计算机视觉——NCC计算视差图中窗口大小的影响
1、实验需求从理论角度,分析以窗口代价计算视差的原理实现NCC 视差匹配方法,即给定左右两张视图,根据NCC计算视差图分析不同窗口值对匹配结果的影响,重点考查那些点(或者哪些类型的点)在不同窗口大小下的匹配精度影响2、语言和平台语言:python2.7.13 (anaconda2)平台:pycharm 2018.23、实验原理极线校正关于几何原理见上一篇博客https://...
1、实验需求
- 从理论角度,分析以窗口代价计算视差的原理
- 实现NCC 视差匹配方法,即给定左右两张视图,根据NCC计算视差图
- 分析不同窗口值对匹配结果的影响,重点考查那些点(或者哪些类型的点)在不同窗口大小下的匹配精度影响
2、语言和平台
语言:python2.7.13 (anaconda2)
平台:pycharm 2018.2
3、实验原理
计算视差图
在该立体重建算法中,我们将对于每个像素尝试不同的偏移,并按照局部图像周围归一化的互相关值,选择具有最好分数的偏移,然后记录下该最佳偏移。因为每个偏移在某种程度上对应于一个平面,所以该过程有时称为扫平面法。虽然该方法并不是立体重建中最好的方法,但是非常简单,通常会得出令人满意的结果。
当密集地应用在图像中时,归一化的互相关值可以很快地计算出来。我们使用每个像素周围的图像块(根本上说,是局部周边图像)来计算归一化的互相关。对于这里的情形,我们可以在像素周围重新写出公式(2.3)中的 ncc,如下所示
n c c ( p , d ) = ∑ ( x , y ) ∈ W p ( I 1 ( x , y ) − I 1 ‾ ( p x , p y ) ) ( I 2 ( x + d , y ) − I 2 ‾ ( p x + d , p y ) ) ∑ ( x , y ) ∈ W p ( I 1 ( x , y ) − I 1 ‾ ( p x , p y ) ) 2 ∑ ( x , y ) ∈ W p ( I 2 ( x + d , y ) − I 2 ‾ ( p x + d , p y ) ) 2 ncc(p,d)=\frac {\sum_{(x,y)∈W_p}^{} {(I_1(x,y)-\overline{I_1}(p_x,p_y))(I_2(x+d,y)-\overline{I_2}(p_x+d,p_y))}} {\sqrt {\sum_{(x,y)∈W_p}^{} {(I_1(x,y)-\overline{I_1}(p_x,p_y))^2}\sum_{(x,y)∈W_p}^{} {(I_2(x+d,y)-\overline{I_2}(p_x+d,p_y))^2}}} ncc(p,d)=∑(x,y)∈Wp(I1(x,y)−I1(px,py))2∑(x,y)∈Wp(I2(x+d,y)−I2(px+d,py))2∑(x,y)∈Wp(I1(x,y)−I1(px,py))(I2(x+d,y)−I2(px+d,py))
左边为图像 I 1 I_1 I1,右边为图像 I 2 I_2 I2。图像 I 1 I_1 I1蓝色方框表示待匹配像素坐标 ( p x , p y ) (p_x,p_y) (px,py),图像 I 2 I_2 I2蓝色方框表示坐标位置为 ( p x , p y ) (p_x,p_y) (px,py),红色方框表示坐标位置 ( p x + d , p y ) (p_x+d,p_y) (px+d,py)。
Wp表示以待匹配像素坐标为中心的匹配窗口,通常为3*3匹配窗口。
I 1 I_1 I1表示匹配窗口中某个像素位置的像素值, I 1 ‾ \overline{I_1} I1表示匹配窗口所有像素的均值。 I 2 I_2 I2同理。
上述公式表示度量两个匹配窗口之间的相关性,通过归一化将匹配结果限制在 [-1,1]的范围内,可以非常方便得到判断匹配窗口相关程度:
若NCC = -1,则表示两个匹配窗口完全不相关,相反,若NCC = 1时,表示两个匹配窗口相关程度非常高。
双目立体匹配
- 采集图像:通过标定好的双目相机采集图像,当然也可以用两个单目相机来组合成双目相机。
- 极线校正:校正的目的是使两帧图像极线处于水平方向,或者说是使两帧图像的光心处于同一水平线上。通过校正极线可以方便后续的NCC操作。由标定得到的内参中畸变信息中可以对图像去除畸变,接着通过校正函数校正以后得到相机的矫正变换R和新的投影矩阵P,接下来是要对左右视图进行去畸变,并得到重映射矩阵;根据上述得到的重映射参数map1,map2,我们需要进一步对原始图像进行重映射到新的平面中才能去除图像畸变,通过上述两步操作,我们成功地对图像去除了畸变,并且校正了图像极线。
- 特征匹配:这里便是我们利用NCC做匹配的步骤啦,匹配方法如上所述,右视图中与左视图待测像素同一水平线上相关性最高的即为最优匹配。完成匹配后,我们需要记录其视差d,即待测像素水平方向x_l与匹配像素水平方向xr之间的差值 d = x r − x l d = x_r - x_l d=xr−xl,最终我们可以得到一个与原始图像尺寸相同的视差图D。
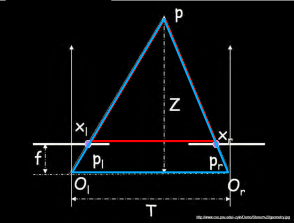
- 深度恢复:通过上述匹配结果得到的视差图D,我们可以很简单的利用相似三角形反推出以左视图为参考系的深度图。计算原理如下图所示:
T − ( x r − x l ) f = T Z = > Z = f T x r − x l \frac {T-(x_r-x_l)} {f}=\frac {T} {Z}=>Z=\frac {fT} {x_r-x_l} fT−(xr−xl)=ZT=>Z=xr−xlfT
假设两幅图像经过了矫正,那么对应点的寻找限制在图像的同一行上。一旦找到对应点,由于深度是和偏移成正比的,那么深度(Z 坐标)可以直接由水平偏移来计算。
其中,f 是经过矫正图像的焦距,T 是两个照相机中心之间的距离, x l x_l xl 和 x r x_r xr 是左右两幅图像中对应点的 x 坐标。分开照相机中心的距离称为基线。
4、实验代码
首先,因为 uniform_filter() 函数的输入参数为数组,我们需要创建用于保存滤波结果的一些数组。然后,我们创建一个数组来保存每个平面,从而能够在最后一个纬度上使用 argmax() 函数找到对于每个像素的最佳深度。该函数从 start 偏移出发,在所有的 steps 偏移上迭代。使用 roll() 函数平移一幅图像,然后使用滤波计算NCC 的三个求和操作。然后将图片灰度化。接下来,设置扫平面函数所需的参数,包括尝试偏移的数目、初始值和 NCC 路径的宽度。除了在滤波中使用了额外的参数,该代码和均匀滤波的代码相同。我们需要在gaussian_filter() 函数中传入零参数来表示我们使用的是标准高斯函数,而不是其他任何导数。
# coding=utf-8
from PIL import Image
from pylab import *
from numpy import *
from numpy.ma import array
from scipy.ndimage import filters
import scipy.misc
def plane_sweep_ncc(im_l,im_r,start,steps,wid):
""" 使用归一化的互相关计算视差图像 """
m,n = im_l.shape
# 保存不同求和值的数组
mean_l = zeros((m,n))
mean_r = zeros((m,n))
s = zeros((m,n))
s_l = zeros((m,n))
s_r = zeros((m,n))
# 保存深度平面的数组
dmaps = zeros((m,n,steps))
# 计算图像块的平均值
filters.uniform_filter(im_l,wid,mean_l)
filters.uniform_filter(im_r,wid,mean_r)
# 归一化图像
norm_l = im_l - mean_l
norm_r = im_r - mean_r
# 尝试不同的视差
for displ in range(steps):
# 将左边图像移动到右边,计算加和
filters.uniform_filter(np.roll(norm_l, -displ - start) * norm_r, wid, s) # 和归一化
filters.uniform_filter(np.roll(norm_l, -displ - start) * np.roll(norm_l, -displ - start), wid, s_l)
filters.uniform_filter(norm_r*norm_r,wid,s_r) # 和反归一化
# 保存 ncc 的分数
dmaps[:,:,displ] = s / sqrt(s_l * s_r)
# 为每个像素选取最佳深度
return np.argmax(dmaps, axis=2)
im_l = array(Image.open('D:/PyCharm/Disparitymap/scene1.row3.col1.ppm').convert('L'), 'f')
im_r = array(Image.open('D:/PyCharm/Disparitymap/scene1.row3.col2.ppm').convert('L'),'f')
# 开始偏移,并设置步长
steps = 12
start = 4
# ncc 的宽度
wid = 9
res = plane_sweep_ncc(im_l,im_r,start,steps,wid)
scipy.misc.imsave('D:/PyCharm/Disparitymap/depth.png',res)
show()
5、实验结果及分析
实验组1

