com.mysql.jdbc.NonRegisteringDriver 内存泄漏
问题描述
某天监控突然报警服务器的内存占用较高,然后登陆服务器发现一个连接数据库的服务的内存占用很高,而且还在不断地上涨,于是通过 jmap 命令生成堆 dump文件(jmap -dump:format=b,file=rds.bin PID),然后使用 Eclipse 的 Memory Analyzer Tool (MAT) 工具来分析。
问题分析
表象分析
通过 MAT 工具分析发现,第一个可能的问题就是:com.mysql.jdbc.NonRegisteringDriver 占用比较大的内存,如下图: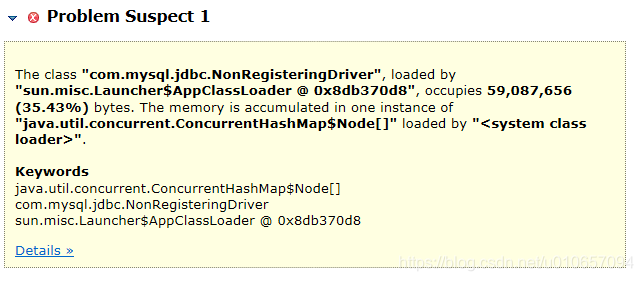 然后看大对象列表,NonRegisteringDriver 对象确实占内存比较多,该对象的成员变量connectionPhantomRefs 占内存最多,其类型是 ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference>,里面存的是数据库连接的虚引用,数量竟然有近1000个。
然后看大对象列表,NonRegisteringDriver 对象确实占内存比较多,该对象的成员变量connectionPhantomRefs 占内存最多,其类型是 ConcurrentHashMap<ConnectionPhantomReference, ConnectionPhantomReference>,里面存的是数据库连接的虚引用,数量竟然有近1000个。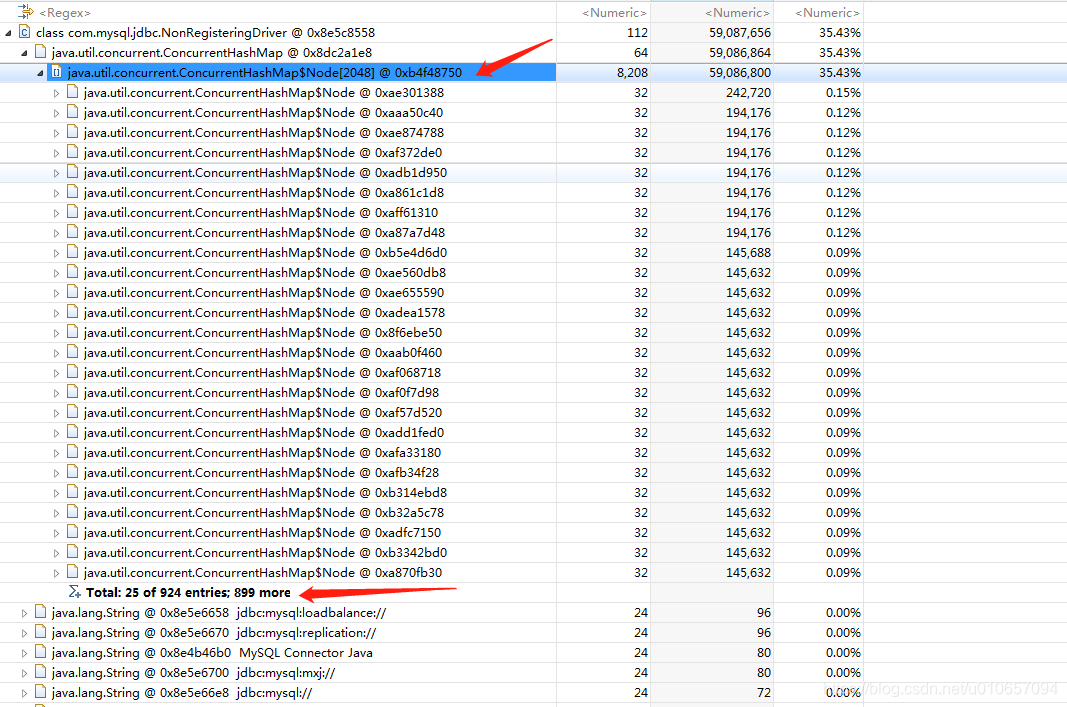
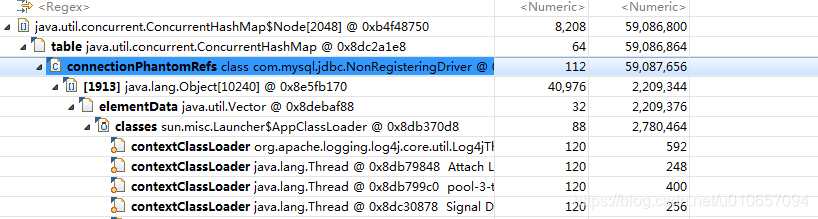
疑问
通过上面的表象,产生了几个疑问:
- 项目用的是 HikariCP 连接池,已经设置了连接池的大小,为什么会创建近 1000 个连接?
