Win10 单机版spark安装
1. 安装JDK1.8
介绍:JDK(Java Development Kit) 是 Java 语言的软件开发工具包(SDK). 在JDK的安装目录下有一个jre目录,里面有两个文件夹bin和lib,在这里可以认为bin里的就是jvm,lib中则是jvm工作所需要的类库,而jvm和 lib合起来就称为jre。
https://jingyan.baidu.com/article/48b37f8d231ca61a65648869.html (安装教程)
安装前,可以检查一下自己的电脑是否之前有安装。通过命令java -version可以查看到jdk的版本,而命令java -verbose可以查看到jdk的安装路径。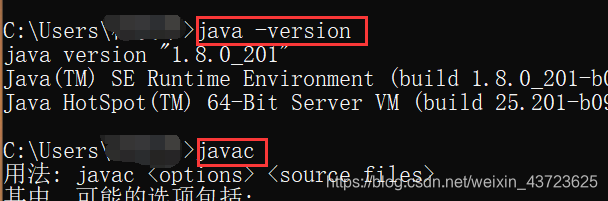
下载安装JDK:
链接:https://pan.baidu.com/s/1f5qvm_BFn3Ro9U7SZ12-LA
提取码:9u1a
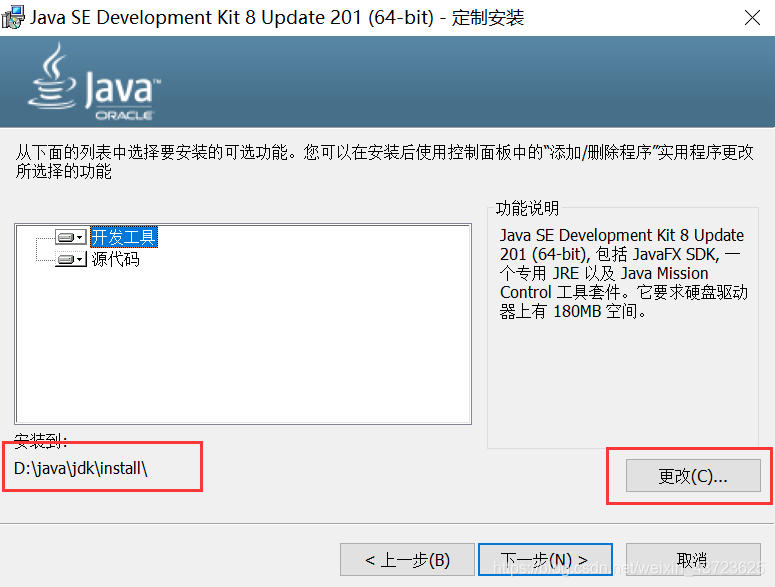
配置环境变量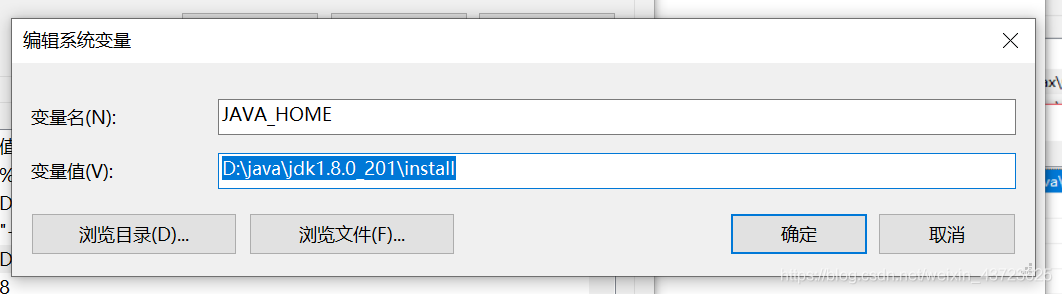
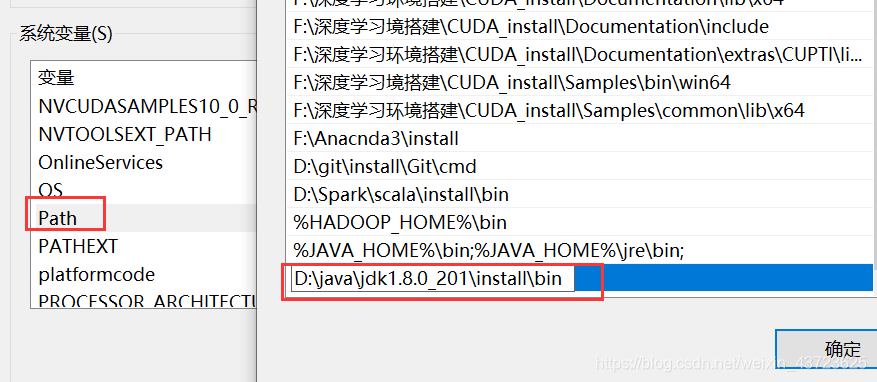
注意:在path变量值最后输入 D:\Java\Jdk…\bin(注意一定要绝对路径,不可以用JAVA_HOME代表的路径。否则,测试的时候,Java会成功,但Javac则会显示失败。
