强化学习1(李宏毅)
·
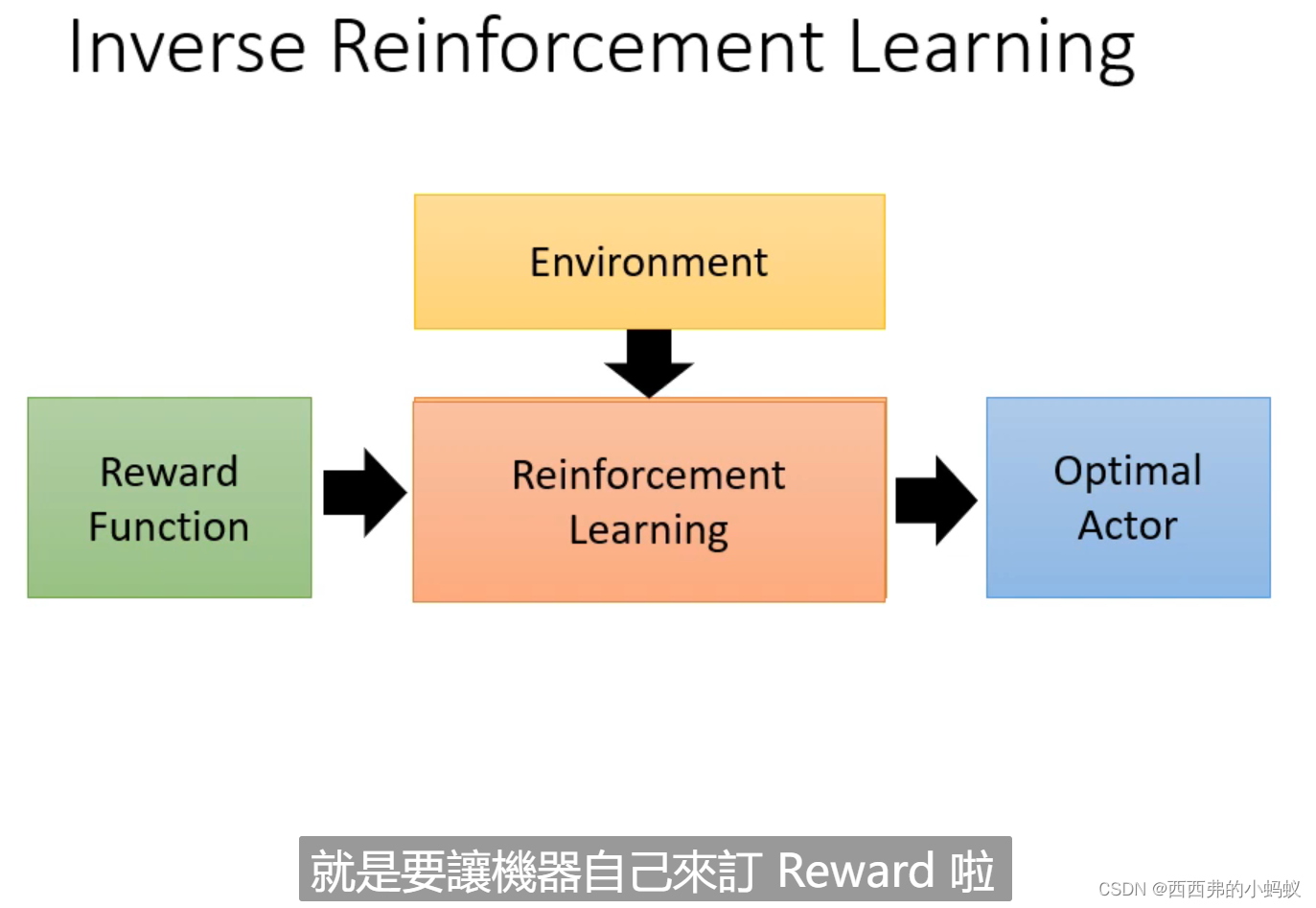
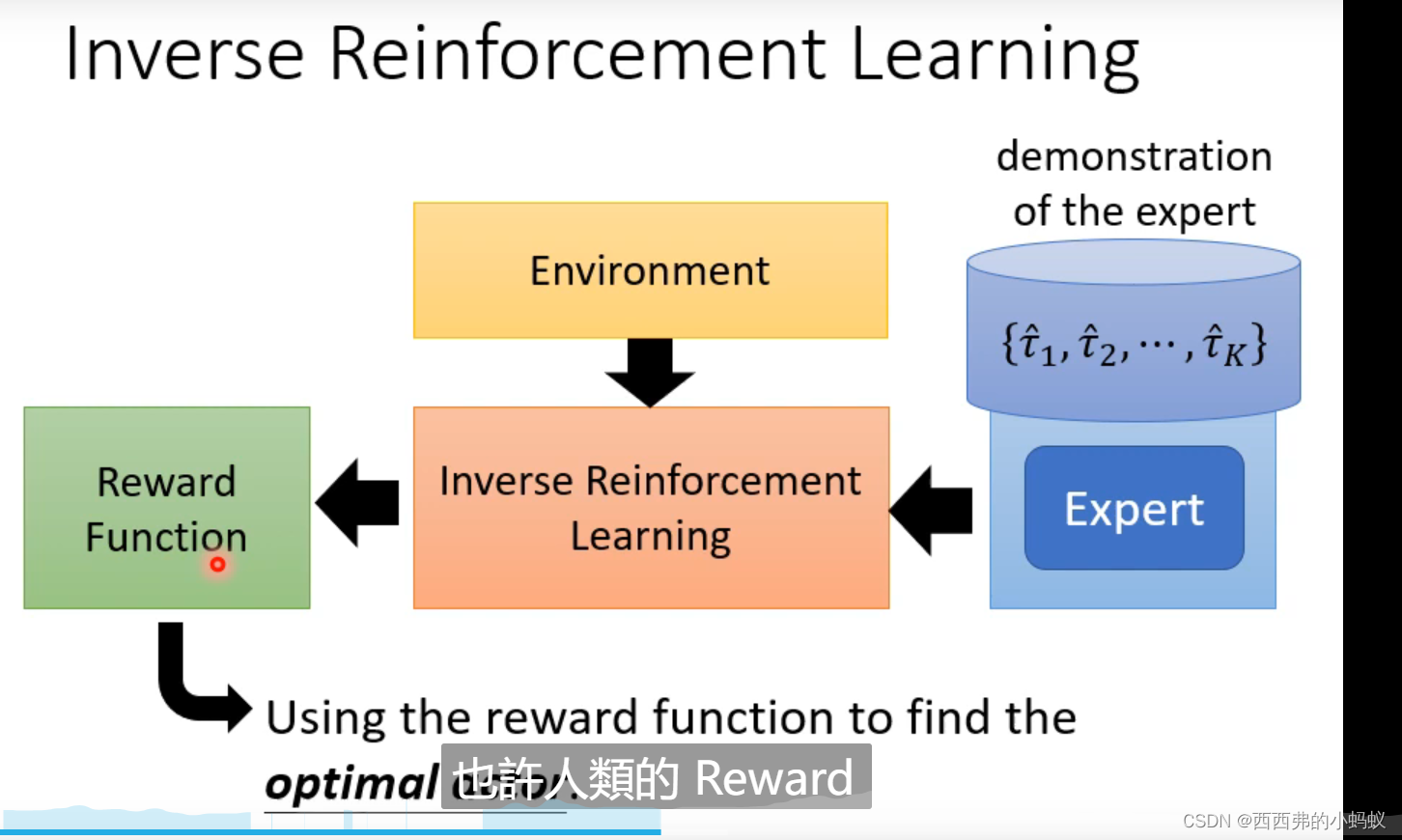
强化学习概述
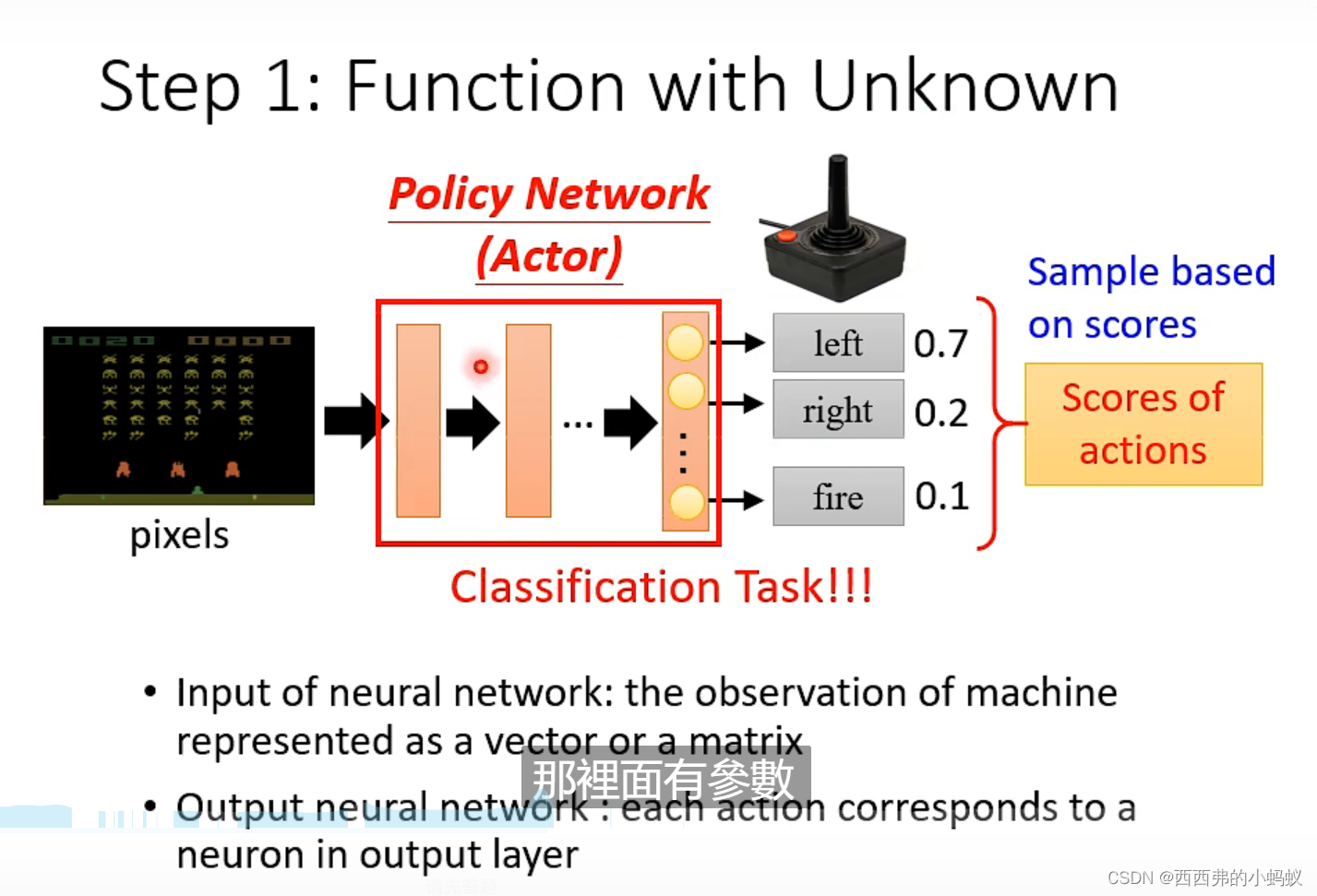
