【论文解读】ReTool: 强化学习让 LLM 学会用代码解释器
ReTool 设计并实现了一个有效且高效的工程框架,它系统性地解决了“如何教 LLM 使用工具”这一核心问题。
1st author
paper: [2504.11536] ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
code: ReTool-RL/ReTool
5. 总结 (结果先行)
ReTool 设计并实现了一个有效且高效的工程框架,它系统性地解决了“如何教 LLM 使用工具”这一核心问题。
它的成功可以归结为两个步骤:
- 分阶段教学: 先用 SFT “教会” 模型工具的基本用法,再用 RL “教会” 它策略性地探索。这解决了 RL 探索空间过大、效率低下的问题。
- 结果导向的反馈: 采用简洁的、基于最终结果的奖励信号,给予模型最大的探索自由度,从而催生出如“代码自修正”这样复杂的、预料之外的智能行为。
从更宏观的视角看,ReTool 的工作是“神经-符号”混合系统(Hybrid Neuro-Symbolic Systems)在实践中一次非常成功的应用。它清晰地指明了一条道路:让 LLM 负责宏观的、语义层面的推理和规划,而将精确的、符号层面的计算和执行外包给确定性的外部工具。这种"人"机(“AI机”)协作的模式,可能是未来构建更强大、更可靠 AI 系统的主流范式。
1. 思想
这篇工作的核心思想,是为 LLM 嫁接一个强大的“外部大脑”——代码解释器(CI, Code Interpreter),并通过强化学习教会它何时以及如何使用这个大脑。
-
大问题:
- 纯文本的“思想链”(Chain-of-Thought)在语言和逻辑推理上表现出色,但在需要精确计算、符号操作或复杂模拟(如几何、组合数学)的任务上,常常会“心算”出错,导致整个推理链条崩溃。
- 如何让 LLM 可靠地、策略性地使用外部工具(如代码解释器),以弥补其内在计算能力的不足?
-
小问题:
- 从零开始太难: 直接用强化学习(RL)让一个对工具一无所知的模型去探索,效率极低且难以收敛。模型需要一个关于“如何使用工具”的初始认知。
- 如何学习“时机”和“方式”: 模型不仅要学会写出能运行的代码,更要学会在推理的哪个环节、为了什么目的(计算、验证、探索)去调用代码。模仿学习(SFT)难以教会这种适应性策略。
- 如何从错误中学习: 当代码执行失败(例如,语法错误、逻辑 bug),模型应该如何利用这些反馈信息来修正自己的思考和代码?
-
核心思路:
该工作提出一个两阶段的训练框架,解决了上述问题。- 冷启动(Cold-start SFT): 先不急于强化学习。首先,通过自动化流程,将现有的纯文本数学推理数据,转换为文本与代码交织的“代码增强”数据。具体做法是识别出文本中的计算步骤,并用 Python 代码片段替换它们。然后,用这份新数据集对基础模型进行监督微调(SFT)。这一步的目的是给模型植入一个关于工具使用的“先验知识”,让它对“什么问题可以用代码解决”以及代码的基本语法有一个初步的认知。