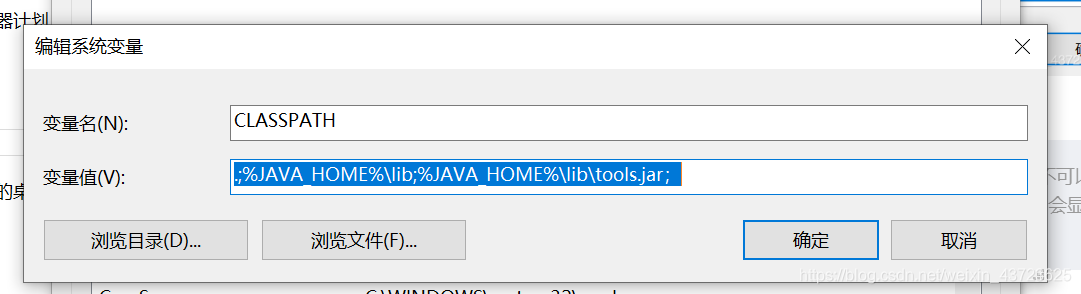
新建ClassPath环境变量,从jdk1.5开始可以不用配置Classpath,这里只给出对应的方法.增加环境变量CLASSPATH值如下:
.;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\lib\tools.jar (注意最前面的 .)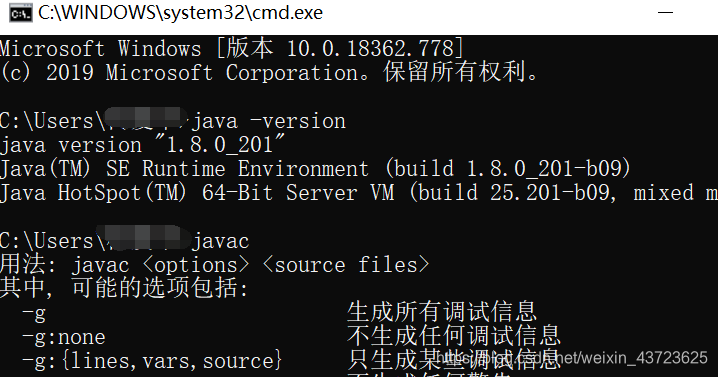
2、安装Scala
介绍:Scala是一门多范式的编程语言,一种类似java的编程语言 ,设计初衷是实现可伸缩的语言 、并集成面向对象编程和函数式编程的各种特性。
https://jingyan.baidu.com/article/5225f26babb1ffe6fa0908a0.html(安装教程)
官网:https://www.scala-lang.org/download/all.html
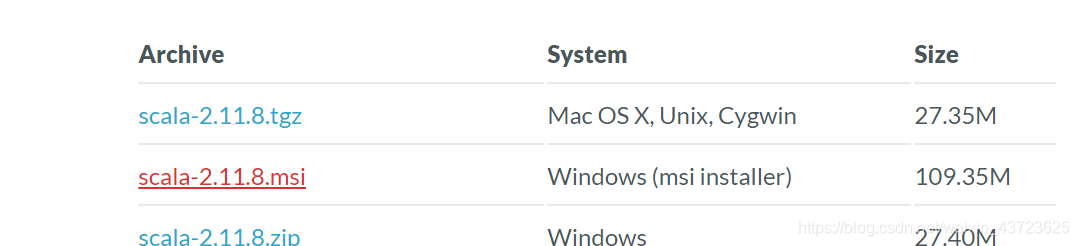
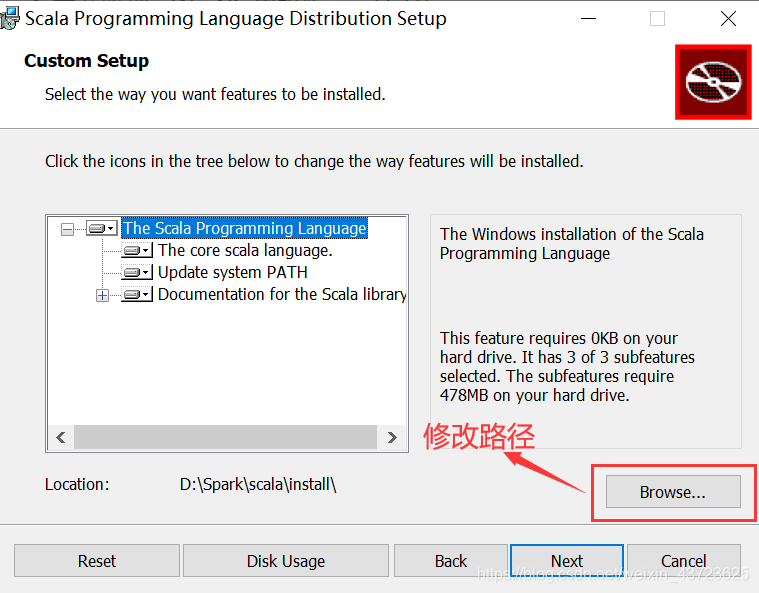
配置Scala的环境变量
