Python 进阶:使用 Matplotlib 进行数据可视化 (二)

简介
接着 使用 Matplotlib 进行数据可视化 (一) ,继续使用 Matplotlib 绘制图像,公众号回复 data2 就可以获得本文章的代码与使用数据。
箱线图 (BoxPlot)
箱线图 (BoxPlot) 也称箱须图 (Box-whisker Plot),它利用数据中的五个统计量:最小值、第一四分位数、中位数、第三四分位数与最大值来描述数据的一种方法,如下图:
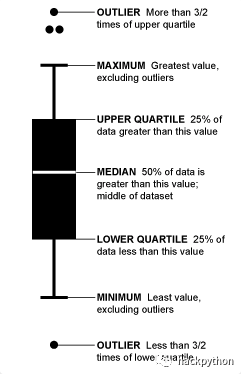
1.minimum (最小值) 与 maximum (最大值) 是数据中的最小值和最大值
2.median (中位数):对数据排序,找到中间位置的数,称为中位数,如果中间位置有两个数,则相加再除以 2,如有数字 1,2,4,5,7,7,8,9,此时中位数为:(5+7)/2 = 6
3.lower quartile,也称为第一四分位数:它是数据排序后,中位数左边数据的中位数,如有数字 1,2,4,5,7,7,8,9,此时第一四分位数为 1,2,4 的中位数,则为 2
4.upper quartile,也称第三四分位数:它是数据排序后,中位数右边数据的中位数,如有数字 1,2,4,5,7,7,8,9,此时第三四分位数为 7,8,9 的中位数,则为 8
5.IQR (Inter Quartile Range),即第一四分位数到第三四分位数这一部分的数据,它估计了中间 50% 的数据,上图没有绘制出 IQR
5.outlier,也称离群值,如果一个值小于 (第一四分位数 - 1.5*IQR) 或大于 (第三四分位数 + 1.5*IQR),则称这个值为离群值
使用箱线图可以粗略的判断出数据是否具有对称性以及数据分布的离散程度,下面就来绘制一下。
一开始,依旧先读取数据并进行简单的处理
exam_data = pd.read_csv('datasets/exams.csv')
# 仅提取考试分数相关的信息
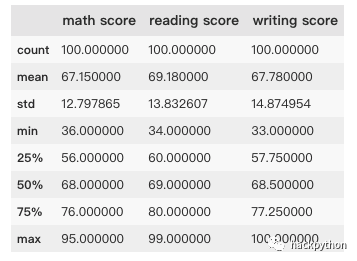
exam_scores = exam_data[['math score', 'reading score', 'writing score']]
exam_scores.head()
为了方便绘制 boxplot,将数据转为 numpy 中的数组类型
exam_scores_array = np.array(exam_scores)
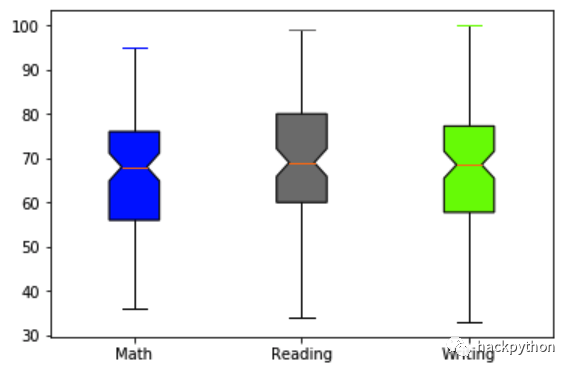
使用 matplotlib 绘制 boxplot
colors = ['blue', 'grey', 'lawngreen']
bp = plt.boxplot(exam_scores_array, # 数据
patch_artist=True, # patch_artist设置为True,在后面才能设置不同的颜色
notch=True) # 显示是否有凹槽