- connectionPhantomRefs 中的数据为什么没有被清除?
为什么会创建那么多连接?
其实通过查看 HikariCP 的代码就可以解释。配置类 HikariConfig 有几个关键的属性:maxPoolSize (连接池最大连接数)、minIdle(最小空闲连接数,默认等于 maxPoolSize)、idleTimeout (连接空闲超时时间,默认 10 分钟)、maxLifetime(连接最大生存时间,默认 30 分钟)。那么当数据库连接空闲时间超过了 idleTimeout,那么将会关闭,直到数量为 minIdle。还有当数据库连接存活时间达到了 maxLifetime ,那么连接也会关闭,然后再创建新的连接,每次创建新的连接,都会创建其虚引用,并存入 connectionPhantomRefs 中。另外还有其他可能导致数据库连接关闭,比如网络问题,数据库无响应等,这个可能是导致短时间内关闭、创建大量数据库连接的原因,从而导致 connectionPhantomRefs 元素不断增加。
第二个问题:connectionPhantomRefs 中的数据为什么没有被清除?
类AbandonedConnectionCleanupThread 是负责清理工作的,它会启动一个线程去不断地清理被 GC 的数据库连接的。其实现如下(mysql-connector-java 5.1.46):
public void run() {
for (;;) {
try {
checkContextClassLoaders();
Reference<? extends ConnectionImpl> ref = NonRegisteringDriver.refQueue.remove(5000);
if (ref != null) {
try {
((ConnectionPhantomReference) ref).cleanup();
} finally {
NonRegisteringDriver.connectionPhantomRefs.remove(ref);
}
}
} catch (InterruptedException e) {
threadRef = null;
return;
} catch (Exception ex) {
// Nowhere to really log this.
}
}
}
连接关闭后,将会被 GC,GC 后连接的虚引用就会进入NonRegisteringDriver.refQueue 队列。上述的程序就是不断从队列中获取连接的虚引用,然后清理执行 cleanup() 方法,主要是关闭网络资源NetworkResources。最后再从Map 中移除虚引用 connectionPhantomRefs.remove(ref)。
ConnectionPhantomReference 中的数据内容: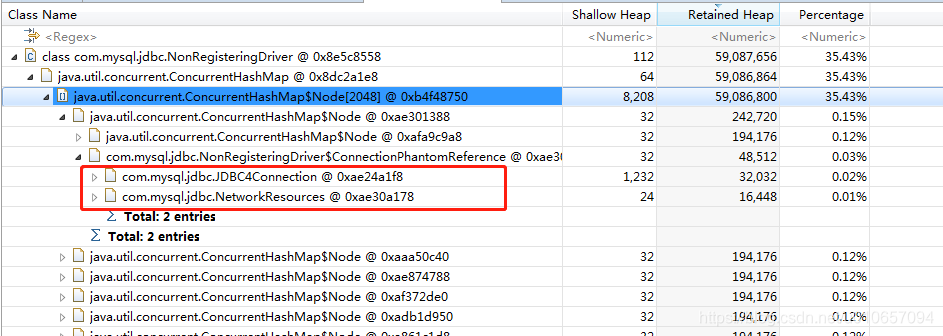
通过上面的分析发现,能够触发清理 connectionPhantomRefs 的关键在于关闭的数据库连接被回收(GC),那么问题就出在了垃圾回收这块了,由于当时没有去检查垃圾回收情况,也没有 GC 日志,服务后面重启了,也就无从考证服务当时的 GC 状况了。推测可能是由于连接生命周期到了,或者网络等原因导致那段时间关闭、创建了很多数据库连接,然而又没有及时 GC 导致内存不断上涨。
重现
可以通过设置连接的生命存活时长(maxLifetime,注意有判断最小值)来不断关闭、创建数据库连接,然后看下堆中对象的情况,再通过调用 System.gc() 触发下GC,就会发现 connectionPhantomRefs 中的数据被清理了,如果不触发 GC 那么 connectionPhantomRefs 中的数据是不会被清理的 。
解决方案
问题的关键在 GC,那么解决方案也就是如何在适当的时候触发 GC (YGC、FGC)了。下面有几种解决方案,不一定是合适的,需要根据实际情况考虑。
- 通过调用 System.gc() 方法触发GC。
- 设置垃圾回收触发间隔,例如 CMS 的 -XX:CMSTriggerInterval
- 服务重启(。。。)

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)