- 强化学习(Tool-Integrated RL): 在模型具备了初步的工具使用能力后,再让模型在解决问题时自由探索,并通过与真实代码沙箱的交互来学习。奖励机制非常简洁:只根据最终答案的正确与否给予稀疏的奖励(+1 或 -1)。这种“结果导向”的反馈,迫使模型去自主发现最优的工具使用策略,而不是简单地模仿。
2. 方法
2.1 冷启动 SFT (为模型打下基础)
这个阶段的目标是创建一个高质量的代码增强解释器数据集 D C I D_{CI} DCI,并用它来微调模型。
- 数据收集与过滤: 从
Open-Thoughts等开源数据集中收集大量数学推理的文本解题过程,记为 D i n i t D_{init} Dinit。通过专家和强模型(如 Deepseek-R1)进行筛选,保证数据质量。 - 自动化数据转换: 设计一个 Prompt 模板,引导一个强大的 LLM 将 D i n i t D_{init} Dinit 中的纯文本计算步骤,自动替换为可执行的 Python 代码片段及其执行结果。
- 两阶段验证:
- 格式验证: 确保代码片段的语法和格式统一,便于后续 RL 阶段的自动解析。
- 答案验证: 过滤掉那些转换后最终答案与原始问题标准答案不符的样本。
- 监督微调 (SFT): 使用最终得到的代码增强数据集 D C I D_{CI} DCI 对基础 LLM 进行微调。
2.2 带工具交互的强化学习 (让模型自我进化)
此阶段采用 PPO (Proximal Policy Optimization) 算法。
-
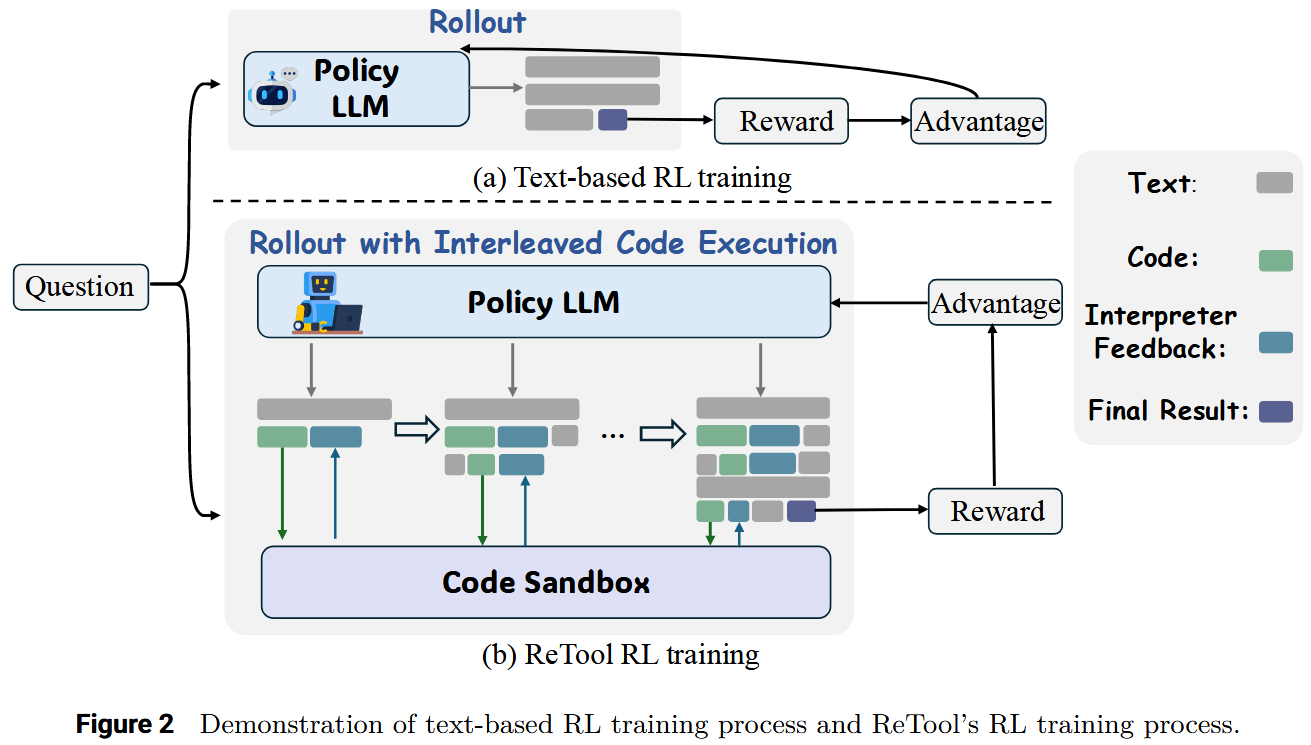
Rollout 机制:与沙箱的动态交互
这是 ReTool 的技术核心。传统的 RL Rollout 是一口气生成整个文本序列。而 ReTool 的 Rollout 是一个动态的、交错的过程:- 模型生成:模型开始生成推理文本。
- 代码触发: 当模型生成一个完整的代码块 (以
</code>标记结束) 时,生成过程暂停。 - 沙箱执行: 该代码块被发送到一个隔离的、异步执行的代码沙箱中运行。
- 结果反馈: 沙箱的输出(无论是正确结果还是错误追溯信息 Traceback),被包裹在
<interpreter>标签中,反馈给模型。 - 继续生成: 模型接收到反馈后,基于这个新的信息继续下一步的推理或修正,直到给出最终答案。

-
奖励设计 (Reward Design)
奖励函数的设计极为简洁,旨在评估最终结果,而非过程。
R ( a , a ^ ) = { + 1 , if is_equivalent ( a , a ^ ) − 1 , otherwise R(a, \hat{a}) = \begin{cases} +1, & \text{if } \ \text{is\_equivalent}(a, \hat{a}) \\ -1, & \text{otherwise} \end{cases} R(a,a^)={+1,−1,if is_equivalent(a,a^)otherwise- a a a: ground-truth answer,即问题的标准答案。
