深度强化学习DRL——价值学习
在深度强化学习DRL中,价值学习(Value-Based-Learning)和策略学习(Policy-Based-Learning)是两种核心方法,它们的区别在于学习的目标和输出形式。本次博客先介绍价值学习部分。
一、深度强化学习的“深度”体现在哪里?
前面介绍了动作价值函数、最优动作价值函数以及状态价值函数,那么如果想直接用数学表达式来写出这些函数是极为困难的,最有效的方法就是使用(深度)神经网络来近似这些价值函数。
强化学习+神经网络=深度强化学习
二、DQN算法
以DQN算法为例,如果要近似学习最优动作价值函数Q⋆Q_{\star}Q⋆,最有效的办法就是深度Q网络(deep Q network, DQN),记作Q(s,a;w)Q(s,a; \bm w)Q(s,a;w),其中的w\bm ww表示神经网络的参数。
首先随机初始化w\bm ww,随后用“经验”去学习w\bm ww。学习的目标是:对于所有sss和aaa,DQN的预测Q(s,a;w)Q(s,a; \bm w)Q(s,a;w)尽量接近Q⋆(s,a)Q_{\star}(s,a)Q⋆(s,a)。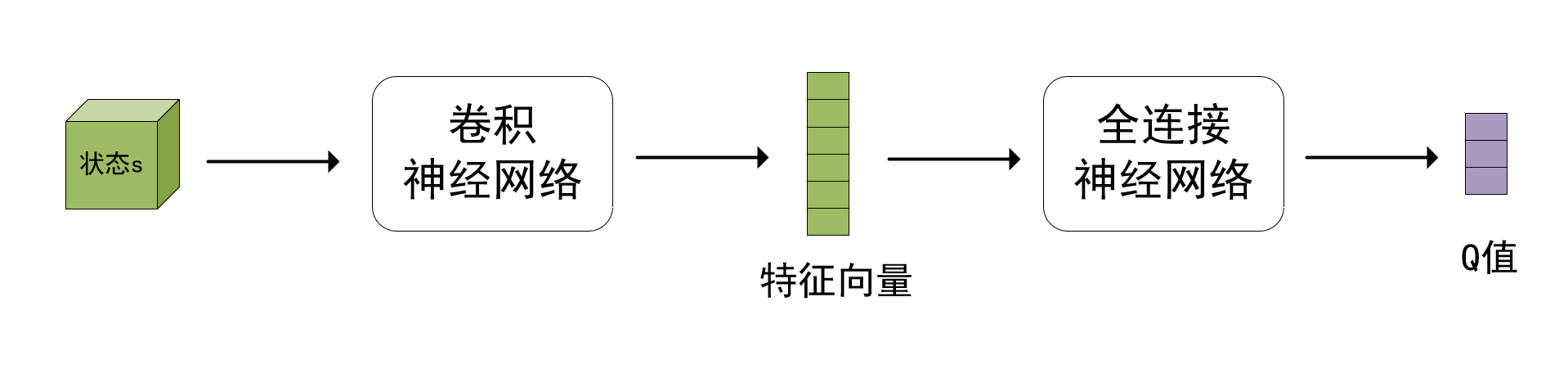
上图是DQN的神经网络架构,输入是状态s,输出是每个动作的Q值。
DQN的输出是∣A∣\vert \mathcal A \vert∣A∣维的向量q^\hat qq^,包含所有动作的价值,而常用的符号Q(s,a;w)Q(s,a; \bm w)Q(s,a;w)是标量(其实就是函数值),是动作aaa对应的动作价值,是向量q^\hat qq^中的一个元素。
三、训练DQN采用TD(temporal difference, 时间差分)算法
3.1 TD算法推导(感兴趣的可以看一下,此处推导的是Q-learning算法)
根据回报的定义:
Ut=Rt+r⋅∑k=t+1nγk−t−1⋅Rk⏟=Ut+1 U_t= R_t+ r \cdot \underbrace { \sum_{k=t+1} ^n \gamma^{k-t-1} \cdot R_k } _{=U_{t+1}} Ut=Rt+r⋅=Ut+1
k=t+1∑nγk−t−1⋅Rk
1、一开始我以为顺序写反了,后来仔细想了一下,这个回报计算公式是对的。因为回报代表的是一轮的奖励,t时刻的回报当然需要知道这一轮中t+1时刻及以后的奖励。反过来说,t+1时刻的回报就已知t时刻以及之前的奖励。注意,不是已知t时刻以及之前的回报。
2、关于回报和奖励的概念,大家需要搞清楚。
最优动作价值函数:
Q⋆(st,at)=maxπE[Ut∣St=st,At=at] Q_{\star}(s_t,a_t) = \max_\pi \mathbb E [U_t \vert S_t =s_t, A_t = a_t] Q⋆(st,at)=πmaxE[Ut∣St=st,At=at]
定理:最优贝尔曼方程
Q⋆(st,at)⏟Ut的期望=ESt+1∼p(⋅∣st,at)[Rt+γ⋅maxA∈AQ⋆(St+1,A)⏟Ut+1的期望∣St=st,At=at] \underbrace {Q_{\star}(s_t,a_t)} _{U_t的期望} = \mathbb E _{S_{t+1} \sim p(\cdot \vert s_t, a_t)} [R_t+ \gamma \cdot \underbrace{ \max_{A \in \mathcal A} Q_{\star}(S_{t+1},A) }_{U_{t+1}的期望}\vert S_t=s_t, A_t=a_t] Ut的期望
Q⋆(st,at)=ESt+1∼p(⋅∣st,at)[Rt+γ⋅Ut+1的期望
A∈AmaxQ⋆(St+1,A)∣St=st,At=at]
同时,rt+γ⋅maxa∈AQ⋆(st+1,a)r_t+\gamma \cdot \max_{a \in \mathcal A} Q_{\star} (s_{t+1},a)rt+γ⋅maxa∈AQ⋆(st+1,a)可以看作期望的蒙特卡洛近似:
ESt+1∼p(⋅∣st,at)[Rt+γ⋅maxA∈AQ⋆(St+1,A)∣St=st,At=at] \mathbb E _{S_{t+1} \sim p(\cdot \vert s_t, a_t)} [R_t+ \gamma \cdot \max_{A \in \mathcal A} Q_{\star}(S_{t+1},A) \vert S_t=s_t, A_t=a_t] ESt+1∼p(⋅∣st,at)[Rt+γ⋅A∈AmaxQ⋆(St+1,A)∣St=st,At=at]
综上,由最优贝尔曼方程和蒙特卡洛近似可得:
Q⋆(st,at)≈rt+γ⋅maxa∈AQ⋆(st+1,a) Q_{\star}(s_t,a_t) \approx r_t+\gamma \cdot \max_{a \in \mathcal A} Q_{\star} (s_{t+1},a) Q⋆(st,at)≈rt+γ⋅a∈AmaxQ⋆(st+1,a)
把最优动作价值函数Q⋆(s,a)Q_{\star}(s,a)Q⋆(s,a)替换为神经网络Q(s,a;w)Q(s,a; \bm w)Q(s,a;w),得到:
Q(st,at;w)⏟预测qt^≈rt+γ⋅maxa∈AQ(st+1,a;w)⏟TD目标yt^ \underbrace {Q(s_t,a_t; \bm w)} _{预测\hat {q_t}} \approx \underbrace { r_t+\gamma \cdot \max_{a \in \mathcal A} Q(s_{t+1},a; \bm w)} _{TD目标\hat {y_t}} 预测qt^
Q(st,at;w)≈TD目标yt^
rt+γ⋅a∈AmaxQ(st+1,a;w)
左边的qt^\hat {q_t}qt^是神经网络在t时刻做出的预测,其中没有任何事实成分。
右边的TD目标yt^\hat {y_t}yt^是神经网络在t+1时刻做出的预测,它部分基于真实观测到的奖励rtr_trt。
qt^\hat {q_t}qt^和yt^\hat {y_t}yt^都是对最优动作价值函数Q⋆(st,at)Q_{\star}(s_t,a_t)Q⋆(st,at)的估计,但是yt^\hat {y_t}yt^部分基于事实,因此比qt^\hat {q_t}qt^更可靠。
TD算法的目标应当鼓励qt^\hat {q_t}qt^=△Q(st,at;w)\overset{\triangle}{=}Q(s_t,a_t; \bm w)=△Q(st,at;w) 接近yt^\hat {y_t}yt^,通过更新参数w\bm ww,使得损失函数L(w)=12[Q(st,at;w)−yt^]2L(\bm w)= \frac 1 2 [Q(s_t,a_t; \bm w)-\hat {y_t}]^2L(w)=21[Q(st,at;w)−yt^]2减小。
3.2 Q-learning算法
TD算法是一大类算法,常见的有Q-learning算法和SARSA算法。
Q-learning算法的目的是学到最优动作价值函数Q⋆Q_{\star}Q⋆,而SARSA算法的目的是学习动作价值函数QπQ_{\pi}Qπ。
上一节介绍的DQN其实就是神经网络形式的Q-learning,而最开始的Q-learning是以表格形式出现的。
表格形式的Q-learning应用条件受限,Q表中状态空间S\mathcal SS和动作空间A\mathcal AA都是有限集合,即集合中元素数量有限。
将最优动作价值函数Q⋆Q_{\star}Q⋆表示为如下的表格形式。即Q表: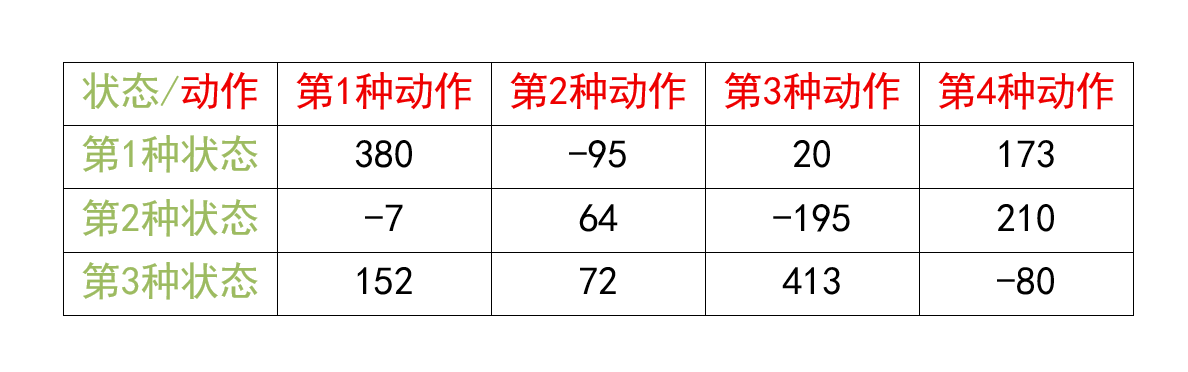
S\mathcal SS中一共有3种状态,A\mathcal AA中一共有4种动作,那么最优动作价值函数Q⋆(s,a)Q_{\star}(s,a)Q⋆(s,a)可以表示为一个3×43 \times 43×4的表格。
例如,当前状态sts_tst是第2种状态,那么查看第2行,发现该行最大的价值是210,那么应当执行的动作ata_tat就是第4种动作。
如果A\mathcal AA是有限集合,而S\mathcal SS是无限集合,可以用神经网络形式的Q-learning,即DQN。
如果A\mathcal AA是无限集合,则问题属于连续控制,应当使用连续控制的方法。
