docker从零开始搭建Hadoop完全分布式(二)-搭建hadoop环境
文章目录前言准备工作域名映射免密配置两个常用脚本搭配使用JPShadoop配置hdfs相关mapreduceyarn分发文件准备启动格式化启动前言在上一篇博客从零开始准备了一台hadoop的机器准备工作域名映射docker exec -it hadoop1 bashdocker exec -it hadoop2 bashdocker exec -it hadoop3 bash分别...
前言
在上一篇博客从零开始准备了一台hadoop的机器
准备工作
域名映射
docker exec -it hadoop1 bash
docker exec -it hadoop2 bash
docker exec -it hadoop3 bash
分别进入三台机器vim /etc/hosts添加如下的域名映射
172.17.0.2 master
172.17.0.3 slave1
172.17.0.4 slave2
添加完成后可以用域名互相ping一下,确保能ping通再进行下一步。
ping master
ping slave1
ping slave2
免密配置
先在master启动ssh/etc/init.d/ssh start接着ssh-keygen三次回车生成密钥,然后将公钥保持到信任的keys中cat ~/.ssh/id_rsa.pub > authorized_keys。
另外两台重复这个操作,这样一来三个节点都各自有个authorized_keys文件,接下来要将这三个文件合并起来,尽量避免windows的编辑而采用cp、cat来实现:
首先将三台机器的keys拿出来
docker cp hadoop1:/root/.ssh/authorized_keys ./authorized_keys_1
docker cp hadoop2:/root/.ssh/authorized_keys ./authorized_keys_2
docker cp hadoop3:/root/.ssh/authorized_keys ./authorized_keys_3
再将三个文件合并为authorized_keyscat authorized_keys_1 authorized_keys_2 authorized_keys_3 > authorized_keys
可以查看新生成的文件,包含了三台机器的公钥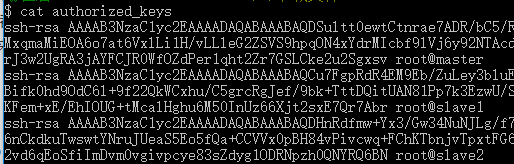
然后将新生成的authorized_keys文件复制回三个节点
docker cp ./authorized_keys hadoop1:/root/.ssh/authorized_keys
docker cp ./authorized_keys hadoop2:/root/.ssh/authorized_keys
docker cp ./authorized_keys hadoop3:/root/.ssh/authorized_keys
一定不要忘记检查authorized_keys所属组和权限,因为linux和mac复制文件到容器中的权限可能不符合要求。
分别进入三台节点chown root:root /root/.ssh/authorized_keys,chmod 400 /root/.ssh/authorized_keys
确保每台机器的权限、拥有者、所属组如此即可
最后就可以通过ssh免密登陆主机了,在三台机器分别执行如下指令,确保互相之间都能够免密登陆。
ssh master
ssh slave1
ssh slave2
两个常用脚本
为了便于之后的操作,在master节点的/bin/中写如两个脚本vim /bin/xcall和vim /bin/xsync,并增加课执行权限chmod u+x /bin/xcall和chmod u+x /bin/xsync
- xcall
#!/bin/bash
if [ $# -lt 1 ]
then
echo "There is no commond to excute!"
exit
fi
LOGIN_USER_NAME=`whoami`
for CLU_HOSTS in master slave1 slave2
do
echo "----------------$CLU_HOSTS-------------------"
ssh $LOGIN_USER_NAME@$CLU_HOSTS $*
done
- xsync
#!/bin/bash
if [ $# -lt 1 ]
then
echo "There is no file to send!"