这台电脑–>右键“属性”–>高级系统设置–>环境变量,我们选择Path环境变量,并点击“编辑”按钮,我们将上图看到的Scala安装目录下的bin目录配置到Path环境变量中即可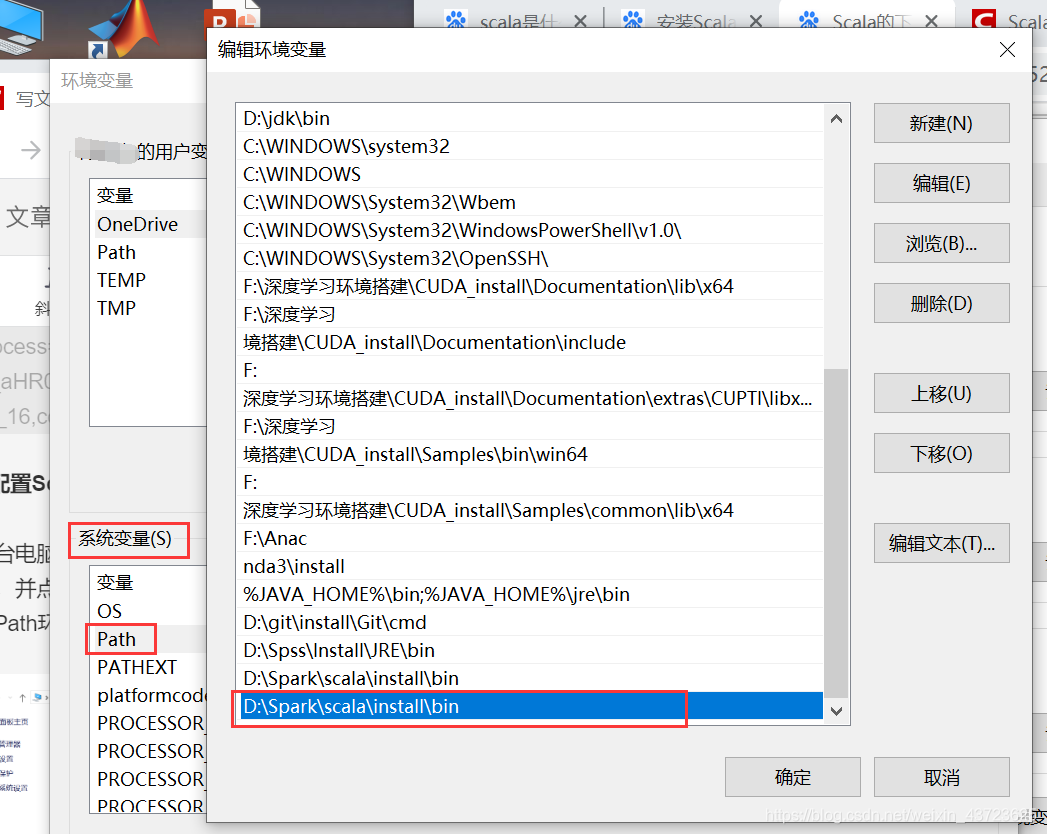
安装完成后我们需要检验是否安装成功,Win+R打开命令行,输入 scala -version,若出现Scala的版本信息则说明安装成功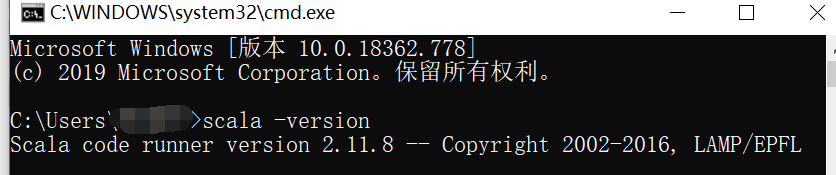
3、安装Hadoop
介绍:Hadoop是一个开源软件框架,用于在商用硬件集群上存储数据和运行应用程序。它为任何类型的数据提供海量存储,巨大的处理能力以及处理几乎无限的并发任务或作业的能力。
https://blog.csdn.net/tototuzuoquan/article/details/79954234 (安装教程)
第一步:前期需要准备的材料:
① Hadoop-3.0.0下载
从http://archive.apache.org/dist/hadoop/core/下载Hadoop-3.0.0,下载二进制压缩包文件:hadoop-3.0.0.tar.gz
(https://blog.csdn.net/mr_yuntuo/article/details/90728174)
② 下载hadoop在windows环境下支持包hadoopwindows-master.
https://github.com/sardetushar/hadooponwindows