DQN更新的是神经网络参数w\bm ww,而表格形式的Q-learning每次更新表格的一个元素,最终初始化的全零表格Q~\tilde QQ~会收敛到Q⋆Q_{\star}Q⋆
四、同策略与异策略
(这两个专业术语,在写论文或者翻译论文的时候,经常会有不同的译文,有时审稿人或者专家也会提出相关意见)
首先介绍一下行为策略和目标策略。
行为策略(behavior policy)是控制智能体与环境交互的策略,其作用是收集经验,即观测到的状态、动作和奖励。
目标策略(target plicy)是一个确定性的策略,例如,使用DQN控制智能体。
at=arg maxaQ(st,a,w) a_t = \argmax_a Q(s_t,a,\bm w) at=aargmaxQ(st,a,w)
{同策略(on−policy):行为策略=目标策略,即收集经验的行为策略和控制智能体的目标策略相同异策略(off−policy):行为策略≠目标策略,即收集经验的行为策略和控制智能体的目标策略不同 \begin{cases} 同策略(on-policy):行为策略=目标策略,即收集经验的行为策略和控制智能体的目标策略相同 \\ 异策略(off-policy):行为策略 \neq目标策略,即收集经验的行为策略和控制智能体的目标策略不同 \end{cases} {同策略(on−policy):行为策略=目标策略,即收集经验的行为策略和控制智能体的目标策略相同异策略(off−policy):行为策略=目标策略,即收集经验的行为策略和控制智能体的目标策略不同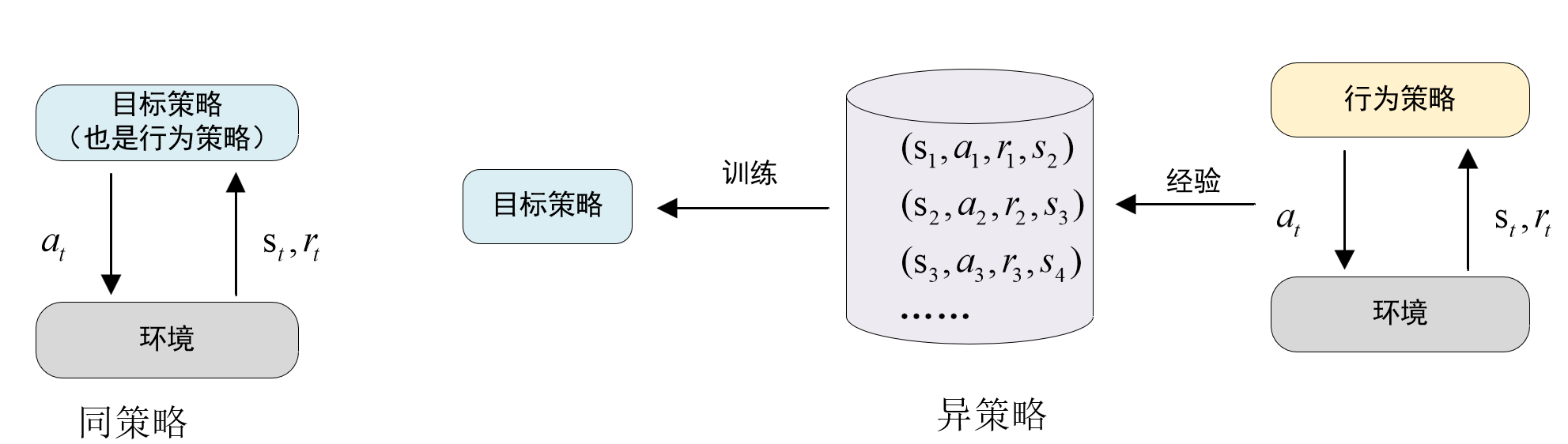
之前介绍的Q-learning和DQN都属于异策略,它们的行为策略最常采用的是ϵ\epsilonϵ-greedy算法:
at={arg maxaQ(st,a;w)以概率(1−ϵ)均匀抽取A中的一个动作以概率ϵ a_t= \begin{cases} \argmax_a Q(s_t,a;\bm w) \quad \quad 以概率(1-\epsilon) \\ 均匀抽取\mathcal A中的一个动作 \quad \quad 以概率\epsilon \end{cases} at={argmaxaQ(st,a;w)以概率(1−ϵ)均匀抽取A中的一个动作以概率ϵ
让行为策略带有随机性的好处是能探索更多没见多的状态。
异策略的好处是可以用行为策略收集经验,把(st,at,rt,st+1)(s_t,a_t,r_t,s_{t+1})(st,at,rt,st+1)这样的四元组记录到一个缓存里,后面反复利用这些经验去更新目标策略。
这个缓存称为经验回放缓存,而这种将智能体与环境交互的记录暂时保存,然后从中采样和学习的训练方式称为经验回放(experience replay)。
经验回放只适用于异策略,不适用与同策略,原因是收集经验时用的行为策略不用于想要训练出来的目标策略。
五、SARSA算法
SARSA也是一种TD算法,其目标是学习动作价值函数Qπ(s,a)Q_{\pi}(s,a)Qπ(s,a)。
SARSA是state-action-reward-state-action的缩写,原因就是它用到了五元组:(st,at,rt,st+1,a~t+1)(s_t,a_t,r_t,s_{t+1},\tilde a_{t+1})(st,at,rt,st+1,a~t+1)
a~t+1∼π(⋅∣st+1) \tilde a_{t+1} \sim \pi(\cdot \vert s_{t+1}) a~t+1∼π(⋅∣st+1)
SARSA算法学到的qqq依赖于策略π\piπ,因为五元组中的a~t+1\tilde a_{t+1}a~t+1是根据π(⋅∣st+1)\pi(\cdot \vert s_{t+1})π(⋅∣st+1)抽样得到的。
Q-learning和SARSA的对比
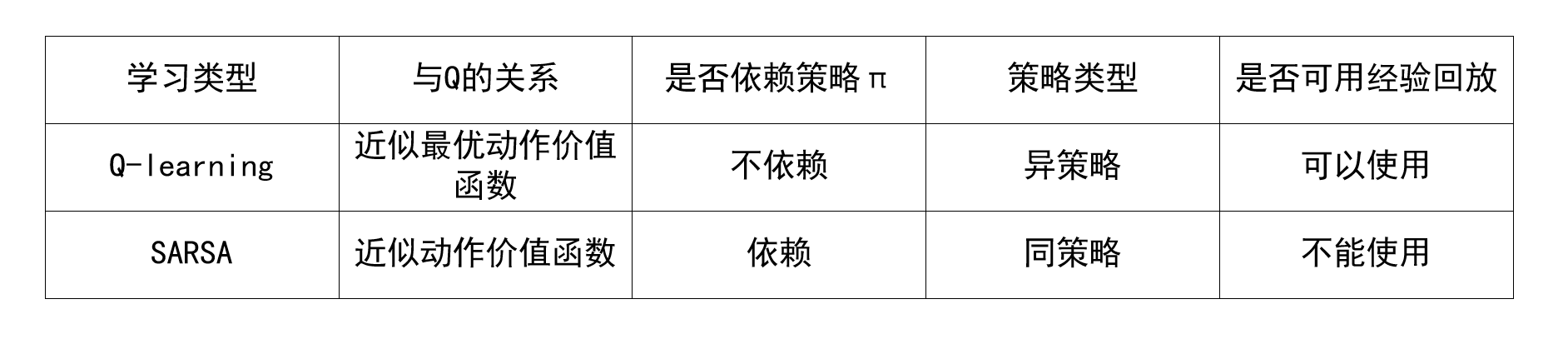