其中网络根据 输入选择不同的网络结构 CNN ,RNN ,或者transformer
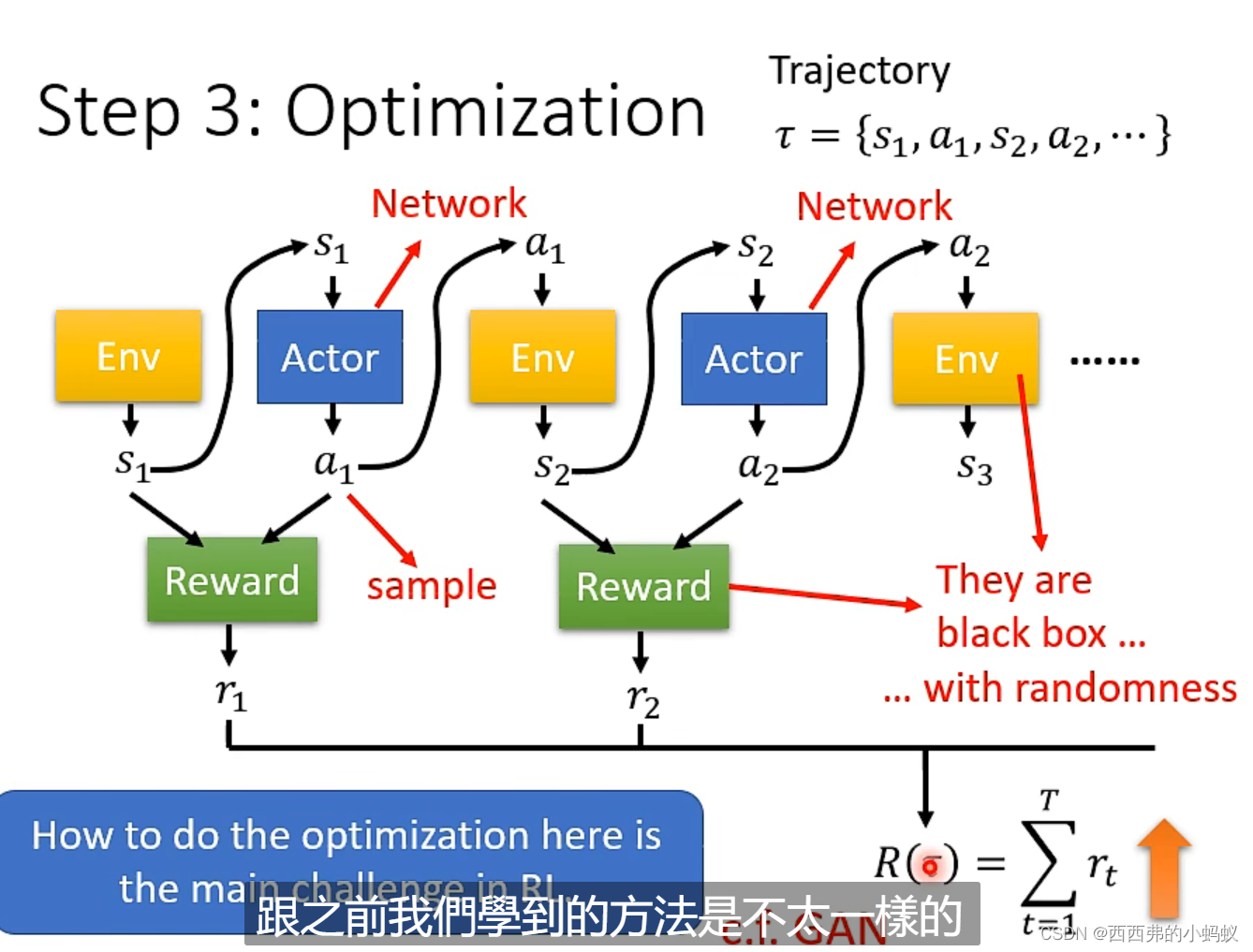
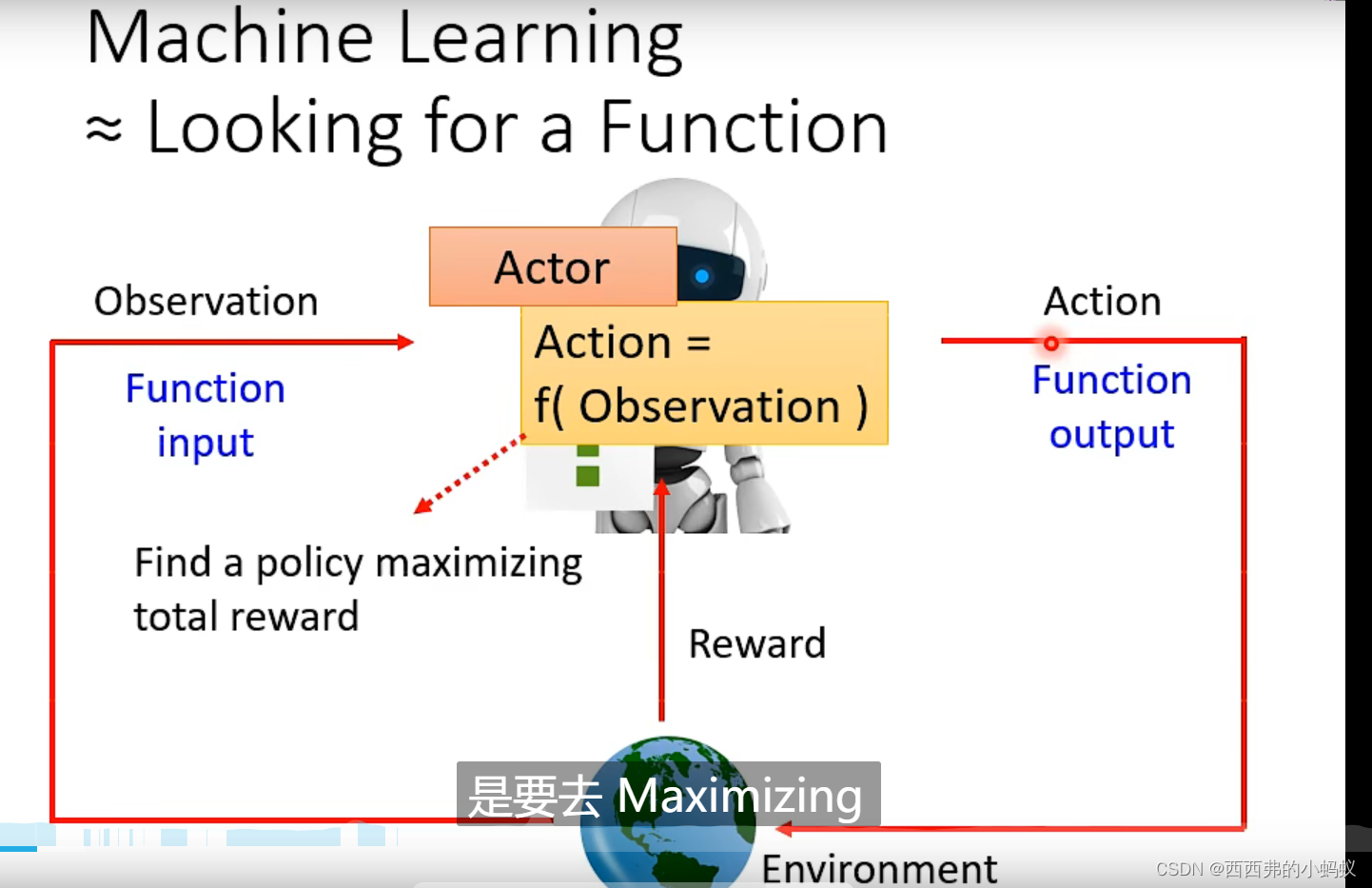
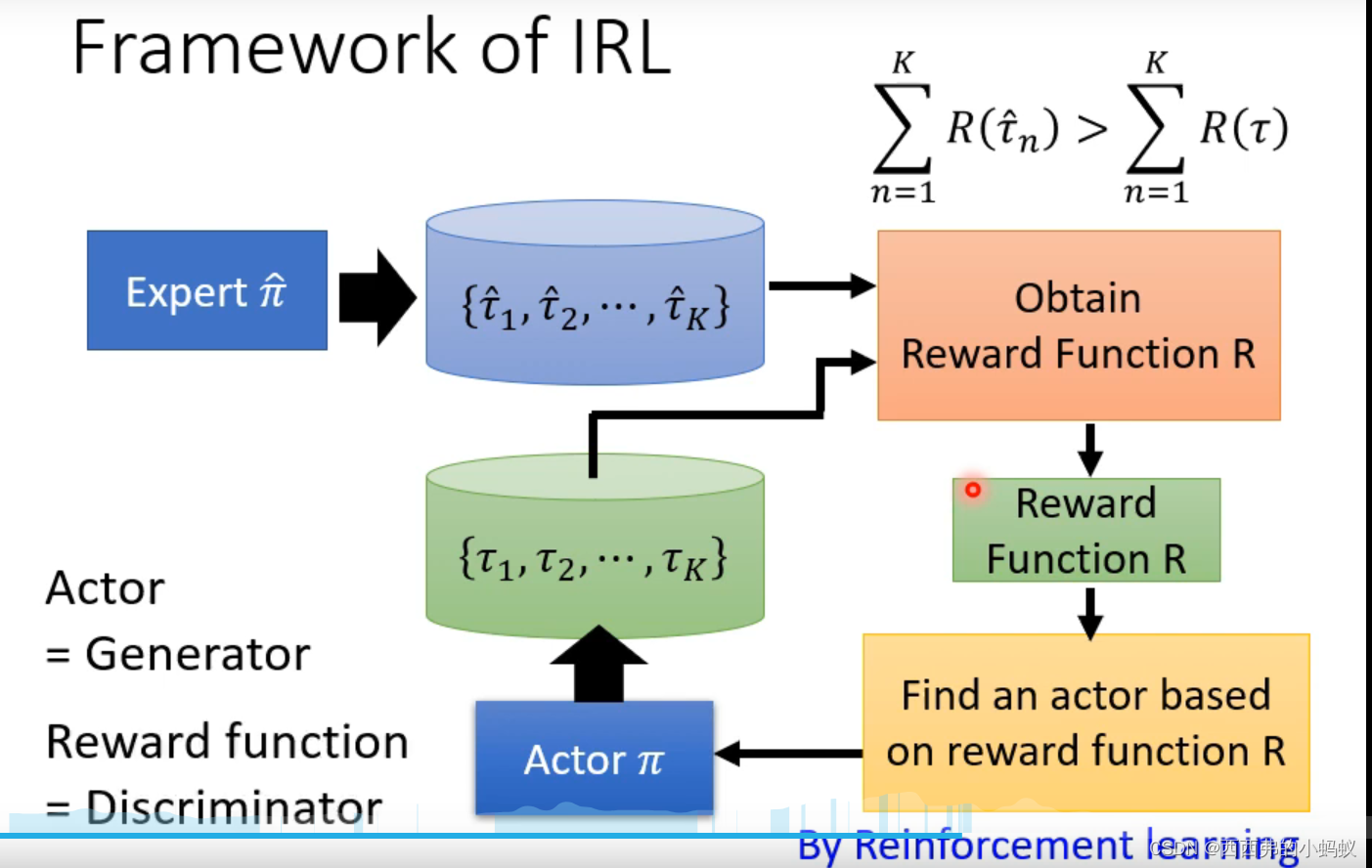
