机器学习-支持向量机与神经网络
一、支持向量机
支持向量机(Support Vector Machine,SVM)是 一 类按监督学习方式对数据进行二元分类的广义线 性分类器(generalized linear classifier), 其决策边界是对学习样本求解的最大边距超平面。
与逻辑回归和神经网络相比,支持向量机,在学习复杂的非线性方程时提供了一种更为清晰,更 加强大的方式。
1)算法思想
找到集合边缘上的若干数据(称为支持向量,Support Vector)用这些点找出一个平面(称为决策面),使得支持向量到该平面的距离最大。
2)支持向量机原理
(1)线性分类:
对于线性可分数据,寻找一个超平面,使得:
间隔最大化:最大化两类样本与超平面的距离。
数学表达:

(2)非线性分类: 通过核函数将原始数据映射到高维空间,使其线性可分常用核函数:
线性核:适用于线性问题
多项式核:解决非线性问题
高斯核(RBF):适用于复杂的非线性问题 三个常用的核函数中,只有高斯核函数是需要调参的。
(3)松弛变量与软间隔:
允许部分样本违反间隔约束,以提升对噪声的鲁棒性。
数学表达:
3)支持向量机的模型优化
交叉验证:使用网格搜索或随机搜索优化超参数。
超参数调优:
1.核函数选择:
数据线性分布:选择线性核;
数据复杂分布:选择RBF 核或多项式核
2.惩罚系数C:
C 小:允许更多误分类,间隔增大,可能欠拟合
C 大:更关注准确率,间隔减小,可能过拟合

4)优劣
1*.优 点
适合高维数据:SVM 在特征数较多的情况下表现良好;
有效控制模型复杂度:最大化分类间隔,避免过拟合;
灵活的核方法:能处理线性和非线性问题;
对少量样本鲁棒:SVM 的决策只依赖少量支持向量。
2*.缺 点
计算复杂度高:大规模数据下训练速度较慢;
对超参数敏感:核函数和参数C 、γ 需要仔细调优;
不适合大规模数据集:训练时间随着样本数的增长显著增加。
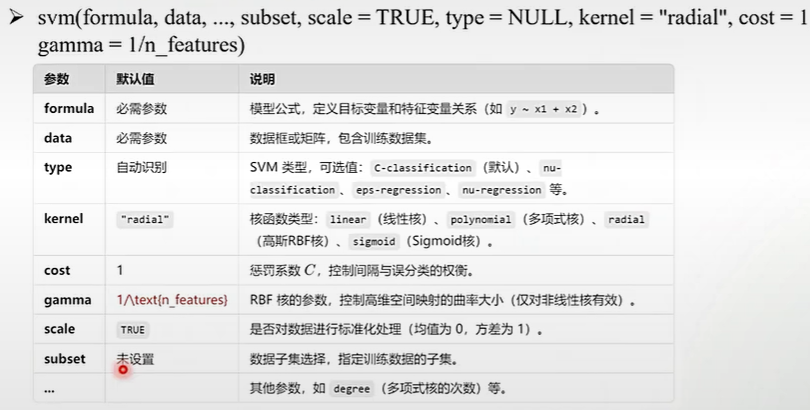
5)R语言实现