Q-learning的目标是学到表格Q~\tilde QQ~,作为最优动作价值函数Q⋆Q_{\star}Q⋆的近似,因为Q⋆Q_{\star}Q⋆与π\piπ无关,所以在理想情况下,不论收集经验用的行为策略π\piπ是什么,都不影响Q-learning得到的最优动作价值函数。因此Q-learning属于异策略,允许行为策略区别于目标策略。Q-learning允许使用经验回放,可以重复利用过时的经验。
SARSA算法的目标是学习到qqq表,作为动作价值函数QπQ_{\pi}Qπ的近似,QπQ_{\pi}Qπ与一个策略π\piπ相对应,用不用的策略π\piπ,对应的QπQ_{\pi}Qπ就会不同。策略π\piπ越好,QπQ_{\pi}Qπ的值越大。经验回放缓存里面的经验(st,at,rt,st+1)(s_t,a_t,r_t,s_{t+1})(st,at,rt,st+1)是过时的行为策略πold\pi_{old}πold收集到的,与当前策略πnow\pi_{now}πnow及其对应的价值QπnowQ_{\pi_{now}}Qπnow不对应。想要学习QπQ_{\pi}Qπ的话,必须用当前策略πnow\pi_{now}πnow收集到的经验,而不能用过时的πold\pi_{old}πold收集到的经验,这就是SARSA算法不能使用经验回放的原因。
六、蒙特卡洛方法和自举
(自举)单步TD目标:y^t=rt+γq^t+1m=1←m步TD目标:y^t=∑i=0m−1γirt+i+γmq^t+mm=n−t+1→(蒙特卡洛方法)观测到的回报:ut=∑i=0n−tγirt+i (自举)单步TD目标:\hat y_t=r_t+\gamma \hat q_{t+1} \quad \quad \underleftarrow{m=1} \quad \quad m步TD目标: \hat y_t=\sum_{i=0}^{m-1} \gamma^i r_{t+i}+\gamma^m \hat q_{t+m} \quad \quad \underrightarrow{m=n-t+1} \quad \quad (蒙特卡洛方法)观测到的回报:u_t= \sum_{i=0}^{n-t} \gamma^ir_{t+i} (自举)单步TD目标:y^t=rt+γq^t+1m=1m步TD目标:y^t=i=0∑m−1γirt+i+γmq^t+mm=n−t+1(蒙特卡洛方法)观测到的回报:ut=i=0∑n−tγirt+i
6.1 蒙特卡洛方法
训练价值网络q(s,a;w)q(s,a;\bm w)q(s,a;w)的时候,将一个回合进行到底,观测到所有的奖励r1,r2,⋯ ,rnr_1,r_2,\cdots,r_nr1,r2,⋯,rn,然后计算回报ut=∑i=0n−tγirt+iu_t= \sum_{i=0}^{n-t} \gamma^ir_{t+i}ut=∑i=0n−tγirt+i,以utu_tut作为目标,鼓励价值网络q(st,at;w)q(s_t,a_t;\bm w)q(st,at;w)接近utu_tut,这种方式称为“蒙特卡洛方法”。用实际观测值utu_tut去近似动作价值函数Qπ(st,at)=E[Ut∣St=st,At=at]Q_{\pi}(s_t,a_t)=\mathbb {E} [U_t \vert S_t=s_t, A_t =a_t]Qπ(st,at)=E[Ut∣St=st,At=at]中的期望,这就是典型的蒙特卡洛方法近似。
6.2 自举
TD目标y^t\hat y_ty^t的一部分是价值网络做出的估计γ⋅q(st+1,at+1;w)\gamma \cdot q(s_{t+1},a_{t+1};\bm w)γ⋅q(st+1,at+1;w),然后SARSA让q(st,at;w)q(s_t,a_t;\bm w)q(st,at;w)去拟合y^t\hat y_ty^t,这就是用价值网络自身做出的估计去更新价值网络自身,属于“自举”。
6.3 对比
| 好处 | 坏处 | |
|---|---|---|
| 蒙特卡洛方法 | 无偏性 | 方差大 |
| 自举 | 方差小 | 有偏差 |
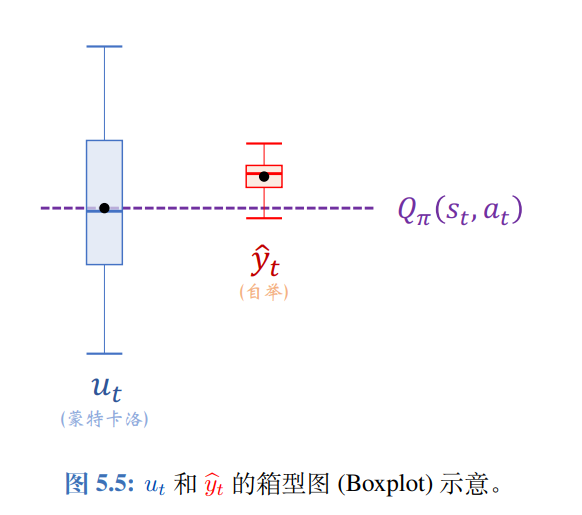