在return最大的约束下,找到Actor中network的参数,满足这个约束,使得R越大越好。但是network训练过程中存在大量的随机性,导致训练困难。RL类似GAN,可以将Actor看成GAN中的Generater;把Reward和环境 看成discriminater。RL只能通过梯度法优化Actor,但是不能优化reward 网络
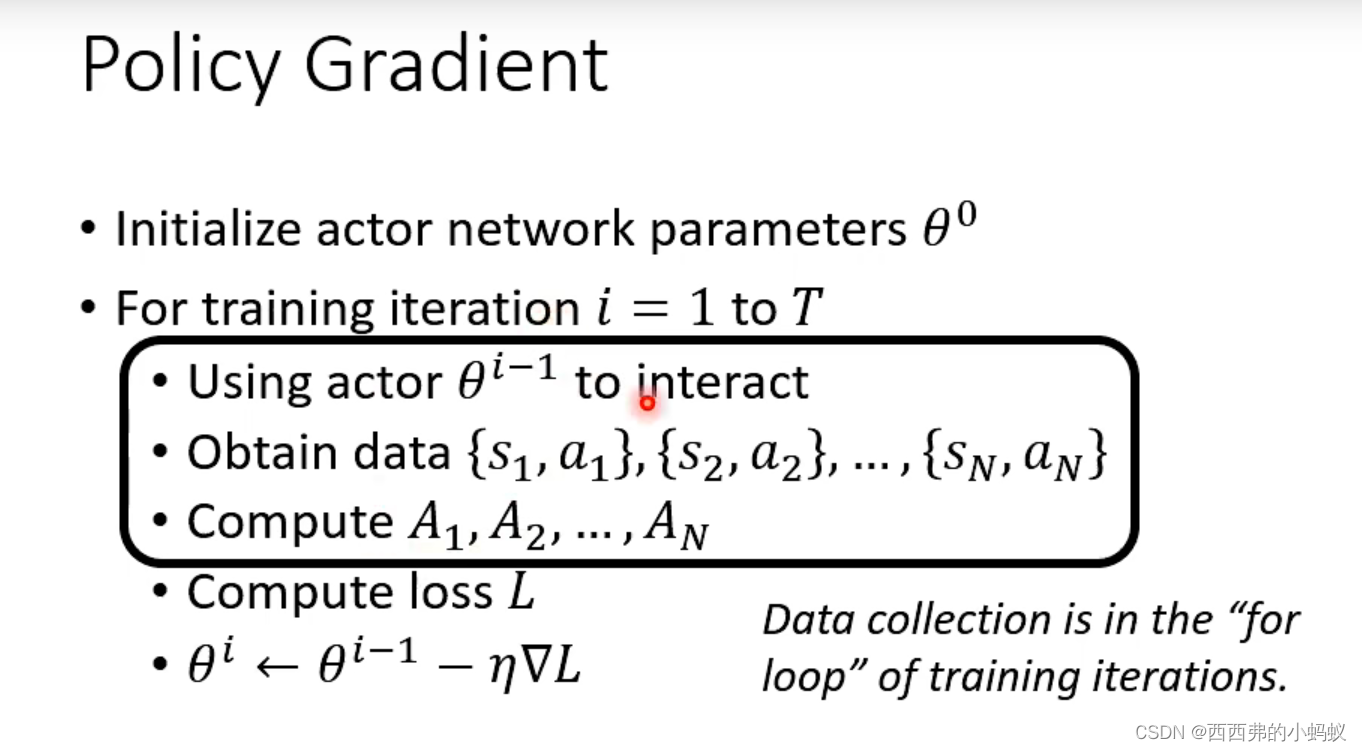
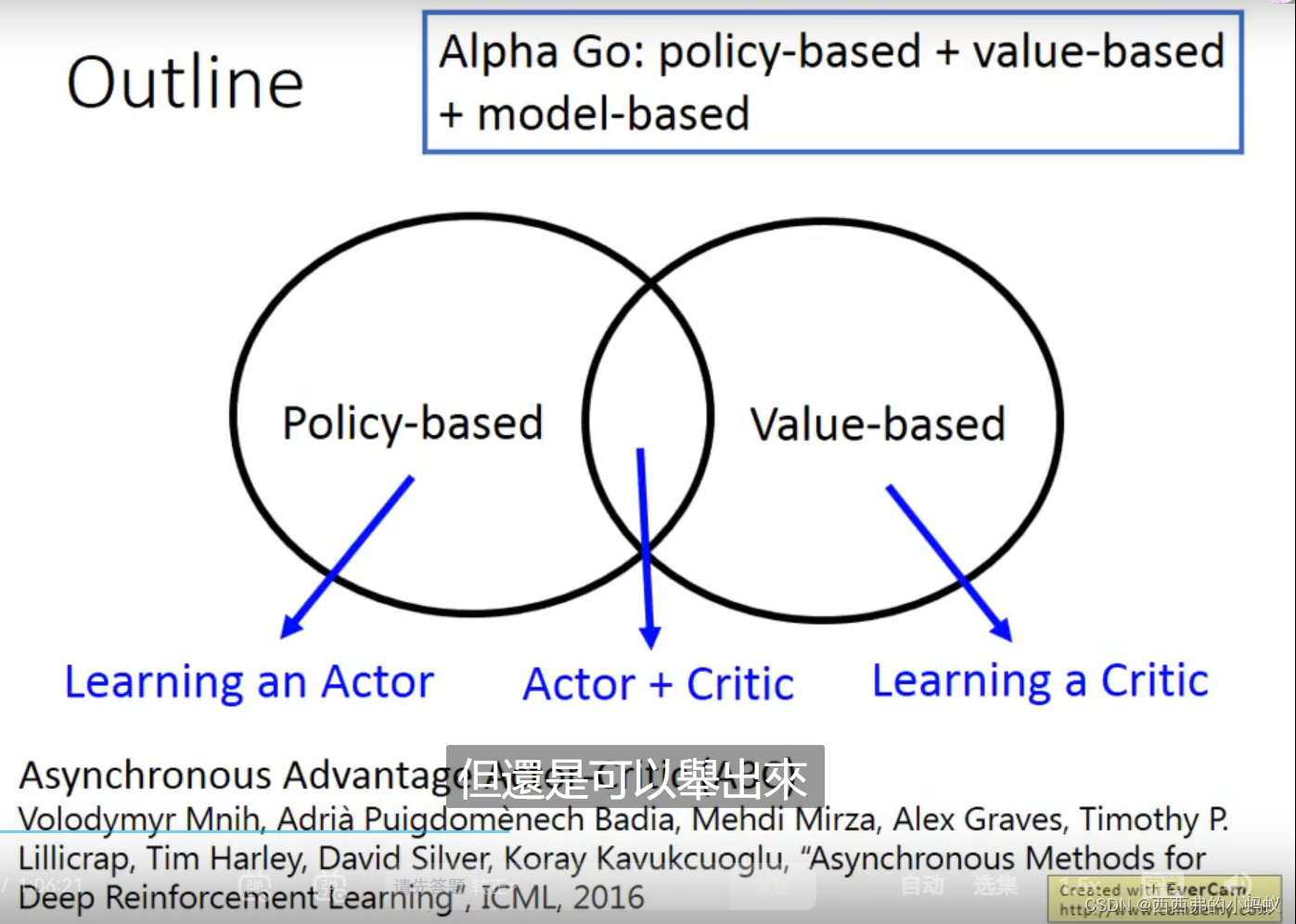
policy Gradient
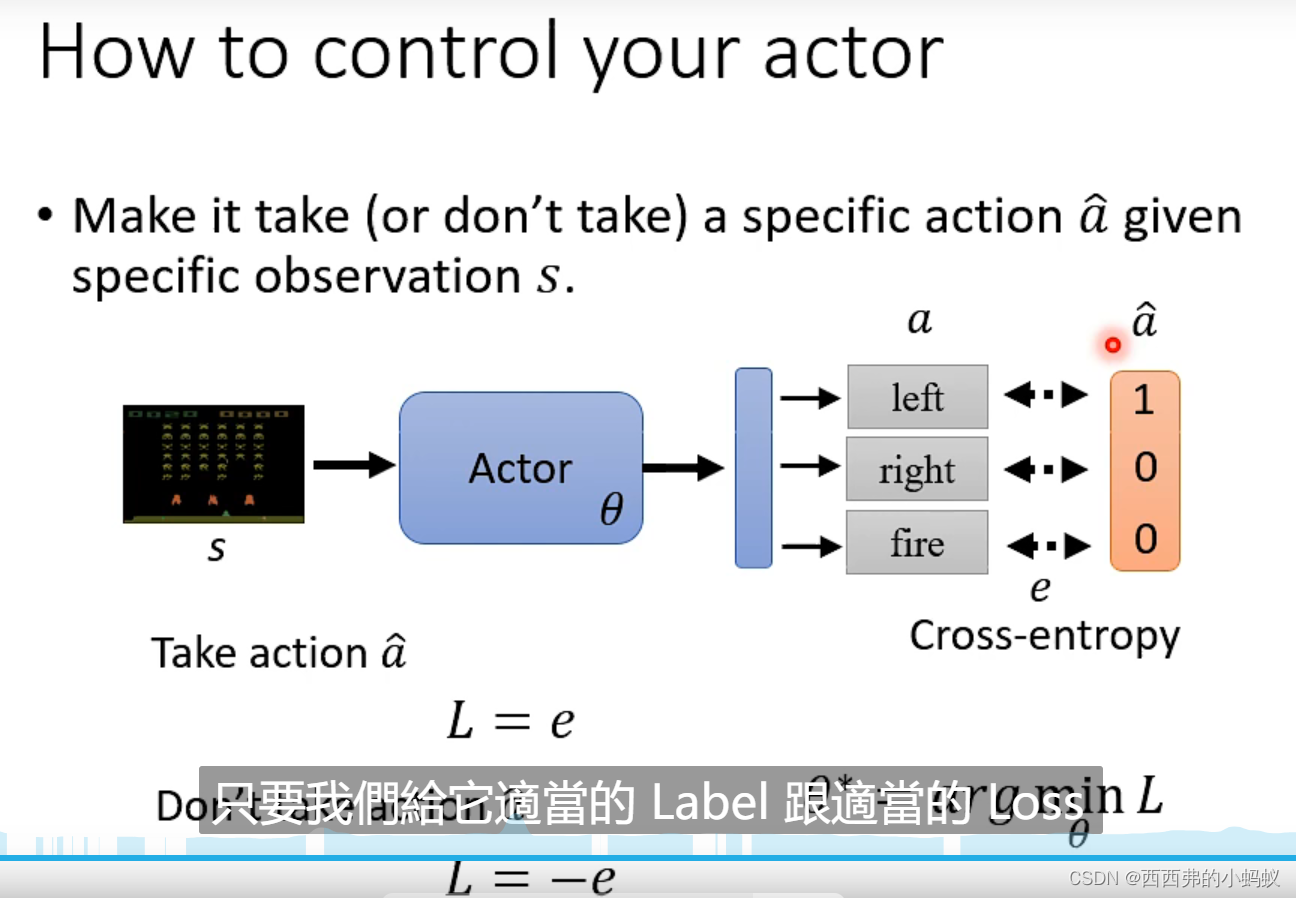
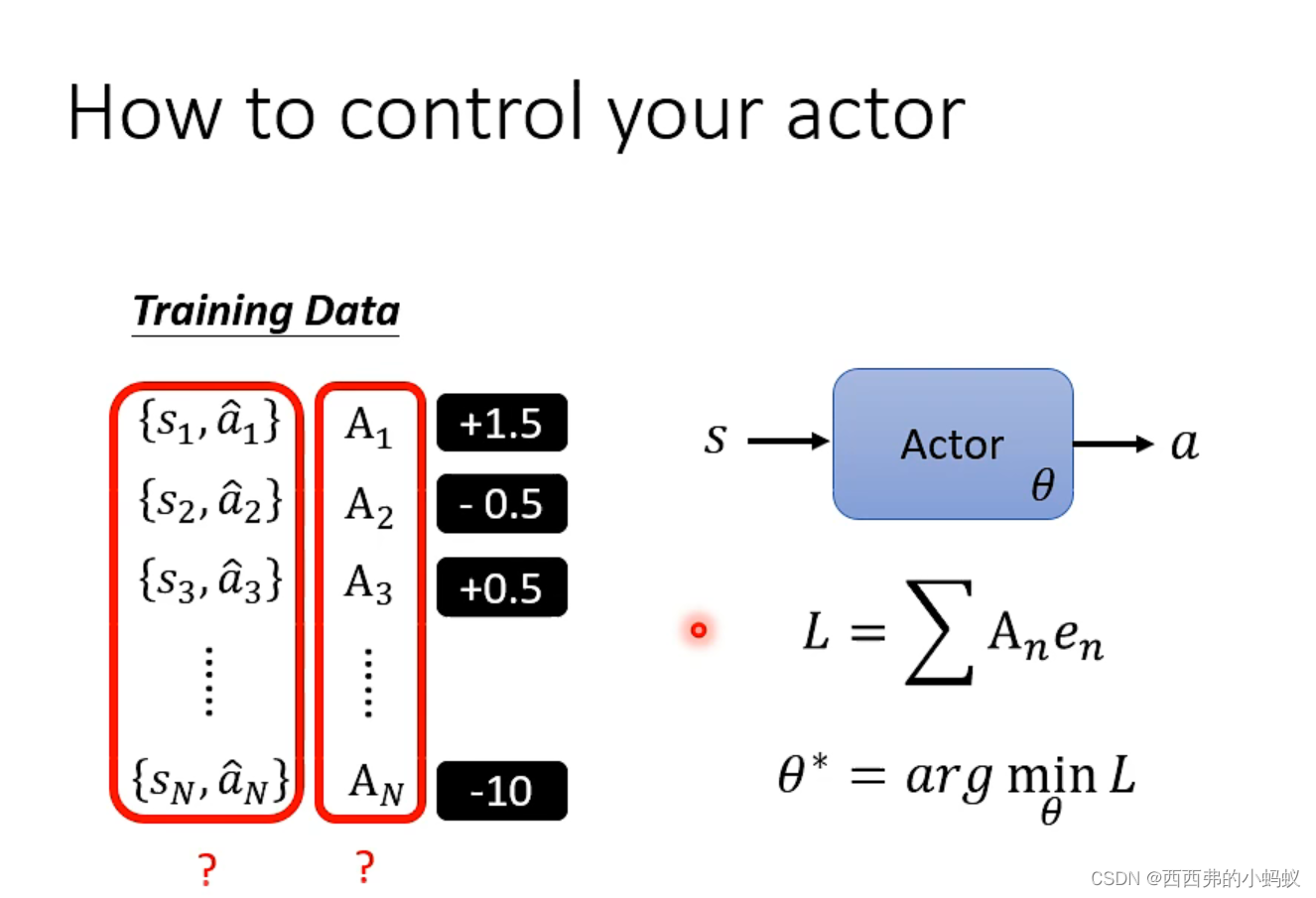