- a ^ \hat{a} a^: predicted answer,即模型在推理最后给出的答案。
- i s e q u i v a l e n t is_equivalent isequivalent: 一个函数,用于判断模型答案与标准答案是否等价。
这种设计的好处是最大程度地减少了“奖励作弊”(Reward Hacking),并鼓励模型为了达成最终目标而进行多样化的策略探索。
-
关键训练细节:损失屏蔽 (Loss Masking)
在计算损失函数时,模型不会去拟合来自<interpreter>标签内的内容。它确保了模型学习的是“如何思考并产生代码”,而不是“如何模仿代码执行器的输出”。
3. 优势
- vs. 纯文本 RL: 引入代码解释器,从根本上解决了 LLM 在精确计算上的短板,大幅提升了在数理任务上的准确率上限。
- vs. 纯 SFT 工具使用: RL 赋予了模型探索和发现新策略的能力。模型不仅仅是模仿,而是通过试错学会了何时调用工具、如何从错误中恢复(代码自修正),这些是 SFT 数据很难覆盖的。
- 训练效率: “冷启动 SFT + RL” 的范式,使得 RL 阶段的训练收敛速度极快,样本效率极高。从实验图表看,ReTool 用远少于纯文本 RL 的训练步数,达到了远超后者的性能。
4. 实验
-
基准和模型: 在极具挑战性的数学竞赛基准 AIME 2024 和 AIME 2025 上进行评估,基础模型为 Qwen2.5-32B-Instruct。
-
核心结论:
-
性能巨大提升: ReTool (67.0% on AIME2024) 显著优于纯文本 RL 基线 (40.0%)。这证明了工具整合的必要性。
-
冷启动策略的有效性: 仅经过 SFT 的冷启动模型(40.9%),其性能已经与经过完整训练的纯文本 RL 模型相当,证明了高质量代码增强数据的价值。
-
涌现的“代码自修正”能力: 实验中观察到一个非常惊艳的现象(“Aha Moment”),模型在初次生成的代码执行失败后,能够读懂解释器的错误反馈 (NameError),并自主地修正代码,生成一个定义了缺失函数的、可执行的新版本。这标志着模型具备了初步的元认知能力。

-
策略演化: 在 RL 训练过程中,模型的行为模式发生了显著变化:
- 代码使用更普遍: 几乎所有问题都会尝试用代码解决。
- 代码更复杂: 生成的代码行数增加了近五倍,表明模型学会了用更复杂的程序来解决问题。
- 调用时机更早: 模型更早地在推理链中引入代码,显示出其策略上的成熟。
- 目的更多样: 代码用途从单纯的“计算”扩展到了“验证”、“优化”和“方案搜索”,体现了更高级的工具使用策略。
-

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 16
16 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)