在价值学习中,用实际观测到的回报utu_tut作为目标的方法称为蒙特卡洛方法,utu_tut是动作价值函数Qπ(st,at)Q_{\pi}(s_t,a_t)Qπ(st,at)的无偏估计,即UtU_tUt的期望等于Qπ(st,at)Q_{\pi}(s_t,a_t)Qπ(st,at),但是它的方差很大,即实际观测到的utu_tut可能离Qπ(st,at)Q_{\pi}(s_t,a_t)Qπ(st,at)很远。
用单步TD目标y^t\hat y_ty^t作为目标的方法称为自举。自举的好处是方差小,y^t\hat y_ty^t不会偏离期望太远,但是y^t\hat y_ty^t往往是有偏的,它的期望通常不等于Qπ(st,at)Q_{\pi}(s_t,a_t)Qπ(st,at),用自举训练出来的价值网络通常有系统性的偏差(低估或者高估)。
在实践中,自举通常比蒙特卡洛方法收敛得更快,这也是训练DQN和价值网络通常用TD算法的原因。
多步TD目标y^t=∑i=0m−1γirt+i⏟蒙特卡洛方法,占比较大+γmq^t+m⏟自举成分,用价值网络自身算出来的\hat y_t=\underbrace{ \sum_{i=0}^{m-1} \gamma^i r_{t+i}}_{蒙特卡洛方法,占比较大}+\underbrace{ \gamma^m \hat q_{t+m}}_{自举成分,用价值网络自身算出来的}y^t=蒙特卡洛方法,占比较大
i=0∑m−1γirt+i+自举成分,用价值网络自身算出来的
γmq^t+m介于蒙特卡洛方法和自举之间。
如果把m设置的比较好,方差和偏差之间就可以达到比较好的平衡,使得多步TD目标优于单步TD目标,也优于回报utu_tut。
七、价值学习中的高级技巧
第一部分:改进Q-learning算法
7.1 经验回放
经验回放每次从缓存里随机抽取一个四元组(st,at,rt,st+1)(s_t,a_t,r_t,s_{t+1})(st,at,rt,st+1),用来对DQN参数做一次更新,这样随机抽取到的四元组之间是相互独立的,消除了相关性。
经验回放的另一个好处是可以重复利用收集到的经验,而不是用一次就丢弃,这样就能用更少的样本数量达到同样的效果。
但是经验回放缓存中的经验通常是过时的行为策略收集的,而真正需要学习的目标策略不同于过时的行为策略,所以经验回放不适用于同策略。
7.2 优先经验回放
优先经验回放给每个四元组一个权重,然后根据权重做非均匀随机抽样。一般来说,TD误差越大的四元组,应当有较高的权重。
7.3 高估问题
Q-learning算法有一个缺陷:用它训练出来的DQN会高估真实的价值,而且高估通常是非均匀的,这个缺陷导致DQN表现很差。但是高估问题不是DQN模型的缺陷,而是Q-learning算法的缺陷。
Q-learning产生高估的原因有两个:
- TD算法属于自举,即用DQN的估计值去更新DQN自己,自举会导致偏差传播。如果Q(sj+1,aj+1;w)Q(s_{j+1},a_{j+1}; \bm w)Q(sj+1,aj+1;w)是对Q⋆(sj+1,aj+1)Q_{\star}(s_{j+1},a_{j+1})Q⋆(sj+1,aj+1)的高估,那么高估会传播到(sj,aj)(s_{j},a_{j})(sj,aj),让Q(sj,aj;w)Q(s_{j},a_{j};\bm w)Q(sj,aj;w)高估Q⋆(sj,aj)Q_{\star}(s_{j},a_{j})Q⋆(sj,aj),所以自举导致DQN的高估从一个二元组传播到更多的二元组。
- TD目标y^t\hat y_ty^t中包含一项最大化,这会导致TD目标高估真实价值Q⋆Q_{\star}Q⋆,Q-learning算法鼓励DQN的预测去接近TD目标,因此DQN会高估Q⋆Q_{\star}Q⋆
虽然高估本身不是问题,但是DQN产生的高估往往是非均匀的,那么DQN做出的决策就是不可靠的。
7.4 高估问题解决方案1——使用目标网络
如果想要切断自举,可以用另一个神经网络计算TD目标,而不是DQN自己计算TD目标,我们把这个神经网络称作目标网络(target network),记作Q(s,a;w−)Q(s,a;\bm w^-)Q(s,a;w−)。它的神经网络结果与DQN完全相同,但是参数w−\bm w^-w−不同于w\bm ww。
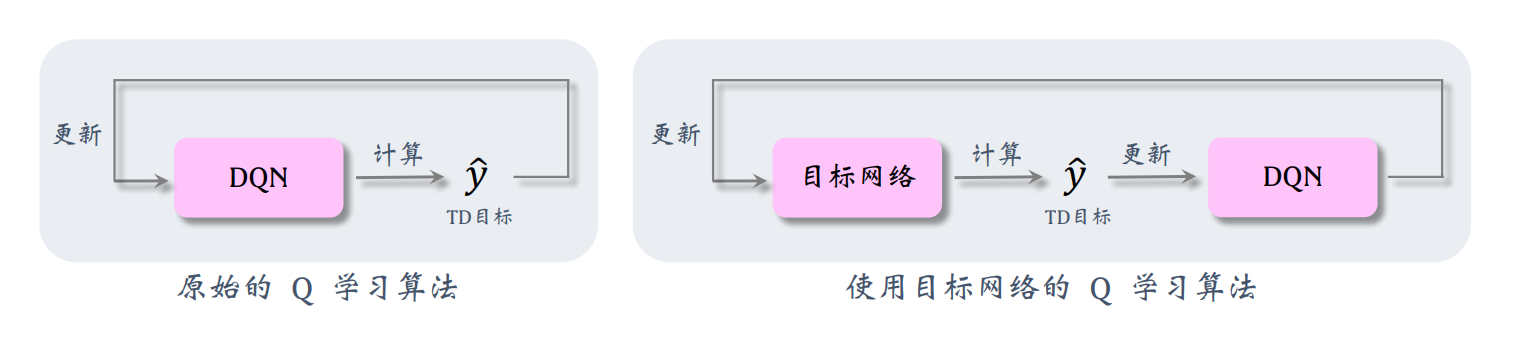