③ 下载hadoop的hadoop.dll和winutils.exe
https://github.com/4ttty/winutils
第二步:安装包及环境变量配置
①解压hadoop-3.0.0安装包到本地路径
②将hadoop.dll和winutils.exe两个文件放入到/hadoop-3.0.0/bin目录下
③配置hadoop环境变量:
⑤ 添加path属性,将;%HADOOP_HOME%\bin;添加到path环境变量中
⑥ 验证hadoop环境,在windows控制台输入: hadoop version
出错:
解决:系统变量里查看JAVA_HOME,发现路径是C:\Program Files,其中包含了空格,因此hadoop报错。所以要把JDK移动到另一个不包含空格名称的文件夹下,例如C:\Java\jdk1.8.0_201


第三步:修改hadoop配置文件
文件位置:hadoop-3.0.0\etc\hadoop\XXX
1.配置core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2.配置hdfs-site.xml
<configuration>
<!-- 这个参数设置为1,因为是单机版hadoop -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/Installed/hadoop-3.0.0/data/namenode</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>/D:/Installed/hadoop-3.0.0/data/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>/D:/Installed/hadoop-3.0.0/data/snn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/Installed/hadoop-3.0.0/data/datanode</value>
</property>
</configuration>
3.配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
4.配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5.运行hadoop
以管理员方式打开cmd,运行hadoop:
cd D:\java\hadoop-3.0.0\bin
hadoop namenode –format

4、安装Spark
1.下载地址:
http://spark.apache.org/downloads.html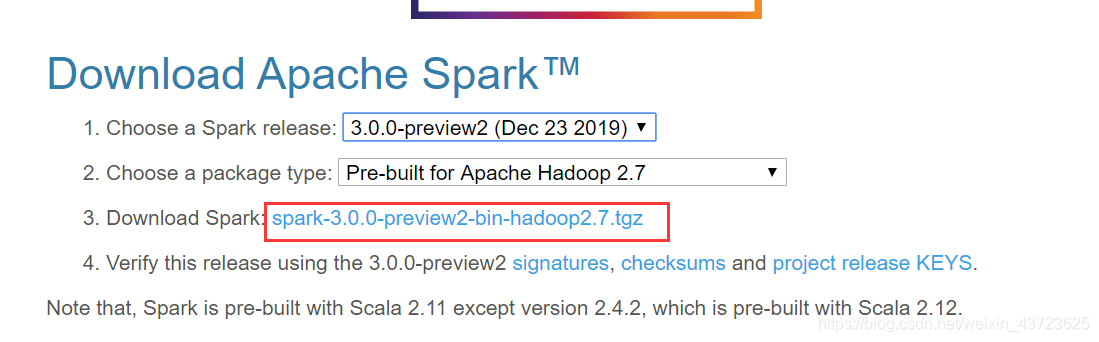