for i in range(len(bp['boxes'])):
bp['boxes'][i].set(facecolor=colors[i]) # 设置颜色,前提是:patch_artist要设置为True
bp['caps'][2*i + 1].set(color=colors[i])
plt.xticks([1, 2, 3], ['Math', 'Reading', 'Writing'])
plt.show()
小提琴图 (ViolinPlot)
小提琴图 (ViolinPlot) 用于显示数据分布以及概率密度,它结合了箱线图与密度图的特征。
形象如图:
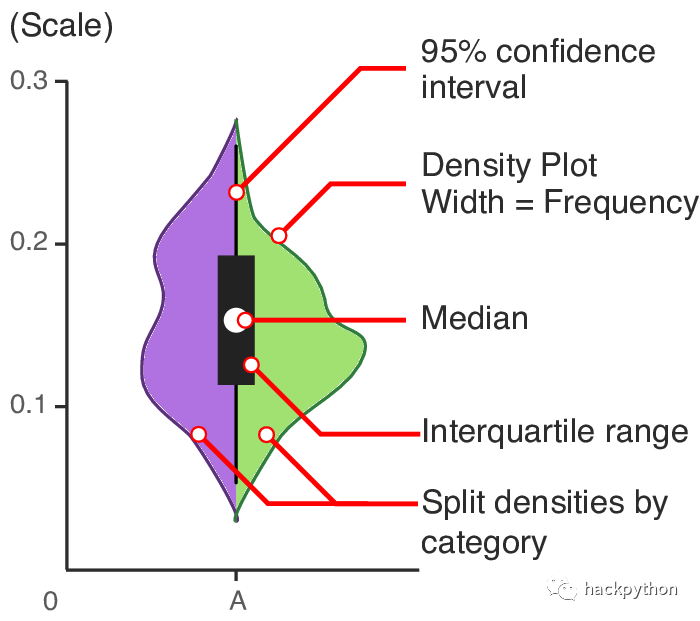
95% confidence interval (95% 的置信区间) 在图中指的是延伸出来的黑色细线 Density Plot ((数据分布) 密度图) Median (中位数) Interquartile range (四分位数范围) Split densities by category (按类别划分密度图)
使用绘制箱线图的数据绘制小提琴图
vp = plt.violinplot(exam_scores_array,
showmedians=True)
plt.xticks([1, 2, 3], ['Math', 'Reading', 'Writing'])
for i in range(len(vp['bodies'])):
vp['bodies'][i].set(facecolor=colors[i])
plt.show()
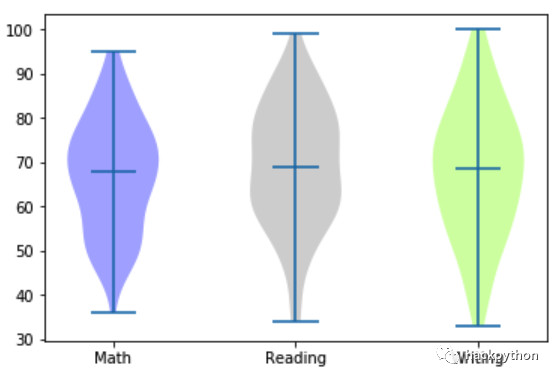
从图中可以看出,小提琴图的中间部分数据分布密度更大,这表明学生分数大部分都在平均水平附近
双轴图 (TwinAxis Plot)
双轴图,顾名思义,就是一张图有两个 y 轴,当我们的数据使用相同 x 轴时,就可以考虑绘制双轴图。
通过双轴图可以很直观的感受出两种数据之间的关联性,比如人口数据与国内生产总值数据在相同的时间轴 (x 轴) 上,此时就可以用双轴图来判断两者的变化有没有关联性。
这里以 Austin (奥斯汀,美国得克萨斯州的首府) 城镇的天气数据来绘制双轴图,主要使用其中的平均气温与平均风速这两列数据,从而判断这两者有没有什么联系
首先,依旧是将数据读入,并取其中需要的数据
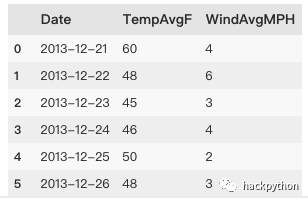
austin_weather = pd.read_csv('datasets/austin_weather.csv')
austin_weather.head()
# Data 日期
# TempAvgF 平均气温,华氏温度
# WindAvgMPH 平均风速,以英里/小时为单位
austin_weather = austin_weather[['Date', 'TempAvgF', 'WindAvgMPH']].head(5)