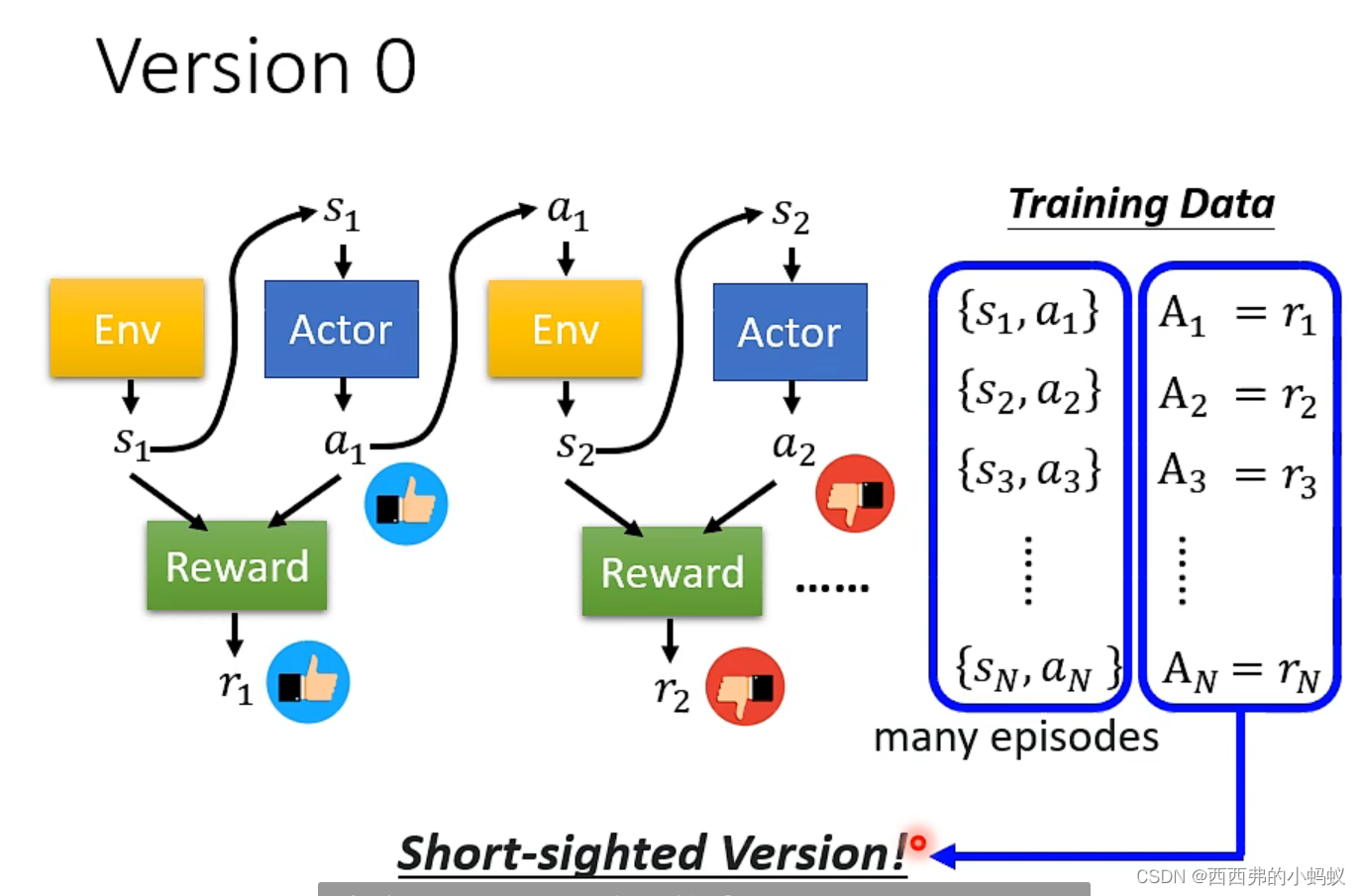
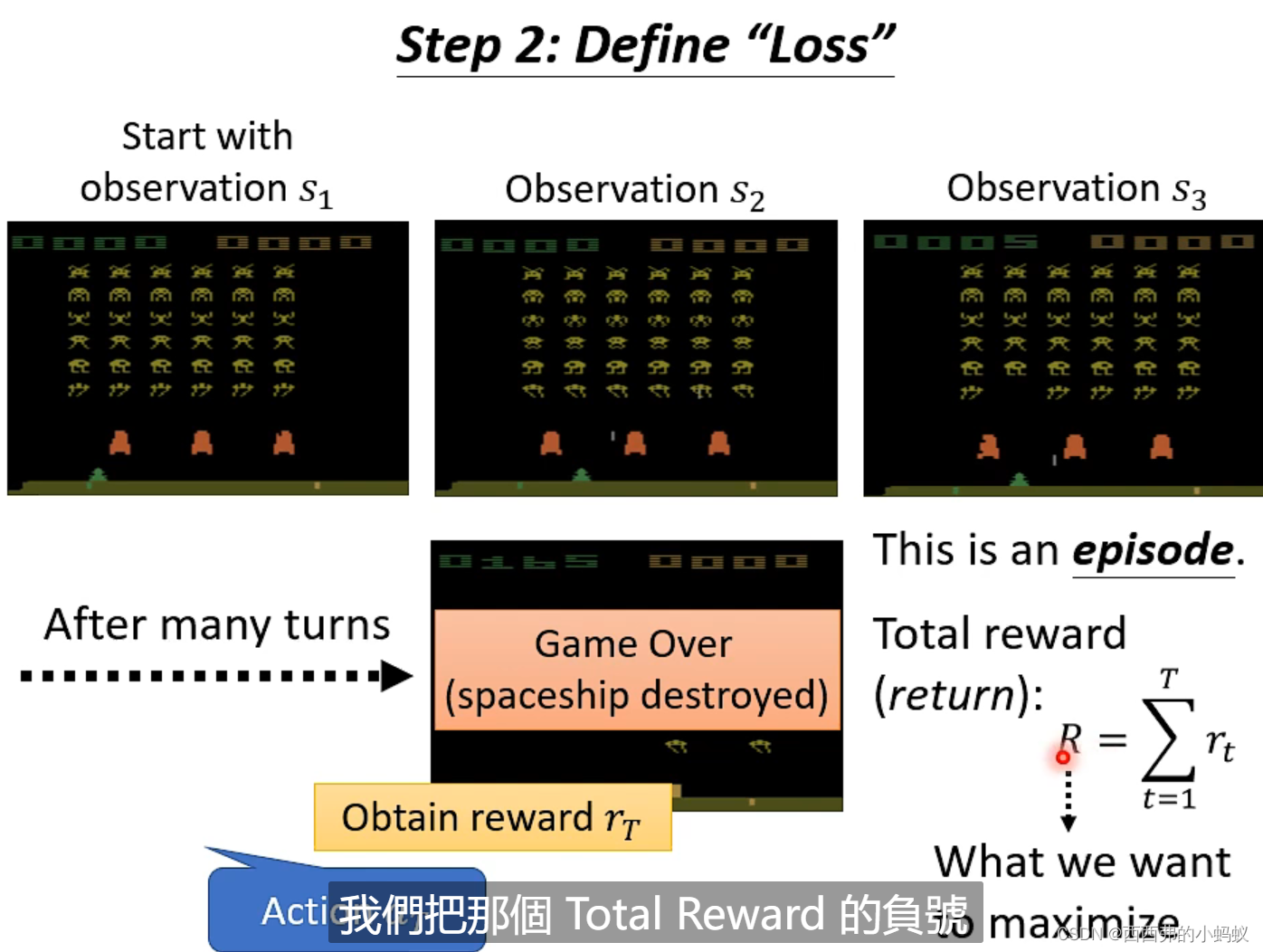
奖励r存在正负性,将这样的轨迹作为训练资料,短期回报
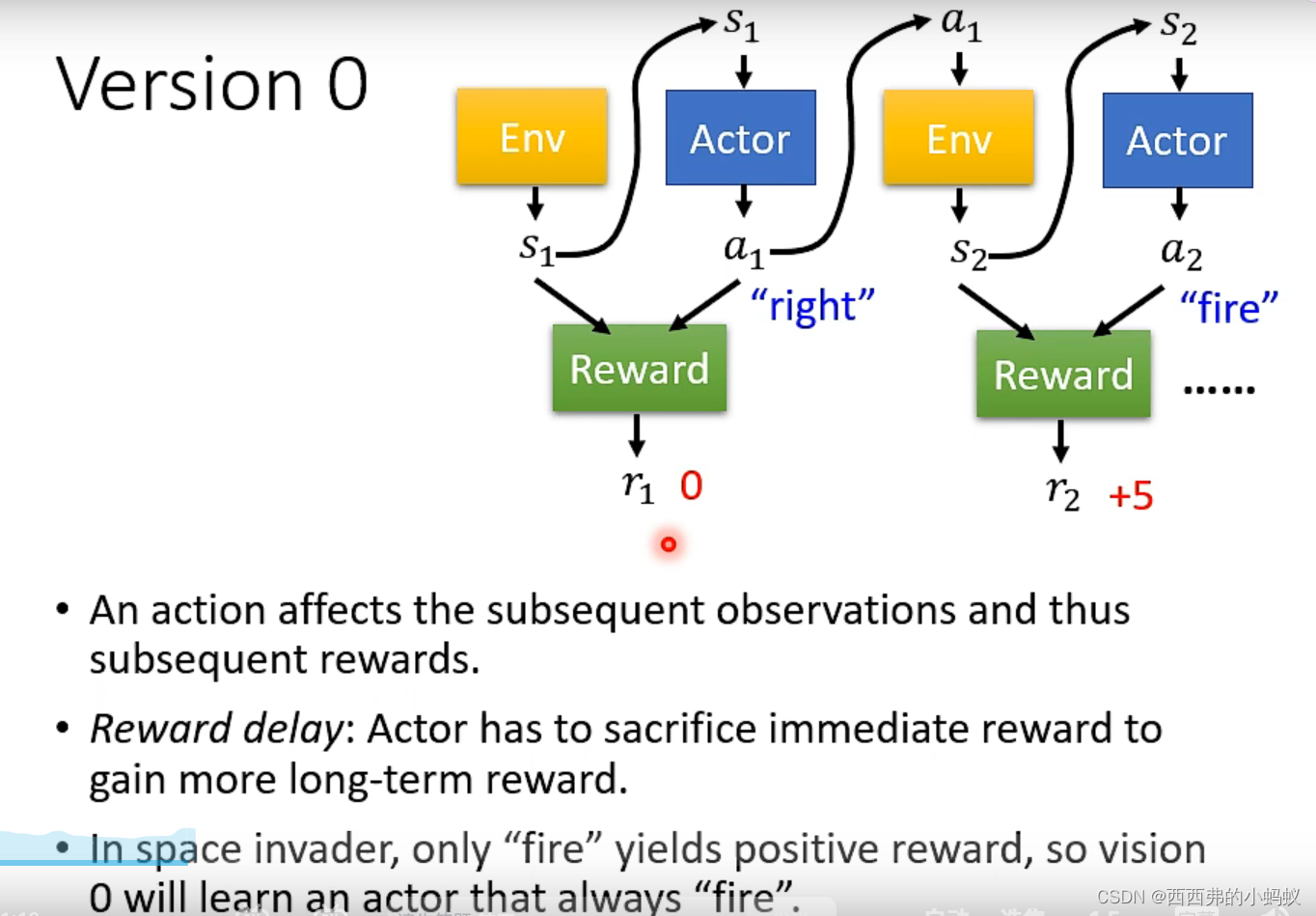
