【分层强化学习】survey
1.分层强化学习简介
问题1:分层强化学习到底是什么?
强化学习作为一种主动式学习范式,非常符合人类在学习新知识时的行为:通过和环境交互 ,获得反馈来学习得到某种技能。那么自然地,在解决这些复杂的问题的时候,可以参考到人的一些做法——将问题抽象成不同的层级,从不同层面来处理,这也是HRL的核心思想。比如在烤牛排的时候,我们将从宏观对问题进行分解,烤牛排需要切牛排、切胡萝卜、切洋葱,再深入,我们则可以了解,每个食材应该如何切,切几段。这种将原问题分层解决的方法,就是分层强化学习。
形式化上,强化学习研究马尔可夫决策过程(MDP)问题,而HRL则研究半马尔科夫决策过程(SMDP)问题。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MatAgD9e-1658995767415)(D:\CSDN图片\v2-c655b33a2fc36ebfae274e9fdb776360_b.jpg)]](https://i-blog.csdnimg.cn/blog_migrate/cfba188aa09f18d765246b1317bd6f48.jpeg)
MDP是每个timepoint,s -> s’;而SMDP则允许经过多个timepoint,s -> s’。更直观的,MDP每次和环境交互(一个action)都发生状态的改变,而SMDP则是多次和环境交互(一系列的actions)后,状态才会发生改变。对应到HRL中,我们一般将这 一系列actions 视为一个option。
https://zhuanlan.zhihu.com/p/191526908
问题2:分层强化学习解决什么问题?
分层强化学习解决的是强化学习中的 稀疏奖励(sparse reward)问题:当环境奖励过于稀疏时,智能体可能长期都没有办法获得具有正奖励的样本,给值函数和策略的学习带来了困难。通过分层把策略分为不同层级的子策略,每个子策略在学习的过程中会得到来自上一层级传递来的奖励,这样可以大大提升 样本的利用效率(sample efficiency)。
或者说通过分层强化学习,我们希望可以解决长期信度分配的问题,实现更快的学习和更好的泛化。在多智能体系统中的信用分配问题,即判断每个智能体对于团体成功的贡献。在单智能体系统中,我们更多考虑的是动作对奖励值的贡献程度,当环境奖励较为稀疏或者会出现延迟时,如何进行信用分配就成为了比较棘手的问题。
https://zhuanlan.zhihu.com/p/501932920
问题3:分层强化学习的有哪几类?
目前分层的解决手段大体分两种,一种是基于目标的(goal-reach),主要做法是选取一定的goal,使agent向着这些goal训练,可以预见这种方法的难点就是如何选取合适的goal;另一种方式是多级控制(multi-level control),做法是抽象出不同级别的控制层,上层控制下层,这些抽象层在不同的文章中可能叫法不同,如常见的option、skill、macro action等,这种方式换一种说法也可以叫做时序抽象(temporal abstraction)。
https://zhuanlan.zhihu.com/p/267524544
问题4:分层强化学习算法的思想更贴近解决复杂的环境,为什么这个方向依然这么冷门?