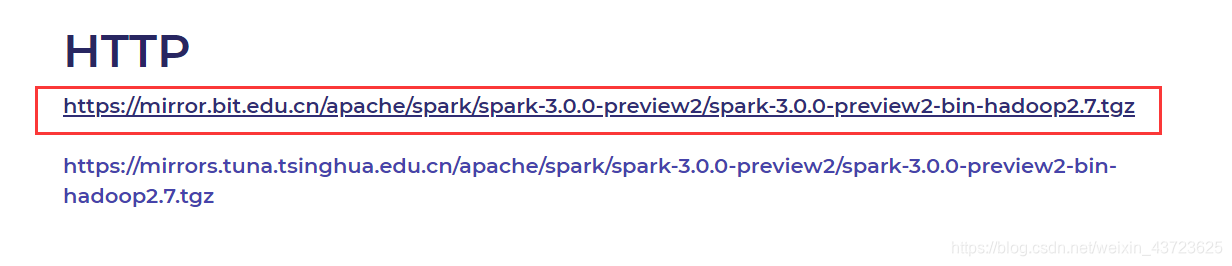
2.环境配置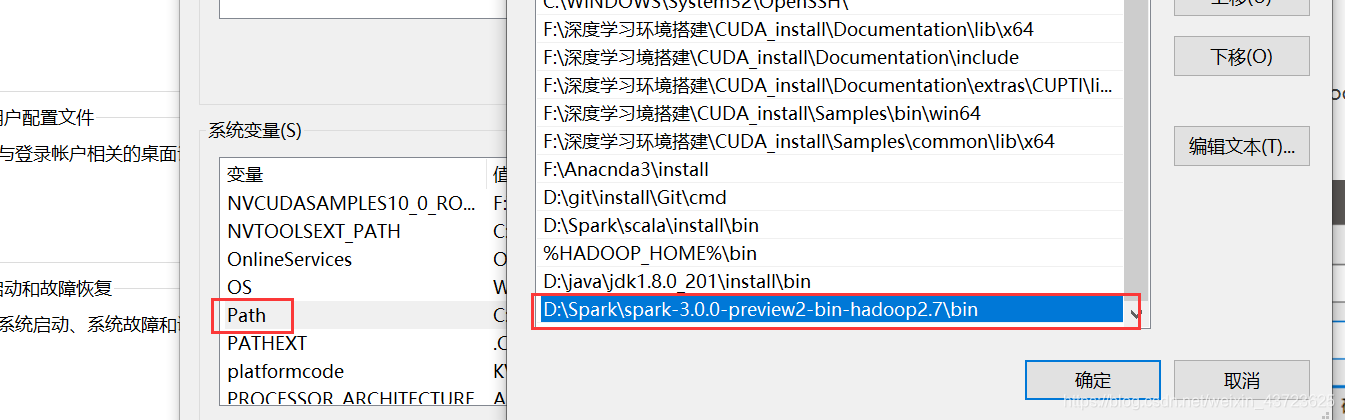
3. 验证是否成功
cmd命令行界面中运行spark-shell来验证是否成功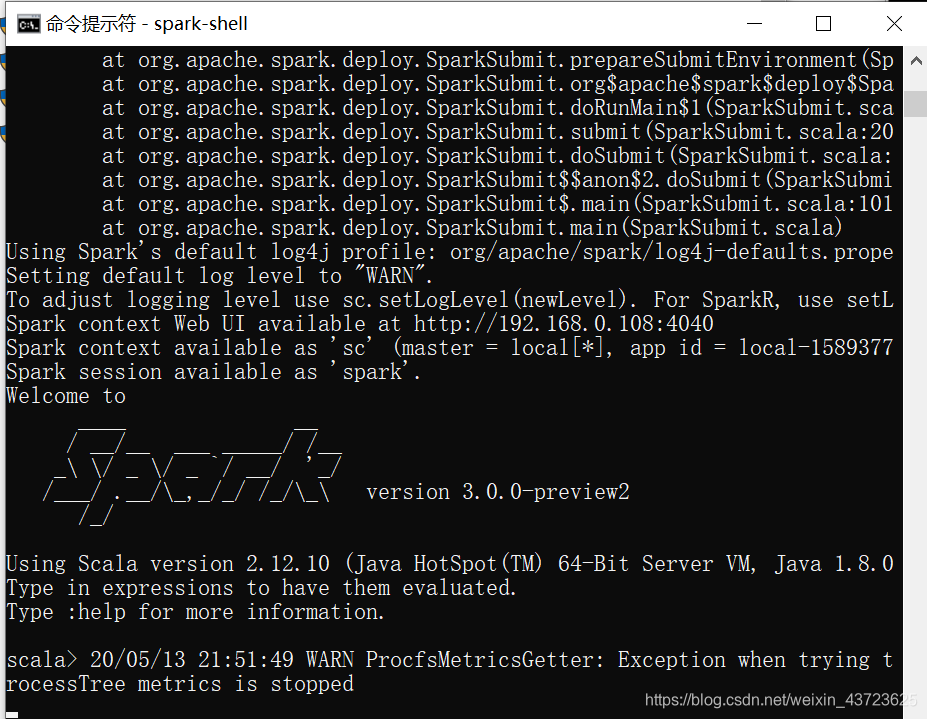
至此,Spark的环境算是基本搭建完成了。下面就开始搭建使用Scala的开发环境。
5. 简单示例
我们在pycharm上编写一个使用Spark进行数据处理的简单示例:
建工程:
1.首先把D:\Spark\spark-3.0.0-preview2-bin-hadoop2.7\python目录下的pyspark文件夹复制到python安装目录(我以我自己的为主,具体按照自己安装目录来)F:\Anaconda3\install\Lib\site-packages下面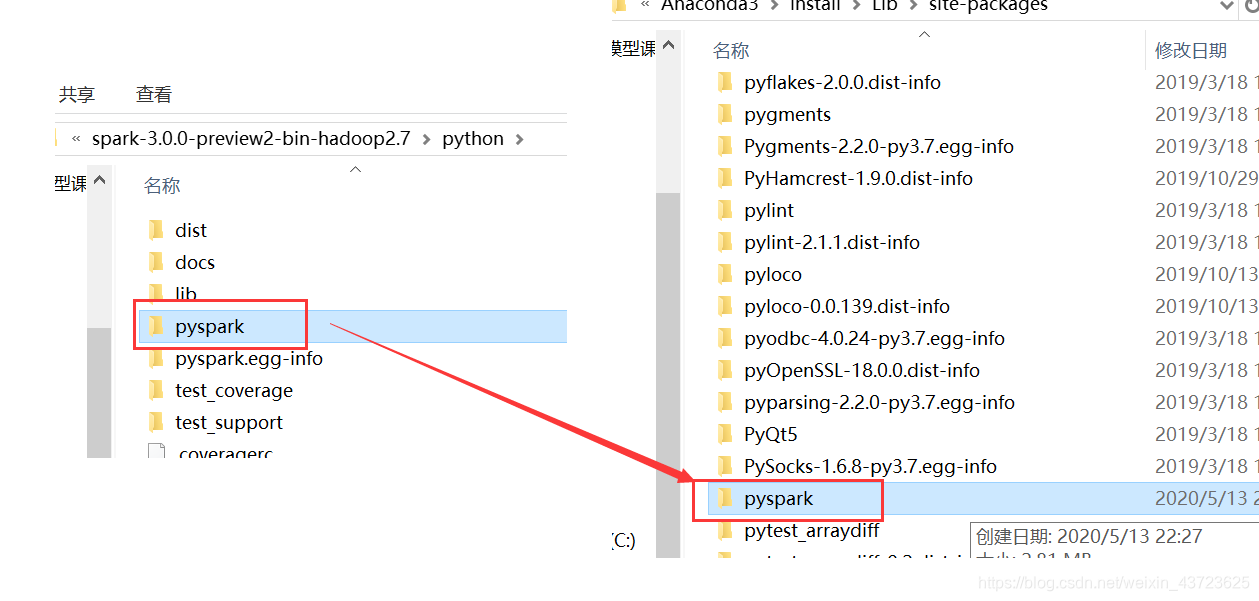
2.之后新建一个SparkPython工程,然后在Pycharm中加入如下配置文件,如图所示:
配置pyCharm
参考网址:https://segmentfault.com/a/1190000009332801
1.随便打开一个project,pycharm右上角“run”三角形的左边有一个configurition,打开它。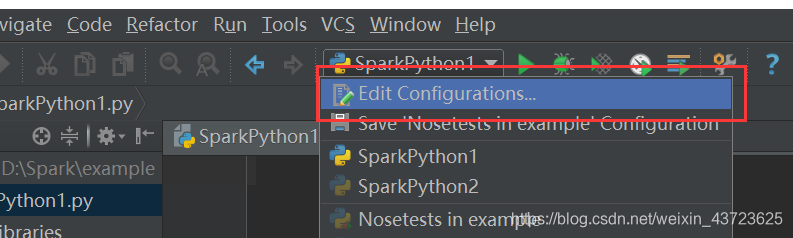
