【论文解读】QwenLong-L1:面向基于强化学习的长上下文大型推理模型
QwenLong-L1 框架是长上下文大型推理模型发展的一个重要进展。它**首次系统地提出并验证了一套完整的、从短上下文到长上下文的RL适配方案**,有效解决了长上下文RL训练中的效率和稳定性两大核心痛点。
1st author: Fanqi Wan’s homepage
paper: [2505.17667] QwenLong-L1: Towards Long-Context Large Reasoning Models with Reinforcement Learning
code: Tongyi-Zhiwen/QwenLong-L1
5. 总结 (结果先行)
QwenLong-L1 框架是长上下文大型推理模型发展的一个重要进展。它首次系统地提出并验证了一套完整的、从短上下文到长上下文的RL适配方案,有效解决了长上下文RL训练中的效率和稳定性两大核心痛点。
- 贡献:
- 范式建立: 明确了长上下文推理RL所面临的独特挑战,并提出了“渐进式上下文扩展”这一核心应对策略。
- 技术整合: 巧妙地将SFT预热、课程学习、难度感知采样与无价值网络的RL算法 (GRPO/DAPO) 及混合奖励机制相结合。
- 发现:
- 渐进式学习是关键: 对于复杂任务和长程依赖,从易到难、从短到长的课程学习对于模型能力的稳定构建至关重要。
- SFT与RL相辅相成: SFT为RL提供了一个良好的起点,降低了RL的探索难度;而RL则能进一步释放模型潜力,达到SFT难以企及的性能高度。
- RL促进“慢思考”: RL训练似乎更能引导模型发展出类似人类的复杂推理策略 (如回溯、验证),而不仅仅是模式匹配。
- 展望:
- 更长上下文的挑战: 随着上下文窗口的持续扩大 (例如百万级tokens),当前框架可能仍面临可扩展性瓶颈,需要更高效的注意力机制和RL算法。
- 任务多样性: 将此框架推广到更多样的长上下文任务,如长篇故事生成、代码理解与生成、科学文献分析等。
- RL范式的演进: 探索从token级决策到更高层次决策单元 (如句子级、段落级甚至文档交互级) 的RL建模,可能有助于模型更好地进行宏观规划和长程推理。
- 无限上下文RL: 终极目标是实现能够处理并有效利用“无限”上下文信息的RL系统,这可能需要与外部记忆、持续学习等机制深度融合。
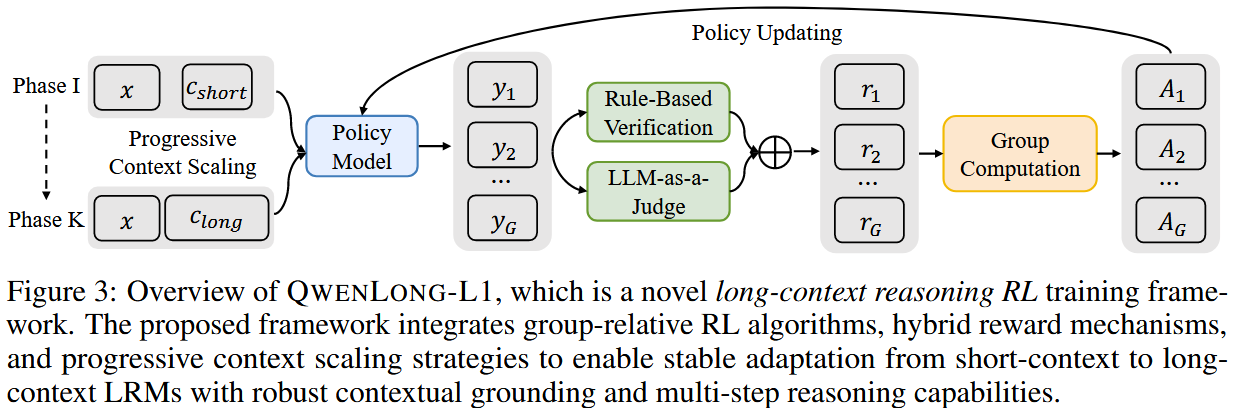
1. 思想
- 大问题: 当前的大型推理模型 (Large Reasoning Models, LRMs) 在短上下文任务上通过强化学习 (Reinforcement Learning, RL) 取得了显著进展,但如何将此能力有效地扩展到长上下文场景,使其能够处理并基于长篇输入进行复杂推理,仍是一个亟待解决的挑战。
- 小问题:
- 训练效率低下: 在长上下文场景下,RL的奖励信号可能更稀疏或延迟,导致奖励收敛缓慢。
- 优化过程不稳定: 长序列输出天然地放大了生成过程中的方差,容易导致KL散度 (Kullback–Leibler divergence, 用以衡量两个概率分布差异的指标) 剧烈波动;同时,模型可能过早地降低输出的熵 (entropy, 衡量随机性的指标),从而限制了策略的探索能力。