二、神经网络
神经网络 (Neural Network,NNET) 是模拟人脑神经联接系统进行 模式识别的计算模型,主要用于模式识别和机器学习任务。 由大量的简单处理单元(神经元)按照某种方式连接在一起构成,这些单元分为输入层、隐藏层、输出层。通过调整各层之间的连接权重,神经网络可以学习复杂的函数映射, 从而从输入数据中提取特征并做出预测。
1)神经网络原理
输入数据通过输入层传递到隐藏层,然后到输出层(前向传播)。在每个节点,输入信号会与该节点的权重相乘,并通过一个激活函数产生输出。激活函数 通常使用非线性函数(如ReLU、Sigmoid 等),以允许网络学习复杂的表示。
通过比较网络的预测值和实际值,计算损失函数。
通 过反向传播计算损失函数的梯度,并根据梯度更新网络的权重和偏置(后向传播)。这个过程反复进行,直到网络的预测值的误差降到可接受的范围 或者达到预设的迭代次数。
激活函数引入非线性,使网络能够学习复杂模式。常见的激活函数有:
Sigmoid: 适合二分类,输出在0到1之间。
Tanh: 输出在-1到1之间,有助于收敛。
ReLU: 当输入大于0时直接输出,解决了梯度消失问题。
Leaky ReLU: 改进版本的ReLU, 增加了小负斜率,防止“死亡ReLU” 问题。
2)优劣
1*.优 点
函数处处连续,便于求导
可将函数值的范围压缩至[0,1],可用于压缩数据,且幅度不变
便于前向传输
2*.缺 点
在趋向无穷的地方,函数值变化很小,容易出现梯度消失,不利于深层神经的反馈传输
幂函数的梯度计算复杂
收敛速度比较慢
3)重要参数
学习率 (Learning Rate): 定义了权值更新的速度。太高的学习率可能导致模型在最优解 附近摇摆难以收敛,太低的学习率又会导致网络训练速度过慢。
激活函数 (Activation Function): 定义一个神经元的输出或激活。常见的激活函数有 sigmoid 、tanh 、ReLU 等。
权 值(Weights) 和偏置(Biases): 是神经网络的主要参数,它们在训练过程中不断调整以优 化模型。
迭代次数 (Numbercof Epochs): 是模型处理完所有训练集数据的次数,太少可能导致模 型未能充分学习,太多可能导致过拟合。
批尺寸 (Batch Size): 是模型同时处理的数据量。太小的批尺寸会导致训练速度缓慢, 太大的批尺寸可能导致内存不足。
4)神经网络的优势
强大的建模能力: 能处理高度复杂和多维的数据,适用范围广泛,包括图像识别、 自然语言处理等。
特征学习:能够自动从原始数据中学习特征,减少了手动特征提取的需求。
适应性强:对于不同类型的数据(如结构化数据、图片、声音等),能够调整网 络结构和参数以优化性能。
并行处理:nnet 的结构允许并行计算,尤其是使用GPU 进行训练时,效率更高。
强大的非线性映射:通过激活函数实现复杂的非线性变换,提升模型的表达能力。
5)神经网络的劣势
计算资源需求大:训练nnet 通常需要大量的计算资源,尤其是对于深度学习网络。
过拟合风险:如果模型复杂且训练数据不足, nnet 容易过拟合,导致在新数据上的表现不佳。
可解释性差:通常被视为“黑箱”,理解其内部工作机制和决策过程相对困难。
需要大量数据:训练神经网络尤其是深度学习模型时,通常需要大量标注数据, 数据稀缺会影响模型效果。
超参数调优困难:模型的性能往往依赖于多种超参数设置(如学习率、隐藏层数、 神经元数等),调优过程复杂且耗时。
6)R语言实现