2.设置环境,创建PYTHONPATH和SPARK_HOME。配置路径如图所示,都可以在Spark安装路径下找到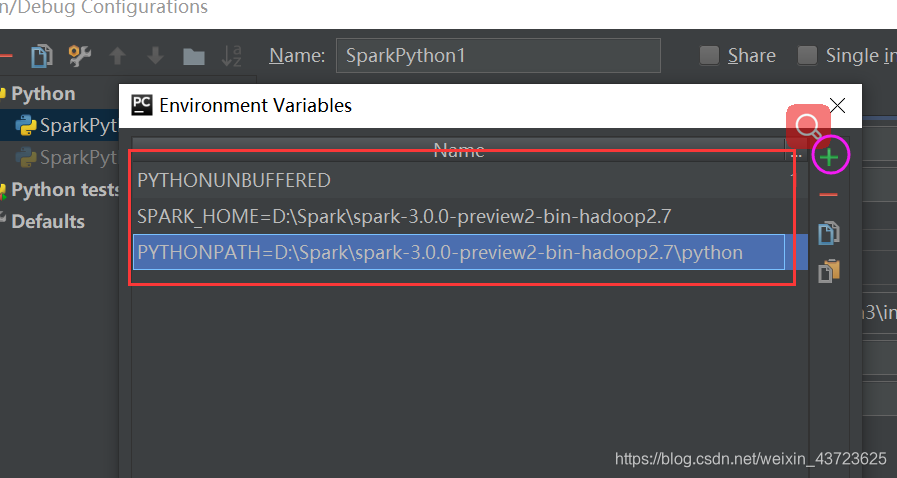
3.选择 File->setting->你的project->project structure。右上角Add content root添加:py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下,自己找一下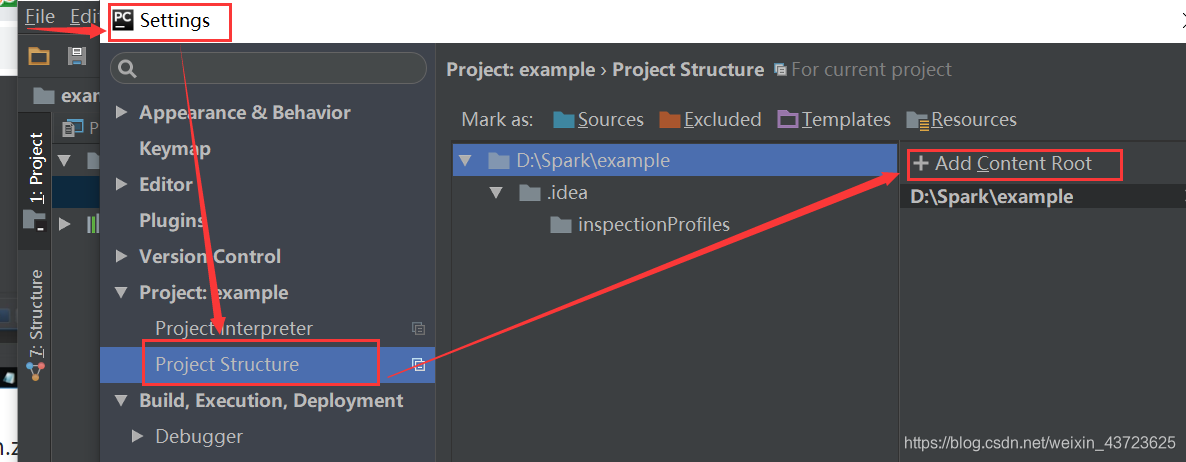
4.配置结束后可通过一个小程序测试下是否配置成功,代码如下:
from pyspark import SparkContext
import os
import sys
os.environ['SPARK_HOME'] = "D:\Spark\spark-3.0.0-preview2-bin-hadoop2.7"
os.environ['JAVA_HOME'] = "D:\java\install"
sys.path.append("D:\Spark\spark-3.0.0-preview2-bin-hadoop2.7\python")
sys.path.append("D:\Spark\spark-3.0.0-preview2-bin-hadoop2.7\python\lib\py4j-0.10.8.1-src.zip")