- 关键思路: 论文提出 QwenLong-L1 框架,其核心在于通过一种渐进式的上下文扩展 (Progressive Context Scaling) 策略,稳定地将预训练于短上下文的LRM适配到长上下文的推理任务中。这一策略主要包含三个关键组成部分:
- 预热监督微调 (Warm-up Supervised Fine-Tuning, SFT): 为RL阶段建立一个鲁棒的初始策略。
- 课程引导的阶段化强化学习 (Curriculum-Guided Phased RL): 逐步增加上下文长度,稳定策略的演进。
- 难度感知的回溯采样 (Difficulty-Aware Retrospective Sampling): 优先处理先前阶段的挑战性样本,激励策略进行更有效的探索。
2. 方法
QwenLong-L1 框架整合了上述思想,并在具体的RL算法和奖励机制上进行了适配。
2.1 长上下文推理RL的数学表述
标准的RL目标是最大化期望累积奖励,通常带有KL散度正则项以稳定训练:
J ( θ ) = E x ∼ D , y ∼ π θ ( ⋅ ∣ x ) [ r ϕ ( x , y ) ] − β D K L [ π θ ( y ∣ x ) ∣ ∣ π r e f ( y ∣ x ) ] J(\theta) = \mathbb{E}_{x \sim D, y \sim \pi_\theta(\cdot|x)} \big[r_\phi(x, y)\big] - \beta D_{KL} \big [\pi_\theta(y | x) || \pi_{ref}(y | x)\big ] J(θ)=Ex∼D,y∼πθ(⋅∣x)[rϕ(x,y)]−βDKL[πθ(y∣x)∣∣πref(y∣x)]
其中:
- π θ \pi_\theta πθ 是待优化的策略模型(即LRM),参数为 θ \theta θ。
- x x x 是从数据分布 D D D 中采样的输入(通常是简短的问题)。
- y y y 是模型 π θ \pi_\theta πθ 根据输入 x x x 生成的输出序列。
- r ϕ ( x , y ) r_\phi(x, y) rϕ(x,y) 是奖励函数,评估输出 y y y 的质量。
- π r e f \pi_{ref} πref 是一个参考策略模型,通常是SFT阶段得到的模型或预训练模型本身。
- β \beta β 是控制KL散度正则化强度的系数。
- D K L [ ⋅ ∣ ∣ ⋅ ] D_{KL} [\cdot || \cdot] DKL[⋅∣∣⋅] 代表KL散度。
对于长上下文推理,该目标被扩展为包含一个额外的长上下文 c \textcolor{red}{c} c 的输入 :
J ( θ ) = E ( x , c ) ∼ D , y ∼ π θ ( ⋅ ∣ x , c ) [ r ϕ ( x , c , y ) ] − β D K L [ π θ ( y ∣ x , c ) ∣ ∣ π r e f ( y ∣ x , c ) ] J(\theta) = \mathbb{E}_{(\textcolor{blue}{x},\textcolor{red}{c}) \sim D, y \sim \pi_\theta(\cdot|\textcolor{blue}{x},\textcolor{red}{c})} \big[r_\phi(\textcolor{blue}{x}, \textcolor{red}{c}, y)\big] - \beta D_{KL} \big[\pi_\theta(y | \textcolor{blue}{x},\textcolor{red}{c}) || \pi_{ref}(y | \textcolor{blue}{x},\textcolor{red}{c})\big] J(θ)=E(x,c)∼D,y∼πθ(⋅∣x,c)[rϕ(x,c,y)]−βDKL[πθ(y∣x,c)∣∣πref(y∣x,c)]
此时,模型 π θ \pi_\theta πθ 需要首先理解长上下文 c \textcolor{red}{c} c 中的相关信息,然后结合问题 x \textcolor{blue}{x} x 生成推理链和答案 y y y。
2.2 核心RL算法的改进与选择
由于长上下文输入使得传统PPO算法中价值网络 (Value Network) 的训练变得异常困难且计算成本高昂,论文采用了无需显式价值网络的RL算法变体:
-
GRPO (Group Relative Policy Optimization):
- 机制: 对于给定的输入 ( x , c ) (x,c) (x,c),策略模型 π θ o l d \pi_{\theta_{old}} πθold (上一轮迭代的策略) 生成 G G G 个候选输出 { y i } i = 1 G \{y_i\}_{i=1}^G {yi}i=1G。计算每个输出的奖励 r i r_i ri。
- 优势估计: 通过对这组奖励进行组内归一化来估计每个token的优势 (Advantage) A i , t A_{i,t} Ai,t,替代了价值网络:
A i , t = r i − mean ( { r j } j = 1 G ) std ( { r j } j = 1 G ) + ϵ A_{i,t} = \frac{r_i - \text{mean}(\{r_j\}_{j=1}^G)}{\text{std}(\{r_j\}_{j=1}^G) + \epsilon} Ai,t=std({rj}j=1G)+ϵri−mean({rj}j=1G)
其中 ϵ \epsilon ϵ 是一个小的稳定项。实践中,作者移除了KL正则项以鼓励探索。
-
DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization):
- 机制: 在GRPO基础上进一步改进,引入了更高的裁剪阈值 (clip thresholds) ϵ l o w , ϵ h i g h \epsilon_{low}, \epsilon_{high} ϵlow,ϵhigh 以避免熵过早崩溃,动态采样策略以移除奖励方差为零的简单样本,以及token级损失以减轻长度偏差,并对过长输出进行惩罚。
- 其优势估计也基于组归一化奖励,但可能采用不同的奖励调整 r f i n a l i r_{final_i} rfinali:
A i , t = r f i n a l i − mean ( { r f i n a l j } j = 1 G ) std ( { r f i n a l j } j = 1 G ) + ϵ A_{i,t} = \frac{r_{final_i} - \text{mean}(\{r_{final_j}\}_{j=1}^G)}{\text{std}(\{r_{final_j}\}_{j=1}^G) + \epsilon} Ai,t=std({rfinalj}j=1G)+ϵrfinali−mean({rfinalj}j=1G)
2.3 渐进式上下文扩展策略详解
这是QwenLong-L1的核心,旨在稳定地将模型从短上下文过渡到长上下文。
-
预热监督微调 (Warm-Up SFT):
- 目标: 建立一个能够处理长上下文输入并生成基本合理推理路径的初始策略模型。
- 方法: 使用一个包含 ( x , c , y ∗ ) (x, c, y^*) (x,c,y∗) 的高质量SFT数据集 D S F T D_{SFT} DSFT,其中 y ∗ y^* y∗ 是专家标注的或由强教师模型生成的标准推理路径 (Gold-Standard Reasoning Path) 。模型通过最小化标准负对数似然 (Negative Log-Likelihood, NLL) 损失进行训练:
L S F T ( θ ) = − E ( x , c , y ∗ ) ∼ D S F T [ ∑ t = 1 ∣ y ∗ ∣ log π θ ( y t ∗ ∣ x , c , y < t ∗ ) ] L_{SFT}(\theta) = -\mathbb{E}_{(x,c,y^*) \sim D_{SFT}} \left[ \sum_{t=1}^{|y^*|} \log \pi_\theta(y_t^* | x, c, y_{<t}^*) \right] LSFT(θ)=−E(x,c,y∗)∼DSFT t=1∑∣y∗∣logπθ(yt∗∣x,c,y<t∗)
其中 y t ∗ y_t^* yt∗ 是标准路径中的第 t t t 个token, y < t ∗ y_{<t}^* y<t∗ 是其前缀。 - 约束: SFT阶段的上下文长度通常被限制在课程学习的初始长度 L 1 L_1 L1 内。
-
课程引导的阶段化强化学习 (Curriculum-Guided Phased RL):
- 目标: 平滑地将模型从短上下文适应到目标长上下文,避免直接在极长上下文下训练导致的不稳定。
- 方法: 将整个RL训练过程划分为 K K K 个离散的阶段。每个阶段 k ∈ [ 1 , K ] k \in [1, K] k∈[1,K] 都有一个目标上下文长度 L k L_k Lk。模型在阶段 k k k 仅在满足 L k − 1 < ∣ x ∣ + ∣ c ∣ ≤ L k L_{k-1} < |x| + |c| \le L_k Lk−1<∣x∣+∣c∣≤Lk 条件的样本上进行训练 (其中 L 0 = 0 L_0 = 0 L0=0)。上下文长度 L k L_k Lk 逐阶段递增,直至达到最终的最大目标长度 L K L_K LK。
-
难度感知的回溯采样 (Difficulty-Aware Retrospective Sampling):
- 目标: 在后续的RL阶段中,有选择地重用先前阶段的困难样本,以激励策略模型在挑战性实例上进行更深入的探索。