使用目标网络的Q学习算法,选择动作和求值TD目标都使用目标网络计算得到的。
这种方法不能完全避免自举,原因是目标网络的参数仍然与DQN相关。
7.5 高估问题解决方案2——双Q学习算法(double DQN,即DDQN的基础)
到目前为止,已经接触到了3种训练DQN的TD算法:
原始的Q-learning⟹\Longrightarrow⟹使用目标网络的Q-learning⟹\Longrightarrow⟹双Q学习:选择动作使用DQN网络,求值TD目标使用目标网络。
3种TD算法对比: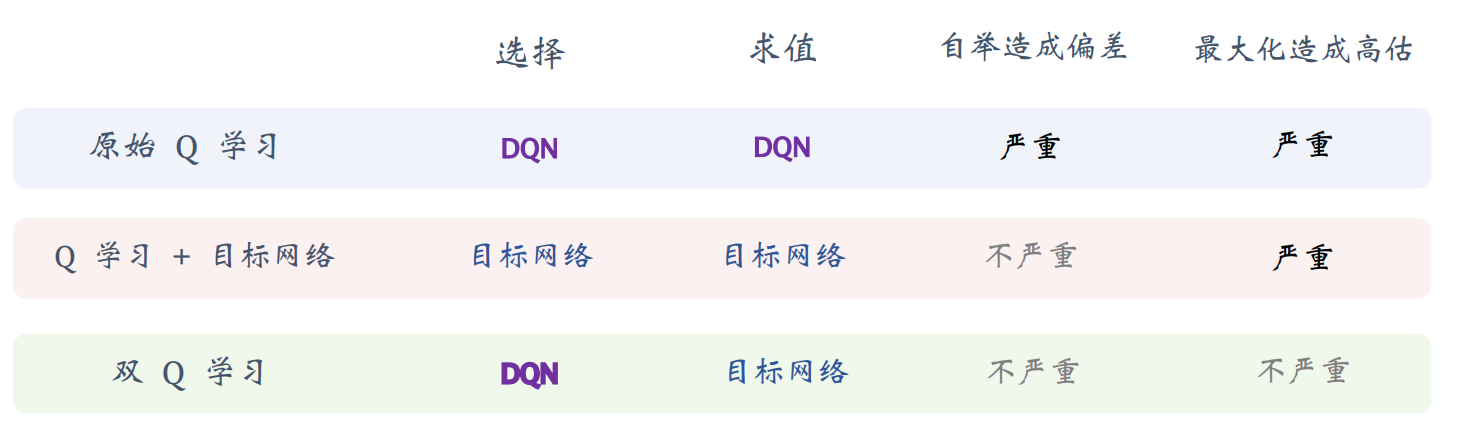
第二部分:改进DQN的神经网络结构
7.6 对决网络(dueling network)
对决网络(dueling network):将最优动作价值Q⋆Q_{\star}Q⋆分解为最优状态价值V⋆V_{\star}V⋆和最优优势D⋆D_{\star}D⋆。
状态价值函数Vπ(s)V_{\pi}(s)Vπ(s)是Qπ(s,a)Q_{\pi}(s,a)Qπ(s,a)关于aaa的期望:
Vπ(s)=EA∼π[Qπ(s,A)] V_{\pi}(s)=\mathbb E_{A \sim \pi} [Q_{\pi}(s,A)] Vπ(s)=EA∼π[Qπ(s,A)]
最优状态价值函数V⋆V_{\star}V⋆:
V⋆(s)=maxπVπ(s),∀s∈S V_{\star}(s) = \max_{\pi} V_{\pi}(s) , \quad \quad \forall s \in S V⋆(s)=πmaxVπ(s),∀s∈S
最优优势函数(optimal advantage function)
D⋆(s,a)≜Q⋆(s,a)−V⋆(s) D_{\star}(s,a)\triangleq Q_{\star}(s, a) - V_{\star}(s) D⋆(s,a)≜Q⋆(s,a)−V⋆(s)
定理
Q⋆(s,a)=V⋆(s)+D⋆(s,a)−maxa∈AD⋆(s,a)⏟恒等于零,同时解决不唯一性的问题,∀s∈S,a∈A Q_{\star}(s, a) = V_{\star}(s) + D_{\star}(s, a) - \underbrace{\max_{a \in \mathcal{A}} D_{\star}(s, a)}_{\text{恒等于零,同时解决不唯一性的问题}}, \quad \forall s \in \mathcal{S}, a \in \mathcal{A} Q⋆(s,a)=V⋆(s)+D⋆(s,a)−恒等于零,同时解决不唯一性的问题
a∈AmaxD⋆(s,a),∀s∈S,a∈A
对决网络也是对最优动作价值函数Q⋆Q_{\star}Q⋆的近似。
对决网络{神经网络1:D(s,a;wD),是对最优优势函数D⋆(s,a)的近似神经网络2:V(s;wV),是对最优状态价值函数V⋆(s)的近似 对决网络 \begin{cases} 神经网络1:D(s,a;\bm w^D) ,是对最优优势函数D_{\star}(s,a)的近似\\ 神经网络2:V(s;\bm w^V), 是对最优状态价值函数V_{\star}(s)的近似 \end{cases} 对决网络{神经网络1:D(s,a;wD),是对最优优势函数D⋆(s,a)的近似神经网络2:V(s;wV),是对最优状态价值函数V⋆(s)的近似
因此,最优动作价值函数Q⋆Q_{\star}Q⋆就可以近似成下面的神经网络:
Q(s,a;w)≜V(s;wV)+D(s,a;wD)−maxa∈AD(s,a;wD) Q(s,a;\boldsymbol{w}) \triangleq V\left(s;\boldsymbol{w}^{V}\right) + D\left(s, a;\boldsymbol{w}^{D}\right) - \max_{a \in \mathcal{A}} D\left(s, a;\boldsymbol{w}^{D}\right) Q(s,a;w)≜V(s;wV)+D(s,a;wD)−a∈AmaxD(s,a;wD)
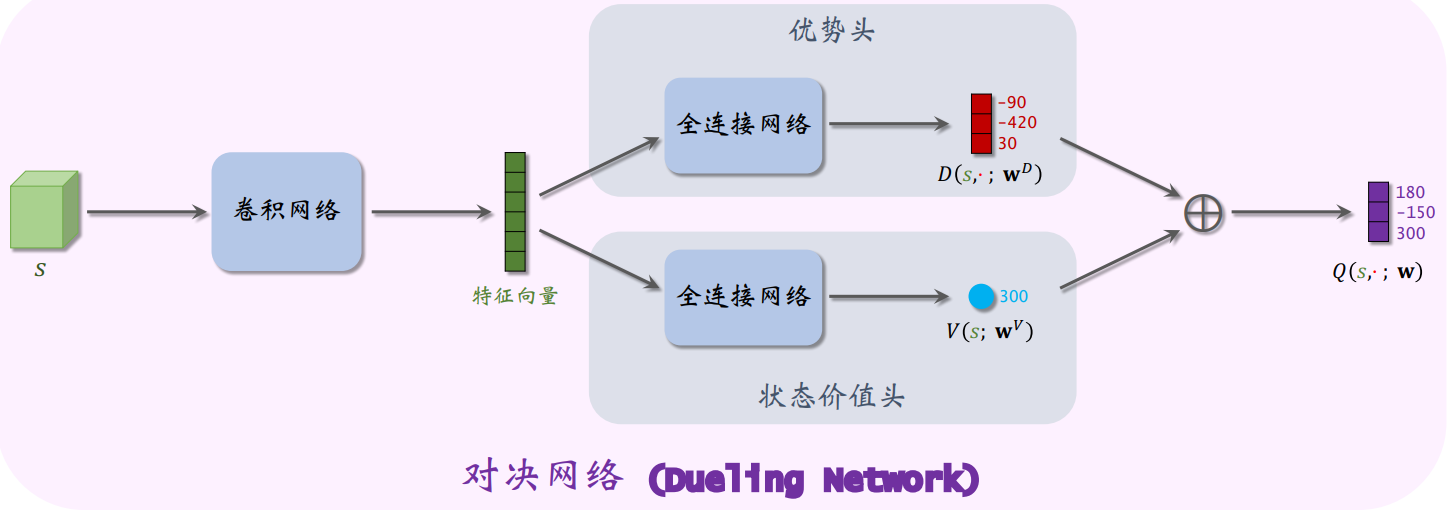