三、R语言实践
# 加载所需R包
library(e1071) # 支持向量机(SVM)
library(neuralnet) # 神经网络
library(pROC) # ROC曲线和AUC计算
library(caret) # 机器学习工具包(用于数据预处理)
# 读取数据
tlog <- read.csv("tlog.csv", row.names = 1)
# 定义筛选特征集合
selected_vars <- c("exercise", "hyperlip", "pregnant",
"age", "glucose", "bmi", "pedigree")
selected_vars_scaled <- c("exercise", "hyperlip", "pregnant", "age_scaled",
"glucose_scaled", "bmi_scaled", "pedigree_scaled")
# 将结局变量因子化
tlog$diabetes <- factor(tlog$diabetes, levels = c(0, 1), labels = c("No", "Yes"))
#########################支持向量机(SVM)#######################################################
##基于标准化后的数据建模
# 参数调整
set.seed(11)
tune_result <- tune.svm(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
kernel = "radial", # 径向核函数RBF
cost = 10^(-1:3), # cost:惩罚参数,用于控制分类错误的惩罚程度
gamma = 10^(-3:1), # gamma:核函数的参数,定义单个训练样本影响的范围
tunecontrol=tune.control(sampling = "cross",cross = 5), #交叉验证
probability = TRUE)
# 查看最佳参数
best_model <- tune_result$best.model
print(tune_result)
# 使用最佳参数拟合SVM模型
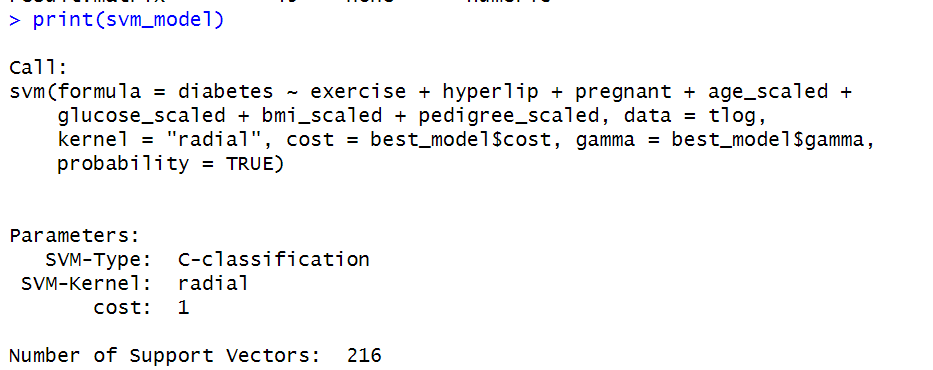
svm_model <- svm(diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled,
data = tlog,
kernel = "radial",
cost = best_model$cost,
gamma = best_model$gamma,
probability = TRUE) # 启用概率
print(svm_model)
#########################神经网络(nnet)#######################################################
# 构建神经网络模型的函数
build_nn_model <- function(hidden_layers) {
formula <- as.formula("diabetes ~ exercise + hyperlip + pregnant + age_scaled +
glucose_scaled + bmi_scaled + pedigree_scaled")
model <- neuralnet(formula, data = tlog, hidden = hidden_layers,
linear.output = FALSE) # 模型输出为分类概率(非线性激活)
return(model)
}
# 初始化变量
best_model_nnet <- NULL
best_auc <- 0
best_hidden_layers <- NULL # 保存最佳隐藏层组合
# 设置隐藏层组合
hidden_layer_combinations <- list(c(2),c(3),c(4), c(2, 1))
# 网格搜索
for (hidden in hidden_layer_combinations) { # 遍历每种隐藏层结构
set.seed(123) # 设置随机种子
nn_model <- build_nn_model(hidden)
# 进行预测
predictions_prob <- predict(nn_model, tlog)[,2] # 获取概率
predictions <- ifelse(predictions_prob > 0.5, "Yes", "No") # 将概率转为分类
# 计算AUC
roc_obj <- roc(tlog$diabetes, predictions_prob)
auc_value <- roc_obj$auc
# 更新最佳模型
if (auc_value > best_auc) {
best_auc <- auc_value
best_model_nnet <- nn_model
best_hidden_layers <- hidden # 保存最佳隐藏层组合
}
}
# 输出最佳模型和AUC值
cat("Best AUC:", best_auc, "\n")
cat("Best Hidden Layer Configuration:", paste(unlist(best_hidden_layers), collapse = ", "), "\n")
nnet_model <- best_model_nnet
#显示模型信息
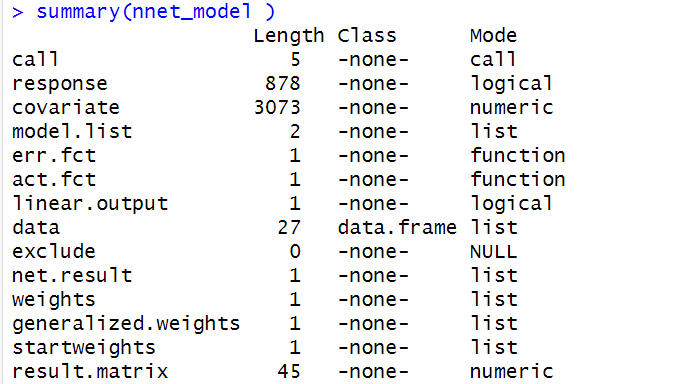
summary(nnet_model )
四、结果展示

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)