pritn(austin_weather)
使用这些数据绘制双轴图
# 创建子图
fig, ax_tempF = plt.subplots()
#fig=plt.figure(figsize=(12,6)) 可以实现相同效果
fig.set_figwidth(12)
fig.set_figheight(6)
# 设置x标签
ax_tempF.set_xlabel('Date')
ax_tempF.tick_params(axis = 'x',
bottom=False, # 禁用 ticks
labelbottom=False # 禁用 x 轴标签
)
# 设置左 Y 轴标签
ax_tempF.set_ylabel('Temp (F)',
color='red',
size='x-large')
# 为左 Y 轴标签设置labelcolor(标签颜色)与labelsize(标签大小)
ax_tempF.tick_params(axis='y',
labelcolor='red',
labelsize='large')
# 将 AvgTemp 绘制到 左 Y 轴上
ax_tempF.plot(austin_weather['Date'],
austin_weather['TempAvgF'],
color='red')
# 为两个图设置相同的x轴
ax_precip = ax_tempF.twinx()
#设置右 Y 轴标签
ax_precip.set_ylabel('Avg Wind Speed (MPH)',
color='blue',
size='x-large')
# 为右 Y 轴标签设置labelcolor(标签颜色)与labelsize(标签大小)
ax_precip.tick_params(axis='y',
labelcolor='blue',
labelsize='large')
# 将 WindAVg 绘制到 右 Y 轴上
ax_precip.plot(austin_weather['Date'],
austin_weather['WindAvgMPH'],
color='blue')
fig.legend(loc=1, bbox_to_anchor=(1,1), bbox_transform=ax_tempF.transAxes)
plt.show()
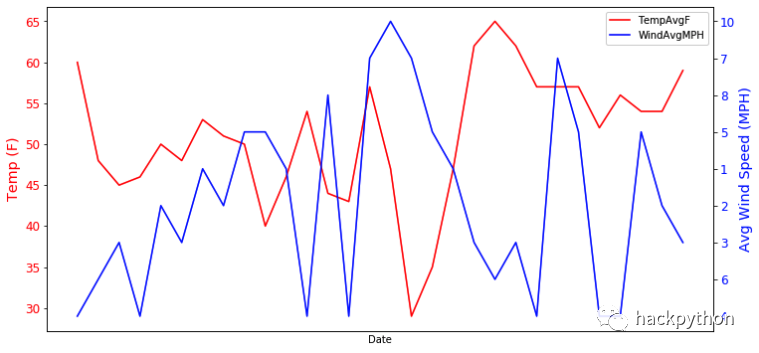
从图中可以看出,两者有些关系,但平均温度并不只受平均风速影响。
堆叠图 (Stack Plot)
堆叠图是一种特殊的面积图,可以用来比较一个区间内的多个变量,与普通面积图不同,堆叠图每个数据面积的绘制起点都是基于前面一个数据面积来绘制的。
这里使用国家公园的数据来绘制堆叠图
np_data= pd.read_csv('datasets/national_parks.csv')
print(np_data.head())
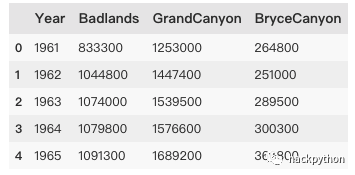