上图为对决网络的结构。输入是状态 s;红色的向量是每个动作的优势值;蓝色的标量是状态价值;最终输出的紫色向量是每个动作的动作价值。
7.7 噪声网络
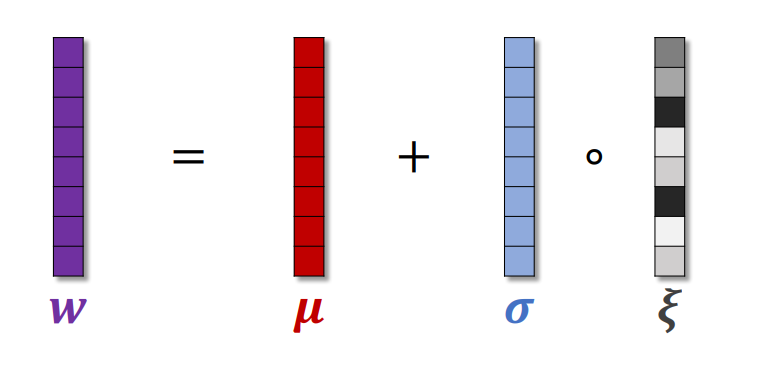
μ\muμ和σ\sigmaσ分别表示均值和标准差,它们是神经网络的参数,需要从经验中学习,ξ\xiξ是随机噪声,它的每个元素独立以标准正态分布N(0,1)N(0,1)N(0,1)中随机抽取。符号∘\circ∘表示逐项乘积。
wi=μi+σi⋅ξi w_i = \mu_i + \sigma_i \cdot \xi_i wi=μi+σi⋅ξi
某一个全连接层记作:
z=ReLU(Wx+b) \boldsymbol{z} = \operatorname{ReLU}(\boldsymbol{W}\boldsymbol{x} + \boldsymbol{b}) z=ReLU(Wx+b)
加入噪声网络后为:
z=ReLU((Wμ+Wσ∘Wξ)x+(bμ+bσ∘bξ)) \boldsymbol{z} = \operatorname{ReLU}\left( \left( \boldsymbol{W}^{\mu} + \boldsymbol{W}^{\sigma} \circ \boldsymbol{W}^{\xi} \right) \boldsymbol{x} + \left( \boldsymbol{b}^{\mu} + \boldsymbol{b}^{\sigma} \circ \boldsymbol{b}^{\xi} \right) \right) z=ReLU((Wμ+Wσ∘Wξ)x+(bμ+bσ∘bξ))
把噪声网络应用于DQN:
Q(s,a;w)⟹Q~(s,a,ξ;μ,σ)≜Q(s,a;μ+σ∘ξ) Q(s,a;\bm w) \Longrightarrow \widetilde{Q}(s, a, \boldsymbol{\xi}; \boldsymbol{\mu}, \boldsymbol{\sigma}) \triangleq Q(s, a; \boldsymbol{\mu} + \boldsymbol{\sigma} \circ \boldsymbol{\xi}) Q(s,a;w)⟹Q
(s,a,ξ;μ,σ)≜Q(s,a;μ+σ∘ξ)
其中的 μ\muμ 和 σ\sigmaσ 是参数,一开始随机初始化,然后从经验中学习;而 ξ\xiξ 则是随机生成,每个元素都从N(0,1)N (0, 1)N(0,1) 中抽取。噪声 DQN 的参数数量比标准 DQN 多一倍。
噪声 DQN 本身就带有随机性,可以鼓励探索,起到与 ϵ\epsilonϵ-Greedy 策略相同的作用。直接用at=argmaxa∈A Q~(s,a,ξ;μ,σ)a_t = \underset{a \in \mathcal{A}}{\operatorname{argmax}}\, \widetilde{Q}(s, a, \boldsymbol{\xi}; \boldsymbol{\mu}, \boldsymbol{\sigma})at=a∈AargmaxQ (s,a,ξ;μ,σ)作为行为策略,效果比ϵ\epsilonϵ-Greedy 更好。因为DQN是异策略,每做一个决策,就要重新随机生成一个ξ\xiξ
做完训练之后,可以用噪声 DQN 做决策。做决策的时候不再需要噪声,因此可以把参数 σ\sigmaσ设置成全零,只保留参数μ\muμ。这样一来,噪声 DQN 就变成标准的 DQN:
Q~(s,a,ξ′;μ,0)⏟噪声 DQN=Q(s,a;μ)⏟标准 DQN. \underbrace{\widetilde{Q}\left(s,a,\boldsymbol{\xi}^{\prime};\boldsymbol{\mu},\boldsymbol{0}\right)}_{\text{噪声 DQN}}=\underbrace{Q\left(s,a;\boldsymbol{\mu}\right)}_{\text{标准 DQN}}. 噪声 DQN
Q
(s,a,ξ′;μ,0)=标准 DQN
Q(s,a;μ).