借用一下知乎上2018年俞扬对该问题的回答:
不分层的强化学习,如果放在人身上,那就是每一时刻我们都要决定控制哪一根肌肉纤维收缩,因为控制肌肉纤维收缩是我们大脑发出的直接决策,不管是迈一下步子、动一下指头、还是说一个音节。然而在我们的思考中,想的是我要去哪、我要吃啥、我要说点什么,已经远远脱离了控制肌肉纤维的层面。在强化学习中,将动作行为从最原始的动作,抽象到多层的动作,是分层强化学习的主要特征。
分层的好处很明显。如果我们的思维是直接控制肌肉纤维收缩,那么吃一顿饭都会极其困难。分层后,我们在高层思维,需要考虑的动作不过是拿起筷子、加一块肉、放进嘴里。。。这样的决策,尽管每一步都会涉及大量的肌肉纤维的活动。
然而正是因为分层对于人(甚至有一定智商的动物)来说如此天然,我们并不清楚在我们的思维中是如何做到分层的,也就不清楚到底该如何实现分层。目前的分层强化学习方式都非常的原始,几乎没有可通用的模型。如果回到人工智能,分层直接对应了概念的抽象以及在抽象层面进行推理。这是目前人工智能最缺乏的能力之一,一旦取得突破,人工智能技术可能进入另一个高度。
https://www.zhihu.com/question/264126494/answer/497956374
分层强化学习算法总结
| 算法简称 | 论文全称 | 时间 |
|---|---|---|
| Feudal | Feudal Reinforcement Learning | 1992 |
| HAM | Reinforcement Learning with Hierarchies of Machines | 1997 |
| MAXQ | Hierarchical reinforcement learning with the MAXQ value function decomposition | 2000 |
| Options | Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning | 1999 |
| Option-Critic | The Option-Critic Architecture | 2016 |
| H-DRL | A Deep Hierarchical Approach to Lifelong Learning in Minecraft | 2016 |
| H-DQN | Hierarchical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation | 2016 |
| FuN | FeUdal Networks for Hierarchical Reinforcement Learning | 2017 |
| UVFA | Universal Value Function Approximators | 2015 |
| 算法简称 | 论文全称 | 时间 |
|---|---|---|
| HER | Hindsight Experience Replay | 2018 |
| HAC | Learning Multi-Level Hierarchies with Hindsight | 2019 |
| HIRO | Data-Efficient Hierarchical Reinforcement Learning | 2018 |
| Skill Chaining | Option Discovery Using Deep Skill Chaining | 2020 |
| Information-Constrained Primitives | Reinforcement Learning with Competitive Ensembles of Information-Constrained Primitives | 2019 |
| DIAYN | Diversity is all you need: Learning skills without a reward function | 2018 |
| DADS | Dynamics-Aware Unsupervised Discovery of Skills | 2020 |
| HIDIO | Hierarchical Reinforcement Learning By Discovering Intrinsic Options | 2021 |
| HIGL | Landmark-Guided Subgoal Generation in Hierarchical Reinforcement Learning | 2021 |
| 算法简称 | 论文全称 | 时间 |
|---|---|---|
| UOF | Hierarchical Reinforcement Learning with Universal Policies for Multi-Step Robotic Manipulation | 2021 |
分层之所以能够提升样本效率,是因为上层控制器给下层控制器提供goal/option的同时还会根据下层控制器的策略好坏反馈一个对应的 内在奖励(intrinsic reward),这就保证了即便在外部奖励为0的情况下,下层控制器依然能够获得奖励,从而一定程度上缓解了奖励稀疏的问题。
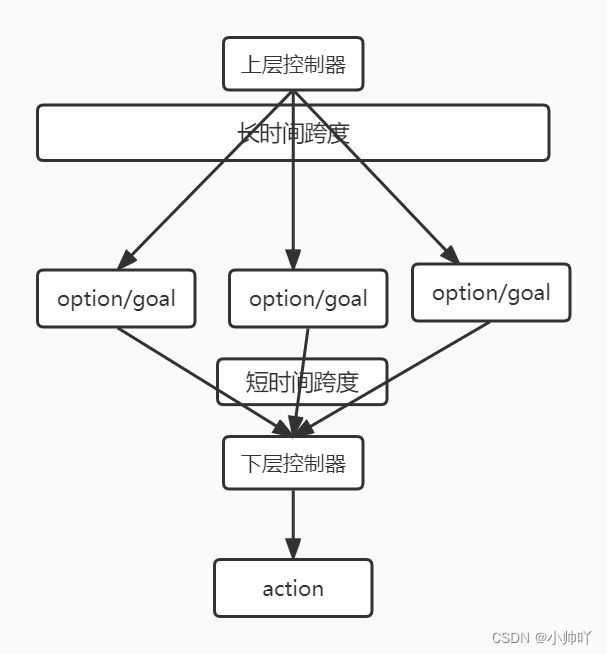
未完待续

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 4
4 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)