sc = SparkContext('local')
doc = sc.parallelize([['a','b','c'],['b','d','d']])
words = doc.flatMap(lambda d:d).distinct().collect()
word_dict = {w:i for w,i in zip(words,range(len(words)))}
word_dict_b = sc.broadcast(word_dict)
def wordCountPerDoc(d):
dict={}
wd = word_dict_b.value
for w in d:
if wd[w] in dict:
dict[wd[w]] +=1
else:
dict[wd[w]] = 1
return dict
print(doc.map(wordCountPerDoc).collect())
print("successful")
运行结果如下图所示,则表明pycharm配置spark成功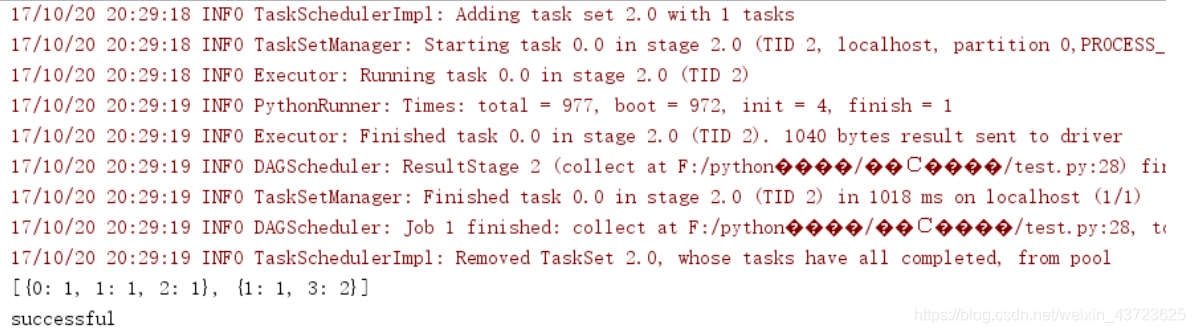

腾讯云面向开发者汇聚海量精品云计算使用和开发经验,营造开放的云计算技术生态圈。
更多推荐
 1
1 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)