长期回报

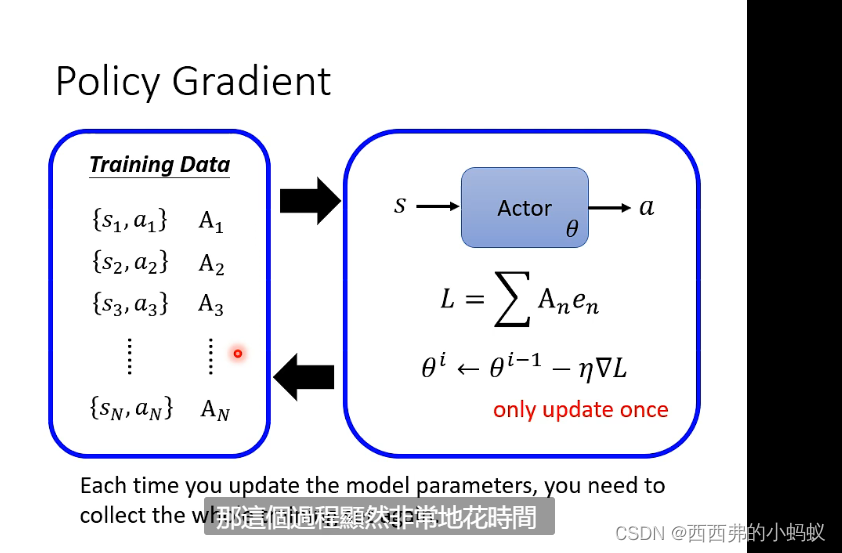
注意在训练模型过程 每次更新模型都需要 重新收集一次资料,比如更新模型参数40次,需要重新收集资料40次,因此模型训练过程需要花费大量的时间
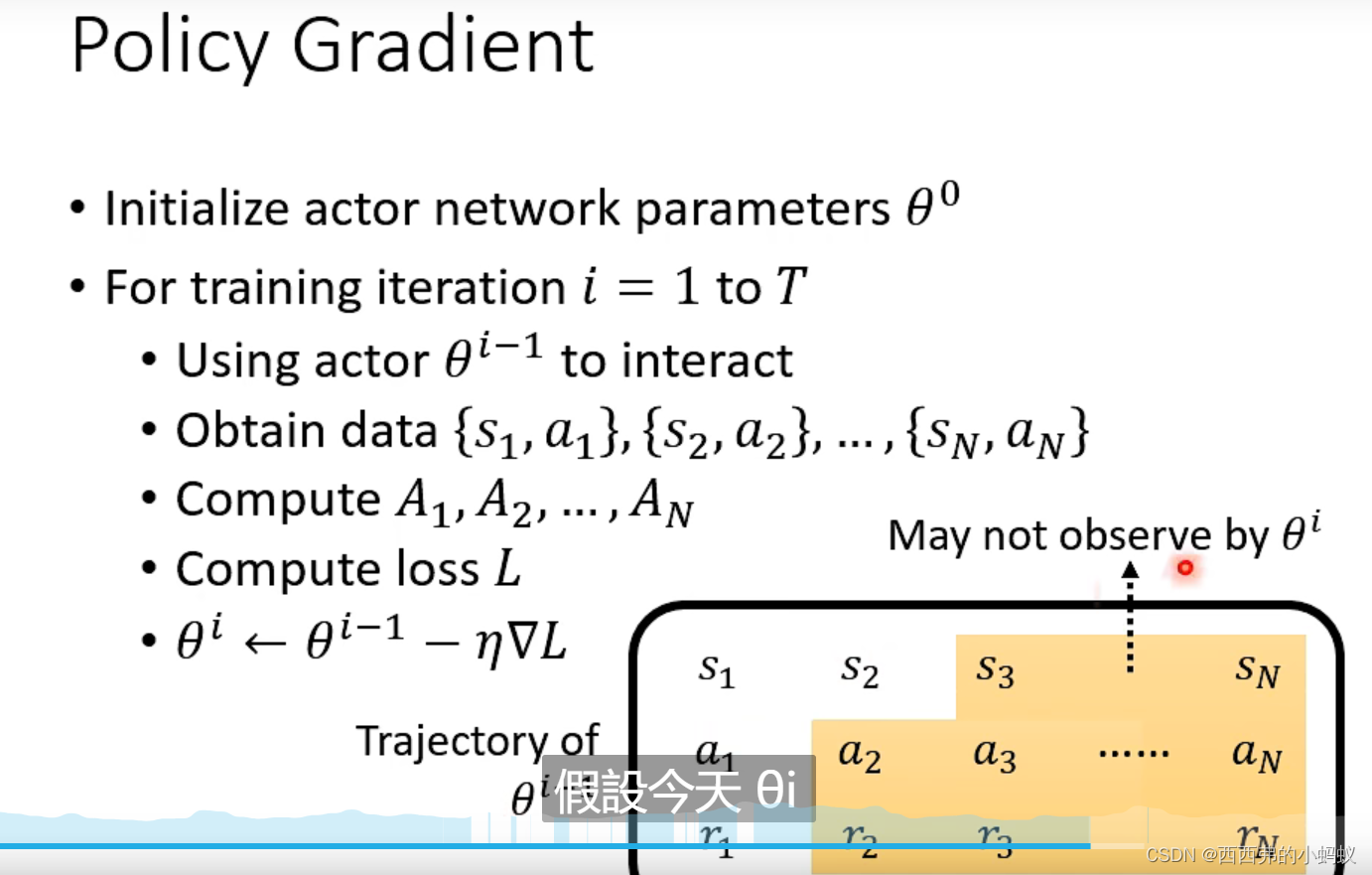