- 方法: 实例 ( x , c ) (x,c) (x,c) 的难度被定义为基模型在该实例上生成的一组输出的平均奖励的倒数:
diff ( x , c ) = 1 mean ( { r i } i = 1 G ) + δ \text{diff}(x,c) = \frac{1}{\text{mean}(\{r_i\}_{i=1}^G) + \delta} diff(x,c)=mean({ri}i=1G)+δ1
其中 δ \delta δ 是一个小的稳定项。平均奖励越低,难度得分越高。通过基于此难度得分进行重要性采样,将先前阶段的困难样本引入当前阶段的训练数据中。
2.4 混合奖励机制
为了更准确地评估长上下文推理的质量,平衡精确性和多样性:
-
基于规则的验证 ( r r u l e r_{rule} rrule): 对从模型生成 y y y 中提取的最终答案 y a n s y_{ans} yans 与标准答案 y g o l d y_{gold} ygold 进行精确字符串匹配。
r r u l e ( y ) = I ( y a n s = y g o l d ) r_{rule}(y) = \mathbb{I}(y_{ans} = y_{gold}) rrule(y)=I(yans=ygold)
其中 I ( ⋅ ) \mathbb{I}(\cdot) I(⋅) 是指示函数。 -
LLM作为裁判 ( r L L M r_{LLM} rLLM): 使用一个独立的、能力较强的LLM来评估生成的答案 y a n s y_{ans} yans 与标准答案 y g o l d y_{gold} ygold 之间的语义等价性。
r L L M ( x , y ) = LLM-Judge ( x , y a n s , y g o l d ) r_{LLM}(x, y) = \text{LLM-Judge}(x, y_{ans}, y_{gold}) rLLM(x,y)=LLM-Judge(x,yans,ygold)
LLM-Judge会输出一个二元正确性分数 (例如,0或1)。 -
组合奖励 ( r ( x , y ) r(x,y) r(x,y)): 取上述两种奖励的最大值,以同时捕获精确匹配和语义一致性。
r ( x , y ) = max ( r r u l e ( y ) , r L L M ( x , y ) ) r(x,y) = \max(r_{rule}(y), r_{LLM}(x,y)) r(x,y)=max(rrule(y),rLLM(x,y))
3. 优势
- 首次系统解决长上下文RL训练不稳定性: 针对长上下文引入的优化难题,提出了包含SFT预热、课程学习和难度感知采样的完整渐进式扩展框架。
- 适配无价值网络的RL算法: 通过采用GRPO和DAPO这类基于组相对奖励的算法,有效规避了在长上下文场景下训练传统PPO中价值网络的巨大计算开销。
- 提供更鲁棒的奖励信号: 混合奖励机制结合了精确匹配的严格性和LLM评估的语义灵活性,为复杂长文本推理任务提供了更全面的反馈。
- 提升训练效率和最终性能: 渐进式扩展和难度感知采样共同作用,使得模型能够更稳定、更高效地学习长程依赖和复杂推理。
4. 实验
- 任务与数据集:
- 主要评估任务: 长上下文文档问答 (DocQA)。