exit
fi
P=$1
FILE_NAME=`basename $P`
FILE_PATH=`dirname $P`
DIR_PATH=`cd -P $FILE_PATH;pwd`
LOGIN_USER_NAME=`whoami`
for CLU_HOSTS in slave1 slave2
do
echo "------------------$CLU_HOSTS-----------------------"
rsync -rlv $DIR_PATH/$FILE_NAME $LOGIN_USER_NAME@$CLU_HOSTS:$DIR_PATH
done
关于脚本的编写,具体可以看这篇文章https://blog.csdn.net/weixin_44112790/article/details/86933415
搭配使用JPS
1.首先创建软连接ln -s /opt/modules/jdk1.8.0_144/bin/jps /usr/local/bin/jps
2.用刚刚编写的xsync分发xsync /usr/local/bin/jps
3.测试一下xcall以及jpsxcall jps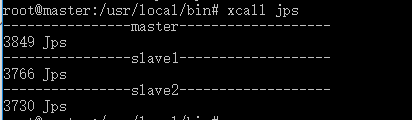
hadoop配置
完成了所有的准备工作,终于可以开始hadoop的配置了
首先检查一下java和hadoop的环境变量是否正确,不正确的话刷新一下环境变量source /etc/profile,然后进入hadoop的配置目录cd /opt/modules/hadoop-2.7.2/etc/hadoop/修改配置文件
hdfs相关
在文件的config中添加如下内容
- core-site.xml
<!-- 指定 HDFS 中 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/hadoop-2.7.2/data/tmp</value>
</property>
- hdfs-site.xml
<!-- 副本数量 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 辅助名称结点 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:50090</value>
</property>
- 指定从节点
vim slaves
master
slave1
slave2
- 环境变量
vim hadoop-env.sh修改JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
mapreduce
mv mapred-site.xml.template mapred-site.xml重命名一下vim mapred-site.xml添加如下内容
<!-- 指定 mr 运行在 yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 环境变量
vim mapred-env.sh修改JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
yarn
vim yarn-site.xml修改yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>172.17.0.3:8088</value>
</property>
- 环境变量
vim hadoop-env.sh修改JAVA_HOME
export JAVA_HOME=/opt/modules/jdk1.8.0_144
分发文件
xsync /opt/modules/hadoop-2.7.2/etc/hadoop/分发刚刚修改的文件,然后查看一下xcall cat /opt/modules/hadoop-2.7.2/etc/hadoop/core-site.xml可以发现三个节点的配置文件都已经更新。
准备启动
格式化
hdfs namenode -format一定要注意这一步的操作用户,我之前都是root,这里也是root操作
启动
由于ResourceManager不再master不能通过start-all.sh,否则ResourceManager无法启动,在mater通过start-dfs.sh在slave1通过start-yarn.sh分别启动hdfs和yarnxcall jps可以看到集群按规划启动了相应的服务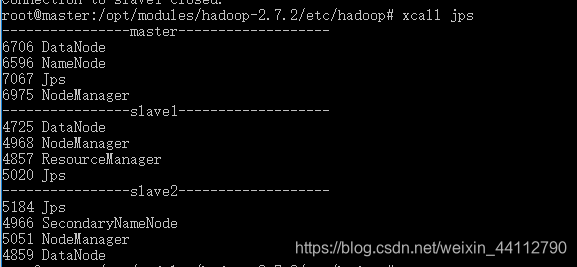
web访问
我的是win10情况比较复杂,docker是先在win10中虚拟了linux再中虚拟的linux中允许docker;如果是mac或者linux情况就比较简单。docker-machine ip default查看虚拟linux的ip,一般是192.168.99.100,windows直接能访问这个ip
Oracle VM VirtualBox只能将我win10的端口映射到192.168.99.100的端口即装有docke的虚拟linux中,不能直接映射到docker创建的容器中。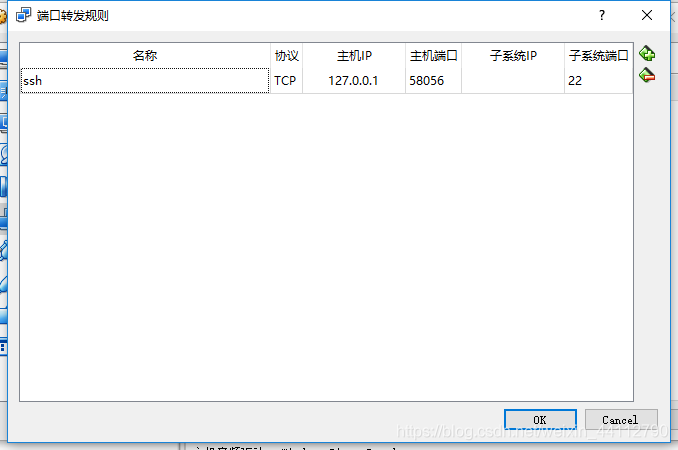
直接通过192.168.99.100:50070可以访问hdfs的web界面,192.168.99.100:8088可以访问yarn的web界面。
初始化脚本
由于docker的容器重启会关闭ssh以及清除掉hosts,导致集群无法正常运行。我编写了一个脚本来解决这个问题。
在master节点中vim /usr/local/bin/node_init.sh,对于不同的节点,修改追加的ip和host即可
#!/bin/bash
echo "172.17.0.3 slave1" >> /etc/hosts
echo "172.17.0.4 slave2" >> /etc/hosts
/etc/init.d/ssh start
exit 0
记得添加可执行权限chmod u+x /usr/local/bin/node_init.shnode_init.sh就可以直接运行,但是容器中的ubuntu不能设置开机自启动,只能每次自己手动初始化如下
docker exec -d hadoop1 node_init.sh
docker exec -d hadoop2 node_init.sh
docker exec -d hadoop3 node_init.sh

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)