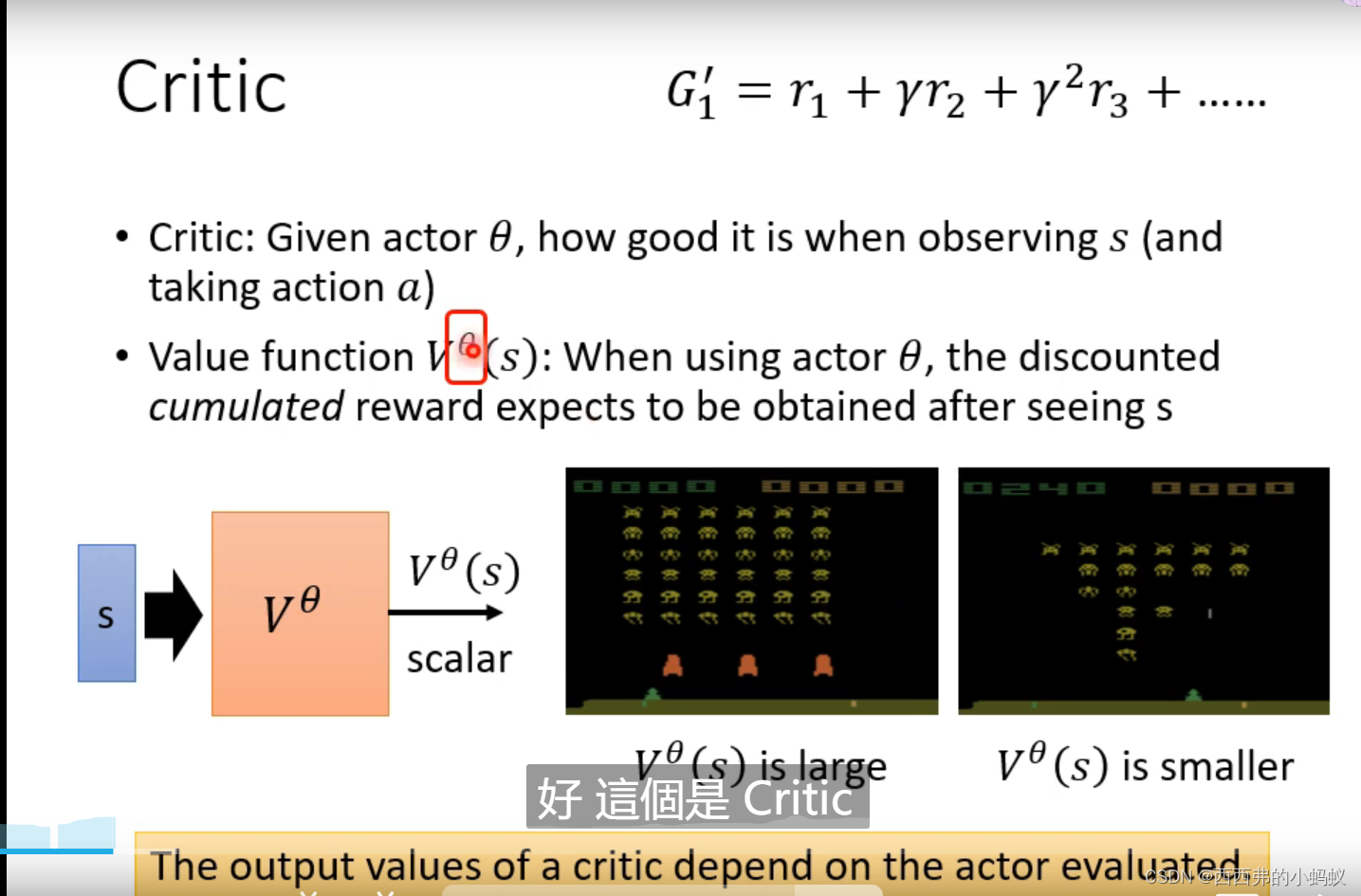
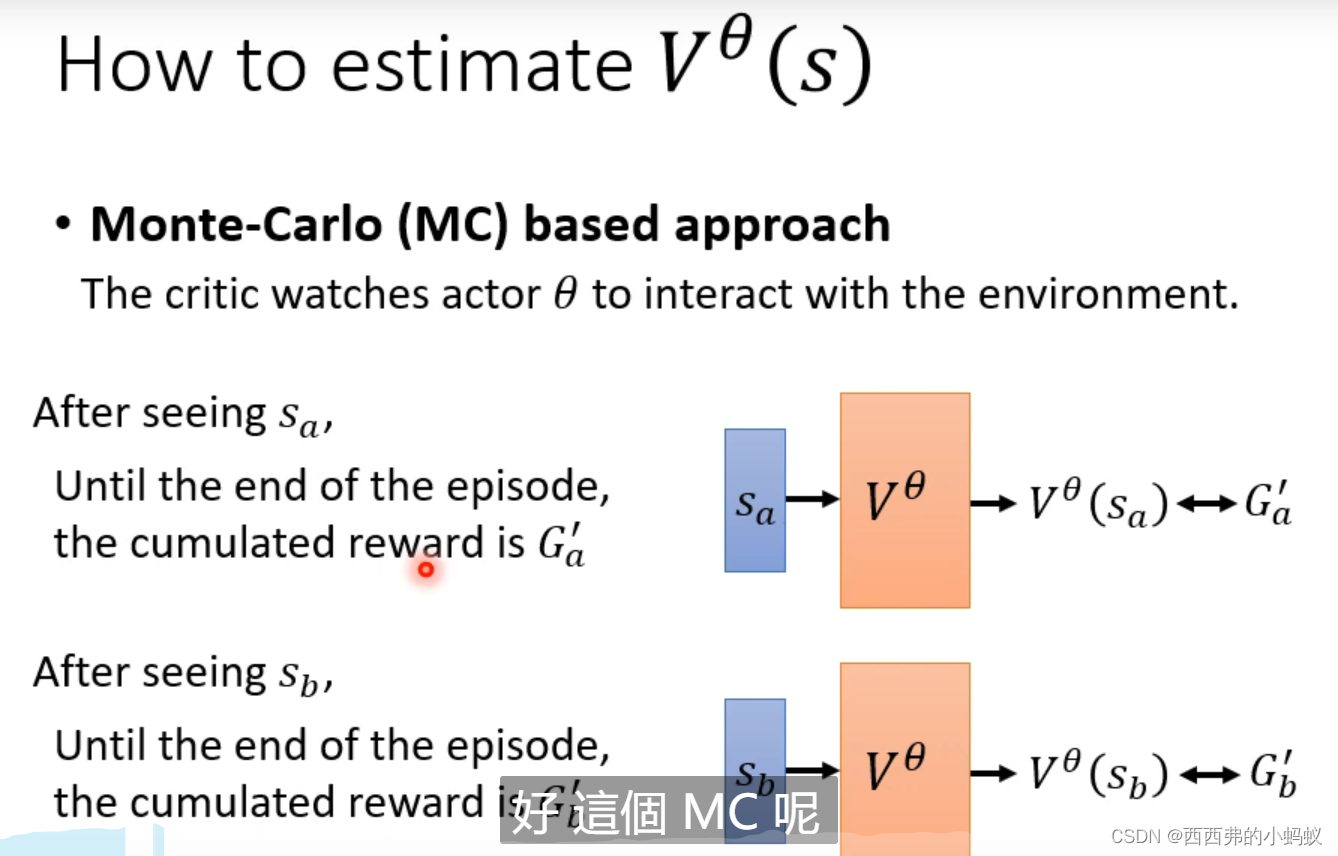
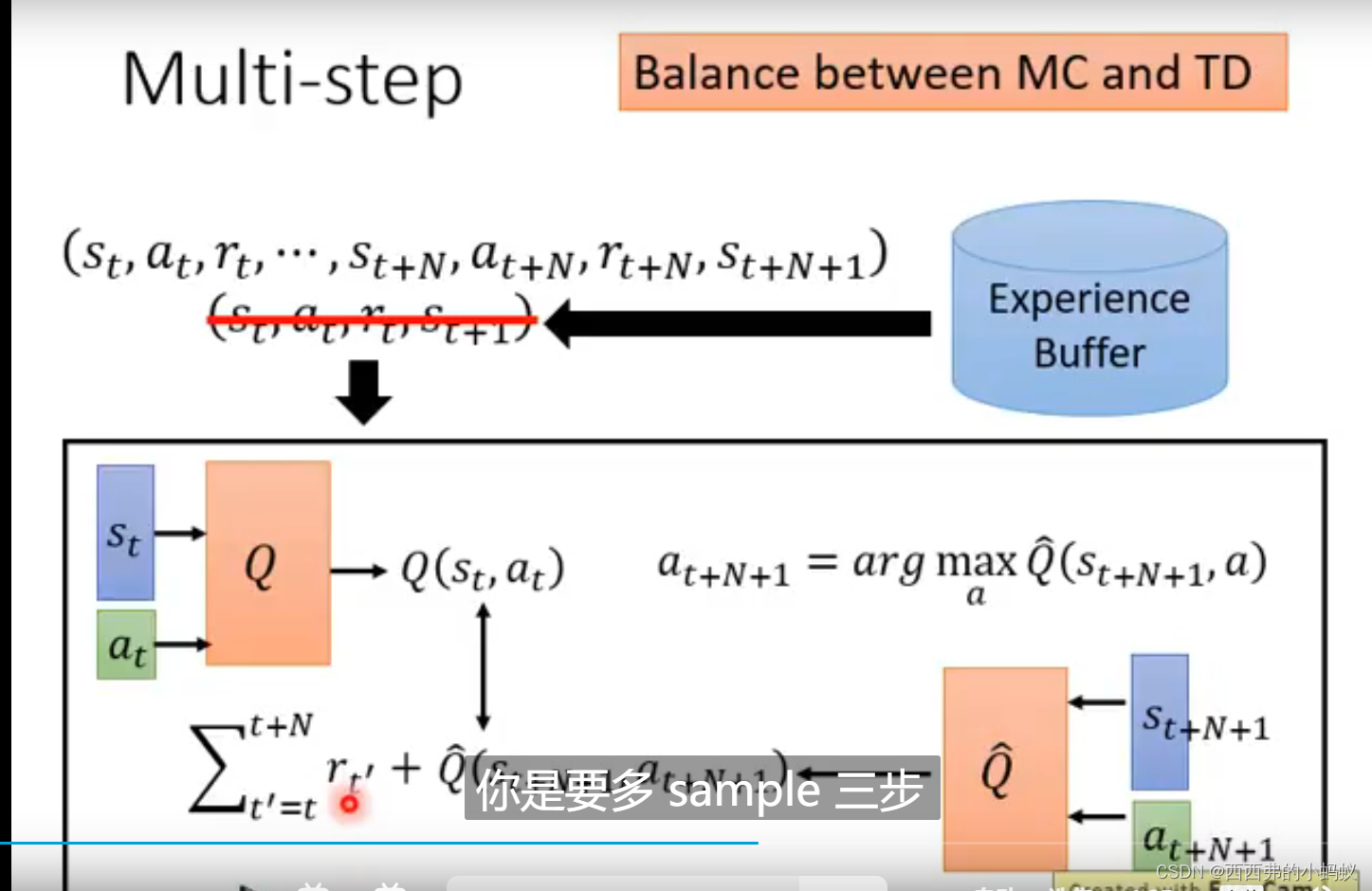
不用等到游戏全部结束,就可以估计出后续的所有状态