- 训练数据: 构建了DocQA-RL-1.6K数据集 (包含数学、逻辑、多跳推理问题) 和一个5.3K样本的SFT数据集 (通过DeepSeek-R1蒸馏得到)。
- 评估基准: 七个长上下文DocQA基准,包括2WikiMultihopQA, HotpotQA, Musique, NarrativeQA, Qasper, Frames, DocMath。
- 模型与训练设置:
- 基础模型: R1-Distill-Qwen-14B 和 R1-Distill-Qwen-32B。
- RL训练: 课程学习分为两个阶段,输入长度分别为20K和60K tokens。
- SFT训练: 输入长度20K tokens。
- 对比模型: OpenAI的o1-preview, o3-mini; Anthropic的Claude-3.7-Sonnet-Thinking; Google的Gemini-2.0-Flash-Thinking; 以及其他开源模型如DeepSeek-R1, Qwen3系列。
- 实验结论:
-
QwenLong-L1-32B (使用DAPO) 在七个基准上的平均准确率达到70.7%,与Claude-3.7-Sonnet-Thinking (70.7%) 持平,并超越了OpenAI-o3-mini (70.4%) 和Qwen3-235B-A22B (70.6%) 等强大对手。
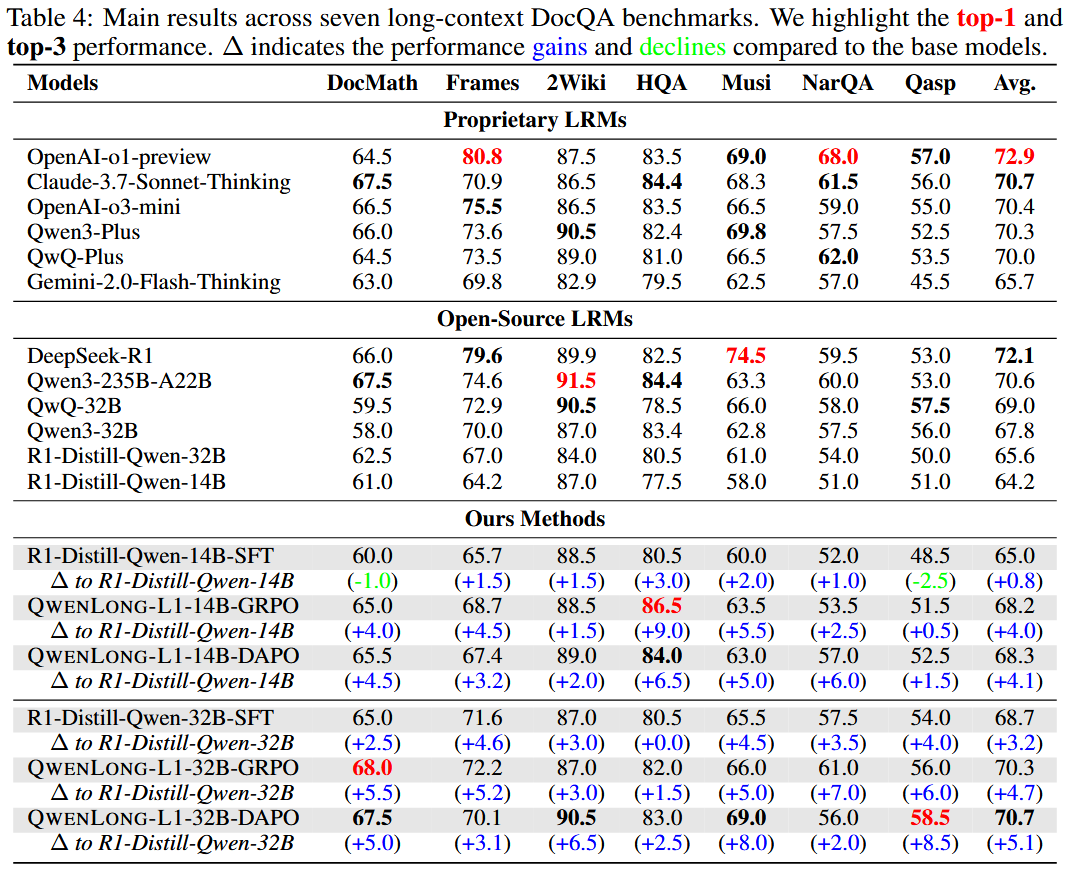
-
仅SFT对长上下文推理能力的提升有限 (14B模型平均提升0.8点,32B模型提升3.2点),而后续的RL整合则带来了显著的性能提升 (14B模型约4点,32B模型约5点)。
-
渐进式上下文扩展策略的有效性验证 (消融实验, Figure 5):
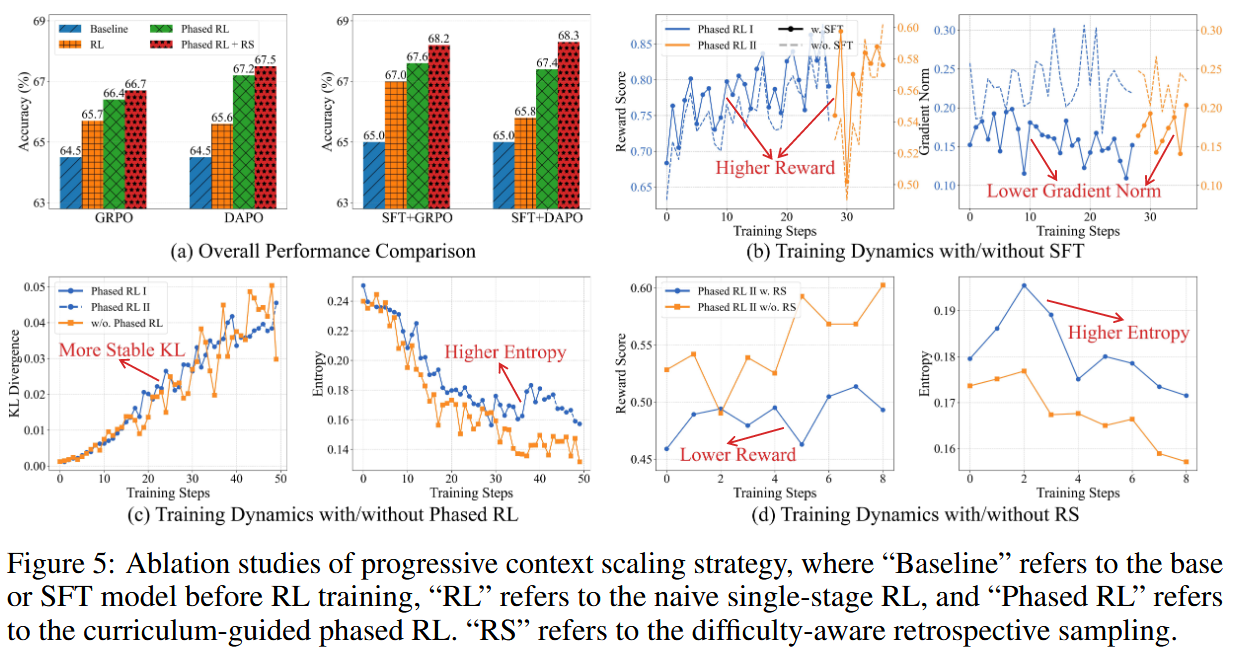
- Warm-up SFT 显著改善了RL的起点,加速了奖励收敛,并使得RL训练过程中的梯度范数更低更稳定。
- 课程引导的阶段化RL 相比于直接在长上下文进行的单阶段RL,展现出更高的训练稳定性 (更平稳的KL散度和更高的策略熵)。
- 难度感知的回溯采样 进一步提升了模型性能,通过聚焦困难样本激励了策略探索。
-
SFT与RL的权衡:
- 直接进行长上下文SFT (Long SFT) 也能获得不错的性能,且计算成本相对较低。
- 但为了达到最佳性能,RL是不可或缺的。
- 有趣的是,在短上下文SFT模型基础上进行RL,其最终性能优于在长上下文SFT模型基础上进行RL,这可能表明短SFT+RL的组合能更好地学习通用推理能力并迁移到长上下文。
-
推理行为的演化: RL训练能够显著增强模型在长上下文中的关键推理行为,如信息定位 (Grounding)、子目标规划 (Subgoal Setting)、错误修正 (Backtracking) 和答案验证 (Verification),并且这些行为的增强与最终性能的提升正相关。而SFT虽然也能一定程度上增加这些行为的出现频率,但这种增加未必能有效转化为性能提升。
-

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 3
3 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)