在训练的时候往 DQN 的参数中加入噪声,不仅有利于探索,还能增强鲁棒性(健壮性)。意思是即使参数被扰动,DQN 也能对最优动作价值 Q⋆Q_{\star}Q⋆做出可靠的估计
八、实际编程DQN的完整实现流程
应用优先经验回放、双Q学习、对决网络、噪声DQN来编程实现DQN的完整流程:
开始随机初始化μ、σ\mu、\sigmaμ、σ,并且把它们赋值给目标网络参数:μ−←μ、σ−←σ\mu^-\leftarrow\mu、\sigma^-\leftarrow\sigmaμ−←μ、σ−←σ;然后重复下面的步骤更新参数。
(把当前的参数记作μnow、σnow、μnow−、σnow−)\mu_{\mathrm{now}}、\sigma_{\mathrm{now}}、\mu_{\mathrm{now}}^-、\sigma_{\mathrm{now}}^-)μnow、σnow、μnow−、σnow−)
-
1、用优先经验回放,从数组中抽取一个四元组,记作(sj,aj,rj,sj+1)(s_j,a_j,r_j,s_{j+1})(sj,aj,rj,sj+1)。
-
2、用标准正态分布生成 ξ\xiξ,对噪声 DQN 做正向传播,得到:
q^j=Q~(sj,aj,ξ;μnow,σnow).\widehat{q}_j=\widetilde{Q}(s_j,a_j,\boldsymbol{\xi};\boldsymbol{\mu}_\mathrm{now},\boldsymbol{\sigma}_\mathrm{now}).q j=Q (sj,aj,ξ;μnow,σnow). -
3、根据噪声 DQN 选出最优动作:
a~j+1=argmaxa∈AQ~(sj+1,a,ξ;μnow,σnow).\tilde{a}_{j+1}=\underset{a\in\mathcal{A}}{\operatorname*{\operatorname*{argmax}}}\widetilde{Q}\left(s_{j+1},a,\boldsymbol{\xi};\boldsymbol{\mu}_{\mathrm{now}},\boldsymbol{\sigma}_{\mathrm{now}}\right).a~j+1=a∈AargmaxQ (sj+1,a,ξ;μnow,σnow). -
4、用标准正态分布生成ξ′\xi^{\prime}ξ′,根据目标网络计算价值:
q^j+1−=Q~(sj+1,a~j+1,ξ′;μnow−,σnow−).\hat{q}_{j+1}^-=\widetilde{Q}\left(s_{j+1},\tilde{a}_{j+1},\xi^{\prime};\boldsymbol{\mu}_{\mathrm{now}}^-,\boldsymbol{\sigma}_{\mathrm{now}}^-\right).q^j+1−=Q (sj+1,a~j+1,ξ′;μnow−,σnow−). -
5、计算 TD 目标和 TD 误差:
y^j−=rj+γ⋅q^j+1− 和 δj=q^j−y^j−.\widehat{y}_j^-=r_j+\gamma\cdot\widehat{q}_{j+1}^-\quad\text{ 和 }\quad\delta_j=\widehat{q}_j-\widehat{y}_j^-.y j−=rj+γ⋅q j+1− 和 δj=q j−y j−.
-
6、设 αμ\alpha_{\mu}αμ 和 ασ\alpha_{\sigma}ασ为学习率。做梯度下降更新噪声 DQN 的参数:
μnew←μnow−αμ⋅δj⋅∇μQ~(sj,aj,ξ;μnow,σnow)σnew←σnow−ασ⋅δj⋅∇σQ~(sj∣,aj,ξ;μnow,σnow).\boldsymbol{\mu}_{\mathrm{new}}\quad\leftarrow\quad\boldsymbol{\mu}_{\mathrm{now}}-\alpha_{\mu}\cdot\delta_{j}\cdot\nabla_{\boldsymbol{\mu}}\widetilde{Q}\left(s_{j},a_{j},\boldsymbol{\xi};\boldsymbol{\mu}_{\mathrm{now}},\boldsymbol{\sigma}_{\mathrm{now}}\right) \\ \\ \boldsymbol{\sigma}_{\mathrm{new}}\quad\leftarrow\quad\boldsymbol{\sigma}_{\mathrm{now}}-\alpha_{\sigma}\cdot\delta_{j}\cdot\nabla_{\boldsymbol{\sigma}}\widetilde{Q}\left(s_{j}|,a_{j},\boldsymbol{\xi};\boldsymbol{\mu}_{\mathrm{now}},\boldsymbol{\sigma}_{\mathrm{now}}\right).μnew←μnow−αμ⋅δj⋅∇μQ (sj,aj,ξ;μnow,σnow)σnew←σnow−ασ⋅δj⋅∇σQ (sj∣,aj,ξ;μnow,σnow). -
7、设 τ∈(0,1)\tau\in(0,1)τ∈(0,1)是需要手动调的超参数。做加权平均更新目标网络的参数:
μnew−←τ⋅μnew+(1−τ)⋅μnow−,σnew−←τ⋅σnew+(1−τ)⋅σnow−.\begin{array} {rcl}\boldsymbol{\mu}_{\mathrm{new}}^{-} & \leftarrow & \tau\cdot\boldsymbol{\mu}_{\mathrm{new}}+ & \begin{pmatrix} 1-\tau \end{pmatrix}\cdot\boldsymbol{\mu}_{\mathrm{now}}^{-}, \\ \\ \boldsymbol{\sigma}_{\mathrm{new}}^{-} & \leftarrow & \tau\cdot\boldsymbol{\sigma}_{\mathrm{new}}+ & \begin{pmatrix} 1-\tau \end{pmatrix}\cdot\boldsymbol{\sigma}_{\mathrm{now}}^{-}. \end{array}μnew−σnew−←←τ⋅μnew+τ⋅σnew+(1−τ)⋅μnow−,(1−τ)⋅σnow−.
一时半会可能消化不了,建议收藏!多次咀嚼消化。

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 24
24 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)