注意:MC和TD得到的结果是不一样的

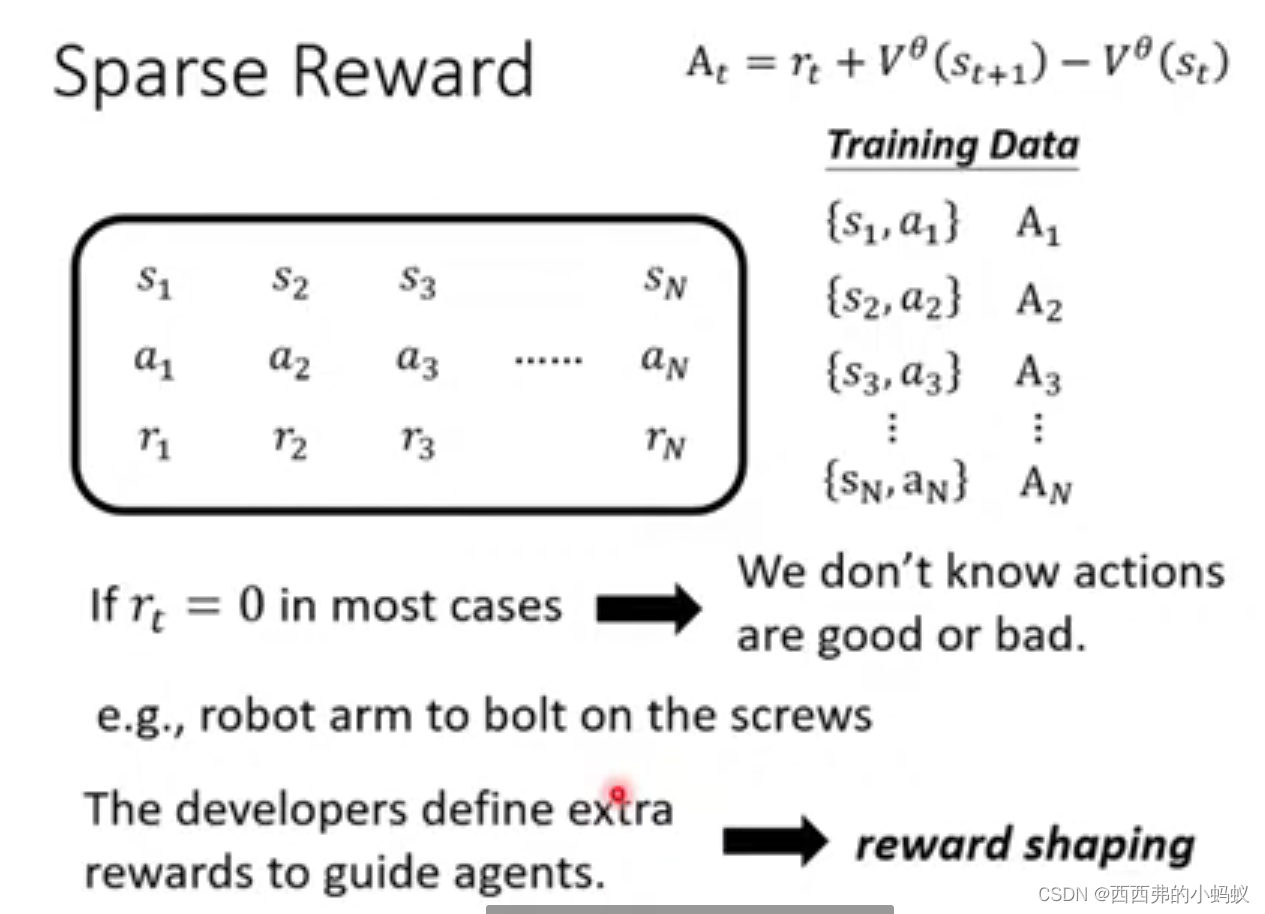
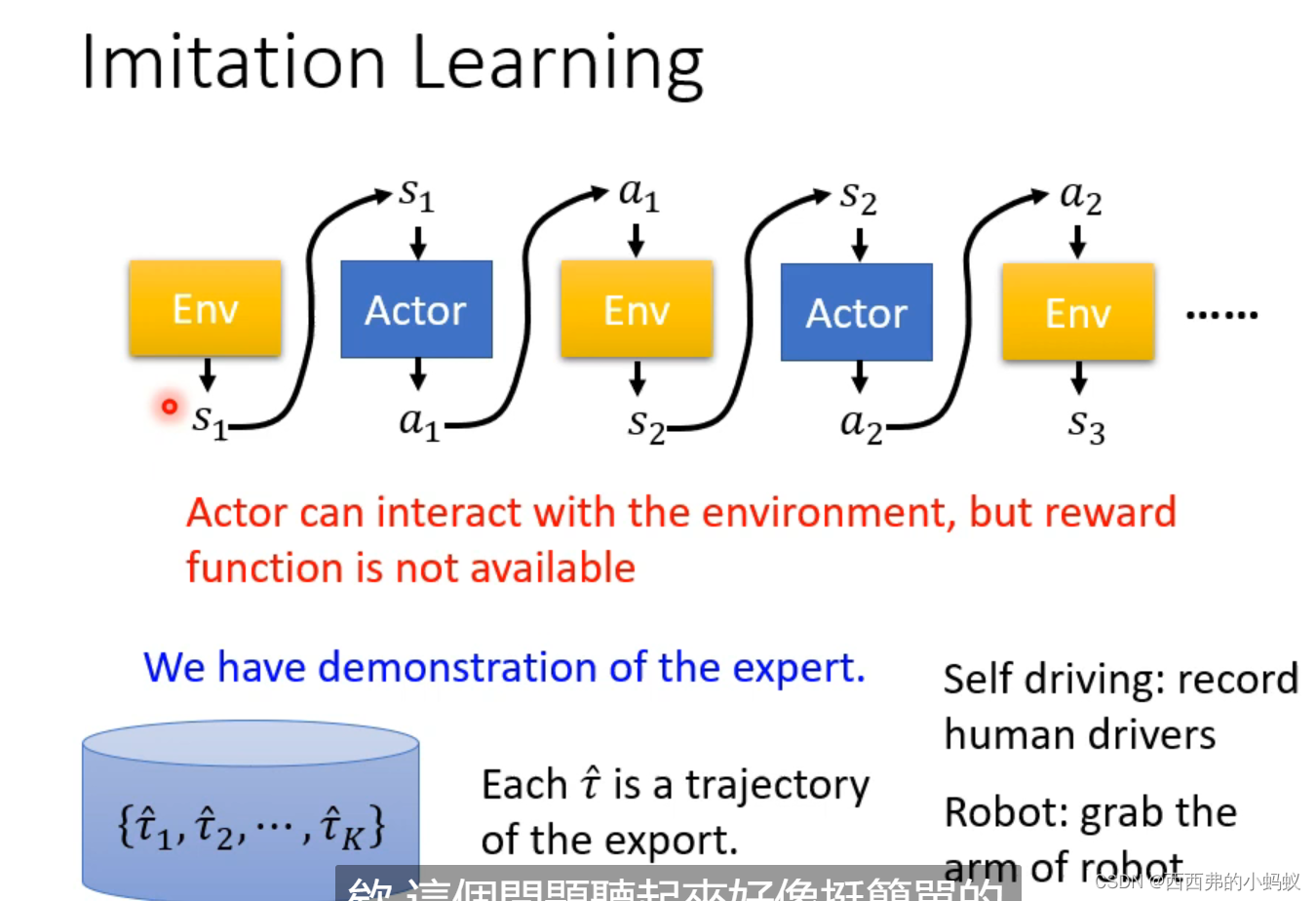








腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)