the rest of the memory reserved for KV Cache is 23.59GiB.来看,主要是KV Cache占用显存较大,占用了23.59GiB,这个可以通过增加参数--gpu-memory-utilization来降低显存占用,这个参数是GPU内存使用率的比例,介于0到1之间,默认值是0.9,可以根据需要来修改,下面改成0.2来降低显存。
在启动脚本api_server.sh中增加参数--gpu-memory-utilization 0.2:
python -m vllm.entrypoints.openai.api_server
--model /LLM/DeepSeek-R1-Distill-Qwen-1.5B
--served-model-name deepseek-qwen-1.5b
--dtype=half
--tensor-parallel-size 1
--max-model-len 1000
--gpu-memory-utilization 0.2
重新启动脚本api_server.sh,启动成功以后GPU占用不到6G。
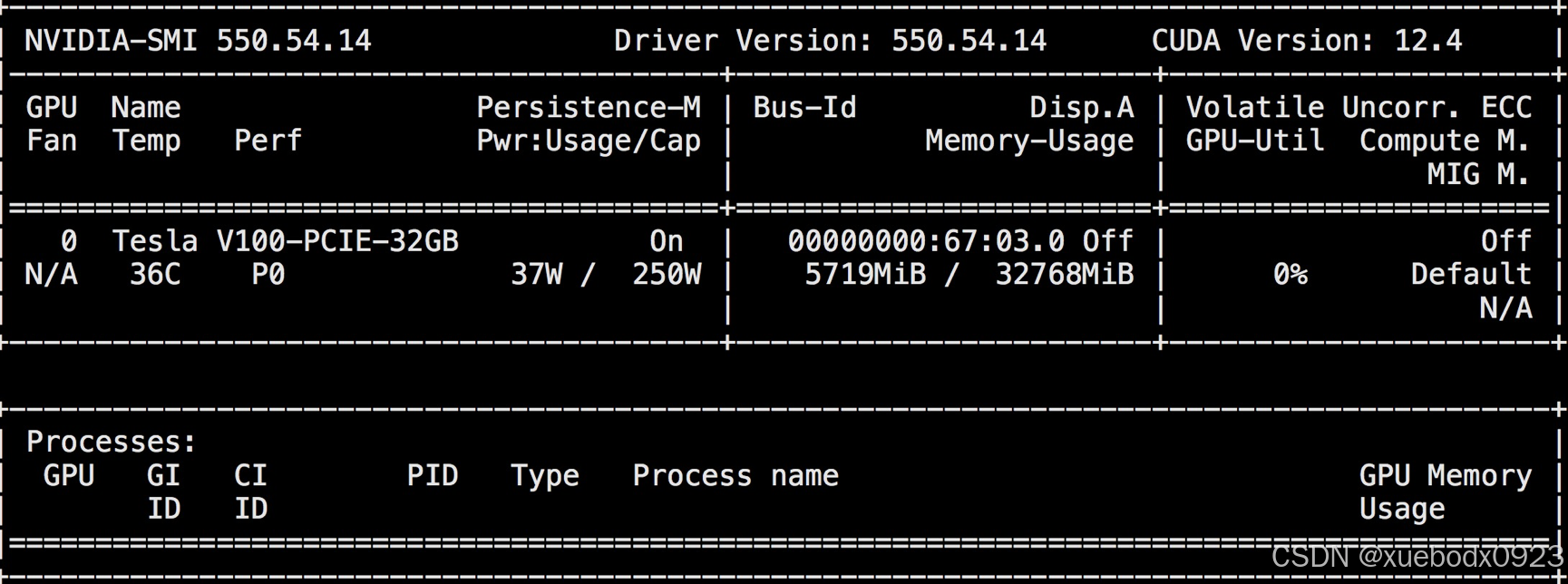
model weights take 3.35GiB; non_torch_memory takes 0.23GiB; PyTorch activation peak memory takes 1.39GiB; the rest of the memory reserved for KV Cache is 1.38GiB.从模型启动信息来看,KV Cache从23.59GiB降到了1.38GiB。
5. 写客户端验证
5.1 写python程序client_demo.py

5.2 运行client_demo.py程序
python client_demo.py
5.3 模型输出


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 37
37 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)