实验结果:
从上到下,从左到右,窗口值依次为3,6,9,12
分析
采用的窗口值分别为3,6,9,12。从上图的比较中可以看出,当窗口值相对小的时候,图片匹配特别敏感,在一些相对平坦没有纹理的地方仍然很杂乱。(上图红框标出,除了红框,还有很多地方都是如此,就不一一标明了)随着窗口值慢慢增大,匹配精度慢慢变高,逐渐剔除那些错误的点,使得图片慢慢清晰。当窗口值为12的时候,匹配的就算很成功了。
实验组2

实验结果:
从上到下,从左到右,窗口值依次为6,12,18,24
分析
采用窗口值分别为6,12,18,24。从上图的比较中可以看出,图片组1的结论是成立的。书与书之间的间隔条纹很清晰。但是这图片里,就算窗口值大到了24,仍然有较多的错误匹配。一方面这组图片景深不如上一张图片高,图片上大部分以白色为主,书页书皮是白的(大多是白色,当然也有其他颜色),但书上写的字是黑色的,字小且密,导致很难匹配正确。于是我大胆将窗口值在往上调。
(从左到右,窗口值分别为30,60,90)
实验效果仍然不好,没有达到预期。但是有了另一个发现:窗口值并不是越大越好,太大的话,反而容易把一些正确的非噪声的点也给去掉,这样反而会影响实验结果。
6、总结
NCC匹配方法计算量大,实时性很差。2M的图片就要跑七八秒

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 0
0 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)