national parks (国家公园) 数据中有 Badlands (荒废土地)、GrandCanyon (大峡谷) 以及 BryceCanyon (布莱斯峡谷) 这 3 种类别的土地面积数据。
因为要绘制堆叠图,所以先要讲 3 中类别土地面积数据整合成一个二维数组,这里直接通过 numpy 的 vstack () 方法来实现这个效果,vstack () 方法简单示例如下:
import numpy as np
a=[1,2,3]
b=[4,5,6]
print(np.vstack((a,b)))
输出:
[[1 2 3]
[4 5 6]]
接着就使用 national parks 数据来绘制一下堆叠图
x = np_data['Year']
y = np.vstack([np_data['Badlands'],
np_data['GrandCanyon'],
np_data['BryceCanyon']])
# 每个面积区域的标签
labels = ['Badlands',
'GrandCanyon',
'BryceCanyon']
# 每个面积区域的颜色
colors = ['sandybrown',
'tomato',
'skyblue']
# 与 pandas 的 df.plot.area() 类似
# stackplot()创建堆叠图
plt.stackplot(x, y,
labels=labels,
colors=colors,
edgecolor='black')
# 绘制标注
plt.legend(loc=2)
plt.show()
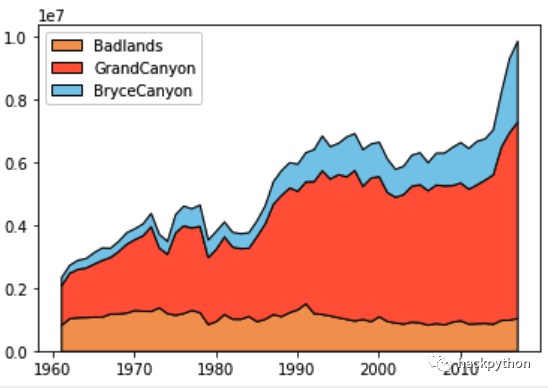
百分比堆叠图
百分比堆叠图类似于普通堆叠图,只是每个数据被转换成了对应的百分比然后再绘制到图中,依旧使用 national parks (国家公园) 数据来绘制百分比堆叠图
plt.figure(figsize=(10,7))
# divide函数:在整数和浮点数除法中均只保留整数部分
data_perc = np_data.divide(np_data.sum(axis=1), axis=0)
plt.stackplot(x,
data_perc["Badlands"],data_perc["GrandCanyon"],data_perc["BryceCanyon"],
edgecolor='black',
colors=colors,
labels=labels)
plt.legend(loc='center left', bbox_to_anchor=(1, 0.5))
plt.show()
效果如下:
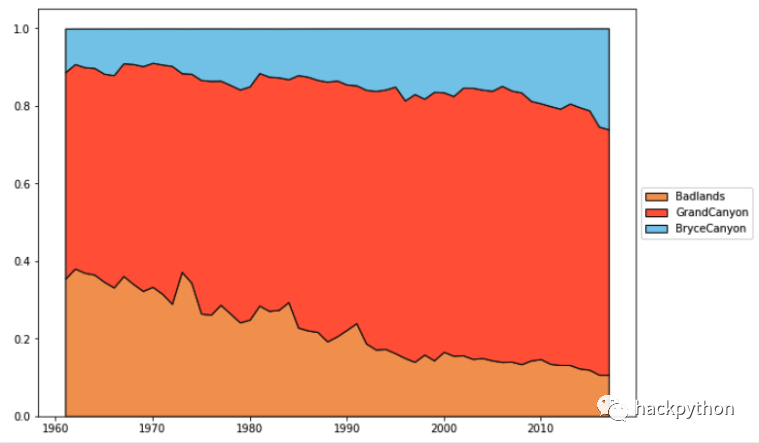
结尾
本篇文章介绍了一部分 Matplotlib 可视化数据的用法,在下一文章中会介绍 Matplotlib 绘制其他图的用法,记得关注 HackPython,拜拜。


腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)